
SYSTEMY
INFORMATYCZNE MIS
MANAGEMENT
INFORMATION SYSTEM
WYKŁAD DLA GIF
Wydział Górniczy Politechniki Wrocławskiej

POJĘCIA
PODSTAWOWE
INFORMACJA
– przyrost wiedzy uzyskany na podstawie
danych:
Beynon-Davies P. : „Dane opisują poszczególne fakty, natomiast
ich interpretacja jest informacją.”
NARZĘDZIA
OLAP (ang. On Line Analitical Processing – bezpośrednie
przetwarzanie analityczne) – system analiz i symulacji dla
menadżerów szczebla strategicznego
EKSPLORACJA DANYCH (data mining) – pozyskiwanie wiedzy
z dużej liczby danych poprzez zastosowanie algorytmów
genetycznych, modeli sieci neuronowych, drzew decyzyjnych
MIS
– system informatyczny przeznaczony do wspierania
kierownictwa w podejmowaniu decyzji.
Zakres MIS: Planowanie finansowe, inwestycyjne, monitoring
realizacji budżetu, analiza i ocena istniejących zjawisk i
procedur.

ZAKRES NAJCZĘŚCIEJ
STOSOWANYCH ANALIZ
• Analizy finansowe
• Analizy i symulacje podatkowe
• Analizy na potrzeby planowania przestrzennego i
zagospodarowania terenu
• Analizy gospodarcze
• Analizy rynku
• Aktywnośc budowlana i inwestycyjna
• Analizy demograficzne i ruchy ludnościowe
• Wydajność i dostępność mediów
• Analizy związane z bezpieczeństwem publicznym
• Analizy komunikacyjne, natężenia ruchu i p[otoki
pasażerskie
• Analizy wyników wyborczych
• Awarie
• .................

ROZWIĄZANIA
SYSTEMU
ZARZĄDZANIA
MIS
Jak wybrać odpowiedni
system typu
MIS ?
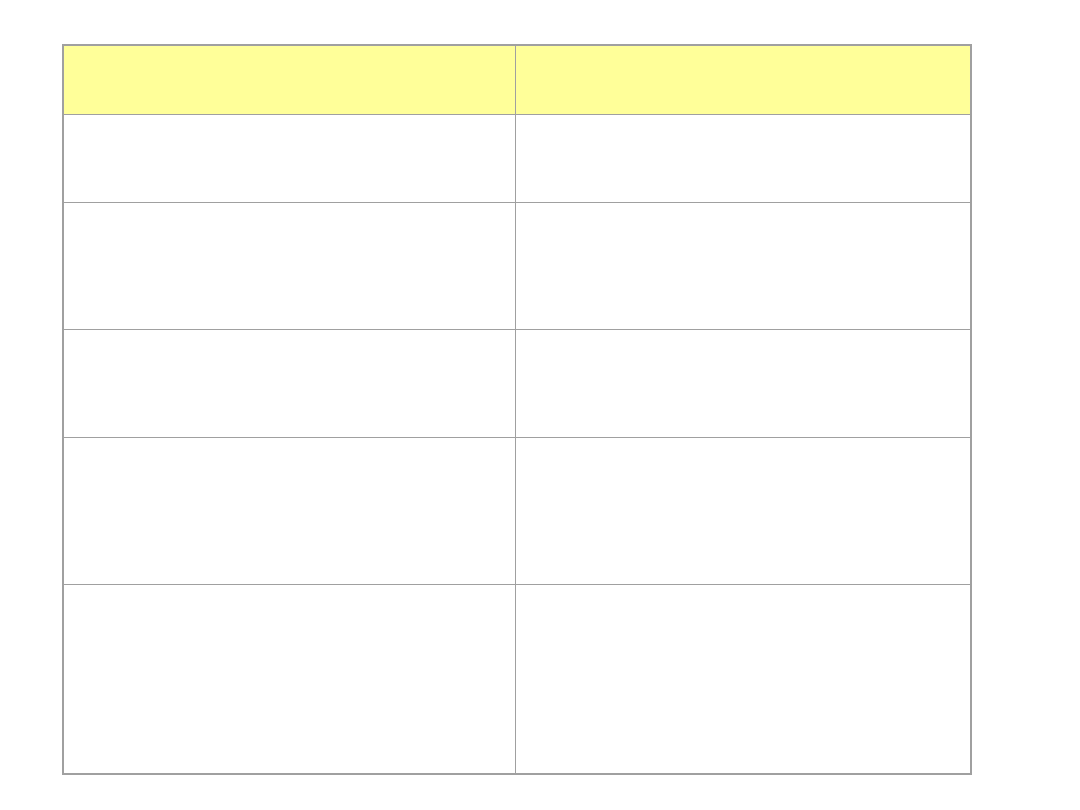
Kryterium oceny
Opcje
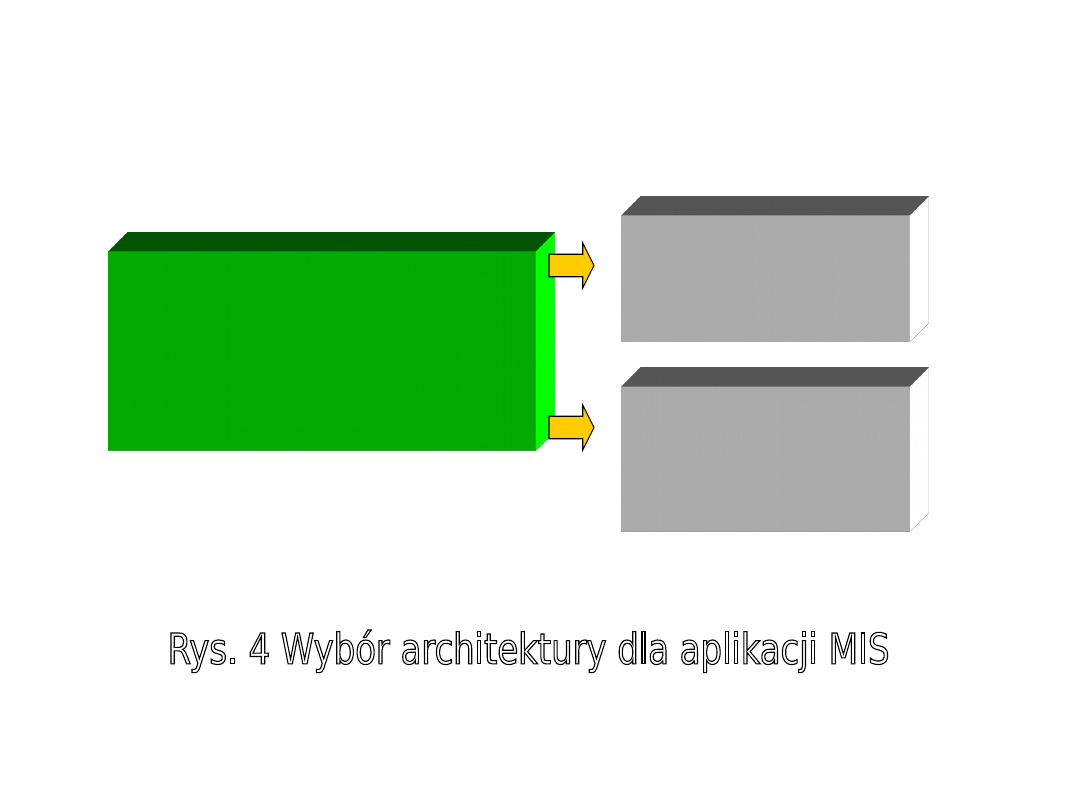
1) Architektura
System scentralizowany
System rozproszony
2) Aplikacja MIS
Rozbudowana aplikacja „klient-
serwer”
Aplikacje w technologii
internetowej
3) Model danych i system
zarządzania bazą danych
Baza relacyjna
Baza obiektowa
Baza obiektowo relacyjna
5) Bezpieczeństwo
Poufność
Autentyczność
Integralność systemu
Dostępność
Rozliczalność
4) Wdrażanie systemu
Zakup systemu
Opracowanie i wdrożenie
systemu we własnym
zakresie
Zakup platformy systemu i
tworzenie aplikacji we własnym
zakresie
System
rozproszony
Architektura MIS
System
scentralizowany

System scentralizowany:
Istotną cechą tej architektury (np. SNA – System Network
Architecture stworzony przez firmę IBM) jest posadowienie na
serwerze (jest to zwykle komputer o bardzo dużej mocy obliczeniowej
– mainframe) zarówno oprogramowania bazowego, aplikacji i baz
danych , do którego podłączone są na stanowiskach użytkowników
terminale. Terminale nie są komputerami pozwalającymi na
przetwarzanie danych, natomiast umożliwiają prowadzenie pracy na
serwerze.

System rozproszony:
Charakteryzuje się zastosowaniem komputerów zazwyczaj klasy
PC w miejsce terminali, oraz wprowadzeniem odpowiedniego
oprogramowania umożliwiającego pracę na komputerze użytkownika
przy wykorzystaniu bazy danych usadowionej na serwerze (serwera
danych i interfejsu użytkownika). Architektura rozproszona ze względu
na późną informatyzację w naszym kraju w odniesieniu do najbardziej
rozwiniętych Państw Europy Zachodniej i Ameryki (lata 90) przyjęła
się jako podstawowa. Wcześniej w krajach wysoko rozwiniętych
rozwijał się przede wszystkim system scentralizowany.
Przykładem systemu rozproszonego jest architektura klient –
serwer. Wówczas serwery przechowują dane i aplikacje, a tzw. Stacje
klienckie – będące komputerami użytkowników końcowych – wykonują
aplikacje na danych z serwera.

HURTOWNIA DANYCH
Hurtownia danych (ang. Data
Warehouse)
– scentralizowana,
nietransakcyjna baza danych
przeznaczona do przechowywania
zagregowanych informacji
pochodzących z baz danych zasilających

Cechy Hurtowni Danych
dla MIS

Zorientowanie tematyczne
– struktura danych przechowywanych
w bazie zbiorczej zbudowana jest wokół głównych obszarów
tematycznych opisujących istotną sferę zainteresowania podmiotu
gospodarczego, lub urzędu:
podstawowe dane o podmiocie
gospodarka finansowa
gospodarowanie majątkiem trwałym
strategia, plany, programy rozwoju, inwestycje
usługi
sytuacja społeczno – ekonomiczna (w przypadku
administracji)
analiza rynku
budżet
podatki (w przypadku administracji)
inne

Uporządkowanie chronologiczne
- dane pobierane z baz
źródłowych z czasem tworzą szereg czasowy, tzn. kolejne wersje tych
samych danych nie są wstawiane w tych samych miejscach, ale
zapisywane w innej warstwie czasowej, co pozwala na zbudowanie
historii procesów w skali podmiotu;
Integralność
– ujednolicenie danych poprzez zaprojektowanie
struktury informacyjnej hurtowni danych i zastosowanie modułu
standaryzacji danych pobieranych z baz źródłowych;
Nieulotność
– hurtownia danych jest zbiorem, którego elementy
pobierane z baz źródłowych nie podlegają modyfikacji, ich
wprowadzenie równoznaczne jest bowiem z uznaniem ich
poprawności.

Hurtownia danych (rysunek 2) jest więc w pewnym
uproszczeniu
zbiorem
rozproszonych
po
różnych
aplikacjach i serwerach danych metodą ich scalania.
System MIS oparty na koncepcji hurtowni danych może
wspierać
też
działalność
operacyjną
zespołów
zarządzających podmiotów gospodarczych i urzędów,
które potrzebują dostępu do informacji o stanie
aktualnym, historycznym i prognozach, a nie koniecznie
do danych źródłowych. Integracja danych w taki sposób
stanowi platformę, która ma stanowić podstawę do
podejmowania decyzji zarządczych w mieście. Hurtownia
pozwoli usystematyzować i zgromadzić informacje
zarządcze z uwzględnieniem danych historycznych w
jednym miejscu, tak aby dostęp do nich miały osoby
odpowiedzialne za strategię podmiotu.
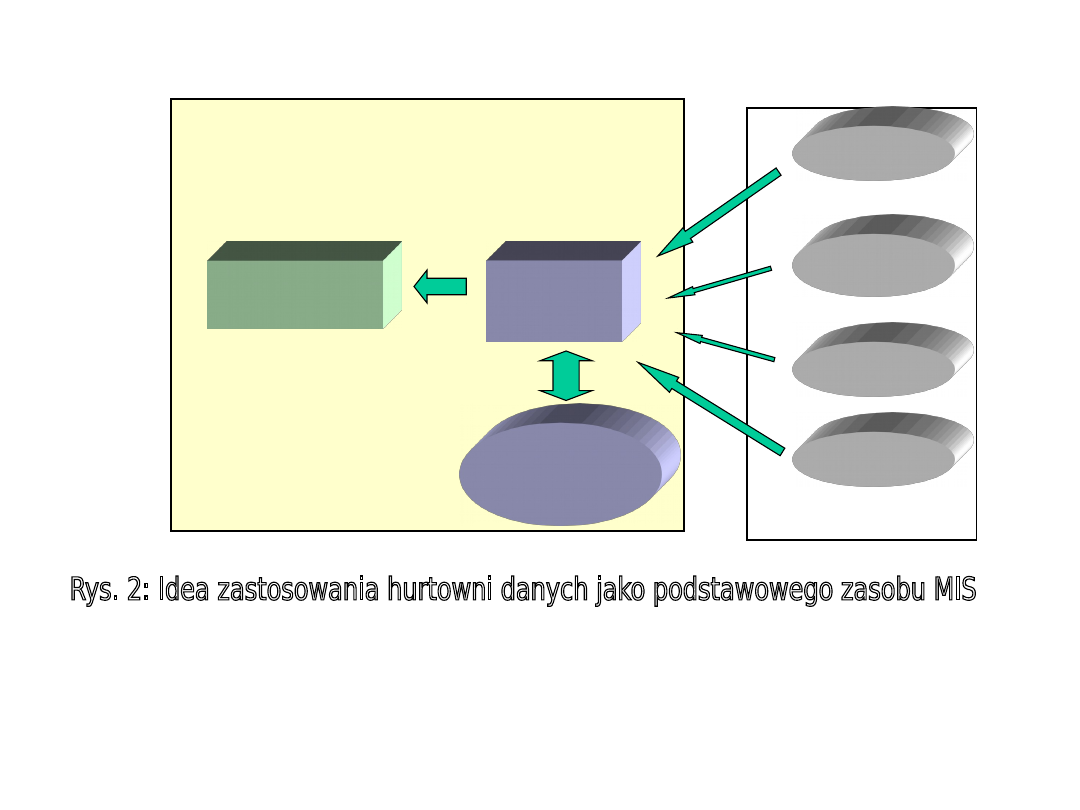
Serwer
MIS
Baza hurtowni
danych
Baza 2
Informacje
zarządcze
HURTOWNIA
DANYCH
System MIS
Zasoby źródłowe – bazy
ewidencyjne miasta
Baza 1
Baza ...
Baza n

Dostarczania informacji do analiz
– wykonywanie analiz i
prognoz w różnych wariantach, na bazie analizy wartości
danych historycznych.
Rozwiniętej eksploracji danych
– przeszukiwanie zbiorów
danych w poszukiwaniu ukrytych zależności, takich jak:
planowane w przyszłości wpływy z podatków a wydatki na
szkolnictwo, koszty informatyki, a zatrudnienie, lub
efektywność inwestycji.
Raportowanie
– generowanie raportów z informacji zawartej w
hurtowni w wymaganych okresach (koniec miesiąca, kwartału,
roku), dotyczących istotnych grup tematycznych.

Moduł standaryzacji danych (rysunek 3) jest ważnym elementem
systemu.Jego zadaniem jest umożliwienie transferu danych
poprzez ujednolicenie danych napływających z różnych źródeł
charakteryzujących się różnymi konwencjami w zakresie
nazewnictwa, jednostek miar, zapisem wartości w systemach
informatycznych itp. oraz ich połączenie w jeden, spójny zbiór,
zgodny ze standardem zapisu w bazie hurtowni. Moduł
standaryzacji ułatwia ponadto wychwycenie wszystkich błędów
jakie mogą znajdować się w bazach ransakcyjnych, co umożliwia
poprawę jakości tych baz danych.
Moduł standaryzacji danych pozwalać powinien na
jednoznacznie formatowanie i weryfikować danych w zależności
od:
typów danych i jednostek miar– normalizacja wartości
pól,
źródeł dostępności baz danych,
kompletności danych,
dokładności,
czasu – historia zmian itp.
kompletności danych,
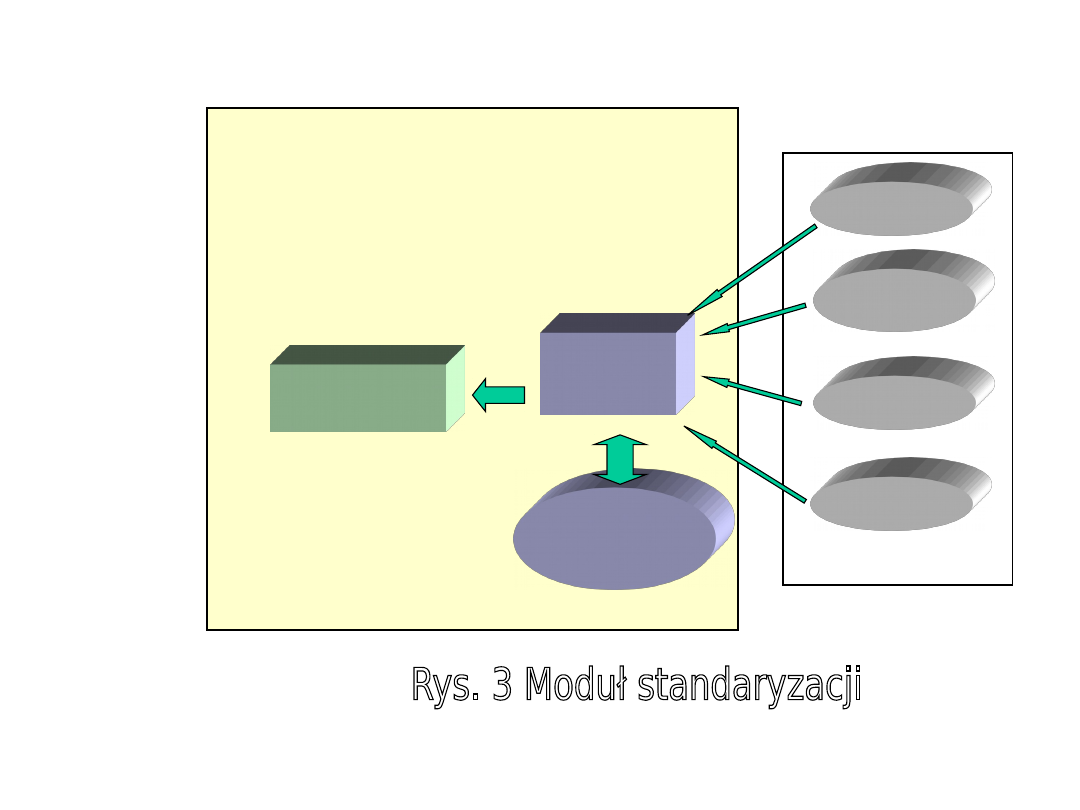
Serwer
MIS
Baza hurtowni
danych
Baza 2
Informacj
e
zarządcze
HURTOWNIA DANYCH
System MIS
Zasoby źródłowe – bazy
ewidencyjne podmiotu
Baza 1
Baza ...
Baza n

WYBÓR ROZWIĄZAŃ
PROGRAMOWYCH W
RAMACH
ROZPROSZONEJ
ARCHITEKTURY
SYSTEMU

W ramach sieciowej architektury rozproszonej każdy
komputer lub program jest klientem (jednostką
pobierającą dane) albo serwerem (jednostką
udostępniającą dane). Serwer przechowuje dane,
przyjmuje zgłoszenia od klientów i świadczy usługi na ich
rzecz.
Można wyróżnić dwie podstawowe wersje architektury
klient – serwer:
Wariant 1. Serwer dostarcza danych dla aplikacji na
komputerze klienta (stacji roboczej), które są
odpowiedzialne za przetwarzanie, edycję i wizualizację
danych;
Wariant 2. Wszystkie aplikacje wykonywane są przez
serwer, a wyniki wyświetlane na ekranie klienta (wariant
terminali serwera).

Charakterystyka wariantu 1.
Większość aplikacji klient – serwer jest projektowana w
bardzo prostym modelu, którego elementami są: aplikacja
klienta i serwer bazy danych. Model ten określany jest mianem
dwuwarstwowej architektury aplikacji. Dla prostych zastosowań
jest to model wystarczający.
W tym przypadku zapewnienie prawidłowego działania
komputerów w sieci wymaga od administratora częstych
interwencji. Użytkownicy swoim nieprzemyślanym działaniem
mogą powodować nieprawidłowości w funkcjonowaniu aplikacji
stacji roboczych, sprowadzające się do ciągłego serwisowania
sprzętu i aplikacji. W przypadku zmian w oprogramowaniu (np.
przy zmianie wersji lub modyfikacjach systemu związanych np.
ze zmianą formatu wydruków) konieczne jest zastąpienie starej
wersji aplikacji nową, co jest szczególnie uciążliwe gdy dostęp
do systemu ma duża liczba użytkowników.

C.D. Charakterystyka wariantu 1
Możliwe jest rozwiązanie tego problemu przez zastosowanie
dodatkowych systemów zdalnego zarządzania komputerami
użytkowników, umożliwiające scentralizowaną administrację i
dystrybucję oprogramowania na komputerach podłączonych do
sieci. Jednakże jest to rozwiązanie bardzo kosztowne i nie
pozwalające na rozwiązywanie wszystkich problemów zdalnego
zarządzania. Ponadto podejście takie nie jest rozwiązaniem
podstawowego problemu, a dążeniem do likwidacji jego
skutków poprzez inny system (wprowadzający dodatkowe,
specyficzne dla niego problemy).
Rozwiązanie takie ogranicza dostęp do systemu, wymaga
bowiem posiadania dostępu do komputera z odpowiednim
oprogramowaniem.

Charakterystyka wariantu 2.
W przypadku, gdy serwer odpowiedzialny jest za
przetwarzanie danych (wariant 2), a komputery użytkowników
pracują w trybie terminali, mamy do czynienia z rozwiązaniem
znacznie prostszym.
W ten sposób rozwiązywane są problemy związane z opieką
nad oprogramowaniem użytkowników (tj. administracją,
dystrybucją oprogramowania, dostępem). Wszystkie programy
pracują na serwerze, na nim też przechowywane są wszystkie
potrzebne dane. Stacje robocze są uproszczone do maksimum –
wymagania z nimi związane sprowadzają się do
oprogramowania terminala (w większości rozwiązań
standardowego. Rozwiązanie takie jest powrotem do klasycznej
idei modelu komputeryzacji.
Współczesne wymagania stawiane systemom
informatycznym uległy zmianie. Obecnie widać, że systemy dążą
do wykorzystywania technologii internetowych. Funkcję
oprogramowania terminali pełnią przeglądarki internetowe,
stanowiące standardowe oprogramowanie systemów
operacyjnych (np. Microsoft Windows, czy systemów klasy Unix-
w środowisku X – Windows).

Wariant 1
Zalety
Wady
•Zmniejszenie
wymagań dla
serwera
•Zwiększenie wymagań dla
komputerów (odpowiedzialnych
za przetwarzanie informacji)
użytkowników,
•Obciążenie sieci komputerowej
w momencie przetwarzania dużej
liczby danych,
•Wymagana opieka nad
oprogramowaniem
zainstalowanym u użytkowników,
•W przypadku zmian wersji
oprogramowania w czasie jego
eksploatacji konieczne jest
zainstalowanie nowej wersji na
każdym z komputerów
użytkowników,
•Ograniczenie w dostępie do
systemu (wymagany dostęp do
komputera z oprogramowaniem
użytkownika).

Wariant 2
Zalety
Wady
•Wymaga tylko
oprogramowania terminala
(za zwyczaj standardowego
np. przeglądarki
internetowej),
•Zmniejszenie wymagań
dla komputerów
użytkowników,
•Nie wymaga dodatkowej
aplikacji – oprogramowania
użytkownika, dlatego też
zlikwidowane zostają
problemy opieki,
•Zmniejszenie
ograniczenia w dostępie do
systemu.
•Wymagana opieka nad
oprogramowaniem
zainstalowanym u
użytkowników.
•Zwiększenie wymagań dla
serwera (odpowiedzialnego
za przetwarzanie
informacji),
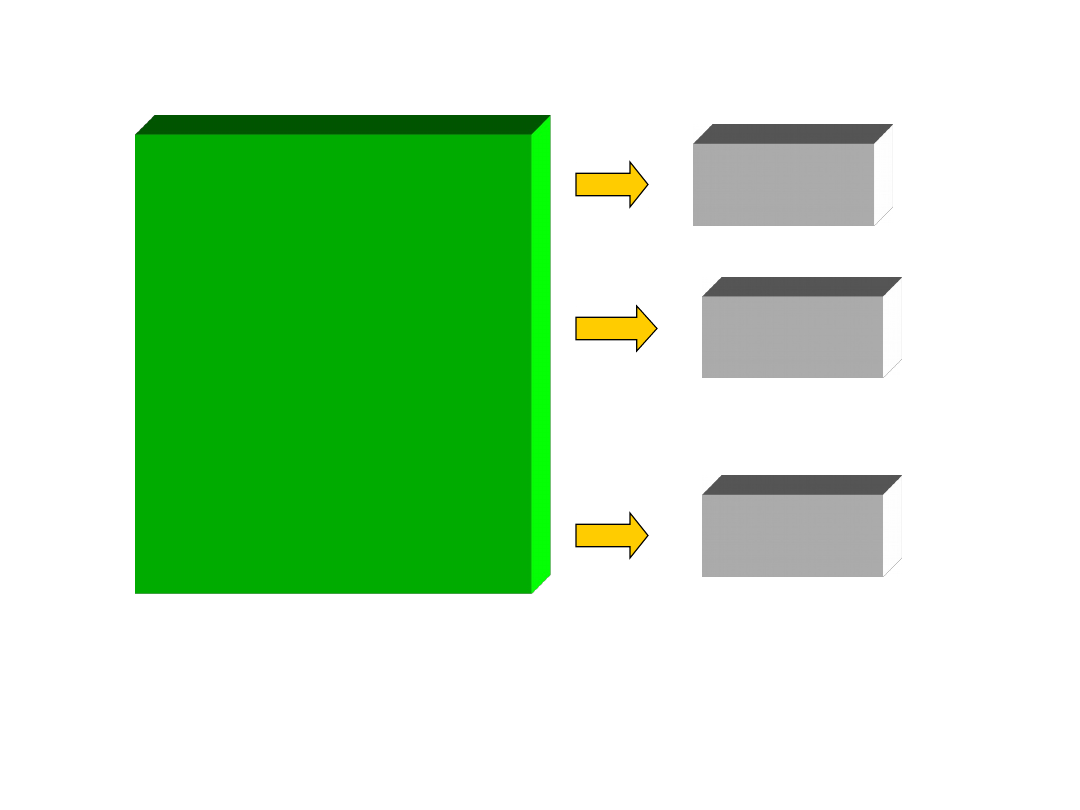
Architektura aplikacji MIS
Rozbudowana
Aplikacja klient - serwer
Aplikacja internetowa

Model dwuwarstwowy nie jest odpowiedni dla złożonych
aplikacji internetowych ukierunkowanych na transakcje,
użytkowanych przez dużą liczbę użytkowników, pracujących za
pośrednictwem WWW.
Aplikacje korzystające z tej technologii mają architekturę
trzywarstwową: dane na serwerze (ang. back-end serwer), logika
aplikacji i kod dostępu do danych na serwerze (w ramach
warstwy pośredniej) oraz aplikacja klienta (przeglądarka
internetowa).
Do zalet technologii internetowych należą:
jednolity sposób prezentacji danych (standaryzowany w
ramach HTML, XML),
duża niezawodność systemu – sprawdzona, stosowana od
wielu lat technologia,
stosowanie standardowych protokołów komunikacyjnych,
niezależnych od producentów,
elastyczność i łatwość rozbudowania systemu,
znacznie szybszy dostęp do żądanej informacji,
możliwość otwarcia dostępu do systemu lub wybranych
informacji korzystając z sieci Internet, a zatem możliwe jest
połączenie z dowolnego miejsca na świecie.

MODEL DANYCH I
SYSTEM ZARZĄDZANIA
BAZĄ DANYCH
System
zarządzania
bazą danych
Relacyjny
Obiektowo-
relacyjny
Obiektowy

W celu wskazania modelu danych dla MIS należy określić
istotne różnice
pomiędzy obiektowym (ODBMS), a relacyjnym (RDBMS)
systemem zarządzani bazą danych. Oto one:
ODBMS pozwalają na przechowywanie danych o dowolnej
strukturze zdefiniowanej przez użytkownika w postaci klas obiektów,
• RDBMS pozwalają na korzystanie z określonego zbioru prostych
typów danych, co stwarza problem dopasowania modelu danych z
modelem używanym przez programistów,
- ODBMS redukują problem dopasowania modelu bazy danych z
modelem używanym przez programistę (zgodność modelu z
obiektowymi językami oprogramowania),
- W przypadku opracowania systemu informacyjnego, istotną
zaletą technologii obiektowej jest ujednolicony model pojęciowy,
pozwalający operować na jednym modelu (wpływa to na efektywność
i elastyczność pracy analityków, projektantów i programistów),

W celu wskazania modelu danych dla MIS należy określić
istotne różnice
pomiędzy obiektowym (ODBMS) a relacyjnym(RDBMS)
systemem zarządzania bazą danych. Oto one:
- Bazy relacyjne zachowują jedynie dane, do których dostęp
realizowany jest przez ich wartość (ang. value-based system) w
odróżnieniu od systemów zapewniających tożsamość (ang. identity-
based system),
- RDBMS wymuszają reprezentowanie danych hierarchicznych,
złożonych lub zagnieżdżonych w postaci powiązanych z sobą tablic.
Prowadzi to do spowalniania przeszukiwania danych już w
przypadku dwóch, trzech poziomów powiązań.
- ODBMS wiążą złożone struktury danych w bezpośrednie
powiązania pomiędzy obiektami (poprzez identyfikatory obiektów).
Tożsamość umożliwia modelowanie różnorodnych powiązań między
obiektami, mających charakter relacji jednoznacznych (model jeden
do jednego, ang. one-to-one), jeden do wielu (ang. one-to-many) lub
wzajemnie wieloznacznych (model wiele do wielu, ang. many-to-
many) pozwalających na opisanie świata rzeczywistego (np.
odwzorowanie w systemie rzeczywistej sytuacji miasta zgodnej z
zawartością informacyjną).

Bazy relacyjne
Bazy obiektowe
Zalety
oparte na solidnych podstawach
teoretycznych i praktycznych, które
pozwoliły na opracowanie metodyki
budowania systemów informacyjnych
stabilna pozycja na rynku
potwierdzona wielością produktów i
producentów
optymalizacja zapytań poprzez
języki zgodne ze standardem SQL
złożone obiekty informacyjne – podstawę
stanowią informacje a nie dane (fakty powiązane są
relacjami, które generują informacje)
nie ma ograniczeń w strukturach danych – typy
danych definiowane przez użytkownika
tożsamość obiektów (identyfikator), trwałość
hierarchia, dziedziczenie danych
łatwa rozszerzalność
metody i funkcje przechowywane wraz z danymi
zgodność we wszystkich fazach życia bazy i
danych
wersjonowanie, rejestracja zmian –
zapewniające bezpieczeństwo i utrzymywanie
wersji
możliwość nowych zastosowań mniejszym
kosztem (budowanie baz multimedialnych,
przestrzennych – wsparcie dla systemów mapowych
stosowanych w miastach)
duża wydajność w przetwarzaniu informacji
wsparcie do analiz OLAP na danych w
hurtowniach
Wad
y
sztywne, ustalone konstrukcje oraz
brak złożonych obiektów
niezgodność modelu pojęciowego z
modelem implementacyjnym
brak oddzielenia implementacji
bazy od jej specyfikacji (brak środków
hermetyzacji i modularyzacji)
brak środków do przechowywania
informacji proceduralnych
brak optymalizacji zapytań (odpowiadającej
SQL w bazach relacyjnych)
niedopracowane mechanizmy zarządzania dużą
bazą obiektów, sterowania wersjami
mała liczba programistów i projektantów
technik obiektowych
standardy w fazie dopracowania

Model obiektowo – relacyjny
wprowadzono jako rozwiązanie mające
zwiększyć elastyczność praktycznych
rozwiązań i w sposób ewolucyjny zapewnić
rozwój produktów relacyjnych w obiektowe.
Przykładem jest produkt firmy Oracle,
system zarządzania bazą danych w wersji 8
ma cechy obiektowo – relacyjne, pozwala
użytkownikom wcześniejszych wersji na
bezproblemową zmianę wersji. Ma to
niebagatelne znaczenie dla użytkowników!
Stąd też wiele wiodących firm korzysta z
możliwości implementacji modelu obiektowo
– relacyjnego.

System relacyjny RDBMS
System obiektowy
ODBMS
System obiektowo –
relacyjny ORDBMS
Przykład
standardu
SQL2 (ANSI X3H2)
ODMG v.2 (język
zapytań QQL),
standardy własne
Object SQL, standardy
własne
Programowanie
(ważne z punktu
widzenia
tworzenia i
utrzymywania
aplikacji)
Niezależność danych od
aplikacji kosztem trudności
w odzwierciedlaniu
złożonych powiązań
(wysoka złożoność i koszt
tworzenia systemów MIS)
Obiekty w naturalny
sposób
odzwierciedlają
dziedzinę, łatwość
modelowania
różnorodnych typów i
powiązań (stosunkowo
niski koszt tworzenia
złożonych systemów)
Niezależność danych
od aplikacji, problemy
z odzwierciedlaniem
złożonych powiązań
(złożoność tworzenia
systemów MIS)
Współpraca z
obiektowymi
językami
programowania
Sprowadza się do
dostosowania programu
obiektowego do wymagań
bazy relacyjnej
Otwarta,
bezpośrednia, szeroko
rozumiana – obejmuje
języki obiektowe
Elastyczna w zakresie
nowych typów danych
(ATD – abstrakcyjne
typy danych)
Użytkowanie
Struktura klasyczna
(tabele), łatwo
przyswajalna dla
użytkownika, wielość
oprogramowania
systemowego i
narzędziowego
Łatwe dla
programistów ze
względu na cechę
obiektowości,
ograniczone
oprogramowanie
narzędziowe (dostęp
przez zapytania SQL
nie zapewnia
korzystania z
wszystkich możliwości
bazy)
Podobnie jak dla baz
relacyjnych, jednakże
z uwzględnieniem
komplikacji
wprowadzonych przez
nowe typy danych
(bardziej
skomplikowana
struktura,
ograniczenia w
oprogramowaniu
narzędziowym –
dostęp przez zapytania
SQL

Rozszerzal
ność
(utrzymywa
nie
systemu i
jego
elastycznoś
ć na
zmiany)
W rzeczywistości
utrudniona i
ograniczona do
prostych rozszerzeń
(wiąże się ze
zmianami na
poziomie
konstytucji
systemu)
Obsługuje
dowolnie
złożoną
dziedzinę, może
być rozszerzona
poprzez metody
oraz dołączane
struktury
modyfikujące i
rozszerzające
system
Zwiększona niż
w przypadku
baz relacyjnych
Złożone
dane i
powiązania
między
nimi
(występują
ce w
przypadku
MIS)
Bardzo trudne w
realizacji
Możliwość
definiowania
typów danych i
struktur oraz
powiązań
między nimi
(obiekty i
relacje)
Trudne w
realizacji
Poziom
rozwoju
Klasyczne, stabilne,
o opracowanej i
przetestowanej
metodologii,
stabilność, silnej
pozycji na rynku
baz danych
(większość
używanych bez
danych)
W fazie
dojrzałości –
głównie dzięki
powszechności
OOA i OOD
Rozwijające się,
na etapie
rozszerzenia, w
procesie
ewolucji i nie
dość dobrze
poznane

Możliwość
utrzymania
się na
rynku
Przewidywana dla
dużych
przedsiębiorstw
obecnych na rynku.
Większość wdrożeń
w Polsce.
Sukces modelu
obiektowego
wydaje się być
oczywisty i
wskazuje na
wzrost rynku.
Wdrożenia w
Polsce.
Przewidywana
dla organizacji
znanych z
RDBMS,
dołączają się
nowi
użytkownicy.
Wdrożenia w
Polsce.
Przykłady
rozwiązań
Oracle (wersje
7.x),
Dynamic Server
(Informix),
DB/2 (IBM),
SQL
(Microsoft),
System 10/11
(Sybase),
OpenIgres
(Computer
Associates)
Gemstone,
Jasmine
(Computer
Associates),
ICOR
(Microplan),
Objectivity/DB
(Objectivity),
ONTOS,
Versant
ODMBS
(Versant)
Oracle
(wersje 8.x),
Illustra
(Informix),
DB/2
Extenders
(IBM),
UniSQL/X
(UniSQL),
OSMOS
(Unisys)

Obecnie na rynku możemy spotkać systemy
zarządzania bazami danych zgodne z modelem
relacyjnym (np. Oracle, Microsoft SQL, Informix
Dynamic Server, IBM DB/2, System 10/11),
obiektowym (np. Gemstone, CA Jasmine, ICOR,
Objectivity/DB, Versant ODMBS) i obiektowo –
relacyjnym (np. Oracle 8, Informix Illustra, DB/2,
IBM Extenders, UniSQL/X, unisys OSMOS).
Zmiany na rynku baz danych zależą głównie od
polityki realizowanej przez wiodących producentów
(Oracle, Microsoft, IBM, Informix, Sybase), których
olbrzymi potencjał ma decydujący wpływ na
kierunek rozwoju baz danych. Należy podkreślić, że
tendencję w rozwoju oprogramowania wymusiły
rozwój kluczowych produktów do zmian. Główne
produkty zmieniają się w większym lub mniejszym
stopniu i przechodzą od modelu tradycyjnego (baz
relacyjnych) do modelu obiektowego lub obiektowo
– relacyjnego.

Przykładem mogą być wybrane propozycje najnowszych wersji
systemów zarządzania bazami danych o cechach obiektowych:
Informix: wprowadził jeden z najbardziej zaawansowanych
systemów zarządzania obiektowo – relacyjnymi bazami danych
– Illustra;
Oracle: obiektowo – relacyjny serwer Oracle8 z nowymi
możliwościami obsługi dodatkowych typów danych (np. wideo,
audio, dane przestrzenne GIS);
Sybase: inne rozwiązanie polegające na stworzeniu pomostu
(ang. gateway) pomiędzy relacyjną bazą danych a bazą
obiektową poprzez konwersje w czasie rzeczywistym obiektów
na relacje przechowywane w bazie danych. Rozwiązanie takie
pozwala na szybsze wprowadzenie produktu obiektowego na
rynek, ale w dłuższym czasie, ale w dłuższym czasie nie jest to
pojęcie konkurencyjne (kosztem jest zbyt duży czas przejścia
danych poprzez pośrednie warstwy przetwarzania podczas
konwersji obiektowo – relacyjnej).

Podsumowując, można powiedzieć, że ODBMS (i ewentualnie
ORDBMS) już teraz sprawują się najlepiej w zastosowaniach,
gdzie relacyjny model tradycyjnie napotyka na trudności. Jest
więc wielce prawdopodobne, że w miarę wzrostu potrzeby
przechowywania danych multimedialnych, rozwoju Internetu i
WWW ORDBMS będą szybko zyskiwać na popularności dzięki
ich naturalnemu dopasowaniu do takich zastosowań.
Cztery poniższe metody implementacji wskazują istotne tematy
dla których ODBMS może okazać się praktycznym
rozwiązaniem:
Powiązanie z istniejącymi systemami
– ODBMS
pozwalają na wyciągnięcie większej ilości informacji z
istniejących danych. Dzięki temu można dodać nową wartość do
istniejących systemów. Stare systemy zostają w swoim miejscu,
podczas gdy w tym samym czasie wykorzystuje się nowe
informacje pochodzące z ODBMS w sposób oszczędzający czas
albo zwiększający zyski.
Systemy rozproszone
– tworzenie aplikacji
rozproszonych, z wieloma kontekstami, wymagających
podwyższonego bezpieczeństwa jest o wiele prostsze z
wykorzystaniem spójnego modelu ODBMS.

Złożone dane – decyzja o wykorzystaniu ODBMS może być
oparta na wielu czynnikach. W niektórych projektach złożoność
danych określa wybór technologii obiektowej.
Złożone zapytania – dzięki wbudowanej rekurencyjności,
nowym typom danych i innym udogodnieniom modelu
obiektowego, można zadawać o wiele bardziej skomplikowane
pytania i uzyskiwać lepsze odpowiedzi.

Obiektowe systemy zarządzania bazą danych wspomagają
rozwiązania informatyczne, co prowadzi do sytuacji, gdy
centralne miejsce wdrożenia i obsługi systemu sprowadza się
do rozwiązania problemów organizacyjnych. Pozwala to
skutecznie wyeliminować typowe problemy technologiczne,
uniemożliwiające uzyskanie:
funkcjonalnie elastycznego systemu (przygotowanie
do szybkiego uzupełniania systemu o nowe
możliwości),
opracowania wysokowydajnego, skalowanego
rozwiązania (którego zasób może być rozszerzany w
ramach potrzeb),
rozwiązania problemu wykorzystania istniejących
systemów Urzędu Miasta. Rozwiązania oparte o
technologie internetowe musi uwzględniać i
wykorzystywać inwestycje poczynione w dawne
systemy.

Zastosowanie sytemu obiektowego i hurtowni
danych spowoduje, że istniejące systemy
ewidencyjne staną się drobnym kawałkiem
całego systemu przepływu informacji.
Informacje zbierane z tych systemów i
ewentualnie uzupełniane przez dodatkowe
dane pozwolą na wykonywanie
wielowymiarowych analiz danych.
Poprzez atrybuty system MIS ma przetwarzać
dowolne dane: wpisywane bezpośrednio przez
użytkowników, jak i pochodzące z połączenia
się z dowolnym źródłem danych (np. relacyjne
bazy danych ewidencyjnych), nawet takim,
które nie będzie miało struktury bazy danych.
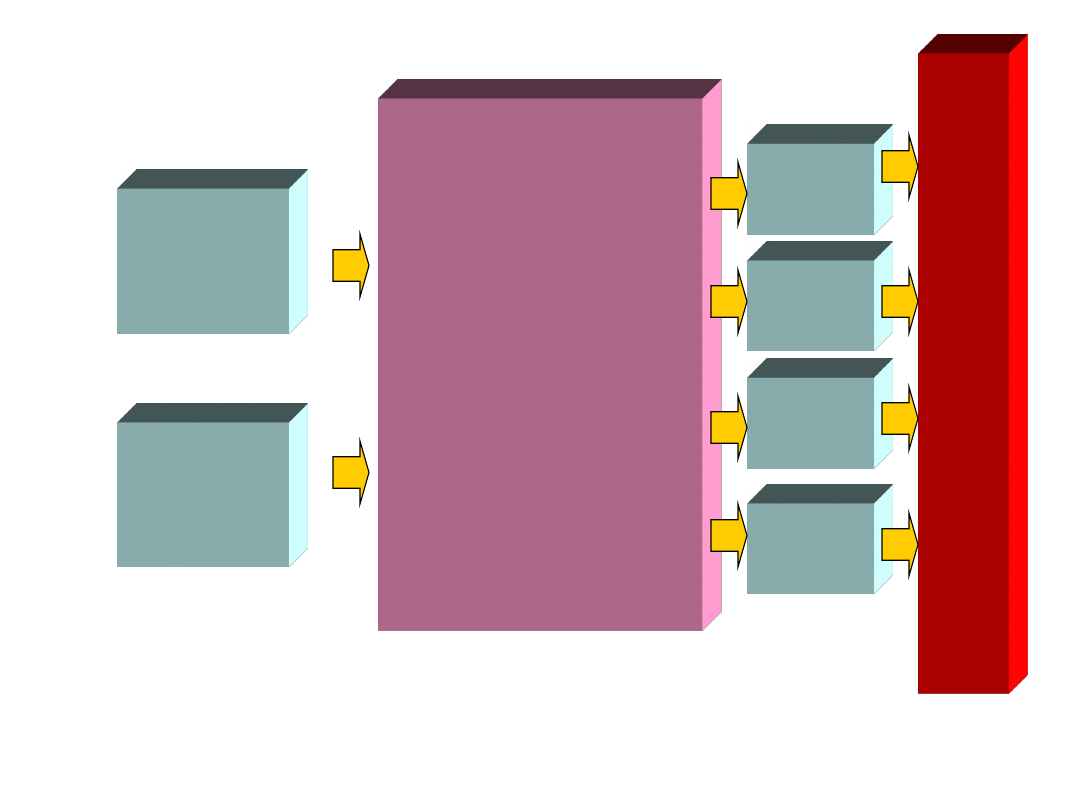
Dane bieżące
wprowadzane
ręcznie
System zarządzania
bazą danych
(hurtownią) MIS
o cechach
obiektowych
Zestawienia
w postaci
wykresów
Zestawienia
w postaci
tabel
Zestawienia
w postaci
map
Zestawienia
w innej
postaci
Dane
szczegółowe
importowane
z aplikacji
U
Ż
Y
T
K
O
W
N
I
C
Y
S
Y
S
T
E
M
U

4.
Bezpieczeństwo
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
Wyszukiwarka
Podobne podstrony:
SYSTEMY INFORMATYCZNE MIS
SYSTEMY INFORMATYCZNE MIS W
SYSTEMY INFORMATYCZNE MIS
OK W2 System informacyjny i informatyczny
OK W2 System informacyjny i informatyczny
Wykorzystanie modelu procesow w projektowaniu systemow informatycznych
SYSTEMY INFORMATYCZNE ORGANIZACJI WIRTUALNEJ1
Metodyka punktow wezlowych w realizacji systemu informatycznego
ZINTEGROWANE SYSTEMY INFORMATYCZNE ZARZĄDZANIA
4 Systemy informatyczne 2 ppt
Wykład VII, politechnika infa 2 st, Projektowanie Systemów Informatycznych
Systemy informatyczne
więcej podobnych podstron