Metody probabilistyczne i statystyka
Laboratorium 7 i laboratorium 8
EF DI2
rok akademicki 2012/13
Wnioskowanie statystyczne - weryfikacja hipotez statystycznych
[1] Ostasiewicz S., Rusnak Z., Siedlecka U.: Statystyka. Elementy teorii i zadania. Wydawnictwo Akademii Ekonomicznej we Wrocławiu, Wrocław 2006.
[2] M. Sobczyk: Statystyka, PWN, Warszawa, 2007.
[3] W. Krysicki, J. Bartos, W. Dyczka, K. Królikowska, M. Wasilewski: Rachunek prawdopodobieństwa i statystyka matematyczna w zadaniach, cz. I, Rachunek prawdopodobieństwa, PWN, Warszawa 2002.
[4] W. Krysicki, J. Bartos, W. Dyczka, K. Królikowska, M. Wasilewski: Rachunek prawdopodobieństwa i statystyka matematyczna w zadaniach, cz. II, Statystyka matematyczna, PWN, Warszawa 2002.
[5] J. Kisielińska, U. Skórnik - Pokrowska: Podstawy statystyki, Wydawnictwo SGGW, Warszawa 2005.
[6] M. Piłatowska: Repetytorium ze statystyki, Wydawnictwo Naukowe PWN , Warszawa 2009
[7] M. Sobczyk: Statystyka. Aspekty praktyczne i teoretyczne, Wydawnictwo UMCS, 2006.
Celem ćwiczenia jest zapoznanie:
Zapoznanie studentów z wykorzystaniem arkusza kalkulacyjnego Excel do zagadnień zwianych z wnioskowaniem statystycznym.
Po odbyciu zajęć studenci powinni nabyć umiejętności w rozwiązywaniu zadań związanych z estymacja przedziałową, umieć określić minimalną liczebność próby, przeprowadzić testy hipotez parametrycznych i nieparametrycznych.
Pojęcia podstawowe
W ramach wnioskowania statystycznego wyróżnia się dwa zasadnicze działy:
estymację, czyli szacowanie wartości parametrów lub postaci rozkładu zmiennej losowej w populacji generalnej, na podstawie rozkładu empirycznego uzyskanego dla próby;
weryfikację (testowanie) hipotez statystycznych, obejmujące zasady i metody sprawdzania określonych przypuszczeń (założeń) dotyczących parametrów lub postaci rozkładu cech statystycznych populacji generalnej na podstawie wyników z próby losowej.
W przypadku estymacji wychodzimy od wyników próby i na ich podstawie formułujemy wnioski o populacji generalnej.
Przy weryfikacji hipotez statystycznych najpierw wysuwamy określone przypuszczenia dotyczące populacji generalnej, a następnie sprawdzamy je na podstawie wyników próby.
Hipotezą statystyczną nazywamy każdy sąd o zbiorowości generalnej, wydany bez przeprowadzenia badania całkowitego. Prawdziwość hipotezy statystycznej orzeka się na podstawie próby losowej.
Sąd taki może być sformułowany na podstawie teorii badanego zjawiska, na podstawie informacji zawartych w próbie, ale też na podstawie intuicji lun nawet w ogóle ad hoc.
Ponieważ do opisu kształtowania się (rozkładu wartości) cech w zbiorowości generalnej używamy jednowymiarowych lub wielowymiarowych zmiennych losowych, zatem hipotezy statystyczne mogą być zapisane w postaci sądów dotyczących tych zmiennych losowych - a konkretnie ich rozkładów lub parametrów.
Hipotezy mogą być:
- parametryczne , gdy dotyczą wartości odpowiednich parametrów statystycznych populacji generalnej , takich jak wartość przeciętna, wariancja czy wskaźnik struktury;
- nieparametryczne , gdy dotyczą np. postaci rozkładu cechy statystycznej, współzależności cech lub losowości próby.
Czasem warto klasyfikować hipotezy według ich merytorycznej treści. Ułatwia to precyzyjną identyfikację problemu badawczego, a dalszej kolejności wybór właściwej metody weryfikacji hipotezy.
Hipotezą zerową H0 nazywamy hipotezę sprawdzaną (testowaną, weryfikowaną),
Hipotezą alternatywną H1 nazywamy hipotezę, którą jesteśmy skłonni przyjąć, gdy odrzucamy hipotezę H0.
Test statystyczny jest to reguła postępowania, która przyporządkowuje wynikom próby losowej decyzję przyjęcia lub odrzucenia hipotezy H0 .
Jest oczywiste, że decyzję prawidłową podejmujemy wówczas, gdy przyjmujemy hipotezę, która jest prawdziwa lub gdy odrzucamy hipotezę fałszywą. W statystyce przyjęto nazywać odrzucenie hipotezy prawdziwej błędem pierwszego rodzaju. Przyjęcie hipotezy fałszywej to błąd drugiego rodzaju.
Błąd I rodzaju polega na odrzuceniu hipotezy H0, mimo że jest ona prawdziwa. Test w którym bierzemy pod uwagę jedynie prawdopodobieństwo błędu I rodzaju, nazywamy testem istotności.
Poziomem istotności α nazywamy prawdopodobieństwo popełnienia błędu I rodzaju. Wartości α są bliskie zera i na ogół są równe: 0,01; 0,02; 0,05; 0,1.
Błąd II rodzaju polega na przyjęciu hipotezy H0, gdy jest ona fałszywa. Prawdopodobieństwo popełnienia tego błędu oznacza się przez β. Dobry test statystyczny powinien mieć tę własność, że β również powinno być bliskie zera.
W budowie testów istotności dla hipotezy H0 można wyróżnić kilka podstawowych etapów, a mianowicie:
określenie hipotezy zerowej H0 i hipotezy alternatywnej H1;
wylosowanie n-elementowej próby prostej i wyznaczenie z niej takiej statystyki Un, której rozkład (dokładny lub graniczny) jest znany przy założeniu prawdziwości sprawdzanej hipotezy H0;
przyjęcie poziomu istotności ; im wyższy jest poziom istotności, tym większa jest szansa odrzucenia H0;
wybór obszaru krytycznego; w zależności od postaci hipotezy alternatywnej H1 obszar krytyczny może być dwustronny lub jednostronny (prawostronny lub lewostronny);
obliczenie z wyników n-elementowej próby wartości un statystyki Un i sprawdzenie, czy należy ona do obszaru krytycznego; jeżeli un należy do obszaru krytycznego, to hipotezę H0 odrzuca się na poziomie istotności , jeżeli zaś nie należy, to stwierdza się, że nie ma podstaw do odrzucenia sprawdzanej hipotezy H0.
Parametryczne testy istotności
Test dla wartości średniej
Z populacji generalnej wylosowano n -elementową próbę w celu zweryfikowania hipotezy zerowej:
Etap I: Formułujemy hipotezy
H0: m=m0
H1: m≠m0 lub m>m0 lub m<m0
m0 - jest pewną hipotetyczną wartością średniej w populacji.
Etap II: Wybieramy statystykę sprawdzającą hipotezę H0
Zakładamy, że rozkład cechy w zbiorowości generalnej ma rozkład normalny N(m,σ).
Wybór statystyki zależy od liczebności próby i od tego, czy parametr σ w zbiorowości generalnej jest znany lub nie.
Etap IIA:
Jeżeli:
σ jest znane i n ≤ 30;
σ jest znane i n > 30;
σ jest nieznane i n > 30, σ ≈S,
Statystyką służącą do budowy testu istotności jest średnia z próby. Sprawdzianem hipotezy zerowej H0 jest statystyka U:
![]()
o rozkładzie N(0,1)
Jeśli hipoteza zerowa H0 jest prawdziwa, to średnia arytmetyczna obliczona z próby nie powinna się istotnie różnić od hipotetycznej wartości m0, czyli wartość bezwzględna statystyki U nie powinna przekraczać wartości krytycznej u, odczytanej z tablic rozkładu normalnego N(0,1) przy ustalonym poziomie istotności , w taki sposób aby zachodziło prawdopodobieństwo:
![]()
Wartości zmiennej U spełniające nierówność :
![]()
tworzą dwustronny (symetryczny) obszar krytyczny testu.
Stosowanie testu istotności z tak zbudowanym obszarem krytycznym sprowadza się do obliczenia z wyników konkretnej próby losowej wartości statystyki i sprawdzenia, czy znajduje się ona w obszarze krytycznym, czy też nie.
Etap IIB:
Jeżeli:
σ jest nieznane i n ≤ 30, to statystyką sprawdzającą jest statystyka T:
![]()
![]()
która, gdy prawdziwa jest hipoteza H0, ma rozkład t-Studenta o n-1 stopniach swobody.
Etap III: Ustalamy α i określamy obszar krytyczny
Na tym etapie procedury weryfikacyjnej przyjmujemy maksymalne dopuszczalne prawdopodobieństwo popełnienia błędu I rodzaju, który polega na odrzuceniu hipotezy zerowej wtedy, gdy jest ona prawdziwa. Prawdopodobieństwo to jest oznaczane symbolem α i nazywane poziomem istotności. Na ogół przyjmujemy prawdopodobieństwo bliskie zeru, ponieważ chcemy aby ryzyko popełnienia błędu było jak najmniejsze. Najczęściej zakładamy poziom istotności α=0,05, czasem przyjmuje się np. α=0,01, α=0,1.
Obszar krytyczny - obszar znajdujący się zawsze na krańcach rozkładu. Jeżeli obliczona przez nas wartość statystyki testowej znajdzie się w tym obszarze, to weryfikowaną przez nas hipotezę H0 odrzucamy. Wielkość obszaru krytycznego wyznacza dowolnie mały poziom istotności α, natomiast jego położenie określane jest przez hipotezę alternatywną. Obszar krytyczny od pozostałej części rozkładu statystyki oddzielony jest przez tzw. wartości krytyczne testu (uα), czyli wartości odczytane z rozkładu statystyki przy danym α, tak aby spełniona była relacja zależna od sposobu sformułowania H1.
przypadek H0:m = m0 ; H1: m ≠ m0
- konstruujemy dwustronny obszar krytyczny spełniający relację: ![]()
przypadek H0: m = m0 ; H1: m > m0
- konstruujemy prawostronny obszar krytyczny, spełniający relację: ![]()
przypadek H0:m=m0 ; H1: m<m0
- konstruujemy lewostronny obszar krytyczny, spełniający relację: ![]()
Etap IV:
Obliczamy wartość wybranej statystyki sprawdzającej
Etap V:
Dokonujemy weryfikacji hipotezy![]()
Wyznaczoną na podstawie próby wartość statystyki porównujemy z wartością krytyczną testu.
Jeżeli wartość statystyki znajdzie się w obszarze krytycznym, to hipotezę zerową należy odrzucić jako nieprawdziwą. Stąd wniosek, że prawdziwa jest hipoteza alternatywna.
Jeżeli natomiast wartość statystyki znajdzie się poza obszarem krytycznym, oznacza to, że brak jest podstaw do odrzucenia hipotezy zerowej. Stąd wniosek, że hipoteza zerowa może, ale nie musi, być prawdziwa, a postępowanie nie dało żadnych dodatkowych informacji uprawniających do podjęcia decyzji o przyjęciu lub odrzuceniu hipotezy zerowej.
Test dla dwóch średnich
Gdy zachodzi konieczność porównania dwóch średnich w dwóch populacjach o rozkładach normalnych: N(m1, σ1) i N(m2, σ2). Chcemy zweryfikować hipotezę H0 : m1 = m2 wobec hipotezy alternatywnej H1 : m1 ≠ m2 (lub H1 : m1 < m2 albo H1 : m1 > m2 ). Niech n1 , n2 wielkości prób, wylosowanych z każdej zbiorowości, a ![]()
oznaczają odpowiednio średnie arytmetyczne i wariancję z prób. W zależności od założeń dotyczących zbiorowości generalnych oraz od liczebności prób - sprawdzian hipotezy zerowej ma różną postać i jest związany z rozkładem normalnym lub rozkładem Studenta.
Jeżeli twierdzimy, że wartości m1 = m2, oraz σ1 i σ2 są znane to przeprowadzamy test wykorzystując statystykę:
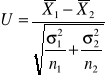
lub gdy: n1>30 i n2>30, przyjmujemy, że ![]()
≈![]()
i ![]()
≈![]()
, wówczas sprawdzian hipotezy ma postać:
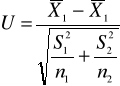
Jeżeli m1, m2 i σ1 , σ2 są nieznane, ale wiemy, że σ1 = σ2, n1≤30 ; n2≤30 to statystyka sprawdzająca obliczana jest wg wzoru:
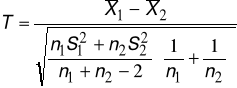
i przy założeniu prawdziwości hipotezy H0, ma rozkład Studenta o (n1+n2-2) stopniach swobody.
Testowanie hipotezy o wariancji
Testy dla wariancji - są to testy parametryczne służące do weryfikacji hipotez statystycznych dotyczących wartości wariancji w populacji generalnej lub też do porównania wartości wariancji w dwóch lub kilku populacjach - na podstawie znajomości wartości badanej cechy w losowej próbie (lub w kilku próbach). Rozstrzygnięcie pytań dotyczących wariancji jest ważne m.in. dlatego, że wiele testów służących do porównania wartości średnich w dwóch lub kilku populacjach wymaga przyjęcia założenia o równości wariancji w tych populacjach (tak zwane założenie o jednorodności wariancji). Ponadto wariancja może być miernikiem dokładności w procesie pomiarowym lub produkcyjnym (zbyt duża wariancja wyników pomiaru może na przykład świadczyć o uszkodzeniu lub rozregulowaniu aparatury lub urządzeń).
Zakładamy, że populacja generalna ma rozkład normalny N(m; σ). Należy zweryfikować hipotezę H0 : ![]()
przeciwko H1 : ![]()
Taką hipotezę alternatywną przyjmuje się najczęściej, gdyż zwykle sytuacja , gdy wariancja cechy w zbiorowości jest duża, niekorzystna.
Jeżeli m jest znane i n ≤ 30, to do sprawdzenia hipotezy wykorzystuje się statystykę:
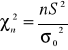
gdzie: ![]()
Przy założeniu prawdziwości hipotezy H0 statystyka ta ma rozkład χ2 o n stopniach swobody.
Natomiast jeśli m jest nieznane i n ≤ 30 to do sprawdzenia hipotezy wykorzystuje się statystykę:
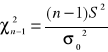
gdzie: ![]()
Przy założeniu prawdziwości hipotezy H0 statystyka ta ma rozkład χ2 o n-1 stopniach swobody. Z uwagi na postać hipotezy alternatywnej relacja : ![]()
Wyznacza prawostronny zbiór krytyczny , gdzie ![]()
jest wartością krytyczną odczytaną z rozkładu ![]()
dla odpowiedniej liczby stopni swobody i P = α. Jeśli dla danej próby losowej relacja wyznaczająca zbiór krytyczny jest spełniona, to hipotezę zerową należy odrzucić na korzyść hipotezy alternatywnej.
Testowanie hipotezy o dwóch wariancjach
Badamy dwie populacje generalne o rozkładzie normalnym N(m1, σ1) i N(m2, σ2).
Należy zweryfikować hipotezę H0 : ![]()
przeciwko H1 : ![]()
Z obydwu populacji generalnych losuje się próby o liczebności: ![]()
. Niech ![]()
oznaczają wariancje (obliczone wg zależności: 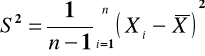
) dla każdej z prób losowych. Ze względu na postać hipotezy alternatywnej tak numerujemy zbiorowości (populacje generalne) aby: ![]()
.
Statystyką sprawdzającą jest statystyka:
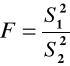
Statystyka ta ma rozkład F-Sendecora o stopniach swobody r1 = ![]()
i r2 = ![]()
.
Relacja wyznaczająca prawostronny zbiór krytyczny jest postaci:
![]()
gdzie: Fα - odczytujemy z tablic rozkładu F- Sendecora dla r1 i r2 stopni swobody.
Jeżeli relacja ta jest spełniona, należy hipotezę zerową odrzucić, w przeciwnym wypadku nie ma podstaw do odrzucenia hipotezy zerowej.
Test dla dwóch wariancji wykorzystuje się najczęściej do sprawdzenia prawdziwości założenia ![]()
, które jest konieczne, aby można było testować hipotezę o równości wartości przeciętnych w dwóch populacjach ( gdy n1≤30 ; n2≤30, σ1 , σ2 są nieznane).
Testy hipotez nieparametrycznych
Nieparametryczne testy istotności dzielimy na trzy zasadnicze grupy:
- testy zgodności;
- testy niezależności;
- testy losowości próby.
Testy nieparametryczne, w przeciwieństwie do testów parametrycznych, mają tę zaletę, że nie wymagają założeń w odniesieniu do postaci rozkładu cechy w populacji (zbiorowości generalnej). Testy nieparametryczne mają mniejszą moc od testów parametrycznych, ale przewyższają je „prostotą” budowy i mało „uciążliwymi” obliczeniami. Dlatego są coraz częściej wykorzystywane w praktyce statystycznej. Stosowanie nieparametrycznych testów jest uzasadnione wtedy, gdy są spełnione następujące warunki:
- liczebność próby jest duża,
- próba losowa jest próbą prostą (losowanie niezależne)'
- poziom istotności jest nie mniejszy niż 0,01.
Jeśli hipoteza jaką stawiamy na temat danego rozkładu nie dotyczy wartości jednego z jego parametrów, a jedynie postaci tego rozkładu, to wówczas procedurę sprawdzenia tego rodzaju hipotezy nazywamy statystycznym testem nieparametrycznym albo testem zgodności. Najprostszą metodą prowadzącą do uzyskania wstępnych informacji o postaci rozkładu interesującej nas cechy elementów populacji jest narysowanie histogramu rozkładu zaobserwowanego w próbie. Uzyskane z rysunku informacje są jednak niepełne i tylko „wzrokowe”. Histogram pozwala nam jednak zorientować się, jakie ewentualnie rozkłady mogą być brane pod uwagę.
Rys. 1. Rys. 2.
O ile na podstawie Rys. 2. można ""podejrzewać" możliwość występowania rozkładu normalnego w populacji generalnej, o tyle w przypadku Rys1. trudno o decyzję. Oczywiście spostrzeżenia oparte na kształtach histogramów nie mogą służyć za podstawę ogólniejszych rozważań. Niezbędna jest bardziej precyzyjna miara zgodności między rozkładem w próbie losowej, a hipotetycznym rozkładem cechy elementów w populacji generalnej (w całej populacji). Pierwszym krokiem jest ustalenie zbioru możliwych w danym zagadnieniu hipotez, tzn. zbioru możliwych rozkładów, które mogą być brane pod uwagę, a następnie wyróżnienie z tego zbioru hipotezy zerowej. Kolejnym krokiem jest przyjęcie odpowiedniej statystyki, która może służyć za test do weryfikacji hipotezy zerowej.
Sposób postępowania przy testowaniu zgodności:
ustalenie zbioru możliwych rozkładów,
wyróżnienie z tego zbioru rozkładów - hipotezy zerowej,
przyjęcie odpowiedniej statystyki służącej do weryfikacji hipotezy zerowej.
Warunkiem stosowania testu zgodności χ2 jest duża próba wylosowana w sposób niezależny z populacji generalnej.
Jednym z testów nieparametrycznych jest:
Test zgodności χ2 Pearsona
Populacja generalna ma dowolny rozkład o dystrybuancie należącej do zbioru rozkładów o określonym typie postaci funkcyjnej dystrybuanty. Mogą to być dystrybuanty typu ciągłego i skokowego. Warunkiem stosowania testu zgodności χ2 jest duża próba wylosowana w sposób niezależny z populacji generalnej. Wyniki losowania dzielimy na k rozłącznych klas. Dla każdej wyróżnionej klasy zostaje przyporządkowana liczebność ni zwana liczebnością klasy. Otrzymany w ten sposób szereg rozdzielczy stanowi rozkład empiryczny. Zadaniem naszym jest sprawdzenie zgodności tego rozkładu z rozkładem teoretycznym (hipotetycznym) populacji generalnej (zbiorowości). Tym rozkładem teoretycznym jest najczęściej rozkład dwumianowy, Poissona lub normalny.
Celem naszym jest więc weryfikacja nieparametrycznej hipotezy zerowej H0: F(x)=F0(x) wobec hipotezy alternatywnej H1: F(x)≠F0(x), gdzie F0(x) jest określona postacią hipotetyczną dystrybuanty.
Sprawdzianem hipotezy H0 jest statystyka:
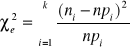
która przy założeniu prawdziwości hipotezy H0, ma rozkład ၣ2 o (k-s-1) stopniach swobody,
gdzie:
k- liczba klas
s -liczba parametrów które trzeba wstępnie obliczyć na podstawie próby
pi - prawdopodobieństwo, że cecha X przyjmie wartość z i-tego przedziału klasowego ( gdy rozkład cechy jest zgodny z hipotezą zerową)
npi- oznacza liczbę jednostek, które powinny się znaleźć w i-tym przedziale, przy założeniu, że cecha ma rozkład zgodny z rozkładem hipotetycznym.
Obliczoną (wg wzoru : 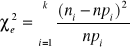
) statystykę χ2 należy porównać z wartością krytyczną ![]()
odczytaną z rozkładu chi-kwadrat, przy ustalonym poziomie istotności α i określonej liczbie stopni swobody. Obszar krytyczny w tym teście buduje się prawostronnie, tzn., aby spełniona była relacja:
![]()
Jeżeli zachodzi związek :
![]()
to hipotezę zerową należy odrzucić (różnica między rozkładem empirycznym a rozkładem hipotetycznym jest statystycznie istotna). W przeciwnym wypadku nie ma podstaw do jej odrzucenia.
Liczebność teoretyczną npi dla przypadku rozkładu normalnego znajdujemy obliczając najpierw wartość dystrybuanty tego rozkładu - z tym, że standaryzujemy prawe (górne) końce przedziałów klasowych. Jeśli xi1 - oznacza prawy (górny) koniec przedziału klasowego, to
![]()
Prawdopodobieństwo teoretyczne pi, że cecha X przyjmuje wartość z i-tego przedziału klasowego, obliczamy następująco:
![]()
![]()
dla i= 2,3,..., r-1
![]()
|
|
|
Miesięczna opłata |
Liczba gospodarstw domowych n |
Xi środek przedziału |
xi*n |
(xi-xsr)^2 * n |
n |
50 |
|
25-45 |
2 |
35 |
70 |
3010,88 |
alfa |
0,05 |
|
45-65 |
15 |
55 |
825 |
5301,6 |
1-alfa |
0,95 |
|
65-85 |
20 |
75 |
1500 |
28,8 |
alfa/2 |
0,025 |
|
85-105 |
10 |
95 |
950 |
4494,4 |
1-alfa/2 |
0,975 |
|
105-125 |
3 |
115 |
345 |
5092,32 |
m0 |
70 |
|
suma = |
50 |
|
3690 |
17928 |
Etap 1: Sformułowanie hipotezy zerowej H0 i hipotezy alternatywnej H1
![]()
Etap 2: Wybór statystyki sprawdzającej hipotezę zerowa H0
Etap 3 Ustalenie poziomów istotności alfa oraz określenie obszaru krytycznego
Etap 4: Obliczenie wartości krytycznej
=ROZKŁAD.NORMALNY.S.ODW(alfa/2) =ROZKŁAD.NORMALNY.S.ODW(1-alfa/2)
obszar krytyczny |
[1,64; +inf) |
![]()
Obliczenie wartości statystyki sprawdzającej U ze wzoru:
U= 1,419017264 |
Etap 5 Podjęcie decyzji weryfikującej
|
xi |
(xi - x śr)^2 |
1 |
3100 |
40000 |
2 |
2900 |
0 |
3 |
3100 |
40000 |
4 |
3200 |
90000 |
5 |
2600 |
90000 |
6 |
2800 |
10000 |
7 |
2700 |
40000 |
8 |
2700 |
40000 |
9 |
3000 |
10000 |
|
suma = |
360000 |
wariancja =WARIANCJA.POPUL(xi) =suma((xi - x śr)^2)/n
S - odchylenie =pierwiastek(wariancja)
T alfa =ROZKŁAD.T.ODW(prawdopodob. ;stopnie_sw)
obszar krytyczny (-inf; -1,39)
![]()
-1,41421
U alfa =ROZKŁAD.NORMALNY.S.ODW(1-alfa) 2,053749
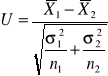
= 2,890098
obszar krytyczny [2,0537; +inf]
t alfa =ROZKŁAD.T.ODW(prawdopodob.; st_swobody(n1+n2-2)) 1,729133
obszar krytyczny (-inf; -1,729]u[1,279;+inf)
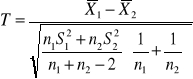
= -2,504
|
xi |
(xi - x śr)^2 |
1 |
2,06 |
0,613285 |
2 |
0,96 |
0,10041 |
3 |
1,41 |
0,017722 |
4 |
1,8 |
0,27366 |
5 |
1,54 |
0,069235 |
6 |
0,89 |
0,149672 |
7 |
0,6 |
0,45816 |
8 |
1,56 |
0,08016 |
9 |
1,13 |
0,021572 |
10 |
0,86 |
0,173785 |
11 |
1,52 |
0,05911 |
12 |
1,26 |
0,000285 |
13 |
1,31 |
0,001097 |
14 |
1,35 |
0,005347 |
15 |
0,7 |
0,332785 |
16 |
1,48 |
0,04126 |
|
suma = |
2,397544 |
![]()
= 0,159836
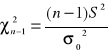
=ROZKŁAD.CHI.ODW(alfa/2;st_swobody(n-1))
=ROZKŁAD.CHI.ODW(1-alfa/2;st_swobody(n-1))
obszar krytyczny (0-7,26]U[25-+inf)
chi^2 |
26,64 |
![]()
= (n/(n-1))*s
F alfa =ROZKŁAD.F.ODW(alfa;n1-1;n2-1) = 1,718
obszar krytyczny [1,718;+inf)
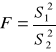
= 1,796
przedziały |
ni |
środek |
środek*ni |
(środek - średnia)^2*ni |
(100-300] |
50 |
200 |
10000 |
6480000 |
(300-500] |
100 |
400 |
40000 |
2560000 |
(500-700] |
150 |
600 |
90000 |
240000 |
(700-900] |
80 |
800 |
64000 |
4608000 |
(900-1100] |
20 |
1000 |
20000 |
3872000 |
![]()
chi^2 alfa =ROZKŁAD.CHI.ODW(alfa;k-s-1) = 5,991465
obszar krytyczny |
[5,99;+inf) |
średnia = suma(środek*ni)/n
s^2 =suma(środek - średnia)^2*ni)/n
s =pierwiastek(s^2)
nr klasy |
górna granica przedziału klas. xi |
ni |
ui=(xi-xsr)/s |
f(ui) =ROZKŁAD .NORMALNY.S(ui) |
pi(ui) pi2=ui2-ui1 itp. |
n*pi |
1 |
300 |
50 |
-1,23390539 |
0,10861908 |
0,108619 |
43,44763 |
2 |
500 |
100 |
-0,2847474 |
0,387918837 |
0,2793 |
111,7199 |
3 |
700 |
150 |
0,664410597 |
0,746786224 |
0,358867 |
143,547 |
4 |
900 |
80 |
1,613568593 |
0,946689483 |
0,199903 |
79,9613 |
5 |
1100 |
20 |
2,562726589 |
0,99480731 |
0,053311 |
21,32421 |
|
|
400 |
|
1 |
1 |
|
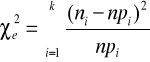
=2,589978
![]()
![]()
![]()
![]()
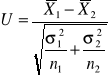
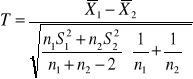
![]()
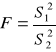
![]()
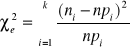
Wyszukiwarka
Podobne podstrony:
laboratorium 9 i 10, Metody probabilistyczne i statystyka
pytania 27-30, ZUT, III Semestr, Metody probabilistyczne i statystyka
Statystyka wykład 7n, Studia INF 1F, Metody probabilistyczne i statystyka
GrupaA, ZUT, III Semestr, Metody probabilistyczne i statystyka
Zmienna losowa typu ciaglego, ZUT, III Semestr, Metody probabilistyczne i statystyka
Probabilistyka - teoria v.0.1, Archiwum, Metody probabilistyczne i statystyka
MPiS wzory, WI ZUT studia, Metody probabilistyczne i statystyka, od kolesia
Metody probabilistyczne i statystyka program
05 Metody Probabilistyczno Statystyczne 25 06 2007id 5752 ppt
GrupaB, ZUT, III Semestr, Metody probabilistyczne i statystyka
Test z odp, ZUT, III Semestr, Metody probabilistyczne i statystyka
Metody probabilistyczne i statystyka
Metody probabilistyczne
metody probablistyczne definicje TVQHLC5TC7JG4EOHQ2LLLL4EDLRIVLTY3DTA2II
Metody probabilistyczne4
Metody probabilistyczne1
Metody Probabilistyczne Koło 1
więcej podobnych podstron