
1
Algorytmy i struktury danych, temat 2
ALGORYTMY I STRUKTURY DANYCH
WAT, 2008
Dr hab..inż. Andrzej Walczak, prof. WAT
awalczak@wat.edu.pl
Konspekt wykładu
Algorytmy i struktury
danych
Struktury danych

3
Algorytmy i struktury danych, temat 2
Wykład 2: Podstawy struktur
danych
definicja struktury danych
liniowe struktury danych
tablice z haszowaniem
struktury drzewiaste
sposoby realizacji struktur danych

4
Algorytmy i struktury danych, temat 2
Definicja struktury danych
Definicja 2.1:
Strukturą danych nazywamy trójkę uporządkowaną
S=(D, R,
e)
,
gdzie:
D
– oznacza zbiór danych elementarnych
d
i, i = 1,..,|D|
(i –
jest indeksem poszczególnych danych),
R={r
we
, N}
– jest zbiorem dwóch relacji określonych na
strukturze danych:
– relacja wejścia do struktury danych S,
– relacja następstwa (porządkująca) strukturę
S,
e
– jest elementem wejściowym do struktury danych S
(nie jest to dana wchodząca w skład struktury danych S).
D
e
r
we
D
D
N

5
Algorytmy i struktury danych, temat 2
Zbiór danych elementarnych
D
Jak widać z definicji struktury danych, zbiór danych
elementarnych jest skończony i dla wygody operowania
oznaczeniem jego elementów poszczególne dane są
indeksowane od wartości 1 w kierunku wartości większych.
Weźmy zatem dla przykładu pięcioelementową strukturę
danych
S
. Zapis zbioru jej danych elementarnych może
wyglądać następująco:
Liczność zbioru danych elementarnych wynosi 5, co
zapisujemy:
|D|=5
5
4
3
2
1
,
,
,
,
d
d
d
d
d
D

6
Algorytmy i struktury danych, temat 2
Dana elementarna, zmienna
programowa
Dana elementarna
d
i
jest pojęciem abstrakcyjnym,
rozumianym jako tzw. „nazwana wartość”. Jest ona określana
jako uporządkowana dwójka elementów:
, gdzie:
n
i
– nazwa danej,
w
i
– aktualna wartość danej z określonej dziedziny
wartości.
Zmienna programowa jest pojęciem związanym z realizacją
danej w konkretnym środowisku programistycznym. Posiada
ona zdefiniowaną etykietę (nazwę zmiennej), wraz z
określeniem dziedziny wartości, którą może przyjmować dana
reprezentowana przez zmienną, a także zdefiniowaną dla tej
dziedziny wartości dziedziną algorytmiczną.
i
i
i
w
n
d
,
7
Algorytmy i struktury danych, temat 2
Relacja
r
we
– wskazanie korzenia
struktury S
Relacja
r
we
, jest opisywana poprzez jedno- lub wieloelementowy
zbiór dwójek uporządkowanych elementów, z których pierwszym
jest zawsze element wejściowy
e
, natomiast drugim elementem
jest jedna z danych elementarnych ze zbioru
D
.
W sytuacji opisanej powyżej mówimy, że
„element
e
należy do dziedziny relacji
r
we
” -
Dz(r
we
),
„dana
d
i
należy do przeciwdziedziny
r
we
” –
PDz(r
we
)
Element (elementy) należące do
PDz(r
we
)
są nazywane
korzeniem (korzeniami) struktury danych S. Struktura musi mieć
zdefiniowany co najmniej jeden korzeń.
Przykład: Załóżmy, że struktura S posiada dwa korzenie, według
opisu:
5
2
,
,
,
d
e
d
e
r
we
8
Algorytmy i struktury danych, temat 2
Relacja
N
– ustalenie porządku
struktury S
Relacja następstwa N opisuje wzajemne uporządkowanie elementów
w strukturze danych S. Porządek struktury opisujemy w postaci
zestawów dwójek uporządkowanych elementów.
Przykład: Opiszmy porządek naszej pięcioelementowej struktury
danych S:
UWAGA: Korzenie struktury S nie mogą być elementami należącymi do
PDz(N)
3
5
4
3
4
1
3
1
1
2
,
,
,
,
,
,
,
,
,
d
d
d
d
d
d
d
d
d
d
N
poprzedn
ik
następni
k
9
Algorytmy i struktury danych, temat 2
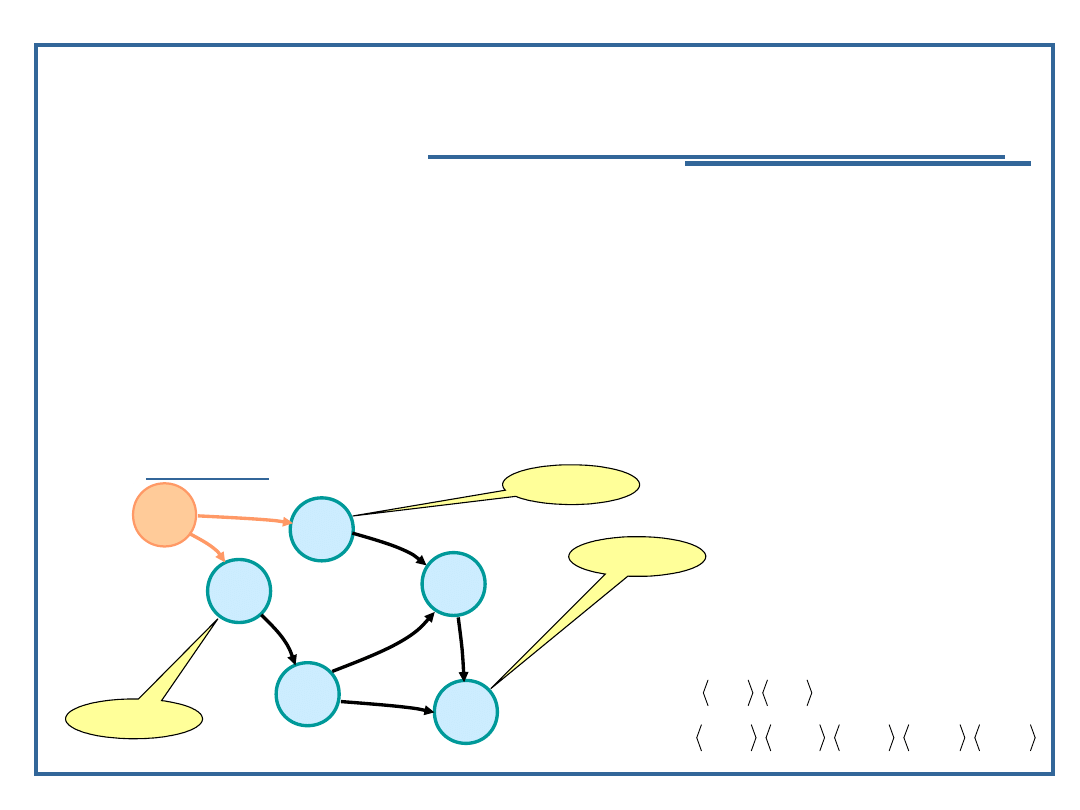
Model grafowy struktury danych
Aby łatwiej zobrazować strukturę danych i w ten sposób lepiej
ją zrozumieć, można zbudować dla niej model grafowy. W
modelu tym:
węzły (kółka) oznaczają poszczególne dane elementarne,
łuki (strzałki) służą do odwzorowania następstw
poszczególnych danych elementarnych w strukturze S.
Przykład: Model grafowy dla opisywanej do tej pory struktury S:
5
4
3
2
1
,
,
,
,
d
d
d
d
d
D
5
2
,
,
,
d
e
d
e
r
we
3
5
4
3
4
1
3
1
1
2
,
,
,
,
,
,
,
,
,
d
d
d
d
d
d
d
d
d
d
N
e
d
2
d
5
d
1
d
3
d
4
liść
korzeń
korzeń
10
Algorytmy i struktury danych, temat 2
Definicja liniowej struktury danych
Definicja 2.2:
Liniową strukturą danych nazywamy strukturę danych
S=(D, R,
e)
, w której relacja porządkująca
N
opisuje powiązania pomiędzy
elementami odpowiednio dla poszczególnych rodzajów list.
Wyróżniamy cztery rodzaje list (jednopoziomowych):
• jednokierunkowe listy niecykliczne
• dwukierunkowe listy niecykliczne
• jednokierunkowe listy cykliczne (pierścienie
jednokierunkowe)
• dwukierunkowe listy cykliczne (pierścienie
dwukierunkowe)
11
Algorytmy i struktury danych, temat 2
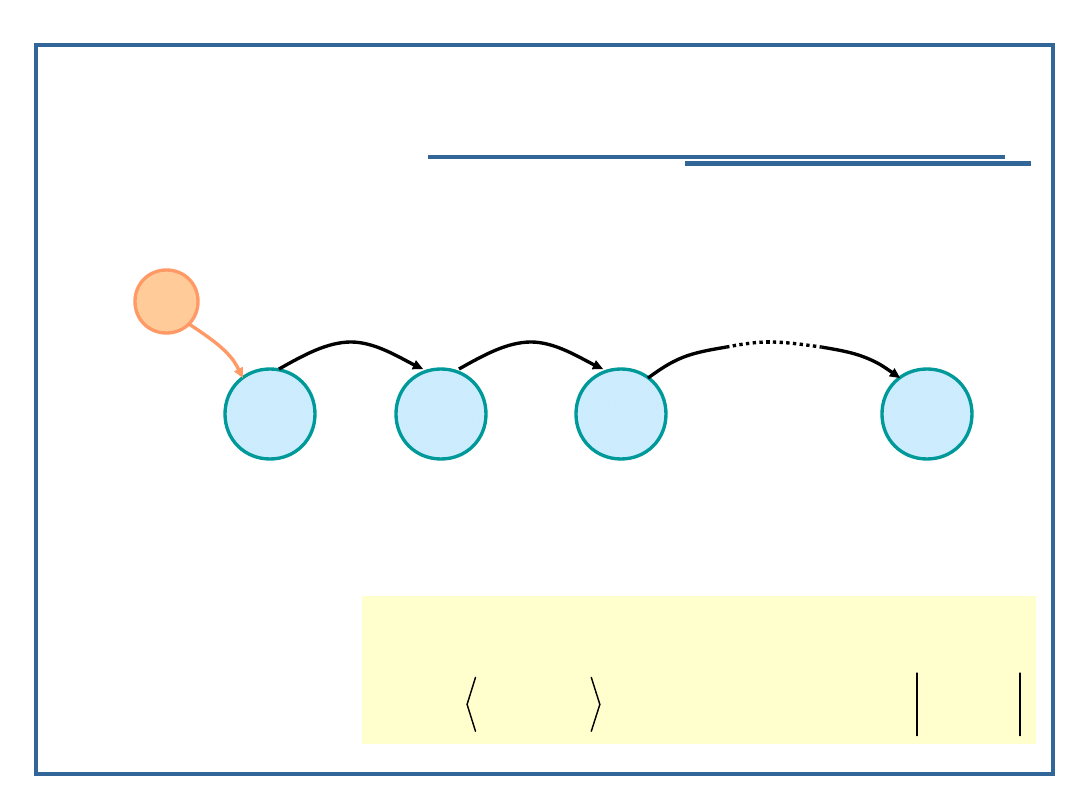
Jednokierunkowe listy niecykliczne
Model grafowy listy jednokierunkowej:
e
d
1
d
2
d
3
d
n
Relacja następstwa dla listy jednokierunkowej L:
1
...
1
,
,
:
,
1
1
D
D
d
d
d
d
N
N
N
i
i
i
i
i
L
L
12
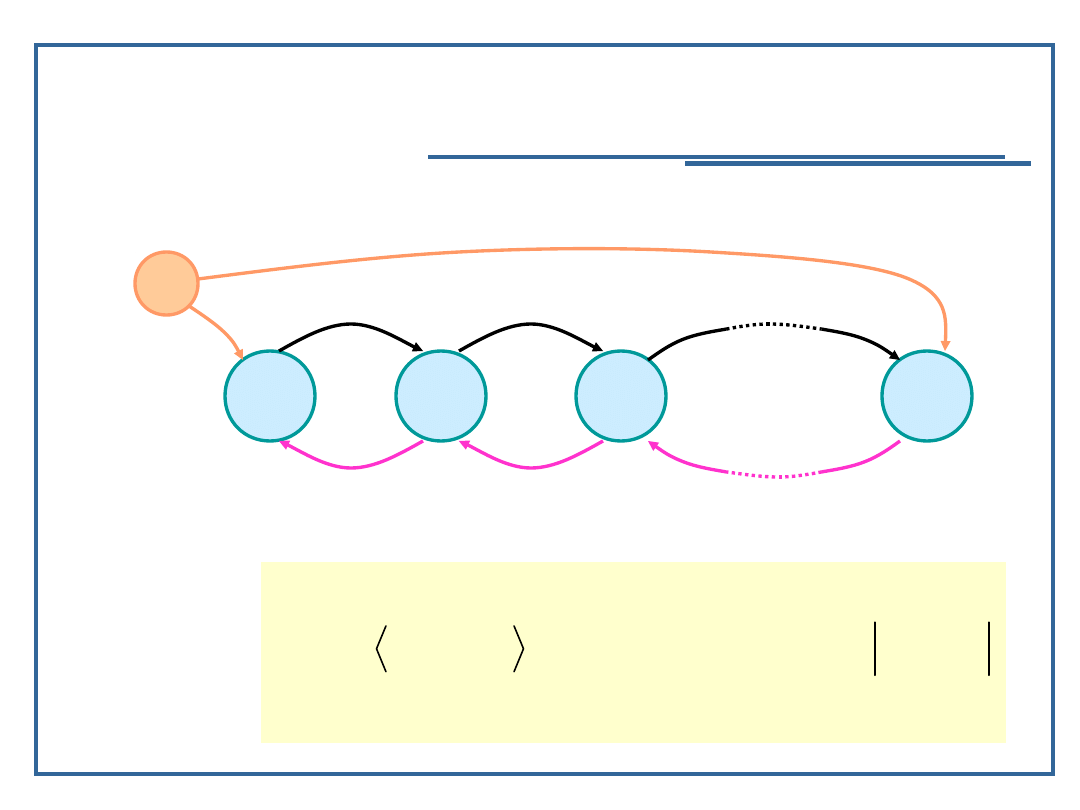
Algorytmy i struktury danych, temat 2
Dwukierunkowe listy niecykliczne
Model grafowy listy dwukierunkowej:
Relacja następstwa dla listy dwukierunkowej Ld:
e
d
1
d
2
d
3
d
n
N
N
D
D
d
d
d
d
N
N
N
N
L
W
i
i
i
i
L
W
L
Ld
i
1
1
1
1
...
1
,
,
:
,
13
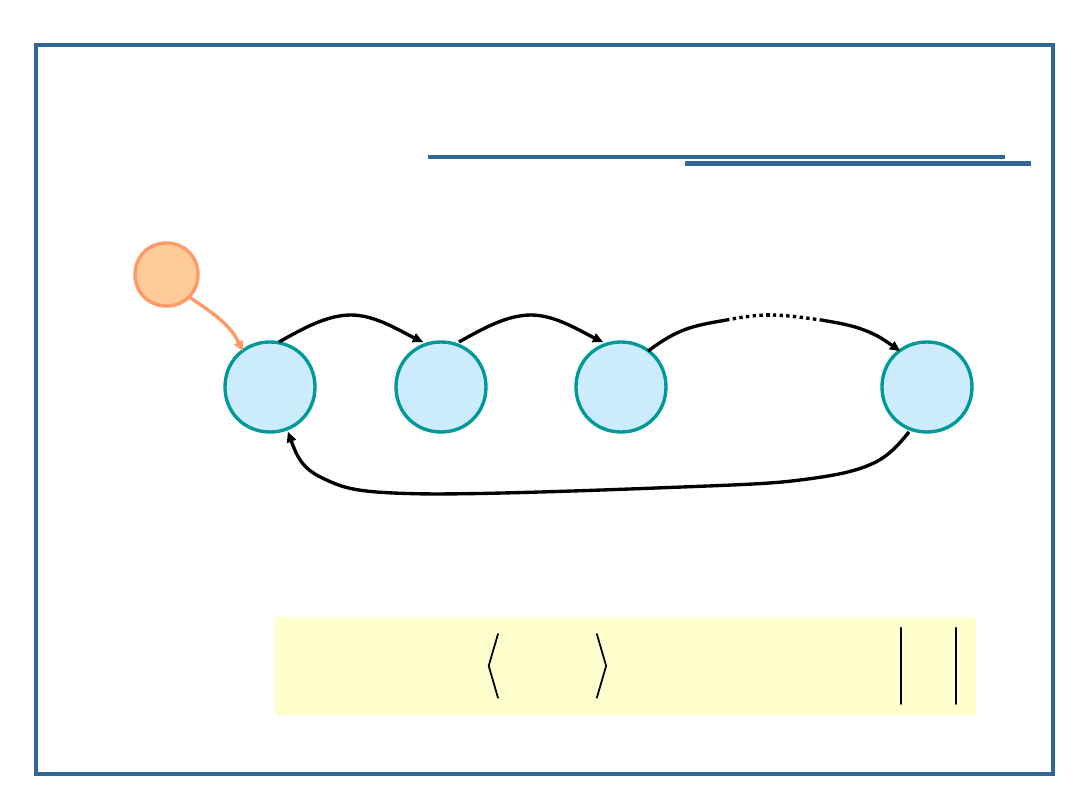
Algorytmy i struktury danych, temat 2
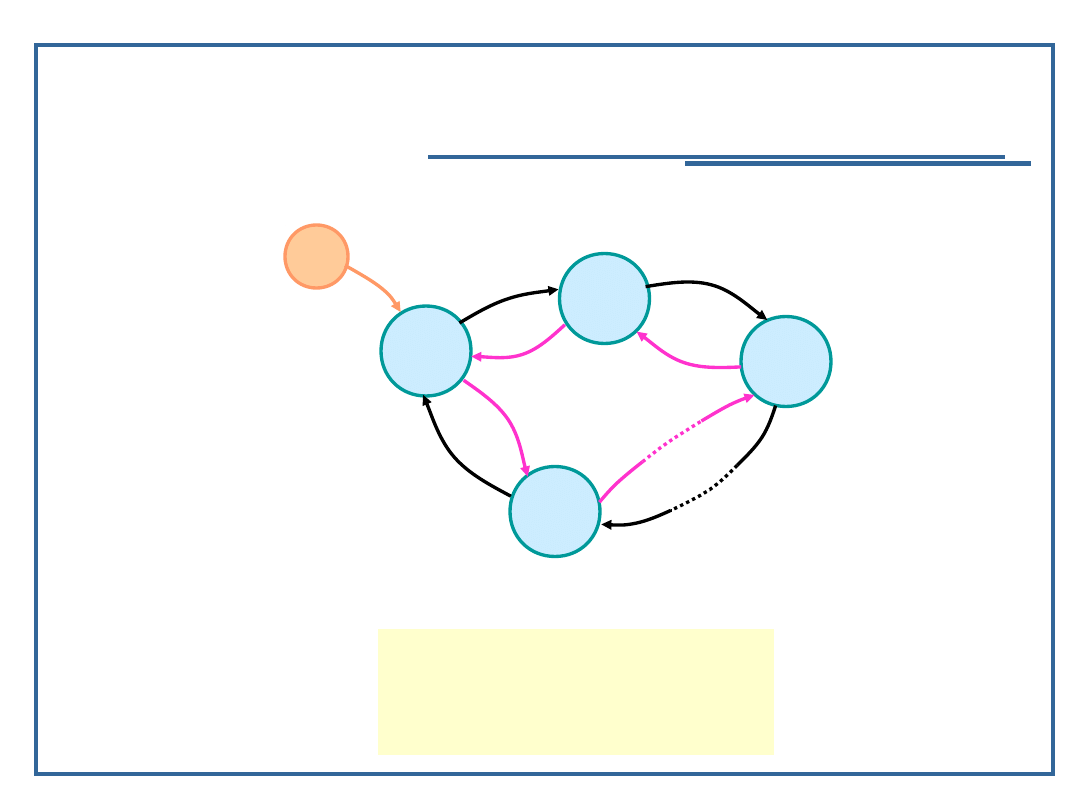
Pierścień jednokierunkowy
Model grafowy pierścienia jednokierunkowego:
Relacja następstwa dla pierścienia jednokierunkowego P:
e
d
1
d
2
d
3
d
n
D
D
d
d
d
d
N
N
n
,
,
:
,
1
n
1
n
L
P
14
Algorytmy i struktury danych, temat 2
Pierścienie dwukierunkowe
Model grafowy pierścienia dwukierunkowego:
Relacja następstwa dla pierścienia dwukierunkowego Pd:
N
N
N
N
N
P
Pw
Pw
P
PD
1
e
d
1
d
2
d
3
d
n
15
Algorytmy i struktury danych, temat 2
Drzewiaste struktury danych
Definicja 2.4:
Drzewiastą strukturą danych nazywamy strukturę danych
S=(D, R, e)
, w której relacja porządkująca
N
opisuje kolejne,
rekurencyjne powiązania pomiędzy danymi elementarnymi
drzewa, tworzącymi kolejne „poddrzewa”.
Wniosek: Drzewo ze swojej natury jest strukturą hierarchiczną
(rekurencyjną). Niezwykle istotne jest tutaj
odpowiednie
przypisanie danych elementarnych ze zbioru
D
do
kolejnych
poziomów drzewa i opisanie porządku w relacji
N
.

16
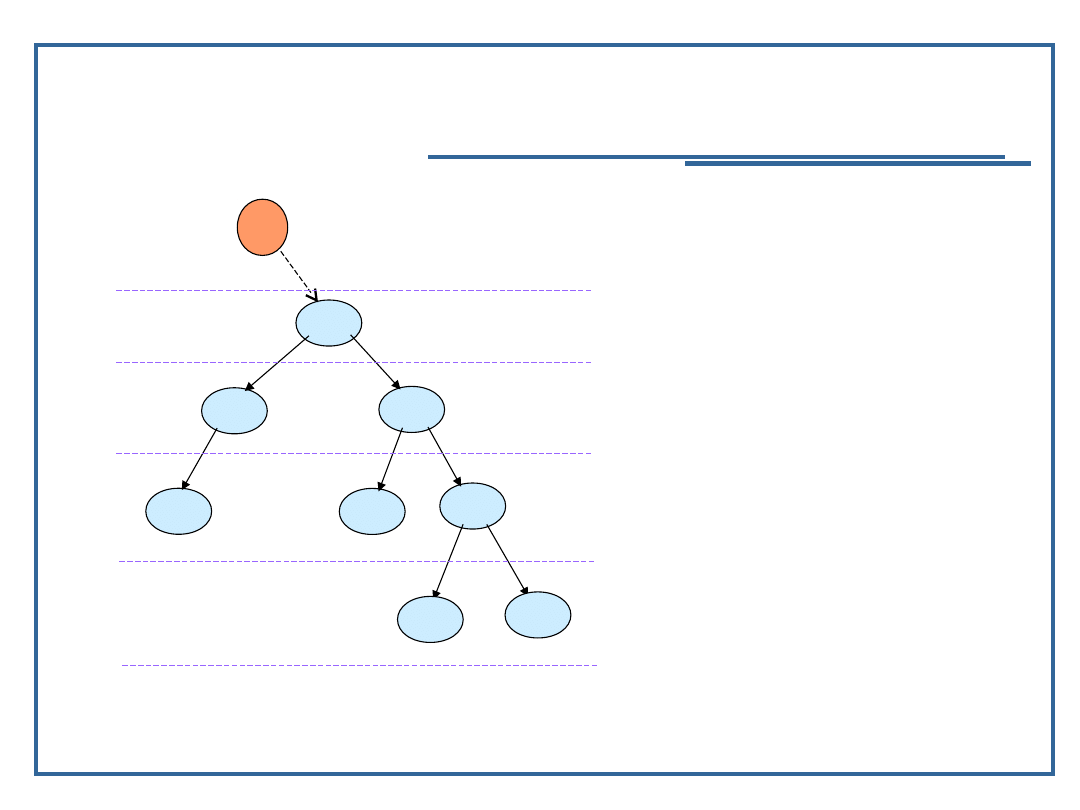
Algorytmy i struktury danych, temat 2
Drzewiaste struktury danych – kilka
pojęć podstawowych
Korzeń drzewa – jest tylko i wyłącznie jeden dla drzewa. Jest
to dana wskazywana przez element wejściowy
e
,
Liść drzewa – jest to dana elementarna, która nie posiada
swojego
następnika w w sensie relacji
N
,
Stopień drzewa – maksymalna liczba możliwych następników
dla
dowolnego elementu drzewa. Najczęściej przyjmuje
się, że stopień drzewa jest potęgą liczby 2 (drzewa
dwójkowe, czwórkowe, ósemkowe, szesnastkowe),
Droga w drzewie – kolejne łuki pomiędzy wskazanymi dwoma
elementami drzewa, które trzeba pokonać, aby dojść
od
jednego elementu drzewa do innego
Poziom drzewa – elementy ułożone w tej samej odległości
(długości
drogi) od korzenia drzewa,
Drzewo zupełne – takie drzewo, którego wszystkie elementy
(oprócz liści) mają taką liczbę następników, ile wynosi
stopień drzewa
17
Algorytmy i struktury danych, temat 2
Przykład modelu grafowego drzewa
dwójkowego
(binarnego)
e
d1
d2
d3
d4
d5
d6
d7
d8
poziom 1
poziom 2
poziom 3
poziom 4
Dla powyższego drzewa: wskaż korzeń, liście, opisz zbiór D, relacje r
we
i N
18
Algorytmy i struktury danych, temat 2
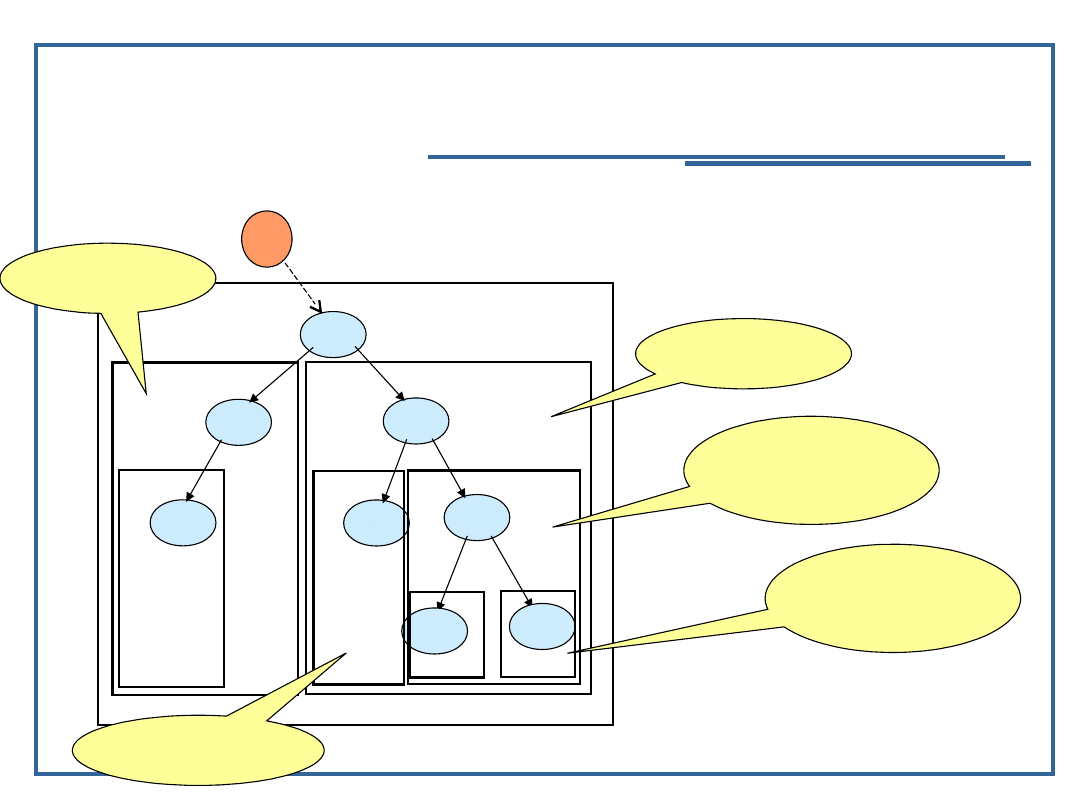
Rekurencja w drzewie
e
d1
d2
d3
d4
d5
d6
d7
d8
prawe
podrzewo
prawe
podrzewo
prawego
podrzewa
prawe
podrzewo
prawego
podrzewa
prawego
podrzewa
lewe
podrzewo
lewe
podrzewo
prawego
podrzewa

19
Algorytmy i struktury danych, temat 2
Drzewiaste struktury danych
W informatyce drzewa są strukturami danych
reprezentującymi drzewa matematyczne. W naturalny
sposób reprezentują hierarchię danych (obiektów
fizycznych i abstrakcyjnych, pojęć, itp.), toteż głównie
do tego celu są stosowane. Drzewa ułatwiają i
przyspieszają wyszukiwanie, a także pozwalają w
łatwy sposób operować na posortowanych danych.
Znaczenie tych struktury jest bardzo duże i ze względu
na swoje własności drzewa są stosowane praktycznie
w każdej dziedzinie informatyki (np. bazy danych,
grafika komputerowa, przetwarzanie tekstu,
telekomunikacja).
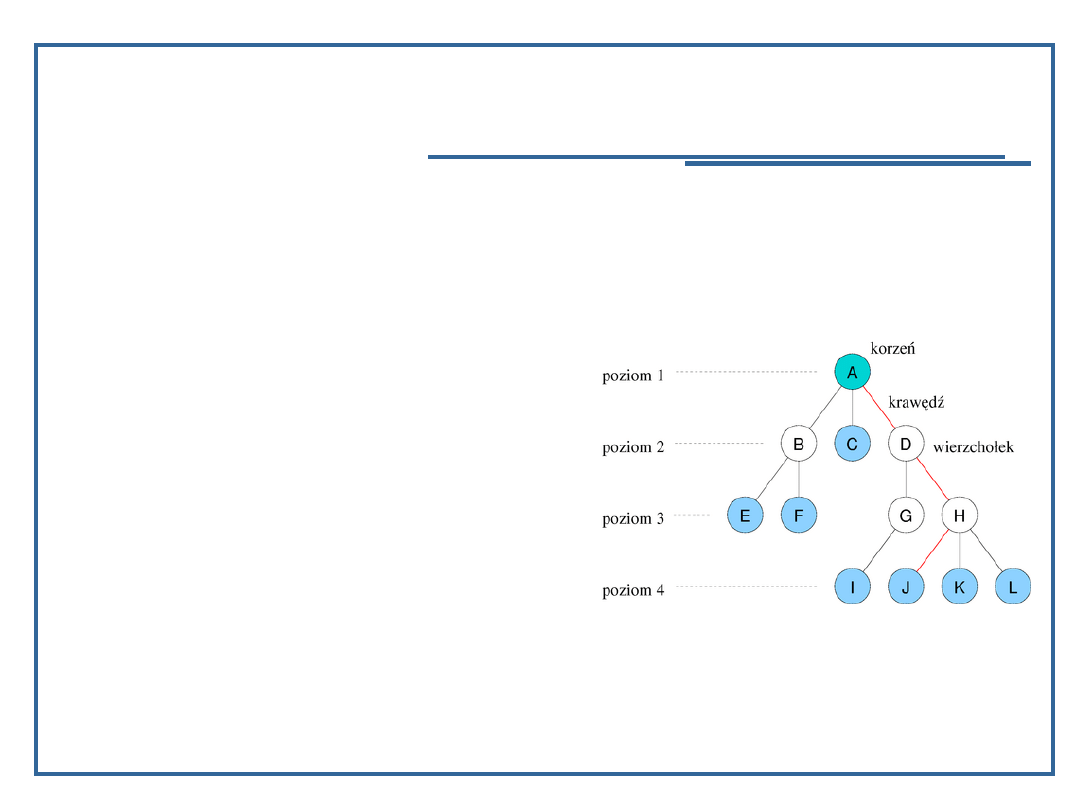
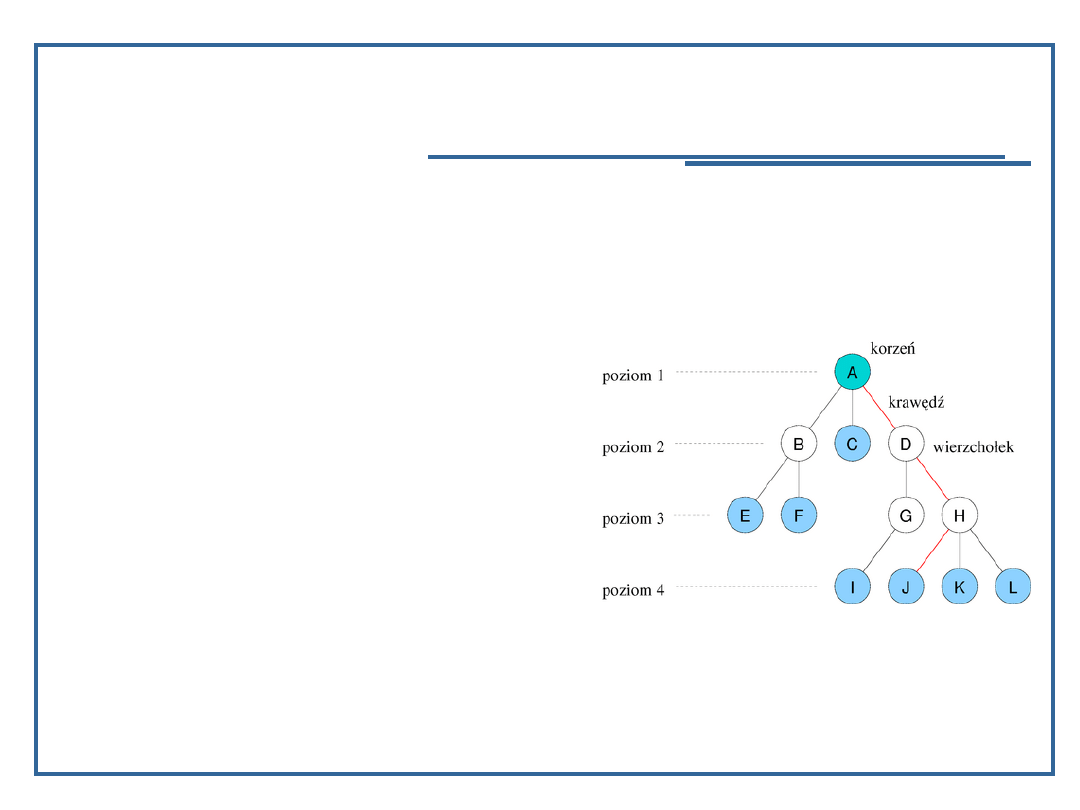
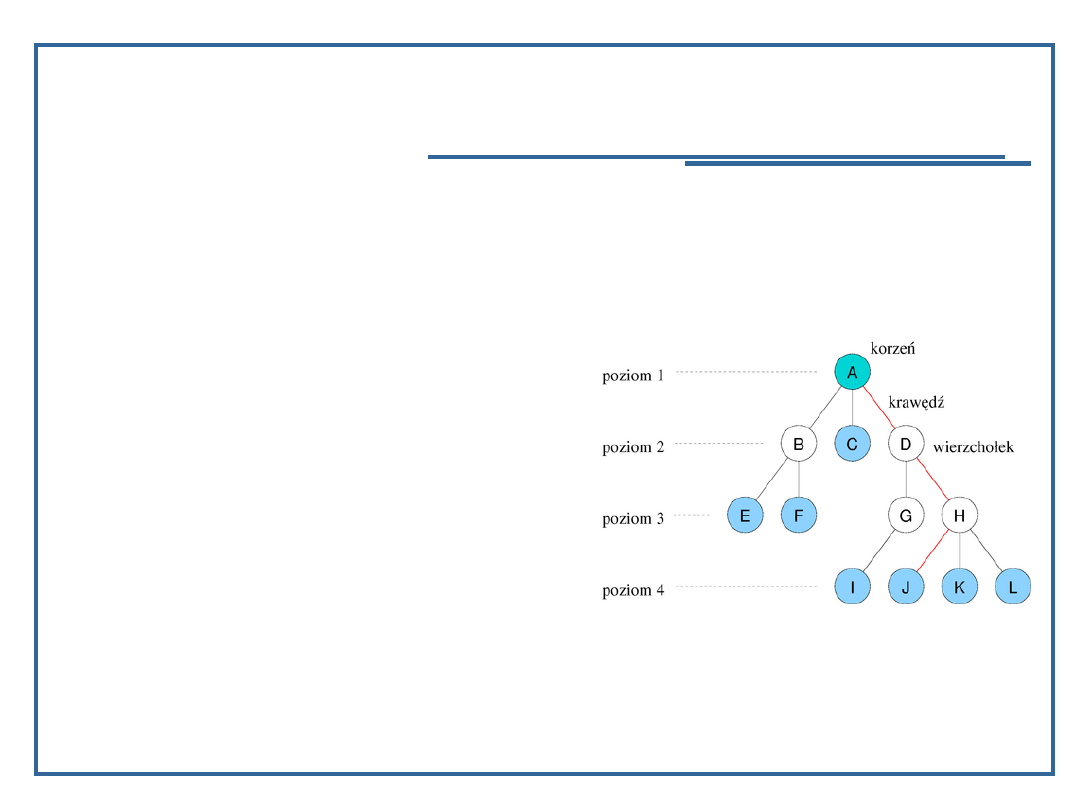
20
Algorytmy i struktury danych, temat 2
Drzewiaste struktury danych
danym wierzchołkiem, a leżące na następnym poziomie są
nazywane dziećmi tego węzła (np. dziećmi wierzchołka D są
G i H, wierzchołka H: J, K oraz L). Wierzchołek może mieć
dowolną liczbę dzieci, jeśli nie ma ich wcale nazywany jest
liściem; na rysunku liście zaznaczone są kolorem niebieskim.
Wierzchołek jest rodzicem dla każdego swojego dziecka;
każdy węzeł ma dokładnie jednego rodzica. Wyjątkiem jest
korzeń drzewa, który nie ma rodzica.
W drzewie istnieje dokładnie jedna ścieżka pomiędzy węzłem
a korzeniem; przez ścieżkę rozumie się ciąg krawędzi, na
rys. przykładowa ścieżka do węzła J jest zaznaczona na
czerwono. Liczba krawędzi w ścieżce jest nazywana
długością (lub głębokością) – liczba o jeden większa określa
poziom węzła. Z kolei wysokość drzewa to największy
poziom istniejący w drzewie (przykładowe drzewo ma
wysokość 4).
21
Algorytmy i struktury danych, temat 2
Drzewiaste struktury danych
Podstawowe operacje na
drzewach to:
* wyliczenie wszystkich
elementów drzewa,
* wyszukanie
konkretnego elementu,
* dodanie nowego
elementu w określonym
miejscu drzewa,
* usunięcie elementu.
22
Algorytmy i struktury danych, temat 2
Drzewiaste struktury danych
Pod pojęciem przechodzenia
drzewa rozumie się
odwiedzanie kolejnych
wierzchołków, zgodnie z
zależnościami rodzic-dziecko.
Jeśli przy przechodzeniu drzewa
na wierzchołkach są
wykonywane pewne działania,
to mówi się wówczas o
przechodzeniu:
* preorder - gdy działanie jest
wykonywane najpierw na
rodzicu, następnie na dzieciach;
* postorder - gdy działanie
jest wykonywane najpierw na
wszystkich dzieciach, na końcu
na rodzicu.
23
Algorytmy i struktury danych, temat 2
Drzewiaste struktury danych
W przypadku drzew
binarnych istnieje jeszcze
metoda inorder, gdzie
najpierw wykonywane jest
działanie na jednym z dzieci,
następnie na rodzicu i na
końcu na drugim dziecku.
Jeśli działaniem byłoby
wypisanie liter
przechowywanych w węzłach
przykładowego drzewa, to
przy przechodzeniu drzewa
metodą preorder otrzymamy
ABEFCDGIHJKL, natomiast
przy przechodzeniu drzewa
metodą postorder:
EFBCIGJKLHDA.

24
Algorytmy i struktury danych, temat 2
Drzewo binarne
w teorii grafów to drzewo, w którym stopień każdego
wierzchołka jest nie większy od 3.
Ukorzenione drzewo binarne to drzewo binarne o
stopniu nie większym niż 2, w którym wyróżniono jeden
z wierzchołków (zwany korzeniem).
W informatyce drzewo binarne to jeden z rodzajów
drzewa (struktury danych), w którym liczba synów
każdego wierzchołka wynosi nie więcej niż dwa.
Wyróżnia się wtedy lewego syna i prawego syna danego
wierzchołka.
Drzewo binarne, w którym liczba synów każdego
wierzchołka wynosi albo zero albo dwa, nazywane jest
drzewem regularnym.
Szczególnymi odmianami drzew binarnych są drzewa
BST oraz kopce.

25
Algorytmy i struktury danych, temat 2
Drzewo AVL
to zrównoważone binarne drzewo poszukiwań (BST), czyli
takie w którym wysokość lewego i prawego poddrzewa
każdego węzła różni się co najwyżej o jeden. Nazwa AVL
pochodzi od nazwisk rosyjskich matematyków: Adelsona-
Velskii oraz Landisa (właściwie: Grigorij Adelson-Wielskij i
Jewgienij Ładnis), którzy zaproponowali rozwiązanie problemu
utrzymania dobrego drzewa wyszukiwań w roku 1962 [1].
Drzewo AVL pozostaje drzewem BST, co oznacza, że
wierzchołki są uporządkowane w określony sposób. Zazwyczaj
przyjmuje się, iż elementy w lewym poddrzewie są mniejsze
od wierzchołka, zaś w prawym - większe. Zrównoważenie
drzewa osiąga się przypisując każdemu węzłowi współczynnik
wyważenia, który jest równy różnicy wysokości lewego i
prawego poddrzewa. Może wynosić 0, +1 lub -1. Wstawiając
lub usuwając elementy drzewa (tak aby zachować własności
drzewa BST) modyfikuje się też współczynnik wyważenia, a
gdy przyjmie on niedozwoloną wartość wykonuje specjalną
operację rotacji węzłów, która przywraca zrównoważenie.

26
Algorytmy i struktury danych, temat 2
Drzewo AVL
Koszt modyfikacji drzewa jest nieco większy niż dla
zwykłego drzewa BST, ale za to własności drzewa AVL
gwarantują, że pesymistyczny czas wyszukiwania
elementu w drzewie o n węzłach wynosi (log
2
n)/2,
podczas gdy dla niezrównoważonego BST (w postaci
listy) czas ten wynosi n.
Drzewa AVL są często porównywane z czerwono-
czarnymi drzewami, ponieważ pozwalają na wykonanie
tych samych operacji (dodawanie, usuwanie oraz
wyszukiwanie elementów) o równej co do rzędu
pesymistycznej złożoności czasowej O(log n). Przy
powtarzających się wyszukiwaniach drzewa AVL są
jednak wydajniejsze. [2]
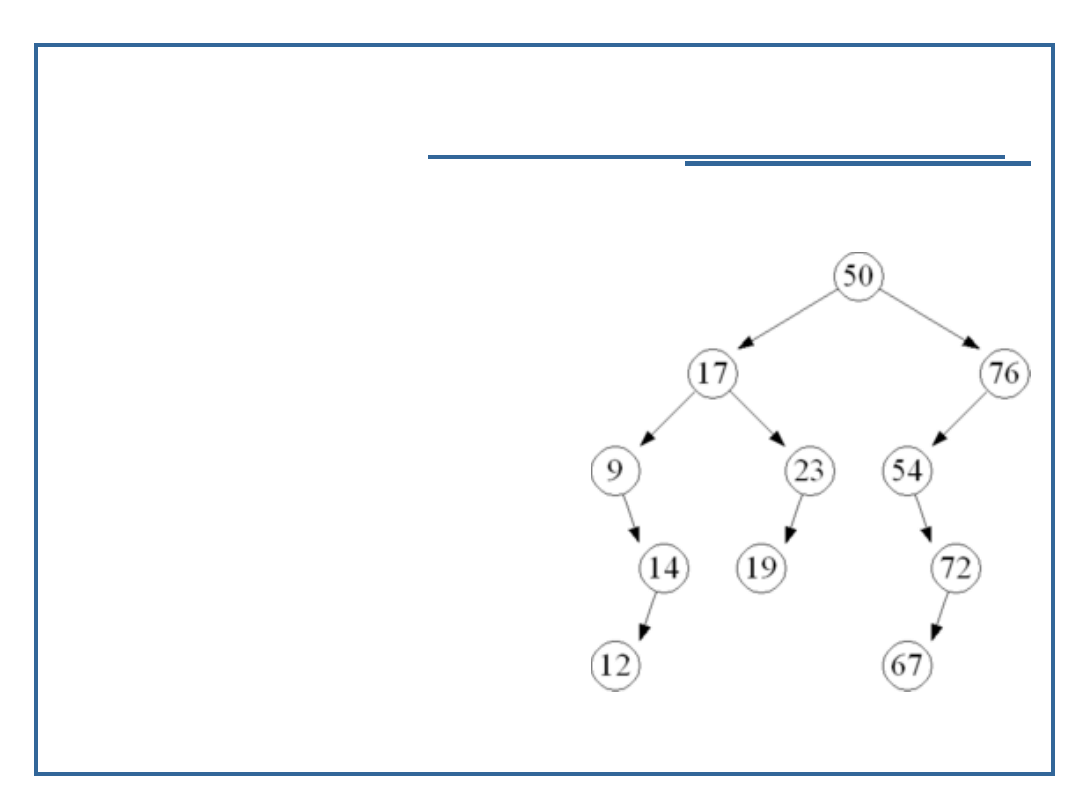
27
Algorytmy i struktury danych, temat 2
AVL
W wielu praktycznych
zastosowaniach zdarza się,
że do części obiektów sięga
się częściej niż do
pozostałych, przykładem
może być słownik. Wówczas
lepszym rozwiązaniem jest
zastosowanie optymalnego
drzewa poszukiwań.
obok AVL niezrównoważone
Podobnie jak w BST, nie jest
możliwe, by drzewo
posiadało dwa równe
elementy. Zazwyczaj
oznacza to, iż elementy
muszą posiadać unikalny
klucz identyfikacyjny.
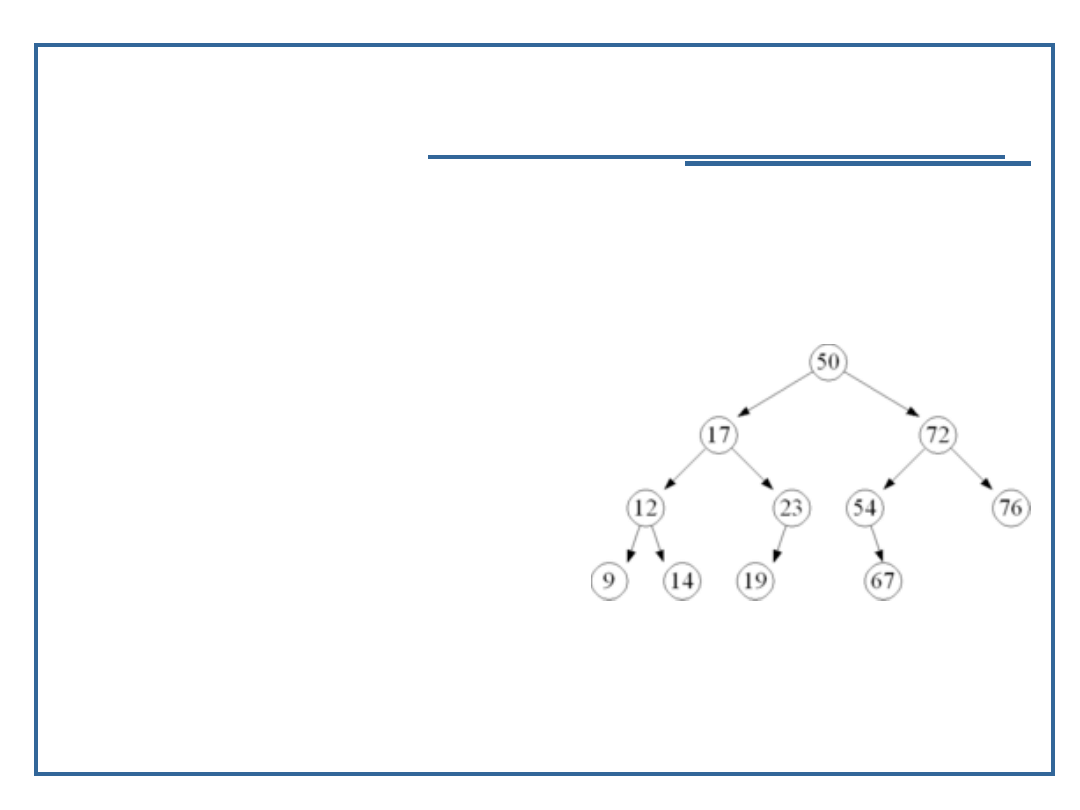
28
Algorytmy i struktury danych, temat 2
AVL
Poprzednie AVL po
zrównoważeniu

29
Algorytmy i struktury danych, temat 2
Realizacje struktur danych
Realizacje sekwencyjne (statyczne) - wtedy, gdy z góry
znamy maksymalny rozmiar przetwarzanej struktury liniowej i z
góry chcemy zarezerwować dla niej określony zasób (pamięć
operacyjne, pamięć zewnętrzna. W czasie wytwarzania
programów komputerowych bazujemy wtedy na zmiennych
statycznych,
Realizacje łącznikowe (dynamiczne) - wtedy, gdy rozmiar
struktury nie jest z góry znany i w czasie jej przetwarzania może
istnieć konieczność dodawania do niej nowych elementów lub ich
usuwania. W czasie wytwarzania programów komputerowych
bazujemy wtedy na zmiennych dynamicznych (wskaźnikowych),
Realizacje łącznikowo-sekwencyjne (hybrydowe) -
połączenie obu powyższych metod - wtedy gdy konieczny jest
odpowiedni balans pomiędzy zmiennymi statycznymi i
dynamicznymi
O statycznych (sekwencyjnych) realizacjach struktur danych mówiliśmy już na
wykładzie wprowadzającym z WdP. Więcej realizacjach dynamicznych (łacznikowych)
będziemy mówić na obecnym wykładzie podczas omawiamia tematu nr 3.
30
Algorytmy i struktury danych, temat 2
Definicja tablicy rozproszonej (z
haszowaniem)
Definicja 2.3:
Tablicą rozproszoną nazywamy trójkę uporządkowaną
h
D
K
T
,
,
, gdzie
K = {k
1
, k
2
, k
3
,..., k
n
} - zbiór kluczy,
D = {d
1
, d
2
, d
3
,..., d
n
} - zbiór adresów,
h - funkcja mieszająca (haszująca)
zdefiniowana następująco:
D
K
:
h
Tradycyjnym obszarem zastosowań tablic
rozproszonych są zagadnienia związane z
przetwarzaniem danych.

31
Algorytmy i struktury danych, temat 2
Tablice rozproszone, funkcja
haszująca
Zadaniem funkcji haszującej h jest w miarę
równomierne obciążanie tablicy rozproszonej (jej
komórek). Zagadnienie definiowania funkcji
mieszającej jest istotne dla efektywności obliczeń
realizowanych na bazie tablic rozproszonych.
Ma to szczególnie duże znaczenie dla tablic
rozproszonych przetwarzanych bezpośrednio w
nośnikach zewnętrznych (taśmach, dyskach)
Nie można jednak wykluczyć powstawania tzw.
konfliktów w tablicach rozproszonych.

32
Algorytmy i struktury danych, temat 2
Konflikty w tablicach rozproszonych
Kolizją (konfliktem) w tablicy rozproszonej nazywamy
sytuację powstałą wtedy, gdy:
k
k
j
i
,
,
h
h
k
k
K
k
k
j
i
j
i
Elementy k
i
, k
j
biorące udział w kolizji nazywamy synonimami.
Dużo więcej o listach i tablicach rozproszonych będziemy mówić na wykładzie 3 i 4

33
Algorytmy i struktury danych, temat 2
Podsumowanie:
poznaliśmy już przykłady struktur danych
wiemy w jaki sposób można realizować struktury danych
dalsze szczegóły poznamy na kolejnych wykładach
Następny wykład:
zajmiemy się implementacjami dynamicznych struktur danych
dziękuję za uwagę
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
Wyszukiwarka
Podobne podstrony:
lecture5 6 data structure
Homework Data Structures
Data Structures
Homework Data Structures
Polymorphing Software by Randomizing Data Structure Layout
43 flytunes data structure example
196 Capital structure Intro lecture 1id 18514 ppt
197 Capital structure lecture Gdansk 2006 Lecture 2id 18521 ppt
lecture 13 spc and data integration handouts
lecture7 dynamic data struc
lecture 3 Structural constraints, 3D structure calculation
196 Capital structure Intro lecture 1id 18514 ppt
IR Lecture1
uml LECTURE
lecture3 complexity introduction
Structures sp11
4 Plant Structure, Growth and Development, before ppt
Lecture VIII Morphology
więcej podobnych podstron