
Decision tree based predictive models for breast
cancer survivability on imbalanced data
Liu Ya-Qin, Wang Cheng, Zhang Lu
Dept. of Biomedical Engineering
School of Basic Medicine, Shanghai JiaoTong University
Shanghai, China
yaqinliu@sjtu.edu.cn
Abstract—Based on imbalanced data, the predictive models for 5-
year survivability of breast cancer using decision tree are
proposed. After data preprocessing from SEER breast cancer
datasets, it is obviously that the category of data distribution is
imbalanced. Under-sampling is taken to make up the
disadvantage of the performance of models caused by the
imbalanced data. The performance of the models is evaluated by
AUC under ROC curve, accuracy, specificity and sensitivity with
10-fold stratified cross-validation. The performance of models is
best while the distribution of data is approximately equal.
Bagging algorithm is used to build an integration decision tree
model for predicting breast cancer survivability.
Keywords-imbalanced data;decision tree;predictive breast
cancer survivability;10-fold stratified cross-validation;bagging
algorithm
I.
I
NTRODUCTION
According to the statistical reports of WHO, the incidence
of breast cancer is the number one form of cancer among
women [1]. It presents a seriously threat to women’s health in
the world today. Therefore, it is crucial to investigate factors of
breast cancer including prognosis and treatment. In general,
predicting breast cancer survivability is a binary classification
problem, “survived” or “not survived”. In the year of 2005,
Delen [2] established the predictive breast cancer survivability
model using data mining techniques based on large datasets.
Though it is reported as the first paper which systematically
established the prognosis of breast cancer model using data
mining techniques, the result of the paper is doubted by other
researchers [3]. After data preprocessing, the percentage of
“survived after 5 years” was 45% while it was reported in
NCI’s official data that in the United States the percentage of
“survived after 5 years” was 88% in the year of 2006 [4]. In
Delen ‘s paper, that is to say, the true status of imbalanced data
is covered.
In recent years we have witnessed exploration of data. A
large amount of data on breast cancer has been collected over
the last years, but much information is hidden. Data mining is
the process of analyzing large quantities of data and
summarizing it into useful information. Most data mining
algorithms assume that data are balanced. However, this is not
always case in reality. Data are imbalanced if the classification
categories are not approximately equally represented.
In this paper, predictive models for breast cancer
survivability based on imbalanced data using decision tree are
proposed. After data preprocessing, the percentage of
“survived after 5 years” is 86.52%. In order to make up the
disadvantage of the performance of model caused by the
imbalanced data, under-sampling method is taken. The
performance of breast cancer survivability models is evaluated
by AUC under ROC curve, accuracy, specificity and sensitivity
with 10-fold stratified cross-validation. Bagging algorithm is
used to increase the performance of the classification by
averaging the decisions of an ensemble of classifiers.
II. D
ATA AND
M
ETHODS
A. Data
The data analyzed in this study is from the surveillance,
epidemiology and end results (SEER) breast cancer incidence
data in the years of 1973-2004. The SEER data [5] are reliable
which is supported by National Cancer Institute (NCI). The
SEER breast cancer incidence data consist of three datasets
named YR1973_2004.SEER9, YR1992_2004.SJ_LA_RG_AK
and YR2000_2004.CA_KY_LO_NJ.
Data preprocessing [6] is a big issue for data mining. Data
preprocessing includes data integration, data cleaning, data
transformation and data reduction. In our study, three datasets
are integrated into one larger data warehouse. After integration,
the total data consist of 779,999 records, 115 variables.
Data cleaning is followed, dealing with the missing value,
identify or remove outliers. For example, the tumor size
variable contains abnormal values greater than 200 mm,
appeared to be incorrect because of data entry errors, and
therefore removed. Another example, extension of disease is an
important factor in breast cancer survivability but 32.25% of
the records contain missing and unknown, therefore those
records are also removed. Data transformation is practiced.
During the years of 1973-2004 breast cancer incidence data
from SEER, there are four versions of data dictionary: ICD-O-
3、ICD-O-2、ICD-O、MOTHAC. In order to deal with the
inconsistence of data records, a mapping relationship is built.
For example, site specific surgery codes variable, the data
definition is differently in four data dictionaries. By code
changing, we divide this value into 10 new categories. Each
record maps into new category according to the four versions
978-1-4244-2902-8/09/$25.00 ©2009 IEEE
1
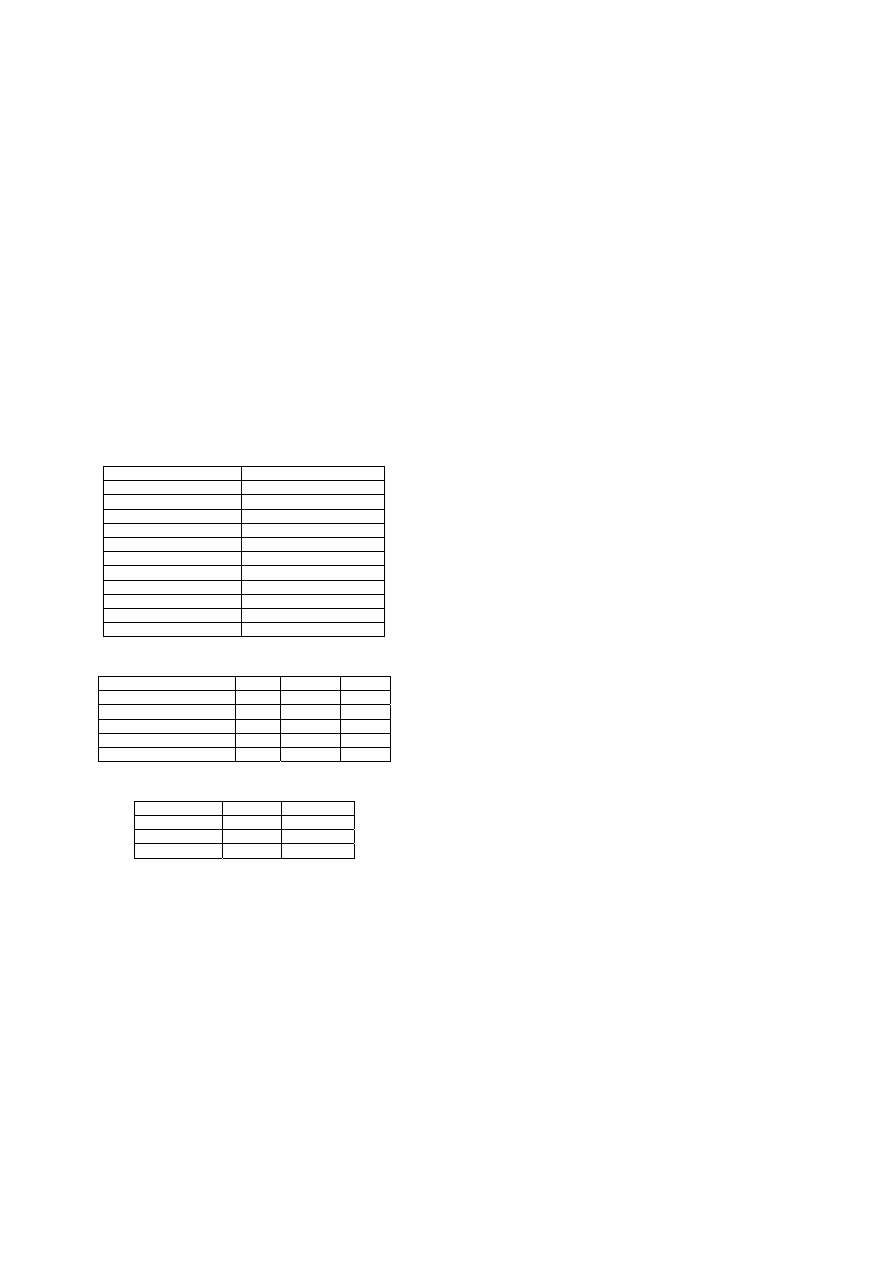
of data dictionary. Delete variables such as patients ID number,
registry ID, birth place etc. Data reduction is mostly based on
feature selection. Feature selection is also implemented with
logistic regression backward selection conducted by using
p>0.1 as the exit criterion and p<0.05 as the entry criterion.
After using these data preprocessing, the final 11 discrete
input variables are shown in Tab. I. The final 5 numeric input
variables are shown in Tab. II. Predicting breast cancer
survivability is a binary classification problem, “survived” or
“not survived”. If survival time record equals or more than 5
years, survive status indicates 1.If survival time record is less
than 5 years and cause of death is beast cancer, survive status
indicates 0 which means did not survive. The dependent
variable is survival status. Distribution of dependent variable is
shown in Tab. III. After data preprocessing there are 16 input
variables, 1 dependent variable named survival status. The total
is 182,517 records. The percentage of “survived after 5 years”
is 86.52% while it is reported in NCI’s official data that in the
United States the percentage of “survived after 5 years” was
88% in the year of 2006.
TABLE I.
D
ISCRETE
I
NPUT
V
ARIABLES
Discrete variable name Number of distinct value
marital status
6
race
28
primary site code
9
grade 5
extension of disease
13
lymph node involve
10
radiation 10
stage of cancer
5
first malignant
2
histology 96
site specific surgery code
10
TABLE II.
N
UMERIC
I
NPUT
V
ARIABLES
Numeric variable name Mean
Std.Dev.
Range
age 59.35
13.52
10-106
tumor size
21.23
17.13
0-200
no of primaries
1.26
0.52
1-8
no of positive nodes
1.63
3.99
0-90
no of nodes
14.68
7.09
0-90
TABLE III.
D
ISTRIBUTION OF
D
EPENDENT
V
ARIABLE
Class Records
Percentage
1: survived
157,916
86.52%
0: not survived 24,601
13.48%
Total 182,517
100%
B. Prediction Model
Decision tree (DT) provides powerful techniques for
classification and prediction. The decision tree is a tree whose
internal nodes are tested on input variables and leaf nodes are
categories. Various decision tree algorithms are available to
guide the classification of data, including ID3, C4.5, C5,
CART and CHAID. In this paper we choose C5 decision tree
algorithm [7] to establish the model. The reasons are given
followed. The C5 decision tree uses information gain ratio
which is robust and consistently give a better choice of tests
than the gain criterion (ID3). After data preprocessing, our
datasets are large. The C5 decision tree is more focus on
classification of large datasets than C4.5. The C5 decision tree
has ability to deal with numeric variables while CHAID is
unable to do that. The theory of CART is binary split while the
C5 decision tree isn’t which make the tree more concise and
flexible.
C. 10-fold Stratified Cross-validation
10-fold stratified cross-validation [8] is used to prepare
training data and test data. After data preprocessing, data are
divided into “survived” and “not survived”. Firstly, “not
survived” records are randomly cut into 10 parts (N
1
,N
2
,…N
10
)
;
“Survived” records are randomly cut into 10 parts
(S
1
,S
2
,…S
10
). Secondly, randomly choose one part from N
1
,
N
2
,…N
10
and one part from S
1
,S
2
,…S
10
, thus new datasets
D
1
,D
2
,…D
10
conducted. The distributed proportion of each part
in D
1
,D
2
,…D
10
has the same proportion as the total data,
86.52% “survived” and 13.48% “not survived”. Thirdly, one
part from D
1
, D
2
,…D
10
used as training data to train the model
and the remaining 9 of 10 parts used as test data to test the
performance of the model. The final result is the average
performance of the 10 test data.
D. Measures for Performance Evaluation
True Negative (TN) is the number of negative examples
correctly classified, False Positive (FP) is the number of
negative examples incorrectly classified as positive, False
Negative (FN) is the number of positive examples incorrectly
classified as negative, True Positive (TP) is the number of
positive examples correctly classified. Accuracy, sensitivity,
specificity are shown in (1), (2) and (3).
accuracy = (TP + TN)/(TP + TN + FP + FN). (1)
sensitivity = TP/(TP + FN). (2)
specificity = TN/(TN + FP). (3)
However, predictive accuracy might not be appropriate
when data are imbalanced. In the presence of imbalanced data,
it is more appropriate to use the Receiver Operating Curve
(ROC). On an ROC curve the X-axis represents FP and the Y-
axis represents TP. ROC curve depicts relative trade-offs
between TP and FP. The area under the Curve (AUC) is an
accepted performance metric for a ROC curve [9]. In our
paper, AUC is the firstly considered as measures for
performance evaluation of model because of imbalanced data
distribution.
E. Sampling Method
After data preprocessing, it is obviously that the category of
data distribution is imbalanced which would seriously affect
the performance of model. In order to balance the data, under-
sampling method [10] is used in our study. Under-sampling
method random eliminates examples in the majority-class,
“survived” class. The sampling method is only used on training
data, not used on test data.
F. Bagging Algorithm
Bagging [11] is a method for improving the predictive
power of classifier learning systems. It forms a set of classifiers
2

that are combined by voting to boost a weak learner to a strong
one. The aggregation averages over the versions when
predicting a numerical outcome and does a plurality vote when
predicting a class.
III. R
ESULTS
After data preprocessing, C5 decision tree model based
predictive model for breast cancer survivability was
established. The result indicated that the AUC of the model is
of 0.6070, the specificity of 0.2325, the sensitivity of 0.9814
and the accuracy of 0.8805. Since AUC is the firstly considered
as measures for performance evaluation of model, the AUC of
0.6070 is too slow which has no medical practical value. The
low AUC is due to imbalanced distribution of the data. In our
paper because data are imbalanced, under-sampling methods
are used. The ratio of under-sampling is m%, the original
training data of “survived” is n, the new data in the training
data of survived class is n*m%. The survived class is under-
sampled at 10%,20%, 30%, 40%, 50%, 60%, 70%, 80%,
90%. The result of imbalanced data for predicting breast cancer
survivability based on decision tree models using under-
sampling method is shown in Fig. 1. In order to compare, the
result of ratio 100% means under-sampling method is not used.
Fig. 1 shows the accuracy, specificity, sensitivity, AUC of
the predictive models for breast cancer survivability based on
decision tree using under-sampling method. From the figure,
the yielding point of AUC occurred between the under-
sampling ratio of 10% and 20%.With more calculation, the
AUC get maximum value while the under-sampling ratio is of
15%. With under-sampling ratio of 15%, the result indicated
that the AUC of the model is of 0.7484, the specificity of
0.7570, the sensitivity of 0.7399 and the accuracy of 0.7422.
The performance of models is best while the distribution of
data is approximately equal.
It is often possible to increase the performance of the
classification by averaging the decisions of an ensemble of
classifiers. Bagging is well-known ensemble learning
algorithms that have been shown to improve generalization
performance compared to the individual base models. With the
under-sampling ratio is of 15%, a bagging decision tree was
built up by using bagging algorithm that improved
classification AUC and generalization of decision tree. In the
training processing, 2/3 of training records was randomly
chosen to train the model. The decision tree model are trained
M times. In this paper, bagging algorithm was taken with
M=5.Thus, some of the records can appear more than once
while others don’t appear at all. After using the bagging
algorithm, the result indicated that the AUC of the model is of
0.7678, the specificity of 0.7859, the sensitivity of 0.7496 and
the accuracy of 0.7659.
IV. D
ISCUSSION
Usually, the classification algorithms exhibit poor
performance while dealing with imbalanced data and results
are biased towards the majority class. The results also show
that the accuracy and sensitivity decrease while the specificity
increases rapidly with the sampling method. However,
predictive accuracy might not be appropriate when data are
imbalanced. Since the sensitivity and specificity are often
trade-off, AUC is an accepted metric to evaluate the
performance of imbalanced data.
This paper clearly shows that the preliminary results are
promising for the application of data mining methods into
breast cancer survivability prediction problem on imbalanced
data. With under-sampling ratio of 15%, the result indicated
that the AUC of the model is of 0.7484. The results also show
that the highest AUC is 0.7484 which use decision tree model
and under-sampling method at the ratio of 15%. The
observation from experiments also conducts that the best
distribution is when the classes are equally represented
approximately. Bagging algorithm is used to increase the
performance of the classification by averaging the decisions of
an ensemble of classifiers. After using the bagging algorithm,
the AUC of the model is increased to 0.7678. The bagging
algorithm work better for unstable learning algorithm. If AUC
is greater than 0.7, in medical field it suggests acceptable
model.
The obtained results in this study differ from the study of
Delen due to the facts that we use newer database (1973-2004
vs. 1973-2000) and a different data preprocessing. In Delen’s
study, “not survived” means survival time record less than 5
years. In our study, “not survived” class means survival time
record less than 5 years and cause of death is beast cancer.
According to the statistical reports of SEER breast cancer
incidence data of 1973-2004, 53.92% died of breast cancer,
46.08% died of other reason. So after data preparation, our
data are imbalanced (survived: not survived=86.52%:13.48%)
while Delen’s data are balanced (survived: not
survived=46%:54%). Survival at five year after the initial
diagnosis is 88% in the year of 2006 according to the
statistical report of NCI official website.
Finally the under-sampling ratio (15%) combined with
decision tree are chosen. After predictive model for breast
cancer survivability correctly established, the production rules
from C5 decision tree is conducted which is easy to explain
and understand by the doctors. For example, the “If-Then”
production rules from C5 decision tree are given in the
following: “If No_positive_nodes > 0 and Stage = Distant then
the survival probability of the breast cancer patient is 3.9%”;
“If No_positive_nodes > 5 and Stage =Regional and
Tumor_size > 23 then the survival probability of the breast
cancer patient is 13.9%”.
V. C
ONCLUSION
In this paper, imbalanced data classification models using
decision tree is proposed to predict the survivability of breast
cancer. The predictive efficacies of combination of under-
sampling method and decision tree presented in order to
balance the data after data preprocessing. With under-sampling
ratio of 15%, the AUC of the model is 0.7484.The performance
of models is best while the distribution of data is approximately
equal. After using the bagging algorithm, the AUC of model is
increased to 0.7678.
3
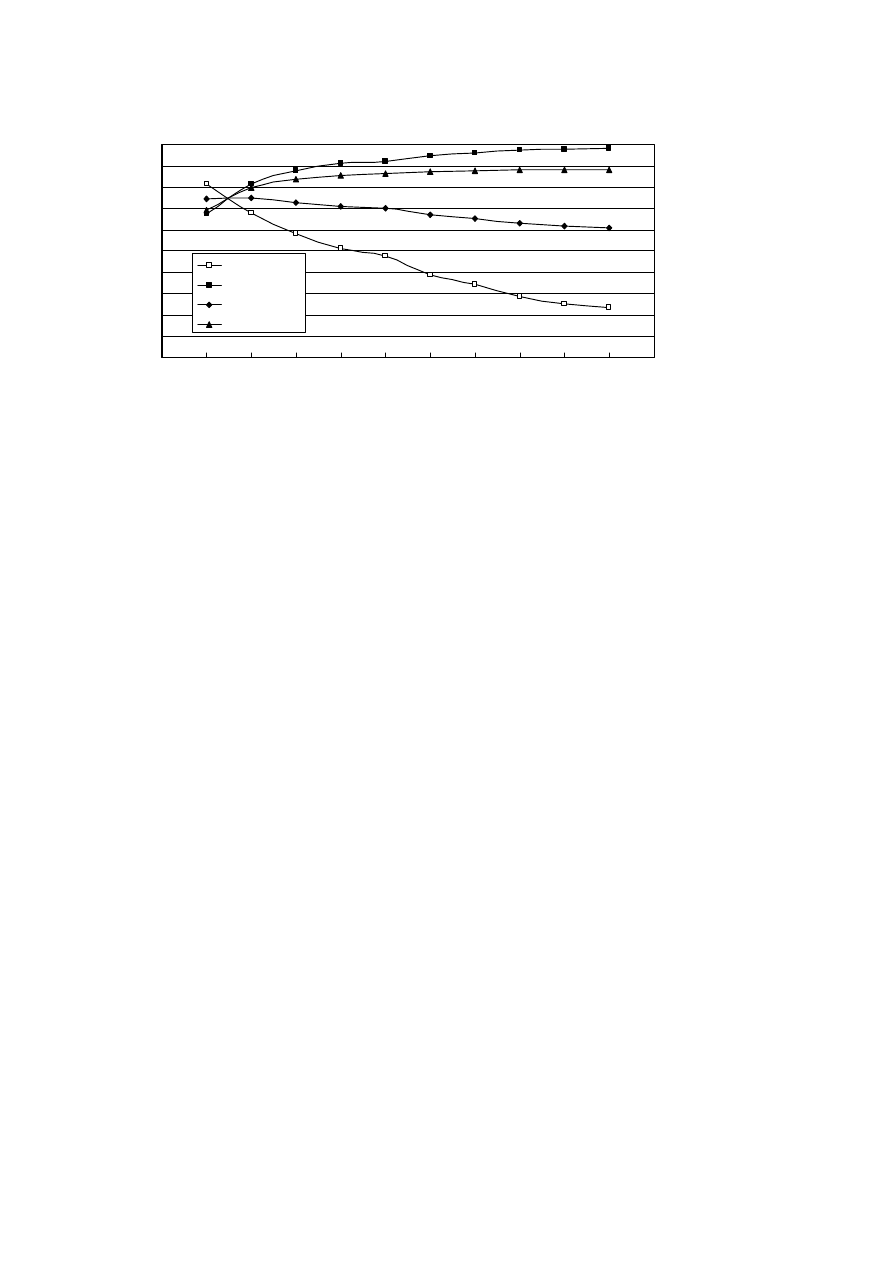
Figure 1. Accuracy、specificity、sensitivity、AUC of the predictive models for breast cancer survivability based on decision tree using under-sampling method
R
EFERENCE
[1] D. M. Parkin, F. Bray, J. Ferlay, “Global cancer statistics 2002,” CA
Cancer J Clin, vol.55, pp. 74-108, 2005.
[2] D. Delen, G. Walker, A. Kadam, “Predicting breast cancer survivability:
comparison of three data mining methods,” Artificial Intelligence in
Medicine, vol. 34, pp. 113-127, 2005.
[3] B. Abdelghani, G. Erhan, “Predicting breast cancer survivability using
data mining techniques,” Chandrika K,Michael B.Proc. of the 6th SIAM
Int'l Conf. on Scientific Data Mining, Maryland, SIAM, pp. 1-4,2006.
[4] L. Ries, D. Melbert, M. Krapcho, “SEER Cancer Statistics
Review,1975-2005,National Cancer Institute,” http
:
//seer.cancer.gov/csr/1975_2005/, 2007.
[5] National Cancer Institute. Surveillance, Epidemiology,and End Results
(SEER) Program Public-Use Data (1973-2004), DCCPS, Surveillance
Research Program,Cancer Statistics Branch, www.seer.cancer.gov,
2007.
[6] J. W. Han, Data mining concepts and techniques, China Machine Press,
China, pp. 44-65,2007.
[7] J. Quinlan, C5.0 Online Tutorial, http : //www.rulequest.com//see5-
win.html, 2006.
[8] M. Stone, “Cross-validatory choice and assessment of statistical
predictions,” Journal of the Royal Statistical Society, vol.36, pp. 111-
147,1974.
[9] T. Fawcett, “An introduction to ROC analysis,” attern Recognition
Letters, vol.27, pp. 861−874,2006.
[10] V. Sofia, “Issues in mining imbalanced data sets-a review paper,”
Proceedings of the Sixteen Midwest Artificial Intelligence and
Cognitive Science Conference, Dayton, MAICS, pp. 67-73,2005.
[11] L. Breiman, “Bagging predictors,” Technical Report 421, Department of
Statistics, University of California at Berkeley, 1994.
Decision Tree
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
110%
under-sampling ratio
specificity
sensitivity
AUC
accuracy
4
Wyszukiwarka
Podobne podstrony:
Gor±czka o nieznanej etiologii
02 VIC 10 Days Cumulative A D O Nieznany (2)
Abolicja podatkowa id 50334 Nieznany (2)
45 sekundowa prezentacja w 4 ro Nieznany (2)
4 LIDER MENEDZER id 37733 Nieznany (2)
Mechanika Plynow Lab, Sitka Pro Nieznany
katechezy MB id 233498 Nieznany
2012 styczen OPEXid 27724 Nieznany
metro sciaga id 296943 Nieznany
Mazowieckie Studia Humanistyczn Nieznany (11)
cw 16 odpowiedzi do pytan id 1 Nieznany
perf id 354744 Nieznany
DO TEL! 5= Genetyka nadci nieni Nieznany
Opracowanie FINAL miniaturka id Nieznany
3 Podstawy fizyki polprzewodnik Nieznany (2)
interbase id 92028 Nieznany
Mbaku id 289860 Nieznany
Probiotyki antybiotyki id 66316 Nieznany
więcej podobnych podstron