Dr hab. Marian Niezgoda
ZASADY ANALIZY MATERIAŁU EMPIRYCZNEGO
1. Co robić z zebranym materiałem?
Analiza zebranego materiału jest uwarunkowana następującymi okolicznościami:
typem badań i rodzajem hipotez, jakie postawiliśmy na etapie eksplikacji programu (w momencie budowy modelu teoretycznego zjawisk, doboru zmiennych i wskaźników),
rodzajem narzędzia, jakim posługiwaliśmy się dla zebrania danych,
rodzajem narzędzia, jakim będziemy się posługiwać w trakcie opracowywania i analizy danych,
typem analiz, jakie pragniemy zastosować w analizie materiału, jaki rodzaj wnioskowania pragniemy zastosować.
Jeśli zależy nam jedynie na jakościowej analizie zebranych danych, to wystarczy posługiwać się indeksami i fiszkami. W wielu wypadkach wystarczy uważna lektura materiału (odpowiedzi na pytania otwarte kwestionariusza), wynotowanie charakterystycznych wypowiedzi (z zaznaczeniem danych identyfikacyjnych rozmówcy: np. „mężczyzna w średnim wieku, mieszkaniec miasta”, lub „wywiad nr 35”, albo „respondent nr 44”.
Ten typ analizy może przypominać takie metody analizy dokumentów osobistych jak:
metoda egzemplifikacji,
metoda typologiczna,
metoda konstrukcyjna.
Tekst wywiadu - odpowiedzi na pytania badacza - służy do wydobywania z niego najbardziej typowych lub najbardziej charakterystycznych wypowiedzi dla ilustracji tez badacza. Przykładem takiego podejścia do materiału badawczego jest np. Praca A. Tyszki, „Uczestnictwo w kulturze”.
Obecnie pojawiły się komputerowe narzędzia (programy) do jakościowych analiz tekstów (np. Nudist, Atlas.ti, Ethnograph itp.) pozwalające poprzez budowanie i stosowanie słowników precyzyjnie analizować teksty. Wymaga to oczywiście wprowadzenia tekstu do pamięci komputera - zapisu na dysku lub dyskietce poprzez wpisanie lub wskanowanie. Daje to możliwości posługiwanie się precyzyjnymi wielowymiarowymi klasyfikacjami, złożonymi typologiami, a także statystyczną analizą zależności, kontyngencji i korespondencji.
Należy dodać, że jest to rodzaj analizy często wspomagającej standardowe analizy statystyczne zebranego materiału. Nie wszystkie pytania otwarte muszą być zamienione na materiał ilościowy i opracowywane statystycznie. Często wypowiedzi respondentów stanowią ilustrację poglądów, opinii, postaw, sposobu formułowania myśli itp., a dodatkowo „ożywiają” sprawozdania z badań.
2. Budowa instrukcji kodowej
Jednak w większości przypadków konieczne jest szczegółowe poklasyfikowanie zebranego materiału i zakodowanie go, tak aby były na nim możliwe dalsze operacje szczególnie, gdy mamy zamiar stosować komputerową analizę statystyczną. Stąd konieczność budowy instrukcji kodowej (klucza kodowego, klucza kategoryzacyjnego). W niektórych typach badań np. w analizie treści w sondażach ankietowych opartych o wysoko wystandaryzowane kwestionariusze, instrukcja kodowa jest albo podstawowym narzędziem gromadzenia informacji (analiza treści) lub „wbudowana” w kwestionariusz (ankiety wystandaryzowane, czy używane w CAPI, CATI).
Warto podkreślić, że obecnie coraz częściej używa się kwestionariuszy wystandaryzowanych w wielu wypadkach generowanych np. przez Data Entry (moduł pakietu SPSS), TeleForm (współpracujący z SPSS). Te pierwsze stosowane są w badaniach typu CA (Computer Assisted), gdzie automatycznie wpisuje się dane do bazy danych, przy zastosowaniu kontroli poprawności wprowadzanych symboli. Te drugie pozwalają na skanowanie danych z kwestionariuszy drukowanych i automatycznie wprowadzanie ich do bazy danych SPSS.
Instrukcja kodowa (klucz kodowy) jest narzędziem umożliwiającym przełożenie danych jakościowych - odpowiedzi na pytania w kwestionariuszu - na symbole (liczbowe lub literowe), a tym samym dalsze opracowanie, głównie statystyczne zebranego materiału. Jest zarazem instrumentem klasyfikowania i typologizowania zebranego materiału badawczego. Zakodowanie zebranego materiału jest niezbędnym krokiem przed przystąpieniem do dalszych analiz (szczególnie analizy statystycznej), ponieważ przy wprowadzaniu danych do komputerów wygodniej jest posługiwać się symbolami, zastępującymi treść odpowiedzi na pytania w kwestionariuszach. W trakcie budowy instrukcji muszą być zachowane następujące zasady:
poprawności teoretycznej
poprawności merytorycznej
poprawności logicznej
poprawności technicznej.
Instrukcja jest poprawna teoretycznie, gdy uwzględnia użyte w programie badań pojęcia teoretyczne i odpowiadające im wskaźniki.
Instrukcja jest poprawna merytorycznie gdy spełnia następujące warunki:
jest dostosowana do struktury zebranego materiału, tzn. uwzględnia treść odpowiedzi na pytania kwestionariusza,
jest zgodna z przyjętymi na etapie eksplikacji określeniami (definicjami) zmiennych i dobranymi wskaźnikami,
jest zgodna z kierunkami planowanej na etapie eksplikacji analizy.
Instrukcja jest poprawna logicznie, gdy spełnia podstawowe kryteria klasyfikacji, tj. nie ma takiej odpowiedzi, której nie dałoby się zaklasyfikować do żadnej z wyróżnionych kategorii oraz nie ma takiej wypowiedzi, którą można zakwalifikować do więcej niż jednej kategorii. Są to zasada wyczerpywalności i rozłączności.
Należy także na etapie konstruowania instrukcji pomyśleć o wielostopniowej klasyfikacji odpowiedzi na to samo pytanie: najpierw ogólnie (np. „tak”, „raczej tak”, „trudno powiedzieć”, „raczej nie”, „nie), a następnie szczegółowo kategoryzować odpowiedzi na „tak” i na „nie”. Można również kodować oddzielnie różne aspekty odpowiedzi na to samo pytanie.
Instrukcja poprawna technicznie to taka, która jest z kolei dostosowana do rodzaju narzędzia używanego do dalszych analiz. Oznacza to konieczność zamienienia pytań na zmienne, które będą polami w obrębie rekordu bazy danych. Komputerowe bazy danych posiadają swoją logikę, którą należy uwzględnić przy konstruowaniu instrukcji kodowej. Odnosi się to zarówno do pytań otwartych jak i zamkniętych. Szczególnie ważne jest przestrzeganie zasady, iż w każdym polu musi być jakiś znak (symbol kodu), ponieważ w przeciwnym wypadku komputer nie przyjmie danych.
2.1. Instrukcja kodowa dla pytań zamkniętych
Pytania zamknięte są w zasadzie samo kodującymi. Z reguły przecież odpowiedzi są numerowane, co odpowiada symbolom kodu. Tak więc do pytań zamkniętych z kafeterią dysjunktywną należy dodać symbol kodu dla braku odpowiedzi ewentualnie dla kategorii „nie dotyczy”, gdy poprzedza je pytanie filtrujące.
Więcej problemów powoduje konieczność zakodowania pytań w postaci tabel, list oraz pytań z kafeterią koniunktywną. Przy kodowaniu tabel musimy pamiętać, aby każdy wiersz (jeżeli zawiera osobną kategorię odpowiedzi) potraktować jako osobną zmienną, a kategoriom odpowiedzi należy przypisać odpowiednie symbole kodu.
Pytania zamknięte z kafeterią koniunktywną są trudniejsze do zakodowania, dlatego, że odpowiedzi na nie, nie są prostą klasyfikacją. Badany z zaproponowanych kategorii odpowiedzi może wybrać albo ich określoną ilość, albo dowolną. Mamy wtedy do wykorzystania dwie możliwości:
potraktowanie każdej kategorii odpowiedzi jako oddzielnej zmiennej kodując podkreślenie (zaznaczenie) odpowiedzi jako informację („1”) i brak zaznaczenia (podkreślenia) jako brak informacji („0”). Jest to tzw. system „zerojedynkowy”.
Jeżeli badany ma wybrać konkretną ilość odpowiedzi (np. trzy) to można trzykrotnie powtórzyć listę kategorii odpowiedzi. Wtedy pytanie będzie miało trzy zamienne (tyle ile odpowiedzi musi wybrać badany).
Tak więc każde pytanie zamknięte z kafeterią koniunktywną czy pytanie z listę czy pytanie w formie tabeli będzie miało więcej zmiennych (jednostek instrukcji kodowej, pól w rekordzie komputerowej bazy danych) niż pytanie z kafeterią dysjunktywną (jedna zmienna, jedno pole rekordu). Jest to istotne, ponieważ później, projektując analizę statystyczną będziemy się posługiwali zmiennymi (ich nazwami czy numerami), a nie numerami czy nazwami pytań.
Schemat instrukcji dla pytań zamkniętych będzie się przedstawiał następująco:
Numer pytania: np. 21
Numer zmiennej: np. 22
Treść pytania: „Czy brał(a) Pan(i) udział w ostatnich wyborach do Sejmu i Senatu?”
Kategorie odpowiedz i: a. Tak, b. Nie
Symbol kodu: tak 1
nie 2
b.o. 3
Uwaga!! W pytaniach tabelach, z listami i kafeteriami konjunktywnymi numery zmiennej odpowiadają kategoriom odpowiedzi, tak więc jest potrzebna dodatkowe rubryki: treść kategorii odpowiedzi, i rodzaj odpowiedzi (informacji) - albo element skali (np. "zdecydowanie tak”, „raczej tak”, „trudno powiedzieć”, „raczej nie”, „zdecydowanie nie”) albo „występuje” „nie występuje”.
2.2. Instrukcja kodowa dla pytań otwartych
Pytania otwarte są do kodowania bardziej kłopotliwe niż najbardziej skomplikowane pytania zamknięte. Przed przystąpieniem do budowy instrukcji kodowej dla tego typu pytań warto sobie przypomnieć, jakie mieliśmy intencje, gdy decydowaliśmy się na ich zamieszczenie w kwestionariuszu. Jeżeli chodziło nam o sprawdzenie sposoby myślenia czy języka, w jakim formułują odpowiedzi badani to musimy odpowiednio zaplanować dalszą analizę pytania. Możemy wtedy poszukiwać np. słów - kluczy, określonych pojęć, czy kontekstu, w jakim się one pojawiają. Wtedy instrukcja kodowa do takiego pytania to lista pojęć (słów kluczy) i druga lista określeń, które im towarzyszą. Wtedy każde pojęcie i każde określenie kontekstowe to oddzielna zmienna, a kategorie odpowiedzi to „występuje” oraz „nie występuje” (system „zerojedynkowy”).
Możliwe jest także, że interesuje nas jedynie globalna odpowiedź (np. „tak”, „raczej tak”, „nie” itp. Wtedy tak kodujemy to pytanie, natomiast odpowiedzi indeksujemy (wypisujemy kolejno na kartce papieru pod numerem pytania i jego treścią kolejne typy odpowiedzi, a jeżeli odpowiedź jest wielowątkowa, to wpisujemy na listę każdy wątek) i wykorzystujemy je później dla ilustracji w tekście opracowania. Możemy również odpowiedzi wpisywać na osobnych kartkach z danymi respondenta (numerem kolejnym respondenta czy dodatkowo określeniem jego płci, wieku, miejsca zamieszkania). Te kartki (fiszki) mogą być pomocne w dalszej analizie.
Gdy jednak chcemy wykorzystać w analizie ilościowej dane z pytań otwartych, to musimy dla nich sporządzić instrukcję kodową. Dla budowy kategorii odpowiedzi należy wykorzystać indeksy lub fiszki. Sposób budowania instrukcji jest podobny jak w wypadku pytań z kafeteriami koniunktywnymi i dowolną ilością wybieranych odpowiedzi. Jednak musimy pamiętać, że może być kilku kodujących w związku z tym do każdej kategorii odpowiedzi musimy dołączyć wskaźniki kategorii odpowiedzi (przykłady odpowiedzi z indeksów lub fiszek).
Schemat instrukcji dla pytań otwartych będzie się przedstawiał następująco:
Numer pytania: 24
Numer zmiennej: 25
Treść pytania: Dlaczego nie brała) Pan(i) udziału w ostatnich wyborach do Sejmu i Senatu?
Kategoria odpowiedzi: bo nie interesuję się polityką
Wskaźniki kategorii odpowiedzi: „nie interesuje mnie to”, „nic mnie to nie obchodzi”, „mam coś innego do roboty”, „nudzi mnie to”
Symbol kodu: występuje 1
Nie występuje 0
Numer pytania: 24
Numer zmiennej: 26
Treść pytania: Dlaczego nie brała) Pan(i) udziału w ostatnich wyborach do Sejmu i Senatu?
Kategoria odpowiedzi: bo nie mam zaufania do polityków
Wskaźniki kategorii odpowiedzi: „nikomu z kandydatów na posłów nie można ufać”, „stale nas oszukują”, „nie ufam politykom bo dbają tylko o siebie, a nie o nas wyborców”
Symbol kodu: występuje 1
Nie występuje 0
Numer pytania: 24
Numer zmiennej: 27
Treść pytania: Dlaczego nie brała) Pan(i) udziału w ostatnich wyborach do Sejmu i Senatu?
Kategoria odpowiedzi: bo udział w wyborach nic nie daje
Wskaźniki kategorii odpowiedzi: „bo to nic nie daje”, „nie ma to sensu”, „co by mi z tego przyszło”
Symbol kodu: występuje 1
Nie występuje 0
Numer pytania: 24
Numer zmiennej: 28
Treść pytania: Dlaczego nie brała) Pan(i) udziału w ostatnich wyborach do Sejmu i Senatu?
Kategoria odpowiedzi: inne
Wskaźniki kategorii odpowiedzi: „byłem chory”, „jestem za stary”, „zapomniałem”
Symbol kodu: występuje 1
Nie występuje, b.o. 0
Pamiętajmy, że w takich wypadkach kategoria odpowiedzi to zmienna. Należy także pamiętać o wielostopniowym i wieloaspektowym kodowaniu takich pytań.
W pewnych szczególnych przypadkach odpowiedzi na pytania otwarte układają się typ kafeterii dysjunktywnej. Wtedy kodujemy je w taki sposób, że kategorii odpowiedzi przyporządkowujemy symbol kodu, jak w przykładzie poniżej:
Numer pytania: 24
Numer zmiennej: 25
Treść pytania: Dlaczego nie brała) Pan(i) udziału w ostatnich wyborach do Sejmu i Senatu?
Kategorie odpowiedzi: a. bo nie interesuję się polityką
b. bo nie mam zaufania do polityków
c. bo udział w wyborach nic nie daje
d. inne
Wskaźniki kategorii odpowiedzi:
a. „nie interesuje mnie to”, „nic mnie to nie obchodzi”, „mam coś innego do roboty”, „nudzi mnie to”
b. „nikomu z kandydatów na posłów nie można ufać”, „stale nas oszukują”, „nie ufam politykom bo dbają tylko o siebie, a nie o nas wyborców”
c. „bo to nic nie daje”, „nie ma to sensu”, „co by mi z tego przyszło”
d. „byłem chory”, „jestem za stary”, „zapomniałem”
Symbol kodu: a 1 b 2
c 3 d 4
b.o. 0
3. Zasady wprowadzania danych
Zakodowane dane albo analizujemy bezpośrednio („na piechotę”) przy pomocy kartki papieru i kalkulatora (ewentualnie arkuszem kalkulacyjnym typu Excell, Lotus 1-2-3, PlanPerfect) albo posługując się jakimś statystycznym programem komputerowym (SPSS, Statistica).
W zależności od programu, jakiego będziemy używać do dalszych analiz, przygotowujemy bazę danych, schemat zmiennych, ich właściwości (charakteru - numeryczne czy alfanumeryczne), długości (ilości znaków). Współczesne pakiety statystyczne - SPSS czy CSS Statistica - posiadają własne moduły wprowadzania danych (np. Data Entry w SPSS), ale mają także możliwości importu baz danych typu Dbase, Paradox, QuatroPro.
Tworzenie szkieletu (schematu) bazy danych (listy pól i ich charakterystyki) polega w gruncie rzeczy na przepisaniu do niej instrukcji kodowej. Wszystkie z nich umożliwiają tworzenie etykiet będących nazwami zmiennych (pytań i kategorii odpowiedzi w kafeteriach koniunktywnych) oraz nazwami kategorii odpowiedzi. Te elementy opisu (etykiety) pojawią się później w tablicach wynikowych.
4. Zasady konstrukcji tabel wynikowych
4.1. Rodzaje zmiennych w tabelach
Odpowiedzi na pytania w kwestionariuszach mają charakter zmiennych jakościowych i zmienne ilościowych. Te pierwsze, to odpowiedzi na pytania dotyczące cech niemierzalnych - opinii o zdarzeniach, poglądów stanu poinformowania. Te odpowiedzi możemy liczyć o obrębie poszczególnych kategorii - czyli liczyć ile osób odpowiedziało tak a nie inaczej na dane pytanie. Wyniki można przedstawić w postaci liczb bezwzględnych lub względnych (proporcji, odsetek).
Uwaga!! Należy pamiętać, aby nie procentować liczebności mniejszych niż 100 osób.
Zmienne ilościowe są znacznie rzadsze w badaniach socjologicznych. Taki charakter ma np. wiek wyrażony w latach, zarobki wyrażone np. w złotówkach, wykształcenie mierzone ilością ukończonych klas (lat nauki). Rozkłady takich zmiennych możemy opisywać przy pomocy miar położenia centralnego (średnich, median, modalnych) i miar skupienia (rozproszenia) (odchylenia średniego, odchylenia standardowego, wariancji, skośności, kurtozy, odchylenia kwartylowego). Jest to opis bardziej precyzyjny niż ten stosowany do zmiennych jakościowych.
Zmienne ilościowe mogą przybierać postać zmiennych ciągłych i zmiennych skokowych. Te ostatnie operują przedziałami. Tę samą zmienną ilościową można przedstawić w postaci ciągłej i skokowej - np. wiek wyrażany rokiem urodzenia (ciągła) i przedziałami np. urodzeni w latach 1960-1965.
Szczególnym sposobem prezentacji danych jest szereg kumulatywny. Jego istota polega na sumowaniu poszczególnych kategorii. Np.
Rok urodzenia %% % skumulowany
1951-1955 15 15
1956-1960 20 35
1961-1965 30 65
1966-1970 20 85
1971-1975 15 100
Interpretacja tych danych skumulowanych polega na tym, że określają nam badanych urodzonych w latach 1971-1975 i wcześniej np. urodzonych w roku 1960 i wcześniej jest w populacji 35%.
Taki szereg można zastosować do prezentacji danych gdy zmienne mają charakter co najmniej porządkowy np. wykształcenia:
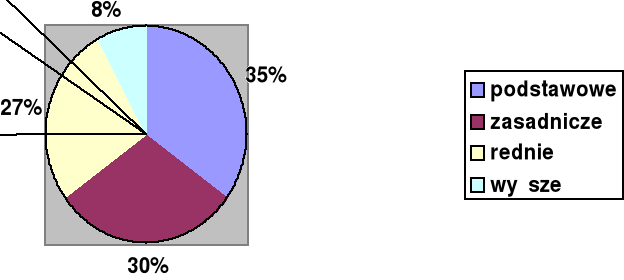
Wykształcenie %% % skumulowany
Podstawowe 35 35
Zasadnicze 30 65
Średnie 27 92
Wyższe 8 100
Oznacza to, że w danej populacji 65% ma wykształcenie zasadnicze i niższe. Są to równocześnie przykłady tablic jednodzielczych, tzn. takich, które przedstawiają rozkład tylko jednej zmiennej.
Takie dane można także prezentować w postaci graficznej: histogramów, diagramów kołowych.
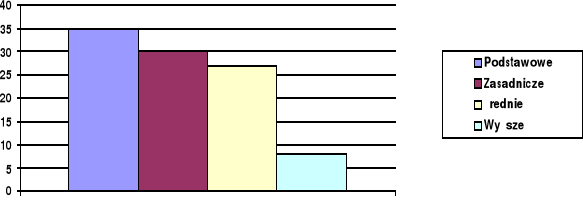
Rys. 1 Wykształcenie badanych (w %%)
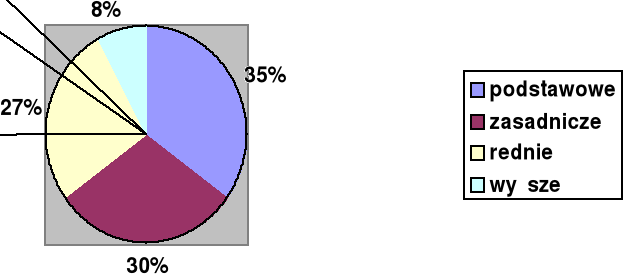
Rys. 2 Wykształcenie badanych (w %%)
Jednak prezentacja danych w tabelach to także testowanie hipotez o zależnościach. Zależność oznacza wpływ jednej ze zmiennych na inną zmienną. Tak więc w tablicy jednodzielczej (patrz wyżej) mamy przedstawiony rozkład (w liczbach bezwzględnych lub względnych) np. odpowiedzi na pytanie w ankiecie w całej badanej populacji, bez jej różnicowania. Wprowadzenie innej zmiennej (niezależnej) np. płci respondentów powoduje, że otrzymujemy - zapisane obok siebie - trzy tablice jednodzielcze (bo płeć ma tylko dwie kategorie - gdyby ich było więcej to odpowiednio byłoby więcej w niej tablic jednodzielczych): rozkład odpowiedzi wśród kobiet, wśród mężczyzn i ogółem. Np.
Tabela 1 Co będzie robić po skończeniu szkoły w zależności od płci (w%%)
Co będzie robić po skończeniu szkoły |
Płeć |
RAZEM |
|
|
Kobieta |
Mężczyzna |
|
|
N=586 |
N=514 |
N=1100 |
Dalej się uczyć |
60 |
65 |
62 |
Pracować i uczyć się |
12 |
15 |
13 |
Pracować |
15 |
10 |
14 |
Jeszcze nie wie |
13 |
10 |
11 |
Razem: |
100 |
100 |
100 |
Zmienne umieszczone w główce tabeli to zmienne niezależne, a w boczku zmienne zależne. W przypadku tabeli trójdzielczej dochodzi jeszcze trzecia zmienna, zmienna stała. Tablica trójdzielcza jest z kolei ustawionymi obok siebie tablicami dwudzielczymi. Jest ich tyle, ile jest kategorii w zmiennej stałej. Np. gdy do zaprezentowanej wyżej tablicy wprowadzimy zmienną stałą miejsce zamieszkania (miasto - wieś) to będzie miała ona następujący wygląd (patrz strona następna).
Trzeba pamiętać, że zmiennymi niezależnymi i stałymi są najczęściej zmienne (cechy) demograficzno-społeczne badanych jednostek: płeć, wiek, miejsce zamieszkania, pochodzenie społeczne, wykształcenie, wykształcenie rodziców, stanowisko pracy itp. Jednak ważna jest przede wszystkim socjologiczna interpretacja wpływu tych cech na inne: np. postawy, aspiracje, poglądy polityczne itp.
Tabela 2 Co będzie robić po ukończeniu szkoły w zależności od miejsca zamieszkania i płci
(w %%)
Co będzie robić po ukończeniu szkoły? |
Miejsce zamieszkania |
Razem |
|||
|
Miasto |
Wieś |
|
||
|
Płeć |
Płeć |
|
||
|
Kobieta |
Mężczyzna |
Kobieta |
Mężczyzna |
|
|
N=300 |
N=274 |
N=286 |
N=240 |
N=1100 |
Uczyć się |
|
|
|
|
|
Uczyć się i pracować |
|
|
|
|
|
Pracować |
|
|
|
|
|
Jeszcze nie wie |
|
|
|
|
|
Razem: |
|
|
|
|
|
Przygotowując projekty tablic wynikowych należy wrócić do programu badań i przypomnieć sobie, jakie zmienne potraktowaliśmy jako zmienne wyjaśniające (niezależne, stałe), a które jako zmienne wyjaśniane (zależne).
5. Zasady analiz danych
przypomnienie programu badań, listy zmiennych, wskaźników, hipotez, modelu zjawisk
wybranie rodzaju analizy - w zależności od rodzaju danych, jakimi się dysponuje.
jakościowej - np. jeżeli są to dane z małej ilości wywiadów np. swobodnych, lub w ogóle mała ilość przebadanych jednostek,
ilościowej: jeśli dysponujemy dużą ilością danych ankietowych wystandaryzowanych.
prostej prezentacji danych (histogramy, diagramy kołowe, tablice jednodzielcze i wielodzielcze w liczbach bezwzględnych i względnych),
analizy statystycznej siły związku między zmiennymi (współczynników korelacji) i analizy wieloczynnikowej. Możliwe to jest wtedy gdy dysponujemy odpowiednimi danymi.
6. Grupowanie danych - analizy typologiczne
Każdą badaną jednostkę można opisać przy pomocy określonego zespołu cech. Najczęściej są to odpowiedzi na pytania w kwestionariuszach. Te cechy określają przestrzeń własności badanego (badanych). Jako rezultat odpowiedzi na pytania otrzymujemy wiele bardzo szczegółowych informacji odnoszących się do ewentualnych zachowań badanych, ich opinii w konkretnych sprawach. Jest to konieczne na tym poziomie badań jakim jest zbieranie informacji. Jednak analiza danych zmusza do przejścia od informacji szczegółowych do analizy typologicznej - uogólniania wyników. Temu między innymi służą procedury redukcji przestrzeni własności, takie jak:
redukcja przez uproszczenie wymiarów
redukcja przy pomocy wskaźników liczbowych
redukcja pragmatyczna
1
9
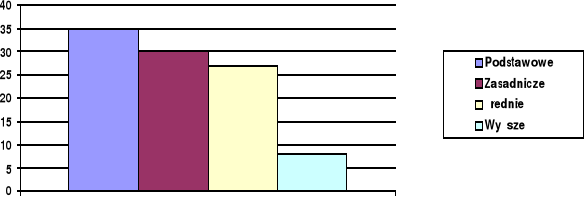
Wyszukiwarka
Podobne podstrony:
analiza treści, Dr hab
Artykuły, 7. CELE WYCHOWANIA MŁODZIEŻY W NAUCZANIU PRYMASA TYSIĄCLECIA. ANALIZA PEDAGOGICZNA W ŚWIET
I Frejman, Metodologia badań pedagogicznych - wykład - prof. dr hab. S. Frejman
PEDcw w4s6, aaa VI semestr, PEDcw prof. dr hab. J.Pięta
egzamin prof dr hab Urlich
BUD WODNE Wyklad 1 dr hab inz Nieznany
TEORIA STOSUNKÓW MIĘDZYNARODOWYCH, Uczelnia - notatki, prof. dr hab. Sebastian Wojciechowski
geografia w1s2, uczelnia, geografia turystyczn, GEOt dr hab. J.Gilarowski
II Frejman, Metodologia badań pedagogicznych - wykład - prof. dr hab. S. Frejman
Pedagogika przedszkolna dr hab Sieradzka Baziur mgr M…
GLOBALNA MŁODZIEŻ opracowanie, Socjologia wychowania - wykład - prof. zw. dr hab. Zbyszko Melosik
3. Wykład z teorii literatury - 20.10.2014, Teoria literatury, Notatki z wykładu dr hab. Skubaczewsk
Ks dr hab D Oko Z papieżem przeciw homoherezji
dr hab RG I II II cz swoboda przeplywu pracownikow
prof dr hab M Smejda,Harmoniza Nieznany
W- 2- monograficzny, WYKŁAD 2 dr hab
Pomiar, Dr hab
Matematyka w ekonomii, dr hab
więcej podobnych podstron