
A
RCHITEKTURY
S
YSTEMÓW
K
OMPUTEROWYCH
Z
AGADNIENIA
NA
E
GZAMIN
I A
RYTMETYKA
K
OMPUTERÓW
1.
Metody reprezentacji liczb całkowitych.
a)
w zapisie znak-moduł, własności reprezentacji
Metody reprezentacji:
W tej reprezentacji daną liczbę możemy zapisać według wag systemu binarnego na N-1 bitach.
Najstarszy bit (nazywany BITEM ZNAKU), służy jedynie do określenia czy liczba jest nieujemna
(ustawiony na „0”) albo niedodatnia (ustawiony na „1”). W związku z tym występują dwie
reprezentacje zera: +0 (00000000
ZM
) i -0 (10000000
ZM
).
Jednocześnie wpływa to na zakres liczb jaki można przedstawić używając kodowania ZM na n
bitach:
Dla 8 bitów (1 bajt) są to liczby od -127 do 127.
Własności:
–
liczbę przeciwną tworzymy za pomocą negacji najstarszego bitu (bitu znaku)
–
są dwie reprezentacje zera
Przykłady:
Zapis liczby -13 na 8 bitach:
bit
B
7
B
6
B
5
B
4
B
3
B
2
B
1
B
0
wartość
1
0
0
0
1
1
0
1
waga
+/-
2
6
2
5
2
4
2
3
2
2
2
1
2
0
1
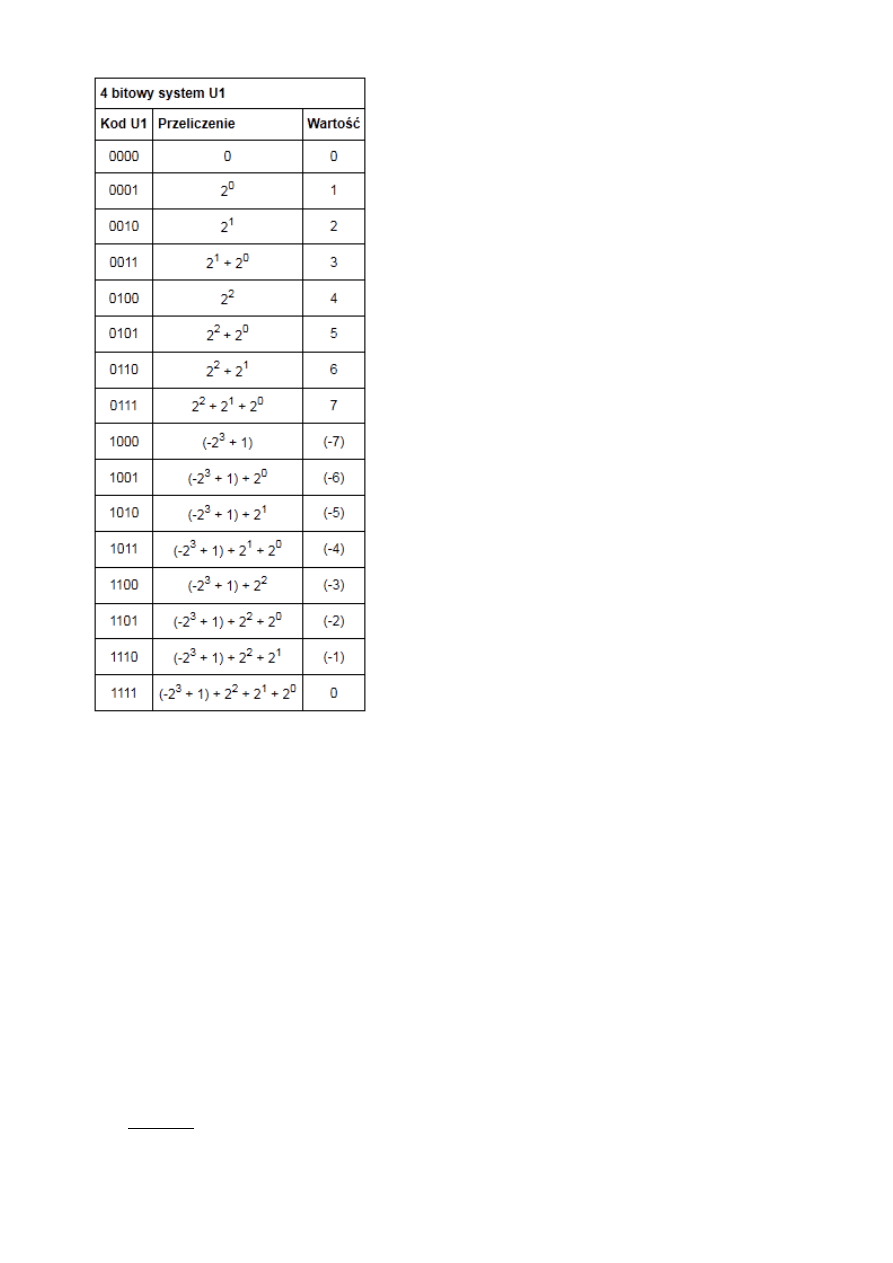
b)
w zapisie uzupełnień do 1, własności reprezentacji
W systemie U1 wszystkie bity zapisu liczby posiadają
swoje wagi. Najstarszy bit jest bitem znaku i ma wagę
równą (-2
n-1
+1), gdzie n oznacza ilość bitów w zapisie
liczby. Pozostałe bity posiadają wagi takie jak w
Bit znaku przyjmuje wartość 0 dla liczb dodatnich, a
dla liczb ujemnych wartość 1 (ponieważ tylko waga tej
pozycji jest ujemna, to jest to jedyny sposób na
otrzymanie wartości ujemnej).
Cechą charakterystyczną kodu U1 jest to, że liczbę
przeciwną do danej tworzy poprzez negację wszystkich
bitów.
c)
w zapisie uzupełnień do 2, własności reprezentacji
Obliczanie U2:
Cyfry mnożymy przez wagi pozycji, na których się znajdują. Waga bitu znakowego jest
ujemna. Sumujemy iloczyny.
b
n−1
b
n−2
⋯
b
1
b
0
U2
=
∑
i=0
n−2
b
i
⋅
2
i
−
b
n−1
2
n−1
, gdzie
b∈{0 , 1} - bit,
n - liczba bitów przechowywanej liczby
Zakres U2:
x
U2
∈[−
2
n−1
, 2
n−1
−
1]
dla liczby zapisanej na n bitach.
Algorytm znajdowania uzupełnienia do U2:
Sposób 1:
Zaneguj wszystkie bity i dodaj 1 (gdyż ujemnych liczb jest o 1 więcej).
2
Sposób 2:
1. Zacznij od pierwszego prawego bitu.
2. Przepisuj wartości bitów 0, aż natkniesz się na bit 1.
3. Ten bit też przepisz jako 1.
4. Pozostałe bity przepisz zanegowane.
np. (szare bity to te, które nie zostały zanegowane)
x
U2
: 1 1 0 1 0 0 0 0
bit nr: 7 6 5 4 3 2 1 0
−
x
U2
: 0 0 1 1 0 0 0 0
Własności:
•
Dokładnie jedna reprezentacja 0
10
: 00000000
U2
(dla 8-bitowych liczb).
•
Zakres dla 8-bitowych liczb wynosi [−2
7
, 2
7
−
1]=[−128,127]
.
•
Najstarszy bit (MSB) traktowany jako bit znaku (0- liczba dodatnia, 1- ujemna).
2.
Dodawanie liczb całkowitych.
a)
dodawanie liczb całkowitych w zapisach: U1, U2, Z-M
Z-M:
W dodawaniu w tym systemie biorą udział tylko moduły liczb, bit odpowiedzialny za
znak (MSB) nie jest brany pod uwagę w dodawaniu. Pełni on specjalną funkcję: przy
dodawaniu jednej liczby dodatniej (0 na ostatnim miejscu) i jednej ujemnej (1 na
ostatnim miejscu) wynik ma znak zależny od większego modułu, wtedy zamiast
dodawania wykonujemy odejmowanie modułu mniejszego od modułu większego.
Kiedy obie liczby są dodatnie wynik jest dodatni, natomiast kiedy obie ujemne wynik
jest ujemny, w obu tych przypadkach wykonujemy zwykłe dodawanie modułów
(wykonywane jest tak jak zwyczajne dodawanie na liczbach binarnych).
Przykłady:
3 + 2
0
0 1 1
+
0
0 1 0
0
1 0 1
5
(-3) + (-2)
1
0 1 1
+
1
0 1 0
1 1 0 1
(-5)
4 + (-6)
1
1 1 0
-
0
1 0 0
1
0 1 0
(-2)
5 + (-3)
0
1 0 1
-
1
0 1 1
0
0 1 0
2
U1:
Dodawanie liczb U1 odbywa się zgodnie z zasadami dodawania liczb binarnych. Jeśli
występuje jednak przeniesienie poza bit znaku, nie można go po prostu przepisać na
początek nowej liczby, tylko trzeba dodać tą jedynkę do nowej liczby.
Przykłady:
3
3 + 2
1
0 0 1 1
+ 0 0 1 0
0 1 0 1
5
3 + (-5)
1
0
0 1 1
+
1
0 1 0
1
1 0 1
(-2)
2 + (-1)
1
1
1
0
0 1 0
+
1
1 1 0
0
0 0 0
+ 0 0 0 1
0
0 0 1
1
(-1) + (-1)
1
1
1
1
1 1 0
+
1
1 1 0
1
1 0 0
+ 0 0 0 1
1
1 0 1
(-2)
U2:
Dodawanie i odejmowanie w systemie U2 jest najprostsze ze wszystkich ponieważ
wykonuje się je identycznie jak zwyczajne dodawanie i odejmowanie na liczbach
binarnych. Przeniesienie w tym przypadku zarówno przy dodawaniu jak i odejmowaniu
ignorujemy.
Przykłady:
3 + 3
0 0 1 1
+ 0 0 1 1
0 1 1 0
6
5 + (-4)
0 1 0 1
+ 1 1 0 0
1
0 0 0 1
1
5 – 4
0 1 0 1
- 0 1 0 0
0 0 0 1
1
(-2) - 3
1 1 1 0
- 0 0 1 1
1 0 1 1
(-5)
b)
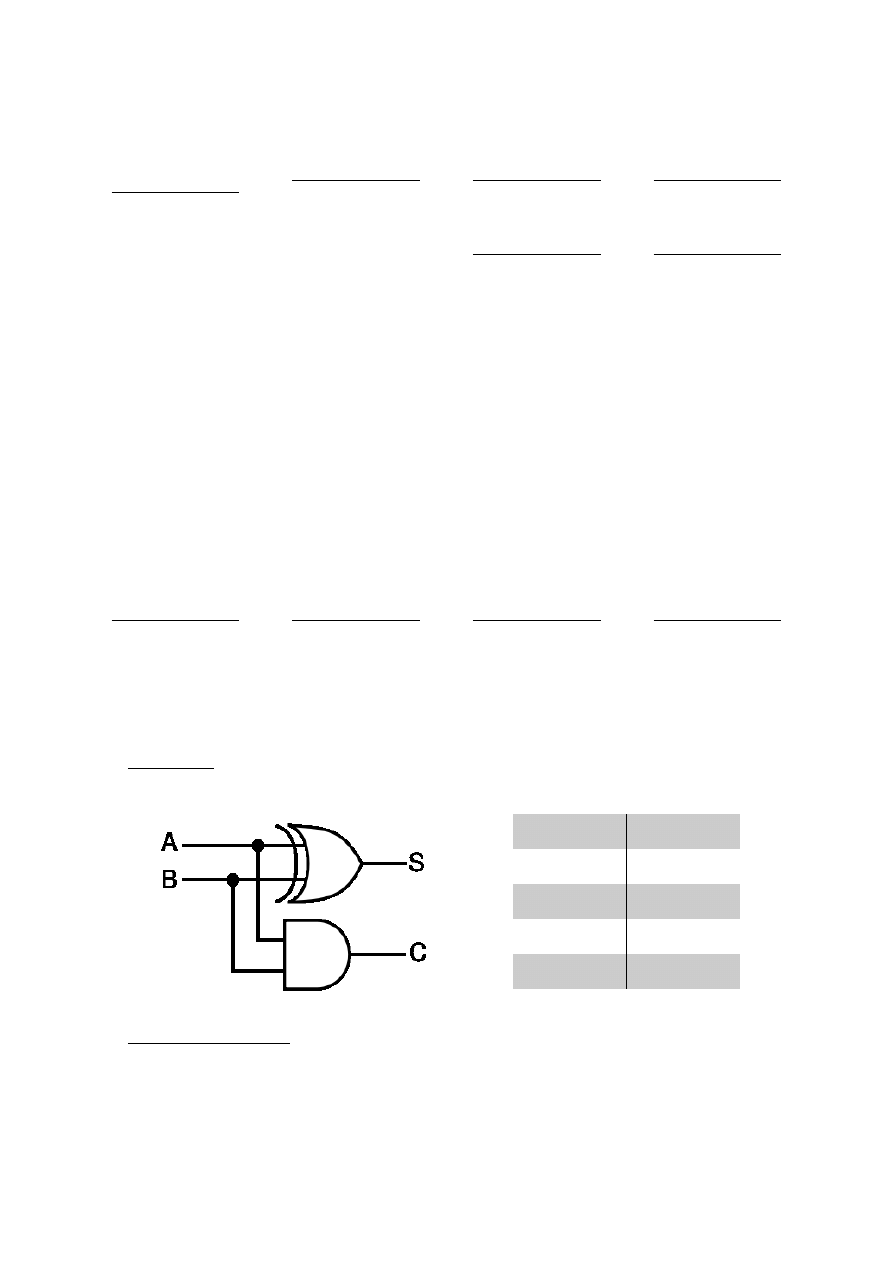
układ półsumatora, układ sumatora – budowa i zasada działania
Półsumator:
Dodawanie cyfr realizowane jak w przypadku liczb dziesiętnych (suma i przeniesienie):
A
B
Carry
Sum
0
0
0
0
0
1
0
1
1
0
0
1
1
1
1
0
Sumator jednobitowy:
4
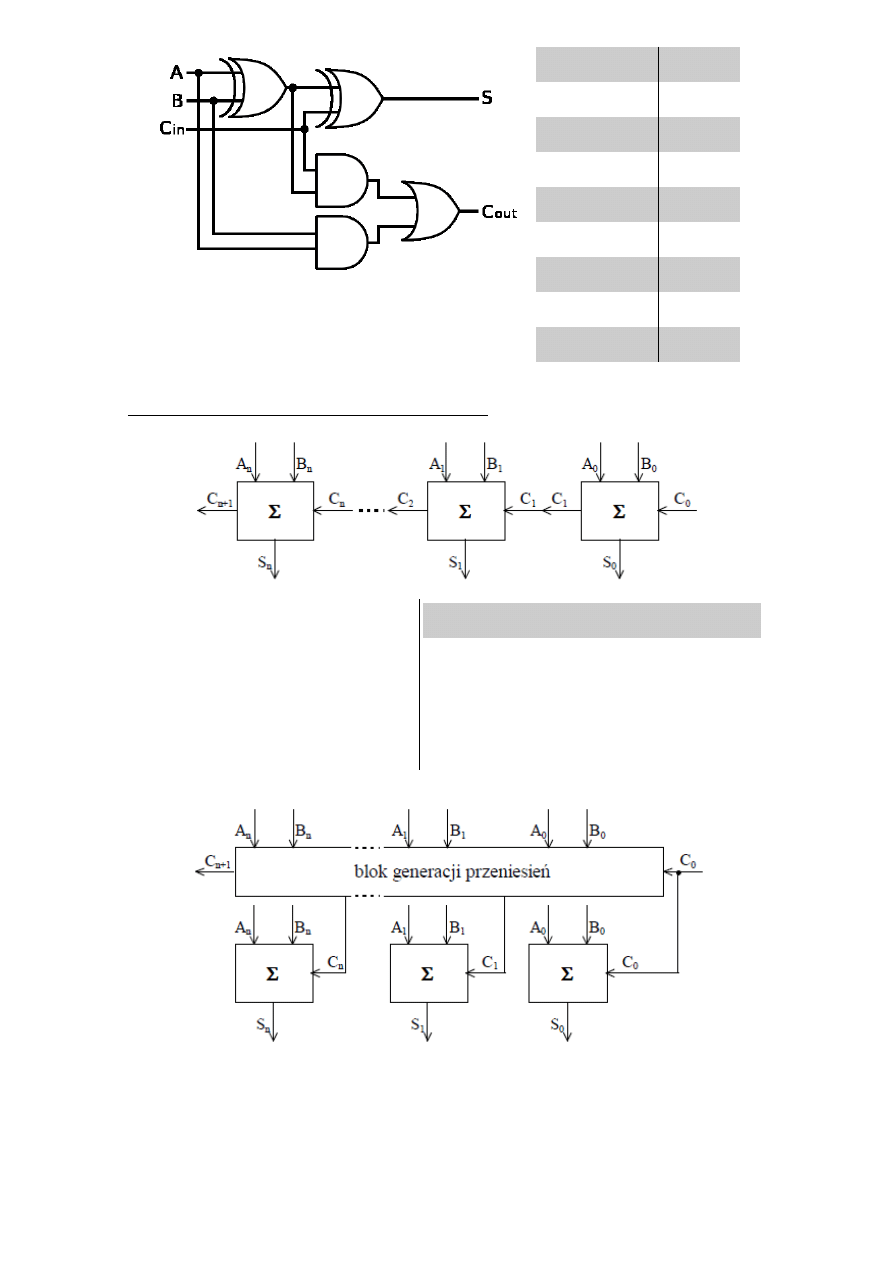
A
B
C
in
C
out
S
0
0
0
0
0
0
0
1
0
1
0
1
0
0
1
0
1
1
1
1
1
0
0
0
1
1
0
1
1
0
1
1
0
1
0
1
1
1
1
1
Sumator n-bitowy z przeniesieniem szeregowym:
•
- sumatory pełne.
•
Połączone są kaskadowo.
•
Przeniesienie przekazywane kaskadowo.
•
Bit ostatniej sumy wyznaczony
po wyliczeniu wszystkich przeniesień.
Zalety
Wady
•
Prostota.
•
Możliwość łatwego
rozszerzenia liczby
bitów.
•
Mała szybkość
działania.
Sumator n-bitowy z przeniesieniem równoległym:
5
•
Przeniesienie generowane jest przez blok
generacji przeniesień.
•
Gdy tylko wartość przeniesienia zostanie
wygenerowana, wszystkie bloki
mogą zwrócić wartość bez oczekiwania na
poprzednie.
•
C
0
=
const
.
Zalety
Wady
•
Szybkość
działania.
•
Skomplikowany układ.
•
Nie jest tak łatwo
rozszerzalny,
jak szeregowy.
•
Zmiana liczby bitów
wymaga modyfikacji
bloku generacji
przeniesień.
Ogólnie:
•
Sumator n-bitowy - układ kombinacyjny przyjmujący na wejście składniki n-
bitowe A, B, oraz 1-bitowe przeniesienie C
0
, a zwracający n-bitową
sumę S i przeniesienie C
n
.
•
Wejścia i wyjścia to liczby całkowite w naturalnym kodzie binarnym lub U2.
•
Sumatory n-bitowe również mogą być łączone ze sobą (szeregowo bądź
równolegle).
3.
Algorytmy mnożenia liczb binarnych.
a)
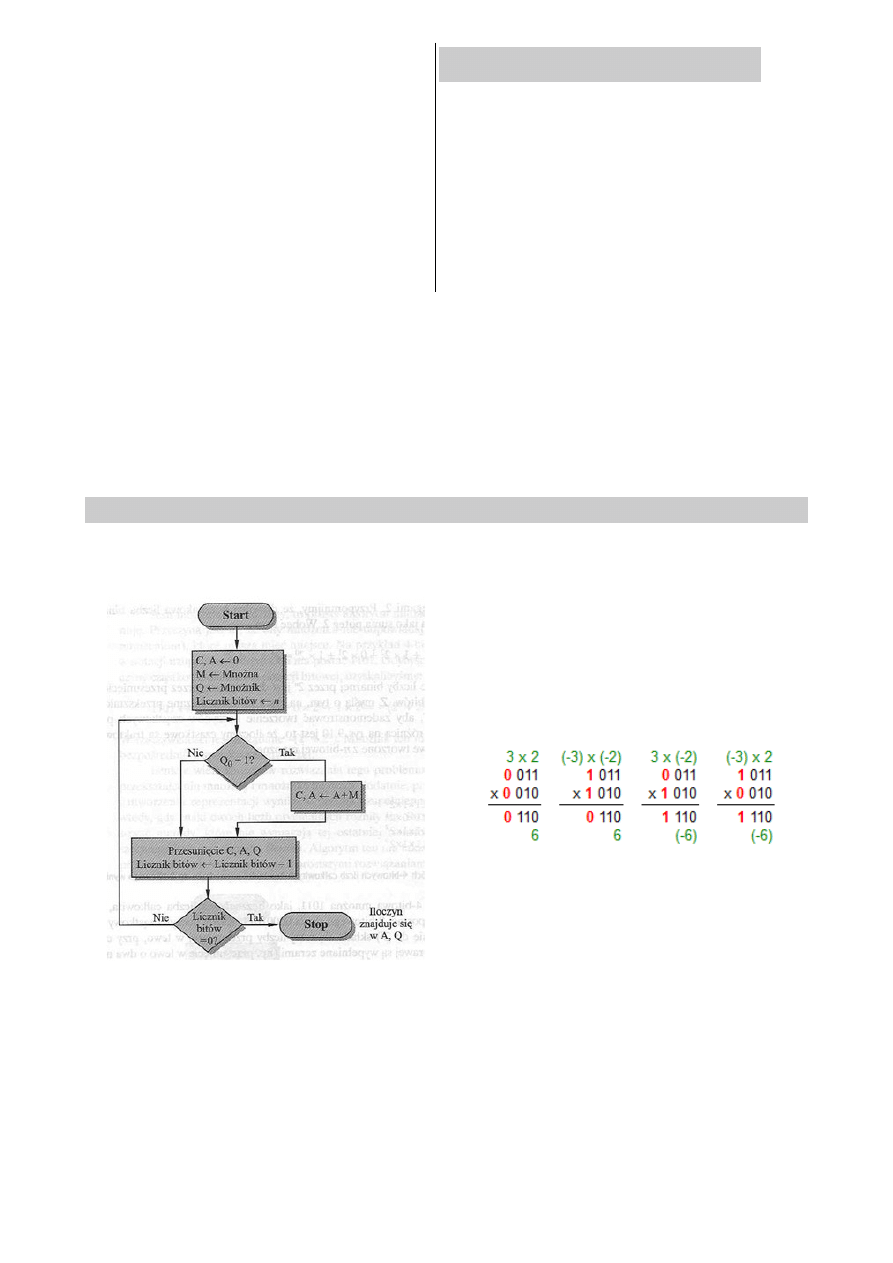
algorytm mnożenia liczb w zapisie Z-M., schemat blokowy, zasada działania
Mnożenie BEZ znaku.
Mnożenie liczb ze znakiem
Wynik mnożenia dwóch liczb a i b w systemie
ZM wygląda następująco:
znak: 0 jeśli znaki mnożników są takie same; 1
jeśli są różne.
liczba: mnożymy pisemnie, z zachowaniem
normalnych zasad mnożenia:
6
b)
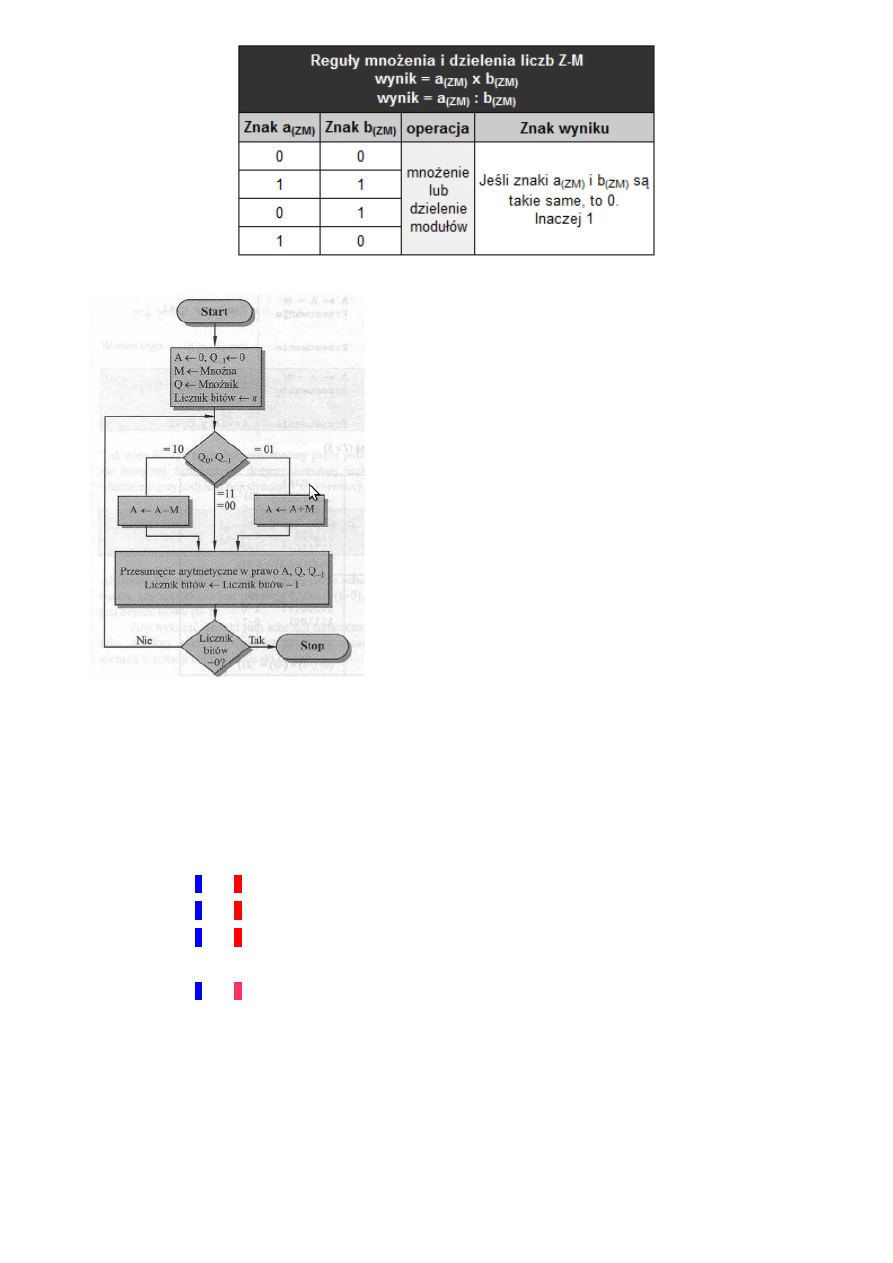
algorytm Bootha mnożenie liczb w zapisie U2, schemat blokowy zasada działania
Zasada działania:
Umieszczamy mnożną i mnożnik odpowiednio w
rejestrach M i Q. Dodatkowo wprowadzamy rejestry A i
jednobitowy rejestr Q
-1
, którym początkowo ustawiamy
wartości 0. W rejestrze Q
-1
będziemy zapisywać najmłodszy
bit z Q po przesunięciu. Musimy również wiedzieć, ile
zajmuje nasza liczba w bitach, bądź ilu bitowe są rejestry w
których przechowujemy liczby.
Przeglądamy mnożnik Q bit po bicie. Dodatkowo
bierzemy bit leżący po prawej stronie badanego bitu i
sprawdzamy czy oba bity są różne od siebie. Jeśli mamy
kombinację 10, to rejestrowi A przypisujemy A-M. Jeśli
mamy kombinację 01, to rejestrowi A przypisujemy A+M.
Natomiast w przypadku, gdy oba bity są jednakowe (00 lub
11) nic nie robimy. Następnie przesuwamy arytmetycznie
(z zachowaniem znaku, czyli najstarszy bit zostaje
przesunięty i zarazem zostaje na swoim miejscu np. 1101
>> 1110) w prawo rejestry A, Q, Q
-1
i dekrementujemy
licznik bitów. Powyższe czynności powtarzamy, aż licznik
bitów będzie równy 0. Wynik mnożenia jest zapisany w
rejestrach A i Q.
Przykład:
3∗4
(
10)
=
12
(
10 )
=
0011∗0100
(
2 )
=
00001100
(
2)
A
Q
Q
-1
M
0000
010
0
0
0011
N = 3
stan początkowy
0000
001
0
0
0011
N = 3
>>
0000
000
1
0
0011
N = 2
>>
1101
0001
0
0011
N = 1
A <- A - M
1110
100
0
1
0011
N = 1
>>
0001
1000
1
0011
N = 0
A <- A + M
0000
1100
0
0011
N = 0
>>
7

4.
Reprezentacja zmiennoprzecinkowa liczb rzeczywistych.
a)
budowa liczby zmiennoprzecinkowej oraz wpływ poszczególnych elementów liczby na
zakres i dokładność danej reprezentacji zmiennoprzecinkowej
Standard IEE754 reprezentacji liczb zmiennoprzecinkowych:
Standard stosowany w dzisiejszych czasach.
Mówi, że każdą liczbę x≠0 można zapisać w postaci: x=s⋅m⋅B
c
, gdzie:
•
s∈{−1 , 1} – znak
•
m∈〈1, 2 – mantysa
•
c – cecha należąca do liczb całkowitych.
•
B – podstawa (w przypadku komputerów jest to 2 ).
Jednakże na komputerze nie jesteśmy w stanie przeznaczyć nieskończenie wiele
pamięci do precyzyjnego zapisu liczby zmiennoprzecinkowej. Jako, że nasze możliwości
są ograniczone, a zbiór liczb rzeczywistych jest zbiorem gęstym (pomiędzy każdą parą
liczb różnych od siebie istnieje nieskończenie wiele liczb) jesteśmy zmuszeni trochę
oszukiwać.
Tak naprawdę na komputerze nie jest przechowywana ani cała cecha, ani cała mantysa.
Realistyczny sposób przechowywania wygląda tak: rd x =−1
e
1
f
z−b
, gdzie
•
z−b - cecha.
•
e∈{−1,1}
•
1
f - mantysa
W pamięci komputera przechowywane jest jedynie f oraz z . Jedynka i bias
(oznaczony przez b ) są niejako 'dokładane' przez komputer w trakcie obliczeń itp.
Oczywiście generuje to niedokładności. Liczby możemy zapisać więc w pewnym
ograniczonym zakresie i z ograniczoną dokładnością.
Za zakres odpowiada cecha (zapisana w kodzie z nadmiarem). Za precyzję mantysa.
Jako, że chcielibyśmy móc swobodnie operować zakresem liczby tak na lewo jak i na
prawo cecha zapisana jest w kodzie z nadmiarem. Jeśli więc bias=127 , a
cecha=12 , to jej wartość wykorzystana przez komputer będzie równa
12−127=−115
. Pozwoli to na przesunięcie przecinka o 115 miejsc w lewo.
Bity przeznaczone na cechę mają szczególne znaczenie, jeśli wszystkie bity są zerami lub
jedynkami, co zostanie pokazane później. Stąd:
Maksymalna wartość 4-bitowej cechy:
1110 // a nie 1111 gdyż wszystkie bity ustawione na 1 mają specjalną wartość
Minimalna wartość 4-bitowej cechy:
0001 // a nie 0000 gdyż wszystkie bity ustawione na 0 mają specjalną wartość.
Wartości specjalne:
8
•
0 – bity cechy i mantysy są równe zero.
•
liczba zdenromalizowana – liczba przy której komputer
nie doda automatycznie jedynki do f. Bity cechy są zerami. Mantysa niezerowa.
•
INF (nieskończoność) – bity cechy to same jedynki. Bity mantysy same zera.
•
NaN (nieliczba) – bity cechy to same jedynki.
Bity mantysy zawierają jakiś bit ustawiony na 1.
Standard IEE754 dla formatu zapisu zmiennoprzecinkowego:
32 bity:
1 bit
8 bitów
23 bity
znak
cecha
mantysa
// bias = 127
64 bity:
1 bit
11 bitów
52 bity
znak
cecha
mantysa
// bias = 1023
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
zn
ak
cecha - 8 b
mantysa - 23 b
0
1 2 3 4 5 6 7 8 9 1
0
1
1
1
2
1
3
1
4
1
5
1
6
1
7
1
8
1
9
2
0
2
1
2
2
2
3
2
4
2
5
2
6
2
7
2
8
2
9
3
0
3
1
3
2
3
3
3
4
3
5
3
6
3
7
3
8
3
9
4
0
4
1
4
2
4
3
4
4
4
5
4
6
4
7
4
8
4
9
5
0
5
1
5
2
5
3
5
4
5
5
5
6
5
7
5
8
5
9
6
0
6
1
6
2
6
3
zn
ak
cecha - 11 b
mantysa - 52 b
// Gdyby nadal coś było niejasnego (mam nadzieję, że nie) to zapraszam na:
// http://edu.i-lo.tarnow.pl/inf/alg/006_bin/0022.php
b)
zakres reprezentacji
[−
x
max
,−x
min
]∪{
0}[
x
min
, x
max
]
Zgodnie ze standardem IEE754 dla formatu zapisu zmiennoprzecinkowego:
•
pojedynczej precyzji [−3.4⋅10
38
,3.4⋅10
38
]
•
podwójnej precyzji [−1.8⋅10
308
, 1.8⋅10
308
]
Niedomiar:
∣
x∣B
E
min
traktowana jest jako niedomiar (underflow).
Nadmiar:
∣
x∣M
max
⋅
B
E
max
traktowana jest jako nadmiar wykładniczy (overflow).
c)
dokładność reprezentacji
Zarówno dla mantysy jak i wykładnika ilość cyfr jest z góry ustalona. Zatem dana liczba jest
reprezentowana z pewną skończoną dokładnością i należy do skończonego zbioru wartości.
Załóżmy, że m to liczba cyfr przeznaczonych na mantysę, natomiast n1 to liczba cyfr
9

przeznaczonych na wykładnik ( n cyfr dla wartości i 1 dla znaku wykładnika). Uznaje się
również, że jedna dodatkowa pozycja (najstarsza) zarezerwowana jest dla zapisu znaku całej liczby.
Wówczas wartości maksymalne i minimalne dla M i E określone są następująco:
Wykładnik E:
•
E
min
=
− B1
•
E
max
=
B− 1
Mantysa M:
•
M
min
=
1
•
M
max
=
B − B // aby napewno? nie przypadkiem : M
max
=
B − B
−
m−1
?
Stąd najmniejsza i największa liczba dodatnia możliwa do zapisania w takiej reprezentacji to:
•
x
min
=
M
min
⋅
B
E
min
=
1⋅
B
E
min
•
x
max
=
M
max
⋅
B
E
max
=
B−B
−
m−1
⋅
B
E
max
B
E
max
1
Błąd:
Błąd względny reprezentacji wynosi
1
B
m−1
(inaczej: waga najmniej znaczącej cyfry mantysy).
Błędów bezwzględnych na ogół się nie podaje.
Błąd reprezentacji liczb zmiennoprzecinkowych.
d)
budowa binarnej liczby zmiennoprzecinkowej
Liczba zmiennoprzecinkowa jest komputerową reprezentacją liczb rzeczywistych
zapisanych w postaci wykładniczej (zwanej również notacja naukową).
Ze względu na wygodę operowania na takich liczbach przyjmuje się ograniczony zakres
na mantysę i cechę. Ogranicza to precyzję i zakres liczby.
Wartość liczby jest określana wg wzoru x=S⋅M⋅B
E
, gdzie:
•
S - znak liczby 1 lub -1 ,
•
M - znormalizowana mantysa, liczba ułamkowa,
•
B - podstawa systemu liczbowego (2 dla systemów komputerowych),
•
E - wykładnik, liczba całkowita.
W celu uproszczenia operacji na liczbach zmiennopozycyjnych wymagane jest zwykle, aby były
one znormalizowane. Liczbą znormalizowaną jest taka liczba, w której najbardziej znacząca
cyfra mantysy jest różna od zera (ta po lewej stronie), zatem
M∈〈1 , 2
. Znormalizowana
liczba niezerowa ma postać:
±
1,
bbb⋯b×2±E , gdzie:
•
b – dowolna cyfra binarna (0 lub 1),
10
•
E – wykładnik.
Dzięki temu możemy np. przechowywać 24-bitową mantysę na polu 23-bitowym. .
e)
własności podstawowych operacji arytmetycznych na liczbach zmiennoprzecinkowych
(dodawanie, odejmowanie, mnożenie, dzielenie)
Arytmetyka zmiennoprzecinkowa nie jest łączna.
To znaczy że dla z , y , z mogą zachodzić różności:
x y z≠x yz
x⋅y ⋅z≠x⋅ y⋅z
•
Kolejność wykonywania działań wpływa na końcowy wynik
Inne problemz przy wykonywaniu obliczeń zmiennoprzecinkowych:
•
Zaokrąglenia
•
Nieprawidłowe operacje
•
Przepełnienie
•
Niedomiar
Sposób wykonywania operacji
dodawanie i odejmowanie
mnożenie i dzielenie
mamy dwie liczby:
x
1
=
M
1
⋅
B
E
1
x
2
=
M
2
⋅
B
E
2
oraz x
1
x
2
wówczas:
x
1
±
x
2
=
M
1
±
M
2
⋅
B
E
2
−
E
1
⋅
B
E
1
mamy dwie liczby:
x
1
=
S
1
⋅
M
1
⋅
B
E
1
x
2
=
S
2
⋅
M
2
⋅
B
E
2
wówczas:
x
1
⋅
x
2
=
S
1
⋅
S
2
⋅
M
1
⋅
M
2
⋅
B
E
1
E
2
x
1
/
x
2
=
S
1
⋅
S
2
⋅
M
1
/
M
2
⋅
B
E
1
E
2
5.
Reprezentacja stałoprzecinkowa liczb rzeczywistych – zakres reprezentacji oraz
własności reprezentacji stałoprzecinkowej.
Do zapisu liczby stałoprzecinkowej przeznaczona jest z góry określona ilość cyfr dwójkowych
(bitów), a pozycję przecinka ustala się arbitralnie, w zależności od wymaganej dokładności.
Podziału na część całkowitą i ułamkową dokonuje arbitralnie projektant systemu lub programista.
Np.: mając do dyspozycji słowo 32-bitowe, można wydzielić 24 bity na część całkowitą, 8 bitów
na część ułamkową, albo po 16 bitów na część całkowitą i ułamkową, albo 30 bitów na część
całkowitą i zostawić tylko 2 bity do zapisu części ułamkowej.
Wartość liczby stałoprzecinkowej jest określana tak jak w pozycyjnym systemie liczbowym.
Wagi bitów części całkowitej mają wartości (kolejno, od najbardziej znaczącego bitu):
2
k−1
2
0
,
Wagi bitów części ułamkowej mają wartości:
2
−
1
2
−
n
.
Dokładność reprezentacji wynosi 2
− n
, czyli jest równa wadze najmniej znaczącego bitu
części ułamkowej.
11

Przykład: Jeśli na część całkowitą zostaną przeznaczone 4 bity
k=4 , natomiast na część
ułamkową 2 bity
n=2 , wówczas:
•
wartość maksymalna:
1111
,
11
2
=
2
3
+ 2
2
+ 2
1
+ 2
0
+
2
-1
+ 2
-2
=
15
,
75
10
•
wartość minimalna:
0000
,
01
2
=
2
-2
=
0
,
25
10
•
przykładowa liczba:
1011
,
10
2
=
2
3
+ 2
1
+ 2
0
+
2
-1
=
11
,
5
10
Działania całkowitoliczbowe:
Jeśli obliczyć wartość liczby stałoprzecinkowej
x w naturalnym kodzie dwójkowym, wartość
ta wyniesie
x2
n
. Wówczas działania całkowitoliczbowe mają postać:
•
Dodawanie/odejmowanie:
a 2
n
±
b 2
n
=
a±b2
n
- wynik nie wymaga korekty, jest to
zapis stałoprzecinkowy z założoną dokładnością.
•
Mnożenie:
a2
n
⋅
b2
n
=
a⋅b⋅2
2n
- wynik wymaga korekty, należy podzielić go przez
2n , aby uzyskać postać
x2
n
.
•
Dzielenie całkowitoliczbowe. W tym przypadku dzielną a należy przemnożyć przez
czynnik 2
n
przed wykonaniem dzielenia i wówczas:
a2
n
⋅
2
n
b 2
n
=
a
b
⋅
2
n
.
Mnożenie i dzielenie przez potęgę dwójki, w tym przypadku 2
n
, jest równoważne
przesunięciu bitowemu (odpowiednio) w lewo bądź prawo o
n bitów; jest to operacja bardzo
szybka.
6.
Logarytmiczna reprezentacja liczb rzeczywistych, własności oraz:
a)
operacje arytmetyczne w systemach logarytmicznych
Logarytmiczna reprezentacja może być traktowana jako specyficzny przypadek reprezentacji
zmiennoprzecinkowej liczb rzeczywistych, kiedy to mantysa jest zawsze równa 1 a wykładnik
posiada część ułamkową (podstawa oczywiście wynosi 2 ):
A=−1
S
A
⋅
2
E
A
,
gdzie
S
A
- bit znaku,
E
A
jest stałą wartością liczbową.
Jeśli E
A
0 , to reprezentowana liczba jest mniejsza od 1. Dzięki temu reprezentacja
logarytmiczna pozwala na zapisanie zarówno bardzo dużych jak i małych liczb.
Format liczby w reprezentacji logarytmicznej:
2
bity
1
bit
część całkowita -
K
bitów wykładnika
część ułamkowa -
L
bitów wykładnika
flagi
znak -
S
A
wykładnik liczby
12

Zakres (bardzo podobny do zakresu w reprezentacji zmiennoprzecinkowej):
Pojedyńcza precyzja:
Dla K=8 i L=23 :
± 2
−
129
ulp
do 2
128−
ulp
≈ 1.5×10
−
39
do 3.4 × 10
38
(gdzie ulp to jednostki najmniejszej precyzji).
Podwójna precyzja:
Dla K=11 i L=52 :
± 2
−
1025
ulp
do 2
1024−
ulp
≈ 2.8×10
−
309
do 1.8 ×10
308
.
Bity flagi służą do reprezentacji takich wartości jak 0, NaN, +INF, -INF
Operacje arytmetyczne w systemach logarytmicznych:
Mnożenie:
Mnożenie 2 liczb w systemie logarytmicznych jest prosto realizowane.
Polega na zwyczajnym dodaniu 2 logarytmów do siebie.
log
2
x⋅y=log
2
xlog
2
y
Flagi dalej odpowiadają za specjalne wartości i ich ustawienie automatycznie zmienia liczbę na
daną wartość. Jeśli wystąpi przekroczenie zakresu liczba automatycznie staje się +INF bądź -INF
Dzielenie:
Dzielenie 2 liczb jest równie proste jak mnożenie.
Polega na odjęciu od siebie logarytmów:
log
2
x
y
=
log
2
x −log
2
y
Tutaj może wystąpić niedomiar i wtedy wynik automatycznie staję się 0 .
Dodawanie i odejmowanie:
Bardziej skomplikowane, niż w reprezentacj floating point.
Realizowane za pomocą algorytmu:
Mamy 2 liczby: A=−1
S
A
⋅
2
E
A
, B=−1
S
B
⋅
2
E
B
. Chcemy policzyć liczbę C=A±B :
Znak liczymy jako: S
C
=
S
A
Wykładnik liczymy jako:
E
C
=
log
2
∣
A±B∣
E
C
=
log
2
∣
A⋅1±
B
A
∣
E
C
=
log
2
∣
A∣log
2
∣
1±
B
A
∣
E
C
=
E
A
f E
B
−
E
A
,
gdzie
f E
B
−
E
A
=
log
2
∣
A∣log
2
∣
1±
B
A
∣=
log
2
∣
1±2
E
B
−
E
A
∣
13

W skrócie: E
C
=
E
A
log∣1±2
E
B
−
E
A
∣
,
S
C
=
S
A
b)
zamiana reprezentacji zmiennoprzecinkowej na reprezentacje logarytmiczną
−
1
S
⋅
M⋅2
E
= −
1
S
⋅
M⋅2
F
⋅
2
E
= −
1
S
⋅
2
FE
Trzeba znaleźć F=log
2
M .
1. Przeszukaj tabelę logarytmów;
2. Wylicz przybliżony logarytm:
•
X
FP
=
z
u
z
u−1
z
0
z
−
v
- liczba binarna
•
z
t
- najstarszy niezerowy bit.
Wtedy X
FP
=
2
t
∑
i=−v
t−1
2
i
z
i
=
2
t
1
∑
i=−v
t−1
2
i−1
⋅
z
i
X
FP
=
2
t
1
x ,
x
LSN
∈〈
0
, 1
•
log
2
X
FP
=
tlog
2
1
x , gdzie
t -charakterystyka logarytmu,
log
2
1
x -mantysa.
Z szeregu tylora f x=
∑
k=0
∞
x
k
k!
f
k
0
,
•
f x=log
2
1
x , f 0=0
•
f ' x =log
2
e
1
1
x
, f ' 0=log
2
e
•
f ' ' x =log
2
e
−
1
1
x
2
, f ' ' x =log
2
−
e
Zatem f x=0x log
2
e−
x
2
fract
2 log
2
e
// do weryfikacji
7.
Budowa i zasada działania:
a)
jednostki arytmetyczno-logicznej procesora
ALU - połączenie układów: logicznego i arytmetycznego. Jest układem cyfrowym.
Służący do wykonywania operacji:
•
arytmetycznych (np. dodawanie, odejmowanie);
•
logicznych (np. Ex-Or) pomiędzy dwiema liczbami;
•
jednoargumentowych (np. przesunięcie bitów, negacja)
ALU jest podstawowym blokiem centralnej jednostki obliczeniowej komputera.
Wszystkie inne elementy systemu komputerowego (jednostka sterująca, rejestry, pamięć, I/O)
istnieją głównie po to, żeby dostarczać dane do ALU w celu ich przetworzenia i odbierać wyniki.
14
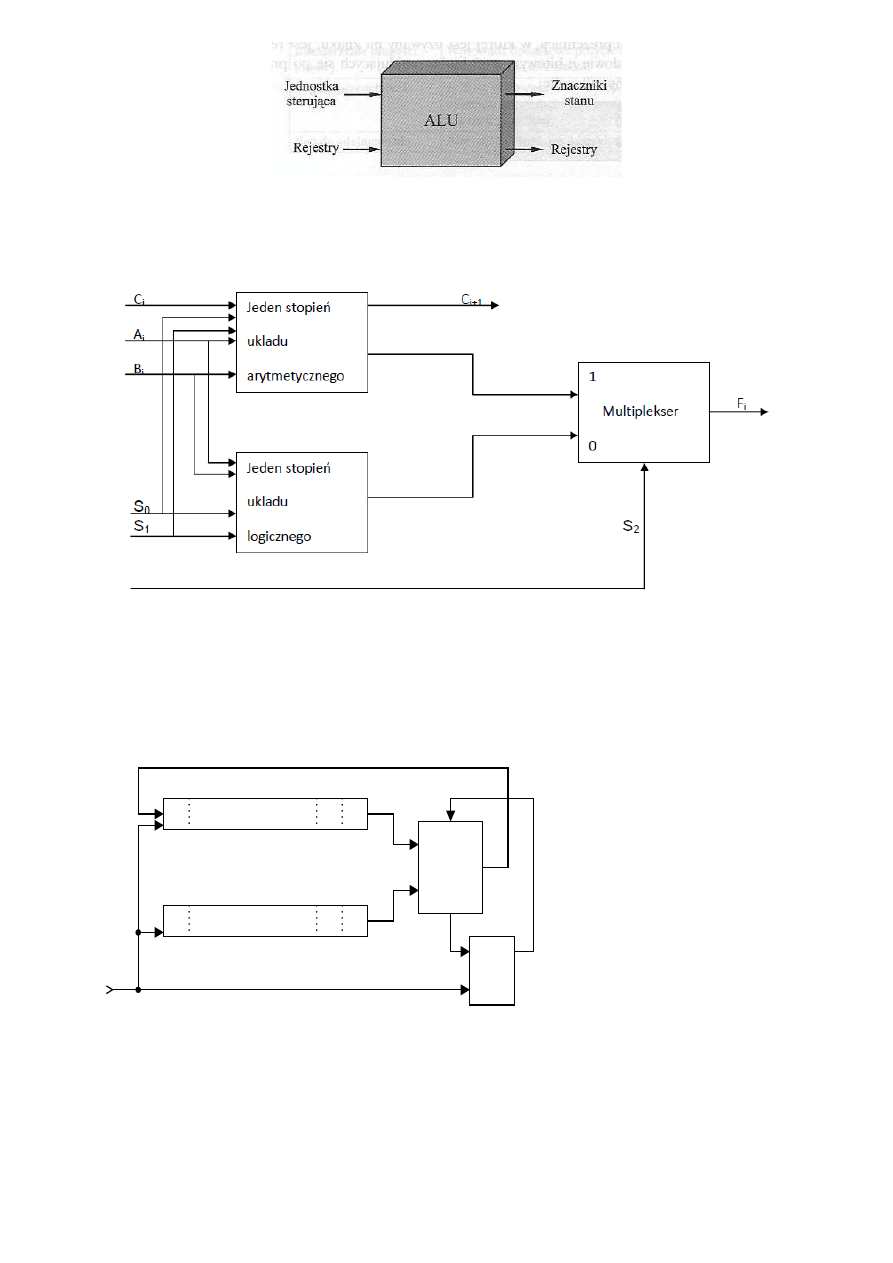
Ogólny sposób połączenia ALU z resztą komputera
ALU wykorzystuje proste, cyfrowe układy logiczne, mogące przechowywać cyfry binarne i
wykonywać proste operacje logiczne Boole’a. Dane są przedstawiane ALU w rejestrach i tam też
przechowywane są wyniki operacji.
Budowa ALU
W zależności od sygnału S
2
na wyjściu multipleksera jest wynik operacji wykonywach przez układ
arytmetyczny albo logiczny. Zmienne wybierające S
0
,
S
1
mogą być wspólne dla obu układów, pod
warunkiem, że użyjemy trzeciej zmiennej (S
2
) która pozwoli rozróżnić układy.
b)
sumatora akumulacyjnego
p
r
z
e
s
u
w
n
y
r
e
je
s
tr
b
ito
w
y
n
−
p
r
z
e
s
u
w
n
y
r
e
je
s
tr
b
ito
w
y
n
−
Σ
A
B
S
C
i-1
C
i
A
k
u
m
u
la
to
r
S
k
ła
d
n
ik
B
Z
e
g
a
r
Q
D
C
Sumator akumulacyjny składa się z sumatora jednobitowego z dodatkiem dwóch rejestrów
przesuwających oraz przerzutnika typu D zapamiętującego przeniesienie. Dodajna (A) i dodajnik (B)
są wprowadzane do sumatora z rejestrów przesuwających. Przed rozpoczęciem dodawania, do
rejestrów 1 i 2 muszą zostać wpisane składniki A i B, a przerzutnik D służący do przekazywania
przeniesień z poprzednich pozycji musi zostać wyzerowany. Dodawanie dwóch bitów składników z
odpowiadających sobie pozycji i bitu przeniesienia z poprzedniej pozycji następuje w kolejnych
taktach wyznaczanych sygnałem zegarowym. Bity składników pojawiają się kolejno na wyjściach
15

szeregowych rejestrów przesuwających 1 i 2, a suma podawana jest na miejsce dodajnej. W miarę
dodawania nowych składników cała suma akumuluje się w tym rejestrze.
II B
UDOWA
P
ROCESORA
1.
Budowa procesora opartego na architekturze von Neumana, podstawowe jego
elementy i ich przeznaczenie.
// Śmierciak Aleksander:
Architektura von Neumanna to pierwszy rodzaj architektury komputera, opracowanej
przez Johna von Neumanna, Johna W. Mauchly'ego oraz Johna Presper Eckerta w 1945
roku. Cechą charakterystyczną tej architektury jest to, że dane przechowywane są
wspólnie z instrukcjami, co sprawia, że są kodowane w ten sam sposób.
W architekturze tej komputer składa się z czterech głównych komponentów:
a) pamięci komputerowej przechowującej dane programu oraz instrukcje programu;
każda komórka pamięci ma unikalny identyfikator nazywany jej adresem,
b) jednostki kontrolnej odpowiedzialnej za pobieranie danych i instrukcji z pamięci oraz
ich sekwencyjne przetwarzanie,
c) jednostki arytmetyczno-logicznej odpowiedzialnej za wykonywanie podstawowych
operacji arytmetycznych.
d) urządzeń wejścia/wyjścia służących do interakcji z operatorem.
Jednostka kontrolna wraz z jednostką arytmetyczno-logiczną tworzą procesor.
System komputerowy zbudowany w oparciu o architekturę von Neumanna powinien:
a) mieć skończoną i funkcjonalnie pełną listę rozkazów,
b) mieć możliwość wprowadzenia programu do systemu komputerowego poprzez
urządzenia zewnętrzne i jego przechowywanie w pamięci w sposób identyczny jak
danych,
c) dane i instrukcje w takim systemie powinny być jednakowo dostępne dla procesora.
Informacja jest tam przetwarzana dzięki sekwencyjnemu odczytywaniu instrukcji z pamięci
komputera i wykonywaniu tych instrukcji w procesorze.
Podane warunki pozwalają przełączać system komputerowy z wykonania jednego zadania
(programu) na inne bez fizycznej ingerencji w strukturę systemu, a tym samym gwarantują jego
uniwersalność.
System komputerowy von Neumanna nie posiada oddzielnych pamięci do przechowywania
danych i instrukcji. Instrukcje jak i dane są zakodowane w postaci liczb. Bez analizy programu
trudno jest określić czy dany obszar pamięci zawiera dane czy instrukcje. Wykonywany program
może się sam modyfikować traktując obszar instrukcji jako dane, a po przetworzeniu tych instrukcji
- danych - zacząć je wykonywać.
Model komputera wykorzystującego architekturę von Neumanna jest często nazywany
przykładową maszyną cyfrową (PMC).
// Stolarczyk Ziemowit:
// (o samym procesorze na wykłądzie było tyle co kot napłakał. W necie też raczej opisana jest
architektura von Neumana, a nie jego procesor. Takowoż stworzyłem odpowiedź będącą
kombinacją wykładu i informacji z internetu)
16
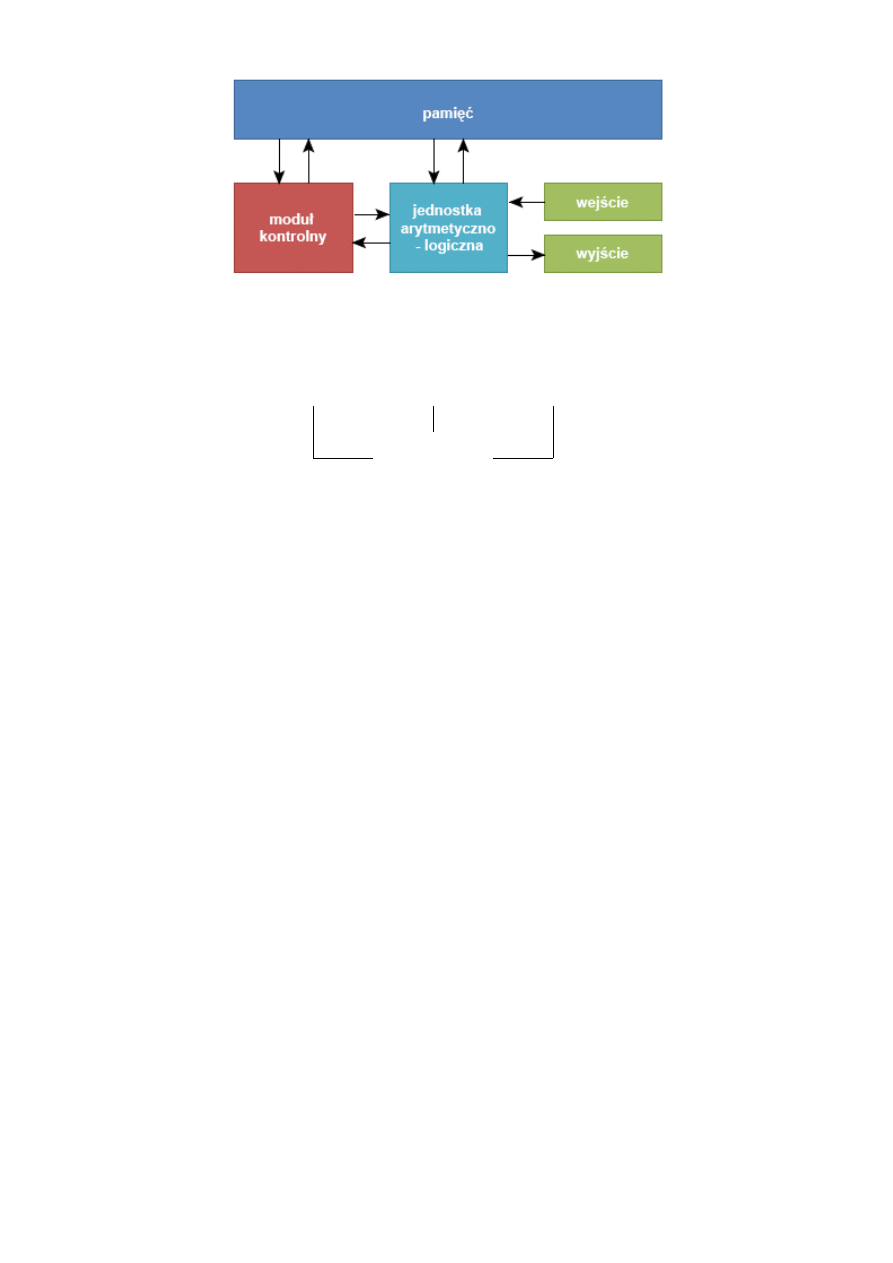
Schemat z internetu:
Schemat z wykładu:
(Procesor, pamięć i urządzenia I/O łączą się z magistralą, która jest łącznikiem między nimi
wszystkimi. W procesorze zawarta jest jednostka arytmetyczno logiczna oraz jednostka sterująca.)
PROCESOR
PAMIĘĆ
URZĄDZENIA I/O
Magistrala
Systemowa
Procesor posiada:
•
jednostka ALU (arytmetyczno-logiczna, przetwarzająca)
(prostych obliczeń arytmetycznych oraz logicznych);
•
jednostka sterująca
(dekoduje z programu rozkaz i na jego podstawie generuje wew. i zew. sygnały);
•
rejestry
(wewnętrzna pamięć procesora);
•
zegar;
•
wewnętrzna magistrala procesora.
4. Rejestry procesora i ich zawartość:
•
PC – adres kolejnego rozkazu do pobrania
•
MAR – adres pamięci skąd pobieramy dane
•
MBR – dane przesłane z pamięci
•
IR – pobrany rozkaz do wykonania
•
AC (akumulator) – dane do przetwarzania przez jednostkęALU
•
rejestry dostępne dla programu, ogólnego przeznaczenia
•
inne
5. Cechy Architektury
•
Procesor łaczy się z urządzeniami I/0 oraz pamięcią za pomocą magistrali systemowej.
•
Informacja przechowywana w komórkach o jednakowym rozmiarze i każda z nich zawiera
jednostkę informacji (tak zwane 'słowo').
•
Instrukcje oraz dane przechowywane w ten sam sposób.
17
•
Struktura słowa nie pozwala odróżnić instrukcji od danych. Interpretacja słowa zależy od
stanu maszyny w chwili pobierania danego słowa.
•
Komórki pamięci stanowią spójną, uporządkowaną przestrzeń adresową.
•
Pamięć to zbiór słów o takiej samej wielkości.
•
Zawartość komórki pamięci może zmienić TYLKO procesor w procesie przesłania słowa do
pamięci.
2.
Formaty i typy rozkazów procesora, wpływ długości rozkazów procesora na
wielkość zajmowanej pamięci przez program oraz na jego czas wykonania.
Typy rozkazów:
Rozkazy arytmetyczne
•
inkrementacja,
•
dekrementacja,
•
dodawanie,
•
odejmowanie,
•
mnożenie,
•
dzielenie.
Rozkazy logiczne operujące na bitach
•
zeruj,
•
iloczyn logiczny,
•
suma logiczna,
•
ex-or,
•
(zeruj | ustaw | zaneguj) bit przeniesienia,
•
(odblokuj | blokuj) przerwania
Rozkazy przesuwania
•
przesuń logarytmicznie (prawo | lewo),
•
przesuń arytmetycznie (prawo | lewo),
•
przesuń cyklicznie (prawo | lewo)
Rozkazy sterujące wykonaniem programu
•
rozgałęzienia,
•
skok (warunkowy | bezwarunkowy),
•
wywołanie podprogramu,
•
powrót z podprogramu,
•
porównywanie (logiczne | arytmetyczne)
Formaty rozkazów:
Rozkazy różnych procesorów mogą mieć różne struktury.
Podstawowe to rozkazy składające się z 2 części:
•
pola
kodu rozkazu
– informacja dla układu sterowania o rodzaju wykonywanej operacji,
•
pola adresowego
– zawierającego adres operandu (np. argument funkcji) lub informacje
potrzebne do jego wyznaczenia
Rozkazy procesora mogą mieć różną długość.
3.
Omówić podstawowe tryby adresowania:
a)
adresowanie natychmiastowe
W adresowaniu natychmiastowym argument pobierany jest bezpośrednio z rozkazu. W tym
trybie wskazywany jest wyłącznie operand źródłowy.
18
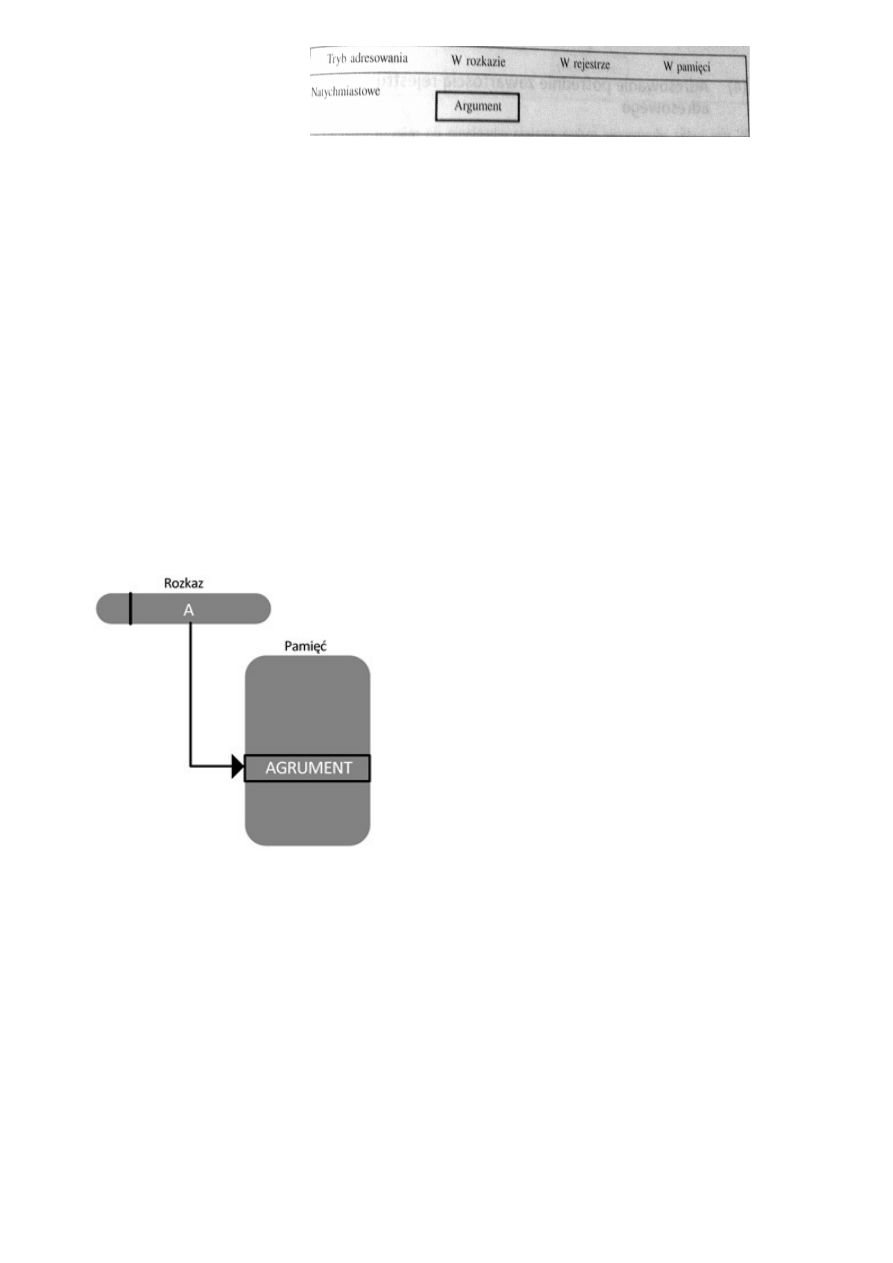
ARGUMENT = A
Tryb stosowany do:
•
definiowania, używania stałych,
•
ustalania początkowych wartości zmiennych.
Liczba jest zwykle przechowywana w postaci uzupełnienia do dwóch; lewy bit pola argumentu jest
używany jako bit znaku. Gdy argument jest ładowany do rejestru danych, bit znaku jest rozszerzany
na lewo w celu wypełnienia słowa danych.
Najprostszym sposobem określenia miejsca argumentu w rozkazie jest umieszczenie w jego części
adresowej samego argumentu, a nie informacji gdzie on się znajduje.
Zalety:
Wady:
•
Nie wymaga dodatkowego odwołania do
pamięci w celu pobrania argumentu.
•
Oszczędzony jeden cykl pamięci głównej lub
podręcznej w cyklu rozkazu.
•
Ograniczenie argumentu do liczby, którą
można zakodować w polu adresowym (małe w
porównaniu z długością słowa).
b)
adresowanie bezpośrednie
W adresowaniu bezpośrednim adres operandu znajduje
się bezpośrednio w rozkazie.
•
A – zawartość pola adresowanego w rozkazie.
•
EA – rzeczywisty (efektywny) adres lokacji
zawierającej odniesiony argument
Wady:
Zalety:
ograniczona przestrzeń
adresowa
prostota
Algorytm: EA = A
Głowna zaleta: prostota
Głowna wada: ograniczona przestrzeń adresowa
Metoda we współczesnych komputerach nie jest bardzo powszechna. Wymaga tylko jednego
odniesienia do pamięci i nie potrzeba żadnych obliczeń. Umożliwia ograniczoną przestrzeń
adresową.
Wyróżniamy adresowanie bezpośrednie ze stałą i rejestrem.
•
STAŁA.
Sekwencja mikroprzesłań zachodzących w adresowaniu bezpośrednim (adres argumentu
reprezentowany za pomocą stałej).
Mikrooperacja wyrażona w notacji RTL:
19
1. MAR(1:6) <- IR(10:16)
2. BUS_ADRES <- MAR
3. MBR <- BUS_DATA
o
Adres argumentu jest umieszczony w rejestrze rozkazów (IR) na bitach o
numerze 10-16
o
Wartość ta nie reprezentuje wartości liczbowej, lecz adres komórki pamięci
operacyjnej, w której argument jest umieszczony.
o
W celu sprowadzenia argumentu z pamięci operacyjnej należy przesłać
odpowiednie bity rejestru (IR) do rejestru (MAR) za pomocą którego zostanie
zaadresowana pamięc operacyjna.
•
REJESTR.
Sekwencja mikroprzesłań zachodzących w adresowaniu bezpośrednim (adres argumentu
przechowywany jest w rejestrze).
Mikrooperacja wyrażona w notacji RTL:
1. MAR <- MBR
2. BUS_ADRES <- MAR
3. MBR <- BUS_DATA
o
Adres argument jest reprezentowany za pomocą stałej ale w określonym
rejestrze
o
Jest on niezbędny w sytuacji, w której program wykonuje operacje na złożonych
strukturach (np. tablice)
o
W przypadku działania na tablicach, indeks jest obliczany dynamicznie.
c)
adresowanie rejestrowe
// Szwed Kamil:
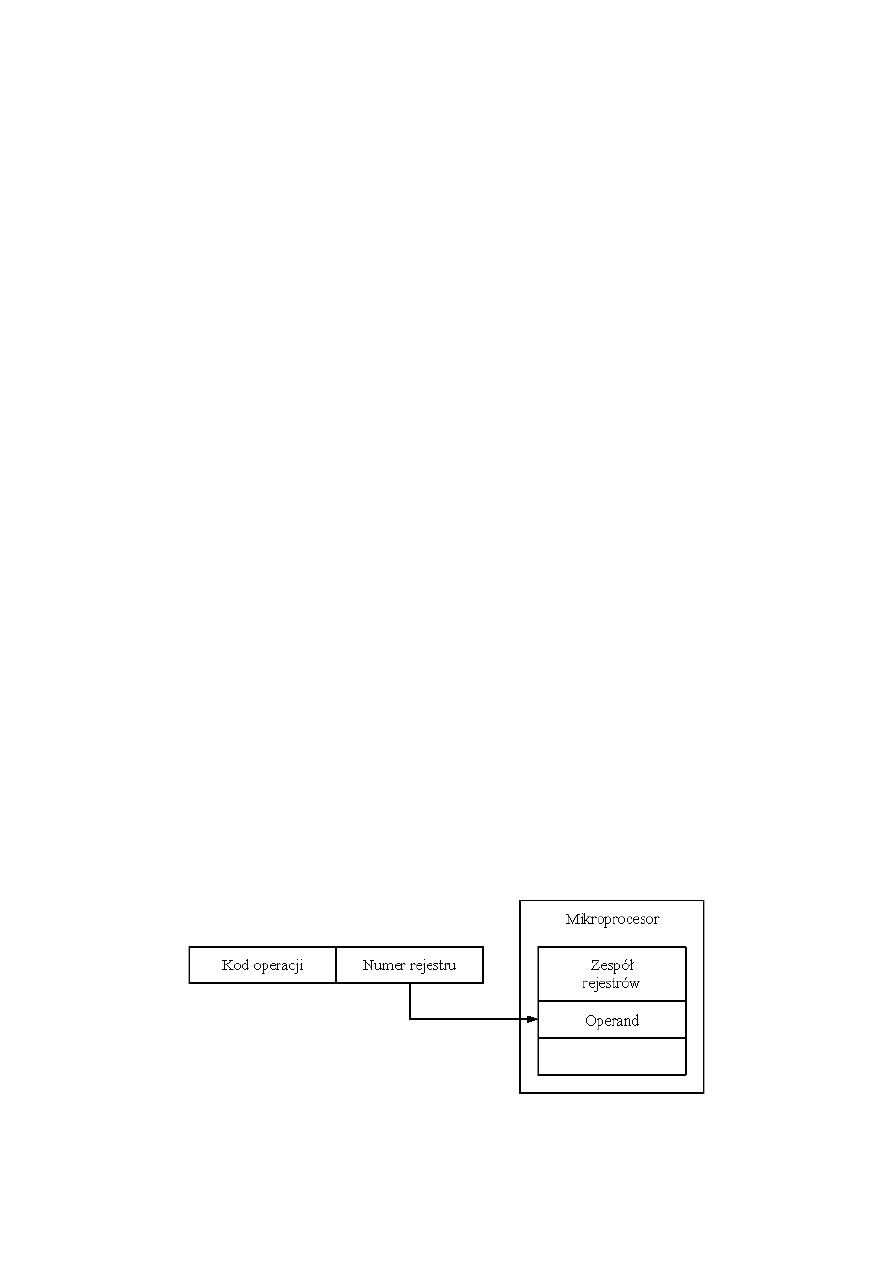
w skrócie: w kodzie rozkazu określony jest rejestr zawierający argument rozkazu.
Jest ono pojęciowo równe adresowaniu bezpośredniemu. W tej formie adresowania
pole adresowe zawiera numer rejestru, w którym zapamiętany jest argument.
Adresowanie rejestrowe oznacza, że w instrukcji mamy zakodowany numer (adres)
rejestru, a nie adres pamięci. Procesory zwykle zawierają od kilku (np. 8), do
kilkudziesięciu (np. 64) rejestrów, dzięki czemu pole adresowe odnoszące się do
rejestru może mieć od 3 do 6 bitów długości. Daje to krótszy czas pobrania rozkazu i
krótsze rozkazy.
// Śmierciak Aleksander:
W adresowaniu rejestrowym operandy znajdują się w rejestrach wewnętrznych
20
mikroprocesora. Jeżeli operand znajduje się w pamięci, to zespół wykonawczy EY
oblicza jego 16-bitowy adres (przesunięcie) wewnątrz segmentu. Zespół BIU oblicza
adres rzeczywisty na podstawie otrzymanego przesunięcia (adresu efektywnego EA) i
zawartości wybranego rejestru segmentowego.
d)
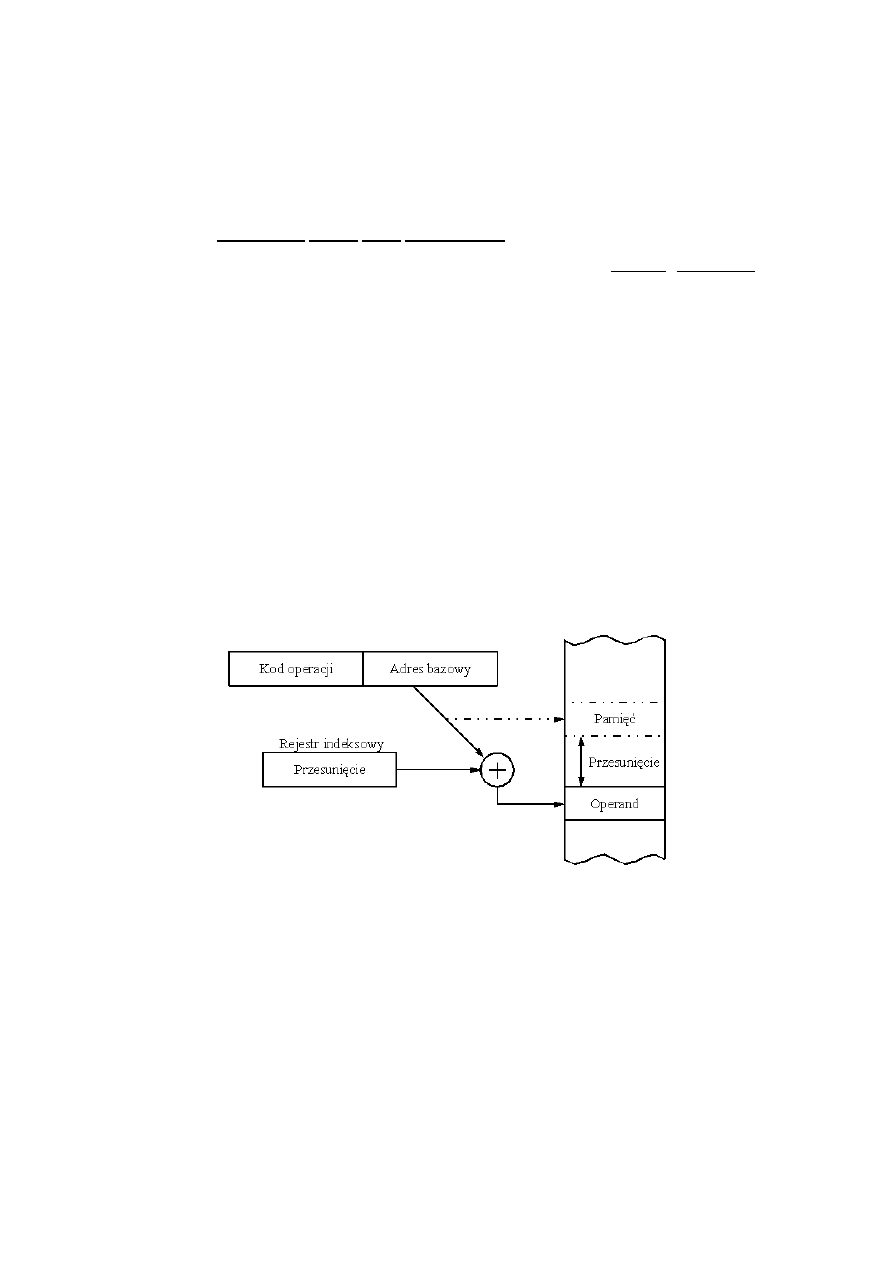
adresowanie indeksowe
W adresowaniu indeksowym adres efektywny jest sumą zawartości rejestru indeksowego SI lub
DI i lokalnego przemieszczenia.
Inaczej nazywane modyfikacją adresu przez indeksowanie.
W tym trybie wykorzystuje się specjalne rejestry procesora, tzw. rejestry indeksowe, które
zawierają przesunięcie, którego trzeba dodać względem adresu istniejącego w rozkazie, aby
wyliczyć adres faktyczny operandu. Ten tryb adresowania pozwala przesunąć adres zawarty w
rozkazie o wartość rejestru indeksowego. Używając adresowania indeksowego we wszystkich
rozkazach programu, można osiągnąć możliwość wykonania programu przy załadowaniu w
dowolne miejsce pamięci. W tym celu należy napisać program wstawiając do rozkazów programu
adresy, które odpowiadają umieszczeniu pierwszej instrukcji programu pod adresem zerowym w
pamięci. Następnie, wiedząc, pod jakim finalnym adresem jest umieszczony pierwszy rozkaz
programu, umieszczamy ten adres w rejestrze indeksowym. Dzięki operacji indeksowania rozkazów
programu, wszystkie adresy operandów zostaną przesunięte o tę sama wartość - stąd nazwa
zawartości rejestru indeksowego: "przesunięcie". Taka organizacja przesuwalności programu w
pamięci nosi nazwę dynamicznej relokacji programu w pamięci.
Rejestrów indeksowych w procesorze jest zwykle wiele, gdyż mogą one być przydzielone różnym
programom lub fragmentom programów, które są wykonywane w tym samym okresie czasu. W
tym przypadku, rejestr indeksowy do użycia, może być określony przy pomocy specjalnego pola
wspomagającego kodowanie trybu adresowania w innym polu rozkazu.
e)
adresowanie bazowe
// Szymski Wojciech:
Bardzo efektywny tryb adresowania łączący możliwości adresowania bezpośredniego i
pośredniego adresowania rejestrowego.
Algorytm
Zaleta:
Wada:
EA = A + (R)
elastyczność
złożoność
Wymaga on dwóch pól adresowych w rozkazie: bazy i przesunięcia. Wartość użyta w polu
adresowym (A) jest używana bezpośrednio (BAZA). Drugie pole adresowe (R), odnosi się do
rejestru, którego zawartość po dodaniu do A daje adres efektywny (PRZESUNIĘCIE).
(analogia z wskaźnikami do tablic w C++. Dodanie do wskaźnika liczby K, przesuwa w pamięci
wskaźnik z elementu o indeksie A do elementu o indeksie A+K).
21

// Śmierciak Aleksander:
W adresowaniu bazowym rozkaz wskazuje na jeden z rejestrów bazowych BX lub BP i może
zawierać 8-; lub 16-bitową wartość stanowiącą lokalne przemieszczenie. Adresem efektywnym
jest suma zawartości rejestru bazowego i przemieszczenia.
f)
adresowanie stosowe
Typ adresowania bezpośredniego. Operand znajduje się na wierzchołku stosu
(rozkazy nie muszą zawierać odniesienia do pamięci).
Wady:
Zalety:
ograniczona
stosowalność
brak odniesienia
do pamięci
4.
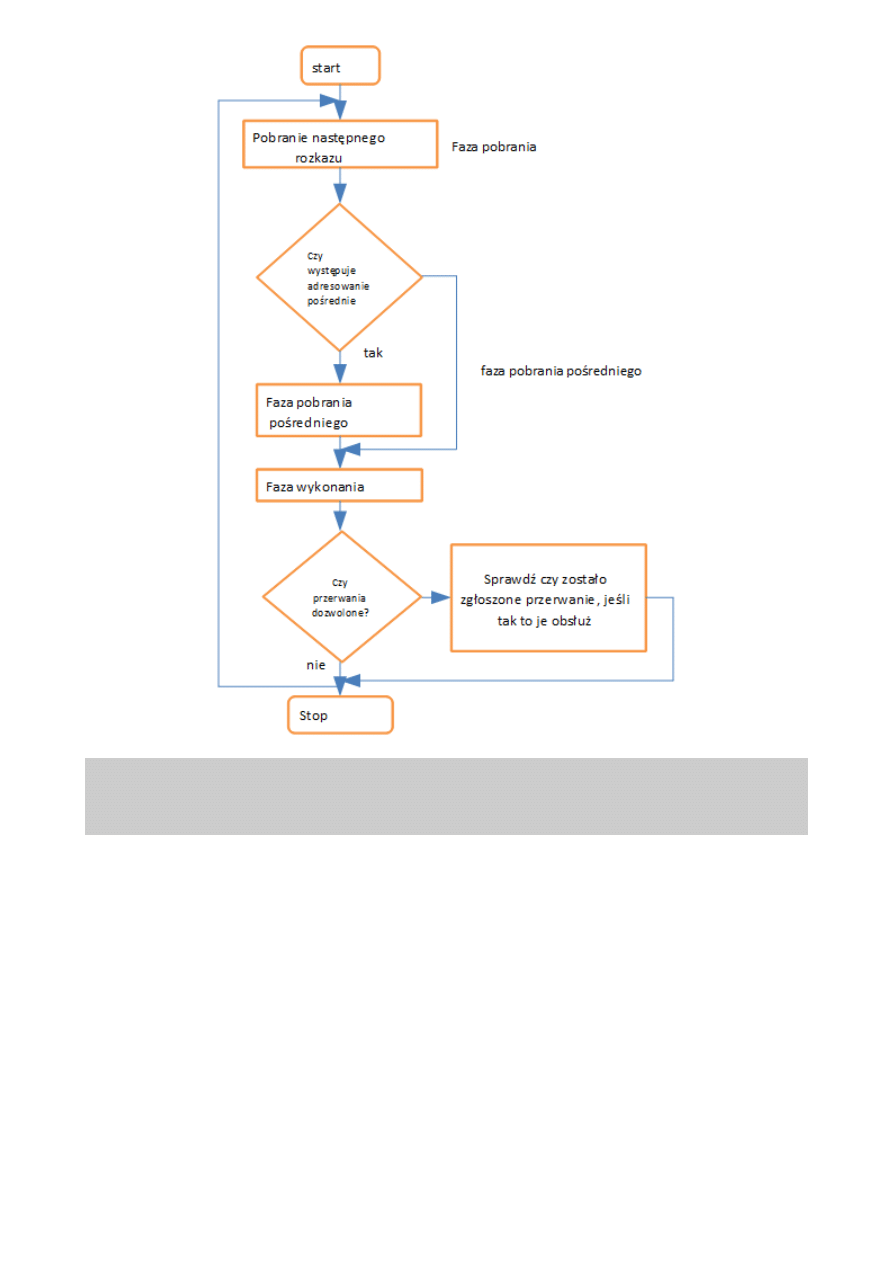
Omówić cykle pracy procesora:
Zadaniem procesora jest wykonywanie rozkazów zapisanych w pamięci. Realizacja
rozkazu w procesorze odbywa się w cyklach. Cyklem nazywamy pewną sekwencję
stałych kroków, których celem jest realizacja bądź całego rozkazu, bądź jego fragmentu.
a)
cykl pobrania
(ang. fetch) – rozkaz zostaje pobrany z pamięci do procesora,
Składa się z 3 etapów:
1. Adresowanie
2. Wczytanie zawartości
3. Zwiększenie licznika rozkazów
W fazie tej kod rozkazu pobierany jest z komórki pamięci o adresie przechowywanym w liczniku
rozkazów, a następnie umieszczany w rejestrze rozkazów (w układzie sterującym). Przesyłanie
odbywa się przez magistralę danych.
Następnie zawartość licznika rozkazów jest modyfikowana w taki sposób, aby wskazywał on na kod
kolejnego rozkazu przeznaczonego do pobrania.
Cykl pobrania w notacji RTL:
MAR – rejestr adresowania; PC – licznik rozkazów; MBR – rejestr buforowy;
CU – jednostka sterująca; IR – rejestr rozkazów;
1. [MAR] <- [PC]
2. [PC] <- [PC + 1]
3. [MBR] <- [M ([MBR]) ]
4. [IR] <- [MBR]
5. CU <- [IR ( KOD OPERACJI) ]
22

Przykładowa sekwencja zdarzeń w cyklu pobierania.
b)
cykl adresowania pośrednie
(ang. read) – jeśli rozkaz tego wymaga następuje pobranie argumentu z pamięci;
zostaje wyznaczony adres efektywny argumentu, a następnie jest on pobierany do
procesora,
// Starzak Mariusz
c)
cykl wykonawczy
(ang. execute) – następuje wykonanie operacji, która jest opisana przetwarzanym
rozkazem. Polega na zdekodowaniu kodu rozkazu i wytworzenia sygnałów sterujących
realizujących dany rozkaz.
d)
cykl przerwania
(ang. write) – jeśli w wyniku operacji powstał rezultat, który ma być umieszczony w
pamięci, zostaje dla owego rezultaty wyznaczony adres efektywny i wykonywany jest
zapis.
Faza przerwania dotyczy skoku do podprogramu obsługi sytuacji wyjątkowych.
23
5.
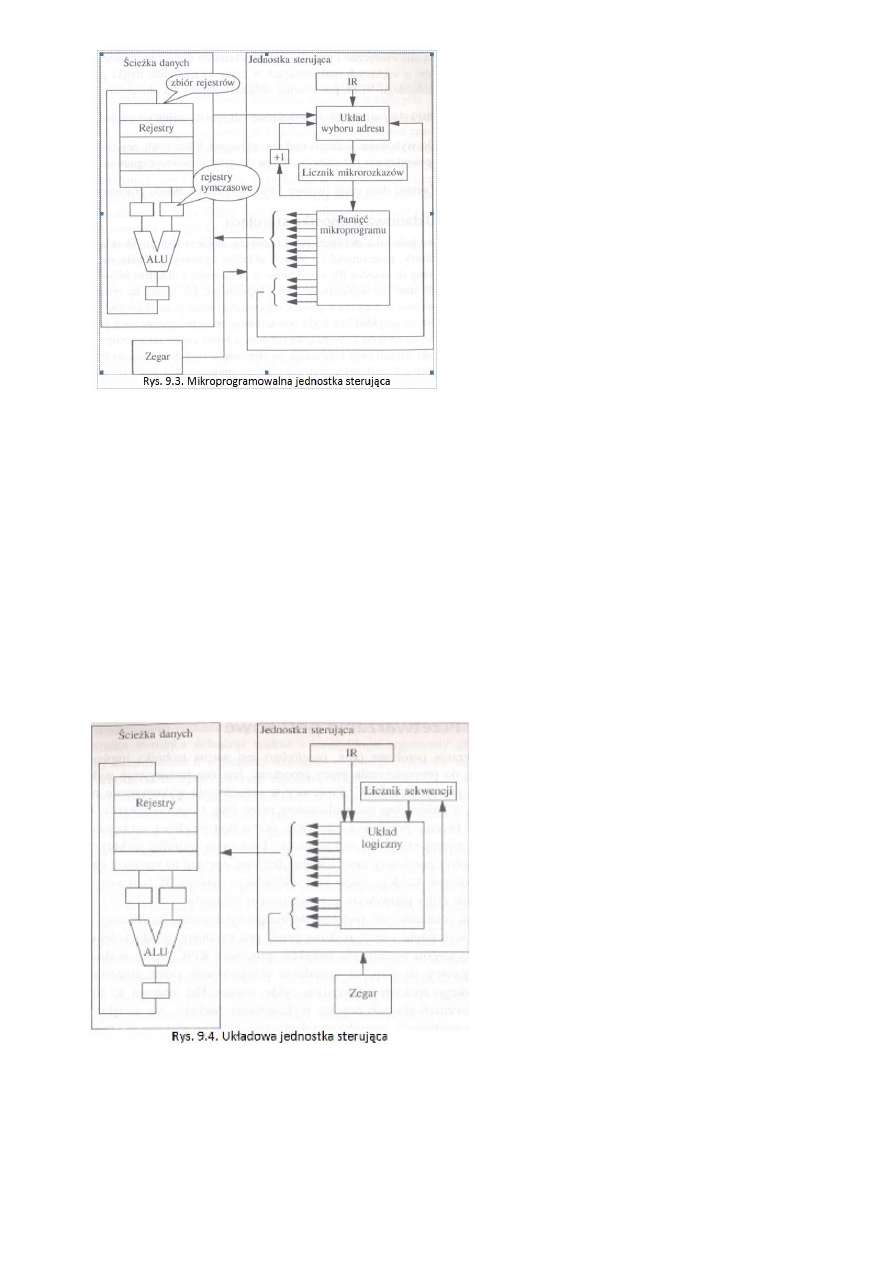
Struktura i zasada działania mikroprogramowanej jednostki sterującej, wady i
zalety procesorów mikroprogramowanych oraz alternatywne metody budowy
jednostki sterującej procesora.
Jedną z najważniejszych cech odróżniających architektury procesorów RISC (układowa) i CISC
(mikroprogramowalna) jest implementacja jednostki sterującej. Z powodu złożoności list rozkazów
w projekcie CISC wykorzystana jest mikroprogramowalna jednostka sterująca, podczas gdy w
projekcie RISC możliwe jest wykorzystanie prostszej i szybszej układowej jednostki sterującej.
Mikroprogramowalna jednostka sterująca przypomina procesor wewnątrz procesora:
•
Zawiera własny licznik mikrorozkazów, którego używa w czasie dostępu do mikroprogramu
przechowywanego w pamięci ROM albo zapisanego w postaci programowalnej tablicy
logicznej (ang. Programmed Logic Array; PLA). Mikroprogram składa się z szeregu
mikrorozkazów, a każdy mikrorozkaz zawiera sekwencję bitów sterującą przemieszczaniem
informacji po ścieżce danych.
•
Podobnie jak w kodzie maszynowym, czyli makrorozkazach, istnieją tutaj rozkazy skoków
warunkowych (ang. branch) i bezwarunkowych (ang. jump) modyfikujące bieg programu i
zmieniające kolejność, w jakiej wykonywane są mikrorozkazy.
24
Najważniejsze fakty związane z mikro-programowalnymi
jednostkami sterującymi:
1.
Są elastyczne. Umożliwiają projektantom
dołączanie nowych rozkazów o większych możliwościach
w miarę zwiększania (dzięki postępom technologii VLSI)
powierzchni układu dostępnej dla procesora.
2.
Pozwalają usunąć błędy projektowe odkryte na
etapie prototypowym.
3.
Do wykonania każdego rozkazu wymagają kilku
cykli zegarowych (spowodowane czasem dostępu do
pamięci mikroprogramu).
4.
Zajmują dużą część (typowo 55%) powierzchni
układu procesora.
Po pobraniu rozkazu do rejestru rozkazów (instruction register, IR), kiedy układ wyboru adresu
(układ szeregujący) zidentyfikuje adres pierwszego mikrorozkazu i przekaże go do licznika
mikrorozkazów, zaczyna się dekodowanie. Każdy mikrorozkaz jest zakodowaną reprezentacją
mikrooperacji, która w czasie wykonania wysyła sygnały sterujące na ścieżkę danych. Mikrorozkaz
także wysyła do układu wyboru adresu sygnały, które są łączone z bitami reprezentującymi stan na
ścieżce danych, stając się adresem następnego rozkazu.
Właściwością dołączaną do kilku mikroprogramowalnych jednostek sterujących są
mikroprocedury, ponieważ wiele mikroprogramów wymaga jednakowych sekwencji
mikrorozkazów, które mogą być umieszczone w jednym miejscu pamięci. Zmniejsza to wielkość
pamięci mikroprogramu i pomaga ograniczyć „pole" krzemowe zajmowane przez jednostkę
sterującą. Jedną z wad takiego postępowania może być niepotrzebne wykonywanie tych samych
operacji, co zwiększa czas wykonania rozkazów.
Układowa jednostka sterująca (RISC)
Najważniejsze fakty związane z układowymi
jednostkami sterującymi:
1.
Minimalizują średnią liczbę cykli
zegarowych potrzebnych do wykonania rozkazu.
2.
Zajmują stosunkowo niewielki obszar
(typowo 10%) powierzchni układu procesora.
3.
Są mniej elastyczne niż
mikroprogramowalne jednostki sterujące i nie mogą
być łatwo modyfikowane bez potrzeby gruntownej
zmiany projektu.
4.
Nie nadają się do zastosowania ze
złożonymi formatami rozkazów.
Układowa jednostka sterująca jest zasadniczo blokiem logicznym składającym się z bramek,
przerzutników i innych układów cyfrowych. Kiedy rozkaz jest wczytywany do rejestru IR, układ
bitów w połączeniu z układem bitów licznika sekwencji staje się wejściem do bloku logicznego. Pola
kluczowe w rozkazach zawsze odpowiadają ustalonym pozycjom w bloku logicznym na przykład
bity kodu operacji mogą zawsze zgadzać się z pozycjami wejściowymi od 0 do 5. Wejściowa
25
sekwencja bitów zapewnia sygnały sterujące dla ścieżki danych oraz informacje do sterowania
sygnałem czasowym generowanym przez licznik sekwencji w czasie następnego cyklu zegarowego.
W ten sposób każdy rozkaz powoduje wygenerowanie odpowiedniej sekwencji sygnałów
sterujących. Podobnie jak w przypadku mikroprogramowalnych jednostek sterujących, kody
warunkowe albo inne informacje uzyskane ze ścieżki danych mogą być wykorzystane do zmiany
kolejności sygnałów sterujących.
Układowe jednostki sterujące mogą być zmodyfikowane jedynie przez zmianę połączeń między
różnymi elementami logicznymi. Jest to zadanie czasochłonne i zwykle prowadzi do całkowitego
przeprojektowania bloku logicznego. Z drugiej strony, układowe jednostki sterujące są szybsze niż
ich mikroprogramowalne odpowiedniki. Jest tak dlatego, że unika się w nich operacji odczytywania
pamięci mikroprogamu, które są zwykle wolniejsze niż podstawowe operacje logiczne, realizowane
przez układy logiczne, oraz dlatego, że są optymalizowane dla wykorzystania stałego formatu
rozkazów.
6.
Budowa i zasada działania następujących procesorów.
a)
procesor potokowy
// Szeliga Bartosz:
Idea procesora potokowego polega na tym żeby zrobić jak najwięcej operacji równocześnie które
mogą być wykonywane równocześnie (współbieżnie).
Dwuetapowy potok rozkazów (schemat uproszczony):
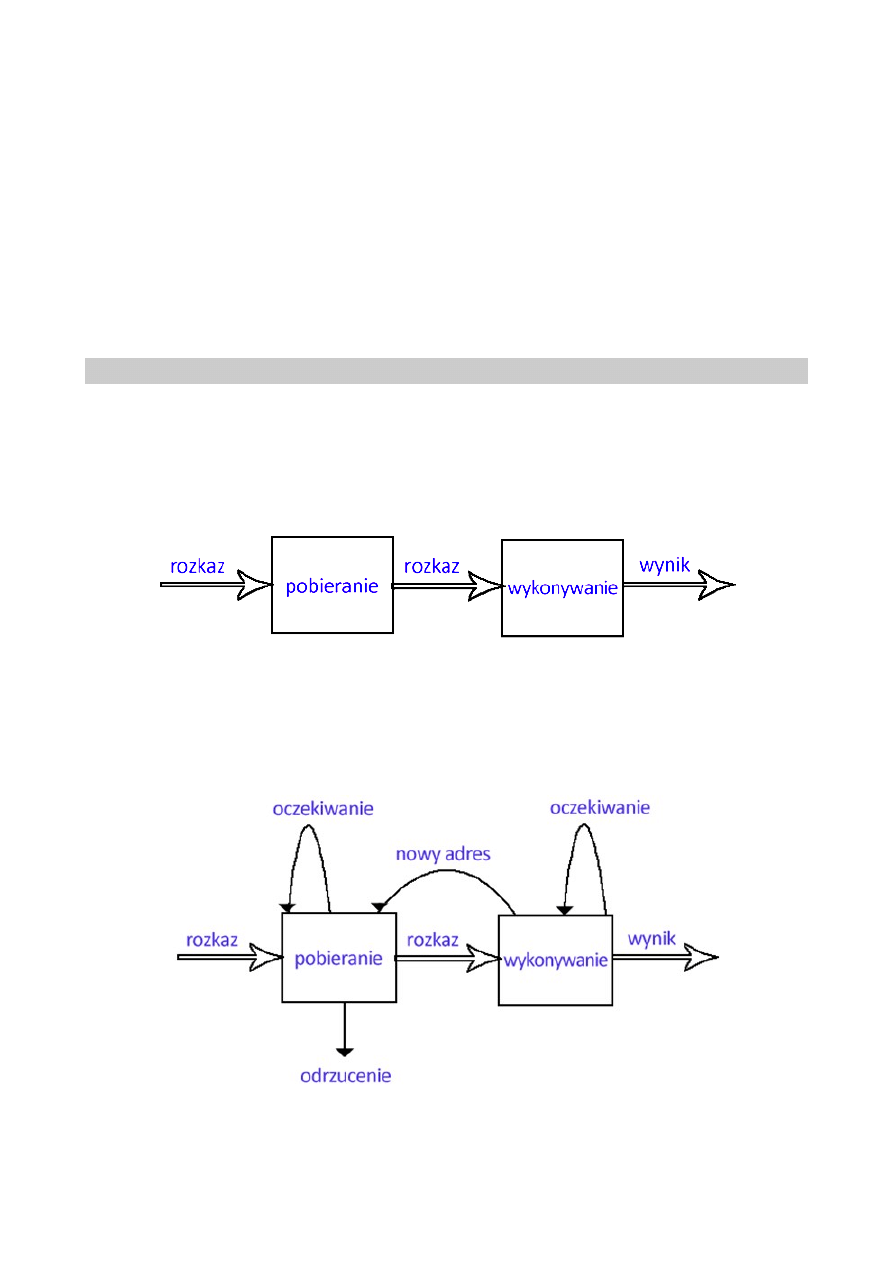
Jest jasne, że tan proces przyspiesza wykonywanie rozkazów. Jeśli etapy pobierania i
wykonywania zajmowałyby tyle samo czasu, czas cyklu rozkazu zmniejszyłby się do
połowy.
Jeśli jednak przyjrzymy się bliżej przetwarzaniu potokowemu to stwierdzimy, że z
dwóch powodów to podwojenie szybkości wykonywania nie jest prawdopodobne.
Dwuetapowy potok rozkazów (schemat rozszerzony):
Zwiększenie liczby etapów potoku
pobieranie rozkazu | analiza rozkazów | wyznaczanie adresu | pobieranie danych | wykonywanie rozkazów
kierunek przetwarzania rozkazu ->
26

Rezultatem zwiększenia liczby etapów potoku będzie to, że prawdopodobnie poszczególnie etapy
będą zajmowały mniej więcej tą samą długość czasu.
Etapy potoku (sześcioetapowy)
1. Pobranie rozkazu (FI). Wczytanie następnego spodziewanego rozkazu do bufora.
2. Dekodowanie rozkazu (Di). Określenie kodu operacji i specyfikatorów argumentu
3. Obliczanie argumentów (CO). Obliczenie efektywnego adresu każdego argumentu
źródłowego. Może to obejmować obliczanie adresu z przesunięciem, adresu rejestrowego
pośredniego, adresu pośredniego lub innych form.
4. Pobieranie argumentów (FO). Pobranie każdego argumentu z pamięci. Argumenty w
rejestrach nie muszą być pobierane.
5. Wykonanie rozkazu (EL). Przeprowadzenie wskazanej operacji i przechowanie wyniku, jeśli
taki jest, w ustalonej lokacji docelowej.
6. Zapisanie argumentu (WO). Zapisanie wyniku w pamięci.
W przypadku skoku bezwarunkowego może nastąpić zaburzenie potoku, ponieważ rozkazy są
wykonywane jeden za drugim, więc podczas przeskoku należy zainicjalizować przetwarzanie od
początku w nowym miejscu (chociaż z tym jeszcze da się jakoś poradzić). Konkretną klęską jest
operacja skoku warunkowego, bo do ostatniej chwili nie wiadomo gdzie przeniesie się program.
Etapy potoku – przyczyny nieefektywności potoku (rozkazy skoku, rozgałęzienia)
Rozkaz skoku warunkowego powoduje, że adres następnego rozkazu przewidzianego do pobrania
jest nieznany. Wobec tego realizacja etapu pobierania może nastąpić dopiero po otrzymaniu
adresu
następnego rozkazu, który zostanie określony po zakończeniu etapu wykonywania. Następnie na
etapie wykonywania następuje oczekiwanie na pobranie kolejnego rozkazu.
27
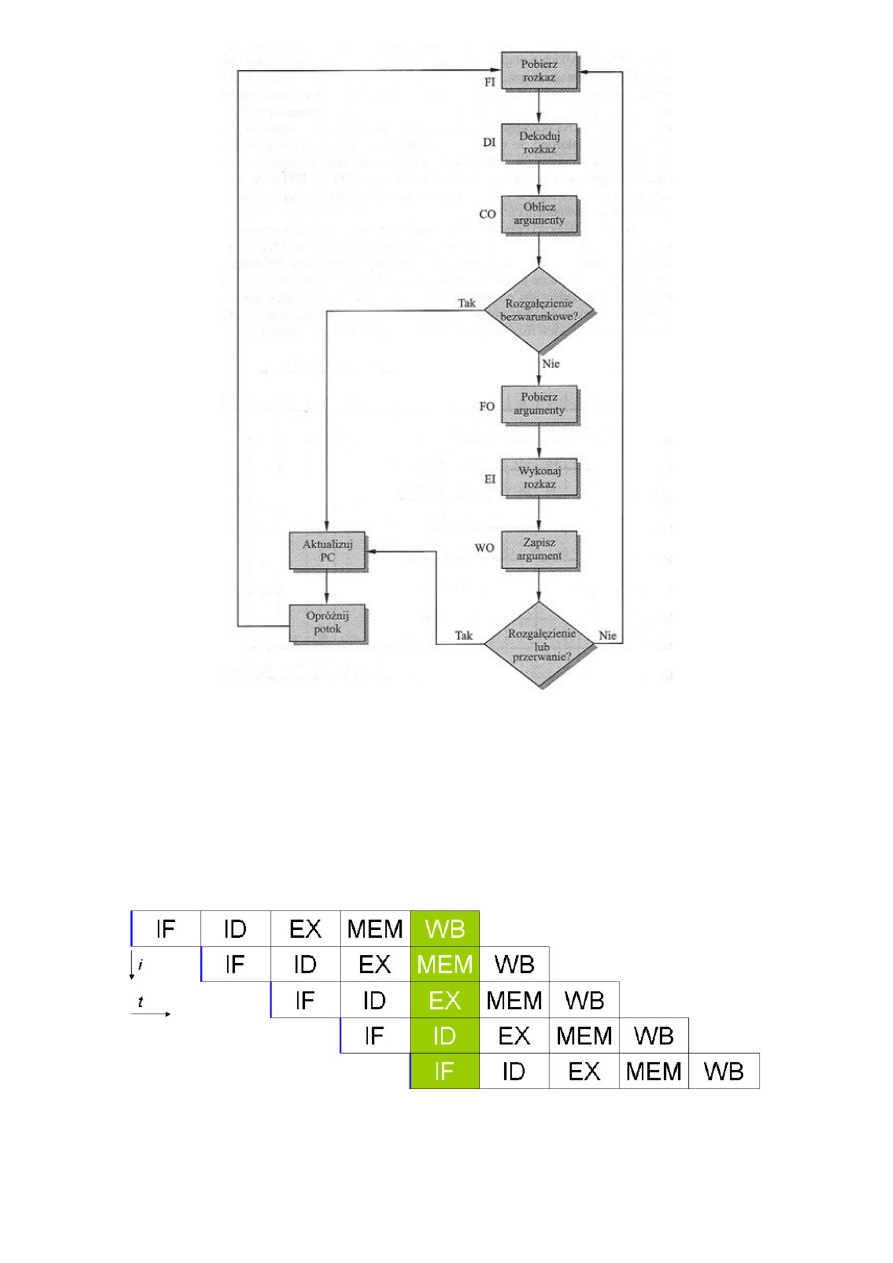
// Śmierciak Aleksander:
(pipelining processor) – procesor odznaczający się podziałem logiki odpowiedzialnej za
proces wykonywania programu (instrukcji procesora) na specjalizowane grupy w taki
sposób, aby każda z grup wykonywała część pracy związanej z wykonaniem rozkazu.
Grupy te są połączone sekwencyjnie – w formie potoków (pipe) – i wykonują pracę
równocześnie, pobierając dane od poprzedniego elementu w sekwencji. W każdej z
tych grup rozkaz jest na innym stadium wykonania. Można to porównać do taśmy
produkcyjnej. W uproszczeniu, potok wykonania instrukcji procesora może wyglądać
następująco:
Uproszczony schemat potokowości. Części rozkazów oznaczone na zielono wykonywane są równocześnie.
pobranie instrukcji z pamięci – ang. instruction fetch (IF)
28

Zdekodowanie instrukcji – ang. instruction decode (ID)
Wykonanie instrukcji – ang. execute (EX)
Dostęp do pamięci – ang. memory access (MEM)
Zapisanie wyników działania instrukcji – ang. store; write back (WB)
W powyższym 5-stopniowym potoku, przejście przez wszystkie stopnie potoku
(wykonanie jednej instrukcji) zabiera co najmniej 5 cykli zegarowych. Jednak ze względu
na jednoczesną pracę wszystkich stopni potoku, jednocześnie wykonywanych jest 5
rozkazów procesora, każdy w innym stadium wykonania. Oznacza to, że taki procesor w
każdym cyklu zegara rozpoczyna i kończy wykonanie jednej instrukcji i statystycznie
wykonuje rozkaz w jednym cyklu zegara. Każdy ze stopni potoku wykonuje mniej pracy
w porównaniu do pojedynczej logiki, dzięki czemu może wykonać ją szybciej – z większą
częstotliwością – tak więc dodatkowe zwiększenie liczby stopni umożliwia osiągnięcie
coraz wyższych częstotliwości pracy.
Podstawowym mankamentem techniki potoku są rozkazy skoku, powodujące w
najgorszym wypadku potrzebę przeczyszczenia całego potoku i wycofania rozkazów,
które następowały zaraz po instrukcji skoku i rozpoczęcie zapełniania potoku od
początku od adresu, do którego następował skok. Taki rozkaz skoku może powodować
ogromne opóźnienia w wykonywaniu programu – tym większe, im większa jest długość
potoku. Dodatkowo szacuje się, że dla modelu programowego x86 taki skok występuje
co kilkanaście rozkazów. Z tego powodu niektóre architektury programowe (np. SPARC)
zakładały zawsze wykonanie jednego lub większej ilości rozkazów następujących po
rozkazie skoku, tzw. skok opóźniony. Stosuje się także skomplikowane metody predykcji
skoku lub metody programowania bez użycia skoków.
b)
procesor CISC
// Śmierciak Aleksander:
(Complex Instruction Set Computer)
Cechy:
występowanie złożonych, specjalistycznych rozkazów (instrukcji) - które do
wykonania wymagają od kilku do kilkunastu cykli zegara,
szeroka gama trybów adresowania,
przeciwnie niż w architekturze RISC rozkazy mogą operować bezpośrednio na
pamięci (zamiast przesłania wartości do rejestrów i operowania na nich)
Powyższe założenia powodują iż dekoder rozkazów jest skomplikowany.
Istotą architektury CISC jest to, iż pojedynczy rozkaz mikroprocesora, wykonuje kilka operacji
niskiego poziomu, jak na przykład pobranie z pamięci, operację arytmetyczną i zapisanie do
pamięci.
// Szwed Kamil:
–
występowanie złożonych, specjalistycznych rozkazów (instrukcji) - które do wykonania
wymagają od kilku do kilkunastu cykli zegara
–
duża liczba rozkazów
–
szeroka gama trybów adresowania
–
przeciwnie niż w architekturze RISC rozkazy mogą operować bezpośrednio na pamięci
29

(zamiast przesłania wartości do rejestrów i operowania na nich)
–
mniejsza od układów RISC częstotliwość taktowania procesora
–
powyższe założenia powodują iż dekoder rozkazów jest skomplikowany
Istotą architektury CISC jest to, iż pojedynczy rozkaz mikroprocesora, wykonuje kilka operacji
niskiego poziomu, jak na przykład pobranie z pamięci, operację arytmetyczną i zapisanie do
pamięci.
c)
procesor RISC
(Reduced Instruction Set Computer) - nazwa architektury mikroprocesorów.
Ówczesne procesory (budowane w architekturze CISC) charakteryzowały się bardzo
rozbudowaną listą rozkazów, ale jak wykazały badania, statystycznie tylko nieliczna ich część była
wykorzystywana w programie. Okazało się np. że ponad połowa rozkazów w kodzie to zwykłe
przypisania, tj. zapis zawartości rejestru do pamięci i odwrotnie.
W związku z powyższym zaprezentowano architekturę mikroprocesorów, w której uwzględniono
wyniki badań. Jej podstawowe cechy to:
zredukowana liczba rozkazów do niezbędnego minimum. Ich liczba wynosi kilkadziesiąt,
podczas gdy w procesorach CISC sięga setek. Upraszcza to znacznie dekoder rozkazów.
redukcja trybów adresowania, dzięki czemu kody rozkazów są prostsze, bardziej
zunifikowane, co dodatkowo upraszcza wspomniany wcześniej dekoder rozkazów. Ponadto
wprowadzono tryb adresowania, który ogranicza liczbę przesłań.
ograniczenie komunikacji pomiędzy pamięcią, a procesorem. Przede wszystkim do
przesyłania danych pomiędzy pamięcią, a rejestrami służą dedykowane instrukcje, które
zwykle nazywają się load (załaduj z pamięci), oraz store (zapisz do pamięci); pozostałe
instrukcje mogą operować wyłącznie na rejestrach. Schemat działania na liczbach
znajdujących się w pamięci jest następujący: załaduj daną z pamięci do rejestru, na
zawartości rejestru wykonaj działanie, przepisz wynik z rejestru do pamięci.
zwiększenie liczby rejestrów (np. 32, 192, 256, podczas gdy np. w architekturze x86 jest
zaledwie 8 rejestrów), co również ma wpływ na zmniejszenie liczby odwołań do pamięci.
// Murias Tomasz:
Główne założenia:
•
redukcja listy rozkazów;
•
wyposażenie procesora w dużą
liczbę rejestrów (namiastka pamięci
podręcznej);
•
przechowywanie wyników obliczeń
w rejestrach, zamiast wysyłania ich do
pamięci operacyjnej.
Cechy charakterystyczne procesorów typu RISC:
1. Stosunkowo niewiele rozkazów wykonywanych w
pojedynczym cyklu rozkazowym.
2. Stosunkowo niewiele trybów adresowania ( 1 lub 3 ).
3. Łatwe do zdekodowania, stałej długości formaty
rozkazów.
4. Dostęp do pamięci ograniczony do rozkazów STORE i
LOAD
5. Stosunkowo obszerny zbiór uniwersalnych rejestrów
( ok. 32 ).
6. Rozkazy działające zazwyczaj na argumentach
zapisanych w rejestrach, a nie w pamięci operacyjnej.
7. Układowo zrealizowana jednostka sterująca.
30

Inne cech charakteryzujące nie tylko procesory RISC, to
8. Intensywne wykorzystanie przetwarzania potokowego,
w tym potokowe wykonywanie rozkazów.
9. Kompilatory o dużych możliwościach optymalizacji
kodu, wykorzystujące architekturę potokową.
10. Skomplikowane funkcje zaimplementowano częściej
programowo niż sprzętowo.
W procesorach RISC proces dekodowania rozkazów zazwyczaj był jednoetapowy (wszystkie rozkazy
tej samej długości). Dzięki temu można było zastosować przetwarzanie potokowe.
d)
procesor wektorowy
(vector processor)
Procesory wektorowe są stosowane w superkomputerach, mogą one wykonywać setki operacji
zmiennopozycyjnych na sekundę. Wykonywanie operacji jest realizowane za pomocą tablic lub
wektorów (kilka jednostek ALU wykonuje operacje jednocześnie).
Istnieją 3 główne kategorie procesorów wektorowych:
1. ALU z przetwarzaniem potokowym
2. Równoległe ALU
3. Równoległe procesory
Operacje zmiennoprzecinkowe ALU z przetwarzaniem potokowym przebiegają następująco:
1. Porównaj wykładniki
2. Przesuń mantysę
2. Dodaj mantysy
3. Normalizuj
Równoległe ALU
1. Obliczenia wykonywana na niezależnych procesorach:
Przesyłanie danych z pamięci do rejestrów wejściowych potem do konkretnego ALU i następnie
do rejestru wyjściowego. Znaczne przyspieszenie wykonywania operacji dzięki kilku jednostkom
ALU.
e)
procesor superskalarny
(superscalar processor)
Rozwiązanie pozwalające równolegle wykonywać wiele rozkazów. Paralelizm ma
31

poziomie rozkazu odnosi się do stopnia przeciętnej możliwości równoleglego
wykonywania.
Procesor superskalarny zawiera dwa lub więcej potoków. Potoki nie są niezależnymi
obiektami - korzystają ze wspólnych zasobów, co ogranicza paralelizm.
Kompilatory bądź programiści dbają o dososowanie sekwencji rozkazów do procesorów
superskalarnych tak, by istniało jak najmniej zależności między następującymi po sobie
rozkazami maszynowymi. Np. instrukcje:
a = b + 5
c = a + 10
nie będą mogły zostać wykonane równolegle, ponieważ wartość c zależy od
wyliczanego wcześniej a. Jeśliby jednak usunąć zależność i napisać równoważnie :
a = b + 5
c = b + 15
Zalety:
•
zwiększona wydajność,
•
prawdziwa zależność danych,
•
zależność proceduralna,
•
konflikt o zasoby,
•
zależność wyjściowa,
•
anty-zależność.
III B
UDOWA
K
OMPUTERA
1.
System przerwań i jego rola w systemie komputerowym.
a)
typy przerwań: (przerwanie programowe, przerwanie zewnętrzne, przerwanie
wewnętrzne)
// Szymski Wojciech:
przerwania programowe:
Polega na wykonywaniu zapisanych w programie rozkazów i śledzeniu przez procesor stanu
urządzenia zewnętrznego, czekając na ustawienie znacznika (flagi w module sprzęgającym), że
można wykonać następne przesłanie danych. Program okresowo sprawdza zawartość rejestru
kontrolno-sterującego związanego z każdym urządzeniem i na podstawie ustawienia odpowiednich
bitów określa czy urządzenie wymaga obsługi, czy też nie.
W tym typie przerwań obowiązuje obsługa priorytetowa (urządzenie o największym priorytecie
jest testowane w każdym cyklu sprawdzania jako pierwsze)
Wada: Komunikacja z urządzeniami zewnętrznymi zajmuje czas procesora.
przerwania zewnętrzne – źródłem przerwania jest urządzenie zewnętrzne
Ten typ przerwań wykorzystuje specjalne polecania dla modułu sprzęgającego, które polecają
modułowi zgłosić przerwanie, gdy np. urządzenie zewnętrzne będzie wolne. Moduł zgłasza
przerwanie procesorowi, który zatrzymuje wykonywania bieżącego programu i przechodzi do
obsługi odpowiedniej procedury, która jest związana z urządzeniem zgłaszającym przerwanie.
32

W tym typie przerwań nie występuje zjawisko zbędnego absorbowania czasu procesora przez
wykonywanie rozkazów wejścia-wyjścia. Procesor może zajmować się wykonywaniem innego
programu podczas, gdy moduł-sprzęgający obserwuje stan urządzenia zewnętrznego.
Identyfikacja źródła przerwania: metoda przeglądania realizowana programowo lub sprzętowo.
przerwania wewnętrzne – powstanie błędu w trakcie obliczeń, który uniemożliwia kontynuowanie
wykonywania programu
// Stolarczyk Ziemowit:
A) Sprzętowe
a) Zewnętrzne – przerwanie pochodzi z zewnętrznego układu obsługującego przerwania
sprzętowe np. modułu sprzęgającego. Służy do komunikacji z takimi urządzeniami jak
klawiatura, mysza, dysk twardy itp. Przerwania te służą do komunikacji procesora z
urządzeniami zewnętrznymi. Pozwala to uniknąć jałowego przeglądania przez procesor
stanu urządzeń (czy aby czasem nie wymagają obsługi). Przerwania są zgłaszane w
wypadku potrzeby obsługi urządzenia przez procesor. Zazwyczaj przerwania te są
przesyłane do samego procesora przez pośrednika (moduł sprzęgający), który obserwuje
stan urządzenia, zwalniając z tej pracy procesor. W przypadku zgłoszenia przerwania
procesor przechodzi do jego obsługi.
b) Wewnętrzne – są zgłaszane przez sam procesor w celu zasygnalizowania wyjątkowej
sytuacji (dzielenie przez zero, wejście w pułapkę w trybie debugowania). Dzielą się na 3
grupy:
b1) niepowodzenie – przypadki gdy wykonywanie aktualnych zadań się nie powiodło.
Gdy procesor powraca do wykonywania przerwanego kodu wykonuje tę samą instrukcję
która wywołała wyjątek .
b2) pułapki - sytuacja, która nie jest błędem, jej wystąpienie ma na celu wykonanie
określonego kodu; wykorzystywane przede wszystkim w debugerach. Gdy procesor
powraca do wykonywania przerwanego kodu, wykonuje następną, po tej która wywołała
wyjątek, instrukcję.
b3) nienaprawialne – błędy których nie da się naprawić.
B) Programowe
c) Programowe – z kodu programu wywoływana jest procedura obsługi przerwania; najczęściej
wykorzystywane do komunikacji z systemem operacyjnym, który w procedurze obsługi przerwania
umieszcza kod wywołujący odpowiednie funkcje systemowe w zależności od zawartości rejestrów
ustawionych przez program wywołujący, lub oprogramowaniem wbudowanym jak procedury BIOS
lub firmware.
b)
metody identyfikacji źródła przerwania
// Stolarczyk Ziemowit:
a) Przeglądanie – w przypadku zgłoszenia jakiegokolwiek przerwania procesor przegląda
listę wszystkich urządzeń zewnętrznych (a dokładnie ich odpowiednie rejestry służące do
sygnalizacji potrzeby obsługi przerwania). W przypadku natrafienia na takie urządzenie
procesor przechodzi do obsługi przerwania. Przeglądanie kończy się wraz z dojściem do
końca listy (przeglądnięcia wszystkich urządzeń).
b) Przerwanie skierowane/wektoryzowane – przeglądanie jest w tym przypadku zbędne
gdyż wraz z sygnałem przerwania podawany jest adres komórki zwanej wektorem
przerwania. Komórka zawiera instrukcję obsługi przerwania lub adres procedury
przerwania. Zwalnia to procesor z przeglądania wszystkich urządzeń.
// Starzak Mariusz
33

c)
mechanizm obsługi przerwania
Oczywiście aby zgłoszone przerwanie w ogóle zostało obsłużone procesor musi mieć ustawione
odpowiednie falgi zezwalające na obsługę przerwań. W innym wypadku zgłoszone przerwania będą
ignorowane.
W obsłudze przerwań istotną rzeczą jest aspekt priorytetu. W przypadku zgłoszenia
przerwania przez więcej niż jedno urządzenie wpierw obsługiwane jest to o wyższym priorytecie.
Praktyczna realizacja zagadnienia może być różna np. w przypadku metody identyfikacji
polegającej na przeglądaniu (patrz metody identyfikacji źródła przerwania) wyraża się kolejnością
przeglądania urządzeń.
Następnie gdy konkretne przerwanie zostanie wybrane jako to obsługiwane przez procesor
to przed jego obsługą procesor musi na stosie zapamiętać wszelkie dotychczasowe dane potrzebne
w aktualnym zadaniu, a w szczególności wartość rejestru PC czyli w tym przypadku adres powrotny
z procedury obsługi przerwania. Wszelkie potrzebne dane są odkładane na stos. Zawsze jest to
wartość rejestru PC. Mogą to być także wartości i innych rejestrów, jeśli zawarte w nich dane będą
potem potrzebne, a mogą zostać utracone w procesie obsługi przerwania.
Następnie do PC jest ładowany adres procedury obsługi przerwania. I skok do tej procedury.
Po wykonaniu obsługi przerwania ze stosu są ściągane wcześniej włożone tam dane, a
wszczególności wartość rejestru PC. Dalsze wykonywanie programu rozpoczyna się od miejsca na
który wskazuje wartość ściągnięta ze stosu do rejestru PC.
2.
Omówić tryby przesyłania danych w systemie komputerowym.
Możliwe są 3 typy przesłań danych między centralną częścią komputera, a urządzeniami
zewnętrznymi
:
a)
przesyłanie danych zrealizowane programowo
Polega na programowym przesyłaniu danych w oparciu o funkcje wejścia/wyjścia
zawartych w programie. Zmusza to procesor do jałowych iteracji w pętli oczekując na dane z
wolniejszych urządzeń zewnetrznych lub w oczekiwaniu na pobranie wszystkich danych od niego
przez urządzenie zewnętrzne. Istotną wadą tego podejścia jest marnotrawienie mocy
obliczeniowych procesora oraz niemożność jakiejkolwiek innej akcji z jego strony do czasu, gdy
operacja wejścia/wyjścia się zakończy.
b)
przesyłanie danych inicjowane przerwaniami
Bardziej efektywna metoda polega na wykorzystaniu przerwań, dzięki czemu urządzenia
wejścia-wyjścia mogą sygnalizować procesorowi konieczność obsługi. Pozwala to zwolnić większość
czasu procesora, który można przeznaczyć na bardziej pożyteczne działania, takie jak wykonywanie
programów użytkownika albo zarządzanie zasobami systemowymi.
Przerwania // sprawdzić, na ile opisane przerwania i czy jest sens powtarzać
Niemal wszystkie procesory mają jedną lub więcej końcówek zgłaszania przerwań, służących do
wykrywania i rejestrowania nadchodzących żądań przerwań. Gdy interfejs albo inny układ zgłasza
przerwanie, jak na rysunku 7.15, wtedy procesor rejestruje żądanie jako oczekujące na obsługę.
Przy końcu każdego cyklu rozkazowego procesor sprawdza, czy są jakieś żądania, i decyduje, czy je
zaakceptować i obsłużyć, czy zignorować i kontynuować wykonywanie aktualnego programu.
Decyzja zależy od ustawienia bitu (albo bitów) maski przerwań w rejestrze stanu procesora.
Po zaakceptowaniu przerwania procesor przekazuje sterowanie do programu obsługi przerwania
(ang. interrupt handler) albo inaczej procedury obsługi (ang. service routine), która wykonuje
niezbędne działania, takie jak np. wysłanie znaku do drukarki.
34

Zanim sterowanie zostanie przekazane do procedury obsługi, procesor zachowuje zawartości
licznika rozkazów PC i rejestru stanu SR, umieszczając je na stosie. Przed załadowaniem adresu
procedury obsługi do licznika rozkazów procesor ustawia w rejestrze stanu maskę bitową, aby
ustalić poziom priorytetu przerwania.
W przypadku samowektorującej obsługi przerwań adres początkowy jest znajdowany przez
wygenerowanie numeru wektora, który związany jest z poziomem priorytetu wskazanym przez
końcówki, na które zgłoszone zostało przerwanie. Na tej podstawie wyznaczany jest adres
początkowy, czyli wektor w tablicy wektorów przerwań (wyjątków) przechowywanej w ustalonym
miejscu pamięci.
Przy zwektoryzowanej obsłudze przerwań procesor po otrzymaniu przerwania wysyła sygnał
potwierdzenia przerwania, zaznaczony na rysunku 7.15 linią przerywaną. Urządzenie odpowiada,
umieszczając numer wektora na magistrali danych. Procesor czyta ten numer i używa go do
indeksowania tablicy wyjątków.
Po załadowaniu do licznika rozkazów adresu procedury obsługi wykonywalny jest program
obsługi przerwania, który kończy się po napotkaniu rozkazu powrotu z przerwania (ang. ReTurn
from Exception; RTE). Rozkaz ten odtwarza ze stosu zawartości rejestrów SR i PC i przekazuje
sterowanie do przerwanego programu.
c)
przesłanie danych zrealizowane przez bezpośredni dostęp do pamięci
// Stolarczyk Ziemowit:
Samo przesyłanie danych odbywa się z pominięciem procesora. Jedyny wkład procesora polega
na zaprogramowani kontrolera DMA oraz na czas przesyłania danych zwolnić magistralę
systemową. Pozwala to na bezpośredni dostęp urządzeń zewnętrznych (karty graficzne, karty
dźwiękowe, dyski twarde itp.) do pamięci operacyjnej. Znacząc zwiększa to wydajność systemu.
Ponieważ przesył danych w stosunku do możliwości procesora jest mizernie wolny. Odciążenie
procesora od kontroli nad nim pozwala na wykonywanie w tym czasie innych operacji np. na
danych zgromadzonych w pamięci cache (na tych z RAMu nie może gdyż magistrala jest zajęta
przez kontroler DMA).
Niejednokrotnie transfer danych za pomocą kontrolera DMA jest szybszy niż zrobiłby to
procesor.
// Szeliga Bartosz:
W tym trybie przesyłania CPU inicjuje transmisje sterowaną przez DMA, przesyłając do DMA adres
pamięci oraz liczbę słów do przesłania. Rozpoczynając przesyłanie, DMA najpierw testuje, czy
jednostka pamięci nie jest zajęta w związku z operacją wykonywaną przez CPU, a następnie
„wkrada” jeden cykl pamięciowy aby uzyskać odstęp do komórki pamięciowy. Tryb z bezpośrednim
dostępem do pamięci jest preferowanym sposobem przesyłania danych w przypadku szybkich
urządzeń zewnętrznych takich jak np. dyski. DMA jest procesem wykonywanym zupełnie poza
35

procesorem, dzięki czemu jest to najwydajniejsza z wymienionych.
Algorytm funkcjonowania układu DMA
Układ DMA pracuje w dwóch trybach:
– jako układ podporządkowany (slave)
– jako układ nadrzędny (master)
Procedura transmisji
Procesor inicjuje transmisje wpisując adres do LA oraz liczbę przesłanych słów do LS a do rejestru C
informacje określającą kierunek przesyłania. To powoduje przejście DMA do pracy w trybie
nadrzędnym
•
I/O → DMA;
•
DMA → CPU;
•
CPU → DMA
•
DMA → I/O
Po zakończeniu przesłania LA=LA+1; LS = LS 1;
jeżeli DRQ = 1 nadal dalej kontynuowany jest proces przesyłania w przeciwnym przypadku DMA kasuje
HOLD.
3.
Budowa magistrali i jej przeznaczenie oraz metody arbitrażu magistrali.
// Ziemowit Stolarczyk:
1. Schemat
PROCESOR
I
------------------------------------MAGISTRALA SYSTEMOWA----------------------------------
I
I
I
Moduł Sprzęgający
Moduł Sprzęgający
Moduł Sprzęgający
I
I
I
Pamięć
Karta graficzna
Karta dźwiękowa itd.
2. Magistrala – składowe:
a) Szyna danych – składa się z linii danych (8,16,32... potęgi dwójki). Liczba linii stanowi o
szerokości szyny. Każda linia w danym czasie może przesyłać 1 bita informacji w jedną ze
stron. Liczba linii jest więc równa przepustowości szyny. Określa ona wydajność całego
systemu. (Np. Gdy procesor 32 bitowy, a szyna 16 bitowa to szyna 'dławi' pocesor. On musi
łączyć się z nią dwukrotnie żeby być w stanie przesłać lub pobrać całą informację).
b) Szyna adresowa – złożona jest z linii adresowych określających miejsce do lub z którego
przesłać/pobrać dane magistralą. Jej szerokość determinuje mkasymalną, możliwą
pojemność pamięci systemu [Gdy liczba linii jest ograniczona nie możesz za ich pomocą
przesłać dowolnie dużego adresu ;) ]
Linie adresowe, adresują także porty wejścia/wyjścia.
c) Szyna sterująca – steruje dostępem do dwóch pozostałych szyn, a także ich
wykorzystaniem. Sygnały przesyłane za jej pomocą zawierają nie tylko rozazy, ale także
informacje dotyczące synchronizacji.
36

Zadania szyny:
–
Odczyt z pamięci
–
Odczyt/Zapis do/z I/O.
–
Potwierdzenie przesłania.
–
Zgłoszenie zapotrzebowania na magistralę.
–
Rezygnacja z magistrali.
–
Zgłoszenie przerwania.
–
Potwierdzenie przerwania.
Do magistrali podłączonych może być wiele urządzń. Urządzenia te dzielone są na:
a) master – inicjujący działanie.
b) slave – odpowiadający na żądanie master.
W przypadku podłączenia do magistrali więcej urządzeń typu master musi istnieć sposób arbitrażu
pomiędzy nimi – przyznający priorytety i chroniący przed niedopuszczeniem do magistrali
urządzeń o niskim priorytecie.
Wyróżniamy arbitraże:
a) Szeregowy - wykorzystuje się linie sterujacą przydzielajacą magistrale, przekazywaną od
urządzenia o najwyższym priorytecie do tego o najniższym.
b) Scentralizowany równoległy - każde urządzenie ma linie sterujacą żądającą dostepu do
magistrali, a centralny arbiter wybiera urządzenie otrzymujące dostep.
c) Zdecentralizowany oparty na samodzielnym wyborze – jak scentralizowany, ale urządzenia same
ustalają które ma jaki priorytet.
d) Zdecentralizowany z wykrywaniem kolizji – każde urządzenie może wysłać żądanie do
magistrali, a jeśli magistrala wykryje kolizję odmówi i urządzenie będzie musiało wysłać żądanie
jeszcze raz.
// Szwed Kamil:
a) Centralną funkcję w systemie pełni procesor, który komunikuje się z pozostałymi komponentami
za pomocą trzech magistral:
–
Magistrala adresowa — służy do przekazywania adresu komórki lub rejestru wejścia
wyjścia. Szerokość magistrali adresowej określa obszar adresowy komputera. Ponieważ
adres jest liczbą binarną, to dla n linii adresowych obszar ten ma rozmiar
2
n
.
–
Magistrala danych — służy do przesyłania danych pomiędzy procesorem a pamięcią lub
rejestrami wejścia/wyjścia. Magistrala danych jest dwukierunkowa, tzn. te same linie są
używane do zapisu i odczytu informacji.
–
Magistrala sterująca — umożliwia procesorowi zapis lub odczyt informacji w pamięci lub w
rejestrach wejścia/wyjścia.
b) Magistrala ta zawiera cztery linie sterujące: R, W, MEM oraz IO.
–
Linia R — steruje odczytem danych do pamięci lub do rejestrów wejścia/wyjścia.
37
–
Linia W — steruje zapisem danych z pamięci lub z rejestrów wejścia/wyjścia.
–
Linia MEM — stan wysoki na linii MEM wybiera pamięć do operacji zapisu/odczytu. Gdy na
linii tej panuje stan niski, pamięć jest odłączona (nieaktywna) i nie reaguje na zmiany
sygnałów R i W.
–
Linia IO — steruje operacjami zapisu i odczytu portów wejścia/wyjścia. W stanie niskim
porty są odłączone od magistrali danych i nie reagują na zmiany sygnałów R i W.
–
Liniami wyboru pamięci i rejestrów wejścia/wyjścia steruje układ adresowy w procesorze.
c) Metody arbitrażu magistrali:
W systemach z więcej niż jednym urządzeniem master wymagany jest arbitraż magistrali
przyznający priorytet określonym urządzeniom master i gwarantujący niezablokowanie urządzeń o
niższym priorytecie.
–
Arbitraż szeregowy — wykorzystuje sie linie sterująca przydzielająca magistrale,
przekazywana od urządzenia o najwyższym priorytecie do tego o najniższym.
–
Scentralizowany arbitraż równoległy — każde urządzenie ma linie sterująca żądająca
dostępu do magistrali, a centralny arbiter wybiera urządzenie otrzymujące dostęp.
–
Zdecentralizowany arbitraż oparty na samodzielnym wyborze — podobny do arbitrażu
scentralizowanego, ale urządzenia same określają, które ma wyższy priorytet.
–
Zdecentralizowany arbitraż z wykrywaniem kolizji — każde urządzenie może zażądać
dostępu do magistrali, a jeżeli magistrala wykryje kolizje, to urządzenie będzie musiało
wysłać zadanie jeszcze raz.
4.
Typy pamięci, hierarchia pamięci w systemie komputerowym.
// Stolarczyk Ziemowit:
Pamięci możemy dzielić ze względu na:
ulotność:
•
pamięci ulotne przechowują dane tak długo, jak długo włączone jest ich zasilanie
•
pamięci nieulotne zachowują dane także po odłączeniu zasilania
•
możliwość zapisu i odczytu:
•
tylko do odczytu (zapis odbywa się w fazie produkcji)
•
jednokrotnego zapisu
•
wielokrotnego zapisu, ale ograniczoną liczbę razy, długotrwałego i utrudnionego
•
wielokrotnego trwającego porównywalnie z odczytem, łatwego i nieograniczoną
liczbę razy
•
wymagająca kasowania przed zapisem nowych danych
•
nośnik:
•
półprzewodnikowy (układ scalony)
•
optyczny
•
magnetyczny
•
magnetooptyczny
•
polimerowy
•
papierowy (np. karta dziurkowana)
•
miejsce w konstrukcji komputera:
•
rejestry procesora
•
pamięć podręczna, czyli cache
38
•
pamięć operacyjna - dostępna bezpośrednio przez procesor, w tym RAM
•
zewnętrzna - dostępna dla procesora jako urządzenie zewnętrzne, w tym pamięci
USB, masowa (stacje dysków, taśm itp.)
•
pamięć robocza podzespołów (np. rejestry stanu urządzenia, bufory w kartach
sieciowych, bufor wysyłanego lub odebranego znaku w łączu szeregowym, pamięć
obrazu w k. graficznych)
•
sposób dostępu do informacji:
•
pamięć o dostępie swobodnym - po wybraniu adresu dostępna jest dowolna
jednostka pamięci
•
pamięć o dostępie szeregowym (cyklicznym) (rejestry przesuwne, pamięć taśmowa)
- dostęp do danych wymaga odczytania ich kolejno
•
pamięć skojarzeniowa(asocjacyjna) - miejsce dostępu do niej jest zależne od
zawartości innej pamięci
•
pamięć wielopoziomowa - pamięć o dostępie szeregowym w obrębie szeregowym, z
możliwością wyboru sektorów
// Murias Tomasz:
Rejestry
Pamięć
podręczna:
Pamięć operacyjna
(RAM)
Pamięć wtórna
(dyskowa)
Archiwa
Czas dostępu: 0,5 - 5 [ns]
20 - 120 [ns]
1 - 15 [ms]
-
Pobór mocy:
duży
mały
bardzo mały bardzo mały
Można wyróżnić 3 podstawowe typy pamięci (ze względu na sposób dostępu do przechowywanych
danych):
1. Pamięć o dostępie swobodnym ( RAM – Random Acces Memory )
2. Pamięć o dostępie sekwencyjnym ( SAM – Sequentialy Acces Memory )
3. Pamięć adresowana zawartością ( Contents Addressable Memory-CAM)
Dostęp swobodny - niezależnie do którego elementu się odwołujemy, czas dostępu taki sam.
Dostęp sekwencyjny - streamery zapisujące dane.
Czas dostępu - czas upływający do chwili ustabilizowania się informacji wskazujących lokalizację.
W przypadku systemów komputerowych pamięć dzieli się na statyczną i dynamiczną
•
p. statyczna wykorzystywana jako pamięć podręczna. Poszczególne komórki pamięci są
zbudowane w oparciu o przerzutniki typu D
39

Wadą pamięci statycznej jest to, że pamięć ta charakteryzuje się dosyć dużym poborem
mocy.
•
p. dynamiczna Nośnikiem informacji jest ładunek, który jest gromadzony na poszczególnych
tranzystorach typu MOSFET. Kondensatory charakteryzują się tym, że z czasem tracą ładunek.
Aby tego uniknąć pamięć jest co jakiś czas odświeżana. Jest to mankament mający wpływ na
moc obliczeniową całego systemu komputerowego.
5.
Pamięć podręczna.
a)
idea pamięci podręcznej oraz założenia na których jest oparte funkcjonowanie pamięci
podręcznej
Pamięć podręczna (cache) jest to najwyżej umieszczona pamięć w hierarchii pamięci komputera.
Pośredniczy między procesorem a pamięcią główną (RAM). Ma ona względnie niedużą pojemność
i jest bardzo szybka (najszybsza ze wszystkich pamięci).
Pamięć podręczna jest elementem właściwie wszystkich systemów - współczesny procesor ma 2
albo 3 poziomy pamięci podręcznej oddzielającej go od pamięci RAM.
Systemy pamięci podręcznej s tak wydajne dzięki lokalności odwołań. Dane, do których
odwołanie następuje względnie często, są pamiętane w pamięci przez cały czas. Niektóre systemy
pamięci podręcznej umożliwiają wyprzedzanie żądań procesora i wcześniejsze wczytywanie
danych, które będą dla niego potrzebne po wielokroć oraz umożliwiają informowanie systemu na
temat charakteru danych, które będą buforowane.
Część systemu komputerowego zajmująca się buforowaniem danych (pamięć podręczna) powinna
charakteryzować się następującymi właściwościami:
•
powinna być jak najbardziej automatyczna
•
jej działanie nie powinno wpływać na semantykę pozostałych części systemu
•
powinna w jak największym stopniu poprawiać wydajność systemu w warunkach
rzeczywistej pracy
b)
budowa pamięci podręcznej
Ma jeden lub więcej poziomow oznaczanych L1, L2, itd., zazwyczaj:
•
L1 cache - przyśpiesza dostęp do bloków pamięci wyższego poziomu
(operacyjną lub podręczną kolejnego poziomu). Zawsze najmniejsza.
•
L2 cache - bufor pomiędzy RAM-em, a procesorem.
•
L3 cache - wykorzystana, gdy L2 nie jest w stanie pomieścić
potrzebnych danych.
40
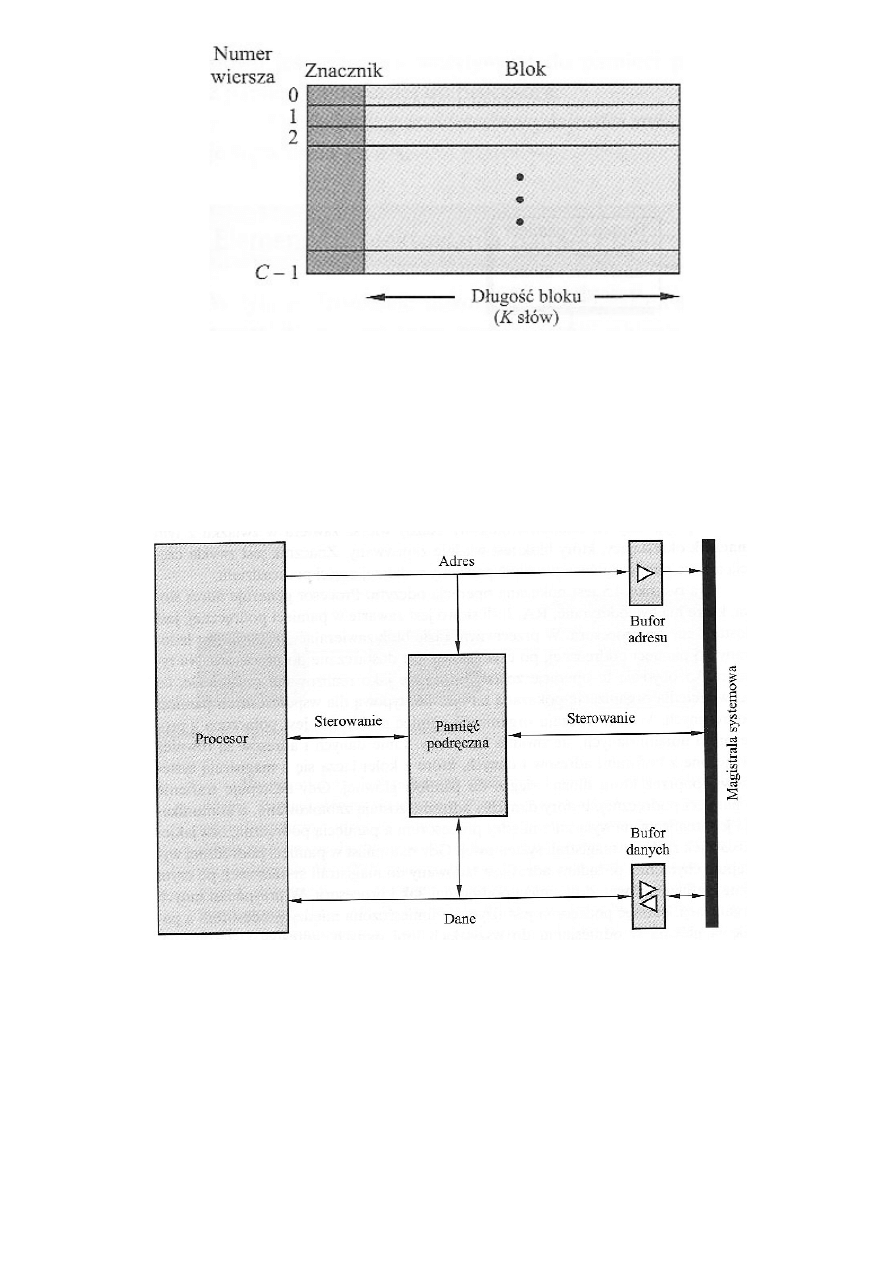
Struktura pamięci podręcznej.
Pamięć podręczna zawiera C wierszy K po słów każdy. Liczba wierszy jest
znacząco mniejsza od liczby bloków w pamięci głównej ( C≪M ). W każdej chwili
pewien zespół bloków pamięci głównej zostaje pozostaje w wierszach pamięci
podręcznej. Jeśli słowo jest odczytywane, to odpowiedni blok jest przenoszony do
wiersza pamięci podręcznej. Żaden wiersz nie może być jednoznacznie i trwale
przypisany danemu blokowi, gdyż C≪M . Stąd każdy wiersz zawiera znacznik
określający właśnie zapisany blok (zwykle część adresu pamięci głównej).
Typowa organizacja pamięci podręcznej.
c)
parametry opisujące efektywność funkcjonowania pamięci podręcznej
Z punktu widzenia użytkownika dwiema najważniejszymi własościami pamięcia są pojemność i
wydajność. Używane są trzy parametry będące miarą wydajności:
•
czas dostępu – czas niezbędny do zrealizowania operacji odczytu lub zapisu – czas od chwili
doprowadzenia adresu do chwili zmagazynowania lub udostępnienia danych (dla pamięci o
dostępie swobodnym). W przypadku pamięci o dostępie nieswobodnym czas ten jest
41

czasem potrzebnym na umieszczenie mechanizmu odczytu-zapisu w pożądanym miejscu.
•
czas cyklu pamięci – pojęci to było pierwotnie sotosowane do pamięcie o dostępie
swobodnym. Czas cyklu składa się z czasu dostępu oraz dodatkowego czasu, który musi
upłynąć, zanim będzi mógł nastąpić kolejny dostęp. Ten dodatkowy czas może być
potrzebny dla zaniku sygnałów przejściowych lub do regeneracji danych, jeśli odczyt jest
niszczący.
•
szybkośc przesłania (transferu). Jest ot szybkość z jaką dane mogą być wprowadzane do
jednostki pamięci lub z niej wyprowadzane. W przypadku pamięci o dostępie swobodnym
jest ona równa 1/(czas cyklu).
d)
obsługa pamięci podręcznej
Linia jest jednostką wymiany danych pomiędzy pamięcią główną, a pamięcią podręczną.
Trafienie podczas obsługi, to znalezienie odpowiedniej linii w pamięci podręcznej. Chybienie to nie
znalezienie odpowiedniej linii. Podczas obsługi pamięci podręcznej może dojść do:
•
unieważnienia linii - podczas inicjowania pamięci, przed pierwszym wypełnieniem
(ponieważ stan linii jest nieznany) lub podczas modyfikacji linii w pamięci głównej (kopia w
pamięci podręcznej przestaje być kopią);
•
wypełnienia linii – najczęściej na skutek chybienia podczas odczytu, może być wykonywane
jako obsługa wyjątku, zwykle wykonywane w trybie szybkiej transmisji blokowej;
•
odczyt danych z linii – trafienie podczas odczytu, nie wymaga podejmowania dodatkowych
czynności; chybienie powoduje uruchomienie procedury wypełniania linii
zapis danych do linii – zapis skrośny (jednoczesny), modyfikujący również kopię wyższego poziomu
(write trought, WT), zwykle realizowany jako aktualizacja wszystkich kopii poziomów wyższych;
zapis lokalny (zwrotny), ograniczony do kopii lokalnej, i opóźniony zapis do linii wyższego poziomu
podczas usuwania linii lokalnej (write back, WB); zapis bezpośredni (omijający) do pamięci głównej
(write aside), z jednoczesnym unieważnieniem linii trafionej.
IV A
RCHITEKTURY
R
ÓWNOLEGŁE
1.
Cel konstrukcji komputera o architekturze równoległej, typy problemów
rozwiązywanych z zastosowaniem komputerów: pojęcie problemu wielkiej skali,
pojecie klasy trudności problemu (złożoności obliczeniowej problemu).
Fizyczne ograniczenia powodujące niemożność zwiększenia częstotliwości taktowania
procesorów, a co za tym idzie wzrostu mocy obliczeniowej doprowadziły do idei
architektury równoległej która pozwalałaby rozwiązywać problemy przy użyciu wielu
procesorów.
2.
Podział architektur równoległych zaproponowany przez Flynna.
Taksonomia Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach
sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się na liczbie przetwarzanych
strumieni danych i strumieni rozkazów.
W taksonomii tej wyróżnia się cztery grupy:
a) SISD (Single Instruction, Single Data) - przetwarzany jeden strumień danych przez jeden
wykonywany program - komputery skalarne (sekwencyjne).
b) SIMD (Single Instruction, Multiple Data) - przetwarzanych jest wiele strumieni danych przez
jeden wykonywany program - tzw. komputery wektorowe.
42
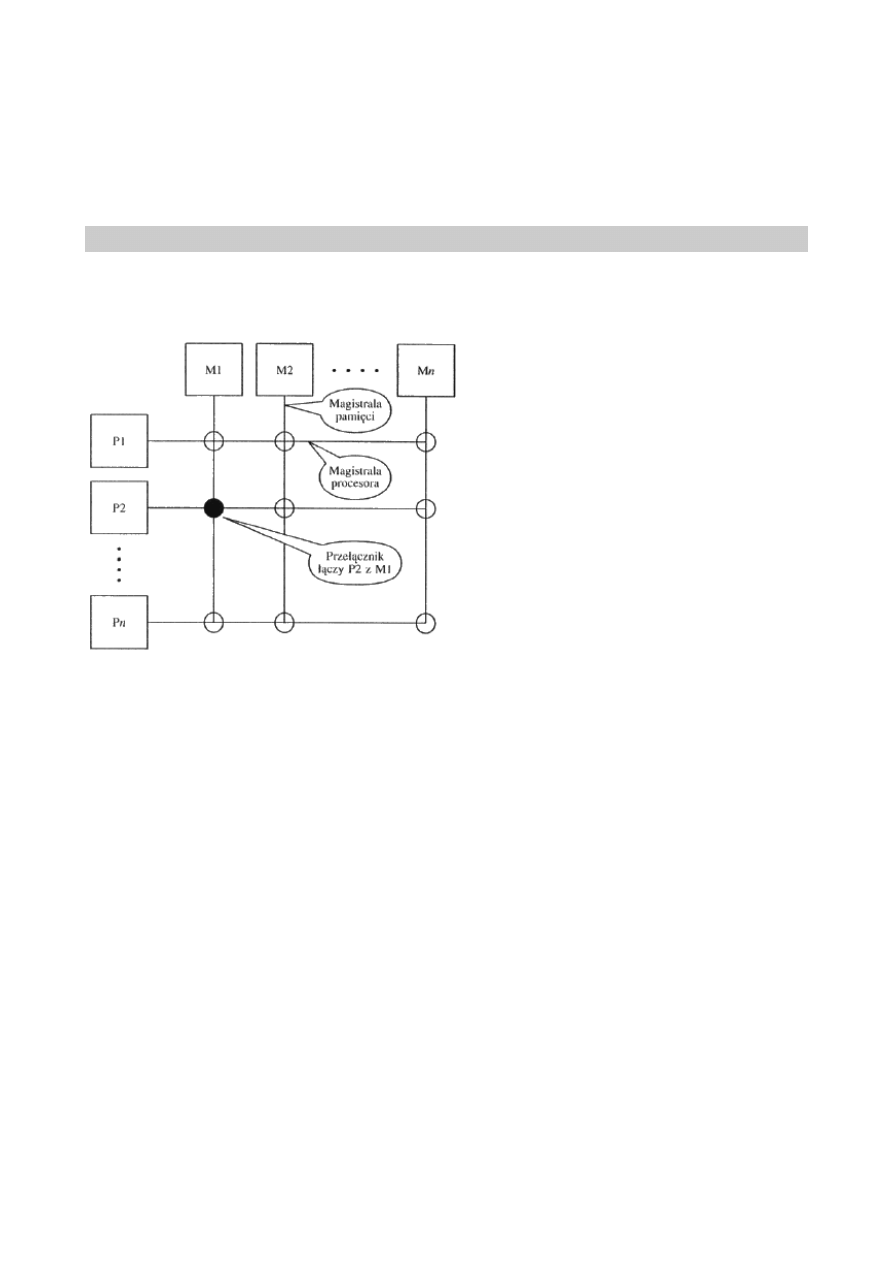
c) MISD (Multiple Instruction, Single Data) - wiele równolegle wykonywanych programów
przetwarza jednocześnie jeden wspólny strumień danych. W zasadzie jedynym
zastosowaniem są systemy wykorzystujące redundancję (wielokrotne wykonywanie tych
samych obliczeń) do minimalizacji błędów.
d) MIMD (Multiple Instruction, Multiple Data) - równolegle wykonywanych jest wiele
programów, z których każdy przetwarza własne strumienie danych - przykładem mogą być
komputery wieloprocesorowe, a także klastry i gridy.
3.
Architektury MIMD ze wspólną pamięcią operacyjną.
a)
architektura systemu z wykorzystaniem przełącznika krzyżowego
Jednym ze sposobów łączenia procesorów z pamięcią współdzieloną jest użycie wielu modułów
pamięci, do których procesory są przyłączane za pomocą matrycy przełączników.
Architektura z pamięcią wspólną
z wykorzystaniem przełącznika krzyżowego
Zalety:
•
Problem konfliktu o magistralę
ograniczony do sporadycznych konfliktów o
magistralę pamięci.
•
Procesory mogą używać modułów
pamięci równolegle, co znacznie zwiększa
szybkość przesyłania danych.
•
Możliwa dynamiczna
rekonfiguracja sieci.
Wady:
•
Koszt sprzętu
•
Liczba przełączników rośnie z
kwadratem liczby procesorów (dlatego sieci
przełączników krzyżowych używane raczej do
łączenia niewielkiej liczby procesorów).
Przełączniki krzyżowe są skomplikowanymi urządzeniami potrafiącymi łączyć magistrale danych,
adresową i sterującą procesora z jednym z modułów pamięci. Każdy przełącznik zawiera układ
arbitrażowy do rozstrzygania wielu jednoczesnych prób dostępu do tego samego modułu.
b)
architektura systemu z pamięcią wieloportową
Pamięć wieloportowa
Użycie pamięci wieloportowej umożliwia bezpośredni, niezależny dostęp każdego procesora
i każdego modułu wejścia-wyjścia do modułów pamięci głównej. DO rozwiązywania
konfliktów są wymagane układy logiczne związane z pamięcią. Często stosowaną metodą
rozwiązywania konfliktów jest stałe przypisanie priorytetu każdemu portowi pamięci.
Zwykle interfejs fizyczny i elektryczny każdego portu jest identyczny z tym, jaki
występowałby w jednoportowym module pamięci. Potrzeba więc niewiele (lub wcale)
modyfikacji procesora lub modułów wejścia-wyjścia, aby dostosować je do pamięci
wieloportowej.
Rozwiązanie z pamięcią wieloportową jest bardziej złożone niż magistralowe, wymaga
bowiem dodania do systemu pamięci dość dużej liczby układów logicznych. Powinno jednak
umożliwić uzyskanie większej wydajności, ponieważ każdy procesor ma własną ścieżkę do
43

każdego modułu pamięci. Inną zaletą rozwiązania wieloportowego jest umożliwienie
skonfigurowania części pamięci jako pamięci "własnych" jednego lub wielu procesorów
i/lub modułów wejścia-wyjścia. Własność ta pozwala na poprawę zabezpieczenia przed
nieupoważnionym dostępem oraz na przechowywanie podprogramów regeneracji w
obszarach pamięci, które nie mogą być modyfikowane przez inne procesory.
Do sterowania pamięciami podręcznymi powinna być używana metoda jednoczesnego
zapisu, ponieważ nie ma innych środków alarmowania innych procesorów o aktualizacji
pamieci.
c)
architektura systemu z wspólną magistralą
Topologia magistrali (szynowa) – jedna z topologii fizycznych sieci komputerowych
charakteryzująca się tym, że wszystkie elementy sieci są podłączone do jednej magistrali
(zazwyczaj jest to kabel koncentryczny). Większość topologii logicznych współpracujących z
topologią magistrali wychodzi z użytku (wyjątkiem jest tutaj 10Base-2, który nadal może
znaleźć zastosowanie).
Sieć składa się z jednego kabla koncentrycznego (10Base-2, 10Base-5 lub 10Broad36).
Poszczególne części sieci (takie jak hosty, serwery) są podłączane do kabla koncentrycznego
za pomocą specjalnych trójników (zwanych także łącznikami T) oraz łączy BNC. Na obu
końcach kabla powinien znaleźć się opornik (tzw. terminator) o rezystancji równej
impedancji falowej wybranego kabla, aby zapobiec odbiciu się impulsu i tym samym zajęciu
całego dostępnego łącza. Maksymalna długość segmentu sieci to w przypadku:
•
10Base-2 – 185 m,
•
10Base-5 – 500 m,
•
10Broad36 – 1800 m.
Przesyłanie danych
Sieć o takiej topologii umożliwia tylko jedną transmisję w danym momencie (wyjątkiem jest
tutaj 10Broad36, który umożliwia podział kabla na kilka kanałów). Sygnał nadany przez
jedną ze stacji jest odbierany przez wszystkie (co bez zastosowania dodatkowych
zabezpieczeń umożliwia jego przechwycenie, które opiera się wyłącznie na przestawieniu
karty sieciowej w tryb odbierania promiscuous), jednakże tylko stacja, do której pakiet
został zaadresowany, interpretuje go. Maksymalna przepustowość łącza w tych trzech
podanych standardach sieci Ethernet to 10 Mb/s.
Zalety :
•
małe użycie kabla,
•
brak dodatkowych urządzeń (koncentratorów, switchów),
•
niska cena sieci,
•
łatwość instalacji,
•
awaria pojedynczego komputera nie powoduje unieruchomienia całej sieci .
Wady :
•
trudna lokalizacja usterek,
•
tylko jedna możliwa transmisja w danym momencie (wyjątek: 10Broad36),
•
potencjalnie duża ilość kolizji,
•
awaria głównego kabla powoduje unieruchomienie całej domeny kolizji,
44
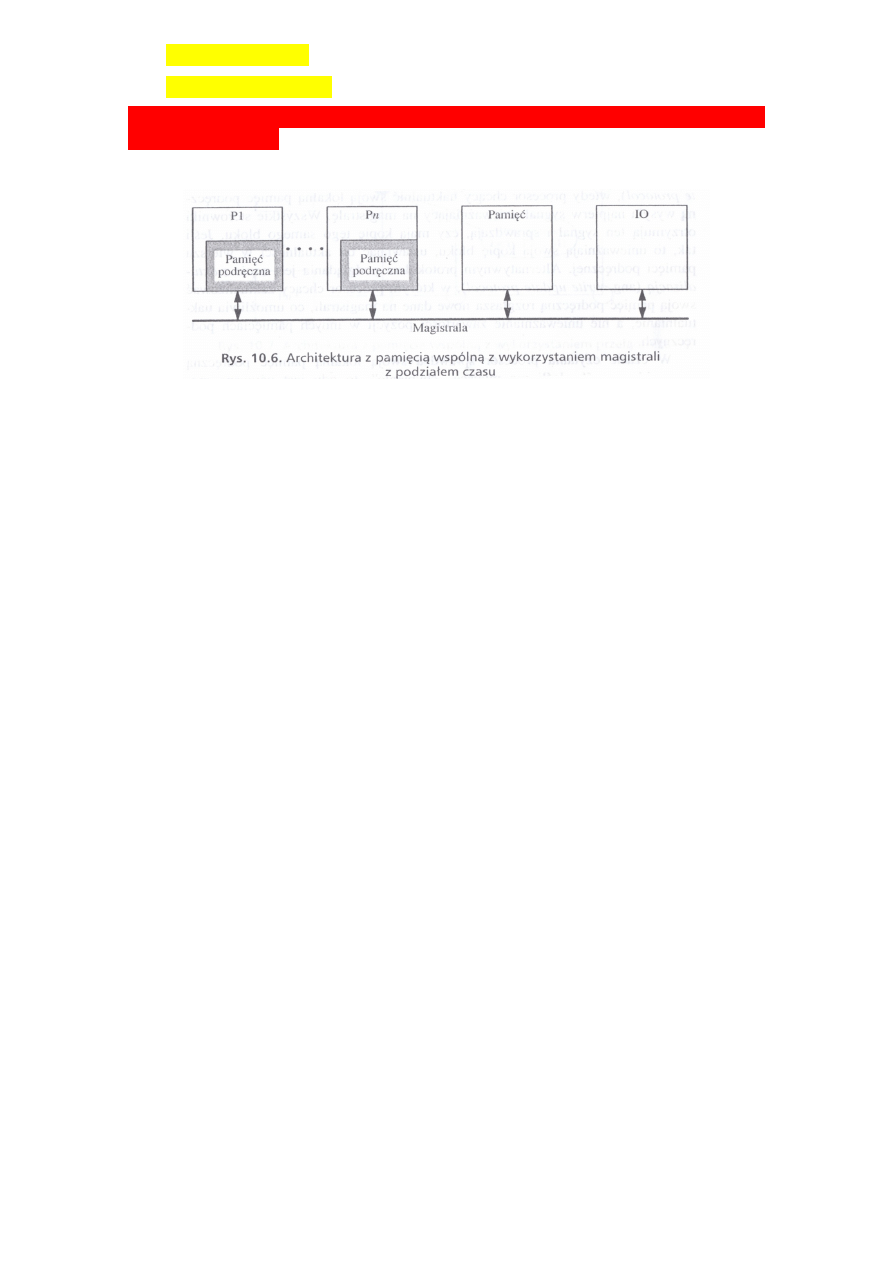
•
słaba skalowalność,
•
niskie bezpieczeństwo.
Według mnie jest to źle co napisał Olo(to na żółto), więc proszę sprawdzcie i zostawcie
odpowiednią wersję
// Szczygieł Michał:
Każdy procesor ma oddzielną lokalną pamięć podręczną do przechowywania rozkazów i danych.
Jedna wspólna magistrala jest używana przez procesory P
1
, P
2
... P
n
do uzyskania dostępu do
pamięci.
Jeśli procesor chce uzyskać dostęp do pamięci, to zanim przejmie kontrolę nad magistralą i
zacznie przesyłanie, najpierw musi sprawdzić, czy magistrala jest dostępna. Kiedy jeden z
procesorów używa magistrali, pozostałe mogą używać tylko swoich lokalnych pamięci podręcznych
i muszą czekać, aż zwolni on magistralę, zanim będą mogły dostać się do wspólnej pamięci.
Wspólna magistrala jest więc źródłem konfliktów. Jeśli zgłoszonych jest jednocześnie kilka żądań do
magistrali, w tym żądanie operacji wejścia-wyjścia zlecone przez sterownik urządzeń zewnętrznych,
to musi istnieć jakaś forma arbitrażu, w wyniku którego zapadnie decyzja o tym, który procesor
może kontynuować pracę, a które muszą zaczekać. Może to być zrobione przez przypisanie
każdemu z procesorów różnych priorytetów przy użyciu urządzenia zwanego arbitrem magistrali.
Jednym z głównych problemów przy dzieleniu wspólnej magistrali jest jej nasycenie, które
powstaje, kiedy dołączonych jest zbyt wiele procesorów. W takich warunkach procesory, zamiast
wykonywać rozkazy, większość czasu oczekują, aż będą zarządzać magistralą. To wąskie gardło jest
częściowo likwidowane przez wyposażenie każdego procesora w lokalną pamięć podręczną, ale
niestety wprowadza dodatkowy problem ze zgodnością wielu pamięci podręcznych.
Przy wielu pamięciach podręcznych w systemie może istnieć kilka kopii tych samych danych.
Jeśli jeden procesor uaktualnia pamięć podręczną, wykonując np. operację zapisu przez to w
pozostałych lokalnych buforach, które zawierają ten sam blok, pozostawione są „nieświeże dane".
W celu zapobiegania tego rodzaju zakłóceniom programu konieczna jest jakaś forma
dynamicznego sprawdzania zgodności, prowadząca do unieważnienia takich pozycji w pamięciach
podręcznych i być może uaktualnienia ich danymi „poprawnymi". Jednym z typowych sposobów
osiągnięcia tego jest użycie protokołu zgodności zwanego podglądaniem (ang. snooping).
Przy podglądaniu wszystkie sterowniki pamięci podręcznych monitorują (podglądają)
magistralę, aby stwierdzić, czy mają kopię tego samego bloku. Kiedy używany jest protokół
zapisów z unieważnieniem (ang. write invalidate protocol), wtedy procesor chcący uaktualnić
swoją lokalną pamięć podręczną wysyła najpierw sygnał unieważniający na magistralę. Wszystkie
sterowniki otrzymują ten sygnał i sprawdzają, czy mają kopię tego samego bloku. Jeśli tak, to
unieważniają swoją kopię bloku, ustawiając bit aktualności w wierszu pamięci podręcznej.
Alternatywnym protokołem podglądania jest zapis z aktualizacją (ang. write update protocol), w
którym procesor chcący zaktualizować swoją pamięć podręczną rozgłasza nowe dane na
magistrali, co umożliwia uaktualnianie, a nie unieważnianie zawartości pozycji w innych
pamięciach podręcznych.
W czasie czytania procesor sprawdza swoją lokalną pamięć podręczną w zwykły sposób. Jeśli
ma miejsce „chybienie", to gdy jest używana metoda zapisu z opóźnieniem, we wszystkich innych
45
pamięciach podręcznych trzeba sprawdzić, czy nie ma w nich żądanych danych. Jeśli są, to muszą
być dostarczone do żądającego procesora. Jeśli nie ma, to muszą być pobrane z pamięci.
d)
problem skalowania systemów z wspólna pamięcią typu MIMD
// Do uzupełnienia
4.
Architektury MIMD z rozproszoną pamięcią operacyjną.
a)
budowa transputera
•
Transputer – mikrokomputer w jednym układzie scalonym. Zaprojektowany specjalnie do
obliczeń równoległych (szybka komunikacja i łatwość połączenia innymi transputerami).
Wraz z transputerem opracowany został język programowania równoległego OCCAM.
•
W skład transputera wchodzi procesor typu RISC, wewnętrzna pamięć RAM oraz łącze
pamięci zewnętrznej, która umożliwia adresowanie w przestrzeni 4 GB. Do komunikacji z
innymi transputerami wykorzystywane są cztery kanały DMA.
•
Pierwszym modelem transputera był T-414 z 1985. Zawierał on 32-bitowy procesor oraz 2
kB pamięci RAM. Jego następcą był T-800, w skład którego wchodziła także jednostka
zmiennoprzecinkowa. W 1994 powstał model T-9000 wyposażony w 16 kB pamięci, 64-
bitową jednostkę zmiennopozycyjną oraz kanały o przepustowości 100 MB/s.
b)
podstawowe topologie połączeń transputerów oraz parametry opisujące daną strukturę
Z wykładu:
Potok:
Tabela 2D:
Całkowite połączenie:
wszystko ze wszystkim
Z internetu:
Ring:
Hypercube:
Mesh:
Torus:
46

// uzupełnić o parametry struktur
c)
wpływ struktury architektury równoległej na złożoność obliczeniową algorytmu, pojęcie
adekwatności struktury architektury równoległej z strukturą problemu
Klasy algorytmów:
•
pspace - problem dający się rozwiązać bez ograniczenia na czas przy wielomianowym
zapotrzebowaniu na jednostki pamięci;
•
PH (hierarchia wielomianowa) - problemy o coraz większej złożoności czasowej;
•
NP - problemy, dla których istnieją wielomianowe algorytmy niedeterministyczne -> funkcja
złożoności jest wykładnicza dla deterministycznych maszynowych.
•
P - problemy dające się rozwiązać w wielomianowym czasie na deterministycznych
maszynach sekwencyjnych.
Obliczenia klasy P - problemy dużej skali:
•
większość problemów dużej skali;
•
aplikacyjny charakter;
•
w fizyce, sztucznej inteligencji, zagadnieniach militarnych;
•
dane zorganizowane w macierze lub prae // prae?
•
przyczyniły się do utworzenia koncepcji pozwalających na szybkie przetwarzanie problemów
dużej skali:
◦
procesora wektorowego,
◦
procesora wektorowego z przetwarzaniem potokowym,
◦
wektora procesorów wektorowych;
Obliczenia klasy NP:
Dla tej klasy problemów, koncepcje systemów równoległych stały się adekwatnymi
modelami obliczeniowymi dla tej grupy problemów.
Adekwatność ta polega na zgodności między strukturą problemów a strukturą połączeń
w systemach równoległych.
Założenia dot. architektur grafopodobnych:
I postulat regularnośi struktury grafu - wyodrębnienie podgrafu, który można
replikować. Ułatwia to rozwiązywanie kwestii dopasowania postaci algorytmu do
systemu.
II postulat (stopień wierzchołka, długość drogi):
◦
maksymalny stopień D1 jak największy,
◦
maksymalna droga D2 jak najkrótsza;
Stopień wierzchołka D1 określa maksymalną ilość procesorów sąsiednich danemu. W
praktyce powinno się dążyć do minimalizacji D1 ze względu na koszty interfejsu.
Jeśli graf jest nieregularny (wierzchołki mają różne stopnie), wymóg modularności
narzuca stosowanie procesorów zdalnych do obsługi maksymalnej możliwej ilości linii
iterfejsu. Z tego powodu drugim postulatem jest stałość oraz minimalna wartość
wielkości D1.
Długość drogi D2 określa maksymalą drogę w systemie między dowolną parą
47

procesorów. Wielkość ta definiowana jest jako ilość łączy pośredniczych w przesyłaniu
informacji między zadaną parą.
III postulat (brak centralnych wierzchołków):
// prosiłam Marcina Ślósarza o jakieś wytłumaczenie tego fragmentu,
// bo to z jego notatek:
Czwartym postulatem jest nieistnienie w grafie modelu wierzchołków centralnych,
które wchodzą w skład stosunkowo względem innych wierzchołków, ilości drug grafu.
Można oczekiwać, iż wierzchołki taki mogą uczestniczyć w proporcji ilości transmisji.
5.
Architektury współczesnych systemów komputerowych.
a)
cc-NUMA, NUMA, UMA, NORMA
•
UMA (ang. Uniform Memory Access) - architektura komputerowa, służąca do przetwarzania
współbieżnego.
Charakteryzuje się tym, że w jej modelu wszystkie procesory dzielą spójną fizyczną
pamięć. Czas dostępu do danego miejsca w pamięci jest niezależny zarówno od
procesora wykonującego żądanie jak i od modułu pamięci zawierającego dane.
Urządzenia peryferyjne są podobnie dzielone.
W modelu UMA każdy procesor może mieć prywatną pamięć podręczną.
Model UMA jest dobrze przystosowany do aplikacji ogólnego użytku oraz dzielenia
czasu dla wielu użytkowników. Zastosowanie może zwiększyć szybkość wykonania
pojedynczego dużego programu w aplikacjach o krytycznym znaczeniu czasu.
Model UMA jest architekturą komputerową, w której procesory graficzne są
wbudowane w płytę główną, a część głównej pamięci komputera jest wydzielona na
pamięć graficzną (integracja GPU).
Przeciwieństwem modelu UMA jest model NUMA (ang. Non-Uniform Memory Access).
•
NUMA (ang. Non-Uniform Memory Access) – architektura komputerowa, służąca do
przetwarzania współbieżnego.
Architektura NUMA charakteryzuje się tym, że udostępnia użytkownikowi spójną
logicznie przestrzeń adresową, chociaż pamięć jest fizycznie podzielona. Komputery
zbudowane w tej architekturze posiadają wiele procesorów.
Niejednorodność w dostępie do pamięci polega na tym, że dany procesor szybciej
uzyskuje dostęp do swojej lokalnej pamięci, niż do pamięci pozostałych procesorów lub
pamięci współdzielonej.
•
CC-NUMA (ang. Cache Coherent Non-Uniform Memory Access) - architektura
komputerowa, charakteryzująca się niejednorodnym dostępem do pamięci oraz spójną
pamięcią podręczną.
Maszyny oparte na CC-NUMA udostępniają użytkownikowi spójną logicznie przestrzeń
adresową pomimo fizycznego podziału pamięci.
Niejednorodność w dostępie do pamięci oznacza, że procesor uzyskuje szybciej dostęp
do pamięci swojej niż do innych. W wieloprocesorach typu NUMA istnieje pojedyncza
wirtualna przestrzeń adresowa widoczna przez wszystkie procesory. Wartość zapisana
przez dowolny procesor jest natychmiastowo widoczna dla wszystkich pozostałych,
dlatego też następna operacja odczytu z tej komórki pamięci przez dowolny procesor
poda właśnie tą wartość.
48
W CC-NUMA pamięci podręczne muszą być spójne. Spójność ta jest zrealizowana za
pomocą dodatkowego sprzętu oraz protokołu. Wykorzystywany do tego jest katalog,
czyli dodatkowa pamięć, która służy do zapamiętywania faktu pobrania danych z
pamięci i przesłania ich do węzła lub, w bardziej skomplikowanych przypadkach,
miejsca pobytu wszystkich kopii danych.
•
NoRMA (ang. No Remote Memry Acces).
Najprostszy system wieloprocesorowy, bez dostępu do pamięci zewnętrznej. Cała
pamięć, jaką widzi procesor, to pamięć lokalna tego węzła. Komunikacja między
węzłami opiera się na wiadomościach między procesorami.
Gdy jeden komputer potrzebuje danych z pamięci innego komputera, oprogramowanie
przejmuje zdalny dostęp do pamięci i musi podjąć wewnętrzną komunikację, by
zarządać danych z zewnętrznej maszyny. Wszystkie aplikacje wstrzymują się, dopóki
rządający system nie otrzyma danych. Gdy dane są przeniesione w oczekiwane miejsce,
oprogramowanie zarządzające pozwala pracować dalej wszystkim procesom.
Podział:
shared-nothing - żadne urządzenia I/O nie są dzielone między węzłami,
shared-disk - dwa lub więcej portów kontrolerów dysku jest podpiętych do
oddzielnych węzłów.
Zalety:
Wady:
najtańsza przy projektowaniu, gdyż można
wykorzystać istniejące jedno- lub wieloprocesorowe
systemy jako węzły, następnie połączyć je
wyspecjalizowanymi urządzeniami I/O;
wysoka tolerancja na usterki (gdyż węzły są
fizycznie odseparowane od siebie);
skomplikowane
tworzenie oprogramowania;
Określenia:
“private memory”,
“message passing”,
“multi-computers”.
Ten rodzaj komputerów nazywany jest także DSM (ang. Distributed Shared Memory).
b)
SMP, PSMP
•
SMP (ang. Symmetric Multiprocessing, przetwarzanie symetryczne) - architektura
komputerowa, która pozwala na znaczne zwiększenie mocy obliczeniowej systemu
komputerowego poprzez wykorzystanie dwóch lub więcej procesorów do jednoczesnego
49

wykonywania zadań.
W architekturze SMP każdy procesor może zostać przypisany do wykonywania każdego
zadania, tak aby wyrównać obciążenie („obowiązki” są dzielone „po równo”). W
architekturze SMP procesory te współdzielą zasoby pamięci oraz wejścia/wyjścia przy
pomocy magistrali.
Ważną rzeczą jest wykorzystanie wielowątkowości przez programy komputerowe (oraz
obsługa wielowątkowości przez system operacyjny) - upraszcza to możliwość
„podzielenia” procesu dla kilku procesorów. Szczególną korzyść z przetwarzania
równoległego czerpią aplikacje do renderingu i edycji wideo oraz nowoczesne gry, małą
natomiast pakiety biurowe.
Systemami obsługującymi SMP jest większość Uniksów, Windows NT oraz BeOS.
Alternatywną architekturą do SMP jest MPP (ang. Massively Parallel Processing) -
przetwarzanie równoległe.
•
MPP (ang. Massively Parallel Processors, komputery masowo równoległe) – architektura
komputerowa, której zadaniem jest umożliwienie przetwarzania współbieżnego
(jednoczesnego) na wielu procesorach.
Do najistotniejszych realizowanych funkcji należą:
1. zarządzanie przydziałem zasobów komputera równoległego do procesów i
organizacja komunikacji między procesami
2. szeregowanie zadań (procesów) w czasie i przestrzeni
3. zarządzanie pamięcią wirtualną
4. rekonfiguracja systemu i redystrybucja zasobów między procesami w
przypadku awarii jednego z węzłów.
c)
Systemy RAS, SAN, NAS
•
RAS (ang. Remote Access Services) to pojęcie odnoszące się do każdej kombinacji sprzętu
(hardware) z oprogramowaniem (software) pozwalającej na wykorzystanie narzędzi do
zdalnego dostępu lub uzyskania informacji, które znajdują się w sieci urządzeń.
Server RAS jest specjalistycznym komputerem, który agreguje wiele dwukierunkowych
kanałów komunikacji. Z uwagi na ową dwukierunkowość jawią nam się dwa rodzaje
hipotetycznych zdarzeń:
1. Wiele bytów łączy się z jednym zasobem,
2. Jeden byt łączy się z wieloma zasobami.
Obydwa modele są szeroko rozpowszechnione i wykorzystywane; zarówno fizyczne, jak
i wirtualne zasoby mogą być zapewniane przez serwer RAS. Scentralizowane
przetwarzanie może dodatkowo zapewnić dostęp wielu użytkownikom do wirtualnego
systemu operacyjnego.
Dostawcy Internetu często używają serwerów RAS aby przerwać fizyczne połączenie z
ich klientami, przykładowo z tymi, którzy dostęp do Internetu otrzymują za pomocą
modemu.
•
SAN (ang. Storage Area Network) – sieć pamięci masowej; rodzaj sieci służący do dostępu
do zasobów pamięci masowej przez systemy komputerowe.
W chwili obecnej sieci SAN wykorzystywane są głównie w firmach, zastosowanie
domowe jest mocno ograniczone ze względu na bardzo duże koszty oraz
skomplikowanie budowy wymaganej infrastruktury: przełączniki SAN, karty Host Bus
50

Adapter czy w końcu macierze dyskowe lub biblioteki taśmowe.
•
NAS (ang. Network Attached Storage) – technologia umożliwiająca podłączenie zasobów
pamięci dyskowych bezpośrednio do sieci komputerowej.
Dzięki takiemu rozwiązaniu można łatwo skonfigurować dostęp do danych znajdujących
się w jednym miejscu z różnych punktów sieci. Zaletą NAS jest możliwość jego
stosowania w heterogenicznych sieciach opartych na różnych rozwiązaniach klienckich
przez co dane są osiągalne bez względu na rodzaj zainstalowanego systemu
operacyjnego.
51
Document Outline
- Architektury Systemów Komputerowych
- Zagadnienia na Egzamin
- 1. Metody reprezentacji liczb całkowitych.
- 2. Dodawanie liczb całkowitych.
- 3. Algorytmy mnożenia liczb binarnych.
- 4. Reprezentacja zmiennoprzecinkowa liczb rzeczywistych.
- a) budowa liczby zmiennoprzecinkowej oraz wpływ poszczególnych elementów liczby na zakres i dokładność danej reprezentacji zmiennoprzecinkowej
- b) zakres reprezentacji
- c) dokładność reprezentacji
- d) budowa binarnej liczby zmiennoprzecinkowej
- e) własności podstawowych operacji arytmetycznych na liczbach zmiennoprzecinkowych (dodawanie, odejmowanie, mnożenie, dzielenie)
- 5. Reprezentacja stałoprzecinkowa liczb rzeczywistych – zakres reprezentacji oraz własności reprezentacji stałoprzecinkowej.
- 6. Logarytmiczna reprezentacja liczb rzeczywistych, własności oraz:
- 7. Budowa i zasada działania:
- 1. Budowa procesora opartego na architekturze von Neumana, podstawowe jego elementy i ich przeznaczenie.
- 2. Formaty i typy rozkazów procesora, wpływ długości rozkazów procesora na wielkość zajmowanej pamięci przez program oraz na jego czas wykonania.
- 3. Omówić podstawowe tryby adresowania:
- 4. Omówić cykle pracy procesora:
- 5. Struktura i zasada działania mikroprogramowanej jednostki sterującej, wady i zalety procesorów mikroprogramowanych oraz alternatywne metody budowy jednostki sterującej procesora.
- 6. Budowa i zasada działania następujących procesorów.
- 1. System przerwań i jego rola w systemie komputerowym.
- 2. Omówić tryby przesyłania danych w systemie komputerowym.
- 3. Budowa magistrali i jej przeznaczenie oraz metody arbitrażu magistrali.
- 4. Typy pamięci, hierarchia pamięci w systemie komputerowym.
- 5. Pamięć podręczna.
- 1. Cel konstrukcji komputera o architekturze równoległej, typy problemów rozwiązywanych z zastosowaniem komputerów: pojęcie problemu wielkiej skali, pojecie klasy trudności problemu (złożoności obliczeniowej problemu).
- 2. Podział architektur równoległych zaproponowany przez Flynna.
- 3. Architektury MIMD ze wspólną pamięcią operacyjną.
- 4. Architektury MIMD z rozproszoną pamięcią operacyjną.
- 5. Architektury współczesnych systemów komputerowych.
Wyszukiwarka
Podobne podstrony:
Opracowanie Zagadnień na egzamin Mikroprocki
Opracowanie zagadnień na egzamin z MO
Przemiany geopolityczne (opracowane zagadnienia na egzamin)
Opracowane zagadnienia na egzamin
Andragogika opracowane zagadnienia na egzamin
opracowane zagadnienia na egzamin, ►► UMK TORUŃ - wydziały w Toruniu, ►► Socjologia, Praca socjalna,
Dydaktyka [opracowane zagadnienia na egzamin], Metodyka nauczania, język polski, teksty i notatki, e
Opracowanie zagadnień na egzamin z judaizmu, 2. GENEZA JUDAIZMU, Religia patriarchów
Konflikty opracowanie zagadnien na egzamin 2
opracowane zagadnienia na egzamin piachy
Opracowanie Zagadnień na egzamin Mikroprocki ściąga
Nauka?ministracji Opracowanie zagadnień na egzamin z NA
Zestaw 1, Opracowane zagadnienia na egzamin
Zestaw 15, Opracowane zagadnienia na egzamin
ściąga opracowane zagadnienia na egzamin piachy
Zestaw 22, Opracowane zagadnienia na egzamin
Zestaw 11, Opracowane zagadnienia na egzamin
Zestaw 14, Opracowane zagadnienia na egzamin
opracowanie zagadnień na egzamin, bromy 101-150, PYT
więcej podobnych podstron