
Analiza
treści

Definicja analizy treści
•
Stone, Dunphy, Smith i Ogilvie (1966);
Weber (1990)
–
Metoda wykorzystująca zbiór systematycznych i
obiektywnych procedur pozwalających na
wyciąganie wniosków z tekstów
•
Holsti (1969)
–
Każda technika, która pozwala na wyciąganie
wniosków na podstawie obiektywnie i
systematycznie wyodrębnionych cech przekazu.

Zbieranie danych
•
Wywiad psychologiczny
•
Indywidualny vs. grupowy
•
Standardowy vs. pogłębiony (tzw. swobodny)
•
Badania archiwalne
•
np. Badania treści publikowanych w internecie
•
Badania obserwacyjne
•
np. obserwacja zachowań podmiotu w relacjach
interpersonalnych

Kiedy AT
•
Badania komunikacji
–
Jakie cechy własnej osoby używane są do opisu siebie w
sytuacji zapoznawania się z kimś nowym?
•
Badania treści stereotypów i postaw
–
Jakie cechy innych grup najczęściej pojawiają się w ich
opisach?
•
Badania treści samoświadomości
–
Jakie schematy Ja aktywizowane są w sytuacjach stresu?
•
Analiza literatury
–
Jaką perspektywę teoretyczną przyjmują autorzy polskich
publikacji na temat wywiadu diagnostycznego?
•
Analiza przekazów wizualnych
–
Jaki obraz kobiety dominuje w kolorowych magazynach?
Jak problem higieny prezentowany jest w reklamie?

Transkrypcje
•
Transkrypcja, niejednokrotnie jest wstępną
obróbką danych surowych nawet jeżeli
jest próbą dokładnego spisania słów
badanego.
•
Pomijane są informacje dodatkowe: ton
głosu, zachowanie, mimika, itp.
•
W podejściu interpretacyjnym, podkreśla
się rolę zanotowania kontekstu, w jakim
powstają słowa. Odchodzi się od prób
idealnego oddania treści.

Spisywanie nagrań
•
„Yyy miałam bardzo szczęśliwe dzieciństwo, yyy
ponieważ mam dobry kontakt z rodzicami i nie
pochodzę z jakiejś rozbitej rodziny, także...
wszystko było w porządku i myślę, że to jest
bardzo ważne, booo mmm dało mi to... energię
na..., na dalsze życie. Wiem, że to jest bardzo
ważne, aby rodzice kochali swoje dziecko iii i to
dostałam w domu, na pewno. Mmm nadal
mieszkam z rodzicami, yyy teraz studiuję iii i
myślę, że rozwijam się i robię to, co lubię. Yyy
(westchnięcie) jeśli chodzi jeszcze o dzieciństwo,
to... mmm”

Zasady podczas spisywania
nagrań
•
Odzwierciedlenie morfologii tekstu
mówionego z zachowaniem podstawowych
zasad interpunkcji.
–
pozostawienie oryginalnych zwrotów
językowych
–
“gramatyka” języka mówionego.
•
Zachowanie struktury dialogu (w wypadku
wywiadu).
•
Transkrypcje powinny być jak najbardziej
dosłowne.

Instrukcje do
transkrypcji
•
Instrukcje do transkrypcji powinny być
zrozumiałe dla każdego.
•
Wskazówki dla tworzenia transkrypcji powinny
być uniwersalne. Oznacza to, że nie są zależne
od osób przepisujących tekst i są zrozumiałe
również dla innych badaczy, mogą być
wykorzystane w replikacjach badania.
•
Instrukcje transkrypcji powinny być fasadowo
eleganckie, czyli proste, łatwe do opanowania i
w niewielkiej liczbie.
•
Instrukcje powinny umożliwiać wykorzystanie
transkrypcji zarówno w analizie komputerowej,
jak i manualnej.

Kodowanie przekazu
•
Kodowanie to redukcja danych
•
Opercjonalizacja:
–
Wybór jednego z istniejących systemów
kodowania
–
Tworzenie własnego systemu kodowania

System kodowania
(code book)
•
System kodowania - spis kategorii
jakościowych zawierających:
–
nazwę wraz z definicją (opisem) ich znaczenia,
–
przykłady treści, które mogą być zaklasyfikowane
do każdej z kategorii, oraz
–
instrukcję kodowania dla sędziów kompetentnych.
•
Obok kategorii jakościowych może zawierać
skale ocen:
–
np. ocena abstrakcyjności (abstrakcyjna – konkretna),
pozytywności (pozytywne – negatywne), aprobaty
społecznej (wysoka – niska).

Role
Role
społeczne
społeczne
1
1
Ja Student
1
Ja
Profesjonalis
ta
2
Ja Dziecko
3
Ja w zabawie
4
Ja w
Ja w
relacjach z
relacjach z
innymi
innymi
2
2
Relacje z
rodziną
1
Relacje z
rówieśnikami/
przyjaciółmi/
innymi
2
Bliskie
związki;
miłość
3
Spostrzegani
e przez
innych
4
Opis Ja
Opis Ja
3
3
Stałe cechy
1
Funkcjonowani
e poznawcze
2
Spostrzegan
a
wyjątkowoś
ć Ja
3
Własne
doświadczeni
a
4
Głębokość
Głębokość
opisu Ja
opisu Ja
4
4
Ja
obserwowal
ne
1
Ja głębokie
2

Wybór jednostki analizy
•
Zmienne obserwowalne:
–
słowa,
–
znaki (symbole pozawerbalne i niewerbalne np.
uśmiech, emotikony),
–
znaki przystankowe,
–
postacie,
–
bezpośrednie miary czasu i przestrzeni.
•
Zmienne latentne:
–
jednostki znaczeniowe (meaning units),
–
tematy (themes) lub
–
tezy (thesis).

Poziomy
obserwowalnych
jednostek analizy treści
•
Grey i współpracownicy (1965) w
eksperymencie metodologicznym
wykazali, że wykorzystywanie do analizy
szerszych jednostek kodowania, np.
akapitów, powoduje, że cały przekaz
klasyfikowany jest jako mniej neutralny.

Techniki analizy treści
•
Zliczanie frekwencji określonych słów czy
wyrażeń
•
Identyfikowanie zdań – kontekstów
•
Kategoryzowania znaczeń przez
sędziów kompetentnych (coders)

Szukanie jednostek
znaczeniowych w tekście
•
„Podziel, proszę, każdą wypowiedź na
mniejsze jednostki. Kryterium podziału jest
spójność logiczna jednostki. Każda
wyodrębniona jednostka powinna mówić
wyłącznie o jednej rzeczy, zjawisku, cesze,
odczuciu, itd. Podczas podziału nie należy
kierować się podziałem gramatycznym czy
interpunkcyjnym. Jedna jednostka to może
być równie dobrze jedno słowo, jak i zdanie
złożone.”

Przykład podziału na
jednostki znaczeniowe
1.
Yyy miałam bardzo szczęśliwe dzieciństwo,
2.
yyy ponieważ mam dobry kontakt z rodzicami
3.
i nie pochodzę z jakiejś rozbitej rodziny, także... wszystko
było w porządku
4.
i myślę, że to jest bardzo ważne, booo mmm dało mi to...
energię na..., na dalsze życie.
5.
Wiem, że to jest bardzo ważne, aby rodzice kochali swoje
dziecko
6.
iii i to dostałam w domu, na pewno.
7.
Mmm nadal mieszkam z rodzicami,
8.
yy teraz studiuję
9.
iii i myślę, że rozwijam się
10.
i robię to, co lubię.
11.
Yyy (westchnięcie) jeśli chodzi jeszcze o dzieciństwo, to...
mmm wspólne wyjazdy wakacyjne iii.. zwierzęta w domu, no
to wszystko było ważne.

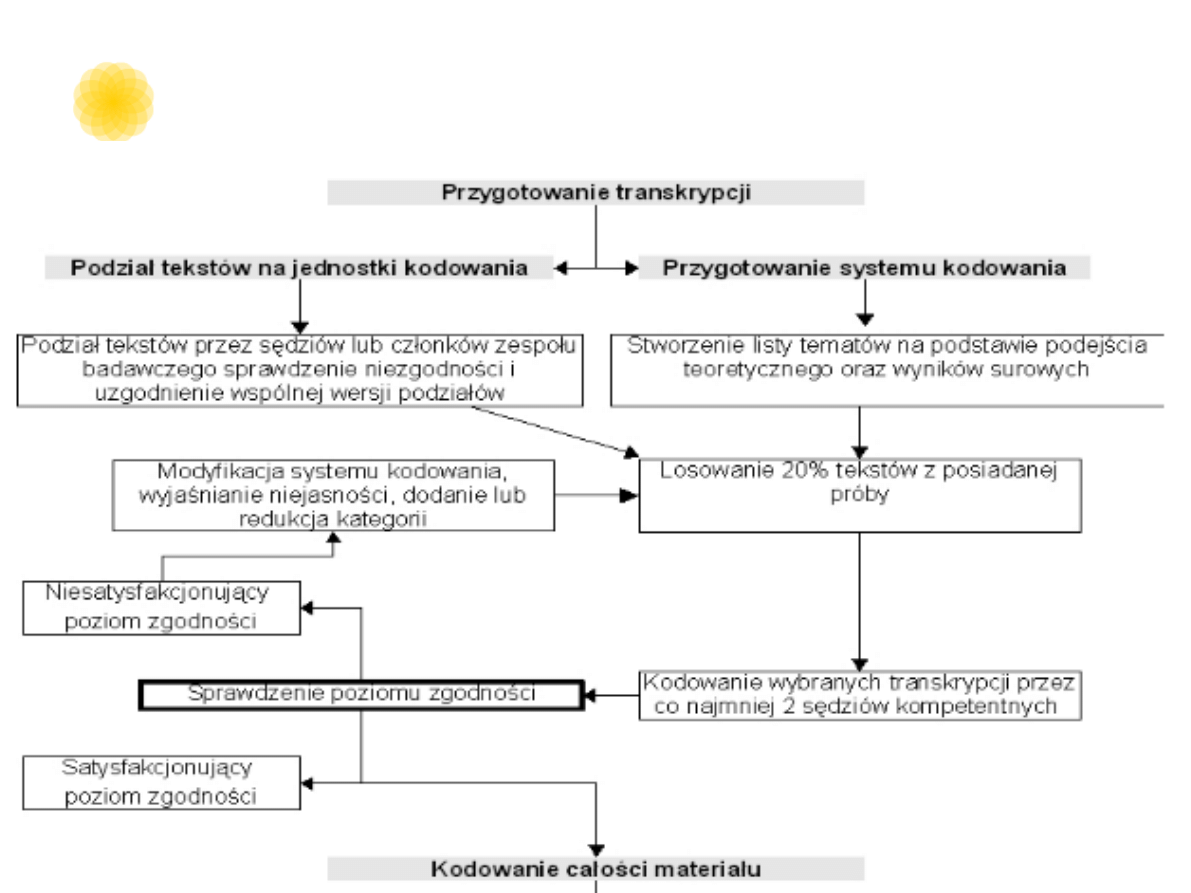
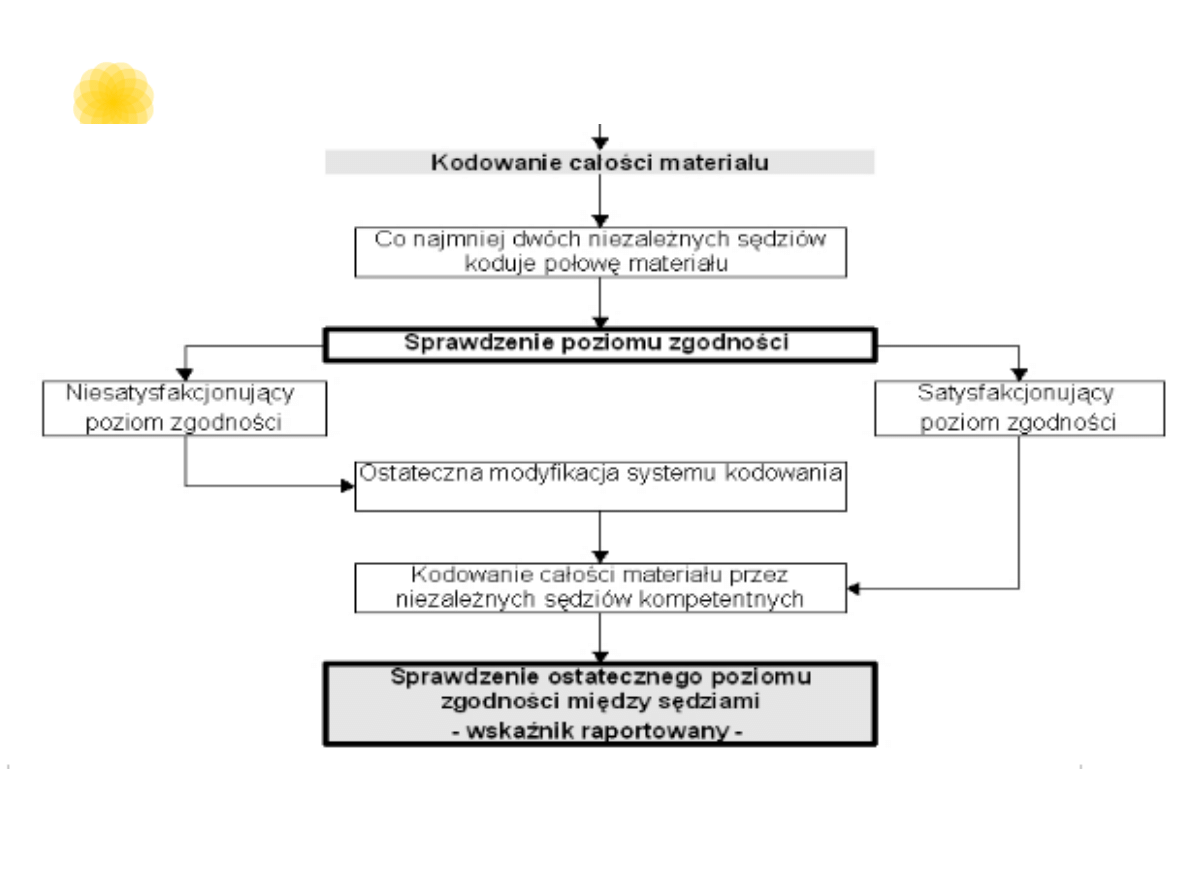
Problem rzetelności
w analizie treści

Podejście 1
•
Metody jakościowe, tworzą odrębny
paradygmat metodologiczny i w związku z
tym kryteria oceny badań, takie jak
rzetelność czy trafność, nie powinny być
brane pod uwagę przy ich ewaluacji (Guba
i Lincoln, 1994; Madill, Jordan i Shirley,
2000).

Podejście 2
•
Inni badacze i metodologów podkreślają
znaczenie wysokiej trafności i rzetelności,
–
w celu osiągnięcia wysokich współczynników
zgodności i trafności należy zachować szereg
standaryzowanych procedur podczas całego
procesu analizy: od przygotowywania
transkrypcji po wyciąganie wniosków
(Krippendorff, 1980; Weber, 1990)

Rzetelność kodowania
•
Badaczowi zależy na stworzeniu
rzetelnych i trafnych narzędzi, które
posłużą później sędziom do redukcji
materiału badawczego.
•
Ważne jest, aby narzędzia te zostały
poprawnie zrozumiane i zastosowane
przez osoby kodujące.

Trzy typy
rzetelności
stabilność, dokładność i
spójność

Stabilność (stability)
•
Polega na powtórnym zakodowaniu tych
samych danych przez te same osoby.
–
Np. interesujemy się treścią snów osób
depresyjnych, możemy poprosić o zakodowanie
wybranych snów według przygotowanego
uprzednio systemu kodowania. Po upływie kilku
tygodni prosimy te same osoby kodujące o
powtórną klasyfikację treści tych samych snów.

Dokładność (accuracy)
•
Mierzy zgodność zakodowania materiału w
odniesieniu do standardu, ustalonego
przez grono ekspertów lub na podstawie
wcześniejszych badań.

Spójność
(reproducibility)
•
W raportach z badań wykorzystujących
metody jakościowe najczęściej spotkamy
statystyki odnoszące się do zgodności
rozumianej jako spójność kodowania
materiału przez kilka osób kodujących
–
Pomiar tego typu rzetelności opiera się na
oszacowaniu proporcji zgodnych kategoryzacji
między sędziami do wszystkich podjętych przez
nich decyzji.
–
W tym przypadku rzetelność często określana jest
jako stopień zgodności między sędziami lub
rzetelność między sędziami (inter-rater reliability).

•
Przypisanie wartości liczbowej może
oznaczać zarówno określenie natężenia
jakiejś cechy na skali typu Likerta, jak i
przydzielenie danemu fragmentowi tekstu
określonej kategorii jakościowej.

kodowanie
•
„…można powiedzieć, że jestem perseweratywna i
po prostu nie potrafę przejść dalej jeżeli mam
jakiś problem, że ktoś mi sprawił jakąś przykrość
tylko zagłębiam się nad tym, myślę nad tym
ciągle i to mi jednak przeszkadza.”
–
Jeżeli powyższą wypowiedź jeden z sędziów oceni jako
negatywną i przydzieli jej wartość 1, a drugi oceni ją na 5
(pozytywna), wtedy podjęte decyzje nie są spójne ze sobą.
W takiej sytuacji badacz nie może uznać, iż wypowiedź
została zakodowana w sposób rzetelny.
•
Przy obliczaniu stopnia zgodności
interesujemy się tym, jak wiele identycznych
decyzji podjęli sędziowie kompetentni.

Statystyki zgodności –
czego nie powinniśmy robić
•
Nie możemy zastosować analizy korelacji:
–
Współczynnik korelacji mówi o kowariancji wyników, a
nie o tym, czy porównywane pary wartości są identyczne
–
Przy obliczaniu współczynnika korelacji operujemy na
danych wystandaryzowanych. Informuje on o
relatywnym uporządkowaniu wartości
•
Podobnie, w przypadku danych nominalnych nie
powinniśmy posługiwać się wskaźnikiem chi-
kwadrat, który jest miarą siły związku dla
zmiennych kategorialnych.
–
Współczynnik chi-kwadrat odpowiada na pytanie, na ile
rozkład obserwowany różni się od oczekiwanego.

Procent zgodnych
kategoryzacji
–
Obliczeniu proporcji zgodnych kategoryzacji do
całkowitej liczby podjętych przez sędziów
decyzji
–
Wybierając tę statystykę nie uwzględniamy
prawdopodobieństwa przypadkowej spójności sędziów
w ocenie materiału.

Pi Scotta
•
Uwzględnia on przypadkową zgodność
między sędziami
•
Uważany za statystykę konserwatywną
•
Teoretycznie przyjmuje wartości od -1 do
1, gdzie -1 oznacza zupełną niezgodność
między sędziami a 1 idealną zgodność,
natomiast 0 oznacza zgodność pomiędzy
sędziami na poziomie przypadku

Kappa Cohena
•
Tworzona jest tabela krzyżowa z taką
samą liczbą kategorii w rzędach i
kolumnach odpowiadającą liczbie kategorii
systemu kodowania
•
W kolumnach znajdują się klasyfikacje
jednego z sędziów, a w rzędach decyzje
podjęte przez drugiego z sędziów
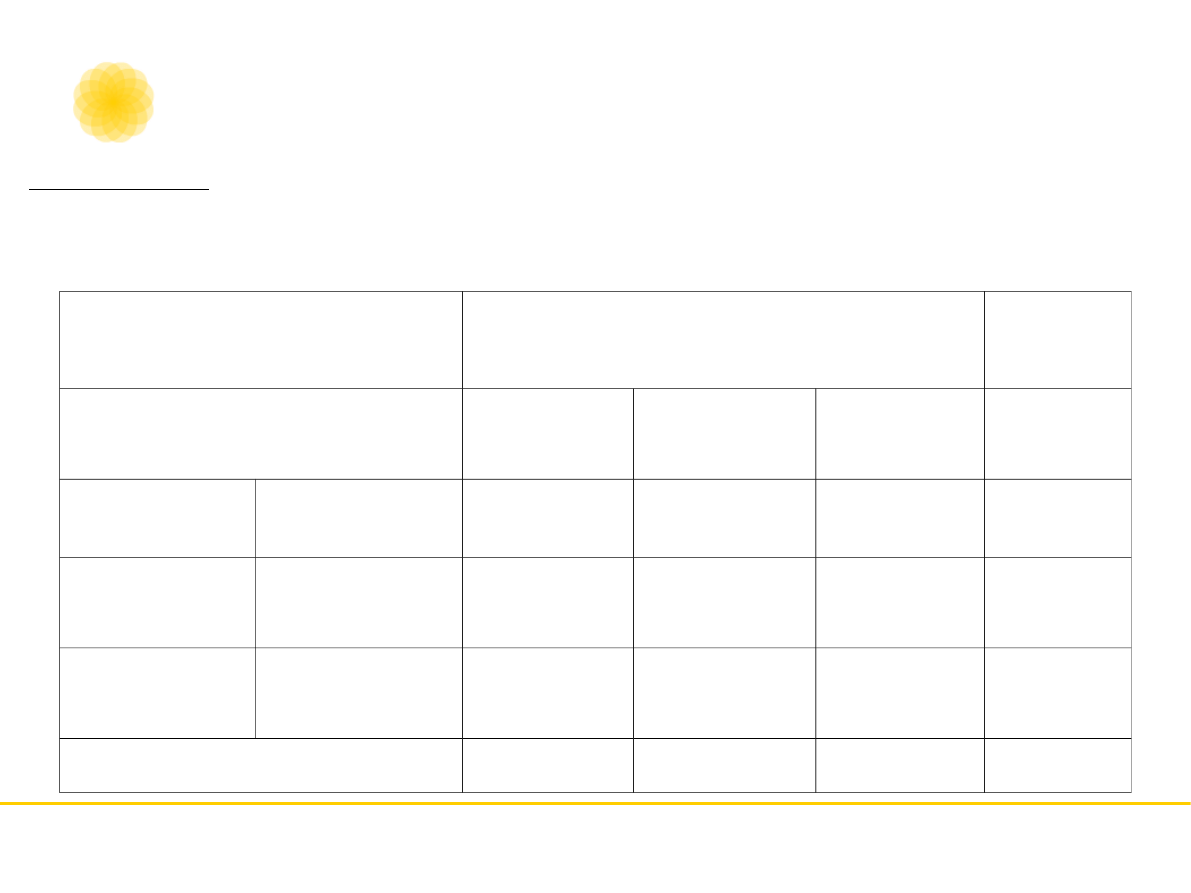
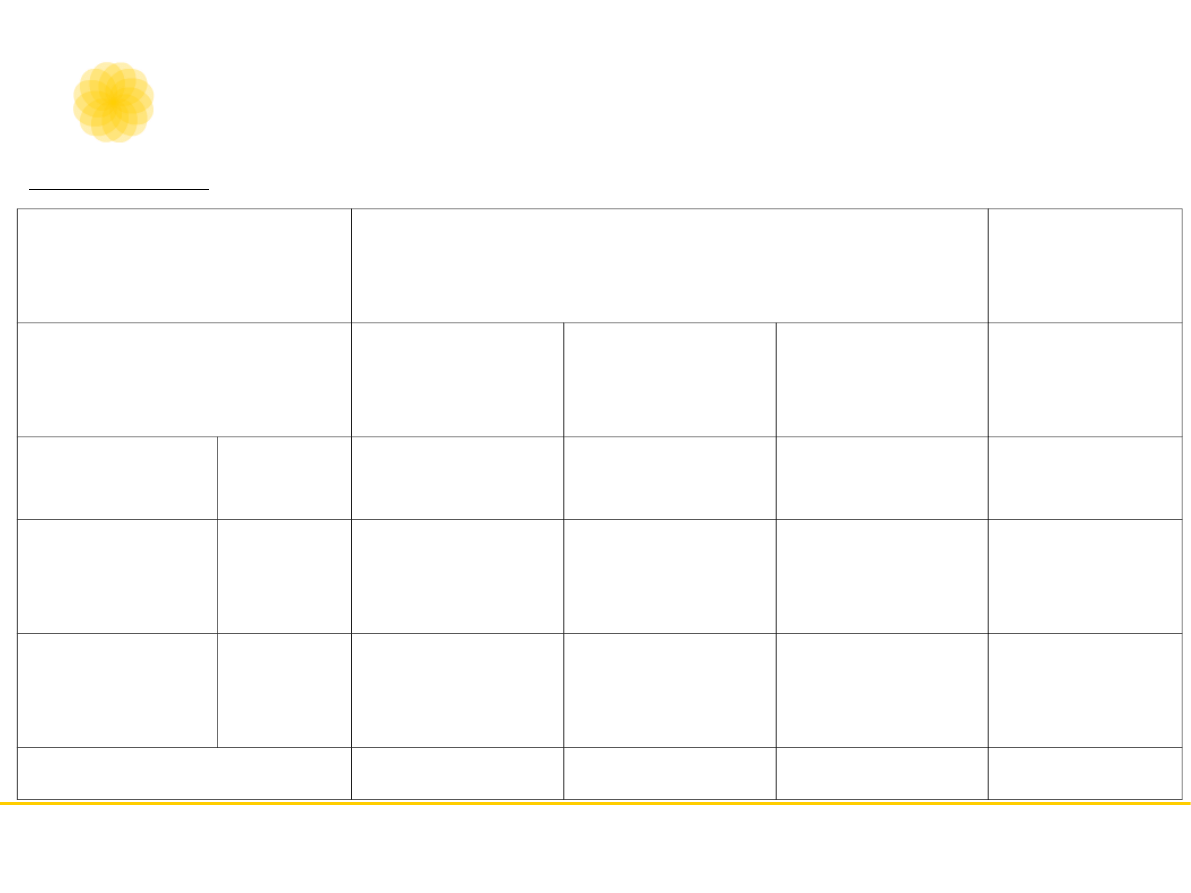
ocena - sędzia 1
Suma
liczebności
pozytywn
e
negatywn
e
mieszane
ocena -
sędzia 2
pozytywne
3
2
1
6
negatywne
1
5
1
7
mieszane
1
1
5
7
Suma
5
8
7
20
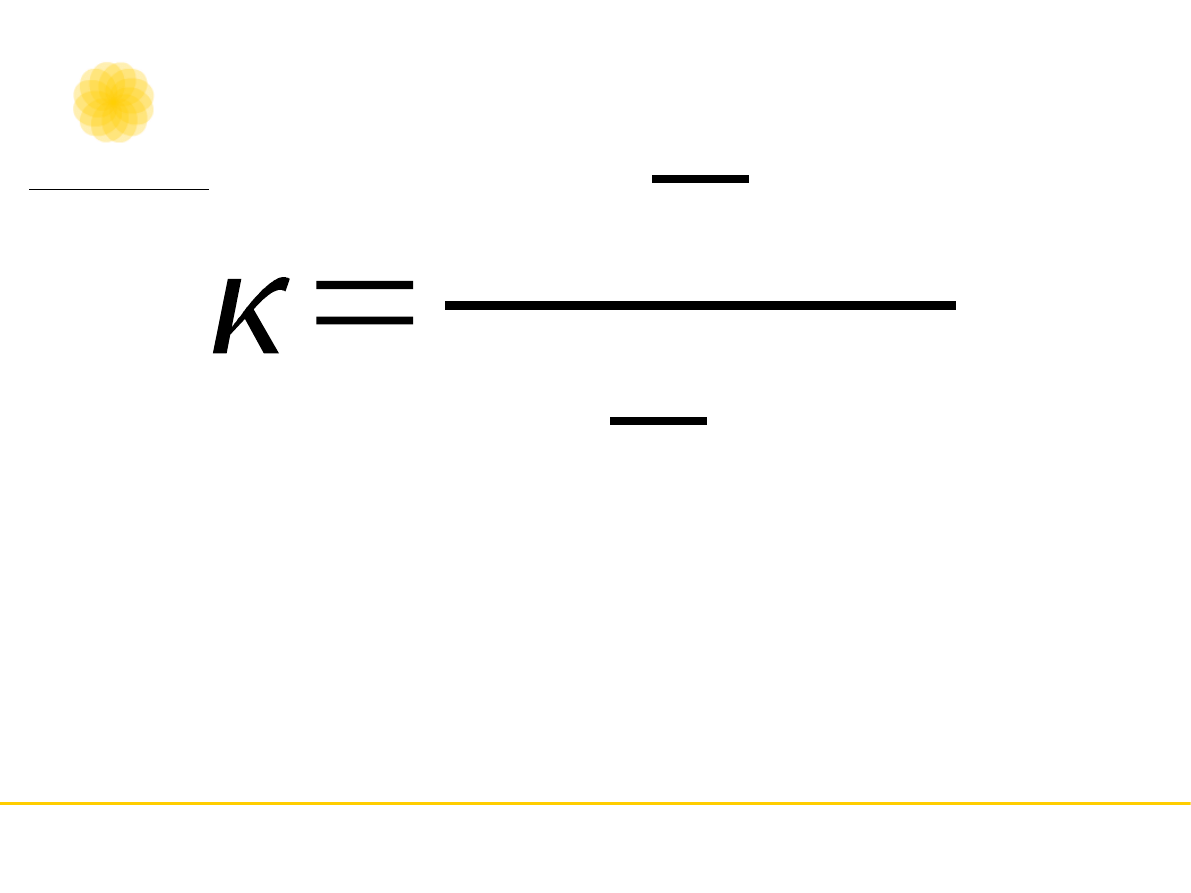
•
Po – proporcja decyzji zgodnych; Pe –
proporcja oczekiwanych decyzji zgodnych
przez przypadek.
P
o
P
e
1
P
e
Współczynnik kappa obliczany jest z proporcji,
które wyliczamy dzieląc wartość obserwowaną w
danej celce przez wartość wszystkich
kategoryzacji (w tym wypadku 20). W wyniku
tego działania otrzymujemy poniższą tabelę
ocena - sędzia 1
Suma
proporcje
pozytywne
negatywne
mieszane
ocena -
sędzia 2
pozyty
wne
0,15
(0,075)
0,10 (0,12)
0,05 (0,105) 0,30
negaty
wne
0,05
(0,0875)
0,25 (0,14) 0,05
(0,1225)
0.35
miesza
ne
0,05
(0,0875)
0,05 (0,14)
0,25
(0,1225) 0.35
Suma
0.25
0,40
0.35
1,00
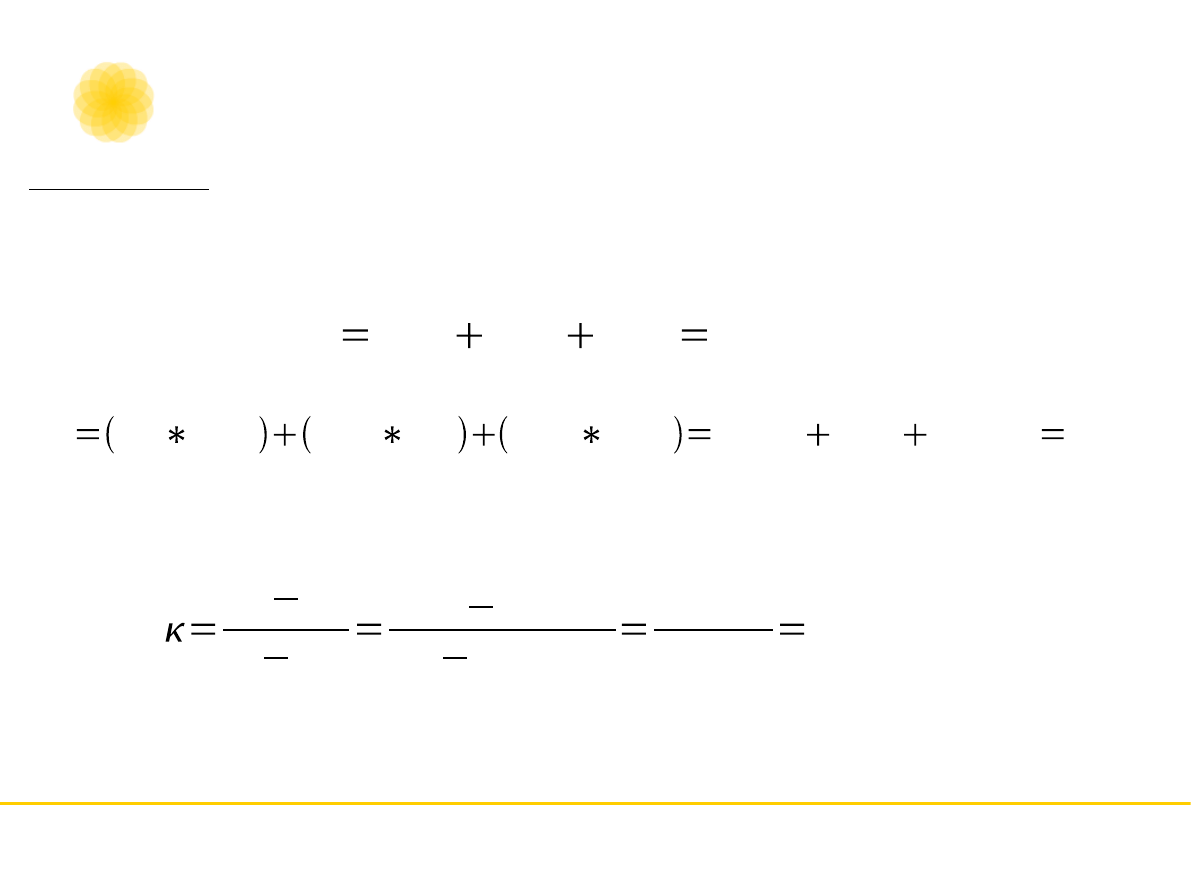
P
o
0,15
0,25
0,25
0,65
P
e
0,3
0,25
0,35
0,4
0,35
0,35
0,075
0,14
0,1225
0,3375
P
o
P
e
1
P
e
0,65
0,3375
1 0,3375
0,3125
0,6625
0,472
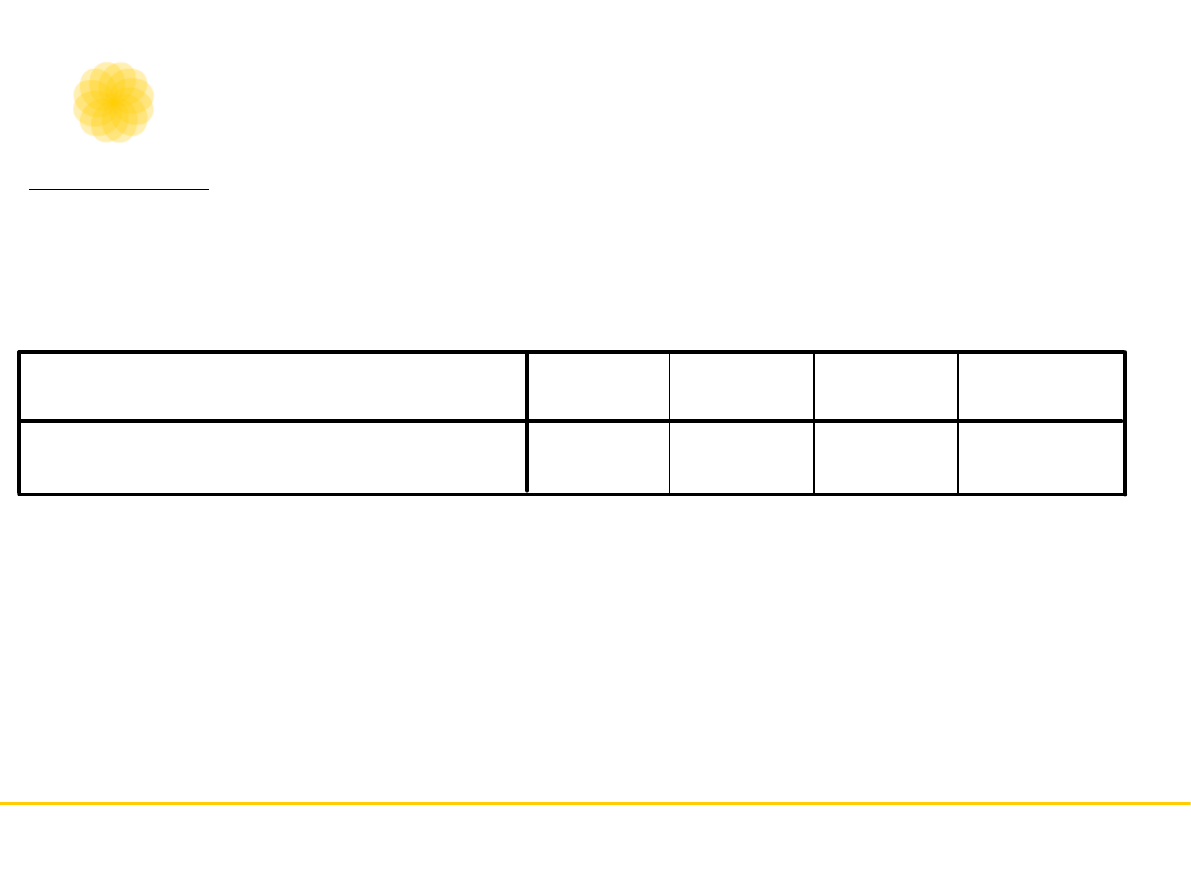
Symmetric Measures
,472
,159
2,984
,003
20
Kappa
Measure of Agreement
N of Valid Cases
Value
Asymp.
Std. Error
a
Approx. T
b
Approx. Sig.
Not assuming the null hypothesis.
a.
Using the asymptotic standard error assuming the null hypothesis.
b.

Interpretacja
współczynników zgodności
•
Możemy ogólnie przyjąć, iż wartości
współczynnika rzetelności powyżej 0,8
oznaczają bardzo wysoką rzetelność.
•
W niektórych przypadkach, przy
zastosowaniu bardziej konserwatywnych
współczynników.
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
Wyszukiwarka
Podobne podstrony:
Metodologia badań z logiką dr Izabela Krejtz wykład 7aa Analiza danych w modelu regresyjnym
Metodologia badań z logiką dr Izabela Krejtz wykład 5c Analiza efektów interakcyjnych
Metodologia badań z logiką dr Izabela Krejtz wykład 6b Wprowadzenie do analizy regresji
Metodologia badań z logiką dr Izabela Krejtz wykład 7b Hierarchiczna analiza regresji
Metodologia badań z logiką dr Izabela Krejtz wykład 2a Psychologia jako nauka empiryczna
Metodologia badań z logiką dr Izabela Krejtz wykład 13 Obserwacja zachowania
Metodologia badań z logiką dr Izabela Krejtz wykład 15 Powtórzeniowy wykład podsumowujący
Metodologia badań z logiką dr Izabela Krejtz wykład 8a Badania porównawcze osób depresyjnyc
Metodologia badań z logiką dr Izabela Krejtz wykład 5b Randomizacja
Metodologia badań z logiką dr Izabela Krejtz wykład 6aaa Plany mieszane
Metodologia badań z logiką dr Izabela Krejtz wykład 6a Plany z powtarzanymi pomiarami
Metodologia badań z logiką dr Izabela Krejtz wykład 8 Psychofizyka poznawcz
więcej podobnych podstron