
Wstęp do Informatyki
Wykład 6
Pamięć wewnętrzna
Autor: Dr hab. Marek J. Greniewski
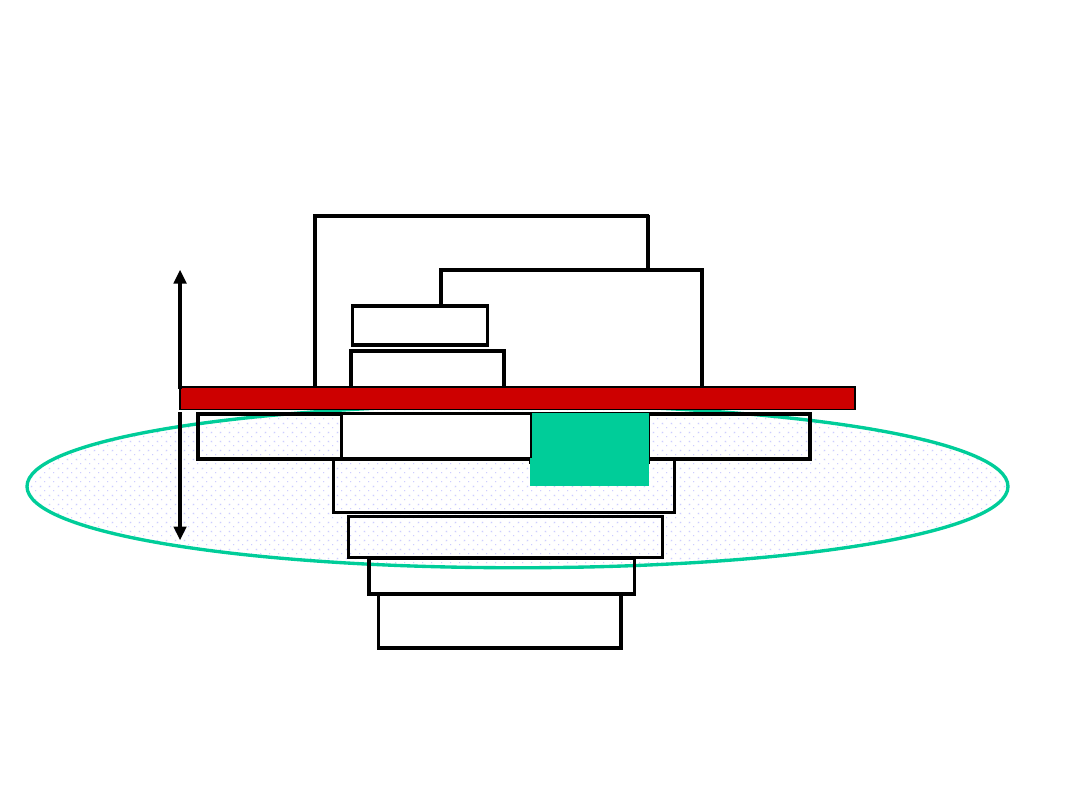
Podział na części architektoniczną i
układową współczesnego komputera
Układy we-wy
Procesor
Kompilator
System
operacyjny
(Windows 2K)
Aplikacje (np. Netscape)
Układy cyfrowe
Obwody
scalone
Lista rozkazów
określająca architekturę
Ścieżki danych i sterowanie
Bramki i
elementy
pamięci
Pamię
ć
Hardware
Software
Assemble
r
Magistrala

Wprowadzenie
• Pamięć komputera, pozornie prostą koncepcyjnie,
cechuje najszerszy zakres rodzajów, technologii,
organizacji, wydajności i kosztów – w stosunku do
pozostałych modułów współczesnego komputera.
• Nie istnieje jedna technologia, która optymalnie
spełniałaby wymagania współczesnego komputera
dotyczące pamięci.
• W rezultacie współczesny komputer zawiera hierarchię
podsystemów pamięci:
– Niektóre z nich są wewnętrzne w stosunku do komputera, czyli
bezpośrednio dostępne przez procesor,
– Pozostałe z nich są zewnętrzne, czyli dostępne dla procesora za
pośrednictwem modułu wejścia-wyjścia.
• Podstawowym aspektem pamięci jest jej położenie w
stosunku do procesora.
• Pamięć wewnętrzna jest często identyfikowana z
pamięcią główną (operacyjną). Są jednak również inne
formy pamięci wewnętrznej.

Własności systemów pamięci
• Położenie
– procesor
– wewnętrzna (główna)
– zewnętrzna (pomocnicza)
• Pojemność
– długość słowa
– liczba słów
• Jednostka transferu
– słowo
– blok
• Sposób dostępu
– sekwencyjny
– bezpośredni lub
swobodny
– skojarzeniowy
• Wydajność
– czas dostępu
– czas cyklu
– szybkość transferu
• Rodzaj fizyczny
– półprzewodnikowa
– magnetyczna
– optyczna
• Własności fizyczne
– ulotna albo nie-ulotna
– wymazywalna albo nie-
wymazywalna
• Organizacja
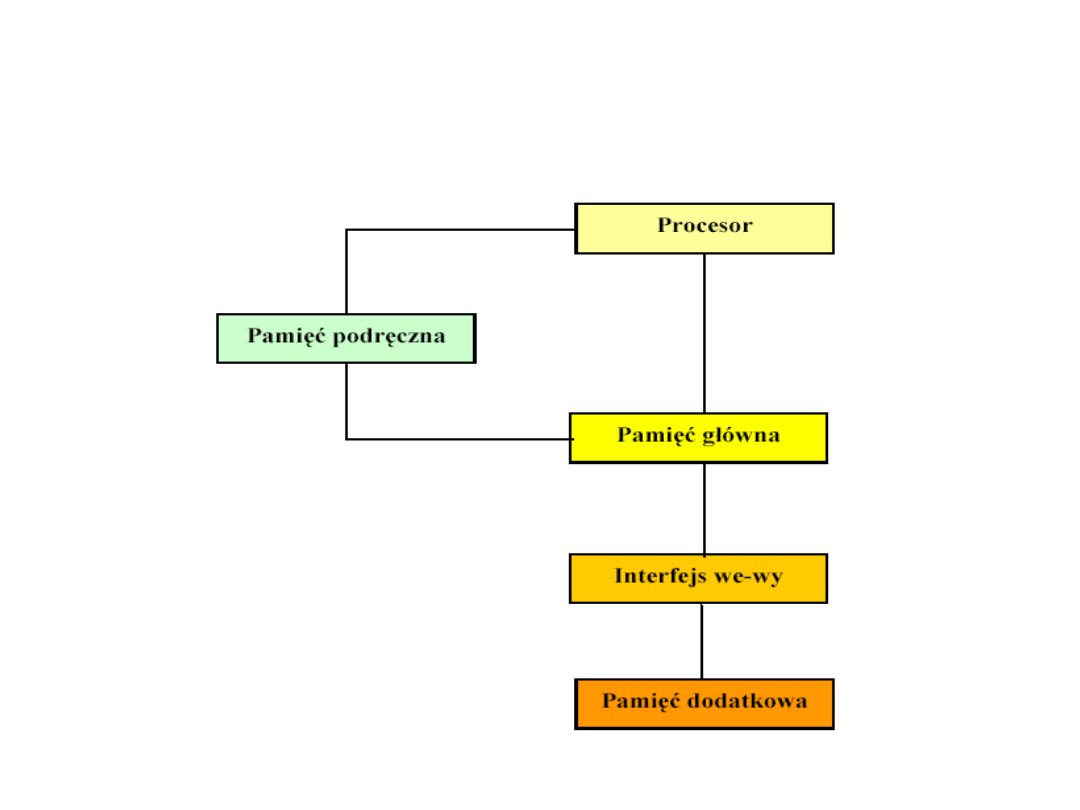
Położenie pamięci
Hierarchia pamięci
składa się z kilku
poziomów pamięci.
Każdy poziom
charakteryzuje się
inną szybkością
działania i inną
pojemnością.

Organizacja pamięci
wewnętrznej komputerów
• Własności systemów pamięci
• Hierarchia pamięci.
• Półprzewodnikowa pamięć główna
(zwana również pamięcią operacyjna)
• Pamięć typu
cache
.
• Pamięć wirtualna.

Sposoby dostępu
• Dostęp sekwencyjny. Pamięć jest zorganizowana za pomocą jednostek
zwanych rekordami. Dostęp jest możliwy w określonej kolejności
liniowej uporządkowania rekordów. Do oddzielania rekordów i do
pomocy przy odczycie są wykorzystywane przechowywane informacje
adresowe. Odczyt i zapis są wykonywane przy pomocy tego samego
mechanizmu.
• Dostęp bezpośredni. Poszczególne bloki lub rekordy mają unikalny
adres oparty na fizycznej lokalizacji. Dostęp jest realizowany do
najbliższego otoczenia rekordu, poczym następuje sekwencja
przeszukiwań.
• Dostęp swobodny. Każda adresowana komórka pamięci ma
przyporządkowany unikalny adres. Czas dostępu (odczytu/zapisu) nie
zależy od sekwencji poprzednich operacji dostępu i jest stały.
• Dostęp asocjacyjny. Jest to rodzaj dostępu swobodnego, jak pokażemy
dwupoziomowego z wykorzystaniem zgodności cech zawartości słów
na wyższym poziomie pamięci, z ewentualną wymianą zawartości
części pamięci wyższego poziomu z zawartością pamięci poziomu
niższego. Badanie zgodności cech dotyczy równocześnie wszystkich
słów pamięci poziomu wyższego.

Wydajność
• Dla użytkownika dwiema najważniejszymi
własnościami pamięci są pojemność i wydajność.
• Miarą wydajności są trzy parametry:
– Czas dostępu. Dla pamięci o swobodnym dostępie jest to czas
potrzebny dla wykonania operacji odczytu/zapisu – liczony od
momentu wprowadzenia adresu do rejestru adresowego
pamięci do chwili zakończenia odczytu do rejestru buforowego
pamięci lub zapisu zawartości rejestru buforowego w pamięci.
– Czas cyklu pamięci = czas dostępu + czas potrzebny dla
zaniku sygnałów przejściowych.
– Szybkość transferu. Jest to szybkość z jaką dane mogą być
zapisywane do pamięci lub odczytywane z pamięci – wg wzoru
T
N
= T
A
+ N/R
gdzie
T
N
–
średni czas odczytu lub zapisu
N
bitów
, T
A
–
średni czas dostępu
, N –
liczba bitów
, R –
szybkość
transferu w bitach na sekundę [bit/s].
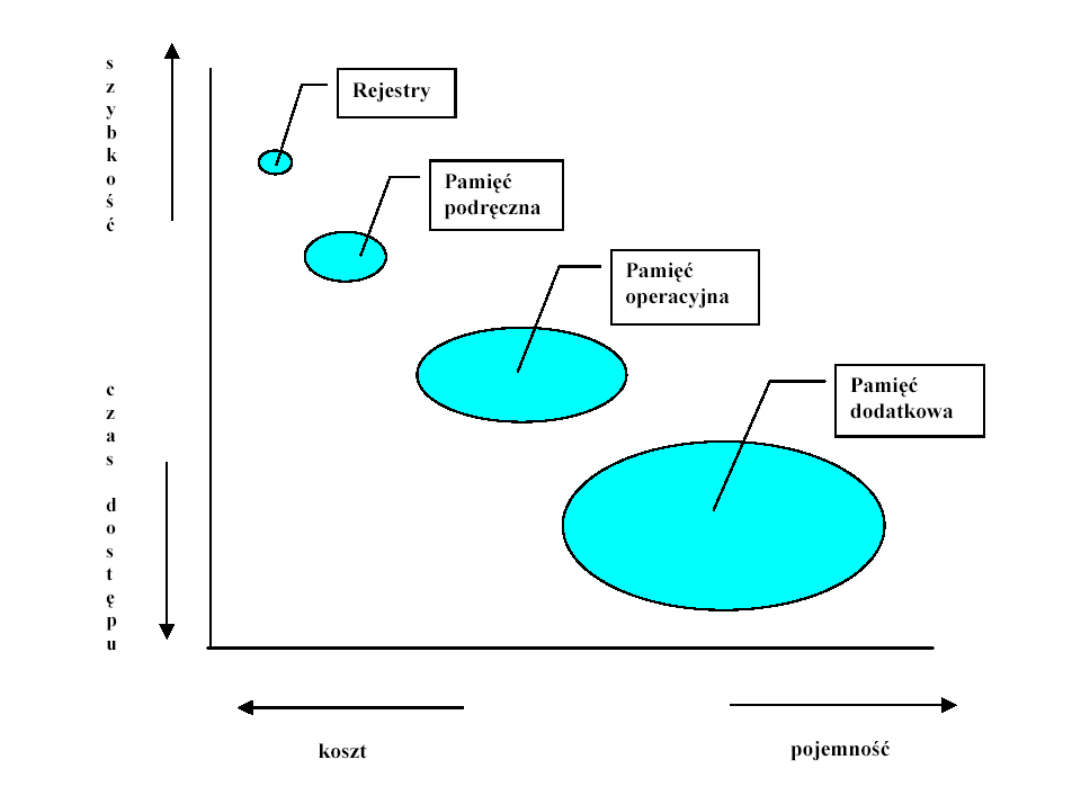
Hierarchia pamięci

Obszary zastosowania
technologii
• Technologia półprzewodnikowa umożliwia
szybki dostęp do danych i jest stosowana w
pamięciach podręcznych i pamięciach
głównych oraz w zewnętrznych pamięciach
wymiennych, oddalonych od procesora i
współpracujących za pośrednictwem modułu
wejścia-wyjścia.
• Technologie wykorzystujące powierzchnie
magnetyczne albo optyczne, są stosowane w
pamięciach zewnętrznych (zarówno
wymiennych jak i nie-wymiennych),
oddalonych od procesora i współpracujących
za pośrednictwem modułu wejścia-wyjścia.

Koszt jednego bitu - a czas
dostępu
• krótszy czas dostępu – większy koszt na bit,
• większa pojemność – mniejszy koszt na bit,
• większa pojemność – dłuższy czas dostępu.

Koszt jednego bitu - a czas
dostępu
• Rejestry wewnętrzne procesora
- zbiór szybkich rejestrów, zajmuje
najwyższy poziom hierarchii i jest zbudowana z przerzutników.
Najwyższy koszt jednego bitu i najkrótszy czas dostępu
.
• Pamięć podręczna cache
– umiejscowiona pomiędzy procesorem a
pamięcią operacyjną, a do jej realizacji używa się zwykle droższe
układy pamięci statycznej.
Bardzo wysoki koszt jednego bitu i
bardzo krótki czas dostępu
.
• Pamięć główna (operacyjna)
- jest największym obszarem pamięci,
dostępnym bezpośrednio dla procesora. W celu obniżenia kosztu
pamięć operacyjna jest realizowana z wykorzystaniem układów
pamięci dynamicznej.
Stosunkowo wysoki koszt jednego bitu i
krótki czas dostępu
.
• Pamięć wirtualna
(widoczna dla programów aplikacyjnych, ale
fizycznie nie istniejąca) – jest fizycznie realizowana na pamięci
dyskowej z pomocą pamięci głównej i specjalnych mechanizmów
procesora (hardware) i systemu operacyjnego (software).
Znacznie niższy koszt jednego bitu i akceptowalny czas dostępu
dla wielu aplikacji
.
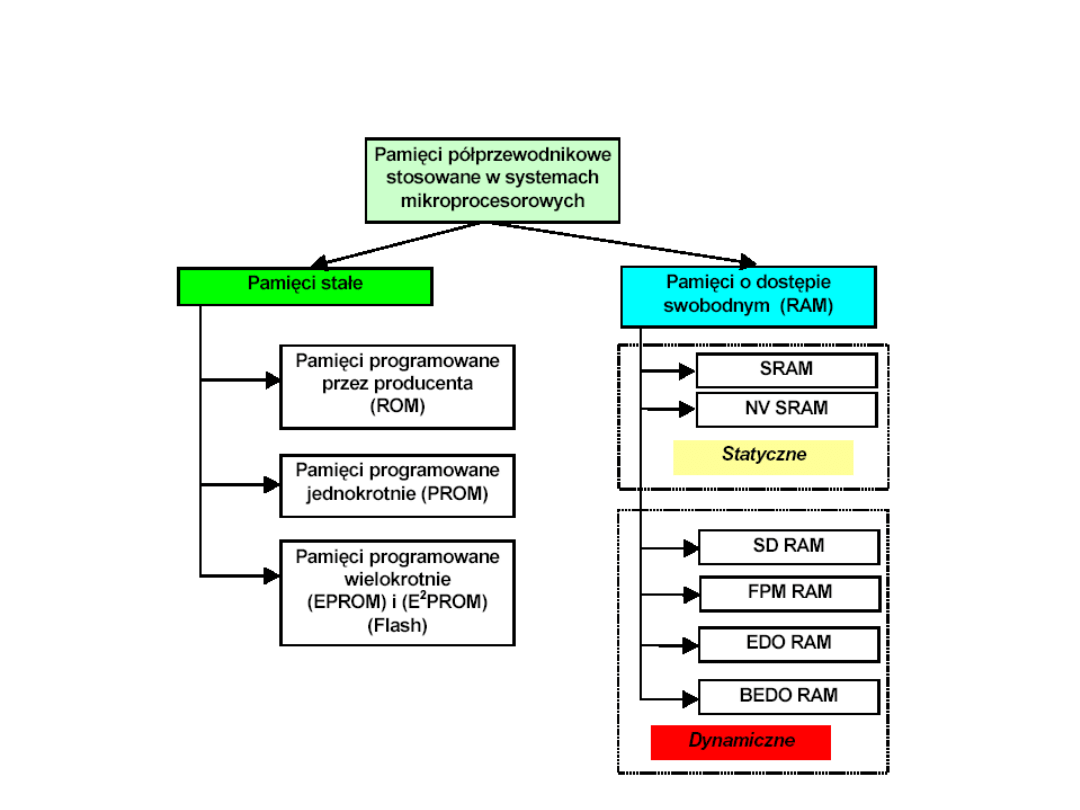
Pamięci
półprzewodnikowe

Pamięci półprzewodnikowe
• W
statycznych pamięciach RAM
wartości binarne
są przechowywane za pomocą przerzutników.
Statyczne pamięci RAM zachowują dane tak
długo, jak długo są zasilane.
• Dynamiczna pamięć RAM
jest wykonana z
komórek, które przechowują dane podobnie, jak
kondensatory przechowują ładunek elektryczny.
Obecność lub brak ładunku w kondensatorze
mogą być interpretowane jako binarne 1 i 0.
Dynamiczne pamięci RAM wymagają okresowego
odświeżania ładunku w celu zachowania danych.

Wyjaśnienie wprowadzonych
pojęć
• NV RAM
- jest to pamięć firmy Intel. Pamięć po wyłączeniu zasilania nie
traci zawartości. Uzyskano to dzięki zastosowaniu w jednym układzie
dwóch rodzajów pamięci: SRAM oraz EEPROM. W czasie normalnej pracy
jest ona widoczna jako normalna pamięć typu SRAM. W momencie
zaniku zasilania odpowiednim sygnałem podanym przez mikroprocesor
cała zawartość pamięci RAM jest przepisywana do pamięci EEPROM. Po
powrocie napięcia zasilania zawartość pamięci EEPROM jest ponownie
przepisywana do SRAM. Producent gwarantuje 10000 cykli.
• EDO RAM
- jest to typ pamięci, w której jeszcze gdy dane są
odczytywane może zostać wystawiony adres następnej komórki.
Przyspiesza to znacznie odczyt kolejnych komórek pamięci. Teoretyczny
przyrost prędkości do 20% w porównaniu z pamięciami FPM (Fast Page
Mode) RAM. Zysk w praktyce maleje do kilku procent ponieważ danych
nie można nakładkować przy zapisie.
• BEDO RAM
- jest to pamięć stanowiąca połączenie technik „burst” i
EDO RAM. Zamiast jednego adresu odczytywane jest jednocześnie
cztery. Na magistrali adresowej adres pojawia się tylko na początku
cyklu odczytu, co wydatnie skraca średni czas dostępu.

Wyjaśnienie wprowadzonych
pojęć
• FPM RAM
(Fast Page Mode)- jest to pamięć pracująca na zasadzie
adresowania stronicowego. Stronicowanie jest techniką zwiększenia
wydajności pamięci, poprzez podzielenie jej na strony mające długość od
512 bajtów do kilku kilobajtów. Zwykłe odczyty i zapisy danych w pamięci
wymagają wybrania wiersza i kolumny, co zabiera dodatkowy czas.
Stronicowanie polega na udostępnianiu komórek z tego samego wiersza,
dzięki czemu należy zmieniać tylko adres kolumny.
• SDRAM
(Synchronous Dynamic RAM) - jest to pamięć dynamiczna w której
odczyt poszczególnych komórek następuje synchronicznie, zgodnie z
taktami zegara CPU. Układy te są zsynchronizowane z magistralą
systemową (100 MHz i szybsze).
• RDRAM
(Rambus DRAM) - jest pamięcią opartą na zupełnie innych
rozwiązaniach.
Dzięki podwojeniu znajdującej się w układzie magistrali danych i
zwiększeniu częstotliwości pracy do 800 MHz, umożliwia uzyskanie
przepustowości rzędu 1,6 GB/s.
• DDR SDRAM
(Double Data Rate) SDRAM jest rozwinięciem projektu
standardowych układów SDRAM, w którym dane przesyłane są z dwa razy
większą szybkością. Poza zwiększeniem częstotliwości taktowania, pamięci
DDR osiągają podwojenie wydajności dzięki wykonywaniu 2 transferów
podczas jednego taktu zegara (przy narastającym i opadającym zboczu).

Obudowy pamięci
• SIMM
- moduły pamięci na karcie ze 32-stykami.
Szyna danych ma 8-bitów. Obecnie nie
stosowane.
• Modul PS/2
- moduły pamięci na karcie ze 72-
stykami. Pracują z szyną adresową o szerokości
32-bitów. Stosowane w pamięciach typu EDO RAM
i FPM RAM. Nazwa pochodzi od pierwotnego
zastosowania tego rodzajów modułów pamięci w
komputerach PS/2 IBM.
• DIMM
- moduły pamięci na karcie ze 168-
stykami.
Pracują z szyną adresową o szerokości 64-bitów.

Podstawowe parametry
pamięci
• Pojemność mierzona np. w bajtach
• Organizacja logiczna dostępu do danych
• Pobór mocy w przeliczeniu na jeden bit
• Parametry dynamiczne

Parametry dynamiczne
pamięci
• czas cyklu odczytu t
RC
• czas dostępu t
A
–
czas dostępu od wejść adresowych t
AA
lub t
SA
–
czas dostępu od wejść wybierania układu pamięci t
ACE
lub t
SCA
–
czas dostępu od wejść sygnału odczytu/zapisu t
ARW
• cykl czasu zapisu t
WC
• czas stabilizacji stanu po sygnale zapisu t
WR
• czas regeneracji (odświeżania) - dla pamięci
dynamicznych
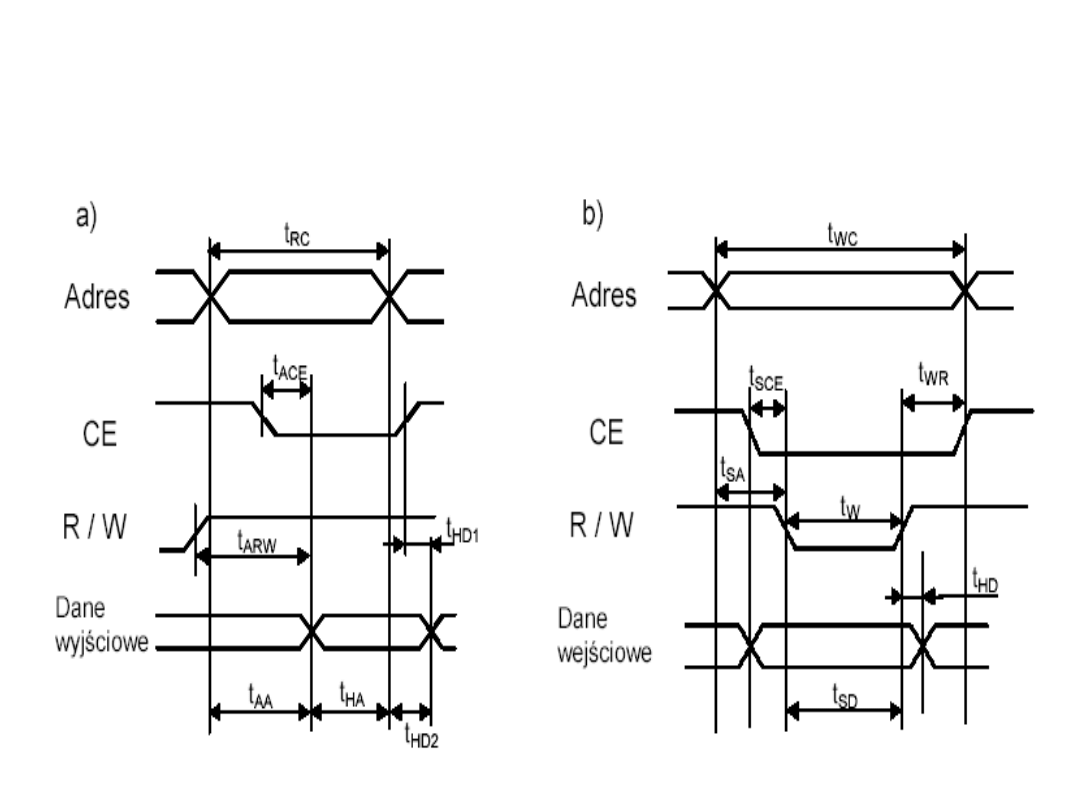
Parametry dynamiczne pamięci
dla cyklu odczytu (a) oraz cyklu
zapisu (b).

Odświeżanie - przykład
• Kostka pamięci pojemności 16 Mb (4M × 4 – 4 M
słów
4-bitowych)
• Odświeżanie sprowadza się do pobudzenia
(zaadresowania) linii wiersza, przy czy
odświeżeniu ulegają wszystkie komórki należące
do tego wiersza.
• Konieczne jest wprowadzenie mechanizmu
generującego regularnie impulsy odświeżające
przebiegające kolejno wszystkie wiersze nie
rzadziej niż raz na okres czasu nazywany cyklem
odświeżania (Refresh Time).

Typowe wartości cyklu
odświeżania
Pojemnoś
ć
Organiza
cja
Liczba
wierszy
Cykl
4 MB
256k x
16
512
8 ms
4 MB
4M x 1
1024 (1k)
16 ms
16 MB
4M x 1
2048 (2k)
32 ms

Cykl odświeżania
• Podział cyklu odświeżania na odcinki czasowe
równej wielkości daje w wyniku okres przebiegu
zegarowego (Refresh Rate) wymaganego do
spełnienia wymogu czasowego narzuconego przez
cykl odświeżania (na przykład, 16 ms/1024 = 15,6
s).
• Pojedyncze impulsy odświeżające można zgrupować
w jeden pakiet (Burst Refresh) lub też rozłożyć
równomiernie (Distributed Refresh) w obszarze okna
czasowego wyznaczonego przez cykl odświeżania.
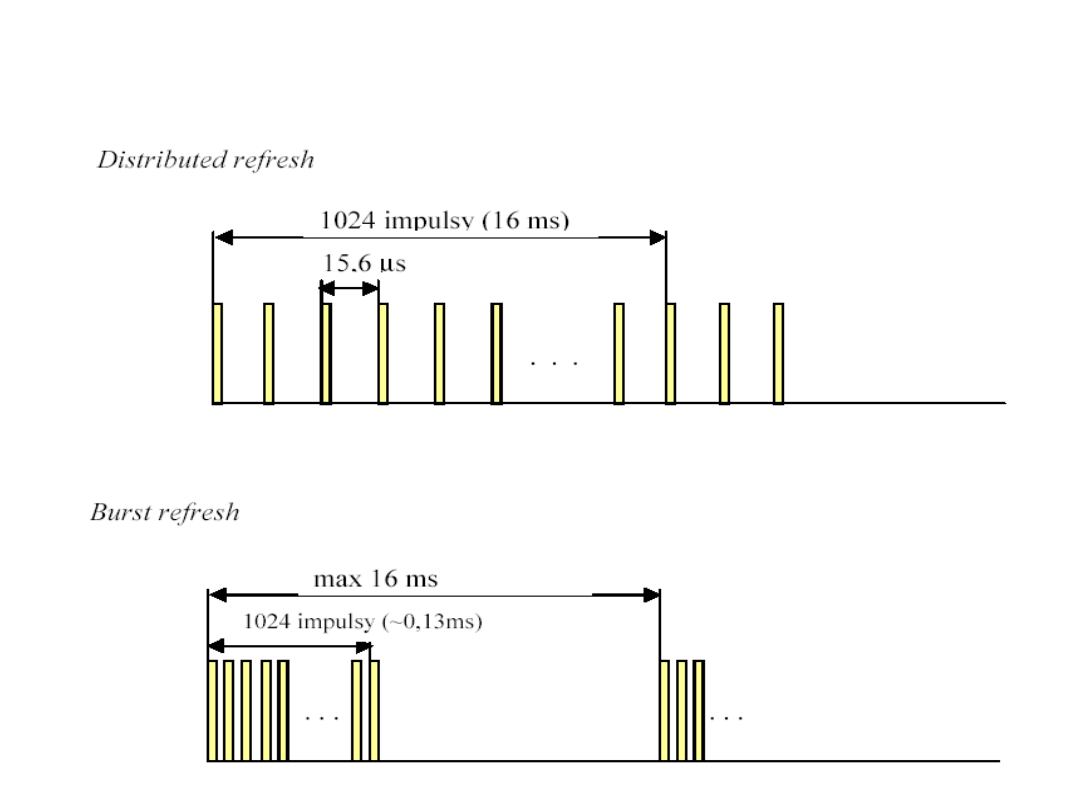
Rozkład impulsów
odświeżania
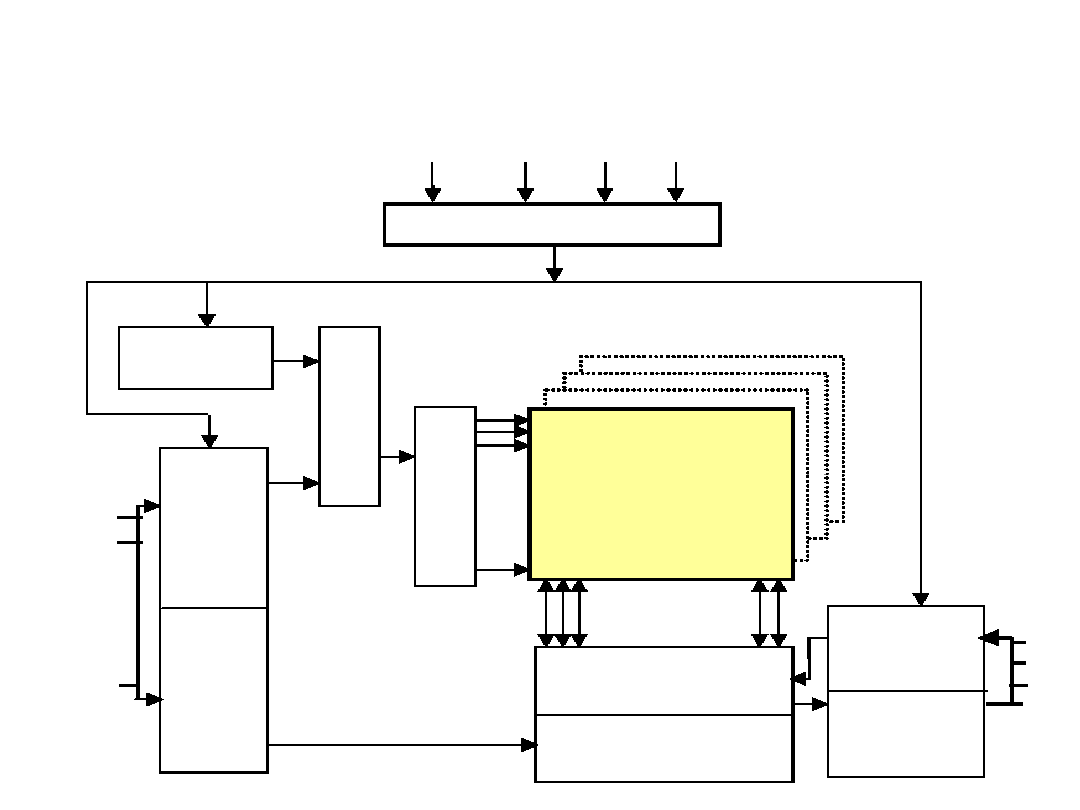
Organizacja pamięci DRAM o
pojemności 16 Mbit (4 M x 4)
Taktowanie i sterowania
Tablica pamięci
2048x2048x4
Wzmacniacz
odczytu i bramka I/O
Dekoder kolumny
Bufor danych
wejście
Bufor danych
wyjście
D1
D2
D3
D4
RAS CAS W
OE
Licznik
odświeżania
MU
X
D
e
k
o
d
e
r
w
ie
sz
a
A0
A1
.
.
.
A10
Bufor
adresu
wiersza
Bufor
adresu
kolumny

Błędy pamięci i ich korekcja
• Błędy przypadkowe – źródło powstawania
• Wprowadzenie dodatkowych bitów korekty.
• Zasady działania układu korekcji kodu:
– Nie wykryto żadnych błędów. Odczytane bity danych są
przesyłane.
– Wykryto błąd, którego korekta jest możliwa. Bity danych i
bity korekty błędu są doprowadzone do układu korektora,
który tworzy poprawiony zestaw bitów danych
przeznaczonych do przesłania.
– Wykryto błąd niemożliwy do poprawienia. Stan jest
zgłaszany w formie przerwania „błąd pamięci”.
• Jednym z najprostszych kodów korekcyjnych jest
kod Hemminga, opracowany przez Richarda
Hamminga z Bell Laboratories.
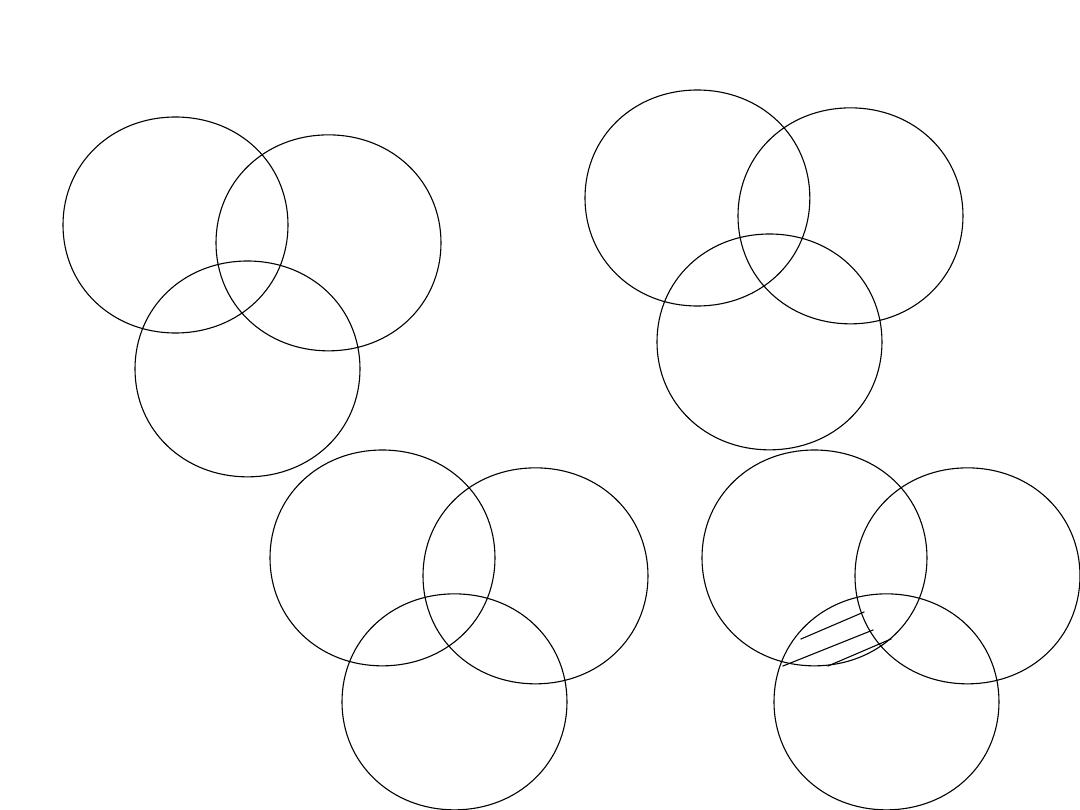
Wykresy Venna dla kodu Hemminga
(M=4, K=3)
1
1
1
0
1
1
1
0
1
0
0
1
1
0
0
1
0
0
1
1
0
0
1
0
0
A
B
C
2
K
– 1 M +
K
Gdzie M bitów
danych
i K bitów
kontrolnych
Korekta błędu-przyrost
długości słowa
Liczba
bitów
danych
Bity
kontrolne
poprawieni
a
pojedyncze
go błędu
% wzrostu
dla SED
Bity
kontrolne
dodatkowo
wykrywające
podwójne
błędy
% wzrostu
dla SED-
DED
8
4
50,00
5
62,50
16
5
31,25
6
37,50
32
6
18,75
7
21,88
64
7
10,94
8
12,50
128
8
6,25
9
7,03
256
9
3,52
10
3,91
SED
– Single-Error-Correcting;
DED
– Dual-Error-Detecting

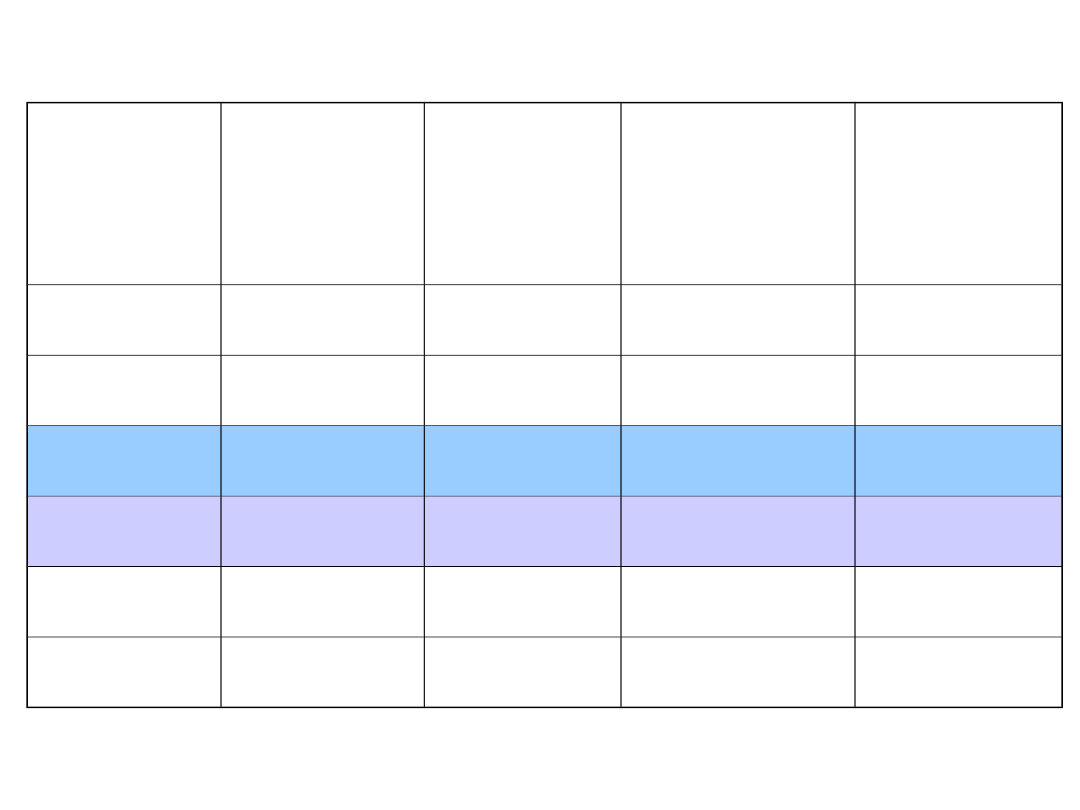
Metody zwiększania szybkości
dostępu
W komputerach wyższej klasy stosowane były różne sposoby
zwiększenia szybkości dostarczania informacji przez
zrównoleglenie działania pewnych bloków funkcjonalnych, np.:
(a) zwiększenie szerokości dostępu, co wymaga rozszerzenia
magistrali danych
(b) zastosowanie przeplotu, czyli podział pamięci na banki.
Uwaga: Zastosowanie przeplotu polega na adresowaniu
poszczególnych bloków pamięci operacyjnej za pomocą dwóch
ostatnich bitów adresu, dane zapisywane w pamięci operacyjnej
„kolejno” znajdą się w rzeczywistości w różnych blokach i mimo
względnie wolnego czasu dostępu do pojedynczego bloku przy
odpowiedniej synchronizacji w czasie odczytów z poszczególnych
bloków nie będą one blokować się wzajemnie i efektywny czas
odczytu może ulec skróceniu. Rzeczywista efektywność takiego
rozwiązania zależy od rozkładu odwołań do pamięci operacyjnej.
Metody zwiększania szybkości
dostępu
(a) Odczyt czterech niezależnych „porcji” danych z
klasycznej pamięci
(b) Odczyt z przeplotem cztery bloki pamięci - dwa ostatnie bity adresu

Pamięć podręczna (cache)
• Równolegle z poszerzaniem słowa przesyłanego z pamięci
operacyjnej trwały prace nad zwiększaniem „widzianej
przez procesor” szybkości dostępu do pamięci, co
zaowocowało pojawieniem się w kolejnych modelach
„szybkiej pamięci buforowej”, zwanej kieszeniową lub
ostatnio bardziej popularnej pod angielską nazwą cache.
• Czas dostępu do takiej pamięci jest koło 5-10 razy krótszy
od pamięci głównej, natomiast jej pojemność we
współczesnych komputerach waha się od 8-32 KB dla
cache 1 poziomu, czyli w strukturze chipa procesora, oraz
do 1 MB dla pamięci cache 2 poziomu, zwykle znajdującej
się na zewnątrz struktury krzemowej procesora.
• W wypadku niektórych nowoczesnych procesorów mówi
się również o pamięci cache 3 poziomu, umieszczonej na
płycie głównej, której pojemność jest obecnie rzędu 2 – 4
MB.

Pamięć podręczna (cache)
• Usytuowanie pamięci cache. Logicznie pamięć
cache jest umieszczona między procesorem a
pamięcią operacyjną i dostarcza procesorowi
względnie szybko danych. Pamięć podręczna
poszerza wąskie gardło powstające w wyniku różnic
szybkości działania procesora i pamięci głównej,
korzystając z własności zachowania programu
zwanej zasadą lokalności.
• Zasada lokalności. Programy mają tendencję do
ponownego używania danych i rozkazów, które były
niedawno używane. Rozkazy i dane używane w
krótkim odstępie czasu są zwykle położone także
blisko siebie w pamięci (lokalność przestrzenna).

Zasada działania pamięci
cache
• Półprzewodnikowa pamięć podręczna zawiera
ograniczoną liczbę obszarów albo wierszy
służących do przechowywania bloków z pamięci
głównej.
• Każdy blok ma typowo wielkość od 4 – 16 słów.
• W czasie wykonywania programu procesor zamiast
czytać rozkazy czy dane bezpośrednio z pamięci
głównej, szuka ich najpierw w pamięci podręcznej.
• Jeśli słowo zostaje znalezione, to sygnalizowane
jest „trafienie” i słowo przesyłane jest do
procesora.
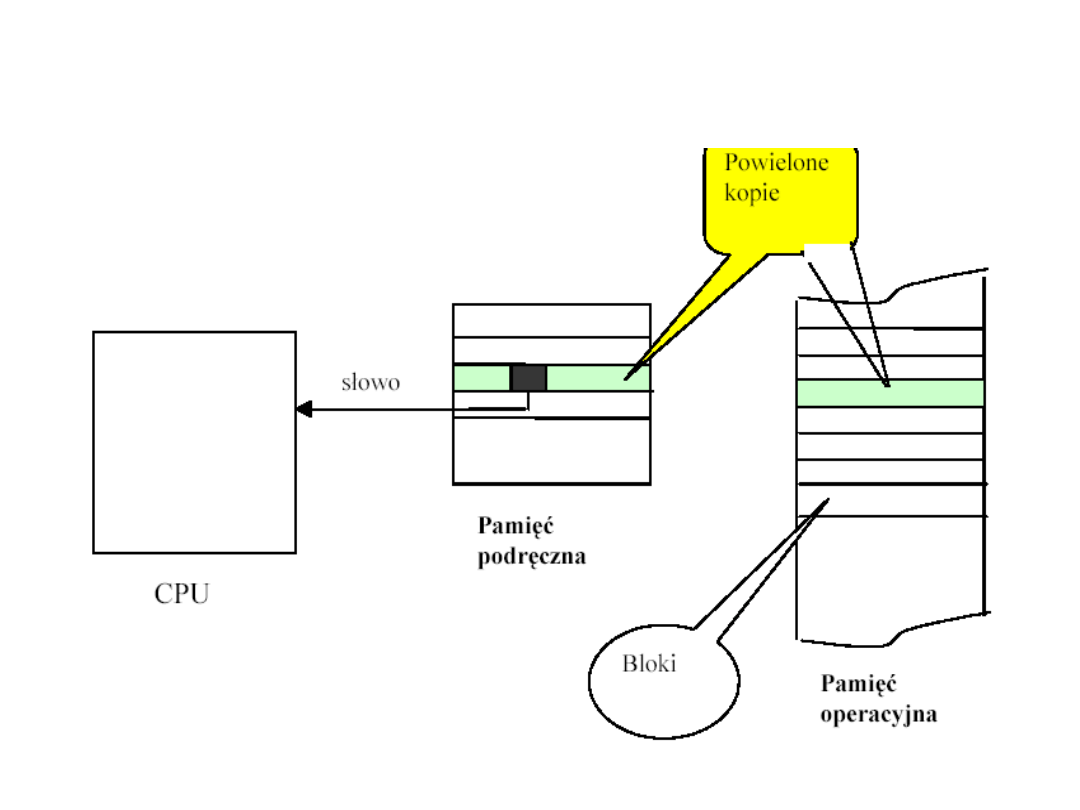
„Trafienie” w pamięci cache
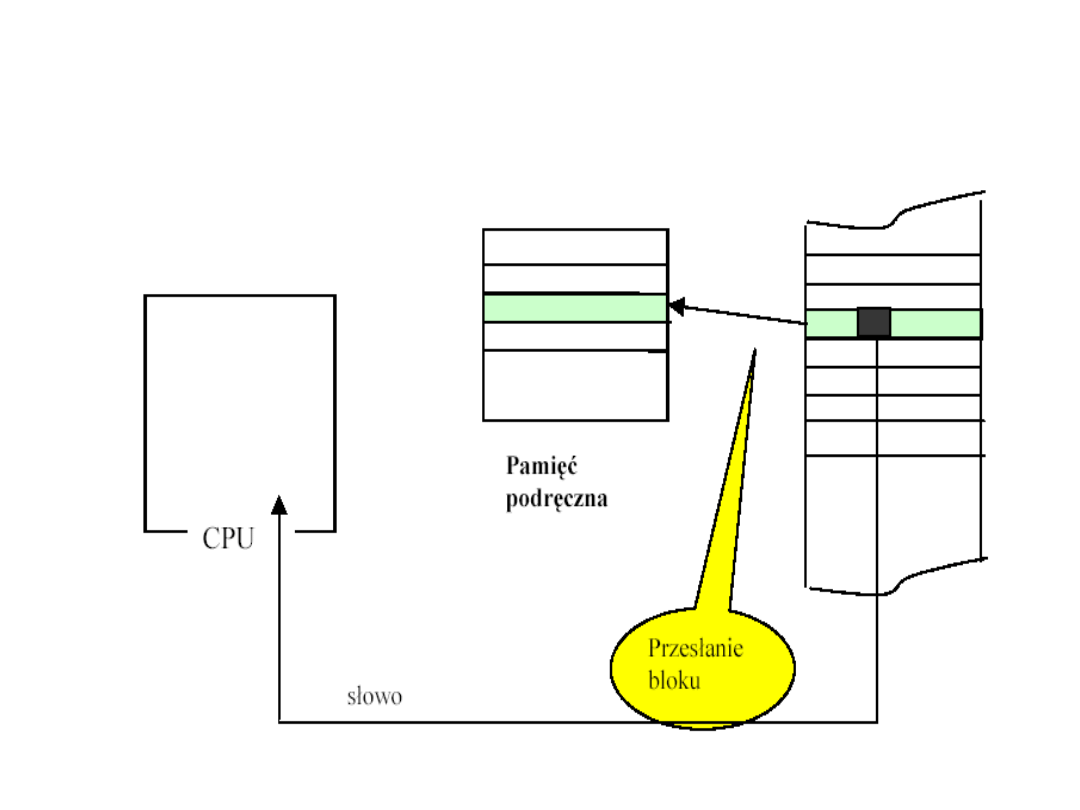
„Chybienie” w pamięci cache
Pamięć
operacyjna

Cykl pracy z pamięcią cache
• Procesor wystawia na szynę adresową adres
danej, którą chce odczytać z pamięci
operacyjnej oraz wystawia sygnał odczytu na
szynie sterującej
• MMU sprawdza, czy w cache znajduje się żądane
słowo, i jeśli tak, dostarcza je procesorowi
znacznie szybciej niż pamięć operacyjna
• Równocześnie jest inicjowany odczyt z pamięci
operacyjnej, który przy trafieniu jest anulowany,
zaś przy chybieniu jest kontynuowany - celem
odczytania danej.
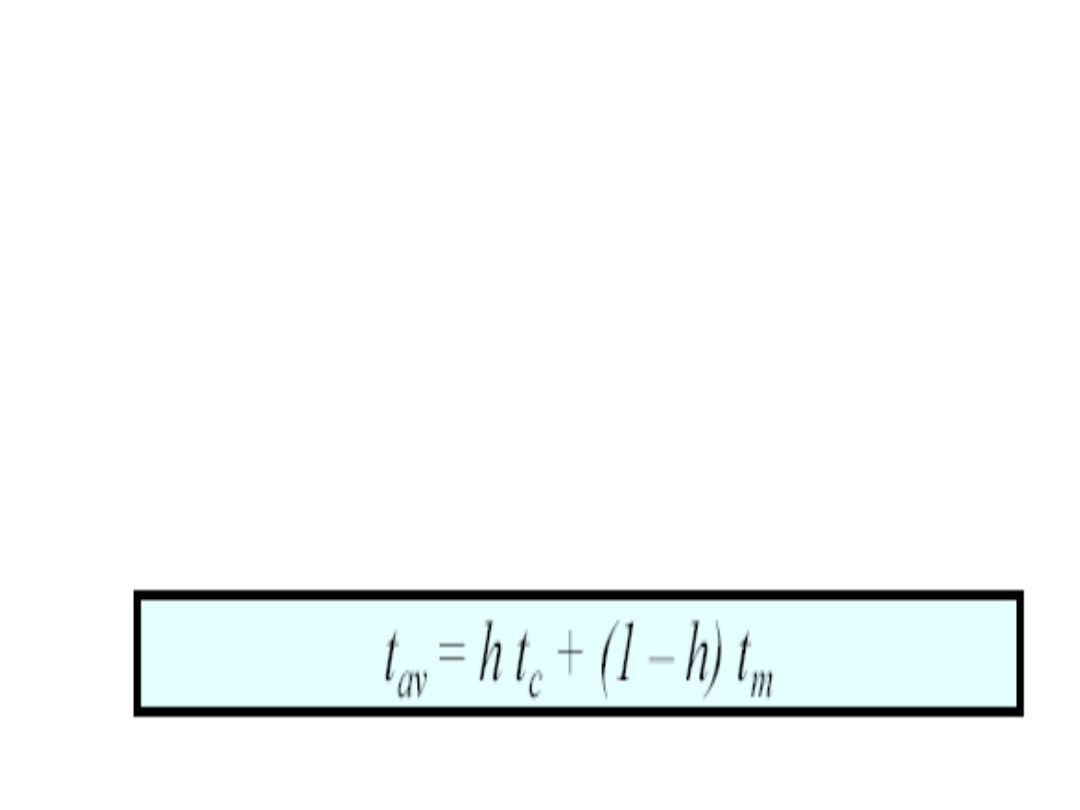
Miara wydajności pamięci
podręcznej
Miarą wydajności pamięci podręcznej jest
współczynnik trafień
(ang. hit ratio; h),
który określa, jaka część odwołań do
pamięci została obsłużona przez pamięć
podręczną, unikając korzystania z pamięci
głównej.
Jeżeli czasy dostępu do pamięci
podręcznej i pamięci głównej wynoszą
odpowiednio: t
c
i t
m
, to średni czas
dostępu do słowa t
av
wyraża się wzorem:

Uwagi realizacyjne
• Dla zwiększenia efektywności pracy takiego systemu, tzn.
zwiększenia współczynnika trafień stosuje się odczyt z pamięci
operacyjnej do cache nie pojedynczych słów ale linii,
stanowiących całkowitą wielokrotność szerokości szyny danych
procesora.
• Dzięki własności lokalności odwołań, (zarówno przestrzennej jak i
czasowej) typowej dla programów, jeśli w danej chwili jest nam
potrzebna zawartość słowa n, istnieje duże prawdopodobieństwo,
że następna instrukcja do wykonania będzie pochodziła z
następnej komórki pamięci operacyjnej bądź w przypadku
niewielkich pętli z bezpośredniego jej otoczenia.
• Podobnie dla danych , przetwarzanie tablic również ma charakter
sekwencyjny np. przegląd w celu znalezienia elementu
największego.
• Aby przechowywać w cache informacje najczęściej potrzebne – a
w cyklu pracy procesora potrzebne są dwa strumienie informacji,
jeden to kolejne instrukcje do wykonania, drugi to przetwarzane
dane, stosuje się nie jak poprzednio, jedną pamięć cache,
wspólną dla danych i rozkazów, ale rozdzielone bloki pamięci, z
różnym przeznaczeniem.

Struktura pamięci cache
•
Pamięć danych właściwych (tzn. wierszy instrukcji lub
danych z pamięci operacyjnej)
•
Pamięć adresów wiersza komórek, których zawartość jest
przechowywana w części danych właściwych
•
Pamięć znaczników, przeznaczonych dla wspomagania
zarządzaniem pamięcią cache np. wyznaczaniem, które
wiersze można usunąć w przypadku zapełnienia pamięci
cache oraz konieczności wprowadzenia nowych wierszy
danych
•
Jednostka zarządzania pamięcią, m.in. porównująca adresy
odwołań i przechowywanych kopii zawartości komórek
pamięci operacyjnej oraz podejmująca decyzje o usunięciu
wiersza przy zapełnieniu cache. Konieczne jest zapewnienie
sterowania przez sprzęt, a nie oprogramowanie, gdyż dla
wykonania odczytu z pamięci należałoby odczytać z pamięci
podprogram obsługujący odczyt z pamięci itd.

Pojęcia, związane z pamięcią
cache
• Odwzorowania: bezpośrednie, blokowo-
asocjacyjne, zbiorowo-asocjacyjne, w pełni
asocjacyjne,
• Współczynnik trafień (hit ratio) oraz
współczynnik chybień,
• Algorytmy wymiany wierszy,
• Zapis metodami write-through, write-back,
• Bity ważności, wieloportowość – są
związane z organizacją komputerów, ale
przy omawianiu architektury także się
pojawiają.
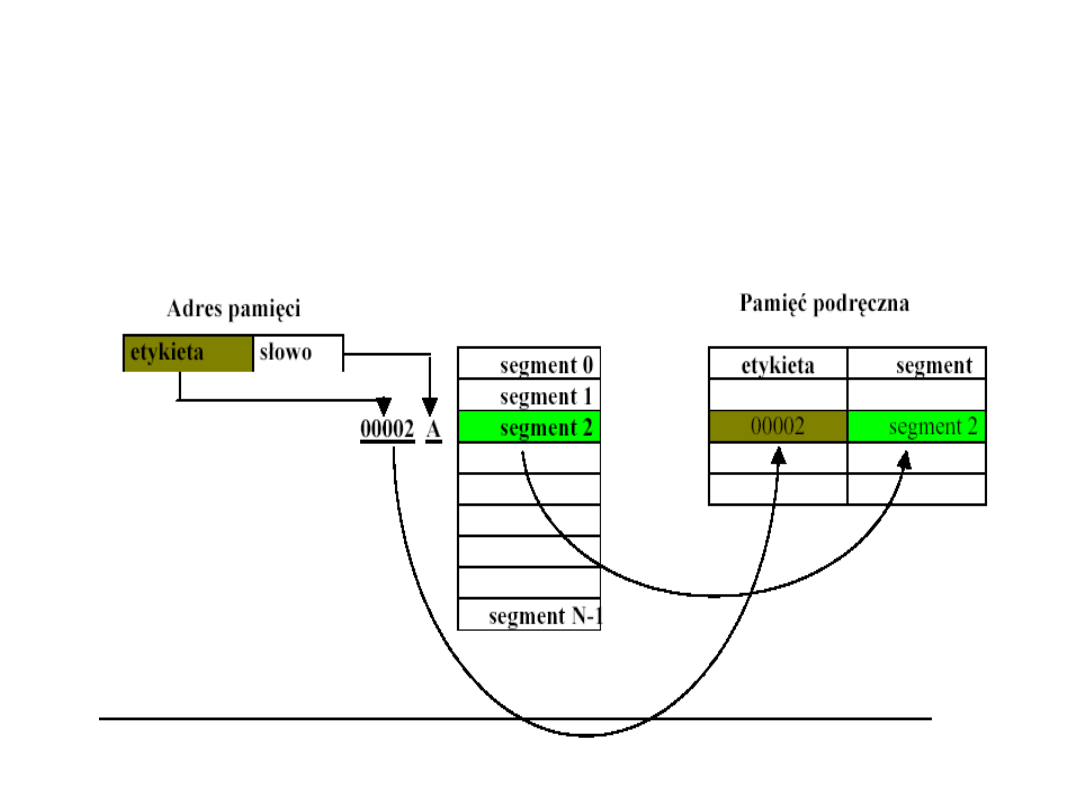
Pamięć cache asocjacyjna
Segmenty pamięci głównej są odwzorowane w obszary
pamięci podręcznej oraz znakowane numerem wiersza lub
etykietą. Etykieta jest wyznaczana przez bardziej znaczącą
część adresu, zwaną polem etykiety.
Pamięć
operacyjna
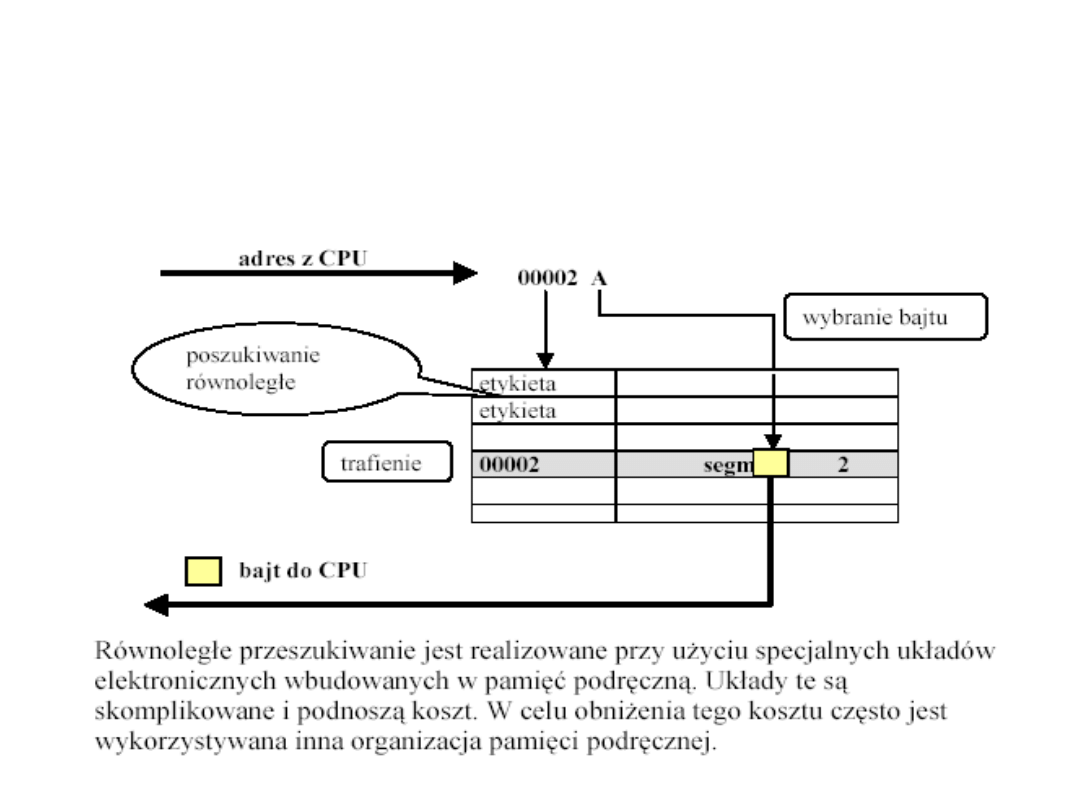
Pamięć cache asocjacyjna
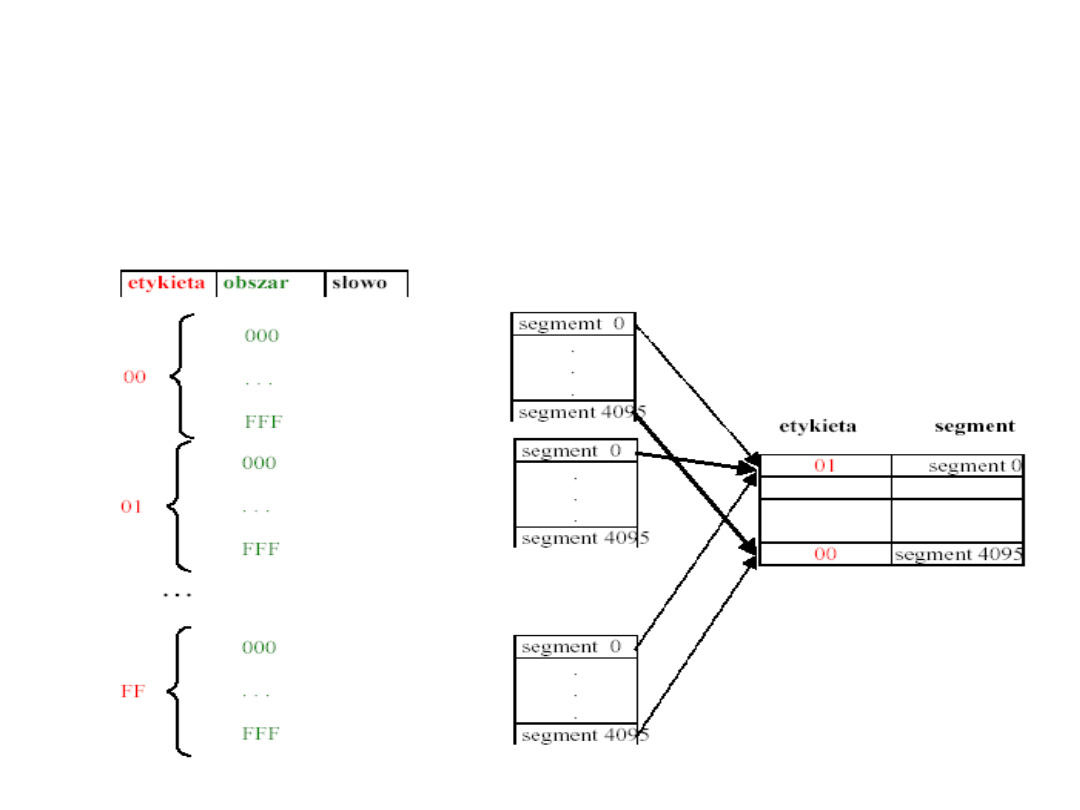
Pamięć cache odwzorowana
bezpośrednio
Przy organizacji pamięci podręcznej z odwzorowaniem
bezpośrednim unika się problemu przeszukiwania bufora
przez przypisanie każdego wiersza pamięci do tylko
jednego obszaru pamięci podręcznej.

Pamięć cache odwzorowana
bezpośrednio
• Głównym problemem przy odwzorowaniu
bezpośrednim jest to, że tylko jeden z wierszy
współdzielących pewne obszary w pamięci
podręcznej może znajdować się w niej w
danym momencie.
• Jeśli program często odwołuje się do dwóch
wierszy, które odwzorowane są w ten sam
obszar, to muszą być one cyklicznie usuwane i
ładowane do pamięci podręcznej, poważnie
obniżając jej wydajność.
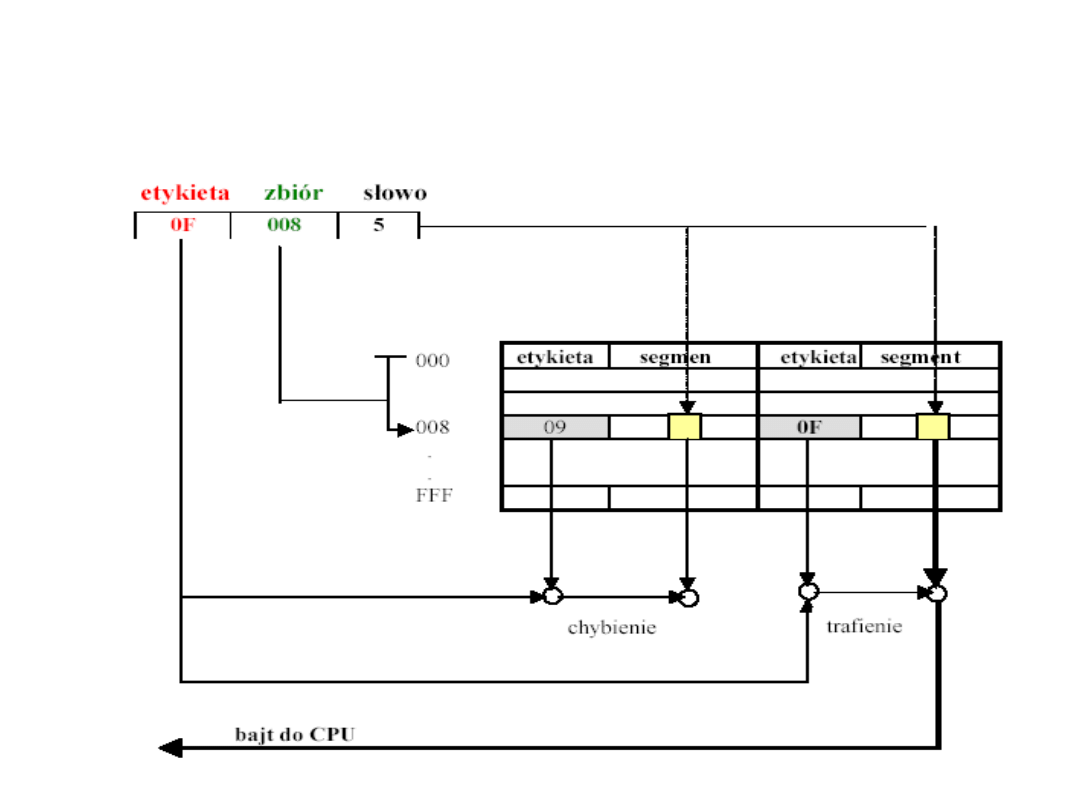
Pamięć cache ze zbiorowym
odwzorowaniem asocjacyjnym

Pamięć cache ze zbiorowym
odwzorowaniem asocjacyjnym
• W każdym wierszu pamięci podręcznej ze
zbiorowym odwzorowaniem asocjacyjnym może być
przechowywanych kilka par etykieta – segment,
tworzących zbiór.
• Kiedy następuje odwołanie procesora do pamięci
podręcznej, wtedy pole zbioru jest używane w
buforze jako indeks w taki sam sposób, jak używane
było pole obszaru w schemacie odwzorowania
bezpośredniego.
• Po wyznaczeniu zbioru obie etykiety są jednocześnie
porównywane z polami etykiet adresów.

Pamięć wirtualna
•
Pamięć wirtualna (virtual memory), jest tworem
realizowanym z pomocą dodatkowych mechanizmów
sprzętowych oraz programowych.
•
Użytkownik odnosi wrażenie, że pojemność pamięci
operacyjnej jest wielokrotnie od pojemności fizycznej
RAM, ponieważ użytkownik widzi jako pamięć
operacyjną odpowiednio duży obszar pamięci dyskowej.
•
Przy wykorzystaniu tej techniki adresy generowane
przez procesor nie są używane do bezpośredniego
dostępu do pamięci, ale są przekształcane w prawdziwe
adresy, które mogą wskazywać na pamięć RAM, pamięć
dodatkową albo kombinację ich obu.
•
W pamięci operacyjnej RAM - odwzorowane są tylko te
części programu, które są aktualnie niezbędne do
wykonania, reszta pozostaje na dysku do czasu aż
będzie potrzebna.

Pamięć wirtualna
•
Koncepcja pamięci wirtualnej bierze się z faktu, że dla
właściwego wykonania programu prawdopodobnie niezbędne
jest przechowywanie w RAM tylko pewnej jego części –
instrukcji i danych, które w najbliższym czasie będą
przetwarzane.
•
W przypadku niedoboru RAM w stosunku do wymagań
programu, niepotrzebne w danym okresie czasu fragmenty
kodu oraz danych - mogą być przechowywane w tańszej i
bardziej pojemnej, ale o rząd wielkości wolniejszej pamięci
zewnętrznej, zwykle na dysku twardym.
•
Zjawisko to, w przypadku wykonywania przez komputer tylko
jednego programu, było nazywane nakładkowaniem i
pozostawiane programistom aplikacyjnym, ale wraz z
pojawieniem się systemów wielodostępnych i
wieloprogramowych, zarządzaniem wymianą fragmentów
kodu oraz danych - dla różnych zadań między RAM i dyskiem
zajął się system operacyjny.
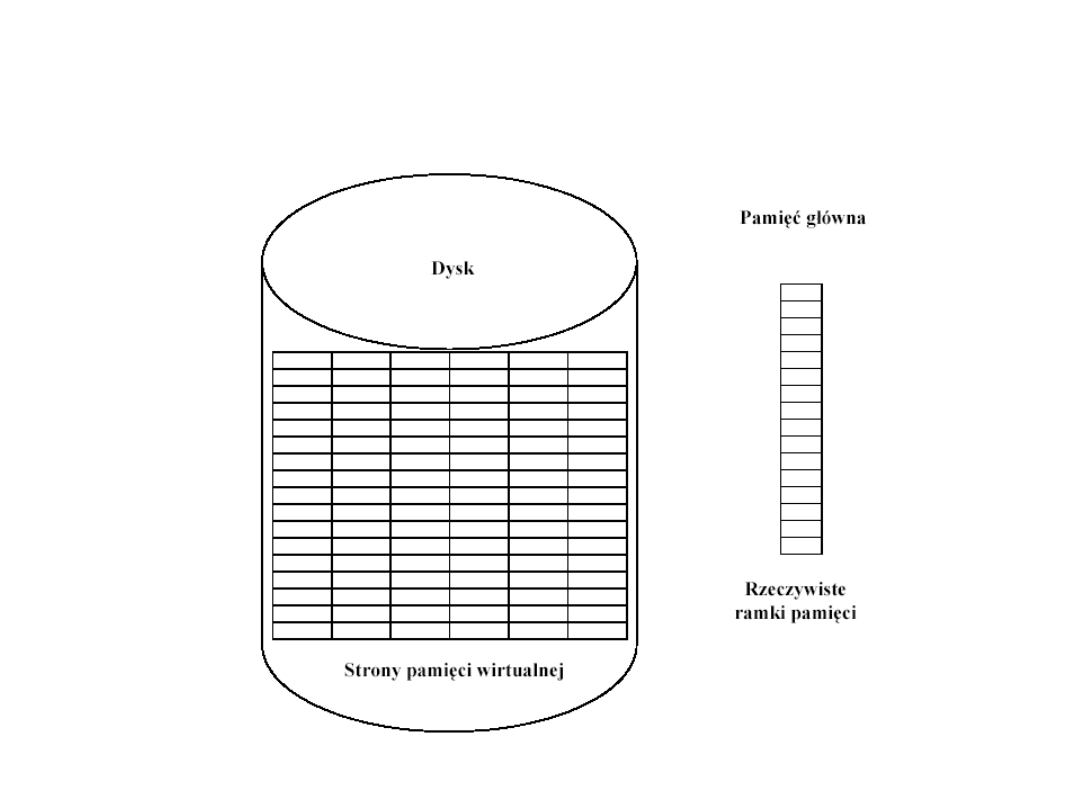
Pamięć wirtualna

Pamięć wirtualna
• Problemem, pozornie tylko błahym, jest podział programu w sensie
instrukcji oraz danych na fragmenty o stałej długości (mówimy wtedy o
stronicowaniu) lub zmiennej długości (nazywanego czasem
segmentacją).
• Z wyborem strategii stron albo segmentów wiążą się ważne aspekty,
związane z efektywnością wykorzystania miejsca w RAM i na dysku,
koniecznością scalania wolnej pamięci (de-fragmentacja), możliwością
stosowania ochrony zadań przed nieuprawnionym dostępem przez innych
użytkowników systemu, w tym również innych zadań własnych - z
powodów świadomych (atak) oraz nieświadomych (błąd, nieuctwo lub
niedbalstwo).
• Pojawia się nowe pojęcie zadania, czyli „dynamicznego”, „żyjącego”
programu, a raczej procesu obliczeniowego wykonywanego przez system,
który w danej chwili może być aktywny bądź znajdować się w
zawieszeniu, np. w oczekiwaniu na dostęp do określonego zasobu (takich
jak - program drukujący, który czeka na załadowanie papieru do
podajnika), a tym czasie procesor może w tle wykonywać inne obliczenie,
np. kontrola antywirusowa.
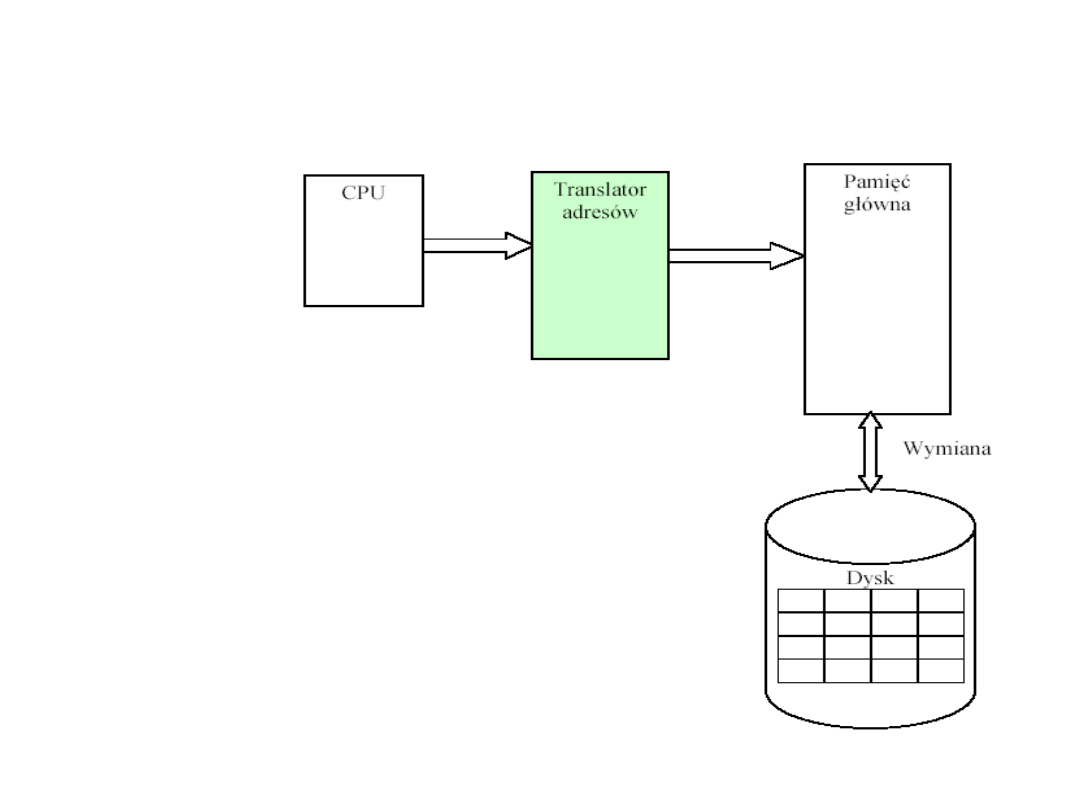
System zarządzania pamięcią
wirtualną
W czasie działania programu
przesyłanie fragmentów kodu
oraz danych do RAM z dysku
(i odwriotnie) - jest
kontrolowane przez część
systemu operacyjnego zwaną
systemem zarządzania
pamięcią wirtualną.

Stronicowanie
•
Krytyczny dla efektywności mechanizmu
stronicowania - jest rozmiar ramki i strony.
•
Stały rozmiar ramki i strony: nie występuje de-
fragmentacja, nie wiadomo co strona zawiera
(dane, kod, stos ?), nie można współużytkować
obszaru strony.
•
Mała strona: niewielki obszar „zmarnowany”, ale
dużo wierszy w tablicy stron, częste krótkie
transmisje z/do dysku, duża transmisja z/do dysku
przy zmianie tablic stron po przełączeniu zadania
•
Duża strona: duży obszar zmarnowany (średnio ½
strony), mało wierszy, rzadsze błędy stron, krótki
czas transmisji a długi pozycjonowania dla
współczesnych dysków.
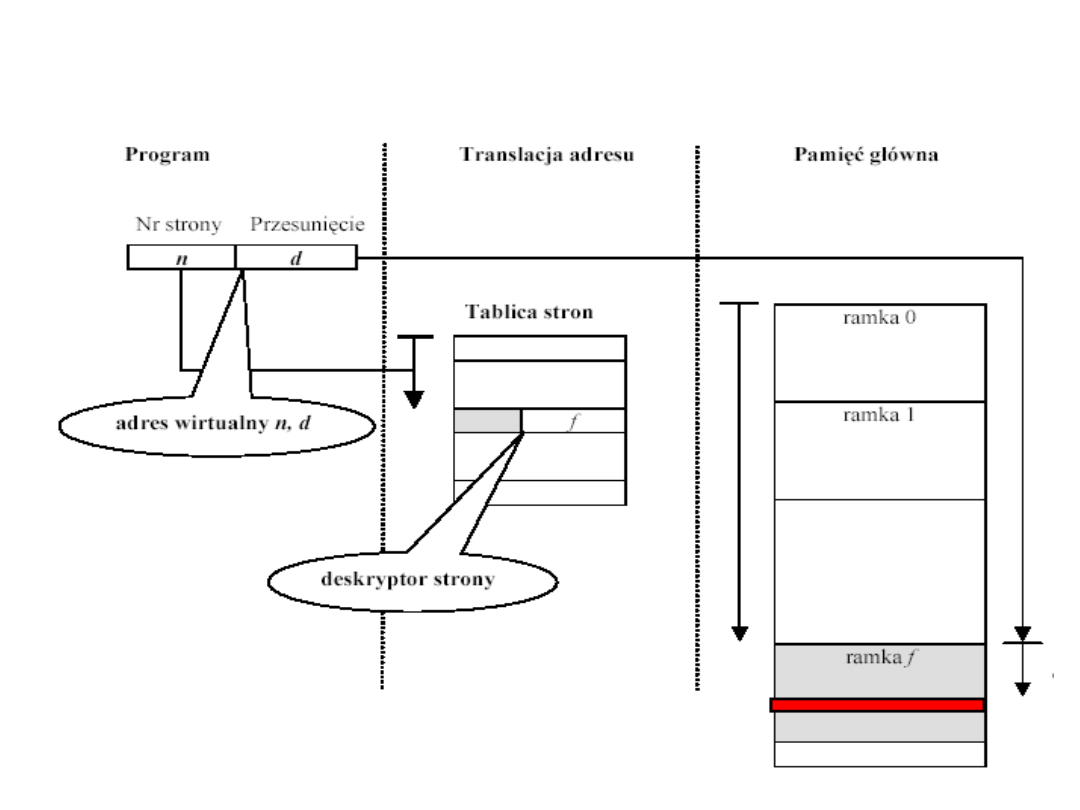
Stronicowanie a adresowanie
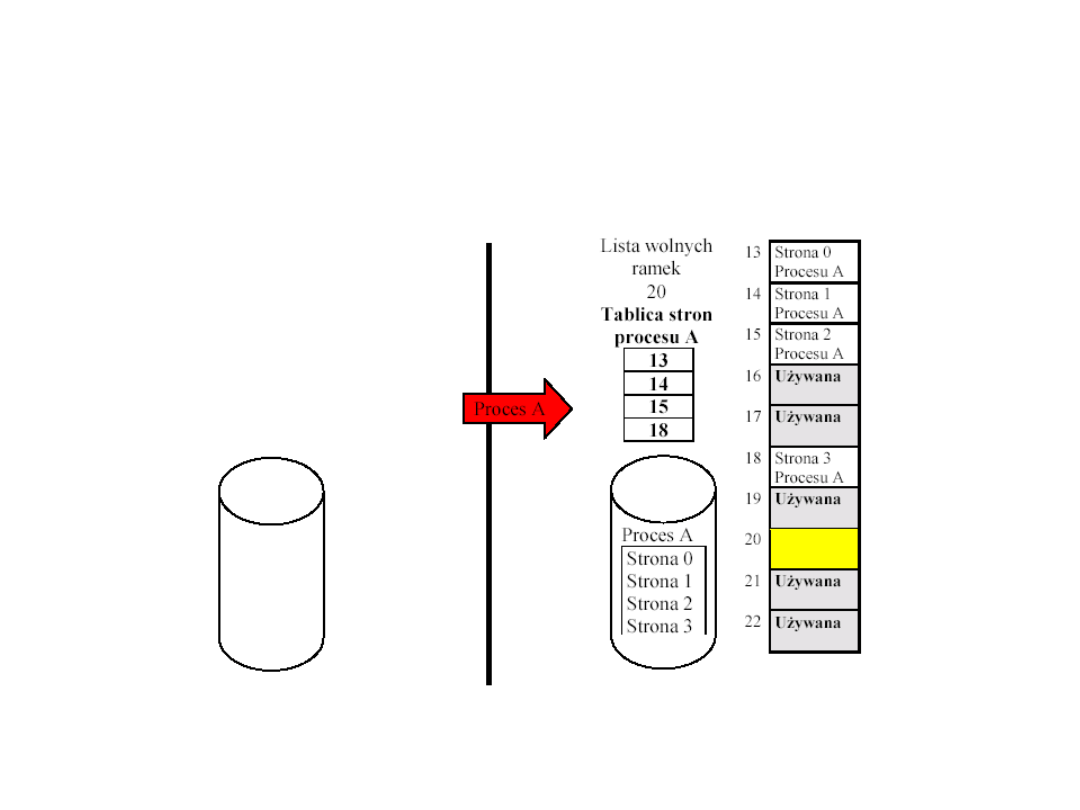
Stronicowanie a adresowanie

Struktura tablicy stron
• Tablica stron procesu ma zmienną długość,
zależną od rozmiaru procesu. Zatem nie możemy
przechowywać jej w rejestrach procesora. Musi
ona znajdować się w pamięci głównej.
• Rejestr procesora przechowuje adres początkowy
tablicy stron wykonywanego procesu.
• Numer strony adresu wirtualnego służy do
indeksowania tablicy stron oraz znalezienia
odpowiedniego numeru ramki. Po połączeniu go z
adresem względnym, stanowiącym część adresu
wirtualnego, można otrzymać adres rzeczywisty.
• Jak duża powinna być tablica stron?

Przykład – architektura VAX (adres
32-bitowy)
• Każdy proces może zajmować do 2
31
= 2 GB pamięci
wirtualnej.
• Wielkość strony 512 B = 2
9
, co oznacza, że na jeden
proces może przypadać 2
22
zapisów tablicy stron (4
M !).
• Tablice stron są przechowywane również w pamięci
wirtualnej. Oznacza to, że tablice stron również
podlegają stronicowaniu.
• Gdy proces jest realizowany, przynajmniej część jego
tablicy stron musi znajdować się w pamięci głównej.
• Sposoby organizacji dużych tablic stron:
– dwupoziomowy schemat,
– odwrócona tablica stron.

Bufor translacji adresów
• Każde odwołanie do pamięci wirtualnej wywołuje
co najmniej dwa dostępy do pamięci głównej:
–
pobranie odpowiedniego zapisu tablicy stron,
–
pobranie żądanych danych.
• Przyjęcie prostego schematu pamięci wirtualnej
powoduje podwojenie czasu dostępu do pamięci.
• Sposób zmniejszenia czasu dostępu:
–
zastosowanie specjalnej pamięci podręcznej
zapisów tablicy stron, nazywanej buforem
translacji adresów (translation look-a-side buffer
- TLB).
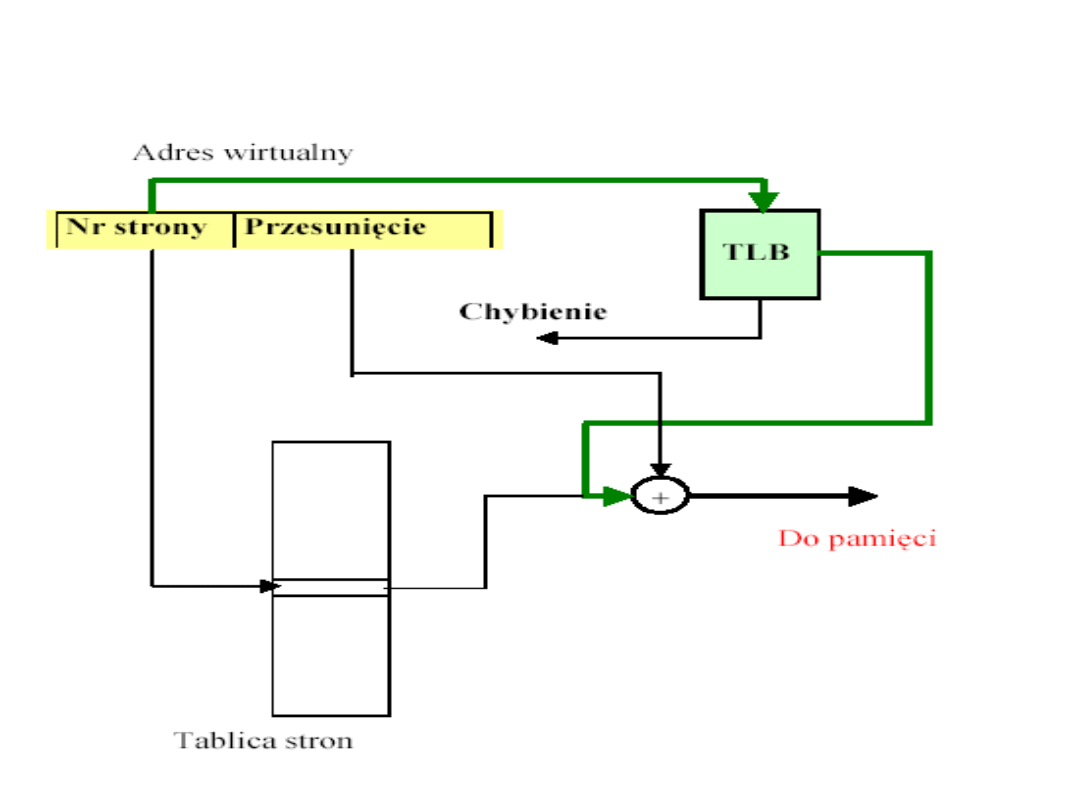
Schemat działania bufora translacji
adresów

Segmentacja
• Zmienny rozmiar ramki i segmentu,
zależny od potrzeb, nie występują
wówczas straty na pustej ostatniej
stronie, znana jest zawartość ramki.
• Można chronić dane i stos przed
wykonaniem czy kod przed zapisem.
• Można współużytkować segmenty –
tylko jedna kopia w pamięci i mogą z
niej korzystać różne zadania.

Pamięć wirtualna a pamięć
cache
• Pamięć wirtualna jest mechanizmem jakościowo
różnym od omawianych poprzednio pamięci
podręcznej cache.
• Aby pokazać pamięć cache, należałoby wskazać kilka
układów, w skrajnych przypadkach jeden układ - VLSI,
realizujących wspólnie zadanie podawania
procesorowi często używanych danych i rozkazów
szybciej, niż jest to w stanie zrobić pamięć
operacyjna.
• Pamięć wirtualna jest zespołem zarówno elementów
sprzętu (rejestrów procesora, elementów pamięci
operacyjnej, elementów pamięci dyskowej), jak i
oprogramowania – zarządzanie pamięcią wirtualną
realizuje system operacyjny.

Opis działania pamięci
wirtualnej
• Zadanie odwołuje się do komórki RAM, generując
adres logiczny;
• MMU tłumaczy adres logiczny na fizyczny: adres
początku bloku + offset w ramach bloku;
• MMU sprawdza, czy żądany blok znajduje się w
RAM (najpierw w TLB, potem w tablicy bloków w
RAM)
– jeśli tak, obsługa odczytu/ zapisu;
– jeśli nie, zawieszane jest wykonywanie bieżącego
zadania i generowany jest wyjątek, obsługiwany przez
jądro systemu operacyjnego; sprawdzana jest
możliwość sprowadzenia żądanej strony z dysku do
„wolnego” obszaru w PAO, jeśli nie ma wolnego, należy
wyznaczyć jakiś do usunięcia, sprawdzić, czy usuwany
był modyfikowany w stosunku do kopii odczytanej
poprzednio z dysku, jeśli modyfikowany, zapisać nową
postać usuwanego, wczytać żądany obszar do PAO i
wznowić wykonanie zawieszonego zadania;

Trzypoziomowy mechanizm
wirtualny
• Poziom jądra systemu operacyjnego: obsługa braku
żądanych bloków (page fault), procedury umieszczania
bloków w wolnej RAM, procedury wymiany bloków;
• Poziom jednostki zarządzania pamięcią:
przechowywanie i interpretacja bitów sterujących
– valid/ invalid bit czy ramka zawiera kopię bloku z dysku, czy
informację nieaktualną
– dirty bit: blok był modyfikowany po odczycie z dysku
– read/ write bit: strona do odczytu, zapisu ?
– licznik dostępów: dla implementacji algorytmów wymiany
– generacja sygnałów do SO: błąd pamięci, błąd strony, zapis do
bloku o atrybucie „tylko do odczytu”;
• Poziom procesora: instrukcje muszą być restartowalne
zarówno przy próbie pobrania instrukcji jak i jej
argumentów, wprowadza się dodatkowe instrukcje i
rejestry do obsługi pamięci wirtualnej.

Pomiar wydajności pamięci
wirtualnej
Efektywny_czas_dostępu =
(1 – współczynnik_chybień) * czas_dostępu_do_RAM
+ współczynnik_chybień * czas_obsługi_chybienia
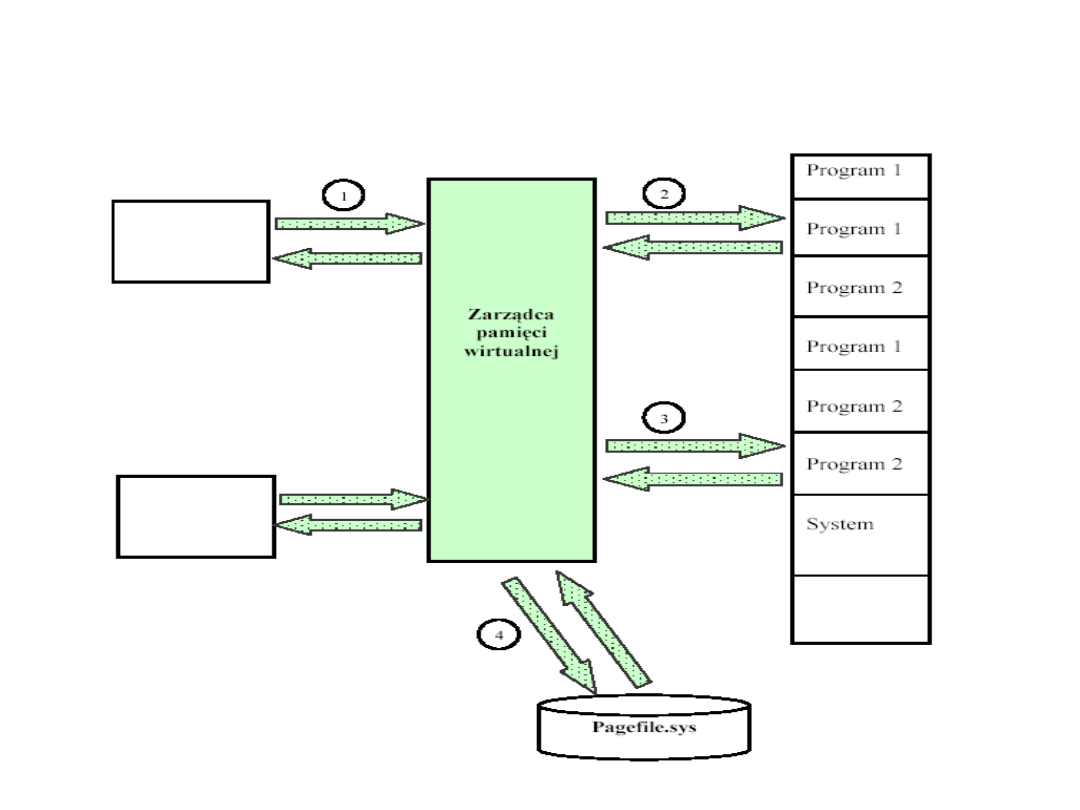
Pamięć wirtualna

Pamięć wirtualna systemu
Windows NT
• Proces zarządzania stronami w systemie Windows
NT (t.j. decydowanie, które strony wirtualne mają
być umieszczone w RAM, a które mają znajdować
się w pliku stronicowania) nazywany jest
stronicowaniem na żądanie (demand paging).
• Zalety pamięci wirtualnej systemu Windows NT:
– większa logiczna przestrzeń adresowa dla programu,
mogąca przekraczać rozmiar fizycznie zainstalowanej
pamięci Windows i swap file,
– stopień wieloprogramowości na danym komputerze
może być zwiększony,
– dzięki przemyślanej strukturze i umieszczeniu
zarządzania w jądrze systemu operacyjnego, procesy
przydziału/ wymiany /zwalniania - są przezroczyste dla
programisty (mniej błędów).

Tryb wirtualny procesorów
• Ochrona zasobów polega na wprowadzeniu czterech
poziomów uprzywilejowania. Hierarchia poziomów
uprzywilejowania odpowiada numerom PL0, PL1,
PL2, PL3 (patrz schemat).
• Poziom oznaczony cyfrą zero jest najbardziej
uprzywilejowany.
• Poziomy te stanowią rozszerzenie stosowanej
powszechnie w minikomputerach struktury
systemowego i użytkowego poziomu
uprzywilejowania.
• Wprowadzenie czterech poziomów uprzywilejowania
umożliwia stosowanie mechanizmów ochrony
również wewnątrz zadań programowych.
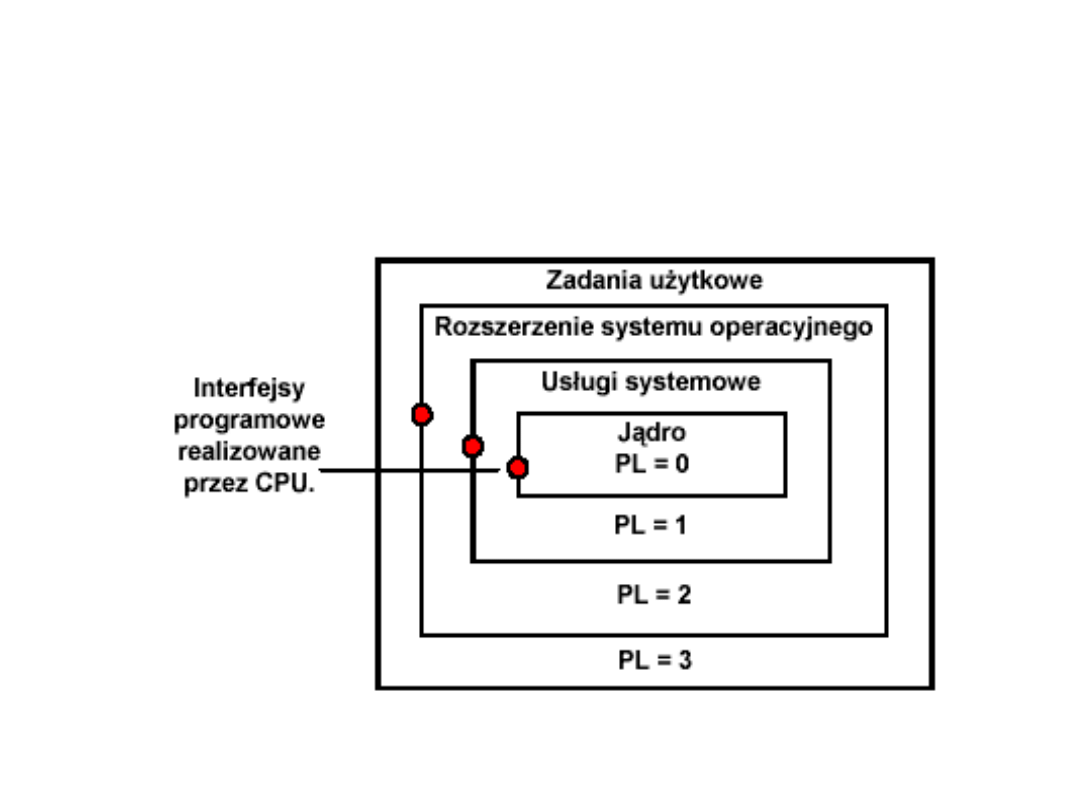
Hierarchia poziomów
uprzywilejowania

Hierarchia poziomów
uprzywilejowania
• W wirtualnej przestrzeni adresowej każdego zadania mogą
być zawarte procedury systemowe, procedury obsługi
przerwań i inne procedury programowe. Atrybut poziomu
uprzywilejowania jest przypisywany zadaniom
programowym, deskryptorom i selektorom.
• Poziom uprzywilejowania zadania wpływa na rodzaj
rozkazów jakie mogą być wykonywane i na zestaw
deskryptorów, który może być wykorzystany przez zadanie.
• Bieżący poziom uprzywilejowania CPL (Current Privilege
Level) jest określany przez poziom uprzywilejowania
aktualnie realizowanego zadania programowego; określają
go dwa najmniej znaczące bity rejestru segmentu
(selektora) CS.

Hierarchia poziomów
uprzywilejowania
• Bieżący poziom uprzywilejowania CPL, może być
zmieniony tylko przez odwołanie do mechanizmów
przekazania sterowania.
• Poziom uprzywilejowania deskryptora DPL określa zestaw
zadań, które mogą odwoływać się do danego
deskryptora. Aby zadanie mogło uzyskać dostęp do
deskryptora numer CPL nie może być większy od DPL.
• Żądany poziom uprzywilejowania określany przez
selektor, może być wykorzystany do obniżenia poziomu
uprzywilejowania zadania.
• Mechanizm ten zapewnia, że wywoływane procedury o
wysokim poziomie uprzywilejowania nie będą miały
dostępu do struktur danych umieszczonych na wyższym
poziomie uprzywilejowania, niż procedura wywołująca.

Hierarchia poziomów
uprzywilejowania
•
Dodatkowym sposobem ochrony jest separacja
zadań. Polega ona na tym, że każde zadanie
dysponuje własną przestrzenią adresową.
•
Zrealizowane jest to za pomocą tabeli translacji.
•
Każde zadanie posiada własną, lokalną, tablicę
deskryptorów - LDTR.
•
Dzięki temu różne zadania pomimo tego, że
posługują się tym samym adresem wirtualnym,
odwołują się do różnych obszarów pamięci,
wynikających z zawartości ich lokalnych tabel
deskryptorów.
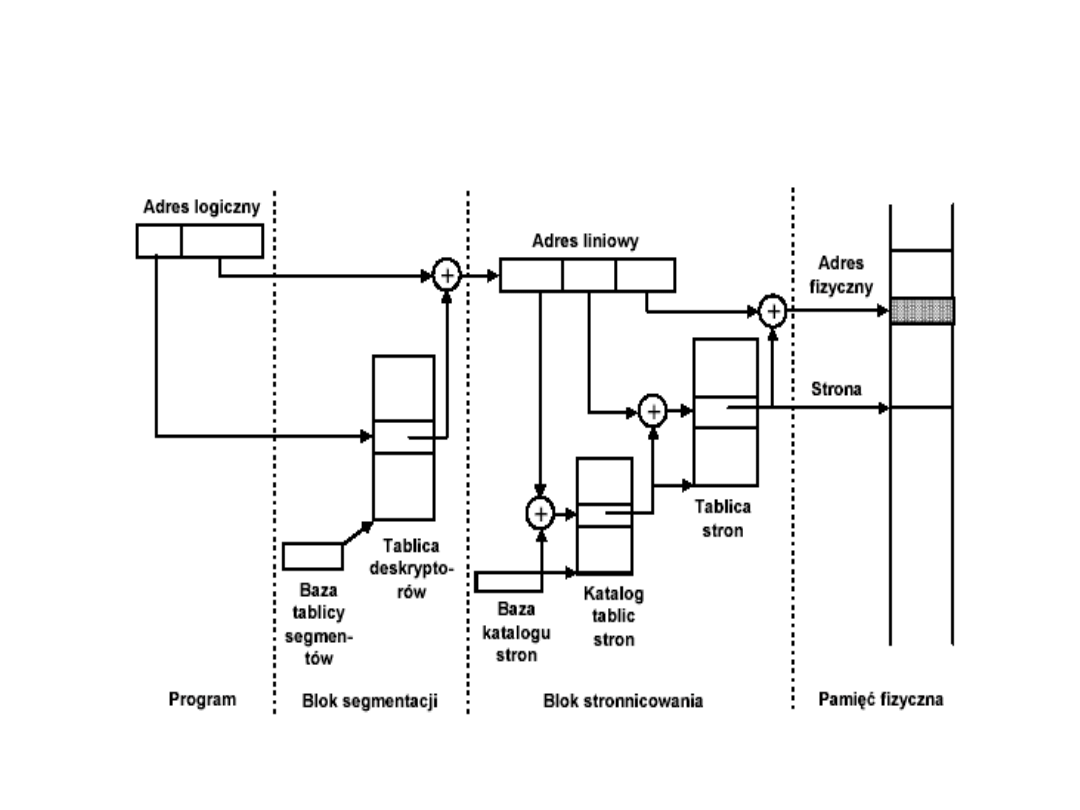
Mechanizm translacji
adresów

Deskryptory procesora – Intel
80286
• P - segment obecny; określa czy dany segment (strona)
znajdują się w pamięci operacyjnej komputera - P = 1, jeżeli
P = 0 wówczas generowany jest wyjątek w wyniku czego
przygotowywana jest odpowiednia ilość miejsca w pamięci i
brakujący segment (strona) wprowadzana jest do pamięci
operacyjnej.
• DPL - poziom ochrony opisywanego segmentu. Pole to
zawiera podstawową informację o segmencie,
wykorzystywaną przez mechanizm ochrony mikroprocesora.
• S - rodzaj deskryptora. Deskryptory mogą opisywać
segmenty pamięci - danych lub kodu – S = 1, oraz specjalne
systemowe struktury danych - segmenty systemowe i
bramki zadań – S = 0.
• A - segment użyty. Bit ten jest ustawiany przez procesor
przy ładowaniu selektora do rejestru segmentu lub
deskryptora do rejestru deskryptora.
• typ - określa prawa dostępu do danego segmentu.

Prawa dostępu do segmentu
• Prawa dostępu do segmentu określa deskryptor typ:
– 0 - segment danych tylko odczyt;
– 1 - segment danych - odczyt i zapis;
– 2 - segment danych rozszerzany w dół tylko odczyt;
– 3 - segment danych rozszerzany w dół - odczyt i zapis;
– 4 - segment kodu tylko wykonywanie;
– 5 - segment kodu - wykonywanie i odczyt;
– 6 - zgodny segment kodu tylko wykonywanie;
– 7 - zgodny segment kodu - wykonywanie i odczyt;
• Segment zgodny różni się od zwykłego segmentu kodu
tym, że po przekazaniu sterowania do procedury
zawartej w tym segmencie nie następuje zmiana
poziomu ochrony (na wartość określoną w
deskryptorze segmentu).
• Procedura wykonuje się na poziomie ochrony procesu
wywołującego.

Deskryptory procesorów - 80386
oraz i486
• G - ziarnistość. Umożliwia opis segmentu do 4GB przy
użyciu jedynie 20-bitowego pola wielkość. Jednostką
długości segmentu może być jeden bajt - G = 0 -
można wówczas zdefiniować segment o długości do
1MB, albo wielkość może być zdefiniowana w
jednostkach alokacji 4KB, co daje możliwość
zdefiniowania segmentu o rozmiarze do 4GB.
• D - długość słowa. Dla D = 1 oznacza stosowanie 32-
bitowego przemieszczenia w adresie argumentu oraz
32-bitowych argumentów. Dla D = 0 16-bitowe
przemieszczenie i 16- bitowe argumenty.
• AVL - pole nie jest interpretowane przez
mikroprocesory, może być użyte przez
oprogramowanie.
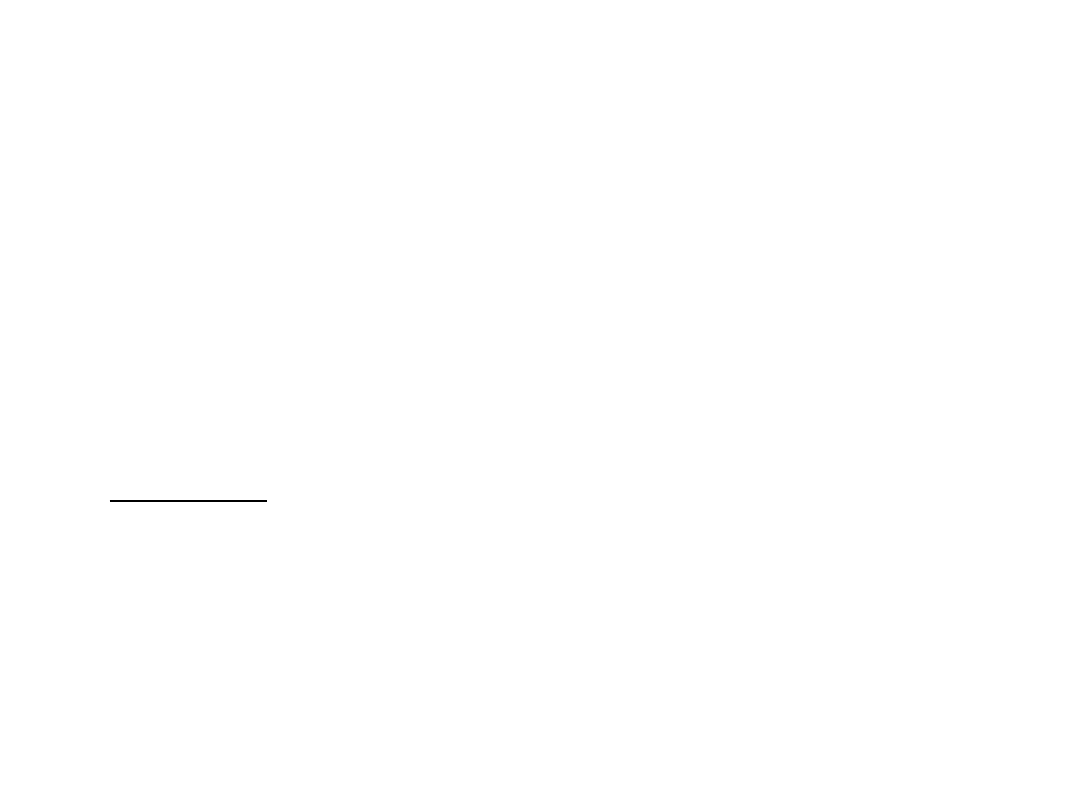
Opis bitów selektora
• TI - określa rodzaj tablicy deskryptorów do,
której chce się odwołać program. TI = 0
odwołanie dotyczy tablicy globalne, TI = 1
oznacza, że odwołanie dotyczy tablicy lokalnej.
• RPL - poziom ochrony zadania żądającego
dostępu. Służy do osłabienia bieżącego poziomu
ochrony.
• Przykład: Jeżeli zadanie o poziomie ochrony 3
próbuje przez wywołanie funkcji systemowej o
poziomie ochrony 0 - uzyskać dostęp do danych
na poziomie 2, to nie uzyska takiego dostępu
gdyż wartość RPL selektora wywołującego
będzie równa 3.

Segmentacja w procesorach
Intela
• Deskryptory są umieszczane w pamięci kolejno
tworząc tzw. tablice deskryptorów.
• Wykonywany program ma dostęp do dwóch tablic
deskryptorów: globalnej tablicy deskryptorów GDT i
lokalnej tablicy deskryptorów LDT, których wielkość
wynosi 64KB. Numer deskryptora w jednej z tablic
GDT lub LDT jest wybierany na podstawie 13 bitów
selektora (bity 3...15). Zatem każda z tablic może
zawierać do 8192 deskryptorów.
• Rozmiar logicznej przestrzeni adresowej określa się
jako maksymalną wielkość widzianą przez
pojedyncze zadanie. Ponieważ zadanie ma dostęp
do obu tablic dlatego też może w sumie korzystać
z 16384 segmentów, czyli 16K. O wielkości
logicznej przestrzeni adresowej decydują liczba
segmentów i ich długość.

Segmentacja w procesorach
Intela
• Dlatego też w mikroprocesorze 80286, gdzie
maksymalna długość segmentu wynosiła 64KB logiczna
pamięć zwana też pamięcią wirtualną ma pojemność
16K * 64K = 2
14
* 2
16
= 2
30
bajtów = 1GB
.
• Analogicznie w 80386 (i486), gdzie maksymalna długość
segmentu jest równa 4GB (przemieszczenie 32-bity),
jest ona równa:
16K * 4GB = 2
14
* 2
32
= 2
46
bajtów = 64TB
.
• Tak więc pamięć widziana przez zadanie jest znacznie
większa od pamięci, którą może zaadresować procesor.
Jednak istnieje możliwość wykorzystania całej pamięci
zadania dzięki odpowiednim mechanizmom
wbudowanym w procesor, które umożliwiają
implementację pamięci wirtualnej.
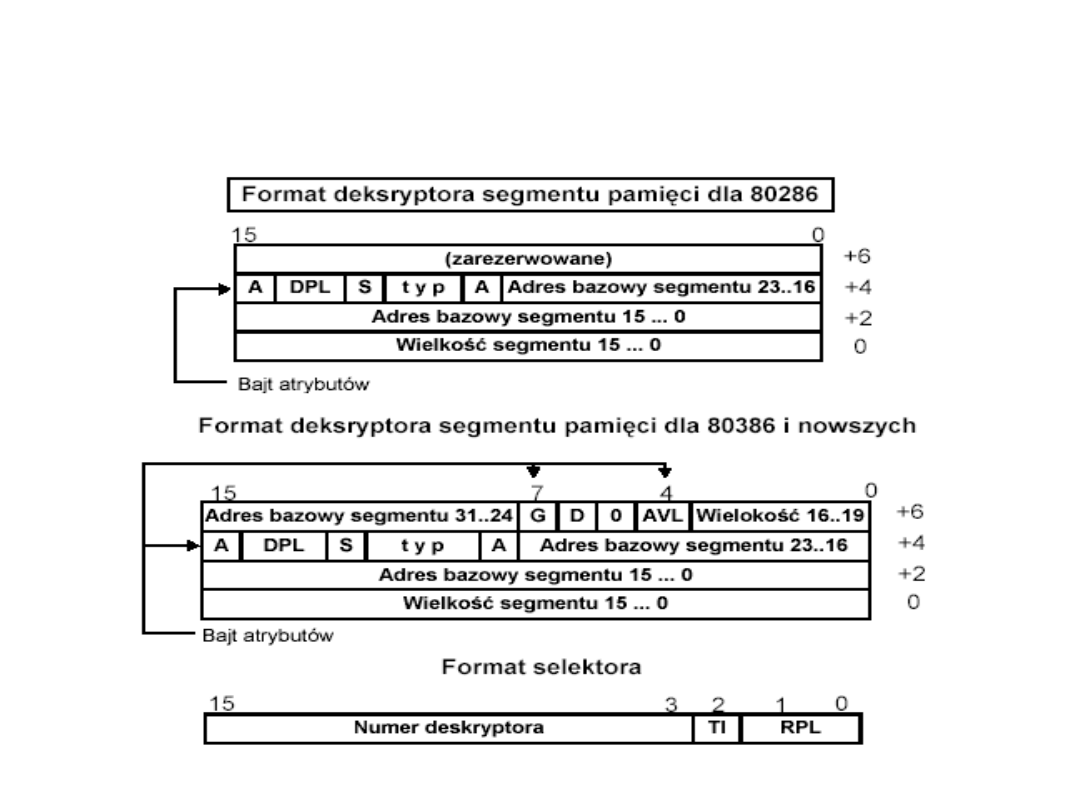
Formaty deskryptorów segmentu
pamięci

Stronicowanie w
procesorach Intela
• Polega na podziale całej przestrzeni adresowej na bloki o
długość 4KB, które są rozmieszczone sekwencyjne
począwszy od adresu 0.
• W przestrzeni adresowej mikroprocesora znajdują się więc
2
32
/ 2
12
= 2
20
stron = 1M stron. Położenie strony jest
jednoznacznie określane za pomocą jej 20-bitowego
numeru.
• W 32-bitowym adresie liniowym można więc wyróżnić 12
mniej znaczących bitów określających położenie wewnątrz
strony, oraz 20-bitowy numer strony wskazujący jej
położenie w przestrzeni adresowej.
• Jeżeli założymy wykorzystanie tablicy translacji, w której
każdy element składałby się z 4-bitów jej rozmiar musiałby
wynosić 4 * 2
20
= 4Mb.
• Ze względu na tak duży rozmiar ewentualnej tablicy
translacji w mikroprocesorze 80386 zastosowano
dwupoziomowe stronicowanie, wprowadzając dwie tablicę:
– tablicę stron wskazującą na położenie strony w przestrzeni adresowej
oraz
– tablice wyższego poziomu zwane katalogami stron, którego to
elementy wskazują na właściwą tablicę stron.
• Elementy obydwu tych tablic mają identyczny format.
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
- Slide 46
- Slide 47
- Slide 48
- Slide 49
- Slide 50
- Slide 51
- Slide 52
- Slide 53
- Slide 54
- Slide 55
- Slide 56
- Slide 57
- Slide 58
- Slide 59
- Slide 60
- Slide 61
- Slide 62
- Slide 63
- Slide 64
- Slide 65
- Slide 66
- Slide 67
- Slide 68
- Slide 69
- Slide 70
- Slide 71
- Slide 72
- Slide 73
- Slide 74
- Slide 75
- Slide 76
- Slide 77
- Slide 78
- Slide 79
Wyszukiwarka
Podobne podstrony:
Podstawowe info dot amortyzacji
Diagnoza autyzmu podstawowe info, PEDAGOGIKA i PSYCHOLOGIA, AUTYZM
Podstawy info 3
Podstawy info 7
Podstawy info 9
Podstawy info 11
Podstawy info 8
Podstawy info 2
Podstawy info 10
Podstawy info 5
Podstawowe info dot amortyzacji
podstawowe info o AF z netu
Podstawy info 3
Mat. info EKG, PIELĘGNIARSTWO 1 sem, Podstawy Pielęgniarstwa, laborka
Mat. info EKG, PIELĘGNIARSTWO 1 sem, Podstawy Pielęgniarstwa, laborka
OSOBOWOŚCI MAŁŻEŃSKIE - info podstawowe, psychologia sądowa
USTAWA o ochronie info niejawnych, Politologia UMCS - materiały, IV Semestr letni, Prawne podstawy k
Jednym z podstawowych obowiazkow pracodawcy jest prowadzenie dokumentacji pracowniczej, Prawo pracy(
Podstawowe pojecia statystyczne, ekonomia, logika, biznes, info
więcej podobnych podstron