
V Konferencja PLOUG
Zakopane
Październik 1999
Problematyka optymalnej konfiguracji serwera bazy danych
Oracle na platformach unixowych
Piotr Kołodziej
ZUI Otago sp. z o.o., Gdańsk
Autor
Autor jest specjalistą systemowym i administratorem baz danych.
Streszczenie
Referat omawia problemy związane z możliwie najbardziej optymalną konfiguracją serwera bazy Oracle na
systemach unixowych. Podstawowymi zagadnieniami są konsekwencje wynikające z wyboru unixowego
systemu plików ("tradycyjny" UPS, VxFS/JFS) bądź urządzeń surowych (raw devices) do umieszczenia plików
bazy. Omówiony jest przede wszystkim wpływ na poziom współbieżności, efektywność i koszty buforowania
oraz na zarządzanie pamięcią przez system operacyjny (m.in. wpływ na stronicowanie). Poruszony jest także
problem optymalnego doboru rozmiaru plików baz danych oraz jego wpływ na strategie zarządzania przestrzenią
w bazie. Na końcu omówione są niektóre specyficzne dla platform unixowyxh cechy serwera bazy Oracle
związane z wydajnością systemu, m.in. blokowanie SGA w pamięci operacyjnej, zapis asynchroniczny, itd.

2
Rola platformy unixowej
Systemy unixowe stanowią obecnie najważniejszą platformę dla rozwiązań opartych o RDBMS i narzędzia
Oracle. Oracle w tym wypadku nie jest wyjątkiem – również dla jego konkurentów (np. Informix, Sybase)
kluczowe znaczenie posiada platforma unixowa.
Producenci sprzętu i oprogramowania dokładają starań, by mogły one sprostać wymaganiom użytkowników
coraz bardziej złożonych systemów informatycznych. Konstrukcje maszyn wieloprocesorowych SMP (m.in.
Sun, Hewlett-Packard) oferują coraz większą skalowalność i niezawodność. Usunięcie wąskiego gardła w
postaci współdzielonej szyny systemowej w architekturach opartych np. o sieć przełączników między
procesorami a modułami pamięci oraz urządzeń wejścia/wyjścia (crossbar) pozwala na znaczne
zrównoleglenie transmisji wielkich ilości danych. Ponadto, możliwość identyfikacji i łatwego odłączenia
wadliwego modułu pamięci bądź procesora minimalizuje zakres problemów związanych z awarią.
Rozwój sprzętu idzie w parze z rozwojem systemów operacyjnych. Są one coraz lepiej przystosowywane do
pracy wieloprocesorowej, m.in. poprzez redukcję do niezbędnego minimum ścieżek krytycznych w kodzie
jądra i przeniesienie uwagi na ochronę jego krytycznych zasobów (danych). Nowoczesne mechanizmy
serializacji pozwalają na jednoczesne wykonywanie wielu procesów w trybie jądra bez wstrzymywania
pozostałych, o ile te nie odwołują się do tych samych zasobów. Jest to szczególnie istotne dla serwerów baz
danych intensywnie korzystających z funkcji systemowych, zwłaszcza przy wykonywaniu operacji
dyskowych, komunikacyjnych, synchronizacji oraz gospodarowaniu pamięcią.
Innym przykładem rozwoju platform unixowych są rozwiązania oparte o klastry. Głównym powodem ich
budowy jest zapewnienie systemom wysokiej dostępności poprzez podtrzymanie bądź bardzo szybkie
przywrócenie funkcjonalności w razie awarii pewnych ich części. W tym przypadku, stosowane są głównie
klastry z dzielonymi dyskami – wykrycie awarii jednego z węzłów powoduje przeniesienie usług do innego,
sprawnego węzła. Rozwiązanie to jest przezroczyste dla użytkowników i aplikacji, stwarzając iluzję pracy
z maszyną, która może być na pewien czas wyłączona. Z kolei klastry oparte o dzielenie pamięci
(architektura NUMA – Non Uniform Memory Access) stwarzają znacznie większe możliwości
podtrzymywania funkcjonalności oraz, co nie mniej istotne, skalowania wydajności systemów.
Rozwój systemów wieloprocesorowych i konfiguracji klastrowych jest jedynie częścią działań mających na
celu zapewnienie niezawodności i wydajności konkurencyjnej dla rozwiązań opartych dotychczas o maszyny
mainframe. Z drugiej strony, znacznie obniżany jest próg dostępności dla mniej rozbudowanych systemów
opartych o procesory RISC, istnieje też coraz lepszy wybór systemów unixowych na maszyny oparte
o procesor Intel. W tym przypadku, istotną rolę odgrywa bodziec w postaci gwałtownej ekspansji systemów
opartych o platformę Intel/Windows NT. Dzięki swemu rozwojowi, platformy unixowe umożliwiają obecnie
tworzenie rozwiązań o coraz bardziej zróżnicowanej skali, wymaganiach i budżecie.
Potrzeba optymalnej konfiguracji platformy systemowej i serwera bazy Oracle
Z reguły, najistotniejszy wpływ na wydajność systemu ma właściwe zestrojenie aplikacji, zwłaszcza
optymalizacja struktury danych i zapytań. Z drugiej strony, odłożenie optymalizowania konfiguracji serwera
bazy Oracle oraz platformy systemowej do czasu usunięcia ewentualnych problemów z pracą aplikacji nie
musi stanowić właściwej strategii.
Przede wszystkim, optymalna konfiguracja ma zapewnić nie tylko wydajną rutynową pracę, powinna
zapewnić odpowiednią stabilność, minimalizację częstotliwości awarii bądź problemów uniemożliwiających
eksploatację systemu oraz, w razie awarii, skrócenie czasu koniecznego do przywrócenia systemowi pełnej
funkcjonalności. Ponadto, odpowiednio wczesny trafny wybór pozwala na uniknięcie kosztów
rekonfiguracji, szczególnie kosztownej w przypadku reorganizacji fizycznej struktury bazy. Przykładowo,
zmiana rodzaju systemu plików, zmiana rozmiaru bloku bazowego bądź przeniesienie plików bazy na
urządzenia surowe (raw devices) w bazie produkcyjnej pociąga za sobą niedostępność systemu na czas
wykonania operacji, nakład pracy oraz zwiększony poziom ryzyka.
Nie mniejsze znaczenie ma fakt, że odpowiednia konfiguracja może znacznie złagodzić niekorzystny wpływ
źle zoptymalizowanych zapytań na wydajność systemu, szczególnie, gdy są to zapytania kluczowe,
wielokrotnie powtarzane przez pracujących równolegle użytkowników. Przykładowo, poza bezpośrednim
zajmowaniem czasu procesora, zapytania te wpływają na jego zajętość w sposób wtórny, np. poprzez
wywołanie szamotania w buforze serwera bazy danych. Jeśli stosowany jest buforowany przez system
operacyjny dostęp do plików, podobne zjawisko może dotyczyć bufora systemowego. Ciągłe kopiowanie
dużej ilości danych między buforem systemowym a bazowym dodatkowo angażuje procesor. O ile rozmiar

3
bufora systemowego jest zmieniany dynamicznie, zwiększone potrzeby buforowania wywołują zwiększone
zapotrzebowanie na pamięć. Aby je zaspokoić, konieczne jest zwolnienie ostatnio nie używanych stron
pamięci. Ponieważ ostatnim okresie mało co było używane poza buforem plikowym, zaś zapotrzebowanie na
pamięć jest bardzo duże, prawdopodobne jest, iż demon stronicowania (też w takich przypadkach
absorbujący procesor) wybierze do zwolnienia obszary procesów, dla których ostatni dostęp miał miejsce
nawet przed kilkunastoma sekundami. W efekcie, w pewnych konfiguracjach oprócz eskalowania zajętości
procesora, źle zoptymalizowane zapytania mogą spowodować poważną dysfunkcję mechanizmu zarządzania
pamięcią wirtualną. Przykład ten pokazuje, że należy poszukiwać konfiguracji pozwalającej na uniknięcie
całkowitej degradacji wydajności systemu w przypadkach wykonywania źle zoptymalizowanych zapytań.
Właściwa konfiguracja jest warunkiem koniecznym dla uzyskania odpowiedniej przepustowości przez
dłuższy czas eksploatacji. Nie wydaje się być właściwe unikanie prac nad wydajną konfiguracją bazy danych
ze względu na posiadaną rezerwę zasobów. Rezerwa szybko może się okazać iluzoryczna (np. dostępna
pamięć), zaś możliwości rozbudowy sprzętu są skończone, z kolei wymagania nowych wersji
oprogramowania zapewne wzrosną. Widać to na przykładzie systemów zbudowanych przed kilku laty, w
których bez konfiguracji bliskiej optimum często nie sposób uzyskać zadawalającej wydajności.
Wraz ze wzrostem możliwości nowoczesnych maszyn RISC-owych oraz tendencją rozwoju „warstwy
środkowej” oprogramowania (np. w architekturze NCA), coraz częściej może pojawiać się konieczność
dzielenia zasobów maszyny przez serwer bazy Oracle oraz inne usługi (np. serwer aplikacyjny). W takim
przypadku, optymalna konfiguracja wykluczająca niepożądane interakcje może stanowić klucz do wydajnej
pracy systemu.
Wpływ konfiguracji serwera bazy Oracle na wykorzystanie procesora
Serwer bazy Oracle, podobnie jak ogromna większość dostępnego oprogramowania, skonstruowany jest
według zasady, by każdy proces był uśpiony w czasie, gdy oczekuje na wystąpienie zdarzenia i nie wykonuje
żadnej użytecznej pracy. Ponieważ śpiący proces nie angażuje procesora, strategia ta pozwala na skuteczne
wykorzystanie mocy obliczeniowej przez realizujące się w tym czasie zadania. Minimalizowana jest ponadto
kolejka procesów oczekujących na wykonanie.
Konfiguracja serwera Oracle ma niewielki bezpośredni wpływ na wykorzystanie czasu procesora. Jawnie
specyfikowanym parametrem instancji mającym taki wpływ jest spin_count określający maksymalną
liczbę nawrotów pętli w której proces usiłuje uzyskać zatrzask (latch)
1
. W przypadku silnie obciążonych
maszyn, w których występuje długa, nie dająca się w łatwy sposób skrócić kolejka do procesora, warto
rozważyć obniżenie tej wartości (domyślnie 2000) w celu uzyskania drobnej poprawy przepustowości.
W serwerze bazy Oracle, najistotniejsze znaczenie dla wykorzystania procesora posiada charakter procesów
(rodzaj realizowanych czynności), optymalizacja zapytań (zwłaszcza dla czasu procesora w trybie
użytkownika) i zazwyczaj w mniejszym stopniu, fizyczna struktura bazy – przede wszystkim wybór między
buforowanym przez system operacyjny dostępem do plików a dostępem niebuforowanym (dla czasu
procesora w trybie jądra).
Do rutynowych zadań przy utrzymaniu systemu należy obserwacja wykorzystania czasu procesora oraz
kolejki (run-queue) na poziomie systemu oraz identyfikacja i minimalizacja liczby najbardziej obciążających
procesów.
Pomiar wykorzystania czasu procesora na poziomie systemu
Systemy unixowe udostępniają standardowe narzędzia pozwalające na wykonywanie podstawowych
pomiarów wykorzystania procesora (procesorów). Są nimi pochodzący z dystrybucji Systemu V sar(1) oraz
vmstat(1) wywodzący się z BSD.
Pozwalają one na uzyskanie informacji o strukturze wykorzystania czasu procesora w trybie użytkownika
(%usr), jądra (%sys), oczekiwania na operację wejścia/wyjścia (%wio) oraz wolnego czasu procesora
(%idle). Miary te, określając ogólną zajętość procesora, w niewielkim stopniu odzwierciedlają stopień
obciążenia systemu. Szczególnie myląca może być interpretacja czasu wolnego procesora. Jego brak nie
musi oznaczać dużego obciążenia. Dopiero długość kolejki do procesora pozwala określić, czy system jest
silnie obciążony, czy też nie jest.
1
W przypadku niepowodzenia, proces zasypia albo wykonuje alternatywną ścieżkę.

4
Jako generalną regułę często ustala się, że powinno się dążyć do minimalnego %wio, zaś %sys nie powinien
być znaczący w stosunku do %usr. Nie kwestionując jej słuszności należy zauważyć, że w pewnych
warunkach stosowane oprogramowanie może częściej wywoływać funkcje systemowe. Z drugiej strony,
wysoki poziom %usr też może świadczyć o problemie, np. o błędzie w oprogramowaniu (np. długotrwałe
zagnieżdżone pętle). Może ponadto być jednym ze skutków nieoptymalnego planu wykonania zapytania
przez procesy serwera bazy Oracle, zwłaszcza przy dużych złączeniach, w których wiersze „wiodącej” tabeli
są dobierane za pomocą nieselektywnego indeksu.
Problemy związane z pomiarem wykorzystania procesora
Podstawowym problemem w badaniu wykorzystania procesora jest ryzyko obarczenia pomiarów błędem,
wynikającym z metody pomiarowej zastosowanej w standardowych narzędziach systemu Unix. Narzędzia te,
wykorzystują próbkowanie stanu tablic systemowych w chwilach zgłoszenia przerwania zegarowego,
stanowiącego również podstawę przełączania zadań (standardowo, przerwanie występuje co 10 milisekund).
Ponieważ czas aktywności wielu procesów, łącznie z pętlą jałową procesora, może zmieścić się w przedziale
między kolejnymi przerwaniami, uzyskane wyniki mogą być dalekie od wartości rzeczywistych. Sytuację
pogarsza fakt, że wielkość błędu nie jest stała i w praktyce zależy od bieżącej charakterystyki badanego
systemu. Metoda ta ponadto nie jest w stanie uchwycić zjawisk związanych z obsługą większości przerwań.
Dla typowych zastosowań błąd ten nie wyklucza użyteczności dokonywanych w ten sposób pomiarów.
Należy jednak z dużą rezerwą podchodzić do wszelkich prób ekstrapolacji, mających na celu określenie
granicznej wydajności systemu na podstawie pomiarów wykonanych przy nieznacznym obciążeniu, gdyż
błąd w takim przypadku może być szczególnie wysoki.
Tego rodzaju problemów pozbawione są narzędzia oparte o pomiar czasu mikrostanów procesów (np. SE
Toolkit firmy Sun, Glance firmy HP). Z drugiej strony wprowadzają one dość duże obciążenie mające
niekiedy wpływ na wyniki pomiarów.
Identyfikacja procesów zużywających najwięcej procesora i ich śledzenie
Procesy serwera bazy Oracle usiłujące ,,zawłaszczyć” procesor są zazwyczaj skrajnym przypadkiem. Cechą
charakterystyczną takich procesów jest szybki wzrost czasu działania procesu (kolumna TIME w wyjściu z
programu ps(1) bądź top(1)), zaś statystyka wstrzymań wykonywania procesu wykazuje znaczny udział
oczekiwania na procesor z powodu obniżanego priorytetu
. Na maszynie jednoprocesorowej niemal
natychmiast występuje brak czasu jałowego procesora. Obecność w systemie kilku bądź kilkunastu tego
rodzaju procesów (w zależności od zasobów) znacznie wydłuża kolejkę procesów gotowych do wykonania a
oczekujących na procesor (load), istotnie pogarszając czas reakcji i przepustowość systemu.
O ile wspomniane procesy są dużymi zadaniami wsadowymi, których charakter uzasadnia tak wielkie
zapotrzebowanie na zasoby systemowe (np. ładowanie dużych ilości danych, długotrwałe przetwarzanie itd.)
optymalizacja stanowi przede wszystkim rozwiązanie problemu organizacyjnego – konieczne jest ustalenie
,,okien czasowych” przeznaczonych na realizację poszczególnych zadań. Celem jest uniknięcie równoległego
wykonywania bardzo obciążających procesów, gdyż ze względu na ograniczone zasoby systemu czas ich
sekwencyjnej realizacji może być dużo krótszy od czasu równoległego wykonania.
Inny przypadek stanowią procesy realizujące zapytania, dla których plan wykonania daleki jest od
optymalnego. Duża liczba dostępów i operacji na danych, niewspółmiernie wysoka w stosunku do
zwróconych, bądź efektywnie przetworzonych wierszy, stanowi znaczne obciążenie dla procesora przede
wszystkim ze względu na wielkość przetwarzanego zbioru danych. Dodatkowy narzut jest spowodowany
zarządzaniem kolejkami buforów. Typowym objawem jest przede wszystkim wysoka wartość statystyki
consistent gets, odzwierciedlająca liczbę dostępów do bloków tabel i indeksów, po uzyskaniu prawa dostępu
za pośrednictwem zatrzasku (latch). Z reguły, każdorazowy dostęp do bufora, wymaga aktualizacji końca
kolejki LRU, odpowiedniego dla typu dostępu. W efekcie, duża zajętość zatrzasków (tzw. latch contention
widoczne w postaci wysokiej wartości statystyki latch free w tabeli v$waitstat) i zajętość buforów (statystyka
buffer busy waits w tabeli v$waitstat) mogą ograniczyć równoległość w dostępie do danych.
2
System Unix usiłuje ,,sprawiedliwie” przydzielać procesor. Dlatego, by nie ,,zagłodzić” innych procesów, chwilowo obniża priorytet
tym procesom, które usiłują go zawłaszczyć. Z drugiej strony, procesy o niższym priorytecie otrzymują dłuższy kwant czasu.

5
Identyfikację procesów najmocniej obciążających procesor najłatwiej przeprowadzić za pomocą programu
top(1) standardowo dostarczanego np. w systemie HP-UX
3
, bądź innych narzędzi. Odpowiadającą sesję w
bazie Oracle można zrealizować poprzez zapytanie bazujące na dynamicznych tabelach serwera bazy Oracle.
Poniżej przedstawiony jest przykład dla serwera pracującego w trybie DEDICATED i procesu bazy Oracle o
identyfikatorze systemowym PID równym 9464:
SQL> select s.sid, s.serial#
from v$session s, v$process p
where s.paddr = p.addr
and p.spid = 9464;
SID SERIAL#
--------- ---------
14 8843
Identyfikacja sesji pozwala na uzyskanie jej statystyk (z dynamicznej tabeli v$sesstat) oraz informacji o
zdarzeniach, na które oczekiwała sesja (tabela v$session_event). Szczególnie przydatne może okazać
się zebranie statystyk SQL dla danej sesji w celu uzyskania informacji na temat wykonanych zapytań (za
pomocą analizatora tkprof). Do wymuszenia zbierania statystyk w trakcie trwania sesji posługujemy się
pakietem dbms_system. Poniżej przedstawione jest wywołanie dla zidentyfikowanej wcześniej sesji:
SQL> exec sys.dbms_system.set_sql_trace_in_session(14,8843,true);
Przedtem należy zapewnić zbieranie przez system statystyk czasowych. O ile serwer nie był uruchomiony z
parametrem timed_statistics=true, można zmodyfikować tę właściwość serwera bazy poprzez
polecenie alter system.
W pewnych przypadkach, pomocne może być zidentyfikowanie wywołań funkcji systemowych. Dotyczy to
zarówno procesów serwera bazy Oracle jak i dowolnych innych procesów. W systemie Sun Solaris jest to
możliwe za pomocą obecnego w standardowej dystrybucji programu truss(1). Pozwala on na uzyskanie
pełnej listy wykonanych przez proces wywołań funkcji systemowych wraz z ich argumentami i zwracanymi
wartościami. Poniżej przedstawiony jest fragment listingu z śledzenia procesu serwera bazy oracle
(PID=4380), wykonującego pewne zapytanie:
# truss -p 4380 2>&1 | tee Plik.z.logiem
read(10, 0x0086FC36, 2048) (sleeping...)
read(10, "\0BE\0\006\0\0\0\0\003 G".., 2048) = 190
pread(14, "0601\0\004\003 A\0\011 s".., 4096, 3411968) = 4096
[
opuszczone wywołania]
pread(14, "0601\0\004\01AB8\0\0 EDA".., 4096, 0x01AB8000) = 4096
open("/export/home/ORADATA/dbtst/ts_tab01.dbf", O_RDWR|O_DSYNC) = 16
fcntl(16, F_GETFD, 0x00000000) = 0
fcntl(16, F_SETFD, 0x00000001) = 0
ioctl(16, 0x0403, 0xEFFFA064) Err#25 ENOTTY
pread(16, "0501\0\01C\0F0 3\0\0\v $".., 4096, 0x0F033000) = 4096
[
następne wywołania]
Pierwsze dwie linie związane są z komunikacją między procesem serwera bazy oracle i procesem klienta
(plik FIFO o deskryptorze równym 10), następne (funkcje pread z dekryptorem równym 14) dotyczą
pobierania informacji o obiektach na potrzeby data dictionary z pliku należącego do przestrzeni tabel
SYSTEM, później otwierany jest plik danych /export/home/ORADATA/dbtst/ts_tab01.dbf
(przydzielony jest deskryptor równy 16), ustawiane są dodatkowe atrybuty dostępu (za pomocą fnctl), po
czym zaczyna się odczyt danych. Informacje o deskryptorach otworzonych plików można uzyskać za
pomocą programu pfiles(1).
Z kolei w systemie HP-UX, narzędzie Glance pozwala jedynie na uzyskanie ogólnej statystyki
wywoływanych funkcji. Bardzo wysoka częstotliwość ich wywoływania może świadczyć o istniejącym
problemie w oprogramowaniu. W przypadku procesu serwera bazy Oracle, bardzo częste wywoływanie
funkcji read() i lseek() jest częstokroć skutkiem nieoptymalnego planu wykonania zapytania.
3
Program ten jest także udostępny w postaci źródłowej przez jego głównego autora, Williama LeFebvre i może być uruchomiony na
wielu platformach unixowych. URL autorskiego archiwum:
ftp://ftp.groupsys.com/pub/top
.

6
Zwiększanie wydajności serwera bazy Oracle na maszynach SMP
RDBMS Oracle pozwala na dobre skalowanie wydajności na maszynach SMP. Podobnie jak w konstrukcji
jądra systemu operacyjnego, jednym z podstawowych problemów jest uniknięcie wąskich gardeł w postaci
procesów oczekujących na wejście ścieżki krytycznej.
Już w ostatnich wersjach serwera Oracle7 zaczęto stosować ochronę krytycznych zasobów serwera bazy w
miejscu ochrony sekcji krytycznych kodu. Listę chronionych zasobów można uzyskać poprzez wykonanie
zapytania (począwszy od Oracle 7.3):
SQL> select name, count(*) from v$latch_children group by name;
Poniżej przedstawiony jest przykładowy wynik wykonania zapytania na serwerze bazy Oracle 7.3.4.4 z
parametrem db_block_buffers=9000, pracującym na maszynie dwuprocesorowej:
NAME COUNT(*)
---------------------------------- ----------
cache buffers chains 2251
cache buffers lru chain 2
enqueue hash chains 2
global transaction 77
global tx hash mapping 78
library cache 3
lock element parent latch 1
parallel query stats 2
redo copy 4
session idle bit 2
Pozostałe zatrzaski wymienione w tabeli v$latch stanowią prawdopodobnie klasyczne wejście do sekcji
krytycznej kodu. Jednak prawdopodobieństwo wstrzymywania na nich procesów serwera bazy jest
niewielkie. Administrator bazy Oracle ma bezpośredni wpływ na liczbę zasobów cache buffers lru
chain
, ustawiając parametr inicjalizacyjny db_block_lru_latches oraz redo copy przez parametr
log_simultaneous_copies
. Wyliczane na podstawie liczby procesorów wartości domyślne są z
reguły o połowę za niskie. Pozostałe zasoby krytyczne ustawiane są automatycznie przez serwer bazy Oracle.
Istotne z punktu widzenia możliwości równoległej pracy wielkiej liczby sesji ma znaczenie fakt, że
pojedynczy zasób typu cache buffer chains chroni dostęp do niewielkiej liczby (zazwyczaj kilku) buforów.
Istotnie zwiększa to poziom równoległości procesów w dostępie do danych, o ile nie zachodzi sytuacja, gdy
pewna liczba procesów wielokrotnie sięga do tych samych buforów stanowiących tzw. ,,gorący obszar”
systemu (hot-spot area). Jeśli stanowi to kluczową przeszkodę w zwiększeniu wydajności, jedynym
rozwiązaniem pozostaje strojenie aplikacji, szczególnie wyeliminowanie złej optymalizacji zapytań. W
pewnej klasie przypadków, podobnie jak przy minimalizowaniu liczby dostępów do buforów przez niektóre
przeszukania, dobre efekty może przynieść uporządkowanie wierszy w tabelach według pewnego klucza
(data proximity), bądź partycjonowanie.
Innym problemem jest alokacja bloków wewnątrz segmentów bazowych (np. tabel, indeksów), mogąca
sprawić problem w trakcie równoległych, intensywnych operacji tworzenia zapisów (insert) bądź ich
modyfikacji, powodujących konieczność wykorzystania przestrzeni w dodatkowych blokach. Pojedyncza
mapa wolnych bloków dla segmentu (freelist) może stanowić przeszkodę w uzyskaniu pożądanego poziomu
równoległości, gdyż w danej chwili tylko jeden proces może otrzymać wyłączny dostęp do bloku
zawierającego listę. Począwszy od serwera bazy Oracle 6.0.35 problem ten można rozwiązać przez ustalenie
większej liczby list wolnych bloków dla segmentu (parametr freelists). Inną własnością jest liczba grup
zawierających listy (parametr freelist groups). Pomimo, że stanowi przede wszystkim rozwiązanie
problemu przydziału wolnej przestrzeni w środowisku Oracle Parallel Server (ze względu na wysoki koszt
synchronizacji bloków), niekiedy zwiększenie liczby grup może przynieść pozytywny efekt w „zwykłym”
serwerze bazy Oracle.
Przy konfigurowaniu bazy na maszynach SMP należy unikać ryzyka serializacji przy dostępie przez procesy
do krytycznych zasobów systemowych. Ponieważ wraz ze wzrostem liczby procesorów wzrasta liczba
procesów potencjalnie rywalizujących o zasób, stosowną uwagę należy przywiązać do zminimalizowania
prawdopodobieństwa oczekiwań, związanych z ochroną struktur jądra systemu operacyjnego.
Jednym z przykładów jest problem blokowania inode’ów przy wykonywaniu operacji plikowych.
Blokowanie ma zapobiec sytuacjom, gdy inode (bądź związany z nim zasób metadanych) może zawierać

7
niespójne informacje, np. rozmiar lub adresy bloków. W przypadku, gdy występują częste zapisy i odczyty
,
konieczne może okazać się stosowanie możliwie najmniejszego rozmiaru plików do składowania często
używanych obiektów, bądź ominięcie warstwy systemu plików przez zastosowanie urządzeń surowych (raw
devices). W celu zaobserwowania blokad inode’ów konieczne jest wykorzystanie specjalnego
oprogramowania monitorującego system operacyjny (np. Glance w systemie HP-UX).
Architektura SMP pozwala ponadto na efektywne wykorzystanie opcji Parallel Query. Szczegółowe jej
omówienie wykracza jednak poza zakres opracowania.
Zarządzanie pamięcią w systemie Unix
Współczesne systemy unixowe bez wyjątku są systemami udostępniającymi mechanizm pamięci wirtualnej
ze stronicowaniem, pozwalający na wykonywanie procesów, dla których łączne zapotrzebowanie na pamięć
przekracza rozmiar pamięci operacyjnej udostępnionej procesom. Obszar ten jest mniejszy od rozmiaru
pamięci RAM, gdyż podczas ładowania systemu operacyjnego, jądro rezerwuje pewien obszar pamięci na
swoje wyłączne potrzeby, m.in. na kod rezydujący w pamięci i statyczne tablice systemowe. Uzyskiwanie
informacji o wielkości obszaru pamięci dostępnego dla procesów zależy od systemu. Przykładowo,
w systemie HP-UX można odszukać komunikat jądra wyświetlany w chwili jego ładowania:
# /etc/dmesg | grep "vmunix.*available"
vmunix: Physical: 65536 Kbytes, lockable: 43752 Kbytes, available: 52880 Kbytes
Jeśli bufor komunikatów został przepełniony, należy skorzystać z zapisów w dzienniku:
# cat /var/adm/syslog/syslog.log | grep "vmunix.*available"
System operacyjny rezerwuje w przestrzeni wymiany obszar równy łącznemu rozmiarowi procesu na
wypadek konieczności zwolnienia całości zajmowanej przez niego pamięci i zapisania zawartości w tym
obszarze (swap). Jakkolwiek, system operacyjny unika podejmowania tego rodzaju działań, jednak sytuacja
taka może się zdarzyć w przypadku znacznego niedoboru wolnej pamięci. Konsekwencją mechanizmu
rezerwowania obszaru wymiany jest także fakt, iż łączny rozmiar wykonywanych procesów jest ograniczony
rozmiarem przestrzeni wymiany. Mechanizmem pozwalającym na przekroczenie tej granicy jest m.in.
możliwość rezerwowania obszarów wymiany w pewnym obszarze dostępnej pamięci operacyjnej (tzw.
pseudo-swap). Rozwiązanie to jest stosowane np. w systemie HP-UX, w którym pseudo-swap może
zaalokować do 75% obszaru pamięci dostępnej procesom. Z drugiej strony, zarezerwowanie nawet skromnej
części tego obszaru na potrzeby wymiany może przynieść spadek wydajności przy zwiększonym
zapotrzebowaniu na pamięć.
Metody optymalizacji wykorzystania pamięci stosowane w systemach
unixowych
Współczesne systemy unixowe oferują szereg mechanizmów zwiększających efektywność wykorzystania
pamięci. Należy do nich m. in. współdzielenie pewnej części stron w segmentach kodu (text segment) i w
segmentach danych przez procesy wykonujące ten sam program. W pewnych rozwiązaniach (np. w systemie
HP-UX) stosowane jest całkowite współdzielenie obszaru kodu przez tego rodzaju procesy. Każdy z
procesów posiada prywatny stos oraz pamięć alokowaną dynamicznie (heap). Sytuacja ta pozwala oszczędne
wykorzystanie pamięci m. in. w przypadku serwera bazy Oracle, gdzie wiele procesów współużytkuje
segment kodu dość znacznych rozmiarów. Sprzyja temu architektura two-task separująca proces klienta od
procesu serwera, mającego ten sam kod niezależnie od aplikacji (Oracle Forms, SQL*Plus, aplikacja Pro*C
itd) oraz mechanizmu wywołania. Sytuacja taka nie jest możliwa w przypadku architektury singletask’owej,
w której kod jądra Oracle jest dołączony do kodu aplikacji. Z drugiej strony, nie ma nic darmo: ponosi się
większe koszty komunikacji międzyprocesowej, szczególnie odczuwalne w przypadku wymiany dużej ilości
danych pomiędzy procesami. Dlatego do dużych zadań ładowania, eksportu bądź importu danych warto
skorzystać z singletask’owych wersji narzędzi sqlldr, exp oraz imp.
Kolejną optymalizacją jest technika ładowania na żądanie (load on demand), pozwalająca na odroczenie
załadowania strony pamięci do chwili pierwszego odwołania. W efekcie, występuje skrócenie czasu
uruchomienia procesów, z drugiej zaś strony unika się ładowania do pamięci niewykorzystywanych
4
Jest to cecha silnie zależna od konstrukcji systemu operacyjnego. W „klasyczych” implementacjach, odczyt może nawet blokować
odczyt [1].

8
obszarów kodu i danych. Inną techniką jest opóźnione przydzielanie bloków wypełnianymi zerami (zero fill
on demand), dotyczące stron segmentów danych niezainicjalizowanych (bss segment) oraz pamięci
dynamicznej. Podobnie, kopiowanie przy zapisie (copy on write), obok oszczędności pamięci dla segmentów
danych zainicjalizowanych (data segment) pozwala na znaczne przyspieszenie tworzenia procesów.
W większości systemów unixowych od lat dostępne jest dynamiczne wiązanie, dzięki któremu unika się
wielokrotnego powielania w segmentach kodu funkcji standardowo wykorzystywanych bibliotek (libc,
libsocket, libposix itd.). Polecenie file(1) pozwala na uzyskanie informacji o tym czy program wykorzystuje
dynamiczne wiązanie, np:
$ file $ORACLE_HOME/bin/oracle
oracle: PA-RISC1.1 shared executable dynamically linked -not stripped
Szacowanie zapotrzebowania na pamięć
Przy konfiguracji serwera bazy Oracle, jedną z kluczowych decyzji jest określenie parametrów
pamięciowych serwera. Łączne zapotrzebowanie procesów na pamięć nie powinno przekroczyć rozmiaru
pamięci pozostawionej procesom przez system operacyjny. W
przeciwnym razie może dojść do
stronicowania a nawet wymiany. Formuła pozwalająca na oszacowanie maksymalnego zapotrzebowania na
pamięć przez serwer bazy uwzględnia obszar dzielony segmentu kodu, SGA oraz sumę prywatnych
obszarów danych.
Zapotrzebowanie = SGA + Text + N*(Text’+Data+BSS+Stack+Heap)
SGA – rozmiar SGA
Text – rozmiar dzielonych stron w segmencie kodu
Text’ – rozmiar prywatnych stron w segmencie kodu
N – liczba procesów serwera
Data – rozmiar segmetu danych
BSS – rozmiar segmentu danych niezainicjalizowanych
Stack – rozmiar stosu
Heap – rozmiar dynamicznie alokowanej pamięci, m.in. na obszar sortowania
Większość ze składników (rozmiar segmentu kodu, danych i bss) można oszacować na podstawie wyniku
wyprowadzonego przez program size(1).
$ size oracle
9486048 + 184920 + 184894 = 9855862
Na tej podstawie niemożliwe jest jednak oszacowanie rozmiaru np. pamięci dynamicznej. W bilansie nie
można ponadto ująć segmentów prywatnych alokowanych na potrzeby dynamicznie wiązanych bibliotek.
Ponadto, na niektórych platformach, strony pamięci zawierające segment kodu nie są w pełni współdzielone
(np. Solaris).
Przy dobieraniu wielkości SGA należy pamiętać, że w niektórych systemach wraz ze wzrostem jego
rozmiaru może wtórnie wzrosnąć zapotrzebowanie na pamięć w wyniku alokacji tabel translacji stron z
adresów wirtualnych na adresy fizyczne. Przykładowo, jeśli planowany jest rozmiar SGA równy 512MB, zaś
rozmiar bloku systemowego wynosi 4kB, to każdy z procesów musi zaadresować 131072 strony pamięci
dzielonej. Skromnie szacując, iż na translację pojedynczej strony potrzeba tylko 8 bajtów (dwa adresy 32-
bitowe), dla każdego z procesów serwera jądro musi zaalokować ponad 1MB pamięci na tabelę translacji.
W przypadku kilkuset równoległych sesji, alokacja pamięci związana z tabelami translacji stron może
przekroczyć rozmiar SGA. Dodatkowym problemem jest spadek efektywności układów bufora translacji
stron (Translation Lookaside Buffer) stosowanych w procesorach.
Nie jest to problemem w systemach operacyjnych stosujących wspólną tabelę translacji stron dla wszystkich
segmentów dzielonych (np. HP-UX). Inne z kolei systemy udostępniają specjalny tryb obsługi pamięci
dzielonej, w którym możliwe jest także współdzielenie tabeli translacji adresów. Przykładem jest system
Solaris udostępniający specjalny rodzaj pamięci dzielonej – Intimate Shared Memory (ISM).
Problemy związane z pomiarem wykorzystania pamięci
Niezależnie od dokładności dokonanych wcześniej szacunków, konieczne jest przynajmniej okresowe
wykonywanie sprawdzenia wykorzystania pamięci przez procesy bazy Oracle. Niestety, poza ipcs(1)
udostępniającym informacje o segmentach pamięci dzielonej, standardowe narzędzia unixowe nie są w stanie
udzielić sensownych wyników, pozwalających na uzyskanie odpowiedzi na temat rzeczywistego
wykorzystania pamięci. W dużej mierze o ich funkcjonalności zadecydował fakt, że zostały opracowane w

9
bardzo wczesnych wydaniach systemu Unix – bez mechanizmu dzielenia stron w segmentach procesów,
ładowania na żądanie, kopiowania przy zapisie itd.
Oparcie się jedynie o łączny rozmiar wirtualny, bądź obszar procesów rezydujących w pamięci może być
mylące. Kluczem do zagadki jest określenie, jaką część ich rozmiaru zajmują obszary dzielone (zwłaszcza
segmentu kodu), jaką zaś obszary prywatne. Informacje uzyskane za pomocą programu file(1) są mało
użyteczne: z jednej strony nie są uwzględnione segmenty dynamicznie wiązanych bibliotek, z drugiej strony,
dzięki mechanizmowi ładowania na żądanie, rozmiar obecnego w pamięci obszaru kodu może przyjmować
szeroki zakres wartości. Nieznany jest ponadto udział obszarów prywatnych w segmentach, dla których może
mieć miejsce częściowe współdzielenie stron. W przypadku nawet nieznacznego błędu szacowania rozmiaru
segmentów w procesach bazy Oracle, duża liczba procesów może spowodować znaczne odchylenie
w uzyskanym rezultacie.
Poniższa tabela ilustruje rozbieżność w sytuacji, gdy średni rozmiar procesów serwera bazy Oracle wynosi
około 8,3MB, zaś ich liczba wynosi 200:
Rozmiar segmentów
dzielonych [kB]
Rozmiar segmentów
prywatnych [kB]
Łączne zapotrzebowanie procesów
serwera bazy na pamięć przy 200
procesach [MB]
7300
1000
207,3
7400
900
187,4
7500
800
167,5
7600
700
147,6
7700
600
127,7
7800
500
107,8
Bardziej użyteczne bywają narzędzia specyficzne dla platformy, bądź dodatkowe pakiety oprogramowania.
W standardowej dystrybucji systemu Solaris dostępny jest program pmap(1) pozwalający na uzyskanie mapy
pamięci procesu. Poniżej przedstawiona jest przykładowa mapa pamięci procesu serwera bazy Oracle.
# /usr/proc/bin/pmap -x 4442
4442: oracley2k (DESCRIPTION=(LOCAL=YES)(ADDRESS=(PROTOCOL=beq)))
Address Kbytes Resident Shared Private Permissions Mapped File
00010000 8288 6416 4168 2248 read/exec oracle
00836000 80 80 40 40 read/write/exec oracle
0084A000 328 304 - 304 read/write/exec [ heap ]
80000000 52776 52776 - 52776 read/write/exec/shared [shmid…]
EF580000 592 576 544 32 read/exec libc.so.1
EF622000 32 32 8 24 read/write/exec libc.so.1
EF630000 8 8 - 8 read/write/exec [ anon ]
EF640000 16 16 16 - read/exec libmp.so.2
EF652000 8 8 8 - read/write/exec libmp.so.2
EF660000 24 24 24 - read/exec libaio.so.1
EF674000 8 8 8 - read/write/exec libaio.so.1
EF676000 8 8 - 8 read/write/exec [ anon ]
EF680000 448 344 336 8 read/exec libnsl.so.1
EF6FE000 40 40 8 32 read/write/exec libnsl.so.1
EF708000 24 8 - 8 read/write/exec [ anon ]
EF720000 16 16 16 - read/exec libc_psr.so.1
EF730000 24 24 24 - read/exec libposix4.so.1
EF744000 8 8 8 - read/write/exec libposix4.so.1
EF760000 88 64 64 - read/exec libm.so.1
EF784000 8 8 8 - read/write/exec libm.so.1
EF790000 32 32 32 - read/exec libsocket.so.1
EF7A6000 8 8 8 - read/write/exec libsocket.so.1
EF7A8000 8 - - - read/write/exec [ anon ]
EF7B0000 8 8 8 - read/exec libdl.so.1
EF7C0000 8 8 - 8 read/write/exec [ anon ]
EF7D0000 112 112 112 - read/exec ld.so.1
EF7FA000 8 8 8 - read/write/exec ld.so.1
EFFF8000 32 32 - 32 read/write/exec [ stack ]
-------- ------ ------ ------ ------
total Kb 63040 60976 5448 55528
10
W powyższym listingu, obszar pamięci dzielonej nieprawidłowo klasyfikowany jest jako prywatny (w
pakiecie MemTool dostępny jest funkcjonalnie zbliżony program pmem, pozbawiony tego mankamentu). W
związku z tym, obszar prywatny procesu rezydujący w pamięci wynosi 2752 kB. Poniżej przedstawiono
szacowanie dla 200 procesów, oparte na powyższych wynikach. Nie uwzględniono w nim obszarów jądra
na tabele translacji stron dla SGA. Ich rozmiar może być znaczny (kilkaset MB) w przypadku braku ich
współdzielenia.
Zapotrzebowanie = SGA + dzielony_kod_i_dane + prywatny_kod_i_dane*200 =
= 52776kB + 5448kB + 200*2752kB = 608 624 kB.
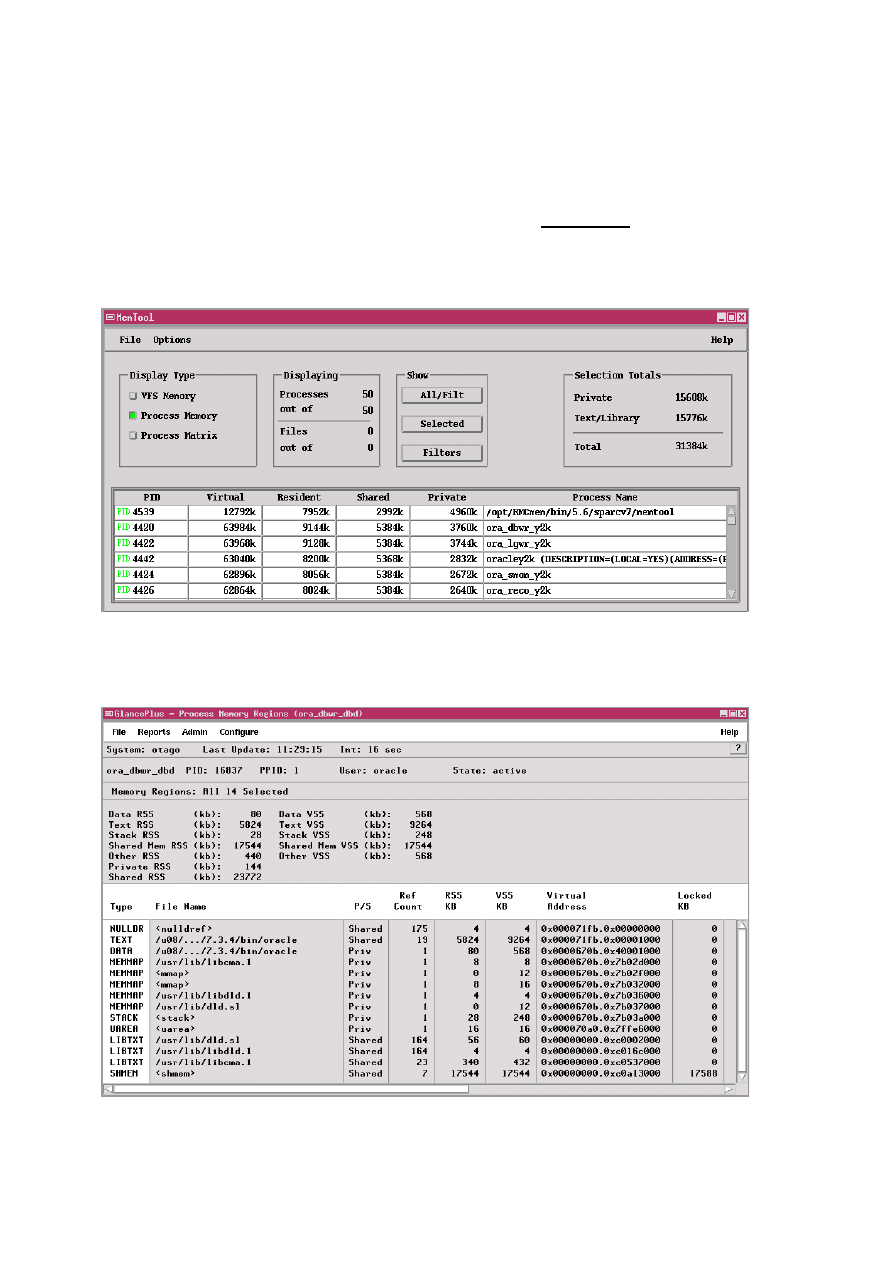
Na platformie Solaris dostępne jest również narzędzie GUI (memtool) pozwalające na uzyskanie listy
procesów z sumaryczną informacją o alokacji pamięci oraz po kliknięciu, szczegółowej mapy wybranego
procesu (p. rysunek poniżej).
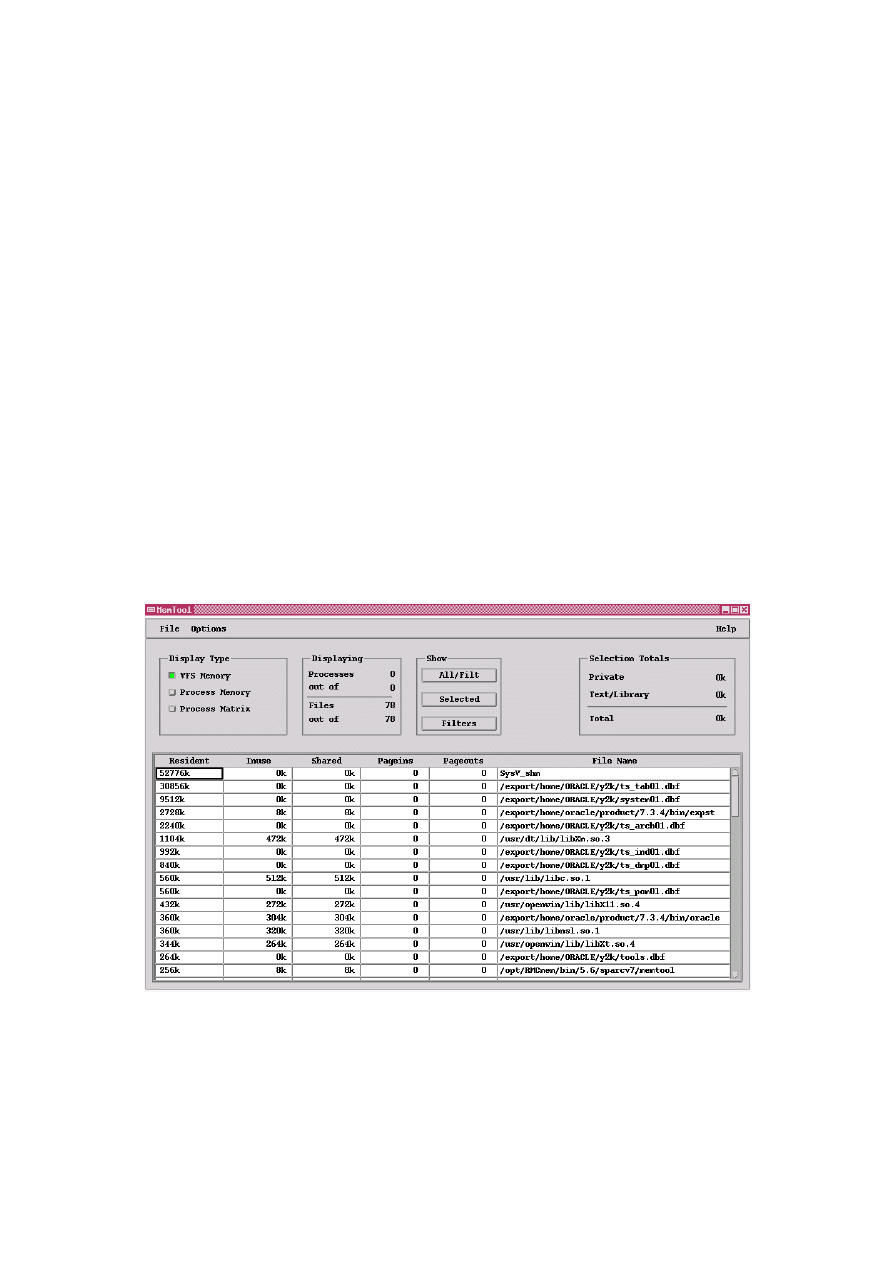
Z kolei na platformie HP-UX uzyskanie precyzyjnej informacji o obszarach procesów możliwe jest za
pomocą programu Glance (p. rysunek poniżej). Na platformie HP-UX, segment kodu jest w pełni
współdzielony.
11
Problemy związane z dynamicznym buforem plikowym
Buforowanie dostępu do plików przez system operacyjny stanowi jeden z podstawowych sposobów
optymalizowania operacji plikowych. W początkowych implementacjach systemu Unix, buforowanie miało
miejsce na poziomie bloków dyskowych [1]. W związku z tym, każdorazowe odwołanie do pliku wymagało
wyznaczenia adresu fizycznego bloku (za pośrednictwem inode’a oraz bloków pośrednich), dopiero w
następnej kolejności można było wykonać dostęp do bloku znajdującego się w buforze. W nowszych
implementacjach, bufor ten bywa wykorzystywany m.in. jako pamięć podręczna metadanych (np. bloków
pośrednich) dla danego typu systemu plików.
Wraz z rozwojem wirtualnego systemu plików (VFS) ujednolicającym dostęp do plików składowanych w
różnorodnych systemach (np. NFS, UFS, VxFS), zintegrowano mechanizm buforowania plików z
mechanizmem pamięci wirtualnej. Każda zajęta strona pamięci stanowi bufor plikowy bądź stronę należącą
segmentu procesu, bądź segmentu dzielonego. Metoda ta (lub jej mutacja) stosowana jest m.in. w systemach
bazujących na Systemie V Wydaniu 4 (SVR4). Rozmiar bufora ustalany jest w miarę zapotrzebowania.
Strategia ta jest niezwykle skuteczna w przypadku niezbyt intensywnego dostępu do plików. W systemach
intensywnie wykonujących operacje dyskowe za pośrednictwem warstwy systemu plików, żądania wolnych
stron wprowadzają znaczne zapotrzebowanie na wolną pamięć. O ile bufor dynamiczny może rosnąć bez
ograniczeń (np. w systemie Sun Solaris), bądź górna granica rozmiaru bufora jest ustawiona zbyt wysoko,
istnieje duże prawdopodobieństwo, iż demon stronicowania zwolni strony należące do procesów. Zwalnianie
stron szczególnie dotyka procesy oczekujących na zdarzenie nawet przez stosunkowo krótki czas. W
aplikacjach interaktywnych może być to czas pomiędzy wyświetleniem nowego ekranu zawierającego dane a
naciśnięciem klawisza po podjęciu przez operatora decyzji o dalszych działaniach, stosownie do
wyświetlonej informacji. Efektem może być długi czas reakcji systemu, który w tym czasie mógł zwolnić
strony należące do obszarów danych procesu.
Poniższy przykład ilustruje stosunkowo wysokie wypełnienie pamięci buforami plikowymi (pliki bazy
/export/home/ORACLE/y2k/*.dbf
) przy wykonaniu zadania pobierającego znaczną ilość danych za
pośrednictwem systemu plików (np. eksport danych). Rozmiar bufora plikowego sięga niemal rozmiaru SGA
(pierwszy wiersz w tabeli – SysV_shm):
O ile system operacyjny na to pozwala, konieczne może się okazać obniżenie górnej granicy rozmiaru bufora
plikowego, szczególnie, gdy ze względu na masowość dostępów do plików bazowych, zawartość bufora
systemowego jest w dużym stopniu zmonopolizowana przez ich bloki buforowane dodatkowo w SGA.
Przykładowo, w systemie HP-UX wartością domyślną jest 50% pamięci dostępnej dla procesów. W
przypadku znaczącego rozmiaru SGA oraz dużej liczby procesów serwera alokujących duże obszary pamięci
dynamicznej rozpoczyna się rywalizacja między zasobami serwera Oracle a buforem plikowym,

12
obserwowana jako silne stronicowanie. Zalecane często zmniejszanie obszaru SGA nie stanowi dobrego
rozwiązania, gdyż podstawową przyczynę stronicowania stanowi nieużyteczny rozrost bufora plikowego.
Do niedawna nierozwiązywalnym problemem (poza zastosowaniem dostępu niebuforowanego) w systemie
Sun Solaris był brak jakiejkolwiek możliwości ograniczenia „wykradania” stron z obszarów procesów na
rzecz bufora w chwili znacznego rozmiaru operacji wejścia/wyjścia za pośrednictwem systemu plików.
Począwszy od wersji 2.7 (także wersji 2.5.1 oraz 2.6, z tym, że wymaga to zainstalowania stosownego
zestawu poprawek) udostępniony został mechanizm stronicowania z zachowaniem priorytetów (priority
paging). W zastosowanym rozwiązaniu, najpierw (gdy rozmiar wolnej pamięci spada poniżej wartości
cachefree
równej 2*lotsfree) zwalniane są bloki pamięci zawierające bufor plikowy. Dopiero, gdy
rozmiar wolnej pamięci spada poniżej wartości lotsfree, włączany jest standardowy mechanizm
stronicowania[5].
Innym rozwiązaniem jest pominięcie buforowania systemowego przy dostępie do znacznej ilości danych, np.
przez zastosowanie urządzeń surowych. W przypadku serwera bazy Oracle najbardziej skuteczne
buforowanie ma miejsce w obszarze SGA, zaś bufor plikowy nie jest dla niego alternatywą. W przypadku
zastosowania dostępów niebuforowanych, „odzyskaną” z bufora plikowego pamięć najlepiej przeznaczyć
na zwiększenie buforów serwera (parametr db_block_buffers). Serwer bazy Oracle8 pozwala uzyskać
wpływ na buforowanie poprzez mechanizm puli buforów (buffer pool). Dodatkową korzyścią może być
bardziej racjonalne wykorzystanie bufora plikowego przez pozostałe rodzaje dostępów. Oczyszczenie bufora
systemowego ze stron zawierających bloki bazowe może przynieść efekt w postaci lepszej pracy pozostałych
procesów i dodatkowego wzrostu przepustowości systemu.
Ochrona obszaru SGA przed stronicowaniem
Intensywne stronicowanie obszaru SGA dotkliwie zmniejsza wydajność systemu, gdyż jego zawartość ma w
dużej mierze charakter intensywnie wykorzystywanej pamięci podręcznej, np. bufory plików bazowych,
bufory dziennika powtórzeń, library cache, dictionary cache. Niektóre platformy unixowe oferują możliwość
zablokowania obszaru pamięci przed stronicowaniem za pośrednictwem funkcji plock() oraz shmctl(). Na
tych platformach RDBMS Oracle umożliwia zabezpieczenie obszaru SGA przed stronicowaniem.
Jedną z takich platform stanowią maszyny Hewlett-Packard serii s800 pracujące pod kontrolą systemu
HP-UX. Standardowo, system operacyjny dopuszcza, by do 75% obszaru pamięci dostępnej procesom
zostało zablokowane. Rozmiar ten określa się jako pamięć możliwą do zablokowania (lockable memory). W
praktyce, wspomniany limit dotyczy pamięci zablokowanej przez procesy oraz zarezerwowanej jako pseudo-
swap. Informację o jego rozmiarze uzyskuje się w sposób analogiczny do uzyskiwana informacji o wielkości
pamięci dostępnej procesom.
Chcąc zablokować obszar SGA, należy nadać grupie systemowej dba (SYSDBA) przywilej systemowy
MLOCK oraz wystartować instancję Oracle z parametrem inicjalizacyjnym
lock_shared_memory=true
. Ewentualne niepowodzenie zostanie odnotowane w pliku alert.log przez
komunikat „Unable to lock shared memory segment”. Oprócz braku przywileju MLOCK może on być
spowodowany zbyt dużym obszarem zarezerwowanym w przestrzeni pseudo-swap.
Z kolei w systemie Solaris, mechanizm Intimate Shared Memory (ISM) automatycznie powoduje
zablokowania stronicowania tego rodzaju pamięci. Dodatkowo, począwszy od wersji 2.6 systemu Solaris,
obszary ISM nie powodują rezerwacji w przestrzeni swap. Obszar SGA serwera bazy Oracle na platformie
Solaris może wykorzystać pamięć ISM w wyniku uruchomienia instancji z parametrem use_ism=true.
Wybór rodzaju składowania plików bazowych
W systemach unixowych istnieją dwie możliwości składowania plików bazowych (pliki kontrolne, pliki
dziennika powtórzeń oraz pliki danych). Pierwszą z nich są pliki utworzone w systemie plików, zaś drugą
urządzenia surowe. Urządzenie surowe (raw device) reprezentowane jest jako plik specjalny urządzenia
znakowego, do którego dostęp omija warstwę bufora systemowego
odwołując się bezpośrednio do
sterownika. Może ono reprezentować zwykłą partycję na dysku bądź obszar zarządzany przez warstwę
Volume Manager’a. Logical Volume Manager jest standardowo dostępny w systemie HP-UX, udostępniając
zalecany przez producenta mechanizm zarządzania dyskami na tej platformie. Na innych platformach,
5
Zazwyczaj, plik urządzenia surowego posiada „bliźniaka” w postaci pliku urządzenia blokowego (buforowanego). Jednak nie ma
powodu ani możliwości, by baza Oracle z niego mogła skorzystać.
13
Volume Manager stanowi najczęściej odrębny produkt. Dokonując wyboru pomiędzy systemem plików
a urządzeniami surowymi, warto przeanalizować możliwie najszerszy zakres „za i przeciw”.
Porównanie podstawowych właściwości składowania plików bazy Oracle w unixowym systemie plików i na
urządzeniach surowych:
Cecha
System plików
Urządzenie surowe
Wyliczenie adresu bloku
przy lseek()
Konieczność sięgania do bloków pośrednich.
Możliwe dodatkowe odczyty metadanych.
Natychmiastowe wyliczenie na
podstawie geometrii urządzenia.
Narzut na buforowanie
przy operacjach read() i
write()
Kopiowanie między buforem systemowym a
buforem serwera bazy Oracle zużywające moc
procesora. Konieczność zarządzania kolejkami
buforów systemowych. W pewnych konfiguracjach
możliwość wywołania silnego stronicowania.
Brak.
Serializacja dostępu
(blokowanie inode’ów)
Możliwa.
Brak.
Prawdopodobieństwo
alokacji nieciągłych
obszarów na dysku
Zależy od systemu plików i jego parametrów.
Szczególnie wysokie w przypadku UFS, w którym
ma miejsce wysoka aktywność tworzenia,
usuwania i rozszerzania plików.
Urządzenia surowe alokują duże ciągłe
obszary dyskowe.
Możliwość wykonania
odczytu z
wyprzedzeniem
Możliwe przy zachowaniu pewnych warunków,
zwłaszcza ciągłości obszarów dyskowych.
Brak.
Łatwość zarządzania
Dość łatwe zarządzanie.
Trudne zarządzanie o ile nie jest
używany Volume Manager. W celu
umożliwienia łatwego przemieszczania
plików, krytyczne znaczenie ma
standaryzacja ich rozmiarów.
Archiwizowanie
i odtwarzanie
Możliwość zastosowania szerokiej gamy komend
unixowych oraz pakietów oprogramowania
archiwizującego. W niektórych implementacjach
możliwość uzyskania spójnej migawki systemu
plików.
Ze standardowych narzędzi systemu
unix, dostęp możliwy jedynie przez
dd(1). Możliwe wykorzystanie pakietów
oprogramownia archiwizującego.
Wrażliwość na krach
systemu bądź zanik
zasilania
Konieczne wykonanie fsck. Czas i efekty
wykonania zależne są od rodzaju i konfiguracji
systemu plików. Uzyskanie spójnej zawartości
plików bazowych następuje dopiero przy
odtwarzaniu instancji bądź, wyjątkowo,
odtwarzaniu nośników.
Uzyskanie spójnej zawartości przy
odtwarzaniu instancji. Bardzo niskie
prawdopodobieństwo konieczności
odtwarzania nośników (w tym
przypadku związanym z problemem
sprzętowym lub software’owym)
W większości systemów, możliwe jest wykorzystanie kilku rodzajów systemów plików. Naturalnie, nie ma
najmniejszych powodów by skorzystać z mającego raczej historyczne znaczenie systemu plików s5.
Najczęstszy wybór dotyczy systemu UFS i VxFS.
System UFS, bazujący na rozwiązaniu zaczerpniętym z dystrybucji BSD 4.2 (FFS – Fast File System)
realizuje strategię alokacji pojedynczych bloków. Strategia ta, odpowiadając większości ze spotykanych
potrzeb (składowanie wielu plików niedużych rozmiarów), w niewielkim stopniu odpowiada potrzebom
systemów baz danych. W związku z tym, wiele implementacji wprowadziło możliwość grupowania bloków
przy dużych operacjach zapisu. Oprócz zmniejszenia kosztu zarządzania przestrzenią, umożliwione jest
ulokowanie bloków plikowych w dużych ciągłych obszarach. Mechanizm ten przyniesie oczekiwane
rezultaty, o ile wolna przestrzeń jaką dysponuje system plików jest ciągła. Z całą pewnością, nie będzie to
miało miejsca w przypadkach, gdy przestrzeń była wielokrotnie wypełniana i zwalniana. Wówczas celowe
może być ponowne utworzenie systemu plików.
System plików VxFS (znany także jako JFS) realizuje strategię alokacji ekstentów. Dzięki niej unika się
dużego rozproszenia bloków i wysokich kosztów zarządzania przestrzenią. VxFS umożliwia ponadto
prowadzenie dziennika (lub jak kto woli, kroniki - journal) dla metadanych oraz danych, dzięki czemu
uzyskuje się zwiększony poziom bezpieczeństwa w razie krachu systemu (bądź zaniku zasilania). Okupione
jest to jednak wysokim kosztem synchronicznego zapisu dzienników, dla których konieczne może być użycie
dedykowanych dysków. Od pewnego czasu, kronika metadanych przestała być unikalną cechą systemu
VxFS: dostępna jest także w pewnej części implementacji systemów UFS.

14
Dokonując wyboru systemu plików oraz parametrów składowania należy z dużą ostrożnością traktować
wyniki niektórych testów wydajnościowych. Ich rezultaty mogą silnie zależeć od warunków pracy.
Przykładowo, jeśli ze względu na dużą liczbę dostępów sekwencyjnych, uważa się, że warto zastosować
składowanie w systemie plików w celu wykorzystania odczytu z wyprzedzeniem (read ahead) – należy
rozważyć sytuacje, w których może on być zablokowany. Odczyt z wyprzedzeniem może nie zostać
uruchomiony w sytuacji, gdy adresy kolejnych bloków w pliku nie sąsiadują ze sobą, kilka procesów
równolegle odczytuje zawartość pliku (np. UFS w systemie Solaris) bądź w przypadku braku pamięci (np.
HP-UX).
Należy też zwrócić uwagę, by w ścieżkach dostępu do plików (zwłaszcza często otwieranych) nie pojawiały
się zbyt długie nazwy. Każdy z systemów posiada wewnętrzny limit, powyżej którego ścieżka nie znajdzie
się w pamięci podręcznej. W związku z tym, uzyskanie inode’a na podstawie nazwy pliku może wymagać
pewnej liczby dostępów dyskowych.
Niezależnie od wyboru systemu plików, do dobrej praktyki należy unikanie stosowania plików o zbyt dużych
rozmiarach (blokowanie operacji wejścia/wyjścia, brak możliwości rozproszenia „gorących regionów” na
różne dyski). Wraz z usunięciem limitów rozmiaru segmentów zależnych od rozmiaru bloku (począwszy od
serwera Oracle 7.3) bez większych przeszkód można zastosować ekstenty o ze standaryzowanych rozmiarach
ekstentów, zapobiegające fragmentacji w
przestrzeniach tabel, z drugiej zaś strony zapewniające
efektywność przy pełnym przeglądaniu
.
Z dużą ostrożnością należy także stosować automatyczne rozszerzanie plików. W szczególności należy
unikać zbyt małych przyrostów – wprowadzają one narzut na dynamiczne zarządzanie przestrzenią oraz w
przypadku UFS doprowadzają do braku ciągłości w adresach dyskowych. Stosowanie większych przyrostów
może przynieść dobre efekty, jeśli UFS udostępnia mechanizm alokowania dużych ciągłych obszarów przy
zapisie.
Dostęp niebuforowany z wykorzystaniem Quick I/O
Jednym z rozwiązań mającym na celu uzyskanie wydajności porównywalnej z urządzeniami surowymi przy
zachowaniu elastyczności systemu plików jest produkt Veritas Quick I/O+ for Databases. Zawiera on
sterownik pozwalający na dostęp do plików składowanych w systemie VxFS jak do urządzeń surowych. W
konfiguracji wykorzystującej Quick I/O, tworzone są dodatkowe pliki specjalne, których otworzenie pozwala
na dostęp do danych w trybie znakowym.
Opublikowane wyniki testów[3] wyglądają zachęcająco – wykazano, że w pewnych warunkach mechanizm
Quick I/O może zapewnić wydajność zbliżoną do wydajności osiąganej przy zastosowaniu urządzeń
surowych. Z drugiej strony, testy prowadzono na maszynie dysponującej znaczną nadwyżką zasobów. Nie
pozwala to na wyciągnięcie daleko idących wniosków na temat wydajności osiąganej w przypadku silnego
obciążenia. Należy też zachować pewną rezerwę przy zastosowaniu nowych warstw oprogramowania
w systemie produkcyjnym, gdyż większa ich liczba zwiększa ryzyko niepoprawnej pracy systemu, m.in.
uszkodzeń bloków danych w wyniku błędów programowych, ujawniających się w specyficznych warunkach,
np. przy bardzo silnym obciążeniu
. Do minimalnych środków ostrożności należy skonsultowanie się z
Działem Asysty Technicznej Oracle w celu uzyskania informacji, czy konfiguracje wykorzystujące ww.
warstwy są certyfikowane i czy nie zgłoszono związanych z nimi problemów mogących zagrozić
integralności danych bądź dostępności funkcji systemu.
Problemy związane z pomiarem obciążenia pamięci dyskowej
Współczesne konstrukcje dysków pozwoliły na przełamanie bariery sekwencyjnego trybu obsługi żądań.
Nowoczesne urządzenia SCSI mogą zrównoleglać kilkadziesiąt operacji optymalizując m.in. ruch głowicy.
Dzięki temu, radykalnie zwiększa się przepustowość operacji dyskowych.
Dokonując interpretacji pomiarów obciążenia dysków, nie zawsze należy się kierować ich zajętością,
zwłaszcza gdy zastosowane narzędzie pomiarowe przeprowadza wyliczenia w oparciu o model, w którym w
6
W miejsce pojedynczych ekstentów o dużych rozmiarach, które w dość powszechnym mniemaniu są wyłączną metodą zwiększenia
efektywności pełnego przeglądania tabel.
7
Uszkodzenia bloków spowodowane programowo, objawiające się m.in. występowaniem błędów ORA-1578, ORA-600[3374], ORA-
600[3398] są wyjątkowo podstępne i groźne w skutkach. W takich przypadkach, zazwyczaj nie jest możliwe przeprowadzenie pełnego
odtwarzania uszkodzonych plików.

15
danej chwili może być obsługiwane tylko jedno żądanie (np. „klasyczny” sar, iostat). Zniekształceniu ulega
ponadto pomiar czasu obsługi. Najbardziej miarodajnym pomiarem jest ustalenie długości kolejek do dysku
(na poziomie sterownika), pozwalające na wychwycenie wąskich gardeł. O ile istotne jest dokonanie
precyzyjnych pomiarów zajętości dysków oraz czasów obsługi, konieczne jest wykorzystanie
oprogramowania pomiarowego, w którym obliczenia oparte są o model urządzeń dyskowych zdolnych do
zrównoleglania operacji. Należy do nich m.in. SE Toolkit firmy Sun oraz Glance firmy Hewlett-Packard.
Zapis asynchroniczny
Jednym z problemów w uzyskaniu pożądanej wydajności serwera bazy jest stosowanie synchronicznego
zapisu do plików bazowych, wymuszanego przez ustawienie znacznika D_SYNC przy otwieraniu plików. W
standardowych konfiguracjach, jest to jedyna metoda uniknięcia zapisu opóźnionego, mogącego mieć
katastrofalny wpływ na integralność danych. Negatywną cechą zapisu synchronicznego jest jednak
ograniczona przepustowość – oczekiwanie przez proces na zakończenie pojedynczego zapisu, redukuje
możliwość obsługi wielu żądań. Częstokroć, konieczne staje się uruchomienie dodatkowych procesów
zapisujących bloki z bufora do plików (db writer slaves).
Częstokroć, nawet duża liczba procesów zapisujących nie jest w stanie zapewnić wystarczającej
przepustowości (pomijając fakt, że osobnym problemem może być ich synchronizacja). Wówczas konieczne
staje się stosowanie zapisu asynchronicznego, generalnie dostępnego dla urządzeń surowych oraz systemu
plików VxFS na większości z platform. W asynchronicznym zapisie, jądro bezzwłocznie inicjuje zapis (w
przeciwieństwie do zapisu opóźnionego) nie wstrzymując procesu aż do chwili jego zakończenia. Pozwala
to na zainicjalizowanie w krótkim czasie dość dużej liczby zapisów, co jest działaniem bardzo efektywnym w
urządzeniach zrównoleglających operacje wejścia/wyjścia.
Uruchomienie zapisu asynchronicznego różni się pomiędzy platformami. W przypadku systemu HP-UX,
konieczna jest przebudowa jądra w celu dołączenia sterownika operacji asynchronicznych i utworzenie pliku
specjalnego /dev/async za pomocą instrukcji mknod(1) i udostępnienie stosownych praw do zapisu. Przy
przebudowie jądra, należy zwrócić uwagę, by wystarczająca liczba procesów miała możliwość otworzenia
/dev/async
(parametr max_async_ports).
W serwerze bazy Oracle7, w celu wymuszenia asynchronicznych zapisów konieczne jest uruchomienie
instancji z parametrem use_async_io=true. Z kolei w serwerze bazy Oracle8, stosowanie zapisu
asynchronicznego jest ustawieniem domyślnym.
Literatura
[1] M.J. Bach „Budowa systemu operacyjnego UNIX”, WNT Warszawa 1995.
[2] A.H.Majidimehr „Optymalizacja systemu UNIX”, WNT, Warszawa 1998.
[3] M.Bhyravabhotla, B. Rader, V. Wagman - „Veritas Quick I/O Equivalent to Raw Volumes, Yet Easier”, URL:
http://www.oracle.com/support/library/news/veritas_lss.html
[4] A Cockroft – „Getting to Know the Solaris Filesystem, Part 1”, SunWorld, May 1999,
URL:
http://www.sunworld.com/sunworldonline/swol-05-1999/swol-05-filesystem.html
[5] R. Mc Dougall, T. Vo, T. Pothier - „Priority Paging” –
URL:
http://www.sun.com/sun-on-net/performance/priority_paging.html
[6] „The Solaris Memory System. Sizing, Tools and Architecture”
URL:
Wyszukiwarka
Podobne podstrony:
Problemy I Dylematy Planowania Nieznany
Problem komiwojazera Sformuowa Nieznany
Problemy pielegnacyjne w opiece Nieznany
IIL Wybrane problemy optymalizacji
Problemy pielegnacyjne u choryc Nieznany
Świadome działanie jako rozwiązanie problemu optymalizacyjnego Nauczyciel i Wychowanie, nr 6(62), 19
problematyka transportu samocho Nieznany
Świadome działanie jako rozwiązanie problemu optymalizacyjnego Nauczyciel i Wychowanie, nr 6(62), 19
problemy edukacji i wychowania Nieznany
Problemy2 2 id 393106 Nieznany
Cw1 Problemy optymalizacyjne
Pgik glowne problemy do rozwiaz Nieznany
Problemy diagnostyczne u choryc Nieznany
problemy rewitalizacji billetrt Nieznany
Lopatka wybrane problemy id 101 Nieznany
Filozofia W3b Problem wolnej wo Nieznany
Problemy w komunikacji zespolu Nieznany
NoM 2012 egzamin problemy id 32 Nieznany
więcej podobnych podstron