
Adam Pawełczak
Technologie informacyjne
- Podstawy technik informatycznych

Spis treści

Technologie informacyjne - Podstawy technik informatycznych
Strona 3 z 72
6.4.4. Specyficzne zagrożenia związane z bankowością i handlem elektronicznym. ............... 65

Technologie informacyjne - Podstawy technik informatycznych
Strona 4 z 72
Wprowadzenie
Rozwój cywilizacyjny obdarzył społeczeństwo szeregiem nowoczesnych rozwiązań technicznych, które
znajdują zastosowanie nie tylko w obszarze szeroko rozumianej działalności gospodarczej, ale zostały
upowszechnione i towarzyszą człowiekowi we wszystkich dziedzinach życia.
Obecnie komputery i inne urządzenia cyfrowe wraz z oprogramowaniem oraz sieci komputerowe
wykorzystywane są tak w produkcji, usługach, handlu jak i w nauce, edukacji, rozrywce, kontaktach z
administracją publiczną, służbą zdrowia i życiu codziennym. Upowszechnienie się tych rozwiązań
doprowadziło do powstania społeczeństwa informacyjnego. Jego cechą charakterystyczną jest to, że
obok dóbr o charakterze materialnym wartość posiada również informacja. W związku z tym pojawiło
się na rynku szeregu nowych usług związanych z gromadzeniem, przetwarzaniem i przesyłem
informacji, z których korzystanie ma obecnie charakter powszechny.
Z technicznego punktu widzenia urządzenia i media cyfrowe oraz oprogramowanie przeznaczone są do
rejestrowania, przechowywania, przetwarzania i przesyłania na odległość informacji. Zespół
wykorzystywanych do tego technologii określany jest terminem Technologii Informacyjnych i
Komunikacyjnych oznaczanych angielskim skrótem ICT (Information and Communication Technology).
Dla ich efektywnego wykorzystania niezbędne jest zrozumienie podstaw, na jakich oparta jest
konstrukcja urządzeń i sposób ich działania. Posiadanie wiedzy w tym zakresie niestety nie jest
równomiernie upowszechnione w społeczeństwie, co rodzi ryzyko tzw. wykluczenia cyfrowego. W
praktyce oznacza to wykluczenie ze społeczeństwa ze względu na brak możliwości (i tym samym
umiejętności) korzystania, a przede wszystkim komunikowania się z wykorzystaniem mediów i
urządzeń cyfrowych.
Coraz szybsze upowszechnianie się tych technologii wymaga od użytkowników zdobywania nowych
umiejętności posługiwania się nimi. Staje się to obecnie jednym z kluczowych warunków efektywnego
uczestnictwa w społeczeństwie informacyjnym i funkcjonowania na rynku pracy.
1. Informacja
1.1. Dane i informacje
Swoistym surowcem w technologii informacyjnej jest informacja, a przedmiotem dziedziny
„informatyka” jej gromadzenie, przetwarzanie i przesyłanie na odległość. Czym jest więc informacja?
Istnieje szereg definicji, jednak na potrzeby tego kursu wystarczające jest, aby pod tym pojęciem
rozumieć to, co podnosi nasz stan wiedzy o otaczającym nas świecie. Informacją jest konstatacja
stanu rzeczy, otrzymana wiadomość czy wyobrażenie.
W informatyce odróżnia się dane od informacji. Informacja to dane osadzone w kontekście. Wartość
liczbowa to dana. Natomiast wartość liczbowa wraz z określeniem, czego dotyczy to informacja.
Wartość 123,34 nie opatrzona żadnym komentarzem to dana - nie wiadomo, czego dotyczy i co
opisuje. Mówiąc jednak, że stan konta wynosi 123,34 zł przekazujemy informację. Na jej podstawie
można podejmować decyzje.
Technologie informacyjne - Podstawy technik informatycznych
Strona 5 z 72
Przykład
Przykłady danych i informacji:
Dane
Informacje
543,45
Wartość posiadanego portfela akcji spadła o 543,45.
zielony
Kolor zielony na tablicy oznacza wzrost wartości akcji.
okrągły
Zamówiono okrągły stół konferencyjny.
papierowy Postanowiono, że obrus będzie papierowy.
otwarty
Sklep jest otwarty.
naładowany Akumulator jest już naładowany.
Informacje możemy podzielić na proste i złożone.
Informacje proste to te, które podnoszą nasz stan wiedzy o jednym z dwóch możliwych stanów
danego zjawiska.
Przykład
Informacją prostą będzie odpowiedź na pytanie o stan wyłącznika światła (przy założeniu, że jest to
wyłącznik dwustanowy, a nie np. ściemniacz) lub sygnał przekazywany z czujnika dymu w muzeum.
W pierwszym przypadku wyłącznik może być włączony lub wyłączony, w drugim, sygnał z czujnika
informuje, czy w pomieszczeniu pojawił się dym czy nie.
Informacje proste nazywane są
informacjami binarnymi
(z łac. bis „dwa razy”), ponieważ na pytanie o
nie możliwe są tylko dwie odpowiedzi.
Większość zjawisk w otaczającym nas świecie ma jednak charakter bardziej złożony niż dwa stany. Do
ich opisu wykorzystujemy informacje złożone.
Przykład
Gdy pytamy o informacje złożone, potencjalnych odpowiedzi jest więcej niż dwie. Stan rachunku
bankowego to z pewnością informacja złożona. Istnieje, bowiem, potencjalnie nieskończenie wiele
stanów rachunków. Podobnie, informacja o temperaturze powietrza, kolorze ścian, składzie
chemicznym paliwa, stopie procentowej, kursie waluty itd.
1.2. Zapis informacji w systemach informatycznych
Wszelkie informacje, aby mogły być przetwarzane, muszą najpierw zostać zakodowane w postaci liczb.
Każda informacja jest w urządzeniach takich jak odtwarzacze mp3, komputery czy aparaty
fotograficzne reprezentowana przez szereg liczb (cyfr). Stąd mówimy o nich „cyfrowe”. Reguła ta
obowiązuje niezależnie od tego, czy informacje dotyczą wartości i czy, w potocznym rozumieniu, mają
wymiar liczbowy. Reprezentację cyfrową przed wprowadzeniem do komputera przyjmują zarówno
teksty, grafika, dźwięk, informacje o smaku, zapachu czy opisie pogody.
Technologie informacyjne - Podstawy technik informatycznych
Strona 6 z 72
Przykład
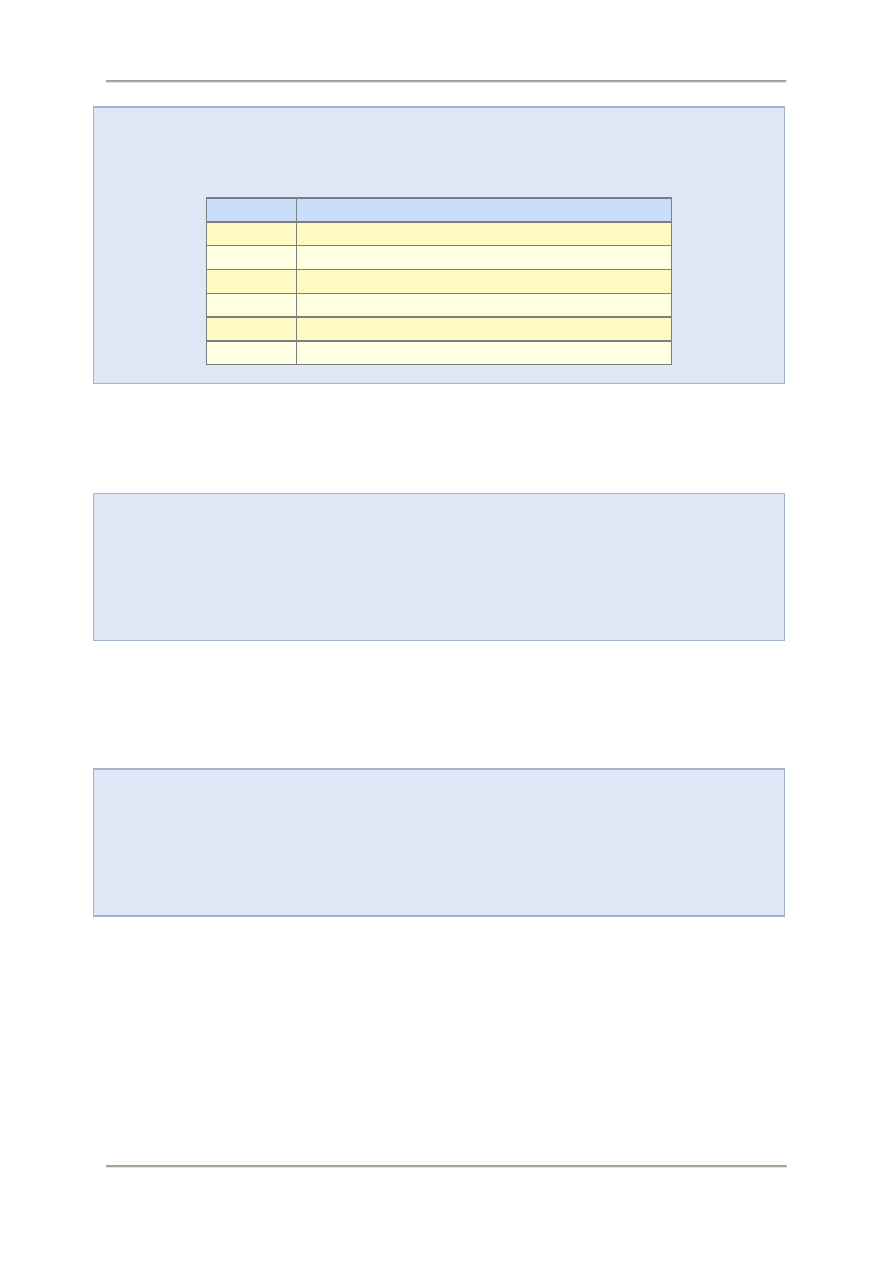
Weźmy za przykład badanie preferencji kolorystycznych kierowców samochodów uczęszczających
pewną drogą. Dla uproszczenia badania przyjmiemy, że kolory będą klasyfikowane do czterech
grup: czarny, czerwony, niebieski i biały. Informacje o poszczególnych kolorach zostaną
zakodowane za pomocą dwucyfrowych sekwencji zer i jedynek. Kody kolorów przedstawiają się w
następujący sposób:
Zera i jedynki podczas przetwarzania, czy przesyłania informacji mogą być reprezentowane
odpowiednio przez niski i wysoki stan napięcia elektrycznego:
Przebieg napięcia
Reprezentuje następujące dane:
a te informacje o kolorach samochodów:
W ten sposób, za pomocą danych binarnych (0 i 1) przesyłanych z miejsca pomiaru do centrum
obliczeniowego w postaci wysokich i niskich stanów napięcia, dostarczono informację złożoną o
czterech grupach kolorystycznych przejeżdżających na badanym odcinku drogi samochodów.
Technologie informacyjne - Podstawy technik informatycznych
Strona 7 z 72
Operacje na danych binarnych reprezentowanych przez dwa stany napięcia mogą być łatwo
wykonywane, a urządzenia do tego przeznaczone (tzw. bramki logiczne) są stosunkowo proste i małe.
Dzięki temu można ich bardzo wiele zbudować na niewielkiej powierzchni przy niskim koszcie
jednostkowym. Podstawowymi elementami składowym bramek logicznych są tranzystory. Obecnie
układy, z których złożone są urządzenia cyfrowe cechuje bardzo wysoka skala integracji, tj. składają
się z milionów tranzystorów i innych elementów zbudowanych pojedynczej płytce półprzewodnika.
Przykład
Najnowsze (maj 2009) procesory dla serwerów firmy Intel o rozmiarach niespełna 4x4 cm składają
się z setek milionów tranzystorów. Odległości między łączącymi je ścieżkami wynoszą zaledwie 45
nm tj. 45 milionowych części milimetra. Takie procesory taktowane impulsami tzw. zegara o
częstotliwości 3 GHz wykonują dziesiątki miliardów operacji zmiennoprzecinkowych na sekundę.
Przetwarzanie informacji za pomocą urządzeń cyfrowych wymaga wcześniejszego zakodowania ich w
postaci danych binarnych reprezentowanych przez zera i jedynki.
Jedna cyfra zapisu binarnego (0 lub 1) to jeden bit. Za pomocą jednego bitu można zakodować jedną
informację prostą. Może to być stan wyłącznika światła 1- włączony, 0 wyłączony lub informacja z
czujnika dymu w muzeum: 1 – wykryto zadymienie, 0 – brak zadymienia. Bit to jednocześnie
najmniejsza jednostka ilości informacji.
Przykład
W przykładzie dotyczącym kolorów samochodów mieliśmy do czynienia z kodami dwubitowymi. Do
zakodowania każdego z kolorów użyto dwóch cyfr systemu binarnego
Posługiwanie się pojedynczymi bitami jest nieefektywne. Pierwsze komputery osobiste przetwarzały
równolegle 8, późniejsze 16, 32, a dzisiejsze 64 bity. Przyjęto, że porcję ośmiu bitów będzie się
określać mianem bajt. Wobec tego dzisiejsze komputery posługują się wielokrotnościami bajtów, np.
komputery 32-bitowe przetwarzają jednocześnie 4 bajty a 64-bitowe osiem.
Zwróć uwagę
Jednostkę bajt oznaczamy dużą literą B a bit małą.
1B = 8b
W praktyce mamy do czynienia ze znacznymi ilościami danych. Przydatne stają się wielokrotności
bitów i bajtów takie jak kilobit, megabit i gigabit czy kilobajt, megabajt i gigabajt. Jednak inaczej niż w
systemach dziesiętnych w informatyce przedrostkom kilo-, mega- i giga- nie odpowiadają krotności
1000 lecz 1024 czyli 2
10
. Wobec tego:
Technologie informacyjne - Podstawy technik informatycznych
Strona 8 z 72
1 kb =
1 kilobit
= 1024 bity = 2
10
bitów
1 Mb =
1 Megabit
= 1024 kb
= 2
20
bitów
1 Gb =
1 Gigabit
= 1024 Mb = 2
30
bitów
1 Tb =
1 Terabit
= 1024 Gb = 2
30
bitów
1 kB =
1 kilobajt
= 1024 bajty = 2
10
bajtów
1 MB =
1 Megabajt = 1024 kB
= 2
20
bajtów
1 GB =
1 Gigabajt
= 1024 MB = 2
30
bajtów
1 TB =
1 Terabajt
= 1024 GB = 2
40
bajtów
Wyjątek od powyższej reguły stanowią podawane przez producentów i sprzedawców pojemności
dysków. W ich produktach przyjmuje się bowiem, że 1 GB to 1000
3
a nie 1024
3
bajtów. Prowadzi to do
zaskoczenia, gdy po zainstalowaniu dysku okazuje się, że komputer podaje mniejszą pojemność dysku
niż wydawało nam się, że kupiliśmy.
Przykład
W ofercie znajdujemy np. dysk o pojemności 500 GB. Spodziewamy się, że na dysku znajduje się
500*1024
3
bajtów co zostanie wyświetlone przez komputer jako 500 GB. Gdy wczytamy się jednak
w etykietkę dowiemy się, że producent pisząc 500 GB miał na myśli 500*1000
3
bajtów. Nasz
komputer jednak policzy rzeczywistą ilość bajtów i przeliczy na gigabajty zgodnie z „informatyczną”
regułą. Wynik będzie następujący 500*1000
3
/ 1024
3
= 500 * 0,9313 = 465,66 GB.
1.2.1. Kiedy ilość informacji wyrażamy w bitach a kiedy w bajtach?
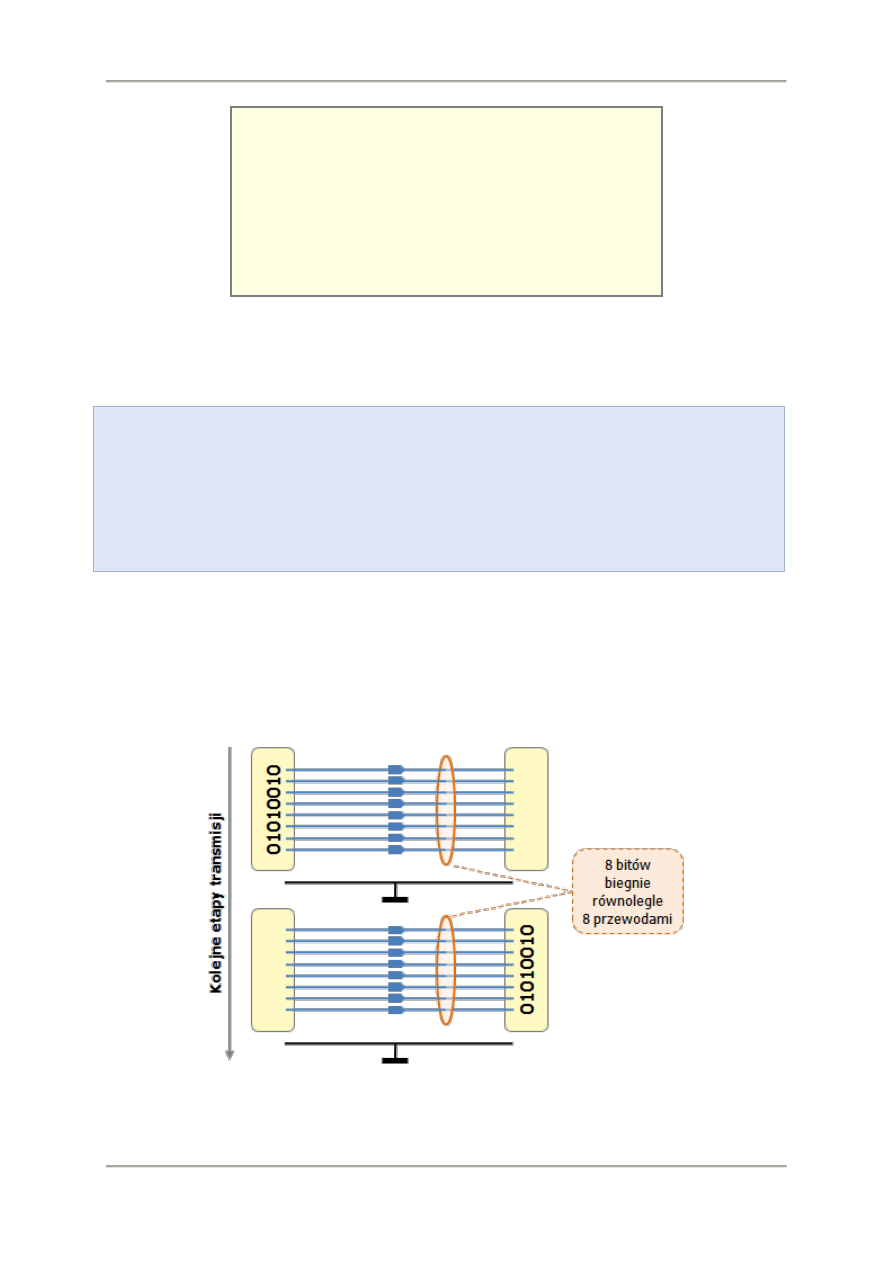
Wielkości plików, pojemności nośników wyrażamy w bajtach. Prędkości transmisji wyrażamy w bitach
lub w bajtach w zależności od typu transmisji (równoległa lub szeregowa).
Równoległa transmisja danych
Jeżeli dane transmitowane są łączem równoległym, czyli takim, w którym między urządzeniami
jest łącze wieloprzewodowe (np. kabel drukarki typu Centronics) i wiele bitów danych jest równolegle
transmitowanych poszczególnymi przewodami to prędkości transmisji wyrażane są w bajtach,
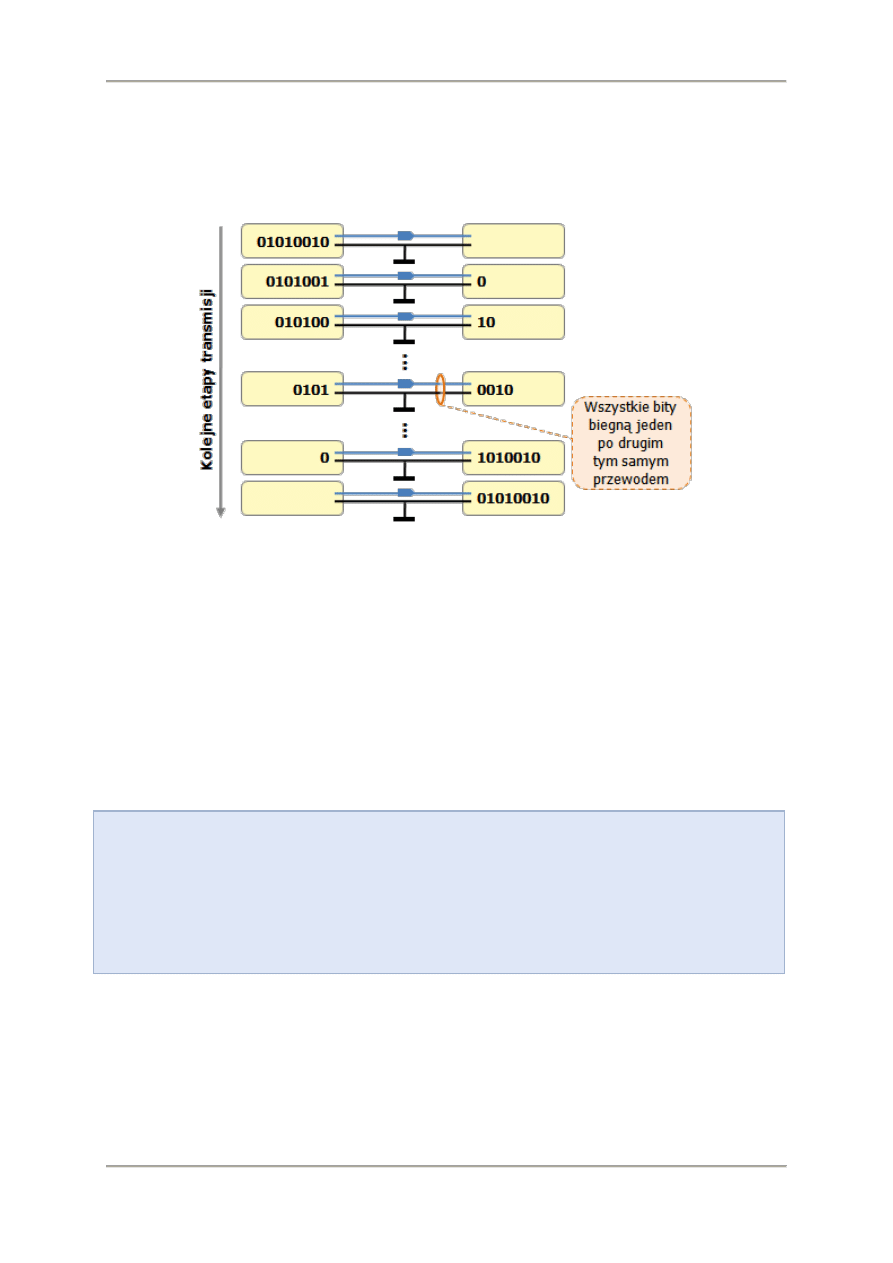
Technologie informacyjne - Podstawy technik informatycznych
Strona 9 z 72
kilobajtach, megabajtach i gigabajtach na sekundę. Z taką sytuacją mamy do czynienia, przy
połączeniu dysku twardego lub czytnika płyt z interfejsem typu ATA lub urządzeniami z interfejsem
SCSI. W podobny sposób transmitowane są dane z między procesorem a pamięcią.
Szeregowa transmisja danych
Jeżeli dane transmitowane są jedną parą przewodów bit po bicie to prędkość transmisji wyrażana jest
w bitach, kilobitach, megabitach i gigabitach na sekundę. Tak odbywa się transmisja w sieciach
komputerowych (np. Internet) lub pomiędzy komputerem, a urządzeniami z interfejsem USB, Firewire
lub Serial ATA czy SAS (Serial SCSI).
1.2.2. Kodowanie wartości liczbowych
System dziesiętny
Najprawdopodobniej dlatego, że mamy 10 palców u rąk posługujemy się systemem dziesiętnym.
Oznacza to, że każdą liczbę możemy przedstawić jako sumę iloczynów jednej z dziesięciu cyfr i liczby
dziesięć (podstawy systemu) podniesionej do potęgi odpowiadającej pozycji, na której występuje
cyfra.
Przykład
Weźmy za przykład liczbę 139. Możemy ją zapisać następująco:
1
3
9
=
1
*10
2
+
3
*10
1
+
9
*10
0
a liczbę 8126:
8
1
2
6
=
8
*10
3
+
1
*10
2
+
2
*10
1
+
6
*10
0
System binarny
W systemie binarnym każdą liczbę możemy przedstawić jako sumę iloczynów 0 lub 1 i liczby 2
(podstawy systemu) podniesionej do potęgi odpowiadającej pozycji, na której występuje cyfra.

Technologie informacyjne - Podstawy technik informatycznych
Strona 10 z 72
Przykład
Liczbę 139
(10)
możemy zapisać:
139
(10)
= 1*2
7
+0*2
6
+0*2
5
+0*2
4
+1*2
3
+0*2
2
+1*2
1
+1*2
0
czyli
139
(10)
= 10001011
(2)
a liczbę 8126
(10)
:
8126
(10)
= 1*2
12
+1*2
11
+1*2
10
+1*2
9
+1*2
8
+1*2
7
+0*2
6
+1*2
5
+1*2
4
+1*2
3
+1*2
2
+1*2
1
+0*2
0
czyli
8126
(10)
=1111110111110
(2)
Przykład
Oto kilka przykładów wartości liczbowych w systemie dziesiętnym i binarnym:
195
(10)
=
11000011
(2)
255
(10)
=
11111111
(2)
256
(10)
=
100000000
(2)
1000
(10)
=
1111101000
(2)
1024
(10)
= 10000000000
(2)
1155
(10)
= 10010000011
(2)
Ważne zależności
Zwróć uwagę
Liczba wartości, jakie można zakodować w systemie binarnym zależy od liczby bitów
przeznaczonych do ich zapisu. Zależność ta zapisana może być następująco:
n=2
i
gdzie
i
liczba bitów.
Jeżeli dysponujemy 4 bitami to możemy za ich pomocą zapisać 2
4
czyli 16 różnych wartości (0-15). Z
kolei jeden bajt może posłużyć do zakodowania 2
8
czyli 256 różnych wartości (0-255).
Dla uniknięcia niejasności, oznaczenie systemu zapisu umieszczane będzie w nawiasie przy liczbie np. 10
(10)
to liczba 10 w
systemie dziesiętnym, natomiast 10
(2)
to wartość 4 zapisana w systemie dwójkowym

Technologie informacyjne - Podstawy technik informatycznych
Strona 11 z 72
Przykład
Jeżeli do zapisania numeru identyfikującego produkt w bazie danych przeznaczonych zostanie 8
bitów (1 bajt), to znaczy, że możemy zapisać informacje o 256 różnych produktach. Jeżeli na taki
numer przeznaczymy 16 bitów będzie to 2
16
czyli 32768 różnych produktów.
Inne systemy zapisu liczb stosowane w informatyce
System dwójkowy jest dla ludzi uciążliwy w notacji i analizie. System dziesiętny też nie jest wygodny
do analizy danych zapisywanych w pamięci operacyjnej czy wykorzystywanych do sterowania
urządzeń. Często informatycy wykorzystują system szesnastkowy (inaczej hexadecymalny). Jego
zaletą jest to, że pełne wartości w zapisie binarnym i hexadecymalnym pokrywają się. Do zapisu
wartości 8 bitowej (1 bajt) potrzeba dokładnie dwóch cyfr. Jedna cyfra odpowiada dokładnie czterem
bitom. Zamiana zapisu binarnego na zapis szesnastkowy można łatwo przeprowadzić w pamięci bez
użycia kalkulatora.
System szesnastkowy opiera się na szesnastu cyfrach. Wykorzystuje się tu cyfry od 0 do 9 oraz litery
odpowiadające kolejnym wartościom:
A – 10, B – 11, C – 12, D – 13, E – 14 ,F – 15 .
Przykład
Zapis 5D oznacza liczbę:
5*16
1
+13*16
0
= 93.
Zapis dwójkowy tej wartości to:
1011101
(2)
5
D
0101 1101
Wartość dziesiętna 11509 w systemie szesnastkowym będzie zapisana jako 2D46, a binarnie 0010
1101 0100 0110 .
Przykład
Zapis taki możemy zobaczyć analizując tekst źródłowy stron WWW. Wykorzystuje się go do
wskazania koloru tła, czcionki czy innego elementu strony. Zapis koloru składa się wówczas z trzech
bajtów określających intensywność poszczególnych barw składowych w układzie RGB: Czerwony,
Zielony, Niebieski.
1.2.3. Zapis z kompresją
Nośniki informacji takie jak płyty CD, DVD, dyski twarde, czy pamięci stosowane w urządzeniach
elektronicznych mają ograniczoną pojemność. Dla podniesienia efektywności zapisu informacji

Technologie informacyjne - Podstawy technik informatycznych
Strona 12 z 72
częstokroć stosuje się pewne przekształcenia danych, pozwalające zapisać określone informacje za
pomocą mniejszej liczby bitów. Proces takiego przekształcania nazywany jest kompresją. Dekompresja
to przekształcenie skompresowanego zbioru informacji do pierwotnej postaci.
Przykład
Dane opisujące pewną informację stanowią następującą sekwencja wartości liczbowych (dla
uproszczenia przedstawiona w systemie dziesiętnym zamiast dwójkowego). Każda z liczb zajmuje
jeden bajt. Dane te zajmują 40 bajtów.
20 20 20 20 45 45 45 45 45 80 80 80 80 80 43 43 43 43 43 43 43 77 77 77
77 88 88 88 36 36 36 87 87 87 87 87 99 99 99 99
Łatwo zauważyć, że występują tu sekwencje powtarzających się wartości. Proces kompresji może
obejmować zmianę zapisu z powtarzających się wartości na opis ile określonych wartości występuje
po sobie. Zamiast 20 20 20 20 można zapisać 4 20 (cztery dwudziestki) potem 5 45 (pięć wartości
45). Każda sekwencja zostanie, więc zredukowana do dwóch bajtów. Informacja z powyższego
przykładu po kompresji tą metodą będzie zapisana następująco:
4 20 5 45 5 80 7 43 4 77 3 88 3 36 5 87 4 99
Zajmuje ona teraz tylko 18 bajtów co oznacza oszczędność 22 bajtów, czyli ponad 55%.
Zastosowany w przykładzie zapis informacji pozwala na odtworzenie jej pierwotnej postaci bez utraty
jakichkolwiek danych, a metoda (algorytm) tu wykorzystywana nazywana jest bezstratną. Jest to jest
to jeden z najprostszych ze stosowanych algorytmów kompresji. W zależności od rodzaju
zapisywanych informacji stosowane są inne.
Definicja
Bezstratny algorytm kompresji, to taki, którego zastosowanie nie powoduje utraty informacji.
Bezstratne algorytmy kompresji mogą być stosowane do zapisu dowolnych informacji. Ich wadą jest
jednak stosunkowo słaba efektywność tam, gdzie jest mała powtarzalność występujących wartości
liczbowych. Przykładem jest fotografia, gdzie niemal każdy punkt obrazu ma inny kolor. Podobnie jest
z zapisem dźwięku czy obrazu audio-wideo. Pliki zawierające takie dane po poddaniu kompresji
bezstratnej zajmują zaledwie od kilku do kilkunastu procent mniej miejsca.
Poprawę efektywności kompresji zapisu obrazu czy dźwięku uzyskuje się stosując algorytmy stratne
dedykowane poszczególnym rodzajami informacji. Innymi algorytmami dokonuje się kompresji
dźwięku a innymi obrazu.
Wszystkie one bazują jednak wspólnym założeniu, że zmysły ludzkie nie są doskonałe i nie rejestrują
dźwięku i obrazu tak dokładnie jak robią to urządzenia rejestrujące (kamera, aparat, mikrofon). W
rezultacie zapis zawiera informacje, których nasze uszy i oczy i tak nie dostrzegą. Wobec tego
stworzono algorytmy kompresji, które w procesie zapisu eliminują te informacje o obrazie i dźwięku,
których braku odbiorca i tak nie dostrzeże. Taki algorytm nie może być stosowany przypadku
kompresji danych takich jak teksty, obliczenia, bazy danych, ponieważ tutaj istotny jest każdy bit
informacji.
Technologie informacyjne - Podstawy technik informatycznych
Strona 13 z 72
Definicja
Algorytmy stratne to takie, które w procesie kompresji i dekompresji informacji pomijają część
danych. Zakłada się, że utracone zostaną tylko takie dane, których braku odbiorca i tak nie
dostrzeże.
1.2.3. Kodowanie i kompresja grafiki
Rysunki i fotografie podobnie jak inne informacje zapisywane są w postaci sekwencji wartości
liczbowych. Przetworzenie obrazu do takiej postaci wymaga rozbicia go na punkty (tzw. piksele)
wyświetlane na ekranie, bądź drukowane na papierze. Każdy punkt jest jednokolorowy.
Źródło: MS Windows XP Professional
W zależności od ilości bitów przeznaczonych na zapisanie informacji o kolorze, może on przyjmować
barwy z palety o określonej liczbie barw. Biorąc pod uwagę poprzednie rozważania przeznaczenie na
każdy punkt jednego bitu oznacza, że będzie on mógł być w jednym z dwóch kolorów, a nasz obraz
będzie czarno-biały. Jeżeli przeznaczymy na każdy punkt 4 bity to oznaczać to już będzie 2
4
, czyli 16
kolorów.
W środowisku Windows możemy w panelu właściwości ekranu wybrać paletę 256 kolorów. Oznacza
to, że każdy z punktów opisany jest przez jeden bajt. Mamy też do wyboru paletę 16 bitowy (tzw.
High Color), a więc 2
16
= 65536 barw. Obecnie wykorzystywane karty graficzne udostępniają tryb 24
bitowy (tzw. True Color – prawdziwy kolor), w którym na zapisanie pojedynczego punktu potrzeba aż
trzech bajtów. Paleta barw jest jednak imponująca: 16 777 216 kolorów (2
24
).
Ilość pamięci potrzebnej do przechowania obrazu zależy od tego z ilu punktów on się składa oraz z jak
dużej palety barw pochodzą kolory poszczególnych pikseli.

Technologie informacyjne - Podstawy technik informatycznych
Strona 14 z 72
Przykład
Jeżeli weźmiemy rysunek wypełniający ekran o rozmiarze 800 x 600 punktów, to jeżeli byłby on
czarno-biały, to do jego zapisania potrzeba 800 x 600 = 480000 bitów. Na każdy punkt przypada,
bowiem jeden bit. Po podzieleniu przez 8 daje to 60 000 bajtów.
Jednak, jeżeli poszczególne punkty takiego obrazu pochodziłyby z palety 256 barw, do zapisania
każdego z nich potrzebny byłby jeden bajt i obraz zajmowałby 480 000 bajtów. Z kolei, gdyby nasz
rysunek czy zdjęcie było zapisane w trybie koloru 24 bitowego, to na każdy punkt przypadają 3
bajty. Zajmowałoby ono wówczas 800 x 600 x 3 = 1440000 bajtów – czyli tyle, ile używana do
niedawna dyskietka.
Im wyższej jakości grafikę chcemy przechować, tym więcej pamięci będzie potrzeba do jej zapisania.
Obliczenia z przykładu dotyczą zapisu bez zastosowania kompresji danych. Najpopularniejszym
sposobem kompresji grafiki jest stratny algorytm JPEG. Pozwala on użytkownikowi na określenie
stopnia kompresji i oczekiwanej jakości skompresowanego obrazu.
Założenie, że w trakcie kompresji stratnej tracone są tylko te dane, których braku odbiorca nie
dostrzeże oparte jest na subiektywnych odczuciach osoby zapisującej obraz. Podnosząc stopień
kompresji godzimy się na utratę większej ilości danych. W konsekwencji obraz traci na jakości. Im
większego stopnia kompresji będziemy oczekiwali, tym większej utraty jakości musimy się spodziewać.
Jest też na odwrót – im wyższej jakości zapisujemy obraz, tym większy będzie zawierający go plik.
Osoba dokonująca zapisu musi więc ocenić, jak wysoki stopień kompresji zapewnia akceptowalną
jakość rezultatu końcowego.

Technologie informacyjne - Podstawy technik informatycznych
Strona 15 z 72
Zdjęcie zapisane bez kompresji.
Zdjęcie zapisane w formacie JPG
ze współczynnikiem jakości
wynoszącym 90.
Zdjęcie zapisane w formacie JPG
ze współczynnikiem jakości
wynoszącym 20.
Fotografia zapisana w 24 bitowej
palecie barw. Każdy jej punkt
zapisany jest za pomocą 3 bajtów.
Wobec tego obraz o rozmiarach
300x451 zajmuje bez kompresji
405 954 bajty.
Fotografia zapisana w formacie
JPG ze współczynnikiem jakości
wynoszącym 90. W stosunku do
oryginału nie widać praktycznie
różnicy, jednak do jej zapisania
wystarczyło 43 416 bajtów – 9,4
razy mniej niż bez kompresji.
Jeśli
zmniejszyć
współczynnik
jakości do 20, wielkość zdjęcia
wyrażona w bajtach spada do
10 189 bajtów. Jakość jednak jest
trudna
do
zaakceptowania.
Pojawiają
się
zniekształcenia
widoczne szczególnie na dużych
płaszczyznach
o
płynnie
zmieniających się kolorach.
Warto zapamiętać
W zależności od potrzeb oraz zawartości rysunku trzeba dobrać taki współczynnik kompresji, aby
osiągnąć kompromis pomiędzy jakością a ilością informacji potrzebnych do jego zapisania.
Formaty plików graficznych
Grafika może być zapisywana w plikach o różnych formatach. Dobór właściwego formatu zależy od
rodzaju przechowywanego obrazu oraz jego przeznaczenia. Z użytkowego punktu widzenia formaty
różnią się:
zastosowanymi algorytmami kompresji i wielkością plików,
wielkością palety barw,
obsługą przezroczystości (pewne elementy mogą być przezroczyste, pozwalając na
„prześwitywanie” treści, która jest pod obrazem),
zdolnością do przechowywania metadanych, tj. informacji o fotografii takich jak model
aparatu, którym wykonano zdjęcie, parametry (przesłona, migawka flesz), data i godzina i
wiele innych. Dodatkowo istnieje możliwość uzupełnienia pliku o opis, komentarz, informacje
o autorze i prawach autorskich, pozycja geograficzna (z GPS) i wiele innych.
Technologie informacyjne - Podstawy technik informatycznych
Strona 16 z 72
Format Rozszerzenie
nazwy pliku
Paleta
barw
Kompresja Przezro-
czystość
Metadane
Uwagi
BMP
BMP
16,7 mln brak lub
bezstratna
nie
nie
duże pliki wynikowe,
brak utraty jakości
podczas edycji
JPEG
JPG
16,7 mln stratna
nie
tak
małe pliki wynikowe,
utrata jakości przy
kolejnych sesjach
zapisu i odczytu,
najlepszy do
zastosowań w
Internecie
GIF
GIF
256
bezstratna
tak
nie
możliwość tworzenia
animacji, nadaje się do
rysunków składających
się z ograniczonej
palety barw
PNG
PNG
16,7 mln bezstratna
tak
nie
następca formatu GIF,
nie pozwala na
tworzenie animacji ale
obsługuje paletę barw
pozwalającą na wierne
zapisanie fotografii bez
utraty jakości
TIFF
TIF
16,7 mln
brak lub
bezstratna
tak
nie
podstawowy format w
branży graficznej,
umożliwia
przechowywanie
obrazów
kilkustronicowych w
jednym pliku
Zdecydowanie najpopularniejszym formatem zapisu obrazu jest JPEG. Należy jednak pamiętać, że
każdy proces zapisu nowej wersji zdjęcia podczas prace edycyjnych powoduje utratę części danych
(kompresja stratna). W rezultacie po kilku sesjach modyfikacji fotografii może ona utracić tak wiele ze
swojej jakości, że nie będzie nadawać się do publikacji. Dlatego najlepiej zdjęcie przed obróbką
zapisać w formacie TIFF i w takim dokonywać edycji. Dopiero po zakończeniu prac, wersję ostateczną
należy zapisać w formacie JPG. Ważną zaletą takiego postępowania jest to, że podczas zamiany
formatów JPEG-TIFF-JPEG nie nastąpi utrata metadanych.
W sieci Internet wykorzystuje się te formaty, które zapewniają dobrą jakość na ekranie oraz małe
rozmiary plików. Stąd najczęściej spotykamy pliki w formatach JPG, GIF i PNG. Pozostałe (TIFF i BMP)
do tego celu całkowicie się nie nadają z uwagi na duże rozmiary plików.
1.2.3. Kodowanie i kompresja dźwięku
Dźwięk niezależnie od tego czy to jest mowa, muzyka czy hałas ma postać fali akustycznej, a więc
drgań powietrza. Na potrzeby rejestracji dźwięku i jego odtwarzania przez urządzenia audiowizualne
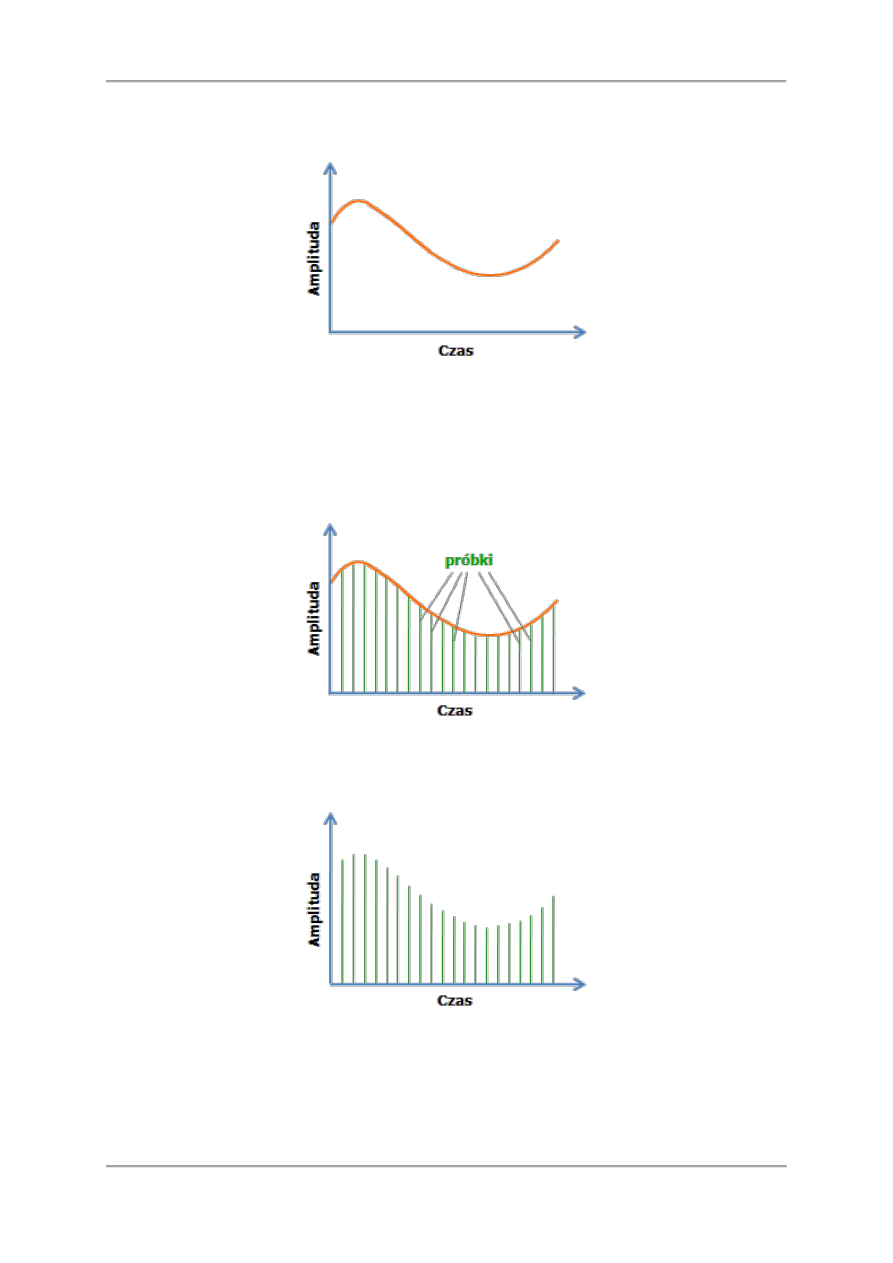
fala ta zamieniana jest na przebieg napięcia elektrycznego. Przykład takiego przebiegu
reprezentującego krótki fragment zapisu dźwięku przedstawia poniższy rysunek:
Technologie informacyjne - Podstawy technik informatycznych
Strona 17 z 72
Przebieg napięcia elektrycznego reprezentującego fragment fali dźwiękowej.
Zjawiska ciągłe (takie jak przebieg fali dźwiękowej) nie da się zapisać w naturalnej postaci. Aby mogły
być przetwarzane przez systemy informatyczne muszą zostać poddane procesowi próbkowania. Polega
on na tym, że przeprowadzany jest pomiar poziomu dźwięku w bardzo krótkich odstępach czasu.
Wyniki pomiarów to próbki. Wartości próbek zapisuje się w postaci liczb szesnastobitowych. Cyfrowy
zapis dźwięku składa się więc z sekwencji próbek zebranych w procesie próbkowania.
Próbkowanie dźwięku
Podczas jej odtwarzania następuje proces odwrotny. Na podstawie próbek tworzony jest zbliżony do
oryginalnego przebieg poziomu dźwięku.
Próbki, na podstawie których odtwarzany jest oryginalny przebieg fali dźwiękowej.
Wierność odtwarzanych dźwięków zależna jest od częstotliwości próbkowania. W przypadku płyt CD
wynosi ona 44 100 Hz, co oznacza, że próbki są wyznaczane 44 100 razy w ciągu sekundy.
Przy zapisie dźwięku stereofonicznego w danym momencie wyznaczane są dwie próbki, po jednej dla
kanału prawego i lewego. Mamy wobec tego na każdy kanał 44100 próbek na sekundę, każda po 2
bajty. Na tej podstawie możemy wyznaczyć ilość bajtów niezbędną do zapisania 1 sekundy muzyki.

Technologie informacyjne - Podstawy technik informatycznych
Strona 18 z 72
Wystarczy przemnożyć częstotliwość próbkowania przez liczbę kanałów i liczbę bajtów przypadającą
na jedną próbkę. Mamy więc:
n
= 44100 x 2 x 2 = 176400 bajtów.
Na zapisanie utworu muzycznego trwającego 3 minuty potrzeba wobec tego:
3 x 60 x 176400 = 31752000,
czyli ok. 30,3 MB.
Przykład
Pojemność standardowej płyty CD wynosi 650 MB. Ile minut muzyki pomieści?
650 MB to 650*1024*1024 bajtów tj. 681574400 bajtów. Skoro jedna sekunda dźwięku zajmuje
176400 bajtów to na płycie mieści się 681574400/176400 tj. 3864 sekundy dźwięku, co odpowiada
ok. 64 minutom muzyki.
Na potrzeby telefonii (transmisja wyłącznie mowy) nie ma konieczności zapewnienia bardzo wysokiej
jakości dźwięku. Stosuje się tu częstotliwość próbkowania obniżoną do 8 kHz i zapis jednego kanału
(mono a nie stereo). Poza tym próbki mają długość 8, a nie 16 bitów. Prowadzi to do 22 krotnego
zmniejszenia ilości przesyłanych między telefonami rozmówców danych. Towarzyszy temu jednak
znaczne obniżenie wierności odtwarzanego dźwięku. Dla prowadzenia rozmów jest ona jednak
całkowicie wystarczająca.
Podobnie jak dla grafiki, również dla dźwięku opracowano algorytmy kompresji stratnej, które
pozwalają na bardziej efektywny zapis danych o dźwięku. Najpopularniejsze obecnie formaty zapisu z
kompresją stratną to MP3 (ang. MPEG-1/2 Audio Layer-3
), AAC (Advanced Audio Coding), WMA
(Windows Media Audio). Dostępne są też formaty zapisu bez kompresji lub z kompresją bezstratną np.
WAV (waveform audio format) lub FLAC (Free Lossless Audio Codec).
Należy pamiętać, że tak jak w przypadku grafiki, edycji plików należy dokonywać w formatach
bezstratnych, a dopiero po zakończeniu prac, wersję końcową przekształcić do docelowego formatu z
kompresją stratną. Istnieje tu możliwość określenia stopnia kompresji i tym samym jakości rezultatu
końcowego. Zależność: im wyższa jakość tym większy plik (niższy stopień kompresji) obowiązuje tu
tak samo jak w grafice.
Szczególne cechy posiada format WMA. Wyposażony jest w mechanizm DRM cyfrowego zarządzania
uprawnieniami. Służy on do zabezpieczenia zawartości pliku przed dostępem osób nieuprawnionych.
Wykorzystywany jest m.in. w celu egzekwowania opłat za prawo do odtwarzania zawartości.
Zabezpieczony w ten sposób plik jest zaszyfrowany i może być swobodnie dystrybuowany. Jednak
odtworzony może być po wykupieniu licencji. Wówczas do odtwarzacza dostarczana jest odpowiednio
przygotowana informacja pozwalająca na odtworzenie zawartości.
Pliki w formacie Midi
Odtworzenie pliku w formacie midi (rozszerzenie nazwy pliku - mid) prowadzi do odtworzenia
materiału dźwiękowego. Jednak taki plik nie zawiera zapisu próbkowanego dźwięku, a to co słyszymy
w głośnikach generowane jest przez wbudowany w komputer syntezator. Pliki w formacie midi
zawierają polecenia dla syntezatora określające wysokości dźwięków, ich barwy (symulowane
instrumenty) i czas odtwarzania każdego z nich. Dzięki temu plik zawierający kilka minut muzyki może
mieć rozmiar kilkudziesięciu kilobajtów. Z uwagi na fakt, że dźwięki generowane są przez syntezator
plik midi nie może zawierać muzyki wokalnej, czy innych dźwięków zarejestrowanych z natury.

Technologie informacyjne - Podstawy technik informatycznych
Strona 19 z 72
Standard midi wykorzystywany jest przez twórców muzyki. Istnieje możliwość podłączenia
klawiatury instrumentu klawiszowego, za pomocą których można grać na syntezatorze wbudowanym
w komputer. Zagrany utwór można zarejestrować i za pomocą odpowiedniego oprogramowania
przedstawić w postaci zapisu nutowego. Można oddzielnie rejestrować partie poszczególnych
instrumentów (np. skrzypce, klarnet, fortepian, perkusja itp.), skorygować zapis nutowy, a potem
odtworzyć cały utwór napisany np. dla orkiestry symfonicznej. Syntezatory wbudowane w popularne
komputery nie mają zbyt wysokich parametrów. Można wobec tego podłączyć do komputera
zewnętrzny syntezator (jeden lub kilka), który będzie sterowany z komputera i zapewni wymaganą
jakość dźwięku.
1.2.3. Audio-video
Obrazy ruchome powstają, przez wyświetlanie najczęściej 25 obrazów na sekundę. Wymaga to
przesłania i przetworzenia znacznych ilości danych. Jedna minuta filmu z popularnej kamery wideo o
rozmiarach obrazu 720x525 pixeli zajęłaby ok. 1,6 GB (720*525*25*60= 1701000000 bajtów).
Do zapisu informacji o obrazach ruchomych powstało szereg różnych, wciąż udoskonalanych
algorytmów. Cechuje je zróżnicowana jakość oraz efektywność kompresji (stratnej). Najpopularniejsze
należą do rodziny MPEG. Powstało kilka wersji tego standardu:
MPEG-1 – zapewnia jakość odpowiadającą kasetom VHS, stosowany na płytach VCD
MPEG-2 – zapewnia wysoką jakość (przekraczającą możliwości standardów SECAM, PAL i
NTSC) stosowany na płytach SVCD, DVD, Blueray i telewizji cyfrowej
MPEG-4 – stosowany w telewizji cyfrowej HD i płytach Blueray, wykorzystywany w
systemach wideokonferencji.
Na bazie MPEG-4 powstały popularne standardy Divx i Xvid. Pliki z zakodowanym zgodnie z nimi
obrazem noszą rozszerzenie AVI. Firma Microsoft utworzyła też swój standard WMV (windows media
video), którego wyróżnia spośród pozostałych mechanizm DRM.
1.2.3. Kodowanie tekstu
Podobnie jak inne informacje również tekst trzeba rozłożyć na możliwe najmniejsze cząstki składowe i
przypisać im wartości numeryczne, aby było możliwe przetwarzanie ich za pomocą urządzeń
cyfrowych. Najmniejszą jednostką tekstu jest litera. Każdej z liter jest przypisana wartość liczbowa.
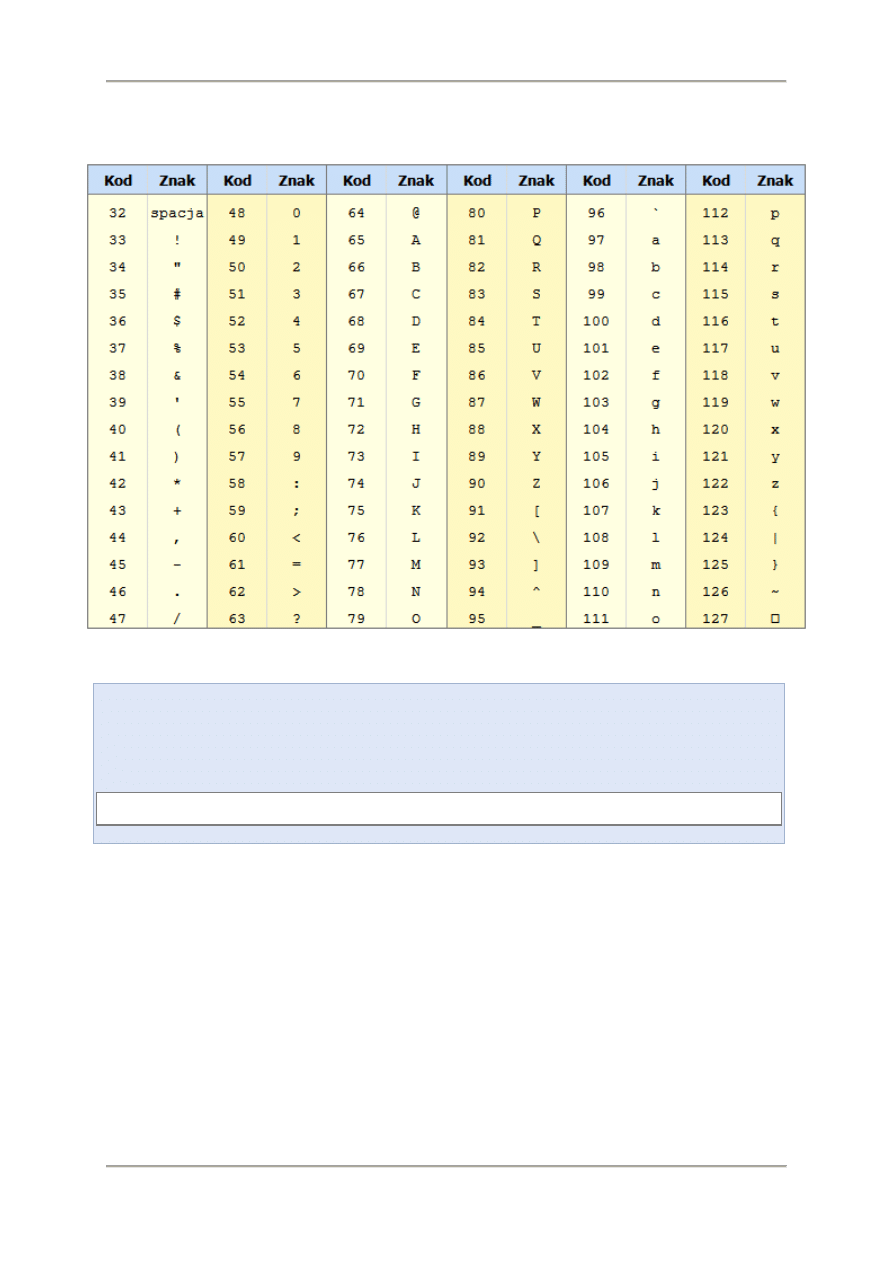
Amerykańska organizacja standaryzacyjna opracowała standard ASCII określający jakie wartości
liczbowe reprezentują poszczególne znaki pisarskie (litery, cyfry, znaki interpunkcyjne).
Zakres wartości od 32 do 127 przedstawiono w tabeli poniżej. Standard ASCII obejmuje również
wartości od 0 do 31, ale są to tzw. kody sterujące i nie odpowiadają one żadnym widocznym znakom.
Przeznaczone są do sterowania np. drukarką (wysunięcie papieru o 1 wiersz, wysunięcie kartki,
zmiany kroju czcionki itp.).
Technologie informacyjne - Podstawy technik informatycznych
Strona 20 z 72
Tabela kodów ASCII
Źródło: www.asciitable.com
Przykład
Napis o treści „Podstawy informatyki” zapisany będzie w komputerze za pomocą szeregu
następujących liczb odpowiadających odpowiednim poszczególnym literom:
80 111 100 115 116 97 119 121 32 105 110 102 111 114 109 97 116 121 107 105
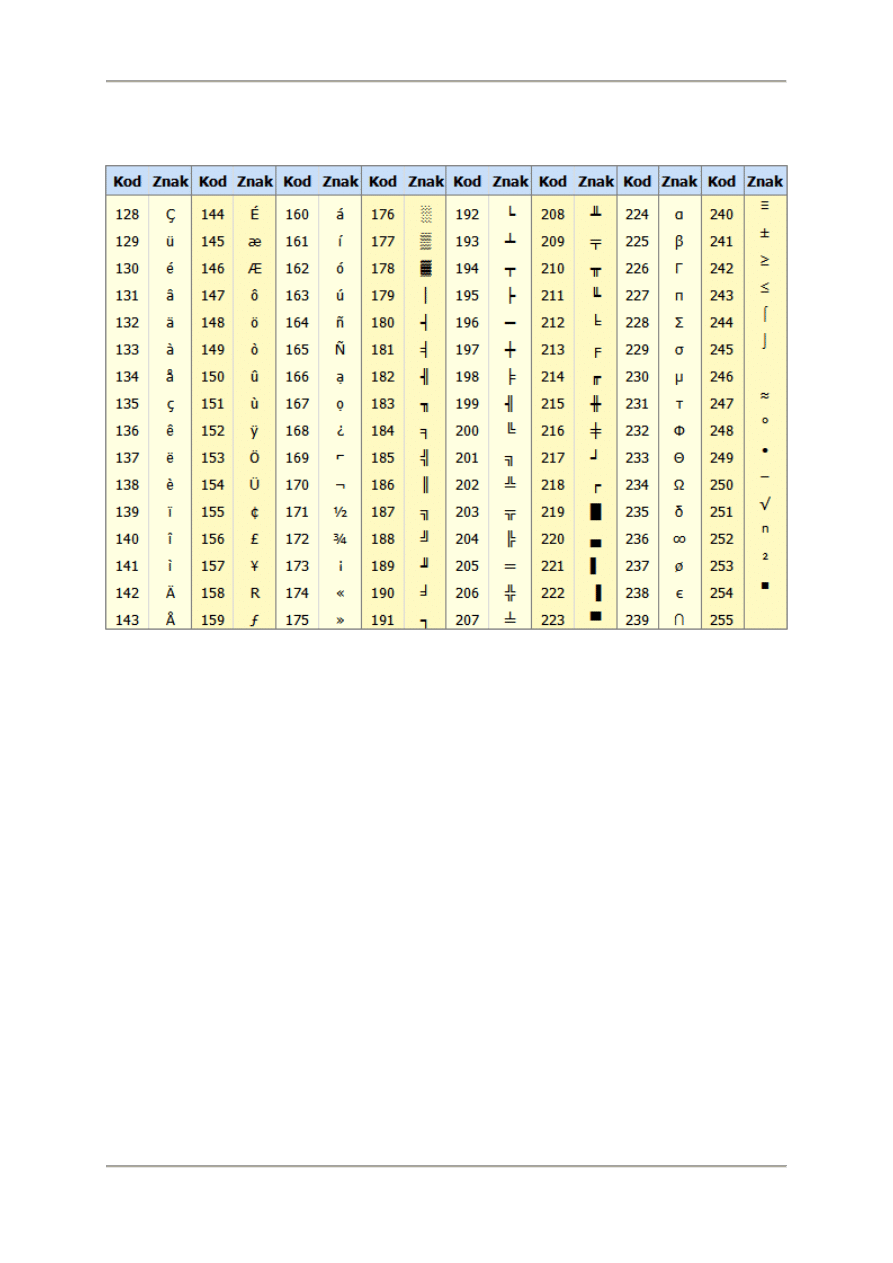
Podstawowy standard ASCII definiuje pierwszych 128 liczb z przedziału 0-127 i obejmuje jedynie znaki
stosowane w USA. Jak już wiemy za pomocą 1 bajtu możemy zapisać liczby z przedziału 0 - 255.
Drugą połowę tego przedziału (wartości od 128 – 255) wykorzystano do przypisania znaków
semigraficznych i liter występujących tylko w niektórych językach. Jest to tak zwane rozszerzenie
zestawu kodów ASCII i jego zawartość przedstawia tabela.
Technologie informacyjne - Podstawy technik informatycznych
Strona 21 z 72
Rozszerzony zestaw kodów ASCII
Źródło: Marciniak, A., Nowe elementy systemu i języka Turbo Pascal w wersji 6.0 z opisem biblioteki Tubo
Vision.
Uważny czytelnik zauważy, że nie znajdziemy w niej liter (tzw. znaków diakrytycznych) występujących
tylko w języku polskim takich jak „ą”, „ę”, „ó”, „ć” itd. Podobne problemy występowały w innych
językach Europy środkowowschodniej. Dla rozwiązania problemów stworzono kilka wersji tabeli
rozszerzonej. Kilka z nich powstało u wielkich producentów oprogramowania i sprzętu za granicą
(Microsoft, IBM) inne powstały na rynku polskim. W rezultacie jeszcze kilka lat temu można było
spotkać na rynku kilkanaście standardów kodowania polskich znaków.
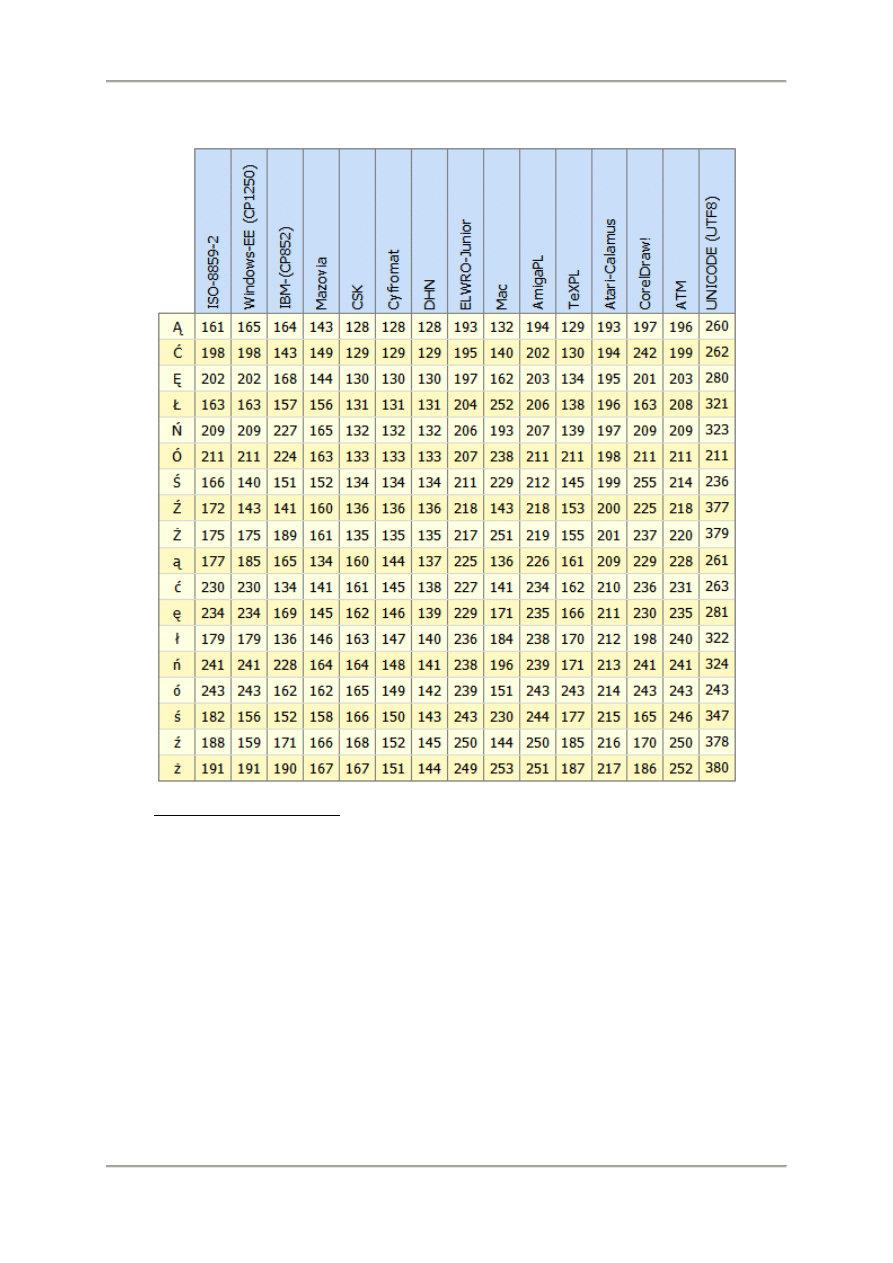
Niezależnie od różnych standardów kodowania polskich znaków powstały normy w tym zakresie:
polska (PN-93 T-42118),
międzynarodowa (ISO 8859-2).
Co do treści są one tożsame, ale jednocześnie są niezgodne z wszelkimi innymi standardami
kodowania polskich znaków. Na czym polega zgodność lub jej brak? Najpierw przyjrzyjmy się, pod
jakimi liczbami występują polskie znaki w poszczególnych standardach.
Technologie informacyjne - Podstawy technik informatycznych
Strona 22 z 72
Polskie znaki w różnych standardach kodowania
Źródło: http://www.agh.edu.pl/ogonki/, http://www.kurshtml.boo.pl/generatory/unicode.html
Ta sama litera w zależności od standardu zapisywana jest za pomocą różnych liczb.

Technologie informacyjne - Podstawy technik informatycznych
Strona 23 z 72
Przykład
Tekst „Żeglując po mieście Łódź”
w standardzie ISO będzie miał postać (wytłuszczonym drukiem wskazano znaki diakrytyczne):
175 101 103 108 117 106 177 99 32 112 111 32 109 105 101 182 99 105 101
32 163 243 100 188
a w standardzie CP852:
189 101 103 108 117 106 165 99 32 112 111 32 109 105 101 152 99 105 101
32 157 162 100 171
natomiast w Windows CP1250:
175 101 103 108 117 106 185 99 32 112 111 32 109 105 101 156 99 105 101
32 163 243 100 159
Dla zapewnienia poprawności wyświetlania, czy drukowania tekstów oprogramowanie i urządzenia
muszą pracować w tym samym standardzie, którym napisany jest tekst. Inaczej w miejscu polskich
znaków pojawią się błędy. Możemy się z nimi spotkać na niektórych, niepoprawnie napisanych
stronach WWW.
Przykład
Jeżeli strona jest przygotowana w standardzie CP1250, a nasza przeglądarka jest skonfigurowana
do pracy z ISO 8859-2, to zamiast tekstu
„Żeglując po mieście Łódź”
na ekranie pojawi się napis:
„Żeglujšc po miecie Łód„
Niestety trzymając się wymienionych wyżej standardów nie ma możliwości jednocześnie wyświetlania
treści zapisanych w różnych językach np. rosyjskim, polskim i chińskim. Obecnie, w dobie Internetu i
wymiany informacji w skali globalnej znaczenia nabierają standardy powszechne, które pozwolą, aby
każdy tekst mógł być tak samo poprawnie wyświetlony niezależnie od wykorzystywanego systemu
operacyjnego, oprogramowania, sprzętu czy języka, w którym został napisany.
Dla sprostania oczekiwaniom światowej społeczności opracowano uniwersalny standard
kodowania znaków Unicode. Jego uniwersalność polega na tym, że pozwala na objęcie wszystkich
znaków, używanych we wszystkich językach. Znaki pisarskie mogą mieć przypisane kody 1, 2, 3 i 4
bajtowe (we wcześniejszych standardach ograniczeniem było założenie, że kody są jednobajtowe).
Istnieje kilka metod kodowania Unicode. Najważniejsze z nich to UTF8, UTF16 i UTF32.
Obecnie w Internecie spotykamy (w odniesieniu do języka polskiego) treści kodowane w standardach:
CP1250 – nazywany też windows środkowoeuropejski,
ISO 8859-2 - inna nazwa środkowoeuropejski ISO oraz
UTF-8.
Starsze aplikacje pracujące w systemie operacyjnym DOS wciąż posługują się starszymi systemami
kodowania. Najpopularniejsze z nich to Mazovia i CP852.

Technologie informacyjne - Podstawy technik informatycznych
Strona 24 z 72
1.3. Bazy danych
Informacje, aby mogły być przetwarzane muszą najpierw zostać zarejestrowane i zapisane na
nośnikach informacji. W toku przetwarzania są one odczytywane, następnie dokonywane są procesy
obliczeniowe, a ich rezultaty zapisywane na nośnikach i/lub prezentowane na ekranie bądź wydruku.
Jednym z podstawowych czynników wpływających na sprawność przetwarzania informacji jest sposób
ich zapisu. Systemy służące do przetwarzania dużych ilości danych zapisują informacje w postaci tzw.
baz danych. Nie każdy jednak zbiór informacji jest jednak bazą danych.
Przykład
Dla przykładu posłużmy się zbiorem informacji o klientach:
Jan Nowak, 60-392 Poznań, ul.Niska 33, WL2309231,66070892915
Roman Niwiński, Poznań 61-983, ul.Wysoka 4, 54032304213, BB432134
Maliński Piotr, ul.Krótka 200/2, Poznań, 430222056325
Zielińska Magdalena, 78032408932, WL4402030, ul.Zielona 45, 62-312 Stęszew
78032408932, WL99321032,ul.Słoneczna 3, 60-234, Mosina, Dorota Tomczak
WL3432133, 801231094329, Roman Wolski, 62-231 Poznań, ul. Mokra 3
Marek Urban, 61-342 Poznań, os. Lipowe 3/2, 430202045431, DB3212342
Krystyna Nowowiejska, ul.Polska 4, 61-321 Poznań, WA2341234,45111203214
Poszukiwanie informacji w takim zbiorze jest bardzo utrudnione. Aby odnaleźć jakąkolwiek
informację (np. klienta o nazwisku Wolski) niezbędne jest przeszukanie (przeczytanie) wszystkich
danych poprzedzających go tj. wszystkich informacji o wszystkich klientach zapisanych przed
nazwiskiem poszukiwanego klienta. Ponadto problemem jest identyfikacja danych – przedostatni
klient ma na imię Marek a nazywa się Urban, czy może jest na odwrót?
Sposób na usprawnienie operowania danymi jest prosty – wystarczy zapisywać je w sposób
uporządkowany tj. tak, aby cechy poszczególnych klientów były zapisywane w ustalonym wcześniej
porządku np. nazwisko, imię, ulica, kod pocztowy, miasto, nr dowodu osobistego, numer PESEL
Tak uporządkowany zbiór informacji wyglądać będzie następująco:
Nowak, Jan, ul.Niska 33,60-392, Poznań,WL2309231,66070892915
Niwiński, Roman, ul.Wysoka 4, 61-983, Poznań,BB432134 54032304213
Maliński, Piotr, ul.Krótka 200/2, Poznań, WA4432542,43022205635,
Zielińska, Magdalena, ul.Zielona 45, Stęszew, 62-312, WL4402030,78032408932
Tomczak, Dorota, ul.Słoneczna 3, 60-234, Mosina, WL9932103, 78032408932
Wolski, Roman, ul. Mokra 3, 62-231, Poznań, WL3432133, 80123109439
Urban, Marek, os. Lipowe 3/2, 61-342, Poznań, DB3212342, 43020204543
Nowowiejska, Krystyna, ul.Polska 4, 61-321 Poznań, WA2341234, 45111203214
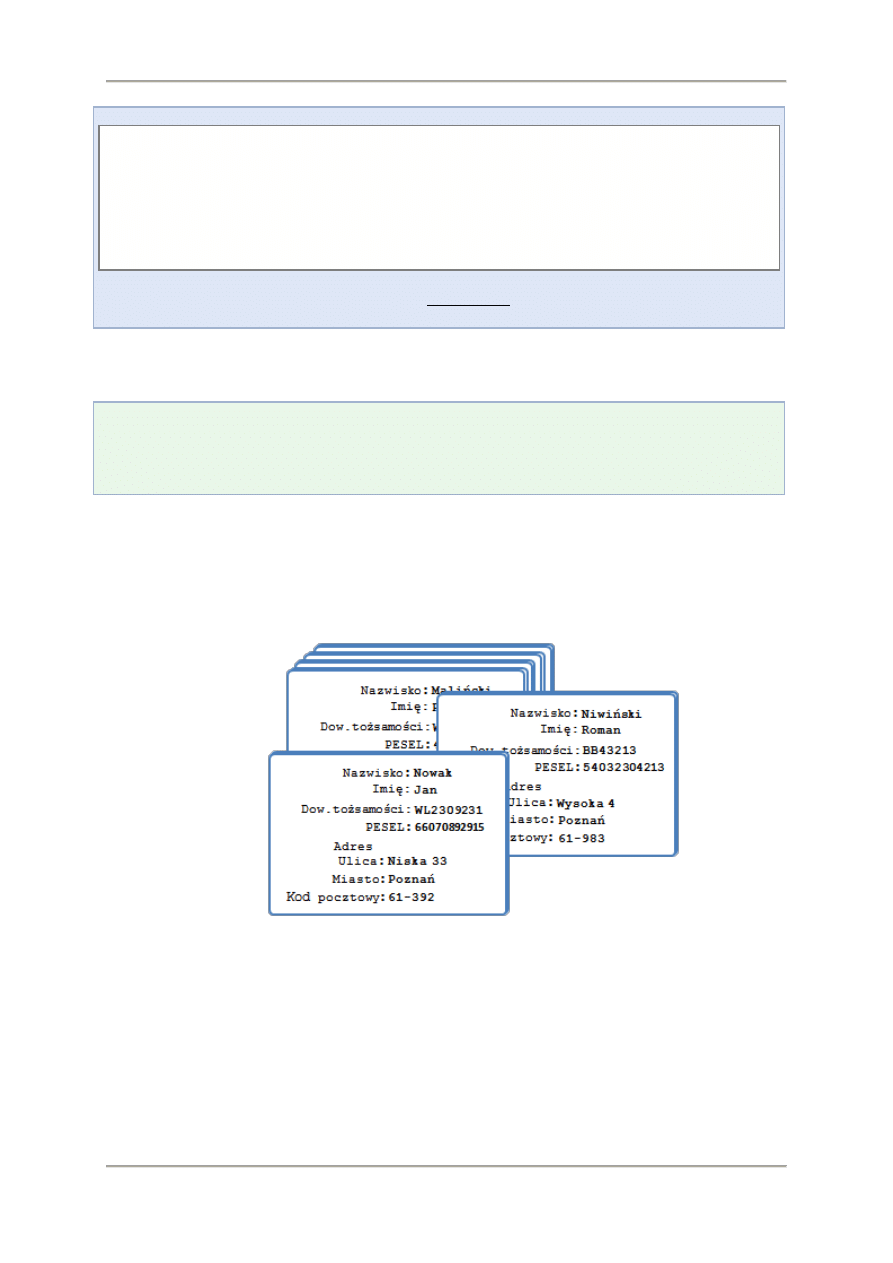
Uporządkowanie polegające na określeniu kolejności zapisu cech w poszczególnych wierszach nie
jest wystarczające. Zbiór byłby bardziej czytelny, gdyby opisy poszczególnych cech klientów
zaczynały się w tym samym miejscu wiersza. Oznacza to, że oprócz kolejności poszczególnych cech
deklarujemy ilość miejsca jaką przewidujemy na każdą z nich. Gdy to uwzględnimy nasz zbiór
informacji będzie miał następującą postać:
Technologie informacyjne - Podstawy technik informatycznych
Strona 25 z 72
Nowak Jan ul.Niska 33 60-392 Poznań WL2309231 66070892915
Niwiński Roman ul.Wysoka 4 61-983 Poznań BB43213 54032304213
Maliński Piotr ul.Krótka 200/2 Poznań WA4432542 43022205635
Zielińska Magdalena ul.Zielona 45 62-312 Stęszew WL4402030 77231231232
Tomczak Dorota ul.Słoneczna 3 60-234 Mosina WL9932103 78032408932
Wolski Roman ul. Mokra 3, 62-231 Poznań WL3432133 80123109439
Urban Marek os. Lipowe 3/2 61-342 Poznań DB3212342 43020204543
Nowowiejska Krystyna ul.Polska 4 61-321 Poznań WA2341234 45111203214
Taki uporządkowany zbiór informacji nazywamy bazą danych.
W przykładzie posłużono się szczególnym przypadkiem bazy danych składającej się z jednej tablicy. W
praktyce spotykamy bazy danych, na które składa się wiele podobnych do powyższej tablic.
Definicja
Baza danych to zbiór informacji, o wspólnych cechach ułożonych w określonym porządku.
Bazę danych można wyobrazić sobie zarówno jako tabelę, jak przedstawiono wyżej lub jako plik
kartotek. Każdy wiersz tabeli lub każda kartoteka zawiera informacje o pojedynczym kliencie. Są one
ułożone w ściśle określonym porządku. Taką porcję informacji o pojedynczym obiekcie (w przykładzie
jest to klient, ale mógłby to być rachunek, dokument księgowy, książka, artykuł w sklepie) nazywamy
rekordem. Rekord natomiast składa się z pól. Nasza tablica informacji o klientach składa się z 7
kolumn. Pojęcia pola i kolumny możemy używać zamiennie.
W praktyce tablica bazy danych może być prezentowana na ekranie komputera w postaci formularza
lub tabeli.
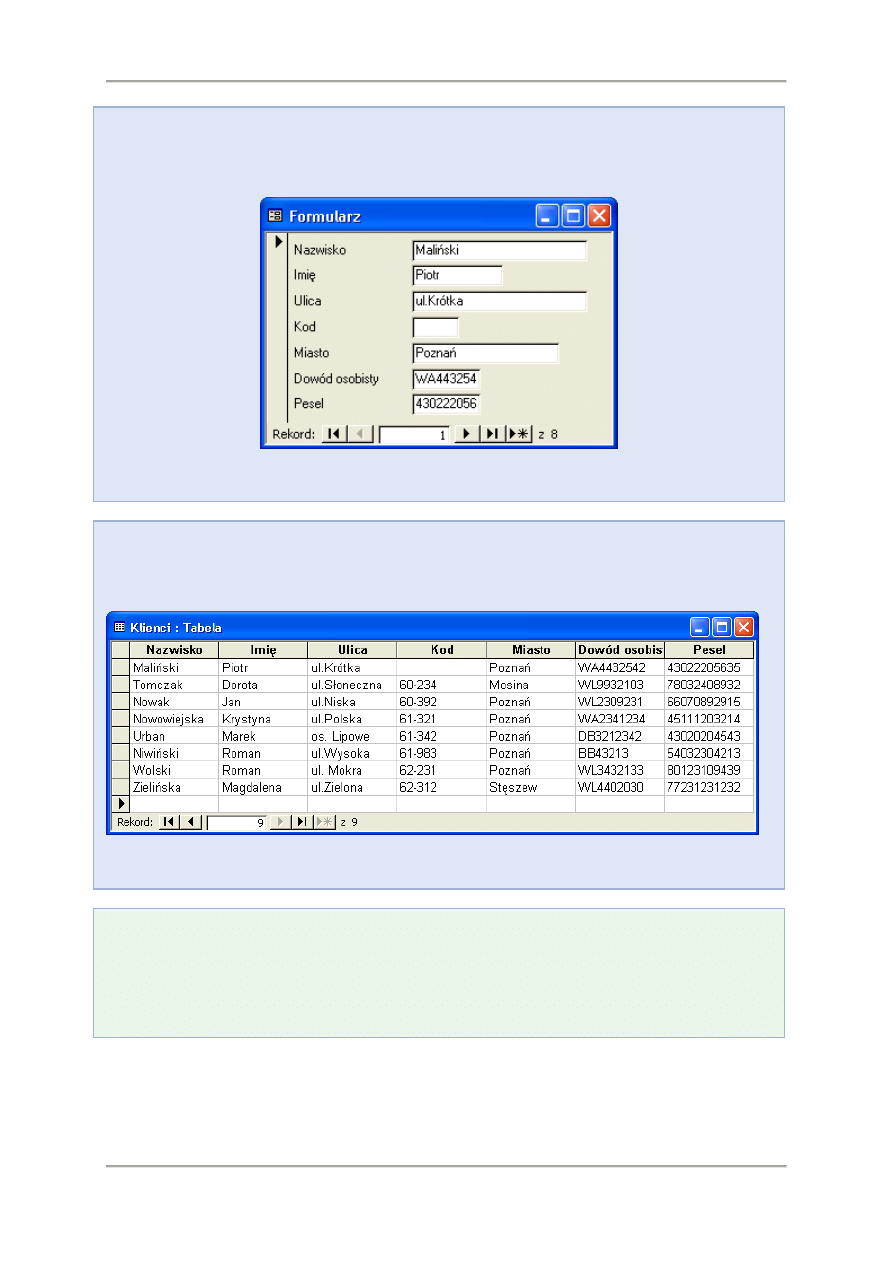
Technologie informacyjne - Podstawy technik informatycznych
Strona 26 z 72
Przykład
Wyświetlanie danych w postaci formularza programu Microsoft Office Access 2003:
Źródło: Microsoft Office Access 2003
Przykład
Wyświetlanie danych w postaci tabeli programu Microsoft Office Access 2003:
Źró
dło: Microsoft Office Access 2003
Definicja
Obecnie wykorzystywane systemy oparte są o bazy danych składające się z wielu, powiązanych ze
sobą logicznie tablic. Takie bazy danych nazywamy relacyjnymi, a powiązania między nimi to
relacje.
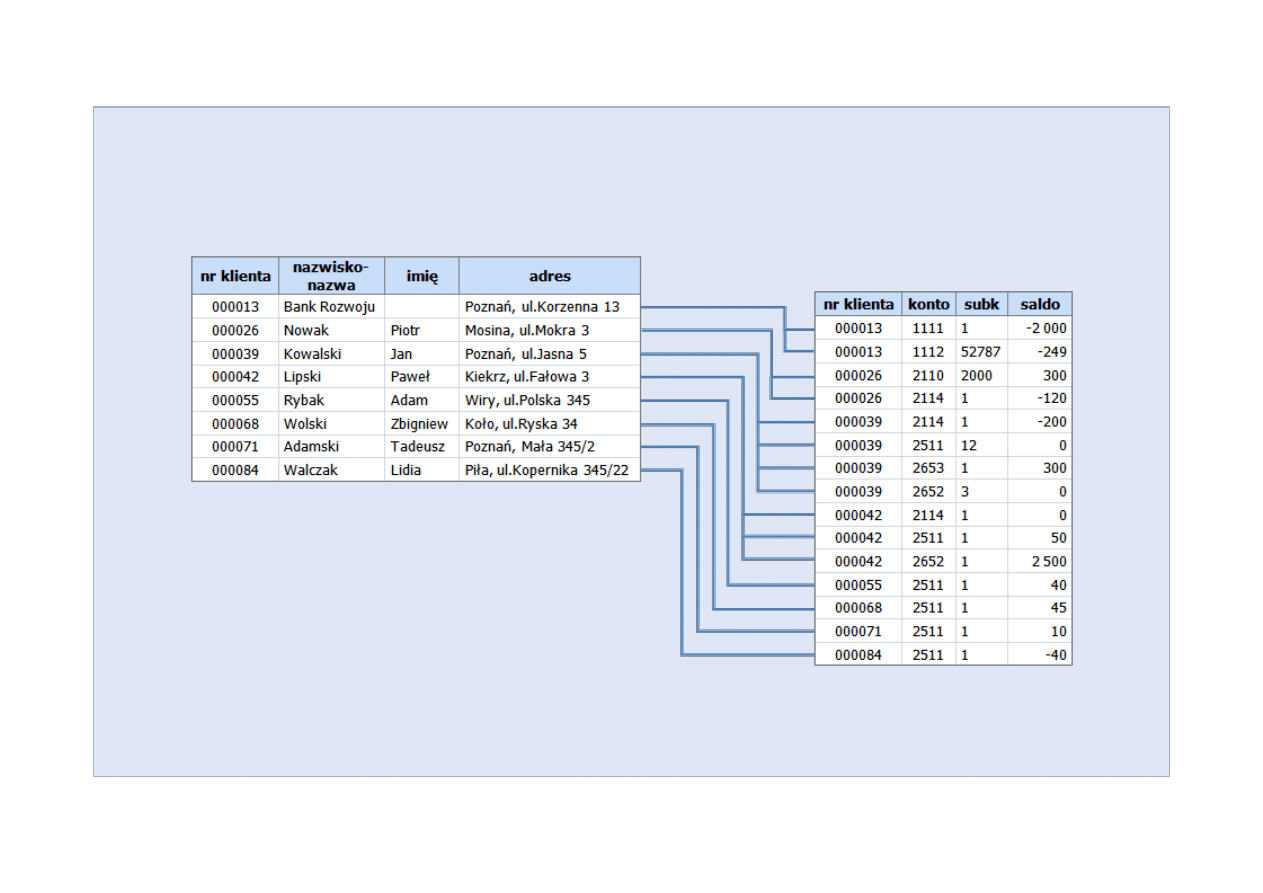
Przykład
Przykład dwóch tablic powiązanych ze sobą logicznie przedstawiono na rysunku poniżej.
Przykład dwóch tablic powiązanych ze sobą logicznie
Klienci
Rachunki
Rysunek przedstawia dwie tablice z informacjami o klientach i ich rachunkach. Każdemu z klientów nadano unikalny numer. Staje się on również integralną
częścią każdego rachunku tego klienta. Dzięki temu można bardzo łatwo odnaleźć wszystkie rachunki danego klienta. Jeżeli poszukiwane są informacje
o rachunkach np. Pawła Lipskiego to trzeba odszukać wszystkie rekordy w tablicy „Rachunki”, u których w polu nr klienta jest numer 000042. Ustalenie
właściciela rachunku również nie nastręcza problemów, bowiem również można posłużyć się tym samym polem w tablicy „Klienci”.
Analizując przykład można by zadać pytanie – dlaczego danych nie zebrać w jednej tablicy np.
„Rachunki”, ale rozszerzonej o pola, które są w tablicy „Klienci”. Wówczas pełna informacja o
właścicielu byłaby zawarta w każdym rachunku. Rozwiązanie ta miałoby jednak szereg wad:
te same dane klienta przechowywane byłyby w bazie danych wielokrotnie, co
niepotrzebnie zajmowałoby miejsce na nośnikach,
zwiększona ilość danych przekładałaby się na dłuższy czas ich przetwarzania,
dane opisujące klienta byłyby niejednoznaczne, bo podczas zakładania rachunków
w różnym czasie przez różne osoby dane klienta byłby wpisywane w różny sposób (np. długie
nazwy ulic czy osiedli byłyby skracane na różne sposoby),
w przypadku zmiany danych klienta (np. adresu zamieszkania lub nazwiska) konieczna byłaby
ich wielokrotna aktualizacja - dla każdego rachunku oddzielnie.
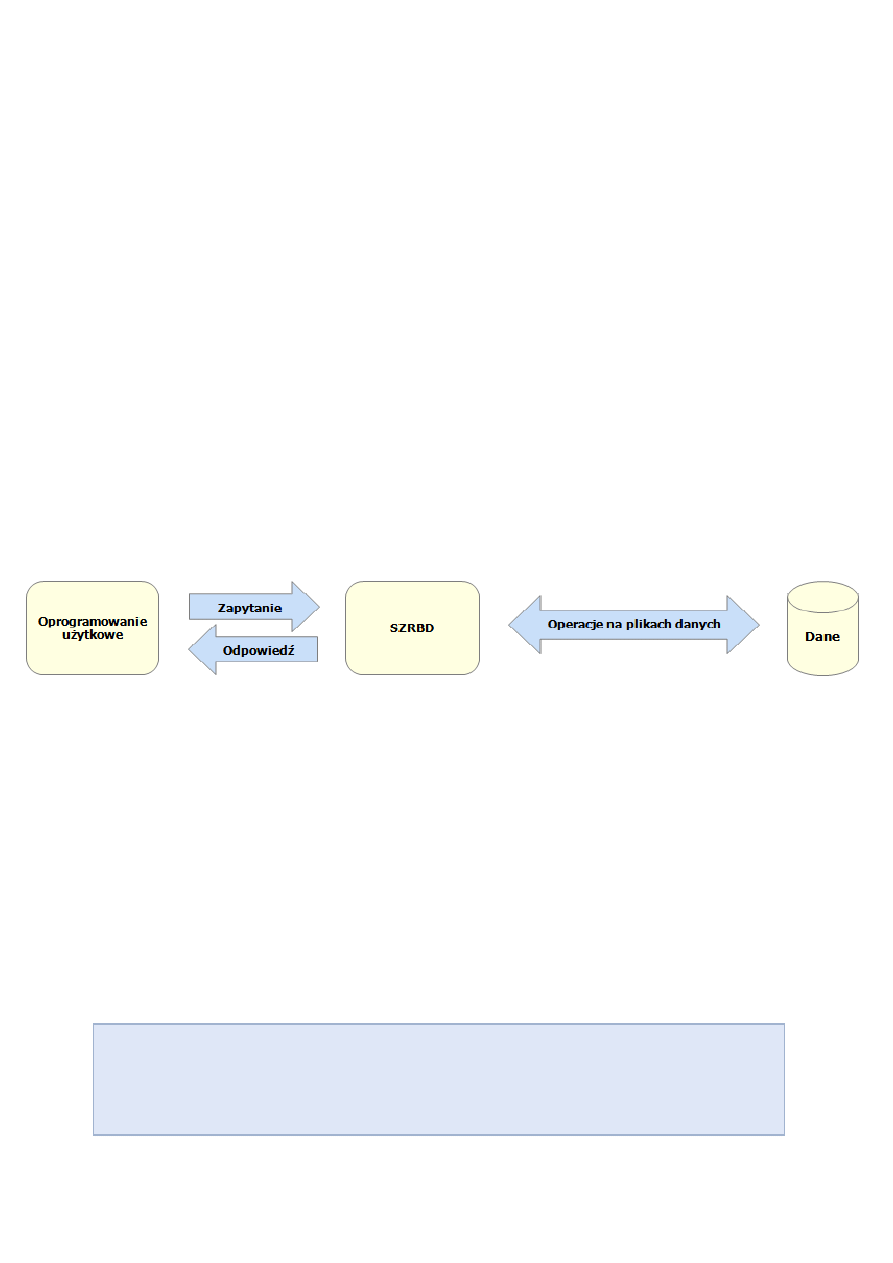
Złożone systemy informatyczne takie jak systemy bankowe, finansowo-księgowe, wspomagania
zarządzania i in. oparte są wyłącznie na relacyjnych bazach danych. Wszelkie operacje na danych
(zapisywanie, aktualizacja, odczyt) wykonywane są za pośrednictwem specjalizowanego
oprogramowania nazywanego System Zarządzania Relacyjnymi Bazami Danych (SZRBD). W
literaturze często używany jest anglojęzyczny skrót RDBMS (Relational DataBase Management
System). Oprogramowanie użytkowe (np. program księgowy) wykonuje operacje na danych wyłącznie
za pośrednictwem systemu zarządzania bazą danych. Nie dokonuje ingerencji w dane w inny sposób.
Zapis, aktualizacja, modyfikacja czy usuwanie danych odbywa się w rezultacie wykonania tzw.
zapytania (z ang. query) do SZRBD.
Systemy zarządzania bazami danych są produkowane, przez producentów zwykle nie związanych
z twórcami systemów użytkowych. Obecnie stosowane SZRBD wykorzystają zestandaryzowany język
zapytań SQL (Structured Query Language). Oddzielenie oprogramowania użytkowego od SZRBD
oraz standaryzacja języka zapytań pozwala na dużą swobodę wyboru spośród gamy systemów
zarządzania bazami danych różnych producentów, przeznaczonych na różne platformy systemowe i
sprzętowe. Ponadto pozwala na integrację dodatkowych systemów (np. analitycznych) korzystających
z tej samej bazy danych, co dany system użytkowy. Wystarczy, że będą one w stanie komunikować
się z posiadanym SZRBD w języku SQL. Takie możliwości mają np. arkusze kalkulacyjne pozwalając na
analizę danych pobieranych z bazy danych system magazynowego na bieżąco.
Poza podstawowymi operacjami zapisu i odczytu danych z bazy danych, SZRBD spełnia szereg
niezwykle istotnych funkcji.
Wbudowane mechanizmy ochrony integralności danych pozwalają na takie skonstruowanie bazy
danych, aby niezależnie od tego jakie oprogramowanie dokonuje w niej zmian, były one
przeprowadzone zgodnie ze zdefiniowanymi w niej zasadami.
Przykład
W SZRDB istnieje możliwość określenia, że nie można usunąć rekordu zawierającego dane klienta,
jeżeli istnieje choć jeden powiązany z nim rachunek.

Technologie informacyjne - Podstawy technik informatycznych
Strona 29 z 72
Dzięki tym mechanizmom znacznie ograniczona jest możliwość nieuprawnionego ingerowania w dane.
Systemy SZRDB zapewniają również rozbudowany system uprawnień użytkowników. Pozwalają
dzięki temu na bardzo selektywne nadawanie praw do odczytu i zapisu informacji w bazie danych.
Każdy pracownik może mieć dostęp do niezbędnych na jego stanowisku danych (do zapisu i odczytu
lub tylko do odczytu), podczas gdy pozostałe będą niedostępne. Zapewnia to poufność informacji i
ogranicza możliwość przypadkowej modyfikacji tych danych, które modyfikowane być nie powinny.
Przykład
Niewiele osób w banku ma prawo do modyfikowania informacji o kursach walutowych. Wszyscy
jednak mogą dowiedzieć się, jakie one są. Z kolei dane kadrowe dostępne mogą być dla bardzo
niewielkiej grupy pracowników zarządzania zasobami ludzkim lub rachuby płac. Pozostali pracownicy
nie będą mieli wglądu w te informacje.
Uprawnienia dostępu mogą być nadawane do bazy danych jako całości, wybranych tablic lub
pojedynczych pól.
Kolejną funkcją SZRBD jest zapewnienie bezpiecznego jednoczesnego dostępu do bazy
danych przez wiele osób. Jeżeli kilka osób chce uzyskać dostęp do tego samego rekordu, z czego
dwie chcą go zmodyfikować istnieje ryzyko, że zapisane dane będą niespójne, a osoby odczytujące
informacje zostaną prowadzone w błąd. Zadaniem systemu jest tu umożliwienie jednej tylko osobie
modyfikowania informacji w określonym momencie. Pozostałe będą miały dostęp tylko do odczytu lub
nie będą miały dostępu wcale. Pojawi się wówczas na ekranie stosowny komunikat.
Ważną funkcjonalnością SZRBD jest obsługa tzw. transakcji. Na większość aktualizacji danych
składa kilka zmian w kilku tablicach. Z różnych powodów może dojść do zakłóceń w pracy bazy
danych np. nagła przerwa w dopływie energii elektrycznej. Mogłoby wówczas dojść do sytuacji, w
której część zamian w bazie danych składających się na transakcję nie zostałaby zapisana. Byłoby to
naruszenie integralności danych. Dla wyeliminowania takiej sytuacji stworzono mechanizm obsługi
transakcji. Dzięki niemu, jeżeli z jakiegoś powodu transakcja nie zostanie zakończona, to wszelkie
wykonane w jej ramach operacje zostaną automatycznie wycofane. Oznacza to, że baza danych
zostanie przywrócona sprzed rozpoczęcia transakcji. W rezultacie działania tego mechanizmu
transakcja jest realizowana w całości lub wcale.
Nowoczesne SZRBD dysponują efektywnymi funkcjami archiwizacji i odtwarzania danych. Jest to
niezwykle istotne, gdyż ręcznie odtworzenie bazy danych z dokumentów papierowych w przypadku
awarii jest praktycznie niemożliwe.
Jedną z ważniejszych cech SZRBD jest otwartość. Polega ona na tym, że z bazy danych mogą
korzystać różne programy, nie tylko te, dla których powstała, (np. system bankowy). Mogą to być
systemy analityczne, informowania kierownictwa, hurtownie danych czy arkusze kalkulacyjne zawarte
w oprogramowaniu biurowym. Dostęp taki jest możliwy, jednak z zachowaniem wszelkich zasad
wynikających z uprawnień użytkownika czy mechanizmów zapewnienia integralności danych. Dzięki
temu łatwo można integrować z podstawowym systemem użytkowym programy innych producentów
lub tworzone przez zespół informatyków firmy.
Separacja SZRBD od oprogramowania użytkowego powoduje, że dane mogą znajdować się na różnych
platformach systemowych i sprzętowych, a ich zmiana jest dla użytkownika końcowego
niedostrzegalna i nie wymaga ingerencji w oprogramowanie użytkowe. Najczęściej tego typu systemy
służą do budowy architektury klient-serwer. Polega ona na tym, że na stacjach roboczych
(komputerach użytkowników) instaluje się oprogramowanie użytkowe (klienta), a na centralnym
serwerze znajduje się baza danych i system zarządzania nią.
Technologie informacyjne - Podstawy technik informatycznych
Strona 30 z 72
Oprogramowanie użytkowe komunikuje się z bazą danych za pomocą przesyłanych siecią
komputerową zapytań SQL. Do klienta docierają tylko rezultaty zapytań: dane przy odczycie lub
potwierdzenia wykonanych operacji przy zapisie, modyfikacji, czy usuwaniu rekordów. Przy takiej
architekturze można łatwo zmienić sprzęt i system operacyjny serwera bazy danych i będzie to
niewidoczne dla użytkownika końcowego, gdyż nie pociąga to za sobą zmian w oprogramowaniu
użytkowym.
2. Sprzęt komputerowy
2.1. Podstawowe bloki funkcjonalne komputera
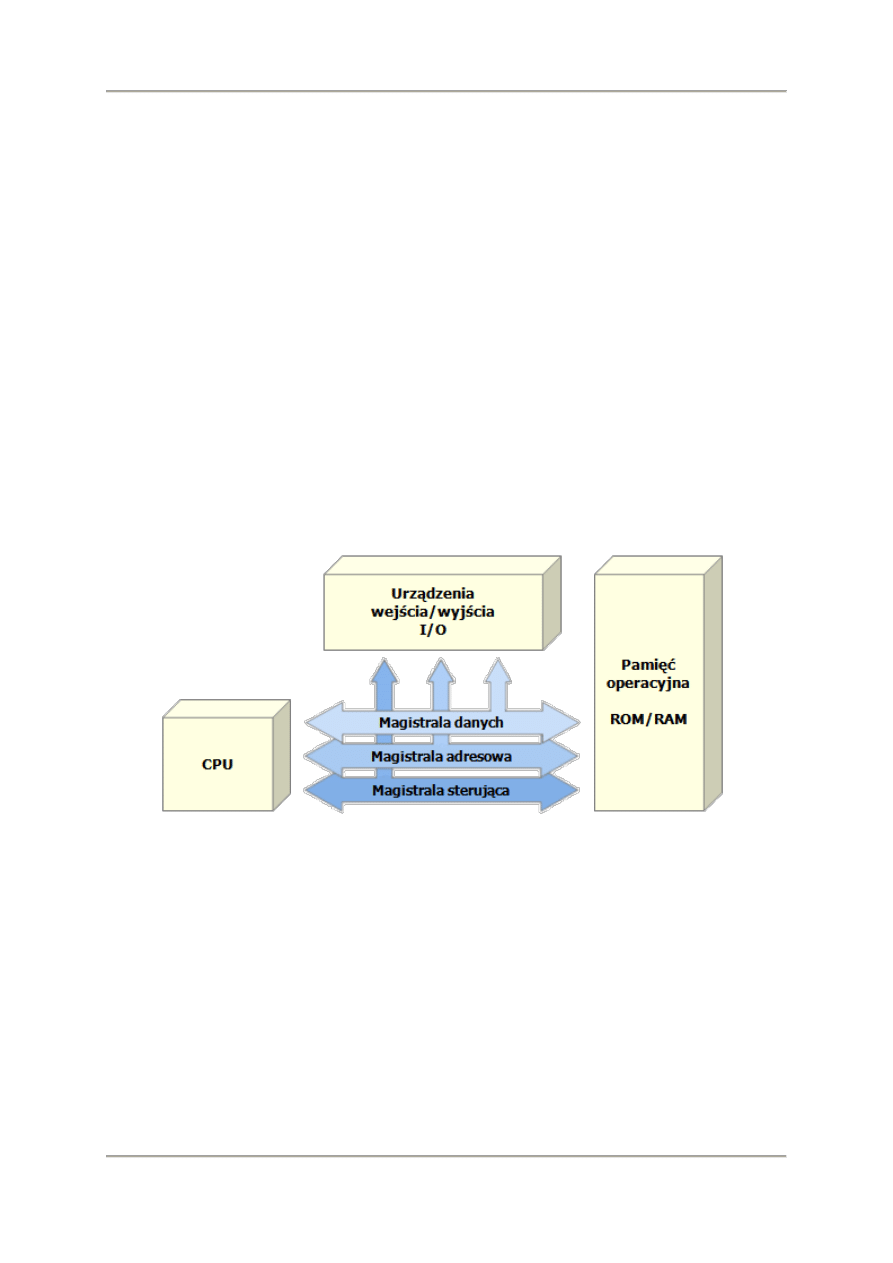
Urządzenia komputerowe mają podobną konstrukcję funkcjonalną. Niezależnie od tego, czy mówimy
o komputerze PC, notebooku, telefonie komórkowym, komputerze pokładowym w samochodzie czy
samolocie, cyfrowo sterowanej obrabiarce można w nich wyróżnić trzy podstawowe bloki
funkcjonalne:
procesor centralny (CPU),
pamięć operacyjna,
urządzenia wejścia wyjścia.
Podstawowe bloki funkcjonalne komputera
Poszczególne bloki funkcjonalne komunikują się miedzy sobą za pomocą trzech magistral: danych,
adresowej i sterującej.
2.2. Procesor
Zadaniem procesora jest przetwarzanie danych. To on dokonuje wszelkich procesów
obliczeniowych, realizuje zadania zawarte w programach komputerowych. Od wydajności procesora w
głównej mierze zależy wydajność komputera. Potrafi on wykonać z pozoru proste operacja takie jak
przesyłanie informacji między poszczególnymi komórkami pamięci, pomiędzy pamięcią i urządzeniami
wejścia wyjścia oraz pomiędzy rejestrami procesora i pamięcią bądź urządzeniami wejścia-wyjścia oraz
dokonywać obliczeń. Z takich, z pozoru prostych, operacji złożone są jednak najbardziej nawet
skomplikowane systemy, począwszy od systemu operacyjnego poprzez oprogramowanie biurowe,
systemy zarządzania przedsiębiorstwem, symulatory lotnicze, na których szkolą się piloci czy
symulatory zjawisk fizyki kwantowej. Jest to możliwe, ponieważ dzisiejsze procesory są zdolne do
przeprowadzania miliardów operacji na sekundę.

Technologie informacyjne - Podstawy technik informatycznych
Strona 31 z 72
Procesor można podzielić na dwa podstawowe bloki:
jednostkę arytmetyczno-logiczną, która de facto dokonuje wszystkie operacje,
rejestry, stanowiące wewnętrzne komórki pamięci procesora.
Najszybciej procesor wykonuje operacje na danych, które najpierw zostały przesłane z pamięci
operacyjnej do rejestrów.
Fizycznie procesor to układ scalony o bardzo wysokiej skali integracji montowany na płycie głównej
komputera.
Procesor
2.3. Pamięć operacyjna
Zadaniem pamięci operacyjnej jest przechowywanie uruchomionych programów i przetwarzanych
danych. Jeżeli uruchomimy edytor tekstu, a w nim otworzymy dokument to zarówno program edytora
oraz dokument zostaną przesłane do pamięci operacyjnej.
Pamięć składa się z komórek, z których każda przechowuje dokładnie 8 bitów, czyli 1 bajt. Do
poszczególnych komórki można odwoływać się podając jej adres, czyli numer.
Wyróżniamy dwa rodzaje pamięci: ROM i RAM.
ROM to pamięć wyłącznie do odczytu (Random Access Memory). Jej zawartość jest zapisywana na
etapie produkcji komputera. Podczas jego pracy jej zawartość nie ulega zmianie. Zawiera ona
procedury obsługi urządzeń wejścia wyjścia, oraz umożliwia uruchomienie komputera. Zawarte tam
procedury mają za zadanie m.in. załadować system operacyjny z dysku twardego bądź innego
nośnika. Zbiór tych procedur oraz informacji o konfiguracji tzw. płyty głównej komputera nazywany
jest w skrócie BIOS (Basic Input Output System) i stanowi podstawowy system wejścia-wyjścia. Jego
procedury pośredniczą między systemem operacyjnym a sprzętem. System operacyjny nie wykonuje
operacji bezpośrednio na sprzęcie – zamiast tego wywołuje tyko procedury znajdujące się w BIOSie
komputera.
Przechowywanie informacji w pamięci ROM nie wymaga zasilania. W przeszłości pamięć ROM była
faktycznie tylko do odczytu i zawartych tam informacji nie można było zmienić. Z czasem okazało się,
że BIOS wymaga niekiedy aktualizacji, dlatego przechowywany jest w pamięci typu flash. Stosując
odpowiednie oprogramowanie narzędziowe, istnieje możliwość zmiany zawartości takiej pamięci.
Jednakże, z punktu widzenia działającego komputera jest to nadal pamięć wyłącznie do odczytu, a
żaden z programów użytkowych nie ma możliwości zapisania tam czegokolwiek.

Technologie informacyjne - Podstawy technik informatycznych
Strona 32 z 72
Fragment pamięci operacyjnej
RAM to pamięć o dostępie swobodnym (Random Access Memory) przeznaczona do przechowywania
uruchamianych programów i przetwarzanych danych. Zapis informacji odbywa się w trakcie pracy
komputera. Przechowywanie w niej informacji wymaga energii elektrycznej. Gdy komputer zostanie
wyłączony zawartość pamięci ginie. Stąd konieczność okresowego zapisywania opracowywanego
dokumentu na dysku, aby nie stracić rezultatów pracy w wyniku awarii zasilania.
Fizycznie pamięć to układ scalony bardzo wysokiej skali integracji montowany na tzw. płycie głównej
komputera.
Moduł pamięci
2.4. Urządzenia wejścia -wyjścia
Procesor i pamięć operacyjna to podzespoły zdolne do przetwarzania informacji. Trzeba je jeszcze w
jakiś sposób do nich dostarczyć i umożliwić możliwość odbioru rezultatu ich przetworzenia. Do tego
celu służą urządzenia wejścia-wyjścia. Jak nietrudno domyślić się urządzenia wejścia służą
wprowadzaniu, a wyjścia wyprowadzaniu informacji. Wiele urządzeń ma charakter dwukierunkowy i
służy tak dostarczaniu jak i odbiorowi informacji.
Technologie informacyjne - Podstawy technik informatycznych
Strona 33 z 72
Przykład
Przykłady urządzeń wejścia, wyjścia oraz wejścia i wyjścia:
Urządzenia wejścia: Urządzenia wyjścia:
Urządzenia wejścia i wyjścia:
klawiatura,
mysz,
trackball,
skaner.
tablet graficzny
karta graficzna z
monitorem,
drukarka,
ploter.
karta dźwiękowa,
karta sieciowa,
modem telefoniczny,
streamer,
terminal.
Urządzenia wejścia-wyjścia podłączane są do magistrali danych poprzez elementy pośredniczące
nazywane interfejsami. Część z nich ma swoje wyprowadzenia wewnątrz komputera, a część na
zewnątrz, w zależności od tego jakie urządzenia są do nich podłączane.
Interfejsy dostępne wewnątrz komputera:
Nazwa
Szeregowy/
Równoległy
Przeznaczenie
Port FDD
R
Napęd dyskietek.
Uwaga: wychodzi z użycia.
ATA
(EIDE)
R
Dyski twarde, CD, DVD.
Uwaga: wychodzi z użycia na rzecz Serial ATA.
Serial ATA
S
Dyski twarde, CD, DVD.
PCI
R
Gniazdo rozszerzeń – pozwala na zamontowanie dodatkowego
interfejsu np. modemu, karty sieciowej, karty urządzeń pomiarowych,
dodatkowego interfejsu SCSI itp.
Uwaga: wychodzi z użycia na rzecz PCI-E i interfejsów zintegrowanych
z płytą główną.
PCI-E
S
Gniazdo rozszerzeń pozwalające podłączyć dodatkowe interfejsy – np.
kartę graficzną, interfejs SAS lub SCSI, Serial ATA itp.
SCSI
R
Dyski twarde, streamery.
Uwaga: zastępowane przez SAS.
SAS
S
Dyski twarde, streamery.
Interfejsy dostępne na zewnątrz komputera
Nazwa
Szeregowy/
Równoległy
Przeznaczenie
PS/2
S
2 złącza dedykowane do klawiatury (fioletowe) i myszy(zielone)
USB
S
Uniwersalne złącze szeregowe służące do podłączenia większości
urządzeń peryferyjnych tj. drukarki, skanery, telefony komórkowe,
aparaty fotograficzne, kamery, zewnętrzne napędy dysków twardych,
nagrywarki CD/DVD, pamięci pendrive, czytniki kart pamięci flash,
klawiatury, myszki, joysticki i inne.

Technologie informacyjne - Podstawy technik informatycznych
Strona 34 z 72
IEEE1394
(firewire)
S
Uniwersalne złącze szeregowe przeznaczone głównie do przesyłania
danych multimedialnych (audio-wideo). Najczęściej wykorzystywane do
podłączania kamer wideo (camcorderów) i zewnętrznych nagrywarek
CD/DVD oraz dysków twardych.
External
Serial ATA
S
Zewnętrzne złącze interfejsu Serial ATA, przeznaczone do podłączania
zewnętrznych dysków twardych, macierzy dyskowych.
SAS
S
Zewnętrzne złącze interfejsu Serial SCSI, przeznaczone do podłączania
zewnętrznych dysków twardych, macierzy dyskowych, skanerów
wielkoformatowych.
SCSI
S
Zewnętrzne złącze interfejsu SCSI, przeznaczone do podłączania
zewnętrznych dysków twardych, macierzy dyskowych, skanerów
wielkoformatowych.
2.5. Magistrale
Podstawowe bloki funkcjonalne (procesor, pamięć i urządzenia wejścia-wyjścia) są ze sobą
skomunikowane za pomocą trzech magistral:
Magistrala danych służy do przesyłania danych przetwarzanych przez procesor oraz
rozkazów dla procesora.
Magistrala adresowa służy do wskazywania, z której lub, do której komórki pamięci mają
być przesłane dane. W przypadku komunikacji z urządzeniami wejścia-wyjścia pozwala na
wskazanie adresu (numeru) urządzenia.
Magistrala sterująca służy do informowania pozostałych bloków funkcjonalnych o tym czy
procesor zamierza pobrać, czy wysłać informację oraz z którym z bloków funkcjonalnych chce
się komunikować. Z pomocą tejże magistrali urządzenia wejścia-wyjścia informują procesor,
że powinien uruchomić podprogram obsługi tzw. przerwania. Dzięki mechanizmowi przerwania
procesor nie musi tracić czasu na „odpytywanie” poszczególnych urządzeń, czy nie wymagają
obsługi zdarzenia (np. naciśnięcie klawisza, ruch myszką). Gdy takie zdarzenie pojawi się,
urządzenie zgłasza do procesora sygnał przerwania i ten chwilowo „porzuca” realizowany
program, przechodzi do odpowiedniej procedury przerwania (np. powodującej odczytanie z
klawiatury kodu naciśnietego klawisza, a po jej zakończeniu wraca do przerwanego
programu).

Technologie informacyjne - Podstawy technik informatycznych
Strona 35 z 72
Fizycznie magistrale znajdują się na tzw. płycie głównej komputera. Na niej montowane są moduły
pamięci i procesor. Obecnie większość interfejsów wykorzystywanych przez urządzenia wejścia-wyjścia
jest również zintegrowana z płytą główną. Najczęściej mamy tylko do wyboru czy płyta ma mieć
zintegrowaną kartę graficzną czy nie. W pierwszym przypadku płyta główna dysponuje gniazdem do
podłączenia monitora, w drugim konieczne jest zamontowanie karty graficznej (jednej lub dwóch) w
gniazdach PCI-E. Jeżeli jednak na płycie głównej brakuje jakiegoś interfejsu (np. dodatkowej karty
sieciowej, karty do podłączenia urządzeń pomiarowych) można zamontować taki interfejs korzystając
ze złączy PCI lub PCI-E (PCI express).
2.6. Elementy odpowiedzialne za wydajność komputera
Wydajność komputera zależy od wielu elementów, z których został złożony. Właściwego doboru
jego komponentów powinien dokonać wykwalifikowany informatyk, jednak zgrubnej oceny można
dokonać samodzielnie. Potrzebna jest jednak do tego znajomość podstawowych parametrów
głównych podzespołów.
Procesor – od jego parametrów zależy szybkość przetwarzania danych:
Częstotliwość taktowania zegara. Procesor swoje zadania wykonuje w takt tzw.
zegara
, czyli
generatora impulsów. Im częściej otrzymuje impulsy tym szybciej pracuje. Niestety procesory
są projektowane do pracy z określoną częstotliwością wyrażaną obecnie w Gigahercach (1
GHz to miliard impulsów na sekundę). Taktowanie ich wyższą częstotliwością niż przewidział
producent powoduje większą emisję ciepła, w następstwie czego dochodzi do awarii.
Dzisiejsze procesory sa taktowane zegarami o częstotliwości od 2 do 3,3 Ghz. Im więcej tym
lepiej.
Liczba rdzeni. Obecnie w jednej strukturze układu scalonego tworzy się kilka jednostek
przetwarzających. Są to tzw.
rdzenie
. Każdy z nich może być traktowany jak odrębny
procesor. Im więcej rdzeni tym więcej zadań może procesor wykonywać równolegle.
Szerokość magistrali danych mówi o tym, ile bitów można przesłać równoległymi przewodami
między pamięcią a procesorem. Nie trudno domyślić się, że im więcej tym lepiej. Jednak
warunkiem skorzystania z dobrodziejstw szerszej magistrali danych jest dysponowanie
oprogramowaniem wykorzystującym tę możliwość. Obecnie na rynku są dostępne procesory
32 i 64 bitowe. Większość dostępnego oprogramowania jest jednak zoptymalizowania pod
systemy 32 bitowe. Nie mniej sytuacja z czasem będzie się zmieniać.
Technologie informacyjne - Podstawy technik informatycznych
Strona 36 z 72
Częstotliwość taktowania magistrali danych FSB wyrażana w megahercach (1 MHz to milion
impulsów na sekundę). Im wartość FSB jest większa tym lepiej, bo oznacza, że procesor może
szybciej transmitować i odbierać dane.
Przykład
Przykładowe dane procesora Intel Core2 Quad Q9650 3,00 GHz BOX:
liczba rdzeni
4
częstotliwość taktowania
3 000 MHz
częstotliwość taktowania magistrali danych 1 333 MHz
Pamięć operacyjna – zasadnicze znaczenie mają tu dwa parametry:
częstotliwość pracy magistrali danych (FSB) - decyduje o tym, jak szybko dane mogą być
transmitowane od lub do procesora. Wobec tego im ten parametr ma wyższą wartość tym
lepiej. Nie ma sensu jednak wyposażać komputera w pamięci szybsze niż procesor, bo ich
koszt będzie wyższy, a nie będzie można w pełni wykorzystać ich możliwości. Zawsze
decydujące znaczenie ma najwolniejszy z elementów z uczestników transmisji danych.
pojemność (ilość) pamięci - w pamięci operacyjnej przechowywane są zarówno dane jak i
uruchomione programy. Jeżeli okaże się, że jest ich za dużo, aby zmieściły się w pamięci
system operacyjny przeniesie niewykorzystywane chwilowo dane na dysk twardy do tzw. pliku
wymiany. Dzięki temu uwolni część pamięci na potrzebne w danym momencie dane. Proces
ten jednak spowalnia pracę komputera. Zapis i odczyt z dysku odbywa się około tysiąckrotnie
wolniej niż z pamięci operacyjnej. Jeżeli jest jej za mało to często wykorzystywany jest plik
wymiany, a cały system pracuje wolniej. Zwiększenie ilości pamięci operacyjnej pozwoli na
uruchomienie jednocześnie większej liczby aplikacji i przetwarzanie większych zbiorów danych
bez wyraźnego spadku wydajności.
Przykład
Przykładowe dane modułu pamięci:
częstotliwość pracy 1 333 MHz
pojemność pamięci 1 024 MB
Płyta główna komunikuje ze sobą procesor, pamięć i urządzenia wejścia-wyjścia. Poza doborem
płyty dla danego procesora jedynym istotnym, z punktu widzenia wydajności parametrem jest
częstotliwość taktowania magistrali danych (FSB). Powinna ona być co najmniej tak szybka jak
wolniejszy z dwóch podzespołów: procesora i pamięci. W przeciwnym wypadku stanie się wąskim
gardłem spowalniającym cały system.
Technologie informacyjne - Podstawy technik informatycznych
Strona 37 z 72
Przykład
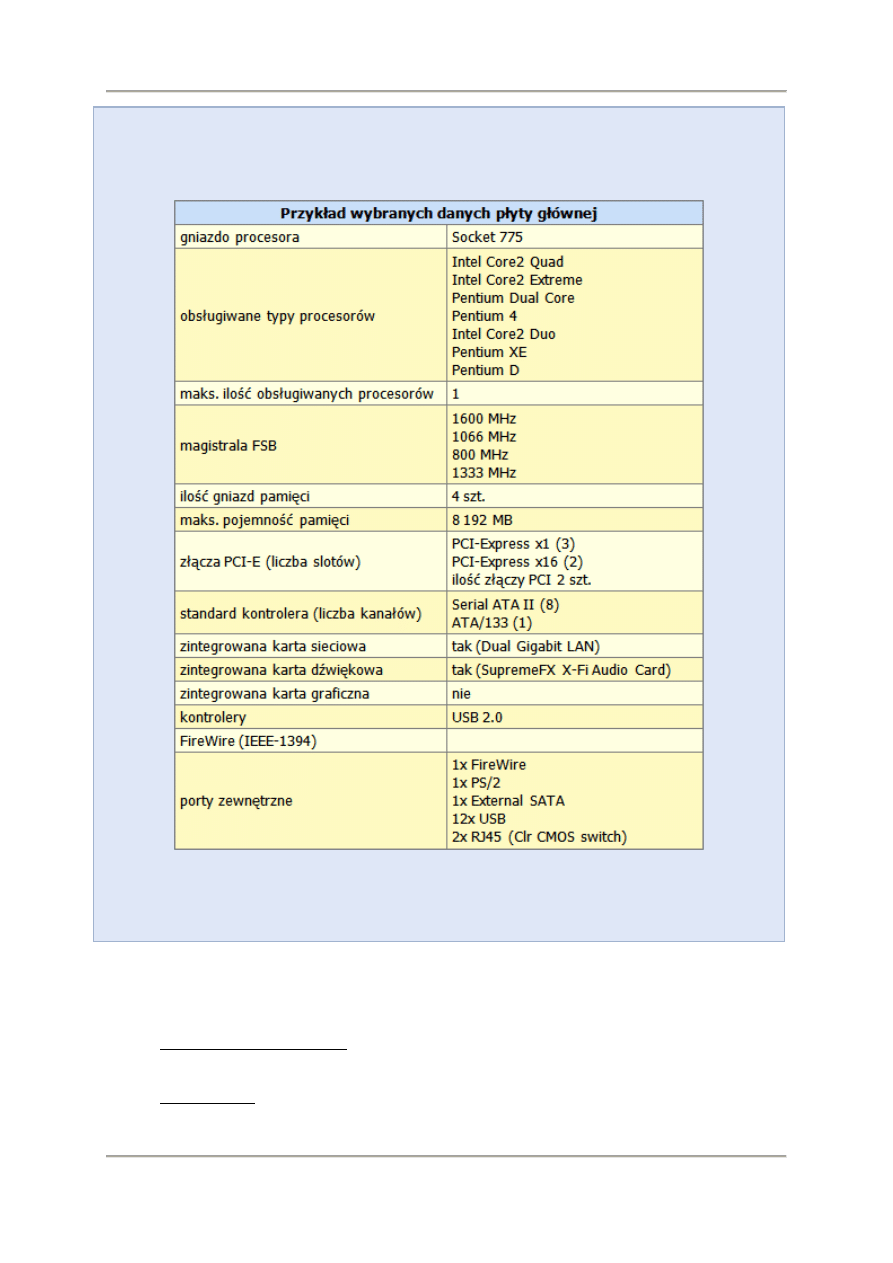
Przykład wybranych danych płyty głównej:
Dane płyty głównej zawierają informacje o tym, do jakich procesorów przeznaczona jest płyta,
parametry FSB, maksymalną ilość pamięci jaką można zainstalować oraz jakimi interfejsami i
złączami dysponuje.
Istotny wpływ na wydajność komputera ma też dysk twardy, na którym zapisane są zainstalowane
programy i dane. Dwa parametry mają wpływ na wydajność. Są to:
prędkość transferu danych - wyrażana w MB na sekundę lub w przypadku urządzeń
pracujących na interfejsach szeregowych w Gb na sekundę. Im wyższa wartość tym lepiej.
czas dostępu, czyli ile średnio upływa czasu od momentu zgłoszenia żądania odczytu
informacji do udostępnienia jej interfejsowi. Im ten parametr ma mniejszą wartość tym lepiej.
Obecnie tradycyjne (tj. wyposażone wirujące z dużą prędkością metalowe dyski, na których
Technologie informacyjne - Podstawy technik informatycznych
Strona 38 z 72
zapisywane są dane) dyski twarde dostępne na rynku nie różnią się znacznie między sobą w
tym zakresie (ok. 8 ms). Wart jednak odnotowania jest fakt, że nowoczesne urządzenia (SSD
– solid state disk) oparte na pamięciach flash mają ten parametr równy 0 ms. Te bardziej
dostępne cenowo modele ustępują jednak ciągle tradycyjnym dyskom w zakresie prędkości
transmisji i pojemności.
Karta graficzna odpowiedzialna jest za generowanie obrazu wyświetlanego na monitorze
ekranowym. Jeżeli komputer przeznaczony jest do prac biurowych (edycja tekstu, arkusze
kalkulacyjne, systemy finansowo-księgowe, magazynowe itp.), korzystania z usług internetowych oraz
oglądania filmów typowa karta graficzna zintegrowana z płytą główną jest całkowicie wystarczająca.
Jednak osoby projektujące obiekty w przestrzeni trójwymiarowej bądź fani gier komputerowych będą
potrzebowali bardziej zaawansowanego urządzenia.
Obecnie dostępne na rynku karty graficzne to właściwie samodzielne komputery wyposażone w
procesory graficzne częstokroć przewyższające wydajnością centralną jednostkę komputera. Posiadają
też swoją niezależną pamięć. O wydajności karty decydują więc takie same parametry jak w
przypadku samego komputera – częstotliwość taktowania, szerokość magistrali danych i ilość pamięci.
Przykład
Przykładowe parametry karty graficznej:
wielkość pamięci
512 MB
taktowanie rdzenia
650 MHz
taktowanie pamięci
1 900 MHz
szyna danych pamięci 256 bit
3. Systemy operacyjne
Definicja
System operacyjny (ang. skrót
OS
-
operating system
) - jest to zbiór programów
pośredniczących pomiędzy aplikacjami użytkownika, a sprzętem.
Do głównych zadań systemu operacyjnego należy zarządzanie zasobami komputera: procesorem
(dokładniej
czasem procesora
), pamięcią, urządzeniami peryferyjnymi oraz przydzielanie ich
poszczególnym procesom. Przywykliśmy już do tego, że na komputerze uruchomionych jest

Technologie informacyjne - Podstawy technik informatycznych
Strona 39 z 72
jednocześnie kilka programów. Wszystkie wykonywane są przez ten sam procesor, znajdują się we
wspólnej pamięci i mogą wymagać dostępu do tych samych dysków, drukarki i innych wspólnych
zasobów. Zadaniem systemu operacyjnego jest takie zarządzanie zasobami, aby działające
równocześnie programy nie zakłócały się nawzajem.
W systemach jednoprocesorowych, gdy procesor składa się tylko z jednego rdzenia, zadaniem
systemu operacyjnego jest przydzielanie czasu procesora poszczególnym procesom. W określonym
momencie procesor może wykonywać tylko jedno zadanie. Dla zapewnienia możliwości pracy kilku
programów jednocześnie procesor wykonuje część jednego z nich, potem część drugiego, następnie
trzeciego i kolejnych, po czym powraca do pierwszego itd. Przełączanie pomiędzy procesami odbywa
się tak szybko, że użytkownik ma wrażenie, że wszystkie zadania realizowane są jednocześnie.
Gdy mamy do dyspozycji procesor wielordzeniowy lub komputer jest wyposażony w wiele procesorów,
system operacyjny przydziela ich czas rozdzielając go pomiędzy wszystkie uruchomione procesy.
Poszczególnym procesom przydzielana jest pamięć operacyjna. Zadaniem systemu operacyjnego jest
ochrona pamięci tak, aby jeden proces, w wyniku błędu lub zamierzonego działania, nie mógł
zniszczyć lub pozyskać danych należących do innego.
Do komputera podłączonych jest szereg urządzeń peryferyjnych. Dla uniknięcia sytuacji, gdzie
procesor okresowo sprawdza, czy któreś z nich nie wymaga uruchomienia procedury obsługi zdarzenia
stworzono mechanizm przerwań. Procesor realizuje określone procesy zgodnie z programem. Gdy
któreś z urządzeń wymaga obsługi np. naciśnięto klawisz na klawiaturze zgłaszane jest tzw.
przerwanie. W jego wyniku procesor czasowo „porzuca” realizowany proces i przechodzi do
zdefiniowanego w systemie operacyjnym podprogramu obsługi klawiatury. Po jego zrealizowaniu
(odczytaniu kodu naciśniętego klawisza) procesor wraca do przerwanego programu. Dzięki temu
procesor nie traci czasu na sprawdzanie aktywności poszczególnych urządzeń.
System operacyjny pośrednicząc pomiędzy programem użytkowym a sprzętem powoduje niejako
ukrycie skomplikowania i specyfiki sprzętu. Faktycznie ten sam system operacyjny możemy
zainstalować na różniących się między sobą komputerach, wytworzonych przez różnych producentów
w oparciu o różne komponenty. Na jego bazie możemy uruchomić te same programy i używać ich w
jednakowy sposób. Oprogramowanie użytkowe jest tworzone dla określonego systemu operacyjnego a
nie konkretnej konfiguracji komputera. Dzięki temu, z punktu widzenia programu użytkowego
wszystkie komputery pracujące pod określonym systemem operacyjnym są jednakowe. Upraszcza to
projektowanie oprogramowania.
Przykład
Dla przykładu przenieśmy się do czasów systemu operacyjnego DOS, który nie zapewniał
wielozadaniowości i dużo mniejszym zakresie pośredniczył między aplikacjami użytkownika, a
sprzętem niż dziś. Istniał bardzo dobry edytor tekstu, ale jego twórcy musieli w nim stworzyć
oprogramowanie odpowiedzialne za wydruki na różnych drukarkach. Dopóki modeli drukarek było
niewiele zadanie nie było trudne.
Jednak z czasem pojawiały się nowe konstrukcje sprzętu o nowych możliwościach. Konieczne więc
było nieustanne rozwijanie oprogramowania zapewniającego poprawne wydruki. Narażało to na
dodatkowe koszty posiadaczy komputerów. Wymiana drukarki na nowy model wiązała się z
ryzykiem, że edytor nie będzie potrafił na niej drukować i konieczna będzie płatna aktualizacja
oprogramowania. Z kolei producenci oprogramowania coraz więcej wysiłku (i środków) musieli
wkładać w śledzenie rozwoju sprzętu i dostosowywanie do niego swoich produktów
W sytuacji, gdy na przestrzeni kilku lat na rynku pojawiło się już wiele tysięcy modeli drukarek takie
rozwiązanie nie byłoby efektywne.

Technologie informacyjne - Podstawy technik informatycznych
Strona 40 z 72
Obecne systemy operacyjne pośredniczą w procesie drukowania stawiając do dyspozycji
oprogramowaniu użytkowemu programowy interfejs niezależny od tego, jakie drukarki mamy
podłączone do komputera. Z podłączeniem drukarki (czy innego urządzenia) wiąże się instalacja tzw.
sterownika. Jest to oprogramowanie, które integruje się z systemem operacyjnym i zapewnia, że
różne aplikacje użytkownika będą poprawnie współpracować z danym urządzeniem. Dzięki temu
twórcy oprogramowania i użytkownicy nie muszą obawiać się, że nie będzie ono funkcjonować
poprawnie z urządzeniami, które dopiero zostaną skonstruowane w przyszłości.
Inne urządzenia, tak zintegrowane z płytą główną, jak i montowane na zewnątrz komputera
współpracują z oprogramowaniem użytkowym za pośrednictwem sterowników, które po
zainstalowaniu stają się częścią systemu operacyjnego.
Zadaniem systemu operacyjnego jest również organizacja zapisu na nośnikach danych. W
rzeczywistości dyski podzielone są na tzw. ścieżki i sektory. Każdy z dysków składa się z dwóch
metalowych talerzy, na powierzchniach, których głowice (z reguły 3) zapisują i odczytują informacje.
Poszczególne fragmenty plików mogą być rozrzucone po różnych talerzach, ścieżkach i sektorach.
Zadaniem systemu operacyjnego jest przedstawianie plików, jako dokumentów umieszczonych w
folderach zdefiniowanych przez użytkownika i ukrycie faktycznej struktury zapisu na dysku.
Podsumowując, ilekroć aplikacja użytkownika sięga do zasobów sprzętowych robi to wywołując
funkcje systemu operacyjnego. Nigdy nie dokonuje operacji bezpośrednio na urządzeniu. Zapewnia to
kontrolę nad zasobami przez system operacyjny.
Technologie informacyjne - Podstawy technik informatycznych
Strona 41 z 72
Przykład
Najlepiej to widać, gdy używamy anglojęzycznego programu zainstalowanego na komputerze z
polskojęzycznym systemie operacyjnym. Gdy wybieramy z menu „File->Open” celem wczytania z
dysku określonego dokumentu pojawia się okno z polskimi opisami.
Anglojęzyczny program na polskojęzycznym systemie operacyjnym.
Źródło: Zrzut ekranu programu Google SketchUp
Dzieje się tak dlatego, że program wywołał funkcję systemu operacyjnego (polskojęzycznego)
otwarcia okna z wyborem pliku.
Dzisiejsze systemy operacyjne dostarczają gotowych funkcji wykorzystywanych przy tworzeniu
oprogramowania. Dzięki temu programiści nie muszą pisać programów zamknięcia, otwarcia okna,
reakcji na kliknięcie w menu, czy inne elementy sterujące. Są to gotowe funkcje systemu
operacyjnego wywoływane jedynie przez określony program. Prowadzi to do ujednolicenia sposobów
posługiwania się pisanymi przez różnych twórców programami. Niemal wszystkie wykorzystują te
same elementy interfejsu użytkownika takie jak ikony w prawym rogu okna, menu, menu kontekstowe
(otwierane prawym klawiszem myszy) paski narzędzi, paski stanu, krawędzie i narożniki okna, czy
pasek tytułowy. Twórca programu musi jedynie określić, które z nich mają być dostępne. Określa też
zawartość pasków narzędzi i menu. Pozwala to na skoncentrowanie się na tworzeniu głównych funkcji
programu. Takie rozwiązanie upraszcza i obniża koszty tworzenia oprogramowania.
Obecnie na rynku funkcjonuje szereg systemów operacyjnych. Zestawienie ich głównych cech zawiera
poniższa tabela.

Technologie informacyjne - Podstawy technik informatycznych
Strona 42 z 72
System operacyjny
Interfejs
użytkownika
Wielozadaniowość
Sieci
Ograniczenie
dostępu
do danych
MS-DOS
znakowy
nie
tylko stacja robocza
1
nie
Windows9x/Me
graficzny
tak
stacja robocza,
niededykowany
serwer, sieci P2P
nie
Windows Server
NT/2000/2003/2008
graficzny
tak
dedykowany serwer
plików
i aplikacji
tak
Windows
NT/2000/Workstation,
Windows XP
Home/Professional,
Windows Vista
graficzny
tak
stacja robocza,
niededykowany serwer
plik, sieci P2P
tak
2
NetWare Novell
znakowy/graficzny
tak
dedykowany serwer
plików
tak
Unix, Linux
znakowy/graficzny
tak
serwer plików aplikacji
tak
OS/2
graficzny
tak
stacja robocza,
niededykowany
serwer, sieci P2P
nie
Mac OS X
graficzny
tak
stacja robocza
tak
4. Oprogramowanie użytkowe i firmware
Lata rozwoju technologii informacyjnych zaowocowały powstaniem tysięcy programów dotyczących
wszystkich dziedzin życia. Począwszy od rozrywki, poprzez komunikację, automatyzacje prac
biurowych, systemy prowadzenia przedsiębiorstw, projektowanie, sterowanie, symulacje zjawisk,
wspomaganie podejmowanie decyzji.
Definicja
Programy, które instalujemy na komputerach pracujących pod kontrolą systemu operacyjnego to
programy użytkowe.
Z systemem operacyjnym z reguły otrzymujemy zastaw oprogramowania obejmującego proste
rozrywki, edukacje, dostęp do Internetu, podstawowe do redagowania tekstu i inne. Mimo, że
instalowane są wraz systemem operacyjnym nie są jego częścią. Są programami użytkowymi.
Przykład
Za przykład programów użytkowych niech posłużą programy Notepad, Windows Movie Maker, Paint
czy Kalkulator.
1
Po instalacji oprogramowania klienta sieci
2
Po zastosowaniu systemu plików NTFS
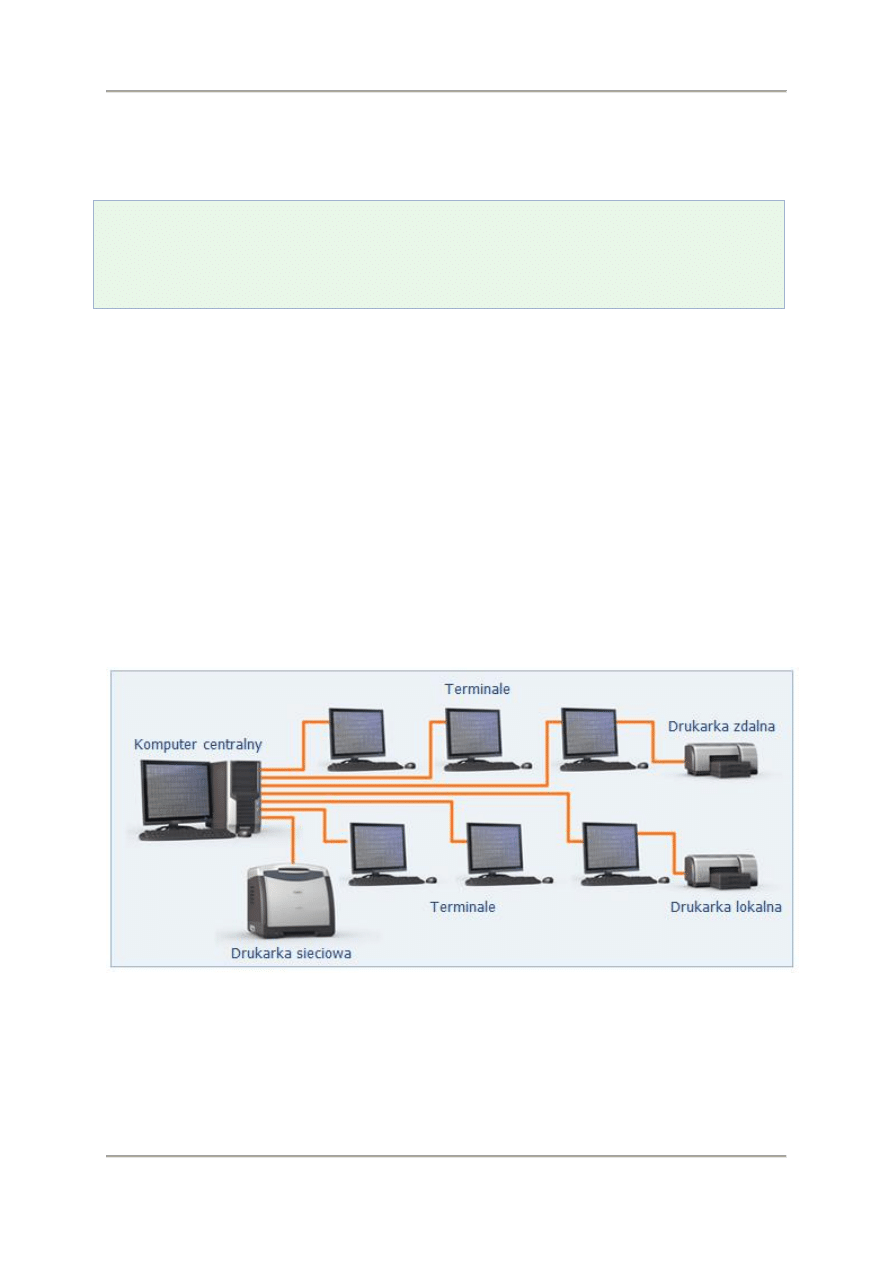
Technologie informacyjne - Podstawy technik informatycznych
Strona 43 z 72
Wiele urządzeń, również tych podłączonych do komputera takich nagrywarki płyty DVD, telefony
komórkowe, kamery video (camkordery), interfejsy, dyski twarde, skanery, drukarki, kalkulatory i
inne, ma własne pamięci i procesory przetwarzające informacje i sterujące ich komponentami.
Oprogramowanie dla ich procesorów znajduje się w pamięciach ROM i nazywane jest firmware.
Definicja
Firmware to dedykowane konkretnemu urządzeniu oprogramowanie wewnętrzne, wykorzystujące
jego pamięć i procesor.
Niektóre urządzenia pozwalają na aktualizację tego oprogramowania. Wówczas funkcję pamięci ROM
pełnią moduły flash.
5. Sieci komputerowe
W dzisiejszych organizacjach istnieje konieczność korzystania ze wspólnych zasobów informacyjnych
oraz komunikowania się drogą elektroniczną. Realizacja tych zadań może być realizowana przez różne
architektury systemowe.
5.1. Wielodostęp
Historycznie rzecz ujmując, najwcześniej zaczęto stosować rozwiązanie o nazwie wielodostęp.
Polega ono na tym, że do jednego wspólnego komputera podłączonych jest szereg terminali, tj.
urządzeń wejścia – wyjścia, składających się, w pewnym uproszczeniu, z monitora i klawiatury, jak
przedstawiono to na rysunku.
Terminal nie jest zdolny do przetwarzania informacji, gdyż nie jest wyposażony w pamięć i procesor,
które są niezbędne do tych celów. Zadaniem terminala jest przekazywanie za pomocą klawiatury
poleceń do komputera centralnego. Na monitorze z kolei wyświetlany jest obraz generowany przez
komputer centralny w rezultacie wykonywanego na nim programu. Na terminalu nie można uruchomić
żadnego programu.
W przypadku wielodostępu użytkownicy pracują na wspólnych zasobach danych zgromadzonych na
dyskach centralnego komputera, a w trakcie pracy użytkownicy wspólnie wykorzystują jego pamięć i
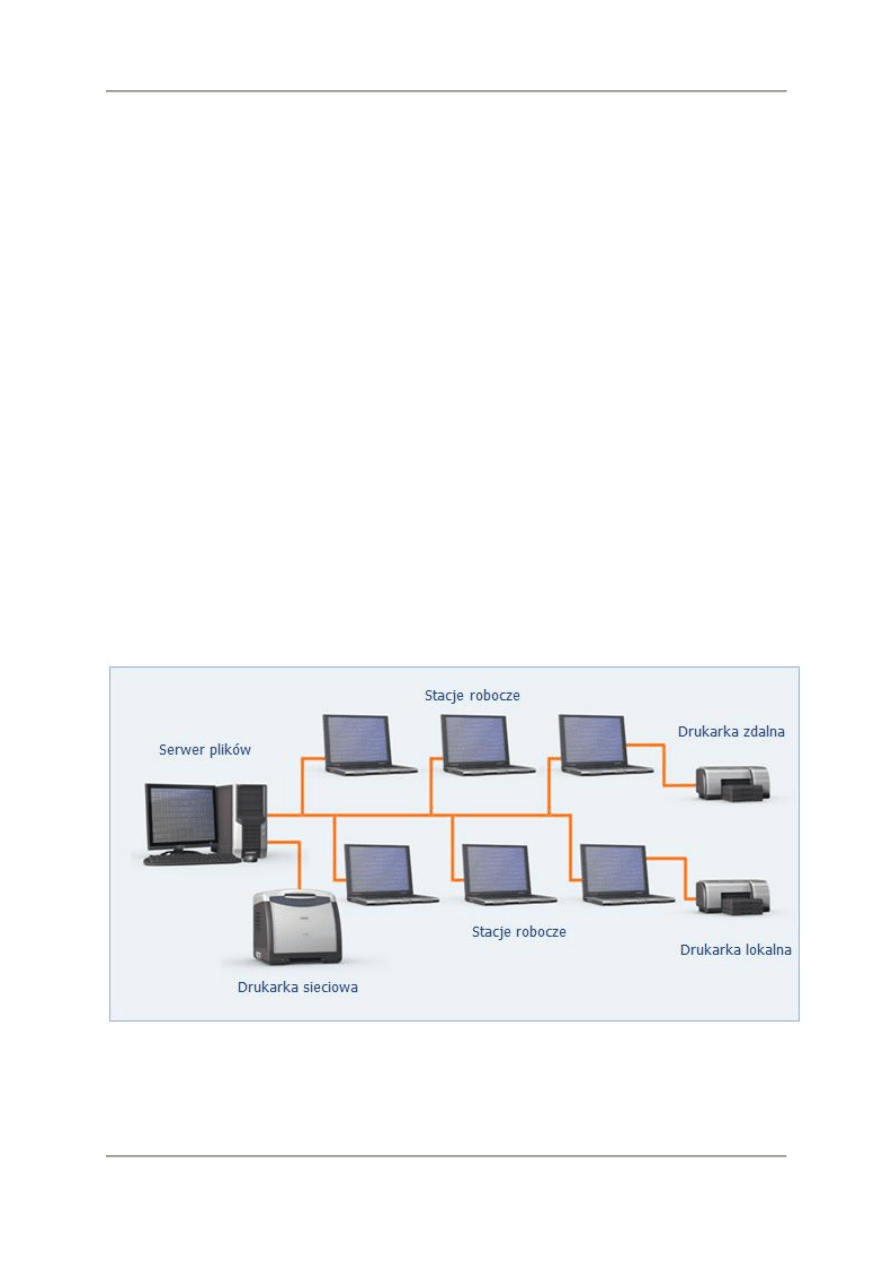
Technologie informacyjne - Podstawy technik informatycznych
Strona 44 z 72
procesor (lub procesory, jeśli jest ich więcej). Wobec tego, jeśli kilka osób pracuje jednocześnie to
oznacza to, że jednocześnie uruchomionych jest na jednym komputerze kilka programów.
Równoległość ich realizacji na komputerze centralnym jest jednak tylko symulowana. Procesor
realizuje w danym momencie tylko jeden program. Robi to jednak przez krótki czas, po czym
przełącza się na kolejny. W ten sposób procesor wykonuje krótkie fragmenty poszczególnych
programów przełączając się między nimi tak szybko, że każdemu z użytkowników wydaje się, że
komputer pracuje wyłącznie dla niego. Faktyczne równoczesne wykonywanie zadań występuje wtedy,
gdy komputer posiada kilka procesorów.
W systemie wielodostępu można współdzielić zasoby drukowania. Oznacza to, że możliwe jest
wykorzystanie jednej drukarki przez kilku użytkowników. Podłącza się ją bezpośrednio do komputera
centralnego (drukarka sieciowa), bądź do jednego z terminali (sieciowa drukarka zdalna). Każdy
wydruk kierowany jest wówczas do tzw. kolejki wydruków zarządzanej przez centralny komputer,
który zarządza zleceniami wydruków przechowując je w postaci elektronicznej i sukcesywnie
przekazując je do właściwej drukarki. Oprócz drukarek sieciowych, dostępnych dla wielu
użytkowników, istnieje możliwość podłączenia drukarki do pojedynczego terminala jako drukarki
lokalnej. Wówczas mogą na niej drukować tylko osoby pracujące przy terminalu, do którego jest ona
podłączona.
5.2. Sieć z serwerem plików
Innym rozwiązaniem zapewniającym równoległą pracę wielu osób na wspólnych zasobach danych jest
sieć z serwerem plików. W przeciwieństwie do wielodostępu mamy tu wiele komputerów (stacji
roboczych) podłączonych do sieci komunikujących się za jej pomocą z serwerem plików. Każda ze
stacji roboczych zdolna jest do samodzielnego przetwarzania danych, gdyż jest wyposażona w
procesor, pamięć i urządzenia wejścia-wyjścia. W rozwiązaniach sieciowych programy uruchamiane są
na stacjach roboczych i na nich przetwarzane są dane. Jeżeli dane znajdują się na serwerze, to
oznacza to, że muszą one najpierw zostać przesłane do stacji roboczej, a po aktualizacji zapisywane
są na serwerze.
Z punktu widzenia użytkownika serwer plików to jeden wspólny zasób informacji, który może być
przetwarzany przez stacje robocze. Zadaniem serwera plików jest jedynie dystrybuowanie danych do
stacji roboczych i zapisywanie przesłanych przez nie informacji. Stacje robocze mogą (najczęściej są)
wyposażone we własne (lokalne) zasoby przeznaczone do przechowywania danych. Są to dyski
twarde, napędy płyt CD, DVD, wychodzących już z użycia dyskietek czy zastępujących je pamięci

Technologie informacyjne - Podstawy technik informatycznych
Strona 45 z 72
flash. W takich sieciach realizuje się współdzielenie zasobów drukowania w ten sam sposób jak
w wielodostępie.
5.3. Wielodostęp a sieć z serwerem plików
Zasadnicza różnica pomiędzy siecią komputerów a systemem z wielodostępem polega na miejscu, w
którym następuje przetwarzanie danych. W przypadku wielodostępu odbywa się ono w komputerze
centralnym, a w sieci w stacjach roboczych. W praktyce gospodarczej rzadko stosuje się obecnie
powyższe rozwiązania „w czystej postaci”. Najczęściej stosuje się architekturę klient-serwer, gdzie
zadania są rozdzielone pomiędzy serwer a stację roboczą, na której znajduje się część
oprogramowania zwana klientem.
Porównanie wybranych cech wielodostępu i sieci z serwerem plików:
Cecha
Wielodostęp
Sieć z serwerem plików
Współdzielenie przestrzeni dyskowej
serwera
tak
tak
Współdzielenie zasobów drukowania
tak
tak
Procesy obliczeniowe
na serwerze
w stacjach
Przechowywanie danych
na serwerze
w serwerze i stacjach roboczych
Maksymalna dostępna moc obliczeniowa
dla pojedynczego procesu
taka jak serwera taka jak najsilniejszej stacji
roboczej
Pojęcie serwera wymaga tu jednak dokładniejszego wyjaśnienia. Potocznie mówiąc serwer, przeciętny
użytkownik ma na myśli wyspecjalizowany komputer. O ile jest faktem, że konfiguracja serwerów i
stacji roboczych różni się, to funkcjonalnie są to takie same komputery. Te przeznaczone na serwery
będą miały znacznie więcej pamięci operacyjnej i dysków twardych, bardziej wydajny procesor lub
kilka procesorów. To jednak nie przesądza o tym, że dany komputer będzie serwerem. Często zdarza
się tak, że komputer, który przez kilka lat był serwerem, ale został zastąpiony nowym, wykorzystany
jest później jako stacja robocza.
Co więc przesądza o funkcji komputera? Decyduje o tym uruchomione na nim oprogramowanie. Na
danym komputerze można zainstalować oprogramowanie czyniące go serwerem plików, stron WWW,
poczty elektronicznej, wydruków czy innych usług. Mówiąc serwer powinniśmy, więc raczej myśleć o
usłudze oferowanej przez komputer niż o sprzęcie. Wobec tego w przypadku sieci mówimy o
serwerze plików, a w przypadku wielodostępu o serwerze aplikacji. Oba pełnią też funkcję
serwerów wydruku. Określony komputer może więc być serwerem wielu usług jednocześnie.
Obecnie w przedsiębiorstwach mamy najczęściej do czynienia z wykorzystującym bazy danych
oprogramowaniem, które uruchamiane jest na stacji roboczej (klient), natomiast na serwerze
zainstalowany jest System Zarządzania Relacyjną Bazą Danych, zwany czasami motorem bazy danych
lub po prostu serwerem bazy danych. Część zadań zarządzania danymi i ich analizy realizowanych jest
przez serwer, a część przez klienta. Klient odpowiada też za tzw. interfejs użytkownika, czyli
prezentację informacji na ekranie oraz komunikację z użytkownikiem (wyświetlanie ikon, reagowanie
na polecenia wydawane za pomocą myszy i klawiatury.
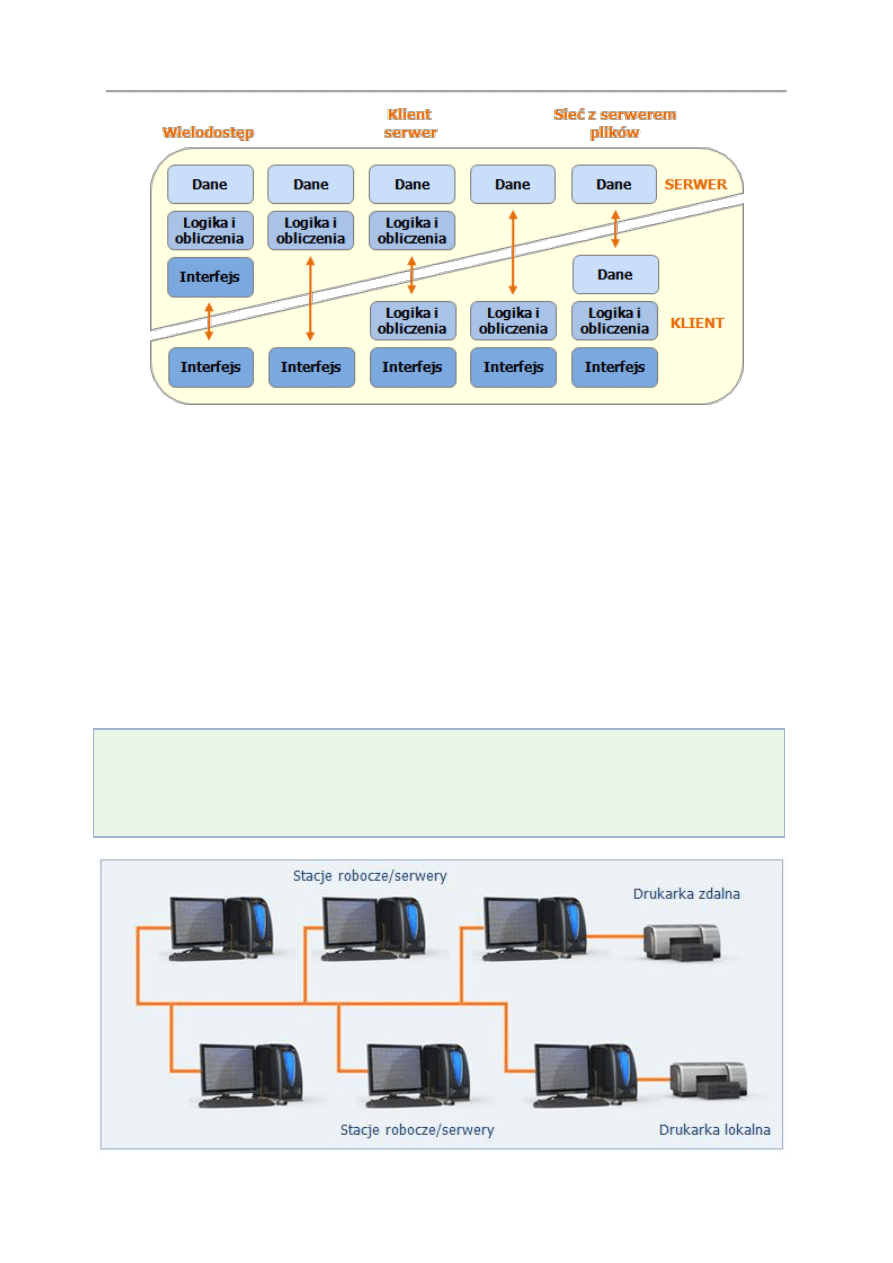
Technologie informacyjne - Podstawy technik informatycznych
Strona 46 z 72
Powyższy rysunek prezentuje spotykane rozwiązania podziału ról pomiędzy serwer i klienta
uporządkowane od wielodostępu poprzez klient-serwer po sieć z serwerem plików.
5.4. Sieci Peer-to-peer
Jak wspomniano wcześniej rola, w jakiej występuje komputer zależy od tego, czy świadczy usługi dla
innych komputerów (serwer) czy funkcjonuje tam oprogramowanie użytkowe wykorzystane przez
pracującego na nim użytkownika (stacja robocza, klient). Stosowane dziś systemy operacyjne dla
stacji roboczych oferują również funkcje serwerów. Wśród podstawowych usług należy wymienić
udostępnianie plików i drukarek.
Można więc stworzyć sieć pozbawioną komputera pełniącego wyłącznie funkcję serwera różnych
usług. Wystarczy połączyć stacje robocze siecią komputerową. Każda z nich może udostępniać
pozostałym swoje pliki oraz podłączone do niej drukarki. W ten sposób powstaje sieć komputerów
określana jako Peer-to-peer (równy z równym) lub w skrócie P2P.
Definicja
Sieć Peer-to-peer powstaje w wyniku połączenia komputerów udostępniających pewną usługę, w
ramach której są dla siebie nawzajem zarówno klientami jak i serwerami.

Technologie informacyjne - Podstawy technik informatycznych
Strona 47 z 72
Podobne sieci można tworzyć przez Internet. Istnieje szereg internetowych systemów sieci P2P.
Przykład
Najpopularniejsze internetowe systemy sieci P2P to: Napster (pierwszy serwis tego typu, później
zamknięty wyrokiem sądu, obecnie serwis płatny), FastTrack, Gnutella, eDonkey, Bittorent. Każdy z
nich wymaga zainstalowania na komputerze oprogramowania, które czyni z niego zarówno serwer
udostępniający pliki lub ich części oraz klienta pozwalającego na wyszukiwanie plików
udostępnionych przez innych użytkowników. Zasadą jest tutaj, że pobrane fragmenty pliku są
udostępniane innym użytkownikom jeszcze w trakcie ściągania.
5.4.1. Dostęp do zasobów sieci
Fakt fizycznego podłączenia komputera do sieci nie oznacza, że wszystkie zasoby udostępniane przez
serwery są dostępne dla każdego użytkownika.
Przykład
W każdej organizacji istnieją ograniczenia w dostępie do informacji. O ile każdy może
zapoznać się z kursami walutowymi czy stopami procentowymi w banku, to modyfikować je mogą
jedynie uprawnieni pracownicy. Z kolei dane kadrowo–płacowe objęte są szczególną tajemnicą.
Wobec tego dostęp do nich mogą mieć tylko odpowiednie osoby z działu kadr. Z kolei zasoby, które
dany pracownik ma za zadanie współtworzyć muszą być dla niego dostępne w pełnym zakresie, tj.
zarówno w celu odczytu jak i modyfikacji.
Użytkownik sieci może mieć pełny dostęp do danych, co oznacza możliwość zapoznania się z nimi,
modyfikowanie, usuwanie oraz tworzenie nowych danych. Do pewnych danych będzie miał dostęp
wyłącznie do odczytu. Do innych danych nie będzie miał w ogóle dostępu.
Skoro różnym osobom serwer ma udostępniać dane w różnym zakresie, to musi posiadać informacje o
uprawnieniach osoby chcącej uzyskać do nich dostęp. Wymaga to dokonania identyfikacji
użytkownika.
5.4.2. Identyfikacja użytkownika
Identyfikacja użytkownika następuje podczas nawiązywania połączenia z serwerem. Każdy
użytkownik sieci posiada na serwerze konto zawierające nazwę użytkownika (tzw. login), dane o haśle
oraz uprawnieniach.
Definicja
Proces identyfikacji potocznie nazywany jest logowaniem. Polega na podaniu przez
użytkownika nazwy konta (nazywanej też loginem, nazwą użytkownika lub username) oraz hasła,
które następnie są porównywane z informacjami zapisanymi na serwerze. Po pomyślnym wyniku
porównania serwer udostępnia zdefiniowany dla danej osoby zakres zasobów.

Technologie informacyjne - Podstawy technik informatycznych
Strona 48 z 72
Definicja
Nazwa konta użytkownika jest informacją jawną, często jest to też nazwa konta pocztowego.
Definicja
Hasło jest informacją poufną, której zadaniem jest potwierdzenie, że osoba, która podała nazwę
konta określonego użytkownika rzeczywiście jest jego właścicielem. Zakłada się, bowiem, że hasło
zna tylko właściciel konta.
Warto zapamiętać
Ujawnienie hasła do konta innej osobie oznacza, że inna osoba będzie mogła zalogować się w
naszym imieniu. Konsekwencje tego faktu mogą być trudne do przewidzenie. Wszystko zależy od
tego, jakie mamy uprawnienia i jakie intencje kierują osobą, która poznała nasze hasło.
W interesie każdego użytkownika leży dbałość o utrzymanie hasła w tajemnicy. Leży to również
w interesie pracodawcy. Ważne, żeby osoby postronne nie mogły wykonywać czynności w systemie
informatycznym w imieniu pracowników. Dlatego wiele systemów można skonfigurować tak, aby
wspierały użytkownika w utrzymaniu poufności hasła wymuszając odpowiednie działania lub reagując
na określone sytuacje.
Długość hasła.
Hasło składające się z dwóch znaków łatwo podejrzeć, gdy ktoś się loguje. Łatwo też można trafić je
metodą prób i błędów, szczególnie, gdy zaprzęgnie się do tego stosunkowo prosty program. Dlatego
zalecaną minimalną długością hasła jest 6 znaków. Gdy użytkownik deklaruje hasło, system nie
zaakceptuje krótszego niż określony przez administratora sieci. Wymuszanie zbyt długich haseł nie
prowadzi do pożądanych rezultatów, gdyż użytkownicy nie mogąc ich zapamiętać będą je zapisywali,
co też niesie ryzyko ujawnienia ich.
Złożoność hasła.
Użytkownicy mają skłonność do tworzenia prostych haseł. System może wymuszać w tworzonym
haśle użycia małych i dużych liter oraz cyfr. Powoduje to urozmaicenie hasła skutecznie utrudniając
odgadnięcie go przez osoby postronne. Zaleca się też stosowanie w haśle znaków interpunkcyjnych i
innych np.#,$,@,_,+,= ,/,? .
Okresowa zmiana.
Hasło z czasem może zostać odgadnięte przez osoby postronne na podstawie tego, co widać podczas
pisania na klawiaturze. Poza tym możliwe jest też odtworzenia hasła na podstawie pliku z hasłami
znajdującego się na serwerze. Hasła na serwerze nie są zapisane otwartym tekstem. Tym samym
administrator sieci nie jest w stanie nam go podać, gdy go, np. zapomnimy. Hasła zapisane są w pliku
haseł w postaci tzw. skrótów. Na podstawie skrótu nie ma możliwości odtworzenia hasła (funkcja
skrótu jest jednokierunkowa – nie istnieje proces odwrotny). Odkrycie hasła dysponując plikiem z
hasłami polega na automatycznym generowaniu treści wszelkich możliwych haseł, wyznaczaniu ich
skrótów i porównywanie ze skrótami w pliku haseł. Jeśli skrót z danego hasła jest identyczny ze
skrótem w pliku to oznacza to, że odkryto hasło użytkownika. Zakłada się, że proces taki zajmuje ok.
1 miesiąca. Wobec tego zalecane jest zmienianie haseł raz w miesiącu. System może wymuszać na
użytkowniku dokonywanie takiej okresowej zmiany. Wówczas na kilka dni przed upływem ważności
hasła użytkownik jest o tym informowany i zachęcany do zmiany.

Technologie informacyjne - Podstawy technik informatycznych
Strona 49 z 72
Różnorodność haseł.
Obowiązek zmiany hasła postrzegany jest przez użytkowników za uciążliwość. Wymusza, bowiem jego
wymyślenie zgodnie z regułami i nauczenie na pamięć. Wielu użytkowników chętnie oszukałoby
system „zmieniając” hasło na takie, jakie już było. Dla uniemożliwienia takiego postępowania
administrator może określić, że nowe hasło nie może być identyczne jak kilka ostatnio używanych.
Blokada konta po błędnych logowaniach.
Dla zapobieżenia próbom wykorzystania komputerów do odgadnięcia parametrów logowania metoda
prób i błędów często funkcjonuje mechanizm blokowania konta użytkownika po zadanej liczbie błędnie
podanych haseł np. 5. Po piątej nieudanej próbie logowania konto użytkownika może być blokowane
na pewien czas bądź bezterminowo. Uniemożliwia to wykorzystanie programu, który będzie
podejmował kilka tysięcy prób logowania na godzinie celem „trafienia” hasła. Po zablokowaniu konta,
konieczna jest wizyta użytkownika z u administratora celem odblokowania konta.
Przykład
W pewnym brytyjskim banku już w roku 2002 przeprowadzono ankietowe badanie 1000 klientów
bankowości internetowej. Jednym z pytań było, czego używają jako hasło dostępu do danych o
koncie bankowym. Wyniki były zatrważające
3
:
Odsetek użytkowników
Hasło
23%
imię dziecka
19%
imię partnera
12%
data urodzenia
9%
nazwa drużyny piłkarskiej
9%
celebryci i nazwy zespołów
9%
słynne miejsca
8%
własne imię
8%
imię domowego zwierzęcia
Jaki z powyższego badania płynie wniosek? Tabela stanowi zestawienie złych haseł. Ktoś, kto będzie
chciał podszyć pod nas z pewnością sprawdzi, czy naszym hasłem nie jest jedna z powyższych
informacji.
Używanie kombinacji nazwa użytkownika i hasło, o ile jest popularne, o tyle dość uciążliwe i w
niektórych zastosowaniach niewystarczająco bezpieczne, ponieważ stosukowo łatwo zdobyć cudze
hasło. Dlatego wynaleziono inne mechanizmy identyfikacji.
Karta magnetyczna lub chipowa.
Poza nazwą użytkownika i hasłem dodatkowo do zalogowania się może być potrzeba karta
magnetyczna lub chipowa. To wzmacnia system zabezpieczeń, jednak gdy zgubimy kartę lub
zostawimy, np. w domu, nie będziemy mogli wykonywać swojej pracy. W praktyce okazało się
również, że i kartę magnetyczną można obecnie stosunkowo łatwo skopiować, co osłabia cały
mechanizm. Karta chipowa wciąż uważana jest za bezpieczną
3
BBC NEWS World Edition – Warning over password security
http://news.bbc.co.uk/2/hi/science/nature/2061780.stm

Technologie informacyjne - Podstawy technik informatycznych
Strona 50 z 72
Metody biometryczne
Bardzo obiecujące jest wykorzystanie tzw. metod biometrycznych do identyfikacji osób. Polegają one
na badaniu indywidualnych cech organizmu ludzkiego takich jak głos, linie papilarne, obraz tęczówki
oka, geometria dłoni czy obraz twarzy. Metody te mają tą zaletę, że nie wymagają od osoby
podlegającej identyfikacji pamiętania tajnych informacji oraz noszenia np. kart. Coraz częściej można
spotkać notebooki wyposażone w mechanizmy rozpoznawania twarzy lub czytniki linii papilarnych.
Zastosowanie niektórych z metod budzi kontrowersje związane z zachowaniem prywatności. O ile
poddanie się identyfikacji w oparciu o linie papilarne jest świadome (trzeba przyłożyć palec do
czytnika, bądź w odpowiedni sposób przesunąć go po nim), o tyle dokonanie jej z wykorzystaniem
obrazu tęczówki czy twarzy może być dokonane bez wiedzy i zgody identyfikowanej osoby. Oznacza
to, że mogą być zbierane informacje o tym, co robimy i gdzie bywamy bez naszej wiedzy i zgody.
Jednakże, wzrost zagrożeń przestępczością i terroryzmem w ostatnich latach otworzył drogę do
stosowania tych metod. Jednocześnie coraz więcej ośrodków miejskich wyposażanych jest w systemy
monitoringu, które mogą zostać wykorzystane do odnajdywania osób poszukiwanych poprzez
automatyczne rozpoznawanie twarzy zarejestrowane przez kamery wideo.
5.5. Rodzaje sieci komputerowych
Dla realizacji połączeń pomiędzy komputerami, bądź komputerami i innymi urządzeniami wykorzystuje
się różnego rodzaju sieci. Poniżej przedstawiono 6 podstawowych typów sieci:
Sieć lokalna – LAN (Local Area Network)
Jest to sieć łącząca komputery w jednej lokalizacji – w jednym budynku lub zespole budynków
leżących blisko siebie. Połączenia odbywają się na niewielkie odległości 100–200 m. Cechują
ją wysokie prędkości transmisji (100 Mbit/s do 10 Gbit/s). Do ich tworzenia wykorzystuje się
kable metaliczne (tzw. skrętka nieekranowana) lub światłowody.
Sieć miejska – MAN (Metropolitan Area Network)
Sieć miejska służy do łączenia sieci lokalnych w jednym mieście. Coraz częściej zbudowana
jest z łączy światłowodowych. Pozwala na przesył danych z wysokimi prędkościami, a jej
przepustowość na różnych odcinkach może sięgać 100 Mbit/s – 2 Gbit/s.
Sieć rozległa – WAN (Wide Area Network)
Tym mianem określa się połączenia realizowane na duże odległości. Jednego połączenia (np.
pomiędzy centralą a oddziałem) może być zestawione z wykorzystaniem różnych mediów.
Mogą to być linie telefoniczne, trakty światłowodowe, radiolinie czy łącza satelitarne. W
zależności od wykorzystanych technologii szybkości transmisji mogą sięgać 64 Kbit/s –
155Mbit/s. Za pomocą sieci rozległych łączy się ze sobą zarówno sieci lokalne jak i pojedyncze
stacje robocze czy terminale.
Sieć Osobista PAN (Personal Area Network)
Jest to bezprzewodowa sieć o zasięgu kilku do kilkudziesięciu metrów, służąca do połączenia
ze sobą urządzeń znajdujących się w najbliższym otoczeniu użytkownika. Mogą to być
komputery, urządzenia peryferyjne jak drukarki, kamery, słuchawki i mikrofony oraz telefony
komórkowe czy urządzenia typu PDA. Sieci tworzone są między urządzeniami wyposażonymi w
uniwersalny interfejs bluetooth. Obecnie najpopularniejsze wykorzystanie tej technologii to
bezprzewodowe połączenie słuchawki i mikrofonu z telefonem komórkowym, przesyłanie
informacji między telefonami lub między telefonem a komputerem.. Prędkości transmisji w
takich sieciach to 720 kb/s (wersja 1.2) lub 3 Mb/s (wersja 2.0).
Bezprzewodowa sieć lokalna WLAN (Wireless LAN lub Wave LAN)
Postęp w technologii przesyłania informacji pozwala coraz częściej rezygnować z układania
kabli dla stworzenia sieci. Przewody metaliczne czy światłowody można zastępować łączami

Technologie informacyjne - Podstawy technik informatycznych
Strona 51 z 72
radiowymi. Dzięki temu możliwe jest budowanie bezprzewodowych sieci LAN. Technologia tu
wykorzystywana to WI-FI (Wireless Fidelity) i termin ten często jest stosowany zamiast WLAN.
Prędkości transmisji w sieciach WI-FI są niższe od przewodowych, ale z roku na rok dostępne
nowe rozwiązania. Obecnie buduje się sieci o przepustowości 11, 54 i 108 Mbit/s.
Bezprzewodowa sieć rozległa WWAN (Wireless WAN)
Również łącza na duże odległości można realizować bezprzewodowo. Wykorzystuje się do
tego sieci telefonii komórkowej. WWAN łączy sieci i urządzenia na odległość do 5 km od stacji
bazowej. Takie sieci oparte są na technologiach GSM, GPRS, EDGE i UMTS.
6. Internet
6.1. Internet i protokół komunikacyjny TCP/IP
Kluczowym rozwiązaniem leżącym u podstaw ARPANETU i Internetu jest protokół komunikacyjny
TCP/IP.
Definicja
Protokół komunikacyjny to zespół reguł stosowanych przez urządzenia w celu nawiązania
łączności i transmisji danych.
Istnieje wiele protokołów komunikacyjnych wykorzystywanych w różnych tzw. warstwach komunikacji.
Protokół TCP/IP odpowiedzialny jest za dostarczanie danych pomiędzy komputerami i zapewnienie
przepływu danych w ramach poszczególnych usług (np. WWW, transfer plików, poczta elektroniczna).
Opiera się na transmisji danych przesyłanych pomiędzy tzw. routerami (pośrednikami) i komputerami.
Dane są przesyłane w porcjach tzw. pakietach TCP/IP. Każdy z pakietów, w których przesyłana jest
np. strona WWW może wędrować od nadawcy do odbiorcy inną drogą tj. przebiegać za
pośrednictwem innych routerów.
Definicja
Internet to pozbawiona centralnego punktu zarządzającego sieć rozległa oparta na protokole
TCP/IP.
Obecnie Internet jest siecią powszechnie dostępną. Do skorzystania z jej zasobów potrzebne jest
urządzenie cyfrowe zdolne do komunikacji w protokole TCP/IP np. komputer podłączony do przez sieci
operatora telekomunikacyjnego lub telefon komórkowy wyposażony w oprogramowanie przeznaczone
do korzystania z dostępnych usług. Jeżeli ktoś nie posiada takich urządzeń, może skorzystać z tzw.
kafejek czy czytelni internetowych w bibliotekach.
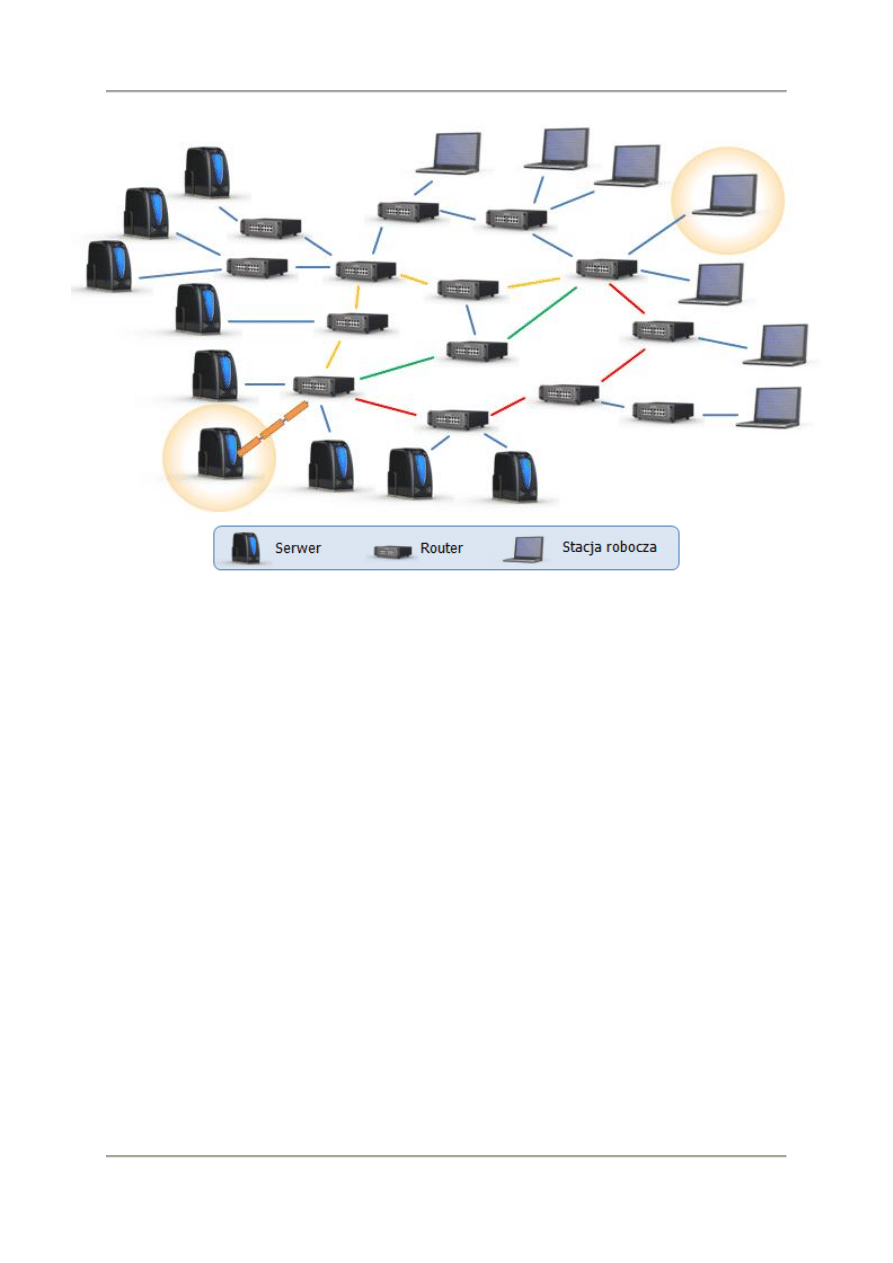
Technologie informacyjne - Podstawy technik informatycznych
Strona 52 z 72
6.2. Usługi internetowe
W Internecie świadczonych jest wiele usług. Najpopularniejsze to:
serwisy WWW (World Wide Web),
poczta elektroniczna (e-mail),
transfer plików,
komunikatory,
grupy dyskusyjne (usenet)
telefonia internetowa.
Z wykorzystywania niektórych usług nie zawsze jesteśmy świadomi. Przykładem jest tu usługa
translacji nazw domen - DNS.
Usługi oferowane są przez serwery. Do korzystania z nich potrzebne jest oprogramowanie klienta
danej usługi. Komunikacja klienta z serwerem odbywa się zgodnie z protokołem specyficznym dla
danej usługi.
Protokół TCP/IP i protokół usługi.
Protokół TCP/IP jest odpowiedzialny za dostarczenia danych (sekwencji bajtów) od jednego
komputera do drugiego. Nie opisuje jednak samych danych. Z punktu widzenia tego protokołu nie jest
istotne czy transmitowane dane to treść przesyłki pocztowej, część strony internetowej, fragment
pliku czy rozmowy telefonicznej. Rola TCP/IP kończy się na dostarczeniu pakietu danych do
docelowego komputera. Dane przeznaczone dla określonej usługi zapisane są zgodnie z protokołem
(tzw. wyższej warstwy) tejże usługi. Każda z nich używa własnego protokołu.

Technologie informacyjne - Podstawy technik informatycznych
Strona 53 z 72
Pakiet TCP/IP składa się z tzw. koperty i danych. Przesyłane dane mają strukturę i treść zgodną z
protokołem określonej usługi.
Pakiet TCP/IP
6.2.1. Usługa WWW
Najpowszechniej stosowaną usługą jest z pewnością WWW (World Wide Web). W zasadzie jej
konstrukcja wydaje się być prosta. Serwer wysyła, bowiem plik tekstowy z treścią, w której
umieszczone są znaczniki wskazujące, jakie elementy poza tekstem mają być w określonych miejscach
wyświetlane przez przeglądarkę internetową na komputerze użytkownika. Mogą to być pliki graficzne i
animacje. W treści stron internetowych mogą być osadzane tzw.
aplety -
skrypty w języku
java script
lub
vbscript
, albo kontrolki
activex
, które uruchomione w przeglądarce pozwalają na dostarczenie
dynamicznej i bardziej interaktywnej treści.
Istotną cechą stron WWW jest to, że dowolny z wyświetlanych elementów może być odnośnikiem
(ang. link) do innej strony znajdującej się na tym samym serwerze lub dowolnym innym. Takie
dokumenty tekstowe nazywane są hipertekstem (z ang. hypertext). Język, w którym są one
tworzone to Hypertext Markup Language nazywany w skrócie HTML, a protokół transmisji to HTTP
(Hypertekst Tranfer Protocol).
Wśród najpopularniejszych przeglądarek internetowych wymienić trzeba:
Mozilla Firefox,
Internet Explorer,
Opera,
Safari,
Google Chrome.
Ta z pozoru prosta technologia pozwala po odpowiednim wyposażeniu serwera w bazy danych i
interpretery języków programowania (np.
perl
,
php
) na tworzenie aplikacji internetowych w
architekturze klient-serwer. Komputer użytkownika z przeglądarką pełni funkcję klienta, a
funkcjonalność aplikacji realizowana jest przez oprogramowanie po stronie serwera. Treści przez nie
generowane, są przez serwer WWW przesyłane do przeglądarki jako strony w języku HTML. W ten
sposób, poza portalami informacyjnymi, funkcjonują banki, sklepy, aukcje internetowe czy serwisy
społecznościowe. Dostępne są też aplikacje wspierające zarządzanie przedsiębiorstwem.
Jednym z najczęściej wykorzystywanych typów aplikacji internetowych są wyszukiwarki
internetowe pozwalające na wyszukiwanie adresów stron internetowych zawierających zadane słowa
kluczowe. O ile odpowiadają na pytanie w ciągu pojedynczych sekund to nie oznacza to, że tak szybko
przeszukują cały Internet. W rzeczywistości 24 godziny na dobę, 7 dni w tygodniu wyszukiwarki
katalogują strony internetowe tworząc opisującą je bazę danych. Wyniki zapytania powstają na
podstawie zgromadzonych w ten sposób danych. Zdarza się więc, że w wynikach znajdują się adresy
stron, których w sieci już nie ma, albo uległy zmianie i nie zawierają interesujących nas informacji.
Wynika to z faktu, że zostały one skatalogowane np. klika tygodni przed naszym zapytaniem.
Technologie informacyjne - Podstawy technik informatycznych
Strona 54 z 72
W technologii WWW tworzone są również kursy do zdalnego nauczania i uczenia się na odległość.
Taka forma kształcenia określana jest mianem e-learning. Na świecie istnieje wiele uczelni wyższych,
w których studenci uczą się na odległość wykorzystując kursy zamieszczone na tzw. platformie e-
learning. Pozwala ona nie tylko na prezentowanie treści, ale również komunikację pomiędzy uczącymi
się i prowadzącym poprzez forum dyskusyjne, komunikatory i audio lub wideo konferencje. Jedną z
ważniejszych funkcji platformy jest śledzenie postępów w nauce oraz aktywności studentów.
Wiele dużych korporacji wykorzystuje e-learning dla obniżenia kosztów szkoleń. Zamiast odrywać duże
grupy pracowników od pracy na kilka dni, ponosić koszty dojazdu, zakwaterowania i sal dydaktycznych
organizuje się szkolenia przez Internet. Osoby uczą się na swoich stanowiskach pracy po 1-2 godziny
dziennie przez np. 2 tygodnie korzystając z kursów internetowych. Na koniec zdają egzamin, którego
wyniki odnotowywane są systemach zarządzania zasobami ludzkimi.
W Internecie można znaleźć kursy e-learning zarówno darmowe jak i odpłatne. Pozwalają na
podnoszenie kwalifikacji wielu dziedzinach.
Korzystając z WWW trzeba mieć na uwadze fakt, że za pomocą protokołu HTTP treści, zarówno, do
jak i od użytkownika, płyną przez sieć otwartym tekstem. W poszczególnych węzłach sieci (routerach)
istnieje wobec tego możliwość podglądu transmitowanych informacji. Posługiwanie się niektórymi
aplikacjami (np. serwisem bankowym lub sklepem internetowym) wymaga przesyłania danych o
charakterze poufnym. Na te potrzeby powstała szyfrowana wersja protokołu HTTP oznaczona literami
HTTPS.
Warto zapamiętać
Ilekroć w formularzu na stronie internetowej istnieje konieczność podania nazwy użytkownika i
hasła lub parametrów karty kredytowej można to zrobić bez nadmiernego ryzyka kradzieży tych
informacji tylko wtedy, gdy w przeglądarce, przy adresie będzie wskazany protokół HTTPS, np.
https://www.mbank.com.pl/.
6.2.2. FTP – transfer plików
Kolejną z usług jest transfer plików nazywany potocznie FTP od nazwy używanego przez nią
protokołu (File Transfer Protocol). Często użytkownicy nie zdają sobie sprawy, że z niej korzystają.
Obecnie najczęściej są oni przekierowywani w wyniku kliknięcia w link do pliku (np. programu,
dokumentu PDF czy innego). Do serwera FTP można również dotrzeć przeglądarką internetową
wskazując w adresie protokół. np. ftp://pozman.pl/. Nazwy serwerów zwyczajowo zaczynają się od
nazwy protokołu np.
Po wejściu przeglądarką na taki serwer widzimy pliki i katalogi w podobnym układzie jak na dysku
lokalnym. Udostępnione na serwerze zasoby można pobrać. Jeżeli serwer to umożliwia i posiada się na
nim konto, można również pliki tam wysłać.
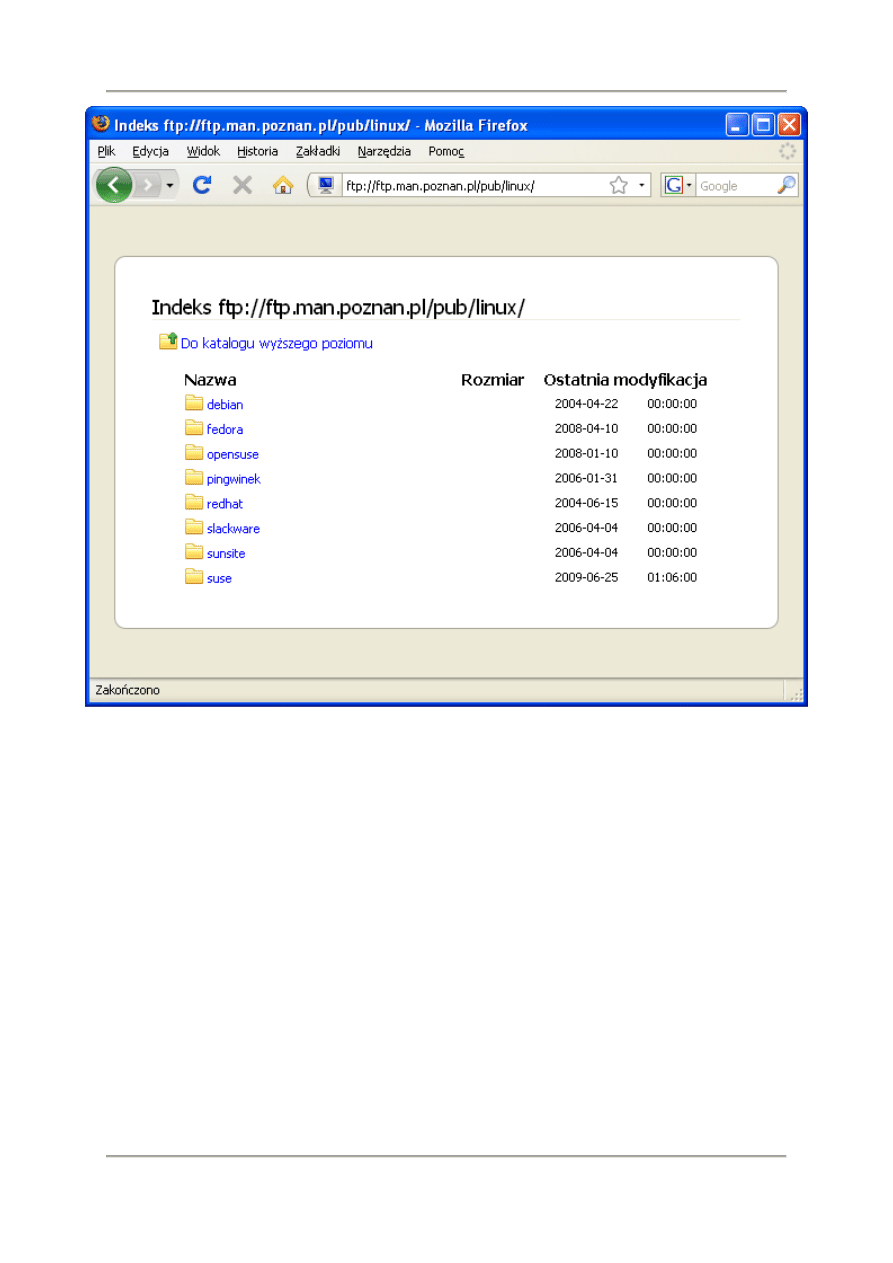
Technologie informacyjne - Podstawy technik informatycznych
Strona 55 z 72
Źródło: Zrzut ekranu programu Mozilla Firefox
6.2.3. Poczta elektroniczna (e-mail)
Usługa poczty elektronicznej pozwala na przesyłanie wiadomości tekstowych wraz z załącznikami
w postaci dowolnych plików. Składa się de facto z dwóch usług – poczty przychodzącej i wychodzącej.
Oprogramowanie po stronie użytkownika (tzw. klient poczty) łączy się z serwerem właściwej usługi
automatycznie w zależności od tego czy wysyłamy czy odbieramy pocztę.
Wysłana przesyłka dostarczana jest do serwera poczty wychodzącej protokołem SMTP. Ten przesyła
ją do serwera poczty, z którego korzysta adresat tym samym protokołem. Po odebraniu przesyłka
umieszczana jest w skrzynce pocztowej adresata. Do swojej skrzynki pocztowej można zajrzeć
korzystając z dwóch protokołów – POP3 lub IMAP.
Korzystając z pierwszego z nich wszystkie przesyłki są przesyłane do klienta poczty na komputerze
użytkownika i usuwane z serwera. Tym samym, gdy zajrzy on do skrzynki pocztowej z innego
komputera nie znajdzie już tych listów, które zostały wcześniej odebrane.
Drugi z protokołów działa inaczej. Do klienta poczty przesyłane są jedynie nagłówki wiadomości
zawierające informacje: kto jest nadawcą, odbiorcą, kiedy przesyłkę nadano i jaki jest jej temat.
Dopiero przy otwieraniu przesyłki następuje pobranie jej kopii na komputer odbiorcy. Wiadomości
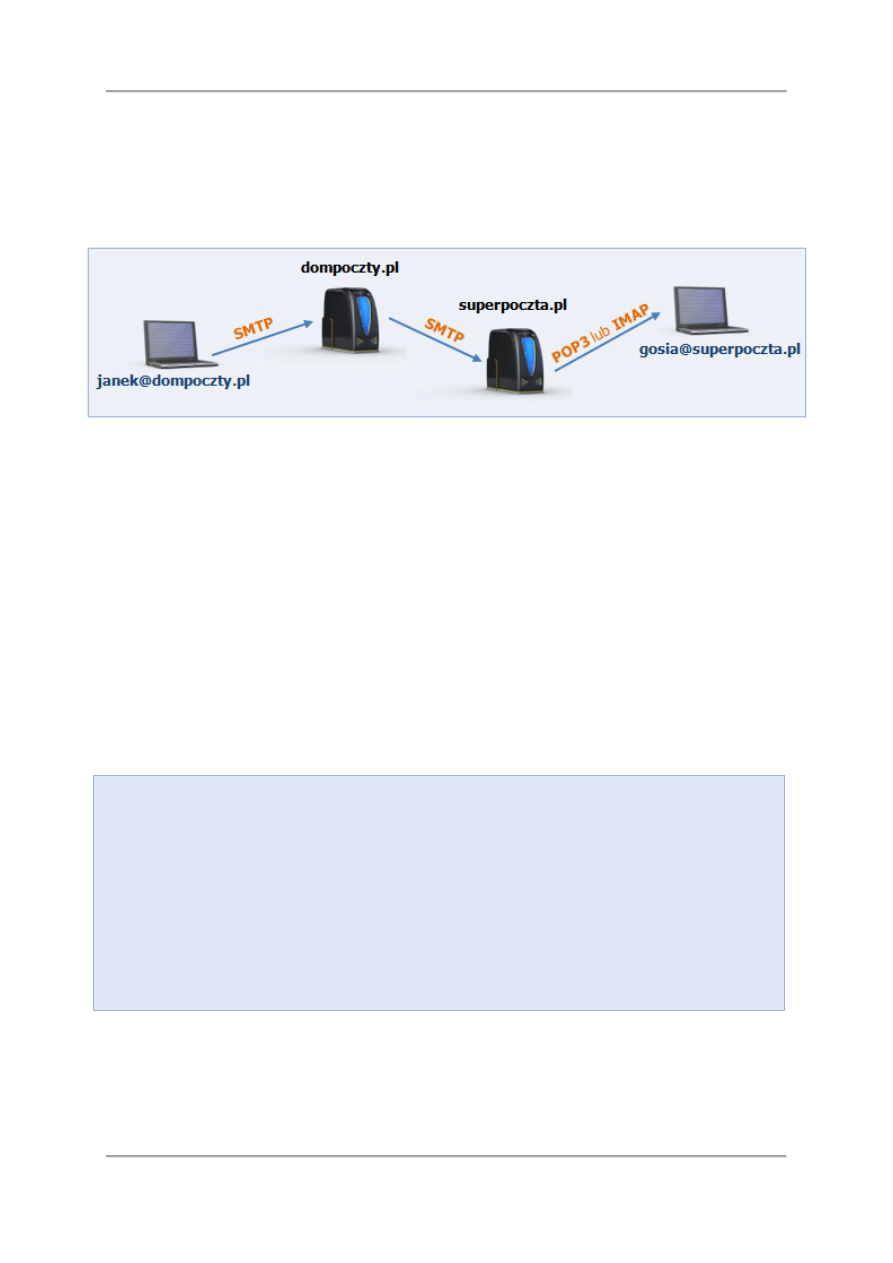
Technologie informacyjne - Podstawy technik informatycznych
Strona 56 z 72
pozostają na serwerze dopóty, dopóki użytkownik nie usunie ich z serwera. Dzięki temu, można
uzyskiwać dostęp do tych samych przesyłek za pomocą różnych komputerów.
Oprogramowanie klienta poczty może być zainstalowane na komputerze użytkownika (np. Outlook,
Thunderbird, Eudora, The Bat!) albo po stronie serwera jako serwis WWW np. poczta.onet.pl,
gmail.com, yahoo.com ). W tym drugim przypadku uzyskujemy dostęp do treści przesyłek poprzez
przeglądarkę WWW.
W celu uzyskania dostępu do swojej skrzynki pocztowej konieczne jest zalogowanie się.
Standardowe protokoły POP3 i IMAP przesyłają nazwę użytkownika i hasło otwartym tekstem, co
czyni je łatwymi do przechwycenia w sieci. Dlatego stworzono ich wersje szyfrowane POP3s i IMAPs.
Wykorzystują one protokół SSL dla zapewnienia poufności transmitowanych informacji oraz
potwierdzenia autentyczności serwera.
6.2.4. Grupy dyskusyjne (usenet, news)
Grupy dyskusyjne
(usenet, news)
-
serwis zbliżony zasadą funkcjonowania do poczty elektronicznej.
Jednak służy prowadzeniu dyskusji. Adresatem przesyłki nie jest tu konkretna osoba tylko grupa
dyskusyjna. Wysłana do grupy dyskusyjnej wiadomość jest rozsyłana do wszystkich serwerów na
świecie, które obsługują tą grupę. Użytkownik danej grupy, może z kolei pobrać wszystkie minione (i
przechowywane jeszcze przez serwer) dyskusje. Do każdej z nich może się włączyć odpowiadając na
dowolną (właściwą tematycznie) wiadomość.
Każda grupa dyskusyjna ma ściśle zdefiniowany obszar tematyczny i regulamin.
Przykład
Przykłady grup dyskusyjnych:
pl.rec.zeglarstwo – polskojęzyczna grupa poświęcona rekreacji, w szczególności żeglarstwu.
comp.os.linux – grupa dot. systemu operacyjnego Linux. Początkowe comp. oznacza tematykę
komputerową. Brak wskazanego języka z reguły oznacza, że dyskusje prowadzone są w języku
angielskim.
pl.biznes.banki – polska grupa dot. bankowości.
Treści dyskusji prowadzone w ramach tej usługi mogą być przechowywane przez serwer przez wiele
lat. Biorąc pod uwagę fakt, że najczęściej tą drogą przesyłane są informacje o charakterze
praktycznym, a największe serwery przechowują treści z setek tysięcy grup dyskusyjnych, usenet jest
olbrzymim repozytorium wiedzy ze wszystkich dziedzin życia. Trzeba jednak pamiętać, że wiadomości
w grupach dyskusyjnych pisane są przez osoby o różnym poziomie profesjonalizmu. Trzeba, więc
liczyć się z tym, że nie wszystkie informacje są wiarygodne i wolne od błędów.

Technologie informacyjne - Podstawy technik informatycznych
Strona 57 z 72
Do korzystania z usługi wystarczy dowolny klient poczty. Każdy ma wbudowaną obsługę grup
dyskusyjnych. Trzeba tylko skonfigurować sobie odpowiednie konto, podając adres serwera, z którego
zamierzamy korzystać oraz swój adres e-mail. To, z którego serwera grup możemy korzystać zależy od
dostawcy łącza internetowego i stamtąd powinniśmy otrzymać informację o jego adresie.
Wykorzystywany tu protokół to News Network Transfer Protocol (NNTP).
6.2.5. Komunikator (Instant Messaging)
Usługa Instant Messaging (IM) służy do natychmiastowego przesyłania komunikatów tekstowych
między użytkownikami Internetu. Pierwszym tego typu rozwiązaniem był izraelski komunikator ICQ.
Później pojawiły się inne o zasięgu międzynarodowym i lokalnym.
Przykład
W Polsce najpopularniejsze komunikatory to:
Gadu-gadu (krajowy),
Skype (międzynarodowy),
Tlen (krajowy),
MSN Messenger (międzynarodowy).
Początkowo pozwalały na przesyłanie wiadomości tekstowych. Obecnie ich funkcjonalność ewoluowała
do rozmów głosowych nie tylko w układzie jeden-do–jednego, ale również możliwe jest prowadzenie
audio konferencji. Ponadto możliwe jest synchroniczne przesyłanie obrazu z kamery, dzięki czemu
rozmówcy mogą siebie widzieć. Oprogramowanie klienta usługi IM informuje też, kto z naszych
potencjalnych rozmówców jest aktualnie dostępny.
Poszczególne systemy IM używają swoich własnych protokołów.
6.2.6. DNS
Usługą najprawdopodobniej najczęściej wykorzystywaną, z czego użytkownicy najczęściej nie zdają
sobie sprawy, jest Domain Name Service (DNS). Komputery podłączone do Internetu są
identyfikowane przez tzw. adres IP, czyli cztero (wersja IPv4) lub ośmiobajtowy numer (wersja IPv6)
np. 150.254.194.5, 213.180.138.148, 217.149.245.170 .Poszczególne liczby składające się na adres IP
oddzielone są kropkami lub dwukropkami (w wersji Ipv6). Posługiwanie się przez użytkowników takimi
adresami serwerów, z których chcemy korzystać byłoby niewygodne, dlatego stworzono system nazw
domenowych, które jest dużo łatwiej zapamiętać, a części po prostu łatwo się domyślić np.
www.wsb.pl, www.onet.pl, www.money.pl .
Wszelkie urządzenia sieciowe przesyłające pakiety danych między sobą na drodze od serwera do
klienta i w przeciwnym kierunku posługują się wyłącznie adresami IP. Dlatego potrzebna jest usługa
DNS, której zadaniem jest dostarczenie informacji, jakiego adresu IP używa określony przez podaną
przez użytkownika nazwę komputer w sieci.

Technologie informacyjne - Podstawy technik informatycznych
Strona 58 z 72
Przykład
Gdy w przeglądarce WWW wpiszemy adres np.
to najpierw zostanie wysłane zapytanie
do serwera DNS o adres IP dla określonej nazwy, a dopiero po otrzymaniu go przeglądarka nawiąże
kontakt z docelowym serwerem. Podobnie jest z dostępem do serwerów poczty elektronicznej, FTP
czy usenetu.
Usługa ta wykorzystuje protokół o tej samej nazwie DNS.
6.2.7. Zestawienie usług i protokołów
Zastawienie usług i wykorzystywanych przez nie protokołów:
Usługa
Protokoły
Opis
DNS
DNS
translacja nazw domen na adresy IP
WWW
HTTP
transmisja hypertekstu
HTTPS
szyfrowana transmisja hypertekstu
FTP
FTP
transmisja plików
USENET
NNTP
transmisja pomiędzy serwerami grup dyskusyjnych oraz od/do klienta
USENET
poczta
elektroniczna
SMTP
poczta wychodząca
IMAP
poczta przychodząca - przesyłki pozostają na serwerze – replikacja
przesyłek do komputera klienta
IMAPS
jak IMAP + połączenie szyfrowane
POP3
poczta przychodząca – przesyłki przenoszone do komputera klienta –
usuwanie przesyłek z serwera
POP3S
jak POP3 + połączenie szyfrowane
6.3. Metody dostępu do Internetu
Dostęp do Internetu jest dziś usługą powszechną. Istnieje wiele metod dostępu. W poniższej tabeli
zebrano te najistotniejsze. Przyjęto, że w każdym z przypadków użytkownik dysponuje komputerem.
Łącze
Wymagania
techniczne
Charakterystyka opłat
Uwagi
Dial-up
(połączenie
telefoniczne)
linia telefoniczna,
modem telefoniczny
koszt naliczany za czas
połączenia
W trakcie połączenia z Internetem
nie można prowadzić rozmów (linia
analogowa).
ADSL
linia telefoniczna,
specjalny modem
stały abonament bez
względu na czas
korzystania z połączenia
Transmisja internetowa nie zakłóca
rozmów telefonicznych.
Prędkość transmisji od użytkownika
do sieci jest kilkakrotnie niższa niż
w druga stronę.
Satelita
(jednokierunkowo)
linia telefoniczna,
odbiornik satelitarny
z anteną
stały abonament bez
względu na czas
korzystania z połączenia +
koszt połączenia
telefonicznego
Transmisja do użytkownika odbywa
się przez łącze satelitarne (wysoka
prędkość), a w drugą stronę przez
linię telefoniczną (niska prędkość).
Satelita
(dwukierunkowo)
odbiornik-nadajnik z
anteną nadawczo-
odbiorczą
stały (wysoki) abonament
lub opłata za ilość
przesłanych danych

Technologie informacyjne - Podstawy technik informatycznych
Strona 59 z 72
Sieć telewizji
kablowej
dostęp do sieci
telewizji kablowej,
specjalizowany
modem
stałe koszty bez względu
na czas połączenia
Najczęściej prędkość w kierunku
od użytkownika jest mniejsza niż w
przeciwnym.
Telefonia
komórkowa
telefon komórkowy,
dostępne
technologie: GSM,
GPRS, EDGE lub
UMTS
opłaty za czas połączenia
(GSM), ilość przesłanych
danych lub stały
abonament (GPRS, EDGE,
UMTS)
Hot spot (WI FI)
karta sieci
bezprzewodowej
koszt stały (abonament)
lub opłata za czas
połączenia,
istnieją darmowe hot-spoty
(w restauracjach, centrach
handlowych, uczelniach)
Prędkość łącza jednakowa w obu
kierunkach.
WI-MAX
specjalizowane
urządzenie odbiorcze
(karta sieciowa)
Technologia dedykowana na tereny
o małej gęstości zaludnienia.
Stosowana głównie do zestawienia
łącza między siecią Internet a siecią
abonentów końcowych (np.
osiedle), wysoka prędkość
transmisji w obu kierunkach.
Istnieje możliwość dostarczenia
sygnału bezpośrednio do abonenta.
6.4. Utrzymanie ciągłości funkcjonowania systemu
informatycznego
Nietrudno wyobrazić sobie, jakie skutki dla przedsiębiorstwa lub banku i jego klientów niesie ze sobą
utrata danych. Nie byłoby wiadomo ile środków zdeponowali poszczególni klienci i ile są dłużni.
Oznaczałoby to nieuchronną upadłość np. banku. Z tego powodu konieczna jest ochrona danych
przed ich utratą.
Dokumentacja papierowa posiada szereg wad. Są to m. in. całkowita nieczytelność dla systemów
komputerowych (wczytanie danych z dokumentów księgowych możliwe jest tylko za pomocą
klawiatury) oraz stosunkowo duża ilość miejsca potrzebna do ich przechowywania. Poza tym, w
obecnych czasach część dokumentacji nigdy nie zostaje przelana na papier i funkcjonuje wyłącznie w
formie elektronicznej.
Podstawową metodą ochrony danych jest wykonywanie kopii na zapasowym nośniku (tzw. backup
danych). Z takiej kopii archiwalnej można skorzystać, gdy dojdzie do awarii systemu, która
spowoduje utratę danych, ich uszkodzenie (system nie potrafi ich poprawnie przeczytać i przetwarzać)
lub nie można uznać za wiarygodne (podejrzenie o przekłamania niektórych wartości).
Odtwarzanie danych z kopii archiwalnych jest czasochłonne i może trwać kilka godzin. Większość firm
nie może pozwolić sobie na tak długą przerwę w pracy. Dlatego opracowano metody zapobiegania
niektórym z możliwych awarii systemów przetwarzania informacji.
Głównymi powodami utraty bądź uszkodzenia danych są:
awaria zasilania (zanik napięcia lub zakłócenia w instalacji elektrycznej),
awaria nośników informacji,
wirusy komputerowe.

Technologie informacyjne - Podstawy technik informatycznych
Strona 60 z 72
6.4.1. Awarie zasilania
Awarie zasilania powodują, iż ostatnie wykonane operacje mogą nie zostać zapisane na dysku
wcale lub w części (np. z sześciu zapisów księgowych składających się na transakcję zapisane zostały
tylko trzy). Ponadto może dojść do zaburzenia informacji w katalogu i tablicy alokacji plików, co
powoduje bezpośrednią utratę dostępu do danych. W przypadku poważnych zakłóceń w sieci
(następujące po sobie kilkukrotne włączenie i wyłączenie zasilania) może dojść do zapisów
przypadkowych wartości w przypadkowych miejscach na dysku lub jego fizycznego uszkodzenia i
utraty zapisanych informacji.
Zakłócenia w sieci zasilającej mogą również powodować uszkodzenia innych elementów systemu
komputerowego prowadząc do przerw w jego działaniu i narażając na straty finansowe.
Tam gdzie zapewnienie ciągłości funkcjonowania systemu nie jest krytyczne (np. komputery w domu)
dla wyeliminowania zakłóceń pojawiających się w sieci energetycznej stosuje się listwy zasilające.
Nie zapewnią one zasilania w przypadku jego zaniku w sieci, jednak uchronią komputer przed
skutkami tzw. przepięć, które pojawiają się w momencie włączania i wyłączania prądu. Eliminują też
zakłócenia wnoszone do sieci przez niektóre zakłady produkcyjne.
Dla uniknięcia wymienionych sytuacji w przedsiębiorstwach stosowane są tzw. urządzenia UPS (z
ang.
uninterruptible power supply
). Ich integralną częścią jest bateria akumulatorów służących do
gromadzenia i przechowywania energii elektrycznej. W sytuacji normalnego zasilania komputery
pobierają energię z sieci zasilającej. W przypadku zaniku napięcia w instalacji energetycznej lub jego
poważnych zakłóceń komputery zasilane są z akumulatorów. Są one ładowane, gdy przywrócona
zostanie normalna praca instalacji elektrycznej.
UPS-y stosowane są na dwa sposoby.
W przypadku pierwszego z nich wykorzystuje się małe zasilacze pozwalające na zasilenie serwera i
konsoli operatorskiej przez okres pozwalający na jego bezpieczne wyłączenie. Pozostałe komputery
podłączone są do indywidualnych UPS-ów. Pojemność baterii akumulatorów nie pozwala na
kontynuowanie pracy. Ich zadaniem jest tylko podtrzymanie zasilania przez czas potrzebny do
zapisania edytowanych danych i zamknięcie systemu operacyjnego.
Druga metoda wykorzystania UPS-ów pozwala na podtrzymania zasilania dla wszystkich
użytkowników systemu. Konieczne jest w tym wypadku stworzenie oddzielnej instalacji elektrycznej
przeznaczonej wyłącznie do zasilania urządzeń związanych z siecią komputerową. Często do
podłączenia do niej urządzeń stosuje się nietypowe wtyczki lub blokady uniemożliwiające włączenie
np. grzałki lub czajnika. Daje to dodatkową korzyść, jaką jest wyeliminowanie zakłóceń wnoszonych
do instalacji przez podłączenie urządzenia dużej mocy nie związanych z siecią komputerową. Cała
instalacja zasilana jest przez UPS dużej mocy. Najczęściej jest to urządzenie, które nie tylko
zabezpiecza przed skutkami całkowitego zaniku zasilania, ale również stabilizuje napięcie, co
dodatkowo eliminuje zakłócenia docierające z sieci energetycznej wytwarzane np. przez znajdujące się
w pobliżu zakłady czy warsztaty.
Zwykle takie UPS-y dysponują też łączem, poprzez które serwer jest informowany o parametrach
zasilania lub jego zakłóceniach. W sytuacji awaryjnej użytkownicy otrzymują informację (w postaci
komunikatu na ekranie) o tym, iż muszą zakończyć pracę z systemem w ciągu np. 5 minut. Po tym
czasie następuje procedura wyłączenia serwera. Najczęściej uruchamiana jest ona automatycznie bez
konieczności ingerencji operatora. Zastosowanie dodatkowych baterii akumulatorów pozwoli na
wydłużenie możliwego czasu w trakcie awarii do kilku godzin.
Dla zapewnienia ciągłości pracy zastosowanie znajdują agregaty prądotwórcze napędzane
silnikiem spalinowym. Wówczas UPS musi być w stanie zasilić wszystkie urządzenia podłączone do

Technologie informacyjne - Podstawy technik informatycznych
Strona 61 z 72
sieci komputerowej, lecz tylko przez krótki czas niezbędny do rozruchu agregatu. Takie rozwiązania
stosuje się np. w szpitalach oraz innych miejscach, gdzie ciągłość zasilania jest niezbędna, a
jednocześnie istnieje ryzyko, że przywrócenie zasilania może potrwać wiele godzin.
W wyniku zmian klimatycznych nasz kraj nawiedzają trąby powietrzne i huragany, które niszczą sieci
energetyczne. Ich naprawa na niektórych obszarach trwa czasami kilka dni. Jeżeli firmy tam
zlokalizowane nie chcą być narażone na straty związane z brakiem zasilania, muszą wyposażyć się w
agregat prądotwórczy i centralny UPS.
6.4.2. Awarie nośników
Magnetyczne nośniki informacji są bardzo wrażliwe na zanieczyszczenia, wstrząsy, pole magnetyczne i
wyładowania elektrostatyczne. Ponadto w trakcie eksploatacji zużywają się mechanicznie. Dla
uniknięcia lub ograniczenia skutków awarii twardych dysków stosowanych jest kilka metod.
Podstawowe to:
mirroring (z ang.
mirror
- lustro) wymaga podwojenia ilości dysków. Wszystkie zapisy
wykonywane są jednocześnie na dwóch dyskach (każdy zapis ma lustrzane odbicie na
bliźniaczym dysku). W przypadku awarii jednego z nich jest on wyłączany. Dysk bliźniaczy
zawiera poprawne informacje i system może kontynuować pracę Rozwiązanie takie jest mało
efektywne gdyż dla uzyskania efektywnej pojemności dysku 1 TB potrzeba dysków o
pojemności 2 TB (2 x 1 TB).
macierze dyskowe - są bardziej efektywne niż mirroring. Wykonuje się je często jako
urządzenie zewnętrzne. Zawierają kilka dysków, z których jeden przechowuje wyłącznie
informacje potrzebne do odtworzenia danych w przypadku awarii jednego z pozostałych.
Awaria dowolnego z dysków powoduje tylko wyłączenie go z użytku. System dalej pracuje
normalnie korzystając z danych zawartych na dodatkowym dysku. Dopiero awaria kolejnego
dysku oznacza utratę danych i zatrzymanie pracy systemu. Macierze pozwalają na wymianę
dowolnego z dysków bez konieczności przerywania pracy serwera. Po wymianie uruchamia się
proces rekonstrukcji danych i całość wraca do normalnej pracy. Poza zapewnieniem ciągłości
funkcjonowania systemu mimo awarii rozwiązanie to ma jeszcze inne zalety.
Na rynku dostępne są dyski o określonych pojemnościach. Obecnie (maj 2009) największe z
nich mają pojemność 1,5 TB. Jeśli potrzebujemy zasobów dyskowych o większych
pojemnościach niż największe z dostępnych dysków, macierz jest jedynym rozwiązaniem.
Użycie macierzy złożonej z 6 takich dysków pozwala stworzyć zasób o pojemności 7,5 TB (5
dysków z danymi, szósty dodatkowy)
Kolejną zaletą macierzy i przewagą nad mirroringiem jest jej wydajność. Każdy dysk cechuje
ograniczoną prędkość, z jaką może zapisywać bądź odczytywać dane. Zastosowanie macierzy
powoduje, że informacje dzielone są na porcje, a każda z nich zapisywana jest na innym
dysku. Dzięki temu zapis bądź odczyt poszczególnych porcji następuje jednocześnie na wielu
dyskach, co skraca czas całej operacji.
Podstawową zaletą obu opisanych rozwiązań jest zapewnienie ciągłości funkcjonowania systemu
informatycznego mimo awarii tak newralgicznego elementu, jakim jest dysk twardy. Mimo wszystkich
zalet zastosowanie ich nie może zastępować wykonywania kopii danych na dodatkowym nośniku.
Dobra praktyka nakazuje przechowywanie kopii archiwalnych w innym budynku niż serwer. Zapewni
to możliwość przywrócenia systemu do pracy również po takich zdarzeniach jak pożar i zalanie
serwerowni.
6.4.3. Szkodliwe oprogramowanie (wirusy, robaki, konie trojańskie)
Jednym z istotniejszych zagrożeń jest szkodliwe oprogramowanie (Malware –
malicious
software
). Do tej grupy zagrożeń zaliczyć możemy wszelkie pogramy, których zadaniem jest

Technologie informacyjne - Podstawy technik informatycznych
Strona 62 z 72
zakłócenie pracy systemu, zniszczenie danych, kradzież danych (tzw. spyware) czy rozsyłanie spamu.
Wyróżniamy tu trzy typy programów: wirusy, robaki i konie trojańskie.
Wirusy komputerowe
Istotnym zagrożeniem dla systemu informatycznego mogą być wirusy komputerowe. Są to krótkie
programy, które nie występują samodzielnie, lecz są „przyklejone” do innych programów będących
nosicielami. Mają natomiast zdolność do samodzielnego przenoszenia się na inne programy (tzn.
zarażania ich). Poza mnożeniem się w zależności od intencji autora mogą (w 99% robią to)
wykonywać dodatkowe czynności. Są to
efekty wizualne na ekranie np. spadanie literek pisanego tekstu, odwrócenie obrazu do góry
nogami, komunikat quasi systemowy lub wyświetlenie jakiegoś obrazku,
wydawanie dźwięków z głośnika komputera np. piosenka Yankee Doodle,
niszczenie zarażonych programów,
zamazywanie danych systemowych na dyskach uniemożliwiając korzystanie z zawartych na
nich informacji,
Nie wiadomo kto napisał program pierwszego wirusa. Jedni uważają, iż pierwszy wirus powstał jako
dowcip zdolnego informatyka. Na skutek jednak błędu w programie poza oczekiwanym efektem na
ekranie uszkadzał on swojego nosiciela. Inni twierdzą, że powstały w firmie produkującej
oprogramowanie, aby groźba zarażenia odstraszała od korzystania z nielegalnie kopiowanego
oprogramowania.
Wśród wirusów komputerowych można ze względu na sposób rozprzestrzeniania się wyróżnić:
Wirusy plikowe
Wirusy, aby mogły się przenosić, potrzebują nosiciela. Dopisują się na końcu pliku programu
użytkowego, a następnie modyfikują jego początek tak, aby w momencie uruchomienia w
pierwszej kolejności wykonywał się program wirusa, a dopiero po nim właściwy program. W
określonych przez autora warunkach np. zadana data i godzina wskazywana przez zegar
systemowy oraz ilość dokonanych infekcji wykonywane są wymienione wcześniej dodatkowe
czynności. W bardziej prymitywnych wirusach wykonanie ich programu powodowało zarażenie
jednego lub kilku innych. Ponieważ praktycznie proces ten jest niezauważalny, użytkownik
przekonywał się o zainfekowaniu swoich programów dopiero, gdy wirus pokazał skutki swojej
działalności.
Bardziej zaawansowane wirusy (najczęściej spotykane dzisiaj) w momencie uruchamiania
zainfekowanego programu instalują się w pamięci operacyjnej komputera (tzw. wirusy
rezydentne) i infekują inne programy przy jakiejkolwiek próbie czytania i pisania na dysku.
Jak wiadomo system operacyjny to też oprogramowanie. Może więc ulec infekcji. Wirus taki
jest uaktywniany w trakcie uruchamiania komputera podczas wczytywania systemu
operacyjnego. Rozmnażające się w opisany sposób wirusy plikowe zawdzięczają swoją nazwę
faktowi, że przenoszone są wraz z plikami programów.
Makrowirusy - wirusy dokumentów.
Najnowsze wersje pakietów biurowych (np. MS Office) pozwalają na tworzenie dokumentów,
które mają „wbudowane” programy, tzw. makra automatyzujące pracę z nimi. Jest to
możliwe, ponieważ w ramach dokumentu np. tekstowego lub arkusza kalkulacyjnego można
pisać programy, które są automatycznie wykonywane, często bez wiedzy użytkownika
dokumentu. Dzięki temu można arkusz kalkulacyjny rozbudować o nieistniejące dotąd funkcje.
Takie udogodnienie otworzyło jednak drogę dla wirusów komputerowych. Twórcy szkodliwego
oprogramowania wykorzystali tą okazję tworząc dokumenty np. Worda czy Excela
„wzbogacone” o wirusy. W momencie otwierania takiego dokumentu wirus zaraża inne

Technologie informacyjne - Podstawy technik informatycznych
Strona 63 z 72
posiadane przez nas dokumenty i zależnie od inwencji autora wykonuje również inne
czynności (najczęściej destrukcyjne). W odróżnieniu od programów, dokumentami bardzo
często się wymieniamy. Zabieramy je na dyskietce czy pamięci flash, przekazujemy innym np.
poprzez pocztę elektroniczną wewnątrz firmy czy przez Internet. Powoduje to błyskawiczne
rozprzestrzenianie się tego typu wirusów.
Wirusy dyskowe
Na każdym nośniku danych istnieje obszar przeznaczony na program ładujący system
operacyjny. Po włączeniu komputera program zawarty w BIOSie w pamięci ROM wczytuje
zawartość tego obszaru do pamięci RAM i uruchamia go. Jeżeli nośnik zawiera system
operacyjny to zostanie on uruchomiony, jeśli nie – pojawi się komunikat informujący o tym
użytkownika. Ponadto na nośnikach typu pendrive czy płyty CD i DVD może znajdować się
plik, którego zadaniem jest automatyczne uruchomienie wskazanego w nim programu. Z
czasem pojawiły się więc wirusy, które wykorzystują te mechanizmy do swojego
rozprzestrzeniania się.
Każdemu zdarzyło się zapomnieć wyjąć dyskietkę z napędu czy pendrive z portu USB przed
włączeniem komputera lub przy jego powtórnym uruchamianiu. Komputer chcąc wczytać
system operacyjny uruchomi znajdujący się w obszarze startowym nośnika program. Jeżeli w
tym obszarze znajdowałby się wirus, to może on już zarazić dysk twardy komputera. Jeżeli
nośnik nie zawiera systemu operacyjnego komputer zawiesi się lub zażąda włożenia dysku
systemowego, ale obszar startowy dysku twardego może zdążyć ulec zarażeniu. Od tego
momentu wirus będzie uaktywniał się przy każdym uruchomieniu systemu operacyjnego, a
wszystkie zapisywalne nośniki będą infekowane.
Podobny mechanizm wykorzystywany jest przez wirusy związane z funkcja autostartu z
wykorzystaniem pliku autorun.inf. Jeżeli podłączany nośnik danych (płyta CD, DVD, pendrive
czy inna pamięć flash) zawiera w katalogu głównym plik autorun.inf to go wczytuje i realizuje
zawarte w nim polecenia, np. uruchomienia wskazanego w nim programu. Tym programem
może być wirus, który zainfekuj komputer. Od tego momentu infekowane będą podłączane do
takiego komputera nośniki.
Wirusy poczty elektronicznej
Wraz z upowszechnieniem się Internetu pojawiły się nowe rodzaje wirusów wykorzystujące
usługę poczty elektronicznej. Przesyłki pocztowe mogą być skonstruowane w taki sam sposób
jak strony internetowe. Te z kolei mogą do ich wyświetlenia wymagać uruchomienia
zawartych w nich skryptów w napisanych w językach
java
czy
visual basic
. W rezultacie
powstaje ulubiony przez twórców szkodliwego oprogramowania mechanizm, dzięki któremu,
przy otwieraniu przesyłki pocztowej następuje automatyczne uruchomienie przesłanych nam
programów. Powstały więc listy, o konstrukcji stron WWW zawierających skrypty, które
instalowały na komputerze programy, których zadaniem było wysłanie kopii przesyłki do
wszystkich osób, których adresy były dostępne w książce adresowej użytkownika. U osoby,
która otrzymała taki list scenariusz się powtarzał. W ten sposób wirusy tego typu potrafiły
dotrzeć do milionów komputerów na całym świecie w zaledwie 3 dni. Poza
rozprzestrzenianiem się wirus może podejmować inne zadania, takie jak niszczenie, bądź
wykradanie danych czy rozsyłanie spamu. Dzięki wbudowanym przez twórców
oprogramowania pocztowego mechanizmów ochrony jest to wymierający typ szkodliwego
oprogramowania.
Robaki komputerowe
Robaki komputerowe to oprogramowanie bardzo podobne do wirusów. W odróżnieniu jednak od nich
są samodzielnymi programami i nie wymagają „żywiciela”, z którym mogłyby się przenosić. Najczęściej
takie szkodliwe oprogramowanie przedostaje się do komputerów poprzez błędy w oprogramowaniu
użytkowym. Głównie, odpowiedzialne są za to błędy i luki w zabezpieczeniach przeglądarek

Technologie informacyjne - Podstawy technik informatycznych
Strona 64 z 72
internetowych. Robak wykorzystujący je znajduje się na odpowiednio spreparowanej stronie
internetowej. Po wejściu na nią następuje zainfekowanie komputera. Użytkownik najczęściej nie zdaje
sobie sprawy, że infekcja miała miejsce, dopóki nie pojawią się inne tego efekty.
Konie trojańskie
Konie trojańskie to programy, które użytkownik mniej lub bardziej świadomie instaluje sobie sam.
Może to być program podający jakieś parametry komputera lub wygaszasz wyświetlający nasze
zdjęcia z wakacji, czy inne, z pozoru użyteczne czynności. Te funkcje to tylko pretekst mający zachęcić
użytkownika do jego zainstalowania. W rzeczywistości program może niszczyć nasze dane, wykradać
hasła, numery kart płatniczych, czy czynić z naszego komputera pośrednika w przesyłaniu spamu.
Konie trojańskie mogą też znajdować się na stronach internetowych. Po wejścia na taka witrynę
otrzymujemy komunikat, że niezbędny jest jakiś moduł programowania, gdy zgodzimy się,
instalowane jest szkodliwe oprogramowanie.
Metody zapobiegania „zarażeniu” wirusem komputerowym
Środki przeciwdziałania rozprzestrzenianiu się wirusów można podzielić na dwie grupy:
Środki
organizacyjno-behawioralne
-
stosowanie
szeregu
zasad
dotyczących
wykorzystywania komputera, utrudniających bądź uniemożliwiających przedostanie się i/lub
uaktywnienie się wirusa. Są to:
użytkowanie oprogramowania zakupionego legalnie, instalowanego z oryginalnych
nośników,
użytkowanie oprogramowania pozyskanego z zaufanych źródeł,
nie instalowanie żadnych programów z niewiadomego pochodzenia i nieznanej reputacji,
nie otwieranie dokumentów niewiadomego pochodzenia,
nie otwieranie przesyłek pocztowych od nieznanych osób, w szczególności wtedy, gdy z
tematu niewiadomo, czego dotyczy lub wiadomo, że nas nie dotyczy,
jeżeli przesyłka pocztowa została otwarta, powstrzymanie się od uruchomienia
załączonych do niej programów, nie otwieranie załączników,
nie wyłączanie zabezpieczeń dotyczących potencjalnie niebezpiecznych załączników,
regularne aktualizowanie przeglądarek internetowych, oprogramowania pocztowego (i
innego służącego do komunikacji przez Internet) i systemu operacyjnego,
czytanie komunikatów pojawiających się po wejściu na stronę internetową i godzenie się
na instalację proponowanego w nich oprogramowania tylko wtedy gdy mamy pewność, że
jest to niezbędne i bezpieczne,
nie wyłączanie zabezpieczeń związanych z tzw. makrami w dokumentach środowiska
biurowego. Obecnie domyślne ustawienia nie pozwalają na automatyczne uruchomienie
makr. Najwygodniejszym ustawieniem jest takie, przy którym program będzie
każdorazowo pytał nas o zgodę na ich uruchomienie przy otwarciu dokumentu,
utworzenie na komputerze odrębnych kont użytkownika do prac administracyjnych (np.
instalacja oprogramowania) oraz bieżącego użytkowania. Pracując na koncie zwykłego
użytkownika, szkodliwe oprogramowanie ma utrudnione zadanie, bo do swojej instalacji
najczęściej wymaga uprawnień administratora i często nie dojdzie do zainfekowania
komputera.
Środki techniczne - stosowanie oprogramowania antywirusowego. Szereg firm produkuje
programy, które znając tysiące wirusów potrafią „wyleczyć” komputery. Następuje to przez
usuniecie szkodliwego kodu i przywrócenie programu, dokumentu nosiciela czy ustawień
systemowych do stanu sprzed zarażenia. Ponieważ każdego miesiąca powstaje wiele wirusów,
warunkiem skutecznego działania programów antywirusowych jest ich częsta aktualizacja.
Obecnie programy mogą automatycznie ściągać aktualizacje przez Internet kilka razy dziennie.

Technologie informacyjne - Podstawy technik informatycznych
Strona 65 z 72
6.4.4. Specyficzne zagrożenia związane z bankowością i handlem
elektronicznym.
Zagrożenia związane z bankowością elektroniczną można podzielić na:
wewnętrzne - wynikają z niedopełnienia obowiązków lub przekroczenia kompetencji przez
pracowników banku, braku kontroli, nadmierne nadanie przywilejów pracownikom, braku
dokumentowania zdarzeń, braku procedur postępowania. Często przyczyną jest też zbyt późne
reagowanie na nieprawidłowości.
zewnętrzne - związane są z oprogramowaniem i sprzętem, wirusami, kradzieżą witryn
internetowych, działaniem bez upoważnienia. Problemy mogą dotyczyć również samego
klienta, gdy nie strzeże on w należyty sposób informacji dających dostęp do jego rachunku.
W ślad za rozwojem bankowości elektronicznej pojawił się szereg specyficznych dla niej przestępstw.
To, co je wszystkie łączy, to cel: uzyskanie dostępu do cudzych pieniędzy dostępnych na rachunku.
Wyróżniamy tu następujące przestępstwa:
Phishing – wyłudzenie od właściciela informacji pozwalających na przejęcie kontroli nad
rachunkiem lub środkami znajdującymi się na karcie np. przez skierowanie klienta na stronę
do złudzenia przypominającą stronę banku, lub inne działania (np. przez telefon) skłaniające
do ujawnienia istotnych danych (kod dostępu, PIN itp).
Pharming – przestępstwo związane z phishiniem, polegające na takiej ingerencji w systemy
informatyczne (serwery DNS, stacje robocze użytkowników), aby przy próbie wejścia na
stronę swojego banku byli oni przekierowywani na stronę służąca do wyłudzenia istotnych
danych.
Karding - pobranie środków bądź dokonanie płatności za pomocą kradzionej lub skopiowanej
karty albo informacji o karcie (numer, data ważności dane właściciela kod).
Skimming - polega na kopiowaniu zawartości paska magnetycznego karty płatniczej bez
zgody jej właściciela. Później tak skopiowany pasek jest nanoszony na inną kartę płatniczą,
którą przestępcy dokonują zakupów. Najczęściej skopiowaniu karty towarzyszy nagranie video
podawanego w bankomacie PIN’u. Do skimmingu może dojść w bankomacie bądź punkcie
akceptującym karty.
Kluczową rolę w obronie przed wymienionymi przestępstwami odgrywa budowanie świadomości i
wykształcenie odpowiednich nawyków u użytkowników kart bankowych i Internetu (zarówno klientów
jak i akceptantów). Istnieje szereg żelaznych zasad, które pozwalają dość skutecznie uniknąć strat.
Związek Banków Polskich na swojej stronie internetowej prezentuje rady dla posiadaczy kart
bankowych i klientów korzystających z usług bankowości elektronicznej.
7. Podpis elektroniczny i elementy kryptografii
7.1. Podpis elektroniczny
Obowiązujące w Polsce prawo pozwala na stosowanie podpisu elektronicznego i stawia go na
równi z podpisem złożonym własnoręcznie na dokumencie papierowym. Umożliwia wobec tego
zawieranie umów, składanie oświadczeń woli, przesyłanie deklaracji (np. do ZUS, czy urzędów
skarbowych), wystawianie faktur na odległość za pośrednictwem Internetu.

Technologie informacyjne - Podstawy technik informatycznych
Strona 66 z 72
Warto zapamiętać
Podpis elektroniczny pozwala na podpisanie wyłącznie dokumentu elektronicznego.
Podpis tradycyjny na dokumencie papierowym służy potwierdzeniu autorstwa treści lub oświadczenia
woli, które podpisujemy. Przez lata powinniśmy „wyrobić” sobie podpis, tj. nauczyć się go stawiać w
identycznej, charakterystycznej dla siebie formie, tak, abyśmy nawet po latach mogli stwierdzić czy to
nasza sygnatura, czy nie. Tak więc pod różnymi dokumentami nasz podpis powinien wyglądać
identycznie. Inaczej jest z podpisem elektronicznym. Jego zawartość jest inna dla każdego
podpisywanego dokumentu. Istnieje jednak metoda pozwalająca na określenie, kto podpis złożył i czy
od momentu podpisania dokumentu do jego dostarczenia nie uległ on modyfikacji. Tym samym
pozwala ona na potwierdzenie autentyczności i integralności dokumentu.
Do wygenerowania podpisu elektronicznego stosowane są techniki (algorytmy) kryptograficzne.
Ich zrozumienie jest istotne dla zrozumienia jego istoty i sposobu wykorzystania. Będziemy tu mówić o
algorytmach szyfrowania i skrótu.
7.2. Szyfrowanie
Definicja
Szyfrowanie to przekształcenie treści za pomocą pewnego algorytmu, do postaci nieczytelnej dla
osoby postronnej. Odbiorca posiadający informacje o algorytmie, którego użyto do szyfrowania i
tzw. klucza może dokonać przekształcenia odwrotnego otrzymując tym samym oryginalną treść.
Będziemy tu zajmowali się tylko takimi algorytmami, które są znane (nie stanowią tajemnicy), a
elementem, który jest tajny będzie tzw. klucz, czyli pewna wartość liczbowa.
Wyróżniamy dwa rodzaje algorytmów szyfrowania:
symetryczne,
asymetryczne.
Szyfrowanie - algorytmy symetryczne
Symetryczne algorytmy szyfrowania to takie, które do zaszyfrowania i odszyfrowania informacji
wykorzystują ten sam klucz. Tym samym odbiorca i nadawca muszą go znać, aby mogli się
komunikować z jego wykorzystaniem.
Najprostszym algorytmem symetrycznym jest szyfr Cezara. Polega on na tym, że w treści
wiadomości każdą z liter zastępuje się inną, znajdującą się w alfabecie o określoną przez klucz liczbę
znaków dalej.

Technologie informacyjne - Podstawy technik informatycznych
Strona 67 z 72
Przykład
Treść do zaszyfrowania: „Alicja w Warszawie”.
Klucz: 5
Treść po zaszyfrowaniu (wg kodowania ISO Latin-2) :” Fqnhof%|%\fwx•f|nj”.
Zamiast A pojawiło się więc F, zamiast l – q, i – n, j – o itd. Każda z liter została więc przesunięta o 5
znaków w tabeli ISO-Latin II. Dokładniej ilustruje to poniższa tabela:
Tekst przed zaszyfrowaniem: A
l
i
c
j
a
w
W
a
r
s
z
a
w
i
e
Kody ISO-LatinII przed
zaszyfrowaniem: 65 108 105 99 106 97 32 119 32 87 97 114 115 122 97 119 105 101
Kody ISO-LatinII po
zaszyfrowaniu: 70 113 110 104 111 102 37 124 37 92 102 119 120 127 102 124 110 106
Tekst po zaszyfrowaniu: F
q
n
h
o
f
%
|
%
\
f
w
x
•
f
|
n
j
Do każdego kodu ISO-Latin II dodano wartość klucza i otrzymano nową wartość, zaprezentowaną
następnie jako literę odpowiadającą nowemu kodowi.
Odszyfrowanie jest proste. Wystarczy od każdego kodu tekstu zaszyfrowanego odjąć wartość klucza.
Do poznania wiadomości potrzebna jest znajomość algorytmu i klucza użytego do szyfrowania.
O sile algorytmu, czyli odporności na odszyfrowanie mimo nieznajomości klucza, decydują dwie
cechy:
Długość klucza wyrażana jest w bitach i wskazuje na potencjalną liczbę kombinacji klucza.
W przykładzie szyfrowania tekstu „Alicja w Warszawie” kluczem mogła być wartość z
przedziału od 0 do 255 daje to 256 kombinacji, co można zapisać 2
8
. Oznacza to, że ten
algorytm wykorzystuje ośmiobitowy klucz. Podjęcie 256 prób odszyfrowania treści używając
wszystkich możliwych wartości klucza zajmuje dzisiejszym komputerom ułamki sekund. Tak
więc algorytm Cezara jest bardzo słaby, z uwagi na zbyt krótki klucz.
Atak polegający na wielokrotnych próbach odszyfrowania wiadomości z wykorzystaniem
wszystkich możliwych wartości klucza nazywany jest atakiem siłowym lub brutalnym.
Pojęcie to wykorzystywane jest do określenia próby złamania hasła dostępu tą samą metodą.
Zwróć uwagę
Im dłuższy klucz, czyli z im większej liczby potencjalnych wartości pochodzi, tym algorytm
szyfrowania jest bezpieczniejszy.
Druga słabość algorytmu Cezara to mała odporność na kryptoanalizę. Polega ona na
ustalaniu klucza lub treści wiadomości dzięki wiedzy matematycznej (w szczególności w
dziedzinie kryptologii) oraz wiedzy o języku, w którym napisano wiadomość.

Technologie informacyjne - Podstawy technik informatycznych
Strona 68 z 72
Przykład
Prostej kryptoanalizy można dokonać na wcześniejszym przykładzie szyfrowania tekstu
„Alicja w Warszawie”. Wiadomo, że w tekstach w języku polskim najczęściej występującą
literą jest „a”. W zaszyfrowanej wiadomości najczęściej występuje litera „f”. Kod litery
„a” to 97, a „f” – 102. Różnica między kodami wynosi 5 (102-97) i to ona stanowi
wartość klucza. Ta prosta kryptoanaliza pozwoliła na ustalenie klucza, dzięki któremu
można już odszyfrować całą wiadomość.
Symetryczne algorytmy szyfrowania stosowane są podczas transmisji danych w sieciach (np. strony
serwisów bankowych, sklepów internetowych).
Obecnie wykorzystywane algorytmy symetryczne przedstawiono w poniższej tabeli:
Algorytm
Długość klucza
Liczba kombinacji klucza
3DES (potrójny DES) 168 bitów
2
168
= 3,74*10
50
IDEA
128 bitów
2
128
=3,40*10
38
AES
256 bitów
2
256
=1,158*10
77
Szyfrowanie - algorytmy asymetryczne
Drugim typem szyfrów są algorytmy asymetryczne. Występuje tu para kluczy. Jeżeli jednego
użyjemy do zaszyfrowania wiadomości to tylko za pomocą drugiego od pary można ją odszyfrować.
Kluczy tych można używać zamiennie. Nie jest jednak możliwe zaszyfrowanie i odszyfrowanie treści
tym samym kluczem.
Ta metoda szyfrowania jest nazywana algorytmem z kluczem publicznym, ponieważ jeden z pary
kluczy jest rozpowszechniany (publiczny), a drugi (prywatny) utrzymywany w ścisłej tajemnicy.
Jeżeli nadawca użyje swojego klucza prywatnego do zaszyfrowania wiadomości, wszyscy będą mogli
ją odszyfrować posługując się jego kluczem publicznym. Będą mogli jednak mieć pewność, że autorem
wiadomości jest posiadacz klucza prywatnego.
Z kolei, jeżeli wiadomość zostanie zaszyfrowana kluczem publicznym adresata, nikt poza nim nie
będzie mógł wiadomości odszyfrować. Adresat nie będzie mógł jednak mieć pewności, kto jest
nadawcą, bowiem każdy ma dostęp do klucza publicznego, którym wiadomość zaszyfrowano.
Pierwsza z powyższych właściwości algorytmów asymetrycznych wykorzystywana jest w podpisie
elektronicznym, druga - dla zapewnienia, że z treścią przesyłki będzie mógł zapoznać się wyłącznie
adresat.
7.3. Funkcja skrótu
Szyfrowanie wiadomości algorytmami asymetrycznymi jest procesem stosunkowo długotrwałym. Z
kolei podpisywane wiadomości mogą niekiedy mieć duże rozmiary. Dla uniezależnienia procesu
podpisywania od wielkości przesyłki wykorzystuje się dodatkowo funkcję skrótu.
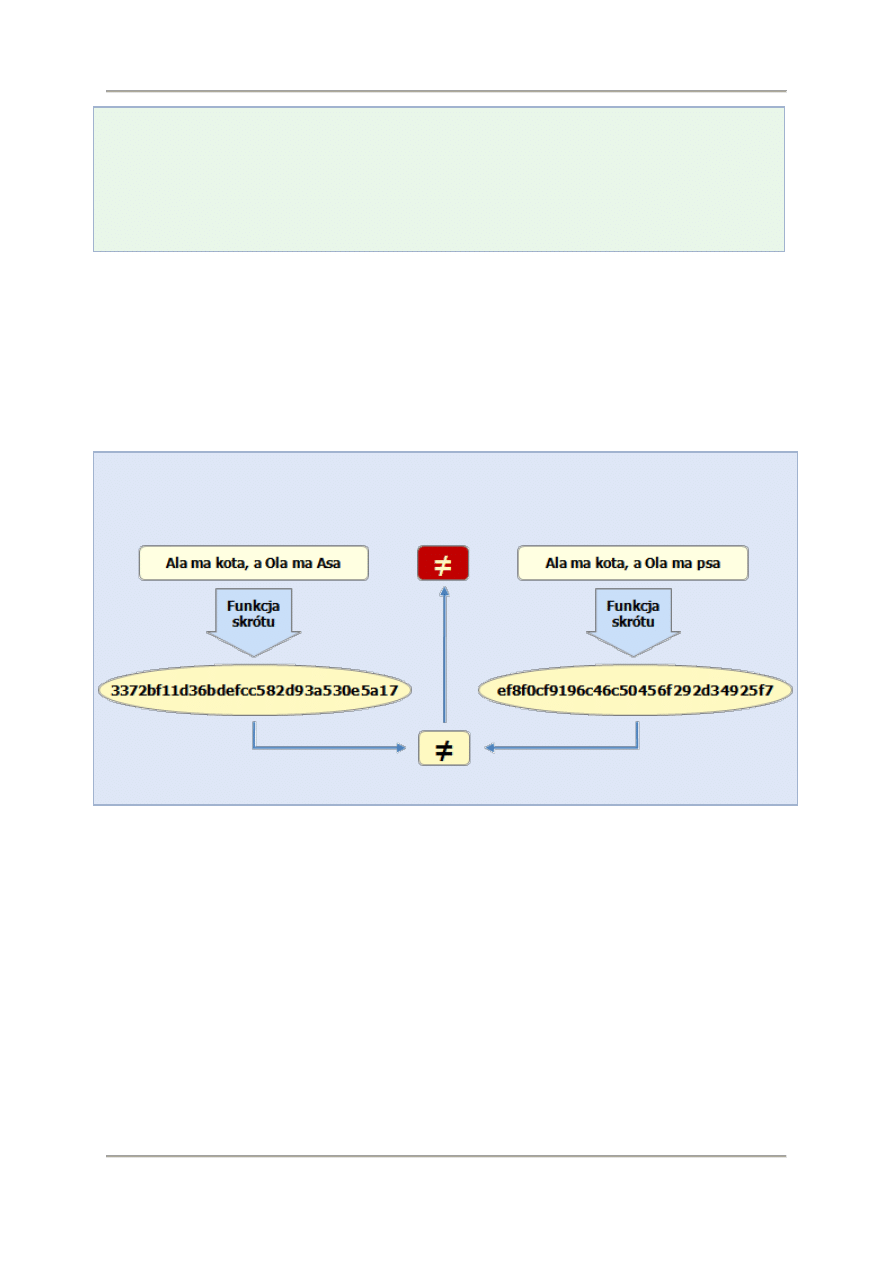
Technologie informacyjne - Podstawy technik informatycznych
Strona 69 z 72
Definicja
Funkcja skrótu jest to przekształcenie binarnej postaci treści wiadomości, w rezultacie którego
otrzymuje się tzw. skrót. Jest on inny dla każdej wiadomości wejściowej. Zakłada się, że nie istnieją
dwie wiadomości o identycznych skrótach. Jest to funkcja jednokierunkowa, co oznacza, że na
podstawie skrótu nie jest możliwe odtworzenie oryginalnej wiadomości.
Głównym zastosowaniem funkcji skrótu jest potwierdzenie identyczności dokumentów lub plików. Do
stwierdzenia, czy dwa dokumenty są identyczne wymagane jest porównanie ich skrótów. Dysponując
skrótami można stwierdzić, czy dwie wiadomości są identyczne nie znając ich treści. Właściwość tę
wykorzystuje się w procesie generowania podpisu elektronicznego oraz logowania użytkowników do
serwera. (na serwerze przechowywane są wyłączne skróty haseł użytkowników, dzięki czemu
administrator ich nie zna ich haseł. Podczas logowania hasło wpisywane przez użytkownika
zamieniane jest na skrót, który porównywany z istniejącym na serwerze. Jeśli skróty są jednakowe, to
znaczy, że hasło wpisane podczas logowania i zadeklarowane wcześniej są identyczne.)
Przykład
Przykład funkcji skrótu:
7.4. Tworzenie i weryfikacja podpisu elektronicznego
Z wiadomości, która ma być podpisana generowany jest skrót. W drugim kroku zostaje on
zaszyfrowany z wykorzystaniem klucza prywatnego nadawcy. W ten sposób uzyskujemy podpis. Teraz
wiadomość i podpis można wysłać do odbiorcy.
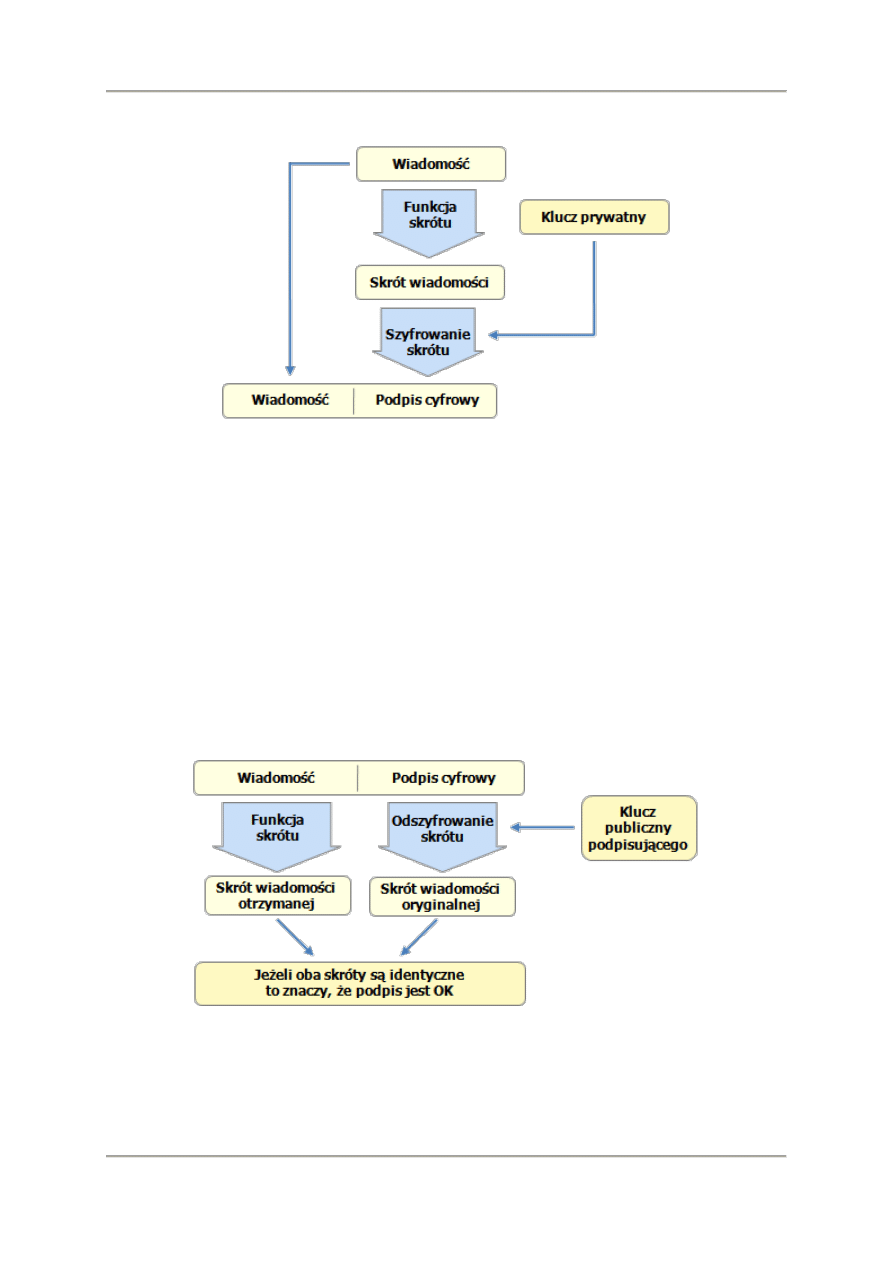
Technologie informacyjne - Podstawy technik informatycznych
Strona 70 z 72
Tworzenie podpisu cyfrowego
Odbiorca otrzymuje wiadomość i podpis cyfrowy. Posługując się kluczem publicznym nadawcy
odszyfrowuje skrót oryginalnej wiadomości. Jest to ten skrót, który został wygenerowany przez
nadawcę, odpowiadający treści, którą podpisał. Z treści otrzymanej wiadomości generuje się drugi
skrót. Jeżeli skrót z otrzymanej wiadomości jest identyczny, ze skrótem otrzymanym z podpisu, to
oznacza to, że treść otrzymanej wiadomości jest identyczna z wiadomością napisaną przez nadawcę.
Innymi słowy oznacza to, że wiadomość rzeczywiście została napisana przez właściciela klucza
publicznego użytego do odszyfrowania podpisu.
Pozytywny rezultat weryfikacji podpisu upewnia nas w jeszcze jednej kwestii. Oznacza on, ze treść
wiadomości nie została zmieniona podczas transmisji, tak to na skutek awarii, czy celowego działania
człowieka. Gdyby wiadomości została zmodyfikowania po podpisaniu, to skrót otrzymanej wiadomości
nie odpowiadałby skrótowi otrzymanemu z rozszyfrowanego podpisu i fakt modyfikacji wiadomości
wyszedłby na jaw.
Weryfikacja podpisu cyfrowego
Przedstawiony mechanizm podpisu elektronicznego ma jednak pewną potencjalną lukę. Jeżeli ktoś
dostarczy nam klucz publiczny (do którego posiada klucz prywatny) i powie, że należy on do Billa
Clintona, będzie mógł do nas pisać, a my będziemy przeświadczeni, że autorem otrzymanych treści
jest Bill Clinton. Problem leży w tym, że wprowadzono nas w błąd informując o właścicielu klucza
publicznego. W celu wyeliminowania tego problemu powołane zostały firmy, które poświadczają
klucze publiczne i zapewniają, że posługująca się nimi osoba jest tą, za którą się podaje. Takie

Technologie informacyjne - Podstawy technik informatycznych
Strona 71 z 72
poświadczenie nazywane jest certyfikatem klucza publicznego. Usługa certyfikacji klucza publicznego z
nielicznymi wyjątkami jest odpłatna.
Warto zapamiętać
Podsumowując, podpis cyfrowy jest informacją, która wiąże autora z konkretną treścią wiadomości.
Weryfikacja podpisu elektronicznego pozawala zidentyfikować autora wiadomości i stwierdzić, czy
nie została zmodyfikowana podczas transmisji.
7.5. Protokół SSL
Problem autentyczności dotyczy nie tylko informacji, ale również serwerów. Gdy łączymy się ze
sklepem internetowym i przystępujemy do zapłaty kartą płatniczą, będziemy musieli podać poufne
dane. Musimy mieć możliwość upewnienia się, że strona internetowa, na której je podajemy jest tą,
na którą wygląda, a nie jedynie kopią służącą wyłudzeniu danych. Istnieje bowiem w sieci wiele witryn
udających sklepy internetowe i banki utworzonych tylko po to, aby nieświadomi tego klienci
pozostawili niezbędne do płacenia ich kartami dane. Przestępstwo to nazywane jest phishingiem. Aby
temu przeciwdziałać powstał protokół SSL.
Jego zadaniem jest uczynienie transmisji danych bezpieczniejszą. Zapewnia on, że dane
transmitowane między przeglądarką internetową a serwerem są szyfrowane, a ponadto możliwe staje
się zweryfikowanie czy strona WWW jest rzeczywiście tą, za którą się podaje i kto za to stwierdzenie
odpowiada (również finansowo). Gdy wchodzimy na stronę zabezpieczoną protokołem SSL w
przeglądarce pojawia się zamknięta kłódka. Jej kliknięcie pozwala na zapoznanie się z certyfikatem.
Zawiera on informacje, przez kogo i dla kogo został wystawiony oraz w jakim okresie jest ważny.
Protokół SSL wykorzystywany jest nie tylko na stronach WWW (protokół https). Jest również
stosowany w poczcie elektronicznej (pop3s i imaps) .
Technologie informacyjne - Podstawy technik informatycznych
Strona 72 z 72
Przykład
można śmiało podać dane do logowania się. Używany jest protokół
https, w dolnym rogu kłódka jest zamknięta, a jej kliknięcie powoduje wyświetlenie informacji o
certyfikacie, z którego wynika, że strona należy do BRE Banku, a poświadcza ten fakt firma Verisign.
Źródło: https://mbank.com.pl
Podobnego sprawdzenia witryny należy dokonać ilekroć proszeni jesteśmy o podanie danych
służących identyfikacji lub innych poufnych informacji.
Wyszukiwarka
Podobne podstrony:
Materialy do czytania Encyklopedia prawa
polityka turystyczna materiał do czytania
materialy do czytania
polityka turystyczna materiaê do czytania
Materiały do kolokwium III
POBIERANIE I PRZECHOWYWANIE MATERIAŁÓW DO BADAŃ wiRUSOLOGICZNYCH prezentacja
Materialy do seminarium inz mat 09 10 czesc III
Enzymologia materiały do ćwiczeń
materiały do egazaminu CHIR
Materiały do wykładu 4 (27 10 2011)
Gotowość dzieci przedszkolnych do czytania a ich dojrzałość językowa
napisy do czytania globalnego(2)
Materiały do izolacji termicznych
Materiały do ćwiczeń z geologii
BHP materiały do lekcji
MATERIALY DO WYKLADU CZ IV id Nieznany
Zadanie z kompensacji, Elektrotechnika-materiały do szkoły, Gospodarka Sowiński
więcej podobnych podstron