
Programowanie mikrokontrolerów – kompilacja 2009
Powodzenia w zaliczeniach :)!
Hexe
Spis treści
1
MSP
2
1.1
Co oznacza ortogonalność rozkazów w MSP?
. . . . . . . . . . . . . . . . . .
2
1.1.1
Ver. 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2
1.1.2
Ver. 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2
1.2
Tryby adresowania w MSP
. . . . . . . . . . . . . . . . . . . . . . . . . . . .
2
1.3
Co to są rozkazy bazowe i emulowane w MSP?
. . . . . . . . . . . . . . . . .
3
1.4
Finalne rozkazy po asemblacji RET i RETI . . . . . . . . . . . . . . . . . . .
3
1.5
Omówić ogólną strukturę MSP . . . . . . . . . . . . . . . . . . . . . . . . . .
3
1.6
Omówić system przerwań w MSP . . . . . . . . . . . . . . . . . . . . . . . . .
3
1.7
Źródła sygnałów taktujących w MSP . . . . . . . . . . . . . . . . . . . . . . .
4
1.7.1
Ver. 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
4
1.7.2
Ver. 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
4
1.8
Tryb pracy z niską mocą . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
4
1.9
Jakie kroki wykonuje procesor MSP430 po przyjęciu przerwania? . . . . . . .
4
1.9.1
Ver. 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
4
1.9.2
Ver. 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5
1.10 Co jest wykorzystywane do programowania MSP?
. . . . . . . . . . . . . . .
5
1.11 Różnice między UART a USART . . . . . . . . . . . . . . . . . . . . . . . . .
5
1.12 Opisać działanie modulatora UART
. . . . . . . . . . . . . . . . . . . . . . .
6
1.13 Opisać działanie watchdoga . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6
1.14 Opisać jak działa mnożnik hardware’owy w MSP430 . . . . . . . . . . . . . .
6
1.15 Sposób rozmieszczania zmiennych w pamięci MSP
. . . . . . . . . . . . . . .
6
1.16 Podać wartości rejestrów generatora (w tym rej. modulatora) UART-a . . . .
7
1.17 Jakie elementy i rozwiązania decydują o małym poborze prądu przez mikro-
kontrolery z rodziny MSP430? . . . . . . . . . . . . . . . . . . . . . . . . . . .
7
1.18 Jak są wnoszone i zwracane zmienne w funkcjach w IAR dla MSP430? . . . .
7
1.19 Deklaracja modelu pamięci dla MSP430X . . . . . . . . . . . . . . . . . . . .
8
1.20 Co trzeba zrobić, aby wykonał się rozkaz bezpośrednio po komendzie wpro-
wadzenia MSP w stan uśpienia? . . . . . . . . . . . . . . . . . . . . . . . . . .
8
1.21 Opisać, jak wyłączyć tryb uśpienia przy wyjściu z procedury obsługi przerwania
8
1.22 Porównanie MSPX i MSP . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
8
1.23 Porównanie mnożników w MSP i MSPX . . . . . . . . . . . . . . . . . . . . .
9
1.24 ADC12 vs. DAC12 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
9
1.25 Porównanie LCD i LCD A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.26 SVS - kontroler napięcia zasilania . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.27 SD16 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.28 Flash - pamięć programu i danych
. . . . . . . . . . . . . . . . . . . . . . . . 10
1.29 Timery w MSP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.30 Bootstrap Loader . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.31 DMA
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.32 Co należy zrobić, aby program z MSP430X zadziałał na MSP430? . . . . . . 14
2
ARM
14
2.1
Główne cechy architektury ARM . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.2
Tryby pracy, wyjątki . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3
System rejestrów . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.4
Opis słowa rozkazowego . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.5
Instrukcje warunkowe
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.6
Pipelining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.7
Sposób tworzenia adresu branch instruction (skoki) . . . . . . . . . . . . . . . 15
2.8
Opisać VIC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.9
Rodzaje przerwań
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.10 Opóźnienia procedur obsługi przerwania . . . . . . . . . . . . . . . . . . . . . 17
2.11 Magistrale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.12 Taktowanie (CCLK, PCLK) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.13 Rodzaje adresowania . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.14 ALU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.15 Barrel Shifter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.16 Cache . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.17 ADC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.18 Pseudoinstrukcje . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.19 Porównanie trybów ARM i THUMB . . . . . . . . . . . . . . . . . . . . . . . 19
2.20 !!Procedura obsługi przerwania . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.21 W których trybach blokowane są IRQ i FIQ? . . . . . . . . . . . . . . . . . . 19
2.22 Jak w kompilatorze Keil obsłużyć przerwanie IRQ? . . . . . . . . . . . . . . . 19
2.23 Jak w kompilatorze Keil obsłużyć przerwanie FIQ? . . . . . . . . . . . . . . . 20
2.24 Dlaczego przy zagnieżdżaniu przerwań konieczne są dodatkowe makroproce-
dury?
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.25 Wyjaśnić różnice w przyjęciu przerwania IRQ i FIQ dla procesorów ARM . . 20
2.26 Timer w ARM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.27 Jakie kroki wykonuje procesor ARM po przyjęciu przerwania? . . . . . . . . . 21
2.28 Kiedy można modyfikować bity SPR?
. . . . . . . . . . . . . . . . . . . . . . 21
2.29 Porównanie rejestrów CPSR i SPSR w ARM - cel użycia . . . . . . . . . . . . 21
2.30 MAM - tryby pracy, opis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.31 MMC (Memory Map Concepts) - opis . . . . . . . . . . . . . . . . . . . . . . 22
2.32 GPIO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
1

3
Kompilatory, inne nie wiadomo skąd
23
3.1
Zasady łączenia plików c i asm w IAR . . . . . . . . . . . . . . . . . . . . . . 23
3.2
Funkcje z równoczesnym wielokrotnym wywołaniem (reentrant) . . . . . . . . 24
3.3
Funkcje wywoływane z podprogramu obsługi przerwania . . . . . . . . . . . . 24
3.4
Jak w C zadeklarować adres stały? . . . . . . . . . . . . . . . . . . . . . . . . 24
3.5
Opisz linkera w pakiecie µVision . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.6
Podana jest liczba 0xC14800000. Jaka jest jej wartość w systemie dec, jeżeli
jest to zapis w pamięci zmiennej typu float? . . . . . . . . . . . . . . . . . . . 25
3.7
Różnice i cechy wspólne parametrów pierwotnej i wtórnej asemblacji . . . . . 25
3.8
Czym się różnią makro procedury i podprogramy? . . . . . . . . . . . . . . . 25
3.9
Napisać podstawowe elementy procedury asemblerowej w środowisku IAR (..) 26
3.10 Napisać podstawowe elementy procedury asemblerowej w środowisku IAR (..) 26
3.11 Jak w IAR napisać funkcję, która zostanie umieszczona w RAM? . . . . . . . 26
3.12 Funkcje specjalne w C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
1
MSP
1.1
Co oznacza ortogonalność rozkazów w MSP?
1.1.1
Ver. 1
Można używać wszystkich rozkazów z wszystkimi trybami adresowania. Ułatwia to pisanie
programów i translację z języków wysokiego poziomu.
1.1.2
Ver. 2
Pojęcie ortogonalności oznacza unifikację instrukcji wg następujących zasad:
• każda instrukcja może operować na dowolnym rejestrze roboczym, procesor nie ma więc
wyróżnionych rejestrów, które są specjalizowane do wykonywania określonych rodzajów
operacji,
• każda instrukcja może wykorzystywać dowolny tryb adresowania argumentów, nie ma
ukrytych związków między instrukcjami (efektów ubocznych), które spowodowałyby
nieprzewidziane reakcje systemu w zależności od kontekstu użycia rozkazów w progra-
mie,
• kody rozkazów i formaty instrukcji są zunifikowane; w szczególności wszystkie instrukcje
zajmują w pamięci programu taką samą ilość bajtów.
Ortogonalność zbioru instrukcji radykalnie upraszcza budowę układu sterowania, który może
zrealizować cykl wykonania każdego rozkazu według identycznego algorytmu. Stąd prostszy
układ sterowania może pracować znacznie szybciej, dlatego cykl rozkazowy ulega skróceniu.
1.2
Tryby adresowania w MSP
• Tryb rejestrowy (Rn) - zawartość rejestru jest operandem.
ADD R7, R8 ⇒ (R7) + (R8) → R8
• Tryb indeksowany (X(Rn) - Rn+X) - zawartość rejestru wskazuje na operand. X jest
zapisywane w następnym słowie.
MOVE 2(SP ), R7 ⇒ przesuń drugi element stosu doR7
• Tryb symboliczny (ADDR - PC+X) - wskazuje na operand. X zapisywane jest w na-
stępnym słowie. Używany jest tryb indeksowany X(PC).
ADD EDE, T ON I ⇒ (EDE) + (T ON I) → (T ON I)
• Tryb absolutny (&ADDR) - słowo z tą instrukcją jest adresem absolutnym.
ADD &CCR1, &CCR2 ⇒ (CCR1) + (CCR2) → (CCR2)
2

• Pośredni tryb rejestrowy (@Rn) - Rn używane jako wskaźnik operandu.
ADD @R8, R9 ⇒ ((R8)) + (R9) → (R9)
• Pośredni z autoinkrementacją (@Rn+) - Rn używane jako wskaźnik operandu, jest
postinkrementowane.
ADD @R8+, R9 ⇒ ((R8)) + (R9) → (R9), (R8) + 2 → (R8)
• Tryb natychmiastowy (#N) - słowo za instrukcją zawiera stałą natychmiastową. Jest
użyty tryb pośredni z autoinkrementacją @PC+.
MOV.B #01F h, 0(R12) ⇒ 01f h → ((R12) + 0)
1.3
Co to są rozkazy bazowe i emulowane w MSP?
Jądro (CORE) opiera się na architekturze RISC. Rozkazy bazowe (core instructions) są im-
plementowane sprzętowo. Są to mnemoniki, które po przetłumaczeniu na kod maszynowy
wykonuje procesor, np. MOV src, dst. Rozkazy emulowane nie są fizycznie zaimplementowa-
ne , ale wykonywane na podstawie odpowiedniego składania istniejących rozkazów bazowych
(są zmieniane na instrukcje bazowe, a potem tłumaczone na kod maszynowy), np. CLR dst
→ MOV #0, dst.
1.4
Finalne rozkazy po asemblacji RET i RETI
Ponieważ instrukcja RET jest instrukcją emulowaną, to po asemblacji w miejscu użycia
instrukcji RET zobaczymy: MOV @SP+, PC
Natomiast instrukcja RETI nie jest instrukcją emulowaną, więc po asemblacji w miejscu jej
użycia dalej będzie się znajdowało RETI.
1.5
Omówić ogólną strukturę MSP
• Procesor RISC (27 instrukcji bazowych i 24 emulowane) 16-bitowy,
• architektura von Neumana (brak rozdzielenia pamięci programu i danych, jednolity
sposób adresowania wszystkiego), zapis danych Little Endian,
• 16-bitowa magistrala danych (jest też 8-bitowa),
• 16-bitowa magistrala adresowa (jest też 8-bitowa),
• peryferia:
– liczniki,
– watchdog,
– porty (konfigurowane jako we/wy),
– kontroler DMA,
– łącza szeregowe,
– przetwornik A/C,
– komparator,
– kontroler LCD,
• 5 trybów redukcji mocy,
• 12 rejestrów ogólnego przeznaczenia,
• 4 rejestry dedykowane (PC, SP, SR i CONST generator),
• struktura statyczna, możliwość pracy niskimi częstotliwościami, może pracować dla
różnych częstotliwości taktowania,
• 3 formaty instrukcji (bitowe, bajtowe, jedno- i dwuargumentowe),
• różne źródła taktowania (zewn. i wewn.),
• niski pobór prądu w trybie uśpienia,
• 7 trybów adresowania.
1.6
Omówić system przerwań w MSP
Priorytety przerwań są ustalone i nie mogą być zmieniane. Najwyższe priorytety mają prze-
rwania niemaskowalne (15 i 14 priorytet) Zagnieżdżanie wykonuje się przez ustawienie GIE
w procedurze obsługi przerwania. Priorytety przerwań ustalone są w zakresie 0 (najniższy,
np. układy peryferyjne) - 15 (najwyższy, np. zewnętrzny reset).
Typy przerwań:
• systemowe,
• niemaskowalne (NMI),
• maskowalne.
Źródła przerwań systemowych:
• dostarczenie napięcia zasilania @ POR, PUC,
• stan niski na RST/NMI (w trybie resetu) @ POR, PUC,
• przepełnienie licznika watchdog (w trybie watchdoga) @ PUC,
• naruszenie klucza bezpieczeństwa watchdoga @ PUC,
• pisanie do WDTCTL ze złym hasłem.
3

Źródła przerwań niemaskowalnych:
• zbocze na RST/NMI (w trybie NMI),
• błąd oscylatora.
Źródła przerwań maskowalnych:
• przepełnienie watchdoga (w trybie timer),
• zgłoszenia od innych modułów posiadających możliwość zgłoszenia przerwania.
Wykonanie przerwania:
• Kończenie aktualnie wykonywanej instrukcji (ewentualnie wyłączenie trybu oszczędno-
ści),
• PC, SR przenoszony na stos,
• wybór przerwania o najwyższym priorytecie,
• kasowanie flagi przerwania (jeśli jej źródłem jest tylko to przerwanie), resetowanie GIE,
• wektor przerwania jest ładowany do PC i wykonanie obsługi przerwania, na koniec
RETI,
• SR i PC przywracane ze stosu.
1.7
Źródła sygnałów taktujących w MSP
1.7.1
Ver. 1
• LFXT1CLK - kwarc 32 768 Hz, rezonator lub kwarc: 450 kHz - 8 MHz,
• XT2CLK - rezonator, kwarc lub wejście zewnętrzne: 450 kHz - 8 MHz, w MSP430F47x
do 16 MHz,
• DCOCLK - wewnętrzny generator RC; po sygnale PUC ok. 800 kHz,
• zewnętrzny sygnał zegarowy podany na nóżkę XT2IN.
1.7.2
Ver. 2
• Główny generator DCO (sterowany cyfrowo) - bardzo szybki start, pełen zakres gene-
rowanych częstotliwości,
• generator RC - skokowo regulowana częstotliwość, bez rezystorów zewnętrznych do 4/9
MHz (z rezystorami więcej),
• oscylator zegarkowy 32 kHz (X1) - stabilna częstotliwość,
• oscylator kwarcowy / ceramiczny wysokiej częstotliwości (X2) - stabilna częstotliwość,
największe zużycie energii.
W procesorze stosuje się następujące sygnały zegarowe:
• ACLK (Auxiliary Clock) - sygnał o częstotliwości równej częstotliwości dołączonego
kwarcu (jest buforowany, może być dzielony, jest wybierany software’owo, może takto-
wać wybrane peryferia),
• MCLK (Main Clock) - sygnał będący wielokrotnością częstotliwości dołączonego kwar-
cu (może być taktowany różnymi źródłami, może być dzielony, ustawiany jest progra-
mowo, używany przez PCU i system),
• SMCLK (SubMain Clock) - sygnał zegarowy używany przez moduły zewnętrzne (mo-
że być taktowany różnymi źródłami, może być dzielony, może służyć do taktowania
peryferiów).
Odpowiedniego ustawienia wielokrotności dla sygnału MCLK dokonujemy w rejestrze
SCFQCTL (System Clock Frequency Control). Zawartość tego rejestru pozwala na usta-
wienie MCLK na wielokrotności od 3+1 do 127+1. Zmniejszenie zawartości rejestru poniżej
3 lub powyżej 127 powoduje nieprzewidywalną pracę całego mikrokontrolera.
1.8
Tryb pracy z niską mocą
• LPM0 - (CPU) off, (FLL, ALCK, MCLK) on, 50µA
• LPM1 - (CPU, FLL) off, (ALCK, MCLK) on, 50µA
• LPM2 - (CPU, FLL, MCLK) off, (ALCK) on, 6µA
• LPM3 - (CPU, FLL, MCLK, DC generator) off, (ALCK) on, 1.3µA
• LPM4 - (CPU, FLL, ACLK, MCLK, DC generator) off, 0.1µA
1.9
Jakie kroki wykonuje procesor MSP430 po przyjęciu przerwa-
nia?
1.9.1
Ver. 1
• CPU aktywne - aktualnie wykonywana instrukcja jest kończona; CPU w trybie zatrzy-
mania - tryby oszczędzania energii są wyłączane,
• PC → stos,
• SR → stos,
4

• wybierane jest przerwanie z najwyższym priorytetem, jeśli w czasie wykonywania ostat-
niego rozkazu zgłosiło się kilka przerwań,
• jeśli przerwanie ustawia flagę, której źródłem jest tylko to przerwanie, to flaga jest
resetowana automatycznie. Jeśli kilka przerwań ustawia daną flagę, to zostaje ona za-
chowana w celu obsługi przez oprogramowanie,
• general interrupt bit (GIE) jest resetowany; bity CPUOff, OscOff i SCG1 są czyszczone;
bity statusu V, N, Z i C są resetowane,
• odpowiedni wektor przerwania jest ładowany do PC i procedura obsługi przerwania jest
obsługiwana (opóźnienie pomiędzy zgłoszeniem, a startem procedury obsługi wynosi 6
cykli). Procedura obsługi przerwania kończy się rozkazem RETI, który wykonuje dalsze
czynności,
• stos → SR,
• stos → PC (powrót z przerwania trwa 5 cykli).
Zagnieżdżanie przerwań może być wykonane poprzez ustawianie GIE w procedurze obsłu-
gi przerwania. Maskowanie przerwań jest dokonywane w rejestrach IE1 i IE2. Priorytety
przerwań są ustalone i nie można ich zmienić.
1.9.2
Ver. 2
Wejście do obsługi przerwania:
• następuje zakończenie aktualnie wykonywanej instrukcji lub wyprowadzenie ze stanu
uśpienia,
• licznik stosu jest zmniejszany o 2,
• zawartość PC jest chowana na stos,
• licznik stosu jest zmniejszany o 2,
• rejestr statusowy jest chowany na stos,
• jeśli jest zgłoszonych kilka przerwań, obsługiwane jest to o najwyższym priorytecie,
• znacznik odpowiadający danemu przerwaniu jest kasowany, jeśli dotyczy to pojedyn-
czego źródła przerwania,
• znacznik przerwań: ogólnego GIE, CPUOff, OscOff i SCG1 są zerowane; nie jest zero-
wany SCG0,
• znaczniki V, N, C są zerowane,
• zawartość wskazywana przez odpowiedni wektor jest wstawiana do licznika rozkazów,
• rozpoczyna się wykonywanie podprogramu obsługi przerwania.
Wejście do obsługi przerwania trwa 6 cykli maszynowych.
Wyjście z obsługi przerwania (po instrukcji RETI):
• jest odtwarzana ze stosu zawartość rejestru statusowego,
• licznik stosu jest zwiększany o 2,
• jest odtwarzana ze stosu zawartość licznika programu,
• licznik stosu jest zwiększany o 2.
Powrót z obsługi przerwania trwa 5 cykli maszynowych.
1.10
Co jest wykorzystywane do programowania MSP?
• JTAG - specjalne wyprowadzenia w mikrokontrolerze. Port JTAG-a jest wyposażony w
bezpiecznik. Jego przepalenie (przy pomocy programatora) jest nieodwracalne i dostęp
poprzez JTAG jest niemożliwy,
• poprzez program ładujący (bootstrap loader – BSL). Odpowiednie wyprowadzenia mi-
krokontrolera umożliwiają wpis i odczyt pamięci flash poprzez łącze szeregowe. Dostęp
do pamięci jest zabezpieczony 256-bitowym kodem zdefiniowanym przez użytkownika.
Sposób dostępu określa dokumentacja techniczna mikrokontrolera,
• z programu użytkownika, np. przepisanie danych z RAM.
1.11
Różnice między UART a USART
UART:
• 4 rejestry kontrolne ulokowane w obszarze SFR. Jeden z nich wykorzystywany jest do
transmisji danych, następny steruje wyborem trybu transmisji, dwa pozostałe pełnią
rolę odczytu (działają jak bufory zapobiegające utracie danych w czasie, gdy CPU
obsługuje np. przerwanie o wyższym priorytecie i jednostka centralna jest zaangażowana
w obsługę innego procesu),
• transmisja asynchroniczna może być prowadzona w niemalże wszystkich powszechnie
stosowanych formatach,
• sygnał taktujący pracę UART pochodzi z wbudowanego w strukturę Timer1, który z
kolei może być taktowany z zewnętrznego generatora lub własnego generatora jednostki
centralnej.
USART:
5
• MSP posiada jeden uniwersalny synchroniczny/asynchroniczny moduł peryferyjny
USART (odbiór/transmisja), służący do komunikacji szeregowej,
• USART umożliwia transmisję synchroniczną SPI i asynchroniczną UART (odpowiednie
protokoły transmisji dla danych),
• podwójnie buforowane kanały transmisji/odczytu.
Odpowiednie tryby: wykład Watchdog, USART, LCD
1.12
Opisać działanie modulatora UART
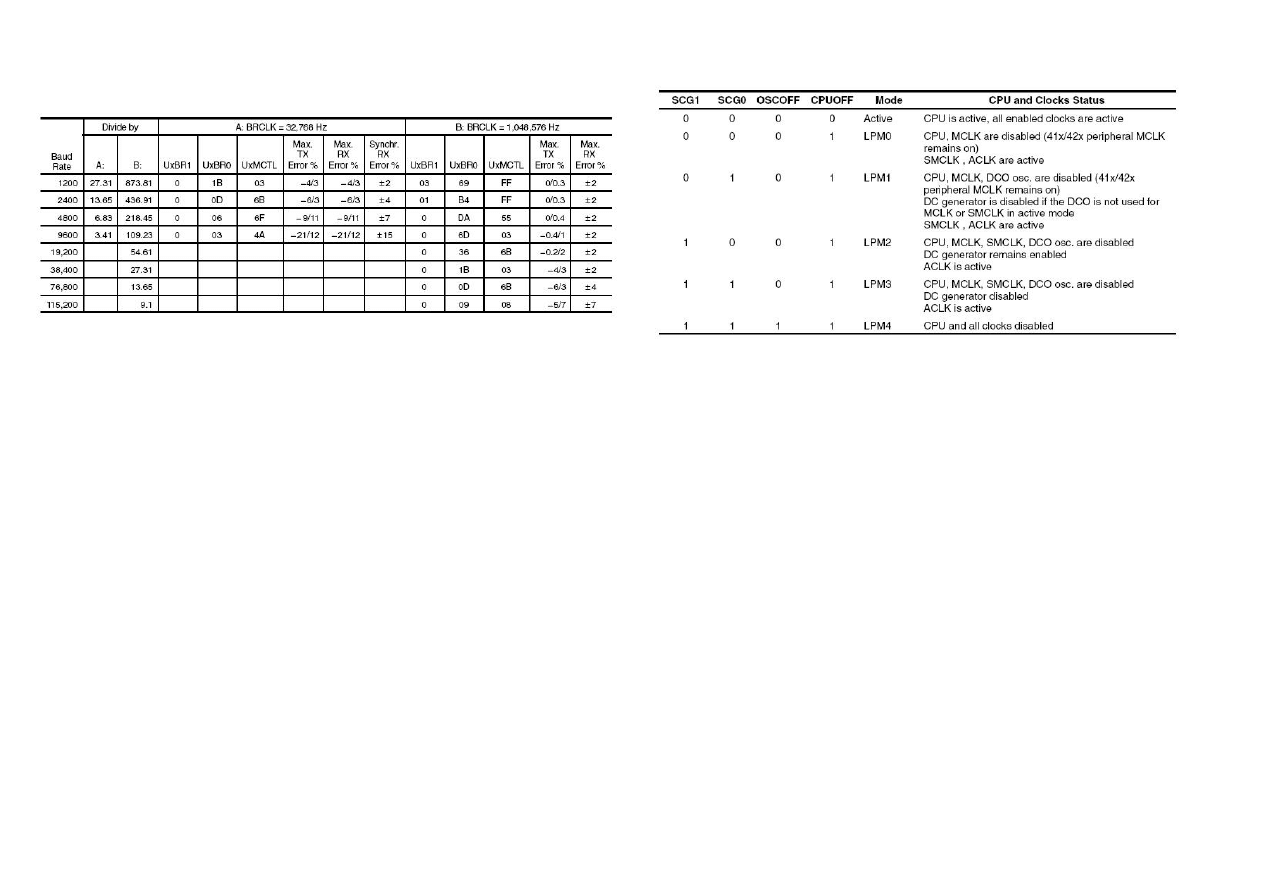
Baud rate =
BRCLK
N
=
BRCLK
U xBR +
1
n
P
n−1
0
m
i
BRCLK - częstotliwość taktująca port szeregowy
N - współczynnik podziału
n - liczba bitów w ramce
m - stan bitu
i - pozycja bitu
MSB
LSB
m
7
m
6
m
5
m
4
m
3
m
2
m
1
m
0
Przykład:
Baud rate = 2400
Ramka: bit startu, 8 bitów danych, bit parzystości, jeden bit stopu (11 bitów)
BRCLK = 32, 768 (ACLK)
↓
N =
32768
2400
= 13, 65
UxBR = 13
Liczba jedynek = 0, 65 · 11 = 7, 15 > 7
Rozłożone w miarę równomiernie:
UxMCTL = 0x6B
m
7
= 0, m
6
= 1, m
5
= 1, m
4
= 0, m
3
= 1, m
2
= 0, m
1
= 1, m
0
= 1
1.13
Opisać działanie watchdoga
• 16-bitowy licznik,
• różne źródła taktowania,
• tryb pracy: watchdog lub licznik,
• kod zabezpieczający przy wpisie do rejestru (5Ah),
• po resecie aktywny tryb watchdoga.
Główną funkcja watchdoga jest wykonywanie restartu układu po wystąpieniu błędu w dzia-
łaniu programu. Jeżeli ustawiony czas minie, zostanie wykonany reset układu. Jeżeli funkcja
watchdoga nie jest potrzebna, moduł może być skonfigurowany jako licznik.
Zatrzymanie watchdoga: MOV #WDTPW+WDTHOLD, &WDTCTL
Zerowanie watchdoga: MOV #WDTPW+WDTCNTL, &WDTCTL
1.14
Opisać jak działa mnożnik hardware’owy w MSP430
Mnożnik ten umożliwia mnożenie liczb całkowitych 8- i 16-bitowych ze znakiem i bez znaku.
Mnożenie trwa 3 cykle. Zaraz potem można odczytać wynik, chyba że jedna ze zmiennych
była adresowana pośrednio (wtedy należy odczekać jeden cykl). Możliwa jest także operacja
typu MAC (mnożenie i dodawanie). Przekroczenia zakresów nie są raportowane i muszą być
sprawdzane na drodze programowej.
Sam adres pierwszego operandu określa rodzaj operacji (MPY, MPYS, MAC) mnożnika
po modyfikacji drugiego operandu. Nie jest podejmowana akcja, jeśli tylko zmodyfikujemy
pierwszy operator.
Przykład: bezznakowe mnożenie (MPY). Dwa operatory są w rejestrach R14 i R15.
MOV R15, #130h
MOV R14, #138h ;start z drugim operatorem
1.15
Sposób rozmieszczania zmiennych w pamięci MSP
Bajty w pamięci są umieszczane na pozycjach parzystych i nieparzystych. Słowa są umiesz-
czane w porządku rosnącym z wyrównaniem do parzystych adresów. Niższy bajt jest umiesz-
czany przy parzystym (even) adresie, a bajt wyższy przy nieparzystym (odd).
Rozpoczynając od adresu 0x0000:
• SFP 0x0000 - 0x0100: dostęp bajtowy,
• 8-bit Peryferia 0x0100: dostęp bajtowy,
• 16-bit Peryferia 0x0200: dostęp za pomocą słowa,
• pamięć danych (RAM) 0x0C00: dostęp bajtowy i za pomocą słów,
• Bootstrap Loader (BSL): dostęp bajtowy i za pomocą słów,
• pamięć programu 0xFFE0: dostęp bajtowy i za pomocą słów,
• tablica Wektora Przerwań 0xFFFF: dostęp bajtowy i za pomocą słów.
6
1.16
Podać wartości rejestrów generatora (w tym rej. modulatora)
UART-a
1.17
Jakie elementy i rozwiązania decydują o małym poborze prą-
du przez mikrokontrolery z rodziny MSP430?
MSP430 posiada 5 różnych trybów oszczędzania energii. Oznaczone są one jako LMP0..4
(Low Power Modes). Indeks przy LPM oznacza “głębokość” uśpienia mikrokontrolera. Spo-
soby wyprowadzania z trybów uśpienia zależą od skali aktywności zasobów mikrokontrolera.
Dla LPM0 może to być dowolne przerwanie, podczas gdy z LMP4 wyjść można już tylko
poprzez zerowanie.
• Tryby niskiego poboru mocy (5 trybów),
• możliwość wyboru trybu pracy,
• 0.1µA - podtrzymanie RAM,
• 0.8µA - RTC,
• 250µA @ 1 MIPS w trybie aktywności,
• zasilanie 1.8 - 3.6 V
• start zegara w mniej niż 6µs, skraca to czas aktywnej pracy, co sprzyja redukcji energii
(szybkie DCO),
• prąd upływności portów < 50nA,
• −40 - +85
◦
C - przemysłowy zakres temperatur pracy.
Podstawowe zasady tworzenia aplikacji o niskim poborze energii:
• mikrokontroler powinien pozostawać przez większość czasu w trybie o obniżonym po-
borze energii (LPM3 lub wyższym),
• użycie kwarcu 32 k i szybkiego DCO pozwala wykonać zadania w krótkim czasie,
• używanie peryferiów zamiast programowej kontroli zadań,
• używanie przerwań do kontroli działania programu,
• stosowanie tablic w miejsce obliczeń numerycznych,
• skomplikowane obliczenia wykonywane na rejestrach,
• ograniczenie wywoływania podfunkcji,
• preferowane bezpośrednie zasilanie z baterii, bez przetwarzania energii,
• kontrolowanie zasilania układów zewnętrznych.
1.18
Jak są wnoszone i zwracane zmienne w funkcjach w IAR dla
MSP430?
Od wersji kompilatora 4.11 do wnoszenia parametrów są wykorzystywane na stałe 4 rejestry,
można więc wnosić do 4 parametrów 8-/16-bitowych do funkcji bez potrzeby wykorzystania
stosu. Do wnoszenia większej ilości parametrów musimy użyć stosu. Poprzez stos są rów-
nież wnoszone parametry związane z uniami, strukturami i klasami, a także nienazwane
parametry do funkcji o zmiennej liczbie parametrów, np. funkcji printf.
7

Dane
Wnoszenie
Zwracanie
8-bitowe
R12, R13, R14, R15
R12
16-bitowe
R12, R13, R14, R15
R12
20-bitowe
R13:R12, R15:R14
R13:R12
32-bitowe
R13:R12, R15:R14
R13:R12
64-bitowe
R15:R14:R13:R12, R11:R10:R9:R8
R15:R14:R13:R12
Jeżeli funkcja zwraca strukturę, adres w pamięci, pod którym struktura się znajduje jest
przekazywany poprzez rejestr R12 jako parametr ukryty.
1.19
Deklaracja modelu pamięci dla MSP430X
W kompilatorze (ale tylko dla procesorów MSP430X) można uzyskać domyślny dostęp do
pamięci poprzez wybór modelu danych, co nie przeszkadza na ulokowanie wybranej danej
w dowolnym miejscu pamięci.
Modele pamięci:
• small - określa segment data16, co oznacza pierwszych 64 KB pamięci. Dostęp do peł-
nego obszaru 1MB jest tylko poprzez użycie funkcji intrinsic,
• medium - wyznacza segment data16 jako domyślny i tam są lokowane dane, ale nie
ogranicza to dostępu do całej pamięci 1MB,
• large - określa segment data20 jako pamięć domyślną, co oznacza dostęp do całej pa-
mięci.
Model pamięci może być wybierany opcją –data model.
Zmiana modelu dla wybranej danej lub danych może nastąpić poleceniem #pragma ty-
pe attribute.
data20 int i, j;
int
data20 k, l;
1.20
Co trzeba zrobić, aby wykonał się rozkaz bezpośrednio po
komendzie wprowadzenia MSP w stan uśpienia?
Musi być odblokowane przerwanie (jakiekolwiek) i procesor musi wyjść z uśpienia poprzez
to przerwanie. Wewnątrz przerwania należy wejść w zwykły tryb pracy (przywrócić tryb
aktywny).
1.21
Opisać, jak wyłączyć tryb uśpienia przy wyjściu z procedury
obsługi przerwania
MSP430 jest przełączany w tryb niskiego poboru mocy poprzez ustawienie bitów w rejestrze
statusowym. Po wejściu do przerwania możemy zmodyfikować pamięć, gdzie na stosie został
odłożony rejestr statusowy na początku przerwania. Po instrukcji RETI rejestr zostanie
pobrany ze stosu i proceser będzie działać już w nowym trybie.
Aby to zrobić, musimy wyzerować odpowiednie bity w rejestrze statusowym, który został
zachowanu na stosie, np. wyjście z trybu LMP0 przy pomocy instrukcji
BIC #CPUOFF, 0(SP)
RETI
Analogicznie wyjście z trybu LMP3:
BIC #CPUOFF+SCG1+SCG0, 0(SP)
RETI
1.22
Porównanie MSPX i MSP
• Architektura RISC,
• architektura ortogonalna,
• 16 rejestrów ogólnego przeznaczenia,
• jednocyklowe operacje na rejestrach,
• tryby obniżonego poboru mocy,
• 7 trybów adresowania,
• architektura statyczna,
• generator stałych,
• ten sam dostęp do peryferiów.
MSP430
MSP430X
Magistrala adresowa
16-bit
20-bit
Instrukcje
Niektóre wykonywane szybciej
+ dodatkowa RRUX
Jednostka ALU
16-bit
20-bit
Rejestry ogólnego
16-bit
20-bit (oprócz R2 - Status
przeznaczenia
Register - 16-bit)
Obsługa przerwań
szybsza
Przestrzeń adresowa
do 64 kB
do 1 MB
Zestaw instrukcji
Rozszerzony o instrukcje umożliwiające
wykonanie programu w pamięci 1 MB
Opóźnienie ISR
11 cykli
8 cykli
Ponadto MSPX nie wymaga stronicowania pamięci, a na niektóre instrukcje przypada mniej
cykli maszynowych do wykonania.
8

1.23
Porównanie mnożników w MSP i MSPX
MSPX posiada dwa układy mnożące: 16- i 32-bitowy.
Mnożnik 16-bitowy, taki sam jak w MSP, umożliwia realizację następujących operacji:
• mnożenie liczb bezznakowych,
• mnożenie liczb ze znakiem,
• mnożenie liczb bezznakowych z sumowaniem,
• mnożenie liczb ze znakiem z sumowaniem,
• powyższe operacje na liczbach: 16x16, 16x8, 8x16, 8x8 (bitów),
• czas wykonania operacji: 3 cykle MCLK; odczyt wyniku może nastąpić w kolejnym
rozkazie po wpisanu danej do rejestru OP2, chyba że rozkaz jest rozkazem pośrednim
(wymagane użycie NOP).
Mnożnik 32-bitowy:
• mnożenie liczb bezznakowych,
• mnożenie liczb ze znakiem,
• mnożenie bezznakowe z akumulacją,
• mnożenie ze znakiem i akumulacją,
• operacje na danych 8-, 16-, 24- i 32-bitowych,
• saturacja,
• operacje na ułamkach,
• operacje 8- i 16-bitowe kompatybilne z 16-bitowym mnożnikiem,
• operacje 8- i 16-bitowe nie wymagają rozciągania znaku,
• wynik mnożenia zawsze jest 64-bitowy i dostępny przez rejestry RES0 - RES3,
• operacje ze znakiem z użyciem rejestrów MPYS lub MACS powodują rozciągnięcie
znaku na wszystkie wolne miejsca w rejestrach.
1.24
ADC12 vs. DAC12
ADC12:
• maksymalna częstotliwość przetwarzania większa od 200 kHz,
• liczba kanałów pomiarowych zależy od konkretnego mikrokontrolera,
• 12-bitowa monotoniczna charakterystyka bez zbędnych kodów,
• programowo ustalany czas dla układu próbkująco-pamiętającego,
• wyzwalanie programowe lub z liczników Timer A lub Timer B,
• programowo wybierane zewnętrzne lub wewnętrzne napięcie odniesienia,
• niezależne kanały pomiarowe dla wewnętrznego czujnika temperatury,
• niezależne kanały pomiarowe dla dodatniego i ujemnego napięcia odniesienia,
• pogramowe wybieranie źródła sygnału taktującego,
• pomiar pojedynczy lub wielokrotny w wybranym kanale, pomiar pojedynczy lub wie-
lokrotny w zaprogramowanych kanałach,
• układ przetwornika oraz układ napięcia odniesienia mogą być wyłączane niezależnie,
• 16 rejestrów dla przechowywania wyników przetwarzania.
DAC12:
• 12-bitowy przetwornik cyfrowo-analogowy z wyjściem napięciowym. Jeśli w mikrokon-
trolerze występuje kilka przetworników C/A, to mogą one pracować synchronicznie,
• wyjście 12-bitowe monotoniczne,
• 6 lub 12 bitów rozdzielczości,
• programowe ustalenie szybkości narastania sygnału wyjściowego,
• wewnętrzne lub zewnętrzne źródło sygnału odniesienia,
• format danych: binarny lub z uzupełnieniem do 2,
• autokalibracja napięcia offsetu,
• możliwość synchronizacji przy pracy kilku przetworników.
9
1.25
Porównanie LCD i LCD A
• LDA A posiada lampę ładunkową, z której można zasilać wyświetlacz; napięcie pompy
można zmieniać programowo (regulacja kontrastu wyświetlacza),
• LCD A nie potrzebuje taktowania Basic Timer0, jest taktowane bezpośrednio z ACLK,
• LCD A posiada blok Bias Voltage Generator, dzięki czemu nie trzeba stosować ze-
wnętrznych rezystorów ustalających poziomy napięć dla LCD.
1.26
SVS - kontroler napięcia zasilania
• Testowanie napięcia AV
CC
,
• kanał zewnętrzny do generowania napięcia zewnętrznego,
• możliwość generowania sygnały POR,
• wyjście komparatora SVS dostępne programowo,
• stan niskiego napięcia jest zapamiętywany i dostępny przez program,
• 14 poziomów napięć odniesienia.
∗
∗
W procesorach MPS430x412 i MSP430x213 jest tylko jeden poziom. Dla VLDx = 0 układ
jest wyłączony. Każda inna wartość ustala napięcie odniesienia na 1,9 V.
1.27
SD16
Moduł SD16 składa się z trzech niezależnych przetworników analogowo-cyfrowych tpu delta-
sigma i wewnętrznego źródła napięcia odniesienia. Każdy kanał może mieć do 8 różnicowych
wejść, z czego 6 jest dostępnych z zewnątrz, jedno wejście służy do pomiaru temperatury
z wewnętrznego czujnika temperatury, a pozostałe wejście jest zwarte do ewentualnego po-
miaru offsetu. Przetwornik zawiera modulator delta-sigma drugiego rzędu. Napróbkowanie
może wynosić 256.
Napięcie odniesienia może być zewnętrzne lub wewnętrzne. Przetwornik posiada jeden
wzmacniacz wstępny o programowalnym wzmocnieniu. Zakres napięcia przetwarzania okre-
ślony jest zależnością:
V
F SR
=
V
REF
/2
GAIN
P GA
Odczyt wszystkich bitów można uzyskać automatycznie podczas dwukrotnego odczytu od-
powiedniego rejestru pamięci wyniku. Należy tylko znacznik SD16LSBTOG ustawić w stan
1. Po pierwszym odczycie z pamięci wyniku znacznik SD16LSBACC zmieni swój stan au-
tomatycznie na przeciwny i podczas kolejnego odczytu pamięci otrzyma się kolejne bity
wyniku pomiaru.
SD16SNGL
SD16GRP
Tryb
1
0
Pojedynczy kanał, pojedyncze przetworzenie
0
0
Pojedynczy kanał, przetwarzanie ciągłe
1
1
Pojedyncze przetwarzanie dla grupy kanałów
0
1
Ciągłe przetwarzanie dla grupy kanałów
1.28
Flash - pamięć programu i danych
• Wewnętrzny generator napięcia programującego,
• programowanie bitowe, bajtowe lub słowem,
• kasowanie segmentami lub całościowe.
Napięcie zasilania procesora podczas programowania nie może spać poniżej 2,7 V!
Kasowanie pamięci:
MERAS
ERASE
0
1
kasowanie segmentu
1
0
kasowanie całej pamięci
1
1
kasowanie pamięci programu i danych
Kasowanie pamięci programem z Flash: na czas procesu procesor wstrzymuje wykonywanie
programu:
Zablokowanie watchdoga → wpis do rejestrów sterujących → wpis dowolnej danej → LOCK
= 1 → odblokowanie watchdoga
Kasowanie pamięci programem z RAM : w trakcie kasowania program dalej jest realizowa-
ny:
Zablokowanie watchdoga → jeśli BUSY = 0 wpis do rejestrów sterujących → → wpis do-
wolnej danej → jeśli BUSY = 0 LOCK = 1 → odblokowanie watchdoga
Programowanie pamięci:
Na czas programowania przerwania są automatycznie blokowane.
Wybór trybu programowania:
BLKWWRT
WRT
0
1
zapis bajtu/słowa
1
1
zapis bloku
Podczas zapisu jest ustawiany znacznik BUSY. Próba dostępu do zapisywanego segmentu
gdy BUSY = 1 powoduje ustawienie znacznika ACCVIFG i może zniekształcić zapis.
10
Programowanie z pamięci flash:
Zablokowanie watchdogaa → wpis do rejestrów sterujących WRT = 1 → wpis bajtu lub
słowa → LOCK = 1 → WRT = 0 → odblokowanie watchdoga
Programowanie z pamięci RAM:
Zablokowanie watchdoga → jeśli BUSY = 0 wpis do rejestrów sterujących WRT = 1 → wpis
bajtu lub słowa → jeśli BUSY = 0 → LOCK = 1 → WRT = 0 → odblokowanie watchdoga
1.29
Timery w MSP
Timer A:
• asynchroniczny, 16-bitowy licznik z czterema trybami pracy,
• wybór i konfiguracja różnych źródeł taktowania (ACLK, SMCLK, ewentualnie TACLK,
INCLK),
• 3 lub 5 konfigurowalnych rejestrów typu zatrzask / komparator,
• konfigurowane wyjścia, możliwość trybu PWM (modulacja szerokości impulsów),
• asynchroniczne zatrzaskiwanie wejścia i wyjścia,
• rejestr wektora przerwań do szybkiego dekodowania wszystkich przerwań.
Timer B - identyczny jak Timer A z wyjątkami:
• długość licznika B może być programowana jako 8, 10, 12 lub 16 bitów,
• rejestry TBCCRx są podwójnie buforowane i mogą być grupowane,
• wszystkie wyjścia licznika mogą być ustawione w stan wysokiej impedancji,
• funkcja SCCI nie jest zaimplementowana w Timerze B.
Basic Timer1:
• dwa niezależne 8-bitowe timery,
• możliwość połączenia w kaskadę, z funkcjami 16-bitowego timera,
• LCD taktowane z Basic Timer1,
• możliwe przerwania,
• programowa inkrementacja czasu.
1.30
Bootstrap Loader
• Specjalna procedura umieszczona w pamięci ROM umożliwiająca programowanie mi-
krokontrolerów poprzez łącze szeregowe RS232,
• obecnie procedura ta umożliwia programowanie pamięci w obszarze 64 KB, powyżej
tego obszaru należy najpierw wgrać odpowiedni program umożliwiający programowanie
powyżej 0x10000, dodatkowy program może przyspieszyć transmisję,
• można programować pamięć ROM i RAM z prędkością od 9600 do 38400 bod/s,
• program BSL mieści się w obszarze 0xC00 – 0x0FFF,
• każda komenda wysyłana do BSL rozpoczyna się bajtem 0x80. Jest to bajt synchroni-
zacyjny umożliwiający poprawną komunikację,
• po przyjęciu danych BSL wysyła bajt potwierdzenia (ACK) o wartości 0x90. Jeżeli
ramka zawiera błędy BSL wysyła bajt (NAK) o wartości 0xA0.
Komendy zabezpieczone - kod: zawartość wektora resetu pod adresem 0xFFFE -0xFFFF.
Komendy zabezpieczone hasłem:
• przesłanie bloku danych do zaprogramowania pamięci flash lub RAM,
• odczytanie bloku danych,
• usunięcie segmentu,
• sprawdzenie poprawności usunięcia danych,
• ustawienie offsetu pamięci,
• ustawienie licznika rozkazów i start programu użytkownika,
• zmiana szybkości transmisji (od wersji V2.01).
Komendy niezabezpieczone:
• przesłanie hasła,
• usunięcie całej pamięci (pamięć główna i informacji),
• odczytanie wersji bootloadera,
• zmiana szybkości transmisji (wersja V1.60 i V1.61).
11

Obliczanie sumy kontrolnej:
16-bitowa suma kontrolna jest obliczana na podstawie odebranych lub wysłanych bajtów
B1, ..., Bn znajdujących się w ramce danych z pominięciem samej sumy kontrolnej (B1 –
nagłówek (Hdr), Bn – ostatni bajt danych przed bajtem CKL).
SUMA KONTROLNA = INV [(B1+256xB2) XOR (B3+256xB4) XOR ... XOR (Bn-
1+256xBn)]
lub:
CKL = INV[B1 XOR B3 XOR... XOR Bn-1]
CKH = INV[B2 XOR B4 XOR... XOR Bn]
Przykład:
Do BSL: 80 (bajt synchronizacji)
Od BSL: 90 (potwierdzenie)
Do BSL: 80 14 04 04 F0 0F 0E 00 85 E0 (komenda odczytu pamięci od 0x0F00 o długości
0x000E)
Od BSL: 80 00 E0 0E F2 13 40 40 00 00 00 00 00 02 01 01 01 C0 A2
1.31
DMA
Układ bezpośredniego dostępu do pamięci umożliwia przesyłanie danych spod jednego ad-
resu pod inny adres bez pośrednictwa jednostki centralnej. W zależności od modelu mikro-
kontrolera może on zawierać od jednego do trzech układów DMA. Użycie kontrolera DMA
może zwiększyć przepustowość danych pomiędzy peryferiami, może również zmniejszyć po-
bór energii, gdyż na czas działania układu jednostka centralna wprowadzana jest w stan
uśpienia.
Własności:
• do trzech niezależnych kanałów transmisyjnych,
• wybór i konfiguracja priorytetów dla kanałów,
• tylko dwa cykle na transfer,
• możliwość transmisji bajt, słowo lub bajt/słowo,
• blok transmisji danych do 65535 bajtów lub słów,
• wybór źródła wyzwalania,
• wybór wyzwalania zboczem lub poziomem,
• cztery tryby adresowania,
• trzy tryby transmisji (blokowa, blokowa przerywana, pojedyncza).
Tryby adresowania (ustawianie trybów adresowania jest dla każdego kanału niezależne):
• stały adres do stałego adresu,
• stały adres do bloku adresów,
• blok adresów do stałego adresu,
• blok adresow do bloku adresów,
Transfer pojedynczy:
• znacznik DMASRCINCRx określa, czy adres źródła jest inkrementowany, dekremento-
wany czy pozostaje bez zmian,
• jeżeli następuje transfer słowo – bajt, to przesyłany jest tylko mniej znaczący bajt
słowa,
• jeżeli następuje transfer bajt – słowo, bardziej znaczący bajt słowa jest zerowany,
• rejestry:
– DMAxSZ - jest używany do określenia liczby transferów,
– DMAxSA – rejestr z adresem źródła,
12

– DMAxDA - rejestr z adresem przeznaczenia.
• jeżeli DMAxSZ = 0, to nie ma transmisji,
• zawartości rejestrów DMAxSA, DMAxDA i DMAxSZ są kopiowane do rejestrów po-
mocniczych,
• zawartość rejestru DMAxSZ jest dekrementowana po każdej operacji transferu,
• jeżeli stan rejestru po dekrementacji osiągnie 0, to rejestr ten jest ładowany z rejestru
pomocniczego i jest ustawiany znacznik DMAIFG – start przerwania,
• jeżeli znacznik DMADTx = 0, znacznik DMAEN jest kasowany automatycznie, kiedy
DMAxSZ osiągnie wartość 0 i musi być ustawiony ponownie, by odbył się kolejny
transfer,
• w trybie powtarzania DMAEN = 1 i transfer następuje po przyjściu sygnału wyzwala-
nia.
Transfer blokowy:
• w trybie pracy blokowej jeden sygnał wyzwalający uruchamia przesyłanie całego bloku
danych,
• w trakcie przesyłania danych inne sygnały wyzwalające są pomijane,
• gdy znacznik DMADTx = 1, po skończonej transmisji znacznik DMAEN jest zerowany
(przed kolejną transmisją musi on być ustawiony ponownie),
• DMAxSZ - liczba przesłanych danych, DMADSTINCRx inkrementację/dekrementację
adresu przeznaczenia, a DMASRCINCRx - inkrementację/dekrementację adresu źró-
dła,
• rejestry DMAxSA, DMAxDA i DMAxSZ pracują tak samo, jak przy przesyłaniu poje-
dynczym,
• znacznik DMAIFG jest ustawiany, gdy rejestr DMAxSZ osiągnie wartość 0,
• w trakcie transmisji jest wstrzymywana praca CPU,
• transmisja blokowa trwa 2xMCLK x DMAxSZ,
• jeżeli transfer blokowy jest powtarzany cyklicznie, to znacznik DMAEN pozostaje usta-
wiony po skończonym przesłaniu bloku i układ oczekuje na następny sygnał wyzwalania.
Transfer blokowy przerywany:
• w tym trybie układ DMA pracuje na przemian z CPU,
• CPU wykonuje 2 cykle MCLK po każdy przesłaniu czterech bajtów lub słów,
• po skończonej transmisji znacznik DMAEN jest kasowany (przed następną transmisją
musi być ponownie ustawiony),
• przychodzące sygnały wyzwalające podczas transferu są ignorowane,
• praca rejestrów i ustawianie znaczników jest taka sama, jak podczas pracy blokowej, za
wyjątkiem przesyłania ciągu bloków,
• po skończeniu transmisji jednego bloku znacznik DMAEN pozostaje ustawiony i trans-
misja kolejnego loku następuje od razu - bez sygnału wyzwalającego,
• przerwanie transmisji może nastąpić poprzez zerowanie znacznika DMAEN lub prze-
rwanie niemaskowane NMI jeżeli jest odblokowane.
Zatrzymanie pracy DMA:
• każdy rodzaj transmisji można zatrzymać przerwaniem niemaskowalnym NMI, gdy w
rejestrze DMACTL1 jest ustawiony znacznik ENNMI,
• przerywana praca blokowa moze być zatrzymana po wyzerowaniu znacznika DMAEN.
Priorytety układu DMA:
• priorytety dla układu DMA są następujące: DMA0-DMA1-DMA2,
• jeżeli przyjdą równocześnie dwa lub trzy sygnały wyzwalające, to startuje układ o
najwyższym priorytecie,
• następnie jest uruchamiany układ o niższym priorytecie, a na końcu o najniższym prio-
rytecie, niezależnie od trybu pracy układów DMA,
• kanał o wyższym priorytecie czeka na zakończenie trwającej transmisji kanału o niższym
priorytecie,
• priorytety kanałów DMA można ustawiać znacznikiem ROUNDROBIN; jeżeli znacznik
ten jest ustawiony, to kanał który skończy transmisję przyjmuje najniższy priorytet,
natomiast układ priorytetów nie ulegają zmianie, tzn. zachowana jest kolejność: DMA0
- DMA1 - DMA2,
• priorytety dla kanałów DMA nie mają zastosowania dla procesorów serii MSP430
FG43x.
13
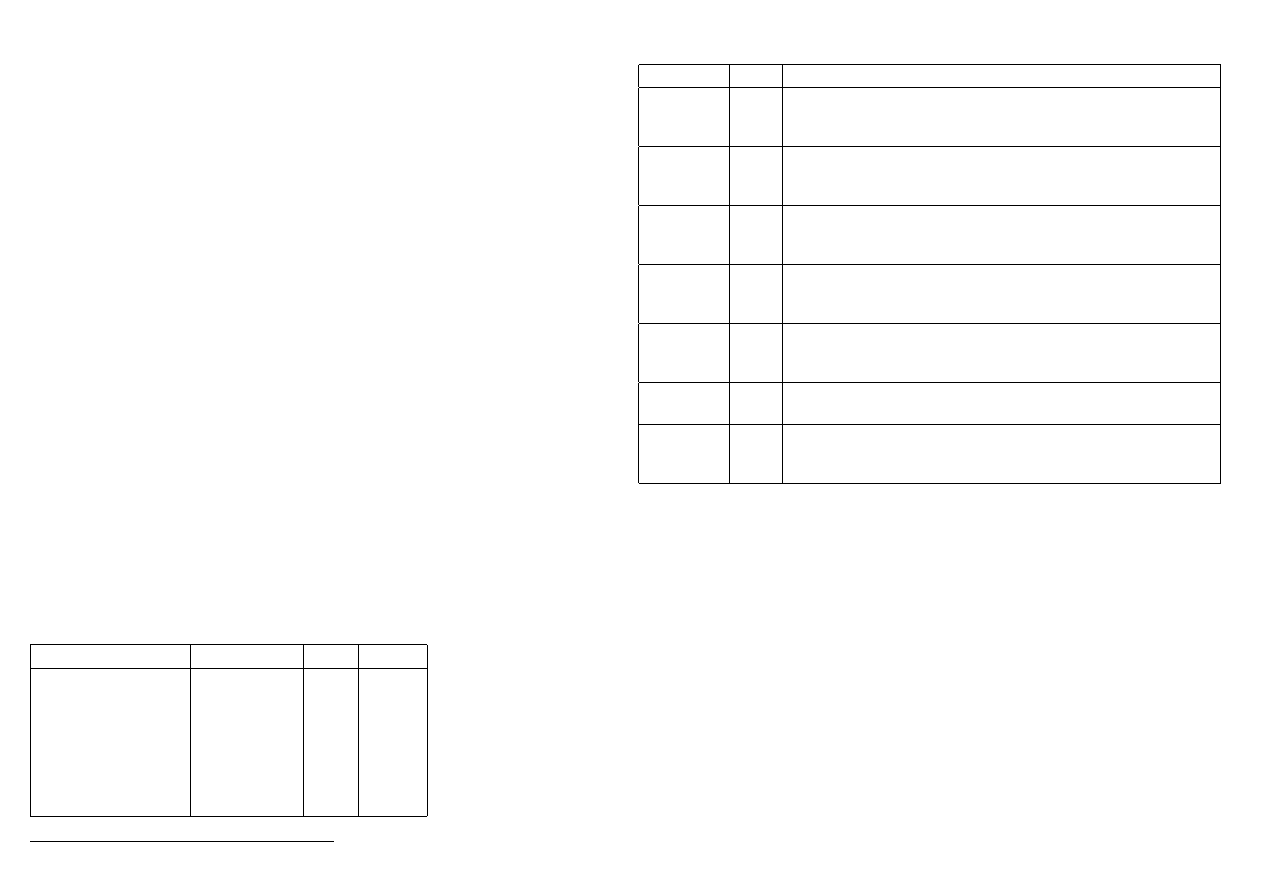
1.32
Co należy zrobić, aby program z MSP430X zadziałał na
MSP430?
• Należy umieścić wszystkie dane w pamięci poniżej 64 kB, umożliwi to korzystanie wy-
łącznie z 16-bitowego adresowania,
• stałe podprogramów umieścić bezpośrednio w kodzie podprogramu, umożliwi to adre-
sowanie symboliczne w zakresie PC + 32 kB.
2
ARM
2.1
Główne cechy architektury ARM
• 32bity, RISC z pipeliningiem 3-etapowym,
• architektura Von Neumana,
• 7 trybów optymalizowanych (budowa do obsługi systemu operacyjnego),
• 5 trybów adresowych,
• 37 rejestrów (31 ogólnego przeznaczenia, 6 statusowych),
• architektura load-store (operacje arytmetyczno-logiczne tylko na rejestrach),
• Big lub Little Endian,
• tryb 32-bitowych instrukcji (ARM) i 16-bitowych (THUMB),
• przerwania FIQ, IRQ wektorowe, IRQ niewektorowe, SWI.
2.2
Tryby pracy, wyjątki
Gdy pojawia się przerwanie, procesor zmienia tryb - PC wykonuje skok do skojarzonego
wektora.
Exception type
Vector address
Mode
Priority
Reset
0x 0000 0000
svc
1
Undefined instruction
0x 0000 0004
undef
6
Software interrupt
0x 0000 0008
svc
6
Prefetch abort
0x 0000 000C
abort
5
Data abort
0x 0000 0010
abort
2
Reserved
0x 0000 0014
n/a
n/a
Interrupt (IRQ)
0x 0000 0018
irq
4
Fast Interrupt(FIQ)
0x 0000 001C
fiq
3
Wszystkie tryby wyjątków są uprzywilejowane.
Tryb pracy
Skrót
Opis
User
usr
Tryb normalnego wykonywania programu
Tryb nieuprzywilejowany
Większość zadań wykonywanych w tym trybie
System
sys
Tryb uprzywilejowany
Korzysta z tych samych rejestrów, co tryb usr
Do wykonywania uprzywilejowanych zadań systemowych
Supervisor
svc
Tryb wyjątku
Tryb ochronny systemu
Uruchamiany przez reset lub SWI
Abort
abt
Tryb wyjątku
Tworzy (implementuje) pamięć wirtualną i/lub ochrania pamięć
Używany w sytuacjach naruszenia dostępu do pamięci
Undefined
und
Tryb wyjątku
Używany w momencie wystąpienia niezdefiniowanych instrukcji
Wspomaga programową emulację sprzętowych koprocesorów
IRQ
irq
Tryb wyjątku
Używany do obsługi niskopriorytetowych przerwań
FIQ
fiq
Tryb wyjątku
Używany do obsługi przerwań FIQ (szybkich)
Wspomaga szybki transfer danych i procesy kanałowe
2.3
System rejestrów
• 6 rejestrów statusowych SPR (CPSR i 5xSPSR) oraz 31 rejestrów ogólnego przezna-
czenia (w tym PC),
• rejestry 32-bitowe,
• R13, R14 i R15 jako rejestry specjalnego przeznaczenia (odpowiednio SP, LR i PC),
• bankowane rejestry R8-R12 dla FIQ.
• CPSR (Current Program Status Register) - zawiera znaczniki wyniku wykonywanych
operacji arytmetycznych i logicznych, flagi pozwalające na kontrolę przyjmowania prze-
rwań oraz bity ustawień trybu ochrony; gdy procesor znajduje się w trybie uprzywilejo-
wanym, dodatkowo widoczny jest jeden z pięciu rejestrów SPSR (Saved PSR), będących
kopią CPSR utworzoną tuż przed zmianą trybu na inny,
• SPRR - w tym rejestrze zachowany jest stan rejestru CPSR przed wejściem w określony
tryb; każdy tryb (oprócz user i system) ma swój osobny rejestr SPSR; po zakończeniu
obsługi wyjątku rejestr CPSR jest odtwarzany z SPSR,
14

• R13: często jest on wykorzystywany jako SP, ponieważ jest on bankowany we wszystkich
trybach ochrony. Umożliwia to implementację osobnych stosów dla każdego trybu,
• R14: link register (kopiowanie zawartość licznika rozkazów PC do R14, a następnie skok
pod wskazany adres, powrót – przywrócenie PC). Dla zagnieżdżonych podprogramów
trzeba „ręcznie” chronić LR. Gdy nie używamy instr Branch Link (BL) możemy używać
R14 jak zwykły rejestr,
• R15: licznik rozkazów PC, do jego zawartości można odwoływać się za pomocą wielu
instrukcji.
2.4
Opis słowa rozkazowego
2.5
Instrukcje warunkowe
W rejestrze CPSR znajdują się flagi, które określają stan wyników operacji arytmetyczno-
logiczno-porównawczych: N (negative), Z (zero), V (overflow) i C (carry).
2.6
Pipelining
Przetwarzanie potokowe 3-etapowe:
• fetch (pobranie rozkazu z pamięci),
• decode (zdekodowanie instrukcji THUMB na ARM, dekodowanie instr. ARM i z jakich
rejestrów korzystają),
• execute (wykonanie instrukcji) → odczyt rejestrów, wykonywanie operacji w ALU bądź
Barrel Shifter i zapis do rejestrów
Pipeling wpływa na prędkość wykonywanych operacji i przyczynia się do skrócenia wyko-
nywania instrukcji do 1 cyklu.
Pipelining is implemented in hardware level. Pipeline is linear, what means that in simple
data processing processor executes one instruction in single clock cycle while individual
instruction takes three clock cycles. But when program structure has branches then pipeline
faces difficulties, because it cannot predict which command will be next. In this case pipeline
flushes and has to be refilled what means execution speed drops to 1 instruction per 3 clock
cycles. But it isn’t true actually. ARM instructions has nice feature that allow to smooth
performance of small branches in code that assures optimal performance. This is achieved
in hardware level where PC (Program Counter) is calculated 8 bytes ahead of current
instruction.
2.7
Sposób tworzenia adresu branch instruction (skoki)
Tryb ARM:
• B - skok bezwarunkowy, pozwala na skok w zakresie +/- 32 MB, ładuje adres skoku do
rejestru R15 (PC),
• BL - skok z zachowaniem adresu powrotu w R14 (odpowiednik CALL),
• BX - skok ze zmianą trybu z ARM na THUMB,
• BLX - skok do podprogramu ze zmianą trybu z ARM na THUMB.
Tryb THUMB:
• B, BL, BX, BLX,
• tylko B wykonywane z warunkiem.
Instrukcje skoku opóźniają kolejkę przetwarzania potokowego. aby selektywnie wykonać
instrukcje bez konieczności opóźniania kolejki, należy warunkowo wykorzystać instrukcje
poprzez dodanie odpowiednich przedrostków do mnemoników (tzn. nie stosować skoków
warunkowych, a instrukcje wykonujące się warunkowo) - tylko tryb ARM!
15

2.8
Opisać VIC
System przerwań organizuje VIC (Vectored Interrupt Controller), który umożliwia przypisa-
nie priorytetów przerwań, włączanie i wyłączanie poszczególnych przerwań oraz ustawienie
wektorów do procedur obsługi przerwania. VIC nie jest częścią rdzenia procesora, jest pod-
łączony do magistrali AHB która jest taktowana z prędkością rdzenia.
Z dokumentacji:
The Vectored Interrupt Controller (VIC) takes 32 interrupt request inputs and programma-
bly assigns them into 3 categories, FIQ, vectored IRQ, and non-vectored IRQ. The program-
mable assignment scheme means that priorities of interrupts from the various peripherals
can be dynamically assigned and adjusted.
Fast Interrupt reQuest (FIQ) requests have the highest priority. If more than one request
is assigned to FIQ, the VIC ORs the requests to produce the FIQ signal to the ARM
processor. The fastest possible FIQ latency is achieved when only one request is classified
as FIQ because then the FIQ service routine can simply start dealing with that device. But
if more than one request is assigned to the FIQ class, the FIQ service routine can read a
word from the VIC that identifies which FIQ source(s) is (are) requesting an interrupt.
Vectored IRQs have the middle priority, but only 16 of the 32 requests can be assigned to
this category. Any of the 32 requests can be assigned to any of the 16 vectored IRQ slots
among which slot 0 has the highest priority and slot 15 has the lowest.
Non-vectored IRQs have the lowest priority.
The VIC ORs the requests from all the vectored and non-vectored IRQs to produce the IRQ
signal to the ARM processor. The IRQ service routine can start by reading a register from
the VIC and jumping there. If any of the vectored IRQs are requesting, the VIC provides
the address of the highest-priority requesting IRQs service routine, otherwise it provides
the address of a default routine that is shared by all the non-vectored IRQs. The default
routine can read another VIC register to see what IRQs are active.
Z powyższego wynika:
• priorytet przerwań: FIQ > IRQ > niewektorowe IRQ,
• ponieważ zazwyczaj jest tylko jedno przerwanie FIQ można powiedzieć, że VIC nie
obsługuje FIQ oraz niewektoryzowanych IRQ,
• VIC używany jest do obsługi zwykłych przerwań IRQ; źródeł przerwań jest 32, ale
jako wektorowe może być obsłużonych tylko 16 (bo mamy tylko 16 wektorów); w re-
jestrach VICVectAdr[0:15] umieszczane są adresy procedur przerwań od odpowiednich
źródeł, natomiast rejestry VICVectCntl[0:15] kontrolują każdy z 16 slotów (ładniejsze
słowo: przyporządkowań :) od wektoryzowanych IRQ (np. VICVectCntl0 = 0x20 — 13;
oznacza: 0x20 to odblokowanie przerwania IRQ, przez — 13 wskazujemy jako źródło
przerwania RTC).
Ze slajdów:
• Vectored Interrupt Controller (VIC) ORs the requests from all the vectored and non-
vectored IRQs to produce the IRQ signal to the ARM processor,
• IRQ service routine can start by reading a register from the VIC and jumping there,
• if any of the vectored IRQs are requesting, the VIC provides the address of the highest-
priority requesting IRQs service routine, otherwise it provides the address of a default
routine that is shared by all the nonvectored IRQs,
• default routine can read another VIC register to see what IRQs are active,
• all registers in the VIC are word registers - byte and halfword reads and write are not
supported.
2.9
Rodzaje przerwań
• FIQ for fast, low latency interrupt handling, not nested – generally, you only use a
single FIQ source at a time in a system to provide a true low-latency interrupt:
– you can execute the interrupt service routine directly without determining the
source of the interrupt,
– it reduces interrupt latency – you can use the banked registers available for FIQ
interrupts more efficiently, because you do not require a context save,
– highest priority,
– the fastest, short interrupt response time,
– entry to first Instruction, Latency = 12 cycles = 200 ns @ 60MHz
• vectored IRQ
– middle priority,
– only 16 of the 32 requests can be assigned to this category, but the priority of each
can be settled [0:15],
– entry to first instruction + Nesting, Latency = 25 cycles = 416ns @ 60MHz
• nonvectored IRQ
– lowest priority,
– the slowest, long interrupt response time, program defined Latency.
• programmed interrupt.
16
2.10
Opóźnienia procedur obsługi przerwania
• FIQ ze względu na dużą liczbę bankowanych rejestrów jest najszybsze,
• instrukcją, która zajmuje najwięcej czasu jest LDM lub STM. Jeżeli pracują one na
wszystkich rejestrach R0. . . R14 i PC i wykorzystywana jest pamięć pracująca bez opóź-
nień potrzeba na to 20 cykli procesora,
• wejście do pierwszej instrukcji FIQ zajmuje 2 cykle procesora,
• opóźnienie IRQ znajduje się w przedziale od 20 do 25 cykli procesora
2.11
Magistrale
• AMBA (Advanced Microcontroller Bus Architecture) jest specyfikacją definiującą stan-
dardy projektowania bardzo wydajnych mikrokontrolerów. Specyfikacja ta określa trzy
różne magistrale:
– AHB (Advanced High-performance Bus) służy do połączenia z kontrolerem prze-
rwań oraz z magistralą VPB; może być taktowania częstotliwością rdzenia,
– ASB (Advanced System Bus) służy do łączenia szybszych modułów,
– APB (Advanced Peripheral Bus) to magistrala przeznaczona do wolniejszych ukła-
dów, oferuje łatwiejszy dostęp do peryferiów.
• VPB: do podłączenia pozostałych układów peryferyjnych,
• Local Bus: wykorzystywana do podłączenia pamięci operacyjnej, w niektórych kontro-
lerach podłączana jest również Flash i RAM.
2.12
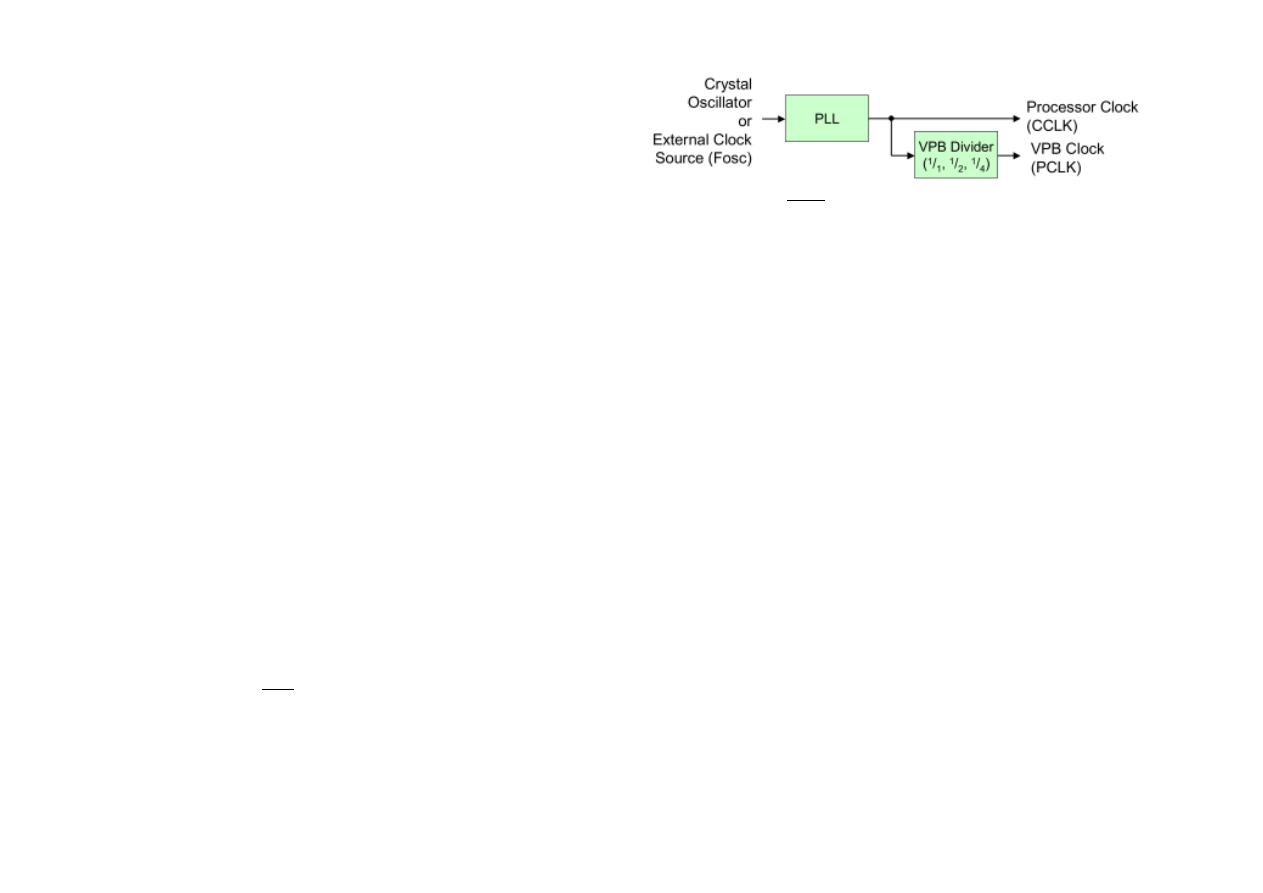
Taktowanie (CCLK, PCLK)
Z rezonatora kwarcowego dostajemy F
OSC
(np. 12 MHz). Częstotliwość ta trafia do pętli
PLL (zwielokrotnia częstotliwość taktowania rdzenia), w wyniku czego otrzymujemy sygnał
zegarowy CCLK.
CCLK = M · F
OSC
lub CCLK =
F
CCO
2·P
, w zakresie od 10 MHz do F
M AX
F
CCO
- częstotliwość oscylatora o sprzężeniu prądowym, musi być w zakresie 156 MHz do
320 MHz
F
OSC
musi być w zakresie 10 MHz do 25 MHz
M - mnożnik (bity w PLLCFG [4:0]), M = 1...32
P - dzielnik (bity w PLLCFG [6:5]), P = 1, 2, 4, 8
Wewnętrzny sygnał zegarowy CCLK taktuje CPU oraz magistralę AHB. Sygnał CCLK po
przejściu przez dzielnik taktuje VPB jako sygnał PCLK.
Po włączeniu V P B =
CCLK
4
2.13
Rodzaje adresowania
Instructions use 5 addressing modes:
• addressing Mode 1 – Data-processing operands,
• addressing Mode 2 – Load and Store Word or Unsigned Byte,
• addressing Mode 3 – Miscellaneous Load and Stores,
• addressing Mode 4 – Load and Store Multiple,
• addressing Mode 5 – Load and Store Coprocessor.
2.14
ALU
• Operacje arytmetyczno-logiczne (dodawanie z i bez carry, odejmowanie z i bez carry,
odejmowanie odwrotne z i bez carry, AND, OR, XOR, NAND, porównanie, porównanie
negatywne, porównanie bitów),
• Bezpośrednie połączenie z Barrel Shifter umożliwia w jednej instrukcji dodawanie z
przesunięciem (operacje arytmetyczne z przesunięciem),
• trzy operandy w instrukcji (source, source, dest),
• Barrel Shifter obsługuje 5 rodzajów przesunięcia argumentów (logiczne w prawo, w
lewo, arytmetyczne w prawo, rotacja, rotacja w prawo z rozszerzeniem).
2.15
Barrel Shifter
• Ma możliwość przesuwania 32-bitowych binarnych liczb w rejestrze źródłowym w lewo
lub w prawo o określoną liczbę pozycji przed wejściem do ALU,
• przesuwanie zwiększa moc i elastyczność wielu operacji przetwarzania danych,
• 5 różnych operacji przesuwania:
– logiczne w lewo przez n bitów (LSL) - mnożenie przez 2
n
,
17
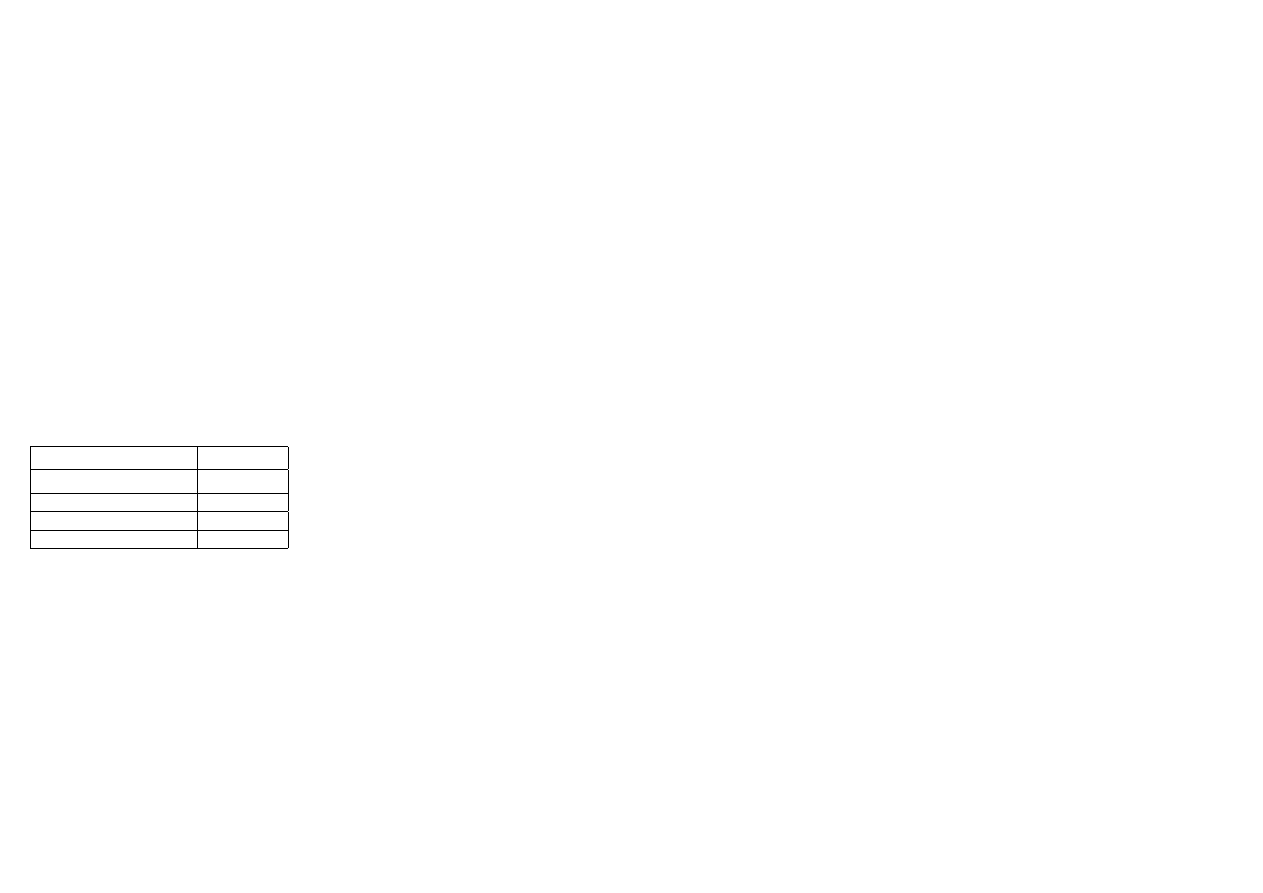
– logiczne w prawo przez n bitów (LSR) - dzielenie przez 2
n
,
– arytmetyczne w prawo przez n bitów (ASR) - dzielenie ze znakiem przez 2
n
,
– rotacja w prawo przez n bitów (ROR) - bez bitu CF, ale w bicie tym znajduje się
ostatnio przesunięty bit z prawej strony,
– rotacja w prawo z rozszerzeniem przez n bitów (RRX) - przesuwa razem z bitem
CF.
2.16
Cache
• Znacznie szybszy niż pamięć główna,
• Write Buffer działa jak tymczasowy bufor zwalniający dostępną przestrzeń w cache,
• cache zapisuje linie do Write Buffer z dużą prędkością, a Write Buffer powoli przepisuje
to do pamięci,
• cache reprezentuje bardzo mały obszar pamięci głównej, który zapełnia się bardzo szyb-
ko,
• gdy cache jest pełny kontroler usuwa procesy, które zdają się występować sporadycznie
zostawiając część danych, a usuwając inne.
Przyśpieszenie pracy spowodowane używaniem cache:
Cache
Wydajność
Bez cache
1
Tylko dla danych
1,13
Tylko dla instrukcji
1,95
Dla instrukcji i danych
2,5
Tryby pracy cache:
• bezpośrednio mapowany,
• pełno asocjacyjny,
• dwustronny zestawowy asocjacyjny.
Cechy cache:
• rozmiar 8 kB,
• może przechowywać zarówno dane, jak i instrukcje,
• skonfigurowany jako 2 · 128 linii po osiem 32-bitowych słów każda,
• 16 stronic adresów pamięci, co umożliwia zamapowanie każdego adresu,
• dzięki pracy z pamięcią z opóźnieniem i cache osiagamy efekt pracy z pamięcią bez
opóźnienia.
2.17
ADC
• Jeden lub dwa przetworniki AD,
• zakres pomiarowy od 0 do V
REF
, nie może przekroczyć V
DDA
,
• 10-bitowy sukcesywny konwerter aproksymujący analog do cyfry,
• maksymalna 10-bitowa rozdzielczość może być zredukowana do 3 bitów dla szybszej
konwersji,
• podstawowy sygnał przetwornika AD to VPB (11 cykli VPB dla największej dokład-
ności),
• multipleksowane wejścia 4/6/8 pinów,
• tryb konwersji typu burst dla pojedynczego lub wielu wejść,
• globalna komenda startu dla obu przetworników,
• tryb obniżonego poboru mocy,
• ADC może być źródłem przerwań po zakończeniu konwersji.
2.18
Pseudoinstrukcje
Jest to zestaw instrukcji wspieranych przez asembler ARM, które w czasie translacji za-
mieniane są na odpowiednią kombinację instrukcji ARM, THUMB, THUMB2. Ułatwiają
pisanie programów, umożliwiając zapisanie typowo wykonywanych operacji w jednej linijce,
gdy standardowe zestawy operacji nie umożliwiają zrobienia tego bezpośrednio.
Przykładowo: instrukcja LDR, która generuje odpowiedni kod, gdy stała jest poza zasięgiem
instrukcji MOV (lub MVN).
• No ARM instruction moves a 32-bit constant into a register, since ARM instructions
are 32 bits in size,
• two pseudo instructions are provided to move a 32-bit value into a register.
Consider a processor that has no NOP instruction per se. An assembler might synthezize
NOP out of a redundant register operation. That is a pseudo-instruction. Or on some proces-
sors (ARM, PA-RISC e.g) there is no way to load a 32-bit immediate into a 32-bit register.
Assemblers will either declare a hidden constant in ROM and generate an instruction that
loads indirect from that ROM address (ARM), or generate two instructions (PA-RISC),
one to load the hi side, one the lo side of the register. In either case, ldi reg, #imm32 is a
pseudo-instruction.
18

2.19
Porównanie trybów ARM i THUMB
THUMB:
• Podzestaw instrukcji ARM,
• dostęp tylko do wybranych instrukcji, które są w locie tłumaczone na instrukcje ARM,
• tryb instrukcji 16-bitowych, dwuargumentowe (source, source/dest),
• nie ma dostępu do wszystkich rejestrów (dostęp tylko do R0-R7),
• nigdy nie stosowany w przerwaniach (nie da się obsłużyć przerwania, przy wejściu w
przerwanie automatyczna zmiana na ARM),
• gorsza obsługa instrukcji warunkowych,
• instrukcje warunkowe są realizowane za pomocą skoków (conditional branch),
• pozwala zaoszczędzić pamięć (do 30%) kosztem prędkości (40%) względem trybu ARM.
ARM
THUMB
32-bit
16-bit
Ułożenie instrukcji całymi
Ułożenie instrukcji półsłowami
słowami
Wartości w PC w bitach [0:1]
Wartość PC w bicie [0]
niezdefiniowana
niezdefiniowana
Instrukcje 3-argumentowe
Instrukcje 2-argumentowe
(source, source, dest)
(source, source/dest)
Dostęp do wszystkich rejestrów
Dostęp tylko do rejestrów R0:R7
Analiza pola condition w instrukcjach
Brak analizy pola condition; instrukcje
warunkowe realizowane przez skoki war.
Tryb obługi wyjątków
Nie może obsługiwać wyjątków
2.20
!!Procedura obsługi przerwania
To nie jest chyba prawidłowa odpowiedź na pytanie... najlepiej spisać ze slajdów.
Przerwanie IRQ, na przykładzie T0:
• określenie priorytetu przerwania: VICVectAddr0 = (unsigned long) tc0,
• przyporządkowanie T0 odpowiedni slot: VICVectCntl0 = 0x20 — 4,
• odblokowanie przerwania od wybranego źródła: VICIntEnable = 0x00000010.
Slot oznacza przyporządkowanie. Maksymalnie może być 32 źródeł przerwań, z czego wek-
toryzowanych może być 16. Przyporządkowanie źródła odpowiedniemu slotowi jest czymś
w rodzaju przypisania źródła do odpowiedniego kanału odpowiadającego za priorytet prze-
rwania.
Wejście w obsługę przerwania:
• kontroler VIC określa źródło przerwania, do rejestru VICVectAddr kopiuje zawartość
rejestru VICVectAddr0 stanowiącą adres procedury obsługi aktywnego przerwania o
najwyższym priorytecie,
• rdzeń wykonuje skok pod adres wektora wyjątku IQR (0x00000018), gdzie znajduje się
instrukcja LDR PC, [PC, #-0xFF0]. Jej wykonanie powoduje odczytanie i skok pod
adres wektora procedury obsługi przerwania umieszczonego w rejestrze VICVectAddr
(dokładniej: PC jest inkrementowany do 0x20 [0x18 + 8], a następnie od tej wartości
odejmowany jest offset 0xFF0, co w rezultacie daje nam adres obsługi przerwania IRQ
czyli 0xFFFFF030).
Wyjście z procedury obsługi przerwania:
• wyzerowanie flagi zgłoszenia przerwania T0IR = 1
• wpisanie do rejestru VICVectAddr dowolnej wartości, będącej sygnałem dla kontrolera
VIC, że przerwanie zostało obsłużone.
2.21
W których trybach blokowane są IRQ i FIQ?
Tryb
IRQ
FIQ
Reset
T
T
Undefined
T
BZ
Software (SWI)
T
BZ
Prefetch Abort
T
BZ
Data Abort
T
BZ
IRQ
T
BZ
FIQ
T
T
2.22
Jak w kompilatorze Keil obsłużyć przerwanie IRQ?
• Zadeklarowanie przerwania typu IRQ
VICVectAddr0 = (unsigned long) tc0;
VICVectCntl0 = 0x20 | 4;
VICIntEnable = 0x00000010;
19
• zadeklarowanie funkcji przerwania
__irq void tc0(void) {
...
T0IR = 1;
VICVectAddr = 0; }
2.23
Jak w kompilatorze Keil obsłużyć przerwanie FIQ?
Przede wszystkim należy odpowiednio zmodyfikować plik startup.s:
• ustawić rozmiar stosu dla FIQ
FIQ Stack Size EQU 0x00000080
• poinformować linker o ułożeniu stosu ośmiobajtowym
PRESERVE8
• ustawienie zewnętrznego “chwytacza”
IMPORT RTC fiq
• nazwać punkt wejściowy dla FIQ
FIQ Addr DCD RTC fiq
• usunąć fragment
; FIQ Handler B FIQ Handler
Następnie należy zainicjować przerwanie FIQ:
VICIntSelect = 0x00002000;
VICIntEnable |= 0x00002000;
A potem należy opisać funkcję przerwania:
__irq void RTC_fiq(void) {
...
ILR = 0x00000003;
2.24
Dlaczego przy zagnieżdżaniu przerwań konieczne są dodatko-
we makroprocedury?
Podczas wystąpienia przerwania zawartość licznika rozkazów PC (R15) kopiowana jest do
rejestru LR (R14). Powrót do programu odbywa się poprzez skopiowanie zawartości LR z
powrotem do PC.
Jeśli podczas wykonywania przerwania typu IRQ procesor przyjąłby i zaczął obsługiwać
kolejne przerwanie IRQ, procedura kopiowania rejestru PC do LR powtórzyłaby się, co spo-
wodowałoby nadpisanie rejestru LR, a w konsekwencji po zakończeniu przerwań powrót do
programu byłby niemożliwy. Dla zagnieżdżonych przerwań jedyną możliwością zachowania
stanu LR jest chowanie go na stos. Dlatego właśnie konieczne są makroprocedury, w których
kopiowany byłby LR.
2.25
Wyjaśnić różnice w przyjęciu przerwania IRQ i FIQ dla pro-
cesorów ARM
Adresy wektorów przerwań:
FIQ - 0x1c
IRQ - 0x18
• W przerwaniach FIQ można umieścić obsługę tego przerwania od adresu 0x1c, bo jest
to ostatni adres w tablicy wektorów przerwań. Oszczędza to czas na wykonanie skoku
do podprogramu obsługi przerwania.
• W przerwaniu IRQ wykorzystuje się sprzętowy kontroler przerwań do wektorowej ob-
sługi przerwań. Kontroler wystawia adres obsługi początku podprogramu obsługi prze-
rwania o najwyższym priorytecie.
• FIQ ma wyższy priorytet od IRQ i jest wykonywany szybciej. W przypadku przyjęcia
wielu przerwań FIQ jest przyjmowany jako pierwszy. Obsługiwanie FIQ powoduje za-
blokowanie IRQ zapobiegając obsłużeniu ich zanim uchwyt do FIQ ich ponownie nie
uaktywni. Jest to zwykle wykonywane poprzez odzyskanie CPSR z SPSR na końcu
uchwytu.
• Przerwania FIQ i IRQ inaczej modyfikują rejestr CPSR i każde z nich ma swój rejestr
SPCR. W obu przerwaniach bankowane są rejestry R13, R14 i SPCR, ale dodatkowo
w FIQ bankowane są jeszcze rejestry R8-R12, co wpływa na czas przejścia do obsługi
przerwania (nie trzeba ich odkładać na stos).
• Do przerwań IRQ należą również przerwania niewektorowe.
• Jeżeli wystąpiło przerwanie IRQ, a źródło przerwania nie zostało zdeklarowane jako
przerwanie wektorowe IRQ (IRQ może “zobaczyć” maksymalnie 16 z 32 źródeł prze-
rwań), kontroler przerwań zwróci adres domyślny, czyli adres przerwania niewektorowe-
go. W tym przypadku dla kilku takich źródeł przerwań podprogram obsługi przerwania
musi sam sprawdzić źródło przerwania (odpytywanie).
• Opóźnienie FIQ to 12 cykli (200 ns @ 60 MHz), natomiast opóźnienie IRQ to 25 cykli
(416 ns @ 60 MHz + ew. czas zagnieżdżenia).
20
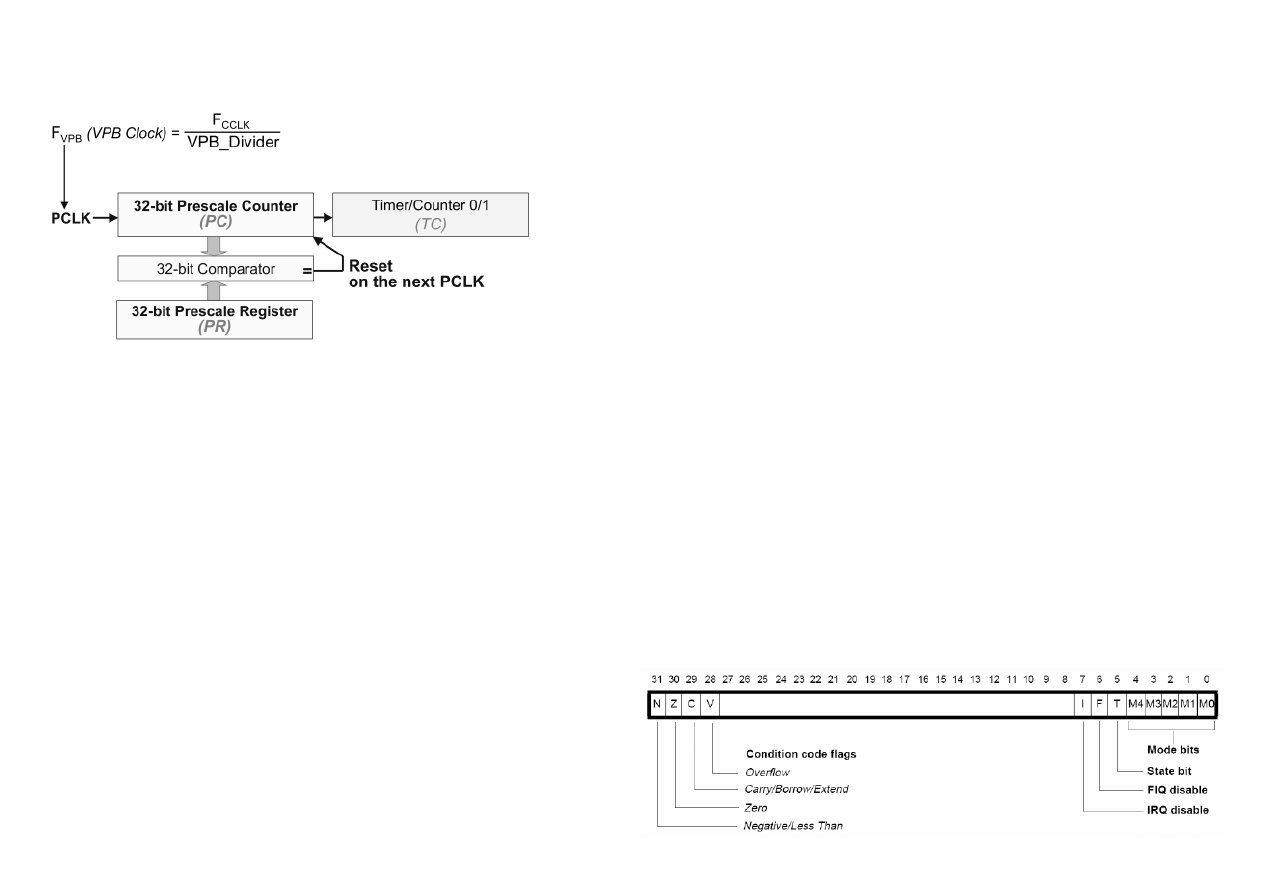
2.26
Timer w ARM
• Liczniki są 32-bitowe z 32-bitowym preskalerem,
• można nimi odmierzać odcinki czasu (Timer) lub zliczać impulsy (Counter),
• posiada 4 rejestry porównawcze (MR0...MR3), które pozwalają na działanie ciągłe,
opcjonalne przerwania - zatrzymanie timera lub reset,
• 4 rejestry zliczajace impulsy (cztery 32-bitowe kanały); zdarzenie zliczenia odpowiedniej
ilości impulsów może opcjonalnie wywołać przerwanie,
• do 4 wyjść zewnętrznych współpracujących z rejestrami porównawczymi z następujący-
mi możliwościami: ustaw HIGH/LOW przy zrównaniu, zmień na stan przeciwny przy
zrównaniu, nie rób nic przy zrównaniu,
• TC zwiększa swoją wartość przy każdym PR + 1 cykl sygnały PCLK,
• PR (Prescale Register) i PC (Prescale Counter Register) to rejestry preskalera; PR
ustawia co ile cykli ma być zwiększany PC; PC to licznik zwiększający się za każdym
cyklem sygnału PCLK do wartości PR,
• przerwania można włączyć w rejestrze MCR dla wyrównania bądź CCR dla zliczania
impulsów,
• w rejestrze EMR zliczamy sposób sterowania liniami zewnętrznymi przez rejestry MR0-
MR3.
2.27
Jakie kroki wykonuje procesor ARM po przyjęciu przerwania?
• Zachowanie PC w Link Register,
• CPSR → SPSR,
• ustawienie bitów w CPSR na przerwanie,
• ustawienie PC na wektor przerwania,
• skok do obsługi przerwania,
• wykonanie przerwania,
• przywrócenie PC,
• SPSR → CPSR,
• wyczyszczenie flagi przerwania.
2.28
Kiedy można modyfikować bity SPR?
• Bity w rejestrze CPSR można modyfikować tylko w trybach uprzywilejowanych (system
i tryby wyjątków),
• modyfikacja bitów CPSR w trybie user jest ignorowana (tylko aktualizacja flag N, Z,
V, C przynosi efekty),
• rejestry SPSR dostępne są tylko w trybach wyjątków; jakikolwiek wpis w SPCR w
innym trybie ma nieprzewidywalny rezultat,
• SPSR nie występuje w trybach user i system, gdyż nie należą one do trybów wyjątków
(nie można do niego zapisywać ani odczytywać).
2.29
Porównanie rejestrów CPSR i SPSR w ARM - cel użycia
21
Górne cztery bajty są wykorzystywane do sterowania instrukcjami warunkowymi. Aktuali-
zują się na skutek operacji logicznych i arytmetycznych. Mogą być testowane przez wszystkie
instrukcje trybu ARM, ale z trybu THUMB jedynie przez instrukcję branch.
Dolne osiem bitów to bity kontrolne. Aktualizują się wraz z nadejściem wyjątku. Program
użytkownika może je modyfikować jedynie wtedy, gdy procesor pracuje w jednym z trybów
uprzywilejowanych.
M[4:0]
Tryb
Dostępne rejestry
10000
User
PC, R14:R0, CPSR
10001
FIQ
PC, R14 fiq:R8 fiq, R7:R0, CPSR, SPSR fiq
10010
IRQ
PC, R14 irq, R13 irq, R12:R0, CPSR, SPSR irq
10011
SVC
PC, R14 svc, R13 svc, R12:R0, CPSR, SPSR svc
10111
Abort
PC, R14 abt, R13 abt, R12:R0, CPSR, SPSR abt
11011
Undef
PC, R14 und, R13 und, R12:R0, CPSR, SPSR und
11111
System
PC, R14:R0, CPSR
CPSR - Current PSR:
• 1 rejestr we wszystkich trybach, można go modyfikować jedynie w trybach uprzywile-
jowanych (system + tryby wyjątków),
• w trybie user możliwa jest jedynie aktualizacja flag,
• jakakolwiek próba zapisu w trybie user będzie zignorowana,
• przechowuje kopie flag statusowych N, Z, C, V; ponadto znajdują się tam bity odpo-
wiadające za zablokowanie lub odblokowanie przerwań,
• jeśli procesor był w trybie THUMB 16-bitowym, to automatycznie tryb jest zmieniany
na 32-bitowy,
• po wystąpieniu przerwania IRQ w CPSR ustawiana jest flaga I uniemożliwiająca ob-
sługę kolejnego przerwania IRQ; możliwe jest programowe zdjęcie flagi, co umożliwia
obsłużenie kolejnego przerwania w trakcie trwania pierwszego,
• po wystąpieniu przerwania FIQ w CPSR ustawiane są flagi I oraz F.
SPCR - Saved PSR:
• 5 rejestrów - po jednym dla każdego trybu wyjątku; zachowują stan rejestru CPSR w
trybie wyjątku,
• można modyfikować tylko w trybach wyjątku, nie występuje w trybach user i system.
2.30
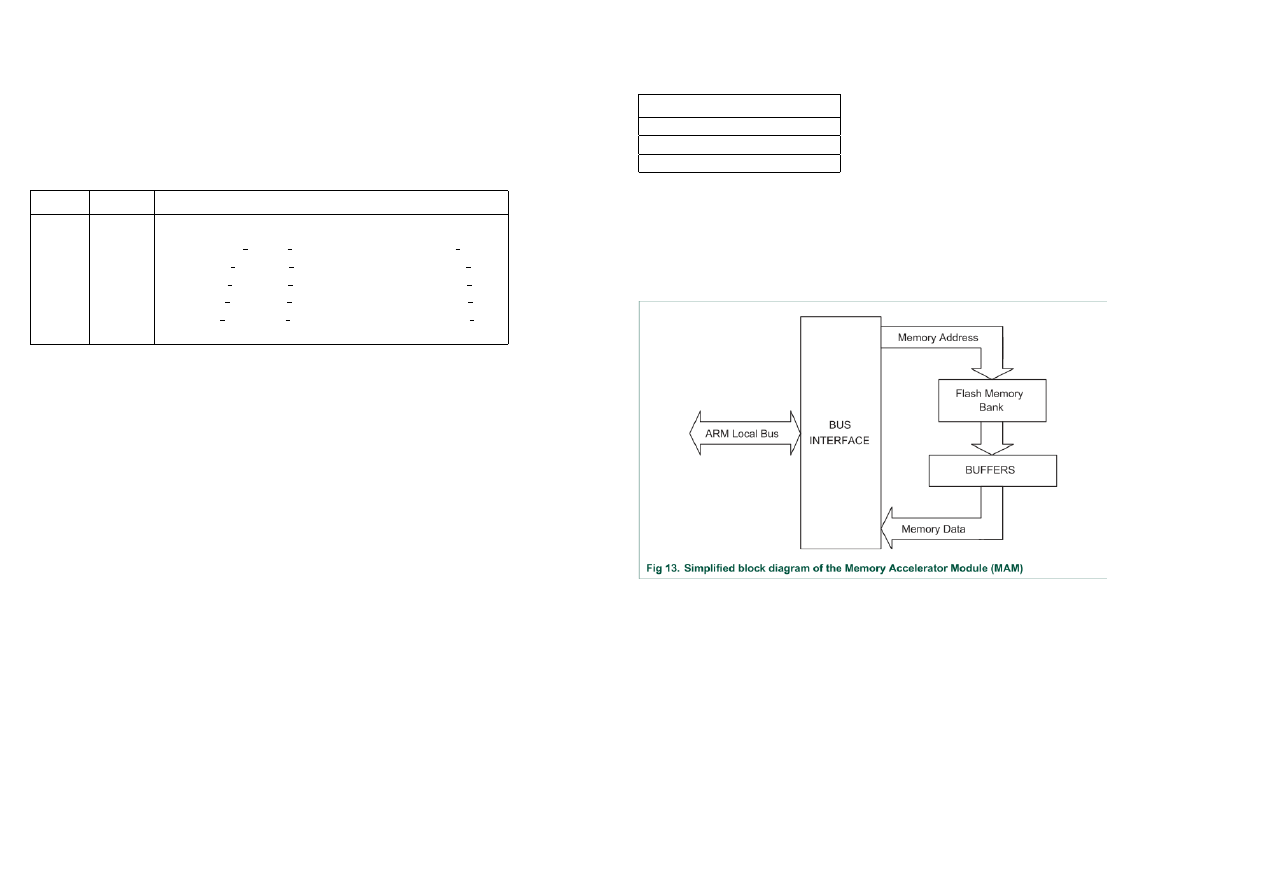
MAM - tryby pracy, opis
jądro ARM
ARM local bus
MAM (obecny na local bus)
Flash
Moduł MAM niejako pośredniczy w transporcie instrukcji między Flash a procesorem. Jego
rola polega na zwiększeniu szybkości komunikacji. Moduł MAM działa jako magazyn faz
instrukcji pochodzących z Flash, także poszczególne fazy instrukcji pochodzących z Flash
pobierane są z MAM, a nie bezpośrednio z Flash, co daje bardziej efektywną, szybszą pracę.
Maksymalna prędkość pracy Flash — 20 MHz
Maksymalna prędkość pracy MAM — 60 MHz
Fetch: wyraźne żądanie ARM odczytu z Flash
Pre-Fetch: oznacza instrukcję odczytu Flash poza bieżącym adresem fetch procesora
Tryby MAM:
• Mode 0: MAM wyłączony, CPU odczytuje bezpośrednio z Flash,
• Mode 1: MAM częściowo dostępny, rozgałęzienia i stałe ładowane bezpośrednio z Flash,
kod sekwencyjny wczytywany przez MAM,
• Mode 2: MAM całkowicie dostępny, dostęp do Flash zawsze przez MAM.
2.31
MMC (Memory Map Concepts) - opis
Od adresu 0x7FFFD000 umieszczono na stałe program bootloadera, pozwalającego na za-
programowanie Flash poprzez port szeregowy.
22

Z powodu lokalizacji tablicy wektorów przerwań część przestrzeni Boot Block i SRAM musi
być remapowana, żeby zezwolić na alternatywne wykorzystanie przerwań w sytuacjach, gdy
program jest ładowany z innych obszarów pamięci niż Flash. Remapowanie, czyli przeniesie-
nia wektorów przerwań, umożliwia rejestr MEMMAP (Memory Mapping Control Register
— MMC).
Powody wprowadzenia MEMMAP:
• program z Flash może być bez przeszkód realizowany, bo ma bezpośredni dostęp do
tablicy wektorów przerwań,
• następuje minimalizacja wymagań SRAM i wektorów Boot Block, które nie muszą
zajmować się arbitrażem granic podczas realizowania kodu,
• dostarczenie przestrzeni do przechowywania danych do skoków poza granice pojedyn-
czych instrukcji rozgałęzień.
2.32
GPIO
• General purpose I/O ports - porty wejścia/wyjścia ogólnego przeznaczenia,
• każdy pin portów jest dwukierunkowy i w pełni konfigurowalny dzięki zestawowi reje-
strów,
• IO0PIN, IO1PIN – stan portów P0 i P1,
• IO0SET, IO1SET – ustawianie stanu “1” na liniach portów P0 i P1 Ustawienie 1 na
danym bicie rejestru zmienia stan odpowiadającej mu linii portu na “1“,
• IO0CLR, IO1CLR – ustawianie stanu ”0“ na liniach portów P0 i P1 Ustawienie 1 na
danym bicie rejestru zmienia stan odpowiadającej mu linii portu na ”0“,
• IO0DIR, IO1DIR – zmiana kierunku (wejscie/wyjscie) linii portów P0 i P1 Ustawienie 1
na danym bicie rejestru zmienia status odpowiadającej mu linii portu na ”WYJSCIE“,
• ustawienie 0 na danym bicie rejestru zmienia status odpowiadającej mu linii portu na
”WEJSCIE”.
Wszystkie piny portów procesorów produkowanych przez NXP są multipleksowane. W pro-
cesorach produkowanych przez firmę Atmel mamy rozróżnienie na dwa typy pinów:
• MPIO - Multiplexed I/O Lines – zestaw linii multipleksowanych, każdy pin kontrolo-
wany niezależnie, każdy może generować przerwanie,
• UIPIO - Unified Parallel I/O Lines – mają ściśle określoną konfigurację podłączeń.
Niektóre procesory produkowane przez NXP są wyposażone zestaw portów, które mogą być
opcjonalnie podłączone do magistrali Local Bus i taktowane z prędkością rdzenia. Porty te
działają około 3,5 raza szybciej niż zwykłe.
FastGPIO obsługuję się tak samo jak zwykłe porty GPIO, inna jest tylko nazwa rejestrów
konfiguracyjnych a mianowicie wszystkie zaczynają się literką F (FIOxPIN, FIOxSET itd.)
Wyboru czy wybrany port, o ile ma taką możliwość, ma pracować w trybie normal czy fast
odbywa się poprzez rejestr SCS (System Control and Status Flags Register)
3
Kompilatory, inne nie wiadomo skąd
3.1
Zasady łączenia plików c i asm w IAR
• Stworzyć dwa pliki *.asm i *.c,
• dołączyć je do projektu,
• w asemblerze stworzyć i nazwać moduł, segment relokowalny,
• w plikach linkera dołączyć segment do linkowania.
Slaa140.pdf:
The mechanics to combine C and assembler functions are fairly straightforward. Basically C
code within .c files imports labels exported by the assembler files using the extern keyword.
Assembler codes within .s43 files export labels to the C code using the PUBLIC keyword.
Assembler code import labels exported by C code using the EXTERN keyword. No keyword
is required to export C labels to assembler code.
Once the .c and .s43 files are written, they are added to the workbench project and the
project is built.
Łączenie plików *.c i *.asm:
• Możliwość ulokowania wstawek asemblerowych:
asm (“MOV.B &PIN, &flag”);
lub
asm(“Label: nopln”
“jmp Label”);
• gdy C wywołuje asm:
.s43:
#include "msp430.h"
23

NAME NAZWA_MODULU
PUBLIC Nazwa_Funkcji
RSEG CODE
Nazwa_funkcji:
mov R4, R5 // to tylko przykład
ret
END
.c:
#include <msp430.h>
extern void Nazwa_Funkcji(void);
// dla C++ będzie extern "C" void, etc.
main() {
Nazwa_Funkcji();
... }
• gdy asm wywoluje C:
.c:
#include <msp430.h>
void jakas_funkcja(void) {
opis co robi funkcja... }
.s43:
#include "msp430.h"
NAME NAZWA_MODULU
EXTERN jakas_funkcja
RSEG CODE
call #jakas_funkcja
END
3.2
Funkcje z równoczesnym wielokrotnym wywołaniem (reen-
trant)
Funkcje z parametrem reentrant mogą być funkcjami rekurencyjnymi, tzn. mogą wywoływać
same siebie lub mogą być wywoływane równocześnie z innych funkcji (np. gdy funkcja jest
wykonywana po wywołaniu przez inną funkcję i następuje przerwanie, w trakcie którego
funkcja ta jest wywoływana ponownie).
Przykład procedury generującej liczby Fibonacciego:
#include <stdio.h>
unsigned fib(int n) {
if (N <= 2) return 1;
return fib(n-1) + fib(n-2);
}
unsigned results[11];
main() {
int loop;
for (loop = 1; loop < 10; loop++) {
results[loop] = fib(loop);
printf("fib(%d) = %d\n", loop, results[loop]);
}}
3.3
Funkcje wywoływane z podprogramu obsługi przerwania
Funkcja wywoływana z podprogramu obsługi przerwania musi mieć ten sam bank rejestrów,
co podprogram.
Przed wykonaniem właściwej funkcji, zawartość rejestru PSW jest chowana na stos, a znacz-
niki RB0 i RB1 są tak ustawiane, by wybrać odpowiedni bank rejestrów. Po wykonaniu funk-
cji odtwarzana jest początkowa wartość rejestru PSW. Użycie przełącznika using, ze względu
na operacje ze stosem, umożliwiają zwracanie przez funkcję wartości bitowych. Przełączania
banków rejestrów najlepiej stosować do funkcji nie pobierających i nie zwracających para-
metrów; w przeciwnym razie w momencie wywołania funkcji lub odbioru przesyłanej przez
nią danej musiałby być ustawiony taki sam bank rejestrów, jaki jest ustawiony dla samej
funkcji.
3.4
Jak w C zadeklarować adres stały?
Są trzy metody deklaracji adresu stałego:
• użycie odpowiedniego makro (CBYTE, CWORD, DBYTE, DWORD, ...),
• deklaracja zmiennej w autonomicznym module i zastosowanie dyrektyw asemblera do
przydziału adresu absolutnego,
24
• konstrukcja at : {typ zmiennej} {typ pamięci} {nazwa zmiennej} at {adres}
3.5
Opisz linkera w pakiecie µVision
• Łączy wiele modułów programu w jeden końcowy program dołączając wszystkie progra-
my biblioteczne (symbole deklarowane jako PUBLIC EXTRN zapewniają odwołania
do zmiennych),
• łączy wszystkie moduły relokowane o tej samej nazwie,
• przyporządkowuje modułom absolutnym i relokowalnym odpowiadające im obszary
pamięci programu,
• łączy wzajemnie wszystkie symbole deklarowane jako PUBLIC i EXTRN,
• oblicza absolutne adresy we wszystkich modułach relokowalnych,
• tworzy kod wynikowy programu,
• tworzy plik z informacjami o sposobie rozlokowania wszystkich segmentów i symboli,
wzajemnych powiązaniach między symbolami deklarowanymi jako PUBLIC i EXTRN,
• sygnalizuje błędy w czasie pracy i w sposobi wywołania,
• tworzy mapę wszystkich segmentów z podaniem ich nazwy, sposobu rozmieszczenia,
długości i adresu bazowego,
• całkowita długość wszystkich segmentów nie może przekraczać rozmiarów pamięci da-
nego typu w danym mikrokontrolerze,
• segmenty absolutne nie są łączone z innymi segmentami, są bezpośrednio kopiowane do
pliku wyjściowego.
3.6
Podana jest liczba 0xC14800000. Jaka jest jej wartość w syste-
mie dec, jeżeli jest to zapis w pamięci zmiennej typu float?
adres
+0
+1
+2
+3
format
SEEEEEEE
EMMMMMMM
MMMMMMMM
MMMMMMMM
hex
C1
48
00
00
bin
11000001
01001000
00000000
00000000
S - bit znaku
E - wykładnik dziesiętny
M - mantysa
L = (−1)
8
· 2
(e−127)
· 1, m = (−1)
8
· 2
(130−127)
· 1, 5625 = −8 · 1, 5625 = −12, 5
Więc: 0xC14800000 = -12,5 d
3.7
Różnice i cechy wspólne parametrów pierwotnej i wtórnej
asemblacji
Cechy wspólne: poprzedzane znakiem $.
Różnice:
Parametry pierwotne:
• pojawiają się jednokrotnie i nie zmieniają innych sterowań,
• są umieszczane na początku kodu źródłowego programu,
• znak $ musi się znajdować w pierwszej kolumnie,
• między znakiem $ i parametrem może znajdować się znak spacji lub tabulacji,
• mogą wystąpić jako parametry wywołania asemblera,
• charakter raczej globalny.
Parametry wtórne:
• mogą być wielokrotnie używane i są stosowane do określenia konfiguracji asemblera,
• mogą wystąpić wielokrotnie, w dowolnym miejscu kodu,
• bez ograniczeń,
• parametr bezpośrednio po znaku $,
• używane tylko z kodem źródłowym asemblera,
• charakter częściej lokalny.
3.8
Czym się różnią makro procedury i podprogramy?
• Instrukcje tworzące makro wstawiane są bezpośrednio w program, natomiast podpro-
gram wywoływane jest instrukcją CALL,
• makro jest stosowane przy dużej szybkości działania mikrokontrolera i pewnej rozrzut-
ności pamięci ROM, zaś podprogramy są stosowane przy wielokrotnym wywoływaniu
tych samych operacji i oszczędnym gospodarowaniu ROM,
• w makro procedurach można łatwiej modyfikować treść procedury przy zmianie sposobu
pobierania i odsyłania argumentów.
25
3.9
Napisać podstawowe elementy procedury asemblerowej w śro-
dowisku IAR (..)
(..) wywołującej funkcję zadeklarowaną w C w następującej postaci: int funkcja
(char zm a, int zm b, long zm c)
EXTERN FUNKCJA_C
RSEG CODE
MOV.B #zm_a, R12
MOV.W #zm_b, R14
PUSH #HIGH_zm_c
PUSH #LOW_zm_c
CALL FUNKCJA_C
MOV.W R12, Rezultat
3.10
Napisać podstawowe elementy procedury asemblerowej w śro-
dowisku IAR (..)
(..) wywołującej funkcję zadeklarowaną w C w następującej postaci long funkcja
(long zm a, long zm b, int zm c, char zm d)
EXTERN FUNKCJA_C
RSEG CODE
MOV #HIGH_zm_a, R13
MOV #LOW_zm_a, R12
MOV #HIGH_zm_b, R15
MOV #LOW_zm_b, R14
PUSH #zm_c
PUSH.B #zm_d
CALL #FUNKCJA_C
MOV R12, LOW_Rezultat
MOV R13, HIGH_Rezultat
3.11
Jak w IAR napisać funkcję, która zostanie umieszczona w
RAM?
Polecenie
ramfunc umieszcza daną w RAM - ma atrybut odczyt / zapis. Taka funkcja jest
kopiowana z ROM do RAM podczas startu przepisywania.
Przykładowo:
ramfunc void nazwa func(void)
Funkcje w RAM działają przy zablokowanym ROM. Przerwania również powinny być za-
blokowane chyba, że tablica wektorów przerwań została przeniesiona do RAM.
3.12
Funkcje specjalne w C
• a =
bcd add short(b, c) - opcje dodawania na liczbach BCD,
• a =
bcd add long(b, c),
• a =
bcd add long long(b, c),
•
bic SR register(unsigned short) - kasuje wskazane w danej bity rejestru SR,
•
bic SR register on exit(unsigned short) - kasuje wskazane w danej bity rejestru SR
przed powrotem funckji typu interrupt lub monitor,
•
bis SR register(unsigned short) - ustawia wskazane w danej bity rejestru SR,
•
bis SR register on exit(unsigned short) - ustawia wskazane w danej bity rejestru SR
przed powrotem funckji typu interrupt lub monitor,
•
disable interrupt() - blokuje przerwania,
•
enable interrupt() - odblokowuje przerwania,
• unsigned short
even in range(adr, zakr) - przekazuje wartość wskazanego adresu i
podanym zakresie,
•
get interrupt state(void) - pobiera stan przerwań,
•
istate t s =
get interrupt state(),
•
set interrupt state(s),
• unsigned short
get R4 register(void) - zwraca zawartość rejestru R4
◦
,
• unsigned short
get R5 register(void) - zwraca zawartość rejestru R5
◦
,
• unsigned short
get SP register(void) - zwraca zawartość rejestru SP,
• unsigned short
get SR register(void) - zwraca zawartość rejestru SR,
• unsigned short
get SR register on exit(void) - zwraca zawartość rejestru SR w funk-
cjach interrupt i monitor,
• void
low power mode n(void) - wprowadza tryb oszczędnościowy n (0 - 4),
• void
low power mode off on exit(void) - wyprowadza procesor z trybu oszczędnościo-
wego przy wyjściu z procedury obsługi przerwania,
• void
set interrupt state( istate t) - odtwarza stan przerwań,
• void
set R4 register(unsigned short) - wpisuje daną do rejestru R4
◦
,
26

• void
set R5 register(unsigned short) - wpisuje daną do rejestru R5
◦
,
◦
Tylko dla zablokowanych rejestrów
• void
no operation(void) - rozkaz,
• nop,
• void
set SP register(unsigned short) - wpisuje daną do rejestru SP,
• unsigned short
swap bytes(unsigned short) - zamiana połówkowa danej,
• a =
swap bytes(0x1234) //a = 3412,
27
Wyszukiwarka
Podobne podstrony:
Kolokwium 1 (zbiorcze opracowane), GRUPA PONIEDZIAŁKOWA: (gr
pol pieniężna zebrane zbiorcze opracowanie
Receptura zbiorczy GWSH 2
Opracowanka, warunkowanie
OPRACOWANIE FORMALNE ZBIORÓW W BIBLIOTECE (książka,
postepowanie w sprawach chorob zawodowych opracowanie zg znp
opracowanie 7T#2
opracowanie testu
Opracowanie FINAL miniaturka id Nieznany
Opracowanie dokumentacji powypadkowej BHP w firmie
2 1 I B 03 ark 02 zbiorczy plan kolizji
przetworniki II opracowane
Opracowanie Programowanie liniowe metoda sympleks
Nasze opracowanie pytań 1 40
haran egzamin opracowane pytania
201 Czy wiesz jak opracować różne formy pisemnych wypowied…id 26951
więcej podobnych podstron