
P O L I T E C H N I K A K O S Z A L I Ń S K A
I N Ż Y N I E R S K I E Z A S T O S O W A N I A K O M P U T E R Ó W
Projekt sieci komputerowej w budynku mieszkalnym pięciokondygnacyjnym dla 50-ciu użytkowników z dostępem do Internetu.
Praca przejściowa
Autor
Krzysztof Wiśniewski
IZK - Aplikacje Internetowe
Semestr VII
I Wstęp
Przedmiotem niniejszego opracowania jest projekt sieci komputerowej w pięciokondygnacyjnym budynku mieszkalnym. Zgodnie z ustaleniami przeprowadzonymi z mieszkańcami określono ilość stanowisk komputerowych jaką ma obsłużyć sieć.
Całość ma składać się z:
-jednego serwera sieciowego,
-10 stacji roboczych na parterze,
-10 stacji roboczych na 1-szym piętrze,
-10 stacji roboczych na 2-gim piętrze,
-10 stacji roboczych na 3-cim piętrze,
-10 stacji roboczych na 4-tym piętrze,
Serwer ma obsługiwać sieć w technologii FastEthernet. Wymagany jest dostęp do Internetu. Użytkownicy zastrzegli sobie możliwość rozbudowy sieci w przyszłości o kilka stanowisk komputerowych. Wykonanie sieci powinno być względnie tanie.
1. Założenia ogólne
Okablowanie strukturalne
Rozwój telekomunikacji oraz technik łączności spowodował w poprzednim wieku rozwój technik łączenia różnych środków przekazu. W ostatniej dekadzie XX wielu ilość informacji wzrastała lawinowo i stanął przed użytkownikami problem szybkości przekazu informacji.
Jednocześnie rozwój budownictwa i technik biurowych spowodował konieczność unifikacji infrastruktury kablowej. Należy podkreślić, że system okablowania strukturalnego jest dedykowany dla budynku, a nie dla jakiegokolwiek wybranego sprzętu i musi on spełniać normy obowiązujące dla transmisji kanałów telekomunikacyjnuch : fonii, danych i wizji. Potrzeba przekazu wizji, danych i dźwięku spowodowała konieczność wypracowania norm / standardów / okablowania, które umożliwiają podłączenie i wykorzystanie sprzętu różnych producentów oraz różnego przeznaczenia tanio i pewnie.
Kolebką sieci komputerowych oraz ich standaryzacji są Stany Zjednoczone i tam też powstały pierwsze normy i zalecenia dla parametrów i montażu. Podstawową normą jest wydana w 1995 r. norma EIA/TIA 568A / ,, TIA/EIA Building Telecommunications Wiring Standards ,,/ powstałą na bazie normy EIA.TIA 568 / złącza i kable do 16 Mhz / z uwzględnieniem biuletynów TSB 36 / kable do 100MHz /, TSB 40 / złącza do 100MHz /, TSB 40A / złącza i kable krosowe do 100 Mhz / oraz projektu SP-2840 / złącza i kable do 100 Mhz /.
Ważniejsze inne normy
EIA/TIA 569 "Commercial Building Telecommunications for Pathways and Spaces" (Kanały telekomunikacyjne w biurowcach)
EIA/TIA 606 "The Administration Standard for the Telecommunications Infrastructure of Commercial Building" (Administracja infrastruktury telekomunikacyjnej w biurowcach)
EIA/TIA 607 "Commercial Building Grounding and Bonding Requirements for Telecommunications" (Uziemienia w budynkach biurowych)
TSB 67 "Transmission Performance Specification for Field Testing of Unshielded Twisted-Pair Cabling Systems" (Pomiary systemów okablowania strukturalnego)
TSB 72 "Centralized Optical Fiber Cabling Guidelines" (Scentralizowane okablowanie światłowodowe)
TSB 75 "Nowe rozwiązania okablowania poziomego dla biur o zmiennej aranżacji wnętrz"
TSB 95 "Additional Transmission Performance Guidelines for 4-Pair 100 W Category 5 Cabling"
Na ich podstawie powstała norma międzynarodowa
ISO/IEC 11801 "Information technology - Generic cabling for customer premises",
A na podstawie tej normy opracowano normę europejską
EN 50173 "Information technology - Generic cabling systems”, w której zawarto specyfikę rynków Unii Europejskiej.
Inne europejskie normy związane, to:
EN 50167 "Okablowanie poziome"
EN 50168 "Okablowanie pionowe"
EN 50169 "Okablowanie krosowe i stacyjne"
Przedstawione powyżej normy są w chwili obecnej obowiązującym unormowaniem w zakresie okablowania strukturalnego budynków. Wymienione normy określają parametry techniczne torów transmisyjnych przyporządkowując je do określonych klas - normy europejskie i międzynarodowe lub kategorie - normy amerykańskie.
Najwyższą dotychczas unormowaną kategorią / klasą / jest kategoria 5 / klasa D /, zapewniająca transmisje sygnałów w paśmie do 100MHz na odległość do 100 m.
Rozwój telekomunikacji i sprzętu spowodował wprowadzenie propozycji dla
6 Cat / klasa E / do 200 / 250 / Mhz na złączu RJ 45
7 Cat / klasa F / do 600 Mhz na złączach kompatybilnych ze złączami RJ 45.
Pasmo przenoszenia
Pasmo transmisyjne |
Norma TIA/EIA |
Norma ISO 11801 |
do 100 kHz |
kategoria 1 |
Klasa A |
do 1 Mhz |
kategoria 2 |
Klasa B |
do 16 Mhz |
kategoria 3 |
Klasa C |
do 20 Mhz |
kategoria 4 |
- |
do 100 Mhz |
kategoria 5 |
Klasa D |
do 200 (250) Mhz* |
kategoria 6* |
Klasa E (kategoria 6)* |
od 10 Mhz |
- |
Klasa optyczna |
* projektowana norma
2. Podstawy projektowania
Okablowanie strukturalne w założeniu powinno zapewnić łatwy dostęp do sieci komputerowej jak i telekomunikacyjnej z każdego punktu (pomieszczenia, miejsca pracy ) budynku, biura.
Niestety powyższe założenie w prosty sposób prowadzi do stwierdzenia, że projektując instalacji należy przewidzieć nadmiarową ilość punktów (gniazd) abonenckich niż przewidywana ilość miejsc pracy. W dotychczasowej praktyce przyjmujemy, że na jedno stanowisko pracy należy instalować 3 zakończenia kablowe / 1,5 x RJ 45 / chociaż normy przewidują 2 zakończenia kablowe.
Projektując instalacje okablowania strukturalnego należy wyróżnić niektóre elementy infrastruktury sieciowej:
1. topologia sieci - sposób rozprowadzenia kabli w budynku - gwiazda, pierścień, szyna,
2. okablowanie pionowe - sposób połączenia kablami miedzianymi lub/i światłowodem poszczególnych punktów dystrybucyjnych z wykorzystaniem istniejących kanałów technologicznych budynku,
3. okablowanie poziome - ułożona skrętka pomiędzy punktem dystrybucyjnym a punktem abonenckim,
Segment |
Medium |
Możliwości użytkowe |
Okablowania poziome |
Skrętka |
Głos i dane |
|
Światłowód |
Dane |
Okablowanie pionowe |
Skrętka |
Głos i wolne aplikacje danych |
|
Światłowód |
Szybkie aplikacje danych |
Okablowanie pionowe |
Światłowód |
Zalecane |
|
Skrętka |
W wyjątkowych wypadkach |
4. punkt dystrybucyjny - miejsce / szafa / pozwalające na bezpośrednie konfigurowanie sieci za pomocą kabli krosowych. W punkcje dystrybucyjnym znajdują się końcówki okablowania poziomego, pionowego oraz systemowego. W punkcje tym znajduje się przeważnie także miejsce instalacji urządzeń aktywnych.
Punkt dystrybucyjny |
Norma TIA/EIA 568A |
Norma ISO 11801 |
Między-budynkowy |
Campus Distribution |
Campus Distributor - CD |
Główny (budynkowy) |
Main Distribution |
Building Distributor - BD |
Pośredni (piętrowy) |
Intermediate |
Floor Distributor - FD |
5. gniazda abonenckie - punkt przyłączenia abonenta do sieci komputerowej poprzez sieć strukturalną.
6. połączenia telekomunikacyjne budynków - nazywane okablowaniem międzybudynkowym. Zazwyczaj realizowane jest za pomocą sieci światłowodów wielomodowych lub w niektórych przypadkach przy pomocy skrętki.
3. Klasy i kategorie
Kategoria medium |
Klasa A |
Klasa B |
Klasa C |
Klasa D |
Łącze światło- |
Kategoria 3 |
2000 m |
500 m |
100 m |
- |
- |
Kategoria 4 |
3000 m |
600 m |
150 m |
- |
- |
Kategoria 5 |
3000 m |
700 m |
160 m |
100 m |
- |
Para skręcona |
3000 m |
400 m |
250 m |
150 m |
- |
światłowód |
nie |
nie |
nie |
nie |
2000 m |
światłowód |
nie |
nie |
nie |
nie |
3000 m |
II Najważniejsze zasady projektowe.
Z powyżej przytoczonych norm dla okablowania strukturalnego 5 Cat / klasa D / należy przyjmować poniższe odcinki graniczne:
- maksymalna odległość punktu dystrybucyjnego od gniazda abonenckiego nie może przekraczać 90 m, zaś po doliczeniu kabli krosowych, kabli przyłączeniowych sprzętu aktywnego oraz kabla stacyjnego odległość ta nie może przekroczyć 100 m;
- długość okablowania pionowego nie powinna przekraczać 500m, zaś przy okablowaniu między budynkowym 1500 m. Przy zastosowaniu światłowodu jednomodowego odległość można zwiększyć do 3000 m.
Okablowanie poziome winno biec na całej swojej długości w sposób nieprzerwany do punktu abonenckiego.
Ogólne zalecenie mówi, że na każde 10 metrów kwadratowych powierzchni powinno przypadać na jeden punkt abonencki / 2 x RJ 45 /, na każde 1000 metrów kwadratowych jeden punkt dystrybucyjny. Także jeden punkt dystrybucyjny powinien przypadać na piętro. Bezwarunkowo wszystkie użyte kable powinny być zakończone odpowiednimi końcówkami, W obrębie jednej wykonanej sieci okablowania strukturalnego powinno się używać kabli o jednakowej impedancji nominalnej oraz światłowodowe o jednakowych parametrach włókien, Dla sieci Cat 5 maksymalna długość, na której można wykonać rozplot par przy złączu wynosi 13 mm, Wszystkie elementy sieci powinny być oznaczone numerami, po wykonaniu instalacji należy wykonać dokumentacje sieci, przechowywaną i aktualizowaną przez administratora sieci.
Koncepcja sieci.
Projektując instalacje okablowania strukturalnego należy wyróżnić niektóre elementy infrastruktury sieciowej:
Założenia projektowe systemu - określenie rodzaju medium na którym oparta jest instalacja (światłowód, kabel miedziany ekranowany lub nieekranowany itp.), sekwencja podłączenia żył kabla, protokołów sieciowych, zgodność z określonymi normami i innych zasadniczych cech instalacji.
Punkty rozdzielcze - miejsca będące węzłami sieci w topologii gwiazdy, służące do konfiguracji połączeń. Punkt zbiegania się okablowania poziomego, pionowego i systemowego. Zazwyczaj gromadzą aktywny sprzęt sieciowy (koncentratory, przełączniki itp.). Najczęściej jest to szafa lub rama 19-calowa o danej wysokości wyrażonej w jednostkach U (1U=45 mm).
Okablowanie pionowe (wewnątrz budynku) - kable miedziane lub/i światłowody ułożone zazwyczaj w głównych pionach (kanałach) telekomunikacyjnych budynków, realizujące połączenia pomiędzy punktami rozdzielczymi systemu.
Okablowanie poziome - część okablowania pomiędzy punktem rozdzielczym a gniazdem użytkownika /skrętka/.
Gniazda abonenckie - punkt przyłączenia użytkownika do sieci strukturalnej oraz koniec okablowania poziomego od strony użytkownika. Zazwyczaj są to dwa gniazda RJ-45 umieszczone w puszce lub korycie kablowym.
Połączenia systemowe oraz terminalowe - połączenia pomiędzy systemami komputerowymi a systemem okablowania strukturalnego.
1. Punkty dystrybucyjne
Punkt rozdzielczy jest miejscem, w którym znajdują się wszystkie elementy łączące okablowanie pionowe z poziomym oraz elementy aktywne sieci teleinformatycznej (koncentratory, przełączniki, itp.). Fizycznie jest to szafa (stojąca lub wisząca) lub rama rozdzielcza z panelami oraz elementami do przełączania i podłączania przebiegów kablowych. Możliwe jest także umieszczenie elementów rozdzielczych bezpośrednio na ścianie lub półce.
Główny punkt rozdzielczy (MDF - ang. Main Distribution Frame) - stanowi centrum okablowania w topologii gwiazdy. Zbiegają się w nim kable z sąsiednich budynków, pięter i miejskiej centrali telefonicznej oraz odchodzą przebiegi pionowe (do pośrednich punktów dystrybucyjnych IDF w obiekcie) i poziome do punktów abonenckich zlokalizowanych w pobliżu MDF (do 90m). Często umieszczony jest na parterze lub na środkowej kondygnacji budynku (np. 2 piętro budynku 4 piętrowego), w jego pobliżu znajduje się centralka telefoniczna, serwer lub inny sprzęt aktywny.
Pośredni punkt rozdzielczy (IDF - ang. Intermediate Distribution Frame lub inaczej SDF - ang. Sub-Distribution Frame) - jest lokalnym punktem dystrybucyjnym obsługującym najczęściej dany obszar roboczy lub piętro.
Aby przydzielić użytkownikowi podłączonemu do gniazda abonenckiego wybrany kanał komunikacji w systemie komputerowym lub telefonicznym, wystarczy połączyć odpowiednie gniazdo (port) panelu systemowego z gniazdem panelu rozdzielczego odzwierciedlającego gniazda użytkowników. Umiejscowienie punktów rozdzielczych jest wyznaczane przy uwzględnieniu maksymalnej długości 90m przebiegów kablowych poziomych, obejmujących dany obszar roboczy.
Na rysunku pokazany jest typowy punkt rozdzielczy dla niewielkich instalacji (do kilkuset punktów). Uwzględniono na nim zalecony rozkład dla elementów w szafie rozdzielczej. Przy dużych instalacjach sieci okablowania strukturalnego, należy tak projektować układ punktów rozdzielczych, aby minimalizować długości kabli krosowych.
SuperStack III Switch 4400
wersja 24-portowa - widok z przodu |
widok z tyłu |
Przełącznik gigabitowy o dużej wydajności (ponad 9.8 miliona pakietów na sekundę) pozwala na przełączanie do 36 portów 10/100 Mb/s i od 1 do 3 portów 1000Mb/s. Łącza gigabitowe mogą zostać zagregowane tworząc łącze o paśmie 3Gb. SuperStack III Switch 4400 jest dostępny w dwóch wersjach: z 24 lub 36 portami 10/100 Ethernetu/szybkiego Ethernetu. Obie wersje posiadają port 1000BASE-SX i dwa gniazda na moduły gigabitowego Ethernetu, które pozwalają na instalację dwóch dodatkowych modułów gigabitowego Ethernetu. Moduły dostępne są w wersji 1000BASE-SX lub 1000BASE-LX. Opcja 1000BASE-SX korzysta z wielomodowego łącza światłowodowego, podczas gdy opcja 1000BASE-LX korzysta ze światłowodu jednomodowego.
Wieża przełączników SuperStack III Switch 4400 |
Kluczowe cechy przełącznika SuperStack III Switch 4400
- obsługa 16.000 adresów MAC
-monitorowanie ruchu rozsyłania grupowego (multicast) z wykorzystaniem IGMP: w pełni - automatyczna funkcja oszczędzająca pasmo sieci poprzez ograniczenie ruchu ramek rozsyłania grupowego do określonych portów
- kontrola sztormów ramek rozgłoszeniowych dla każdego z portów.
-obsługa standardu kontroli przepływu IEEE 802.ID dla portów pracujących w trybie full-duplex
-funkcja RAP (Roving Analisys Port), wysyłane i otrzymywane dane mogą być pojedynczo kierowane do analizatorów sieci przyłączonych do oddzielnych portów umożliwiając dokładne monitorowanie łączy pracujących w trybie full-duplex
-obsługa RMON (zdalny monitoring), wbudowany system RMON dla wszystkich portów szybkiego Ethernetu i gigabitowego Ethernetu obsługuje następujące grupy RMON: Statistics, History, Alarms, Events, Host, Traffic Matrix i Host TopN
-obsługa sieci wirtualnych VLAN oparta na standardzie IEEE 802.Q z automatyczną dystrybucją informacji o przynależności do sieci wirtualnych VLAN między przełącznikami - GVRP
-obsługa Class of Service zgodna ze standardem IEEE 802.1p, priorytety obsługiwane przez sprzętowy mechanizm Dual Queues (podwójne kolejki)
-wbudowana funkcja serwera WWW opartego na protokole HTTP umożliwia podstawowe zarządzanie i konfigurację przełączników z dowolnej standardowej przeglądarki sieci WWW
przełączanie nieblokujące z pełną szybkością (6.6 Gb/s i ponad 9.8 miliona pakietów na sekundę)
-agregacja łączy szybkiego i gigabitowego Ethernetu, maksymalnie sześć równoległych łączy można połączyć w jedno logiczne łącze o zwielokrotnionej wydajności, każde urządzenie może obsługiwać maksymalnie cztery takie niezależne połączenia logiczne
-praca w trybie full-duplex na wszystkich portach gigabitowego i szybkiego Ethernetu
2. Okablowanie pionowe
Okablowanie pionowe łączy ze sobą główny punkt dystrybucyjny z pośrednimi punktami dystrybucyjnymi. Wykonane jest ono najczęściej z kabli światłowodowych. Okablowanie pionowe to minimum 6-cio włóknowy kabel światłowodowy wielomodowy (długość do 1500 m dla okablowania szkieletowego międzybudynkowego - z ang. backbone). Można wykonywać okablowanie pionowe również w oparciu o skrętkę czteroparową. W tym przypadku długość jego nie może przekroczyć 90m. Podane odległości są zgodne z normami: amerykańską (EIA/TIA 568), międzynarodową (ISO/IEC 11801) i europejską (EN 50173).
Kable światłowodowe oferowane na rynku do zastosowań w okablowaniu strukturalnym można zasadniczo podzielić na kable o konstrukcji ścisłej lub luźnej tuby. Inne konstrukcje są rzadziej spotykane (np. kable rozetowe, taśmowe). Kable o konstrukcji ścisłej tuby stosuje się zazwyczaj wewnątrz budynku. Są to włókna światłowodowe umieszczone w buforze/izolacji o średnicy zewnętrznej 0.9 mm. Na takich włóknach można zakładać bezpośrednio złącza światłowodowe (ST, SC, MT-RJ lub inne). Kable światłowodowe o konstrukcji luźnej tuby zazwyczaj stosuje się na zewnątrz budynku (podwieszane - kabel światłowodowy dielektryczny, w kanalizacji wtórnej lub bezpośrednio zakopywane w ziemi - kabel światłowodowy zbrojony). Włókna światłowodowe umieszczone są w tubach wypełnionych żelem silikonowym, zapewniających ochronę włókien przez naprężeniami i oddziaływaniem warunków atmosferycznych (temperatura, wilgotność).
Kabel uniwersalny przeznaczony jest standardowo do kładzenia w kanalizacji wtórnej na zewnątrz budynku. Posiada on niepalną izolację (LSZH - z ang. Low Smoke Zero Halogen) i spełnia wymogi przepisów przeciwpożarowych, dlatego może być również stosowany wewnątrz budynków.
Kabel zbrojony może być zakopywany bezpośrednio w ziemi. Posiada metalowe zbrojenie chroniące kabel przez gryzoniami, jak też przypadkowym uszkodzeniem.
3. Okablowanie poziome
Typowy przykład implementacji okablowania poziomego pokazany jest na rysunku.
Standardowym nośnikiem sygnałów w okablowaniu poziomym jest skrętka czteroparowa miedziana kategorii 5. Chociaż coraz częściej spotkać można jako medium transmisyjne kabel światłowodowy wielomodowy (instalacja OFTD - z ang. Optical Fibre to the Desk - czyli światłowód do biurka).
Występują dwa rodzaje skręconych kabli miedzianych czteroparowych:
- kabel nieekranowany - UTP (z ang. Unshielded Twisted Pair);
- kabel ekranowany z ekranem w postaci folii lub plecionki z drutów stalowych - FTP (z ang. Foiled Twisted Pair) lub STP (z ang. Shielded Twisted Pair).
Skręt każdej pary kabla jest inny co wpływa na zmniejszenie zjawiska przesłuchów pomiędzy poszczególnymi przewodami, co w znacznym stopniu powodowało zakłócenia. Skręcenie tych par przewodów nazywane jest splotem norweskim.
4. Okablowanie ekranowane
Okablowanie ekranowane jest droższe w instalacji i trochę bardziej wymagające uwagi niż okablowanie nieekranowane. Ocenia się, że wykonanie instalacji ekranowanej zwiększa całkowity koszt o około 50%. Okablowanie ekranowane ma jednak niezaprzeczalne zalety: zmniejsza emisję elektromagnetyczną na zewnątrz sieci i zwiększa odporność na zakłócenia, przy spełnieniu rygorystycznego warunku jakim jest poprawne zakańczanie kabli i uziemianie ekranu kabla oraz paneli i całych punktów dystrybucyjnych. Uziemienie takie powinno spełniać wymagania określone w zaleceniach producenta okablowania (np. firma Molex Premise Networks zaleca, aby uziom do którego podłączona jest instalacja ekranowana miał rezystancję poniżej 1Ω .
Zastosowanie okablowania STP w szybkich sieciach teleinformatycznych wynika na ogół z potrzeby:
Zabezpieczenia przesyłanych sygnałów od wpływów otoczenia (ochrona danych sygnałowych przed zakłóceniami środowiskowymi EMI oraz RFI),
Odizolowanie środowiska od przesyłanych sygnałów (utajnienie przesyłanych danych,
Ochrony sygnałów przed zakłóceniami pochodzącymi od innych kabli informatycznych,
Minimalizacji potencjalnych przyszłych problemów związanych z zagęszczaniem sprzętu i linii w budynku.
Kable instalacyjne należą do grupy produktów pełniących funkcję tzw. fizycznej magistrali informatycznej połączeń tworzących strukturę sieci. Kabel instalacyjny dostępny jest w wersji standardowej 4*(2*AWG24) oraz w wersji podwójnego kabla 2*(4*2*24AWG).Asortyment obejmuje kable w zakresie 100 MHz, 200 MHz i 600 MHz. Wszystkie rodzaje kabla dostarczane są z oznakowaniem długości w metrach
i oznaczeniem barwnym każdego przewodu, co w połączeniu z kablem na złączu blokowym modułu RJ 45, ułatwia poprawne "rozszycie" kabla według sekwencji 586A lub 586B. Oferowane kable w systemie Eltra LexCom wystepują w izolacji HFFR (bez halogenowej). Kable instalacyjne posiadają certyfikaty niezależnych laboratoriów pomiarowych.
DELTA (Dania) i ETL (USA) testowane do 160 MHz.
5. Punkt abonencki
Punkt abonencki, do którego przyłączony jest użytkownik sieci strukturalnej składa się standardowo z podwójnego gniazda typu RJ 45 (rysunek) i ewentualnie dodatkowego gniazda światłowodowego, umieszczonych najczęściej w puszce instalacyjnej (natynkowej, podtynkowej lub przeznaczonej pod suchy tynk).
III Montaż
Podczas układania kabli należy zwrócić szczególną uwagę na promienie gięcia oraz naciągi, nie dopuszczając do powstania naprężeń i załamań.
Łączenie kabli UTP jest zabronione. Poszczególne kable od szafy KK do gniazd muszą stanowić jednolitą całość.
Na obu końcach poszczególnych kabli UTP pozostawić zapasy w ilości: szafa KK 2m,gniazdo komputerowe 0,3m
Wszystkie kable oznakować w sposób czytelny w odległości 0,15m od końców oraz w miejscach krzyżowania się dużej liczby kabli. Kable należy oznaczać zgodnie z oznaczeniami gniazd komputerowych według kodu: K BB CC Gdzie:
K - symbol gniazda komputerowego
BB - oznacza nr pomieszczenia
CC - oznacza nr gniazda w pomieszczeniu
Kable układać w odległości minimum 0,3m od kabli energetycznych.
W przestrzeni między sufitowej kable układać w istniejących korytkach metalowych przeznaczonych dla instalacji niskonapięciowych i sygnałowych (alarmy, ppoż, telefony, sieć teleinformatyczna)
Nad ciągami komunikacyjnymi kable układać w istniejących w przestrzeni między sufitowej korytkach metalowych.
Połączenie poszczególnych elementów w obrębie szafy KK oraz połączenia stacji PC z gniazdami wykonać za pomocą kabli połączeniowych UTP.
Nadmiary kabli od strony liniowej ułożyć w prowadnicach będących na wyposażeniu szafy krosowo-serwerowej a po stronie stacyjnej w prowadnicach kabli zwracając uwagę na promienie gięcia.
Korytka mocować do ścian wykonanych cegły pełnej otynkowanej za pomocą kołków min co 0,5m oraz min 0,05m od końców listew.
Z pomieszczeń kable prowadzić w korytkach PCV pionowo po ścianach do przestrzeni między sufitowej umocowując je za pomocą opasek do przegrody korytka co 1m .
Zakończenia korytek oraz miejsca zagięć wyposażyć w zaślepki oraz kąty płaskie.
Serwer i HUB będą umieszczone w jednym z pomieszczeń. Wybrane karty sieciowe są kompatybilne z obowiązującymi standardami, posiadają gniazdko RJ - 45 i współpracują ze standardem 100BaseTX.
1. Opis budynku
Budynek nie posiada istniejącej sieci, tylko komputery stacjonarne, które mają być połączone w sieć (50 stanowisk). Plany budynku, rozkład pomieszczeń oraz ich wymiary dostarczyła administracja.
Pomieszczenia na pięciu kondygnacjach są rozmieszczone w sposób analogiczny, różnią się tylko niektórymi ściankami działowymi.
Budynek składa się z parteru i 4 pięter. Na każdej kondygnacji znajduje się 10 mieszkań.
IV Projekt Logiczny sieci
Projektowana sieć komputerowa będzie składać się z:
Serwera - 1 szt.
50 stacji roboczych,
Switch 24-portowy - 5 szt.
Router Cisco 1005 - 1 szt.
Modem HDSL Zyxel InterDSL 2000 2Mbit - 1 szt.
wtyki RJ-45,
okablowanie: skrętka,
UPS - 1 szt.
karty sieciowe,
gniazda sieciowe,
korytka PCV
Serwer oraz switch będą mieściły się na parterze w zapleczu. Ponieważ sieć będzie administrowana poprzez jedną z końcówek sieci, komputer działający jako serwer nie będzie obsługiwany bezpośrednio ze swojego stanowiska.
Aby spełnić wymagania użytkownika co do dalszej możliwej rozbudowy sieci, będzie zastosowany switch 24 portowy na każdym z pięter. Wówczas pozostanie wolnych 14 portów na każdym z pięciu pięter, co daje możliwość przyłączenia 70 nowych stacji roboczych.
Aby spełnić wymagania użytkownika zastosowana będzie technika sieciowa Fast Ethernetu o strukturze sieci typu gwiazda oraz interfejs międzynośnikowy 100BaseTX, który określa oryginalną specyfikację 100BaseX dla kategorii 5 nieekranowej skrętki UTP. W ten sposób maksymalna przepustowość sieci wyniesie 100Mbps, a wykorzystanie tego typu okablowania gwarantuje ewentualną rozbudowę sieci.
Do połączenia sieci lokalnej z internetem będzie służył serwer połączony za pomocą usługi Polpak-T.
Server będzie zawierał konta użytkowników, sluzyl jako serwer WWW i e-mail.
1. Serwer
Serwer będzie udostępniał połączenie sieci internet poprzez NAT. Z tego powodu będą zastosowane: maskarada, firewall oraz SSH - w celu ochrony komputerów w sieci przed ingerencją użytkowników internetowych.
W celu zmniejszenia kosztów serwer będzie miał zainstalowany system operacyjny LINUX RedHat. Ze względu na możliwość przyszłej rozbudowy sieci wystarczającą konfiguracją serwera będzie AMD 1300 256MbRAM, HDD 80Gb 7200Rpm Seagate + karta graficzna + karta sieciowa. Komputer nie będzie zawierał monitora i klawiatury oraz innych urządzeń zewnętrznych ze względu na administrację serwera z wybranej stacji roboczej sieci. System LINUX umożliwi dalszą rozbudowę sieci (www, serwer plików ,FTP).
2. Karty sieciowe
Zgodnie ze zleceniem zamawiającego wszystkie stacje robocze wyposażyć w karty sieciowe Fast Ethernet PCI Realtek RTL8139. Serwer sieciowy ze względu na duży przepływ danych wyposażyć w kartę 1000Base T Ethernet .
3. Przełącznik (switch)
W rozwiązaniu zaproponowano zastosowanie nowoczesnego przełącznika firmy Przełącznik SuperStack III Baseline w pełni zarządzalnego.
Proponowany Projekt Logiczny sieci
V Projekt sieci
1. Rzut pomieszczeń
Rzut parteru projektowanej sieci obrazuje schemat. Opis poszczególnych pomieszczeń:
Nr pomieszczenia |
Nr gniazda sieci |
Długość kabla[m] |
01 |
K 01 01 |
12,5 |
02 |
K 02 02 |
16,5 |
03 |
K 03 03 |
30,0 |
04 |
K 04 04 |
34,0 |
05 |
K 05 05 |
41 |
06 |
K 06 06 |
44 |
07 |
K 07 07 |
43 |
08 |
K 08 08 |
41 |
09 |
K 09 09 |
38 |
10 |
K 10 10 |
5 |
Suma |
340 (na każde piętro) |
|
Okablowanie pionowe(między switchami) |
ok 50 |
|
Medium transmisyjne stanowi skrętka nieekranowana kat. 5, która jest w każdym połączeniu zakończona z obu stron wtykiem RJ - 45. Zastosowano zgodne podłączenie końcówek, tzn. wszystkie kabelki wewnątrz przewodu podłączone są do wtyków w następujący sposób: styk pierwszy we wtyczce pierwszej do styku pierwszego we wtyczce drugiej, itd.
2. Połączenia kabli
Ponizej przedstawione sa polaczenia kabli we wtyczkach RJ - 45. Proste i skrosowane (1-2:3-6 i 3-6:1-2).
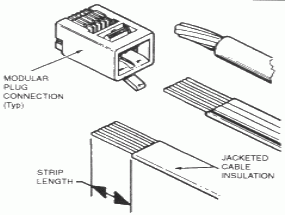
Aby zainstalować wtyczkę na kablu należy:
- Przyciąć końcówkę kabla tak, aby była prostopadła do obrysu przewodu i aby wszystkie osiem składowych przewodów transmisyjnych miało równą długość.
- Kolejnym krokiem jest usunięcie (zazwyczaj szarej) izolacji zewnętrznej na długości około 1cm. Należy przy tym uważać, aby nie uszkodzić żadnego z wewnętrznych (kolorowych) przewodów transmisyjnych.
- Teraz należy włożyć do wtyczki kabelki w zgodnej kolejności.
- Umieszczenie tak przygotowanej RJ-45 do zaciskarki i ściśnięcie szczypiec, co spowoduje przebicie przewodów blaszkami i zaciśnięcie przewodu we wtyczce.
Wykorzystano gniazda sieciowe z dwoma stykiami RJ - 45.
Do każdego z gniazd przewidziano kabel przyłączeniowy do komputera nie dłuższy niż 3 m. Kable będą przeprowadzone w korytkach PCV 5cm od warstwy podłogowej. Korytka będą mocowane za pomocą kołków rozporowych o średnicy 8mm, które będą instalowane w odległości 1m od siebie.
VI Omówienie systemu
1. Historia linuxa i licencja GNU GPL
Wyjaśniając pochodzenie Linuksa wypadałoby rozszyfrować, co oznacza samo słowo Linux. Można się spotkać z paroma jego interpretacjami. Jednak najczęściej używaną jest pierwsza chyba najbardziej słuszna. Nazwa systemu jest skrótem od LINUS UNIX, bo historia Linuksa związana jest z systemem operacyjnym Unix. Druga równie często spotykana interpretacja jest taka, że Linux to akronim od LINUX IS NOT UNIX, czyli Linux nie jest Uniksem. Jednak prawidłowym stwierdzeniem jest to, że UNIX jest ojcem Linuksa. Unix to dość stary system operacyjny, jego początki sięgają wczesnych lat 70. Programiści z laboratorium AT&T napisali pierwszą wersję tego systemu w języku C, który stał się standardem, jeśli chodzi o pisanie wielozadaniowych systemów operacyjnych. Na początku kod Uniksa był darmowy, taki jaki jest obecnie kod Linuksa. Niestety od roku 1979 firma AT&T zaczęła pobierać opłaty za udostępnianie kodu źródłowego. Konsekwencją tego było powstanie wielu nowych odmian tego właśnie systemu. Wówczas powstał m.in. system BSD, SunOS. Powstanie takiej ich liczby sprawiło, że poszczególne programy pisane, na konkretne systemy nie były ze sobą kompatybilne. By zlikwidować ten problem organizacja IEEE stworzyła wspólny standard Posix. Dokument definiował i opisywał poszczególne części Uniksowego systemu, aby zachować zgodność programową poszczególnych wersji. Wadą systemów Uniksowych były dość duże wymagania obliczeniowe. Na tak potężne maszyny było więc stać tylko instytucje i uniwersytety. Zmieniło się to wraz z pojawieniem się procesora 80386 firmy INTEL®. Skłoniło to młodego fińskiego studenta - Linusa Torvaldsa, do prac nad nowym systemem,
a dokładnie mówiąc jądrem systemu . Linux został pierwszy raz udostępniony przez Linusa Torvaldsa w 1991 r. na uniwersytecie
w Helsinkach. Początkowo system nie wzbudził szerszego zainteresowania. Dopiero dostosowanie go do norm standardu Posix, wbudowanie kompilatora języka C oraz kilku podstawowych poleceń Uniksa sprawiło, że szersze grono osób się nim zainteresowało.
Na dynamiczny rozwój Linuksa miał wpływ fakt, że podlega on licencji GPL (General Public License) opracowanej przez FSF (Free Software Foundation). System wiele zawdzięcza FSF, ale również FSF wiele zawdzięcza właśnie Linuksowi. FSF po polsku można przetłumaczyć jako Fundacja Wolnego Oprogramowania. Wolne w tej nazwie nie oznacza koniecznie darmowe, chociaż prawie we wszystkich przypadkach tak jest. Wolne oznacza, że kod źródłowy oprogramowania jest powszechnie dostępny, co umożliwia ich dowolną modyfikację. W ten sposób, jeżeli chcemy coś zmienić lub poprawić w programie, to nie jesteśmy zdani na łaskę producenta. Ma to również wpływ na poprawę jakości kodu, gdyż liczba osób piszących program nie ogranicza się do wyznaczonej przez daną firmę, jest ich nieporównywalnie więcej,
a co za tym idzie liczba środowisk, w jakich jest on uruchamiany
i testowany, jest też dużo większa. FSF została założona w 1984 roku przez Richarda Stallmana. Równocześnie z powołaniem do życia organizacji postanowił stworzyć otwarty system oparty na Uniksie. Jednym z jego priorytetów przy tworzeniu tego systemu była jego kompatybilność. Nazwał go GNU (GNU Is Not UNIX). Rozpowszechniany miał być na licencji GPL gwarantującej jego wolność. Licencja ta została stworzona właśnie przez FSF. Licencja GPL - obejmuje oprogramowanie prawami autorskimi, oraz oferuje legalne pozwolenie na kopiowanie, dystrybucję i modyfikację oprogramowania - o czym pisze w preambule. Tak więc każdy użytkownik otrzymując oprogramowanie na licencji GPL musi wiedzieć, że „nie ma gwarancji na to oprogramowanie. Jeśli program jest modyfikowany przez kogoś innego i przekazany, chcemy, żeby odbiorcy programu wiedzieli, że to co otrzymał to nie jest oryginał, żeby problemy wprowadzone przez innych nie odbiły się na reputacji oryginalnych autorów.” Po pewnym czasie od tych wydarzeń pojawił się Linux. Jednak czym jest Linux i jaki ma on związek z FSF, GNU i GPL? Pojęcie Linux może być i jest używane w dwóch znaczeniach:
jako jądro systemu stworzone przez Linusa Torvaldsa,
jako dystrybucja, czyli jako jądro systemu i oprogramowanie rozpowszechniane z nim.
Pierwsze znaczenie jest bardziej prawidłowe, lecz drugie częściej używane. Linux jako system operacyjny powinno się określać mianem GNU / Linux, czyli system GNU z jądrem Linuksa. Linux powstał więc z połączenia dwóch rzeczy:
jądra systemu stworzonego przez Linusa Torvaldsa
oprogramowania dostarczanego przez GNU na licencji GPL
2. Zastosowania i dystrybucje Linuxa
Linux dzisiaj to doskonały odpowiednik systemów Uniksowych na komputery osobiste. Przejął najlepsze cechy Uniksa. Jest idealny do zastosowań sieciowych, ale można używać go również jako systemu na zwykłym, domowym komputerze. Z czasem zainteresowały się nim wielkie firmy, takie jak INTEL® i Corel. Jest wielozadaniowy i ma małe wymagania sprzętowe. Da się uruchomić nawet na procesorze 80386, jak również na systemach z innym procesorami: SPARC, DEC Alpha, M68k. Linux jest systemem wieloużytkownikowym, posiada wsparcie dla wielu procesorów, posiada również ochronę pamięci, przez co wadliwy program nie zawiesi całego systemu. Jest również systemem oszczędnym przez współdzielone biblioteki, a także przez stronicowanie (selektywne kopiowanie nieużywanych stron pamięci na dysk twardy). Posiada także obsługę ważniejszych protokołów sieciowych, takich jak na przykład: TCP/IP, SLIP, PPP, IPX. Jego chyba największą zaletą jest oczywiście to, że jest darmowy.
Linux stał się popularny wraz z obecną generacją użytkowników komputerów z tego samego powodu, z jakiego wcześniejsze wersje systemu Unix zdobywały swoich fanów 20 lat temu. Wielkie sukcesy odnoszą firmy związane z Linuksem, na przykład firma Redhat - twórca jednej z dystrybucji - odnosi sukcesy na giełdzie.
W stworzenie swojej dystrybucji zainwestował również Corel, przeniósł na platformę Linuksową niektóre ze swych programów.

Za logo Linuksa przyjęto znaczek siedzącego pingwinka. To sympatyczne logo od razu przyjęło się i jeśli jest mowa
o systemach spod znaku pingwina każdy wie o co chodzi.
Każda licząca się firma z branży informatycznej stworzyła coś, co miałoby związek z systemem Linux. Efektem tego jest bardzo dużo dystrybucji tego systemu, które są dostępne na rynku.
Dystrybucją można nazwać składankę jądra Linuksa wraz ze zbiorami oprogramowania oraz instalatorem. Stwierdzenie to jest stwierdzeniem umownym, ale moim zdaniem trafnym. Dystrybucje są przygotowywane przez różne firmy, które dobrały niezależnie od siebie zbiory oprogramowania. Czasami też różny jest format pakietów programów i menedżer służący do zarządzania nimi. Najczęściej wykorzystywane są pakiety RPM, po raz pierwszy zastosowane przez firmę Redhat Software oraz pakiety DEB pochodzące z Debiana. Wszystkie odmiany Linuksa opierają się na tym samym jądrze, ewentualnie jego nowszej lub starszej wersji i korzystają często z tego samego zestawu oprogramowania systemowego. Oznacza to, że w środowisku dowolnej dystrybucji może być uruchamiana każda aplikacja linuksowa. Praktycznie
w skład każdej poważnej dystrybucji wchodzą pokaźne zbiory programów: serwerów WWW i FTP, poczty elektronicznej, przeglądarek plików, edytorów tekstu, klientów poczty oraz grup dyskusyjnych. Od twórcy dystrybucji zależy tylko jaki program i jaką jego wersję zamieści jako główną. Dlatego jedne dystrybucje mogą zawierać jako serwer poczty Sendmaila, a inne na przykład Postfixa bądź Qmaila. Wybór dystrybucji zależy od stopnia zaawansowania oraz łatwości obsługi, jednak najczęściej to co dla niektórych jest łatwe dla drugich jest trudne i na odwrót. Dlatego zawsze wybór dystrybucji jest osobistym wyborem użytkownika.
Najbardziej popularną dystrybucją Linuksa jest chyba Redhat, który jest dość łatwy do zainstalowania i późniejszego zarządzania. Dystrybucja ta jest dostępna w Internecie, a do niego firma Redhat Software dość szybko wprowadza różne poprawki i uaktualnienia. Większość początkujących użytkowników wybiera tę dystrybucję. Inne spotykane na rynku wydania Linuksa to: Corel Linux, Debian GNU, Slackware, Mandrake, SuSE, Caldera. Programiści, studenci oraz administratorzy w Polsce postanowili stworzyć swoją własną dystrybucję o nazwie PLD (Polish Linux Distribution), w której duży nacisk położono na bezpieczeństwo i funkcjonalność. Dystrybucje są często dołączane do różnych pism komputerowych, a także obrazy płyt można znaleźć w sieci Internet. Dystrybucje można kupić także u samego producenta, taka dystrybucja najczęściej jest wyposażona w pudełko z dokumentacją i wsparciem technicznym oraz w dodatkowe pakiety oprogramowania takie jak StarOffice firmy Sun Microsystems czy bazy danych Oracle.
VII Instalacja systemu

Wszystkie zagadnienia opisane w tej pracy zostały omówione na podstawie dystrybucji Linux Redhat 6.2, obecnie najczęściej używanej dystrybucji na świecie.
1. Dyskietka startowa
Przed instalacją systemu Linux należy sprawdzić jakie podzespoły znajdują się w naszym komputerze, może to być bardzo przydatne
w przypadku, gdybyśmy napotkali problemy sprzętowe. Większość tych informacji można uzyskać z BIOSu naszego komputera. Głównie należy określić jaki procesor znajduje się w komputerze, jakiego typu mamy karty (graficzną, sieciową) oraz czy posiadamy jakiś nietypowy sprzęt. Jeśli już skompletowaliśmy listę urządzeń można przystąpić do dalszej części - tworzenia dyskietki startowej.
Płyty CD-ROM z nowszymi dystrybucjami Linuksa są tworzone wraz z opcją automatycznego startowania, są to tak zwane płyty bootowalne. Jeśli BIOS nie posiada w menu „Bios Features Setup” opcji „Boot Sequence”, w której można zdefiniować kolejność oraz z jakiego urządzenia będzie uruchamiany nasz system (CD-ROM), potrzebne będzie utworzenie dyskietki startowej - instalacyjnej. Dyskietkę taką przygotowujemy za pomocą programu RAWRITE, który znajduje się na płycie CD-ROM. Program ten przepisuje na dyskietkę jej obraz binarny zapisany w pliku. Należy uruchomić komputer w trybie DOS, z linii poleceń należy przejść na dysk CD-ROM do katalogu \dosutils i uruchomić program rawrite.exe. Najpierw program zapyta o ścieżkę do pliku z obrazem binarnym - boot.img, później o literę napędu stacji dyskietek. Po zatwierdzeniu zostanie utworzona dyskietka startowa. Przykładowe dane podane przy tworzeniu dyskietki startowej mogą być takie:
F:\DOSUTILS> rawrite.exe
Enter disk image source file name: F:\IMAGES\boot.img
Enter target diskette drive: A:
Please insert a formatted diskette into drive A: and press -ENTER- :
F:\DOSUTILS>
Tak przygotowaną dyskietkę zostawiamy w stacji i restartujemy komputer uprzednio ustawiając bootowanie ze stacji dyskietek.
2. Partycje i pakiety
Po ponownym rozruchu komputera włączy się program startowy
z dyskietki, na samym dole którego wyświetli się napis boot:
Ekran ten zawiera informacje dotyczące uruchomienia instalacji wraz z informacjami pomocniczymi. Zasadniczo tutaj uruchamiamy od razu właściwy program instalacyjny wciskając ENTER lub, jeśli nie została wybrana żadna opcja, automatycznie zostanie odpalony program instalacyjny po upływie minuty. Naszym oczom powinien się ukazać postęp dekompresji i ładowania jądra systemu:
Loading initrd.img . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Loading vmlinuz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Uncompressing Linux . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Po zakończeniu odczytu danych powinniśmy zobaczyć pierwszy ekran z pytaniem o język oraz układ klawiatury w jakim chcemy później pracować - wybieramy język angielski oraz klawiaturę US
i naciskamy ENTER. Polską klawiaturę i znaki diakrytyczne zostają ustawione dopiero po zakończeniu instalacji (omówię to w dalszej części mojej pracy). Następne pytanie dotyczy ważniejszej rzeczy, jaką jest rodzaj instalacji. Mamy do wyboru kilka opcji, mianowicie:
stacja robocza GNOME
stacja robocza KDE
system na serwer
instalacja niestandardowa
uaktualnienie systemu do nowej wersji
Zakładając, że nie posiadamy na dysku zainstalowanego żadnego systemu operacyjnego i nasz komputer ma pełnić rolę serwera, wybieramy opcję - instalacja niestandardowa, w której ustawimy samodzielnie pakiety oprogramowania oraz partycje.
Następnie okno dialogowe dotyczy części konfigurowania dysków. Pozwala ono na wybór dwóch narzędzi do podziału dysku na partycje, które dostarczane są z dystrybucją Redhat. Pierwszy to Disk Druid, drugi z nich to polecenie fdisk. Program Disk Druid jest narzędziem typu GUI (Graphical User Interface). Pozwala on na dodanie i kasowanie partycji oraz definiowanie, w jakich miejscach systemu plików zostaną one zamontowane. fdisk jest narzędziem nieco bardziej skomplikowanym, tekstowym przez co trudniejszym w użyciu. Polecam wybrać pierwszy program do partycjonowania.
Ekran dialogowy programu Disk Druid zawiera wiele informacji na temat posiadanych dysków. Na górze ekranu znajduje się lista partycji znalezionych na dysku twardym, w środku znajduje się część opisująca wszystkie znalezione dyski, natomiast dolna część zawiera menu programu. Jeśli nie ma na dysku zdefiniowanych partycji, nasz ekran powinien wyglądać mniej więcej tak:
Oznacza to, że na ponad 6 gigabajtowym dysku twardym (hda) nie posiadamy jeszcze zdefiniowanych żadnych partycji.
Partycje dodajemy przez naciśnięcie klawisza F1 (Add). Pojawi się okno dialogowe dodawania nowej partycji. W naszym przypadku założymy 4 partycje: startową (/boot), domową (/home), główną (/) i wymiany (swap). Zaczniemy od tej pierwszej. Jako system plików podajemy opcję „Linux Native”, a jako miejsce montowanie katalog /boot. Partycja ta chroni nas przed tzw. problemem 1024 cylindra . W dalszej części dodajemy inne partycje podając jako miejsce montowania kolejno /home - dla partycji domowej z katalogami użytkowników oraz / dla partycji głównej, bez której nie można kontynuować dalszej instalacji. Na niej znajdą się główne katalogi systemowe. Partycja ta powinna być wielkości około 1GB - 3GB. Oczywiście może być większa, jest to zależne od tego, jaką rolę będzie spełniał nasz komputer i co się na nim będzie znajdowało. Jeśli z jakiegoś powodu nie uda nam się utworzyć partycji o przez nas wybranym rozmiarze, pojawi się okno wyjaśniające zaistniały problem.
Okno dodawania partycji i montowania /home wyglądać może tak:
Podobnie postępujemy z partycją wymiany. Różnicą jest tylko wybrany typ partycji - Linux Swap, zamiast Linux Native oraz nie definiowany Mount Point. Można również zaznaczyć opcję „Grow to fill disk”, dzięki której program sam dociągnie do maksymalnej dostępnej wielkości dysku. Minimalna wielkość partycji wymiany umownie powinna być podwojeniem ilości pamięci RAM, czyli jeśli ilość posiadanej przez nas pamięci RAM wynosi 128MB, partycja powinna być wielkości minimum 250MB. Jest to również umowne.
Po dodaniu wszystkich partycji nasz ekran główny programu Disk Druid będzie wyglądał tak jak na rysunku zamieszczonym niżej:
Po przydzieleniu nowych partycji na dysku można nacisnąć klawisz F12 (Ok) i potwierdzić wprowadzone zmiany w tablicy partycji hdX. Teraz przechodzimy do następnego ważniejszego punktu instalacji - wybierania pakietów oprogramowania.
Wybieranie pakietów uproszczono tworząc zestawy programów, które są ze sobą powiązane. Wybieramy tylko te pakiety, które będą nam niezbędne do pracy i których chcemy w przyszłości używać. W naszym przypadku komputer będzie miał zastosowanie sieciowe - serwerowe, więc pomijamy takie zestawy jak „Games”, „X Window System” oraz pochodne. Wybieramy tylko te zestawy związane z siecią oraz Internetem. Gdy już pakiety są wybrane, następuje ich kilkudziesięciominutowe instalowanie na dysku.
Po zainstalowaniu pakietów określamy nazwę naszego komputera (hosta, domenę) i określamy strefę czasową. Później wybieramy, jakie serwisy mają zostać uruchamiane przy starcie komputera. Zostawiamy te, które uważamy, że są nam potrzebne. Niektóre
z nich są obowiązkowe i należy je zostawić włączone: atd, crond, inet, kerneld, keytable, network, syslog. Listę demonów, które mają się uruchamiać, można zmienić również po zakończeniu instalacji, więc najlepiej pozostawić tylko te niezbędne oraz takie, których konsekwencje działania znamy.
Teraz określamy rodzaj posiadanej karty sieciowej, jeśli nie została ona automatycznie wykryta przez system. Następnie pojawi się okno dialogowe, w którym określamy numer IP naszego komputera oraz maskę. Dla małych sieci najlepiej wybrać pulę adresów klasy C, czyli numery IP zaczynające się od 192.168.0.X oraz z maską sieci 255.255.255.0. Dla serwera najlepiej przydzielić pierwsze IP tej klasy, czyli 192.168.0.1 - przykład znajduje się poniżej.
Na samym końcu instalator zapyta nas o początkowe hasło dla administratora systemu - użytkownika root. Użytkownik ten ma całkowity dostęp do systemu, może zmienić i przejrzeć dowolny plik w systemie, wszystkie operacje związane z konfiguracją będą odbywały się z jego konta, dlatego hasło dostępu do niego winno być raczej skomplikowane oraz pilnie strzeżone.
Na końcu instalator spyta się nas gdzie zainstalować LILO - Boot Managera systemu Linux. Mamy do wyboru dwie opcje instalacji:
/dev/hda - Master Boot Record
/dev/hda1 - First sector of boot partition
Najlepiej wybrać drugą opcję, ponieważ pozwala ona uniknąć wszelkich problemów związanych z ilością cylindrów partycji 5. Po zainstalowaniu LILO na ekranie zobaczymy komunikat informujący o zakończeniu instalacji. Wyjmujemy dyskietkę startową z napędu, naciskamy ENTER i jeśli cały proces instalacji przebiegł pomyślnie, czekamy na czarny charakterystyczny ekran logowania.
Red Hat Linux release 6.2 (Zoot)
Kernel 2.2.14-5 on an i686
biznes login:
Jesteśmy gotowi do zalogowania się do systemu po raz pierwszy jako administrator systemu - root. Jeśli przebiegło ono prawidłowo, powinniśmy zobaczyć na ekranie znak zachęty.
VIII Konfiguracja systemu
1. Podstawowe komendy
CD - zmiana bieżącego katalogu, np.
# cd /usr/bin # zmiana katalogu na /usr/bin
# cd . . # przejście do katalogu nadrzędnego
# cd ~ # przejście do katalogu domowego
WHEREIS - wyszukanie pliku o podanej nazwie, np.
# whereis find # wyszukanie pliku o nazwie find
LS - wyświetlanie plików i katalogów, np.
# ls # wyświetlanie zawartości katalogu
# ls -F # z wyróżnieniem katalogów
# ls -aF # z ukrytymi plikami i katalogami
# ls -aFl # bardzo szczegółowe informacje
# ls t* # wyświetlenie plików na literę -t-
CAT - wyświetlanie i łączenie plików, np.
# cat test # wyświetlanie zawartości pliku -test-
# cat t1 >> t2 # złączenie pliku -t1- z plikiem -t2-
TOUCH - tworzenie pliku, np.
# touch test # utworzenie pustego pliku -test-
RM - kasowanie plików i katalogów, np.
# rm test # skasuj plik -test- bez potwierdzenia
# rm -r temp # skasuj katalog -temp- i podkatalogi
MKDIR - stworzenie pustego katalogu, np.
# mkdir test # stworzenie katalogu -test-
MV - zmiana nazwy plików i katalogów, np.
# mv t1 t2 # zmiana nazwy -t1- na -t2-
CP - kopiowanie plików i katalogów, np.
# cp p1 /etc # skopiowanie -p1- do katalogu /etc
LN - stworzenie linku symbolicznego do pliku (katalogu), np.
# ln -s plik link # utworzenie linku -link- do -plik-
2. Zabójcze demony
Po instalacji serwera Redhat można zaobserwować, że uruchamia się wiele systemowych demonów (z angielskiego daemons). Każdy z nich jest potencjalnym źródłem niebezpieczeństwa systemu. Wielu użytkowników nie zna przeznaczenia niektórych demonów,
a nawet jeśli, to mogą one zostać błędnie skonfigurowane, przez co nadal stają się zaproszeniem dla tych „złych użytkowników”.
Niżej postaram się omówić pobieżnie działanie niektórych z nich,
a te ważniejsze omówię bardziej szczegółowo.
Zasadniczo każdy demon w systemie Linux Redhat posiada swój osobny skrypt startowy, którym można go włączyć lub wyłączyć. Skrypty te znajdują się w katalogu /etc/rc.d/init.d/. Każdy z tych skryptów posiada zbliżone do siebie komendy. Np. jeśli chcemy wyłączyć demona lpd (drukarki) wydajemy komendę z parametrem stop. Jeśli chcemy go włączyć, dodajemy parametr start, np:
# /etc/rc.d/init.d/lpd stop - wyłączenie demona lpd
# /etc/rc.d/init.d/lpd start - włączenie demona lpd
Postaram się omówić poniżej ważniejsze Linuksowe demony.
Demon named
Jest to chyba jeden z najważniejszych demonów, które spotykane są w sieci. Aby poznać dokładniej jego działanie, trzeba zaczerpnąć trochę wiadomości o historii struktur DNS.
W początkowym stadium tworzenia sieci Internet, kiedy to jeszcze nazywała się siecią ARPNet, informacje odwzorowujące nazwy hostów na adresy IP przechowywano w pliku hosts.txt. Plik ten zawierał dane o wszystkich połączonych komputerach i zostawał rozsyłany do wszystkich połączonych komputerów w sieci, które przetwarzały zawarte w nim wpisy do swoich plików /etc/hosts. Ponieważ liczba komputerów w tej sieci była niewielka, rozwiązanie to wystarczało na ówczesne potrzeby. Jednak szybko wzrastająca liczba komputerów była przyczyną zwiększenia danych zawartych w tym pliku, a także powodowała ogromny ruch poprzez wymianę go między jednostkami. Konieczne stało się utworzenie systemu, który miałby być rozwiązaniem tego problemu. Tak powstał DNS (Domain Name System), stosowany do dziś w Internecie.
System DNS jest rozproszoną bazą danych informacji o hostach. Baza ta jest podzielona na „strefy”. Strefa jest fragmentem nazwy domeny, zdefiniowanym w określonym pliku strefowym (zone file). Każdy serwer DNS odpowiada tylko za pewną część nazw oraz adresów. System składa się z serwera nazw (Name Server), który zawiera bazę danych o innych komputerach w sieci oraz z klienta nazw (Resolver), który kieruje zapytania do serwera nazw.
Serwer nazw, oprócz zamiany nazwy hosta na adres IP, wykonuje też funkcję odwrotną, zwaną „Reverse DNS”. Jest to mechanizm translacji z adresu IP na nazwę hosta. Do tego celu utworzono specjalną domenę IN-ADDR.ARPA. Przykładowo komputer o IP 192.168.0.1 będzie posiadał adres 1.0.168.192.IN-ADDR.ARPA. Ciekawostką jest to, że jeden host może posiadać wiele wpisów w domenie prostej, ale tylko jeden wpis w domenie odwrotnej.
Poniżej znajduje się przykład zapytania serwera nazw o numer IP dla domeny oraz sprawdzenie zwrotnego adresu dla numeru IP:
# host -t a LINUX.PL
LINUX.PL has address 212.160.251.34
# host -t ptr 34.251.160.212.IN-ADDR.ARPA
34.251.160.212.IN-ADDR.ARPA domain name pointer LINUX.PL
System operacyjny Linux posiada wiele serwerów nazw, mniej lub bardziej zaawansowanych, np. djbdns, dents. Jednak najbardziej popularną i najczęściej stosowaną realizacją serwera DNS jest BIND (Berkley Internet Name Domain). Są różne wersje tego serwera nazw, wersja BIND-4 jest najstarsza i obecnie bardzo rzadko spotykana. Wersja BIND-8 jest aktualnie używaną stabilną wersją, jej następca BIND-9 będzie posiadał wiele ulepszeń, jak np. poprawienie poziomu bezpieczeństwa oraz implementację protokołu IPv6.
Najważniejszym plikiem konfiguracyjnym serwera nazw BIND jest plik /etc/named.conf, zawierający ogólne opcje działania programu, a także definicje obsługiwanych stref. Każda strefa definiowana jest w osobnym pliku zawierającym informacje o wszystkich hostach w danej strefie w postaci tzw. rekordów. Są różne rodzaje rekordów: rekordy odwzorowujące nazwę hosta na jego adres (rekord A), definiujące serwery nazw (rekord NS), tworzące aliasy do nazw kanonicznych (rekord CNAME), lub wskazujące na adres serwera przyjmującego pocztę dla domeny (rekord MX).
Przyjrzyjmy się dokładnie plikowi konfiguracyjnemu i plikowi strefy.
plik konfiguracyjny
Składnia poleceń umieszczanych w tym pliku jest podobna do składni języków wysokiego poziomu. Elementy odnoszące się do wspólnego zasobu są zgrupowane za pomocą nawiasów klamrowych, a każda instrukcja kończy się średnikiem. Wszelkie komentarze poprzedza się dwuslashem (//) lub podobnie jak
w języku C umieszcza się między znakami /* oraz */. Najważniejszą instrukcją, jaką powinien zawierać plik konfiguracyjny BINDa jest instrukcja options oraz zawarta w niej dyrektywa directory, wskazująca na katalog, w którym znajdują się wszystkie pliki stref. Przykładowa instrukcja może wyglądać następująco:
options {
directory "/var/named";
};
Definiowanie strefy odbywa się za pomocą dyrektywy zone. Instrukcja ta zawiera nazwę strefy, typ serwera dla tej strefy, wskazanie źródła informacji o strefie oraz dodatkowe opcje. Instrukcja zone wpisywana jest osobno dla każdej strefy.
Ze względów bezpieczeństwa dodaje się również w dyrektywie zone instrukcję allow-transfer, w której ograniczamy dostęp do transferu naszego pliku strefy dla nieupoważnionych hostów.
Przykładowo, jeśli nasz serwer nazw będzie obsługiwał domenę biznes.localhost i jest on serwerem podstawowym dla tej domeny, dyrektywa zone może wyglądać tak:
zone "biznes.localhost" {
type master;
file "p.biznes-localhost";
allow-transfer { 192.168.0.101; };
};
Znaczy to, że nasz plik strefy domeny biznes.localhost będzie znajdował się w katalogu /var/named i nosił nazwę p.biznes-localhost. Dodatkowa instrukcja allow-transfer oznacza, że plik strefy może być przesłany tylko do hosta o numerze IP 192.168.0.101.
konfiguracja strefy
W katalogu /var/named (wskazanym w pliku named.conf) należy stworzyć plik p.biznes-localhost. Umieszczane są w nim rekordy zasobów. Każdy plik strefy musi zawierać niektóre rekordy, które są niezbędne do poprawnego działania. Plik strefy zaczyna się od rekordu SOA (Start of Authority), który określa początek strefy. W jednym pliku strefy może być tylko jeden wpis SOA. Wpis ten składa się z paru części składowych. Przykładowy rekord SOA może wyglądać następująco:
@ IN SOA biznes.localhost.
root.biznes.localhost. (
2001051801 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ; Default TTL
)
Znaczenie poszczególnych pól rekordu SOA:
@ - oznacza nazwę strefy w pliku named.conf
IN - oznacza Internet, jest to jedna z klas danych
Serial - numer wersji, po wprowadzeniu zmian do pliku strefy
należy zwiększyć ten numer, format tego numeru
RRRRMMDDNN (rok, miesiąc, dzień, wersja z dnia)
Refresh - określa jak często serwer pomocniczy ma sprawdzać, czy na serwerze podstawowym nie zaszły zmiany
Retry - czas, po którym serwer pomocniczy będzie próbował odtworzyć dane po nieudanej próbie odświeżania
Expire - maksymalny czas, przez który serwer pomocniczy może utrzymywać dane w cache bez odświeżania
Default - domyślny czas jaki ma zostać użyty dla rekordów, które nie posiadają wpisanych powyższych wartości.
Następne rekordy to główne rekordy zasobów, takie jak:
NAZWA |
TYP |
FUNKCJA |
Name Server |
NS |
Identyfikuje serwer nazw domeny. |
Address |
A |
Odwzorowuje nazwę hosta na adres. |
Poiter |
PTR |
Odwzorowuje adres na nazwę hosta. |
Mail Exchanger |
MX |
Identyfikuje serwer pocztowy domeny. |
Canonical Name |
CNAME |
Definiuje alias dla nazwy hosta. |
Przykładowe wpisy do pliku strefy mogą być takie:
IN NS biznes.localhost.
IN NS druga.biznes.localhost.
IN A 192.168.0.1
IN MX 10 biznes.localhost.
IN MX 20 druga.biznes.localhost
s1 IN A 192.168.0.2
s2 IN A 192.168.0.3
druga IN NS biznes.localhost.
IN NS druga.biznes.localhost.
W przykładzie najpierw zdefiniowaliśmy dwa serwery nazw dla domeny biznes.localhost w rekordach IN NS. Następnie została przydzielona główna domena do IP 192.168.0.1. Później zostały zdefiniowane dwa serwery przechowujące pocztę adresowaną do głównej domeny (10 - pierwszy, 20 - drugi; numery nie mają większego znaczenia, ten z mniejszym jest traktowany jako wcześniejszy). Później przydzielono dwa wpisy adresowe (s1, s2) dla komputerów o numerach IP 192.168.0.2, 192.168.0.3. Na końcu wpisami IN NS została wydelegowana poddomena druga.biznes.localhost oraz określono pierwszy serwer jako ten, który będzie przechowywał dla niego wpisy w pliku strefy, a jego samego jako serwer pomocniczy.
Złożenie w jedną całość rekordu SOA oraz innych podrekordów tworzy poprawnie skonfigurowany plik strefy.
konfiguracja domeny odwrotnej
Konfiguracja domeny odwrotnej praktycznie niczym się nie różni od konfiguracji domeny prostej. Główną różnicą jest to, że do pliku strefy domeny odwrotnej wpisujemy inne rekordy (tylko SOA, NS oraz PTR). Jak już wyżej wspomniałem, dla domen odwrotnych utworzono specjalną domenę IN-ADDR.ARPA.
Konfigurujemy w pliku /etc/named.conf strefę i podajemy plik,
w którym będą przechowywane informacje. Wykonuje się to podobnie jak w domenie prostej, tylko nasza strefa będzie miała nazwę 0.168.192.IN-ADDR.ARPA, natomiast jej plik strefy może na przykład nosić nazwę p.0-168-192-REV.
Przykładowe rekordy PTR strefy domeny zwrotnej, w przypadku gdy zarządzamy pulą adresów 192.168.0.X, mogą być takie:
1 IN PTR biznes.localhost.
2 IN PTR s1.biznes.localhost.
101 IN PTR druga.biznes.localhost.
102 IN PTR s1.druga.biznes.localhost.
Pierwszy rekord PTR oznacza, że dla numeru IP 192.168.0.1 jest przydzielona domena zwrotna biznes.localhost, analogicznie tworzone są kolejne wpisy. Wpis z początkiem 101 oznacza, że dla numeru IP 192.168.0.101 adresem zwrotnym jest druga.biznes.localhost.
Domena prosta i domena odwrotna to praktycznie dwa różne zagadnienia i są konfigurowane w dwóch różnych plikach strefy.
Program BIND jest uruchamiany w czasie ładowania systemu przez jeden ze skryptów startowych, który w systemie Redhat nosi nazwę named i znajduje się w katalogu /etc/rc.d/init.d.
Skrypt ten sprawdza, czy program named i plik /etc/named.conf są dostępne. Jeśli tak jest, uruchamia się serwer nazw BIND.
Komendy wydawane do skryptu named są takie:
# named stop - wyłączenie demona
# named start - włączenie demona
# named status - status działania demona
# named restart - wyłącenie i ponowne włączenie
# named reload - ponowne odczytanie plików konfiguracji
DEMON SENDMAIL
Bez wątpienia najczęściej spotykanym i używanym demonem do obsługi poczty jest pakiet sendmail. Jest on darmowy i dość łatwo konfigurowalny. W Linuksie są spotykane również inne pakiety obsługujące pocztę: Qmail, Smail, Zmailer, Postfix. Sendmail ze względu na swą popularność staje się często celem programistów piszących exploity . Jednak te błędy na szczęście są dość szybko poprawiane w nowych wersjach Sendmaila.
Sendmail to program typu MTA (Mail Transport Agent), którego zadaniem jest nasłuchiwanie na określonym porcie, który odbiera wiadomości od innych serwerów pocztowych, wysyła je w świat oraz przesyła na konta lokalnych użytkowników. Do poprawnego działania Sendmail potrzebuje serwera DNS (np. BIND).
plik konfiguracyjny
Głównym plikiem konfiguracyjnym w demonie Sendmail jest plik /etc/sendmail.cf, w którym określane są parametry programu. Plik ten jest generowany podczas instalacji serwera i odczytywany za każdym razem przy starcie demona. Zawiera on opis ścieżek do pozostałych plików konfiguracyjnych, a także do katalogów, gdzie będą zapisywane obecnie przetwarzane listy. Każda linia tego pliku konfiguracyjnego odpowiada określonej komendzie. Wiersze rozpoczynające się od znaków # są komentarzami, natomiast te, które rozpoczynają się od pojedynczej litery, oznaczają funkcje. Plik konfiguracyjny składa się z siedmiu głównych działów. Plik ten jest generowany za pomocą programu m4. Generowanie owego pliku odbywa się na podstawie utworzonego wcześniej zbioru o rozszerzeniu .mc, który zawiera różnego typu makra. Plik sendmail.cf jest tworzony za pomocą takiej oto komendy:
# m4 /usr/share/sendmail.cf/m4/cf.m4 makra.mc > /etc/sendmail.cf
Przeciętny użytkownik powinien używać już utworzonego pliku konfiguracyjnego, który jest dostarczony w pakiecie RPM
i ewentualnie pozmieniać w nim niektóre funkcje. Przykładowe funkcje, które użytkownik powinien sprawdzić i zmienić to:AliasFile=/etc/aliases
opcja definiuje plik zawierający aliasy pocztowe.
QueueDirectory=/var/spool/mqueue
tymczasowy katalog, w którym są przechowywane listy obecnie przetwarzane przez serwer.
MaxMessageSize=1000000
określa maksymalną wielkość (w bajtach) listu e-mail, jaka może być przesłana przez serwer. Ustawia się tą opcję zależnie od zastosowania serwera poczty, bo wysyłanie zbyt dużych wiadomości może znacznie obciążyć serwer. Ustawienie tej opcji na 0 nie ustawi żadnych ograniczeń.
PrivacyOptions=goaway
opcja ta ustawia zabezpieczenia na serwerze pocztowym. Opcja ta blokuje niektóre opcje, które są wykorzystywane do zidentyfikowania użytkownika na naszym serwerze. Opcja ta jest standardowo ustawiana na inną wartość, dlatego należy ją zmienić w celu poprawy bezpieczeństwa.
MaxRecipientsPerMessage=15
opcja określa liczbę osób, do których może zostać wysłana wiadomość pocztowa jednocześnie. Opcja ogranicza wysyłanie tzw. spamu przez nasz serwer pocztowy.
plik z aliasami
Nazwy użytkowników Linuksa nie mogą być dłuższe niż osiem znaków. Dlatego by utworzyć adres e-mail zawierający pełne imię i nazwisko, utworzono bazę aliasów pocztowych. Pozwala to na założenie konta pocztowego o nazwie innej niż ta, która jest używana przy logowaniu. Aliasy są zdefiniowane w pliku aliases, a jego położenie jest określane w części Options pliku konfiguracyjnego (poprzedni podpunkt). W systemach opartych na dystrybucji Linux Redhat plik ten standardowo znajduje się katalogu /etc. Format wpisu w tym pliku jest następujący:
alias: odbiorca
Alias jest nazwą, którą chcemy się posługiwać, a odbiorca jest nazwą konta użytkownika naszego systemu, kolejnym aliasem, bądź pełnym adresem e-mail, który może znajdować się w innym systemie a na który zostanie przeniesiona wiadomość. Jeden alias może posiadać kilku odbiorców, których w pliku z aliasami oddzielamy przecinkiem. Aliasy więc mogą być pseudonimami niektórych użytkowników, mogą przekazywać pocztę do innych systemów, a także mogą tworzyć swoiste listy adresowe użytkowników. Przykład pliku /etc/aliases w systemie:
MAILER-DAEMON: postmaster
postmaster: root
operator: root
kadra: maciek, piotrek, jakub
maciek: maciej@inny.host.pl
webmaster: piotrek
jakub.nowicki: jakub
konto. testowe: test
Z powyższego przykładu można się dowiedzieć, że poczta
z adresem jakub.nowicki@biznes.localhost tak naprawdę trafi na skrzynkę pocztową użytkownika jakub, a poczta adresowana maciek@biznes.localhost będzie przesyłana na zdalny serwer pod adres e-mail maciej@inny.host.pl.
Po jakiejkolwiek zmianie pliku konfiguracyjnego aliasów, należy uruchomić program newaliases, który odbuduje i odnowi bazę danych użytkowników. Wtedy zmiany dotyczące aliasów będą zaktualizowane i będzie można ich używać.
konfiguracja dostępu
Aby uchronić nasz serwer pocztowy przed tzw. spamem, czyli niechcianą pocztą, która trafia do skrzynek użytkowników bez ich zgody, należy zdefiniować dostęp do naszego serwera. Lista numerów IP lub hostów mających dostęp do naszego serwera poczty znajduje się w pliku /etc/mail/access.db, który jest bazą danych tworzoną za pomocą tekstowego pliku /etc/mail/access
oraz komendy makemap hash.
W pliku tekstowym /etc/mail/access umieszczamy adresy IP komputerów mających dostęp do naszego komputera oraz te adresy, które chcemy by nasz serwer odrzucał. Przykładowo wpis 192.168.0 RELAY, będzie oznaczał, że klasa C naszej sieci lokalnej będzie mogła wysyłać pocztę, a wpis spam-host.pl REJECT, będzie oznaczał, że osoba łącząca się na port TCP 25 naszego serwera, a posiadająca adres w domenie spam-host.pl nie będzie mogła wysyłać wiadomości i zostanie rozłączona
z komunikatem błędu. Po każdorazowej zmianie w pliku /etc/mail/access należy zaktualizować bazę komendą:
# makemap hash /etc/mail/access < /etc/mail/access
działanie sendmaila
Linux Redhat używa do uruchamiania sendmaila skryptu startowego, który znajduje się w katalogu /etc/rc.d/init.d i nosi nazwę sendmail. Kod tego skryptu jest napisany tak, że korzysta on dodatkowo z pliku konfiguracyjnego /etc/sysconfig/sendmail oraz /etc/sendmail.cw. W pierwszym pliku znajdują się standardowo dwie linie:
DAEMON = yes
QUEUE = 1h
Pierwsza linia oznacza, że sendmail będzie uruchamiany jako demon i będzie nasłuchiwał połączeń na porcie TCP 25. Bez tej opcji system nie będzie odbierał nadchodzącej z zewnątrz poczty. Druga linia oznacza, że serwer co godzinę będzie sprawdzał, czy nie ma w kolejce zaległych wiadomości, których na przykład nie mógł wcześniej wysłać. Jeśli takowe znajdzie, spróbuje je wysłać, jeśli mu się nie uda, pozostawi wiadomości
w kolejce i po upływie następnej godziny ponownie spróbuje ją wysłać. Opcję tą można określić w sekundach (s), minutach (m), godzinach (h), dniach (d) lub tygodniach (w).
Natomiast w pliku /etc/sendmail.cw, w każdej nowej linii są umieszczane adresy, które nasz serwer będzie obsługiwał.
Inne komendy wydawane przy skrypcie sendmail są takie:
# sendmail stop - wyłączenie demona
# sendmail start - włączenie demona
# sendmail restart - wyłączenie i ponowne włączenie
# sendmail reload - ponowne odczytanie plików konfiguracji2. DEMON APACHE
Serwer stron WWW Apache zawarty jest w większości dystrybucji Linuksa. Demon ten odpowiada za wyświetlanie na każde żądanie stron WWW, które dla wielu stało się synonimem sieci globalnej. Apache jest najpopularniejszą wersją serwera WWW, ponieważ jego atutem jest łatwość obsługi i przejrzysta konfiguracja.
Demon httpd jest jednym z ważniejszych demonów w środowisku Linuksowym, więc ważne jest jego poprawne skonfigurowanie.
pliki konfiguracyjne
Konfiguracja serwera stron Apache opiera się na trzech plikach: apache.conf, srm.conf oraz access.conf, które w dystrybucji Redhat znajdują się w katalogu /etc/httpd/conf. Pierwszy z nich definiuje ustawienia konfiguracyjne dla protokołu httpd i dla operacji serwera. Drugi konfiguruje sposób zarządzania serwera i jego żądania (np. położenie skryptów CGI). Ostatni definiuje kontrolę dostępu do serwera WWW i dostarczanych przez niego informacji. Wszystkie trzy pliki są plikami tekstowymi.
Plik httpd.conf jest głównym plikiem konfiguracyjnym. Znajdują się w nim funkcje główne serwera Apache, takie jak np. lista dynamicznie ładowanych modułów (komenda LoadModule oraz AddModule), nazwa serwera i inne opcje protokołu httpd. W pliku tym należy zwrócić uwagę na podstawowe funkcje, takie jak:
ServerAdmin root@biznes.localhost
podaje adres administratora naszego serwera WWW
ServerRoot "/home/httpd"
podaje ścieżkę do plików, z których korzysta serwer WWW
ServerName biznes.localhost
określa nazwę dla naszego serwera stron
ServerType standalone
definiuje sposób odpalania naszego serwera. Jeśli serwer jest odpalany poprzez skrypt startowy, to pozostawiamy opcję standalone, jeśli jako usługa „na żądanie” zamieniamy wpis na inetd. Pierwsza opcja jest ustawiana standardowo
MaxClients 50
definiuje ilość osób, które jednocześnie mogą być połączone z serwerem stron Apache.
Port 80
określa port TCP na jakim będą oczekiwane połączenia.
User / Group nobody
definiuje z jakiego użytkownika i grupy będzie uruchamiany serwer WWW. Ustawienie tych dwóch funkcji na nobody zwiększa bezpieczeństwo naszego serwera
ErrorLog /var/log/httpd/error_log
podaję ścieżkę do pliku logującego błędy serwera
TransferLog /var/log/httpd/transfer_log
podaję ścieżkę do pliku logującego żądania dla Apache.
Prawie wszystkie powyższe opcje są ustawiane standardowo po zainstalowaniu serwera Apache. Niektóre z nich mogą zostać zmienione (np. MaxClients, Port, ServerName, ServerAdmin).
Plik srm.conf dostarcza informacji potrzebnych do zarządzania żądaniami serwera. Wskazuje na katalogi, pod którymi znajdują się elementy do formatowania i prezentowania informacji, np.:
DocumentRoot "/home/httpd/html"
podaję ścieżkę do głównych stron WWW serwera.
UserDir www html
określa katalog na koncie domowym użytkownika,
w którym powinny znaleźć się jego prywatne strony WWW, by zostały wyświetlone po otrzymaniu żądania (www i html)
Alias /icons /home/httpd/icons
odwzorowuje ścieżkę /icons na katalog /home/httpd/icons, więc żądanie http://biznes.localhost/icons odwzorowuje http://biznes.localhost/home/httpd/icons.
DirectoryIndex index.html index.php3 index.htm
określa nazwę dla pliku, który zostaje wyświetlony automatycznie po wpisaniu adresu strony.
Plik access.conf definiuje kontrolę dostępu dla serwera WWW. Definiuje dostęp do wszystkich lub tylko niektórych dokumentów serwera lub zezwala na uruchamianie w danych katalogach skryptów CGI. Przykład poniżej zezwala na uruchamianie takich skryptów w katalogu /home/httpd/cgi-bin.
<Directory /home/httpd/cgi-bin>
Options ExecCGI
</Directory>
Standardowo ustawione funkcje w pliku access.conf w systemie Redhat są nastawione na bezpieczeństwo serwera i nie trzeba ich modyfikować.
adresy wirtualne
Jeśli chcemy, aby serwer Apache obsługiwał wiele adresów wirtualnych, na których będą się znajdować strony WWW trzeba zastosować opcję VirtualHost, która jest standardowo nie jest używana (jest zakomentowana) w pliku httpd.conf. Aby obsłużyć witrynę informacja.biznes.localhost i rekrutacja.biznes.localhost na jednym serwerze biznes.localhost, należałoby umieścić takie linie w pliku konfiguracyjnym serwera Apache:
<VirtualHost informacja.biznes.localhost>
DocumentRoot /home/httpd/html/informacja
ServerName informacja.biznes.localhost
</VirtualHost>
<VirtualHost rekrutacja.biznes.localhost>
DocumentRoot /home/httpd/html/rekrutacja
ServerName rekrutacja.biznes.localhost
ErrorLog /var/log/httpd/rekrutacja/error_log
TransferLog /var/log/httpd/rekrutacja/transfer_log
</VirtualHost>
Pierwszy przykład zawiera tylko podstawowe funkcje, jakie są potrzebne do uruchomienia na serwerze adresu wirtualnego dla strony. Podaje tylko nazwę adresu wirtualnego (ServerName) oraz ścieżkę, w której znajdują się dokumenty do wyświetlenia (DocumentRoot). Drugi przykład zawiera również te funkcje, ale za pomocą funkcji ErrorLog i TransferLog wszystkie żądania na ten adres wirtualny będą logowane nie do głównych plików serwera, ale do osobnych plików w podanej lokalizacji.
Definicje adresów wirtualnych można wzbogacić również o inne dyrektywy, na przykład jeśli dwa adresy wirtualne odwołują się do tego samego dokumentu, można użyć dyrektywy ServerAlias, w której podajemy te dodatkowe adresy. Dla dwóch adresów informacja.biznes.localhost, info.biznes.localhost definicja adresu wirtualnego wyglądać będzie tak jak w przykładzie poniżej:
<VirtualHost informacja.biznes.localhost>
ServerAlias info.biznes.localhost
DocumentRoot /home/httpd/html/informacja
ServerName informacja.biznes.localhost
</VirtualHost>
Aby jakiś adres wirtualny był prawidłowy, DNS musi definiować go w swoim rekordzie IN CNAME lub IN A, odwzorowywać go na adres IP naszego serwera lub nazwę.
działanie Apache
Linux jest doskonałą platformą dla serwera WWW używającego zawarte w dystrybucji oprogramowanie Apache. Za pomocą Linuksa można skutecznie obsługiwać witryny WWW dużych organizacji, które zawierają wiele adresów wirtualnych.
W systemie Linux Redhat serwer Apache uruchamiany jest za pomocą skryptu startowego o nazwie httpd, który znajduje się
w katalogu /etc/rc.d/init.d. Skrypt ten sprawdza istnienie oraz poprawność plików konfiguracyjnych, gdy nie wykryje żadnych błędów, uruchamia serwer WWW, w innym wypadku wyświetla komunikat o błędzie i przerywa działanie.
Funkcje stosowane przy skrypcie httpd są takie:
# httpd stop - wyłączenie demona
# httpd start - włączenie demona
# httpd restart - wyłączenie i ponowne włączenie
# httpd reload - ponowne odczytanie plików konfiguracji
# httpd status - status działania demona
Demon ftp
Ostatnim z ważniejszych dla użytkownika demonów Linuksa jest demon FTPD (File Transfer Protocol). Jego działanie polega na nawiązaniu przez użytkownika połączenia z serwerem na ustalony port TCP i przesyłania plików za pomocą protokołu FTP. Usługa ta wymaga do połączenia podania nazwy użytkownika i poprawnego hasła. Niektóre z serwerów umożliwiają anonimowy dostęp do swoich zasobów po uprzednim skonfigurowaniu demona, wtedy nazwa użytkownika to anonymous, a używanym hasłem jest adres pocztowy osoby logującej się. Anonimowe FTP jest znakomitą usługą, ale może stanowić problem dla bezpieczeństwa, jeśli nie jest prawidłowo skonfigurowane. Powstają również różne wersje oprogramowania spełniającego rolę demona FTP. Najczęściej spotykane to demon Wu-FTP, który jest standardowo umieszczony
w dystrybucji Redhat; demon ProFTP - ostatnio często używany, ponieważ jest uważany za jeden z bardziej bezpiecznych; oraz demon BSD-FTP, którego można zobaczyć w dystrybucjach Uniksa serii BSD. Standardowy demon FTP dystrybucji Linux Redhat jest niestety najmniej bezpieczny, posiada dość dużo błędów, które opublikowano na liście BUGTRAQ , więc dość ważnym krokiem jest zamiana oprogramowania demona na inną wersję, np. ProFTP.
Plik konfiguracyjny powinien nosić nazwę proftpd.conf i znajdować się w katalogu /etc naszego serwera. Definicje konfiguracyjne tego serwera FTP są takie same jak definicje serwera WWW - Apache.
Przykładowe wpisy pliku konfiguracyjnego, które są potrzebne do uruchomienia demona działającego na oprogramowaniu ProFTP, mogą wyglądać następująco:
ServerName "Szkoła”
ServerType inetd
Port 21
User nobody
Group nobody
Konfiguracja anonimowego demona w Linuksie jest uproszczona, ponieważ w systemie użytkownik anonimowy jest już dodany. Jego nazwa to ftp, a katalog domowy to /home/ftp czego dowiadujemy się pliku zawierającego użytkowników systemu - /etc/passwd.
Pozostaje jeszcze konfiguracja anonimowego dostępu do serwera. Umożliwiamy taką usługę przez dodanie do pliku konfiguracyjnego opcji Anonymous, której składnię można porównać do tworzenia adresów wirtualnych w serwerze Apache. Na przykład:
<Anonymous ~ftp>
User ftp
Group ftp
UserAlias anonymous ftp
RequireValidShell off
</Anonymous>
Powyższy przykład definiuje dostęp anonimowy nadając logującej się osobie nazwę użytkownika ftp z grupy ftp, który może się zalogować również poprzez nazwę anonymous (funkcja UserAlias). Użytkownik ten nie potrzebuje do prawidłowego zalogowania się prawidłowej powłoki systemowej (funkcja RequireValidShell).
Za pomocą funkcji Limit można ograniczyć dostęp dla niektórych hostów do naszego serwera FTP. Aby ograniczyć dostęp do FTP dla hostów z domeny .com dodajemy taki wpis do /etc/proftpd.conf
<Limit LOGIN>
Order deny, allow
Deny from .com,
Allow from all
</Limit>
Podane przykłady przedstawiają tylko podstawowe komendy oraz funkcje, które wystarczają do uruchomienia anonimowego serwera FTP. Plik konfiguracyjny może zostać wzbogacony o różne inne funkcje, a ich opis znajduje się w dołączonej do oprogramowania dokumentacji i plików pomocy.
3. Maskarada sieci lokalnej
Kiedy już nasz serwer posiada połączenie z siecią Internet, można udostępnić wyjście na świat komputerom znajdującym się w sieci lokalnej. Jest kilka możliwych rozwiązań, przez które komputery
z sieci mogą łączyć się z hostami w sieci Internet. Efekt ten można uzyskać stawiając standardowe po bardziej rozbudowane serwery proxy lub poprzez maskaradę. Takie rozwiązanie jest niestety konieczne, ponieważ w usłudze SDI nasz dostawca (tutaj TPSA) przydziela tylko jeden numer IP.
Najmniej skomplikowaną metodą jest zastosowanie maskarady na serwerze wyposażonym w SDI. Maskarada to nic innego jak tzw. maskowanie adresów (numerów IP) sieci lokalnych i wypuszczanie ich w świat z adresem naszego serwera, na którym uruchomiona jest maskarada. W przypadku pakietów wracających z Internetu sytuacja wygląda dokładnie odwrotnie - adres serwera SDI
w pakiecie jest zamieniany na odpowiedni adres lokalny i tam transportowany. Stosowanie maskarady jest wygodnie, ponieważ nie trzeba na serwerze uruchamiać dodatkowych programów, gdyż wszystko dzieje się na poziomie obsługi pakietów w jądrze.
By uruchomić maskaradę trzeba najpierw włączyć tzw. forwarding, czyli proste przekazywanie pakietów z jednego interfejsu na drugi. W dystrybucji Redhat można ustawić forwarding tak, że będzie on uruchamiany samoczynnie przy starcie systemu. Można to zrobić na dwa sposoby. Pierwszym jest zamiana w pliku /etc/sysctl.conf opcji net.ipv4.ip_forwarding równej zero na jedynkę. Drugim jest dodanie do pliku /etc/sysconfig/network linii:
FORWARD_IPV4="yes"
Następnie należy włączyć samą maskaradę. Wykonuje się to za pomocą programu ipchains. Maskaradę włączamy poleceniem:
# ipchains -A forward -j MASQ -s IP_SIECI/MASKA_SIECI -i ppp0
W miejsce IP_SIECI należy wpisać adres sieci lokalnej, natomiast w miejsce MASKA_SIECI jej netmaskę. Aby zautomatyzować tą funkcję, można umieścić taki wpis w pliku /etc/rc.d/rc.local, który jest wczytywany za każdym startem systemu. Przykład ten będzie maskował pakiety i wypuszczał je na świat poprzez interfejs ppp0. Istotną rolę odgrywa tutaj opcja -j MASQ, która informuje system, że ta reguła ma dotyczyć właśnie maskarady.
IX Użytkownicy
Jednym z głównych zadań serwera sieciowego, oprócz roli bramki sieciowej, jest również zarządzanie kontami użytkowników serwera. Administrator takiego serwera powinien potrafić zakładać nowe konta, określać domyślnie używaną powłokę, przydzielać katalogi domowe oraz ustawiać limity na ilość plików i miejsca na dysku.
1. Przygotowanie grup użytkowników
Wszyscy użytkownicy naszego systemu muszą należeć do jakiejś grupy, która posiada swój numer identyfikacyjny w systemie, tzw. GID. Dzięki grupom, możemy nakładać dowolne ograniczenia dla użytkowników. Na przykład możemy określić, jaka grupa może uruchamiać jakiś program a jaka nie. Wszystkie grupy i ich GIDy są wylistowane w pliku /etc/group. Przy zakładaniu nowego konta użytkownika trzeba określić jego grupę. Nową grupę tworzymy poleceniem groupadd wraz z parametrami, np.:
# groupadd -g GID nazwa_grupy
Polecenie to dodaje do systemu nową grupę z podaną nazwą oraz określonym GID. Nazwa może składać się z maksymalnie ośmiu znaków alfanumerycznych. Określanie, do jakiej grupy ma należeć użytkownik, odbywa się przy zakładaniu konta lub, jeśli konto już istnieje, komendą chgrp.
2. Skrypt dodający użytkownika
Nowego użytkownika w Linuksie dodaje się komendą adduser lub w niektórych wersjach komendą useradd. Komendą tą założymy konto wraz z katalogiem użytkownika, którego lokalizację określa się podając odpowiednią opcję przy komendzie zakładania konta. Na przykład by założyć konto piotrek, którego katalog domowy będzie się znajdował w /var/user, a jego domyślną powłoką będzie powłoka BASH, podajemy takie opcje przy zakładaniu konta:
# useradd -d /var/user/piotrek -s /bin/bash piotrek
Można też określić, jaki GID i UID (osobisty numer identyfikujący danego użytkownika w sieci, podobne działanie do GID) będzie posiadał nasz przykładowy użytkownik piotrek. Przy zakładaniu konta dodajemy opcje: -u UID -g GID.
Aby ustawić szczegółowe dane użytkownikowi założonego konta, posługujemy się komendą chfn. Za imię i nazwisko właściciela konta odpowiada opcja -f wydana przy komendzie chfn, np.:
# chfn piotrek -f "Piotr Nowak"
Powyższy przykład ustawia właściciela dla konta piotrek.
Następnym krokiem jest ustawienie limitów posiadanego miejsca na dysku twardym oraz ilości posiadanych na koncie plików. Służy do tego komenda setquota. Limit ustawianego miejsca podajemy
w kilobajtach. System Linux posiada dwa rodzaje limitów - limity miękkie (soft) i twarde (hard). Limity miękkie to minimalna ilość miejsca jaką ma użytkownik, limity twarde to ilość maksymalna. Tak więc, aby ustawić limit miękki i twardy dla przykładowego użytkownika piotrek, którego katalog domowy jest na głównej partycji systemu, wydajemy taką oto komendę:
# setquota -u piotrek /dev/hda5 10000 15000 1000 1500
Liczby podane na końcu oznaczają kolejno: limit miękki miejsca na dysku, limit twardy posiadanego miejsca na dysku, limit miękki posiadanych w systemie plików, limit twardy posiadanych plików.
Najważniejszą rzeczą, jaka pozostała, jest ustawienie hasła dla użytkownika za pomocą komendy passwd. By ustawić hasło dla użytkownika piotrek, należy wydać komendę:
# passwd piotrek
New UNIX password:
Retype new UNIX password:
passwd: all authentication tokens updated successfully
Po naciśnięciu klawisza ENTER system zapyta nas o nowe hasło dla użytkownika i poprosi o potwierdzenie. Wpisujemy dwa razy to samo hasło, inaczej system przerwie procedurę zmiany hasła. Jeśli wszystko przebiegło bez błędów, system wyświetli komunikat potwierdzający zmianę hasła dla użytkownika.
Wszystkie te czynności należy wykonać, by poprawnie założyć konto użytkownika w systemie Linux. Można całą tą procedurę uprościć tworząc skrypt napisany w powłoce, który będzie zawierał wszystkie programy, jakie należy uruchomić i będzie samoczynnie je wywoływał pytając nas tylko o zmienne. Niżej znajduje się przykładowy skrypt napisany w powłoce BASH.
najpierw czyścimy ekran oraz ustalamy dwie stałe skryptu (plik główny i zapasowy z listą wszystkich użytkowników)
#!/bin/bash
clear
echo "* ZAKLADANIE KONTA - szkola biznesu"
PASSWD="/etc/passwd"
PBAK="/etc/passwd-"
następnie skrypt zadaje pytanie o login dla konta, czeka na odpowiedź, a nową zmienną umieszcza pod nazwą ident
echo "> podaj login ? "
read ident
kolejnym krokiem jest sprawdzenie, czy użytkownik podał jakąś zmienną oraz sprawdzenie istnienia nazwy konta, skrypt używa w obu przypadkach instrukcji warunkowej if.. then.., jeśli nie podano żadnej nazwy, bądź w systemie istnieje konto o takiej nazwie, skrypt przerywa swoje działanie
if [ "$ident" = "" ]; then
echo "! musisz podac identyfikator konta !"
echo; exit 1
fi
EXIST=0
id $ident >/dev/null && EXIST=1
if [ $EXIST = 1 ]; then
echo "! identyfikator juz jest uzyty !"
echo; exit 1
fi
w następnym kroku skrypt pyta o imię i nazwisko użytkownika dla konta, również jak poprzednio sprawdza poprawność wpisu
echo "> podaj imie i nazwisko ? "
read nazwisko
if [ "$nazwisko" = "" ]; then
echo "! trzeba podac imie i nazwisko !"
echo; exit 1
fi
później skrypt pyta o rodzaj użytkownika i w zależności, jaki on jest, przydziela mu miejsce dla katalogu domowego, GID oraz rodzaj powłoki systemowej, a w dalszej części skryptu nawet ograniczenie na ilość posiadanego miejsca na dysku
echo "> rodzaj konta [ UCZEN/kadra ] ? "
read luser
if [ "$luser" = "kadra" ]; then
luser=kadra
DGID=kadra
DHOME="/home"
DSHELL="/bin/bash"
else
luser=uczen
DGID=uczen
DHOME="/home/uczen"
DSHELL="/bin/bash"
fi
następnie skrypt pyta o numer UID dla użytkownika i podejmuje sprawdzające działania: poprawność wpisanej zmiennej oraz unikalność podanej zmiennej przeglądając główny plik z listą użytkowników i szukając UID za pomocą komendy cat i grep
echo "> podaj UID uzytkownika ? "
read NUID
if [ "$NUID" = "" ]; then
echo "! musisz podac jakis UID !"
fi
foo=`cat $PASSWD | grep "$NUID"`
if [ "$foo" ]; then
echo "! system posiada juz zajety ten UID !"
echo; exit 1
fi
gdy skrypt uzyskał już wszystkie dane oraz zapamiętał je pod określonymi zmiennymi, przystępuje do zakładania konta, najpierw robi kopię zapasową pliku z listą użytkowników, później za pomocą komendy useradd ze zmiennymi tworzy konto, na samym końcu komendą chfn ustawia imię i nazwisko właściciela
echo "+ tworzenie konta - "
cp $PASSWD $PBAK
useradd -u $NUID -g $DGID -d $DHOME/$ident -s $DSHELL $ident
chfn $ident -f "$nazwisko"
echo " [ OK ] "
jak wcześniej napisałem, ustawia również limity posiadanego miejsca za pomocą programu setquota, zmienne podane przy tym programie pobiera ze stałych, które wcześniej zostały określone dla w zmiennej luser (patrz wyżej - rodzaj konta)
echo "+ ustawianie limitow - "
if [ "$luser" = "uczen" ]; then
soft1=10000; hard1=15000; soft2=1000; hard2=1500;
fi
if [ "$luser" = "kadra" ]; then
soft1=0; hard1=0; soft2=0; hard2=0;
fi
setquota -u $ident /dev/hda5 $soft1 $hard1 $soft2 $hard2
echo " [ OK ] "
jedną z ostatnich czynności, którą wykonuje skrypt jest ustawienie hasła dla nowego użytkownika komendą passwd
echo "+ ustawienie hasla - "
passwd $ident
echo " [ OK ] "
na zakończenie skrypt wyświetla dane nowo założonego konta
i kończy swoje działanie za pomocą komendy exit
echo "* konto <$ident> dodane: "
id $ident
exit
Złożenie całego kodu tworzy skrypt dodający nowego użytkownika w systemie Linux. Powyższy skrypt jest tylko przykładem.
3. Kasowanie użytkowników systemu
Program, który odpowiada za kasowanie użytkownika w systemie Linux nosi nazwę userdel. Wywołuje się go z podaniem nazwy konta i ewentualnie z opcją -r, która kasuje również katalog domowy usuwanego użytkownika. Składnia polecenia wygląda tak:
# userdel -r piotrek
Powyższy przykład kasuje użytkownika piotrek.
X Aktualizacja
Aktualizowanie i instalowanie programów i demonów Linuksa to jedna z najważniejszych rzeczy, które należy wykonywać regularnie. Nowe pakiety oprogramowania zawierają uaktualnienia oraz poprawki, które znaleziono w jego starszych wersjach. Dzięki instalowaniu nowszych wersji oprogramowania nasz serwer staje się bardziej bezpieczny.
Niezależnie od wykorzystywanego systemu operacyjnego instalacja każdej, nieco bardziej złożonej aplikacji powoduje pojawienie się
w różnych miejscach dysku wielu nowych plików oraz modyfikację już istniejących. Aby zapanować nad dużą liczbą programów, które są zainstalowane w systemie, autorzy dystrybucji opracowują specjalne narzędzia, zwane menedżerami pakietów. Składniki systemu są zapisywane w oddzielnych pakietach, a informacja o każdym pakiecie jest składowana w bazie danych. Te pakiety różnią się w zależności od dystrybucji Linuksa. Debian / GNU Linux wprowadził swój standard pakietów o rozszerzeniu .deb, w Linux Redhat znajdują się pakiety RPM, które są zarządzane przez program o tej samej nazwie.
1. Omówienie programu RPM
Program RPM (Redhat Package Manager) pozwala na swobodną manipulację pakietami z rozszerzeniem .rpm w Linux Redhat. Dzięki niemu możliwe jest nie tylko dodawanie nowych aplikacji czy komponentów systemowych, ale też usuwanie niepotrzebnych już składników oprogramowania. Program RPM dysponuje również opcją aktualizacji oprogramowania.
Baza danych, z której korzysta RPM, zapisana jest w plikach, które znajdują się w katalogu /var/lib/rpm. Szczegółowy opis wszystkich dostępnych funkcji tego narzędzia znajduje się w dokumentacji systemowej, którą możemy przejrzeć wydając komendę man rpm.
Dodawanie, usuwanie i aktualizowanie pakietów odbywa się przez podanie odpowiednich opcji przy wywołaniu programu RPM.
Pakiet dodaje się przez podanie opcji -i. Na przykład, jeśli chcemy dodać do systemu pakiet BIND, należy wydać komendę:
# rpm -i nasz_pakiet_BIND.i386.rpm
Oczywiście uprzednio należy odszukać taki pakiet na CD-ROM dołączonym do dystrybucji lub w Internecie.
Jeśli chcemy usunąć jakiś pakiet z systemu, wpisujemy tylko jego nazwę poprzedzając go opcją -e, np.:
# rpm -e nasz_pakiet_BIND
Powyższa komenda usunie program BIND, który wcześniej został zainstalowany. RPM usunie robiąc kopię plików konfiguracyjnych.
Gdy chcemy zaktualizować pakiet komendę rpm wydajemy z opcją -U. Aby zaktualizować wersję pakietu BIND wpisujemy:
# rpm -U nowszy_pakiet_BIND.i386.rpm
Jeśli w systemie jest już zainstalowany jakikolwiek pakiet BIND, zostanie on zaktualizowany do nowszej wersji, jeśli w systemie nie ma zainstalowanego starszego pakietu, program RPM będzie działał tak, jak byśmy uruchomili go z opcją -i.
Czasami zdarzają się wypadki, że nowsza wersja oprogramowania powoduje konflikty z jakimś innym pakietem, który jest w systemie. Program RPM wyświetli odpowiedni komunikat i zatrzyma swoje działanie. Należy wtedy zaopatrzyć się w nową wersję pakietu,
z którym instalowany pakiet powoduje konflikt i go zainstalować. Jeśli natomiast jesteśmy pewni, że konflikt ten tak naprawdę nie ma znaczenia i chcemy „oszukać” program RPM, wydajemy dodatkową opcję --nodeps. Np. jeśli nowo instalowany pakiet BIND powoduje konflikt ze starszą wersją pakietu Apache, a nie chcemy odnawiać tego drugiego, wydajemy taką oto komendę:
# rpm -U --nodeps nowszy_pakiet_BIND.i386.rpm
Liczba i386 przed nazwą rozszerzenie oznacza, że w pakiecie znajdują się pliki binarne programu zoptymalizowane pod procesor INTEL ® 386. Spotykane są jeszcze pakiety zakończone skrótem .src.rpm. Są to pakiety z wersjami źródłowymi, nie binarnymi, które najpierw musimy skompilować na swoim serwerze (tworzymy pakiet i386.rpm, a później go instalujemy). Tych pakietów używamy tylko w wypadku, gdy chcemy wprowadzić poprawki do kodu źródłowego programu, w praktyce wykorzystują je tylko zaawansowani użytkownicy systemu.
XI Bibliografia i adresy
- „Linux - Redhat Linux”, Bill Ball,
Wydawnictwo HELION, Gliwice 1998
- „Serwery sieciowe Linuksa”, Craig Hunt,
Wydawnictwo MIKOM, Warszawa 2000
- „Linux - praktyczne rozwiązania”, Adam Podstawczyński, Wydawnictwo HELION, Gliwice 2000
- „Linux - Czarna Księga”, H, Tsuji, T. Watanabe, Acrobyte, Wydawnictwo HELION, Gliwice 2001
- „UNIX - użytkowanie i administrowanie”, Jerzy Marszyński Wydawnictwo HELION, Gliwice 1999
- Czasopisma “Linux Plus”, “CHIP”, “PC World Computer”
- Strony Internetowe:
The Institute of Electrical and Electronics Engineers, Inc. - organizacja wspierająca rozwój inżynierii informatycznej oraz twórców w rozpowszechnianiu ich projektów - http://www.ieee.com
Wiele osób utożsamia Linuksa z systemem operacyjnym wraz z dołączonym oprogramowaniem do niego, lecz - ściśle rzecz biorąc - Linux jest tylko i wyłącznie samym jądrem systemu operacyjnego, który rozpowszechniany jest wraz z dystrybucją oprogramowania.
Kawałek preambuły licencji GNU GPL z dnia 2 czerwca 1991 roku przetłumaczonej przeze mnie na język polski. Oryginał licencji znajduje się pod adresem - http://www.fsf.org/copyleft/gpl.txt
System operacyjny - tak w dalszej części będę określał jądro wraz z oprogramowaniem GNU.
LILO - Boot Manager Linuksa niezbyt dobrze radzi sobie, gdy jest zainstalowany na partycji, która posiada więcej niż 1024 cylindry. Dlatego zaleca się tworzenie małej partycji startowej.
Tytuł tego podrozdziału wiąże się z tytułem artykułu Jay'a Beale'a „Killing Daemons”, którego cytatami nieraz się posłużę. Killing Daemons w języku polskim brzmi właśnie „Zabójcze demony”.
Skrótem BIND będę określał w dalszej części mojej pracy omawianą przeze mnie ósmą wersję tego serwera nazw.
Exploity to programy wykorzystujące błędy w innych programach, które uruchomione w systemie pozwalają na nieupoważnione przejęcie kontroli nad nim (uzyskanie praw administratora).
BUGTRAQ - największa Internetowa lista dyskusyjna, która podejmuje tylko tematy związane
z bezpieczeństwem systemów operacyjnych. Publikowane są na niej odkryte przez programistów błędy, poprawki do oprogramowania oraz różne exploity - http://www.securityfocus.com/bugtraq
Wyszukiwarka
Podobne podstrony:
projekt o narkomanii(1)
!!! ETAPY CYKLU PROJEKTU !!!id 455 ppt
Wykład 3 Dokumentacja projektowa i STWiOR
Projekt nr 1piątek
Projet metoda projektu
34 Zasady projektowania strefy wjazdowej do wsi
PROJEKTOWANIE ERGONOMICZNE
Wykorzystanie modelu procesow w projektowaniu systemow informatycznych
Narzedzia wspomagajace zarzadzanie projektem
Zarządzanie projektami 3
Metody Projektowania 2
BYT 109 D faza projektowania
p 43 ZASADY PROJEKTOWANIA I KSZTAŁTOWANIA FUNDAMENTÓW POD MASZYNY
Zarządzanie projektami 4 2
Projektowanie systemow zarzadzania
więcej podobnych podstron