
Psychometria 2009
Wykład 7
Teoria odpowiedzi na
pytania testu
(Item Response Theory)

Dwie idee podstawowe IRT
(Item Response Theory
• Istnieje cecha latentna (ukryta), i
istnieje jej natężenie (podobnie
zakładała klasyczna teoria testu, KTT)
– w IRT, natężenie cechy latentnej
symbolizowane jest literą θ (theta)
• Istnieje określone prawdopobieństwo
określonej odpowiedzi na daną
pozycję, przy określonym natężeniu
cechy (odmiennie niż w KTT)
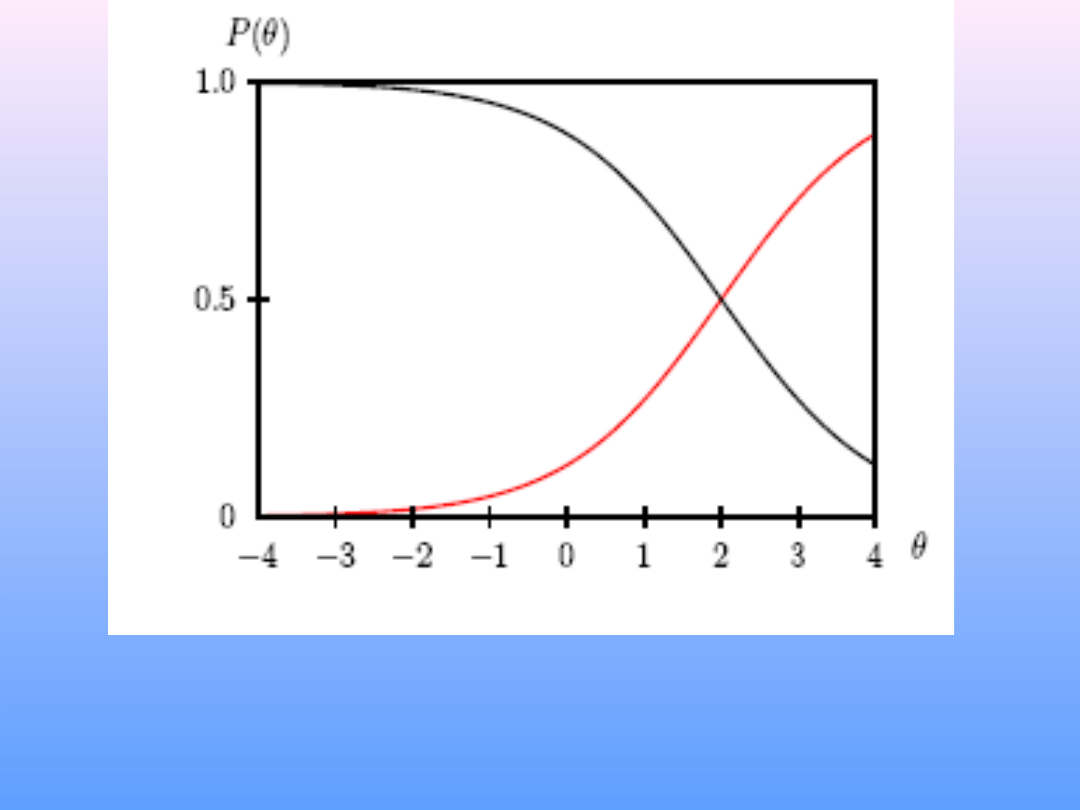
Stolicą Australii jest: Sydney (Tak/Nie)
Stolicą Australii jest: Canberra (Tak/Nie)

• Alternatywną nazwą dla Item
Response Theory mogłoby być więc:
Probabilistic Test Theory

Założenia IRT
• Jedna cecha latentna wyjaśnia kowariancje
między pozycjami (założenie
jednowymiarowości, unidimensionality)
– tzn., jeśli kontrolowałoby się wspólną wariancję
generowaną przez cechę latentną, to itemy
przestaną korelować
• założenie to w 100% w praktyce nigdy nie jest
spełnione
• Łagodniejsza wersja: Jedna cecha latentna
dominuje jako wyznacznik kowariancji
itemów

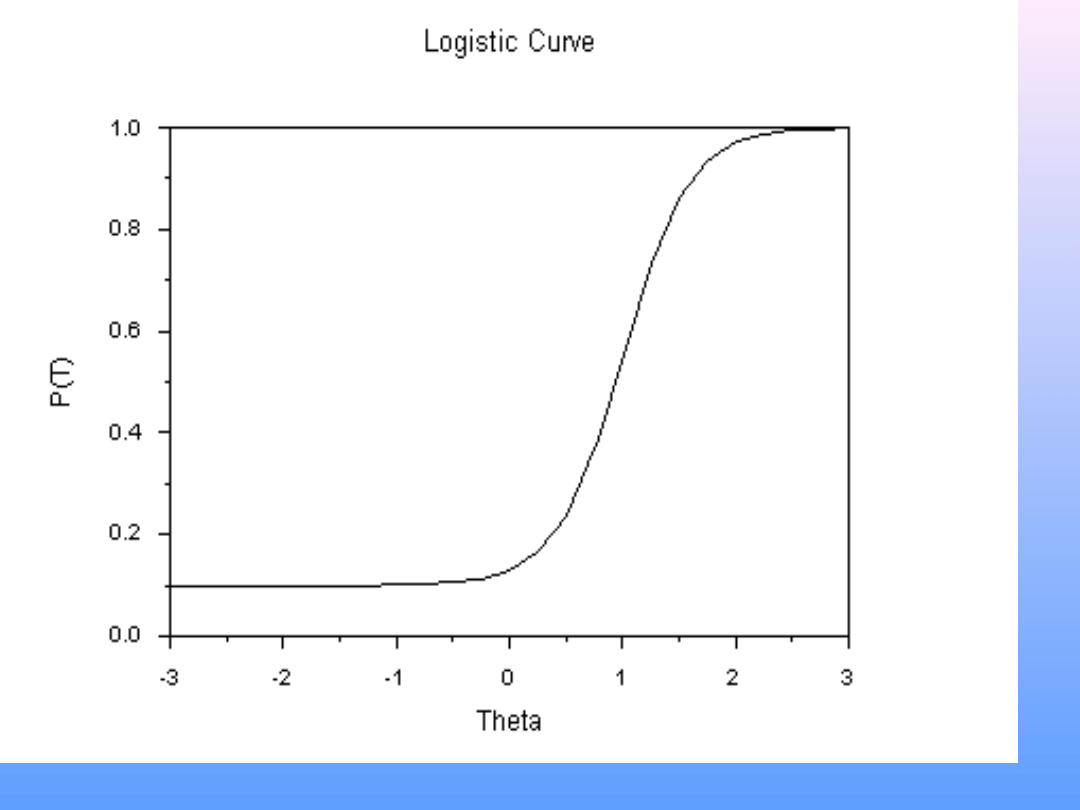
• Relacja między natężeniem cechy
(theta) a prawdopodobieństwem
określonej odpowiedzi ma obliczalny
matematycznie kształt
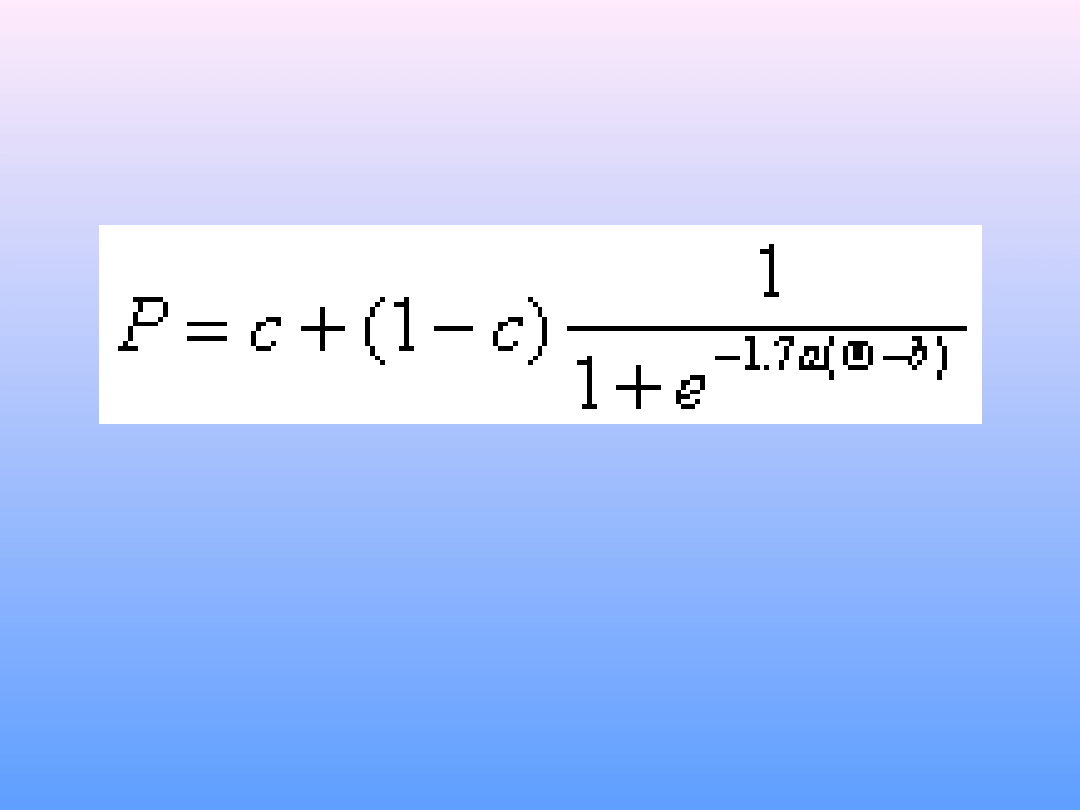
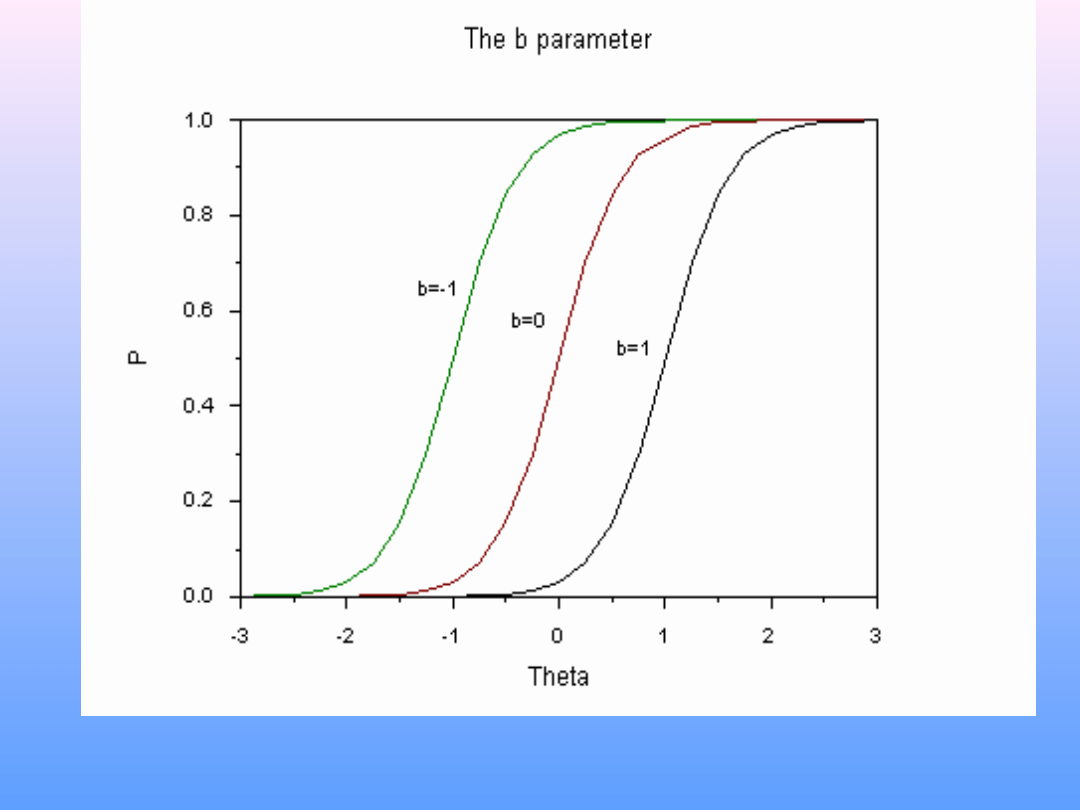
b – trudność pozycji. W KTT ≈ proporcja poprawnych
odpowiedzi
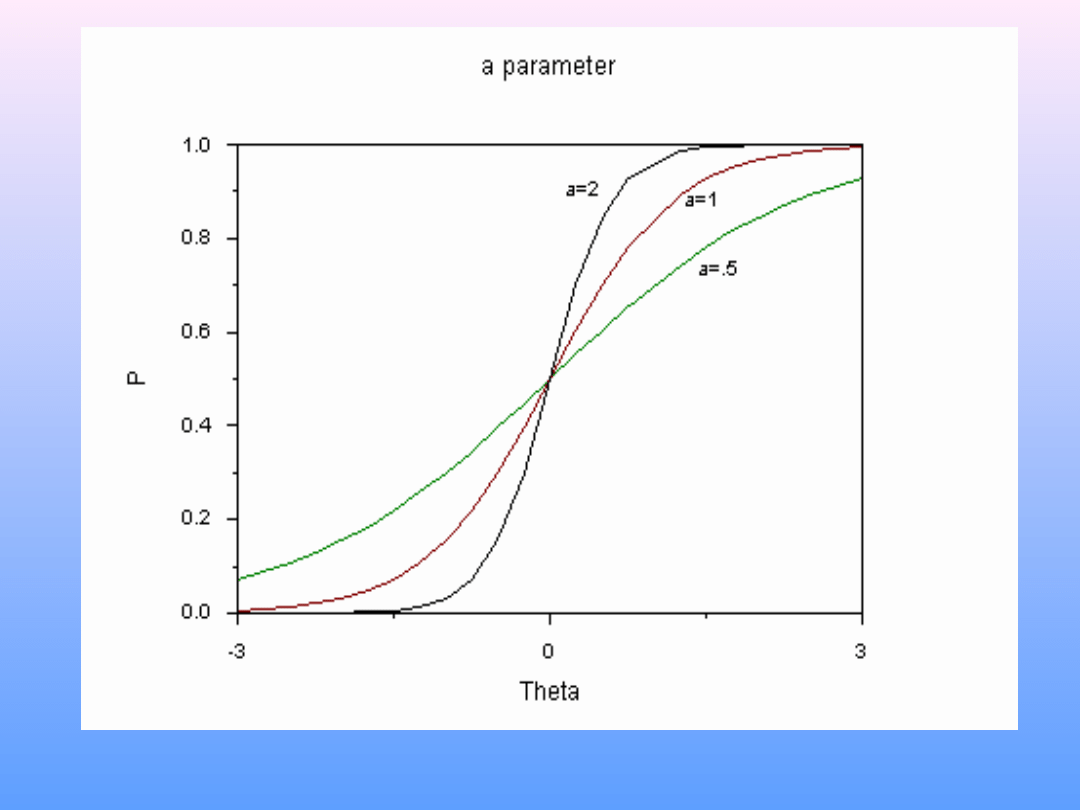
a – moc dyskryminacyjna pozycji. W KTT ≈ korelacja item-
total
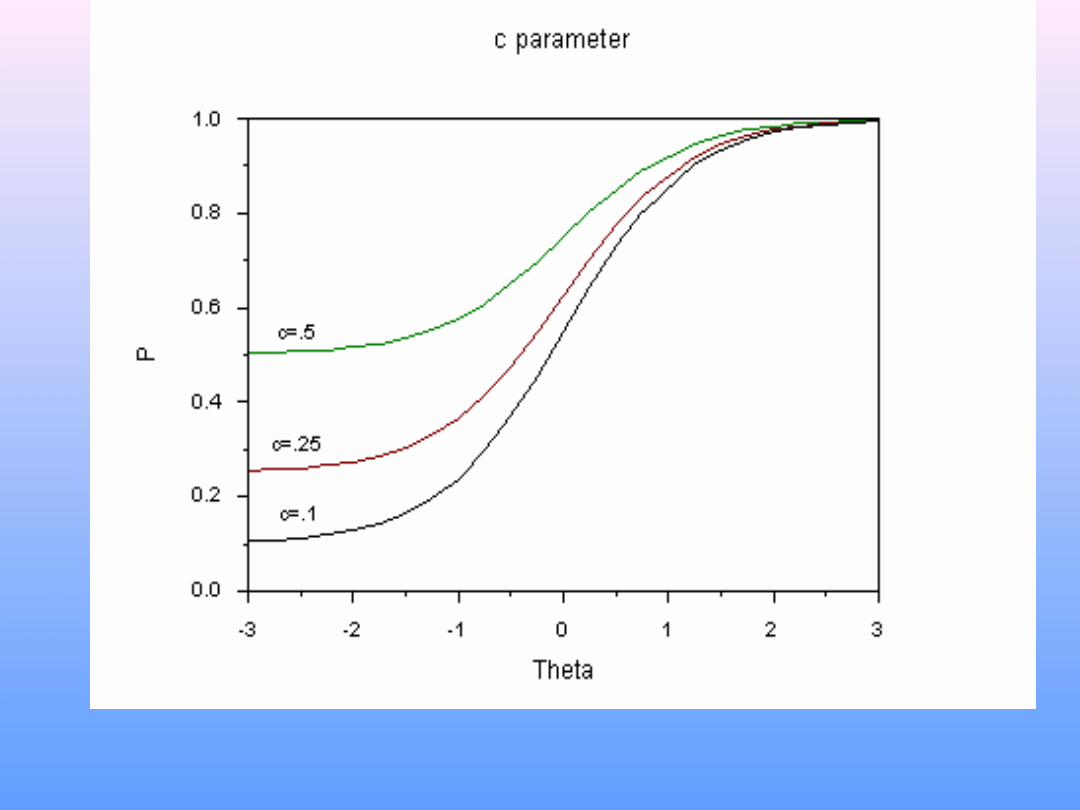
c – parametr zgadywania. W KTT ≈ prawdopodobieństwo
trafienia przypadkowego

• Obliczanie a, b i c: tzw. kalibracja
– iteracyjny proces dochodzenia do wartości a,
b i c na podstawie wyników uzyskanych na
odpowiednio dużej próbie
• Parametry a, b i c są niezmienne między
populacjami
• Nie znaczy to, że typ populacji nie jest
ważny dla wyników kalibracji
– populacje wyselekcjonowane pod względem
natężenia cechy utrudnią lub uniemożliwią
kalibrację
– podobny problem jest też w KTT (im mniejsza
wariancja, tym mniejsza korelacja i tym niższe
np. oszacowanie rzetelności

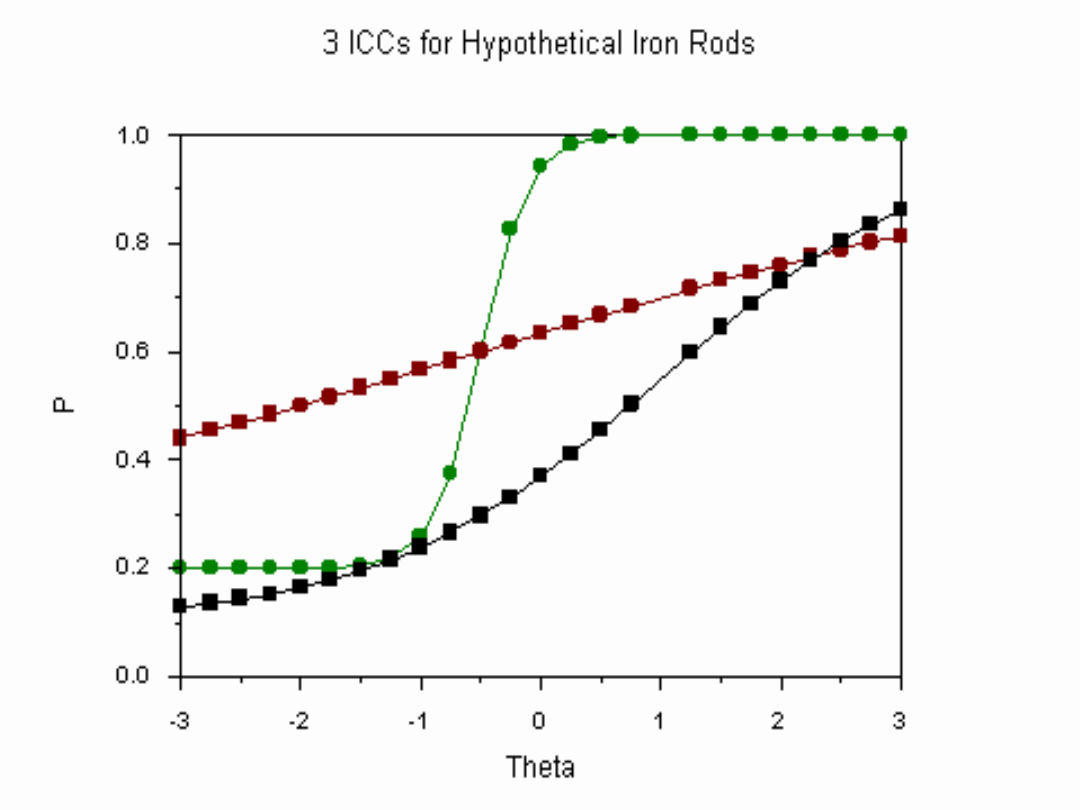
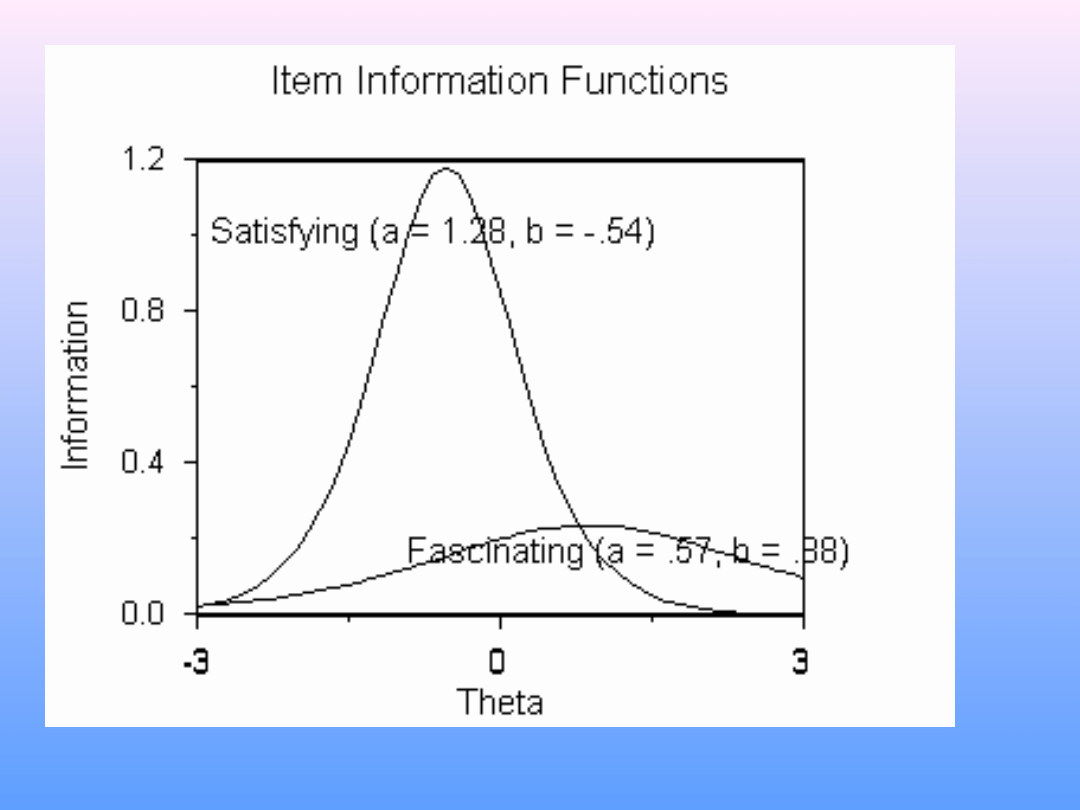
IRT a analiza rzetelności
• Odmienność podejścia IRT:
– rzetelność rozumiana jako zdolność do
redukowania niepewności
– analiza rzetelności na poziomie
poszczególnych pozycji, nie całości testu
(pewien odpowiednik w KTT: analiza
mocy dyskryminacyjnej)
– rzetelność pozycji może być różna dla
różnych wartości (na gruncie KTT jest to
herezja)
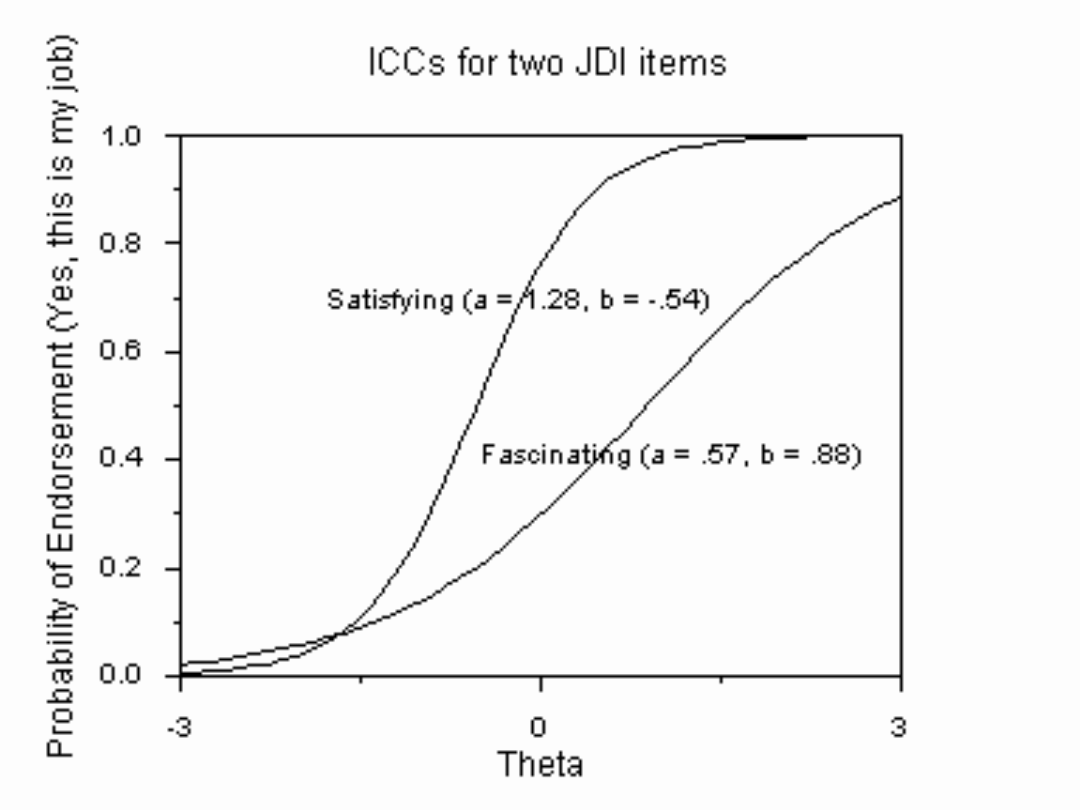

Stronniczość
• W KTT – stronniczość całego testu,
rzadziej analizuje się stronniczość
pozycji, choć jest to możliwe
• W IRT: stronniczość na poziomie
poszczególnych pozycji:
– jeśli parametry krzywych dla danej
pozycji są różne dla różnych populacji, to
pozycja ta jest stronnicza
– Podobnie jak w KTT, tak i w IRT nie
wiadomo, czy stronniczość wynika z np.
różnic genetycznych między populacjami,
czy np. z czynników kulturowych

Wynik końcowy w IRT
• nie jest „sumą” wyników dla
poszególnych pozycji
• można użyć tylko części pozycji
(niemożliwe w KTT)
• można użyć tailored testing: łatwiejsze
pozycje dla osób o niższym natężeniu
cechy, trudniejsze dla osób o wyższym
natężeniu cechy) (herezja na gruncie
KTT)

Tailored testing
• Jeśli osoba zaliczy pierwszą pozycję o
średniej trudności, dajemy jej trudniejszą
• Jeśli ją zaliczy, jeszcze trudniejszą
• … i tak dalej, aż nie zaliczy pozycji, wtedy
łatwiejszą
• Z każdą kolejną pozycją maleje niepewność i
węższe są oszacowane przedziały ufności
• Postępowanie kończymy, kiedy przedziały
ufności są tak wąskie, jak sobie tego
życzyliśmy

Tailored testing
• Można stosować podzbiór pozycji
- np. różnym studentom dawać
różne pytania z puli ogólnej,
unikając powtarzalności.
• Studentom o różnym poziomie
przygotownia można dawać
pytania o różnej trudności -
lepiej przygotowanym - trudne,
gorzej przygotowanym - łatwe.

Model Rascha
• Uproszczona wersja IRT
• Tylko parametr b - trudność pozycji
• Zakłada, że zgadywanie i
dyskryminacja nie mają znaczenia,
albo pozycje złe pod względem
zgadywania i dyskryminacji odrzuca
się

Jak to liczyć
• brak procedur w SPSS i STATISTIKA
•
– Baker, Frank (2001). The Basics of Item
Response Theory. ERIC Clearinghouse on
Assessment and Evaluation, University
of Maryland, College Park, MD.
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
Wyszukiwarka
Podobne podstrony:
Psychometria 8 Item Response Theory
Psychometria 2009, Wykład 11, Inwentarz MMPI
Psychometria 2009, Wykład 9, Techniki projekcyjne
Psychometria 2009, Wykład 5, Trafność
Psychometria 2009, Wykład 13, STATISTICA
Psychometria 2009, Wykład 12, WAIS R Skala Inteligencji Wechslera
Psychometria 2009, Wykład 10, Źródła błędów w testowaniu; Kontrowersje wokół inteligencji
Psychometria 2009, Wykład 2, Klasyczna teoria testu
Psychometria 2009, Wykład 6, Normalizacja
Psychometria 2009, Wykład 1, Definicje i historia psychometrii
Psychometria 2009, Wykład 3, Konstruowanie kwestionariusza psychologicznego
Psychometria 2009, Wykład 11, Inwentarz MMPI
Psychometria 2009, Wykład 9, Techniki projekcyjne
Psychometria 2009, Wykład 5, Trafność
Psychologia w zarzadzaniu Wyklady 2009-2010
szafraniec psychologia spoleczna wyklad 2009-2010
Psychological Conflict in Borderline Personality as Represented by Inconsistend Self report Item Res
Praca psychoterapeutyczna z DDA wykład SWPS
Psychologia ogólna Historia psychologii Sotwin wykład 7 Historia myśli psychologicznej w Polsce
więcej podobnych podstron