
Jarosław Górniak
Analiza głównych składowych
Analiza czynnikowa
Skale Likerta
Skrypt do wykładu

2
Analiza czynnikowa i analiza głównych składowych
1.1
Wstęp
W pakiecie SPSS pod nazwą modułu: Analiza czynnikowa kryją się dwie metody,
które różnią się pod względem założeń: analiza głównych składowych (Principal
Components Analysis — PCA) i analiza czynnikowa (Factor Analysis — FA). Obie
służą sprowadzaniu informacji zawartych w wielu zmiennych (wskaźnikach) do
niedużej liczby zastępujących je/wyjaśniających wymiarów/czynników. Często
traktowane są one jako warianty tej samej metody, chociaż w istocie nimi nie są.
Dodajmy jednak od razu, że, w praktyce, wyniki uzyskiwane za pomocą obu
metod są zbliżone i rzadko prowadzą do odmiennych wniosków. To powoduje,
że niektórzy statystycy, zwłaszcza o orientacji pragmatycznej, postulują:
1)
Stosowanie w większości sytuacji PCA (ze względu na pewne zalety
formalne, o których dalej), zwłaszcza w sytuacji, gdy uzyskane tą metodą
skale czynnikowe chcemy stosować w innych analizach
1
.
2)
Inni, na odwrót, postulują używanie właściwej analizy czynnikowej (zwykle
metodą osi/czynników głównych lub największej wiarygodności), zwłaszcza
w zastosowaniu do analizy testów psychologicznych lub przy
konstruowaniu modeli przyczynowych obserwowanych zjawisk, ze
względu na fakt, że analiza czynnikowa nie dąży do wyjaśnienia całej
wariancji każdej zmiennej w baterii pytań, a więc i jej części wynikającej z
błędu, lecz tylko tej jej części, która jest dzielona z innymi zmiennymi, a
więc może być uznana za pozostającą pod wpływem wspólnego czynnika
— ukrytej zmiennej/konstruktu.
3)
Inni wreszcie, jak np. Holm (rzecz dotyczy typowego zastosowania analizy
czynnikowej do baterii pytań kwestionariuszowych lub testów), podają
praktyczne reguły w rodzaju:
•
jeśli bateria pytań obejmuje wiele pytań (ok. 15 lub więcej) poleca
się wstawianie na głównej przekątnej macierzy korelacji wartości 1,0
czyli przeprowadzenie analizy metodą głównych składowych;
•
przy mniejszych bateriach pytań zaleca się wstawienie na główną
przekątną macierzy korelacji oszacowanych zasobów zmienności
wspólnej, np. podniesionego do kwadratu współczynnika korelacji
wielokrotnej każdej ze zmiennych z pozostałymi zmiennymi z baterii
— tzn. przeprowadzenie analizy czynnikowej metodą głównych
czynników/osi głównych (por. Holm 1976, s. 24 i 27).
Podkreślmy jeszcze raz: w praktyce wyniki różnych metod wyodrębniania
czynników nie prowadzą do odmiennych wniosków. Należy jednak rozumieć
różnice pomiędzy analizą głównych składowych i analizą czynnikową, by metody
te stosować świadomie, gdyż oparte są one na odmiennych założeniach.
1
Np. Leland Wilkinson i Herb Stenson podkreślają, że w — przeciwieństwie do głównych
składowych — model wspólnych czynników nie jest jednoznacznie określony; i to nie ze
względu na to, że może być dowolnie rotowany (tak jak i główne składowe), ale dlatego,
że bazuje na liczbie nieobserwowanych parametrów większej od liczby obserwowanych
danych, co jest „niezwykłą okolicznością w statystyce” (Wilkinson Stenson 1996, s.569).
Dla niektórych rodzajów macierzy możliwa jest nieskończona liczba doskonale
dopasowanych modeli czynnikowych. Ponadto w FA mamy do czynienia z problemem
konieczności szacowania wartości czynnikowych, które nie mogą być bezpośrednio
wyliczone z modelu.

3
1.2
Założenia co do typu danych, które można analizować
PCA i FA prowadzi się z założenia na zmiennych co najmniej interwałowych
a między zmiennymi mamy do czynienia ze związkami liniowymi. Dobre rezultaty
analizy te dają także w przypadku powszechnie stosowanych w badaniach
społecznych i marketingowych skalach typu Likerta (najlepiej co najmniej 5-
punktowych), skalach dyferencjału semantycznego itp., mimo że formalnie
trudno uznać je za skale interwałowe. Prowadzi się także analizy na zmiennych
typu 0-1, choć w ich przypadku mogą wystąpić problemy. Zwłaszcza, gdy mamy
do czynienia ze zmiennymi skokowymi o wielu kategoriach, zakodowanymi przy
pomocy zmiennych pomocniczych typu 0-1, stosowanie zwykłej analizy
czynnikowej nie jest poprawnym podejściem: należy wtedy stosować wielokrotną
analizę korespondencji — HOMALS z modułu SPSS Categories. Także wówczas,
gdy odsetki 1 w poszczególnych zmiennych („ciężkość” kategorii) znacznie się
różnią, analiza czynnikowa może być zwodnicza, gdyż korelacje między
zmiennymi mogą wynikać z różnic w owej „ciężkości”, a nie z merytorycznego
związku cech
2
. Mimo to, używa się analizy zmiennych 0-1 w celu wyodrębnienia
skupień zmiennych. W przypadku zmiennych typu 0-1 lepiej jest jednak użyć,
analizy korespondencji (HOMALS) lub analizy skupień (CLUSTER), dobierając
w przypadku tej ostatniej miarę odległości (PROXIMITY) odpowiednią dla cech
kodowanych binarnie.
Najczęściej eksploracyjnej analizie czynnikowej i analizie głównych składowych
poddaje się zmienne w ich postaci standaryzowanej (tzn. faktoryzuje się macierz
korelacji, a nie macierz kowariancji); standaryzacja uwzględniona jest domyślnie
przez program analizy czynnikowej SPSS. Nasze rozważania ograniczamy tutaj
do analizy opartej na zmiennych standaryzowanych — macierzach korelacji.
1.3
Analiza głównych składowych (PCA)
Główne składowe to liniowe kombinacje
3
zmiennych, które posiadają
następujące własności:
•
są ortogonalne w stosunku do siebie, tzn. nie są wzajemnie skorelowane
•
pierwsza główna składowa wyjaśnia największą ilość łącznej wariancji
zmiennych, druga jest ortogonalna do pierwszej i wyjaśnia największą część
łącznej wariancji zmiennych nie wyjaśnionej przez pierwszą główną składową
itd. Maksymalna liczba głównych składowych potrzebna do wyjaśnienia całości
wspólnej wariancji k zmiennych jest równa k.
Analiza głównych składowych (PCA) jest:
1.
Metodą redukcji przestrzeni danych, to znaczy jej celem jest przedstawienie
informacji zawartej w zbiorze k zmiennych za pomocą j<k głównych
składowych przy zachowaniu jak największej ilości informacji z pierwotnego
zbioru zmiennych. Korzystając z faktu, że kolejne składowe wyjaśniają
malejący zakres łącznej wariancji zmiennych, dla celów prezentacji zależności
2
Zniekształcenia mogą zresztą wystąpić również w przypadku zmiennych porządkowych,
jeśli występują w nich bardzo duże różnice w „ciężkości” poszczególnych kategorii.
3
Kombinacja liniowa ma postać y= a
0
+ a
1
x
1
+ a
2
x
2
+ ... + a
n
x
n

4
w zbiorze danych wykorzystujemy j pierwszych składowych. W celu uzyskania
interpretowalnych wyników główne składowe można poddać rotacji (o tym
dalej).
2.
Metodą przekształcenia k skorelowanych zmiennych wyjściowych w k głównych
składowych. Korzyścią z takiego przekształcenia zbioru zmiennych w zbiór
głównych składowych jest możliwość ujęcia całości informacji zawartej
w zmiennych (ich wariancji) w postaci zestawu ortogonalnych, a więc
niezależnych, składowych. Takie składowe można użyć w wygodny sposób
w analizie regresji lub analizie dyskryminacji, zwłaszcza w sytuacji, gdy
pierwotny zbiór zmiennych niezależnych jest silnie skorelowany (występuje
w nim zjawisko silnej przybliżonej współliniowości zmiennych niezależnych). W
praktyce w dalszej analizie wykorzystuje tylko część wyodrębnionych
składowych głównych. Niżej podaję kilka praktycznych reguł wykorzystania
składowych głównych w modelach liniowych.
3.
Metodą prezentacji graficznej struktury wielowymiarowego zbioru danych na
płaszczyźnie z jak najmniejszym zniekształceniem informacji.
Model analizy głównych składowych można wyrazić następująco:
główna składowa = liniowa kombinacja obserwowanych zmiennych
W analizie głównych składowych przedmiotem wyjaśnienia jest całkowita
wariancja wszystkich zmiennych. Główne składowe, jako liniowe kombinacje
obserwowalnych zmiennych, są jednoznacznie określone. Zatem dla każdego
przypadku w bazie danych można jednoznacznie wyliczyć wartości na głównej
składowej, dodając do siebie wartości standaryzowane danego przypadku na
poszczególnych zmiennych wymnożone przez odpowiednie wagi (współczynniki
wartości czynnikowych).
Matematyczną podstawą analizy głównych składowych jest dekompozycja pełnej
macierzy korelacji zmiennych (z wartościami 1 na głównej przekątnej) na
wektory własne i wartości własne.
1.4
Analiza czynnikowa
Analiza czynnikowa (FA) jest metodą badania struktury leżącej u podstaw
związków obserwowanych między zmiennymi. Celem tej metody jest
sprowadzenie zaobserwowanych korelacji (kowariancji) między wieloma
zmiennymi do niedużej liczby wyjaśniających je zmiennych nieobserwowalnych:
wspólnych czynników, konstruktów. W modelu analizy czynnikowej przyjmuje
się, że na każdą ze skorelowanych ze sobą zmiennych wpływają w różnym
stopniu wspólne czynniki, które wyjaśniają zaobserwowaną korelację. Wariancja
zmiennych dzieli się na:
•
wariancję wspólną, podzielaną przez zmienne z zestawu (wyjaśnioną przez
czynniki wspólne) — część wariancji zmiennej wyjaśnioną przez czynniki
wspólne nazywamy jej zasobem zmienności wspólnej
•
wariancję swoistą każdej ze zmiennych, niesprowadzalną do współzmienności
wywołanej oddziaływaniem wspólnych czynników.
Tę ostatnią dzieli się jeszcze na wariancję specyficzną zmiennej oraz wariancję
wynikającą z błędu.
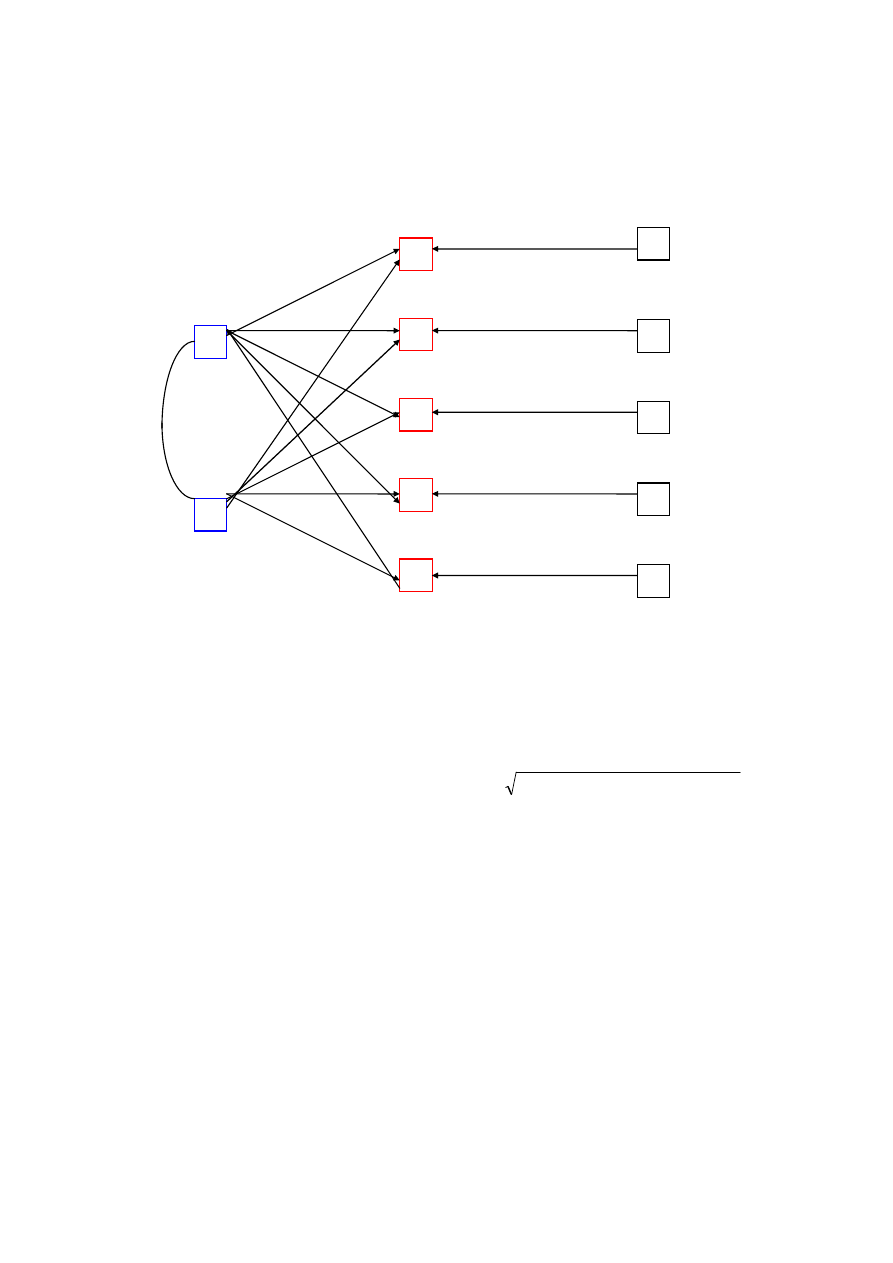
5
Celem analizy czynnikowej jest wyjaśnienie zasobu zmienności wspólnej
mierzonych zmiennych. U podstaw analizy czynnikowej mamy więc model
teoretyczny ukrytej struktury przyczynowej, wyjaśniającej zaobserwowaną
strukturę korelacji wskaźników. Można to przedstawić schematycznie
w następujący sposób (przykład dla dwóch czynników):
gdzie:
F1, F2
— czynniki wspólne (nieobserwowalne)
X
1
do X
5
— zmienne (obserwowalne)
U
1
do U
5
— czynniki swoiste (nieobserwowalne)
f
1
— współczynnik korelacji między czynnikami
b
ij
— ładunki czynnikowe czynników głównych (wspólnych) — współczynniki
regresji standaryzowanej zmiennych na czynniki)
d
ij
— ładunki czynnikowe czynników swoistych (
1
−
zasób zmienno
ś
ci wspó
ej
ln
)
Model analizy czynnikowej można więc wyrazić następująco:
obserwowana zmienna = liniowa kombinacja czynników + błąd
Matematycznie rzecz sprowadza się do analizy struktury tzw. zredukowanej
macierzy korelacji, tzn. macierzy korelacji, w której na przekątnej umieszczone
są wartości wskazujące proporcję wariancji wspólnej — wyjaśnianej przez
wspólne czynniki — w całkowitej wariancji każdej ze zmiennych (zasoby
zmienności wspólnej). Najprostszym sposobem oszacowania tej proporcji
(zasobów zmienności wspólnej) jest wykorzystanie kwadratu współczynnika
korelacji wielokrotnej każdej ze zmiennych z pozostałymi zmiennymi z baterii —
jest to dolna granica zasobu zmienności wspólnej każdej ze zmiennych w
modelu, mająca też tę zaletę, że jest ustalana empirycznie, a nie szacowana.
Innym sposobem jest iteracyjne szacowanie wartości zasobu zmienności
wspólnej poprzez wielokrotne prowadzenie analizy głównych składowych
zredukowanej macierzy korelacji i podstawianie za każdym razem na główną
F1
F2
X
1
X
2
X
3
X
4
X
5
U
1
U
2
U
3
U
4
U
5
f
1
b
11
b
12
b
13
b
14
b
23
b
24
b
25
d
1
d
2
d
3
d
4
d
5
b
21
b
22
b
15

6
przekątną nowo oszacowanych zasobów zmienności wspólnej, aż do osiągnięcia
sytuacji, w której modele z dwóch kolejnych kroków nie różnią się istotnie
(można manipulować kryterium tej zbieżności).
Odrębną metodą wyodrębniania czynników jest metoda największej
wiarygodności: czynniki i zasoby zmienności wspólnej wyznaczone są w taki
sposób, by z największą wiarygodnością wytwarzały zaobserwowaną korelację
między zmiennymi.
śeby lepiej uświadomić sobie różnicę pomiędzy PCA i FA zwróćmy uwagę, że do
wyjaśnienia całkowitej wariancji dwóch zmiennych skorelowanych np. na
poziomie 0,81 potrzeba dwóch głównych składowych (wyznaczony zostanie po
prostu nowy układ współrzędnych), podczas gdy do zupełnego wyjaśnienia
korelacji między nimi (cel analizy czynnikowej) wystarczy jeden czynnik
skorelowany z każdą z tych zmiennych na poziomie 0,9.
1.5
Kiedy stosować analizę głównych składowych
a kiedy analizę czynnikową
Analizę czynnikową stosujemy w sytuacji, gdy:
•
chcemy wyjaśnić zaobserwowaną korelację między zmiennymi za pomocą
modelu przyczynowego opartego na strukturze związków zmiennych
obserwowalnych z ukrytymi czynnikami
•
dysponujemy modelem teoretycznym struktury takiego związku
4
lub
będziemy uzyskane wyniki interpretować w kategoriach teoretycznego modelu
przyczynowego
•
koncentrujemy się na wyjaśnieniu korelacji między zmiennymi i dlatego
chcemy wyłączyć z analizy wariancję swoistą zmiennych
•
zmienne są obciążone względnie dużym błędem pomiarowym, który badacz
chce wyłączyć z analizy
•
celem analizy jest selekcja pozycji/wskaźników do skali sumarycznej Likerta
(choć w tym przypadku, zwłaszcza przy dużej liczbie pozycji, stosuje się też
analizę głównych składowych)
•
celem analizy jest klasyfikacja zmiennych we względnie jednorodne grupy,
w gruncie rzeczy będące właśnie wskaźnikami pewnych konstruktów.
Niektórzy statystycy (np. Wilkinson i Stenson 1996) zalecają porównanie
rezultatów uzyskanych za pomocą analizy czynnikowej (np. metodą największej
wiarygodności, osi głównych czy najmniejszych kwadratów)
z wynikami analizy głównych składowych, żeby „uniknąć oszukania” przez
degeneracje wynikające z niejednoznaczności modelu czynnikowego (por.
przypis 1).
Analizę głównych składowych stosujemy wówczas, gdy:
•
nie dysponujemy potencjalnym modelem „głębokiej” struktury czynników
wyjaśniających związki pomiędzy zmiennymi, taki model nie jest celem naszej
4
W tym wypadku nawet właściwsze będzie zastosowanie konfirmacyjnej analizy
czynnikowej, dostępnej w programie AMOS, odrębnym module SPSS.

7
analizy lub nie chcemy „wtłaczać” w taki model posiadanych danych
empirycznych
•
celem jest eksploracja, rozpoznanie struktury zbioru danych: wyszukujemy
przypadki osobliwe, chcemy przedstawić graficznie strukturę zbioru danych
w przestrzeni dwu- lub trójwymiarowej przy możliwie najmniejszym
zniekształceniu relacji zachodzących pomiędzy obserwacjami, szukamy
skupień obiektów ze względu na podobieństwo w zakresie analizowanych cech,
określamy minimalną liczbę wymiarów przy pomocy których jesteśmy w stanie
wyjaśnić założoną część wariancji zbioru zmiennych
•
jeśli wiemy, że wariancja specyficzna i wariancja wynikająca z błędu jest
niewielka a także, gdy analizujemy dużo (np. więcej niż 15) skorelowanych
zmiennych lub gdy korelacja między zmiennymi jest względnie wysoka, lepiej
jest stosować analizę głównych składowych: główne składowe są
jednoznacznie określone — są kombinacjami liniowymi zmiennych i mogą być
wprost wyliczone, podczas gdy wartości czynników głównych mogą być tylko
szacowane, nie są jednoznacznie określone i przy zastosowaniu są źródłem
pewnych kłopotów (np. oszacowane zmienne z wartościami czynnikowymi
mogą być skorelowane nawet wtedy, gdy czynniki nie są skorelowane lub
mogą nie być doskonale skorelowane z rzeczywistymi czynnikami)
•
chcemy wyliczyć nieskorelowane główne składowe w celu zastosowania ich
w dalszych analizach wielowymiarowych (np. regresji lub dyskryminacji)
•
chcemy wyliczyć jednoznacznie wartości skal reprezentujących wymiary
mierzone przez zestaw zmiennych — alternatywą dla PCA jest proste
sumowanie dla każdego przypadku wartości z poszczególnych zmiennych,
zaklasyfikowanych do skali na podstawie analizy czynnikowej („skala oparta na
czynniku” a nie „skala czynnikowa”); zastosowanie wartości czynnikowych
wyliczonych w analizie czynnikowej (FA) jest problematyczne, choć też
stosowane (por. podręcznikowy przykład w Backhaus i in. 1990).
Etapy analizy czynnikowej i analizy składowych głównych oraz zasady
interpretacja wyników tych dwóch metod (przy świadomości różnic pomiędzy
nimi) są takie, same dlatego potraktujemy je łącznie, a na przykładach
porównamy wyniki uzyskiwane każdą z tych metod.
1.6
Kilka użytecznych definicji
Wzorem Haira i in. (1984) warto podać słowniczek pojęć najczęściej spotykanych
przy okazji analizy czynnikowej i analizy głównych składowych.
Zasób zmienności wspólnej — część wariancji oryginalnej zmiennej dzielona
z wszystkimi pozostałymi zmiennymi włączonymi do analizy; w modelu
ortogonalnym jest równa podniesionym do kwadratu ładunkom czynnikowym
danej zmiennej. W przypadku wstępnej ekstrakcji czynników w analizie
głównych składowych zasób zmienności wspólnej każdej ze zmiennych jest
równy 1, co oznacza że analizie poddana jest cała wariancja zmiennych. Po
odrzuceniu części “najmniejszych” składowych zasób zmienności wspólnej
mówi nam, jak dobrze reprezentowana jest dana zmienna przez model o
zredukowanej przez nas liczbie wymiarów. W analizie czynnikowej szacowanie
zasobu zmienności wspólnej jest jednym z kluczowych elementów procesu
budowania modelu czynnikowego. Ostateczny zasób zmienności wspólnej

8
informuje nas o tym, jaki zakres wariancji zmiennej jest sprowadzalny do
ukrytych czynników ujętych w modelu.
Wartość własna — matematyczna własność macierzy kwadratowej; reprezentuje
zakres wariancji wyjaśnianej przez dany czynnik. We wstępnej fazie analizy,
przed rotacją, czynniki wyodrębniane są w taki sposób, że kolejno wyjaśniają
największą możliwą część wariancji, spełniając jednocześnie warunek braku
wzajemnej korelacji. Prowadzi to do tego, że kolejne czynniki (wektory
własne) mają co raz mniejszą wartość własną. W PCA suma wartości własnej
wszystkich składowych głównych (czyli ich wariancji) równa się liczbie
zmiennych, gdyż każda zmienna standaryzowana ma wariancję równą 1.
W analizie czynnikowej zredukowanej macierzy korelacji suma wartości
własnych równa się sumie wartości umieszczonych na przekątnej tej macierzy
(tzw. ślad macierzy). Procent wariancji wyjaśnionej przez czynnik obliczamy
jako stosunek wartości własnej czynnika do sumy wszystkich wartości
własnych (w PCA procentuje się do sumy równej liczbie zmiennych, gdyż na
przekątnej pełnej macierzy korelacji są jedynki — całkowite wariancje
zmiennych standaryzowanych).
Ładunek czynnikowy — ogólne określenie współczynników umieszczanych
w macierzy ładunków czynnikowych; w węższym znaczeniu: współczynniki
regresji pomiędzy zmienną (standaryzowaną) a zestawem czynników
wspólnych. W przypadku nierotowanych głównych składowych (które są
nieskorelowane) i w przypadku rotacji ortogonalnej w obu opisywanych
metodach są to jednocześnie współczynniki korelacji pomiędzy zmienną
i każdym czynnikiem z osobna, jak i współczynniki regresji pomiędzy zmienną
a zestawem czynników wspólnych. W przypadku rotacji skośnej mamy do
czynienia z dwiema macierzami ładunków czynnikowych: macierzą wzoru
czynników (macierz modelowa) zawierającą ładunki czynnikowe czyli
współczynniki regresji pomiędzy zmienną (standaryzowaną) a zestawem
czynników wspólnych oraz macierzą struktury czynników (macierz struktury)
zawierającą współczynniki korelacji pomiędzy każdą zmienną i każdym
czynnikiem z osobna. W przypadku rotacji skośnej wartości współczynników
w obu rodzajach macierzy te nie są już sobie równe.
Rotacja czynników — proces lokowania (transformacji) czynników ostatecznie
zachowanych w analizie (także głównych składowych) w przestrzeni
zmiennych tak, by uzyskać możliwie najprostszą, interpretowalną strukturę
czynników.
Ortogonalne czynniki — czynniki nie pozostające ze sobą w korelacji;
w przestrzeni: prostopadłe do siebie.
Rotacja ortogonalna — rotacja z zachowaniem niezależności (braku korelacji,
prostopadłości) czynników.
Skośne czynniki — czynniki skorelowane ze sobą, nie tworzące w przestrzeni kąta
prostego.
Rotacja skośna — rotacja czynników dopuszczająca korelację pomiędzy nimi,
reprezentowaną przez odejście od prostopadłości czynników w przestrzeni.

9
Zredukowana macierz korelacji — macierz korelacji, w której na głównej
przekątnej zamiast 1 umieszczone zostały oszacowane wartości zasobu
zmienności wspólnej każdej zmiennej, zazwyczaj wartości współczynnika
determinacji R
2
(wielokrotnego) danej zmiennej w jej regresji na wszystkie
pozostałe zmienne ujęte w macierzy.
1.7
Etapy analizy
W analizie czynnikowej i analizie głównych składowych mamy do czynienia
z pewną sekwencją czynności analitycznych.
1.
Podjęcie przez analityka decyzji o sposobie postępowania z brakiem danych:
eliminacja parami, przypadkami czy zastępowanie średnią? A może należy
podstawić w miejsce braków danych wartości na podstawie któregoś ze
statystycznych modeli imputacji? Odpowiedź na te pytania wymaga
uprzedniej analizy konfiguracji braków danych. Pomocny może być w tym np.
moduł programu SPSS: Missing Value Analysis. Ignorowanie problemów
wynikających z braków danych może prowadzić do zniekształcenia wyników
analizy.
2.
Obliczenie macierzy korelacji (program wykonuje to automatycznie).
3.
Wstępny ogląd macierzy korelacji i usunięcie z analizy zmiennych nie
skorelowanych z pozostałymi (ewentualny test oceniający przydatność
macierzy korelacji do zastosowania modelu czynnikowego) — w praktyce
często jest jednak łatwiej przeprowadzić wstępne analizy metodą głównych
składowych i “wyłapać” zmienne, które pojedynczo budują odrębne czynniki
lub nisko ładują wszystkie czynniki zachowane w analizie.
4.
Wyodrębnienie czynników — wybór metody wyodrębnienia i określenie liczby
czynników pozostawionych do dalszej analizy.
5.
Rotacja czynników w celu uzyskania klarownej interpretacji.
6.
Interpretacja znaczenia uzyskanych czynników na podstawie sensu
zmiennych, które mają wysokie ładunki czynnikowe w przypadku danego
czynnika (na ogół bierze się pod uwagę ładunki czynnikowe o wartościach
bezwzględnych wynoszących co najmniej 0,6, choć nie jest to sztywna zasada
i wiele zależy od konkretnych danych)
7.
Wyliczenie (w razie potrzeby) wartości czynnikowych i użycie ich do
sporządzenia wykresów lub dalszych analiz.
1.8
Metoda wyodrębniania czynników
Problem wyboru pomiędzy analizą głównych składowych a właściwą analizą
czynnikową został przedyskutowany wyżej. Analizę głównych składowych
uzyskujemy wybierając opcję w menu: Wyodrębnianie — Głównych składowych
(syntaks /EXTRACTION PC, opcja domyślna SPSS). W ramach właściwej analizy
czynnikowej stosujemy zazwyczaj:
•
Analizę metodą głównych osi (Osi głównych: PAF) lub metoda najmniejszych
reszt (Nieważonych najmniejszych kwadratów: ULS — metoda nieważonych
najmniejszych kwadratów, znana również w literaturze jako metoda MINRES),

10
które zasadniczo dają identyczne rezultaty
5
. Są to techniki iteracyjne
korzystające z analizy głównych składowych jako punktu wyjścia w analizie
zredukowanej macierzy korelacji, w wyniku których następuje wyodrębnienie
czynników i oszacowanie zasobu zmienności wspólnej zmiennych użytych w
modelu. Są to techniki eksploracyjne, opisowe, dla których nie mamy testu
dopasowania modelu do danych. Syntax: /EXTRACTION PAF (lub alternatywnie
ULS)
•
Metoda największej wiarygodności (Maksymalnej wiarygodności: ML) jest
metodą iteracyjną: czynniki wyznaczone są w taki sposób, by z największą
wiarygodnością wywoływały zaobserwowaną korelację między zmiennymi,
jednak przy założeniu, że próba pochodzi z populacji, w której analizowane
zmienne podlegają wielowymiarowemu rozkładowi normalnemu (co nakłada
postulat normalności rozkładu także na każdą z nich z osobna — zjawisko
rzadko spotykane w badaniach społecznych). Metoda ta daje możliwość
przeprowadzenia testu dopasowania modelu opartego na określonej liczbie
czynników do obserwowanej macierzy korelacji w warunkach dużej próby (test
oparty na rozkładzie CHI
2
). Paradoksalnie, w warunkach dużej próby nawet
niewielkie odchylenia odtworzonej na podstawie modelu czynnikowego
macierzy korelacji od macierzy obserwowanej łatwo prowadzą do odrzucenia
hipotezy o dopasowaniu modelu; chęć uzyskania potwierdzonego testem
dopasowania prowadzi zwykle do zachowania zbyt dużej liczby czynników.
Jeśli posłużymy się innymi kryteriami określania liczby czynników, zwłaszcza
metodą merytorycznej interpretowalności czynników, metoda ta daje dobre
rezultaty w analizie eksploracyjnej i jest często polecana. W procesie
iteracyjnego wyodrębniania czynników tą metodą, w każdym kolejnym kroku,
większa waga przypisywana jest tym zmiennym, które mają większy
oszacowany zasób zmienności wspólnej. Z nazwy „metoda największej
wiarygodności” nie wynika ocena tej metody, a jedynie wskazany jest przez
nią model matematyczny, który stoi u podstaw tej techniki. Metoda ta nie
usuwa problemu niejednoznaczności modelu czynnikowego. Podobne
właściwości ma metoda uogólnionych najmniejszych kwadratów (Uogólnionych
najmniejszych kwadratów — GLS). Opcje: /EXTRACTION ML (lub: GLS).
To, którą opcję wybrać, jeżeli już zdecydujemy się na analizę czynnikową, a nie
głównych składowych, zależy od tego, czy chcemy testować jakość dopasowania
modelu do danych w populacji i czy mamy podstawy ku temu (rozkład normalny,
duża próba) — wówczas ML jest odpowiednia. Jeżeli prowadzimy analizę
eksploracyjną zwykle używamy PAF. Wszystkie metody w praktyce badawczej
dają zwykle takie same (merytorycznie, nie matematycznie) rezultaty.
1.9
Określanie liczby czynników
Kryteria pomocne przy podejmowaniu decyzji o liczbie czynników/głównych
składowych pozostawionych do dalszej analizy:
1.
Kryterium wartości własnej Keisera: wartość własna każdego czynnika-głównej
składowej (= jego wariancji) pozostawionego w dalszej analizie powinna być
większa od 1 (a więc od wariancji pojedynczej zmiennej). Program SPSS także
5
„W warunkach istnienia rozwiązania kanonicznego metoda MINRES jest identyczna z
iteracyjną metodą czynników głównych dla R” (Arminger, s. 52).

11
w przypadku analizy czynnikowej przeprowadza najpierw analizę głównych
składowych i kryteria selekcji odnoszą się do wartości własnych wyliczonych na
tym etapie. Jako domyślne kryterium selekcji czynników stosuje się w tym
programie kryterium Keisera. Opcja /CRITERIA MINEIGEN(1).
2.
Kryterium Jolliffe: w warunkach badania na próbie losowej błąd losowy może
prowadzić do zaniżenia wartości własnej głównej składowej (kryterium to
podane zostało dla PCA). W związku z tym, należy zachować w analizie te
składowe, których wartość własna jest większa od 0,7. Opcja /CRITERIA
MINEIGEN(.7).
3.
Kryterium wystarczającej proporcji wyjaśnionej wariancji (popularne w ramach
PCA): należy pozostawić tyle składowych, by wyjaśniały założony procent
wariancji, np. 80% lub 95%. Opcja /CRITERIA FACTORS(?), gdzie w miejsce ?
należy wpisać taką liczbę czynników, które w świetle wstępnej analizy
wyjaśniają w sumie określony zakres wariancji.
4.
Liczba czynników powinna być mniejsza od połowy liczby zmiennych
(najbardziej „płynne” kryterium ze spotykanych w literaturze, obok kryterium,
że najmniejszy czynnik powinien wyjaśniać co najmniej 1%, 5% lub 10%
całkowitej wariancji w PCA, a całkowitej wspólnej wariancji w FA). Opcja
/CRITERIA MINEIGEN(?).
5.
Kryterium interpretowalności czynników: badacz zachowuje taką liczbę
czynników, która ma sens, da się zinterpretować w ramach jego modelu
teoretycznego. Jest to ważne kryterium, choć jest subiektywne. Dane
obciążone są błędami wynikającymi z losowania i samego pomiaru. Może to
prowadzić do zniekształceń i wyodrębniania czynników reprezentujących
przypadkowe konfiguracje zmiennych. Z drugiej strony, ważny jest walor
„heurystyczny” analizy czynnikowej, jej zdolność ujawniania konfiguracji,
których nie oczekiwaliśmy i podważania tych, z wizją których przystępujemy
do badania. Odrzucenie czynnika, ze względu na jego „nieinterpretowalność”,
musi być więc poprzedzone stosownym namysłem. Opcja /CRITERIA
FACTORS(?), gdzie w miejsce ? należy wpisać taką liczbę czynników,
które w świetle wstępnej analizy da się sensownie zinterpretować.
6.
Kryterium istotności testu statystycznego dopasowania odtworzonej macierzy
korelacji do macierzy obserwowanej (tylko dla metody największej
wiarygodności i GLS): jak już wskazałem, prowadzi często do pozostawienia
dużej liczby „małych” czynników i stawia wymóg normalności rozkładów
zmiennych w populacji, z której pobrana jest próba. Testujemy kolejne modele
zwiększając liczbę czynników o 1 w opcji /CRITERIA FACTORS(?), aż do
uzyskania wartości p>0,05 w teście CHI
2
.
7.
Analiza odchyleń (reszt) obserwowanych współczynników korelacji od
współczynników odtworzonych: opcja /PRINT REPR. Po wybraniu tej opcji
SPSS drukuje macierz, której dolny trójkąt zawiera współczynniki korelacji
pomiędzy zmiennymi odtworzone na podstawie modelu przyjętego
czynnikowego, górny trójkąt — reszty pomiędzy obserwowanymi i
odtworzonymi współczynnikami korelacji, a przekątna — odtworzone
(oszacowane) zasoby zmienności wspólnej każdej ze zmiennych. SPSS
raportuje także odsetek reszt o wartości bezwzględnej przekraczającej 0,05.
Duże odchylenia odtworzonych współczynników korelacji świadczą o słabym
dopasowaniu naszego modelu czynnikowego do danych i każe go
zweryfikować. Musimy jednak pamiętać, że nawet bardzo dobre dopasowanie
modelu do danych nie gwarantuje jego prawdziwości.
8.
Kryterium osypiska (Cattella): należy zachować tyle czynników, ile tworzy
“zbocze”, natomiast zignorować te, które tworzą “osypisko”, “rumowisko”
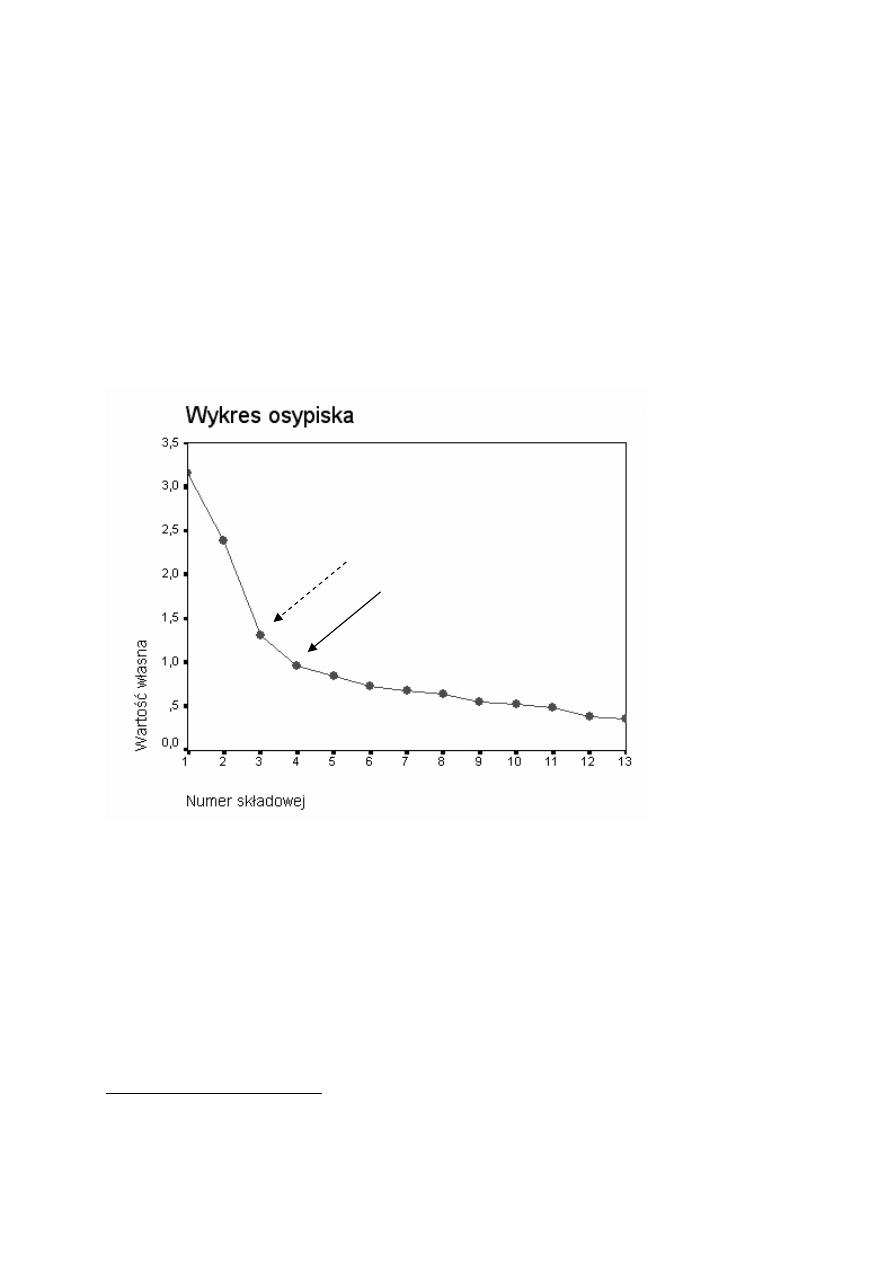
12
u podnóża na wykresie sporządzonym przez połączenie punktów opisujących
wielkość wartości własnej (wariancji) kolejnych czynników.
6
Czasami trudno
jest zdecydować, które miejsce stanowi rzeczywiście początek osypiska i
wybór bywa nieco subiektywny. Metoda ta daje jednak często dobre rezultaty.
Prowadzi zwykle do pozostawienia mniejszej liczby czynników, niż kryterium
Keisera i jest skuteczna zwłaszcza w przypadku analizy koncentrującej się na
najważniejszych czynnikach i ignorującej mniej ważne.
A oto przykładowy wykres ilustrujący kryterium “osypiska”. Osypisko wyraźnie
zaczyna się w przypadku 4 czynników, taką więc ich liczbę należałoby
pozostawić w analizie. Można jednak dopatrywać się początku osypiska już
przy 3 czynnikach. Należy więc odwołać się dodatkowo do kryterium
merytorycznej interpretowalności. Kryterium Keisera sugeruje rozwiązanie
oparte na 4 czynnikach.
W analizie czynnikowej dużą rolę odgrywa doświadczenie i sztuka interpretacji,
stąd badacz powinien elastycznie kierować się powyższymi wskazówkami, by
dotrzeć do ostatecznego modelu.
1.10
Rotacja czynników i interpretacja wyników
Celem jest uproszczenie wzoru czynników tak, by (w idealnym przypadku) każda
zmienna miała wysoki ładunek tylko na jednym czynniku i by każdy czynnik miał
przynajmniej kilka ładunków bliskich 0 i kilka wysokich, bliskich 1 lub -1. Ułatwia
to interpretację uzyskanego modelu. Taki ogólny cel może prowadzić do różnych
6
W literaturze spotyka się dwa stanowiska: jedno każe pozostawić tyle czynników, ile
znajduje się na “zboczu” wraz z tym, od którego zaczyna się “osypisko”; inne stanowisko
każe ignorować ten ostatni czynnik.

13
szczegółowych kryteriów matematycznych, które kierują zmianą położenia
czynników wobec zmiennych.
Aby uzyskać prostą strukturę macierzy ładunków czynnikowych, można dążyć do
uproszczenia interpretacji każdej ze zmiennych za pomocą minimum istotnych
czynników, a więc do uproszczenia wierszy macierzy ładunków. Prowadzi to do
rotacji QURTIMAX
7
, która w szczególnych sytuacjach może jednak skończyć się
wyprodukowaniem wysokich ładunków dla wszystkich zmiennych na jednym
czynniku.
Można też dążyć do uproszczenia interpretacji każdego z czynników, a więc
doprowadzić do tego by względnie niewiele zmiennych miało wysokie ładunki na
jednym czynniku, a pozostałe zmienne miały na tymże czynniku ładunki zerowe
lub bliskie zero; oznacza to dążenie do uproszczenia kolumn macierzy ładunków.
Prowadzi to do rotacji VARIMAX
8
, która daje, ogólnie biorąc, klarowniejsze i
bardziej stabilne wyniki. Jest to domyślna rotacja w programie SPSS.
Kompromisem pomiędzy rotacją QUARTIMAX i VARIMAX jest rotacja EQUAMAX.
Najczęściej stosowaną w praktyce metodą rotacji jest ortogonalna rotacja
VARIMAX (z normalizacją Keisera
9
). Powołując się na eksperymenty Keisera, Kim
i Mueller (1994) piszą: „wzór czynników uzyskany poprzez rotację VARIMAX
bywa bardziej stabilny (invariant) od uzyskanego w rotacji QUARTIMAX, gdy
analizujemy różne podzbiory zmiennych” (s. 104). Z kolei Arminger (1979, s. 94-
95) pisze, że w wielu wykonanych przez siebie analizach nie stwierdził większych
różnic pomiędzy wynikami uzyskanymi przy pomocy tych rotacji, za wyjątkiem
sytuacji, w których wśród zmiennych występowały duże różnice pomiędzy
zasobami zmienności wspólnej.
Konkludując: jeśli zasadne jest wykonanie rotacji ortogonalnej, nie
dopuszczającej korelacji między czynnikami, używamy zazwyczaj rotacji
VARIMAX.
W wielu przypadkach nie mamy powodu zakładać ortogonalności czynników,
należy dopuścić do korelacji między czynnikami, gdyż oczekujemy, że są one
w rzeczywistości skorelowane. W takiej sytuacji przeprowadzamy nieortogonalną
rotację prowadzącą do czynników skośnych. W analizie czynnikowej
wypracowano kilka takich metod. W SPSS dostępny jest skośny odpowiednik
rotacji VARIMAX — rotacja DIRECT OBLIMIN. Dopuszczalny poziom korelacji
między czynnikami reguluje się w niej przy pomocy parametru Delta: wartość 0
lub nieco większa dopuszcza największe skorelowanie; im bardziej ujemna
wartość, tym rozwiązanie bliższe jest uzyskanemu w rotacji VARIMAX.
7
Kryterium rotacji jest w tym wypadku maksymalizacja wariancji podniesionych do
kwadratu ładunków czynnikowych dla każdej zmiennej, przy danej liczbie czynników,
danych zasobach zmienności wspólnej i zachowaniu ortogonalności czynników.
8
Kryterium rotacji jest w tym wypadku maksymalizacja wariancji podniesionych do
kwadratu ładunków czynnikowych dla każdego czynnika, przy danej liczbie czynników,
danych zasobach zmienności wspólnej i zachowaniu ortogonalności czynników.
9
Polega ona na podzieleniu przed rotacją ładunków czynnikowych dla każdej zmiennej
przez pierwiastek kwadratowy z zasobu zmienności wspólnej tej zmiennej, a to w celu
wyrównania wpływu zmiennych na położenie rotowanych czynników niezależnie od ich
zasobu zmienności wspólnej.

14
Nie ma doskonałej recepty na ustawianie parametru DELTA. W analizie
eksploracyjnej G. Arminger poleca następujący sposób postępowania (Arminger
1979, s. 112-113).
(1)
Najpierw zdefiniować konstrukty i zoperacjonalizować je za pomocą
mierzalnych zmiennych.
(2)
Wykonać analizę bez rotacji i sporządzić wykres ładunków czynnikowych
(problem przy większej liczbie czynników). Zmienne definiujące konstrukt
powinny tworzyć zwartą chmurę punktów. Zmienne odosobnione należy
wyłączyć z analizy.
(3)
Jeśli przeprowadzimy osie przez chmury punktów, możemy mniej więcej
ocenić kąt pomiędzy nimi. Cosinus tego kąta umożliwia ocenę korelacji
pomiędzy czynnikami. Jeśli korelacja jest wysoka, ustawiamy DELTA>0, jeśli
niska — DELTA<0.
(4)
Zarówno przy eliminacji zmiennych, jak i przy wyborze DELTA ważne są
rozstrzygnięcia merytoryczne: jeśli z teorii wynika, że nie powinno być
korelacji, a my uzyskujemy niewysoką korelację przy DELTA=0, należy
spróbować obniżyć wielkość DELTA.
Ustawienie parametru delta na 0, sprawdzenie uzyskanej korelacji między
czynnikami i porównanie macierzy wzoru czynników z wynikami rotacji VARIMAX
często pozwala na ostateczne podjęcie decyzji co do sposobu rotacji. Wielu
badaczy sugeruje rotację skośną jako naturalne podejście w analizie czynnikowej
i dopiero wówczas, gdy korelacja między czynnikami jest nieduża, rotowanie
metodą VARIMAX. Trzeba jednak pamiętać, że skorelowane czynniki mogą być
trudniejsze w interpretacji; wymagają często teorii wyjaśniającej zaobserwowaną
korelację między czynnikami. Ponadto, możliwość manipulowania parametrem
DELTA jest przez niektórych traktowana jako nadmiar arbitralności
w modelowaniu rzeczywistości. Często też analizę czynnikową i głównych
składowych prowadzi się po to, by uzyskać ortogonalny układ zmiennych do
dalszych analiz. Wówczas rotacja nieortogonalna nie jest rozwiązaniem
pożądanym.
Od wersji 7.5 pakietu SPSS dostępna jest również rotacja skośna PROMAX, która
polega na potęgowaniu (zazwyczaj do 4 potęgi, co wyznacza parametr KAPPA),
ładunków czynnikowych uzyskanych w rotacji VARIMAX, a następnie wyliczeniu
kąta między czynnikami o uproszczonym przez potęgowanie wzorze czynników.
W tym wypadku korelacja między czynnikami jest więc pochodną prostej
struktury czynników: ich najlepszego dopasowania do poszczególnych skupień
zmiennych. Rotacja PROMAX cieszy się sporym uznaniem w literaturze za jej
efektywność przy odkrywaniu nieortogonalnej struktury czynników leżących
u podstaw korelacji między wskaźnikami.
W wyniku rotacji nieortogonalnej uzyskujemy nie jedną, lecz dwie macierze
współczynników, opisujących związki między czynnikami i zmiennymi.
(1)
Macierz wzoru czynników (macierz modelowa) — zawiera ładunki czynnikowe,
czyli standaryzowane współczynniki regresji pomiędzy każdą zmienną (jako
zmienną zależną) a czynnikami (jako zmiennymi niezależnymi);
(2)
Macierz struktury czynników — zawiera współczynniki korelacji liniowej
pomiędzy zmiennymi a czynnikami: w pierwszej kolumnie mamy
współczynniki korelacji pomiędzy pierwszym czynnikiem i każdą zmienną
z osobna, w drugiej — pomiędzy drugim czynnikiem i każdą zmienną z osobna
itd.

15
W sytuacji, gdy czynniki są skorelowane, współczynniki korelacji pomiędzy
zmienną a każdym z czynników nie są równe standaryzowanym współczynnikom
regresji pomiędzy zmienną a tymi czynnikami jako zestawem zmiennych
niezależnych, gdyż współczynniki regresji uwzględniają wzajemną korelację
zmiennych niezależnych, a współczynniki korelacji — nie. W sytuacji, gdy
czynniki są ortogonalne, współczynniki korelacji są równe standaryzowanym
współczynnikom regresji pomiędzy zmiennymi i czynnikami (ładunkom
czynnikowym) i dlatego mamy do czynienia z jedną macierzą ładunków
czynnikowych.
W analizie czynnikowej rotowanej skośnie (OBLIMIN, PROMAX) interesuje nas
zwykle macierz wzoru czynników — zawierająca ładunki
czynnikowe/współczynniki regresji — co wiąże się z przyczynowym charakterem
interpretacji modelu czynnikowego. Różnice struktury obu macierzy nie są jednak
zwykle istotne dla interpretacji. Są one tym większe, im silniej skorelowane są
czynniki. W przypadku bardzo wysokiej ich korelacji możliwa jest sytuacja, że
ładunki czynnikowe (w Macierzy modelowej) będą w pewnych przypadkach
niskie, a współczynniki korelacji (w Macierzy struktury) wysokie; np. zmienna V
ma niski ładunek i wysoką korelację z czynnikiem X i wysoki ładunek i wysoką
korelację z czynnikiem Y. Taką sytuację należy rozumieć następująco:
a)
zmienność czynnika X pokrywa się w znacznym stopniu ze zmiennością
czynnika Y, gdyż są one silnie skorelowane;
b)
czynnik Y wyjaśnia większą część wariancji zmiennej V niż czynnik X, przy
kontroli wpływu pozostałych czynników;
c)
czynniki X i Y reprezentują pewien wspólny wymiar, a ich wyodrębnienie
w analizie może być wynikiem niekompletnego doboru wskaźników lub np.
część wskaźników ma ambiwalentny charakter; zawsze w takiej sytuacji
pojawia się problem z kwalifikowaniem wskaźników do jednej lub drugiej
skali/czynnika i konieczne jest włączenie kryterium merytorycznej
interpretacji (problem trafności pomiaru).
Macierz struktury czynników ujawnia nam związki pomiędzy zmiennymi
a czynnikami, które mogą być zacierane w macierzy wzorów, w której ładunki są
wyliczane przy charakterystycznym dla regresji wyłączaniu (kontroli) wpływu
innych skorelowanych czynników. Musimy jednak brać pod uwagę to, że proste
współczynniki korelacji mogą reprezentować związki pozorne, właśnie dlatego, że
w ich przypadku nie jest kontrolowany wpływ pozostałych zmiennych
(czynników) w modelu.
Zwykle w przypadku badań kwestionariuszowych zakładamy, że czynniki przez
nas uzyskane powinny być dobrze rozróżnione, powinny posiadać swoją
specyfikę, dlatego też nie powinny być one zbyt silnie ze sobą skorelowane.
Sposobem na zaobserwowaną wysoką korelację nie jest jednak wymuszanie
ortogonalności, lecz przemyślenie modelu teoretycznego i doboru wskaźników.
Niekiedy spotyka się opinię, że o ile rotacja jest naturalnym elementem analizy
czynnikowej, o tyle w analizie głównych składowych rotacja nie jest zasadna. Nie
jest to podejście słuszne. Zarówno doświadczenie badawcze jak i studia
symulacyjne pokazują, że rotowanie głównych składowych w celu uzyskania
klarownej ich interpretacji jest uzasadnione. Główne składowe są po rotacji,
podobnie jak czynniki, często łatwiejsze do interpretacji — a celem analizy

16
danych jest przecież zrozumienie danych a nie ich matematyczne przetworzenie.
Także wówczas, gdy główne składowe obliczamy w celu zastosowania w dalszych
analizach, rotacja często jest lepszym rozwiązaniem. Tak więc w analizie skupień
(cluster analysis) użycie rotowanych “istotnych” składowych głównych (np.
o wartościach własnych powyżej 1) prowadzi do lepszego odtworzenia struktury
danych, niż stosowanie wszystkich wyodrębnionych głównych składowych
(Bacher, 1996, s. 194-198). Rotacja głównych składowych może też poprzedzać
ich użycie w analizie regresji
10
. Takie podejście zbliża analizę głównych
składowych do analizy czynnikowej, nie zacierając jednak ich formalnych różnic
między tymi technikami.
Po rotacji można przystąpić do interpretacji uzyskanego modelu. W przypadku
właściwej analizy czynnikowej nie powinno się interpretować czynników
nierotowanych, wobec niejednoznaczności uzyskiwanego rozwiązania.
W przypadku PCA interpretacja nierotowanych składowych jest możliwa i
niekiedy właściwsza, rotacja zwykle jednak przynosi rozwiązanie łatwiejsze do
interpretacji.
1.11
Wyliczanie wartości czynnikowych
Po wykonaniu rotacji możemy wyliczyć wartości czynnikowe (w sytuacji PCA
można także bez rotacji) — opcja /SAVE=REG (lub /SAVE=BART, lub /SAVE=AR;
w przypadku PCA wszystkie trzy metody obliczania wartości czynnikowych
prowadzą do tych samych rezultatów, w przypadku FA — wszystkie prowadzą do
pewnych kłopotów). Na tym etapie tworzone są nowe zmienne, dodawane na
końcu zbioru. Odpowiadają one poszczególnym czynnikom/głównym składowym.
Zawierają (dla każdego przypadku, w którym nie ma braków danych)
oszacowania wartości, które każdy przypadek uzyskał na wymiarze (skali)
reprezentującym czynnik. Wartości czynnikowe wyliczane są przez pomnożenie
wyliczonych przez program współczynników wartości czynnikowych (macierz
współczynników ocen czynnikowych; opcja: /PRINT FSCORE) dla poszczególnych
zmiennych przez te (standaryzowane) zmienne i dodanie do siebie wyników.
Nowa zmienna jest więc kombinacją liniową wartości zmiennych, ważonych
współczynnikami, określającymi wpływ poszczególnych zmiennych na wartość
danego czynnika. Musimy pamiętać, że w przypadku właściwej analizy
czynnikowej (FA) wartości czynnikowe są tylko oszacowaniem „prawdziwych”
wartości czynników i, ze względu na właściwości tego modelu analizy, mogą być
problematyczne. Dlatego w sytuacji, gdy chcemy używać wartości czynnikowych
w dalszej analizie, lepiej jest skorzystać z analizy głównych składowych. W PCA
wartości czynnikowe są wyliczane jednoznacznie, a nie szacowane. Składowe
główne są liniowymi kombinacjami obserwowanych zmiennych, jednoznacznie
określonymi
11
.
1.12
Wykresy ładunków czynnikowych i wartości czynnikowych
10
“Jeżeli główne składowe są nieinterpretowalne, wówczas możemy rotować zatrzymane
składowe przed użyciem ich w regresji” (Dunteman 1994, s. 215).
11
W przypadku nierotowanych głównych składowych współczynniki wartości
czynnikowych otrzymuje się przez podzielenie ładunków czynnikowych przez wartość
własną czynnika; to dzielenie wykonuje się po to, by uzyskać wartości czynnikowe
znormalizowane tak, żeby wariancja wyliczonej zmiennej była równa 1.

17
Ładunki czynnikowe można przedstawić na wykresie rozrzutu (2W lub 3W). Osie
układu współrzędnych reprezentują czynniki. współrzędne punktów
reprezentujących zmienne wyznaczone są przez ładunki czynnikowe. Skupienia
zmiennych na wykresie wskazują na ich relatywnie silniejsze związki pomiędzy
sobą. Często używa się strzałek, by połączyć punkty oznaczające zmienne
z początkiem układu współrzędnych. Musimy zawsze pamiętać, że oglądamy
obraz uproszczony, w którym sąsiedztwo punktów na wykresie 2W może być
wynikiem „uproszczenia rzeczywistości” i zrzutowania punktu leżącego daleko, na
niewidocznym wymiarze, na analizowaną płaszczyznę. Dotyczy to zwłaszcza
punktów leżących bliżej centrum, czyli początku układu współrzędnych. Pewność
naszego wnioskowania zależy od jakości modelu, mierzonej odsetkiem
wyjaśnionej wariancji lub testem dobroci dopasowania. Jakość reprezentacji
każdej zmiennej na dwuwymiarowym wykresie, opartym na dwóch pierwszych
czynnikach/składowych opisana jest jej zasobem zmienności wspólnej
oszacowanym (jednoznacznie wyliczonym w PCA) dla modelu opartego na dwóch
pierwszych czynnikach.
Wykresy można również sporządzać korzystając z wartości czynnikowych.
Umieszczamy wówczas na wykresie rozrzutu, którego osie reprezentują czynniki,
punkty reprezentujące poszczególne przypadki. Punkty leżące blisko siebie
stanowią skupienia podobnych obiektów. Jest to stwierdzenie tym bardziej
prawdziwe, im większy odsetek wariancji wyjaśniają dwie pierwsze składowe,
które definiują nasz wykres. W przypadku bazy danych złożonej z dużej liczby
przypadków, trudno przedstawić je w komplecie na wykresie. Wylicza się więc
średnie z wartości czynnikowych dla wybranych segmentów (np. wykształcenia) i
lokuje na wykresie te segmenty, posługując się średnimi jako współrzędnymi.
Jest to standardowa technika pozycjonowania.
Można ładunki czynnikowe zmiennych i wartości czynnikowe przypadków
umieścić na jednym wykresie. Wymaga to wykonania uprzednio dość prostych
zabiegów związanych z przygotowaniem wspólnej bazy danych zawierającej
ładunki i wartości czynnikowe na dwóch pierwszych czynnikach oraz zmiennej
odróżniającej jedne od drugich. Następnie wykonuje się wspólny wykres
rozrzutu. Należy jednak pamiętać, że interpretacja odległości pomiędzy punktami
na tym wykresie jest uprawniona tylko odrębnie w zbiorze zmiennych i odrębnie
w zbiorze przypadków. Oba te zbiory należą do odrębnych przestrzeni: ładunków
i wartości czynnikowych, których wspólnym elementem są osie układu
reprezentujące czynniki. Dlatego też używamy punktów (strzałek)
reprezentujących zmienne do interpretacji znaczenia wymiarów/osi układu
współrzędnych, a następnie interpretujemy położenie punktów oznaczających
przypadki (segmenty) względem tych zinterpretowanych wymiarów. Jest to
technika powszechnie używana w pozycjonowaniu i eksploracyjnej analizie
danych.
1.13
Liczba zmiennych i przypadków
Ile przypadków musi być w bazie danych, żeby przeprowadzić analizę czynnikową
i składowych głównych?
Minimum musimy mieć o jeden przypadek więcej niż wynosi liczba zmiennych.
Analizę głównych składowych prowadzi się dla takich niedużych macierzy danych,

18
by odkryć ich strukturę i zredukować do minimum (2 lub 3) wymiarów, w celu
prezentacji graficznej (patrz przykład dalej). Zasadniczo nie powinno się
poddawać analizie czynnikowej prób mniejszych niż 50 przypadków, a jeszcze
lepiej, by miały 100 lub więcej przypadków. Konserwatywne podejście mówi, że
powinniśmy mieć cztery do pięciu razy więcej przypadków niż zmiennych, mniej
konserwatywne zadowala się stosunkiem 2:1. Dyskusje dotyczące wielkości
próby dotyczą zwłaszcza metody największej wiarygodności; w tym wypadku
sugeruje się, że liczba przypadków powinna być o 51 większa od liczby
zmiennych. Można podać wzór:
N - n -1>=50
gdzie:
N - wielkość próby
n - liczba zmiennych
Niektórzy badacze (np. Thurstone) sugerują, że powinniśmy mieć przynajmniej
po trzy zmienne na każdy czynnik, tzn. ładujące istotnie tylko ten czynnik. Jest
to formułowane jako wystarczający warunek identyfikacji czynnika (Bacher 1990,
s. 120). Dość powszechna zgoda panuje co do tego, że powinniśmy mieć co
najmniej dwa razy więcej zmiennych niż czynników (por. Kim & Mueller, s. 144–
145; Hair, Anderson & Tatham, s. 237).
Wpływ doboru zmiennych na wyniki analizy
Na wyniki uzyskane w analizie czynnikowej i analizie głównych składowych ma
wpływ dobór zmiennych do analizy. W przypadku próby z szerszej populacji
korelacja może wystąpić nawet pomiędzy tymi zmiennymi, które w populacji nie
są skorelowane. Im więcej zmiennych używamy w analizie, tym większe jest
prawdopodobieństwo, że w próbie losowej przypadkowo uzyskamy istotne
korelacje nawet pomiędzy oryginalnie nieskorelowanymi zmiennymi, a to wpłynie
na wyniki analizy czynnikowej i PCA. Należy więc dobierać do analizy takie
zmienne, co do których mamy merytoryczne podstawy, by oczekiwać, że będą
skorelowane z grupą innych zmiennych i będą wspólnie z nimi definiowały jakiś
interpretowalny czynnik. Nawet przy takim podejściu zdarzają się różne
niespodzianki (czasami o bardzo twórczych konsekwencjach), łatwiej jednak
ustrzec się błędu interpretacji przypadkowych związków jako teoretycznie
ważnych lub błędu nieuwzględnienia istotnych związków między zmiennymi.
Analiza czynnikowa, jak cała statystyczna analiza danych, nie chroni
automatycznie przed błędami i wymaga namysłu oraz starannej specyfikacji
modelu. To skłania niektórych praktyków analizy czynnikowej do preferowania
analizy konfirmacyjnej. Jednak ta ostatnia nie jest także wolna od problemów
związanych z niejednoznacznością rozwiązania czynnikowego i możliwością
dopasowania do danych wielu alternatywnych modeli.
Wstępna ocena przydatności danych do analizy czynnikowej
W analizie czynnikowej dostępne są także statystyczne techniki wspomagające
wstępną selekcję zmiennych i ocenę przydatności macierzy korelacji do
przeprowadzenia analizy czynnikowej. Takim narzędziem jest przede wszystkim
Miara KMO adekwatności doboru próby — KMO. Służy on ocenie, na ile daną
macierz korelacji można uznać za produkt oddziaływania wspólnych czynników,
odnosząc współczynniki korelacji między zmiennymi (pożądane jest, by były
wysokie, pomiędzy zmiennymi, na które działa wspólny czynnik) do cząstkowych
współczynników korelacji między nimi (jeśli obserwowane korelacje między

19
zmiennymi są wynikiem oddziaływania wspólnego czynników, wówczas korelacje
cząstkowe pomiędzy tymi zmiennymi powinny być niskie). Współczynnik KMO
można obliczyć dla całej macierzy korelacji. Im bliższa 1 jest jego wartość, tym
lepiej model czynnikowy nadaje się do wyjaśnienia struktury danej macierzy
korelacji. Keiser
12
wskazuje następujące dolne progi wartości KMO:
•
0,9 — wspaniały
•
0,8 — godny pochwały
•
0,7 — niezły
•
0,6 — przeciętny
•
0,5 — nędzny
•
poniżej 0,5 — nie do przyjęcia.
Jeśli macierz korelacji ma niski współczynnik KMO, należy rozważyć sensowność
użycia analizy czynnikowej. Współczynnik KMO dla macierzy korelacji
uzyskujemy w procedurze FACTOR dzięki opcji /PRINT KMO.
Współczynnik KMO może zostać wyliczony również dla każdej zmiennej. Jeśli
zmienna uzyska niski KMO, należy rozważyć usunięcie jej z analizy.
Współczynniki KMO dla zmiennych są umieszczone na przekątnej macierzy
Macierz korelacji przeciwobrazów. Nawiasem mówiąc, elementy tej macierzy,
poza przekątną, to pomnożone przez -1 wartości korelacji cząstkowych pomiędzy
zmiennymi
13
. Jeśli zmienne pozostają pod wpływem wspólnych czynników,
wówczas ich korelacje cząstkowe powinny być bliskie 0. Duży odsetek wysokich
wartości korelacji cząstkowych każe rozważyć sensowność modelu czynnikowego
dla danej macierzy korelacji. Tę użyteczną dla wstępnej oceny danych macierz
uzyskujemy dzięki opcji
/PRINT AIC.
1.14
Na marginesie: Użycie głównych składowych w analizie regresji
Głównych składowych używa się w analizie regresji w celu poradzenia sobie ze
zjawiskiem wielowspółliniowości zmiennych niezależnych lub w celu uproszczenia
analizy i interpretacji wyników.
•
Możemy wprowadzić wszystkie nieskorelowane główne składowe —
współczynniki korelacji między każdą z nich a zmienną zależną są równe
standaryzowanym współczynnikom regresji (beta) pomiędzy każdą ze
składowych a zmienną zależną.
•
Możemy wprowadzić część głównych składowych, kierując się przy ich doborze
poziomem korelacji ze zmienną zależną (zazwyczaj pierwsze składowe są
najsilniejszymi predyktorami, zmiennej zależnej, ale nie zawsze.
•
Przed użyciem w analizie regresji składowe główne można poddać rotacji
w celu ułatwienia interpretacji wyników.
1.15
Analiza głównych składowych i analiza czynnikowa gotowej
macierzy korelacji – przykład 1.
Dane pochodzą z badań przeprowadzonych przez Armingera i Nemellę. Badanie
dotyczyło motywacji i przyczyn wyboru kursów przez 344 uczestników
12
cyt. za: Maria Norusis, SPSS Professional Statistics 6.1, s. 52.
13
tzn. wyliczonych pomiędzy resztami pozostałymi po wyodrębnieniu z każdej z tych
zmiennych wpływu pozostałych zmiennych.

20
zawodowego kształcenia dla dorosłych w Instytucie Wspierania Zatrudnienia
w Linzu (por. Arminger, s. 34-35). Między innymi zadano następujące pytanie:
Jakie cechy są niezbędne do awansu zawodowego w Pana(i) zakładzie?
W wyniku pomiaru na pięciostopniowej skali (1 - bez znaczenia, 2 - mniej ważne,
3 - również ważne, 4 - ważne, 5 - bardzo ważne) uzyskano macierz korelacji dla
9 wymienionych cech.
UWAGA: Zastosowano tu macierz współczynników korelacji Pearsona, mimo
dyskusyjności tego rozwiązania w przypadku skal porządkowych tego rodzaju.
Rozwiązanie takie jest szeroko stosowane, choć niezbędna jest ostrożność, ze
względu na możliwe zniekształcenia. Niekiedy postuluje się stosowanie w takich
sytuacjach współczynników tau-b Kendalla (Arminger, s. 148-152), chociaż są
przeciwnicy takiego stanowiska, którzy podkreślają fakt, że zmienne w analizie
czynnikowej muszą być interwałowe i pozostawać w liniowym związku,
a korelacja powinna być mierzona współczynnikiem r Pearsona (czyli być miarą
kowariancji pomiędzy standaryzowanymi zmiennymi) (por. Kim & Mueller).
W analizowanym przypadku zastosowanie r i tau-b prowadzi do takich samych
rezultatów. Bacher (1990) podkreśla stosunkowo dużą odporność analizy
czynnikowej na zniekształcenia spowodowane pomiarem na skali porządkowej.
Jeśli w rzeczywistości mamy do czynienia ze zmiennymi ciągłymi, które są przez
nas tylko mierzone przy pomocy skal porządkowych, to im silniejszy jest związek
pomiędzy tymi „prawdziwymi”, ciągłymi zmiennymi, tym bardziej jest on
tłumiony przez zastosowanie skal porządkowych. Im większa liczba pozycji na
skali, tym efekt tłumienia jest mniejszy. Ogólnie nie zaleca się stosowania skal
mniejszych niż 5-punktowe. Ta wskazówka dotyczy zresztą w ogóle stosowania
skal porządkowych, reprezentujących zmienne ilościowe, w modelach liniowych.
•
Program wczytujący macierz współczynników korelacji oraz etykiety
zmiennych ma następującą postać:
MATRIX DATA VARIABLES=FACH OSIAGN NIEZAW PEWNOSC STAZ WIEK UKLADY
PARTYJN KLUB
/FORMAT NODIAG
/CONTENTS CORR
/N=344.
BEGIN DATA
,563
,541 ,469
,464 ,357 ,437
,138 ,137 ,198 ,039
,058 ,104 ,146 ,051 ,508
,167 ,059 ,263 ,271 ,169 ,167
-,014 -,002 ,028 -,012 ,385 ,295 ,425
-,034 -,074 ,005 ,085 ,037 ,014 ,307 ,305
END DATA.
VARIABLE LABELS
FACH
"umiejętności zawodowe"
/OSIAGN
"osiągnięcia i wydajność"
/NIEZAW
"niezawodność, możliwość polegania na danej osobie"
/PEWNOSC "zdecydowanie i pewność siebie"
/STAZ
"staż pracy"
/WIEK
"wiek"
/UKLADY
"układy i ustosunkowanie"
wskazanie braku
przekątnej (1)
Liczebność próby
dla testów

21
/PARTYJN
"przynależność do partii politycznej"
/KLUB
"członkostwo w zakładowych organizacjach rekreacyjnych".
•
Po wczytaniu macierzy danych uruchamiamy program analizy głównych
składowych, wskazując, że dane mają być pobrane z macierzy a ładunki
czynnikowe (po rotacji VARIMAX) mają być na wydruku posortowane wg
czynników.
FACTOR
/MATRIX IN(COR=*)
/FORMAT SORT
/PRINT INITIAL KMO AIC EXTRACTION ROTATION
/PLOT EIGEN ROTATION
/CRITERIA MINEIGEN(1) ITERATE(25)
/EXTRACTION PC
/CRITERIA ITERATE(25)
/ROTATION VARIMAX .
FACTOR — polecenie wykonania analizy czynnikowej.
/MATRIX IN(COR=*) — analiza na gotowej macierzy korelacji, dostępnej
w aktualnie aktywnym zbiorze danych
/FORMAT SORT — plecenie uporządkowania macierzy ładunków czynnikowych
/PRINT INITIAL KMO AIC EXTRACTION ROTATION — polecenie wydruku
poszczególnych elementów analizy:
INITIAL — wstępnej analizy głównych składowych (domyślne)
KMO — Keiser-Meyer-Olkin (patrz wyżej) oraz test sferyczności Bartletta
AIC —macierz przeciwobrazów kowariancji i korelacji
EXTRACTION ROTATION — domyślnie drukowane wyniki ostatecznego
wyodrębnienia czynników w oparciu o przyjęte kryterium i rotowana macierz
ładunków czynnikowych
/PLOT EIGEN ROTATION — polecenie wykonania wykresów: 1) wartości
własnych (osypiska) i 2) ładunków czynnikowych
/CRITERIA MINEIGEN(1) ITERATE(25) — kryterium wyodrębnienie czynników:
min. wartość własna = 1 (kryterium Keisera) — domyślne oraz określenie
maksimum iteracji przy wyodrębnianiu czynników na 25 (nie ma znaczenia
w PCA)
/EXTRACTION PC — polecenie wyodrębnienia czynników metodą głównych
składowych z pełnej macierzy korelacji czyli wykonania analizy głównych
składowych (PCA)
/CRITERIA ITERATE(25) — domyślne ustawienie maksymalnej liczby iteracji przy
rotacji czynników, przy większej liczbie czynników i przy rotacji OBLIMIN
wymaga niekiedy zwiększenia
/ROTATION VARIMAX — polecenie wykonania rotacji VARIMAX
Pomijam wykonanie polecenia z menu, gdyż jest to czynność bardzo intuicyjne,
jeśli użytkownik rozumie analizę czynnikową.
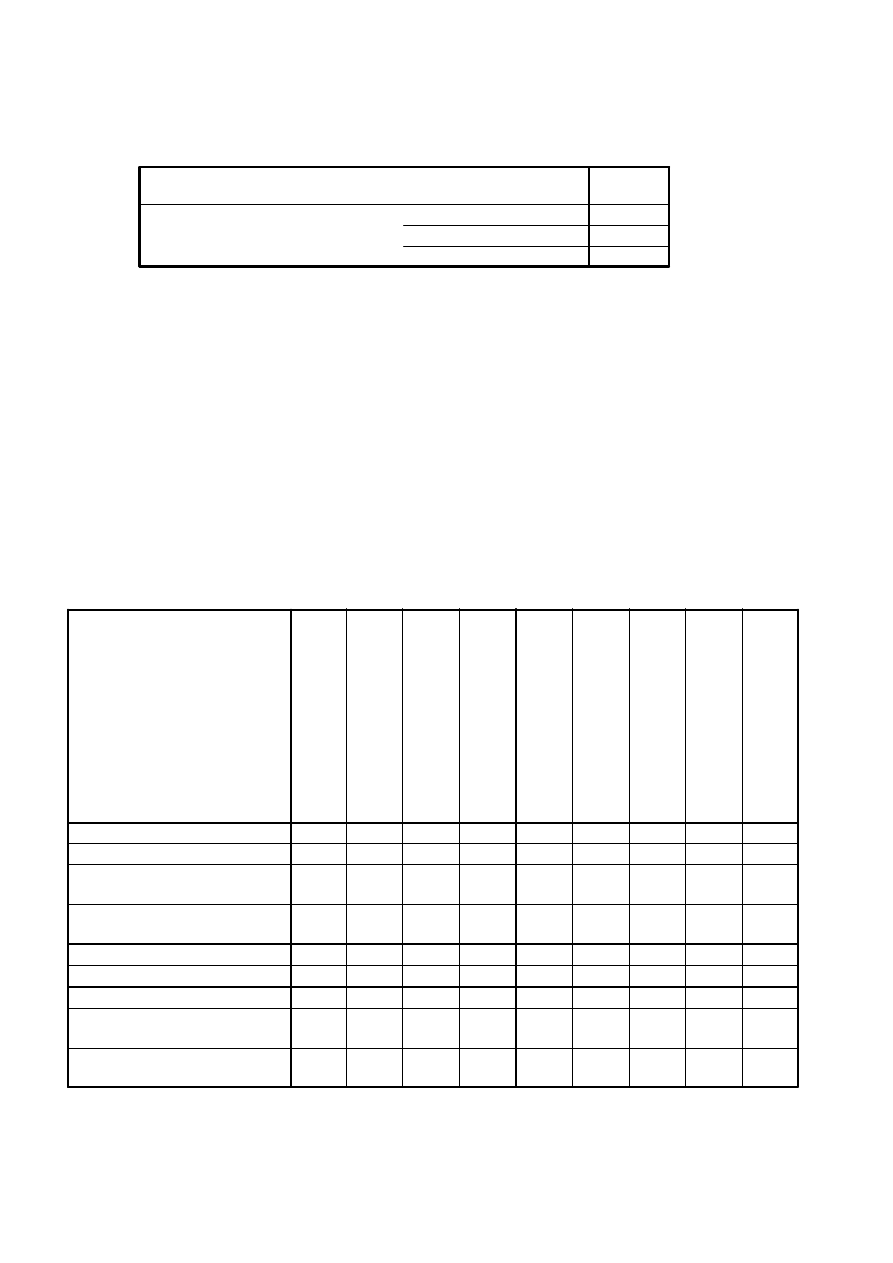
22
•
Po wykonaniu programu przeglądamy wyniki.
Testy Kaisera-Mayera-Olkina i Bartletta
,716
727,983
36
,000
Miara KMO adekwatno
ś
ci doboru próby
Przybli
ż
one chi-kwadrat
df
Istotno
ś
ć
Test sferyczno
ś
ci Bartletta
•
KMO jest na „niezłym” poziomie, co wskazuje, że analiza czynnikowa tej
macierzy korelacji jest sensowna. Test Bartletta wskazuje na to, że możemy
odrzucić hipotezę, że macierz korelacji w populacji jest macierzą jednostkową
(ma jedynki na głównej przekątnej a zera w pozostałych polach).
•
Współczynniki KMO dla poszczególnych zmiennych (umieszczone na
przekątnej) są na przeciętnym, chociaż nie dyskwalifikującym poziomie.
Zatem w analizie zachowujemy wszystkie zmienne.
Jako opcję wyodrębniania czynników wskazaliśmy główne składowe, co prowadzi
do wykonania analizy głównych składowych (sygnałem tego są jedynki w
kolumnie Początkowe tabeli Zasoby zmienności wspólnej, które wskazują, że do
analizy wchodzi cała wariancja zmiennych standaryzowanych, która w przypadku
Macierze przeciwobrazów
Macierz przeciwobrazów korelacji
,748
a
-,380
-,281
-,239
-,071
,067
-,046
,037
,039
-,380
,760
a
-,217
-,107
-,016
-,044
,111
-,042
,059
-,281
-,217
,794
a
-,185
-,110
-,046
-,183
,090
,017
-,239
-,107
-,185
,794
a
,059
-,022
-,193
,099
-,083
-,071
-,016
-,110
,059
,638
a
-,430
,041
-,289
,042
,067
-,044
-,046
-,022
-,430
,661
a
-,048
-,109
,059
-,046
,111
-,183
-,193
,041
-,048
,663
a
-,364
-,189
,037
-,042
,090
,099
-,289
-,109
-,364
,631
a
-,222
,039
,059
,017
-,083
,042
,059
-,189
-,222
,664
a
umiej
ę
tno
ś
ci zawodowe
osi
ą
gni
ę
cia i wydajno
ś
ć
niezawodno
ś
ć
, mo
ż
liwo
ś
ć
polegania na danej osobie
zdecydowanie i pewno
ś
ć
siebie
sta
ż
pracy
wiek
układy i ustosunkowanie
przynale
ż
no
ś
ć
do partii
politycznej
członkostwo w zakładowych
organizacjach rekreacyjnych
u
m
ie
j
ę
tn
o
ś
c
i
z
a
w
o
d
o
w
e
o
s
i
ą
g
n
i
ę
c
ia
i
w
y
d
a
jn
o
ś
ć
n
ie
z
a
w
o
d
n
o
ś
ć
,
m
o
ż
liw
o
ś
ć
p
o
le
g
a
n
ia
n
a
d
a
n
e
j
o
s
o
b
ie
z
d
e
c
y
d
o
w
a
n
ie
i
p
e
w
n
o
ś
ć
s
ie
b
ie
s
ta
ż
p
ra
c
y
w
ie
k
u
k
ła
d
y
i
u
s
to
s
u
n
k
o
w
a
n
ie
p
rz
y
n
a
le
ż
n
o
ś
ć
d
o
p
a
rt
ii
p
o
lit
y
c
z
n
e
j
c
z
ło
n
k
o
s
tw
o
w
z
a
k
ła
d
o
w
y
c
h
o
rg
a
n
iz
a
c
ja
c
h
r
e
k
re
a
c
y
jn
y
c
h
Miary adekwatno
ś
ci doboru próby.
a.
23
każdej zmiennej jest równa 1).
Wartość zasobu zmienności wspólnej po ograniczeniu liczby czynników (kolumna:
Po wyodrębnieniu) informuje nas, jak dobrze reprezentowana jest dana zmienna
w przyjętym modelu o zredukowanej liczbie wymiarów (tu: do trzech). Jeśli
któraś zmienna, ważna dla nas, jest źle reprezentowana, możemy — zwłaszcza
w analizie głównych składowych, zorientowanej na przygotowanie nowych,
ortogonalnych zmiennych do innej analizy (np. regresji) — zdecydować
o zwiększeniu liczby wymiarów, zachowaniu dodatkowych czynników.
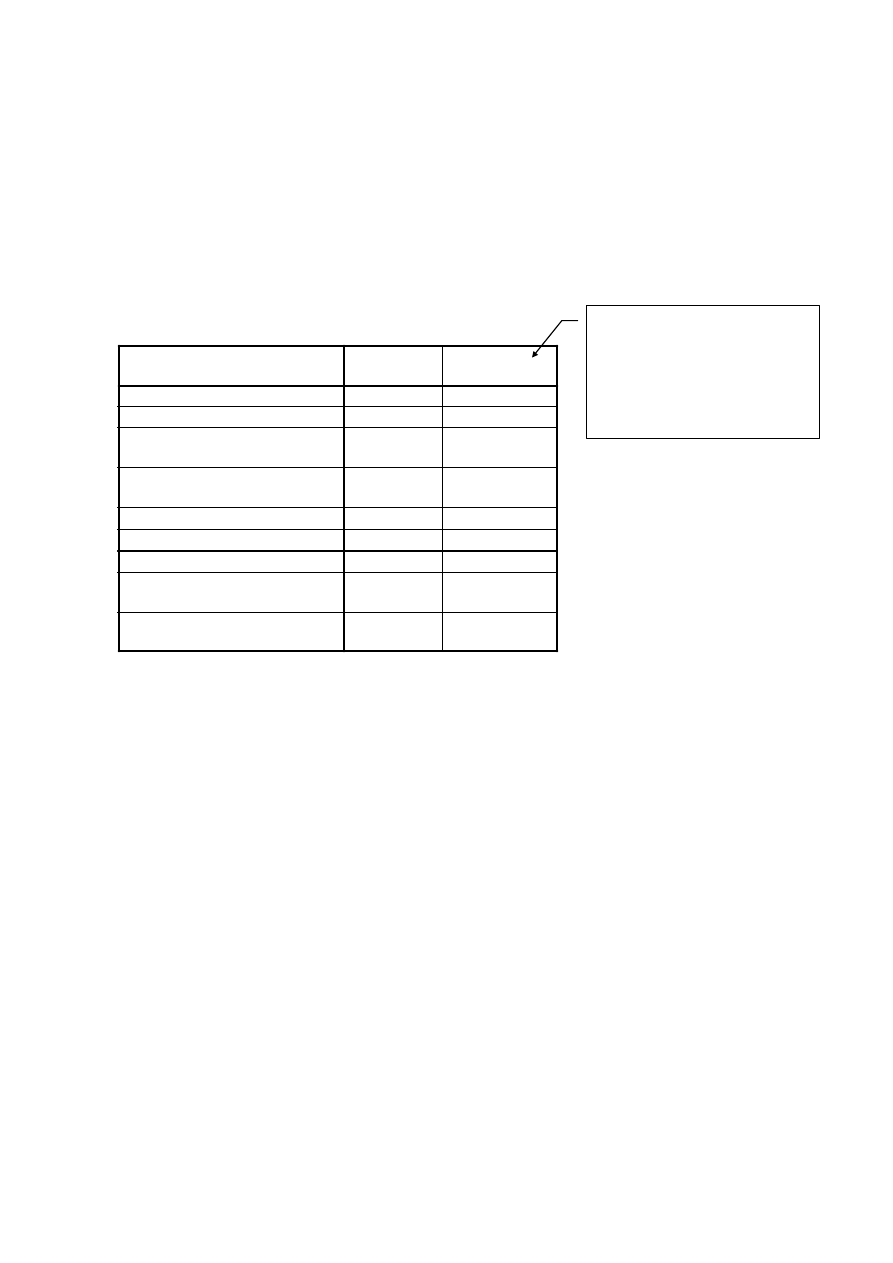
Zasoby zmienno
ś
ci wspólnej
1,000
,698
1,000
,611
1,000
,635
1,000
,577
1,000
,729
1,000
,680
1,000
,644
1,000
,660
1,000
,626
umiej
ę
tno
ś
ci zawodowe
osi
ą
gni
ę
cia i wydajno
ś
ć
niezawodno
ś
ć
, mo
ż
liwo
ś
ć
polegania na danej osobie
zdecydowanie i pewno
ś
ć
siebie
sta
ż
pracy
wiek
układy i ustosunkowanie
przynale
ż
no
ś
ć
do partii
politycznej
członkostwo w zakładowych
organizacjach rekreacyjnych
Pocz
ą
tkowe
Po
wyodr
ę
bnieniu
Metoda wyodr
ę
bniania czynników - Głównych składowych.
Tu widzimy, na ile dobrze
każda ze zmiennych jest
reprezentowana w modelu
3-czynnikowym; wartości
są podobne i nienajgorsza
dla wszystkich zmiennych
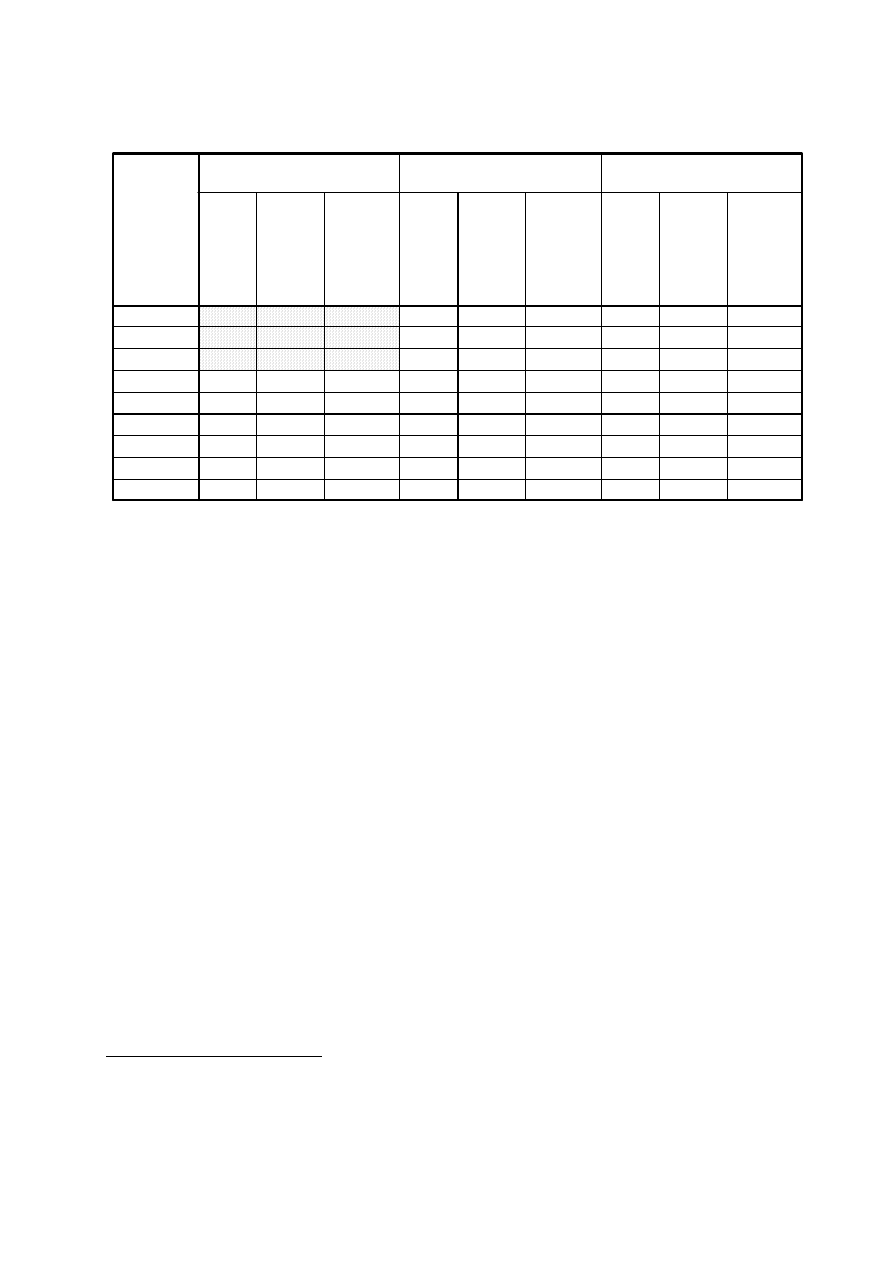
24
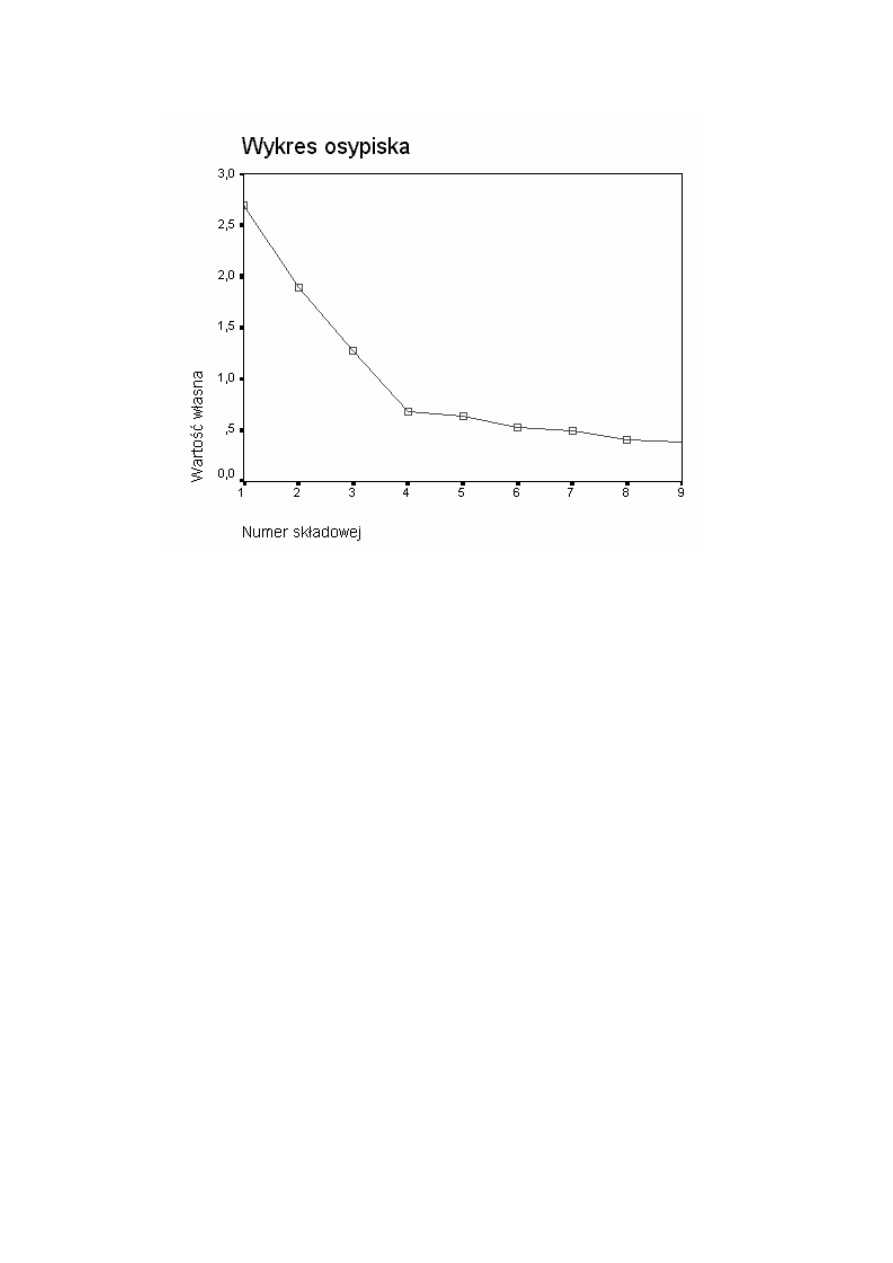
Przede wszystkim musimy określić liczbę „istotnych” składowych, które
pozostawimy w analizie. Musimy więc przyjrzeć się wartościom własnym. Można
do tego celu użyć arkusza wyników po naciśnięciu przycisku: Wartości własne. Na
podstawie kryterium Keisera jesteśmy skłonni zachować 3 główne składowe; na
podstawie bardziej konserwatywnego kryterium Jolliffe — również trzy, gdyż
czwarta składowa ma wartość własną mniejszą od 0,7. Dodatkowo prześledźmy
wykres osypiska (wykres osypiska).
Wykres „osypiska” sugeruje aż 4 czynniki, gdyż dopiero przy czwartym czynniku
następuje zjawisko osypiska. Wartość własna tego czynnika jest jednak tak
niska, że skłaniamy się ku 3 czynnikom, wyjaśniającym łącznie 65% wariancji
zmiennych
14
.
14
W sytuacji, gdybyśmy zamierzali użyć wyników PCA w analizie regresji (ale to w
sytuacji wykonywania analizy na danych surowych a nie na macierzy korelacji),
pozostawienie większej liczby składowych mogłoby być w pewnych sytuacjach sensowne.
Strategia stosowania głównych składowych w analizie regresji jest
omówiona dalej.
Całkowita wyja
ś
niona wariancja
2,696
29,961
29,961
2,696
29,961
29,961
2,478
27,535
27,535
1,886
20,951
50,912
1,886
20,951
50,912
1,739
19,324
46,858
1,279
14,213
65,126
1,279
14,213
65,126
1,644
18,267
65,126
,683
7,585
72,710
,641
7,120
79,831
,524
5,822
85,653
,494
5,491
91,144
,411
4,565
95,709
,386
4,291
100,000
Składowa
1
2
3
4
5
6
7
8
9
O
g
ó
łe
m
%
w
a
ri
a
n
c
ji
%
s
k
u
m
u
lo
w
a
n
y
O
g
ó
łe
m
%
w
a
ri
a
n
c
ji
%
s
k
u
m
u
lo
w
a
n
y
O
g
ó
łe
m
%
w
a
ri
a
n
c
ji
%
s
k
u
m
u
lo
w
a
n
y
Pocz
ą
tkowe warto
ś
ci
własne
Sumy kwadratów ładunków
po wyodr
ę
bnieniu
Sumy kwadratów ładunków
po rotacji
Metoda wyodr
ę
bniania czynników - Głównych składowych.
25
Jak widać, decyzja o wyborze liczby czynników i wyborze samego kryterium
wyboru jest zawsze mniej lub bardziej arbitralna. Należy się ostatecznie odwołać
także do kryterium interpretowalności wybranego układu czynników. Proszę na
własną rękę sprawdzić rozwiązanie z 4 czynnikami.
SPSS użył automatycznie kryterium Keisera (domyślnie umieszcza opcję
/CRITERIA MINEIGEN(1) — minimalna wartość własna = 1 — w tekście
polecenia, chyba że zdecydujemy inaczej). Zachowane zostały trzy „największe”
główne składowe. Bez rotacji trudno je zinterpretować.
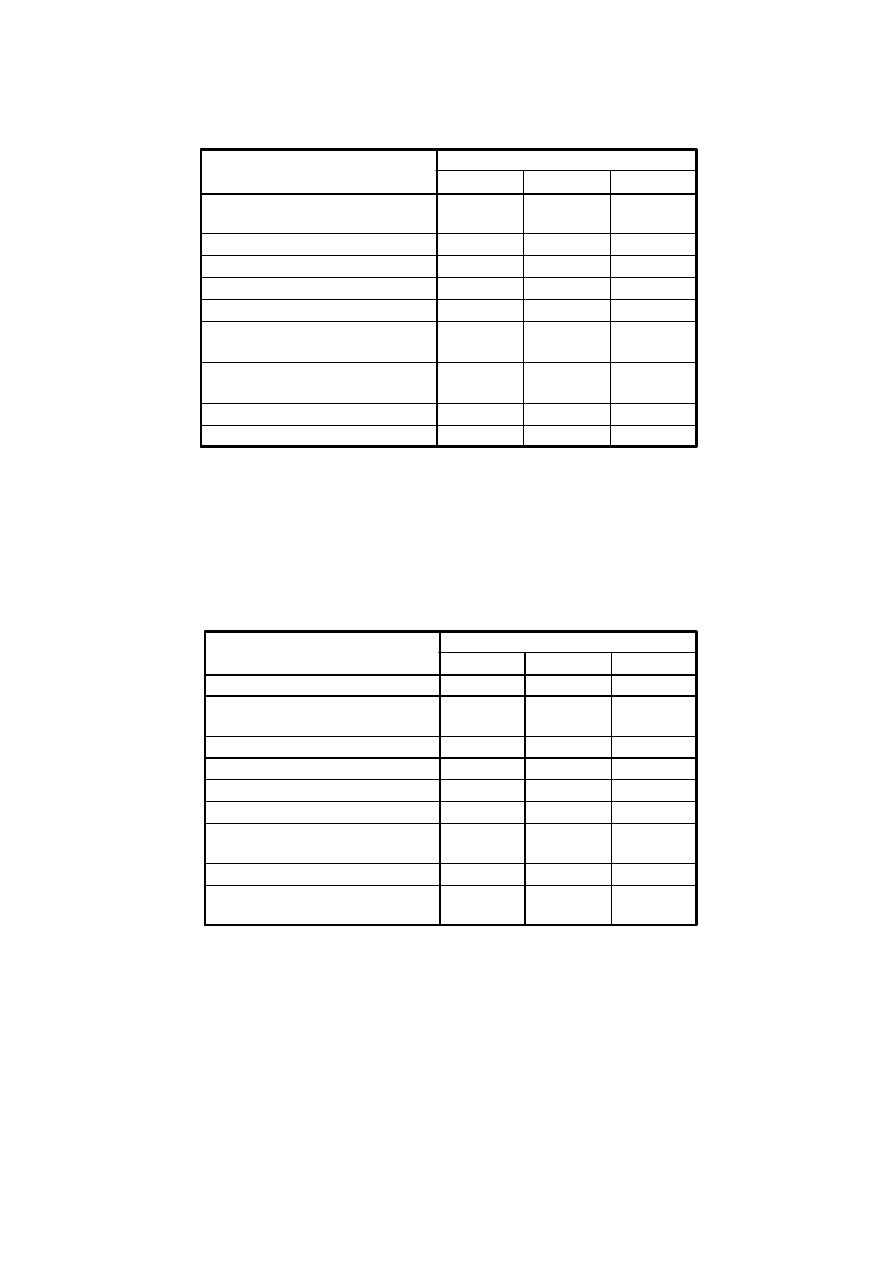
26
A oto rotowane metodą VARIMAX czynniki, posortowane dzięki opcji /FORMAT
SORT.
Zwykle ignoruje się ładunki o wartościach mniejszych od 0,3 (można nawet
spowodować ich niewyświetlanie, wybierając opcję /FORMAT BLANK(.3) .
Najlepiej znaczenie czynników interpretować przy pomocy ładunków co najmniej
Macierz składowych
a
,751
-,266
,004
,728
-,411
,004
,656
-,398
-,149
,640
-,296
,284
,509
,421
,456
,331
,736
,094
,156
,447
,634
,396
,483
-,538
,462
,498
-,517
niezawodno
ś
ć
, mo
ż
liwo
ś
ć
polegania na danej osobie
umiej
ę
tno
ś
ci zawodowe
osi
ą
gni
ę
cia i wydajno
ś
ć
zdecydowanie i pewno
ś
ć
siebie
układy i ustosunkowanie
przynale
ż
no
ś
ć
do partii
politycznej
członkostwo w zakładowych
organizacjach rekreacyjnych
wiek
sta
ż
pracy
1
2
3
Składowa
Metoda wyodr
ę
bniania czynników - Głównych składowych.
3 - liczba wyodr
ę
bnionych składowych.
a.
Macierz rotowanych składowych
a
,834
,044
-,014
,780
,142
,081
,758
,126
-,141
,715
-,112
,232
,112
,844
,070
,062
,822
,025
-,063
-,096
,783
,244
,153
,749
-,091
,518
,619
umiej
ę
tno
ś
ci zawodowe
niezawodno
ś
ć
, mo
ż
liwo
ś
ć
polegania na danej osobie
osi
ą
gni
ę
cia i wydajno
ś
ć
zdecydowanie i pewno
ś
ć
siebie
sta
ż
pracy
wiek
członkostwo w zakładowych
organizacjach rekreacyjnych
układy i ustosunkowanie
przynale
ż
no
ś
ć
do partii
politycznej
1
2
3
Składowa
Metoda wyodr
ę
bniania czynników - Głównych składowych.
Metoda rotacji - Varimax z normalizacj
ą
Kaisera.
Rotacja osi
ą
gn
ę
ła zbie
ż
no
ś
ć
w 5 iteracjach.
a.
27
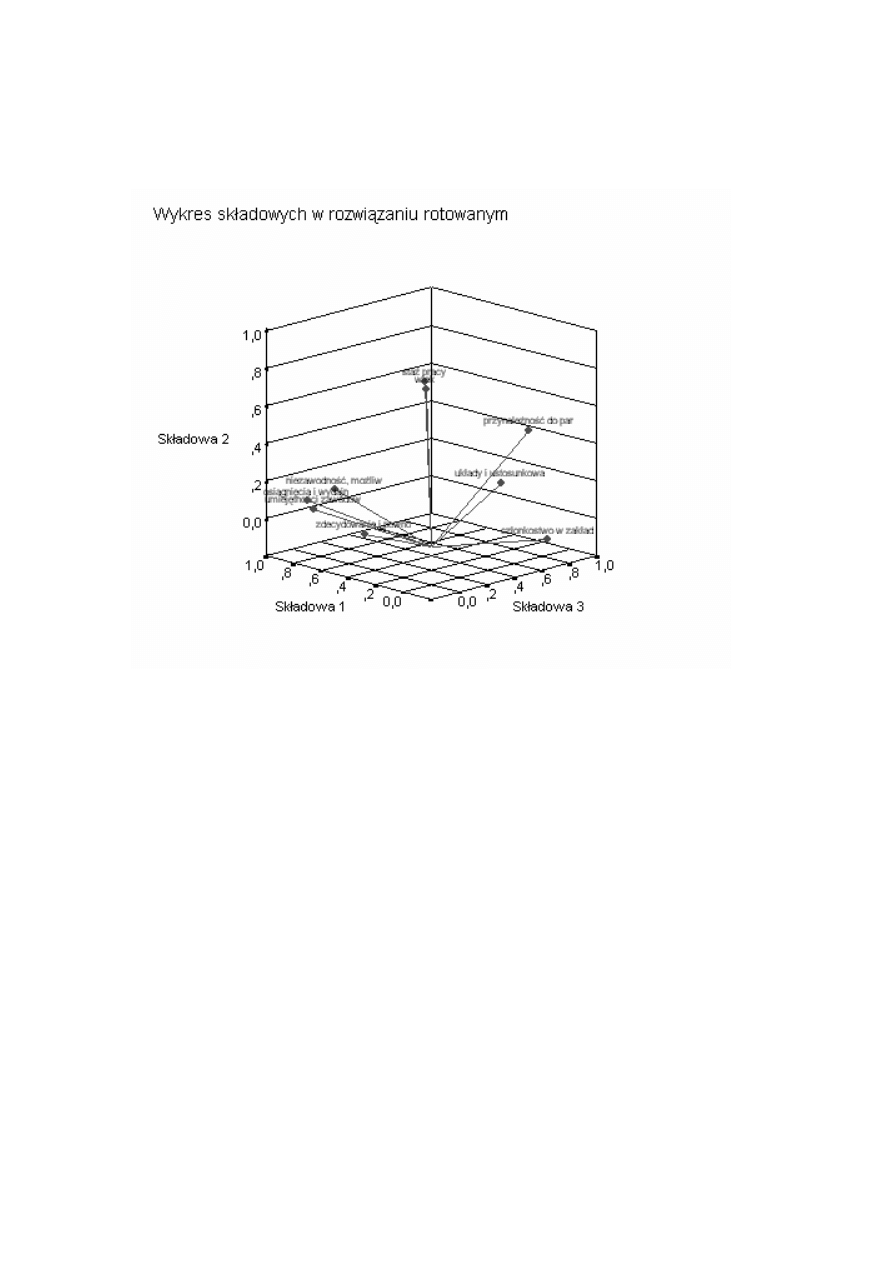
0,5, choć gdy mamy dużo wysokich ładunków można ją podnieść do 0,7.
Możemy ładunki czynnikowe przedstawić także graficznie (uzyskaliśmy wykres
dzięki opcji /PLOT ROTATION).
Uzyskaliśmy dość klarowną strukturę:
•
pierwszy czynnik (główna składowa) grupuje zmienne opisujące umiejętności,
zalety osobiste i osiągnięcia zawodowe pracowników jako kryteria awansu —
nazwijmy go wymiarem kompetencji;
•
drugi czynnik jest silnie skorelowany zwłaszcza ze stażem pracy i wiekiem —
nazwijmy go wymiarem senioratu;
•
trzeci czynnik to przede wszystkim zmienne wskazujące na konieczność
dobrego ulokowania w sieci powiązań i układów ułatwiających awans —
nazwijmy go wymiarem układów osobistych.
Jak widać, potrafiliśmy łatwo nazwać wyodrębnione czynniki, co nie zawsze ma
miejsce. Pewien kłopot interpretacyjny sprawia fakt, że partyjność ma relatywnie
wysokie ładunki zarówno na wymiarze senioratu jak i na wymiarze układów
osobistych (tzw. ładunki krzyżowe). Od dalszej analizy danych zależałaby
odpowiedź, czy związane jest to z pokoleniowym charakterem tego kryterium.
W przypadku analizy macierzy korelacji nie możemy wyliczyć wartości
czynnikowych, gdyż nie mamy informacji o wartościach poszczególnych
zmiennych dla poszczególnych przypadków. Aby wyliczyć wartości czynnikowe
musimy dysponować danymi surowymi. Możemy natomiast wyliczyć
współczynniki wartości czynnikowych (wystarczy kliknąć na stosowny przycisk),
które po wymnożeniu przez wartości standaryzowane zmiennych i zsumowaniu
dadzą wartości czynnikowe dla każdego przypadku.

28
Analiza metodą czynników największej wiarygodności
Wykonajmy dla porównania analizę czynnikową metodą największej
wiarygodności. Zmieniamy w tym celu jedynie metodę wyodrębniania czynników
ma ML (Maximum-likelihood): /EXTRACTION ML i powtarzamy te same kroki
analizy. Tutaj skupimy się na oglądnięciu dwóch rodzajów wyników: rotowanych
ładunków czynnikowych i testu dobroci dopasowania. Ładunki czynnikowe są
ogólnie nieco niższe niż w przypadku analizy głównych składowych, jednak
struktura czynników i ich interpretacja pozostała bez zmian, choć wystąpiły także
pewne różnice we względnej wysokości ładunków. Pamiętamy, że tym razem
wyjaśnieniu podlega nie cała wariancja zmiennych, lecz jedynie jej część
wspólna, podzielana z innymi zmiennym (która też jest nota bene szacowana
iteracyjnie w ramach modelu). Model ten nie wyjaśnia wariancji swoistej
zmiennej, w tym zawartego w niej błędu lecz tylko zasoby zmienności wspólnej,
a więc korelacje między zmiennymi a nie sumę ich całkowitej wariancji.
FACTOR
/MATRIX IN(COR=*)
/FORMAT SORT
/PRINT ROTATION
/CRITERIA FACTORS(3)
/EXTRACTION ML
/ROTATION VARIMAX.
W przypadku metody największej wiarygodności SPSS wylicza automatycznie
test dobroci dopasowania modelu do danych oparty na CHI
2
. Wartość istotność
wynosi: 0,094, a więc jest większa od standardowo przyjmowanego, granicznego
poziomu 0,05 — nie ma zatem podstaw do odrzucenia hipotezy, że reszty
pomiędzy korelacjami odtworzonymi na podstawie modelu a obserwowaną
macierzą korelacji są równe 0, a więc, że model pasuje do danych.
W wyniku rotacji VARIMAX uzyskaliśmy strukturę czynników, która jest taka
sama, jak w przypadku rotowanej PCA. Wartości ładunków czynnikowych są
mniejsze niż w PCA, co wynika z faktu że w analizie czynnikowej wyjaśniane są
tylko szacowane zasoby zmienności wspólnej (zasób zmienności wspólnej<1) a
nie cała wariancja zmiennych (zasób zmienności wspólnej =1), a zasób
zmienności wspólnej = suma podniesionych do kwadratu ładunków
czynnikowych.
Test dobroci dopasowania
18,766
12
,094
Chi-kwadrat
df
Istotno
ś
ć
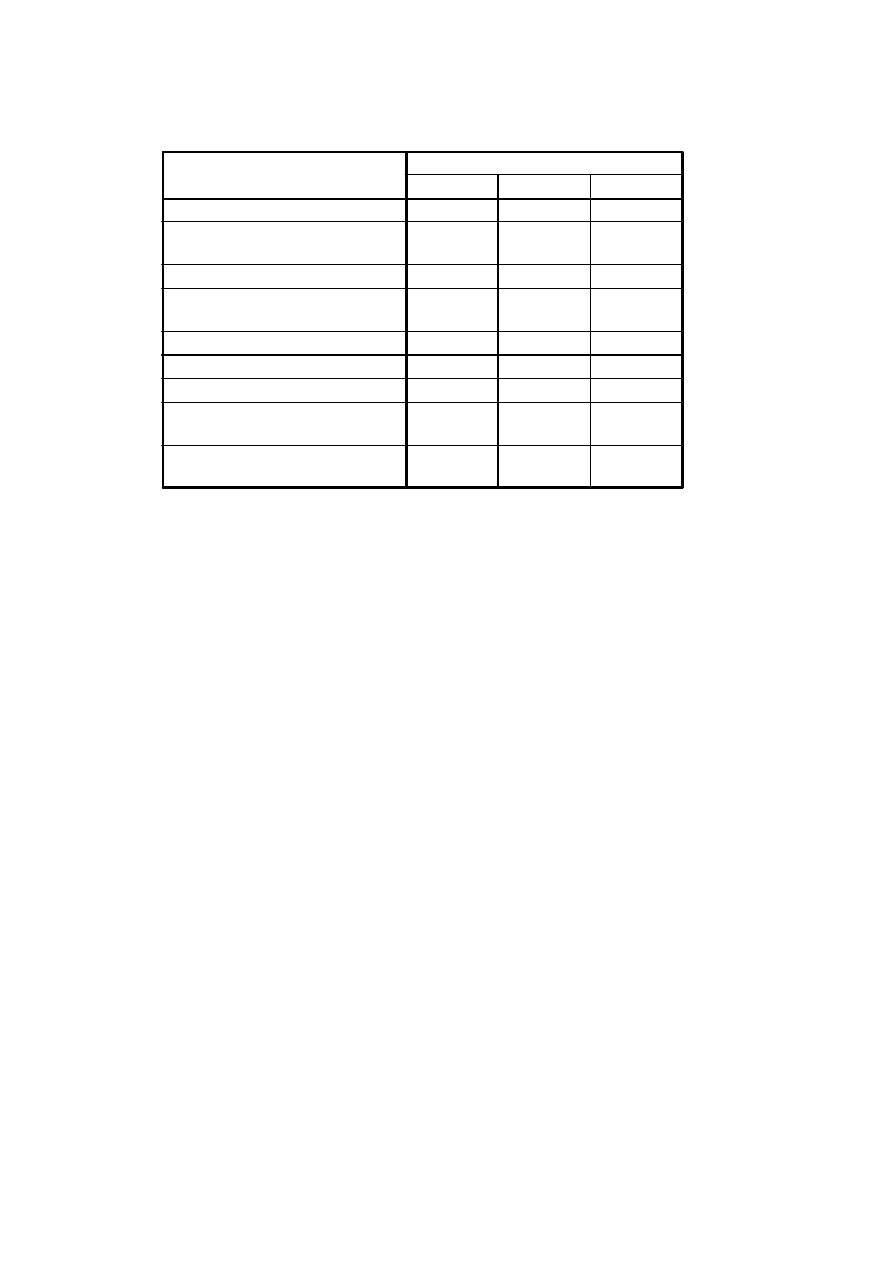
29
Dodatkowo wydrukowane zostały wyniki dla rotacji OBLIMIN przy domyślnym
ustawieniu parametru DELTA=0. Jak już wiadomo, w wyniku rotacji skośnej
otrzymujemy dwie macierze czynników:
•
Macierz modelowa zawierającą ładunki czynnikowe, a więc standaryzowane
współczynniki regresji pomiędzy każdą zmienną (standaryzowaną) a zestawem
czynników (np. o ile odchylenia standardowego zmieni się zmienna FACH, jeśli
FACTOR 1 zmieni się o jedno odchylnie standardowe, przy kontroli pozostałych
czynników).
•
Macierz struktury zawierającą współczynniki korelacji pomiędzy czynnikami
i zmiennymi.
W interpretacji koncentrujemy się na Macierz modelową. Widzimy, że nasza
macierz ładunków czynnikowych zbliżyła się jeszcze bardziej do ideału prostej
struktury. Wnioski są takie same jak przy rotacji VARIMAX, jedynie jeszcze
bardziej zdecydowane.
Macierz rotowanych czynników
a
,791
,057
-,022
,695
,132
,091
,673
,106
-,116
,599
-,054
,176
,111
,823
,068
,068
,597
,095
,230
,120
,726
-,056
,432
,528
-,037
,010
,470
umiej
ę
tno
ś
ci zawodowe
niezawodno
ś
ć
, mo
ż
liwo
ś
ć
polegania na danej osobie
osi
ą
gni
ę
cia i wydajno
ś
ć
zdecydowanie i pewno
ś
ć
siebie
sta
ż
pracy
wiek
układy i ustosunkowanie
przynale
ż
no
ś
ć
do partii
politycznej
członkostwo w zakładowych
organizacjach rekreacyjnych
1
2
3
Czynnik
Metoda wyodr
ę
bniania czynników - Najwi
ę
kszej wiarygodno
ś
ci.
Metoda rotacji - Varimax z normalizacj
ą
Kaisera.
Rotacja osi
ą
gn
ę
ła zbie
ż
no
ś
ć
w 5 iteracjach.
a.
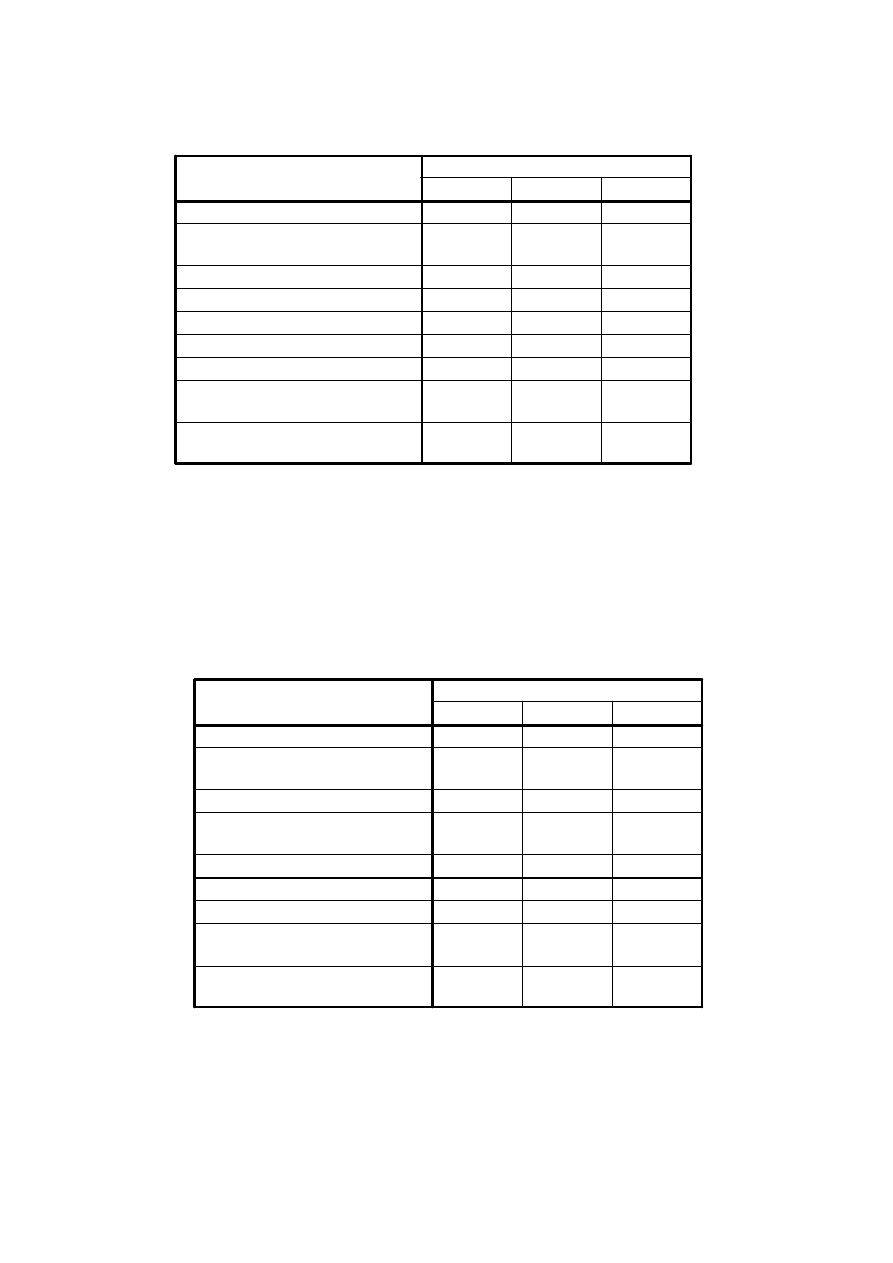
30
W przypadku rotacji skośnej otrzymujemy również macierz współczynników
korelacji pomiędzy czynnikami.
Macierz modelowa
a
,794
,689
,674
,604
,833
,600
,719
,390
,486
,480
umiej
ę
tno
ś
ci zawodowe
niezawodno
ś
ć
, mo
ż
liwo
ś
ć
polegania na danej osobie
osi
ą
gni
ę
cia i wydajno
ś
ć
zdecydowanie i pewno
ś
ć
siebie
sta
ż
pracy
wiek
układy i ustosunkowanie
przynale
ż
no
ś
ć
do partii
politycznej
członkostwo w zakładowych
organizacjach rekreacyjnych
1
2
3
Czynnik
Metoda wyodr
ę
bniania czynników - Najwi
ę
kszej wiarygodno
ś
ci.
Metoda rotacji - Oblimin z normalizacj
ą
Kaisera.
Rotacja osi
ą
gn
ę
ła zbie
ż
no
ś
ć
w 6 iteracjach.
a.
Macierz struktury
,791
,705
,673
,601
,831
,608
,742
,490
,570
,467
umiej
ę
tno
ś
ci zawodowe
niezawodno
ś
ć
, mo
ż
liwo
ś
ć
polegania na danej osobie
osi
ą
gni
ę
cia i wydajno
ś
ć
zdecydowanie i pewno
ś
ć
siebie
sta
ż
pracy
wiek
układy i ustosunkowanie
przynale
ż
no
ś
ć
do partii
politycznej
członkostwo w zakładowych
organizacjach rekreacyjnych
1
2
3
Czynnik
Metoda wyodr
ę
bniania czynników - Najwi
ę
kszej wiarygodno
ś
ci.
Metoda rotacji - Oblimin z normalizacj
ą
Kaisera.
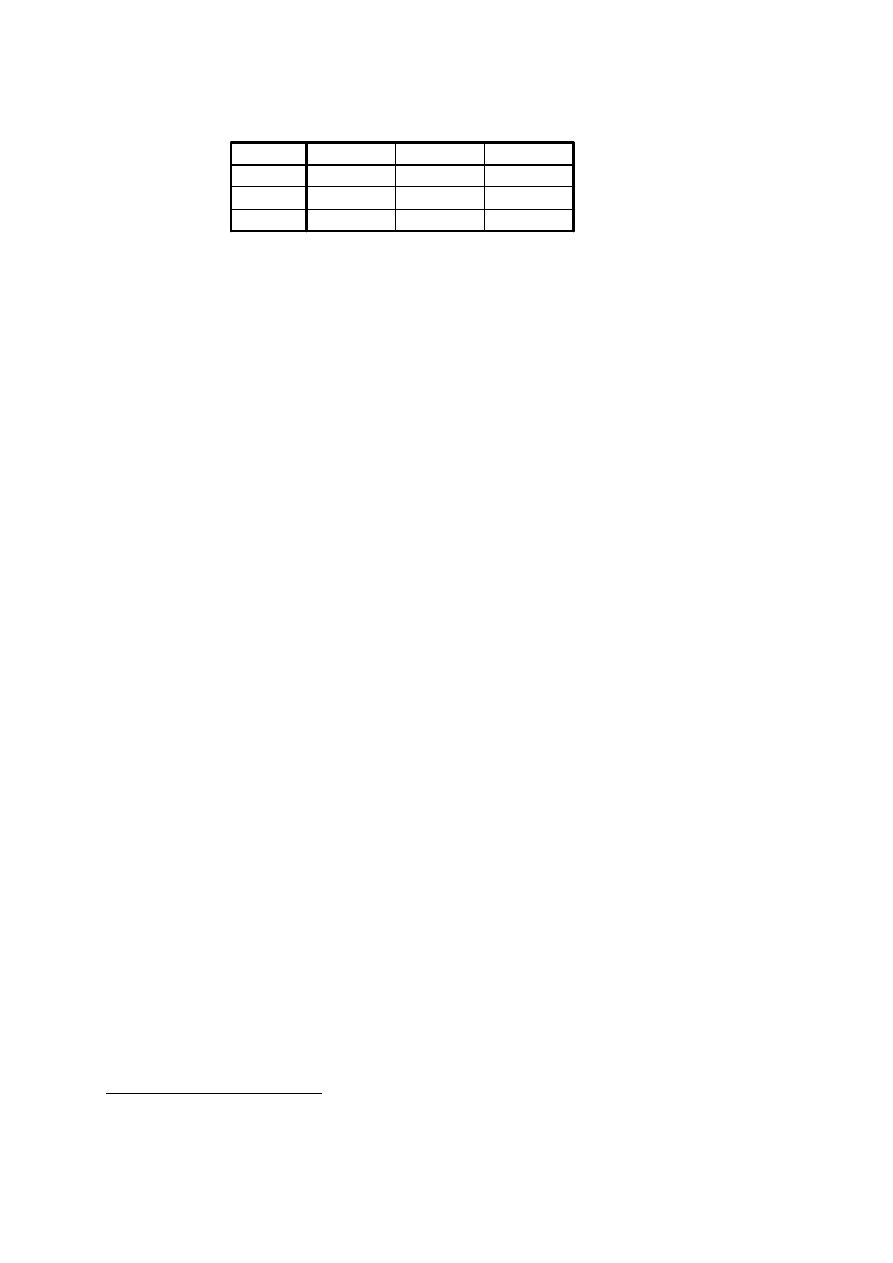
31
Jeśli na podstawie teorii oczekujemy, że pomiędzy zaobserwowanymi czynnikami
nie powinno być korelacji, możemy obniżyć parametr DELTA poniżej 0
i powtórzyć analizę.
Proponuję wykonanie analizy metodą głównych osi z iteracją zasobów zmienności
wspólnej (PAF) i metodą uogólnionych najmniejszych kwadratów (GLS). Nie
odbiegają znacznie od siebie i od wyników uzyskanych metodą największej
wiarygodności. Proszę też samodzielnie wykonać eksperymenty z rotacją
OBLIMIN przy różnym DELTA i porównać wyniki.
1.16
Zastosowanie PCA do prezentacji zależności w zbiorze danych
(pozycjonowanie) – przykład 2.
Wykonamy teraz przykład zastosowania analizy głównych składowych do
wizualnej prezentacji danych. Z tą techniką często spotykamy się w badaniach
marketingowych przy analizie pozycjonowania marek. Dane użyte do przykładu
pochodzą z książki Backhausa i in.
15
Autorzy, dla celów dydaktycznych,
przebadali 32 studentów niemieckich, którym zadano pytanie o ocenę na 7-
punktowej skali (1 - niska ... 7 - wysoka) następujących 11 marek margaryny
i masła:
•
Becel
•
Du darfst
•
Rama
•
Delicado
•
Holl. Markenbutter
•
Weihnachtsbutter
•
Homa
•
Flora
•
SB
•
Sanella
•
Botteram
pod względem każdej z następujących cech:
Nazwa zmiennej
Cecha
SMAR
Łatwość smarowania
CENA
Cena
15
Pozwala to uniknąć problemów związanych z prawem do wykorzystania podobnych
w charakterze wyników komercyjnych badań marketingowych, które dane mi było
analizować.
Macierz korelacji czynników
1,000
,142
,076
,142
1,000
,236
,076
,236
1,000
Czynnik
1
2
3
1
2
3
Metoda wyodr
ę
bniania czynników - Najwi
ę
kszej wiarygodno
ś
ci.
Metoda rotacji - Oblimin z normalizacj
ą
Kaisera.
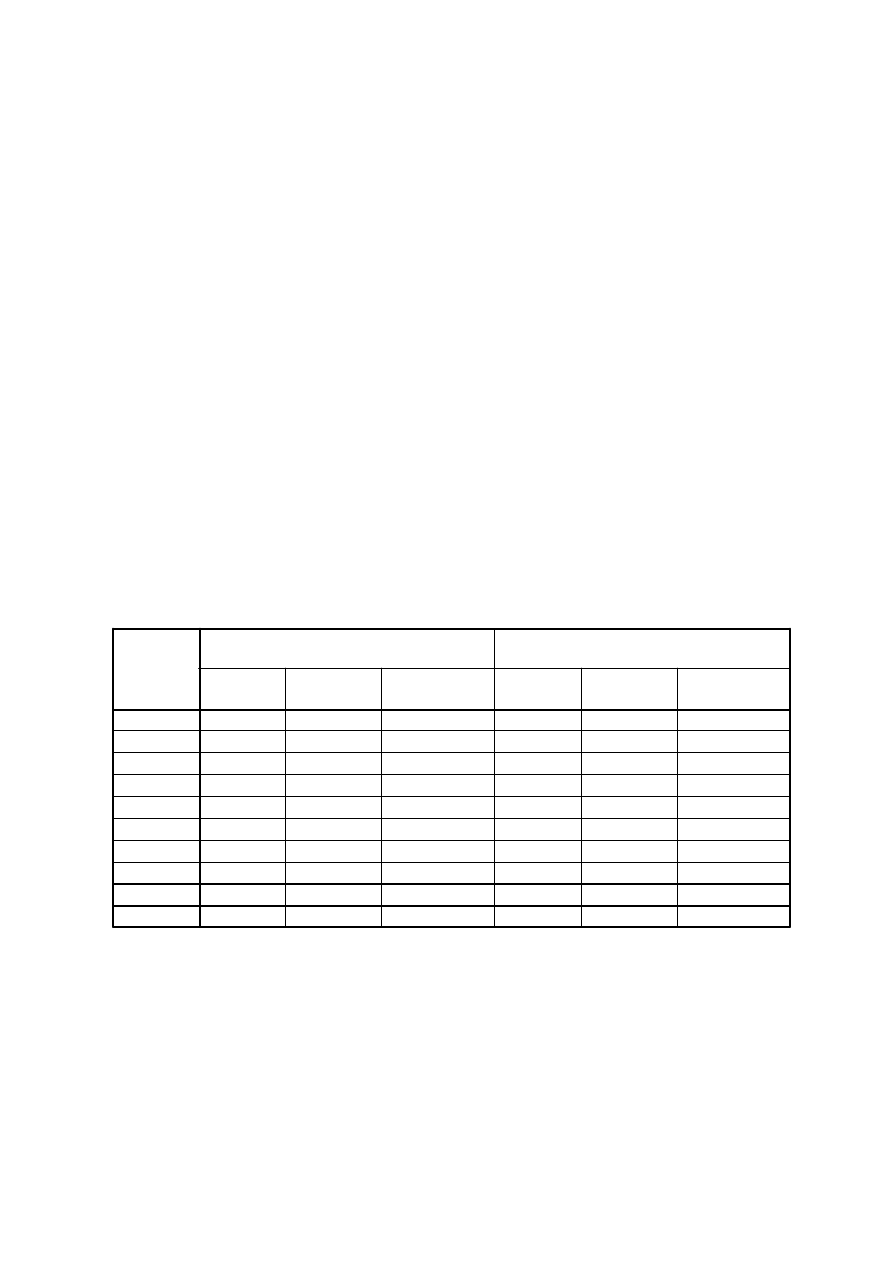
32
TRWAL
Trwałość
NNKT
Zawartość nienasyconych kwasów tłuszczowych
PIECZ
Możliwość użycia do smażenia i pieczenia
SMAK
Ocena smaku
KALOR
Kaloryczność
TLZWI
Zawartość tłuszczów zwierzęcych
WITAM
Zawartość witamin
NATUR
Naturalność
Dla celów pozycjonowania, wyniki uzyskane od 32 osób uśredniono i otrzymano
zbiór danych, którego wiersze odpowiadają poszczególnym markom, natomiast
kolumny — cechom tych marek. Wprawdzie uśrednianie odpowiedzi może
prowadzić do utraty informacji o indywidualnym zróżnicowaniu ocen, jednak
metoda ta jest szeroko stosowana z niezłymi skutkami. Dane zapisane są w pliku
„margaryna_średnie.sav”.
Dane pobieramy do programu jako zwykły zbiór danych surowych. Wykonujemy
analizę głównych składowych zgodnie z krokami poznanymi w Przykładzie 1. Dla
celów analitycznych należałoby przyjąć rozwiązanie oparte na 3 głównych
składowych, na podstawie kryterium Keisera. Wariancja wyjaśniona przez
rozwiązanie 3-czynnikowe sięga 88%. Analiza jakości reprezentacji zmiennych
przez model 3-czynnikowy również jest satysfakcjonująca: ten model dobrze
wyjaśnia wariancję wszystkich zmiennych użytych w analizie.
Kryterium osypiska sugeruje nieco inny werdykt. Widać przede wszystkich
(zresztą już z analizy tabeli wartości własnych), że mamy do czynienia z jednym
dominującym czynnikiem — pierwszą główną składową. Następne składowe mają
wyraźnie niższe wartości własne, ale ciągle wyjaśniają istotny kawałek
zmienności. „Kolanko” na drugim czynniku sugeruje — zgodnie z kryterium
Cattella — pozostawienie tylko dwóch wymiarów. Wtedy jednak zmienna:
Możliwość użycia do pieczenia i smażenia będzie słabo reprezentowany przez
przyjęty model (Communality=0,15), dopiero bowiem trzeci wymiar pozwala
Całkowita wyja
ś
niona wariancja
5,355
53,553
53,553
5,355
53,553
53,553
2,005
20,046
73,599
2,005
20,046
73,599
1,431
14,309
87,908
1,431
14,309
87,908
,777
7,768
95,676
,262
2,619
98,296
,099
,995
99,290
,045
,448
99,738
,020
,203
99,941
,005
,047
99,988
,001
,012
100,000
Składowa
1
2
3
4
5
6
7
8
9
10
Ogółem
%
wariancji
%
skumulowany
Ogółem
%
wariancji
%
skumulowany
Pocz
ą
tkowe warto
ś
ci własne
Sumy kwadratów ładunków po
wyodr
ę
bnieniu
Metoda wyodr
ę
bniania czynników - Głównych składowych.
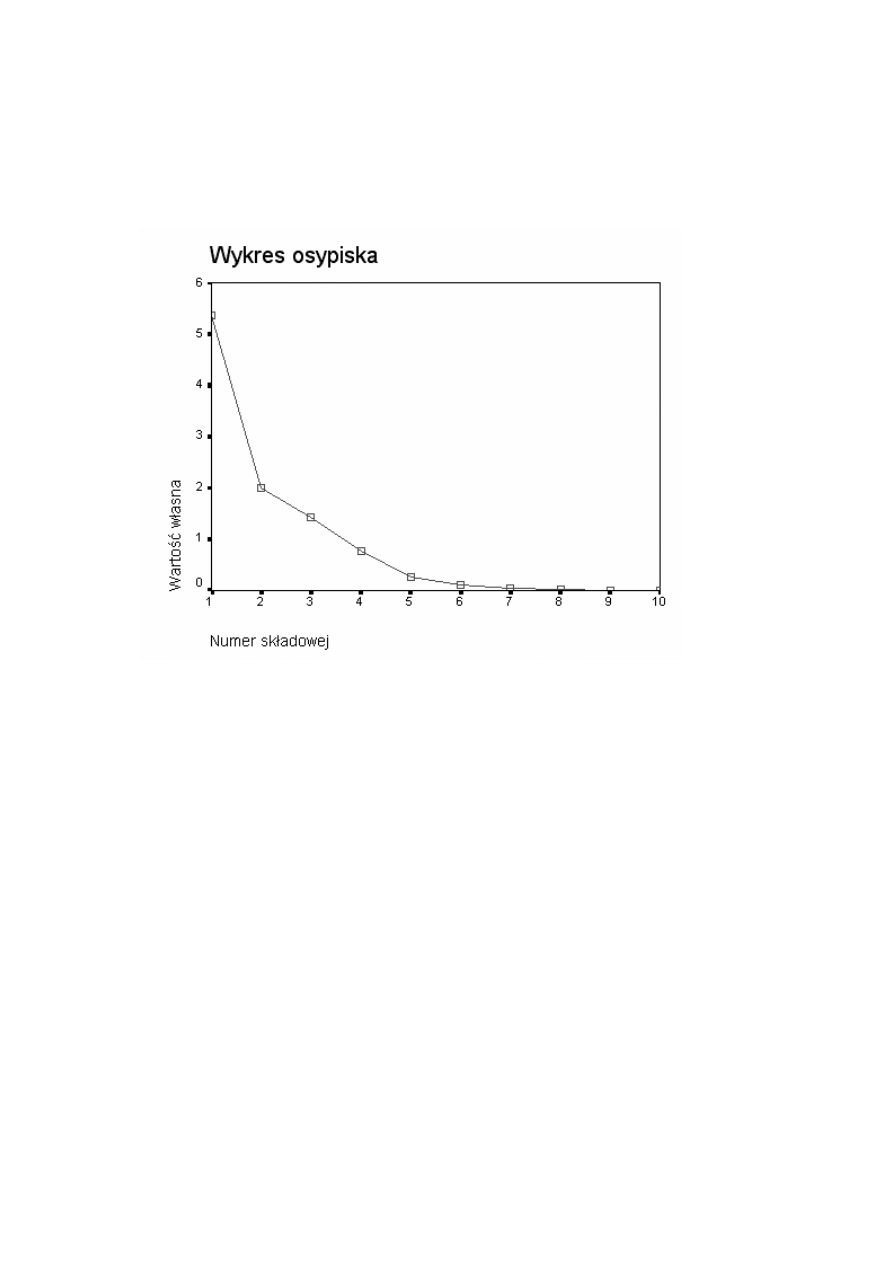
33
uchwycić znaczącą część jej wariancji. Pozostaje jeszcze kryterium
merytorycznej interpretacji czynników.
Proszę porównać modele dwuczynnikowy i trójczynnikowy i spróbować
interpretacji wyodrębnionych czynników.
W dalszej części naszego przykładu pozostaniemy przy dwóch pierwszych
głównych składowych (74% wyjaśnionej wariancji) po to, by w dogodny sposób
pozycjonować marki margaryn i maseł w przestrzeni utworzonej przez ich cechy
(a właściwie w dwuwymiarowej, najlepszej reprezentacji tej przestrzeni). Wiemy
już, że korzystając z dwóch pierwszych składowych przesłonimy zróżnicowanie
pod względem postrzeganej możliwości stosowania badanych marek do
pieczenia. Aby więc nie powodować błędnej interpretacji możemy tę cechę
w ogóle usunąć z analizy. Nasz układ dwóch składowych poddamy rotacji
VARIMAX, choć w przypadku dwóch wymiarów nie ma to wielkiego znaczenia
poznawczego. Wykonujemy wykres ładunków czynnikowych.
FACTOR
/VARIABLES smar cena trwal nnkt smak kalor tlzwi witam natur
/PRINT INITIAL EXTRACTION ROTATION FSCORE
/FORMAT SORT
/PLOT ROTATION
/EXTRACTION PC
/ROTATION VARIMAX
/SAVE REG(ALL) .
34
Marki możemy pozycjonować w układzie dwóch pierwszych składowych
korzystając z wartości czynnikowych jako ich współrzędnych. Wartości
czynnikowe dopisaliśmy do zbioru danych za pomocą opcji
/SAVE REG(ALL)
.
Czynnik 1. definiuje oś poziomą, czynnik 2. definiuje oś pionową. Wykres
sporządzamy korzystając z menu: WYKRESY>ROZRZUTU>PROSTY lub
następującego polecenia:
GRAPH
/SCATTERPLOT(BIVAR)=fac1_2 WITH fac2_2 BY marka (NAME).
Macierz rotowanych składowych
a
-,941
-,186
-,909
-,071
,879
,383
,808
,362
-,710
,263
-,240
,910
,583
,753
,156
,738
,606
,724
Łatwo
ś
ć
smarowania
Trwało
ś
ć
Zawarto
ś
ć
tłuszczów
zwierz
ę
cych
Kaloryczno
ś
ć
Zawarto
ś
ć
NNKT
Zawarto
ś
ć
witamin
Ocena smaku
Cena
Naturalno
ś
ć
1
2
Składowa
Metoda wyodr
ę
bniania czynników - Głównych składowych.
Metoda rotacji - Varimax z normalizacj
ą
Kaisera.
Rotacja osi
ą
gn
ę
ła zbie
ż
no
ś
ć
w 3 iteracjach.
a.

35
W trybie edycyjnym wykresu musimy dodać jeszcze osie układu współrzędnych
(Linie referencyjne) i wykres jest gotowy. Dla celów prezentacyjnych można go
oczywiście poddać obróbce kolorystycznej i opisać osie sensownymi definicjami
czynników.
Na wykresie widać, że pierwszy wymiar separuje masła (o ile Delicado to masło)
od margaryn, a drugi różnicuje marki w obrębie każdej z grup. Często praktykuje
się umieszczanie zmiennych (najlepiej z poprowadzonymi do nich z początku
układu strzałkami) i obiektów/marek przedstawionych jako punkty. Można to
również wykonać w programie SPSS. Wystarczy w jednym zbiorze umieścić
ładunki czynnikowe, wartości czynnikowe, zmienną opisującą zmienne i marki
i zmienną pozwalającą odróżnić jedne od drugich, a następnie wykonać wykres
rozrzutu. Chętni mogą spróbować dorysować w MS Word strzałki prowadzące
z początku układu do punktów wyznaczonych przez ładunki czynnikowe cech.
Lepiej jest jednak wówczas umieścić wykres na całej stronie, zorientowanej
poziomo.
REGR factor score 1 for analysis 1
2,0
1,5
1,0
,5
0,0
-,5
-1,0
-1,5
R
E
G
R
f
a
c
to
r
s
c
o
re
2
f
o
r
a
n
a
ly
s
is
1
2,0
1,5
1,0
,5
0,0
-,5
-1,0
-1,5
-2,0
Botteram
Sanella
SB
Flora
Homa
Weihnachts butter
Hollaendische Butter
Delicado Sahnebutter
Rama
Du darfst
Becel
36
Polecenie SPSS:
GRAPH
/SCATTERPLOT(BIVAR)=wymiar1 WITH wymiar2 BY kod BY etykieta(NAME).
A oto jego wynik:
Becel
-1,05981
1,19109
1
Du darfst
-,48986
-,61077
1
Rama
-,47014
-,25733
1
Delicado Sahnebutter
1,44901
,86806
1
Hollaendische Butter
1,14442
1,59586
1
Weihnachtsbutter
1,66200
-,66994
1
Homa
-,76578
,13543
1
Flora
-1,11770
,60306
1
SB
-,41923
-,45737
1
Sanella
-,30600
-,51851
1
Botteram
,37308
-1,87959
1
Łatwo
ś
ć
smarowania
-,94100
-,18600
2
Cena
,15600
,73800
2
Trwało
ś
ć
-,90900
-,07096
2
Zawarto
ś
ć
NNKT
-,71000
,26300
2
Ocena smaku
,58300
,75300
2
Kaloryczno
ś
ć
,80800
,36200
2
Zawarto
ś
ć
tłuszczów zwierz
ę
c
,87900
,38300
2
Zawarto
ś
ć
witamin
-,24000
,91000
2
Naturalno
ś
ć
,60600
,72400
2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
ETYKIETA
WYMIAR1
WYMIAR2
KOD
37
A oto wykres rozrzutu uzupełniony o wektory.
WYMIAR1
2,0
1,5
1,0
,5
0,0
-,5
-1,0
-1,5
W
Y
M
IA
R
2
2,0
1,5
1,0
,5
0,0
-,5
-1,0
-1,5
-2,0
Natura lno
ś
ć
Z awarto
ś
ć
wi tamin
Zawarto
ś
ć
tłuszczów
Kaloryc zno
ś
ć
Ocena smaku
Zawarto
ś
ć
NNKT
T rwało
ś
ć
Cena
Łat wo
ś
ć
smarowania
Bot teram
Sa nella
SB
Flora
Homa
Weihnachtsbutter
Hol laendische B utter
Delic ado Sahne butter
Rama
Du darfst
Becel

38
1.17
Analiza czynnikowa i składowych głównych - podsumowanie
Analiza czynnikowa i analiza głównych składowych to najpowszechniej stosowane
techniki analizy wielowymiarowej. Są sprawdzonymi i dobrymi narzędziami, pod
warunkiem dobrego zrozumienia, czego możemy od nich oczekiwać i jak je
stosować. Wiele wyborów dokonywanych przez badacza ma charakter arbitralny.
Z drugiej strony, jak to zauważyliśmy, analiza czynnikowa daje podobne
rezultaty przy różnych metodach wyodrębniania czynników oraz podobne do
analizy głównych składowych. W selekcji i interpretacji czynników ważne jest
doświadczenie analityka i merytoryczna znajomość problemu. Najgorszym
podejściem jest wkładanie do analizy czynnikowe danych „na ślepo” i następnie
wiara w uzyskane rezultaty. W tej metodzie również obowiązuje święta zasada
analizy danych: włożysz śmieci — wyjmiesz śmieci. Podkreślam to, niezależnie od
przekonania o fundamentalnej roli eksploracyjnej analizy danych w poznaniu
rzeczywistości i dobrych doświadczeń z użytkowaniem na tym polu analizy
czynnikowej i głównych składowych.
1.18
Literatura nt. analizy czynnikowej i głównych składowych
Norusis M., SPSS Professional Statistics 6.1, SPSS Inc., Chicago 1994.
Kim J.-O., Mueller Ch.W., Introduction to factor Analysis: What It Is and How to
Do It, w: M.S. Lewis-Back, Factor Analysis an Related Technics, Sage, London
1994, s. 1-73.
Kim J.-O., Mueller Ch.W., Factor Analysis: Statistical Methods and Practical
Issues, w: M.S. Lewis-Back, Factor Analysis an Related Technics, Sage,
London 1994, s. 75-155.
Duntemann G.H., Principal Components Analysis, w: M.S. Lewis-Back, Factor
Analysis an Related Technics, Sage, London 1994, s. 157-145.
Hair Jr. J.F., Anaderson R.E., Tatham R.L., Multivariate data Analysis with
Readings, 2
nd
edition, Macmillan, Collier, NY, London 1984.
Backhaus K., Erichson B., Plinke W., Weiber R., Multivariate Analysemethoden,
Springer, Berlin 1990.
Jajuga K., Statystyczna analiza wielowymiarowa, PWN, Warszawa 1993.
Arminger G., Faktorenanalyse, Teubner, Stuttgart, 1979.
Bacher J., Clusteranalyse, Oldenbourg, Muenchen 1996.
Bacher J., Einfuehrung in die Logik der Skalierungsverfahren, Historical Social
Research, Special Issue, Vol. 15, 1990, No. 3., Center for Historical Social
Research, Koeln.
Holm K., Die Befragung 3: die Faktorenalyse, Francke Verlag, Muenchen 1976.
Wilkinson L., Grant B., Gruber Ch., Desktop Analysis with SYSTAT, Prentice Hall
1996.
Wilkinson L., Stenson H., Factor Analysis, w: Systat 6.0 for Windows: Statistics,
SPSS Inc., Chicago, 1996.
Grabiński T., Metody taksonometrii, AE, Kraków 1992.

39
2
Skale Likerta
Jednowymiarowe skale ocen typu Likerta zyskały sobie bardzo dużą popularność
w badaniach społecznych dzięki prostocie konstrukcji i możliwości budowania ich
post hoc, po wykonaniu badań, co oszczędza żmudnych prac wstępnych, jakich
wymagają np. skale Thurstona. Przypomnijmy krótko
16
, że skale Likerta
konstruujemy przez proste sumowanie punktów uzyskanych w zestawie pytań,
które są wskaźnikami badanej zmiennej, zazwyczaj postawy. Pytania, których
używamy jako pozycji budujących skalę, zazwyczaj mają pięciostopniową
kafeterię, np.:
1.
zdecydowanie się zgadzam
2.
raczej się zgadzam
3.
ani się zgadzam, ani nie zgadzam
4.
raczej się nie zgadzam
5.
zdecydowanie się nie zgadzam.
Możliwe są również kategoryzacje sześcio- lub siedmiopunktowe i inne. Pytania z
mniej niż pięcioma stopniami (zwłaszcza z trzema) odpowiedzi nie są zalecane,
gdyż ograniczenie liczby kategorii prowadzi do „tłumienia” współczynników
korelacji, które wykorzystywane są przy diagnostyce skal, np. w analizie
czynnikowej. Pięciopunktowe skale werbalne w postaci zaprezentowanej wyżej,
oryginalnie spopularyzowane przez Rensisa Likerta w jego publikacjach na temat
skal sumowanych ocen, często nazywane są pytaniami typu Likerta lub pytaniami
ze skalą ocen Likerta, a nawet, skrótowo, skalami Likerta, co jednak grozi
pomyleniem typu kafeterii użytej w pytaniach z samą skalą Likerta, która
powstaje w oparciu o co najmniej kilka pytań tego rodzaju .
Odpowiedzi kodowane są zazwyczaj przy pomocy kolejnych liczb naturalnych, od
1 do 5. To, któremu krańcowi skali ocen (kafeterii) przypiszemy 1, a któremu 5,
wynika z konieczności uzgodnienia kodowania w całej grupie pytań, które wejdą
w skład skali. Dobrze jest przyjąć taki kierunek kodowania, by w przypadku
każdego pytania najwyższą liczbę punktów uzyskiwała ta krańcowa kategoria,
która odpowiada wyższemu natężeniu badanej postawy w zgodzie z jej treścią
ujętą przez nazwę skali. Na przykład, jeśli mamy do czynienia ze skala
feminizmu, to w przypadku stwierdzenia: „Jest znacznie lepiej dla rodziny, gdy m
ę
ż
czyzna
zarabia pieni
ą
dze, a kobieta troszczy si
ę
o dom i dzieci” najwy
żej punktowana (5) powinna być
odpowied
ź: „Zdecydowanie się nie zgadzam”.
Jednym z podejść, niekiedy stosowanym przez badaczy, jest budowanie tzw. skal
arbitralnych (indeksów). Badacz w tym wypadku dobiera na podstawie swojej
subiektywnej oceny treści pytań takie pozycje do skali, które jego zdaniem
mierzą badaną postawę czy inny konstrukt. Po dobraniu wskaźników-pytań
sumuje punkty uzyskane na każdym z pytań i otrzymuje sumaryczną skalę.
Można to wykonać przy pomocy prostego polecenia SPSS o ile arbitralnie
zakładamy, że zmienne v1, v2, v3, v7 i v10 budują naszą skalę (indeks)., np.:
16
Konstrukcja skal Likerta jest dobrze opisana w literaturze, m.in. w podręcznikach z
zakresu metod badań psychologicznych autorstwa J. Brzezińskiego, dlatego pomijam
tutaj szersze omówienie.

40
1) compute skala1=v1 + v2 + v3 + v7 + v10. (jeśli choć w jednej pozycji
występuje brak danych
wynik ogólny jest też b.d.)
2) compute skala1=sum(v1,v2,v3,v4). (sumuje wszystkie ważne wartości,
wynikiem jest b.d.
tylko wtedy, gdy wszystkie pozycje są b.d.)
lub:
3) compute skala1=mean(v1,v2,v3,v4).
Jeśli chcemy wykluczyć możliwość obliczenia wartości indeksu w sytuacji, gdy
zbyt wiele pozycji zawiera braki danych, można w poleceniu wskazać minimalną
liczbę ważnych danych – np. poniżej jest to 3 – poniżej której funkcja średniej
(czyli sumy podzielonej przez liczbę pozycji sumowanych) da w wyniku brak
danych:
4) compute skala1=mean.3(v1,v2,v3,v4).
Podejście oparte na arbitralnym kwalifikowaniu pozycji do skali (indeksu) jest
jednak niebezpieczne, gdyż opiera się na przyjęciu pewnych założeń, nawet jeśli
nie są wypowiedziane lub nie zdaje sobie z nich sprawy sam badacz.. Konstrukcja
skali Likerta kończy się wprawdzie obliczeniem sumarycznego indeksu przy
pomocy identycznych poleceń jak te zaprezentowane wyżej, lecz prócz tego
niezbędne jest sprawdzenie, czy pozycje (wskaźniki) dobrane do skali spełniają
warunki skali oraz czy uzyskana skala jest wiarygodna, czyli rzetelna i trafna.
Do założeń, które powinny być spełnione, by indeks sumaryczny mógł być
traktowany jako skala, należą:
•
śe wybrane wskaźniki mierzą jeden ukryty wymiar (jednowymiarowość skali).
•
śe wszystkie wskaźniki mierzą ten sam ukryty wymiar.
•
śe wskaźniki są liniowo związane z ukrytą zmienną i w związku z tym można
sumować ich wartości uzyskując syntetyczną skalę.
Z tych założeń wynika, że wskaźniki powinny być skorelowane pomiędzy sobą,
gdyż tylko w tym przypadku można przyjąć założenie o tym, że są wskaźnikami
jednej zmiennej ukrytej, z którą są skorelowane. Ale tego, przy konstrukcji skal
arbitralnych się nie sprawdza. A można to sprawdzić bardzo łatwo, wykorzystując
technikę analizy głównych składowych lub analizę czynnikową. Jeśli nasze
wskaźniki mierzą jeden konstrukt/zmienną ukrytą, to w analizie głównych
składowych i w analizie czynnikowej wszystkie powinny ładować wysoko tylko
jeden czynnik. Powinien to być czynnik dobrze wyodrębniony, a więc, najlepiej,
słabo skorelowany z innymi czynnikami. Analiza czynnikowa i analiza głównych
składowych mogą więc posłużyć do selekcji pozycji do skali. Same też mogą
posłużyć bezpośrednio do tworzenia skal w wyniku użycia opcji zapisu ocen
czynnikowych w procedurze analizy czynnikowej.
Wyniki analizy głównych składowych i analizy czynnikowa służą zatem do
budowania dwóch rodzajów skal:

41
•
bezpośrednio – skal czynnikowych (factor scales), których wartościami są
dobrze już znane oceny czynnikowe, zapisywane w toku analizy czynnikowej
(opcja w menu analizy czynnikowej SPSS: Zapisz -> Oceny czynnikowe)
•
skal opartych na czynnikach (factor based scales), które uzyskujemy
klasyczną metodą sumowania lub uśredniania wartości kodowych odpowiedzi
uzyskanych na pytania zakwalifikowane do skali na podstawie wyników analizy
czynnikowej (mające wysokie ładunki na jednym czynniku, zwykle przyjmuje
się co najmniej 0,5 lub nawet 0,6), zaś analiza czynnikowa służy jedynie do
sprawdzenia jednowymiarowości skali i właśnie selekcji pozycji do skali.
Skale czynnikowe i oparte ba czynnikach dają zasadniczo bardzo silnie
skorelowane wyniki, a więc mają tę samą zawartość informacyjną, przy czym
skale czynnikowe są automatycznie standaryzowane, natomiast skale Likerta nie
są. Zalecane jest stosowanie skal opartych na czynnikach, lecz pamiętać należy o
tym, by pozycje zakwalifikowane do skali miały zbliżone, wysokie wartości
ładunków czynnikowych z jednym czynnikiem.
Rzetelność skali badamy przy pomocy współczynnika alfa Cronbacha. Reguła
praktyczna mówi, że za „przyzwoicie” rzetelną możemy uważać taką skalę, w
przypadku której alfa wynosi przynajmniej 0,7. Niekiedy zaleca się ostrzejsze
kryterium 0,8, choć wydaje się ono nadmiernie konserwatywne. Zbliżanie się
wartości alfa do 1 nie czyni skali wcale doskonałą, gdyż faktycznie oznacza, że
można zastąpić całą skalę pojedynczą pozycją. Te skrajne sytuacje należą jednak
w badaniach społecznych do rzadkości, nawet gdy stosuje się baterie bardzo
zbliżonych znaczeniowo pytań.
17
Trzeba dodać, że spotyka się w poważnej
literaturze skale, których raportowana rzetelność była niższa od 0,7, ale nie
niższa niż 0,6. W świetle moich własnych doświadczeń badawczych wartość ok.
0,7 zdaje się być rozsądnym wymogiem. Musimy pamiętać, że alfa oparta jest na
korelacji poszczególnych pozycji ze skalą i zależy zarówno od stopnia
skorelowania wskaźników jaki i od liczby pozycji. Można osiągnąć dobrą
rzetelność skali nawet przy umiarkowanych korelacjach wzajemnych
wskaźników, o ile mamy ich wiele. Mimo że oryginalna strategia Likerta zakładała
opieranie procedury skalowania na początkowej liście nawet 50 i więcej pytań, to
jednak w praktyce staramy się ich zadawać zdecydowanie mniej i zwykle w
pilotażach i pracach wstępnych przy tworzeniu kwestionariusza staramy się
zwiększyć szansę, że pytania, dotykając różnych aspektów mierzonego
konstruktu, będą jednak dość silnie skorelowane, co pozwala osiągnąć przyzwoitą
rzetelność skali przy mniejszej liczbie pozycji.
W toku analizy rzetelności możemy także sprawdzić przydatność poszczególnych
pozycji skali przy pomocy opcji obliczania Alfy przy usuniętej pozycji. Procedura
ta polega na wyliczeniu wartości alfa Cronbacha dla skali złożonej z wszystkich
pozycji z wyjątkiem analizowanej. Pozwala to ocenić, na ile dana pozycja jest
ważna dla ogólnej rzetelności skali. W sytuacji, gdy naszym celem jest
zbudowanie dla potrzeb przyszłych lub powtarzalnych badań oszczędnej skali, nie
zajmującej całych szpalt kwestionariusza, technika ta pozwoli pozbyć się tych
pozycji, których brak nie obniża specjalnie rzetelności.
17
Szerzej na temat rzetelności testów można przeczytać w książce A. Machowskiego,
„Rzetelność testów psychologicznych. Dwa ujęcia modelowe”, PWN 1993.
42
A oto przykład analizy prowadzącej do stworzenia dwóch skal w dwóch
wariantach: jako skal czynnikowych i jako skal opartych na czynnikach. Analiza
składa się z 4 etapów:
1.
Analiza głównych składowych prowadząca do ostatecznego ustalenia składów
skal i wyliczenia wartości czynnikowych jako skal czynnikowych.
2.
Analiza rzetelności skal z użyciem współczynnika alfa Cronbacha, w tym
analiza poszczególnych pozycji techniką Skala przy wykluczeniu pozycji
3.
Wyliczenie wartości skal metodą sumowania (uśredniania) ocen z pozycji
4.
Zbadanie korelacji skal otrzymanych dwiema metodami
Na tym etapie nie rozwiążemy jeszcze problemu braków danych. Zastosujemy
eliminację kompletną obserwacji z brakami danych typu usuwanie obserwacjami,
co poważnie, niestety zmniejsza próbę badawczą. Lepiej radzi sobie z problemem
braków danych technika uśredniania ocen, która pozwala obliczyć wartość skali
dla danej osoby także przy niekompletnie wypełnionych odpowiedziach (opcja 4
wśród zaprezentowanych wyżej poleceń compute).
Przedstawiam tutaj tylko polecenia w języku SPSS i wyniki wraz z krótkimi
komentarzami. Reguły stosowania i interpretacji analizy głównych składowych są
opisane w skrypcie z analizy czynnikowej. Na końcu zamieszczone są fragmenty
kwestionariusza zawierające analizowane pytania.
2.1
Analiza czynnikowa
Macierz rotowanych składowych(a)
Składowa
1
2
Mam w sobie do
ś
ć
siły i umiej
ę
tno
ś
ci, by sprosta
ć
zadaniom, które sobie stawiam
,806
Lubi
ę
trudne problemy i czuj
ę
rado
ś
ć
, kiedy uda mi si
ę
je rozwi
ą
za
ć
,732
Lubi
ę
zadania, które s
ą
troch
ę
ryzykowne, ale za to przynosz
ą
korzy
ś
ci
,662
Ch
ę
tniej pracowałbym na własny rachunek, ni
ż
jako czyj
ś
pracownik
,612
Mam uczucie,
ż
e poradz
ę
sobie w ka
ż
dych okoliczno
ś
ciach
,542
Czuj
ę
,
ż
e
ż
yj
ę
i pracuj
ę
dla wa
ż
nych celów
,537
Planuj
ę
swoje przedsi
ę
wzi
ę
cia
,495
Jak Pana(i) zdaniem zmieniła si
ę
sytuacja gospodarcza w Polsce w ci
ą
gu ostatnich
12 miesi
ę
cy? Jest teraz...
,811
Czy my
ś
li Pan(i),
ż
e w ci
ą
gu nast
ę
pnych 12 miesi
ę
cy sytuacja gospodarcza Polski
b
ę
dzie...
,787
Czy, porównuj
ą
c sw
ą
obecn
ą
sytuacj
ę
finansow
ą
z sytuacj
ą
sprzed roku,
powiedział(a)by Pan(i),
ż
e dzisiejsza jest...
,736
Jakich zmian spodziewa si
ę
Pan(i) w poziomie swojego
ż
ycia w ci
ą
gu najbli
ż
szych
12 miesi
ę
cy?
,729
Metoda wyodr
ę
bniania czynników - Głównych składowych. Metoda rotacji - Varimax z normalizacj
ą
Kaisera.
a Rotacja osi
ą
gn
ę
ła zbie
ż
no
ś
ć
w 3 iteracjach.

43
FACTOR
/VARIABLES v1 v2 v6 v7 v17.1 v17.2 v17.3 v17.4 v17.6 v18.1 v18.4
/FORMAT SORT BLANK(.3)
/CRITERIA FACTORS(2)
/ROTATION VARIMAX.
Dwie pierwsze główne składowe wyjaśniają ok. 48% całkowitej wariancji. Po
wykonaniu wstępnie rotacji skośnej (PROMAX, OBLIMIN) oceniamy, że tendencja
do korelowania dwóch wyodrębnionych skal jest mała. Ostatecznie wykonujemy
analizę z rotacją VARIMAX.
Z uzyskanej macierzy ładunków wynika wyraźnie, że mamy do czynienia z
dwoma dobrze wyklarowanymi wymiarami, które można określić jako:
•
motywacja do osiągnięć — pierwsza składowa
•
pesymizm/optymizm ekonomiczny — druga składowa.
Można przyjąć, że uzyskaliśmy dwie jednowymiarowe skale. Aby uzyskać
wartości czynnikowe, które będą wartościami każdej obserwacji na każdej ze skal
wystarczy dodać opcję:
/save=reg(2)
SPSS automatycznie dopisuje do zbioru danych dwie zmienne zawierające
wartości czynnikowe.
44
2.2
Analiza rzetelności
RELIABILITY
/VARIABLES= V17.3 V17.4 V17.1 V17.2 V18.1 V17.6 V18.4
/FORMAT=LABELS
/SCALE(SUKCES)=V17.3 V17.4 V17.1 V17.2 V18.1 V17.6 V18.4
/SUMMARY=TOTAL.
Statystyki rzetelno
ś
ci
Alfa
Cronbacha
Liczba pozycji
,752
7
Statystyki pozycji Ogółem
Ś
rednia skali
po usuni
ę
ciu
pozycji
Wariancja
skali po
usuni
ę
ciu
pozycji
Korelacja
pozycji
Ogółem
Alfa
Cronbacha po
usuni
ę
ciu
pozycji
Mam w sobie do
ś
ć
siły i umiej
ę
tno
ś
ci, by
sprosta
ć
zadaniom, które sobie stawiam
21,06
19,424
,656
,680
Lubi
ę
trudne problemy i czuj
ę
rado
ś
ć
, kiedy uda
mi si
ę
je rozwi
ą
za
ć
21,03
20,198
,559
,702
Lubi
ę
zadania, które s
ą
troch
ę
ryzykowne, ale
za to przynosz
ą
korzy
ś
ci
21,31
20,576
,483
,718
Ch
ę
tniej pracowałbym na własny rachunek, ni
ż
jako czyj
ś
pracownik
21,18
20,627
,424
,733
Mam uczucie,
ż
e poradz
ę
sobie w ka
ż
dych
okoliczno
ś
ciach
21,44
22,126
,421
,732
Czuj
ę
,
ż
e
ż
yj
ę
i pracuj
ę
dla wa
ż
nych celów
21,29
22,164
,374
,741
Planuj
ę
swoje przedsi
ę
wzi
ę
cia
21,61
21,626
,378
,742
Skala motywacji do osiągnięć (SUKCES) jest skalą o rzetelności mierzonej
współczynnikiem alfa Cronbacha wynoszącej 0,75. Jest to więc skala, którą
możemy zaakceptować. Dzięki temu, że zmienne wprowadziliśmy do analizy w
kolejności wynikającej z wielkości ładunków czynnikowych, widać wyraźnie, że im
mniejszy był uprzednio ładunek czynnikowy, tym mniejszy jest poziom korelacji
danej pozycji ze skalą i tym mniejsza strata dla rzetelności skali wynikająca ze
skreślenia danej pozycji z listy wskaźników. Ogólnie jednak, każdy wskaźnik
wnosi coś do rzetelności i w żądnym wypadku wprowadzenie danej pozycji nie
powoduje obniżenia rzetelności. Skalę akceptujemy w tej postaci.
RELIABILITY
/VARIABLES= V1 V2 V6 V7
/FORMAT=LABELS
/SCALE(EKONOPT)=V1 V2 V6 V7
/SUMMARY=TOTAL .
45
Statystyki rzetelno
ś
ci
Alfa
Cronbacha
Liczba pozycji
,761
4
Statystyki pozycji Ogółem
Ś
rednia skali
po usuni
ę
ciu
pozycji
Wariancja
skali po
usuni
ę
ciu
pozycji
Korelacja
pozycji
Ogółem
Alfa
Cronbacha po
usuni
ę
ciu
pozycji
Jak Pana(i) zdaniem zmieniła si
ę
sytuacja gospodarcza w
Polsce w ci
ą
gu ostatnich 12 miesi
ę
cy? Jest teraz...
9,54
4,929
,593
,687
Czy my
ś
li Pan(i),
ż
e w ci
ą
gu nast
ę
pnych 12 miesi
ę
cy
sytuacja gospodarcza Polski b
ę
dzie...
9,84
5,543
,588
,690
Czy, porównuj
ą
c sw
ą
obecn
ą
sytuacj
ę
finansow
ą
z
sytuacj
ą
sprzed roku, powiedział(a)by Pan(i),
ż
e dzisiejsza
jest...
9,57
5,414
,537
,717
Jakich zmian spodziewa si
ę
Pan(i) w poziomie swojego
ż
ycia w ci
ą
gu najbli
ż
szych 12 miesi
ę
cy?
9,93
6,126
,534
,721
Druga skala, choć składająca się tylko z czterech pozycji, jest nawet nieco
bardziej rzetelna w świetle takiego kryterium jakim jest współczynnik alfa.
Również i tutaj nie można bezkarnie wyeliminować żadnego wskaźnika. Ich
indywidualny wkład w rzetelność skali jest zresztą większy niż wkład
pojedynczych pozycji w skali poprzedniej. Wynika to z mniejszej liczby pozycji i z
bardziej wyrównanego poziomu korelacji między pozycjami a skalą.
2.3
Obliczenie wartości skal
Skale oparte na czynnikach tworzymy bardzo prosto przez sumowanie wyników
przy pomocy polecenia COMPUTE (można zastosować też funkcje sum i mean o
podanych wyżej właściwościach; szczególnie zalecana jest funkcja mean – tego
rodzaju obliczenie pozostawiam do własnych ćwiczeń, zwracając uwagę, że
funkcja mean pozwala do pewnego stopnia poradzić sobie z problemem braków
danych, ale dobrze jest ustalić dolną granicę liczby pozycji zawierających ważne
dane warunkujaca obliczenie ważnej wartości skali – funkcja w postaci
mean.k(lista zmiennych), gdzie k oznacza minimalna liczbę ważnych danych).
compute sukces=
V17.3 + V17.4 + V17.1 + V17.2 + V18.1 + V17.6 + V18.4.
compute ekonopt=
V1 + V2 + V6 + V7
.
var lab sukces ‘Skala orientacji na osi
ą
gni
ę
cia’
/ekonopt ‘Skala ekonomicznego pesymizmu/optymizmu’.

46
2.4
Korelacja pomiędzy skalami opartymi na czynnikach a skalami
czynnikowymi
Jak łatwo można zauważyć, bardzo wysoka wartość współczynników korelacji
pomiędzy odpowiednimi skalami potwierdza sensowność stosowania skal
opartych na czynnikach, wyliczonych przez proste sumowanie wartości pozycji,
których rzetelność możemy ustalić przy pomocy alfa.
2.4.1.1.1.1.1.1
ANEKS: Pytania użyte w skalowaniu
V1
Jak Pana(i) zdaniem zmieniła się
sytuacja gospodarcza w Polsce w
ciągu ostatnich 12 miesięcy? Jest
teraz...
CZYTAJ ODPOWIEDZI
:
1. O wiele lepsza....................................
2. Trochę lepsza.....................................
3. Taka sama.........................................
4. Trochę gorsza ....................................
5. O wiele gorsza ...................................
6. Nie wiem ...........................................
1
2
3
4
5
6
V2
Czy myśli Pan(i), że w ciągu
następnych 12 miesięcy sytuacja
gospodarcza Polski będzie...
CZYTAJ ODPOWIEDZI:
1. O wiele lepsza....................................
2. Trochę lepsza.....................................
3. Taka sama.........................................
4. Trochę gorsza ....................................
5. O wiele gorsza ...................................
6. Nie wiem ...........................................
1
2
3
4
5
6
V6
Czy, porównując swą obecną sytuację
finansową z sytuacją sprzed roku,
powiedział(a)by Pan(i), że dzisiejsza
jest...
CZYTAJ ODPOWIEDZI:
1. O wiele lepsza....................................
2. Trochę lepsza.....................................
3. Taka sama.........................................
4. Trochę gorsza ....................................
5. O wiele gorsza ...................................
6. Nie wiem ...........................................
1
2
3
4
5
6
V7
Jakich zmian spodziewa się Pan(i) w
poziomie swojego życia w ciągu
najbliższych 12 miesięcy?
CZYTAJ ODPOWIEDZI:
1. Bardzo się poprawi .............................
2. Trochę się poprawi .............................
3. Pozostanie taki sam ............................
4. Trochę się pogorszy ............................
5. Bardzo się pogorszy............................
6. Nie wiem ...........................................
1
2
3
4
5
6
V17 Przy każdym stwierdzeniu proszę powiedzieć,
w jakim stopniu zgadza się Pan(i) z nim.
POKAś KARTĘ V17
Zdecy-
dowanie
się nie
zgadza
m
Raczej
się nie
zgadza
m
Ani się
zgadzam,
ani się
nie
zgadzam
Raczej
się
zgadza
m
Zdecy-
dowanie
się
zgadza
m
Nie
wiem
1
Lubię zadania, które są trochę ryzykowne, ale za to
przynoszą korzyści
1
2
3
4
5
6
2
Chętniej pracowałbym na własny rachunek, niż jako
czyjś pracownik
1
2
3
4
5
6
3
Mam w sobie dość siły i umiejętności, by sprostać
zadaniom, które sobie stawiam
1
2
3
4
5
6
4
Lubię trudne problemy i czuję radość, kiedy uda mi
się je rozwiązać
1
2
3
4
5
6
6
Czuję, że żyję i pracuję dla ważnych celów
1
2
3
4
5
6
V18 Jak często zdarza się Panu(i) to, o czym mówią poniższe zdania? Proszę przy każdym
stwierdzeniu powiedzieć, czy zdarza się to Panu(i): bardzo rzadko lub nigdy, dość
rzadko, od czasu do czasu, dość często, czy bardzo często?
POKAś KARTĘ V18
Bardzo
rzadko,
nigdy
Dość
rzadk
o
Od
czasu
do
czasu
Dość
często
Bardzo
często
Nie
wiem
1
Mam uczucie, że poradzę sobie w każdych
okolicznościach
1
2
3
4
5
6
4
Planuję swoje przedsięwzięcia
1
2
3
4
5
6

Skrypt kursowy do użytku wewnętrznego
2
Wyszukiwarka
Podobne podstrony:
Analiza czynnikowa II
J Ossowski Analiza czynnikow ujecie kwartale id 221447
Analiza czynnikowa id 59935 Nieznany (2)
Analiza czynnikowa, c:winword emplate
Analiza czynnikowa w SPSS
Metodologia w VIII, WYBRANE METODY ANALIZY WIELOZMIENNOWEJ - PODSTAWOWE ZAŁOŻENIA ANALIZY CZYNNIKOWE
Psychometria 7 Analiza czynnikowa
wyklad3 analiza 1 czynnikowa
Analiza 3 czynnikowa wykres
16 analiza czynników produkcji rynek pracy,kapitału i ziemi 4MSWGOUNSWIMD4H3LZ2THOWU4GQHMEFPQMMTVCY
Analiza czynników wpływających na powrót do pracy pacjentów po aloplastyce całkowitej stawu biodrowe
ANALIZA CZYNNIKOWA
reszta, Analiza czynnikowa - metodologia, Analiza czynnikowa
wykład7 analiza 2 czynnikowa
więcej podobnych podstron