
Wstęp do Informatyki
Wykład 9
Architektura procesora
Listy rozkazów - własności i
funkcje
oraz struktura i działanie
Autor: Dr hab. Marek J. Greniewski
Podział na części architektoniczną i
układową współczesnego komputera
Procesor
Układy we-wy
Kompilator
System
operacyjny
(np. Windows 2K)
Aplikacje (np. Netscape)
Układy cyfrowe
Obwody
scalone
Lista rozkazów
określająca architekturę
Ścieżki danych i sterowanie
Bramki i
elementy
pamięci
Pamięć
Hardware
Software
Assemble
r
Magistrala

Procesor
Procesor jest centralną częścią systemu
komputerowego, ale czy wszyscy zdają sobie sprawę
z tego, jakie zadania ten procesor właściwie powinien
realizować? Otóż procesor musi:
-
Pobierać rozkazy
- w celu odczytania poleceń z
pamięci.
-
Interpretować rozkazy
- polecenia należy
zdekodować, aby wiedzieć jakie operacje należy
wykonać.
-
Pobierać dane
- z pamięci lub modułu wejścia-
wyjścia.
-
Przetwarzać dane
- przeprowadzać na danych
pewne operacje arytmetyczne lub logiczne – czyli
wykonywać funkcje ALU.
-
Zapisywać dane
- w pamięci lub module wejścia-
wyjścia.
Aby procesor miał możliwość wykonywania
powyższych zadań musi dysponować małą pamięcią
wewnętrzną, która wymagana jest do czasowego
przechowywania danych i rozkazów (procesor musi
np. pamiętać lokalizację poprzedniego rozkazu po to,
by "odnaleźć" rozkaz następny).
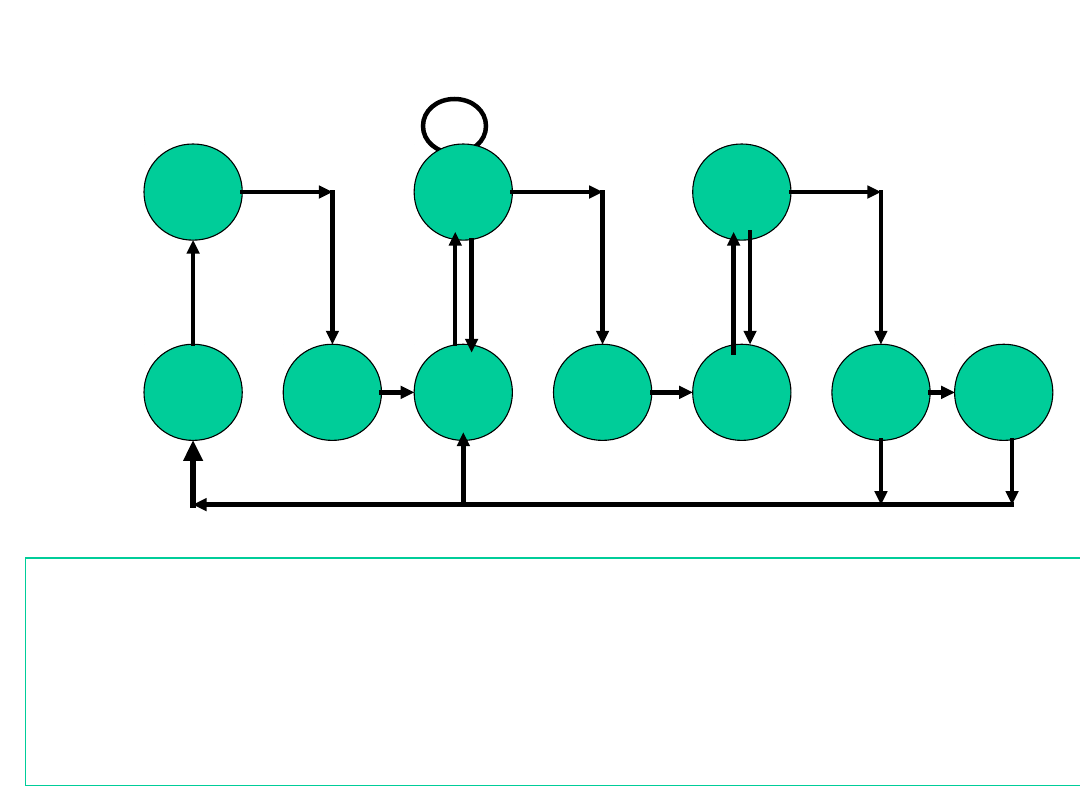
Graf stanów - cyklu instrukcji z
przerwaniami
iac
iod
os
of
if
oac
do
aoc
ic
in
Następna
instrukcja
Łańcuch
lub wektor
Brak
przerwań
Wiele
argumentów
Wiele
wyników
if
–
pobranie instrukcji
;
iod
–
dekodowanie części operacyjnej
;
oac
–
obliczanie adresu argumentu
;
of
–
pobranie argumentu
;
do
–
operacja na danych
;
os
–
zapisanie argumentu
;
ic
–
sprawdzanie czy jest przerwanie
;
in
–
obsługa przerwania
;
iac
–
przesłanie zawartości licznika adresów do rejestru sterowania
.
Wewnętrz
na
operacja
procesora
Dostęp
procesora
do pamięci
lub we-wy

Dramatyczne
zmiany
technologii
komputerów!
• Procesor
– 2 x wzrost szybkości co 1.5 roku
(począwszy od 85);
100 x wzrost wydajności w ciągu
dekady
.
• Pamięć półprzewodnikowa
– DRAM pojemność: 2 x / 2 lata
(począwszy od 96);
64 x wzrost pojemności w ciągu
dekady
.
• Pamięć dyskowa
– Pojemność: 2 x / 1 co roku (począwszy
od ‘97)
– 250 x wzrost pojemności w ciągu
dekady
.
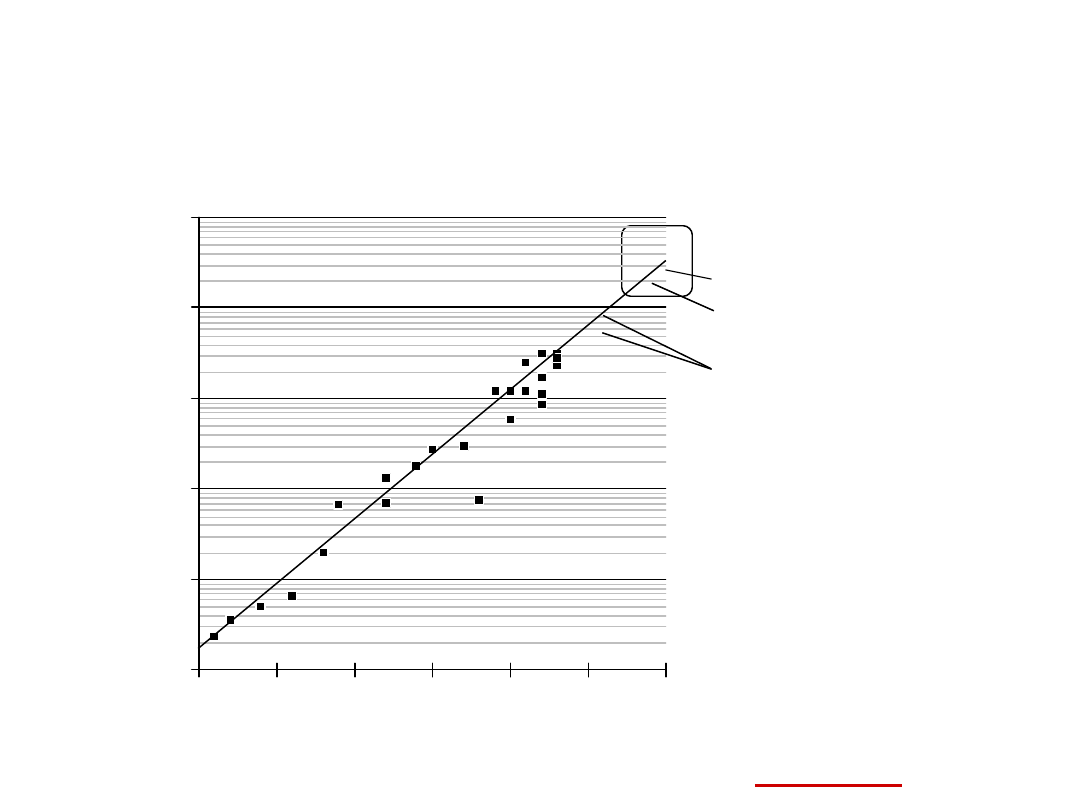
Year
Tr
a
n
s
is
to
rs
1000
10000
100000
1000000
10000000
100000000
1970
1975
1980
1985
1990
1995
2000
i80386
i4004
i8080
Pentium
i80486
i80286
i8086
Trendy technologii:
złożoność mikroprocesorów
2 x
transistors/Chip
co 1,5 roku
zjawisko
nazwano
“
Prawo
Moore’a
”
Alpha 21264: 15 million
Pentium
Pro: 5.5 million
PowerPC 620: 6.9 million
Alpha 21164: 9.3 million
Sparc Ultra: 5.2 million
Prawo Moore’a
Athlon (K7): 22 Million
Do czego zmierzamy?
Jesień 2003
µProc
60%/yr.
(2X/1.5yr)
DRAM
9%/yr.
(2X/10 yrs)
1
10
100
1000
1
9
8
01
9
8
1
1
9
8
31
9
8
4 1
9
8
5 1
9
8
6 1
9
8
71
9
8
8 1
9
8
9 1
9
9
0 1
9
9
1 1
9
9
2 1
9
9
3 1
9
9
4 1
9
9
5 1
9
9
6 1
9
9
71
9
9
8 1
9
9
9 2
0
0
0
DRAM
CPU
1
9
8
2
Processor-Memory
Performance Gap:
(grows 50% / year)
P
e
rf
o
rm
a
n
c
e
Time
“Moore’s Law”
3 4 - b it A L U
L O r e g is te r
( 1 6 x 2 b it s )
Lo
ad
H
I
C
le
ar
H
I
Lo
ad
LO
M u ltip lic a n d
R e g is te r
S h if tA ll
L o a d M p
E
xtr
a
2 b
its
3 2
3 2
L O [ 1 : 0 ]
R e s u lt[H I ]
R e s u lt[L O ]
3 2
3 2
P
re
v
LO
[1
]
B
oo
th
E
nc
od
er
E N C [0 ]
E N C [2 ]
"L
O
[0
]"
C o n t r o l
L o g ic
I n p u t
M u ltip lie r
3 2
S u b / A d d
2
3 4
3 4
3 2
I n p u t
M u ltip lic a n d
3 2 = > 3 4
s i g n E x
3 4
3 4 x 2 M U X
3 2 = > 3 4
s ig n E x
< < 1
3 4
E N C [1 ]
M u lti x 2 / x 1
2
2
H I r e g is te r
( 1 6 x 2 b its )
2
0
1
3 4
ALU
Single/multi-cycle
Data-paths
IFetchDcd
Exec Mem WB
IFetchDcd
Exec Mem WB
IFetchDcd
Exec Mem WB
IFetchDcd
Exec Mem WB
Pipelining
Systemy pamięci
I/O
N
a
s
z
e
C
P
U

Elementy instrukcji
komputera
• Kod operacji
. Określa operację, jaka ma być
wykonana (np.
ADD).
• Odniesienie do argumentów źródłowych
.
Operacja może obejmować jeden lub wiele
argumentów źródłowych, są one danymi
wejściowymi operacji.
• Odniesienie do wyniku
. Operacja może prowadzić
do powstania wyniku
• Odniesienie do następnej instrukcji
. Określa,
skąd procesor ma pobierać następną instrukcję po
zakończeniu wykonania bieżącej.
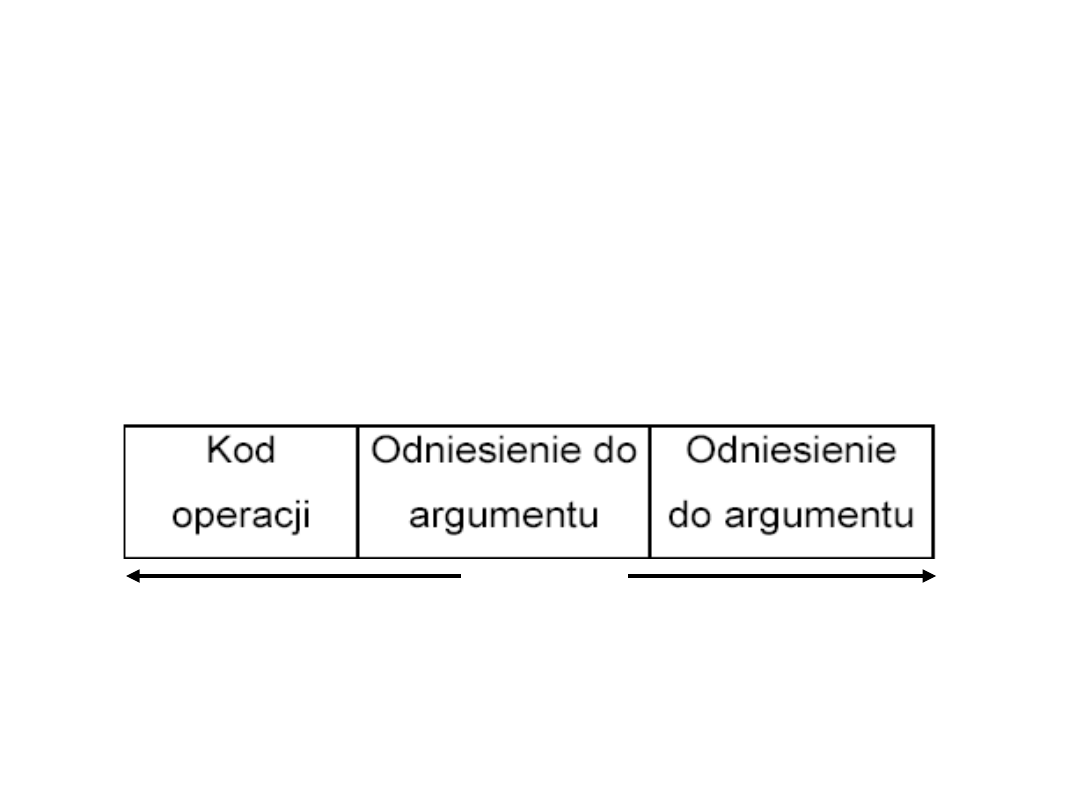
Reprezentacja rozkazu
• Rozkaz jest reprezentowany wewnątrz
komputera jako ciąg bitów.
• Rozkaz dzielony jest na pola odpowiadające
elementom składowym rozkazu.
• Prosty format rozkazu dwu adresowego
• Formaty rozkazów:
– sztywne
– swobodne (zwany również zmiennym formatem).
16 bitów

Kody operacji są zapisywane
za pomocą mnemoników
• ADD m(x)
- dodaj do akumulatora dane pobrane z
pamięci i umieść wynik w akumulatorze
• SUB m(x)
- odejmij od akumulatora dane pobrane
z pamięci i umieść wynik w akumulatorze
• MPY m(x)
- pomnóż zawartość akumulatora przez
dane pobrane z pamięci i umieść wynik w
akumulatorze
• LOAD m(x)
- pobierz dane z pamięci do
akumulatora
• STORE m(x)
- zapisz zawartość akumulatora w pamięci

Liczba adresów
• Rozkazy bez-adresowe (działające na
stosie),
• Rozkazy jednoadresowe,
• Rozkazy dwu- lub trzyadresowe.
Uwaga
: adres następnego rozkazu przy
wykonywaniu sekwencji rozkazów jest
domyślny (uzyskiwany z licznika
programu).

Program -
rozkazy trójadresowe
Y = (A - B) ÷ (C + D * E)
• SUB
Y, A, B
Y = A - B
• MPY
T, D, E
T = D * E
• ADD
T, T, C
T = T + C
• DIV
Y, Y, T
Y = Y ÷ T

Program -
rozkazy
dwuadresowe
Y = (A - B) ÷ (C + D * E)
• MOVE
Y, A
Y = A
• SUB
Y, B
Y = Y - B
• MOVE
T, D
T = D
• MPY
T, E
T = T * E
• ADD
T, C
T = T + C
• DIV
Y, T
Y = Y ÷ T

Program -
rozkazy
jednoadresowe
Y = (A - B) ÷ (C + D * E)
• LOAD
D
Ac = D
• MPY
E
Ac = Ac * E
• ADD
C
Ac = Ac + C
• STORE Y
Y = Ac
• LOAD
A
Ac = A
• SUB
B
Ac = Ac - B
• DIV
Y
Ac = Ac ÷ Y
• STORE Y
Y = Ac

Reprezentacja operacji
arytmetycznych i logicznych
Liczba adresów
Reprezentacja symboliczna
Interpretacja
3
OP
A, B, C
A = B
OP
C
2
OP
A, B
A = A
OP
C
1
OP
A
Ac = Ac
OP
A
0
OP
T
n-1
= T
n
OP
T
n - 1

Stos i jego podstawowe
własności
•
Stos
jest uporządkowanym zestawem elementów, z których
tylko do jednego można mieć dostęp w określonej chwili;
•
Punkt dostępu nazywany jest
wierzchołkiem stosu
;
•
Liczba elementów w stosie, czyli długość stosu, jest
zmienna.
•
Elementy mogą być dodawane lub odejmowane tylko do
wierzchołka stosu;
•
Stos działa według zasady „
Last In – First Out
(w skrócie
LIFO)”, czyli ostatnio wpisany do stosu element, jest
pierwszym do odczytania ze stosu;
•
Operacja
PUSH
dodaje nowy element do stosu, zaś operacja
POP
usuwa element z wierzchołka stosu;
•
Operacje jednoargumentowe
(np. logiczne
NOT
), są
wykonywane na elemencie znajdującym się na wierzchołku
stosu i zmieniają element wierzchołkowy stosu na wynik;
•
Operacje dwuargumentowe
wykonywane są na dwu
wierzchołkowych elementach stosu i powodują usunięcie
dwu kolejnych elementów z wierzchołka stosu wpisując na
wierzchołku stosu wynik operacji;

Stos i jego podstawowe
własności
• Dla poprawnej implementacji funkcjonalności stosu
koniecznym jest wyposażenie procesora w trzy rejestry
zawierające:
– Wskaźnik stosu
, który zawiera adres wierzchołka stosu. Jeśli element
jest dodawany lub usuwany ze stosu, wskaźnik jest odpowiednio
inkrementowany lub dekrementowany, aby w dalszym ciągu pokazywał
wierzchołek stosu;
– Podstawa stosu
, która zawiera adres najniższej lokacji w
zarezerwowanym bloku pamięci. Jeśli dokonywana jest próba operacji
POP, gdy stos jest pusty, zgłaszany jest błąd;
– Granica stosu
, która zawiera adres drugiego końca zarezerwowanego
bloku pamięci. Jeśli dokonywana jest próba operacji PUSH, gdy stos jest
pełny, zgłaszany jest błąd.
• Rozkazy PUSH i POP mogą być instrukcjami
uprzywilejowanymi, a obsługę stosu zapewnia wówczas
system operacyjny komputera.
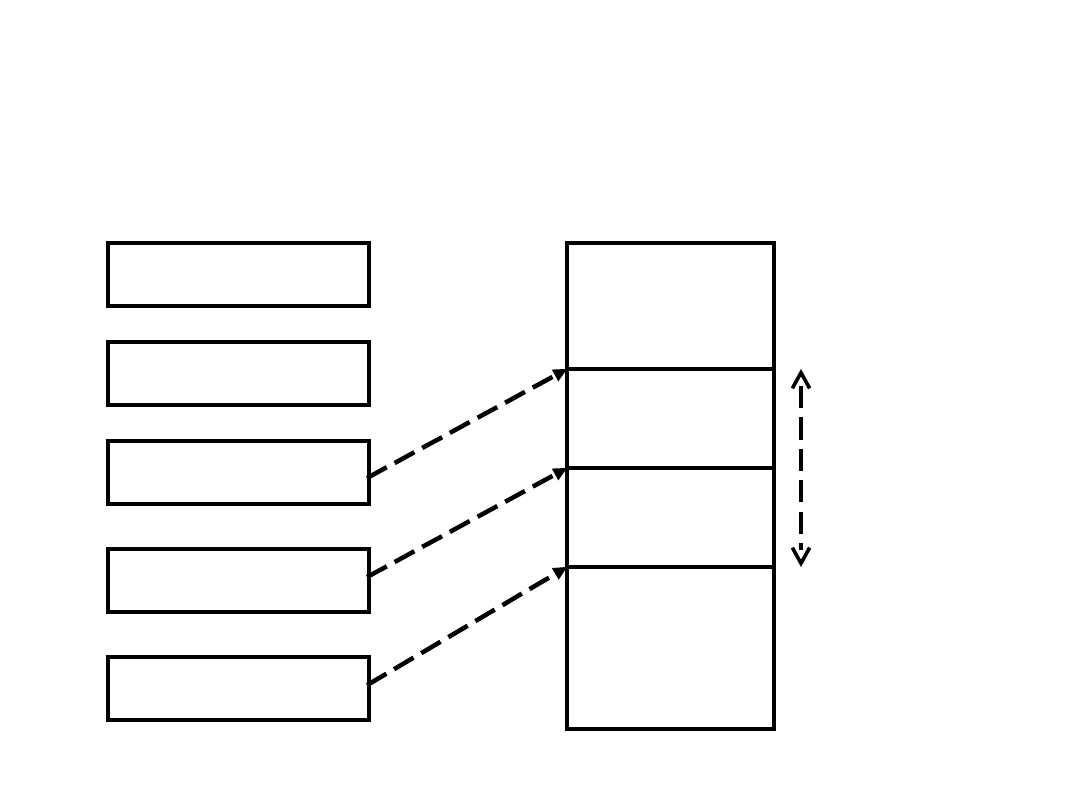
Typowa organizacja stosu
Wierzchołkowy
element stosu
Drugi element stosu
Granica stosu
Wskaźnik stosu
Podstawa stosu
Wolny
Zajęty
Bloki
zarezerwowane
na stos
Rejestry procesora
Pamięć operacyjna
Uwaga: dwa elementy wierzchołkowe stosu przechowywane w rejestrach

Projektowanie listy
rozkazów
• Liczba adresów w rozkazie jest
podstawową decyzją projektową.
• Do najważniejszych problemów
projektowania listy rozkazów należą:
– Repertuar operacji;
– Rodzaje danych;
– Format rozkazu. Długość rozkazu, liczba
adresów, rozmiary pól itp.
– Rejestry. Liczba rejestrów procesora oraz ich
zastosowanie.
– Adresowanie. Tryb lub tryby, w których są
specyfikowane adresy argumentów.

Rodzaje argumentów
• Adresy
(liczba adresów i sposoby adresacji)
• Liczby
(całkowite lub stałoprzecinkowe,
zmiennoprzecinkowe, dziesiętne)
• Znaki
(pojedyncze i łańcuchy znaków)
• Dane logiczne
jednobitowe boolowskie
(Prawda, Fałsz) oraz wielobitowe.

Liczby
• Wszystkie języki maszynowe obejmują dane numeryczne.
• Ważną różnicą między liczbami używanymi w matematyce
a liczbami przechowywanymi w komputerze jest to, że te
ostatnie są ograniczone.
• Po pierwsze, istnieje granica liczb reprezentowanych w
komputerze, a po drugie, w przypadku liczb
zmiennoprzecinkowych, granica ich dokładności.
• Programista powinien więc znać konsekwencje
zaokrąglenia, przepełnienia i niedomiaru.
• W komputerach są powszechne trzy rodzaje danych
numerycznych:
– Liczby całkowite lub stałoprzecinkowe;
– Liczby zmiennoprzecinkowe;
– Liczby dziesiętne.

Znaki
• Powszechną formą danych jest tekst lub ciąg znaków.
• Dla przechowywania, przesyłania i przetwarzania danych
tekstowych – opracowano szereg kodów, za pomocą których
znaki są reprezentowane w postaci ciągów bitów.
• Dzisiaj najczęściej stosowanym kodem znaków jest kod
ASCII. Każdy znak w tym kodzie reprezentowany jest przez
wzór 7-bitów. Czyli w kodzie ASCII rozróżnianych jest 128
różnych kodów znaków. Obok liter i cyfr, kod ASCII zawiera
znaki sterujące.
• Znaki kodu ASCII, są z zasady przechowywane w postaci 8-
bitów. Dodatkowy bit jest używany jako kontrola parzystości.
• Cyfry dziesiętne są reprezentowane w kodzie ASCII jako
011XXXX, gdzie cyfrom dziesiętnym odpowiadają
odpowiednio 0000, 0001, 0010, 0011, 0100, 0101, 0110,
0111, 1000, 1001.
• Innym kodem jest 8-bitowy kod EBCDIC (Extended Binary
Coded Decimal Interchange Code), opracowany przez IBM
dla S/370.

Rodzaje operacji wg. J.
Hayes’a
1. Operacje transferu danych,
2. Operacje arytmetyczne,
3. Operacje logiczne,
4. Operacje konwersji,
5. Operacje wejścia-wyjścia,
6. Operacje przekazywania
sterowania,
7. Operacje sterowania
systemowego.

Transfer danych
• Move
przeniesienie słowa lub bloku ze źródła do
miejsca przeznaczenia;
• Store
przeniesienie słowa z procesora do pamięci;
• Load
przeniesienie słowa z pamięci do procesora;
• Exchange
zamiana zawartości źródła i miejsca
przeznaczenia;
• Clear (reset)
przeniesienie słowa złożonego z 0 do miejsca
przeznaczenia;
• Set
przeniesienie słowa złożonego z 1 do miejsca
przeznaczenia;
• Push
przeniesienia słowa ze źródła na wierzchołek stosu;
• Pop
przeniesienia słowa z wierzchołka stosu do miejsca
przeznaczenia;

Operacje arytmetyczne
• Add
obliczenie sumy dwóch argumentów;
• Subtract
obliczenie różnicy dwóch argumentów;
• Multiply
obliczenie iloczynu dwóch argumentów;
• Divide
obliczenie ilorazu dwóch argumentów;
• Absolute
zamiana argumentu na jego wartość
bezwzględną;
• Negate
zmiana znaku argument;
• Increment
dodanie 1 do argumentu;
• Decrement
odjęcie 1 od argumentu;

Operacje logiczne
• And
wykonanie operacji logicznej „i” na bitach
argumentów;
• Or
wykonanie operacji logicznej „lub” na bitach
argumentów;
• Not
wykonanie operacji logicznej „nie” na bitach
argumentu;
• Exclusive-Or
wykonanie operacji logicznej „albo” na
bitach
argumentów;
• Test
zbadanie określonego warunku i jako wynik
ustawienie odpowiedniej flagi;
• Compare
wykonanie porównania dwóch argumentów i jw.;
• Set control variables
operacje ustawienia barier dla
obszarów pamięci;
• Shift
przesuń argument w prawo lub lewo;
• Rotate
przesuń argument w prawo lub lewo cyklicznie;

Operacje konwersji
• Translate
przetłumaczenie danych, we
wskazanym
bloku pamięci (RAM
lub wirtualnej) na
podstawie tabeli odpowiedniości;
• Convert
przekształcenie zawartości
słowa z jednej
postaci na drugą
(np. z upakowanej
dziesiętnej na binarną);

Operacje wejścia-wyjścia
• Input (read)
przeniesienie danych z określonego
portu lub
urządzenia wejścia-wyjścia do miejsca
przeznaczenia (np. do RAM lub rejestru procesora);
• Output (write)
przeniesienie danych z określonego
źródła do portu
lub urządzenia wejścia-wyjścia;
• Start I/O
przeniesienie rozkazów do procesora wejścia-
wyjścia w celu inicjowania operacji wejścia-wyjścia;
• Test I/O
przeniesienie informacji o stanie urządzenia
wejścia- wyjścia do określonego miejsca przeznaczenia;

Przekazywania sterowania
• Jump (branch)
przekazanie bezwarunkowe, ładowanie argumentu
do rejestru PC;
• Jump Conditional
zbadanie określonego warunku; albo załadowanie
argumentu do rejestru PC, albo przejście do następnego rozkazu
sekwencji – zależnie od wyniku badania warunku;
• Jump to Subroutine
umieszczenie informacji kontrolnej bieżącej
sekwencji we
wskazanym miejscu i przekazanie bezwarunkowe
sterowania do podprogramu;
• Return
zamiana zawartości rejestru PC na informacje kontrolne
umieszczone we wskazanym miejscu;
• Execute
pobranie argumentu ze wskazanego miejsca i wykonanie
go, bez zmiany zawartości rejestru PC;
• Skip
inkrementacja zawartości rejestru PC;
• Skip Conditional
warunkowa inkrementacja zawartości rejestru PC;
• Halt
zatrzymanie wykonywania programu;
• Wait (hold)
zatrzymanie wykonywania programu, powtarzanie
badania
wskazanego warunku – wznowienie pracy programu po
spełnieniu warunku;
• No Operation
nie wykonywanie żadnej operacji, przejście do
następnego
rozkazu sekwencji programu;

Tryby adresowania
1. Adresowanie
natychmiastowe
2. Adresowanie
bezpośrednie
3. Adresowanie
pośrednie
4. Adresowanie
rejestrowe
5. Adresowanie
pośrednie-rejestrowe
6. Adresowanie
pośrednie-rejestrowe z
przesunięciem
7. Adresowanie
stosowe

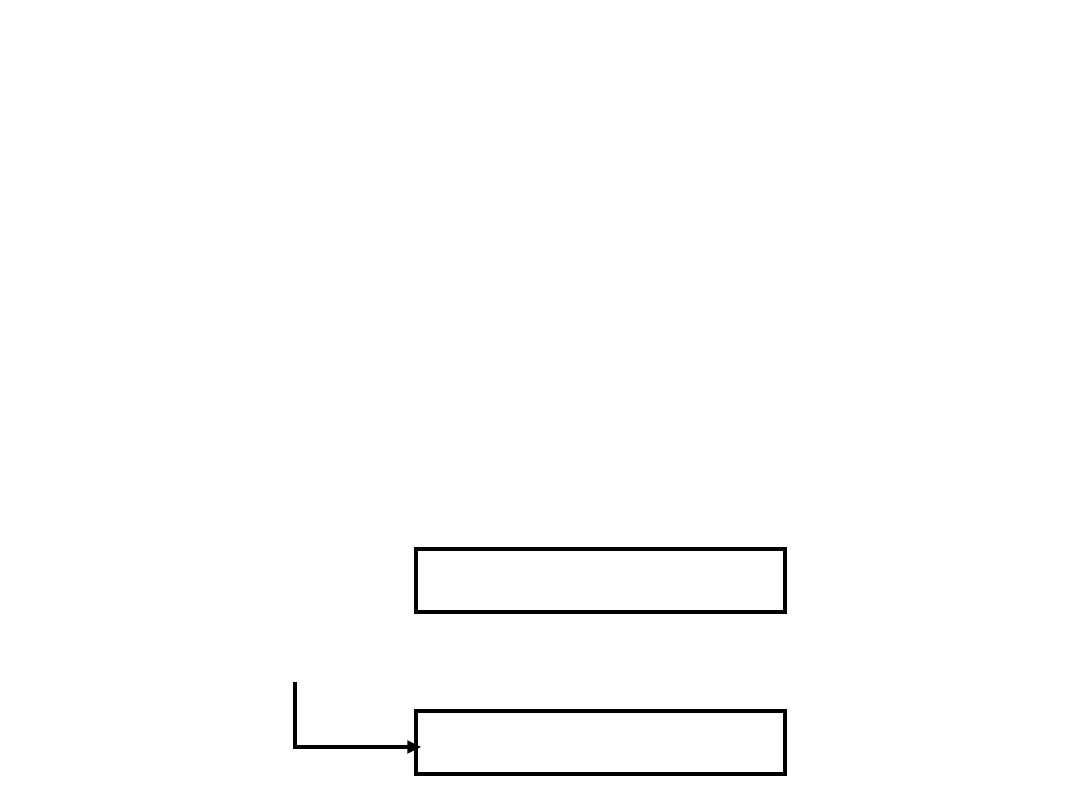
Adresowanie
natychmiastowe
Argument
Rozkaz
Najprostszą formą adresowania jest adresowanie natychmiastowe,
w którym jest obecny w rozkazie, czyli:
Argument = Część adresowa rozkazu
Tryb ten może być stosowany do definiowania i używania stałych
lub ustalania początkowych wartości zmiennych. Liczba ujemna
jest zwykle przechowywana w postaci uzupełnienia do dwóch, czyli
lewy bit argumentu jest używany jako bit znaku.
Gdy argument jest ładowany do rejestru danych, bit znaku jest
rozszerzany na lewo w celu wypełnienia słowa danych.
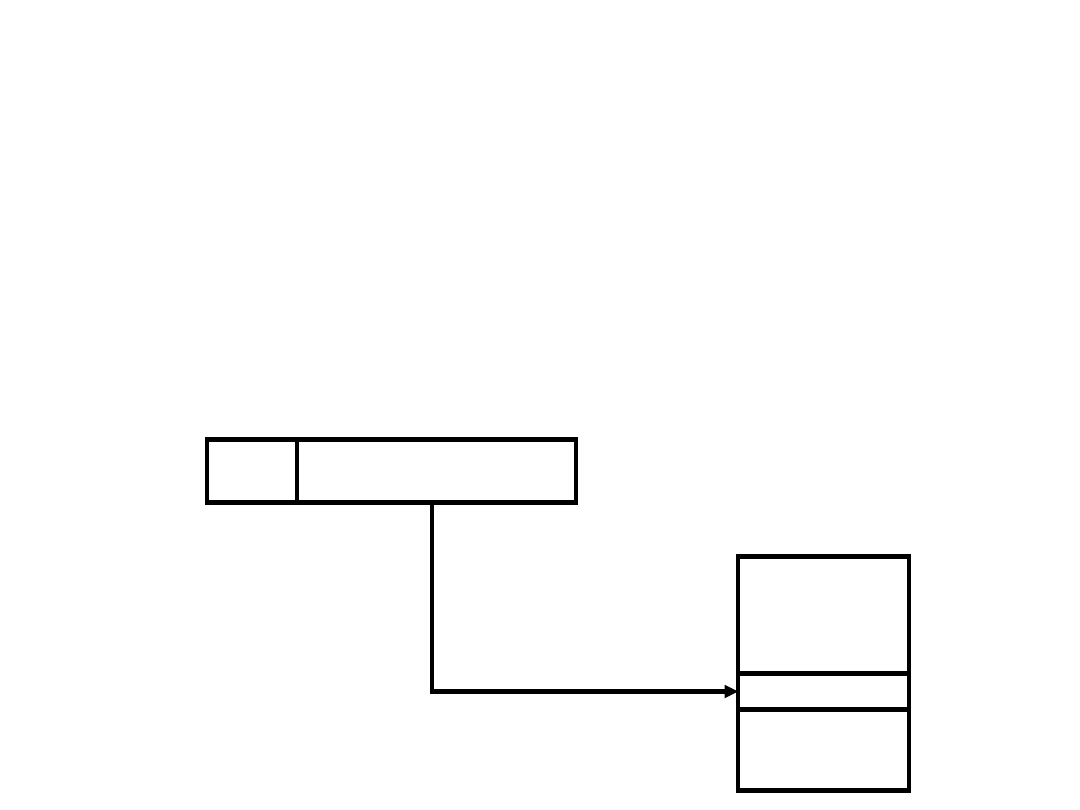
Adresowanie
bezpośrednie
A
Rozkaz
Argument
Pamięć
Prostą formą adresowania jest adresowanie bezpośrednie,w którym
pole adresowe rozkazu zawiera efektywny adres argumentu:
Efektywny adres = Część adresowa rozkazu
Metoda ta była powszechnie stosowana w komputerach pierwszej
i drugiej generacji. Wymaga tylko odniesienia do pamięci i nie wymaga
żadnych obliczeń.
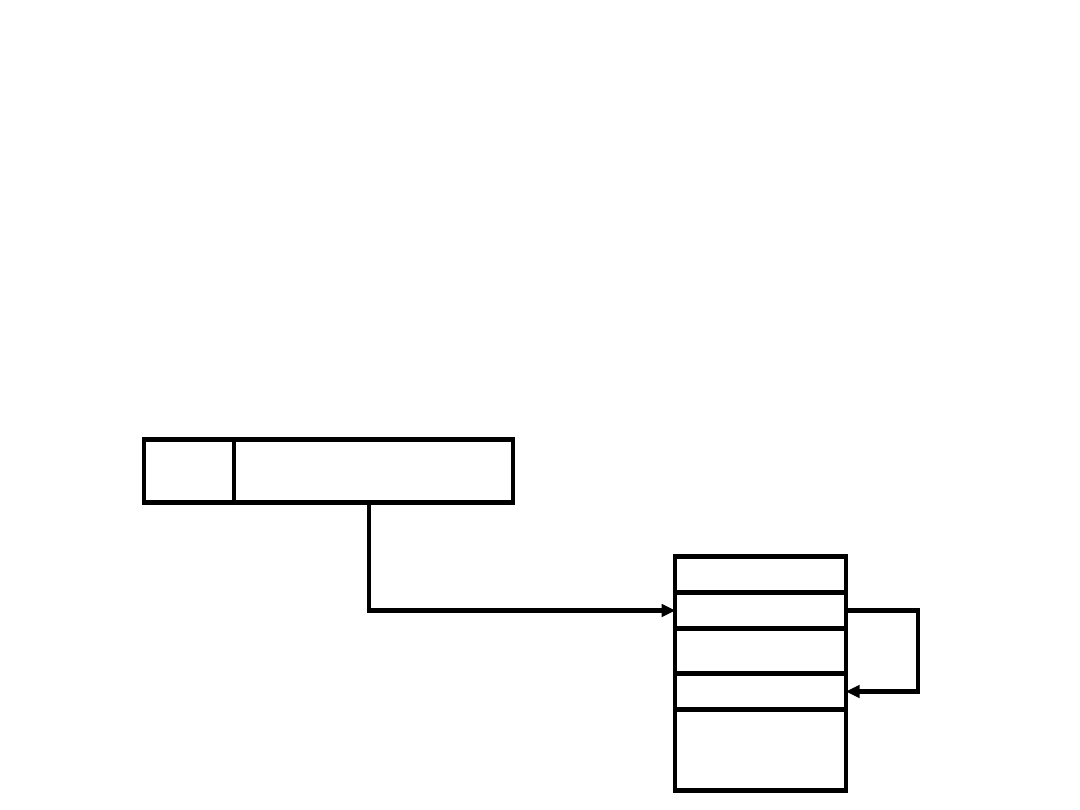
Adresowanie
pośrednie
A
Rozkaz
Argument
Pamięć
Adresowanie pośrednie jest wynikiem faktu, że
długość
K
- pola adresowego rozkazu jest zwykle
krótsza niż wymagana liczba bitów
N
dla
adresowania całej pamięci, gdzie
2
N
liczba
adresowanych jednostek (słów, bajtów) pamięci,
K
< N
. Adres pośredni zawarty w rozkazie, odnosi się
do słowa pamięci umieszczonego w obszarze
niskich adresów, które zawiera adres argumentu
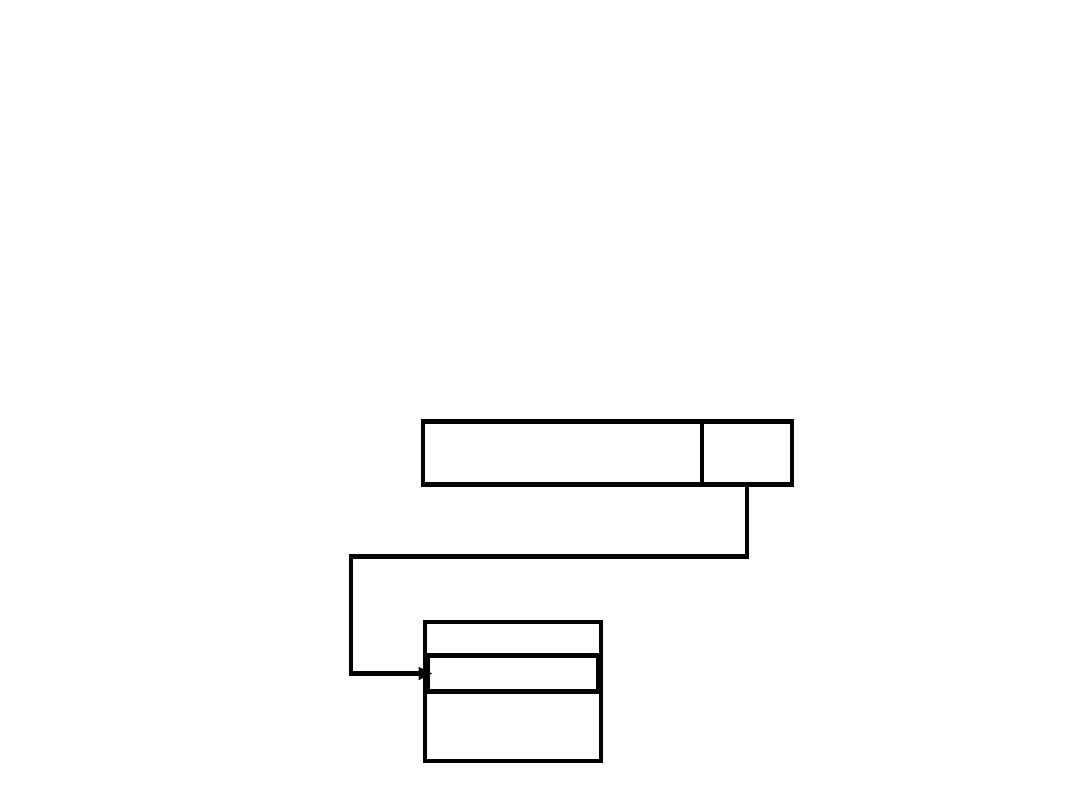
Adresowanie
rejestrowe
Rozkaz
Argument
Rejestry
R
Adresowanie rejestrowe jest podobne do
adresowania bezpośredniego.
Jedyną różnicą jest to, że pole adresowe odnosi się
do rejestru, a nie do adresu w pamięci operacyjnej
komputera. Pole adresowe rejestru ma zwykle tylko
kilka bitów długości, np. 3 lub 4, w tym przypadku
może odwoływać się do 8 lub 16 rejestrów
roboczych.
Efektywny adres = Nr rejestru
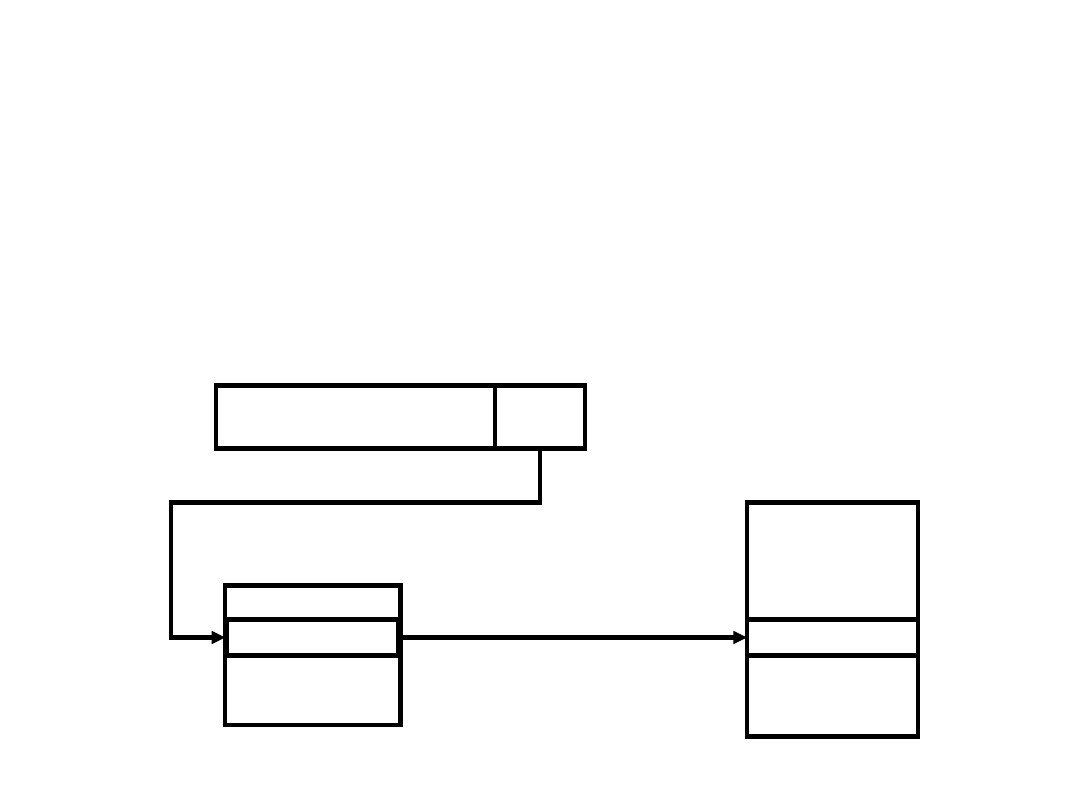
Adresowanie
pośrednie-
rejestrowe
Rozkaz
Argument
Pamięć
Rejestry
R
Adresowanie pośrednio-rejestrowe działa analogicznie do adresowania
pośredniego. Pole adresowe rozkazu zawiera numer rejestru, w którym
z kolei znajduje się adres argumentu odnoszący się do pamięci
operacyjnej komputera.
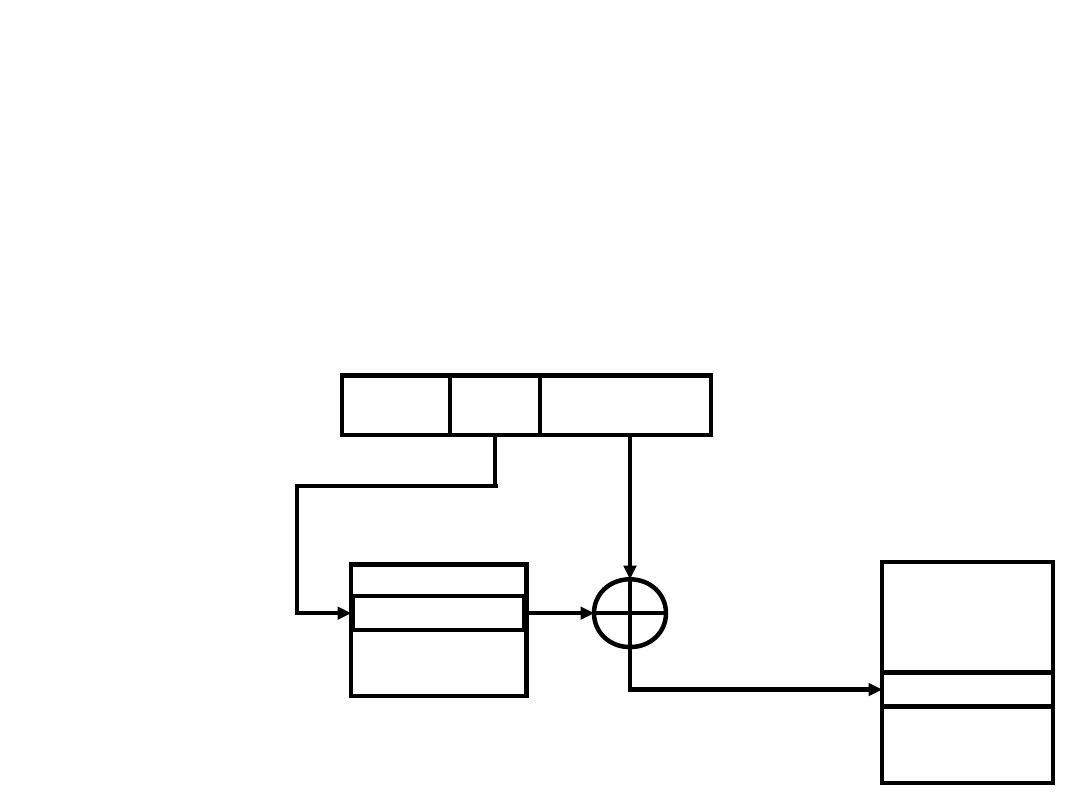
Adresowanie
pośrednie-
rejestrowe
z przesunięciem
Rozkaz
Argument
Pamięć
Rejestry
R
A
Efektywny adres = A + (R)
Adresowanie z przesunięciem wymaga dwóch pól adresowych w rozkazie,
przy czym przynajmniej jedno z nich jest jawne. Wartość zawarta w polu
adresowym A jest używana bezpośrednio. Pole adresowe R odnosi się do
rejestru, którego zawartość po dodaniu do A daje adres efektywny.

Trzy wersje adresowania
pośrednie-rejestrowego z
przesunięciem
• Adresowanie względne
. W przypadku adresowania względnego
rejestrem
domyślnym
jest licznik programu
(
PC
). Oznacza to, że
adres bieżącego
rozkazu jest dodawany do pola adresowego w celu otrzymania adresu
efektywnego
. Pole adresowe jest traktowane jako liczba w notacji
uzupełnienia do dwóch. Adres efektywny jest przesunięty względem adresu
zawartego w rozkazie.
• Adresowanie z rejestrem podstawowym
. Rejestr do którego się odwołujemy,
zawiera adres pamięci, zaś pole adresowe bieżącego rozkazu zawiera
przesunięcie (zwykle w postaci liczby nieujemnej bez znaku). Odniesienie do
rejestru może być jawne lub domyślne.
• Adresowanie z indeksowaniem
. Pole adresowe bieżącego rozkazu odnosi się
do adresu w pamięci operacyjnej, a wywołany rejestr zawiera dodatnie
przesunięcie w stosunku do tego adresu. W przypadku adresowania adres
efektywny może zawierać większą liczbę bitów niż pole adresowe bieżącego
rozkazu.
Ważnym zastosowaniem indeksowania jest możliwość efektywnego
prowadzenia operacji iteracyjnych
. Rozważmy przykład wektora liczbowego,
którego składowe przechowywane są począwszy od komórki pamięci A.
Sekwencja efektywnych adresów składowych wektora: A, A+1, A+2, ...
Wartość A jest przechowywana w polu adresowym rozkazu, a wybrany rejestr
indeksu zawiera w kolejnych krokach iteracji wartości: 0, 1, 2, 3, ... Po każdym
cyklu iteracyjnym zawartość rejestru indeksu zwiększana jest o liczbę 1.

Czwarty przypadek
indeksowanie
automatyczne i
wtórne
• Szczególnym przypadkiem jest auto-indeksowanie, gdzie
rejestr przeznaczony jest jedynie do indeksowania.
• Jeśli indeksowanie jest zastosowane po adresowaniu
pośrednim, to jest określane jako indeksowanie wtórnym
(
post-indexing
):
Adres efektywny = ( A ) + ( R )
Najpierw zawartość pola adresowego jest użyta do
uzyskania dostępu do komórki pamięci operacyjnej
zawierającej adres bezpośredni, a następnie adres ten jest
indeksowany zawartością rejestru.
•
Adresowanie
stosowe
Rozkaz
Rejestr wierzchołka stosu
Domyślny
Stos jest liniową tablicą komórek pamięci i jest zarezerwowanym blokiem
pamięci. Elementy są dodawane na wierzchołek stosu, w wyniku czego
zawartość stosu powiększa się. Stos działa według zasady „ostatni zapis
- pierwszy odczyt”. Ze stosem związany jest rejestr, którego zawartość jest
adresem wierzchołka stosu - 2.
Dwa wierzchołkowe elementy stosu mogą znajdować się w rejestrach
procesora, a wskaźnik stosu odnosi się do trzeciego elementu stosu.
Rozkazy operują na jednym lub parze elementów stosu, a wynik umieszają
w stosie.

Formaty rozkazów
•
Format rozkazu określa rozkład bitów części składowych.
•
Format rozkazu musi zawierać kod operacji oraz, w
sposób jawny lub domyślny, zero lub więcej argumentów
•
Każdy jawny argument jest adresowany za pomocą
jednego z omawianych trybów adresacji
(
natychmiastowe, bezpośrednie, pośrednie, rejestrowe,
pośrednie-rejestrowe, pośrednie-rejestrowe z
przesunięciem
)
•
W większości list rozkazów występuje więcej niż jeden
format rozkazu
•
Rozróżniamy formaty rozkazów o
stałej
i zmiennej
długości
. Omawiany dalej procesor MIPS I – jest
komputerem o rozkazach stałej długości, natomiast
procesory PENTIUM posiadają rozkazy o różnej długości
(16 – 48 bitów)
•
Długość rozkazu
powinna być zsynchronizowana z
długością jednostki transferu danych.

MIPS I
Instruction set
Berkeley, California

Berkeley Vector IRAM chip:
2003
•MIPS CPU +
multimedia
coprocessor +
104 Mbits (13
Mbytes)
of on-chip main
memory
•2 W, 200 MHz
•Die size: 325
mm
2
, in 0.18
micron, 125M
transistors
•App: future
PDAs

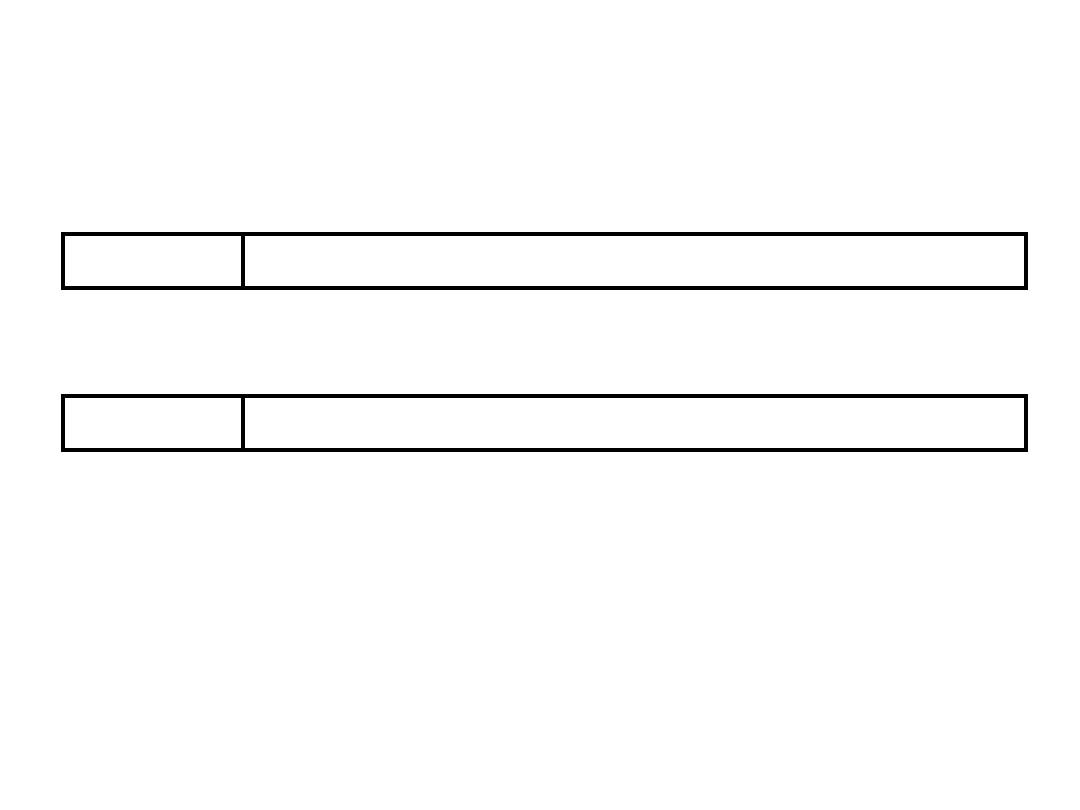
Instruction Formats
• I-format
: used for instructions with
immediates, iw and sw (since the offset
counts as an immediate), and the
branches (beq and bne),
– (but not the shift instructions; later)
• J-format
: used for j and jal
• R-format
: used for all other instructions
• It will soon become clear why the
instructions have been partitioned in this
way.
R-Format Instructions
(1/4)
• Define “
fields
” of the following number of bits each:
6 + 5 + 5 + 5 + 5 + 6 = 32
6
5
5
5
6
5
opcode
rs
rt
rd
funct
shamt
• For simplicity, each field has a
name:

R-Format Instructions
(2/4)
• What do these field integer values tell us?
– opcode
: partially specifies what instruction it
is
•
Note: This number is equal to 0 for all R-Format
instructions.
– funct
: combined with opcode, this number
exactly specifies the instruction
R-Format Instructions
(3/4)
• More fields:
–
rs
(
S
ource
R
egister):
generally
used to
specify register containing first operand
–
rt
(
T
arget
R
egister):
generally
used to
specify register containing second operand
(note that name is misleading)
–
rd
(
D
estination
R
egister):
generally
used to
specify register which will receive result of
computation

R-Format Instructions
(4/4)
• Final field:
– shamt
: This field contains the amount a shift
instruction will shift by. Shifting a 32-bit
word by more than 31 is useless, so this
field is only 5 bits (so it can represent the
numbers 0-31).
– This field is set to 0 in all but the shift
instructions.
R-Format Example
• MIPS Instruction:
add $8,$9,$10
0
9
10
8
32
0
Binary number per field representation:
Decimal number per field representation:
hex representation:
012A 4020
hex
decimal representation:
19,546,144
ten
000000010010101001000
100000
00000
hex

I-Format Example (1/2)
• MIPS Instruction:
addi $21,$22,-50
opcode = 8 (look up in table in book)
rs = 22 (register containing operand)
rt = 21 (target register)
immediate = -50 (by default, this is decimal)
I-Format Example (2/2)
• MIPS Instruction:
addi $21,$22,-50
8
22
21
-50
00100010110101011111111111001110
Decimal/field representation:
Binary/field representation:
hexadecimal representation:
22D5
FFCE
hex
decimal representation:
584,449,998
ten
J-Format Instructions
(1/2)
• Define “fields” of the following number of bits
each:
6 bits
26 bits
opcode
target address
• As usual, each field has a name:
• Key Concepts
– Keep opcode field identical to R-format
and I-format for consistency.
– Combine all other fields to make room
for large target address.

J-Format Instructions
(2/2)
• Summary:
– New PC = { PC[31..28], target address, 00 }
• Understand where each part came from!
• Note: { , , } means concatenation
{ 4 bits , 26 bits , 2 bits } = 32 bit
address
– { 1010, 11111111111111111111111111, 00
} = 10101111111111111111111111111100
The MIPS Instruction
Formats
• All MIPS instructions are 32 bits long.
The three
instruction formats
:
– R-type
– I-type
– J-type
• The different fields are:
– op
: operation of the instruction
– rs, rt, rd
: the source and destination register specifies
– shamt
: shift amount
– func
t: selects the variant of the operation in the “op” field
– address / immediate
: address offset or immediate value
– target address
: target address of the jump instruction
op
target address
0
26
31
6 bits
26 bits
op
rs
rt
rd
shamt
funct
0
6
11
16
21
26
31
6 bits
6 bits
5 bits
5 bits
5 bits
5 bits
op
rs
rt
immediate
0
16
21
26
31
6 bits
16 bits
5 bits
5 bits

Summary: Salient features of
MIPS I
•
32-bit fixed format inst (
3 formats
)
• 32 32-bit GPR (
R0 contains zero
) and
32 FP
registers (and HI LO)
– partitioned by software convention
• 3-address, reg-reg arithmetic instr.
• Single address mode for load/store:
base+displacement
–
no indirection, scaled
–16-bit immediate plus LUI
• Simple branch conditions
–
compare against zero or two registers
for =,
– no integer condition codes
• Delayed branch
– execute instruction after a branch (or
jump) even if the branch is taken
(Compiler can fill a delayed branch with
useful work about 50% of the time)

MIPS I Operation
Overview
• Arithmetic Logical:
– Add, AddU, Sub, SubU, And, Or,
Xor, Nor, SLT, SLTU
– AddI, AddIU, SLTI, SLTIU, AndI, OrI,
XorI, LUI
– SLL, SRL, SRA, SLLV, SRLV, SRAV
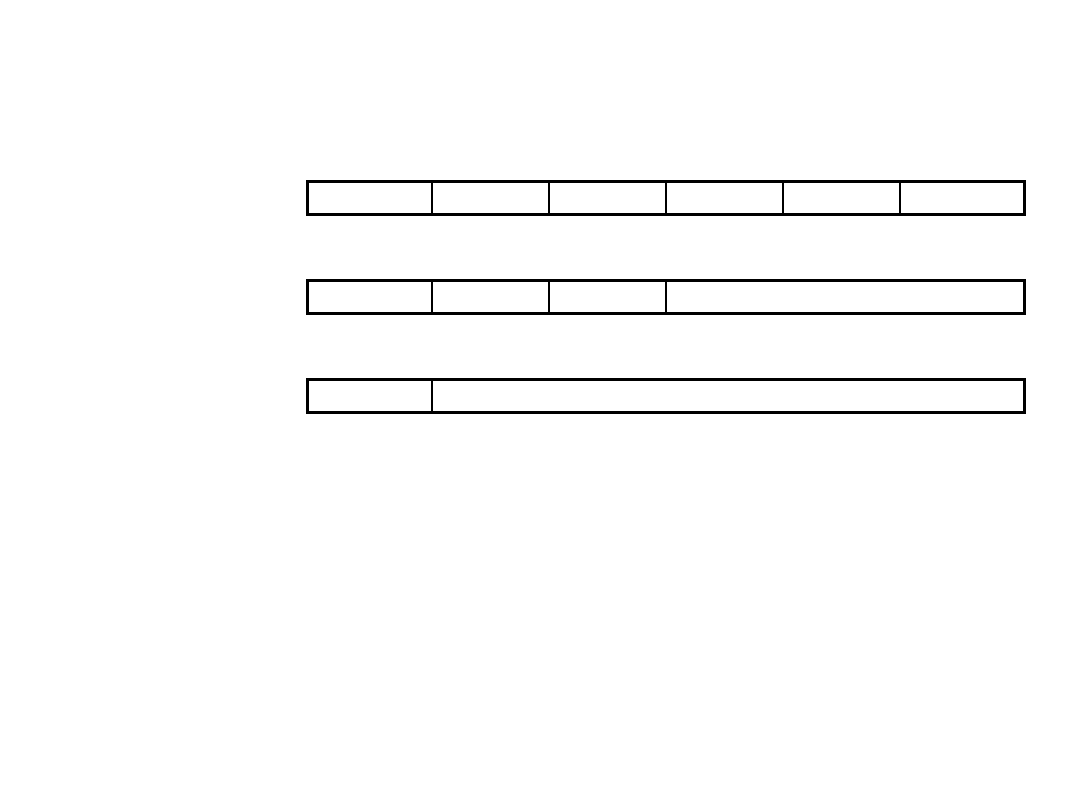
• Memory Access:
– LB, LBU, LH, LHU, LW, LWL,LWR
– SB, SH, SW, SWL, SWR
Multiply / Divide
• Start multiply, divide
– MULT rs, rt
– MULTU rs, rt
– DIV rs, rt
– DIVU rs, rt
• Move result from multiply,
divide
– MFHI rd
– MFLO rd
• Move to HI or LO
– MTHI rd
– MTLO rd
Registers
HI
LO
Q: Why not Third field for
destination?
Data Types
Bit: 0, 1
Bit String: sequence of bits of a particular length
4 bits is a nibble
8 bits is a byte
16 bits is a half-word
32 bits is a word
64 bits is a double-word
Character:
ASCII 7 bit code
UNICODE 16 bit code
Decimal:
digits 0-9 encoded as 0000b thru 1001b
two decimal digits packed per 8 bit byte
Integers:
2's Complement
Floating Point:
Single Precision
Double Precision
Extended Precision
M x R
E
How many +/- #'s?
Where is decimal pt?
How are +/- exponents
represented?
exponent
base
mantissa

MIPS arithmetic
instructions
Instruction
Example
Meaning
Comments
add
add $1,$2,$3
$1 = $2 + $3
3 operands;
exception
possible
subtract
sub $1,$2,$3
$1 = $2 – $3
3 operands;
exception
possible
add immediate
addi $1,$2,100 $1 = $2 + 100+ constant;
exception
possible
add unsigned addu $1,$2,$3
$1 = $2 + $3
3 operands;
no exceptions
subtract unsigned
subu $1,$2,$3 $1 = $2 – $3 3 operands;
no exceptions
add imm. unsign.
addiu $1,$2,100
$1 = $2 + 100+ constant;
no
exceptions
multiply
mult $2,$3 Hi, Lo = $2 x $364-bit signed product
multiply unsigned
multu$2,$3 Hi, Lo = $2 x $3 64-bit unsigned product
divide
div $2,$3
Lo = $2 ÷ $3,
Lo = quotient, Hi = remainder
Hi = $2 mod $3
divide unsigned
divu $2,$3
Lo = $2 ÷ $3,
Unsigned quotient &
remainder
Hi = $2 mod $3
Move from Hi mfhi $1
$1 = Hi
Used to get copy of Hi
Move from Lo mflo $1
$1 = Lo
Used to get copy of Lo
Q: Which add for address arithmetic? Which add for integers?

MIPS logical instructions
Instruction
Example
Meaning
Comment
and
and $1,$2,$3
$1 = $2 & $3
3 reg.
operands; Logical AND
or or $1,$2,$3
$1 = $2 | $3
3 reg. operands;
Logical OR
xor
xor $1,$2,$3
$1 = $2 ^ $3
3 reg.
operands; Logical XOR
nor
nor $1,$2,$3
$1 = ~($2 |$3) 3 reg.
operands; Logical NOR
and immediate
andi $1,$2,10 $1 = $2 & 10
Logical AND reg, constant
or immediate
ori $1,$2,10
$1 = $2 | 10
Logical OR reg, constant
xor immediate
xori $1, $2,10
$1 = ~$2
&~10
Logical XOR reg, constant
shift left logical
sll $1,$2,10
$1 = $2 << 10
Shift left by constant
shift right logical
srl $1,$2,10
$1 = $2 >> 10
Shift right by constant
shift right arithm.
sra $1,$2,10 $1 = $2 >> 10
Shift right (sign extend)
shift left logical
sllv $1,$2,$3 $1 = $2 << $3
Shift left by variable
shift right logical
srlv $1,$2, $3
$1 = $2 >>
$3
Shift right by variable
shift right arithm.
srav $1,$2, $3
$1 = $2 >>
$3
Shift right arith. by variable
Q: Can some multiply by 2
i
? Divide by 2
i
? Invert?
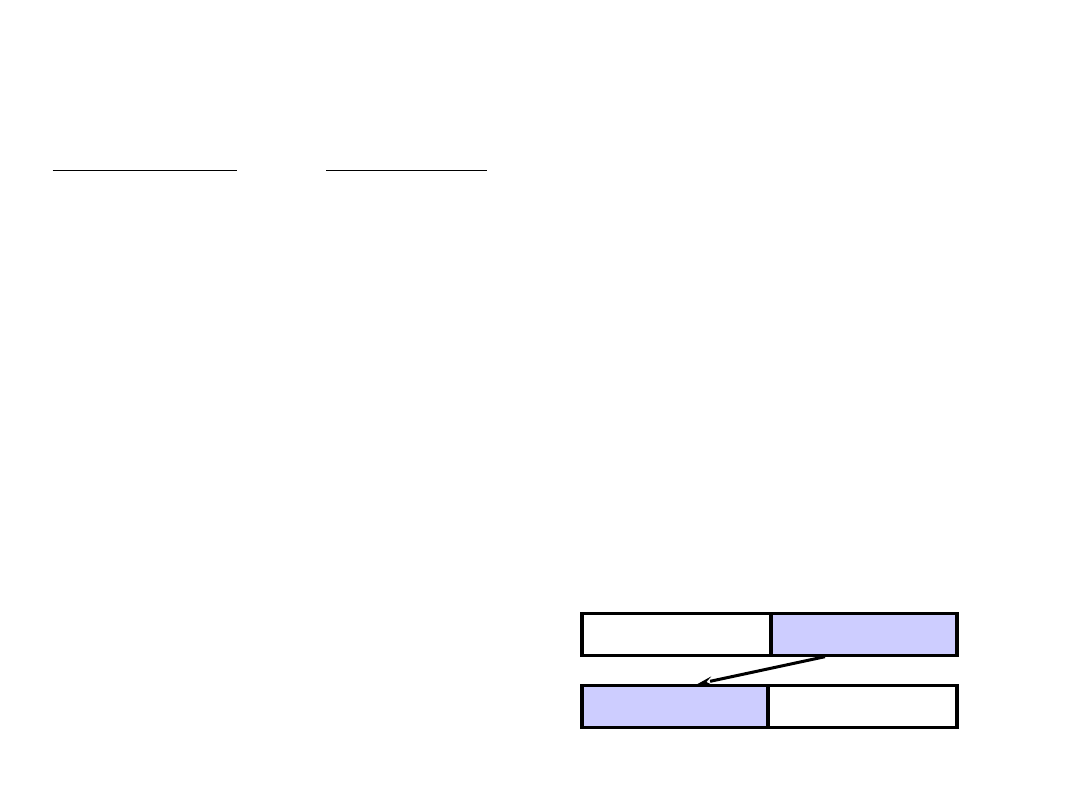
MIPS data transfer
instructions
Instruction
Comment
sw 500($4), $3 Store word
sh 502($2), $3 Store half
sb 41($3), $2
Store byte
lw $1, 30($2)
Load word
lh $1, 40($3)
Load halfword
lhu $1, 40($3) Load halfword unsigned
lb $1, 40($3)
Load byte
lbu $1, 40($3)
Load byte unsigned
lui $1, 40
Load Upper Immediate (16 bits shifted
left by 16)
Q: Why need lui?
0000 … 0000
LUI R5
R5
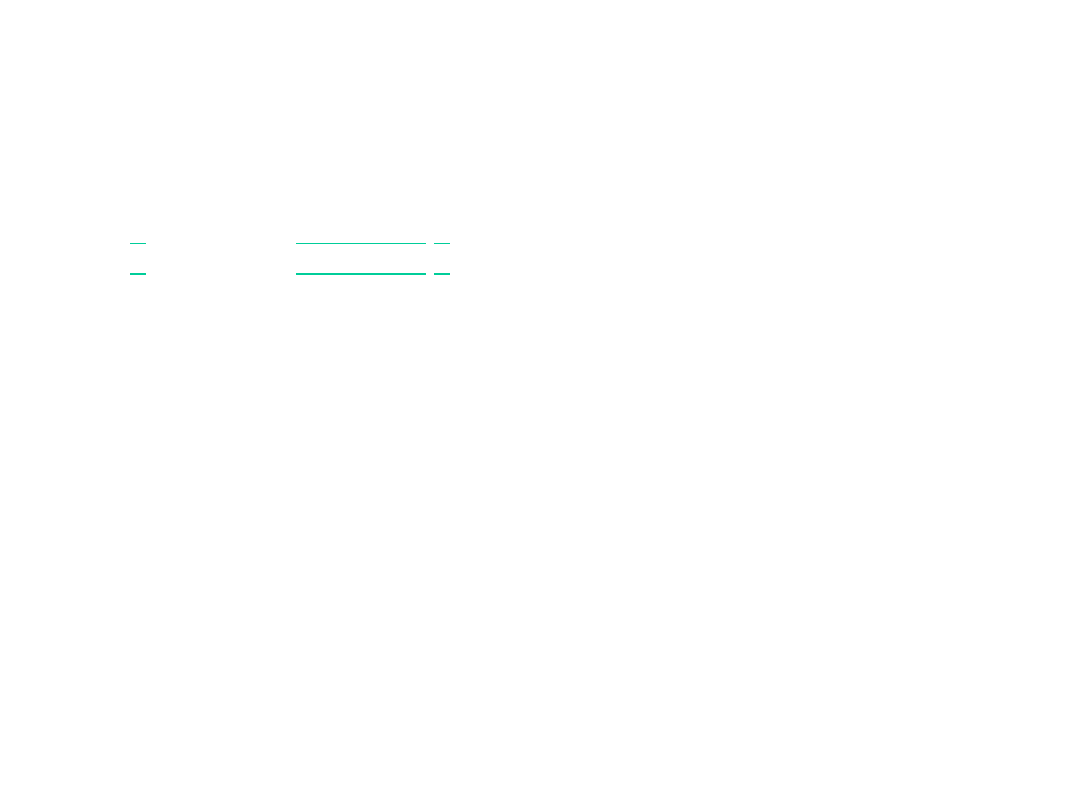
When does MIPS sign
extend?
• When value is sign extended, copy upper bit to full value:
Examples of sign extending 8 bits to 16 bits:
0
0001010
00000000
0
0001010
1
0001100
11111111
1
0001100
• When is an immediate operand sign extended?
– Arithmetic instructions (add, sub, etc.)
always sign extend immediates
even for
the unsigned versions of the instructions!
– Logical instructions
do not sign extend immediates
(They are zero extended)
– Load/Store address computations
always sign extend immediates
• Multiply/Divide have no immediate operands however:
– “unsigned” treat operands as unsigned
• The data loaded by the instructions lb and lh are extended as
follows (
“unsigned”
don’t extend
)
:
– lbu, lhu are zero extended
– lb, lh are sign extended
Q: Then what is does add
unsigned (addu) mean
since not immediate?

MIPS Compare and
Branch
•Compare and Branch
– BEQ rs, rt, offset if R[rs] == R[rt] then PC-
relative branch
– BNE rs, rt, offset
<>
•Compare to zero and Branch
– BLEZ rs, offset
if R[rs] <= 0 then PC-relative
branch
– BGTZ rs, offset
>
– BLT
<
– BGEZ
>=
– BLTZAL rs, offset if R[rs] < 0 then branch and link
(into R 31)
– BGEZAL
>=!
•Remaining set of compare and branch ops
take two instructions
•Almost all comparisons are against zero!

MIPS jump, branch, compare
instructions
Instruction
Example
Meaning
branch on equal
beq $1,$2,100
if ($1 == $2) go to
PC+4+100
Equal test; PC relative branch
branch on not eq.
bne $1,$2,100
if ($1!= $2) go to
PC+4+100
Not equal test; PC relative
set on less than
slt $1,$2,$3 if ($2 < $3) $1=1; else $1=0
Compare less than; 2’s comp.
set less than imm.
slti $1,$2,100
if ($2 < 100) $1=1;
else $1=0
Compare < constant; 2’s comp.
set less than uns.
sltu $1,$2,$3if ($2 < $3) $1=1; else $1=0
Compare less than; natural numbers
set l. t. imm. uns.
sltiu $1,$2,100
if ($2 < 100) $1=1;
else $1=0
Compare < constant; natural numbers
jump
j 10000
go to 10000
Jump to target address
jump register jr $31
go to $31
For switch, procedure return
jump and link jal 10000
$31 = PC + 4; go to 10000
For procedure call

Signed vs. Unsigned
Comparison
$1=
0…00 0000 0000 0000 0001
$2=
0…00 0000 0000 0000 0010
$3=
1…11 1111 1111 1111 1111
•After executing these
instructions:
slt $4,$2,$1 ; if ($2 < $1) $4=1;
else $4=0
slt $5,$3,$1 ; if ($3 < $1) $5=1;
else $5=0
sltu $6,$2,$1 ; if ($2 < $1) $6=1;
else $6=0
sltu $7,$3,$1 ; if ($3 < $1) $7=1;
else $7=0
•What are values of registers $4 -
$7? Why?
$4 = ; $5 = ; $6 = ; $7 =
;
two
two
two
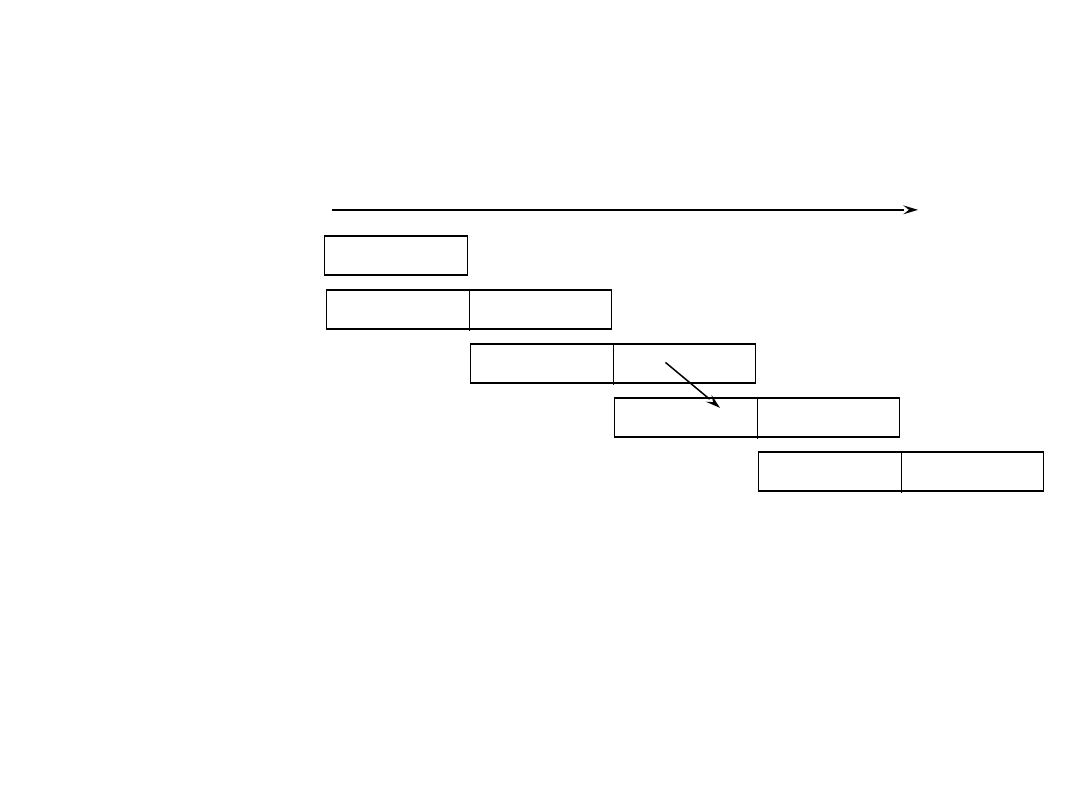
Branch & Pipelines
By the end of Branch instruction, the CPU knows whether or
not the branch will take place.
However, it will have fetched the next instruction by then,
regardless of whether or not a branch will be taken.
Why not execute it?
execute
Branch
Delay Slot
Branch Target
ifetch execute
ifetch execute
ifetch execute
LL: slt
$1, $3, $5
li $3, #7
sub $4, $4, 1
bz $4, LL
addi $5, $3, 1
Time
ifetch execute

Delayed Branches
• In the “Raw” MIPS, the instruction after the branch is
executed even when the branch is taken
– This is hidden by the assembler for the MIPS “virtual machine”
– allows the compiler to better utilize the instruction pipeline (???)
• Jump and link
(jal inst):
– Put the return addr. Into link register ($31):
• PC+4 (logical architecture)
• PC+8 physical (“Raw”) architecture delay slot executed
– Then jump to destination address
li
$3, #7
sub $4, $4, 1
bz
$4, LL
addi $5, $3, 1
subi $6, $6, 2
LL: slt
$1, $3, $5
Delay Slot
Instruction
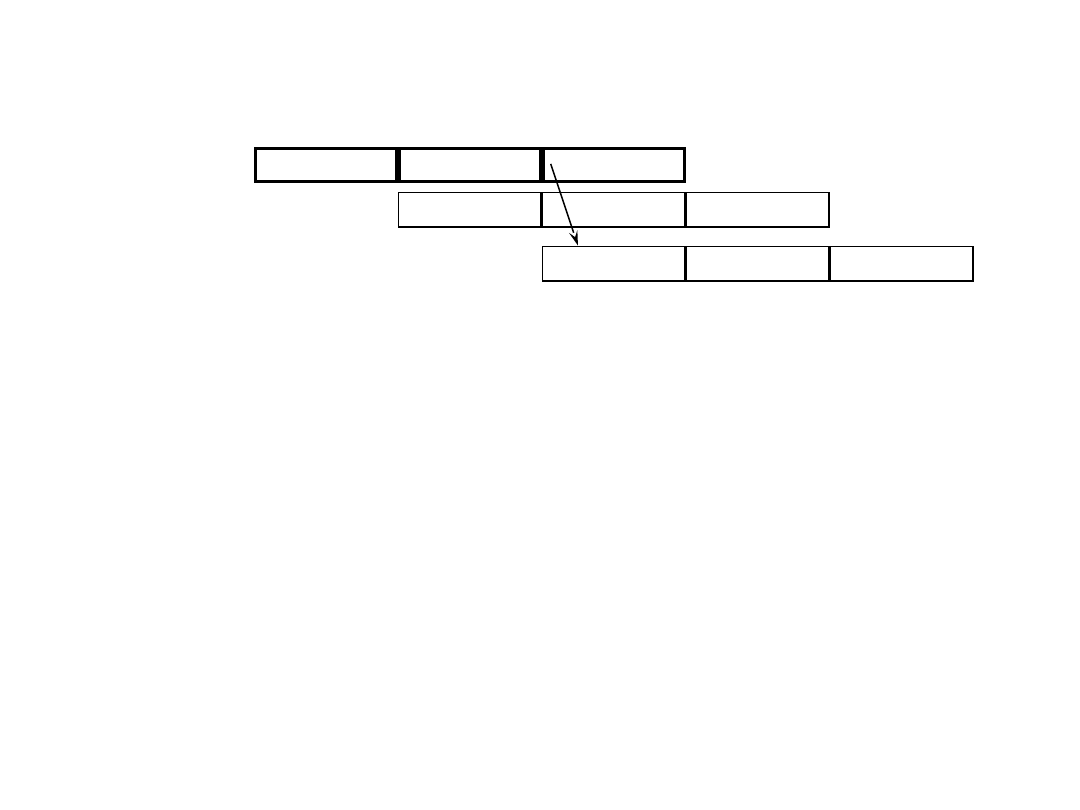
Filling Delayed
Branches
Inst Fetch Dcd & Op FetchExecute
Branch:
Inst Fetch Dcd & Op Fetch
Inst Fetch
Execute
execute successor
even if branch taken
!
Then branch target
or continue
Single delay slot
impacts the critical path
•Compiler can fill a single
delay slot with a useful
instruction 50% of the time.
• try to move down from
above jump
•move up from target, if
safe
add $3, $1, $2
sub $4, $4, 1
bz $4, LL
NOP
...
LL: add rd, ...
Is this violating the ISA abstraction?

Miscellaneous MIPS I
instructions
• break
A breakpoint trap occurs, transfers control
to exception handler
• syscall
A system trap occurs, transfers control to
exception handler
• coprocessor instrs.
Support for floating point
• TLB instructions
Support for virtual memory:
discussed later
• restore from exception
Restores previous
interrupt mask & kernel/user
mode bits into
status register
• load word left/right
Supports misaligned word loads
• store word left/right Supports misaligned word
stores
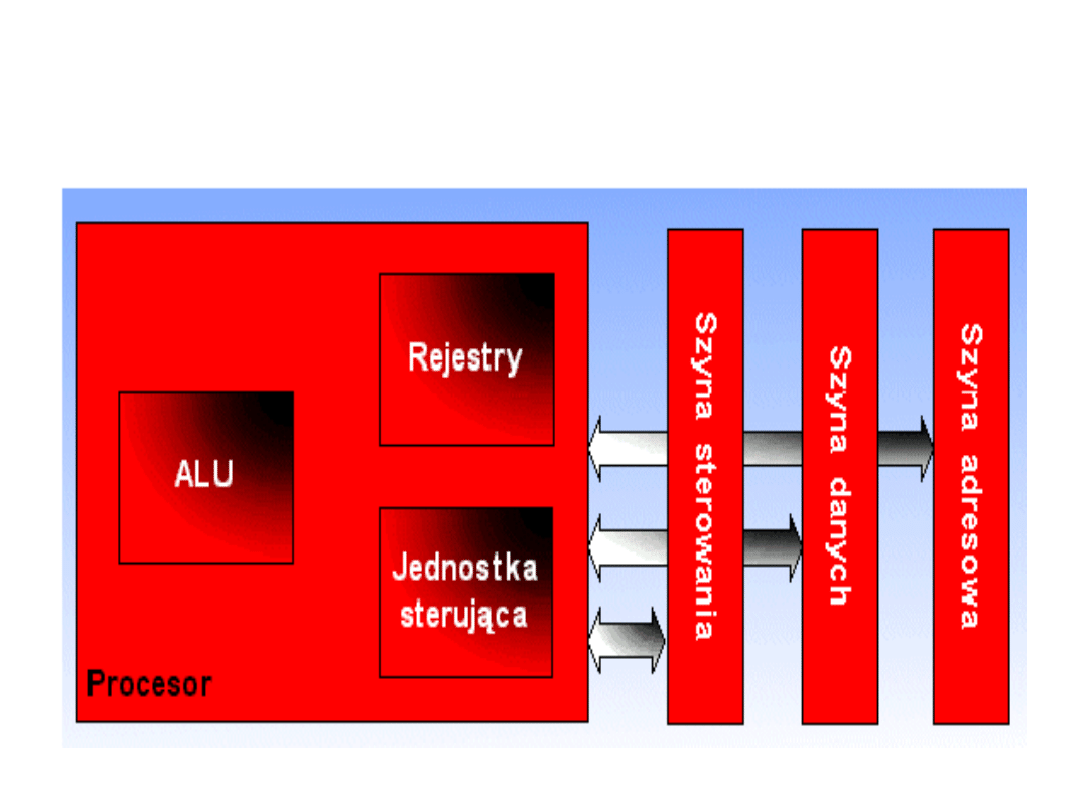
Współpraca procesora
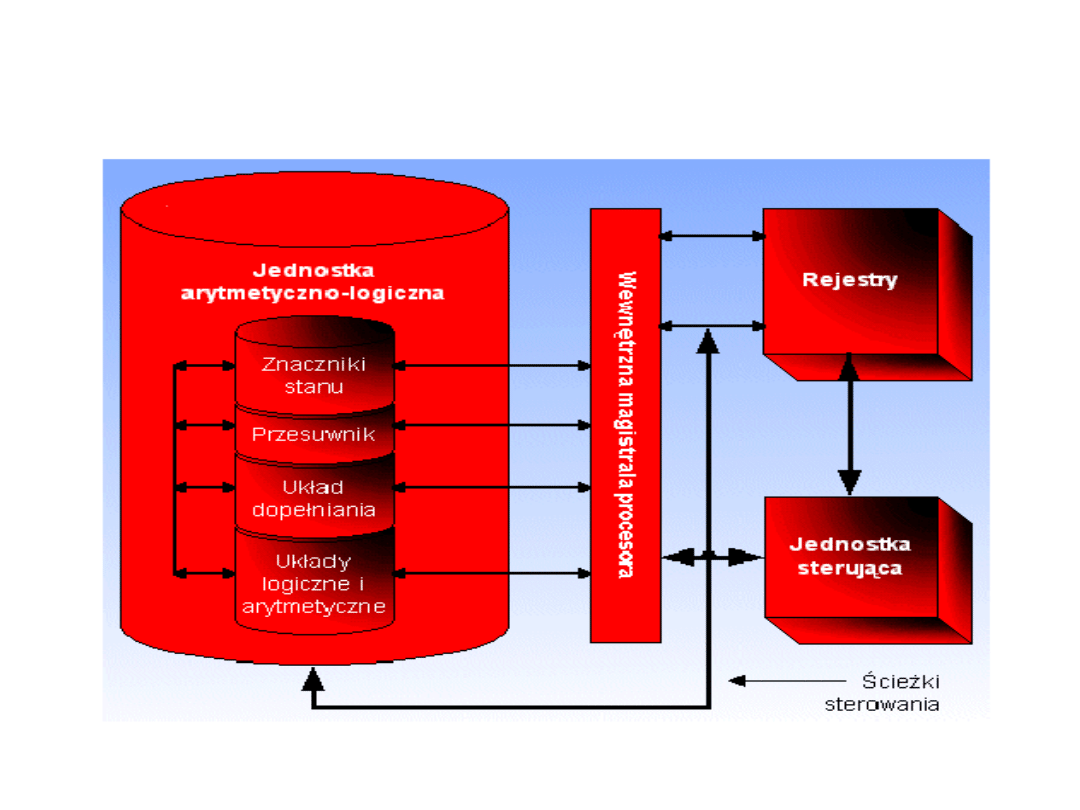
Schemat ideowy
procesora

Organizacja rejestrów
• Rejestry widziane dla użytkownika
. Umożliwiają
programiście programującemu w języku maszynowym
lub symbolicznym minimalizację odwołań do pamięci
operacyjnej drogą na drodze posługiwania się rejestrami.
• Rejestry sterowania i stanu
. Są to rejestry
wykorzystywane bezpośrednio przez jednostkę sterującą
procesora oraz przez uprzywilejowane programy systemu
operacyjnego do sterowania wykonywaniem programów.
Uwaga
: nie ma ścisłego rozgraniczenia między tymi
dwoma kategoriami rejestrów. Np. w komputerze VAX
rejestr PC (licznik programu) jest widziany dla
programisty aplikacyjnego.

Rejestry widoczne dla
użytkownika
• Rejestry ogólnego przeznaczenia
, czyli robocze, mogą być użyte
w programach na wiele sposobów i może mieć charakter
ortogonalny w stosunku do operacji. Oznacza to, że dowolny
rejestr roboczy może zawierać argument dla dowolnego kodu
operacji.
• Rejestry danych
mogą być używane tylko do przechowywania
danych i nie mogą być używane do obliczania adresów
argumentów.
• Rejestry adresowe
mogą być przypisane określonym trybom
adresacji
– Wskaźniki segmentu
– przechowują adres podstawy segmentu
– Rejestry indeksowe
– są używane do adresowania indeksowego i mogą być
modyfikowane automatycznie
– Wskaźniki stosu
– zwykle 5 rejestrów: (1)
wierzchołkowy element stosu
; (2)
drugi element stosu
; (3)
granica stosu
; (4)
wskaźnik stosu
i (5)
podstawa
stosu
.
• Rejestry kodów warunkowych
składają się z bitów
poszczególnych flag, ustawianych automatycznie przez procesor
w wyniku wykonania operacji (np. wynik dodatni, wynik ujemny,
wynik zerowy, przeniesieni, nadmiar, blokada przerwań).
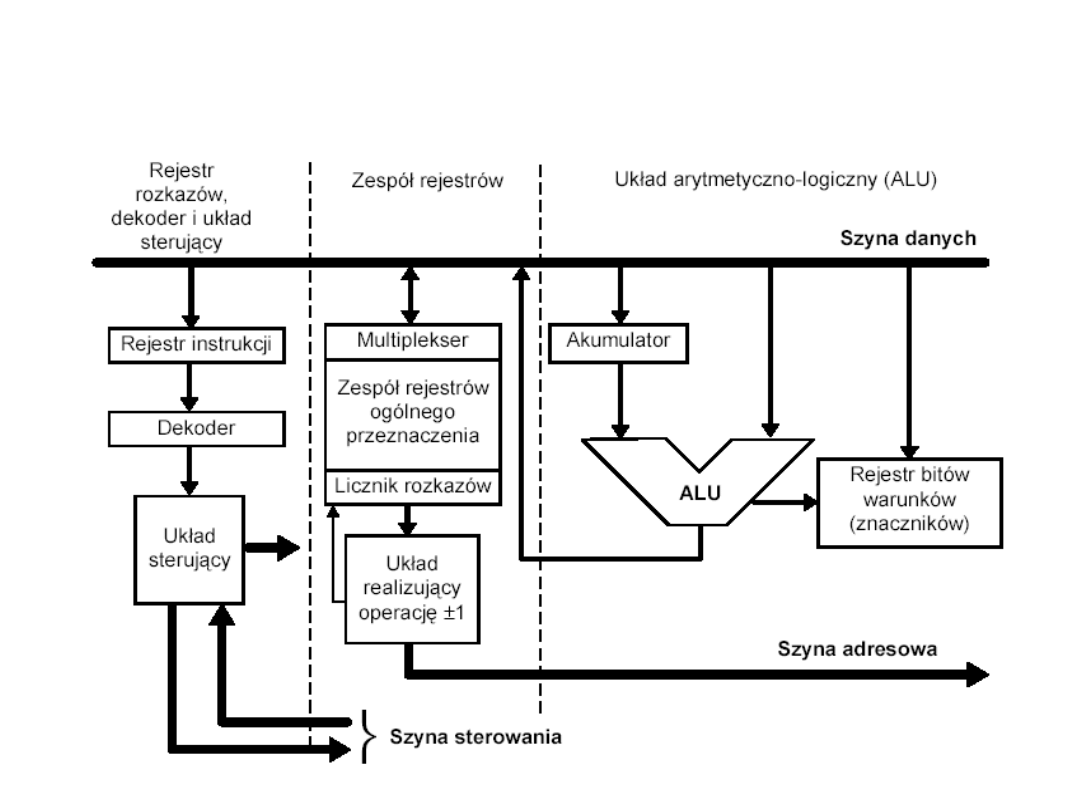
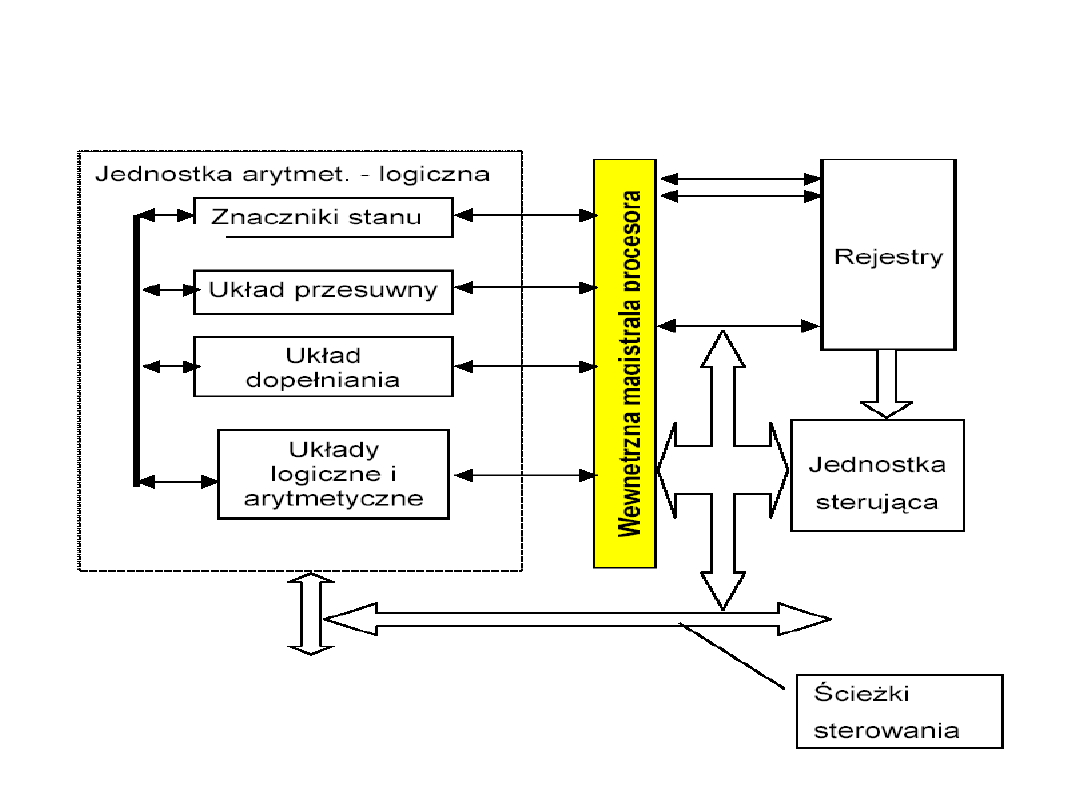
Podstawowe zespoły funkcjonalne
procesora
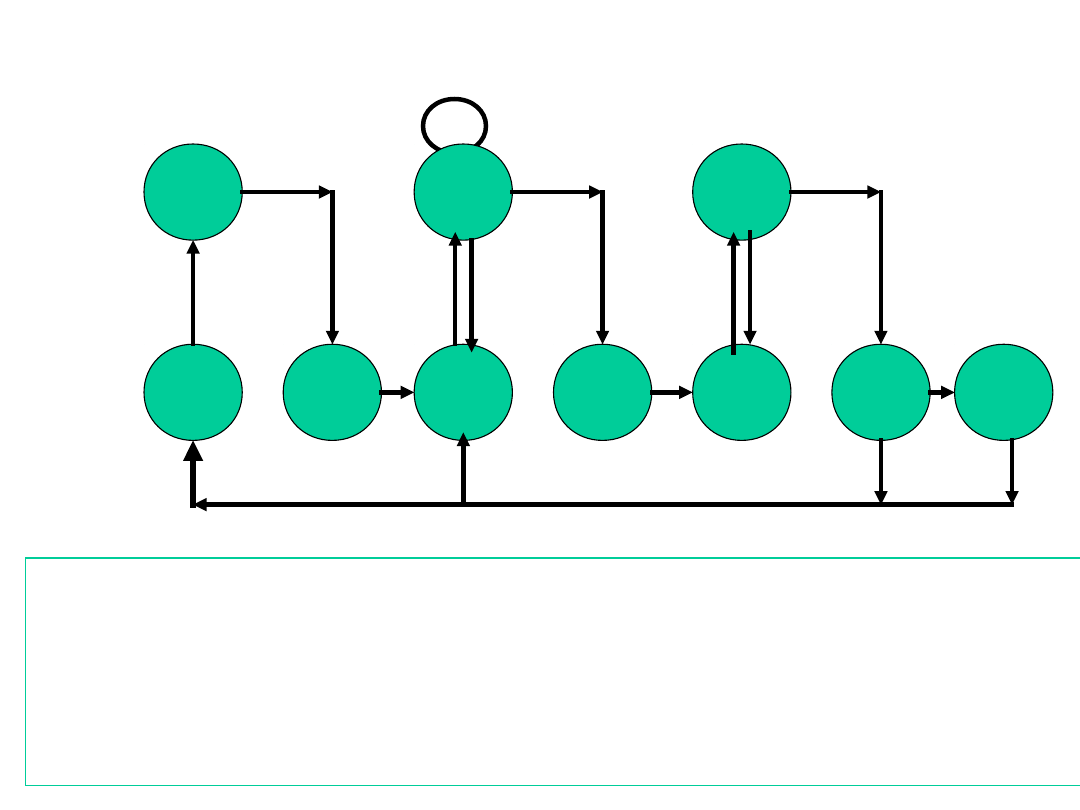
Graf stanów - cyklu instrukcji z
przerwaniami
iac
iod
os
of
if
oac
do
aoc
ic
in
Następna
instrukcja
Łańcuch
lub wektor
Brak
przerwań
Wiele
argumentów
Wiele
wyników
if
–
pobranie instrukcji
;
iod
–
dekodowanie części operacyjnej
;
oac
–
obliczanie adresu argumentu
;
of
–
pobranie argumentu
;
do
–
operacja na danych
;
os
–
zapisanie argumentu
;
ic
–
sprawdzanie czy jest przerwanie
;
in
–
obsługa przerwania
;
iac
–
przesłanie zawartości licznika adresów do rejestru sterowania
.
Wewnętrz
na
operacja
procesora
Dostęp
procesora
do pamięci
lub we-wy
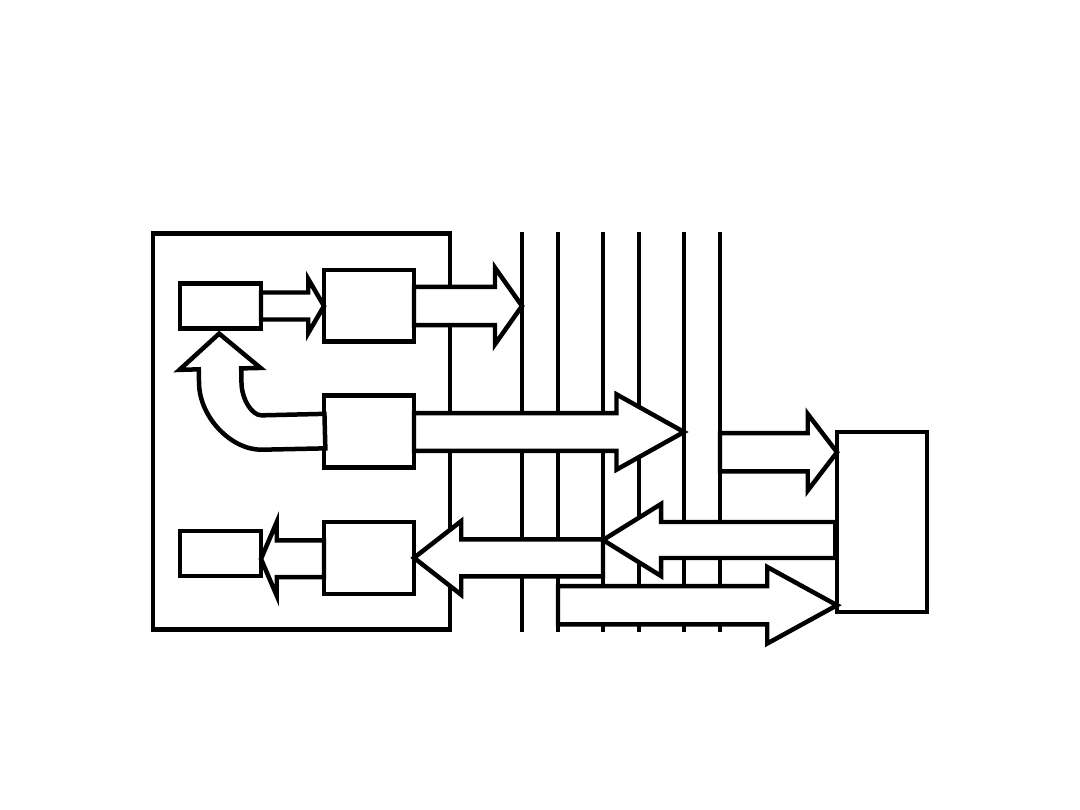
Przepływ danych w cyklu
pobierania
Pamięć
MBR
Jednostka
sterująca
MAR
S
z
y
n
a
a
d
re
s
o
w
a
S
z
y
n
a
d
a
n
y
c
h
S
z
y
n
a
s
te
ro
w
a
n
ia
IR
PC
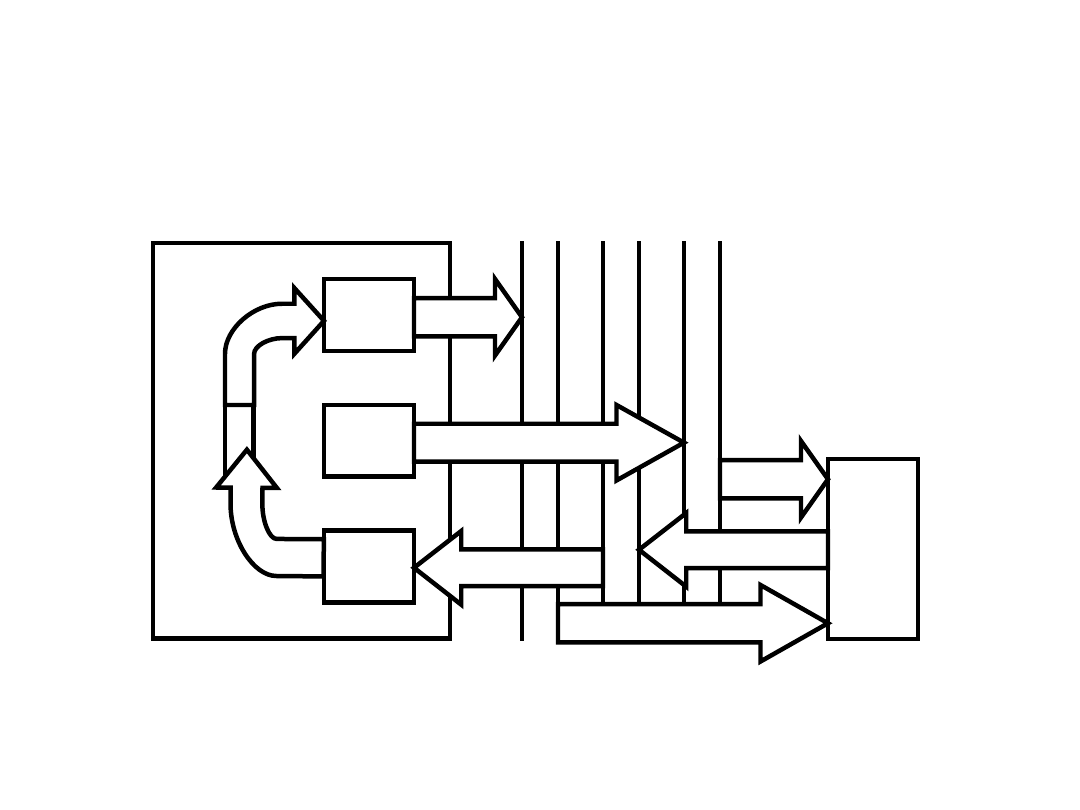
Przepływ danych w cyklu
pośrednim
Pamięć
MBR
Jednostka
sterująca
MAR
S
z
y
n
a
a
d
re
s
o
w
a
S
z
y
n
a
d
a
n
y
c
h
S
z
y
n
a
s
te
ro
w
a
n
ia
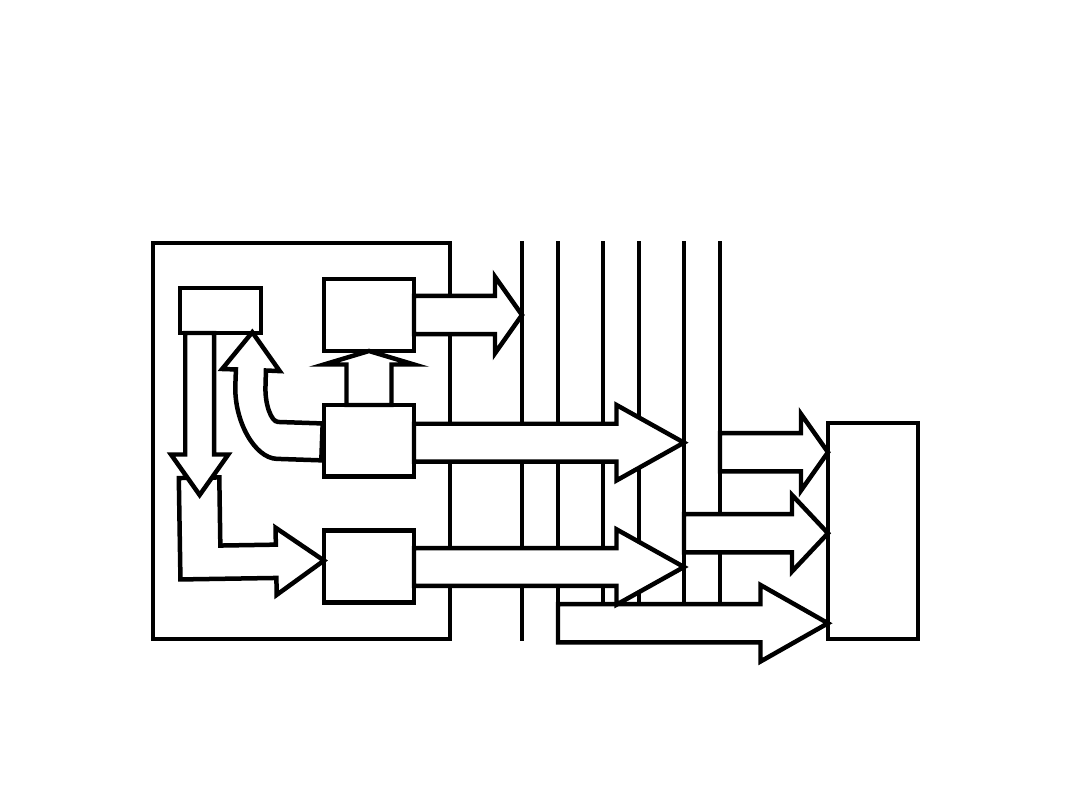
Przepływ danych w cyklu
przerwania
Pamięć
MBR
Jednostka
sterująca
MAR
S
zy
n
a
a
d
re
s
o
w
a
S
z
y
n
a
d
a
n
y
c
h
S
z
y
n
a
s
te
ro
w
a
n
ia
PC
Budowa mikroprocesora
dwuszynowego
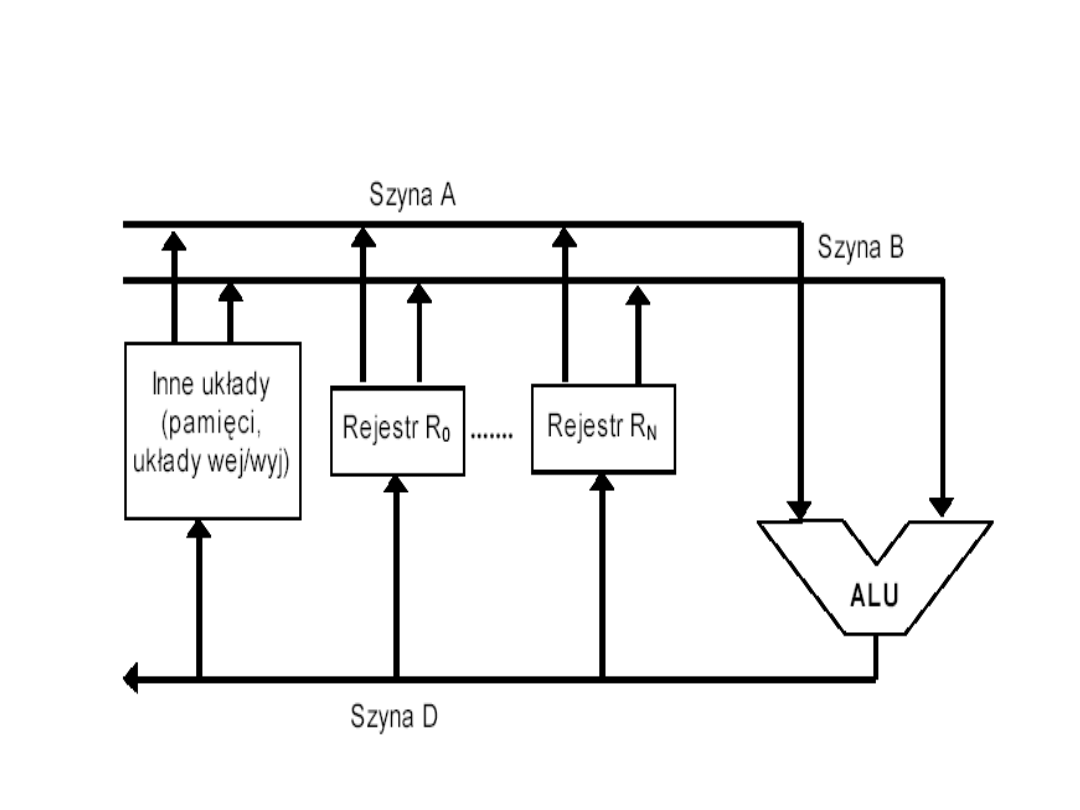
Budowa mikroprocesora
trójszynowego
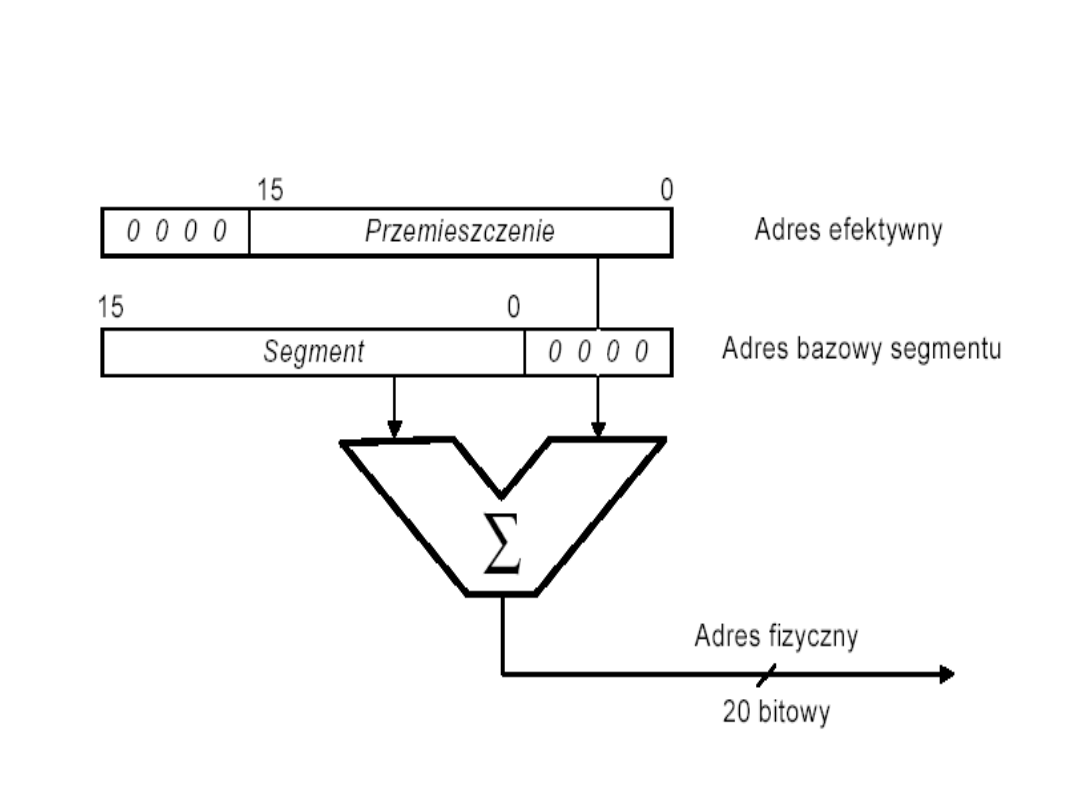
Generacja adresu fizycznego

Rodzaje danych procesora
Pentium
• Ogólne. Lokacje o dowolnej zawartości binarnej obejmujące bajt,
słowo (16 bitów), podwójne słowo (32 bity) lub poczwórne słowo
(64 bity).
• Całkowite. Wartości binarne ze znakiem, zawarte w bajcie, słowie
lub podwójnym słowie, w reprezentacji uzupełnienia do dwóch.
• Porządkowe. Liczby całkowite bez znaku (bajt, słowo, podwójne
słowo).
• Liczba dziesiętna nie-upakowana BCD.
• Liczba dziesiętna upakowana BCD.
• Wskaźnik bliski. 32-bitowy adres efektywny, reprezentujący
przesunięcie wewnątrz segmentu.
• Łańcuch bajtów. Sekwencja sąsiadujących bajtów (od zera do 2
32
-
1 bajtów).
• Zmiennoprzecinkowe:
– pojedynczej precyzji – 32-bitowe słowo, mantysa 24-bity, cecha w systemie
z przesuniętym wykładnikiem;
– podwójnej precyzji – 64-bity, mantysa 52-bity, cecha jw.
– precyzja rozszerzona – 80-bitów, mantysa 64 bitowa, cecha jw.
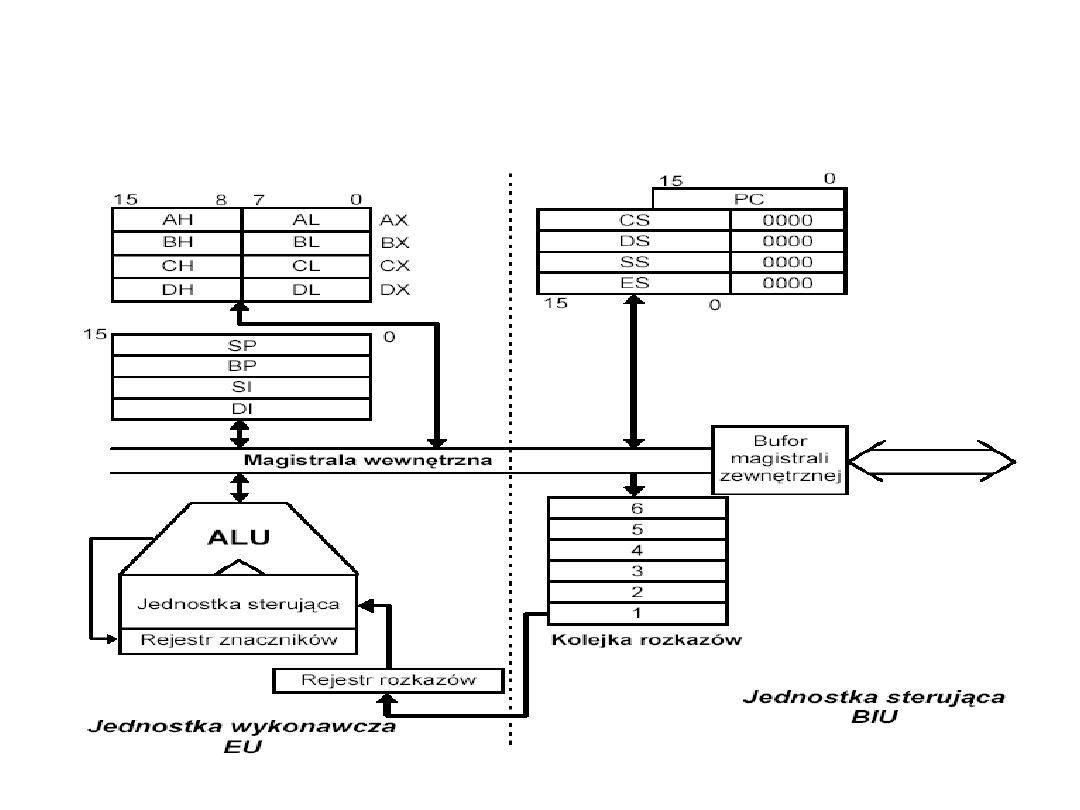
Organizacja procesora
Pentium

Organizacja rejestrów
Pentium
Rejestry w procesorze można podzielić na dwie
grupy:
•
Rejestry widzialne dla użytkownika:
– ogólnego przeznaczenia (ang. general purpose),
– danych,
– adresowe (wskaźniki segmentu, rejestry indeksowe,
wskaźnik stosu).
•
Rejestry sterowania i stanu:
– Licznik programu (PC).
– Rejestr rozkazu (IR).
– Rejestr adresowy pamięci (MAR).
– Rejestr buforowy pamięci (MBR).
– Słowo stanu programu (ang. program status word – PSW).

Rejestr PSW zawiera
następujące flagi
• Znak
. Bit znaku ostatniej operacji arytmetycznej;
• Zero
. Flaga ustawiana, gdy wynik równy zeru;
• Przeniesienie
. Ustawiane, gdy wynikiem operacji jest
przeniesienie do kolejnego słowa (umożliwia realizacje
wielokrotnej precyzji);
• Przepełnienie
. Nadmiar arytmetyczny.
• Zezwolenie / blokowanie przerwania
. Używane do obsługi
przerwań.
• Pułapka
(Trap).
• Tryb procesora
. Wskazuje, czy procesor pracuje w trybie
nadzorcy, czy użytkownika.
• Wskaźnik do bloku sterowania procesem
.
• Wskaźnik tablicy stron
. Dla systemu pamięci wirtualnej.
• itp.
Przykładowa organizacja
rejestrów mikroprocesorach
Intel 8086

Rejestry mikroprocesora
8086
•
Mikroprocesor 8086 zawiera 14 szesnastobitowych rejestrów
widocznych dla programisty
•
Rejestry ogólnego przeznaczenia, służące głównie do
przechowywania wyników pośrednich, ich zawartości mogą
być argumentami większości rozkazów:
– AX
- akumulator; niektóre rozkazy dotyczące tego rejestru wykonują
się szybciej niż na innych rejestrach ogólnych lub są o 1 bajt krótsze.
– BX
- rejestr bazowy; dodatkowo może być wykorzystany do tzw.
adresowania bazowego - zawiera wówczas przesunięcie (OFFSET)
argumentu.
– CX
- rejestr zliczający lub licznikowy; może być wykorzystywany w
rozkazach jako licznik wykonań - jest wówczas zmniejszany o 1 za
każdym wykonaniem i jego zawartość podlega badaniu, czy nie uległa
wyzerowaniu.
– DX
- rejestr danych, jako jedyny może być wykorzystywany do
adresowania obiektów w przestrzeni adresowej wej/wyj (portów) w
rozkazach wejścia/wyjścia, a także w rozkazach o argumentach lub
wynikach długości większej niż jedno słowo (np. rozkazy mnożenia lub
dzielenia).

Rejestry mikroprocesora
8086
• Szesnastobitowe rejestry ogólnego przeznaczenia
mogą być interpretowane jako pary rejestrów
ośmiobitowych stanowiących mniej i bardziej
znaczącą część rejestru szesnastobitowego.
• Identyfikator rejestru stanowiącego mniej znaczącą
część rejestru ogólnego kończy się na L, zaś
identyfikator rejestru stanowiącego bardziej
znaczącą część rejestru ogólnego kończy się na H.
• Argumentami rozkazów mogą być zarówno rejestry
ogólne jako całość, jak i ich ośmiobitowe części.
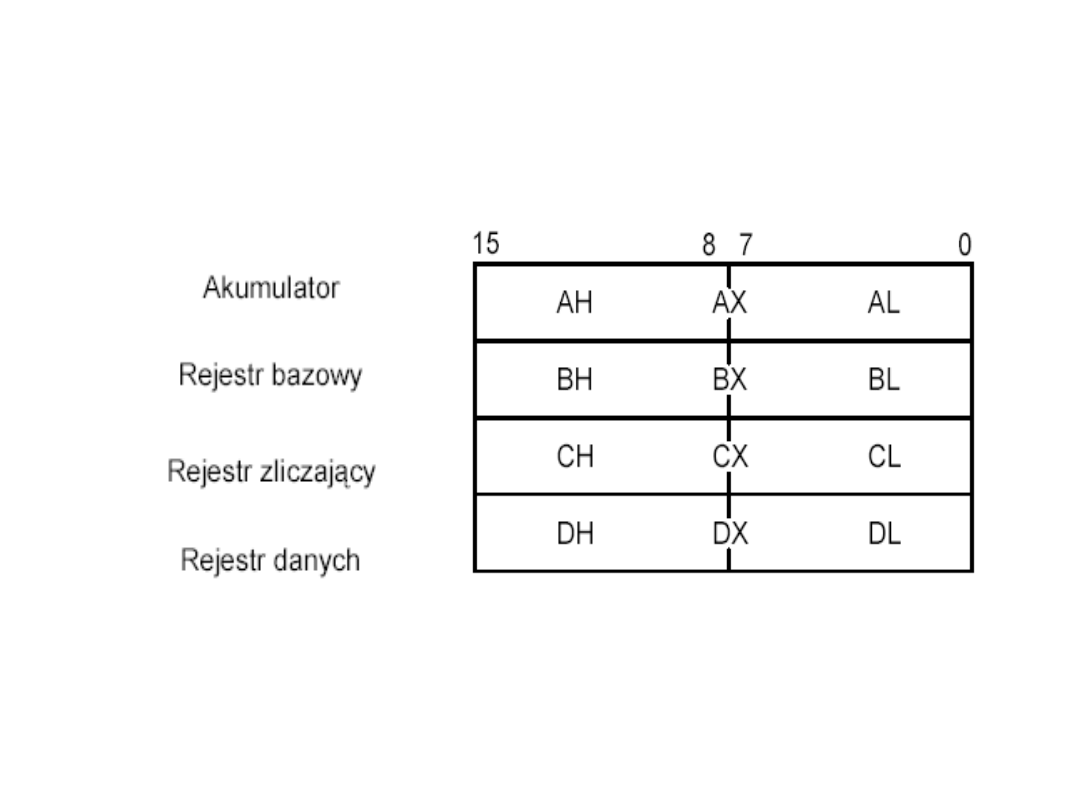
Rejestry ogólnego
przeznaczenia
mikroprocesora 8086
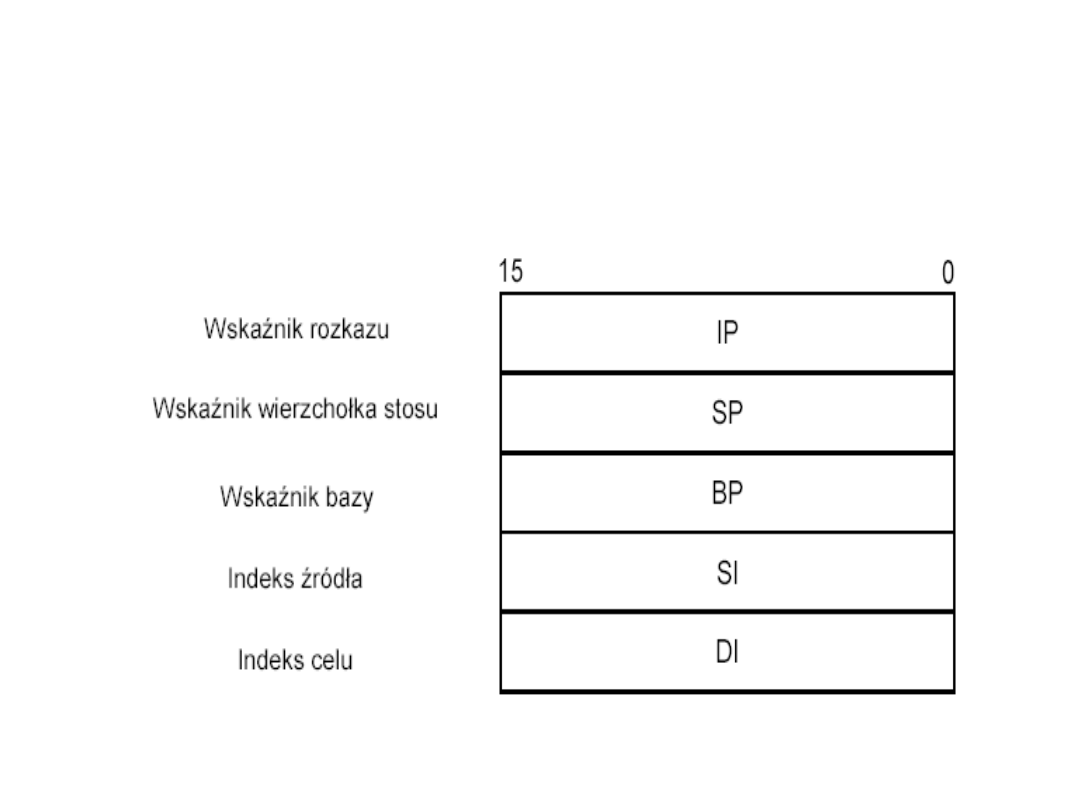
Rejestry adresowe
mikroprocesora 8086
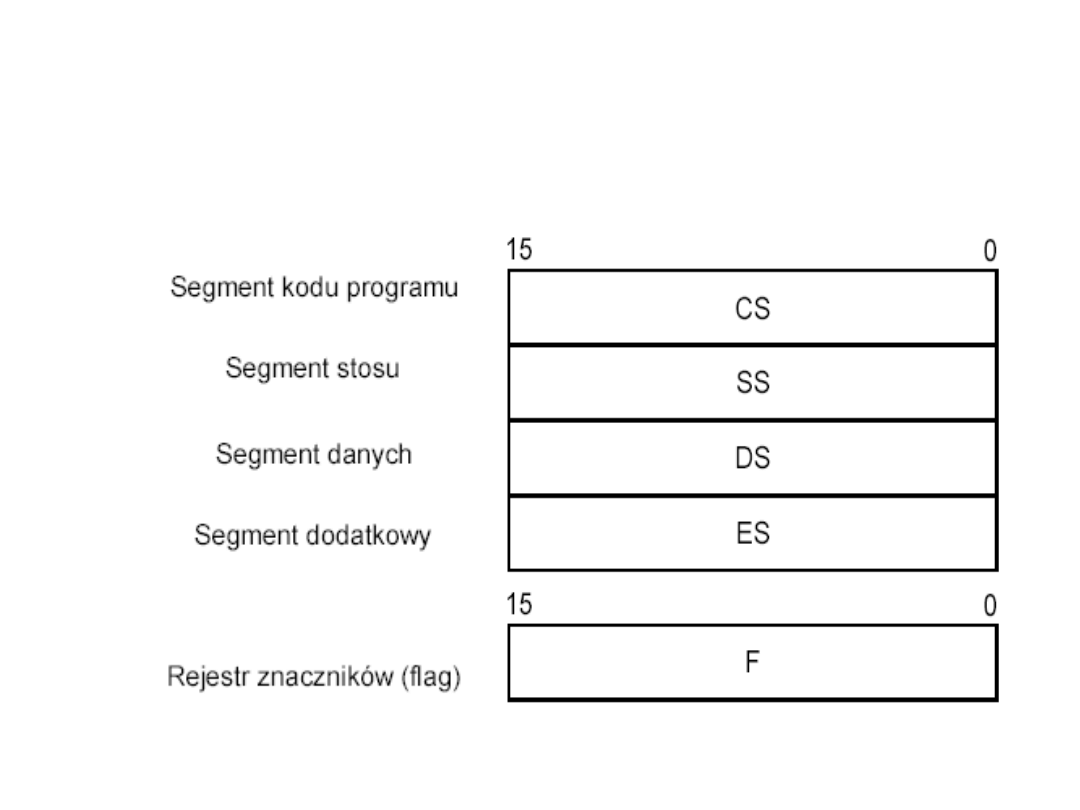
Rejestry segmentowe
mikroprocesora 8086
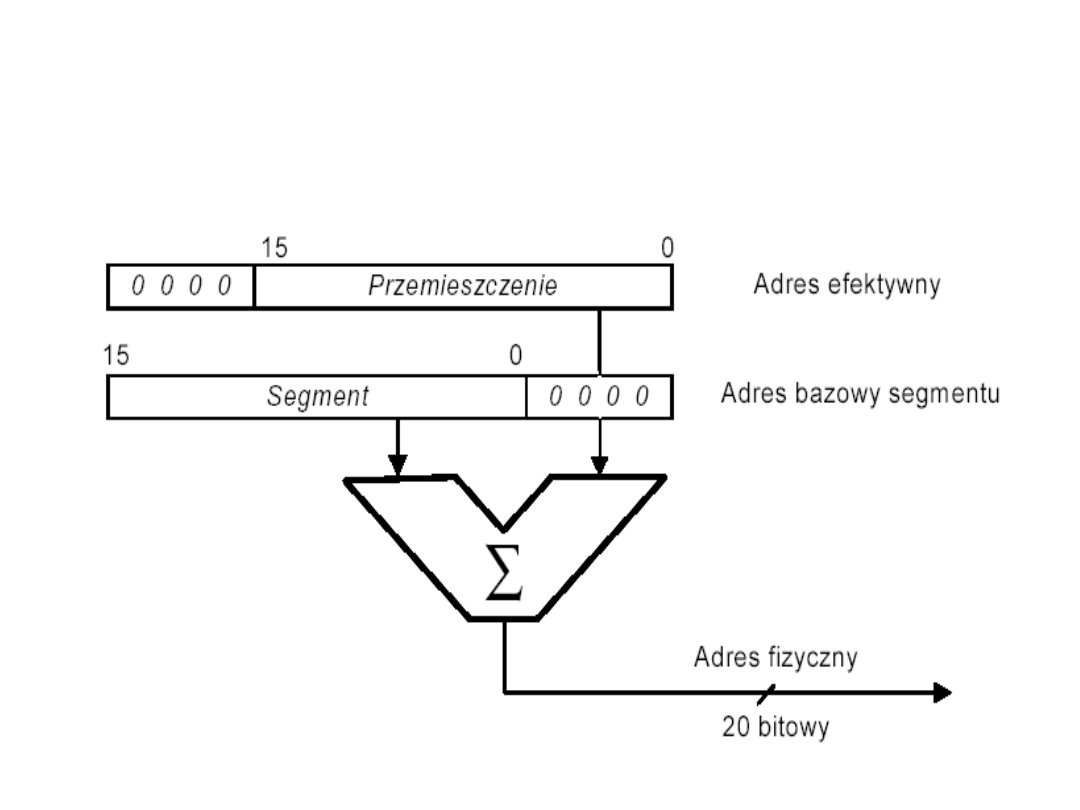
Wyznaczanie adresu fizycznego
RAM przez mikroprocesor
8086

Rejestry adresowe
• Rejestry adresowe, służące głównie do przechowywania adresów względnych
(
OFFSET
), chociaż mogą być też wykorzystywane jako rejestry robocze -
możliwości użycia ich zawartości jako argumentów rozkazów są tylko w
niewielkim stopniu ograniczone w porównaniu z rejestrami ogólnego
przeznaczenia:
– IP
- wskaźnik rozkazu (ang. instruction pointer), zawiera zawsze adres względny
(względem początku segmentu określonego przez zawartość rejestru CS)
aktualnie pobieranego do wykonania rozkazu, rejestr ten stanowi z punktu
widzenia programisty (wraz z rejestrem CS) część licznika rozkazów; rejestr IP nie
może być zmieniany przez program.
– SP
- wskaźnik wierzchołka stosu; zwykle zawiera adres względny (względem
początku segmentu określonego przez zawartość rejestru SS) wierzchołek stosu,
tzn. adres ostatniego słowa odłożonego na stosie; w przypadku pisania
programów przeznaczonych do pracy pod kontrolą systemu operacyjnego należy
rejestrem SP posługiwać się ze szczególną ostrożnością.
– BP
- rejestr wskaźnika bazy; zwykle zawiera adres względny (względem początku
segmentu określonego przez zawartość rejestru SS) parametrów odłożonych na
stosie (dla procedur w językach wysoko poziomowych); rejestr BP może być
wykorzystany także do innych celów.
– SI
- rejestr indeksu źródła (miejsca, z którego pobierane są dane w operacjach
przesyłania danych); zwykle zawiera adres danych względem początku segmentu
określonego zawartością rejestru DS; rejestr SI wykorzystywany jest do tzw.
adresowania indeksowego oraz w rozkazach łańcuchowych (operacjach na
ciągach znaków), może też być wykorzystany do innych celów.
– DI
- rejestr indeksu celu; zwykle zawiera adres danych względem początku
segmentu określonego zawartością rejestru DS; rejestr DI wykorzystywany jest do
tzw. adresowania indeksowego oraz w rozkazach łańcuchowych – w tym
przypadku jednak zawiera adres względem początku segmentu określonego
zawartością rejestru ES, może też być wykorzystany do innych celów.

Rejestry segmentowe
•
Rejestry segmentowe
służą do przechowywania wartości
(
SEGMENT
) określających adresy początkowe segmentów przy
odwołaniach do pamięci:
– CS
- rejestr segmentu kodu programu określa adres początku segmentu
używany w przypadku wszystkich dostępów do pamięci z adresowaniem
względnym za pomocą rejestru IP, tzn. pobierania rozkazów. Z punktu
widzenia programisty rejestr CS razem z rejestrem IP tworzy licznik
rozkazów mikroprocesora 8086 (CS:IP).
– SS
- rejestr segmentu stosu programu określa adres początku segmentu
używany w przypadku wszystkich dostępów do pamięci z adresowaniem
względnym za pomocą rejestru SP lub BP, jeśli zadano wykorzystanie
tego rejestru, tzn. BP specjalnym rozkazem.
– DS
- rejestr segmentu danych określa adres początku segmentu
używany w przypadku wszystkich dostępów do pamięci danych (np. za
pomocą rejestrów BX, SI, DI lub za pomocą adresu podanego
bezpośrednio w rozkazie).
– ES
- rejestr segmentu danych określa adres początku segmentu
używany w przypadku wszystkich dostępów do pamięci danych w
rozkazach łańcuchowych - działania na ciągach adresowanych za
pomocą rejestru DI.
•
Rejestry segmentowe mogą być argumentami wyłącznie
rozkazów przesłania MOV, PUSH i POP
.
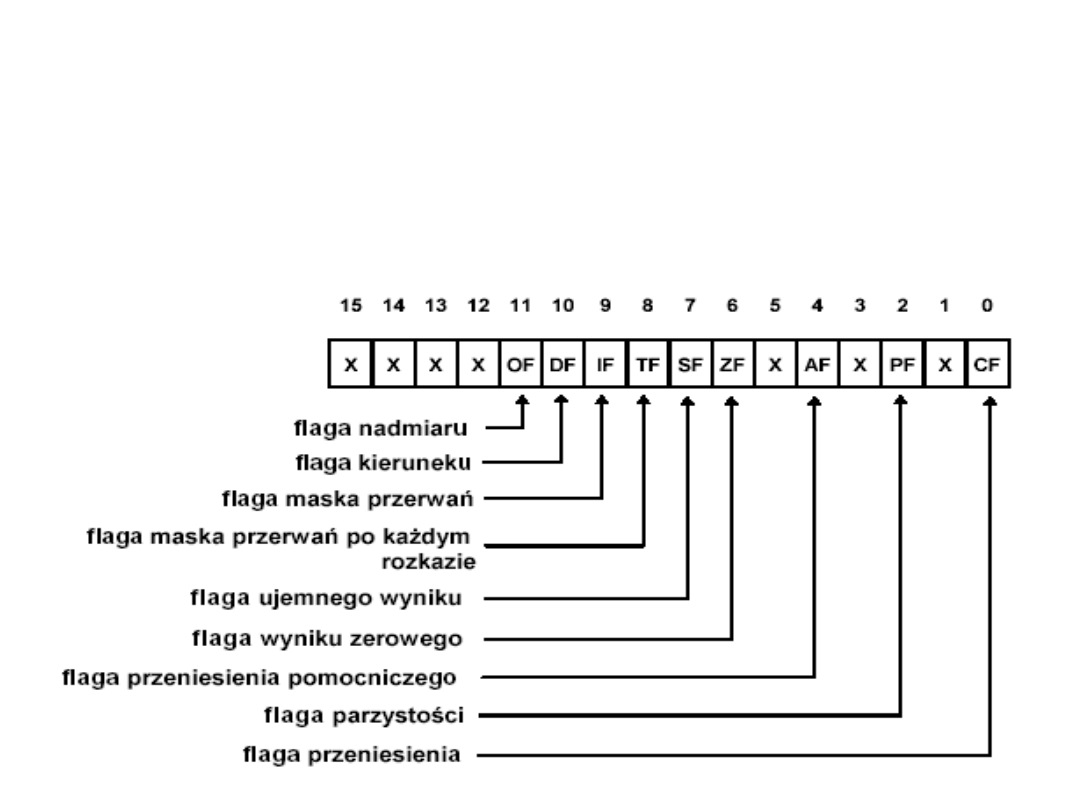
Rejestr znaczników (flag)
F
• Rejestr znaczników F jest konstrukcją składającą się z ciągu
jednobitowych rejestrów określających stan procesora. Rejestr
znaczników (flag) zawiera tzw. słowo stanu. Słowo stanu ma postać
jak na poniższym rysunku

Przykładowe funkcjonalności
flag
• SF
(bit 7) - flaga znaku (ujemnego wyniku),
zmieniany rozkazami arytmetycznymi i
logicznymi;
• ZF
(bit 6) - flaga zera wyniku, zmieniany
rozkazami arytmetycznymi i logicznymi;
• AF
(bit 4) - flaga przeniesienia
pomocniczego (z bitu 3 na 4) ustawiany na
potrzeby rozkazów arytmetyki dziesiętnej.
• PF
(bit 2) - flaga parzystej liczby jedynek w
zapisie binarnym wyniku, zmieniany
rozkazami arytmetycznymi i logicznymi;

Bity rejestru F dzielą się na
dwie grupy
1. Flagi określające sposób działania procesora:
–
TF
(bit 8) - powoduje (wartość 1) przerwanie nr. 3, z jednoczesnym
zgaszeniem TF, po wykonaniu jednego rozkazu - wykorzystywany
przez specjalistyczne oprogramowanie uruchomieniowe;
–
IF
(bit 9) - zezwala (wartość 1) na przyjmowanie przerwań
zewnętrznych; wyzerowanie tego bitu powoduje zablokowanie
przyjmowania przerwań zewnętrznych, poza tzw. przerwaniem
niemaskowalnym (NMI);
–
DF
(bit 10) - określa czy zawartości rejestrów SI i DI w trakcie
wykonywania rozkazów łańcuchowych mają być zwiększane (DF=0),
czy zmniejszane (DF=1).
2. Flagi ustawiane w wyniku wykonywania różnych rozkazów:
–
CF
(bit 0) - wskaźnik przeniesienia globalnego, zmieniany rozkazami
arytmetycznymi i przesunięć, zerowany rozkazami logicznymi;
–
OF
(bit 11) - wskaźnik nadmiaru, zmieniany rozkazami
arytmetycznymi i zerowany rozkazami logicznymi; OF jest zmieniany
również w rozkazach przesunięć, których drugi argument jest równy 1.
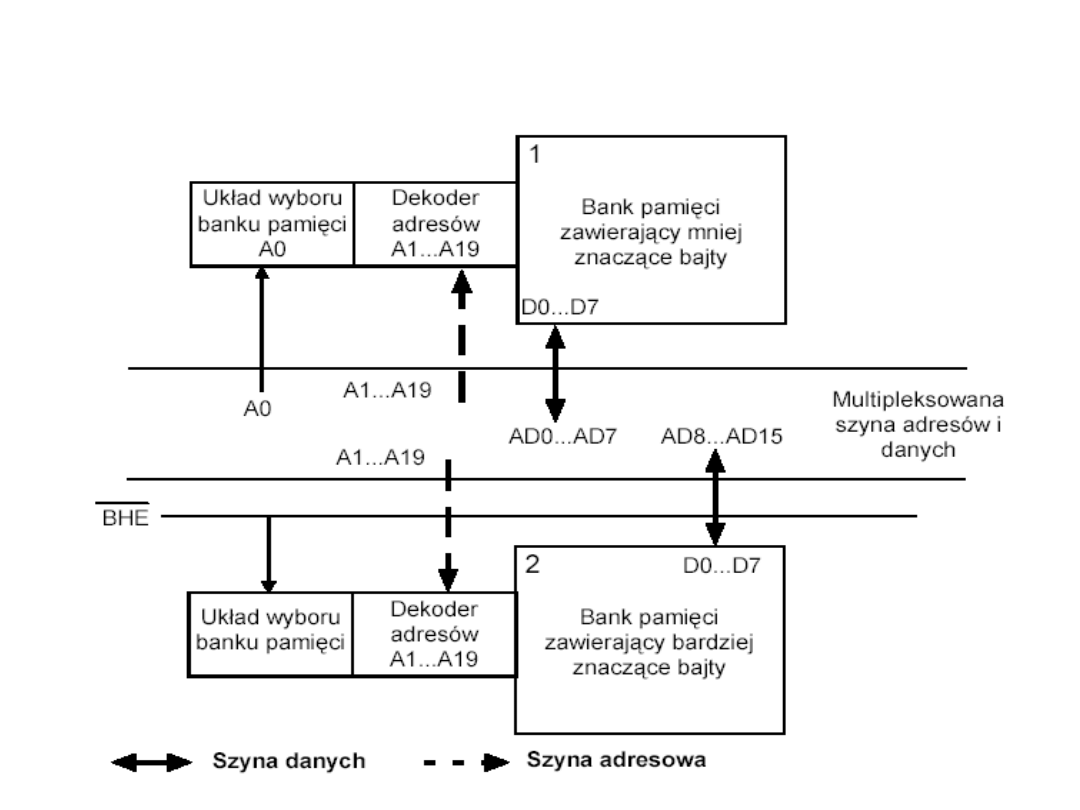
Organizacja pamięci dla 8086
Organizacja procesora Intel
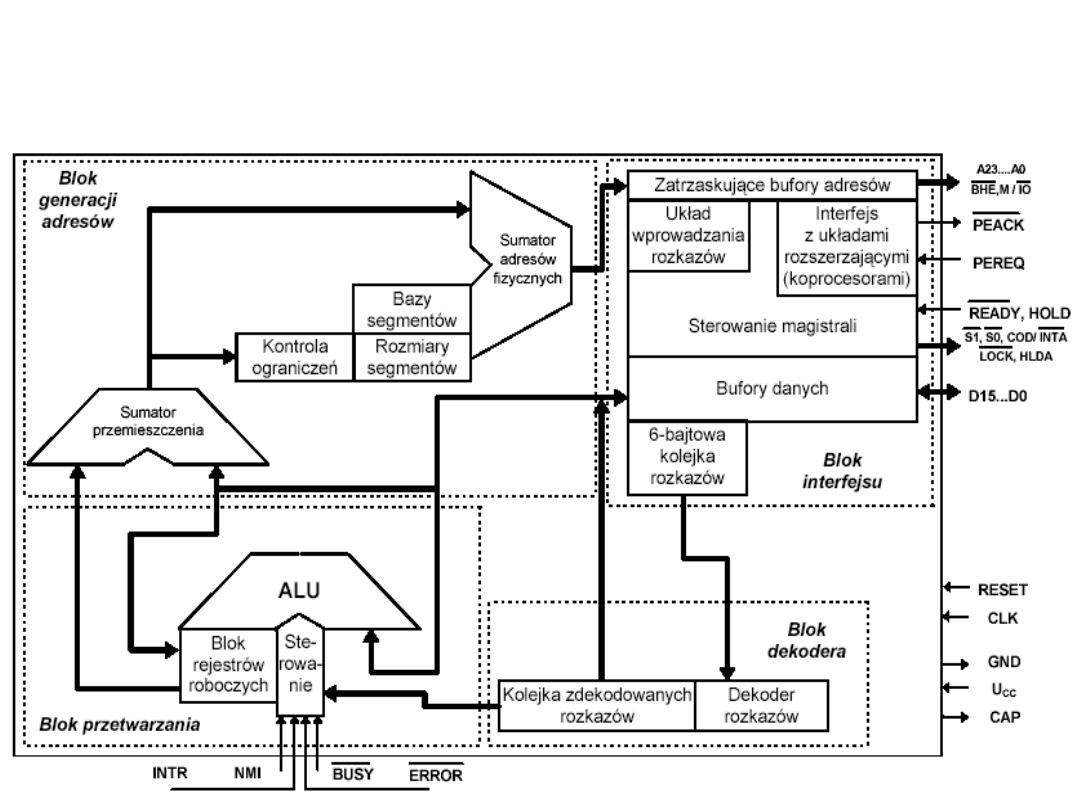
80286
Organizacja procesora Intel
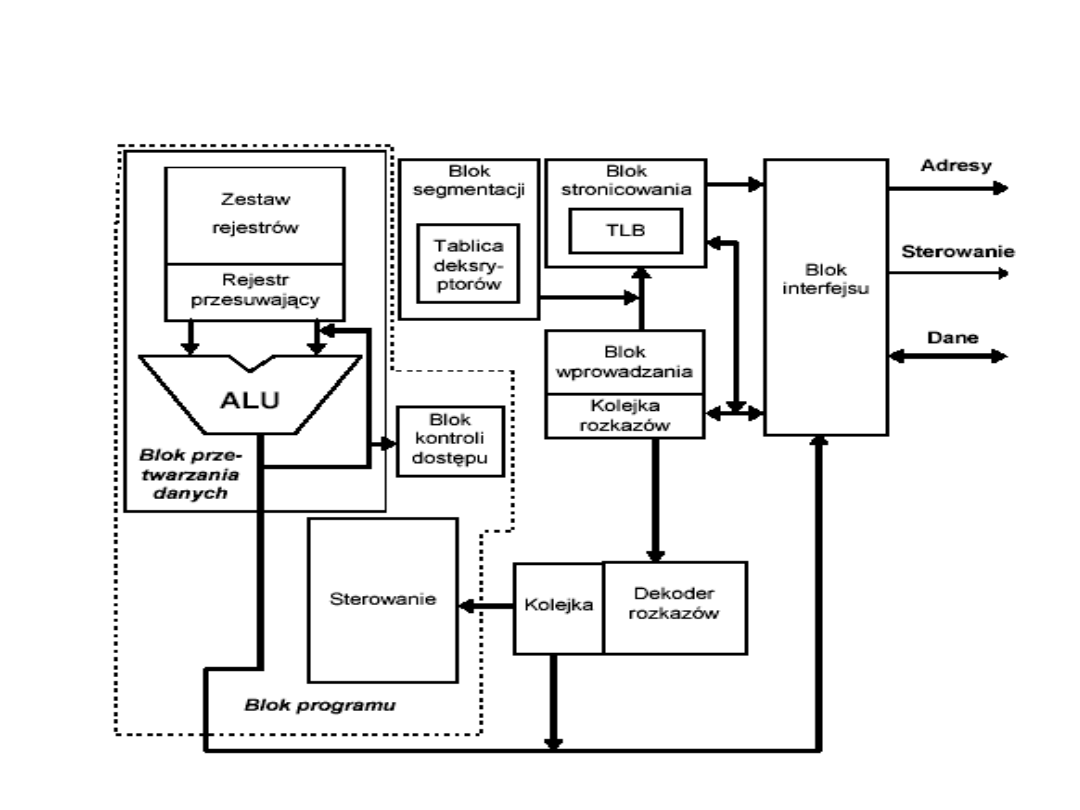
80386
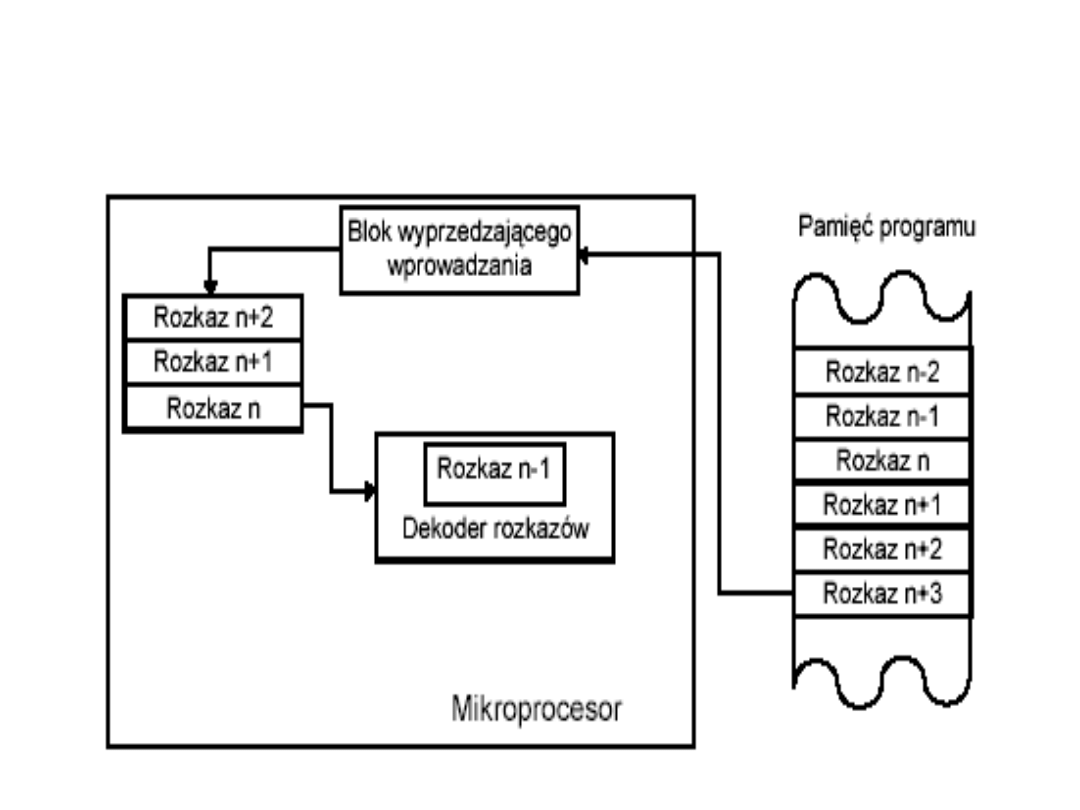
Mechanizm wyprzedzającego
wprowadzania kodów
rozkazów
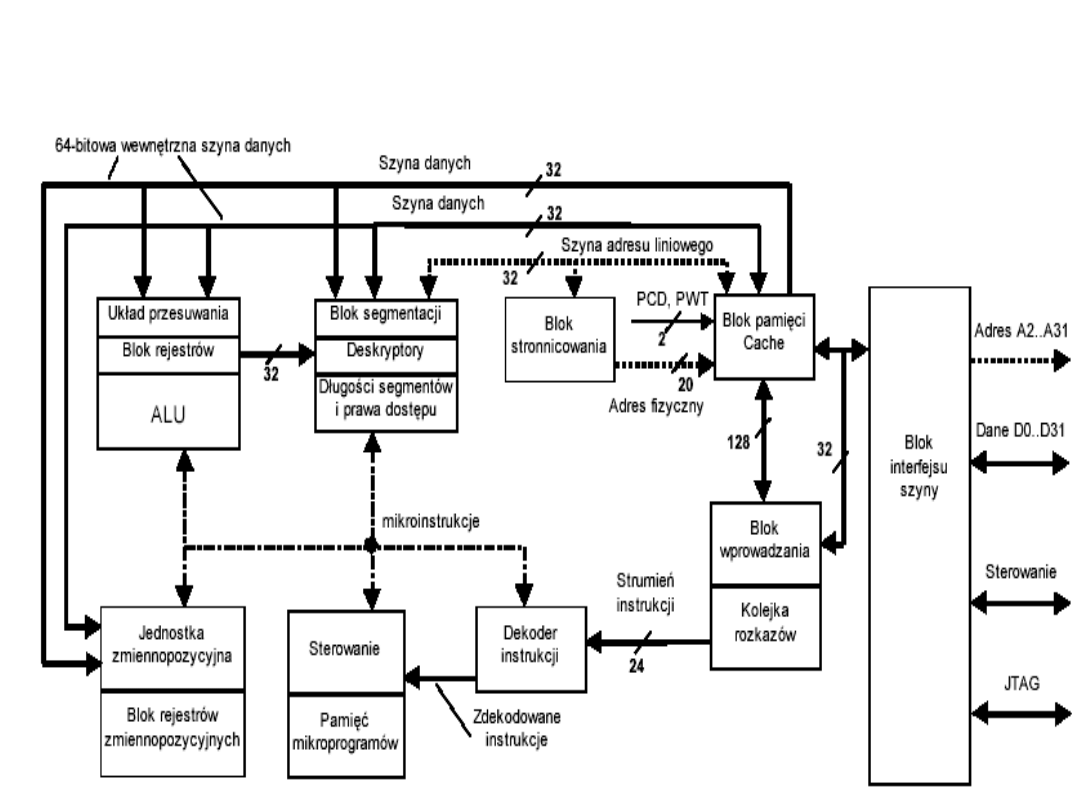
Organizacja procesora Intel
80486
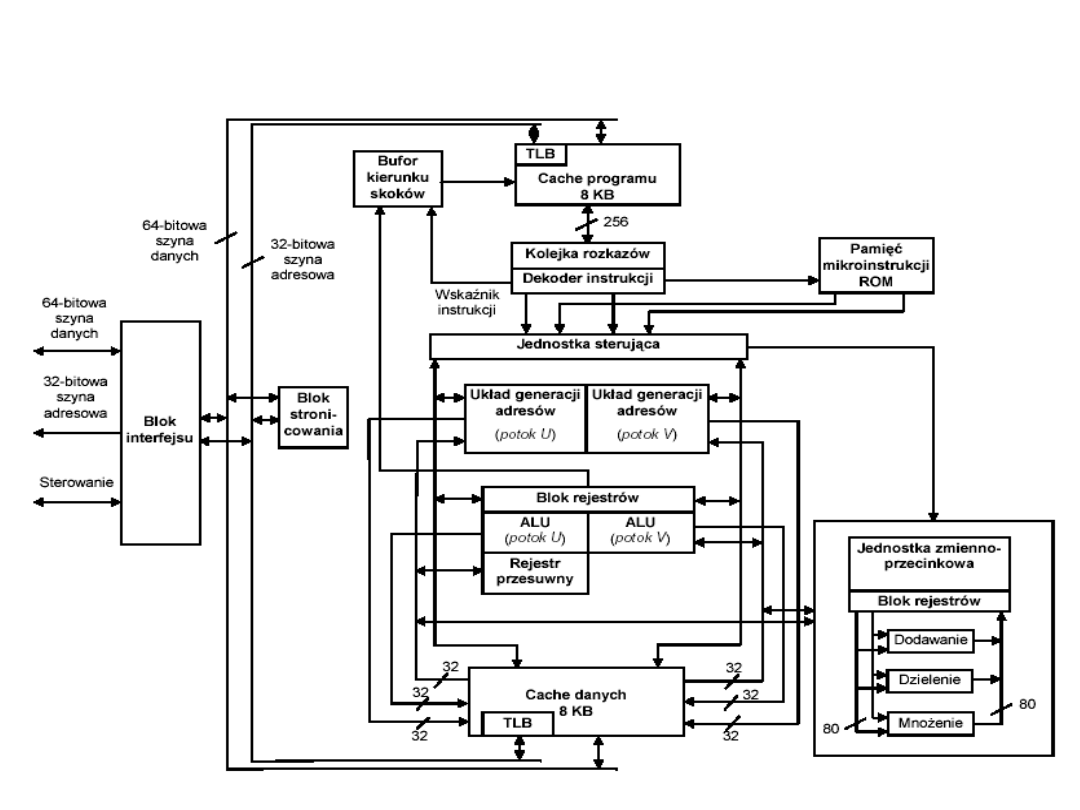
Organizacja procesora
Pentium
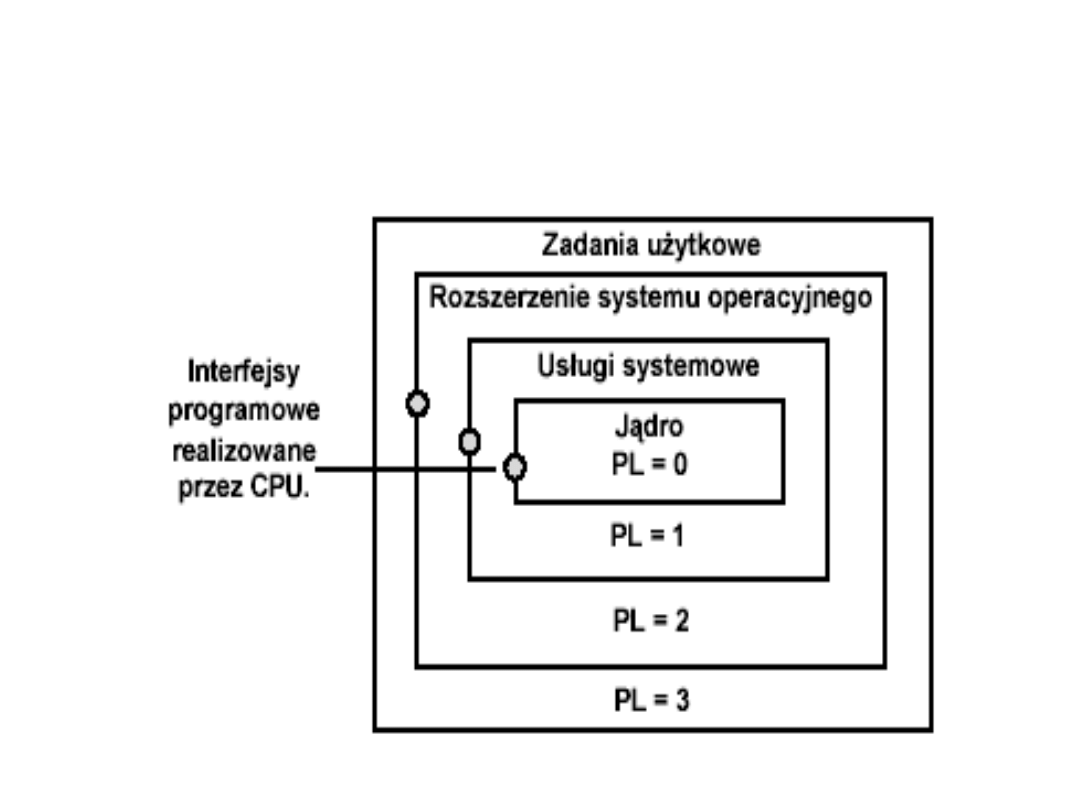
Hierarchia poziomów
uprzywilejowania programów

Rejestry procesora
Pentium
• Rejestry ogólnego przeznaczenia
(rejestry robocze)
- osiem 32-bitowych rejestrów ogólnego przeznaczenia;
• Rejestry segmentowe
- sześć 16-bitowych rejestrów
segmentowych zawiera selektory segmentu służące
jako indeksy w tablicach segmentów.
• Rejestr flag stanu
- rejestr EFLAGS zawiera kody
warunkowe
i różne bity trybu pracy.
• Rejestr wskaźnika rozkazu
- zawiera adres bieżącego
rozkazu.
• Rejestry do współpracy z jednostką
zmiennoprzecinkową:
– Rejestry numeryczne
– osiem rejestrów 80-bitowych,
dostępnych jako stos;
– Rejestr sterowania
ALU – 16-bitowy rejestr sterowania;
– Rejestr stanu
.
• Rejestry sterowania
– cztery 32-bitowe.

Rejestry sterowania
• Procesor Pentium wykorzystuje cztery 32-bitowe rejestry
sterowania CR0, CR2,CR3, CR4.
• Rejestr CR0 zawiera flagi sterowania systemowego, które
sterują trybami lub wskazują stany odnoszące się raczej do
procesora niż do wykonywanego programu. Są to następujące
flagi:
– Zezwolenie ochrony (PE). Włącza lub blokuje tryb chroniony.
– Monitorowanie koprocesora (MP).
– Emulacja (EM). Ustawiany, gdy procesor nie ma jednostki
zmiennopozycyjnej.
– Błąd numeryczny (NE). Umożliwia standardowy mechanizm zgłaszania
błędów zmiennopozycyjnych na zewnętrznych liniach danych.
– Ochrona zapisu (WP). Gdy ten bit jest zerem, strony tylko do odczytu na
poziomie uprzywilejowania użytkownika mogą być zapisane przez
program nadzorczy (SO).
– Brak zapisu jednoczesnego (NW). Wybiera tryb pracy pamięci podręcznej
danych. Gdy bit ten jest ustawiony, operacje zapisu jednoczesnego
pamięci podręcznej są zablokowane.
– Blokowanie pamięci podręcznej (CD). Włącza lub blokuje mechanizm
zapełniania wewnętrznej pamięci podręcznej.

Rejestry sterowania
• Rejestr CR2
służy do przechowania 32-bitowego adresu
liniowego ostatniej strony, która spowodowała błąd strony.
• Rejestr CR3
(20 bardziej znaczących bitów) – adres
podstawowego katalogu stron.
• W
rejestrze CR4
jest zdefiniowanych 6 dodatkowych bitów
kontrolnych.
Układy
wejścia -
wyjścia

Techniki przyśpieszania
procesora
•
Pipelining
(potokowe przetwarzanie danych)
•
Dynamic Execution
–
mechanizm prognozowania rozgałęzień,
–
analiza przepływu danych,
–
spekulacyjne wykonywanie rozkazów.
•
Translation Look-side Buffer
(bufor translacji adresów)
•
Branch Target Buffer
(algorytmy śledzenia zmian
zawartości pamięci podręcznej programu i prognozowania
skoków - opierając się na dotychczasowej historii skoków)
•
Loop Buffer
(bufor pętli)
•
Data Forwarding
(przekazanie danych odczytanych z
pamięci na żądanie jednej instrukcji wszystkim
instrukcjom, które ich żądają - a są przetwarzane w
innych potokach)

Potokowe przetwarzanie
danych (Pipelining)
•
Pipelining
pozwala procesorowi na rozbicie
pojedynczego rozkazu na kilka-kilkanaście części
(etapów), które są następnie przetwarzane potokowo
niczym na taśmie produkcyjnej.
•
Im więcej etapów, tym na pojedynczy etap przypada
mniejszy zakres zadań i może zostać zastosowana
większa częstotliwość taktowania.
•
Każde z typów zadań ma przydzieloną oddzielną
jednostkę do jego wykonywania.
•
Każda jednostka rozwiązuje tylko jeden, określony
typ zadań i wyniki przekazuje do następnego etapu.
•
W rezultacie uzyskuje się wzrost prędkości roboczej
procesora.

Super-skalarność
• Super skalarnymi procesorami
, nazywamy procesory
które są wyposażone w więcej niż jeden potok.
• Procesor przydziela realizację określonych instrukcji
wolnemu w danym momencie potokowi, przy
jednoczesnym usuwaniu zależności pomiędzy
poszczególnymi instrukcjami, aby uniknąć zbędnego
oczekiwania.
• W wyniku tego żaden z rozkazów znajdujących się w
potoku nie musi oczekiwać na wynik realizacji rozkazu
w innym potoku i wstrzymywać przetwarzania
pozostałych poleceń.

Dynamiczne wykonywanie
rozkazów (Dynamic
Execution)
• Pod pojęciem dynamicznego
wykonywania rozkazów kryje się
kombinacja trzech technik, które łącznie
po raz pierwszy zastosowana w Pentium
Pro, dzięki którym procesor ten osiągnął
znaczny wzrost wydajności.
• Są to:
– mechanizm prognozowania rozgałęzień
,
– analiza przepływu danych
,
– spekulacyjne wykonywanie rozkazów
.

Mechanizm prognozowania
rozgałęzień
• Zadaniem mechanizmu prognozowania rozgałęzień -
jest przewidywanie miejsca gdzie nastąpi skok po
wykonaniu rozkazu warunkowego.
• Działanie mechanizmu polega na porównywaniu i
analizie sekwencji rozkazów w poszczególnych etapach
potoku.
• Dzięki czemu jest on wstanie z dużym
prawdopodobieństwem określić, które rozgałęzienie
zostanie wybrane oraz która sekwencja rozkazów
będzie przetwarzana jako kolejna, po czym kontynuuje
wykonywanie programu od tego miejsca.
• Efektywność tego mechanizmu w praktyce sięga 90%.

Analiza przepływu danych
•
Jest to jeden z mechanizmów zaliczanych do
dynamicznego wykonywania rozkazów w
procesorze.
•
Polega na analizie i ustalaniu optymalnej
kolejności wykonywania instrukcji.
•
Analizując przepływające dane procesor
sprawdza i określa, czy kolejne rozkazy są
dostępne i czy mogą być wykonane, tzn. czy ich
realizacja nie jest zależna od wyników aktualnie
wykonywanych rozkazów.

Spekulacyjne wykonywanie
rozkazów (Speculation
Execution)
• Spekulacyjne wykonywanie rozkazów
jest
mechanizmem, który pozwala rozpocząć
wykonywanie rozkazu wcześniej, niż to wynika z
normalnej sekwencji rozkazów.
• Procesor wykonuje następne rozkazy, mimo że
czeka na wynik realizowanej równolegle instrukcji
skoku. Jeśli za pomocą mechanizmu prognozowania
skoków, procesor prawidłowo ocenił adres skoku,
przyjęta spekulacyjnie koncepcja jest właściwa i
przynosi w efekcie duży wzrost wydajności.
• Wyniki przetwarzania spekulacyjnego są
przetrzymywane chwilowo w buforze
ROB
(
Re-
Order Buffer
).

Bufor translacji adresów
TLB (Translation Look-
side Buffer)
• Bufor translacji adresów TLB
jest elementem pamięci
podręcznej, w którym przechowywane są ostatnio
używane odwołania do tablicy pamięci podręcznej.
• TLB
używany jest do przyspieszenia wyznaczania
adresu fizycznego pamięci.
• Jeżeli odwołanie do pamięci wykorzystuje informację
zawartą w
TLB
to czas translacji adresu wynosi tylko
pół taktu zegara.
• Łączny czas przetwarzania adresu logicznego na
fizyczny
(wyliczenie adresu efektywnego, segmentacja
i stronicowanie)
zajmuje wówczas 2 takty zegara
.
• Procesor ma zwykle dwa bufory tego typu
: jeden dla
pamięci podręcznej danych, drugi dla pamięci
podręcznej rozkazów.

Bufor rozgałęzień BTB
(Branch target buffer)
• Bufor rozgałęzień BTB
jest pamięcią
skojarzeniowa o niewielkiej pojemności (zwykle
128-512 pozycji) będąca elementem mechanizmu
prognozowania rozgałęzień, której zadaniem jest
prognozowanie skoków w programie.
• Wykorzystując złożone algorytmy śledzi ona
zawartość pamięci podręcznej programu i
wskazuje, opierając się na historii skoków, który
rozkaz powinien być pobrany w następnej
kolejności.

Przekazywanie danych
(Data forwarding)
• Przekazywanie danych jest mechanizmem, którego
działanie polega na przekazaniu danych odczytanych
z pamięci na żądanie jednej instrukcji wszystkim
instrukcjom, które ich zażądają - a są przetwarzane w
innych potokach.
• Przekazaniem danych steruje procesor.
• Dzięki niemu uzyskuje się dane dla kilku instrukcji,
przy jednokrotnym dostępie do pamięci.
• Mechanizm ten realizuje również czynność
przekazania wyniku operacji z jednego potoku do
instrukcji przetwarzanej w drugim potoku w sposób
bezpośredni, tzn. bez zapisu do pamięci czy rejestrów.
• Mechanizm ten może być stosowany w procesorach
super-skalarnych.

Wzór na wydajność
procesora
• Wydajność procesora jest określona formułą:
czas /zadanie =
(czas /takt) x (takty /rozkaz) x (rozkazy /zadanie) = C
x T x R
• gdzie
– C
: czas przypadający na takt zegarowy,
– T
: liczba taktów zegarowych na rozkaz,
– R
: liczba rozkazów na zadanie
• Zwiększenie wydajności procesora może być
osiągnięte przez
zmniejszenie dowolnego z tych
czynników
, przy czym iloczyn dwóch pierwszych czyli
C x T
jest nazywany czasem trwania cyklu
rozkazowego.

Zwiększanie wydajności
procesorów
• Czynniki
C
,
T
i
R
są od siebie zależne:
– Zwiększenie częstotliwości generatora zegarowego
(zmniejszenie czasu taktu
C
) powoduje zmniejszenie liczby
operacji elementarnych, jakie mogą być wykonane w
jednym takcie przy danej technologii i architekturze.
– To z kolei powoduje zwiększenie liczby taktów dla realizacji
rozkazu.
• W klasycznych procesorach,
CISC
(Complex
Instruction Set Computer) czas trwania taktu jest
dobierany tak, aby w okresie jego trwania było
możliwe wykonanie operacji elementarnej.
• Prostsze rozkazy, składające się z mniejszej liczby
operacji elementarnych będą wymagały mniejszej
liczby taktów, bardziej złożone – więcej.

Liczba taktów na rozkaz
• Zmniejszenie liczby taktów zegarowych w cyklu rozkazowym
prowadzi na ogół do wydłużenia taktu zegarowego.
• Metodą, pozwalającą na zmniejszenie
średniej
liczby taktów
na rozkaz bez wydłużania taktu zegarowego (czyli nie „więcej
krótkich albo mniej długich”, ale mniej krótkich) jest metoda
strumieniowego wykonywania rozkazów, tzw.
pipelining
processing
.
• Jeśli cały proces przetwarzania rozkazu podzielić na prostsze
fazy, które mogą być
niezależnie
wykonywane przez różne
podzespoły, to wydajność procesu się zwiększy.
• Istotą takiego sposobu przetwarzania jest
obecność w
procesorze kilku rozkazów w różnych fazach przetwarzania
,
maksymalnie tylu, ile jest niezależnych elementów
przetwarzających.
• Czas przetwarzania pojedynczego rozkazu nie zmienia się
w
porównaniu z indywidualnym przetwarzaniem każdego
rozkazu, ale
„gotowe” rozkazy pojawiają się na wyjściu z
większą częstotliwością
.
• Zwiększa się więc średnia liczba przetwarzanych rozkazów w
jednostce czasu.
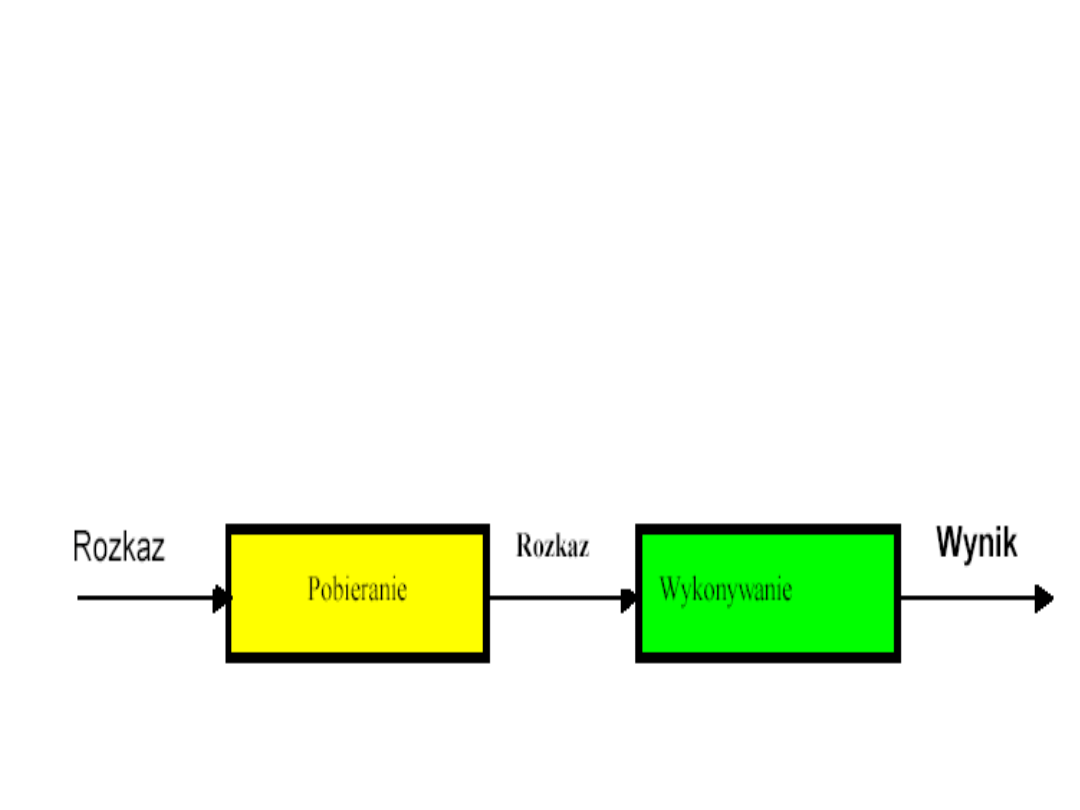
Przetwarzanie potokowe
schemat prosty
• Rozpatrzymy prosty podział przetwarzania rozkazu na dwa etapy:
– pobranie rozkazu,
– dekodowanie rozkazu.
• Potok przebiega na 2 niezależnych etapach (dwa stanowiska
obsługi):
– pobranie i zbuforowanie rozkazu,
– wykonywanie rozkazu.
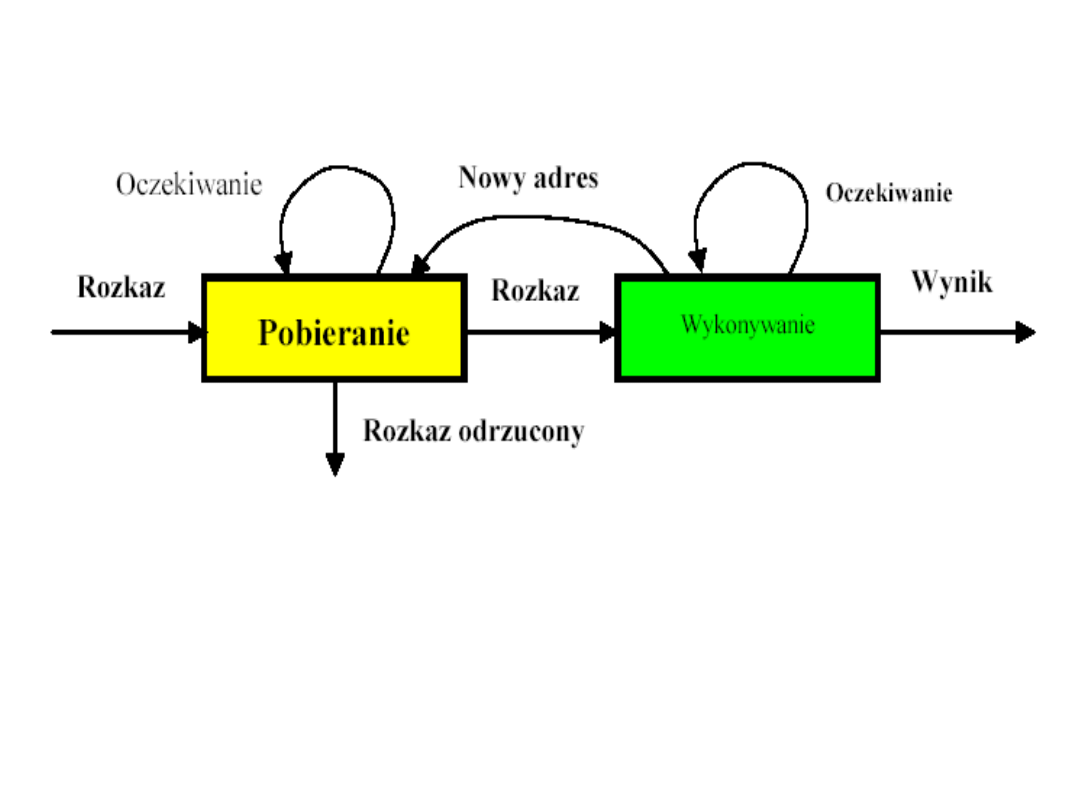
Przetwarzanie potokowe
schemat rozszerzony
• Czas wykonywania jest na ogół dłuższy niż czas pobierania.
• Rozkaz skoku warunkowego powoduje, że adres następnego
rozkazu przewidzianego do pobrania jest nieznany.
• Wobec tego realizacja etapu pobierania może nastąpić dopiero
po otrzymaniu adresu następnego rozkazu, który zostanie
określony po zakończeniu etapu wykonywania.

Przetwarzanie potokowe
• Strata czasu z powodu wystąpienia rozkazu
skoku warunkowego - może być zmniejszona
przez proste zgadywanie.
• Gdy rozkaz rozgałęzienia warunkowego
przechodzi z etapu pobierania do etapu
wykonywania, na etapie pobierania następuje
pobranie następnego rozkazu z pamięci (po
rozkazie rozgałęzienia).
• Jeśli nie nastąpi rozgałęzienie, czas nie jest
stracony. Gdy jednak rozgałęzienie nastąpi,
pobrany rozkaz musi być usunięty, a pobrany
nowy.
• Kluczowym zagadnieniem w organizacji
potokowego przetwarzania rozkazów jest
podział
cyklu rozkazowego na fazy
. Minimalnie liczba faz
wynosi 4, a niekiedy jest ich kilkanaście

Podział cyklu rozkazowego na
4 fazy
• Fetch
: faza pobrania rozkazów z RAM do wewnętrznego
rejestru rozkazów lub wewnętrznej kolejki rozkazów,
umieszczonej w pamięci
cache
instrukcji;
• Decode
: faza dekodowania rozkazów, w czasie której
następuje dekodowanie rozkazu i ustalane jest połączenie
arytmometru z rejestrami, zawierającymi argumenty.
Niekiedy do tej fazy zalicza się także pobranie
argumentów z rejestrów uniwersalnych do rejestrów
roboczych arytmometru;
• Execute
: faza wykonania rozkazu. W przypadku rozkazów
arytmetyczno-logicznych, w arytmometrze wykonywana
jest operacja, ustalona na podstawie kodu rozkazu. W
przypadku rozkazów komunikacji z pamięcią w fazie tej
jest obliczany adres fizyczny argumentu. Niekiedy faza ta
może trwać więcej niż jeden takt zegarowy.
• Write
: faza zapisu wyniku. W przypadku rozkazu
arytmetyczno / logicznego wynik operacji zapisywany jest
w docelowym rejestrze uniwersalnym, dla rozkazów
komunikacji z RAM realizowany jest cykl odczytu / zapisu.

Podział cyklu rozkazowego
na 6 faz
•
Pobranie rozkazu FI
– wczytanie następnego spodziewanego
rozkazu do bufora;
•
Dekodowanie rozkazu DI
– określenie kodu operacji i
specyfikatorów argumentów;
•
Obliczanie argumentów CO
– obliczanie efektywnego adresu
każdego argumentu źródłowego (może to obejmować
obliczenie adresu z przesunięciem, adresu rejestrowego
pośredniego, adresu pośredniego lub innych form);
•
Pobieranie argumentów FO
– pobranie każdego argumentu
z pamięci (argumenty z rejestrów nie muszą być
pobierane);
•
Wykonanie rozkazu EI
– wykonanie wskazanej operacji i
czasowe przechowanie wyniku, jeśli taki jest, w ustalonym
rejestrze;
•
Zapisanie argumentu WO
– zapisanie wyniku w pamięci.

Kolejne fazy realizacji 3
rozkazów
•
Proces przetwarzania potokowego będzie najbardziej
efektywny, jeśli wszystkie fazy będą miały taki sam
czas trwania, który może być przyjęty jako czas
taktu zegarowego.
•
Przetwarzanie sekwencyjne (skalarne) - w
obserwowanym czasie zostaną wykonane 3 rozkazy.
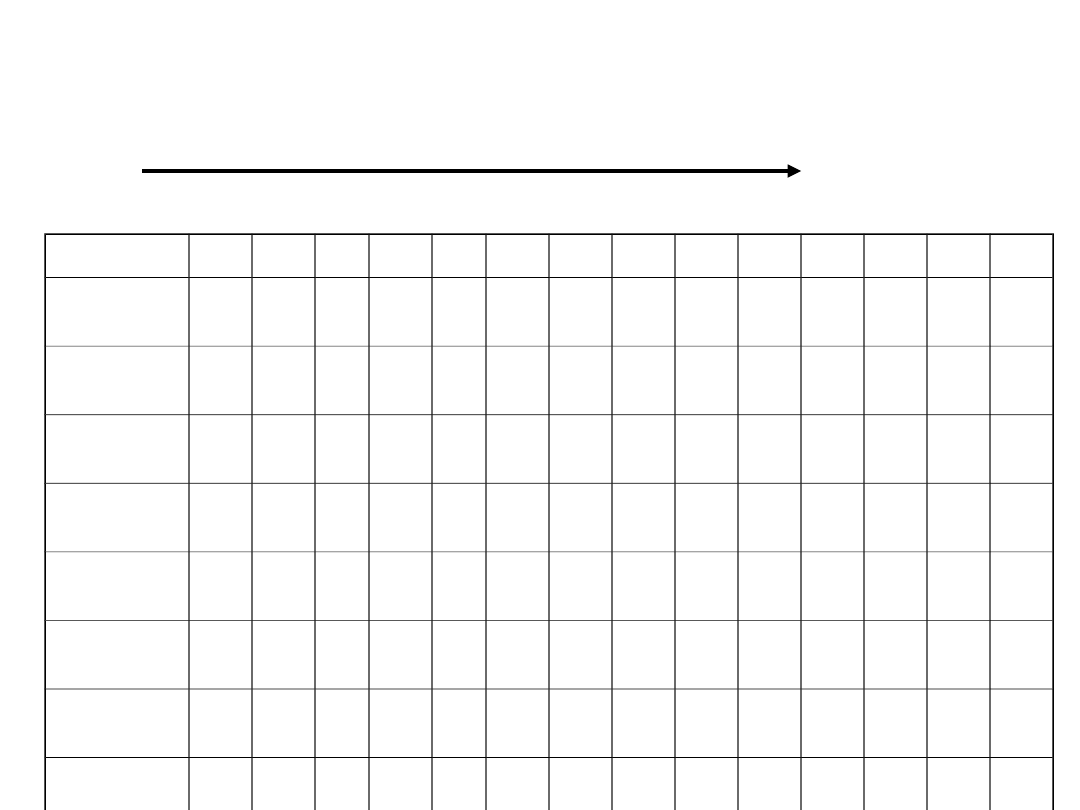
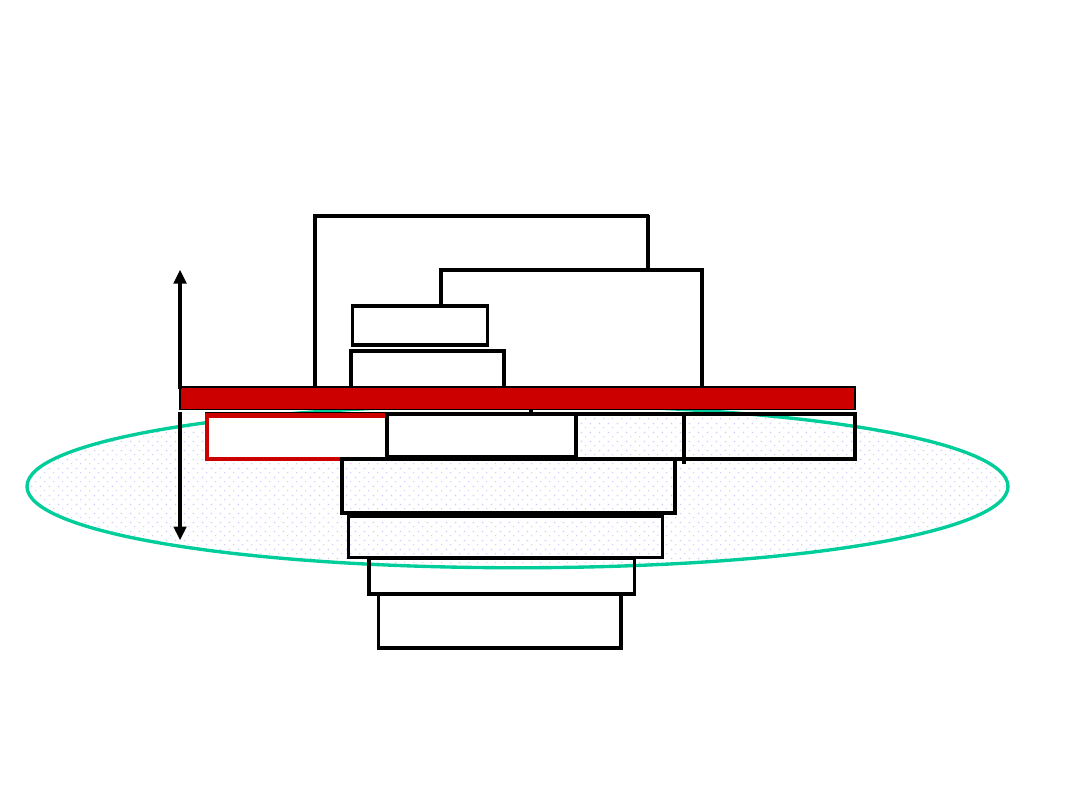
Kolejne fazy realizacji 9
rozkazów
1
2
3
4
5
6
7
8
9
10 11 12 13 14
Rozkaz 1
FI
DI
C
O
FO EI
W
O
Rozkaz 2
FI
DI CO F
O
EI
W
O
Rozkaz 3
FI
DI
C
O
FO EI
W
O
Rozkaz 4
FI
DI CO FO EI
W
O
Rozkaz 5
FI
DI
CO FO EI
W
O
Rozkaz 6
FI
DI
CO FO EI
W
O
Rozkaz 7
FI
DI
CO FO EI
W
O
Rozkaz 8
FI
DI
CO FO EI
W
O
Rozkaz 9
FI
DI
CO FO EI
W
O
Cza
s

Wpływ rozgałęzienia
warunkowego
na funkcjonowanie potoku
rozkazów
1
2
3
4
5
6
7
8
9
1
0
1
1
12 13 14
Rozkaz 1
FI
DI
C
O
FO EI
W
O
Rozkaz 2
FI
DI CO F
O
EI
W
O
Rozkaz 3
FI
DI
C
O
FO EI
W
O
Rozkaz 4
FI
DI CO FO
Rozkaz 5
FI
DI
CO
Rozkaz 6
FI
DI
Rozkaz 7
FI
Rozkaz
15
FI
DI C
O
F
O
EI
W
O
Rozkaz
16
FI
DI C
O
FO EI
W
O
Cza
s

Potok 9 rozkazów
• Przetwarzanie potokowe - w obserwowanym
czasie wykonanych zostanie 9 rozkazów, a 3
dalsze zostaną rozpoczęte.
• Proces przetwarzania rozpoczyna się tu od
momentu, gdy linia przetwarzania była pusta.
• Początkowo nie wszystkie fazy są obciążone,
stan ustalony rozpoczyna się dopiero od
wykonania rozkazu czwartego.
• W stanie ustalonym w czasie jednego cyklu
rozkazowego kończone są 4 rozkazy.

Efektywność potoku – a
liczba faz
• Można przyjąć, że maksymalna efektywność
przetwarzania potokowego wzrasta z krotnością, równą
liczbie faz. Średnia liczba taktów na rozkaz wynosi wtedy
jeden. Tak więc średni czas zakończenia rozkazu wynosi
wtedy 1 takt zegarowy.
• Należy podkreślić, że wynik tez uzyskuje się przy dwóch
bardzo ważnych w rzeczywistych systemach założeniach:
– Po pierwsze jednakowy czas trwania wszystkich faz równy jeden
takt,
– Po drugie brak konfliktów.
• Przy zastosowaniu środków, wprowadzających
nadmiarowości np. kilka takich samych zasobów, część
konfliktów zasobów można rozwiązać i uzyskać średni
rzeczywisty wynik, powyżej jednego zakończonego
rozkazu, na jeden takt zegara.

Przetwarzanie potokowe – a
indywidualne
W przetwarzaniu występują problemy nowe rodzaju:
• Elementy przetwarzające, pracujące na różnych warstwach
(stage tap, okres, stadium), mogą odwoływać się do tych
samych elementów architektury komputera.
• Jeśli elementy te są zajęte, dana faza przetwarzania musi
zostać wstrzymana, co powoduje wydłużenie czasu trwania
fazy.Dany element przetwarzający może rozpocząć swoją
pracę dopiero wtedy, gdy zakończył ją poprzednik, wobec
tego wydłużenie faz może się propagować na następne
warstwy.
• Wreszcie warunki pracy w potoku mogą być takie, że element
przetwarzający, który zakończył swoją pracę nad danym
rozkazem może rozpocząć przetwarzanie następnego dopiero
wtedy, gdy następca odbierze obsłużony obiekt.
• Wykonanie następnego rozkazu może też zależeć od wyników
rozkazu poprzedniego, który nie został jeszcze zakończony.
Zależność taka ma miejsce, gdy argumentem pewnego
rozkazu jest wynik rozkazu poprzedniego, lub gdy wykonanie
następnego rozkazu jest zależne od stanu flag, ustawionych
w rozkazie poprzednim - przypadek skoków warunkowych, od
których zależy wybór drogi wykonania programu.

Konflikty w przetwarzaniu
potokowym
• Konflikty, występujące w czasie przetwarzania
potokowego, muszą być rozstrzygane jak
najszybciej, a więc w sposób sprzętowy
• Konflikty te można je podzielić na 3 główne
kategorie:
– Konflikt zasobów
: ten sam zasób (np. arytmometr, rejestr
uniwersalny, magistrala lub pamięć) jest
wykorzystywany przez dwie lub więcej fazy
równocześnie. W co najmniej jednej z nich musi więc
wystąpić czas oczekiwania.
– Konflikt danych
: argumentem następnego rozkazu jest
rezultat poprzedniego, jeszcze nie zakończonego
– Konflikt sterowania
: rozkaz skoku warunkowego, zależny
od stanu wskaźników, ustawianych przez rozkaz
poprzedni.

Inne rodzaje konfliktów
przetwarzania
potokowego
•
Można wyróżnić jeszcze czwarty rodzaj konfliktów,
wynikający z faktu, że w trakcie wykonania każdego
rozkazu mogą powstać sytuacje wyjątkowe,
uniemożliwiające poprawne zakończenie rozkazu (np.
błędy adresacji czy dzielenie przez zero).
•
Sytuacje takie są zwykle obsługiwane w procesorze za
pomocą mechanizmu przerwań wewnętrznych, zwanych
w nomenklaturze Intela wyjątkami (exceptions).
•
Dla zapewnienia prawidłowej obsługi takich sytuacji,
które są de facto wykonaniami niejawnych skoków do
procedur obsługi wyjątków, wszystkie rozkazy, znajdujące
się w głównym strumieniu rozkazów przed rozkazem,
który spowodował wyjątek, muszą zostać zakończone.

Rozwiązywanie konfliktów
• Konflikt zasobów: dwie lub więcej faz usiłuje skorzystać z tego
samego zasobu. Jeśli przyjąć podział rozkazu na 4 omówione
wcześniej fazy, to konflikt do arytmometru nie wystąpi nigdy,
bowiem fazy
Execute
różnych rozkazów nie nakładają się w
czasie. Dostęp do rejestrów może być konfliktowy, gdyż w
fazie
Execute
pobierane są z nich argumenty, a w fazie
Write
są do nich zapisywane wyniki.
• Rozwiązaniem jest tzw.
multiple port register file
, czyli
udostępnienie każdemu rejestrowi niezależnych połączeń z
każdą fazą. Wtedy konflikt miałby miejsce tylko przy próbie
użycia tego samego rejestru, ale to już zadanie kompilatorów
optymalizujących lub samodzielnej uważnej gospodarki
rejestrami.
• Najtrudniejsze do usunięcia są konflikty w dostępie do
pamięci, gdyż kontakt z RAM zachodzi w fazach
Fetch
i
Write
.
W celu zmniejszenia częstotliwości występowania takich
konfliktów wyposaża się procesor w dodatkowy blok
rejestrów, zwany kolejką pobierania wstępnego lub
prefetcher
’em, do której są pobierane na zapas rozkazy do wykonania w
czasie, gdy pamięć nie jest zajęta w fazie
Write
.
• Oczywiście faza
Write
może nastąpić w sytuacji, gdy kolejka
jest pusta i wtedy musi być wprowadzony takt oczekiwania.

Eliminacja konfliktów dostępu do
pamięci
• Całkowitą eliminację konfliktów w dostępie do
pamięci można uzyskać poprzez niezależne
stworzenie dróg dostępu dla pobierania rozkazów i
osobno dla odczytu/ zapisu danych.
• Ponieważ zwykle rozkazy są w segmencie kodu, a
dane w segmencie danych, to konflikt dostępu do
tej samej komórki nie powinien wystąpić.
• Rozwiązanie to wymaga zastosowanie specjalnego
bloku pamięci, umożliwiającego jednoczesny
dostęp do dwóch różnych komórek - tzw. pamięć
dwuportowa.
• Architektura z rozdzieloną pamięcią danych i
rozkazów nazywa się architekturą typu Harvard.
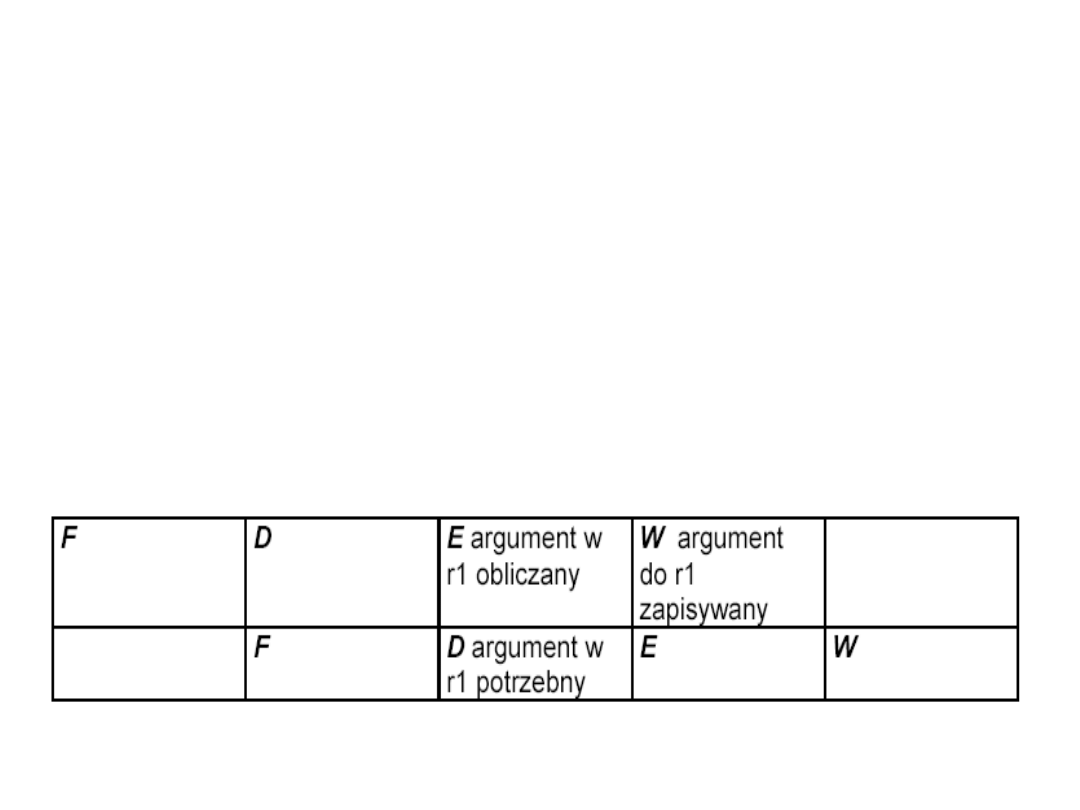
Konflikt danych
• Konflikt danych występuje, gdy wykonywanie rozkazu musi
być wstrzymane z powodu niedostępności argumentu,
będącego rezultatem wcześniejszego, nie zakończonego
jeszcze rozkazu. Rozważmy przykład obliczania średniej
arytmetycznej dwóch liczb, znajdujących się w rejestrach r1 i
r2:
– add r1, r2;
r1 := r1 + r2
– shr r1, 1 ;
r1 := r1 / 2
• Jeżeli rozkazy te są wykonywane w trybie potokowym, to
argument w r1 jest wymagany przez shr w czasie, gdy jest on
dopiero obliczany w add:

Konflikt danych
•
Poprawność działania procesora można uzyskać w tej sytuacji
przez wstawienie taktów oczekiwania za pomocą instrukcji
pustej NOP, dzielącej oba rozważane rozkazy, ale spowoduje
to obniżenie wydajności.
•
Gdyby można wykonać w tym czasie inny, użyteczny rozkaz,
nie powodujący konfliktów, spadek wydajności by nie
wystąpił, ale często nie ma takiej możliwości.
•
W bardziej wyrafinowanych konstrukcjach stosuje się inne
rozwiązanie tego problemu, a mianowicie zmianę przez
procesor kolejności wykonania rozkazów w stosunku do tej,
jaka była zapisana w programie (out of order execution).
•
Jeśli mechanizm kontroli gotowości argumentów wskaże, że
oczekujący rozkaz nie może go otrzymać, jest on wyłączany z
głównego ciągu przetwarzania i oczekuje „z boku” na
dostępność „swojego” argumentu.
•
Po zaistnieniu odpowiednich warunków jego wykonanie jest
wznawiane.
•
Pojawia się tu jedna problem obsługi wyjątków
powodowanych przez rozkazy znajdujące się poza
kolejnością, co wymaga stosowania mechanizmów
synchronizacji programu.

Konflikt sterowania
• Prawidłowa realizacja rozkazów, zmieniających kolejność
pobierania rozkazów (
jump, call, ret
) stanowi najtrudniejszy
problem w przetwarzaniu potokowym.
• W czasie wykonywania rozkazu skoku jest obliczony adres
następnego rozkazu, który staje się dostępny później, niż
wymaga tego faza pobrania następnego rozkazu.
• Aby zmniejszyć wpływ tego opóźnienia, adres skoku powinien
być obliczany w fazie dekodowania rozkazu skokowego.
• Można też stosować tzw. metodę skoku opóźnionego (
delayed
branch
), która polega na wykonaniu przed rozkazem skoku
jednego rozkazu, występującego w programie bezpośrednio za
rozkazem skokowym.

Konflikt sterowania
• Przy skokach warunkowych wprowadza się kilka kopii rejestru
flag
i jeśli zawartość odpowiedniego rejestru warunku nie jest
ustalona
przed rozpoczęciem wykonywania skoku, to wykonywana jest
sprzętowa predykcja skuteczności skoku i zgodnie z tym
przewidywaniem pobierane są kolejne rozkazy do
przetwarzania.
• Po zakończeniu cyklu rozkazowego rozkazu skoku
warunkowego następuje sprawdzenie zgodności warunku
przewidywanego z zaistniałym i jeśli zgodność istnieje, to
przetwarzanie jest kontynuowane bez straty czasu.
• W przypadku błędnej predykcji operacje we wszystkich fazach
są kasowane i proces przetwarzania potokowego wykonywany
jest od początku - bardzo kosztowne czasowo.

Postępowanie z
rozgałęzieniami
• Zwielokrotnienie strumienia;
• Pobieranie docelowego rozkazu z
wyprzedzaniem;
• Bufor pętli;
• Przewidywanie rozgałęzienia;
• Opóźnione rozgałęzienie.

Zwielokrotnienie strumienia
• Polega na powieleniu początkowych etapów
potoku i umożliwieniu równoczesnego pobrania
obu rozkazów za pomocą dwóch strumieni.
• Rozwiązanie to stwarza pewne problemy:
–
W przypadku zwielokrotnionego strumienia
występują opóźnienia, wynikające z rywalizacji o
dostęp do rejestrów i pamięci;
–
Mogą pojawić się następne rozkazy rozgałęzienia,
zanim zostanie rozstrzygnięte dane rozgałęzienie.
Każdy taki rozkaz wymaga dodatkowego strumienia.
• Przykład maszyn w dwoma i większą liczbą
strumieni:
IBM 370/168, IBM 3033.

Pobieranie docelowego
rozkazu
z wyprzedzaniem
• Gdy rozpoznany jest rozkaz
rozgałęzienia warunkowego, następuje
wyprzedzające pobranie rozkazu
docelowego razem z rozkazem
następującym po rozgałęzieniu.
• Rozkaz docelowy jest następnie
zachowywany, aż do czasu wykonania
rozgałęzienia.
• Rozwiązanie to zastosowano w IBM
360/91.
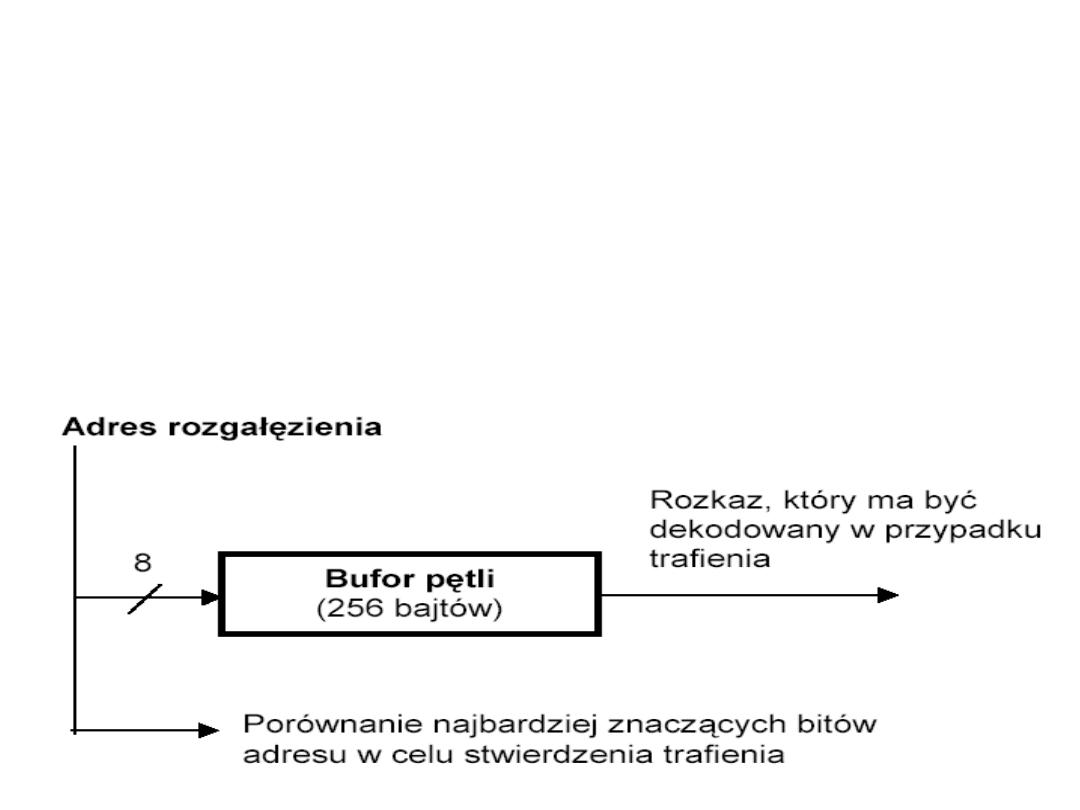
Bufor pętli
• Bufor pętli jest małą, bardzo szybką pamięcią
związaną z etapem pobierania rozkazów potoku.
• Zawiera on n ostatnio pobranych rozkazów.
• Jeśli ma nastąpić rozgałęzienie, sprawdza się
najpierw, czy cel rozgałęzienia znajduje się
wewnątrz bufora.
• Jeśli tak, to pobierany jest rozkaz z bufora.

Trzy zalety bufora pętli
1. Dzięki pobieraniu z wyprzedzeniem bufor pętli zawiera
rozkazy następujące kolejno po adresie bieżącego rozkazu.
2. Jeśli następuje rozgałęzienie do rozkazu znajdującego się o
kilka pozycji dalej od adresu rozkazu rozgałęzienia, to rozkaz
docelowy będzie już znajdował się w buforze. Szczególnie
użyteczne dla sekwencji IF-THEN oraz IF-THEN-ELSE.
3. Jeżeli bufor zmieści wszystkie rozkazy składające się na pętlę,
to rozkazy te musza być pobrane tylko raz, przy pierwszej
iteracji.
•
Bufor pętli jest w zasadzie podobny do dedykowanej
rozkazom pamięci podręcznej. Różnica polega na tym, że
bufor pętli zawiera tylko jedną sekwencje rozkazów i jest o
wiele mniejszy.
•
Przykłady zastosowania: maszyny CDC (Star 660, 7600) oraz
CRAY-1.

Przewidywanie
rozgałęzienia
• Strategie statyczne:
–
przewidywanie zawsze następującego rozgałęzienia,
–
przewidywanie nigdy nie następującego rozgałęzienia,
–
przewidywanie za pomocą kodu operacji.
• Strategie dynamiczne:
–
przełącznik nastąpiło / nie nastąpiło,
–
tablica historii rozgałęzień.
• Tablica historii rozgałęzień jest małą pamięcią
podręczną, powiązaną z etapem pobierania
rozkazu w potoku.
• Każdy zapis w tablicy składa się z trzech
elementów:
–
adresu rozkazu rozgałęzienia,
–
pewnej liczby bitów historii,
–
informacji o rozkazie docelowym (adres rozkazu lub
sam rozkaz).
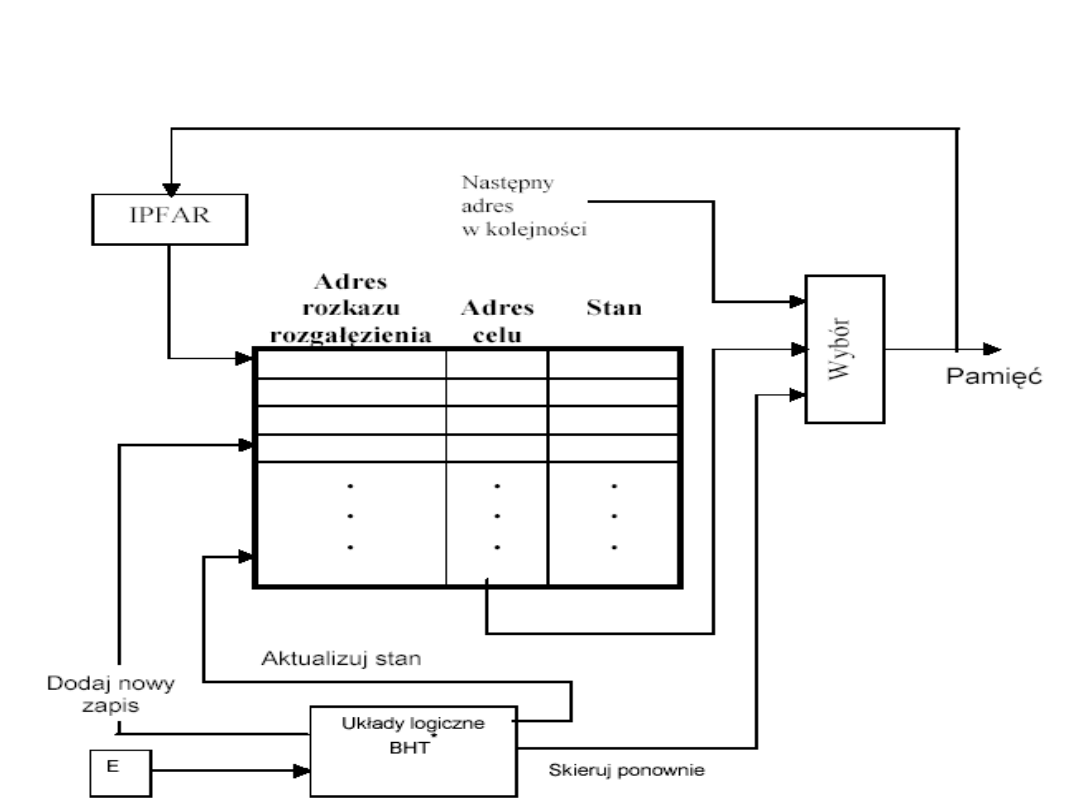
Układ tablicy historii
rozgałęzień

Granice zwiększania
wydajności
• Powstaje pytanie
„Czy istnieją granice zwiększania
wydajności poprzez wydzielenie większej liczby faz
wykonania rozkazu?”, pamiętając że:
• Na każdym etapie potoku występuje pewien narzut
związany z przenoszeniem danych z bufora do bufora
oraz z wykonywaniem różnych działań
przygotowawczych.
• Liczba układów logicznych wymaganych do zapobiegania
konfliktom rejestrów i pamięci oraz do optymalizacji
potoku wzrasta znacząco wraz z liczba faz (etapów).
• Może to prowadzić do sytuacji, gdy układy logiczne
sterujące przejściami między etapami są bardziej złożone
niż układy sterujące wykonaniem etapów.
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
- Slide 46
- Slide 47
- Slide 48
- Slide 49
- Slide 50
- Slide 51
- Slide 52
- Slide 53
- Slide 54
- Slide 55
- Slide 56
- Slide 57
- Slide 58
- Slide 59
- Slide 60
- Slide 61
- Slide 62
- Slide 63
- Slide 64
- Slide 65
- Slide 66
- Slide 67
- Slide 68
- Slide 69
- Slide 70
- Slide 71
- Slide 72
- Slide 73
- Slide 74
- Slide 75
- Slide 76
- Slide 77
- Slide 78
- Slide 79
- Slide 80
- Slide 81
- Slide 82
- Slide 83
- Slide 84
- Slide 85
- Slide 86
- Slide 87
- Slide 88
- Slide 89
- Slide 90
- Slide 91
- Slide 92
- Slide 93
- Slide 94
- Slide 95
- Slide 96
- Slide 97
- Slide 98
- Slide 99
- Slide 100
- Slide 101
- Slide 102
- Slide 103
- Slide 104
- Slide 105
- Slide 106
- Slide 107
- Slide 108
- Slide 109
- Slide 110
- Slide 111
- Slide 112
- Slide 113
- Slide 114
- Slide 115
- Slide 116
- Slide 117
- Slide 118
- Slide 119
- Slide 120
- Slide 121
- Slide 122
- Slide 123
- Slide 124
- Slide 125
- Slide 126
- Slide 127
- Slide 128
- Slide 129
- Slide 130
- Slide 131
- Slide 132
- Slide 133
- Slide 134
- Slide 135
- Slide 136
- Slide 137
- Slide 138
- Slide 139
- Slide 140
- Slide 141
- Slide 142
- Slide 143
- Slide 144
- Slide 145
- Slide 146
- Slide 147
Wyszukiwarka
Podobne podstrony:
Podstawowe info dot amortyzacji
Diagnoza autyzmu podstawowe info, PEDAGOGIKA i PSYCHOLOGIA, AUTYZM
Podstawy info 3
Podstawy info 7
Podstawy info 11
Podstawy info 8
Podstawy info 2
Podstawy info 10
Podstawy info 6
Podstawy info 5
Podstawowe info dot amortyzacji
podstawowe info o AF z netu
Podstawy info 3
Mat. info EKG, PIELĘGNIARSTWO 1 sem, Podstawy Pielęgniarstwa, laborka
Mat. info EKG, PIELĘGNIARSTWO 1 sem, Podstawy Pielęgniarstwa, laborka
OSOBOWOŚCI MAŁŻEŃSKIE - info podstawowe, psychologia sądowa
USTAWA o ochronie info niejawnych, Politologia UMCS - materiały, IV Semestr letni, Prawne podstawy k
Jednym z podstawowych obowiazkow pracodawcy jest prowadzenie dokumentacji pracowniczej, Prawo pracy(
Podstawowe pojecia statystyczne, ekonomia, logika, biznes, info
więcej podobnych podstron