
WYKONYWANIE
ZAPYTAŃ.
PLANOWANIE
INDEKSOW
Przygotował Lech Banachowski na podstawie:
1.
Raghu Ramakrishnan, Johannes Gehrke, Database Management
Systems, McGrawHill, 2000 (książka i slide’y).
2.
Lech Banachowski, Krzysztof Stencel, Bazy danych – projektowanie
aplikacji na serwerze, EXIT, 2001.

Sortowanie
ORDER BY - dane są wymagane w pewnym
porządku.
Budowa indeksu - początkowego B+ drzewa dla
wczytywanego zbioru rekordów.
Złączanie tabel metodą Sort-merge.
Realizacja DISTINCT, GROUP BY, UNION, EXCEPT -
alternatywą haszowanie.
Problem:
posortować 1GB danych przy
pomocy 10MB RAM
.
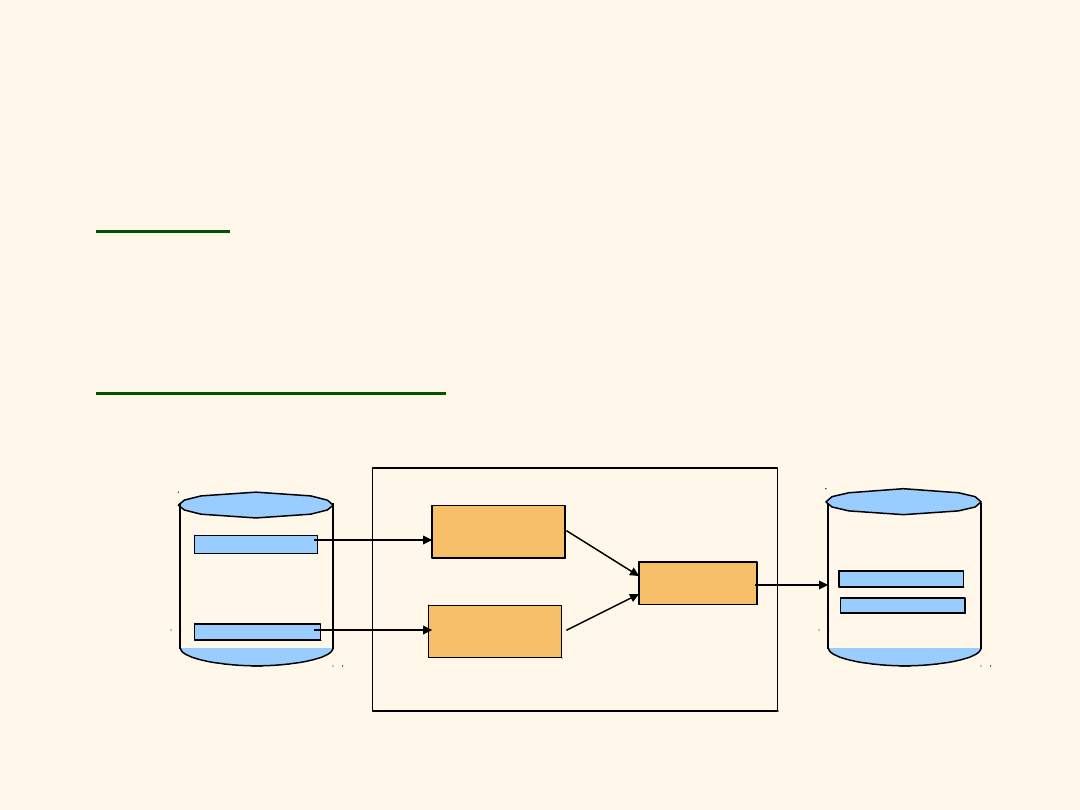
Sortowanie zewnętrzne
(wielofazowe przez scalanie)
Faza 0 – sortowanie rekordów w ramach
stron: Wczytaj stronę, posortuj ją, zapisz na
dysku.
Faza 1,2,3 …, itd: scalaj uporządkowane
podpliki w większe uporządkowane podpliki
aż cały plik zostanie uporządkowany.
Bufory w RAM
INPUT 1
INPUT 2
OUTPUT
Dysk
Dysk
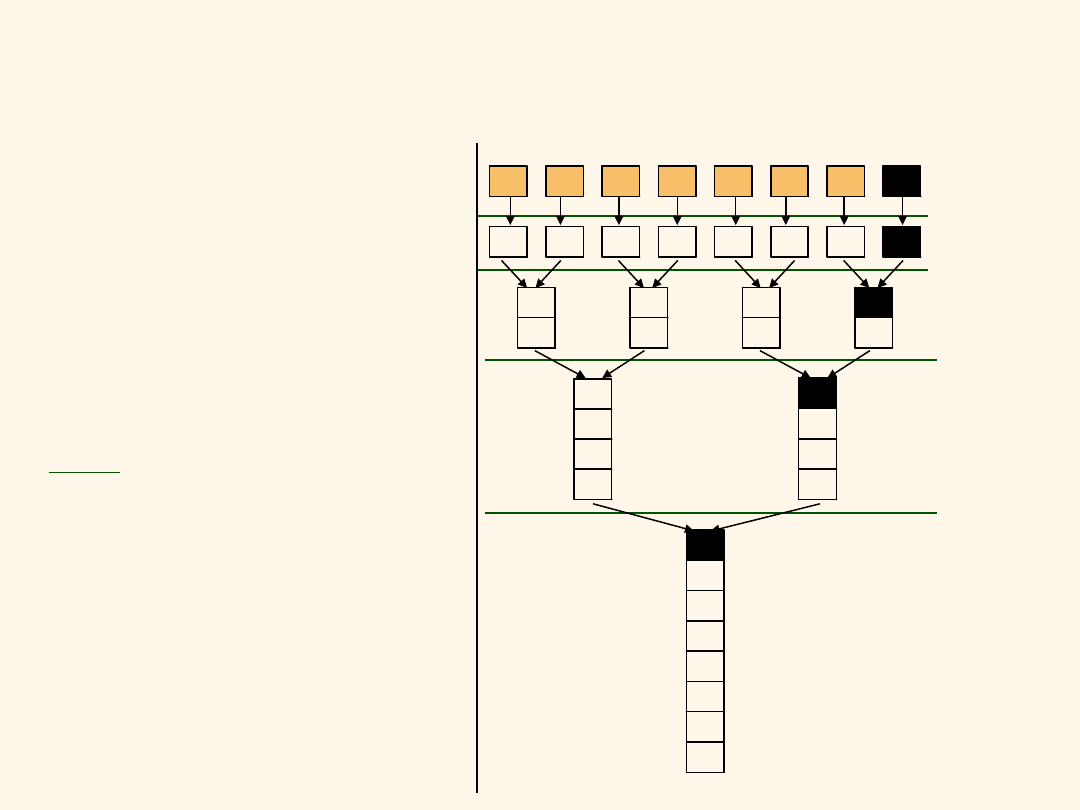
Sortowanie wielofazowe przez
scalanie
W każdej fazie odczytujemy i
zapisujemy każdą stronę w
pliku.
N = # stron => # faz =
Całkowity koszt = N log N
Idea: Dziel i rządź: sortuj
podpliki i je scalaj.
Zamiast dwóch buforów
można użyć więcej.
Praktycznie liczba faz <=3.
log
2
1
N
Plik wejściowy
Faza 0
Faza 1
Faza 2
Faza 3
9
3,4 6,2 9,4 8,7 5,6 3,1
2
3,4
5,6
2,6 4,9 7,8
1,3
2
2,3
4,6
4,7
8,9
1,3
5,6
2
2,3
4,4
6,7
8,9
1,2
3,5
6
1,2
2,3
3,4
4,5
6,6
7,8

Sortowanie przy pomocy B+
drzewa
Scenariusz: Tabela ma indeks na B+ drzewie
względem kolumn sortowania.
Idea:
Przejść po liściach indeksu.
Czy jest to dobra metoda?
Przypadki:
– Indeks
pogrupowany
Bardzo dobra!
– Indeks
niepogrupowany
Może być
bardzo zła!
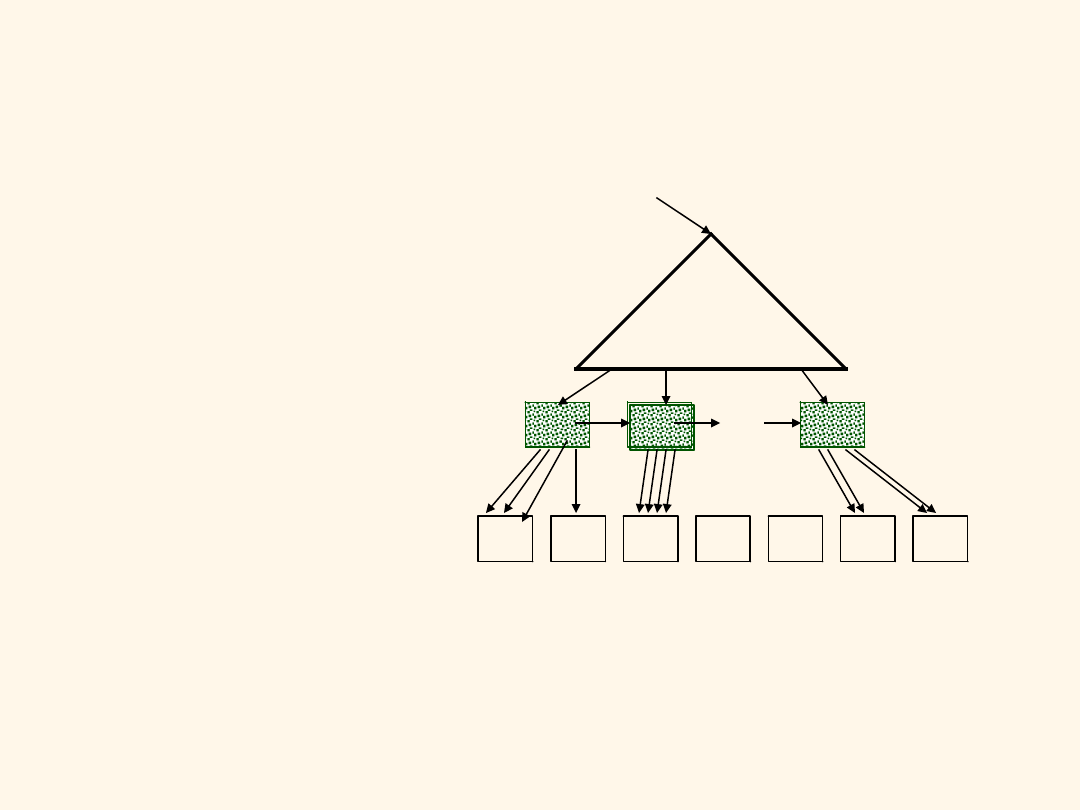
Indeks pogrupowany
Od korzenia przejdź
do skrajnie lewego
liścia a następnie
sekwencyjnie w
prawo po liściach.
Zawsze lepsze od sortowania zewnętrznego!
Rekordy danych
Indeks
Pozycje danych
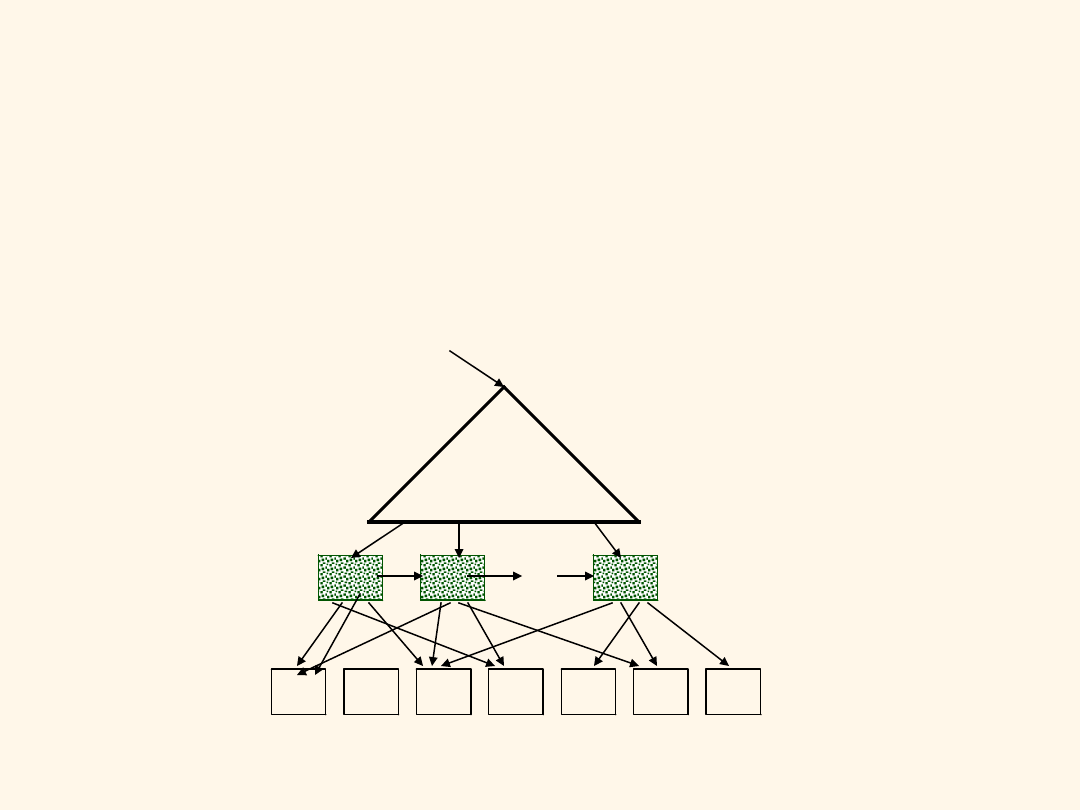
Indeks niepogrupowany
Ogólnie,
jedna operacja We/Wy na
rekord danych!
Rekordy danych
Indeks
Pozycje danych

Operatory relacyjne
–
Selekcja
Selekcja podzbioru wierszy (klauzula
WHERE
).
–
Projekcja
Pominięcie z wyniku niepotrzebnych kolumn
(klauzula
SELECT
).
–
Złączenie
Złączenie relacji (tabel).
–
Suma (UNION)
Suma relacji (tabel).
–
Agregacja
(
SUM
,
MIN
, itd.) i
GROUP BY
.
*
Relacja = tabela

Przykładowe tabele
Reserves R:
– Każdy wiersz (rekord) - 40 bajtów, 100 wierszy na
stronie, 1000 stron.
Sailors S:
– Każdy wiersz (rekord) - 50 bajtów, 80 wierszy na
stronie, 500 stron.
Sailors (sid: integer, sname: string, rating: integer, age: real)
Reserves (sid: integer, bid: integer, day: dates, rname: string)

Implementacja
selekcji
Bez indeksu, nieposortowane:
Koszt jest
M
=
#stron w R.
Z indeksem na atrybucie selekcji:
Użyj
indeksu, wyznacz pozycje danych, przejdź do
rekordów.
– Najlepiej gdy indeks haszowany dla selekcji
równościowych oraz indeks na B+ drzewie dla
selekcji zakresowych.
SELECT
*
FROM
Reserves R
WHERE
R.rname < ‘C%’

Użycie indeksu do selekcji
Koszt zależy od liczby zwracanych wierszy
(selektywności) i od tego czy indeks jest pogrupowany.
– Wyznaczenie pozycji danych w indeksie a następnie
sprowadzenie rekordów (może być kosztowne bez
pogrupowania).
Ulepszenie dla niepogrupowanych indeksów:
1. Wyznacz odpowiednie pozycje danych.
2. Posortuj je względem rid.
3. Sprowadzaj rekordy w takim porządku. Każda
potrzebna strona zostanie sprowadzona tylko raz.

12
Realizacja koniunkcji
• Obliczamy zbiory identyfikatorów rekordów
spełniających dany warunek dla każdego indeksu.
• Dokonujemy przecięcia zbiorów identyfikatorów.
• Sprowadzamy rekordy ewentualnie stosując
pozostałe warunki z klauzuli WHERE.
• Na przykład:
day<8/9/94 AND bid=5 AND sid=3
.
Jeśli mamy indeks B+ drzewo na day oraz indeks na
sid, wyznaczamy identyfikatory rekordów spełniających
warunek
day<8/9/94
używając pierwszego indeksu,
identyfikatory rekordów spełniających warunek
sid=3
używając drugiego indeksu, dokonujemy przecięcia,
sprowadzamy rekordy i stosujemy warunek
bid=5
.

13
Złożone warunki WHERE
(day<8/9/94
AND
rname=‘Paul’)
OR
bid=5
OR
sid=3
Sprowadzamy warunek
WHERE
do
koniunkcyjnej postaci normalnej
conjunctive normal form (CNF):
(day<8/9/94
OR
bid=5
OR
sid=3 )
AND
(rname=‘Paul’
OR
bid=5
OR
sid=3)

14
Selekcja ze złożonym
warunkiem WHERE
1. Zastosować przejście całego pliku.
2. Jeśli jeden z czynników koniunkcji jest prostym
warunkiem, określającym dostęp przez indeks (np.
sid = 8
), używamy tego indeksu i dla każdej
otrzymanej krotki sprawdzamy pozostałe czynniki
koniunkcji.
3. Metoda sumowania wyników składników koniunkcji
np. gdy (
day<8/9/02 OR rname=‘Joe’
): wyznaczamy
zbiory rid dla
day<8/9/02
i dla
rname=‘Joe’
–
stosując indeksy; sortujemy względem rid,
złączamy i wybieramy rekordy danych.

Implementacja
projekcji
Bez DISTINCT – przepisanie.
Z DISTINCT – wymagane jest wyeliminowanie powtórzeń:
– posortowanie;
– haszowanie i eliminacja powtórzeń w ramach segmentów haszowania;
– gdy atrybuty klauzuli SELECT tworzą indeks – wystarczy przejść tylko
indeks.
SELECT
DISTINCT
R.sid,
R.bid
FROM
Reserves
R

Implementacja operatorów
zbiorowych
Przecięcie i iloczyn kartezjański relacji są
specjalnymi przypadkami złączenia.
Union (Distinct) i Except są podobne do siebie.
– Posortuj obie relacje (na kombinacji wszystkich atrybutów).
– Dokonaj odpowiedniego scalenia wyników.
–
Alternatywa
: Sortuj od razu razem obie relacje.
– Zamiast sortowania można użyć haszowania.

Operacje agregacji (
AVG, MIN
itd.)
Bez grupowania:
– Na ogół trzeba rozważyć każdy wiersz.
– Gdy jest indeks, którego klucz wyszukiwania obejmuje wszystkie
atrybuty występujące w klauzulach
SELECT
i
WHERE
, wystarczy
przejrzeć indeks (strategia tylko-indeks).
Z grupowaniem GROUP BY:
– Posortuj względem wartości atrybutów GROUP BY, przejdź po
rekordach w każdej grupie licząc wartości funkcji sumarycznych – w
tym celu można użyć pogrupowany indeks na B+ drzewie.
(Ulepszenie: liczenie wartości w trakcie sortowania.)
– Gdy jest indeks, którego klucz wyszukiwania obejmuje wszystkie
atrybuty występujące w klauzulach SELECT, WHERE i GROUP BY,
wystarczy przejrzeć indeks (strategia tylko-indeks).
– Zamiast sortowania można użyć haszowania.

Złączenia równościowe z jedną
kolumną złączenia
Bezpośrednie podejście: generuj wszystkie
kombinacje wierszy i stosuj selekcję.
M =#stron w R, p
R
=#wierszy na stronie dla
R, N=#stron w S, p
S
=#wierszy na stronie dla
S.
– W przykładzie:
R – Reserves, S - Sailors.
SELECT
*
FROM
Reserves R, Sailors S
WHERE
R.sid=S.sid

Algorytm Nested Loops Join
Dla każdego wiersza zewnętrznej relacji R,
przeglądamy wszystkie wiersze wewnętrznej relacji
S.
–
Koszt: M + p
R
* M * N
= 1000 + 100*1000*500 We/Wy.
Oczywiste ulepszenie: Dla każdej strony w R,
sprowadź każdą stronę w S
–
Koszt: M + M*N
= 1000 + 1000*500.
– Gdy mniejsza relacja (S) jest zewnętrzna, koszt = 500 +
500*1000.
foreach row r in R do
foreach row s in S do
if r
i
== s
j
then add <r, s> to result

Algorytm Index Nested Loops
Join
Gdy jest indeks (najlepiej haszowany) na kolumnie złączenia
relacji wewnętrznej (S), zastosuj indeks.
–
Koszt: M + ( (M*p
R
) * koszt wyznaczenia pasujących wierszy w S).
Dla każdego wiersza w R: koszt wyszukania pozycji w
indeksie dla S jest ok. 1.2 dla indeksu haszowanego; 2-4 dla
B+ drzewa. Mając daną pozycję danych, koszt wyznaczenia
pasujących wierszy w S zależy od tego czy indeks jest
pogrupowany.
–
Indeks pogrupowany: +1 We/Wy (zwykle);
–
Indeks niepogrupowany: +1 We/Wy dla każdego pasującego wiersza
w S.
Razem w przykładzie koszt: 1000+1000*100(1.2+1) We/Wy.
foreach row r in R do
foreach row s in S where r
i
== s
j
do
add <r, s> to result
/* dla r w R użyj indeksu na S do wyznaczenia s w S: r
==s */

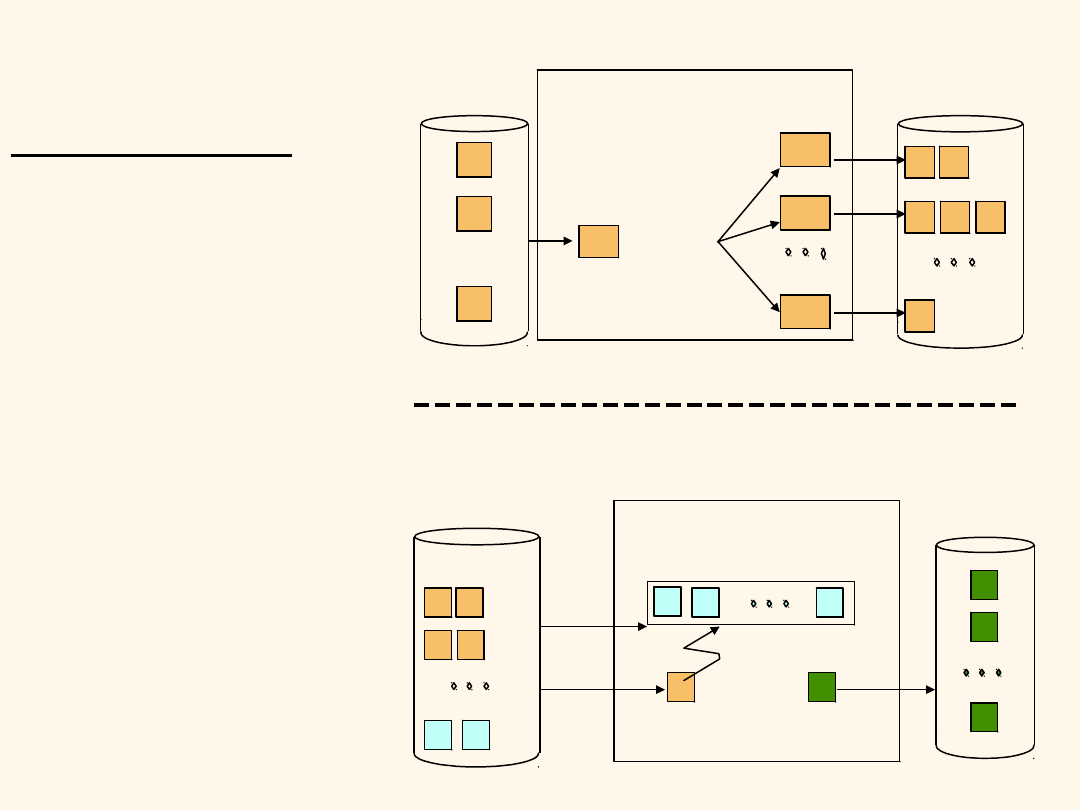
Algorytm Sort-Merge Join
Posortuj R i S na kolumnach złączenia,
następnie scal odpowiadające sobie wiersze w
R i S. Przy scalaniu na ogół każda z
posortowanych relacji R i S jest przeglądana
raz (liniowo).
Przykład Sort-Merge Join
Koszt: M log M + N log N + (M+N)
- w praktyce rzędu liniowego względem (M+N).
W przykładzie: 2000 + 1000 +1000 + 500 = 4500.
sid sname rating age
22 dustin
7
45.0
28 yuppy
9
35.0
31 lubber
8
55.5
44 guppy
5
35.0
58 rusty
10
35.0
sid bid
day
rname
28 103 12/4/96
guppy
28 103 11/3/96
yuppy
31 101 10/10/96 dustin
31 102 10/12/96 lubber
31 101 10/11/96 lubber
58 103 11/12/96 dustin
Algorytm
Hash-Join
Partycje
R & S
Bufor wej. dla
partycji i rel. S
Tablica haszowana
dla partycji i relacji R
B – buforów w RAM
Dysk
Bufor
wyjściowy
Dysk
Wynik
f. h.
h2
h2
B - buforów w RAM
Dysk
Dysk
Oryginalne
relacje
2
1
funkcja
haszująca
h1
B-1
Partycje
1
2
B-1
. . .
Podziel obie relacje R i S
na partycje względem
wartości funkcji
haszujacej
h1
na
kolumnach złączenia:
wiersze R w partycji i
wystarczy złączyć z
wierszami S w partycji i.
Wczytaj partycję i
relacji R dokonując
haszowania przy
pomocy f.h.
h2 (<>
h1
!)
. Wczytuj
elementy partycji i w
S, stosuj
h2
i
uzgadniaj z R.

Koszt algorytmu Hash-Join
Podział na partycje -
2(M+N)
. Uzgadnianie -
M+N
We/Wy.
Porównanie Sort-Merge Join i Hash Join:
– Obie metody mają ten sam koszt
3(M+N) We/Wy
.
– Hash Join lepszy przy większej różnicy rozmiarów;
łatwy do zrównoleglenia .
– Sort-Merge mniej wrażliwy na losowość danych;
wynik posortowany.
Porównanie metod złączania
Gdy SZBD chce wykonać złączenie tabel, rozważa możliwe metody w
następującej kolejności:
Gdy jest zbudowany klaster, złączenie tabel sprowadza się do przejścia
klastra tak jakby to była jedna tabela. Kluczem klastra powinna być
kolumna złączania tabel.
Metoda Simple Nested Loops Join jest prosta i to jest jej podstawowa
zaleta. Może być używana w sytuacji, gdy jedna ze złączanych tabel ma
niewielki rozmiar.
Na koszt metody Index Nested Loops Join istotny wpływ mają własności
indeksu np. czy jest pogrupowany, czy jest selektywny jak np. indeks
główny, jednoznaczny. W połączeniu z selekcją na tabeli zewnętrznej
złączenia bywa najszybszą metodą.
Metoda Hash Join wypada lepiej w oszacowaniach średniej liczby
operacji We/We niż metoda Sort-Merge ale w przypadku pesymistycznym
może się okazać bardzo zła.
Metoda Hash Join wypada lepiej od Sort-Merge gdy rozmiary
sortowanych plików zasadniczo się różnią. Jest łatwiejsza do
zrównoleglenia niż Sort-Merge.
Metoda Sort Merge jest lepsza gdy rozmiary sortowanych plików są
zbliżone. Jest mniej wrażliwa na mało losowe dane oraz rezultat złączenia
jest posortowany.

Podsumowanie
Zaleta relacyjnych SZBD –
zapytania
złożone z kilku
bazowych operatorów
; implementacje tych operatorów
można dokładnie dostroić.
Wiele alternatywnych metod implementacyjnych.
Dla konkretnego zapytania dla każdego występującego
w nim operatora trzeba rozważyć dostępne opcje i
wybrać najlepszą korzystając z dostępnych statystyk.
Jest to zadanie
optymalizacji zapytania
.
Optymalizacja zapytań
Zapytanie SQL ma charakter
deklaratywny
:
określa
co
ma być wyznaczone w bazie danych,
a
nie
jak
to ma być znalezione. Dla każdego
zapytania istnieje wiele sposobów jego
realizacji. Który sposób jest najlepszy, zależy od
dodatkowych okoliczności. SZBD rozważa różne
alternatywy, szacuje ich koszt oraz wybiera
możliwie najlepszy, "optymalny" plan. Proces
ten nazywa się optymalizacją zapytania a
moduł go realizujący optymalizatorem zapytań.

Optymalizacja zapytań
W SZBD zapytaniem najpierw zajmuje się parser, dokonujący
analizy składniowej zapytania.
Po analizie składniowej włącza się optymalizator zapytań w
skład którego wchodzą dwa główne moduły:
– generator planów - moduł generujący możliwe plany wykonania
zapytania, i
– estymator kosztu - moduł obliczający przybliżony koszt
wykonania zapytania według danego planu.
Przy szacowaniu kosztu planu estymator korzysta z informacji
statystycznych zapisanych w słowniku danych (katalogu
systemowym) takich jak: liczba rekordów w pliku, liczba stron
na których są zapisane rekordy w pliku, liczba różnych wartości
w kolumnie, rozkład wartości w kolumnie (histogram).
Optymalizator wybiera plan o najniższym koszcie i przekazuje
go do ewaluatora planu - modułu wykonującego zapytanie.
Gdy zapytanie zostało wcześniej przeanalizowane i kontekst
jego użycia się nie zmienił, system może użyć wyliczony
wcześniej plan.
Optymalizacja zapytań
Plan:
Algorytm wykonania zapytania – np. w postaci
drzewa.
Plan wykonania zapytania obejmuje:
–
drzewo operatorów
SQL tego zapytania,
–
metody dostępu
do każdego wystąpienia tabeli w tym
zapytaniu,
–
metody realizacji
dla każdego wystąpienia operatora
relacyjnego w zapytaniu.
Idealnie:
Chcemy znaleźć najlepszy plan.
Praktycznie:
Staramy się unikać złych planów!
Przykład
Koszt: 1000+500*1000 We/Wy
Nie wykorzystuje:
– wcześniejszego wykonywania
selekcji,
– indeksów.
Cel optymalizacji: Wyznaczyć
inne bardziej efektywne plany
obliczenia tego samego
wyniku.
SELECT
S.sname
FROM
Reserves R, Sailors S
WHERE
R.sid=S.sid
AND
R.bid=100
AND
S.rating>5
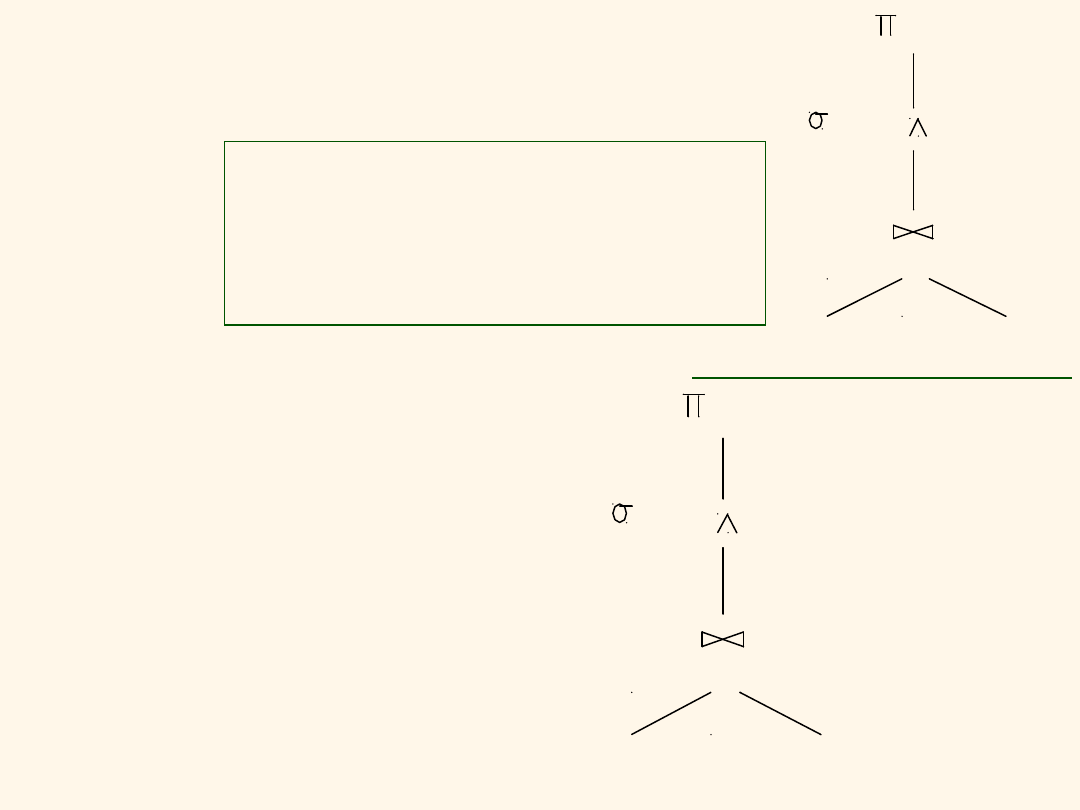
Reserves
Sailors
sid=sid
bid=100 rating > 5
sname
Reserves
Sailors
sid=sid
bid=100 rating > 5
sname
(Simple Nested Loops)
Drzewo
instrukcji:
Plan:
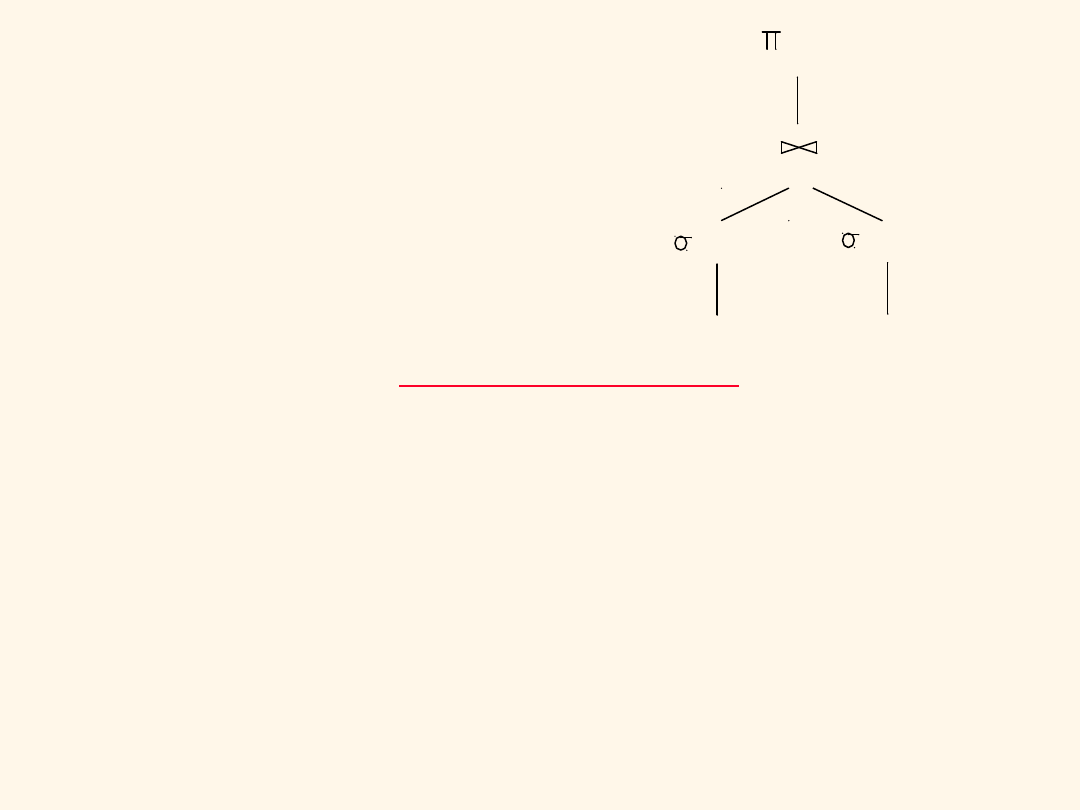
Plan alternatywny 1
(bez indeksów)
Główna różnica: selekcje wcześniej.
Koszt planu:
– Scan Reserves (1000) + write to temp T1 (ok. 10 stron
rezerwacji przy 100 łódkach).
– Scan Sailors (500) + write to temp T2 (ok. 250 stron (połowa)
przy 10 wartościach atrybutu ratings).
– Sort T1 (2*2*10), sort T2 (2*3*250), merge (10+250).
–
W sumie: 3560 We/Wy.
Reserves
Sailors
sid=sid
bid=100
sname
rating > 5
(Scan;
write to
temp T1)
(Scan;
write to
temp T2)
(Sort-Merge Join)
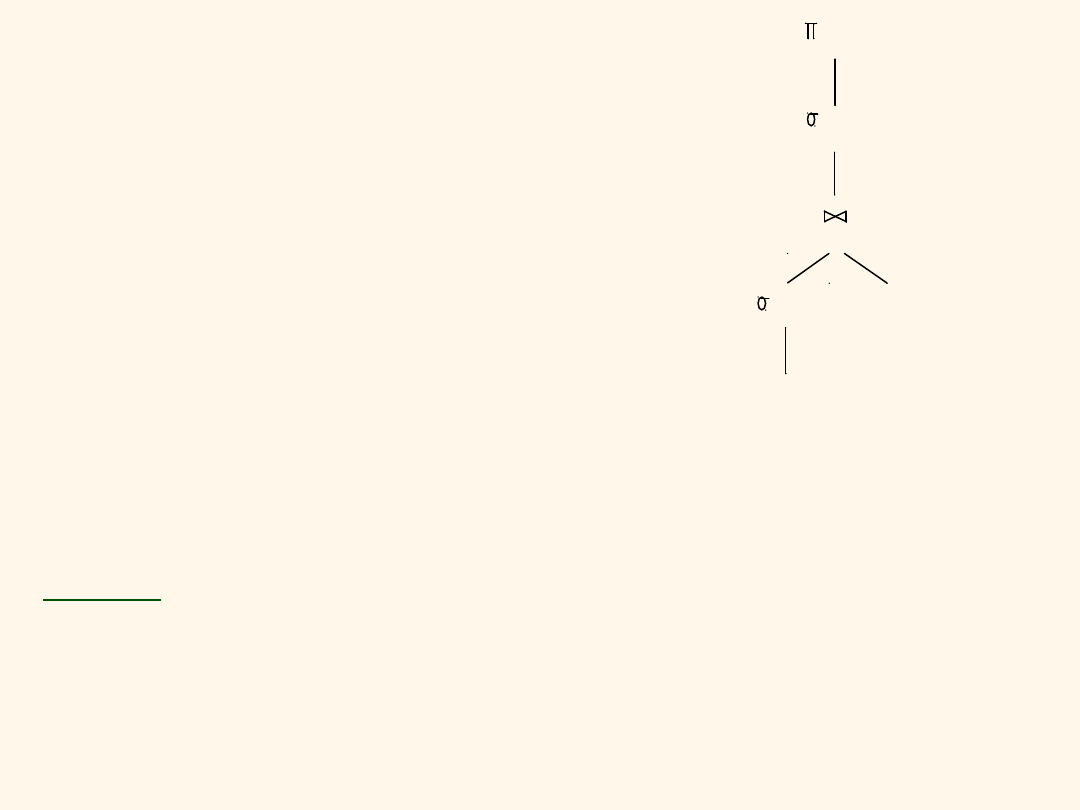
Plan alternatywny 2
(z indeksami)
Z indeksem pogrupowanym na
Reserves(bid), dostajemy
100,000/100 = 1000 wierszy na
1000/100 = 10 stronach.
INL bez zapisywania
wyniku
selekcji jako tymczasowej relacji.
Kolumna złączenia sid jest kluczem dla tabeli Sailors. Wystarczy
indeks niepogrupowany.
Decyzja aby nie dokonywać selekcji rating>5 przed złączeniem,
ponieważ jest dostępny indeks Sailors(sid).
Koszt:
Selekcja wierszy Reserves (10 We/Wy); dla każdego z 1000
wierszy Reserves trzeba uzyskać odpowiadające wiersze tabeli Sailors
(1000*1.2 gdy indeks haszowany jest wewętrzny – połączony z
tabelą, w p.p. 1000*2.2).
W sumie
1210 We/Wy (albo 2210 We/Wy).
Reserves
Sailors
sid=sid
bid=100
sname
rating > 5
(Hash index;
bez temp)
(Index Nested Loops)
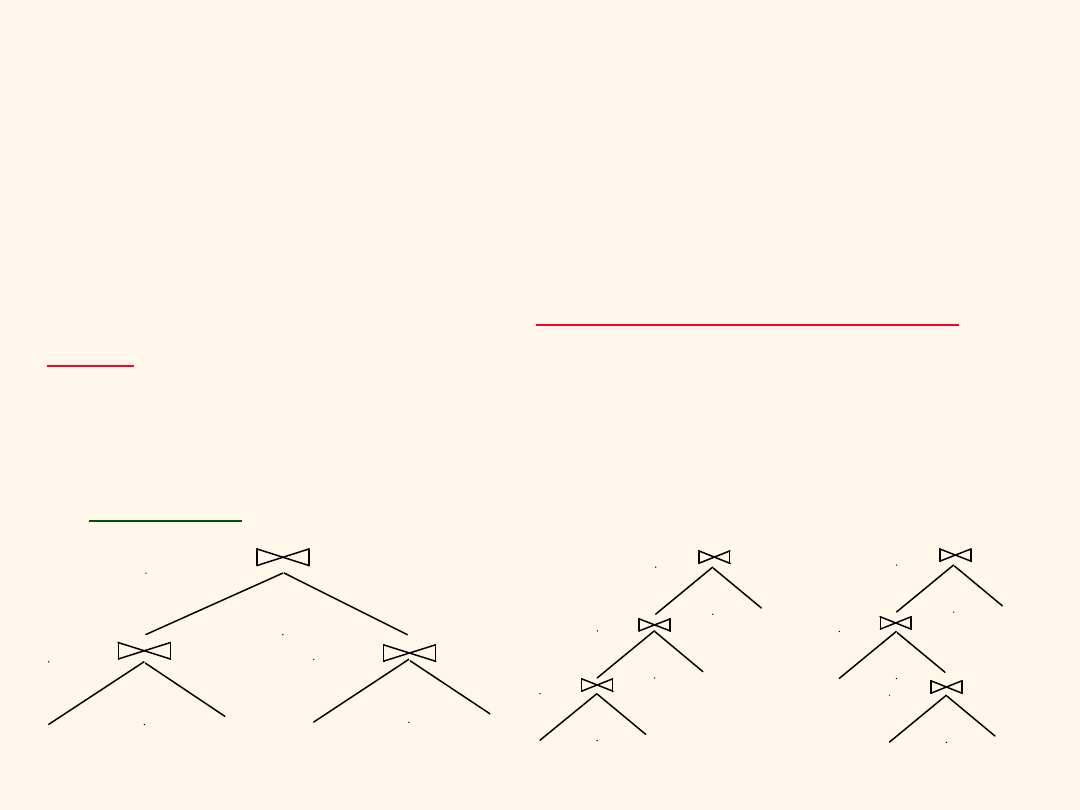
Generowanie przez
optymalizator planów
wykonania zapytania
Najpierw analiza dostępu do poszczególnych relacji z
możliwością zastowania selekcji, indeksu itd.
Na ogół ograniczenie do:
drzew skierowanych w
lewo
.
–
Drzewa skierowane w lewo dają plany umożliwiające
"potokowe" wykonanie zapytania
“w miejscu”
tj. bez
tymczasowych plików.
–
Podstawa: przemienność i łączność operatora złączenia.
B
A
C
D
B
A
C
D
C
D
B
A
Przykład
Faza 1:
Analiza planów dostępu do relacji
Sailors i Reserves:
Sailors:
B+ drzewo na rating
Hash na sid
Scan
Reserves:
B+ drzewo na bid
Scan
Faza 2:
Rozpatrujemy każdy plan z Fazy 1 jako określający
relację zewnętrzną złączenia i badamy jak dokonać złączenia z
drugą relacją (NLJ,INLJ, SMJ, HJ) liczymy orientacyjny koszt
korzystając ze statystyk zebranych przez system jak liczba wierszy,
liczba stron dla plików z danymi i plików indeksów.
np., dla Reserves: Mając dane sid z Reserves można użyć
indeksu haszowanego na Sailors(sid) aby dokonać złączenia
obu relacji.
Reserves Sailors
sid=sid
bid=100 rating > 5
sname

35
Podzapytania
• Podzapytania są optymalizowane niezależnie.
• Główne zapytanie jest optymalizowane z branym
pod uwagę kosztem „wywoływanych”
podzapytań.
• Ewentualnie sprowadzane do złączeń i
optymalizowane łącznie.

Ogólne strategie
optymalizacyjne
Dokonuj jak najwcześniej selekcji zmniejszającej liczbę
rozważanych rekordów – istotne szczególnie wtedy gdy wynik
selekcji przekazujemy do złączenia – które jest najbardziej
kosztowną operacją. W szczególnym przypadku wynik selekcji
może się cały dać zapisać w buforach pamięci RAM co
przyśpieszyłoby istotnie wykonywanie zapytania.
Do wykonania selekcji stosuj indeks - najlepiej indeks główny,
jednoznaczny, pogrupowany lub względem selektywnego warunku
- powiedzmy wybierającego mniej niż 5-10% wszystkich rekordów
w pliku. Jeśli takiego indeksu nie da się zastosować, zamiast
wyszukiwać przez indeks, bardziej opłaca się sekwencyjnie
przejrzeć cały plik (scan) z wyborem rekordów spełniających
zadany warunek.
Staraj się wiązać selekcje z iloczynem kartezjańskim, w celu
zidentyfikowania rodzaju złączenia tabel.
Do wykonania złączenia stosuj indeks na tabeli wewnętrznej
(preferowany indeks główny, jednoznaczny, pogrupowany lub
względem selektywnego warunku).
Wybierz plan działający "w miejscu" bez tymczasowych tabel np. w
postaci drzewa skierowanego w lewo. Stosuj przetwarzanie
potokowe (pipelining) do wykonywania ciągu operatorów
jednoargumentowych jak selekcje i projekcje.

Ogólne strategie
optymalizacyjne
Zamiast operatora złączenia zastosuj klaster, który też umożliwia
działanie w miejscu.
Jeśli to możliwe - ograniczaj się do przechodzenia indeksów, a nie
tabel (strategia tylko-indeks).
Wyszukuj wspólne podwyrażenia i obliczaj je tylko raz.
Przetwórz wstępnie plik we właściwy sposób (indeksy,
sortowanie, haszowanie).
Gromadź statystyki ilościowe dotyczące tabel, kolumn i indeksów
– w tym histogramy to znaczy dystrybucje wartości w kolumnach
tabel. Korzystaj ze statystyk gromadzonych w katalogu
systemowym.
Szacuj koszt każdego planu i wybieraj plan o najmniejszym
koszcie. Przy obliczaniu kosztu planu szacuj koszt realizacji
każdego operatora relacyjnego i rozmiar jego wyników.
Zapamiętuj plan wykonania zapytania, aby móc ten plan
zastosować w tych samych warunkach.

38
Pole działania aplikacji
bazodanowej (workload)
• Najważniejsze zapytania i jak często będą
używane.
• Najważniejsze aktualizacje i jak często będą
używane.
• Pożądana szybkość działania tych zapytań i
aktualizacji.

Wybór indeksów – analiza
zapytań
Dla każdego zapytania w projektowanej aplikacji:
– Jakich relacji i atrybutów dotyczą?
– Które atrybuty występują w warunkach
ograniczających a które w warunkach złączenia?
Jak bardzo selektywne są te warunki?
Podobnie dla instrukcji INSERT/DELETE/UPDATE.

Decyzje
Jakie założyć indeksy?
Jakiego rodzaju?
– Pogrupowany? Hasz/B+ drzewo/Bitmap?
Dynamiczny/statyczny? Czy powinniśmy zmienić schemat tabel?
– Inaczej pogrupować atrybuty w ramach relacji?
– Normalizacja, denormalizacja (pionowy podział)?
– Poziomy podział (np. tabelę Osoby na osobne tabele Pracownicy
i Studenci?)
– Perspektywa zmaterializowana z wynikami obliczeń (np.
statystyka operacji na kontach bankowych)?
Czy połączyć zapis kilku tabel w klaster? Złączenie –
szybsze; operacje na pojedynczych tabelach wolniejsze
niż bez klastra (np. Zamówienia i Pozycje zamówienia).

Decyzje
Czy połączyć zapis kilku tabel w klaster? Złączenie – szybsze;
operacje na pojedynczych tabelach wolniejsze niż bez klastra
(np. Zamówienia i Pozycje zamówienia).
Czy w celu wykonywania konkretnego, ważnego zapytania
zawierającego złożone konstrukcje jak złączenia, agregacje lub
podzapytania, nie utworzyć dla niego perspektywy
zmaterializowanej z założonym odpowiednim indeksem
pogrupowanym pamiętając, że zapytanie będzie wykonywane
szybko ale kosztem aktualizacji perspektywy zmaterializowanej
i zwiększenia zajętości miejsca na dysku? Na przykład, czy
zamiast liczyć przy każdym zapytaniu statystykę stanu kont
bankowych nie warto, mieć ją obliczoną raz na dzień lub raz na
godzinę?

Wybór indeksów
Zaczynając od najważniejszych zapytań przeanalizuj
plany ich wykonania – czy nie powinniśmy dodać
nowy indeks do już wybranych?
Rozpatrz jaki wpływ będzie miał ten indeks na
operacje INSERT/DELETE/UPDATE oraz na ilość
potrzebnego miejsca na dysku?

Wybór indeksów
Atrybuty w klauzuli WHERE są kandydatami na klucze
wyszukiwania w indeksie.
– Równość sugeruje indeks haszowany.
–
Przedział wartości sugeruje B+ drzewo.
–
Wypisanie w kolejności uporządkowanej sugeruje B+ drzewo.
–
Indeks pogrupowany jest użyteczny przy zapytaniach
zakresowych ale także przy mało-selektywnych zapytaniach
równościowych.
Jeden indeks powinien być użyteczny dla wielu
zapytań.

Wybór indeksów
Indeks jest automatycznie tworzony przez system dla
każdego klucza głównego i jednoznacznego.
Indeks bywa zakładany na kolumnach:
– których wartości ograniczają wyszukiwanie wierszy w tabeli np.
Emp.Job='MANAGER' przy czym istotne jest aby wyszukiwanie było
selektywne tj. aby procent wyszukiwanych wierszy nie był zbyt duży,
powiedzmy co najwyżej 5 do 10%;
– które są kluczami obcymi, co przyśpiesza wykonywanie złączeń dwóch
tabel względem warunku klucz obcy=klucz główny – zakładając, że
wykonywanie zapytania ze złączeniem zaczyna się od wyboru wiersza
z tabeli nadrzędnej, tj. z kluczem głównym, po czym szukamy wierszy
w tabeli podrzędnej, tj. z odpowiadającym kluczem obcym;
– które występują w ważnych zapytaniach systemu informacyjnego
umożliwiając realizację strategii tylko-indeks.

Wybór indeksów
Ponieważ tylko jeden indeks może być pogrupowany
dla jednej relacji, jeśli zachodzi potrzeba jego użycia,
wybierz go biorąc pod uwagę najważniejsze zapytania.
Indeks pogrupowany jest szczególnie istotny dla
zapytań zakresowych, z klauzulą ORDER BY oraz przy
duplikatach - nie jest natomiast istotny gdy stosuje się
strategię tylko-indeks.

Wybór indeksów
Gdy klauzula WHERE zawiera kilka warunków należy
rozpatrzyć możliwość założenia indeksu o
wieloatrybutowym kluczu wyszukiwania.
–
Przy warunkach zakresowych istotna jest kolejność atrybutów
w kluczu wyszukiwania.
–
Indeksy takie mogą czasem umożliwić zastosowanie strategii
“tylko-indeks”.
Przy rozpatrywaniu warunku złączenia:
–
Indeks haszowany na relacji wewnętrznej jest dobry dla
metody Index Nested Loops.
Powinien być pogrupowany jeśli kolumna złączenia nie jest
kluczem dla relacji wewnętrznej a wiersze relacji wewnętrznej
mają się znaleźć w wyniku.
–
Pogrupowany indeks na B+ drzewie względem kolumn
złączenia jest dobry dla metody Sort-Merge.

Przykład 1
Indeks na D.dname wspomaga selekcję
D.dname=‘SALES’ (D – relacja zewnętrzna).
Potrzebny jest indeks albo jednoznaczny albo
selektywny albo pogrupowany.
Indeks na E.deptno wspomaga złączenie (E – relacja
wewnętrzna). Powinien być pogrupowany, ponieważ
spodziewamy się wybrania wielu wierszy z E.
SELECT
E.ename, D.mgr
FROM
Emp E, Dept D
WHERE
D.dname=‘SALES’
AND
E.deptno=D.deptno

Przykład
2
Emp E – relacja zewnętrzna złączenia (ze
wzgedu na warunki ograniczające na niej).
Dept D – relacja wewnętrzna złączenia.
–
Na D.deptno mamy indeks, ponieważ jest to klucz
główny
Jaki indeks na relacji Emp?
–
Albo B+ drzewo na E.sal albo indeks haszowany na
E.job. Wybór zależy od ich selektywności. Jeśli jest
zła, mógłby pomóc tylko indeks pogrupowany na
E.Job.
SELECT
E.ename, D.mgr
FROM
Emp E, Dept D
WHERE
E.sal
BETWEEN
10000
AND
20000
AND
E.job=‘SALESMAN’
AND
E.deptno=D.deptno

Przykład 3
Zapytanie
GROUP BY
.
– Indeks pogrupowany na kolumnie E.Deptno. Jeśli
nie jest możliwe założenie takiego indeksu, system
posortuje względem E.Deptno plik rekordów tabeli
Emp E - biorąc pod uwagę tylko rekordy dla których
E.Sal>2000. Następnie wykona zliczanie COUNT(*).
– Indeks na B+ drzewie na kolumnach <E.Deptno,
E.Sal> umożliwiłby zastosowanie strategi tylko-
indeks.
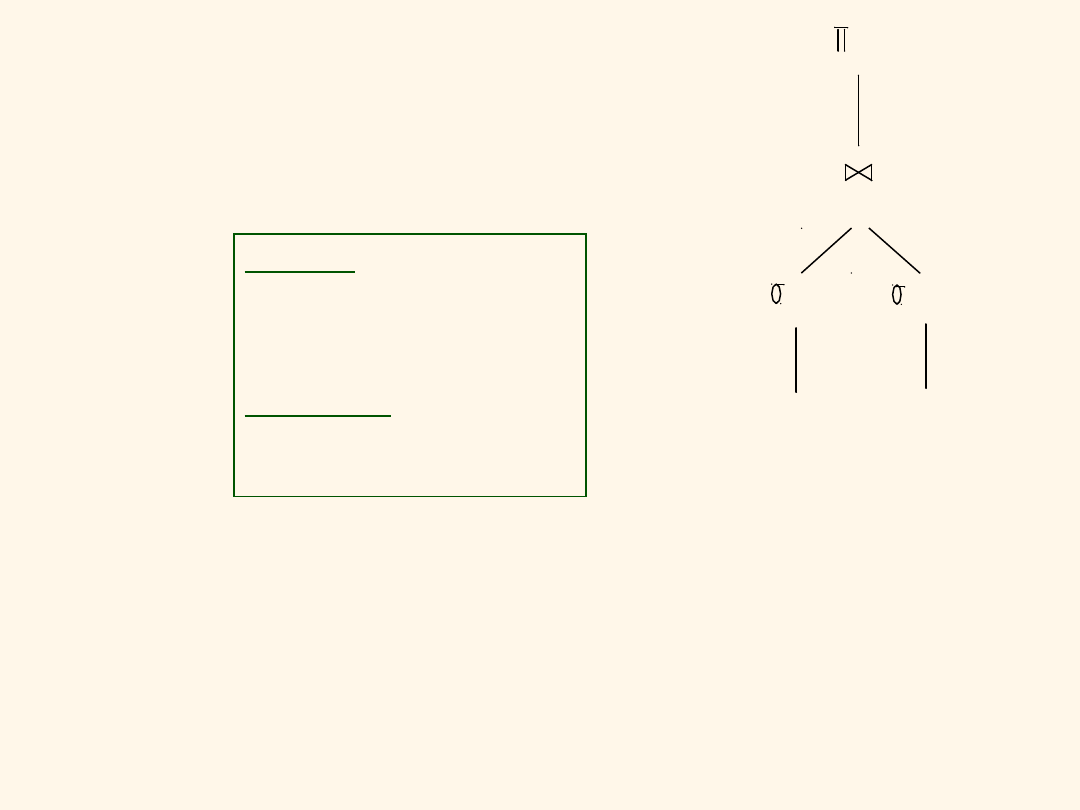
SELECT E.Deptno, COUNT(*)
FROM Emp E
WHERE E.Sal>2000
GROUP BY E.Deptno;
Przykłady
Pewne
zapytania
można
wykonać
bezpośrednio
z indeksu (bez
przechodzenia
do relacji).
SELECT
D.mgr
FROM
Dept D, Emp E
WHERE
D.dno=E.dno
SELECT
D.mgr, E.eid
FROM
Dept D, Emp E
WHERE
D.dno=E.dno
SELECT
E.dno,
COUNT
(*)
FROM
Emp E
GROUP BY
E.dno
SELECT
E.dno,
MIN
(E.sal)
FROM
Emp E
GROUP BY
E.dno
SELECT
AVG
(E.sal)
FROM
Emp E
WHERE
E.age=25
AND
E.sal
BETWEEN
3000
AND
5000
<E.dno>
<E.dno,E.eid>
<E.dno>
<E.dno,E.sal>
B+ drzewo!
<E. age,E.sal>
lub
<E.sal, E.age>
B+ drzewo!

Podsumowanie
Wybór indeksów ma istotny wpływ na szybkość
wykonywania zapytań.
–
Aktualizacja pól wyszukiwania w indeksach zwalnia
INSERT/DELETE/UPDATE.
–
Wybieraj indeksy, które wspomagają wykonywanie
wielu zapytań.
–
Buduj indeksy umożliwiające strategie tylko-indeks.
–
Podejmij decyzję czy założyć indeks pogrupowany dla
tabeli (o ile twój system umożliwia zakładanie takich
indeksów). Tylko jeden indeks pogrupowany może być
założony dla jednej tabeli. Pamiętaj, że wyszukiwanie
przez inne indeksy będzie spowolnione.
–
Kolejność pól w kluczach wielo-atrybutowych może
być istotna.

Podsumowanie
– Unikaj, na ile to możliwe, zagnieżdżonych zapytań
(podzapytań), złożonych warunków, DISTINCT, GROUP
BY, OR, wyrażeń arytmetycznych/napisowych (może
być trudno użyć indeks), tabel tymczasowych.
– Przebudowuj okresowo wszystkie indeksy, w
szczególności statyczne.
– Zbieraj statystyki używane przez optymalizator
zapytań. Okresowo odświeżaj statystyki.
– Sprawdzaj plan wybrany przez optymalizator -
ewentualnie zmień indeks lub zapytanie. Ewentualnie,
dołącz do zapytania wskazówki optymalizacyjne, jeśli
system je umożliwia (Oracle hint).

53
Pułapki eliminacji podzapytań
SELECT DISTINCT *
FROM Sailors S
WHERE S.sname IN
(SELECT Y.sname
FROM YoungSailors Y)
SELECT DISTINCT S.*
FROM Sailors S,
YoungSailors Y
WHERE S.sname = Y.sname
SELECT *
FROM Sailors S
WHERE S.sname IN
(SELECT DISTINCT Y.sname
FROM YoungSailors Y)
SELECT S.*
FROM Sailors S,
YoungSailors Y
WHERE S.sname = Y.sname
=
=

54
Pułapki eliminacji podzapytań
SELECT dname FROM Department D
WHERE D.num_emps >
(SELECT COUNT(*) FROM Employee E
WHERE D.building = E.building)
CREATE VIEW Temp (empcount, building) AS
SELECT COUNT(*), E.building
FROM Employee E
GROUP BY E.building
SELECT dname
FROM Department D,Temp
WHERE D.building = Temp.building
AND D.num_emps > Temp.empcount;
A gdy tabela Employee jest pusta?
=

ORACLE
– optymalizacja
wydajności

Indeksy w Oracle
W Oracle rezultatem wyszukiwania w indeksie są
identyfikatory wierszy będące wartościami specjalnego
typu danych ROWID. Są następujące rodzaje indeksów:
– Indeks oparty na B+ drzewie
– Tabela połączona z indeksem opartym na B+ drzewie
– Indeks oparty na B+ drzewie z odwróconymi wartościami kluczy
– Indeks oparty na klastrze jednej lub więcej tabel, indeks
haszowany
– Indeks z pozycjami określonymi za pomocą wyrażeń
– Indeks bitmapowy

Indeks oparty na B+ drzewie
Pozycja danych składa się z wartości indeksowanych
kolumn oraz z identyfikatora ROWID wiersza w tabeli -
określającego fizyczne położenie danego wiersza na
dysku. Umożliwia szybkie znalezienie wiersza w oparciu
o daną wartość klucza wyszukiwania oraz realizację
zapytań zakresowych. Odpowiada koncepcji indeksu nie
pogrupowanego.
Przy wykonywaniu zapytania system używa indeksu
opartego na B+ drzewie tylko wtedy gdy jest
zapewniona wystarczająca selektywność wyszukiwania,
powiedzmy 5 do 10% wszystkich rekordów w pliku.
Zwykły indeks oparty na B+ drzewie jest automatycznie
tworzony dla każdego klucza głównego i
jednoznacznego.

Tabela połączona z indeksem
opartym na B+ drzewie
Pozycjami danych indeksu głównego są rekordy pliku
tzn. wiersze tabeli są trzymane w indeksie. Jest
zapewniony bardzo szybki dostęp do wierszy przez
wartości klucza głównego. Wiersze nie posiadają
swoich identyfikatorów (ROWID) – identyfikacja
wierszy przebiega wyłącznie przez wartości klucza
głównego; w pozostałych indeksach wynikiem
wyszukania jest wartość klucza głównego – a nie
ROWID. Odpowiada to koncepcji indeksu
wewnętrznego - ale budowanego tylko dla klucza
głównego.
Aby utworzyć taki indeks, na końcu instrukcji
CREATE TABLE (…) piszemy ORGANIZATION INDEX.

Indeks oparty na B+ drzewie z
odwróconymi wartościami kluczy
Jest stosowany tylko z predykatem równości –
nie można w szczególności wypisywać
wierszy wynikowych w kolejności
uporządkowanej względem wartości klucza
wyszukiwania. Bywa stosowany przy podziale
tabeli i indeksu na partycje, gdzie
równomierne rozłożenie wartości kluczy w
poddrzewach B+ drzewa ma istotne
znaczenie.
Aby utworzyć taki indeks, na końcu instrukcji
CREATE TABLE (…) piszemy REVERSE.

Indeks oparty na klastrze jednej
lub więcej tabel, indeks
haszowany
W klastrze wiersze kilku tabel są przechowywane
razem uporządkowane względem wartości wybranych
kolumn - nazywanych kluczem klastra, np. zamówienie
razem ze swoimi pozycjami (kluczem klastra jest
numer zamówienia). Jest to dobra struktura w
przypadku gdy aplikacje często używają złączenia
dwóch lub więcej tabel wchodzących w skład klastra.
Na każdym klastrze jest zakładany indeks zewnętrzny
jednego z dwóch rodzajów:
– zwykły indeks oparty na B+ drzewie,
– indeks haszowany - do wartości klucza stosuje się funkcję
haszującą otrzymując wartość, w oparciu o którą można łatwo
wyznaczyć adres na dysku, gdzie znajduje się odpowiednia
grupa wierszy. Indeks haszowany jest stosowany tylko wtedy
gdy wyszukiwanie jest oparte na równości klucza. Indeks
haszowany w SZBD Oracle występuje tylko w odniesieniu do
klastra tabel, który jednak w szczególnym przypadku może
zawierać pojedynczą tabelę.

Indeks z pozycjami określonymi
za pomocą wyrażeń
Kolumny indeksu mogą być wyrażeniami
zawierającymi funkcje (z wyłączeniem funkcji
agregujących). Na przykład, założenie indeksu
CREATE INDEX Uppercase_idx ON
Emp(UPPER(Ename))
pomaga w realizacji wyszukiwania pracowników w
oparciu o ich nazwiska - nie biorąc pod uwagę
wielkości liter w nazwisku:
SELECT * FROM Emp e
WHERE UPPER(e.Ename)='KOWALSKI';

Optymalizator oparty na
regułach
Optymalizator oparty na regułach wykorzystuje 15 reguł w
kolejności spodziewanego wpływu na efektywność.
Przypisuje wagę każdej strategii wykonania i wybiera tę o
najmniejszej wadze. Gdy waga jest taka sama wybierana
jest strategia związana z tabelą występującą w zapytaniu
SQL wcześniej.

Optymalizator oparty na
koszcie
W Oracle dostępny jest też optymalizator oparty na koszcie.
Optymalizacja oparta na koszcie polega na wybraniu tej
strategii wykonania zapytania, która wymaga najmniejszych
zasobów do przetworzenia wszystkich wierszy, do których
odwołuje się zapytanie.
Ustawiając parametr OPTIMIZER_MODE użytkownik decyduje,
czy optymalizować przepustowość, czy czas wykonania.
Optymalizator oparty na koszcie bierze pod uwagę wskazówki
podane przez użytkownika (hint).
Działanie tego optymalizatora zależy od zgromadzonych
statystyk, istniejących indeksów, perspektyw
zmaterializowanych i klastrów.

Statystyki
Oracle nie zbiera statystyk automatycznie – generuje
je i uaktualnia tylko na życzenie użytkownika.
W celu utworzenia bądź uaktualnienia statystyk
należy wpisać:
exec DBMS_STATS.GATHER_SCHEMA_STATS
(ownname => nazwa_użytkownika, cascade
=>true,estimate_percent =>
dbms_stats.auto_sample_size);
Histogramy
Histogram to struktura danych
pozwalająca poprawić
szacowanie. Istnieją dwa rodzaje
histogramów:
–
Histogram przedziałów stałej
długości
–
Histogram przedziałów stałej
wysokości (Oracle)
W Oracle użytkownik jest
odpowiedzialny za tworzenie i
aktualizowanie histogramów dla
odpowiednich kolumn. Służą do
tego narzędzia z pakietu
DBMS_STATS.

Explain Plan, Trace
Alter Session Set SQL_TRACE = True
Tabela PLAN_TABLE
EXPLAIN PLAN SET STATEMENT_ID =
‘identyfikator’ FOR polecenie_SQL
Polecenie SET AUTOTRACE ON

Explain Plan, Trace
SELECT SUBSTR(LPAD(' ', 2*( LEVEL-1))||operation,1,30)
|| ' ' || SUBSTR(options,1,15)
|| ' ' || SUBSTR(object_name,1,15)
|| ' ' || SUBSTR(DECODE(id,0, 'Koszt: ' || position),1,12)
"Plan wykonania",
SUBSTR(optimizer,1,10) "Optymalizator"
FROM plan_table
START WITH id=0
AND statement_id= ‘identyfikator'
CONNECT BY PRIOR id=parent_id
AND statement_id= ‘identyfikator'
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
- Slide 46
- Slide 47
- Slide 48
- Slide 49
- Slide 50
- Slide 51
- Slide 52
- Slide 53
- Slide 54
- Slide 55
- Slide 56
- Slide 57
- Slide 58
- Slide 59
- Slide 60
- Slide 61
- Slide 62
- Slide 63
- Slide 64
- Slide 65
- Slide 66
- Slide 67
Wyszukiwarka
Podobne podstrony:
Chłoniaki nieziarnicze wykład 2007
Polityka zdrowotna na świecie wykład 1 2007
Kierunki i szko y w nauce organizacji i zarz dzania I wyklad 2007
Wykład 2 9 X 2007, Politologia
Wyklad 1 2007 psychologia poznawcza
Wyklad9 2007
rozwojowka slajdy, Srednia doroslosc wyklad 1 w 2007
0 Program wykładów 2007
Chemia wyklady 2007 2008(1) id Nieznany
Wyklad1 2007[1]
Wykład 1 2 X 2007, Politologia
Maści wykład 2007-2008, Farmacja, Technologia postaci leków
C Wykład I 2007 2008 M Ch
Wyklad I 2007
Niepełnosprawność jako zjawisko wieloaspektowe - wyklady z 2007 WSFiZ, PSYCHOLOGIA(1), Psychologia(1
Wykład 3 2007-11-05 Oscyloskopy
Antropologia Wyklady 2007, SOCJOLOGIA, antropologia kultury
więcej podobnych podstron