
EDI
Elektroniczna wymiana danych.
„Eletroniczne dokumenty” - SGML, HTML, XHTML,
XML , …

EDI – pojęcia podstawowe
EDI - to skrót od ang. nazwy
Electronic Data Interchange
oznaczający w bezpośrednim
tłumaczeniu Elektroniczną
Wymianę Danych.

EDI – pojęcia podstawowe
Według opinii Departamentu Obrony USA
EDI to:
"Wymiana informacji pomiędzy
komputerami, z użyciem powszechnie
akceptowanych standardów. EDI stanowi
centralną część Rynku Elektronicznego,
ponieważ umożliwia elektroniczną wymianę
informacji, szybszą, tańszą i dokładniejszą niż
w przypadku systemów opartych na
dokumentach papierowych"

EDI – pojęcia podstawowe
EDI to wymiana danych w formatach
opisanych międzynarodowymi
standardami, między systemami
informatycznymi partnerów
handlowych, przy minimalnej
interwencji człowieka.

EDI – pojęcia podstawowe
EDI łączy możliwości informatyki i
telekomunikacji.
Umożliwia eliminację dokumentów
papierowych zwiększając efektywność
wszystkich działań związanych z
handlem.

EDI – pojęcia podstawowe
EDI jest najprostszym sposobem
realizacji transakcji handlowych z
pominięciem żmudnej pracy przy
tworzeniu, kopiowaniu i przesyłaniu
dokumentów papierowych.

EDI – pojęcia podstawowe
EDI tworzy pomost, definiuje standardy
które łączą bezpośrednio systemy
informatyczne współpracujących ze
sobą firm.

EDI – pojęcia podstawowe
EDI umożliwia natychmiastowe
przekazywanie informacji, które są
zawarte w typowych dokumentach
handlowych.

EDI – pojęcia podstawowe
Zastosowanie standardowych
i akceptowanych na całym świecie
formatów danych zapewnia, że wszyscy
uczestnicy wymiany używają tego
samego języka.

EDI – pojęcia podstawowe
Dokument EDI jest odpowiednikiem
papierowego dokumentu handlowego o
ustalonej międzynarodowej postaci,
który został przystosowany do celów
elektronicznej transmisji danych.

EDI – pojęcia podstawowe
EDI funkcjonuje niezależnie od rodzaju
oprogramowania użytkownika.
Stosowanie EDI nie jest ograniczone
różnicami w oprogramowaniu, jakie
partnerzy handlowi używają w swoich
przedsiębiorstwach.

EDI – pojęcia podstawowe
EDI nie jest rodzajem poczty
elektronicznej. EDI polega na wymianie
danych w ustalonym formacie,
pomiędzy systemami informatycznymi,
nie pomiędzy ludźmi. Dane te mogą być
automatycznie przetwarzane przez
komputer.

EDI - Fundament Elektronicznego
Rynku
EDI leży u podstaw Rynku Elektronicznego - technologii
stanowiącej podłoże takich strategii, jak:
–
Stałe Uzupełnianie Zapasów (Continuous
Replenishment) w sektorze detalicznym
(wykorzystanie np. kodów kreskowych),
–
JIT (Just-In-Time) w sektorze produkcyjnym,
–
śledzenie transportu w dystrybucji,
–
płatności elektroniczne w każdym ze środowisk
rynkowych.

Standardy EDI
EDIFACT
z ang. Electronic Data Interchange for
Administration, Commerce and Transport
(elektroniczna wymiana danych dla
administracji, komercji i transportu),
międzynarodowy standard EDI, jaki wdrażany
jest przez Narody Zjednoczone (dokumenty
ISO z serii 9735).

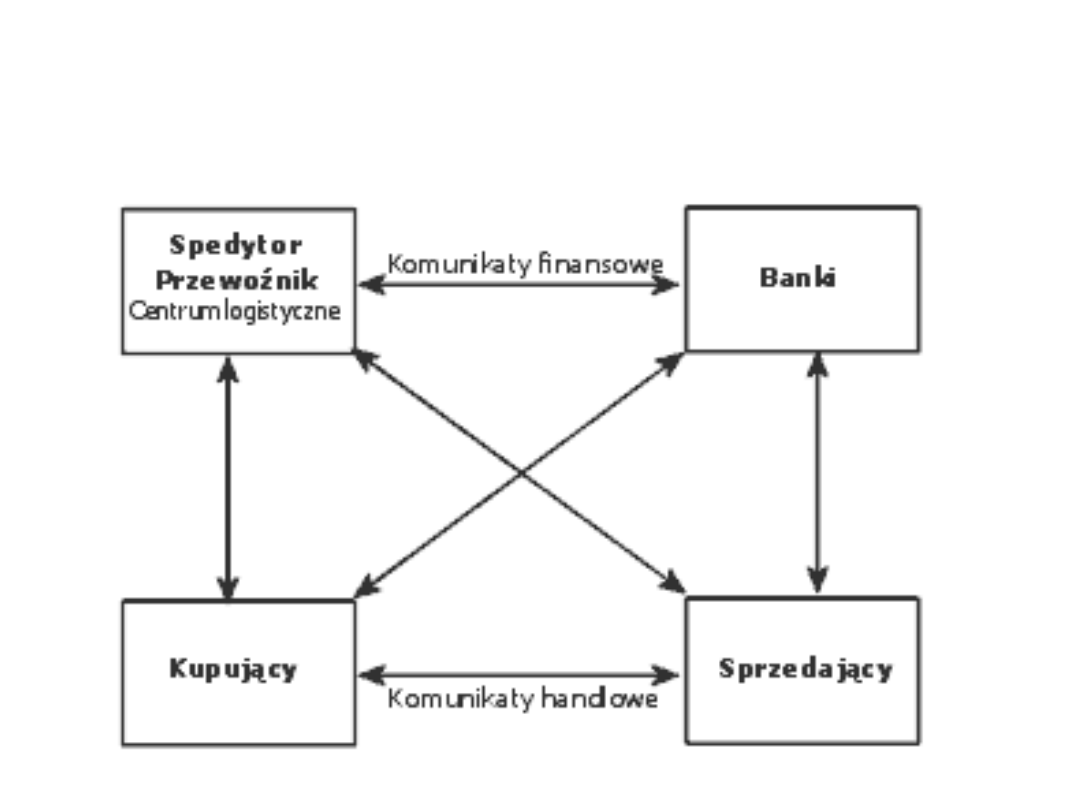
Standardy EDI
Komunikaty (dokumenty) standardu EDIFACT
umożliwiają przesyłanie informacji
niezbędnych do realizacji transakcji
handlowych. Komunikaty te można podzielić
na trzy grupy:
komunikaty handlowe (katalog cenowy,
zamówienie, faktura), które umożliwiają
wymianę informacji pomiędzy sprzedającym i
kupującym,

Standardy EDI
komunikaty transportowe (zlecenie
transportowe, awizo dostawy) używane w celu
organizacji dostawy towaru,
komunikaty finansowe (przelew, informacja o
ruchu na koncie) używane do realizowania
płatności i informowania o ruchach
pieniężnych
Standardy EDI

Standardy EDI
Dokumenty dostępne w
standardzie EDIFACT można
podzielić na następujące grupy:
Dane podstawowe - zawierające informacje
o firmach i produktach, które są wymieniane
pomiędzy partnerami handlowymi, a do
których odwołują się inne komunikaty
przesyłane pomiędzy nimi.

Standardy EDI
Transakcje - opisujące procesy
handlowe pomiędzy współpracującymi
firmami. Rozpoczynają się od
zamówienia towaru lub usługi,
zawierają komunikaty niezbędne dla
transportu towarów i kończą transakcję
fakturą oraz zleceniem płatniczym za
towary lub usługi.

Standardy EDI
Raporty i planowanie, to komunikaty
używane dla informowania partnerów
handlowych o aktualnej sytuacji w
zakresie posiadanych towarów i
planach na przyszłość umożliwiających
efektywne planowanie i zarządzanie
łańcuchem dostaw.
Standardy EDI
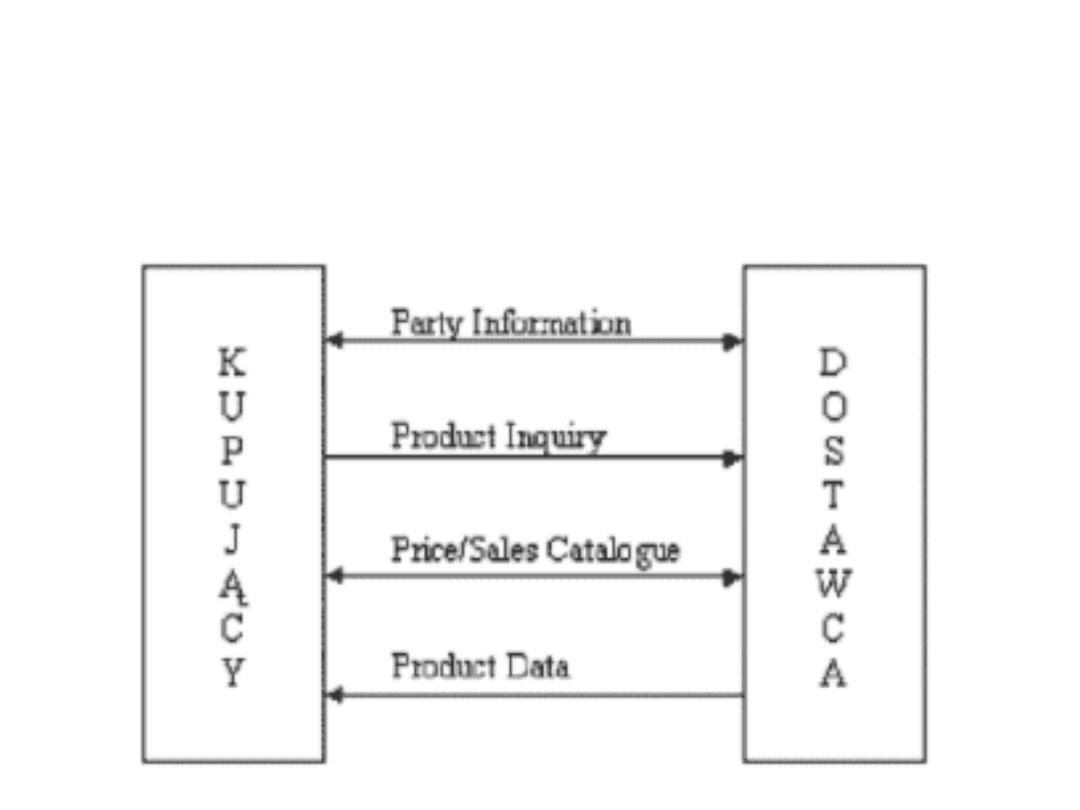
Dane podstawowe

Standardy EDI
Dane podstawowe:
Party Information (PARTIN)
Komunikat wymieniany jako pierwszy pomiędzy firmami
rozpoczynającymi współpracę handlową. Zawiera nazwę
firmy oraz dane o lokalizacji, oddziałach, administracji, dane
handlowe i finansowe. Komunikat może być wykorzystany do
tworzenia centralnego katalogu adresów i podstawowych
informacji, dostępnego dla wszystkich zainteresowanych
firm.
Product Inquiry (PROINQ)
Komunikat umożliwiający kupującemu uzyskanie informacji o
towarach i usługach zawartych w katalogu sprzedającego.

Standardy EDI
Dane podstawowe:
Price/Sales Catalogue (PRICAT)
Komunikat wysyłany przez producenta / dostawcę do
swoich odbiorców. Zawiera katalog lub listę produktów
dostawcy.
Product Data (PRODAT)
Komunikat podobny do Price/Sales Catalogue (PRICAT),
zawierający jedynie dane techniczne i funkcjonale
produktu, a nie zawierający żadnych danych
handlowych i logistycznych.
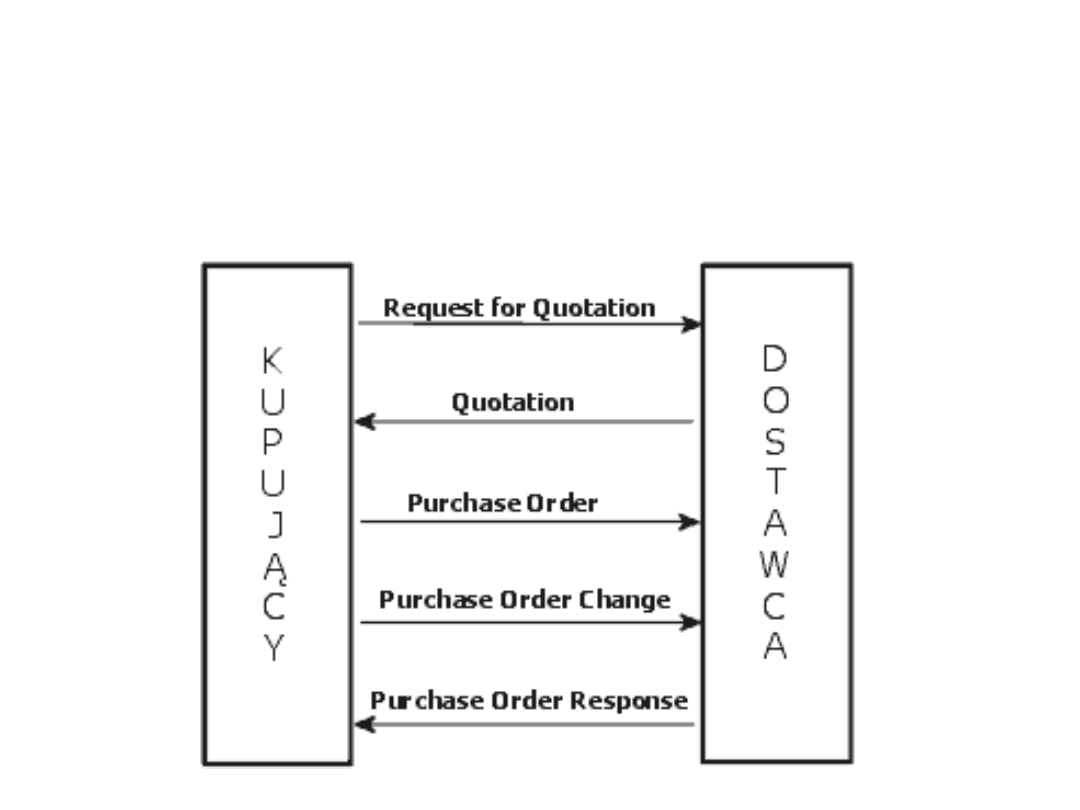
Standardy EDI
Transakcje:

Standardy EDI
Transakcje:
Request for Quotation (REQOTE)
Komunikat wysyłany przez kupującego do sprzedawcy z
prośbą o warunki sprzedaży. Dokument może zawierać
propozycję warunków i terminu płatności oraz określać
wielkość zamówienia wraz ze specyfikacją
poszczególnych miejsc i terminów odbioru towarów.
Quotation (QUOTES)
Komunikat przesyłany od sprzedawcy do kupującego w
odpowiedzi na prośbę o ofertę i zawiera wszystkie
informacje o warunkach płatności, cenach i warunkach
dostawy towarów.

Standardy EDI
Transakcje:
Purchase Order (ORDERS)
Komunikat wysyłany przez kupującego do sprzedawcy w
celu zamówienia towarów lub usług wraz z określeniem
wielkości, terminu i miejsca dostawy. Może odnosić się do
wcześniejszej oferty. Stosowaną praktyką jest składanie
codziennych zamówień z ogólną regułą jedna dostawa,
jeden termin, jedno miejsce dostawy. Komunikat może
być wykorzystany także do przesłania wymagań
dotyczących pakowania i etykietowania towarów.

Standardy EDI
Transakcje:
Purchase Order Response (ORDRSP)
Komunikat wysyłany przez sprzedającego do
kupującego potwierdzający otrzymanie zamówienia.
Komunikat akceptuje całość zamówienia lub służy do
przesłania propozycji zmian czy odwołania części
ewentualnie całego zamówienia.

Standardy EDI
Transakcje:
Purchase Order Change
Request (ORDCHG)
Komunikat wysyłany przez kupującego do
sprzedającego w celu wprowadzenia zmian
we wcześniejszym zamówieniu. Kupujący
może prosić o zmianę lub rezygnację
z jednego lub kilku zamawianych towarów.
Standardy EDI
Transakcje:
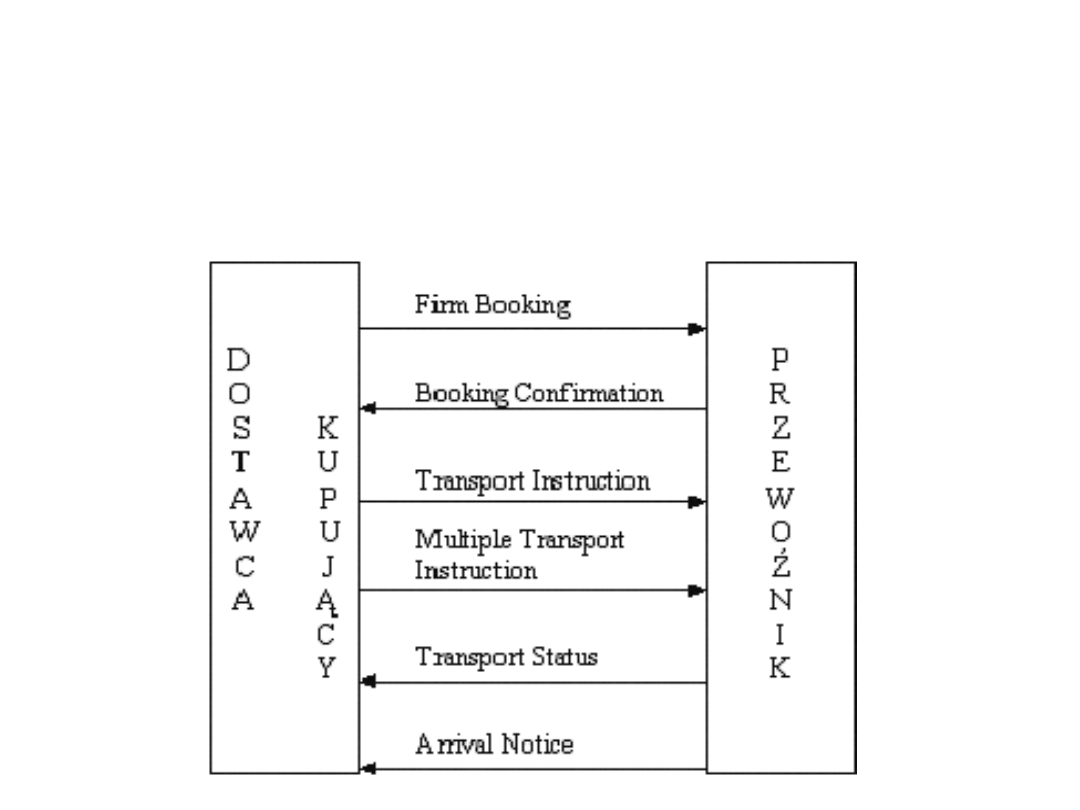
Standardy EDI
Transakcje:
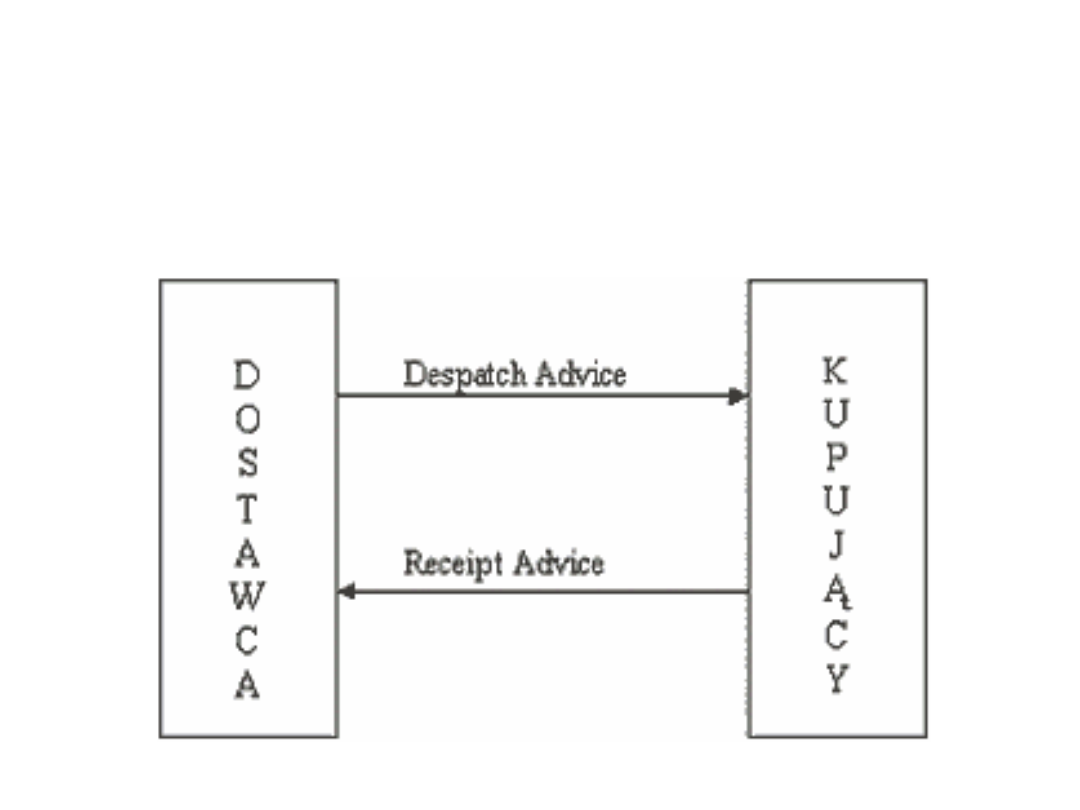
Standardy EDI
Transakcje:
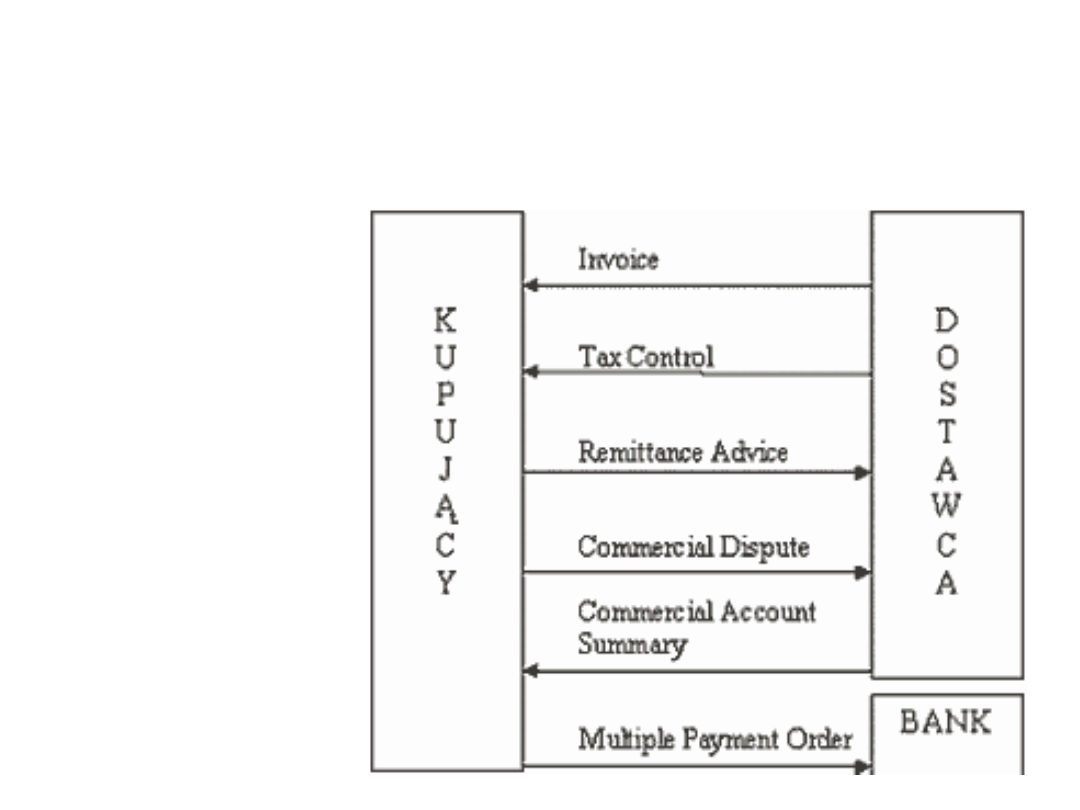
Standardy EDI
Transakcje:
Standardy EDI
Transakcje:
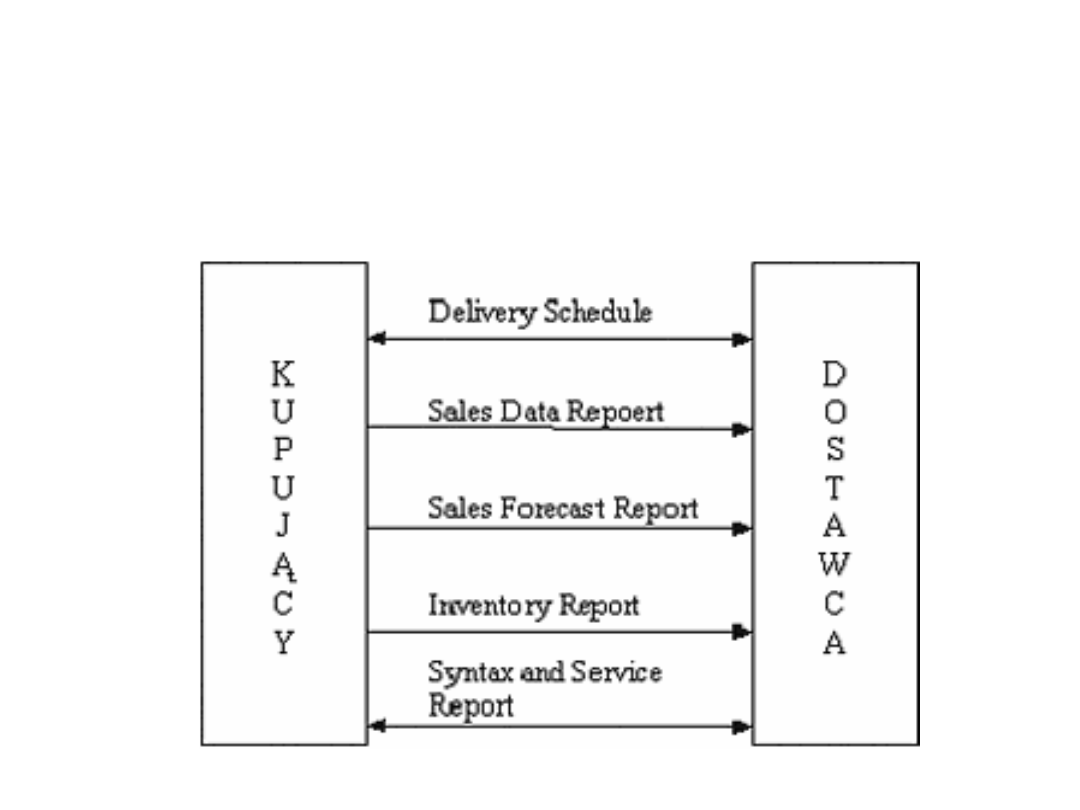
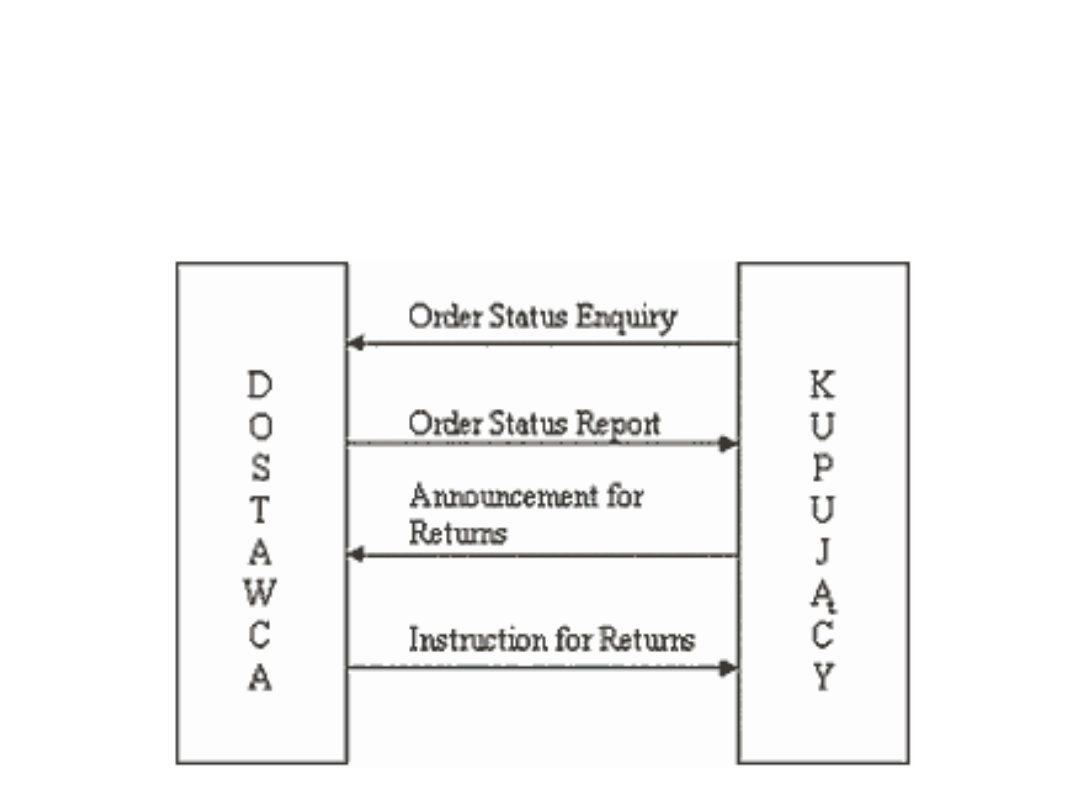
Standardy EDI
Raporty i planowanie:
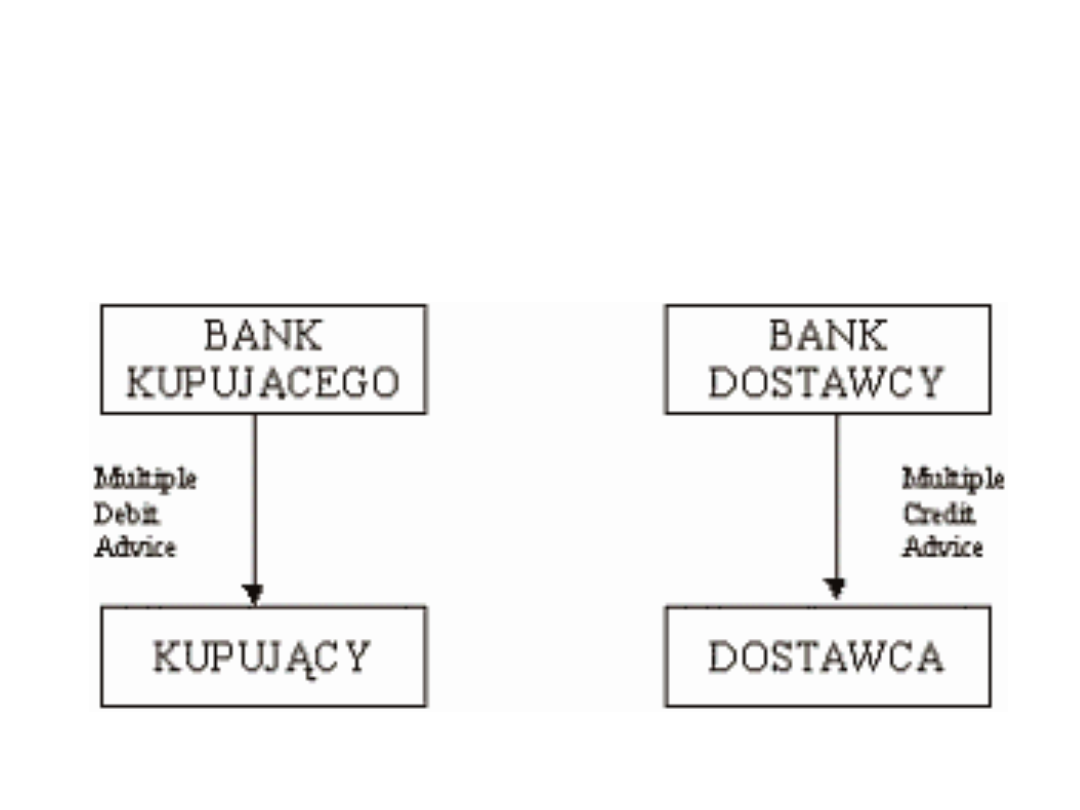
Standardy EDI
Raporty i planowanie:
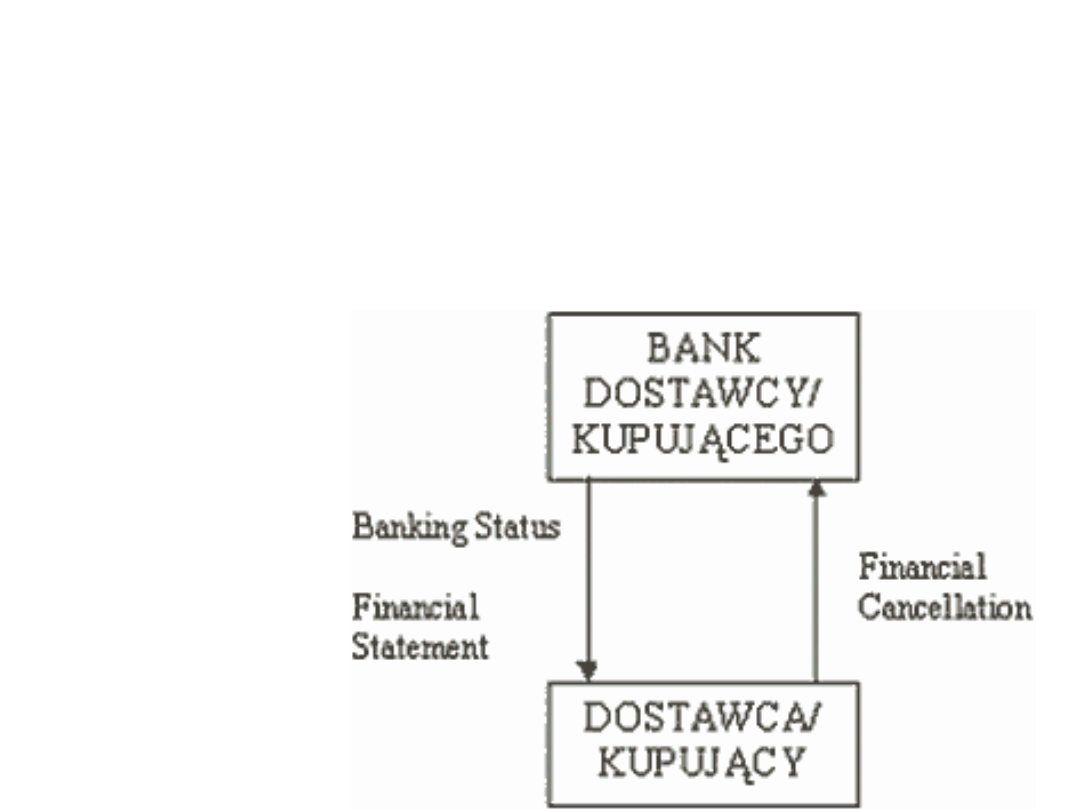
Standardy EDI
Raporty i planowanie:
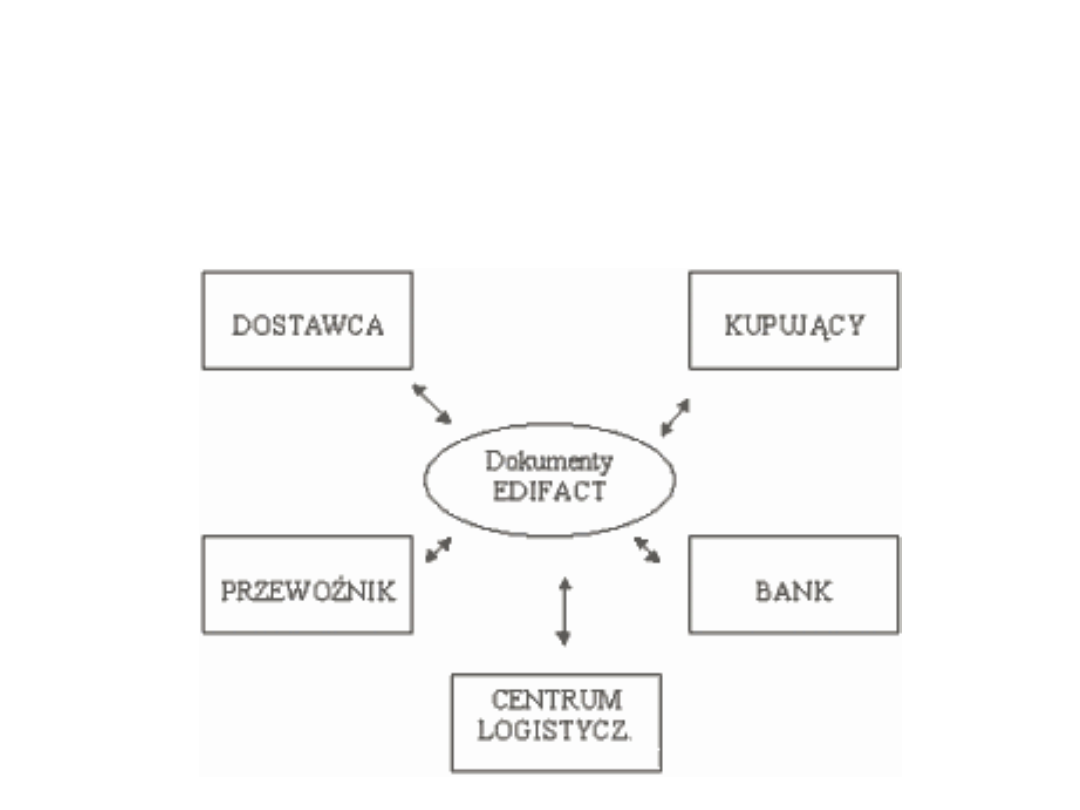
Standardy EDI
Raporty i planowanie:

Standardy EDI -
Bezpieczeństwo
Aby chronić dane, stosuje się szereg metod, a
wśród nich i te, które mają szczególne
znaczenie dla EDI. Wśród metod należy
wymienić szyfrowanie i podpis cyfrowy
zapewniające poufność informacji, autoryzację
nadawcy i odbiorcy, niezaprzeczalność
nadania i odbioru.

Standardy EDI -
Bezpieczeństwo
W czwartej wersji składni standardu EDIFACT
uwzględniono usługi ochrony informacji. Dla
protokołu internetowej poczty elektronicznej
SMTP (Simple Mail Transfer Protocol)
opracowano rozszerzenie MIME (Multipurpose
Internet Mail Extension), umożliwiające
przesyłanie komunikatów EDI, a następnie
S/MIME (Secure Multipurpose Internet Mail
Extension), które pozwala na zastosowanie
usług ochrony.

Standardy EDI -
Bezpieczeństwo
Stosowane w Internecie narzędzia
bezpieczeństwa nie są w pełni uniwersalne.
Brak jest jednolitych i wbudowanych w
internetowe technologie standardów
bezpieczeństwa.
W Internecie problemem jest również brak
mechanizmów śledzenia i potwierdzenia
transakcji. Mogą być one stworzone na
potrzeby zamkniętych społeczności.

Standardy EDI -
Bezpieczeństwo
Do tworzenia bezpiecznych systemów można
jedynie stosować istniejące rozwiązania i
technologie typu PGP (Pretty Good Privacy),
SSL (Secure Sockets Layer), SET (Secure
Electronic Transaction), STT (Secure
Transaction Technology), SEPP (Secure
Electronic Payment Protocol), PCT (Private
Communication Technology), S/HTTP (Secure
Hypertext Transfer Protocol), czy S/MIME i
inne.

Standardy EDI -
Bezpieczeństwo
BQM - przykładowa koncepcja
specyfikacji dla EDI w Internecie
BQM (Business Quality Messaging) jest
koncepcją EDI zaprezentowaną w 1997 r.
przez firmy IBM, Microsoft i Intel.

Standardy EDI -
Bezpieczeństwo
BQM jest specyfikacją techniczną opierającą się
na:
wykorzystywaniu Internetu,
tworzeniu wiadomości przez aplikacje BQM i przekazywaniu
jej do kolejki,
kopiowaniu przez system BQM wiadomości z kolejki
nadawcy do kolejki odbiorcy,
usuwaniu oryginalnej wiadomości po jej skopiowaniu,
przetwarzaniu wiadomości przez aplikację odbiorcy po jej
otrzymaniu,
usuwaniu z kolejki odbiorcy pomyślnie przetworzonej
wiadomości, która jest w tym momencie uważana za
dostarczoną.

Sieci VAN
Sieci VAN - Sieci Usług Dodanych.
VAN funkcjonuje jak biuro rozliczeń dla
transakcji elektronicznych działając jak
prywatna elektroniczna usługa pocztowa o
dużej szybkości.
Wykorzystując VAN, przedsiębiorstwo może
przesyłać wszystkie swoje pliki EDI do tego
samego miejsca. Następnie VAN rozsyła dane
do poszczególnych elektronicznych skrzynek
na listy odbiorców.

Sieci VAN
Wykorzystanie VAN dostarcza następujących
korzyści:
Elastyczność
Wielką zaletą stosowania VAN-a są jego zdolności
komunikacyjne. Wykorzystuje on szeroki wachlarz
standardowych protokołów komunikacyjnych.
Koszt
Koszty korzystania z VAN nie są wysokie. Użytkownicy
płacą roczną opłatę abonamentową oraz opłatę
naliczaną od objętości danych. Analiza korzyści
cenowych prowadzi do konkluzji, że cena serwisu EDI
jest korzystna i opłacalna.

Sieci VAN
Bezpieczeństwo
VAN umożliwia użytkownikowi wysłanie i otrzymanie
informacji tylko z jego własnej skrzynki pocztowej. VAN
obsługuje wszelki transfer informacji od skrzynki
pocztowej nadawcy do skrzynki odbiorcy. Pozwala to
partnerom handlowym czuć się pewnym, że mogą
swobodnie wymieniać informacje, uniemożliwiając
czynnikom zewnętrznym bezpośredni dostęp do swoich
własnych systemów wewnętrznych.
Konserwacja
Przedsiębiorca odpowiedzialny jest tylko za
konserwację sprzętu komunikacyjnego, który umożliwia
dostęp do VAN’a.

Sieci VAN
Księgowanie i rachunki
Transakcje użytkownika są dokładnie śledzone i
zliczane. Większość VAN-ów dostarcza szczegółowego
rozbicia kosztów za usługi wykorzystane przez ich
klienta, w podobny sposób jak towarzystwa kart
kredytowych doliczają usługi do swoich rachunków.

Sieci VAN
Usługi użytkownika
Doświadczony personel służy w razie potrzeby pomocą
w planowaniu i wdrożeniu handlu elektronicznego. VAN-
y dostarczają również różnorodnych usług, aplikacji
programowych i sieciowych, które mogą wzbogacić
powiązania w wymianie elektronicznej. Typowymi
przykładami są katalogi elektroniczne i informacyjne
bazy danych, aplikacje zarządzania magazynem, usługi
płacenia elektronicznego, EDI dla FAX-u, poczta
elektroniczna etc.

EDI - OBI
OBI (Open Buying on the Internet) jest nowym
sposobem zakupu materiałów biurowych i
drobnego sprzętu biurowego dla firm. Pierwsza
wersja specyfikacji OBI została ukończona w
marcu 1997 r. Wersja 1.1 w czerwcu 1998 r.,
kolejna w 1999 r.
OBI definiuje podstawowe elementy transakcji
online między firmami i ich dostawcami oraz
format danych wymaganych w dokumentach
związanych z zamówieniami.

EDI - OBI
Zastosowanie OBI jest znacznie prostsze niż
EDI - nie wymaga dostosowania systemów
informatycznych u współpracujących
partnerów, gdyż rozwiązanie to jest oparte na
otwartych i powszechnie stosowanych
standardach internetowych. (Istnieje wszakże
możliwość zintegrowania systemów EDI z
rozwiązaniami OBI.)

EDI - OBI
Specyfikacja OBI może pracować w połączeniu
z protokołem SET (Secure Electronic
Transactions) w celu ochrony transakcji
biznesowych przez Internet. OBI używa
protokołu SSL (Secure Sockets Layer) do
ochrony transakcji prowadzonych przez WEB.

Zastosowanie EDI
Wyróżniane są trzy poziomy zastosowań EDI w
danej organizacji gospodarczej, w zależności od
stopnia zaawansowania techniki :
Usprawnienie obrotu dokumentowego.
Usprawnienie dotyczy zarówno wystawiania dokumentów,
m.in. poprzez bezpośrednie wykorzystanie potrzebnych
danych z baz danych firmy do tworzenia dokumentu.
Ponadto zamiast wysyłania dokumentu dokonuje się
transmisji komunikatu EDI. Odbiór dokumentu w postaci
komunikatu jest prostszy niż tradycyjnie. Omijane są
procedury doręczenia, rejestracji i dekretacji wymagane w
przypadku odbioru tradycyjnego dokumentu. Ponadto
lokalna sieć komputerowa wewnątrz przedsiębiorstwa
pozwala na błyskawiczne wprowadzenie dokumentu w
obieg.

Zastosowanie EDI
usprawnianie sterowania procesami
zachodzącymi w organizacji
gospodarczej.
Przykładem jest obsługa dostaw na czas Just-in-Time-
Delivery schemat znany od dawna w teorii. Jednak
dopiero technika EDI pozwoliła na jego sprawną
realizację. Dostawca zapewnia określony, minimalny
poziom zapasów na linii produkcyjnej odbiorcy. Stan
zapasów jest monitorowany i pozwala na realizację
dostawy w odpowiednim momencie. Przychodząca do
odbiorcy dostawa jest rejestrowana za pomocą kodu
kreskowego. Następnie automatycznie uruchamia się
procedury: aktualizacji stanu zapasów, księgowania,
wystawienia i wysłania polecenia zapłaty itd.

Zastosowanie EDI
tworzenie nowych organizacji w wyniku
integracji istniejących poprzez
zapewnienie przesyłania danych między
nimi.
W tych zastosowaniach efekty finansowe, w postaci
rachunku kosztów i oszczędności uzyskanych dzięki
EDI, są mniej istotne. Ważniejsza jest oferowana przez
EDI możliwość realizacji strategii integracji między
organizacjami gospodarczymi poprzez długoterminowe
umowy i przesyłanie dokumentów oraz innych danych
między nimi.

Zastosowanie EDI
W zależności od wkładu SI w osiągnięcie celu działalności
gospodarczej obecnie i w przyszłości, systemy dzielimy
na:
systemy "wspomagania",
które w prosty sposób pomagają
uzyskiwać korzyści z działalności gospodarczej, np. systemy
biurowe;
systemy "fabryczne"
od nich zależy sukces organizacji, są
"krytyczne" dla działalności organizacji;
systemy "strategiczne"
"krytyczne" dla osiągnięcia
sukcesu w działalności gospodarczej w przyszłości;
systemy "przetwarzania"
te, które mają duże szanse
rozwoju w przyszłości (są nowym obszarem działalności
gospodarczej lub dotyczą nowych technologii).

SGML, HTML, XML

SGML-system definiowania
języków znacznikowych
SGML (Standard Genralized Markup Language) Nie
jest sam w sobie językiem znaczników! Jest jedynie
szkieletem służacym do opisywania poszczególnych
języków znacznikowych (np.DocBook, HTML, XML).
SGML jest międzynarodowym standardem (ISO
8879:1986) definiującym metody reprezentacji
tekstu w postaci elektronicznej, niezależnej od
platformy sprzętowej i systemu operacyjnego.
DocBook, HTML czy XML są specyficznymi
produktami SGML, zwanymi czasem aplikacjami
SGML .

SGML
Za twórców języka SGML uważa się
Charlesa Goldfarba, Edwarda Moshera oraz
Raymonda Loriego, którzy w 1969 roku
opracowali dla IBM-u język GML (Generalized
Markup Language - również akronim nazwisk
twórców). GML był rezultatem projektu
zintegrowanego systemu informacyjnego dla
kancelarii prawniczych i pozwalał na
edytowanie, formatowanie oraz
przeszukiwanie danych tekstowych.

SGML
Klasyfikacja dokumentów tekstowych wg
ich formatów:
Format znakowy
Historycznie najstarszy sposób przedstawiania
tekstu to reprezentacja znakowa. Niesie ona wyłącznie
informacje o treści, nie interesując się jego strukturą
lub wyglądem.
Przykłady: ASCII, ISO 8859-x, ISO 646

SGML
Format obrazowy - wektorowy
Źródeł powstania tego formatu szukać możemy w
standardzie Postscript. Jest to język programowania
przeznaczony do opisu grafiki i tekstu. Jego dużą zaletą jest
niezależność od platformy sprzętowej i programowej. Opis
strony nie jest powiązany w jakikolwiek sposób z
urządzeniem zewnętrznym i może być wydrukowany na
każdej drukarce wyposażonej w interpreter Postscriptu.
Standard ten został ustanowiony przez firmę Adobe i po raz
pierwszy pojawił się w roku 1985 w drukarkach LaserWriter
firmy Apple. Należy jednak pamiętać, że ostatecznym celem
formatu Postscript był zawsze papier.
Przykłady: PDF - (Adobe Acrobat), EVY - (Corel Envoy)

SGML
Format obrazowy - bitmapowy
Dokumenty zapisane w tym formacie są
przechowywane w postaci grafiki rastrowej. Obraz
dokumentu składa się z pojedynczych, kolejno po sobie
następujących pikseli. Parametry charakteryzujące
mapy bitowe to rozdzielczość (mierzona najczęściej w
punktach na cal) oraz głębokość palety barw.
Przykłady: TIFF, JPEG, GIF

SGML
Formaty oznaczeń tekstowych
W formacie tym wykorzystuje się pewne umowne
znaki (lub ciągi znaków), które umieszcza się w tekście.
Niosą one informacje formatujące lub dane o strukturze
logicznej dokumentu i są przy tym wyraźnie oddzielone
od treści dokumentu. Wśród formatów oznaczeń
tekstowych wyróżnić można ich dwa rodzaje:
Oznaczenia proceduralne - nastawione na jeden
szczególny język formatowania lub edytor tekstu
(RTF,TEX)
Oznaczenia ogólne - opisują strukturę logiczną
dokumentu, nie interesując się zupełnie jego wyglądem
(SGML, ODA)

SGML
Części składowe dokumentu SGML:
prolog SGML (ang. SGML prolog)
Prolog zawiera deklarację SGML (ang. SGML
declaration) oraz definicję typu dokumentu (ang.
Document Type Definition - DTD).
dokument zasadniczy (ang. document
instance)
Dokument zasadniczy zawiera tekst, który jest
oznaczony zgodnie z DTD umieszczonym w prologu.

SGML
Prolog dokumentu SGML zawiera Definicję Typu
Dokumentu (ewentualnie także Deklarację Typu
Odsyłaczy).
W Definicji Typu Dokumentu deklarowane są:
–
typy elementów i model ich zawartości
–
lista atrybutów dla każdego elementu
–
encje
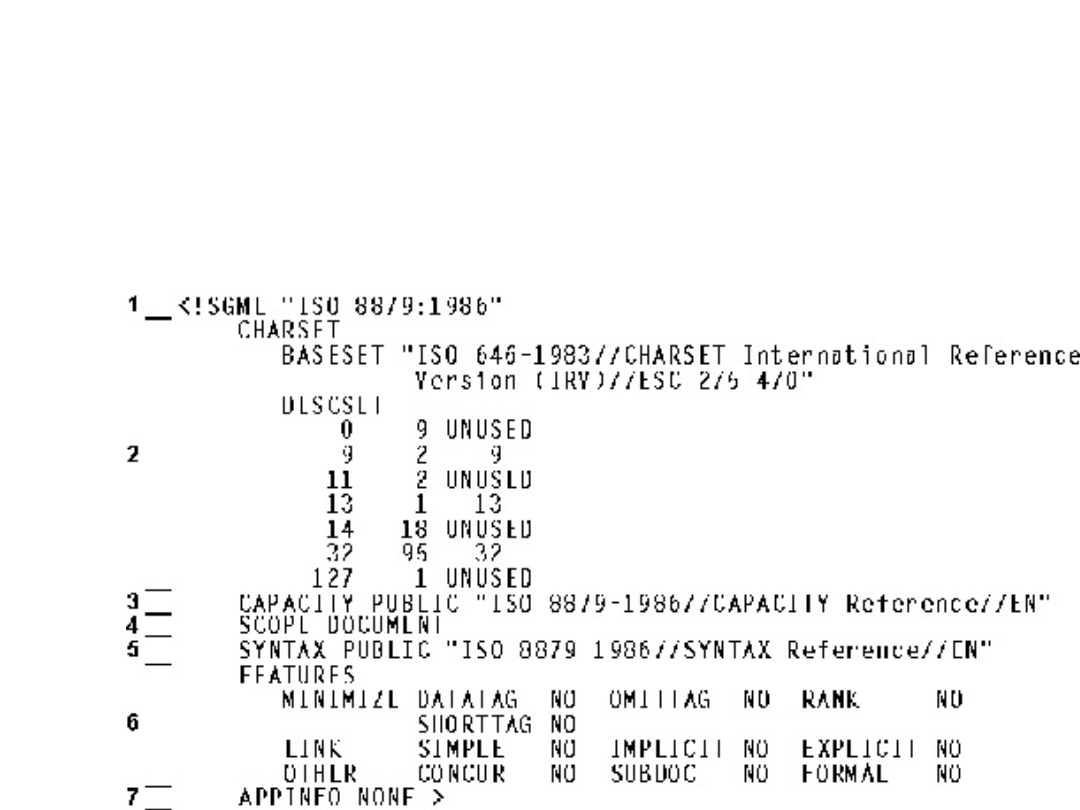
SGML
Przykładowa deklaracja dokumentu w SGML

SGML
Deklarację SGML podzielić możemy na 7
części:
1. Opisowy nagłówek
2. Zestaw znaków
3. Zestaw Pojemności (ang. Capacity Set)
4. Zakres Składni Konkretnej (ang. Concrete
Syntax Scope)
5. Składnia Konkretna (ang. Concrete Syntax)
6. Użycie dodatkowych cech (ang. Features Use)
7. Informacje dla aplikacji (ang. Application-
Specific Information)

SGML
Deklaracja SGML dostarcza wprost lub pośrednio wszystkich
informacji związanych z językiem znakowania i sposobem zapisu,
zgodnie z zasadą całkowitego samoopisania dokumentu.
SGML przewiduje dużo zawiłych i formalnych ustaleń, bowiem nie
tylko nie zakłada żadnego konkretnego programu do edycji czy
interpretacji dokumentów, ale nawet systemu operacyjnego czy
platformy sprzętowej.
W systemach używanych powszechnie dzisiaj, przedmiot owych
ustaleń przesądzony jest często przez sam system operacyjny lub
wpisany jest w program, pozostając niezauważalny dla użytkownika.

SGML
DTD (and. Document Type Definition) określa
on logiczną strukturę dokumentu, wzajemne
zależności zachodzące pomiędzy jej częściami
składowymi oraz ich prawidłową kolejność.
DTD opisuje strukturę nie tylko jednego
dokumentu, ale całej klasy dokumentów

SGML
Elementy DTD:
Deklaracja typu dokumentu
Deklaracja elementu
Deklaracja atrybutu (ang. attribute)
Deklaracja encji (ang. entity)

SGML
Deklaracje typu odsyłaczy (Link Type Declaration).
LTD jest opcjonalną, równoległą do DTD definicją różnych
typów odsyłaczy wiążących struktury dokumentu. Deklarowana
jest nazwa odsyłacza i sposób jego realizacji.
Odsyłacze mogą być trojakiego typu:
–
proste (SIMPLE LINKS) o sposobie realizacji wskazanym przez
atrybut elementu w którym występują,
–
założone (IMPLICIT LINKS) realizowane w przypadku każdego
wystąpienia danego elementu, albo też związane z konkretnym
elementem w dokumencie, wyróżnionym przez unikalny
identyfikator (atrybut typu ID),
–
wskazane odsyłacze (EXPLICIT LINKS) łączą elementy jednego typu
dokumentu z elementami dokumentu innego typu (np. podczas
transformacji dokumentu źródłowego w pochodny)

SGML
SGML – przykład definicji
<! DOCTYPE antologia [
<!ELEMENT antologia - - (wiersz+)>
<!ELEMENT wiersz - - (tytuł?, strofa+)>
<!ELEMENT tytuł - O (#PCDATA)>
<!ELEMENT strofa - O (wers+)>
<!ELEMENT wers O O (#PCDATA)>
]>

SGML

SGML
Minimalizacja oznakowania
Oznakowanie zminimalizowane skraca zapis dokumentu i czyni
tekst bardziej czytelnym dla człowieka. Usuwa z oznakowania
nadmiarową informację, ale też czyni je mniej regularnym.
Dla maszyny z kolei „prostsze” jest oznakowanie pełne. Przy
pomocy funkcji minimalizacji oznakowania można tekst oznakowany
dalece upodobnić do czystego tekstu, co ma duże znaczenie dla interfejsu
ich edycji.
Dawniej korzystano z prostych terminali znakowych, dziś edytory
oferują zwykle kilka różnych interfejsów (znakowy, oddawanie znaczników
ikonami, interpretacja typograficzna, interpretacja schematyczna
(tabelaryczna) lub inne wyspecjalizowane). Odpowiednio
zminimalizowane oznakowanie jednak pozostaje najprostszym i
najtańszym interfejsem edycji.
Minimalizacja polega na szeregu funkcji, wymagających
wskazania w deklaracji SGML i/lub DTD:
–
pomijanie znaczników – tag omission (OMITTAG)
–
upraszczanie znaczników – tag shortening (SHORTTAG)
–
skalowanie znaczników – tag grouping (ranking) (RANK)
–
rozpoznawanie znaczników z tekstu – automatic tag recognition
(DATATAG).

SGML – HTML, XML
Język HTML (Hyper Text Markup Language),
mimo iż oparty na standardzie SGML, należy do
formatów prezentacyjnych i nie bardzo się nadaje do
kodowania struktury dokumentów. Jest to język
stosunkowo prosty i zorientowany na prezentację
dokumentu w okienku przeglądarki WWW. Możliwości
jakie oferuje są bardziej zbliżone (choć dużo uboższe)
do mechanizmów "styli" znanych z WYSIWYG, niż do
prawdziwego kodowania strukturalnego. Standard
HTML (i nie tylko) definiowany jest przez W3
Consortium (W3C) - www.w3c.org.

HTML
HTML powstał w oparciu o język SGML,
który jest poważnym systemem tworzenia
dokumentów. Tworząc strony WWW, nie
trzeba wiedzieć zbyt wiele o SGML-u, ale
znajomość najistotniejszej jego cechy,
czyli faktu, iż jest to język opisu struktury
strony a nie wyglądu konkretnych jej
elementów, może okazać się pomocna.

HTML
HTML odziedziczył po swoim przodku, języku
SGML, jego najistotniejszą cechę, jest językiem
opisu strony a nie wyglądu poszczególnych jej
elementów.
Idea polega na tym, że większość dokumentów
posiada pewne cechy wspólne, takie jak
nagłówki, akapity czy listy. Stąd też przed
rozpoczęciem pisania można określić, jakiego
typu elementy będą używane i nadać im
odpowiednie nazwy.

HTML

HTML
W HTML-u zdefiniowany jest pewien określony
zestaw stylów , używanych na stronach WWW: nagłówki,
akapity, listy i tabele. Kaskadowe arkusze stylów
(w skrócie CSS) dają zaawansowane możliwości
formatowania znaczników HTML
Dodatkowo zostały zdefiniowane również pewne
elementy formatowania znaków, jak, na przykład,
pogrubienie. Każdy taki element posiada swoją nazwę i
występuje w formie czegoś, co zostało nazwane
znacznikiem.
Tworząc stronę WWW, nadaje się różnym
elementom strony etykiety mówiące: „to jest nagłówek”
lub: „to jest element listy”.

XHTML
XHTML 1.0 (eXtensible HyperText Markup Language) ,
napisany w XML, jest standardem stworzonym z myślą o
przyszłości. Technicznie języki XHTML 1.0 i HTML 4 są bardzo
podobne do siebie. Znaczniki i atrybuty w nich użyte są
praktycznie takie same, więc przystosowanie się do specyfikacji
XHTML 1.0 wymaga spełnienia jedynie kilku prostych zasad.
Strony, stworzone w HTML-u to zwykłe pliki tekstowe (ASCII), co
oznacza, że nie zawierają one żadnych informacji właściwych dla
konkretnej platformy systemowej czy programowej.
Plik HTML zawiera następujące elementy:
–
właściwy tekst strony,
–
znaczniki HTML, określające elementy strony, jej strukturę,
sposoby formatowania i hiperpołączenia do innych stron lub
informacji innego rodzaju.
Większość znaczników ma następującą postać:
<NazwaZnacznika>tekst</NazwaZnacznika>

XHTML
XHTML to EXtensible HyperText Markup Language
XHTML jest niemal identyczny z HTML 4.01
XHTML ma czystszą formę niż HTML
XHTML jest aplikacją XML
XHTML 1.0 jest od 26 stycznia 2000 oficjalnym
standardem sieciowym. Rekomendacja W3C oznacza, że
specyfikacja jest stabilna i przetestowana.

XHTML
Po co XHTML?
W sieci umieszczanych jest coraz więcej stron WWW,
rośnie też liczba „złych” stron – stron, napisanych niepoprawnie.
Taki kod HTML:
<html>
<head>
<title>Błędny kod HTML!</title>
</head>
<body>
<h1>TU JEST EWIDENTNY BŁĄD!
</body>
</html>
będzie wyświetlany poprawnie w większości przeglądarek, mimo, że
zawiera błąd składni – brakuje w nim znacznika zamykającego </h1>.
XML nie dopuszcza takich wpadek. Dlatego połączenie języków
XML i HTML daje nadzieję na stworzenie dobrego i stabilnego narzędzia.
Dokumenty XHTML są interpretowane przez wszystkie urządzenia
radzące sobie z językiem XML. XHTML pozwala tworzyć dokumenty o
poprawnej strukturze, które działają we wszystkich przeglądarkach i są
kompatybilne wstecznie.

XHTML
Najważniejsze różnice między XHTML a
HTML:
–
Elementy XHTML muszą być poprawnie
zagnieżdżane,
–
Dokumenty XHTML muszą mieć poprawną formę,
–
Nazwy znaczników muszą być pisane małymi
literami,
–
Wszystkie elementy XHTML muszą być zamknięte

XHTML
Co to oznacza konieczność poprawnego
zagnieżdżania elementów?
W języku HTML wymaganie prawidłowego zagnieżdżania nie
musi być restrykcyjnie spełniane. Na przykład wyrażenie
sformułowane w HTML tak:
<b><i>Tekst pogrubiony i pisany kursywą...</b></i>
będzie w XHTML absolutnie niepoprawne. W XHTML
zagnieżdżenie musi być prawidłowe:
<b><i>Tekst pogrubiony i pisany kursywą... </i></b>

XHTML
Częstym błędem w zagnieżdżonych listach jest zapominanie, że lista zagnieżdżona
musi być umieszczona w obrębie elementu li. Oto zły zapis:
<ul>
<li>Punkt 1</li>
<li>Punkt 2</li>
<ul>
<li>Zagnieżdżony 1</li>
<li>Zagnieżdżony 2</li>
</ul>
<li>Punkt 3</li>
</ul>
A tutaj poprawny odpowiednik błędnego kodu:
<ul>
<li>Punkt 1</li>
<li>Punkt 2
<ul>
<li>Zagnieżdżony 1</li>
<li>Zagnieżdżony 2</li>
</ul>
</li>
<li>Punkt 3</li>
</ul>
W poprawnym przykładzie znacznik </li> został wstawiony za znacznikiem </ul>
listy zagnieżdżanej.

XHTML
Co oznacza, że dokument musi mieć poprawną
formę?
Oto wymagania, które określają poprawność
formy. Wszystkie elementy XHTML muszą być
zagnieżdżone w podstawowym elemencie html. Elementy
podrzędne danych elementów stosowane są w parach i są
prawidłowo zagnieżdżone w elemencie nadrzędnym.
Podstawowa struktura dokumentu prezentuje się tak:
<html>
<head> ... </head>
<body> ... </body>
</html>

XHTML
Dlaczego należy stosować małe litery?
Konieczność stosowania małych liter wynika z tego, że
dokumenty XHTML są aplikacjami XML, a XML to język czuły na
wielkość znaku. Tak więc znaczniki <br> i <BR> zostaną
zinterpretowane jako różne. Zgodnie z tym, zapis kodu w takiej
formie:
<BODY>
<P>Tekst</P>
</BODY>
jest niepoprawny. Poprawna postać powinna wyglądać tak:
<body>
<p>Tekst</p>
</body>

XHTML
Dlaczego należy pamiętać o znacznikach zamykających?
Wszystkie elementy, które nie są puste, muszą mieć znaczniki zamykające. Zgodnie z tym, zapisz
kodu w takiej formie:
<p>Tekst
<p>Kolejny akapit
jest niepoprawny. Poprawna postać powinna wyglądać tak:
<p>Tekst</p>
<p>Kolejny akapit.</p>
A co z elementami pustymi?
Elementy puste muszą także zostać zaopatrzone w znacznik zamykający lub znacznik otwierający
musi kończyć się znakami />. Oto nieprawidłowa postać wyrażenia:
Tu dodamy łamanie wiersza<br>
A tu pojawi się linia pozioma<hr>
Poprawny zapis wygląda tak:
Tu dodamy łamanie wiersza<br />
A tu pojawi się linia pozioma<hr />
lub
Kolejna linia <hr></hr>
Dodatkowa spacja w zapisie znacznika zamykającego, <br />, jest konieczna, aby zachować
zgodność
z obecnymi przeglądarkami.

XHTML
Jakie są obowiązkowe elementy XHTML?
Wszystkie dokumenty XHTML muszą zawierać deklarację DOCTYPE.
Obowiązkowe są także elementy html, head i body, a element title musi być zawarty
w obrębie elementu head. Oto przykład dokumentu XHTML, który może być też
traktowany jako szablon:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html>
<head>
<title>Tytuł dokumentu</title>
</head>
<body>
Zawartość dokumentu
</body>
</html>
Deklaracja DOCTYPE nie jest częścią samego dokumentu XHTML, nie jest też
elementem XHTML i nie może mieć znacznika zamykającego. Deklaracja DOCTYPE
jest zawsze umieszczana w pierwszym wierszu kodu dokumentu XHTML.

XHTML
Aby obsłużyć te różne podejścia, definicje HTML 4.0 jak i XHTML 1.0
udostępniają trzy różne „werjse” HTML-a:
HTML 4.0 lub XHTML 1.0 Transitional — jest przeznaczony głównie dla konserwatywnych
projektantów WWW, którzy chcą obsługiwać jak największą ilość istniejących przeglądarek.
Odpowiada to tej grupie użytkowników, którzy we wcześniejszej — liniowej — wersji kontinuum,
wykorzystywali znaczniki HTML 2.0. Znaczniki te wciąż stanowią absolutne minimum, podstawę
możliwości funkcjonalnych przeglądarek. Jednak aktualnie najczęściej wykorzystywane są
przeglądarki zgodne z HTML 3.2, a zatem, bezpiecznie można założyć, iż to właśnie specyfikacja
HTML 3.2 stanowi dolną, podstawową granicę możliwości przeglądarek.
HTML 4.0 lub XHTML 1.0 Frameset — to zalecane rozwiązanie dla wszystkich projektantów
stron WWW tworzących strony przeznaczone dla przeglądarek zgodnych ze standardem HTML
3.2, którzy jednocześnie chcą prezentować witryny przy wykorzystaniu układów ramek. (We
wcześniejszej wersji kontinuum układy ramek należały raczej do jego „eksperymentalnej”
części.) Aktualnie jest to raczej podejście pośrednie. Choć ta „wersja” języka daje możliwość
użycia większej liczby znaczników niż „wersja” pośrednia (Transitional), to jednak wciąż istnieje
wiele przeglądarek, które nie są w stanie obsługiwać układów ramek;
HTML 4.0 lub XHTML 1.0 Strict — przeznaczona dla projektantów WWW, który lubią
eksperymentować i chcą tworzyć swoje strony, opierając się ściśle na specyfikacjach HTML 4.0 i
XHTML 1.0. Oznacza to rezygnację ze wszystkich znaczników uznanych za „przestarzałe” i
określanie postaci dokumentów wyłącznie przy użyciu kaskadowych arkuszy stylów.

SGML – HTML, XML
XML (eXtensible Markup Language) - kolejna
aplikacja SGML, mająca zachować (niestety niezupełnie)
zgodność "w dół" z językiem HTML.
Uproszczenie w stosunku do "pełnego" standardu
SGML polega przede wszystkim na możliwości
zrezygnowania z definiowania DTD, ponieważ jego
opracowanie jest sprawa złożoną. W wielu praktycznych
zastosowaniach, zwłaszcza związanych z elektroniczną
publikacją dokumentów hipertekstowych o prostej
strukturze, nie jest to nawet konieczne.
XML to jednak jeszcze przyszłość - narzędzia do
przygotowywania oraz prezentacji tekstów dopiero
powstają, a i sama definicja języka XML nie jest jeszcze
ostatecznie ustalona.

XML
HTML i XML są ze sobą spokrewnione –
oba oparte są na Standardowym uogólnionym
języku znaczników (SGML).
Zgodnie ze swoją nazwą SGML jest
językiem bardzo ogólnym o ogromnych
możliwościach. Jednak nie ma nic za darmo: ceną
za tę uniwersalność jest złożoność tego języka,
co utrudnia jego naukę i jest powodem,
dla którego język ten nie zyskał popularności.
XML jest podzbiorem SGML, łatwiej go
używać, natomiast HTML formalnie jest aplikacją
SGML.

XML
HTML 1.0 zawierał zaledwie około tuzina
znaczników, natomiast najnowsza wersja 4.01
zawiera ich już niemal 100. Jeśli policzyć jeszcze
inne znaczniki używane w poszczególnych
przeglądarkach, liczba ta zbliży się do 120. Jeśli
jednak trzeba znakować różnorodne dane
dostępne w Sieci, to oczywiste jest, że 120
znaczników nie starczy (zresztą każda inna liczba
też będzie zbyt mała).
XML to w skrócie metaznacznikowa
specyfikacja umożliwiająca tworzenie własnych
języków znacznikowych.

XML
Jak wygląda XML?
Przykład dokumentu XML:
<?xml version="1.0" encoding="iso-8859-2"?>
<DOKUMENT>
<POZDROWIENIA>
Witaj w XML
</POZDROWIENIA>
<KOMUNIKAT>
Witaj w pokręconym świecie XML.
</KOMUNIKAT>
</DOKUMENT>

XML
Dokumenty XML składają się z elementów XML.
Podobnie jak w HTML, element tworzy się zapisując jego
znacznik początkowy. Dalej może być treść elementu
(nieobowiązkowa) – dowolny tekst i inne elementy,
na końcu jest znacznik końcowy zaczynający się od </,
na przykład </DOKUMENT>.
Istnieją jeszcze specjalne zasady dotyczące tylko
elementów bez treści. Cały dokument poza instrukcjami
przetwarzania musi być zamknięty w pojedynczym
elemencie nazywanym elementem głównym; w naszym
wypadku jest to element DOKUMENT.

XML
Tworzenie języków znacznikowych
Stosując XML można tworzyć specjalizowane języki znacznikowe, co
stanowi o ogromnych jego możliwościach. Jeśli duża grupa ludzi zgodzi się używać
jednego takiego języka, można tworzyć obsługujące taki język specjalizowane
przeglądarki i inne aplikacje. Powstały już setki takich języków, są między nimi:
–
BITS – Język technologii bankowych
–
IFX – Wymiana danych finansowych
–
BIPS – Bankowy system płatności internetowych
–
TIM – Znaczniki wymiany danych telekomunikacyjnych
–
SIF – Szkielet współpracy międzyszkolnej
–
CBL – Biblioteka biznesowa
–
ebXML – XML dla przemysłu elektronicznego
–
PDML – Znacznikowy język opisu produktów
–
FIX – Protokół wymiany danych finansowych
–
TEI – Program kodowania tekstu
Niektóre języki znacznikowe, takie jak CML (Chemiczny język znaczników)
umożliwiają graficzną prezentację złożonych cząsteczek. Łatwo też sobie wyobrazić,
jak użyteczny dla architektów byłby język potrafiący pokazać w przeglądarce
projekty budynków.
XML umożliwia nie tylko tworzenie nowych języków, ale także
rozszerzanie języków istniejących. Tak właśnie jest teraz z Rozszerzalnym HTML
(XHTML) – jeśli używamy tego języka do zakodowania stron, przeglądarka będzie
w stanie wyświetlić takie dokumenty jak zwykły HTML.

XML
Samoopisujące się dane.
Dokumenty XML same się opisują. Przyjrzyjmy się poniższemu
fragmentowi:
<?xml version="1.0" encoding="iso-8859-2"?>
<DOKUMENT>
<POZDROWIENIA>
Witaj w XML
</POZDROWIENIA>
<KOMUNIKAT>
Witaj w pokręconym świecie XML.
</KOMUNIKAT>
</DOKUMENT>
Opierając się tylko na nazwach nadanych poszczególnym
elementom możemy się domyślić, o co tutaj chodzi: jest to
dokument z pozdrowieniami zawierający dodatkową wiadomość.
Jeśli wrócisz po roku do tego dokumentu, i tak nie będziesz miał
problemu z przypomnieniem sobie jego znaczenia. Oznacza to, że
dokumenty XML w znacznej mierze same się dokumentują
(niezależnie od tego możliwe jest wstawianie do plików XML
komentarzy).

XML
Strukturalne, zintegrowane dane
Kolejną zaletą XML jest fakt, że możemy określić nie tylko same dane, ale też ich
strukturę i sposób umieszczania jednych elementów w innych. Jest to ważne
szczególnie wtedy, gdy mamy do czynienia ze złożonymi, ważnymi danymi. Można
na przykład długą transakcję bankową zapisać jako HTML, ale w XML można także
zapisać reguły semantyczne opisujące strukturę dokumentu, aby można było
sprawdzić poprawność takiego dokumentu.
Przykładowy dokumentow XML:
<?xml version="1.0" encoding="iso-8859-2"?>
<SZKOŁA>
<WYKŁAD typ="seminarium">
<WYKŁAD_TYTUŁ>XML w zastosowaniach</WYKŁAD_TYTUŁ>
<WYKŁAD_NUMER>6.031</WYKŁAD_NUMER>
<DATA_ROZPOCZĘCIA>6-1-2002</DATA_ROZPOCZĘCIA>
<STUDENCI>
<STUDENT status="słuchacz">
<IMIĘ>Edward</IMIĘ>
<NAZWISKO>Samson</NAZWISKO>
</STUDENT>
<STUDENT status="zawieszony">
<IMIĘ>Emilia</IMIĘ>
<NAZWISKO>Kowalska</NAZWISKO>
</STUDENT>
</STUDENCI>
</WYKŁAD>
</SZKOŁA>

XML
Dokumenty XML poprawnie sformułowane
Co oznacza poprawne sformułowanie dokumentu XML? Dokument taki
musi spełniać wymagania składniowe stawiane przez utworzoną
przez W3C specyfikację XML 1.0 (znajdziemy ją pod adresem
www.w3.org/TR/REC-xml). Tak najprościej mówiąc poprawność
sformułowania oznacza istnienie co najmniej jednego elementu
w dokumencie oraz istnienie takiego elementu (nazywanego głównym),
który zawiera wszystkie inne elementy występujące w dokumencie. Każdy
element musi być całkowicie zamknięty w elementach nadrzędnych
względem niego. Na przykład poniższy dokument nie jest poprawnie
sformułowany, gdyż znacznik końcowy </POZDROWIENIA> znajduje się
już po znaczniku otwierającym następnego elementu, <KOMUNIKAT>:
<?xml version="1.0" encoding="iso-8859-2"?>
<DOKUMENT>
<POZDROWIENIA>
Witaj w XML
<KOMUNIKAT>
</POZDROWIENIA>
Witaj w pokręconym świecie XML.
</KOMUNIKAT>
</DOKUMENT>

XML
Walidacja dokumentów XML
Większość przeglądarek sprawdza, czy dokumenty są poprawnie
sformułowane, niektóre natomiast przeprowadzają jeszcze walidację. Dokument
XML można walidować, jeśli związana jest z nim definicja typu dokumentu (DTD)
i kiedy dokument jest z nią zgodny.
DTD dokumentu określa jego prawidłową składnię. DTD mogą być przechowywane
w osobnym pliku lub w samym dokumencie, w elemencie <!DOCTYPE>. Oto
przykład, w którym do naszego dokumentu z pozdrowieniami dodano <!DOCTYPE>:
<?xml version="1.0" encoding="iso-8859-2"?>
<?xml-stylesheet type="text/css" href="first.css"?>
<!DOCTYPE DOKUMENT [
<!ELEMENT DOKUMENT (POZDROWIENIA, KOMUNIKAT)>
<!ELEMENT POZDROWIENIA (#PCDATA)>
<!ELEMENT KOMUNIKAT (#PCDATA)>
]>
<DOKUMENT>
<POZDROWIENIA>
Witaj w XML
</POZDROWIENIA>
<KOMUNIKAT>
Witaj w pokręconym świecie XML.
</KOMUNIKAT>
</DOKUMENT>

XML
Parsowanie XML.
Załóżmy, że mamy dokument greeting.xml:
<?xml version="1.0" encoding="iso-8859-2"?>
<DOKUMENT>
<POZDROWIENIA>
Witaj w XML
</POZDROWIENIA>
<KOMUNIKAT>
Witaj w pokręconym świecie XML.
</KOMUNIKAT>
</DOKUMENT>
Teraz chcemy pobrać z niego tekst Witaj w XML. Jednym
ze sposobów jest użycie w Internet Explorerze wysp danych XML
i użycie języka takiego, jak JavaScript, do pobrania treści elementu
POZDROWIENIA i wyświetlenia jej.

Oto jak to będzie wyglądało w stronie sieciowej:
<HTML>
<HEAD>
<TITLE>
Określanie wartości elementów z dokumentu XML
</TITLE>
<XML ID="firstXML" SRC="greeting.xml"></XML>
<SCRIPT LANGUAGE="JavaScript">
function getData()
{
xmldoc= document.all("firstXML").XMLDocument;
nodeDoc = xmldoc.documentElement;
nodeGreeting = nodeDoc.firstChild;
outputMessage = "Pozdrowienie: " + nodeGreeting.firstChild.nodeValue;
message.innerHTML=outputMessage;
}
</SCRIPT>
</HEAD>
<BODY>
<CENTER>
<H1>
Określanie wartości elementu z dokumentu XML
</H1>
<DIV ID="message"></DIV>
<P>
<INPUT TYPE="BUTTON" VALUE="Pobierz pozdrowienia"
ONCLICK="getData()">
</P>
</CENTER>
</BODY>
</HTML>
Na stronie wyświetlony zostanie przycisk Pobierz pozdrowienia. Kliknięcie go spowoduje odnalezienie przez JavaScript pliku
greeting.xml, pobranie z niego treści elementu POZDROWIENIA i wyświetlenie tego tekstu. W ten sposób można tworzyć aplikacje
obsługujące w nietypowy sposób dokumenty, a nawet można tak stworzyć specjalizowane przeglądarki XML. JavaScript używany jest
głównie do stosowania XML „na niewielką skalę”, natomiast pełną obsługę XML najczęściej oprogramowuje się w Javie. Specyfikację XML
utworzyło konsorcjum W3C.

XML
CSS i XSL
Arkusze stylów stale nabierają znaczenia także
w przypadku HTML, gdyż w specyfikacji HTML 4 wiele
wbudowanych dotąd możliwości, takich jak znacznik <CENTER>,
uznano za przestarzałe i przeznaczone do zastąpienia właśnie
przez użycie arkuszy stylów. Jednak większość kodu HTML
całkowicie pomija istnienie arkuszy stylów.
Krótko mówiąc w XML definiuje się strukturę i semantykę
dokumentu, a nie jego postać wizualną. Jeśli XML ma być
bezpośrednio wyświetlany, można albo użyć domyślnej postaci
Internet Explorera, albo użyć arkusza stylów w celu uzyskania
wyglądu niestandardowego.
Do określenia wyglądu dokumentu XML można użyć dwóch
narzędzi: arkuszy CSS lub XSL. Standard CSS używany jest
z HTML i obsługiwany jest przez liczne narzędzia. Za jego pomocą
można określić formatowanie poszczególnych elementów, stworzyć
klasy stylów, definiować czcionki, wybierać kolory, a nawet określać
rozmieszczenie elementów na stronie.

XML
CSS i XSL
Z kolei XSL jest zdecydowanie lepszy do obsługi XML,
gdyż jest znacznie silniejszym narzędziem (zresztą same arkusze XSL
są poprawnie sformułowanymi dokumentami XML). Dokumenty XSL
składają się z reguł dotyczących dokumentów XML. Jeśli wzorzec
reguły XSL pasuje do elementu XML, reguła ta przekształca
dopasowany fragment kodu na coś innego. W ten sposób można
nawet przekształcić kod XML na HTML.
O ile CSS umożliwia jedynie formatowanie elementów
i zmianę ich położenia, to XSL umożliwia zmianę kolejności
elementów, podmianę tych elementów, wyświetlanie jednych
elementów i ukrywanie innych, wybieranie stylu w zależności
nie tylko od samego elementu, ale też od jego atrybutów (elementy
XML, podobnie jak elementy HTML, mogą mieć atrybuty), wybierać
elementy w zależności od ich położenia i tak dalej. XSL składa się
z dwóch części: przekształceń XSL i obiektów formatujących XSL.

XML
XLinks i XPointers.
Trudno sobie wyobrazić Światową Pajęczynę bez łączy (zwanych
też, niezbyt ładnie, linkami) – dokumenty HTML doszły w łączeniu ze sobą
stron do perfekcji. W XML do tworzenia łączy stosuje się specyfikacje XLink
i XPointer.
Język XLink umożliwia przekształcenie elementu w łącze –
dowolnego elementu, nie tylko znanego z HTML <A>. Jest to bardzo
przydatne, szczególnie że w XML nie ma wbudowanego elementu <A>.
W XML to użytkownik definiuje elementy i on decyduje o tym, które z nich
mają być łączami.
Tak naprawdę XLink to technika znacznie potężniejsza
od popularnych hiperłączy, gdyż łącza XLink mogą być dwukierunkowe, co
pozwala użytkownikowi powrócić do punktu początkowego. Łącza te mogą
być też wielokierunkowe – mogą być nawet tak przygotowane, aby
wskazywać najbliżej położoną stronę zawierającą szukany zasób.
Z kolei za pomocą języka XPointer wskazuje się nie cały dokument,
ale jego fragment. Wskaźniki te potrafią nawet wybrać żądany element,
drugie wystąpienie danego elementu lub wystąpienie numer 11 904. Mogą
wskazywać pierwszy element potomny danego elementu i tak dalej. Dzięki
ich zastosowaniu można sięgnąć do dokumentu bez konieczności
umieszczania w nim dodatkowych znaczników.
Z drugiej strony trzeba jednak pamiętać, że XLink i XPointer to
dość nowe technologie i nie zostały jeszcze w pełni zaimplementowane
w żadnej przeglądarce.

XML
ASCII, Unicode i Uniwersalny system znaków
Znaki dokumentu zapisywane są w postaci kodów liczbowych.
Najpowszechniejszym systemem kodowania znaków jest ASCII obejmujący kody od 0
do 127, a po rozszerzeniu od 0 do 255 (czyli jeden bajt). Z powodu dużej liczby języków
(i ich symboli) W3C jako domyślny zestaw znaków XML wybrało nie ASCII, lecz
Unicode (2 bajty). Aby jednak uprościć obsługę nowego standardu, znaki kodu ASCII
pozostawiono bez zmian. W ten sposób Unicode może zawierać przeróżne symbole
używane w zestawach znaków i ideogramów. Obecnie wykorzystanych jest tylko około
40 000 kodów Unicode, z tego 20 000 to kody przeznaczone dla ideogramów Han, choć
z drugiej strony ideogramów takich istnieje ponad 80 000. 11 000 kodów przeznaczono
na koreańskie sylaby Hangul.
Dokumenty XML zapisywane są jako zwykły kod ASCII lub UTF‑8, czyli
skompresowana postać Unicode. Taki zapis jest bardzo użyteczny do zapisywania
dokumentów zawierających głównie kody ASCII, gdyż dzięki temu wszystkie te znaki
potrzebują jednego bajta, natomiast jedynie znaki spoza ASCII są zapisywane na wielu
bajtach. Dokument ASCII zakodowany jako zwykły Unicode byłby dwa razy dłuższy.
Oto jak wskazuje się użycie w dokumencie kodowania UTF‑8:
<?xml version="1.0" encoding="UTF-8"?>
<DOKUMENT>
<POZDROWIENIA>
Witaj w XML
<KOMUNIKAT>
</POZDROWIENIA>
Witaj w pokręconym świecie XML.
</KOMUNIKAT>
</DOKUMENT>

XML
ASCII, Unicode i Uniwersalny system znaków
Domyślnie, jeśli brak deklaracji sposobu kodowania, procesory
XML zakładają, że dokument jest zakodowany jako UTF‑8, więc
w przypadku dokumentów zapisanych w postaci czystego ASCII nie będzie
żadnych problemów.
Jednak nawet Unicode nie zawiera dość kodów, aby przypisać je
wszystkim powszechnie stosowanym symbolom. W związku z tym
stworzono nową specyfikację, Uniwersalny system znaków (UCS,
Universal Character system, znany też jako ISO 10646), w którym
na każdy znak używa się 4 bajtów. W ten sposób uzyskujemy ponad dwa
miliardy kodów, czyli znacznie więcej niż jest potrzebne. Możemy
zaznaczyć dokument jako zakodowany w czystym Unicode – oznaczamy
kodowanie jako UCS-2, co oznacza skompresowany, dwubajtowy UCS
(czyli ISO 10646‑UCS‑2). Można użyć oznaczenia UTF-16 – jest to
specjalne kodowanie reprezentowania symboli UCS na dwóch bajtach, co
odpowiada UCS-2. Zwykłe kodowanie UCS oznaczamy jako UCS-4 (czyli
ISO 10646‑UCS‑4).
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
- Slide 46
- Slide 47
- Slide 48
- Slide 49
- Slide 50
- Slide 51
- Slide 52
- Slide 53
- Slide 54
- Slide 55
- Slide 56
- Slide 57
- Slide 58
- Slide 59
- Slide 60
- Slide 61
- Slide 62
- Slide 63
- Slide 64
- Slide 65
- Slide 66
- Slide 67
- Slide 68
- Slide 69
- Slide 70
- Slide 71
- Slide 72
- Slide 73
- Slide 74
- Slide 75
- Slide 76
- Slide 77
- Slide 78
- Slide 79
- Slide 80
- Slide 81
- Slide 82
- Slide 83
- Slide 84
- Slide 85
- Slide 86
- Slide 87
- Slide 88
- Slide 89
- Slide 90
- Slide 91
- Slide 92
- Slide 93
- Slide 94
- Slide 95
- Slide 96
- Slide 97
- Slide 98
- Slide 99
- Slide 100
- Slide 101
- Slide 102
- Slide 103
- Slide 104
- Slide 105
- Slide 106
Wyszukiwarka
Podobne podstrony:
EDI SGML XML
02 xmlid 3920 ppt
Logika W7 8 2013 14 ppt
W7 PPT
W7 Pojęcie błędu pomiarowego ppt
W7 IMMUNOLOGIA INFEKCJI ppt
03 Sejsmika04 plytkieid 4624 ppt
Choroby układu nerwowego ppt
10 Metody otrzymywania zwierzat transgenicznychid 10950 ppt
10 dźwigniaid 10541 ppt
03 Odświeżanie pamięci DRAMid 4244 ppt
Prelekcja2 ppt
więcej podobnych podstron