Estymacja i weryfikacja liniowych jednorównaniowych modeli ekonometrycznych
Etapy badania ekonometrycznego
Konstrukcja modelu
Specyfikacja i kwantyfikacja zmiennych
Zbieranie informacji statystycznych
Estymacja parametrów
Weryfikacja modelu
Praktyczne wykorzystanie modelu
Modelowanie ekonometryczne - etapy:
I. Sformułowanie celu badania - cel badania oznacza sformułowanie teoretyczno-ekonomicznej hipotezy badanego zjawiska,
Np. sformułowanie teoretyczno-ekonomicznej hipotezy odnośnie kształtowania się popytu na dobro A
![]()
RB - reklama dóbr substytucyjnych i komplementarnych
Ca - cena
CB - cena dóbr substytucyjnych i komplementarnych
D - dochód
Ra - reklama naszego produktu
Inaczej mówiąc powyższy zapis oznacza, że popyt jest funkcją, czyli zależy od czynników, które uwzględniamy w nawiasie
wpływ ceny na popyt zazwyczaj jest zgodny z ujemną korelacją tzn. wzrost ceny powoduje spadek popytu i odwrotnie. Powyższa relacja wypływa z prawa popytu, są od niej pewne wyjątki nazywane paradoksami ekonomicznymi (są trzy sytuacje kiedy wzrost ceny powoduje wzrost popytu)
wpływ dochodów na popyt - korelacja dodatnia (w przypadku dóbr normalnych, wyższego rzędu) i korelacja ujemna (w przypadku dóbr niższego rzędu)
trzykropek w powyższej hipotezie ekonomicznej reprezentuje w części te czynniki co składnik losowy w równaniu ekonometrycznym
II. Dane statystyczne : zbieranie informacji statystycznych i weryfikacja danych w przypadku tworzenia Banku Danych. Może się zdarzyć sytuacja, że z powyższej hipotezy ekonomicznej usuwamy niektóre zmienne objaśniające ze względu na brak danych statystycznych na ich temat.
III. Budowa modelu ekonometrycznego - polega na specyfikacji i kwantyfikacji zmiennych endogenicznych (objaśnianych) i egzogenicznych (objaśniających spoza analizowanego układu) oraz na wyborze postaci analitycznej równań stochastycznych.
IV. Estymacja modelu: znalezienie zgodnych, nieobciążonych i efektywnych ocen parametrów strukturalnych (współczynników stojących przy zmiennych objaśniających) oraz współczynników dopasowania i błędów średnich ocen parametrów (wartości sprawdzianu t-Studenta) i innych parametrów struktury stochastycznej oraz odpowiednich sprawdzianów testów
V. Weryfikacja modelu:
a) statystyczna - testowanie istotności ocen odpowiednich parametrów struktury stochastycznej
b) merytoryczna (ekonomiczna) - analiza sensowności ekonomicznej otrzymanych rezultatów (ocen parametrów strukturalnych)
VI. Testowanie modelu - ewentualnie respecyfikacja i reestymacja
VII. Praktyczne wykorzystanie modelu np. do prognozowania
EKONOMETRIA = ekonometria opisowa + badania operacyjne
Model ekonometryczny:
Matematyczny zapis prawidłowości ekonomicznych (dla empirycznej weryfikacji hipotez teorii ekonomii oraz dla zastosowań praktycznych - prognozowania)
Model ekonometryczny zawiera:
- równania
- nierówności
- funkcje
Typy relacji:
behawioralne (zachowania się)
technologiczne
instytucjonalne (opisują sposób działania instytucji i regulacji prawnych)
bilansowe (tożsamości)
W relacjach występują:
zmienne (losowe lub nielosowe),
parametry.
Relacje bilansowe pozwalają na uwzględnienie w badaniu, że suma tworzy zmienną zagregowaną. Występują w modelach wielorównaniowych.
Zmienne powinny być obserwowane. Wielkości które chcemy oszacować to zaś parametry modelu (tj. stałe współczynniki przy zmiennych) wyrażają one wpływ danej zmiennej na relację opisywaną w modelu (równaniu, funkcji).
Zmienne mogą być losowe i o wartościach z góry ustalonych (nielosowe + losowe z poprzednich okresów czyli „opóźnione”)
W badaniach operacyjnych mamy zmienne decyzyjne.
W ekonometrii opisowej są zmienne:
w modelu jednorównaniowym:
objaśniana
objaśniające
składnik losowy
w modelu wielorównaniowym:
endogeniczne (wewnętrzne)
egzogeniczne (zewnętrzne)
składniki losowe (czyli zmienne wyrażające wpływ wszystkich czynników pominiętych przy budowie modelu jak również wpływ zdarzeń czysto losowych - przypadkowych)
Inne klasyfikacje zmiennych (ze względu na ich rolę):
sterujące,
instrumentalne,
z wyprzedzeniem czasowym,
z opóźnieniem czasowym,
zmienna czasowa (trend)
Zmienne:
- zerojedynkowe (1 - pojawia się cecha, 0 - jej brak)
- dyskretne - przyjmują liczby całkowite ale nie wszystkie
Zmienne zerojedynkowe mają zastosowanie do uchwycenia wpływu sezonowości lub periodyczności, mogą one także skwantyfikować wpływ złożonych zmiennych jakościowych poprzez dychotomizację.
np. w badaniu popytu na dane dobro chcemy uwzględnić wpływ wykształcenia jego uczestników. Dychotomizacja będzie polegała na utworzeniu 3 zmiennych zerojedynkowych:
Z1: 1 - podstawowe,
0 - w pozostałych przypadkach.
Z2: 1 - średnie,
0 - w pozostałych przypadkach.
Z3: 1 - wyższe,
0 - w pozostałych przypadkach.
Parametry w badaniach operacyjnych:
współczynniki funkcji celu,
współczynniki i wyrazy wolne w zbiorze warunków ograniczających.
Parametry w ekonometrii opisowej:
strukturalne (współczynniki przy zmiennych),
struktury stochastycznej (parametry rozkładu składnika losowego)
Klasyfikacja modeli w badaniach ekonomicznych - kryteria:
cel badania,
występowanie lub brak zmiennej losowej,
postać zależności,
liczba relacji,
znaczenie czasu,
zakres badania,
charakter powiązań pomiędzy zmiennymi endogenicznymi,
charakter poznawczy modelu.
Cel badania np. modele opisowe (do weryfikacji pewnych hipotez), modele służące do prognozowania (tzw. modele prognostyczne). Najlepiej jest gdy model ma charakter opisowo-prognostyczny. Stosowane są też modele służące do testowania własności estymatorów tzw. modele symulacyjne (w sensie technik symulacyjnych)
Można mówić o relacjach stochastycznych - to takie w jakich występuje zmienna losowa.
Relacje deterministyczne - brak losowości.
Postać zależności.
Wyróżnia się modele liniowe i nieliniowe. Modele liniowe to takie w których wszystkie relacje mają postać funkcji liniowej lub kombinacji liniowej. Modele nieliniowe to takie w których przynajmniej jedna relacja jest nieliniowa. Modele nieliniowe sprowadzalne są do postaci liniowej np. postać funkcji potęgowej, logarytmicznej, wykładniczej.
Liczba relacji:
modele jednorównaniowe
modele wieorównaniowe:
modele proste - to takie, w których zmienne objaśniające są wyłącznie zmiennymi o wartościach z góry ustalonych tj. egzogeniczne + endogeniczne z poprzednich okresów,
modele rekurencyjne - to takie, w których zmienne endogeniczne pełnią rolę zmiennych objaśniających, ale charakter powiązań pomiędzy nimi jest jednokierunkowy,
modele o równaniach łącznie współzależnych - występują tu różnokierunkowe zależności między zmiennymi endogenicznymi tj. pojawiają się w takim modelu sprzężenia zwrotne, bezpośrednie lub pośrednie.
Znaczenie czasu. Możemy tu mówić o relacjach typu:
dynamicznego (czas odgrywa tu rolę aktywną)
statycznego
Aktywną rolę czasu uwzględnia się poprzez wprowadzenie zmiennych opóźniających egzo- i endo- , czasem też zmiennych antycypowanych oraz też zmiennej czasowej (dla uwzględnienia czynnika czasu).
Zakres badania. Wyróżnia się modele:
mikroekonomiczne - dotyczące decyzji gospodarstwa domowego, funkcjonowania przedsiębiorstwa,
makroekonomiczne - zakres badania obejmuje procesy i decyzje w skali krajowej / regionalnej.
Charakter poznawczy modelu może służyć do:
opisu
diagnozy
prognozy
1. Charakterystyczną cechą modelu ekonometrycznego jest to, że nie jest on układem równań o dowolnych (lub przyjętych a priori) wartościach parametrów. Parametry te są wyznaczane z danych statystycznych.
2. Za oceny parametrów przyjmuje się takie liczby, przy których model jest możliwie dobrze dopasowany do zebranych danych statystycznych.
3. Kryteria zgodności modelu z danymi empirycznymi mogą być różnie zdefiniowane, co prowadzi do różnych metod estymacji.
4. Wybór metody estymacji zależy od:
istniejących powiązań między nieopóźnionymi w czasie zmiennymi endogenicznymi,
własności rozkładu składników losowych modelu.
5. W wyniku działania czynników losowych powodujących odchylenia, nie jest możliwe wyznaczenie liczbowych wartości parametrów dokładnie tzn. bez błędów.
Są to błędy szacunku (a nie błędy przeprowadzonych obliczeń).
6. Prawidłowy wybór metody estymacji pozwala jedynie na ograniczenie, lub wykluczenie systematycznych błędów oraz że wraz ze wzrostem liczby obserwacji prawdopodobieństwo popełnienia błędu maleje do zera.
7. Przy wykorzystaniu metod statystyki matematycznej można określić rząd dokładności szacunku parametrów.
MNK - jest najstarszą historycznie i intuicyjnie najprostszą metodą estymacji.
Jednorównaniowy model z jedną zmienną objaśniającą:
yt = αo + α1xt + εt (1)
yt - zmienna objaśniana
α0, α1 - parametry modelu
xt - zmienna objaśniająca
εt - składnik losowy
Założenia struktury stochastycznej składnika losowego:
składnik losowy εt ma wartość oczekiwaną równą zero:
E(εt) = 0
składnik losowy εt ma stałą (niezależną od wskaźnika t) wariancję σ2 o wartości skończonej
E(εt 2) = σ2 [ D2(εt) = σ2 - const]
obserwacje są niezależne, ciąg {εt} jest ciągiem niezależnych zmiennych losowych
E(εt, εt+s) = 0 [ cov (εt, εt+s) = 0]
Brak autokorelacji składnika losowego
Składnik losowy jest nieskorelowany ze zmiennymi objaśniającymi (lub zmienne objaśniające ze zmiennymi nielosowymi)
cov (εt,xt) = 0
Składnik losowy na rozkład normalny
εt: N(0, σ2)
Zakładamy, że wykorzystana do estymacji próba losowa składa się z n obserwacji dokonanych na zmiennych yt, x1t, x2t, ..., xkt.
Estymacja parametrów polega na nadaniu im takich wartości liczbowych, przy których model (1) jest możliwie dobrze dopasowany do danych empirycznych.
Problem sprowadza się do tego, aby znaleźć takie a0, a1 aby prosta y = ao + a1xt możliwie dobrze była dopasowana do punktów.
W MNK postuluje się aby był spełniony warunek::
Ψ = Σ(yt - a0 - a1xt)2 = minimum (2)
MNK polega na znalezieniu takich ocen parametrów strukturalnych, przy których suma kwadratów odchyleń wartości empirycznych od wartości teoretycznych była jak najmniejsza.
Geometrycznie warunek (2) sprowadza się do tego by suma kwadratów odległości punktów od prostej na wykresie była jak najmniejsza.
Rozwiązaniem warunku (2) jest przy zastosowaniu rachunku różniczkowego znalezienie ekstremum funkcji dwóch zmiennych.
Wartości a0 i a1 znajdujemy rozwiązując układ równań:
a1 Σxt2 + a0 Σxt = Σxtyt
a1 Σxt + na0 = Σyt
względem a0 i a1
a0 = (ΣytΣxt2 - ΣxtΣxtyt) /[nΣxt2 - (Σxt )2]
a1 = (nΣytxt - ΣxtΣyt) /[nΣxt2 - (Σxt )2]
Błędy średnie szacunku parametrów α0 i α1 są odpowiednio równe:
D2(α0) = σ2 Σxt2 /n(Σxt2 - nxśr2)
D2(α1) = σ2/(Σxt2 - nxśr2)
Przy przyjętych założeniach nieobciążoną oceną parametru σ2 jest:
s2 = Σ(Yt - a0 - a1Xt)2 /(n-2)
Klasyczna Metoda Najmniejszych Kwadratów
w zapisie macierzowym dla modelu liniowego z dowolną liczbą zmiennych
(KMNK)
Model jednorównaniowy o dowolnej liczbie zmiennych objaśniających:
yt = Σ αiXit + εt lub Y=X α + ε (3)
Założenia:
1. Zmienne objaśniające x1t, x2t, ......., xnt są wielkościami nielosowymi; zakładamy, ze nie występuje między tymi zmiennymi współliniowość.
2. Składnik losowy εt ma wartość oczekiwaną równą zero i stałą (nie zależną od wskaźnika t) wariancję σ2, o wartości skończonej: E(εt) = 0
D2(εt) = σ2
3. Obserwacje są niezależne, tak że ciąg {εt} jest ciągiem niezależnych zmiennych losowych.
4. Składnik losowy εt jest nieskorelowany ze zmiennymi objaśniającymi.
Założenia techniczne stosowalności KMNK:
1. Zmienne xi są nielosowe lub są zmiennymi losowymi o ustalonych wartościach.
2. n > k liczba obserwacji jest większa od liczby szacowanych parametrów.
3. Żadna ze zmiennych xi nie jest liniową kombinacją innej zmiennej (żaden xi nie jest silnie skorelowany z innymi xi)
Zakładamy, że wykorzystana przy estymacji próba losowa składa się z n obserwacji dokonanych na zmiennych Yt, X1t, X2t,........, X1t.
![]()
- stałe współczynniki stające przy zmiennych są to parametry strukturalne, oznaczają one stopień albo siłę relacji zmiennej y na zmienną x. ![]()
można policzyć jako pochodną cząstkową y względem x.
![]()
![]()
- nie zmienia się w czasie, jest to stała, która mówi nam o ile zmieni się yt jeśli xit zmieni się o jednostkę.
zał. x1t = 1 ![]()
![]()
- wyraz wolny w modelu
Wyraz wolny pozwala nam na wyznaczenie y, jeśli wszystkie x przyjmą wartość zero. Geometrycznie to punkt przecięcia początku układu współrzędnych z płaszczyzną regresji.
![]()
wtedy parametrów mamy k+1
k - zmienna x
![]()
- składnik losowy modelu wyraża wpływ wszystkich czynników pominiętych w specyfikacji, ma on także wykryć pozostałe błędy wynikające z postaci analitycznej oraz ma wychwycić błędy wpływu wszystkich losowych zakłóceń = błędy czysto przypadkowe, losowe.
Pomiędzy y, a x - ami powinny być jak największe związki korelacyjne, a pomiędzy x-ami jak najmniejsze, a najlepiej ich brak.
Oznaczenia:
Y - wektor (n x 1) zaobserwowanych wartości zmiennej objaśnianej Yt
X - macierz (n x k) zaobserwowanych wartości zmiennych objaśniających. Z uwagi na założenie (1) rząd tej macierzy jest równy k. Jeżeli występuje wyraz wolny, to jedna z kolumn jest kolumną samych jedynek
a - wektor (k x 1) ocen parametrów strukturalnych αi
e - wektor (n x 1) reszt et równania
x11 x21 .. ... xk1 y1
x12 x22 .. ... xk2 y2
X = . . .. ... . Y = .
x1n x2n .. ... xkn yn
a1 e1
a2 e2
a = . e = .
. .
ak en
Definicja.
Estymacja parametrów strukturalnych za pomocą MNK polega na znalezieniu takich wartości dla ich ocen, by suma kwadratów odchyleń rzeczywiście zaobserwowanych wartości zmiennej objaśnianej Yt od ich wartości teoretycznych była jak najmniejsza.
Ψ = (Y - Xa)T(Y - Xa) = minimum (4)
Y - Xa = e Ψ = eTe
XTX a = XTY - układ równań normalnych
Twierdzenie I. Jeżeli macierz X jest rzędu k, wówczas Ψ przybiera wartość najmniejszą, gdy wektor a ocen parametrów strukturalnych modelu (3) dany jest wzorem:
a = (XTX) -1 XTY (5)
Estymator jest funkcją wyników z próby.
Przy założeniach 1 - 4 estymator (5) KMNK jest zgodny, nieobciążony i najbardziej efektywny, równoważny estymatorowi metody największej wiarygodności (MNW).
Estymator MNW wprowadza się poprzez maksymalizowanie przekształconej funkcji gęstości zmiennej losowej.
B - best
L - linear
U - unbalast
E - estimator
Oznaczenia:
α 1 ε1
α 2 ε2
α = . ε = .
. .
α k εn
α - wektor (k x 1) prawdziwych wartości parametrów αi
ε - wektor (n x 1) składników losowych εi
1) Zgodność ![]()
Obliczamy granicę prawdopodobieństw. Jeśli zwiększamy liczbą obserwacji to oceny będą coraz bardziej bliskie rzeczywistości.
2) Nieobciążoność E(a) = α
Polegająca na uwolnieniu się od systematycznych błędów szacunków.
3) Największa efektywność Var (a) ![]()
Var (a*)
Twierdzenie II. Jeżeli spełnione są założenia 1 - 4, to wyznaczone wzorem (5) estymatory parametrów strukturalnych modelu (3) są nieobciążone, to znaczy spełniają równość: E(a) = α
Dowód:
E(a) = E[(XTX)-1 XTY], Y = X α + ε
E(a) = E[(XTX)-1 XT(X α + ε)]
E(a) = E[(XTX)-1 XTX α + (XTX) -1 XTε)]
(XTX) -1 XTX = I, E(α) = α
E(a) = α +E[ (XTX)-1 XTε)]
E(a) = α
Twierdzenie III. Jeżeli spełnione są założenia 1 - 4, to macierz wariancji i kowariancji wyznaczonych relacją (5) estymatorów parametrów αi modelu (3) dana jest wzorem:
D2(α) = σ2(XTX)-1 (6)
Macierz D2(α) ma wymiary (k x k). Elementy znajdujące się na jej głównej przekątnej są równe wariancjom poszczególnych parametrów, zaś znajdujące poza przekątną to kowariancje.
Przy przyjętych założeniach elementy macierzy D2(α) dążą do zera, gdy liczba obserwacji w próbie dąży do nieskończoności.
Ponieważ estymatory parametrów αi są nieobciążone, wynika stąd że są one zgodne.
lim P{|α - a| < ξ} = 1
n ->∞
gdzie: ξ - dowolnie mała liczba.
Twierdzenie IV. Jeżeli spełnione są warunki 1 - 5 i oceny parametrów strukturalnych modelu (3) dane są równaniem (5) to nieobciążoną oceną wariancji składnika losowego modelu jest wyrażenie:
s2 = eTe/(n-k), gdzie e = Y - Xa
s2 = [YTY - YTX(XTX)-1XTY]/(n-k)
Twierdzenie V. Jeżeli spełnione są założenia 1 - 5 i jeżeli składniki losowe εt mają rozkład normalny N(0, σ2), to estymatory parametrów α 1, α 2, ..., α k modelu (3) mają k-wymiarowy rozkład normalny o wartościach oczekiwanych równych odpowiednio a1, a2,..., ak i o macierzy wariancji i kowariancji danej wzorem (6).
Bierzemy pod uwagę liczbę stopni swobody zamiast liczbę obserwacji, dlatego że reszty maodelu sa wyznaczone dopiero po oszacowaniu k - parametrów strukturalnych.
![]()
Twierdzenie VI. Jeżeli spełnione są założenia tw.V i cii oznacza element stojący na przecięciu i-tego wiersza i i-tej kolumny macierzy (X'X)-1 to zmienna losowa:
z = (ai - αi)/( σ cii )
ma rozkład normalny N(0,1), zaś zmienna losowa:
t = (ai - αi)/( s cii )
ma rozkład t-Studenta o n-k stopniach swobody.
Twierdzenie to może być wykorzystywane do budowy testów istotności dotyczących poszczególnych parametrów strukturalnych modelu.
Weryfikacja statystyczna rezultatów estymacji
Parametry struktury stochastycznej
Dla opisu stopnia zgodności modelu z danymi empirycznymi używa się:
wariancji resztowej oraz jej pierwiastka tj. odchylenia standardowego reszt
współczynnika zbieżności ϕ2
współczynnika determinacji R2.
Współczynnik zbieżności mówi nam o udziale wariancji nieobjaśnionej w wariancji całkowitej. Współczynnik determinacji mówi o udziale wariancji objaśnionej w wariancji całkowitej.
R2 = 1 - ϕ2
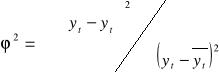
0 ≤ R2 ≤ 1
R2 = 1 ⇔ gdy wszystkie reszty yt - yt* = 0 (brak odchyleń).
R2 = 0 ⇔ gdy zmienne objaśniające modelu zostały dobrane w tak niewłaściwy sposób, że żadna z nich nie jest skorelowana ze zmienną objaśnianą.
Twierdzenie VII.
Przy założeniu, że Yt ma rozkład normalny i jest nie skorelowane ze zmiennymi objaśniającymi (X1, X2, ...., Xk), rozkład zmiennej losowej R jest znany.
Zmienna losowa:
[R2/(k-1)] [(1- ϕ2)/(k-1)]
F = ----------------- = -----------------
[(1-R2)/(n-k)] [ϕ2/(n-k)]
ma rozkład Fishera-Snedecora o (k-1) i (n-k) stopniach swobody.
Korzystna sytuacja jeśli F obliczone jest większe od tabelarycznego.
Fakt ten może być wykorzystany do weryfikacji hipotezy H0, że wszystkie parametry strukturalne (z wyjątkiem wyrazu wolnego) są równe zero. Zatem współczynnik determinacji R2=0.
Wyznaczanie błędów średnich ocen parametrów do testowania ich istotności.
s2 jest nieobciążonym estymatorem wariancji modelu:
s2 = eTe/(n-k), gdzie e = Y - Xa
s2 = [YTY - YTX(XTX)-1XTY]/(n-k)
s = ![]()
s - błąd średni modelu
D2(α) = σ2(XTX)-1 =Ω- macierz wariancji i kowariancji
cii - element stojący na przecięciu i-tego wiersza i i-tej kolumny macierzy (X'X)-1:
s(a0) = s c11
s(a1) = s c22
s(a2) = s c33 itd.
s(ai) - błąd średni estymatora
Przedziały ufności
u = 1 - α
u - współczynnik ufności
α - poziom istotności
P[ai - tα s(ai) < αi < ai + tα s(ai)] = u
tα - wartość zmiennej o rozkładzie t-Studenta o n-k stopniach swobody, dla ustalonego współczynnika ufności.
Interpretacja.
Z prawdopodobieństwem równym „u” można stwierdzić, iż przedział <ai - tα s(ai) ; ai + tα s(ai)> pokrywa faktyczną wartość szacowanego parametru αi .
Twierdzenie VI. Jeżeli spełnione są założenia tw.V i cii oznacza element stojący na przecięciu i-tego wiersza i i-tej kolumny macierzy (X'X)-1 to zmienna losowa:
z = (ai - αi)/( σ cii )
ma rozkład normalny N(0,1), a zmienna losowa:
t = (ai - αi)/( s cii )
ma rozkład t-Studenta o n-k stopniach swobody.
Twierdzenie to może być wykorzystywane do budowy testów istotności dotyczących poszczególnych parametrów strukturalnych modelu.
W estymowanym liniowym modelu ekonometrycznym:
Yt = Σ αiXit + εt
występują zmienne objaśniające, których wpływ na zmienną objaśnianą może być istotny lub nieistotny.
Istotności wpływu zmiennej „xi” na zmienną „y” badamy weryfikując hipotezę:
H0 : αi = 0,
przy hipotezie alternatywnej:
H1 : αi ≠ 0.
Sprawdzianem hipotezy H0 jest statystyka:
t(ai) = ai/s(ai)
posiadająca rozkład t-Studenta o (n-k) stopniach swobody.
Obliczona wartość sprawdzianu jest porównywana z odczytaną z tablic wartością tα , dla (n-k) stopni swobody i poziomu istotności α.
Jeżeli t(ai) < tα , nie ma podstaw do odrzucenia hipotezy H0 . Oznacza to, iż nie jest wykluczone, że otrzymane oszacowanie ai jest przypadkowe. Więc nie stwierdzono istotnego wpływu zmiennej xi na zmienną objaśnianą y.
Jeżeli t(ai) > tα , odrzucamy hipotezę H0 na korzyść hipotezy alternatywnej H1. Oznacza to, że parametr αi różni się istotnie od zera i obserwacje potwierdziły istnienie wpływu zmiennej xi na zmienną objaśnianą y.
Przy około 20 obserwacjach i 2 szacowanych parametrach tα tabelaryczne powinno być około 2 (α=0,05)
Uogólniona Metoda Najmniejszych Kwadratów
Założenia KMNK:
1. E(*t) = 0
2. D2(*t) = *2 - const.
3. E(*t, *t+s) = cov(*t, *t+s) = 0
4. E(Xt, *t) = cov(Xt, *t) = 0
5. *t: N(0, *2)
Z (2) i (3) * macierz wariancji-kowariamcji składnika losowego jest sferyczna (diagonalna o jednakowych elementach na głównej przekątnej):
Ω=![]()
I
Uchylenie założenia 2.
heteroskedastyczność składnika losowego
Macierz wariancji i kowariancji składników losowych jest macierzą diagonalną, ale wariancje składników losowych nie są stałe:
σ12 0 0 . . . 0 c1 0 0. . . 0
0 σ22 0 . . . 0 0 c2 0. . . 0
E(εε') = . . . . . . . . = Π2 . . . . . . . . . = Ω
0 0 0 . . . σn2 0 0 0 .. cn
Uchylenie założenia 3.
Macierz wariancji i kowariancji składników losowych jest macierzą o stałych wariancjach, natomiast kowariancje składników losowych są różne od 0:
D2(εt) = σ2 - constans
E(εt, εt+s) ≠ 0
1 ρ1 .... ρn-1
ρ1 1 .... ρn-2
ΩA = σ2 ... ... ....
ρn-1 ρn-2 .... 1
UMNK pomimo uchylenia założenia 2 lub 3 umożliwia otrzymanie estymatorów dobrych, tzn. zgodnych, nieobciążonych i najbardziej efektywnych.
UMNK polega na uwzględnieniu niesferycznej macierzy * (wariancji - kowariancji składnika losowego) w kryterium MNK:
Φ = (y-Xβ)'Ω(y-Xβ) = e'Ωe min
(kryterium Aitkena)
Z warunków koniecznych ekstremum (∂Φ/∂a=0):
b = (X'Ω-1X) -1 X'Ω-1Y
Alternatywnie UMNK polega na przekształceniu modelu wyjściowego
y=Xβ+ ε
przy zastosowaniu macierzy transformacji P do modelu:
Py = PXβ + P ε
co umożliwia spełnienie warunku 2:
D2(P ε) = σ2I
gdzie: Ω = (P'P)-1 <-> P'P = Ω -1
b=(X'P'PX) -1 X'P'Py = (X' Ω -1X) -1 X' Ω -1Y
D2(β) = σ2(X' Ω -1X)-1
Kroki praktycznej metody uogólnionej:
I. oszacowanie elementów macierzy Ω lub oszacowanie elementów macierzy transformacji P dokonuje się zazwyczaj na podstawie reszt z modułu oszacowanego klasyczną metodą najmniejszych kwadratów.
II. Wykorzystuje się oszacowanie ![]()
lub ![]()
dla wzoru b.
Stosowanie KMNK w tych przypadkach powoduje:
utratę efektywności estymatorów parametrów strukturalnych, natomiast własności zgodności i nieobciążoności estymatorów parametrów strukturalnych zostają zachowane),
utratę zgodności oraz nieobciążoności i efektywności parametrów struktury stochastycznej:
estymatora wariancji resztowej,
wariancji i kowariancji estymatorów parametrów strukturalnych (błędów średnich est.parametrów, statystyk t-Studenta),
współczynnika zbieżności oraz
współczynnika determinacji
Stosowanie standardowych testów istotności jest nieadekwatne.
Rezultaty (wnioski) mogą być obciążone i mylące.
UMNK umożliwia otrzymanie estymatorów dobrych, tzn. zgodnych, nieobciążonych i najbardziej efektywnych.
Idea UMNK polega na przekształceniu modelu wyjściowego do modelu:
PY = PXβ + Pε
D2(Pε) = σ2I (spełnienie warunku 2)
Ω = (P'P)-1
β = (X'Ω-1X) -1 X'Ω-1Y
D2(β) = σ2(X'Ω-1X)-1
P - macierz transformacji
Dekompozycja składnika losowego.
Dekompozycja składnika losowego = analiza wariancji w statystyce
Zmienność zmiennej objaśnianej w modelu, mierzoną jej wariancją, można rozłożyć na części składowe:
1. część wytłumaczoną przez wpływ wyróżnionych w modelu zmiennych objaśniających,
2. część, która nie jest wytłumaczona przez działanie zmiennych objaśniających, a której wielkość jest funkcją wektora reszt.
sy2 = sy*2 + s2
sy2 - wariancja zmiennej Y
sy*2 - część wariancji zmiennej Y wytłumaczona przez X
s2 - część wariancji zmiennej Y nie wytłumaczona przez X (wariancja resztowa)
s2e = Σ(yt - yt*)2 s2y = Σ(yt - ysrt)2
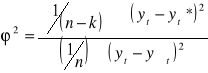
![]()
Współczynnik zbieżności ϕ2 mówi o udziale wariancji odchyleń od modelu (reszt) w ogólnej wariancji zmiennej objaśnianej.
Badanie homoskedastyczności zakłóceń.
Homoskedastyczność = stałość składnika losowego
Heteroskedastyczność = różnicowanie wariancji
Przed zastosowaniem odpowiedniej procedury estymacji dla UMNK należy zastosować odpowiednie testy stwierdzające iż w modelu rzeczywiście istnieje homoskedastyczność albo autokorelacja składnika losowego.
Zgodnie z założeniem:
σ2 = const.
Hipoteza zerowa:
H0 : σ2 = const.
Hipoteza alternatywna:
H1 : σ2 ≠ const.
W praktyce rozważamy trzy następujące sytuacje:
- wariancja zakłóceń wykazuje tendencje do zmian w czasie (wzrostu lub spadku),
- wariancja zakłóceń wykazuje tendencje do zmian, proporcjonalnie do zmian wartości zmiennej objaśnianej i/lub objaśniających,
- obserwacje w próbie pochodzą z kilku populacji różniących się wariancją zakłóceń.
Aby można było sformułować hipotezę alternatywną należy uporządkować obserwacje w próbie.
Test polega na oszacowaniu parametrów równani w dwóch podpróbach i zbadaniu czy wariancje zakłóceń różnią się istotnie w podpróbach.
Test Goldfelda-Quandta.
H0: σ12 = σ22 = const.
H1: σ12 ≠ σ22
Jeśli prawdziwa jest hipoteza zerowa, wówczas stosunek wariancji reszt w podpróbach:
F = s22/s12
ma rozkład F Fishera-Snedecora z liczbą swobody równą odpowiednio stopniom swobody w pierwszej i drugiej podpróbie (jako drugą podpróbę wybiera się tę, w której wariancja reszt jest większa, aby stosunek F był większy od jedności).
Hipotezę zerową o homoskedastyczności zakłóceń odrzucamy, jeśli wartość sprawdzianu F przekroczy krytyczną wartość Fα, odczytaną z tablic dla wybranego poziomu istotności i odpowiednich stopni swobody.
![]()
- odrzucamy H0
![]()
- brak podstaw do odrzucenia Ho
Inne testy: Breuscha-Pagana, White'a.
Jeżeli stwierdzimy heteroskedastyczność zakłóceń, z której wynika fakt, że estymator MNK nie jest efektywny, możemy na kilka sposobów szukać estymatora bardziej efektywnego:
1. Jeśli wariancja zakłóceń ma tendencje wzrostu w czasie, używamy ważonej metody najmniejszych kwadratów, będącej szczególnym przypadkiem UMNK.
2. Jeśli wariancja rośnie proporcjonalnie do kwadratu zmiennej objaśniającej X, można transformować model przez podzielenie równania stronami przez tą zmienną (jeśli zmienna transformowana ma sens ekonomiczny).
3. Zastosować UNMK po oszacownianiu odpowiednich elementów Ω.
4. Pozostać przy ocenach parametrów uzyskanych MNK, pamiętając, że nie jest to estymator efektywny oraz, że odpowiednie charakterystyki mogą być obciążone.
Badanie autokorelacji składnika losowego.
Przyczyny występowania autokorelacji składnika losowego:
1. Fakt dłuższego działania czynników przypadkowych, nie uwzględnionych w modelu.
2. Błędna budowa modelu:
- pominiecie jednej lub kilku istotnych zmiennych objaśniających,
- wprowadzenie do modelu zmiennej z niewłaściwym opóźnieniem czasowym,
- przyjęcie niewłaściwej postaci analitycznej modelu.
3. Autokorelacja zakłóceń, pojawiająca się bez ekonomicznie uzasadnionych przesłanek.
Najczęściej: Autokorelacja I rzędu
E(ၥt, ၥt-1) = ၲ (Ⴙ 0) czyli cov (εt, εt+1)![]()
0
czyli
y = Xၢ + ၥ
ၥt = ၲ ၥt-1 + ၸt
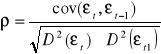
![]()
- parametr ten jest nieznany i trzeba go oszacować
Estymatory parametru ρ - współczynnika autokorelacji I rzędu:
a)
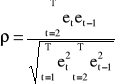
e - reszty MNK modelu liniowego y = x β + ε
b)
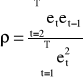
![]()
współczynnik autokorelacji reszt z próby (najczęściej używany)
c)
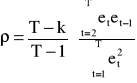
![]()
korekta relacji liczby stopni swobody do liczby obserwacji pomniejszonej o 1
d)
![]()
![]()
d - sprawdzian statystyki Durbina-Watsona
gdzie:
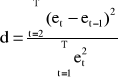
bowiem:
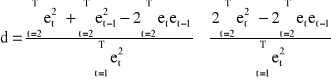
czyli:
![]()
Test Durbina - Watsona
(J.Durbin, G.S.Watson [1950]):
Statystyka d (DW):
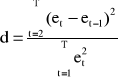
DW jest funkcją nie tylko sekwencji reszt, ale również pośrednio wartości wszystkich zmiennych objaśniających (elementów macierzy X)
Durbin i Watson określili empirycznie funkcję gęstości rozkładu zmiennej d i stwierdzili jej oscylacje pomiędzy dwoma granicznymi krzywymi f(di) i f(ds) w zależności od liczby obserwacji T, liczby zmiennych objaśniających w modelu oraz od sekwencji reszt.
Krzywe te są symetryczne względem pionowej osi symetrii: d=2:
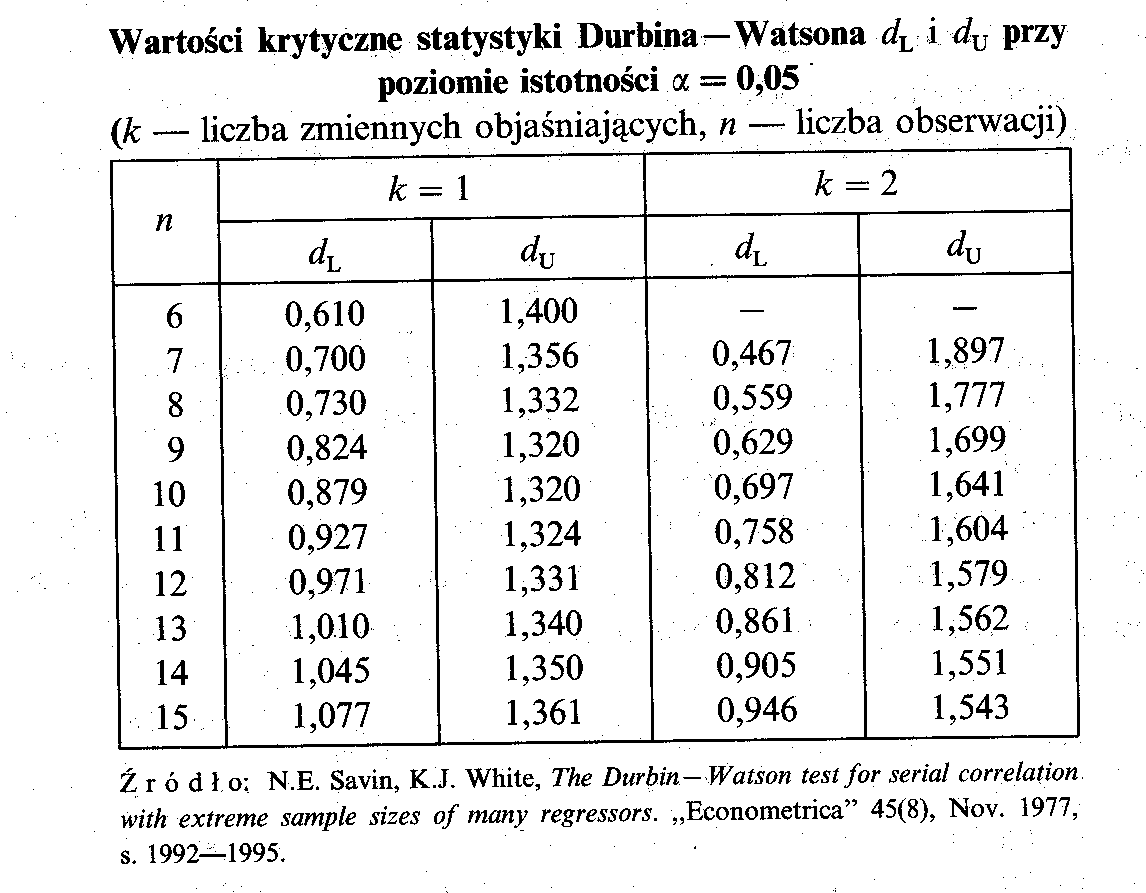
Z tego powodu tablice wartości krytycznych ułożone są ze względu na liczbę obserwacji i liczbę zmiennych objaśniających. Zawierają dwie wartości krytyczne:
dL - dolną oraz dU - górną
Proces wnioskowania (weryfikacji hipotezy dotyczącej istnienia autokorelacji składnika losowego modelu) pokazany jest na wykresie:
Procedura testowania:
1. Estymujemy dany model KMNK i obliczamy wektor reszt:
et = yt - yt*,
2. Obliczamy ocenę (r) współczynnika autokorelacji reszt (ρ):
Σ(etet-1)2
r = ------------
Σ(et)2
3. Badamy istotność współczynnika autokorelacji r, weryfikując hipotezę
H0: ρ = 0
przy jednej z hipotez alternatywnych:
a) H1: ρ > 0, jeśli r jest dodatni,
b) H1: ρ < 0, jeśli r jest ujemny,
Sprawdzianem dla tego układu hipotez jest statystyka d (DW).
Statystyka d ma rozkład empirycznie zbadany przez Durbina i Watsona (nazywany również rozkładem Durbina-Watsona), który jest stablicowany, a jej wartości krytyczne odczytujemy w zależności od liczebności próby n i liczby stopni swobody.
Przy danym poziomie istotności α z tablic rozkładu Durbina-Watsona odczytujemy dwie wartości krytyczne:
wartość dolną dL i wartość górną dU:
np.dla poziomu istotności 0,05; w zależności od liczby obserwacji i liczby zmiennych w modelu, mamy:
I. Dla r > 0 (0<r<1) czyli H1: ρ > 0
jeżeli d ≤ dL, to odrzucamy hipotezę zerową, zatem stwierdzamy występowanie autokorelacji;
jeżeli d ≥ dU, to przyjmujemy ρ = 0, zatem stwierdzamy, że w badanym modelu autokorelacja nie występuje;
jeżeli dL < d < dU, to test nie daje odpowiedzi i nie możemy podjąć decyzji o przyjęciu lub odrzuceniu H0.
(d wpadło tu w przedział niekonkluzywności)
II. Dla r <0 (-1<r<0) czyli H1: ρ < 0
jeżeli 4-d ≤ dL, to odrzucamy hipotezę zerową, zatem stwierdzamy występowanie autokorelacji;
jeżeli 4-d ≥ dU, to przyjmujemy ρ = 0, zatem stwierdzamy, że w badanym modelu autokorelacja nie
występuje;
jeżeli dL < 4-d < dU, to test nie daje odpowiedzi i nie możemy podjąć decyzji o przyjęciu lub
odrzuceniu H0.
Stosowanie testu Durbina-Watsona wymaga, aby:
1. W równaniu obecny był wyraz wolny.
2. Zakłócenia miały rozkład normalny.
3. W równaniu nie występowała opóźniona zmienna objaśniana w charakterze zmiennej objaśniajacej.
Jeżeli w modelu zmienna objaśniającą jest opóźniona zmienna objaśniana:
yt = f(yt-1,…) + εt to statystyka d jest obciążona, a więc nie należy jej stosować.
Stosujemy wtedy statystykę h (DurH) o postaci:
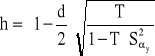
warunek stosowalności: S2 >(1/T).
![]()
- to kwadrat błędu średniego dla parametru α stojącego przy opóźnionej zmiennej objaśnianej
T - liczba obserwacji
Możliwość stosowania przy różnych opóźnieniach zmiennej y.
Wyszukiwarka
Podobne podstrony:
4 ćwiczenia weryfikacja liniowych modeli ekonometrycznych
estymacja i weryfikacja modelu, Ekonometria
rynek - wykład, Ekonomia, ekonomia
EKONOMIA MIĘDZYNARODOWA 16.11.2014-uzupełnienie, V rok, Wykłady, Ekonomia międzynarodowa
Wykład 1, Ekonomia
wykład 8 ekonomika
wykład 3 ekonomika
wykład 2 ekonomika
wykład 1 ekonomika
wykład 4 ekonomika
E1 Ekonomia (wykład 1), Ekonomia, ekonomia
EKONOMIA MIĘDZYNARODOWA 26.10.2014, V rok, Wykłady, Ekonomia międzynarodowa
MIĘDZYNARODOWE STOSUNKI GOSPODARCZE wykład 4, Ekonomia przedsiębiorstwa, Miedzynarodowe stosunki gos
3 wyklad ekonomika iza
Wyklady ekonomia integracji europejskiej
więcej podobnych podstron