Paradygmaty - semantyka zmiennych
Imperatywne języki programowania oferują abstrakcyjne mechanizmy na bazie architektury von Neumanna. Dwa podstawowe składniki tej architektury to procesor i pamięć. Określenie „abstrakcyjne mechanizmy” oznacza, że mamy do dyspozycji narzędzia pozwalające wykorzystać możliwości komputera bez zagłębiania się w szczegóły techniczne. Jednym z takich mechanizmów są zmienne. Stanowią one abstrakcję komórek pamięci: programista może przechowywać dane w pamięci, nie martwiąc się o techniczne szczegóły (np. przydział pamięci). Odpowiedniość między zmiennymi a komórkami pamięci może być bardzo bezpośrednia (np. dla zmiennych typu całkowitego) lub dość odległa (np. wielowymiarowe tablice). Każdą zmienną można jednak scharakteryzować za pomocą sześciu atrybutów [3]:
Nazwa;
Adres;
Wartość;
Typ;
Okres życia;
Zakres widoczności.
Zajmiemy się teraz po kolei wspomnianymi cechami, kładąc nacisk na sprawy mniej oczywiste (np. statyczny i dynamiczny zakres widoczności); kwestie oczywiste omówimy zdawkowo na początku wykładu.
Nazwa jest cechą rozmaitych bytów, nie tylko zmiennych. To, co musimy ustalić w odniesieniu do nazw, to technikalia nie mające większego związku z przyjętym paradygmatem programowania. A więc [3]:
Jakie znaki są dozwolone w nazwach? Tradycyjnie są to litery, cyfry i zwykle znak podkreślenia. Ale np. najnowsza wersja języka Ada (2005) przewiduje użycie dowolnych znaków z zestawu Unicode.
Liczba dozwolonych znaków: współczesne języki nie nakładają istotnych ograniczeń. Warto jednak pamiętać, że ze względu na zgodność z zewnętrznymi zasobami systemu operacyjnego nie wszystkie znaki muszą być brane pod uwagę przy rozróżnianiu nazw.
Czy duże i małe litery są rozróżniane? System Unix i język C zapoczątkowały „modę” na rozróżnianie dużych i małych liter, ale użyteczność tej konwencji wydaje się czasem wątpliwa.
Zmienne
Przypomnijmy najważniejsze informacje. Zmienna to w języku programowania abstrakcja komórek pamięci. Każda zmienna ma sześć istotnych atrybutów: nazwę, adres, wartość, typ, okres życia i zakres widoczności.
Nazwy [3]:
Już o nich mówiliśmy.
Nie każda zmienna ma nazwę: przydzielając pamięć za pomocą new (w języku C++) tworzymy zmienną bez nazwy (nazwę ma użyty wskaźnik, ale nie sama zmienna).
Adresy [3]:
Program może zawierać dwie zmienne o tej samej nazwie, nie mające ze sobą nic wspólnego, np. dwie zmienne lokalne w dwóch różnych podprogramach.
Uwaga: Słowa „podprogram” używamy w znaczeniu dowolnej jednostki kodu, która może być wywoływana. Podprogramami są, zatem funkcje, procedury, metody itp.
Ta sama zmienna lokalna może mieć różne adresy w czasie różnych wywołań tego samego podprogramu.
Nie ma, zatem jednoznacznej odpowiedniości między nazwą a adresem.
Bieżący adres zmiennej zwany jest l-wartością; to określenie bierze się stąd, że właśnie l-wartość jest potrzebna po lewej stronie instrukcji przypisania.
Teraz na przykładzie języka C++ omówimy wybrane zagadnienia związane z semantyką zmiennych.
Zmienne i stałe oraz typy danych
Reprezentacje informacji w dziedzinie komputerów nazywane są danymi. Program musi mieć możliwość przechowywania danych, na których wykonuje określone operacje (zgodnie z algorytmem).
Dzięki zmiennym i stałym istnieje możliwość reprezentowania, przechowywania i przetwarzania (manipulowania) danych. Zmienne to jedno z podstawowych pojęć związanych z programowaniem.
Język musi zarezerwować odpowiednio duży obszar pamięci do przechowywania każdego elementu danej (dana ma określoną strukturę - stąd używa się określenia struktury danych). W językach programowania w tym w języku C++ zmienna służy do przechowywania danych (reprezentacji informacji).
Jest to zaadresowane miejsce w pamięci operacyjnej (ulotnej) komputera, do którego zapisuje (umieszcza) się wartość, i z którego można odczytać zawartość (pobrać wartość) zmiennej.
W zmiennej przechowuje się wartość tymczasowo (wyłączenie komputera powoduje utratę przechowywanych danych w pamięci operacyjnej). Zwykle dane są przechowywane w sposób trwały, dzięki zapisaniu ich w pliku na dysku lub w bazie danych [6].
Pamięć operacyjną komputera można potraktować jako bez drzwiową szafę z ponumerowanymi półkami (położonych jedna nad drugą). Każda półka - komórka (miejsce, np. o organizacji bajtowej) pamięci - ma swój numer (adres). Zmienna rezerwuje zestaw (jedną lub więcej) komórek, w których może przechowywać odpowiednią wartość. Nazwa zmiennej (symboliczny adres) stanowi etykietkę takiego wydzielonego zestawu komórek w pamięci danych.
Dzięki nazwie zmiennej można taki zestaw komórek zlokalizować - bez znajomości jego rzeczywistego adresu.
Pamięć operacyjną można dzielić na pamięć programu i pamięć danych. Różne typy danych w danym komputerze zajmują różne, ale stałe, co do wielkości obszary pamięci (zestawy komórek, np. określone liczby bajtów - przy organizacji bajtowej pamięci). Przykładowy program (poniżej) wywołujący funkcję sizeof(), która umożliwia sprawdzenie rozmiarów poszczególnych typów danych ujętych w nawiasy jako parametr tej funkcji [5, 6].
W linii 1 polecenie #include <iostream> jest instrukcją preprocesora, informującą go: „Po mnie następuje nazwa pliku. Znajdź go i wstaw go w to miejsce”.
W tym programie użyto nowy operator (funkcję) sizeof() w liniach od 9 do 18 (bez linii 12, 14 i 17). Operator ten jest dostarczany z kompilatorem (zwraca rozmiar zmiennej określonego typu przekazanego mu jako parametr).
0
1
|
// Program umożliwiający sprawdzenie wybranych rozmiarow typow zmiennych
#include <iostream> // dyrektywa PREPROCESORA // polecenie cout wyprowadza dane w C++, argumenty sa oddzielane znakami << // dalej beda wyswietlane kolejno: opis typu, rozmiar (liczba bajtów), tekst i nowa linia // znak formatujący /t - wstawienie znaku tabulacji w celu wyrównania wyników
cout << ”Rozmiar zmiennej typu int to: \t\t” << sizeof(int) << ” bajty. \n”; cout << ”Rozmiar zmiennej typu long int to: \t\t” << sizeof(long) << ” bajty. \n”; cout << ”Rozmiar zmiennej typu char to: \t\t” << sizeof(char) << ” bajt. \n”; cout << ”Rozmiar zmiennej typu float to: \t\t” << sizeof(float) << ” bajty. \n”; cout << ”Rozmiar zmiennej typu double to: \t\t” << sizeof(double) << ” bajtow. \n”; cout << ”Rozmiar zmiennej typu bool int to: \t\t” << sizeof(bool) << ” bajt. \n”; system (”PAUSE”); // powstrzymanie zamkniecia okienka konsoli return 0; // funkcja main() zwraca wartość 0 } // zakończenie funkcji main()
|
Przykładowo, zmienna typu int może rezerwować w jednym komputerze 2 bajty, w innym 4 (w danym komputerze ma zawsze ten sam rozmiar).
Zmienna typu char (przechowuje znaki alfabetu) ma najczęściej rozmiar 1 bajtu.
Zmienna typu short int rezerwuje (w większości komputerów) 2 bajty, zaś long int rezerwuje 4 bajty, a zmienna typu int rezerwuje 2 lub 4 bajty.
Ustalono, że typ short int musi mieć rozmiar mniejszy lub równy typowi int, który z kolei musi mieć rozmiar mniejszy lub równy typowi long int. (Najczęściej typ short int ma 2 bajty, zaś typy int i long int mają po 4 bajty.
Znak jest pojedynczą literą (w tym znak _), cyfrą (0 - 9) lub symbolem (np.: znaki interpunkcji, +, -, <, >, = itd.) i zajmuje 1 bajt.
W tym podrozdziale zostaną opisane sposoby deklarowania i definiowania zmiennych i stałych oraz sposoby przypisywania wartości zmiennym.
Program musi odpowiednio reprezentować dane, na których wykonywane są określone operacje - po jego uruchomieniu. Zmienne i stałe umożliwiają pracę z wartościami dowolnego typu, a w szczególności: liczbami, tekstami i wieloma innymi bardziej lub mniej złożonymi strukturami danych. Zatem zmienne pozwalają na przechowywanie w programie danych. Z programistycznego punktu widzenia zmienna to wybrany obszar (komórki pamięci) w pamięci komputera, w którym przechowuje się dane potrzebne do działania aplikacji i z którego można wartość tą pobrać (odczytać). Każda zmienna posiada przede wszystkim swój adres i typ (ponadto posiada: nazwę, wartość, czas życia, zakres widoczności). Jednak dla wygody w programie zmienne są identyfikowane nie poprzez ich adresy, lecz poprzez nazwy. Nazwa zmiennej to etykieta określonego obszaru pamięci (tzw. pamięci danych). Dzięki temu można używać takiej nazwy (adres symboliczny), zamiast adresu.
Gdy definiuje się zmienną w C++ (tutaj występują te same typy danych, co w języku C), to oprócz jej nazwy należy podać, jakiego typu wartość ma ona przechowywać (np.: liczby całkowite, liczby rzeczywiste, łańcuchy znaków itd.). A zatem typ zmiennej określa, jakiego rodzaju dane może ona przechowywać. Na przykład, jeśli chce się przechowywać liczby całkowite, to należy powołać do życia (zadeklarować lub zdefiniować) zmienną o odpowiednim typie pozwalającym na przypisanie jej liczb całkowitych.
Jeśli chce się przechowywać liczby ułamkowe (rzeczywiste: ułamki właściwe i niewłaściwe), to należy użyć zmiennej pozwalającej na przechowywanie liczb ułamkowych, i tak dalej.
Typ zmiennej to informacja dla kompilatora, jaki obszar pamięci ma zarezerwować na wartość przechowywaną przez daną zmienną.
Uwaga: Podczas uruchamiania jakiegoś programu jest on ładowany z pliku (zapisanym na nośniku np.: HDD, FDD, CDROM itp.) do pamięci operacyjnej komputera (RAM w tzw. pamięci programu) i również w tej pamięci przechowywane są powołane do wykonania zadania (określonego algorytmem) wszystkie zmienne (pamięć danych).
Zanim zostanie użyta jakaś nazwa w C++ (dotyczy to każdej nazwy), musi być wcześniej zadeklarowana. Zatem, deklaracje dotyczące zmiennych wprowadzają nazwy odnoszące się do danych (mogą one wystąpić w dowolnym miejscu w bloku, nie tylko na początku).
Deklaruje się, że opisuje ona obiekt określonego typu (całkowitego -int, zmiennoprzecinkowego - float,...) - jest to informacja dla kompilatora, jak ma postępować w przypadku napotkania takiej nazwy. Na przykład, deklaracja int b; informuje kompilator, że napotkana nazwa b jest zmienną typu int.
Taka deklaracja jest jednocześnie definicją, co oznacza, że poza informacją dla kompilatora, co oznacza nazwa b, żąda się by kompilator zarezerwował odpowiedni obszar w pamięci na zmienną b (powołał ją do życia).
Może się zdarzyć, że taka zmienna już istnieje gdzieś w programie, a chce się tylko przekazać do kompilatora informację o jej typie.
Na przykład konstrukcja składniowa, extern int b; informuje kompilator, że obiekt typu int o nazwie b już jest powołany do życia (np. na zewnątrz pliku, którym zajmuje się kompilator, lub może oznaczać to, że ta zmienna występuje w jakiejś funkcji bibliotecznej, którą dołącza się później na etapie linkowania).
Różnica między deklaracją a definicją polega na tym, że:
Deklaracja - informuje kompilator, że napotkana nazwa reprezentuje obiekt określonego typu, jednak nie rezerwuje dla niego obszaru w pamięci operacyjnej.
Definicja analogicznie jak deklaracja informuje kompilator o typie zmiennej, ale dodatkowo rezerwuje na nią odpowiedni obszar pamięci operacyjnej. Definicja jest miejscem, gdzie powołuje się obiekt do życia.
Istotą programowania obiektowego jest projektowanie i rozbudowywanie własnych typów danych, które pasują do danych. Wbudowane typy danych w C++ należą do dwóch kategorii: typy podstawowe (np.: int, float) i typy złożone (oparte na typach podstawowych np.: tablice, łańcuchy, wskaźniki). Program musi zabezpieczyć możliwość odwoływania się do przechowywanych danych. Aby zapisać w pamięci komputera jakąś daną, należy zapamiętać jej trzy podstawowe cechy:
Miejsce (adres) przechowywania danej (reprezentacji informacji; za pomocą operatora & można pobrać adres zmiennej).
Przechowywaną wartość.
Rodzaj (typ) przechowywanej wartości (np. int licznik; z deklaracji tej wynika, że zmienna licznik może przyjmować wartości z określonego zbioru liczb całkowitych).
Zwykle deklaruje się potrzebne zmienne. Typ użyty w deklaracji decyduje o rodzaju reprezentacji informacji, a jej nazwa symbolicznie opisuje wartość.
W C++ zalecanymi nazwami zmiennych są zmienne, których nazwy spełniają następujące zasady [12]:
Dopuszczalnymi znakami są litery, cyfry oraz znak podkreślenia (podkreślnik _).
Pierwszy znak nazwy nie może być cyfrą.
Duże litery są odróżniane od małych.
Nazwa nie może być słowem kluczowym (słowo ze słownika języka komputerowego, np.: int, float, return, void itp.).
Nazwy rozpoczynające się od dwóch podkreśleń lub od podkreśnika i następującej po nim dużej litery są zarezerwowane dla implementacji (tzn. dla kompilatora i wykorzystywanych przez niego zasobów. Natomiast nazwy rozpoczynające się od pojedynczego podkreślnika zarezerwowane są dla globalnych identyfikatorów implementacji (tutaj chodzi o miejsce deklarowania zmiennych).
W języku C++ długość nazwy nie jest ograniczona, gdzie wszystkie znaki są ważne i brane pod uwagę.
Przykładowe deklaracje zmiennych w C++:
int Licznik; // poprawna deklaracja
int licznik; // poprawna deklaracja innej zmiennej niż Licznik
int 5Licznik; // niepoprawna deklaracja (zaczyna się od cyfry 5)
int double; // niepoprawna deklaracja (double jest słowem kluczowym)
int begin; // poprawna deklaracja (begin nie jest słowem kluczowym) int m-zmienna; // niepoprawna deklaracja (nie można stosować znaku -)
short wynik; // poprawna deklaracja zmiennej całkowitej typu short
long liczbaOsob // poprawna deklaracja zmiennej całkowitej typu long
char litera // poprawna deklaracja zmiennej znakowej typu char
Typy całkowitoliczbowe różnią się ilością miejsca (liczbą bitów przeznaczonych do reprezentacji liczby w pamięci komputera) przeznaczonego na zapis wartości.
Podstawowe typy całkowitoliczbowe uporządkowane według szerokości (liczby bitów na reprezentację), to short, int, long. Każdy ma odmianę bez znaku i ze znakiem.
Korzystając z różnej liczby bitów do reprezentacji wartości, typy short, int i long pozwalają zapisywać liczby całkowite o różnej szerokości (wielkości).
Język C++ jest dość elastycznym standardem i określa tylko gwarantowaną wielkość minimalną (analogicznie jak w C) [12]:
Liczby typu short muszą mieć przynajmniej 16 bitów.
Liczby typu int muszą być niemniejsze od liczb typu short.
Liczby typu long muszą mieć przynajmniej 32 bity i być nie mniejsze od liczb typu int.
Wiele obecnie używanych systemów ma typy całkowite ustalone na minimalnym poziomie, tzn. short - 16 bitów, int - 16 bitów, 24 bity lub 32 bity, long - 32 bity. Niektóre implementacje C++ pozwalają ustawiać wielkości liczb typu int [12].
Zatem, program w C++ musi pamiętać: gdzie są przechowywane dane, jaka wartość jest przechowywana i jakiego typu są dane. Deklaracja zmiennych prostych opisuje typ i nazwę symboliczną wartości; wystarcza to programowi do zaalokowania pamięci na wartość i do wewnętrznego zapamiętania położenia tej danej.
Program obiektowy różni się od programu proceduralnego tym, że w programie obiektowym decyzje podejmowane są głównie na etapie (w czasie) wykonywania programu (program jest uruchomiony, decyzje podejmowane zapewniają elastyczność stosownie do okoliczności - np. decyzja o wielkości tablicy), a nie na etapie kompilacji (kompilator zestawia program w całość).
W języku C++ istnieje druga metoda przechowywania danych, która jest niezwykle istotna w przypadku tworzenia klas.
Strategia ta opiera się na wskaźnikach zmiennych (nie przechowują wartości zmiennych), które przechowują jedynie adresy tych zmiennych (tzn. zawartością wskaźników są adresy tych zmiennych).
Aby określić adres zwykłej zmiennej, wystarczy zastosować operator adresu, &, do zmiennej (np. dla zmiennej MojaZmienna, wyrażenie &MojaZmienna oznacza adres tej zmiennej).
Zastosowanie tego operatora można zobaczyć w programie adres.cpp [12]:
0
1 19 20 |
// Program adres.cpp ilustruje użycie operatora & do wyznaczenia adresu zmiennych
#include <iostream> // dyrektywa PREPROCESORA
int MzmiennaCalk = 5; double MzmiennaReal = 3.5; // polecenie cout wyprowadza dane w C++, argumenty sa oddzielane znakami << // tutaj cout wypr.: tekst (Wart. zm. typu =), tabul., zawart. zm., tekst, adres zm., nowa linia cout << ”Wartosc zmiennej typu int = \t” << MzmiennaCalk; cout << ”, a adres zmiennej MzmiennaCalk = \t” << &MzmiennaCalk << endl; //Uwaga: moze okazac się koniecznym uzycie unsigned(&MzmiennaCalk) // oraz uzycie unsigned(&MzmiennaReal), ze wzgledu na klopoty ze zgodnością // implementacji ze standardem C++ cout << ”Wartosc zmiennej MzmiennaReal typu double = \t” << MzmiennaReal; cout << ”, a adres zmiennej MzmiennaReal = \t” << &MzmiennaReal << endl; system (”PAUSE”); // powstrzymanie zamkniecia okienka konsoli return 0; // funkcja main() zwraca wartość 0 } // zakończenie funkcji main() |
W linii 1 polecenie #include <iostream> jest instrukcją preprocesora, informującą go: „Po mnie następuje nazwa pliku. Znajdź go i wstaw go w to miejsce”.
Program obiektowy tym się różni od programu proceduralnego, że w programie obiektowym decyzje podejmowane są głównie na etapie wykonywania programu (czas, kiedy program jest uruchomiony), a nie w okresie kompilacji (okres, kiedy kompilator zestawia program w całość) [12].
Nowa strategia obsługi danych jest skoncentrowana na traktowaniu nazw jako nazwanych wielkości, a wartości są ich pochodnymi. Specjalny rodzaj zmiennej - wskaźnik - zawiera adres wartości, więc nazwa wskaźnika opisuje położenie wartości.
Zastosowanie operatora *, nazywanego operatorem dereferencji, pozwala pobrać wartość umieszczoną pod zadanym adresem. Na przykład, gdy specjalna zmienna Mwskaznik jest wskaźnikiem, to zawiera ona adres, a *Mwskaznik zawiera wartość umieszczoną pod tym adresem. Zatem, jeśli Mwskaznik jest wskaźnikiem wartości typu int, zapis *Mwskaznik staje się równoważny zwykłej zmiennej typu int.
Zmienna Mzmienna typu int (to wartość całkowita) oraz zmienna wskaźnikowa p_Mzmienna to dwa spojrzenia na ten sam byt. Zatem, zmienna o nazwie Mzmienna to przede wszystkim wartość, ale za pomocą operatora & można pobrać adres tej zmiennej.
Zmienna wskaźnikowa p_Mzmienna to przede wszystkim adres, ale za pomocą operatora * można pobrać wskazywaną przez tą zmienną wskaźnikową wartość.
Zmienna wskaźnikowa p_Mzmienna wskazuje zmienną Mzmienna typu int, zatem *p_Mzmienna i Mzmienna są równoważne pod każdym względem. Wyrażenia *p_Mzmienna można użyć wszędzie tam, gdzie normalnie używa się zmiennej typu int.
W programie zm_wskaznikowa.cpp zilustrowano deklarację wskaźnika i użycie operatorów: & i * [12].
0
1 19 20 21
|
// Program zm_wskaznikowa.cpp używa zmienną wskaźnikową i operatory: & i *
#include <iostream> // dyrektywa PREPROCESORA int MzmCalk = 5; // deklaracja zmiennej MzmCalk typu int i przypisanie jej wartości 5 int *p_MzmCalk; // deklaracja wskaznika p_MzmCalk na zmienna MzmCalk typu int p_MzmCalk = &MzmCalk; //przypis. wskaz. p_MzmCalk adresu zmiennej MzmCalk // polecenie cout wyprowadza dane w C++, argumenty sa oddzielane znakami << //Pokazanie wartości dwoma sposobami cout << ”Wartosc zmiennej MzmCalk = \t” << MzmCalk; cout << ”, a watosc wskazana wyrażeniem *p_MzmCalk = \t” << *p_MzmCalk << ”/n"; //Pokazanie adresu dwoma sposobami cout << ”Adres zm. MzmCalk okresla &MzmCalk = \t” << &MzmCalk << endl; cout << ”, a adres zapisany we wskazniku p_MzmCalk = \t” << p_MzmCalk << endl; //Ilustracja uzycia wskaznika do zmiany wartosci wskazywanej zmiennej MzmCalk *p_MzmCalk = *p_MzmCalk +2; cout << ”Po operacji (linia 17) MzmCalk = ” << MzmCalk << endl; system (”PAUSE”); // powstrzymanie zamkniecia okienka konsoli return 0; // funkcja main() zwraca wartość 0 } // zakończenie funkcji main()
|
W linii 1 polecenie #include <iostream> jest instrukcją preprocesora, informującą go: „Po mnie następuje nazwa pliku. Znajdź go i wstaw go w to miejsce”.
Efektem wykonania tego programu są następujące wyniki:
Wartosc zmiennej MzmCalk = 5, a watosc wskazana *p_MzmCalk = 5
Adres zm. MzmCalk okresla &MzmCalk = 0x0065fd48,
a adres zapisany we wskazniku p_MzmCalk = 0x0065fd48
Po operacji (linia 17.) MzmCalk = 7
Typy występujące w języku C++ można podzielić na następujące główne rodzaje: typy arytmetyczne, typy logiczne, typy specjalne. Typy arytmetyczne to typy: znakowe, całkowite oraz zmiennopozycyjne, natomiast typy specjalne to: typ void, typy wskaźnikowe oraz typy referencyjne.
Schematycznie obrazuje to rysunek 1 [1]:
Rys. 1. Podział typów danych [1]
Podział ten jest umowny. Rodzina typów specjalnych zostanie opisana w dalszej części wykładu. Każda zmienna, zanim się zacznie z niej korzystać, musi zostać wcześniej zadeklarowana.
Deklaracja polega na podaniu typu oraz nazwy zmiennej. Np. można rozważyć fragment kodu [1]:
int main()
{
int liczba;
}
Została tu zadeklarowana zmienna typu int o nazwie liczba. Oznacza to, że będzie ona mogła przechowywać liczby całkowite. Deklaracja kończy się znakiem średnika, tak jak każda inna instrukcja programu.
Raz zadeklarowaną zmienną można używać w całym programie, w szczególności można przypisać jej jakąś wartość. Przypisania dokonuje się wykorzystując znak równości.
int main()
{
int liczba;
liczba = 100;
}
Takie pierwsze przypisanie nazywa się inicjowaniem zmiennej.
Aby przekonać się, że istotnie zmiennej liczba została przypisana wartość 100, najprościej będzie zlecić wyświetlenie jej zawartości na ekranie. Można do tego wykorzystać standardowy strumień wyjściowy cout oraz operator <<.
Podobnie można postąpić w tym przypadku [1]:
0
1 15
|
// Program projekt1.cpp ilustruje przypisanie zmiennej liczba wartości 100
#include <cstdlib> // prototypy funkcji biblioteki standardowej
int main() // naglowek funkcji main()
|
W linii 1 polecenie #include <iostream> jest instrukcją preprocesora, informującą go: „Po mnie następuje nazwa pliku. Znajdź go i wstaw go w to miejsce”.
W linii 11znajduje się instrukcja będącą poleceniem: wyślij do standardowego strumienia wyjściowego zawartość zmiennej liczba.
Innymi słowy: wyświetl na ekranie jej zawartość. Można przekonać się, że faktycznie wykonanie tego programu spowoduje wyświetlenie na ekranie liczby 100.
W poprzednio przedstawionych przykładach opisano szczególną funkcję main(). Jej szczególność polega na tym, że uruchomienie programu powoduje jej automatyczne wywołanie (inne funkcje trzeba samodzielnie wywołać w kodzie programu). Program jest wykonywany jest - linia za linią.
Każde wywołanie funkcji skutkuje wstrzymaniem wykonywania sekwencji instrukcji i skok do miejsca w programie, gdzie znajduje się wywołana funkcja. Po zakończeniu wykonywania sekwencji (bloku) instrukcji stanowiących ciało funkcji - sterowanie jest przekazywane do miejsca wywołania tej funkcji (w programie wywołującym tą funkcję).
Funkcje zwracają wartość lub nie zwracają żadnej wartości w zależności od ich parametru (funkcja typu void; oznacza to, że funkcja ta nie zwraca żadnej wartości).
Uwaga: funkcja main() zawsze zwraca wartość typu int.
Przykładowo funkcja wykonująca dodawanie dwóch liczb całkowitych (typu int) daje sumę - też liczbę całkowitą i powinna zwracać wartość typu int.
Natomiast funkcja, która ma za zadanie wyświetlenie na ekranie komunikatu (ciągu znaków ujętych w cudzysłów) nie zwraca żadnej wartości.
Oznacz to, że jest ona typu void. Każda funkcja musi posiadać swój nagłówek i treść (ciało). Nagłówek funkcji określa (zawiera informacje o) typ wartości zwracanej, nazwę funkcji i jej parametry. Parametry umożliwiają przekazanie wartości do funkcji. W opisywanej funkcji (dodawanie liczb całkowitych) parametrami są dwie zmienne typu int, natomiast nagłówek tej funkcji może być następujący [5]:
int Suma(int a, int b);
Typ parametrów a i b przekazuje informację o typie wartości przekazywanej do funkcji.
Konkretne wartości parametrów a i b przekazywane do funkcji są jej argumentami.
Nazwa funkcji i jej parametry (bez typu wartości zwracanej przez funkcję) nazywa się sygnaturą funkcji.
Ciało funkcji (jej treść) rozpoczyna się od otwierającego nawiasu klamrowego ({), instrukcji wewnętrznych i zamykającego nawiasu klamrowego. Tutaj zwrócenie wartości i zakończenie funkcji jest realizowane za pomocą polecenia return (brak tego polecenia w treści funkcji powoduje zwrócenie typu void). Zawsze typ zwracanej wartości musi być zgodny z typem zadeklarowanym w nagłówku funkcji. Przykładowy program dodaj.cpp zawierający funkcję Dodaj() może wyglądać następująco [5].
W linii 1 polecenie #include <iostream> jest instrukcją preprocesora, informującą go: „Po mnie następuje nazwa pliku. Znajdź go i wstaw go w to miejsce”. W liniach 3 - 8 zdefiniowano funkcję Dodaj(). Jest to funkcja dwuparametrowa (pobiera dwa parametry a i b) typu int i zwraca wartość też typu int. Początek programu głównego (nagłowek funkcji main() - linia 10). Polecenie wyświetlenia komunikatu o rozpoczęciu programu) jest w linii 12.
W trakcie wykonywania programu pojawi się prośba o podanie dwóch liczb całkowitych (linie 18 - 22). W linii 25 funkcja main() przekazuje wprowadzone z klawiatury wartości parametrów aktualnych a i b (w linii 20 i 21 - wypełnienie zmiennych a i b z klawiatury) do funkcji Dodaj().
Tutaj sterowanie z programu głównego przechodzi do funkcji Dodaj(). Na ekranie są wyświetlone wartości parametrów przekazywanych do funkcji Dodaj(). W linii 7 zwracany jest wynik działania funkcji (suma wartości parametrów aktualnych).
W linii 18 i 19 wykorzystano obiekt cin, który umożliwia wprowadzanie wartości danych (zmiennych a i b) z klawiatury.
Obiekt obserwuje klawiaturę i rejestruje wciskane klawisze (np. konstrukcja:
cin >> c
oznacza, że program oczekuje na wczytanie do zmiennej c wartości z klawiatury).
W linii 29 jest instrukcja, która umożliwia powstrzymanie okienka konsoli przed zbyt szybkim zamknięciem.
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 18 20 21 22 23 24 25 26 27 28 29 30 31
|
//Program Dodaj.cpp zawierajacy funkcję Dodaj() #include <iostream> // dyrektywa PREPROCESORA
using namespace std; // deklaracja aby uzywac nazw z przestrzeni nazw std
{ // poczatek tresci funkcji main() //, aby użyć cin dolacza się plik nagłówkowy <iostream>; typem cin jest istream // cin obsluguje wprowadzanie roznych typow danych z klawiatury; posiada on // przeciążony operator ekstrakcji (>>) - efektem jest wypełnienie określonej zmiennej cout << "Wprowadz dwie liczby calkowite: " // wyswietla tekst w cudzyslowie
cin >> a; // wypelnienie zmiennej a z bufora cin // a, znak tabulacji, zawartosc zm. b, zmiana linii
cout << "Wywolanie funkcji Dodaj() \n"; // wyswietla tekst i zmienia linie system (”PAUSE”); // powstrzymanie zamkniecia okienka konsoli
return 0; // funkcja main() zwraca 0 |
Wynik wykonania programu jest następujący [5]:
Funkcja main() !
Wprowadz dwie liczby calkowite: 3 5
Wywołanie funkcji Dodaj()
Funkcja Dodaj(), argumenty funkcji: 3 i 5
Ponownie w main() .
c ma wartosc 8
Koniec programu...
Funkcje to moduły, z których składają się programy C++, ponadto są one kluczowe dla definicji obiektowych języka C++. Funkcje w tym języku mają dwie odmiany:
Zwracające wartości;
Niezwracające wartości.
Przykłady obu rodzajów funkcji można odnaleźć w standardowej bibliotece funkcji. Ponadto można budować nowe własne funkcje obu tych odmian.
Jeżeli funkcja zwraca wartość, to tę wartość można przypisać zmiennej.
Przykładowo w bibliotece standardowej języka C/C++ można znaleźć funkcję sqrt(), która zwraca rzeczywisty pierwiastek z argumentu tej funkcji. Gdy chce się wyznaczyć pierwiastek z liczby 3.0 i przypisać go zmiennej x1, to należy napisać instrukcję [12]:
x1 = sqrt(9.0); // funkcja zwraca wartość 3.0 i przypisuje ją zmiennej x1
Wyrażenie sqrt(3.0) wywołuje funkcję sqrt(). Wyrażenie sqrt(3.0) to wywołanie funkcji, sqrt() jest funkcją wywoływaną. Na rysunku 2 przedstawiono wywołanie funkcji [12].
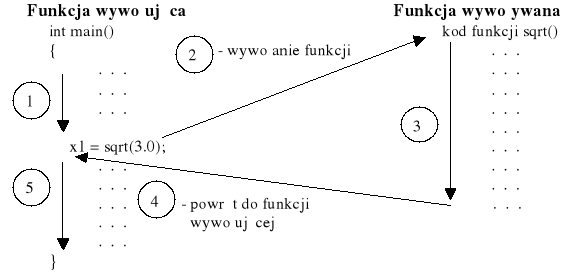
Rys. 2. Ilustracja wywołania funkcji [12]
Argumentem (parametrem) tej funkcji jest wartość 9.0, która jest przekazywana jako dana do funkcji. Funkcja sqrt() wylicza wynik (3.0) i odsyła go do funkcji wywołującej, a odsyłana wartość jest wartością zwracaną. Tę wartość można traktować jako wartość podstawianą w miejsce wywołania funkcji sqrt().
Zatem, ten przykład pokazuje sekwencję przypisania wartości zwracanej (przez funkcję) zmiennej x1.
Oznacza to, że parametr to wartość przekazywana funkcji, natomiast wartość zwracana to wartość przekazywana z funkcji.
Uwaga: program w języku C++ powinien zawierać prototypy wszystkich funkcji występujących w programie.
Prototyp funkcji pełni względem funkcji taką rolę jak deklaracja względem zmiennej. W bibliotece języka C++ zdefiniowano między innymi funkcję sqrt(), której parametrem jest liczba (z opcjonalną częścią ułamkową) oraz wartość zwracaną tego samego typu.
W innych językach np. PASCAL liczby z częścią ułamkową są nazywane liczbami rzeczywistymi - real, w C++ używa się typu double.
Prototyp funkcji sqrt() jest konstrukcją [12]:
double sqrt(double); // prototyp funkcji sqrt()
Słowo kluczowe double na początku tej konstrukcji (prototypu) oznacza, że ta funkcja zwraca wartość typu double. Natomiast słowo double ujęte w nawiasy okrągłe, oznacza, że funkcja sqrt() wymaga parametru typu double.
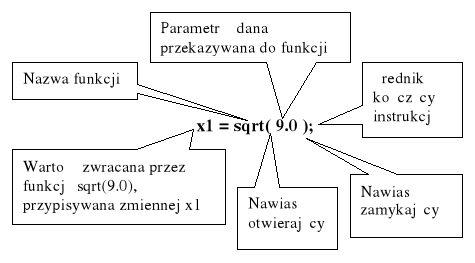
Rys. 3. Składnia wywołania funkcji sqrt() [12]
0
1 15 16 17 |
// Przykładowy program ilustrujący użycie funkcji sqrt()
// w bibliotece standardowej C++ stosowana jest przestrzeń nazw std int main() // nagłowek funkcji main()
{ // poczatek funkcji main() Bok = sqrt(Pow); // zwraca pierwiastek z zawart. zmiennej Pow i przypisuje go zm. Bok cout << ”Bok kwadratowego blatu stolika w metrach = .” << endl; system(”PAUSE”); // powstrzymanie okienka konsoli przed szybkim zamknieciem return 0; // zwracanie przez funkcje main() wartosci 0 } // zakonczenie funkcji main() |
Zatem, gdy w programie używa się funkcji sqrt(), należy podać jej prototyp. Można to zrealizować jedną z dwóch opcji [12]:
Wpisać do kodu źródłowego prototyp funkcji;
Włączyć plik nagłówkowy cmath (lub cmath.h w starszych systemach), ponieważ tam zawarty jest odpowiedni prototyp funkcji.
Nie należy mylić prototypu funkcji z jej definicją.
Prototyp opisuje jedynie interfejs funkcji (wskazuje, jakiego typu dane - parametry są przekazywana do funkcji i jakiego typu daną ta funkcja zwraca).
Definicja zawiera kod realizujący zadania funkcji.
W językach C/C++ prototyp i definicja są rozdzielone w przypadku funkcji bibliotecznych - biblioteka zawiera skompilowany kod funkcji, a prototypy są w plikach nagłówkowych.
Prototyp funkcji należy umieścić przed pierwszym wywołaniem jej wywołaniem. Najczęściej prototyp funkcji umieszcza się przed definicją funkcji main(). Funkcje biblioteczne C++ są umieszczane w plikach bibliotecznych. Kompilator na etapie kompilacji programu musi odnaleźć występujące w programie funkcje. W powyższym listingu programu użyto funkcję sqrt() zwracającą wartość.
Prototyp funkcji sqrt() jest włączany wraz z plikiem nagłówkowym cmath.
Występujące w C++ podstawowe typy danych arytmetycznych i logicznych
Standard języka C++ nie definiuje zakresów wartości, jakie mogą być reprezentowane przez poszczególne typy. Przedstawione w ostatniej kolumnie zakresy są prawidłowe dla większości współczesnych 32- bitowych kompilatorów, nie można jednak zakładać, że będzie tak w przypadku każdego systemu i każdego wykorzystywanego kompilatora.
Typ znakowy ma nazwę char i służy do reprezentacji znaków, czyli liter, cyfr, znaków przestankowych, ogólnie znaków należących do zbioru ASCII. Zmienna typu char zajmuje w pamięci 1 bajt, czyli 8 bitów. Za jej pomocą można, zatem przedstawić 256 znaków (28 = 256). Zmienną typu char tworzy się analogicznie jak wszystkie inne zmienne (char NazwaZmiennej;). Jeśli chce się przypisać do niej jakiś znak, należy ująć go w znaki apostrofu, co zilustrowano niżej:
int main()
{
char Mzmienna = 'a';
cout << Mzmienna;
}
Dla zmiennych typu char w maszynach zgodnych ze standardem ASCII poniższe dwa wiersze przypisują zmiennej znakowej inicjuj taką samą wartość:
char inicjuj = `J';
char inicjuj = 74;
Zatem, typ char zalicza się do typów arytmetycznych, gdyż zmienne takie można traktować jako liczby. Np. kodem ASCII znaku a jest liczba (dziesiętna) 97, zatem zmienna typu char zawierająca ten znak w rzeczywistości będzie przechowywała liczbę 97. Oprócz liter łacińskich, cyfr i symboli wyróżnia się także znaki, które mają specjalne funkcje (sekwencje sterujące).
Do nich należą np.: znak nowego wiersza (/n), znak tabulacji (/t), apostrof (/').
Kolejnym wielkim usprawnieniem C++ w stosunku do języka C to uproszczenie posługiwania się łańcuchami znaków (strings). Łańcuchy takie to wartości ujęte w cudzysłów, które zawierają dowolna kombinację znaków, liczb, liter, spacji lub innych symboli.
Aby używać łańcuchów, konieczne jest dołączenie pliku nagłówkowego string, który zawiera definicję potrzebnych funkcji oraz umożliwia tworzenie zmiennych (łańcuchowych) typu string:
#include <string>
Wykorzystywany już we wcześniejszych przykładach typ int służy do przechowywania liczb całkowitych. Występuje on w kilku odmianach widocznych w tabeli typy danych C++.
Typy te tworzone są w prosty sposób. Jeśli do słowa kluczowego int doda się słowo short otrzyma się typ pozwalający na reprezentacje mniejszego zakresu liczb (patrz ostatnia kolumna tabeli), jeśli natomiast doda się słowo long otrzymuje się typ pozwalający na reprezentacje większego zakresu liczb.
Oprócz tego pojawiają się nowe słowa kluczowe signed i unsigned.
Określają one, czy dany typ całkowity będzie reprezentował tylko dodatnie (unsigned - bez znaku) czy też dodatnie i ujemne (signed - ze znakiem).
W języku C++, do reprezentacji liczb zmiennoprzecinkowych (zmiennopozycyjnych) służą typy float, double i longdouble. Obsługuje on dwa sposoby zapisu takich liczb. Pierwszy to standardowy zapis zawierający kropkę dziesiętną - rozdzielającą cześć całkowitą liczby od ułamkowej np.:
// wartość zmiennoprzecinkowa
3.14159 // wartość zmiennoprzecinkowa
0.0001 // wartość zmiennoprzecinkowa
Druga metoda zapisu takich liczb nazywana jest notacją naukową.
Zawiera ona zapis (bez żadnej spacji) kolejno: liczbę (mantysę) zmiennoprzecinkową zapisywaną w sposób standardowy (z kropką dziesiętną lub bez), znak E (lub e) i liczbę całkowitą ze znakiem (cechę, wykładnik potęgi).
Na rysunku 3.4.2 przedstawiono zapis liczby zmiennoprzecinkowej w notacji naukowej [12].
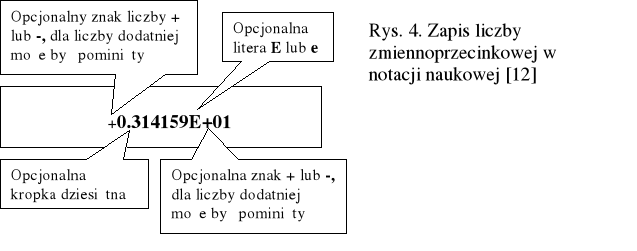
Przykładowo następujące liczby są zapisane w notacji naukowej (wykładniczej):
1.414214e+0 // przybliżona wartość ![]()
, można zamiast e użyć E, znak + jest opcjonalny
17.32051e-01 // przybliżona wartość ![]()
, wykładnik (cecha) może być ujemny
3E8 // prędkość światła w próżni 3 * 108 [m/s] może być zapisana jako 3.e8
- 12.65E1 // wartość określonej całki oznaczonej (może być dodatnia lub ujemna)
5.98e24 // masa Ziemi 5,98 * 1024 [kg]
6.371e3 // promień ziemi r = 6371 [km]
9.11E-31 // masa elektronu 9,11 * 10-31 [kg]
Zapis w notacji naukowej pozwala na przedstawienie najszerszego zakresu wartości. Typ float pozwala na zapis liczb rzeczywistych z pojedynczą, double z podwójną a longdouble z rozszerzoną (wysoką) precyzją. W C++ istnieją dwa sposoby przypisywania wartości zmiennym typu float, co zostało zilustrowane w poniższym programie. Pierwszy sposób standardowy jest intuicyjny. Część całkowitą liczby od części ułamkowej rozdzielone są kropką dziesiętną (kropką a nie przecinkiem).
Sposób drugi to zapis wykładniczy w notacji naukowej, np.: 1.1e1 oznacza wartość wyrażenia 1,1*101, czyli wartość równą 11.
Oznacza to, że w linii 8 zmiennej DLiczba przypisano wartość 11.0. O tym, że zmienna DLiczba faktycznie zawiera wartość 11.0 można się przekonać po wykonaniu 9 linii kodu cout << DLiczba << '/n';
Oczywiście na początku programu musi być linia (2) z dyrektywą preprocesora #include <iostream>, gdyż inaczej kompilator nie rozpozna obiektu cout.
Jeśli wyświetli się ostrzeżenie kompilatora, nie należy się nim przejmować, kompilator po prostu przypomina, że zadeklarowano zmienną Pliczba, z której potem nie skorzystano. W tym programie jedynie zademonstrowano, że zmienna DLiczba faktycznie zawiera wartość 11. Wszystko jest, zatem w porządku.
0
1 |
// Program o nazwie program2.cpp
#include <cstdlib> // prototypy funkcji biblioteki standardowej } // koniec treści funkcji main() |
Po kompilacji i uruchomieniu programu na ekranie pokaże się wynik:
Zatem w C++ istnieją trzy typy zmiennoprzecinkowe: float, double i long double. Typy te przy opisie odwołują się do tzw. liczby cyfr znaczących i dopuszczalnego zakresu wykładnika (cyfry znaczące to cyfry, które maja wpływ na dokładność zapisu liczby).
Drugi sposób przedstawienia liczb (wykładniczy, pół logarytmiczny) to taki system przedstawienia liczb, w którym zakres wyrażalnych liczb jest niezależny od liczby cyfr znaczących [9].
Problem aliasowania [3]:
Niekiedy do tej samej komórki pamięci można dotrzeć za pomocą dwóch różnych nazw.
Tak jest np. wtedy, gdy dwa wskaźniki zostaną ustawione na ten sam adres.
Na przykład [3]:
int x, *p, *q; //deklaracja trzech zmiennych typu int
//dwie ostatnie deklaracje informują, ze zmienna wskazywana wskaznikiem p i q jest typu int
p = &x; q = &x; //przypisanie zmiennym wskaznikowym adresu zmiennej x
Sytuacja taka zwana jest aliasowaniem.
Aliasowanie może prowadzić do przeoczeń i niejasności w kodzie, lepiej, więc go unikać.
Wartość [3]:
Jest to po prostu zawartość komórki pamięci związanej z daną zmienną.
Zwana niekiedy r-wartością (gdyż ją właśnie odczytuje się, gdy zmienna występuje po prawej stronie (relacji) przypisania).
Typ [3]:
Typ to zbiór dopuszczalnych wartości (liczba bitów cechy określa zakres wartości), jakie zmienna może przyjmować.
Gdy mówimy o zmiennych w reprezentacji zmiennopozycyjnej, typ określa też precyzję (liczba bitów mantysy), z jaką liczby są reprezentowane.
Z typem wiąże się również zbiór operacji dopuszczalnych dla danej zmiennej.
Szczegółowe omówienie typów znajduje się w odrębnym module.
Okres życia i zakres widoczności omówimy później.
Wiązania
Będziemy teraz mówili o różnych bytach i atrybutach, które w pewnym momencie zostają powiązane. Rzecz dotyczy bardzo rozmaitych „bytów” takich jak zmienna, operator, wywołania podprogramu i cech takich jak wartość, typ, adres.
Na przykład, deklaracja zmiennej int x powoduje związanie zmiennej x z typem int, zaś wykonanie instrukcji podstawienia powoduje związanie zmiennej z (nową) wartością.
Wiązanie może następować w różnych momentach. Oto kilka przykładów [3]:
W czasie projektowania języka programowania jego twórca wiąże gwiazdkę (* -znak) z operacją mnożenia.
W czasie implementowania języka na konkretnej maszynie (tzn. w czasie projektowania kompilatora) typ int zostaje związany z zakresem liczb całkowitych (wybór określonej liczby bitów na reprezentację typu int) dostępnym na tej maszynie.
W czasie kompilacji zmienna zostaje związana z zadeklarowanym dla niej typem.
W czasie ładowania programu do pamięci zmienna statyczna zostaje związana z konkretnym adresem w pamięci.
W czasie konsolidacji wywołanie funkcji bibliotecznej zostaje związane z kodem tej funkcji.
W czasie wykonania programu zmienna lokalna zostaje związana z przydzieloną jej na stosie pamięcią.
Rozważmy przykładowy fragment w języku C
int x;
...
x = x * 3;
Mamy tu do czynienia z następującymi wiązaniami:
Typ zmiennej x jest wiązany (z int) w czasie kompilacji.
Sam typ int jest wiązany z konkretnym zakresem liczb całkowitych (zakres jest określony liczbą bitów na zapis tych liczb) w czasie projektowania kompilatora.
Gwiazdka * jest wiązana z konkretnym działaniem arytmetycznym (dopiero) w czasie kompilacji. W tym przypadku nie wcześniej, gdyż konkretne znaczenie gwiazdki zależy od typu operandów (argumentów); gdyby jeden z nich był typu float, to gwiazdka oznaczałaby mnożenie zmiennopozycyjne, a nie mnożenie całkowite.
Wewnętrzna reprezentacja liczby 3 jest wiązana z pewnym układem bitów w trakcie projektowania kompilatora.
Wartość zmiennej x jest wiązana z konkretną liczbą w chwili wykonania podstawienia (przypisania).
Wiązania dzielimy na dwie klasy. Wiązania statyczne to te, które następują przed wykonaniem programu i nie zmieniają się w trakcie jego działania. Wiązania dynamiczne to te, które następują lub zmieniają się w trakcie działania programu.
Nie zajmujemy się wiązaniami sprzętowymi, które normalnie są dla nas niewidoczne, np. translacja adresów pamięci wirtualnej. Innymi słowy, wiązanie zmiennej statycznej z miejscem w pamięci uznajemy za statyczne, mimo że fizyczny adres tej zmiennej może zmieniać się na skutek zarządzania stronami pamięci wirtualnej.
W praktyce określenie „statycznie” oznacza „w czasie kompilacji”, zaś „dynamicznie” - „w czasie wykonania programu”.
Wiązanie typu
Każda zmienna musi zostać związana z typem przed pierwszym użyciem w programie. Rozpatrujemy dwa aspekty tej sprawy:
Jak określamy ów typ?
Kiedy następuje wiązanie?
Odpowiedź na pytanie, jak określamy typ zmiennej?
We współczesnych językach zazwyczaj mamy jawną deklarację.
Bywają też deklaracje niejawne, np. pierwsze użycie zmiennej może stanowić deklarację.
W przypadku deklaracji niejawnych konwencja może określać typ. W Fortranie pierwsza litera nazwy wyznaczała typ zmiennej, chyba, że zmienna została zadeklarowana jawnie (taka dowolność bywa myląca...). W Perlu „zasada pierwszego znaku” jest obligatoryjna.
Występuje także mechanizm wnioskowania o typie z kontekstu, np. w języku ML i Haskellu.
Odpowiedź na pytanie, kiedy następuje wiązanie?
Deklaracje dają wiązanie statyczne.
Przy wiązaniach dynamicznych, zmienna jest wiązana z typem przy pierwszym podstawieniu pod nią wartości, np. w PHP i JavaScripcie.
Wiązanie dynamiczne gwarantuje elastyczność, ale ma dwie wady: jest kosztowne (trzeba dynamicznie sprawdzać typ) i utrudnia wykrywanie błędów (kompilator ma małe szanse wykryć niezgodność typów).
Dlaczego dynamiczne wiązanie typu jest kosztowne?
Zgodność typów musi być sprawdzana dynamicznie, czyli w trakcie wykonania programu.
To oznacza, że każda wraz z każdą zmienną trzeba przechowywać deskryptor opisujący jej typ.
Operacje na zmiennej są trudniejsze, gdyż wartości różnych typów mogą wymagać pamięci o zróżnicowanym rozmiarze i zróżnicowanych działań.
W praktyce język z dynamicznymi typami musi być interpretowany a nie kompilowany: w czasie kompilacji nie wiadomo, co będą zawierały zmienne, więc nie da się wygenerować odpowiedniego kodu.
Jak wygląda wnioskowanie o typie?
Posłużymy się przykładem języka funkcyjnego ML.
Rozważmy następujące przykładowe deklaracje funkcji:
fun f(x) = 2.0 * 3.14 * x;
fun g(x) = 2 * x;
fun h(x) = x * x;
W funkcji f pojawiają się stałe zmiennopozycyjne (2.0 i 3.14), więc ML wnioskuje, że i parametr (x), i wynik funkcji f są typu zmiennopozycyjnego (real).
Analogicznie w funkcji g pojawia się stała stałopozycyjna (2) ML wnioskuje, że parametr (x) i wynik funkcji g są typu całkowitego.
W funkcji h wiadomo tylko, że chodzi o wartości liczbowe (ze względu na występowanie operatora mnożenia). Jako „domyślny” typ liczbowy przyjmowany jest typ całkowity, przeto ten właśnie typ przypisywany jest parametrowi i wynikowi funkcji.
Jeśli chcielibyśmy, by funkcja h działała na liczbach zmiennopozycyjnych, wystarczyłoby jawnie wskazać typ real choćby w jednym miejscu, przy parametrze lub wyniku. Reszta zostałaby „otypiona” dzięki wnioskowaniu o typie.
fun h(x) : real = x * x;
fun h(x : real) = x * x;
fun h(x) = (x : real) * x;
fun h(x) = x * (x : real);
Wiązanie pamięci
Wprowadźmy parę pojęć związanych z wiązaniem pamięci:
Okres życia zmiennej to czas, w którym jest ona związana z konkretnym miejscem w pamięci.
Alokacja (przydział) pamięci oznacza pobranie bloku pamięci odpowiedniej wielkości z puli wolnej pamięci i związanie go ze zmienną.
Dealokacja (zwolnienie) pamięci oznacza unicestwienie wiązania bloku pamięci ze zmienną i oddanie tego bloku do puli wolnej pamięci.
Okres życia zmiennej to, zatem czas pomiędzy alokacją a dealokacją.
Rozróżniamy cztery kategorie zmiennych, związane z ich okresem życia [3]:
Statyczne - mówimy wówczas o zmiennych statycznych.
Dynamiczne na stosie - najczęściej mówi się o zmiennych automatycznych lub po prostu lokalnych (oczywiście lokalność odnosi się w istocie nie do okresu życia, lecz do zakresu widoczności).
Dynamiczne na stercie, jawne.
Dynamiczne na stercie, niejawne.
Gdzie:
Sterta to najmniej skomplikowany sposób organizacji plików. Dane są gromadzone w kolejności ich pojawiania się. Każdy rekord przechowuje jedną operację transferu danych. Celem sterty jest proste gromadzenie danych i ich przechowywanie. Rekordy mogą mieć różne pola lub podobne pola występujące w innej kolejności. Tak, więc, każde pole powinno zawierać nazwę pola oraz jego wartość. Długość każdego pola musi być pośrednio określona za pomocą separatora, zwłaszcza dodanego jako podpole lub domyślnego dla danego rodzaju pola. Ponieważ plik typu sterta nie ma żadnej struktury, dostęp do rekordów wiąże się z intensywnym przeszukiwaniem. Oznacza to, że, jeżeli chcemy znaleźć rekord zawierający określone pole o określonej wartości, konieczne będzie sprawdzenie każdego rekordu w stercie do chwili znalezienia rekordu bądź przeszukania całego pliku. Pliki typu sterta są używane w sytuacji, gdy dane są gromadzone i przechowywane przed ich przetworzeniem lub, kiedy danych nie da się łatwo uporządkować. Ten rodzaj plików nie marnotrawi miejsca, gdy przechowywane dane są różnych rozmiarów. W stercie dane różnią się strukturą, umożliwiają zaawansowane przeszukiwanie oraz są łatwe w aktualizacji. Jednakże, poza tymi ograniczonymi zastosowaniami, tego typu plik jest nieodpowiedni w większości przypadków.
Zmienne statyczne [3]:
Wiązane z miejscem w pamięci przed rozpoczęciem wykonania programu; wiązanie to nie zmienia się w trakcie wykonania.
Zaleta: Efektywne, ze względu na bezpośrednie adresowanie.
Wada: Mało elastyczne, nie mogą być używane do obsługi wywołań rekurencyjnych.
Przykład: Zmienne globalne oraz zmienne zadeklarowane jako static w języku C.
Uwaga: W językach takich jak C++, C# i Java deklaracja zmiennej z użyciem static pojawiająca się wewnątrz definicji klasy nie oznacza zmiennej statycznej w powyższym rozumieniu, a jedynie zmienną klasową (wspólną dla całej klasy).
Zmienne dynamiczne na stosie [3]:
Gdzie: Stos (Stack) - uporządkowana lista, w której elementy są dodawane lub usuwane z tej samej listy zwanej szczytem. Oznacza to, że każdy kolejny dodawany element ląduje na szczycie stosu. Ze stosu usuwane są elementy, które są na nim najkrócej (znajdujące się na szczycie stosu). Jest to organizacja działająca wg zasady: pierwszy na wejściu, pierwszy na wyjściu.
Wiązane z pamięcią w chwili, gdy wykonanie programu dociera do ich deklaracji.
Pamięć przydzielana na stosie.
Pamięć zwalniana, gdy kończy się wykonanie bloku zawierającego daną zmienną.
Dla typowych zmiennych prostych (całkowite, zmiennopozycyjne) wszystkie atrybuty z wyjątkiem pamięci są wiązane statycznie.
Zalety: Mogą być używane w wywołaniach rekurencyjnych.
Wady: Mniejsza efektywność ze względu na pośrednie adresowanie, narzut związany z alokacją i dealokacją, brak „historii” (każde wywołanie podprogramu tworzy nową instancję zmiennych).
Przykład: Zmienne lokalne w funkcjach w języku C i w metodach w Javie.
Zmienne dynamiczne na stercie, jawne [3]:
Gdzie: Sterta to najmniej skomplikowany sposób organizacji plików. Dane są gromadzone w kolejności ich pojawiania się. Każdy rekord przechowuje jedną operację transferu danych. Celem sterty jest proste gromadzenie danych i ich przechowywanie. Rekordy mogą mieć różne pola lub podobne pola występujące w innej kolejności. Tak, więc, każde pole powinno zawierać nazwę pola oraz jego wartość. Długość każdego pola musi być pośrednio określona za pomocą separatora, zwłaszcza dodanego jako podpole lub domyślnego dla danego rodzaju pola. Ponieważ plik typu sterta nie ma żadnej struktury, dostęp do rekordów wiąże się z intensywnym przeszukiwaniem. Oznacza to, że, jeżeli chcemy znaleźć rekord zawierający określone pole o określonej wartości, konieczne będzie sprawdzenie każdego rekordu w stercie do chwili znalezienia rekordu bądź przeszukania całego pliku. Pliki typu sterta są używane w sytuacji, gdy dane są gromadzone i przechowywane przed ich przetworzeniem lub, kiedy danych nie da się łatwo uporządkować. Ten rodzaj plików nie marnotrawi miejsca, gdy przechowywane dane są różnych rozmiarów. W stercie dane różnią się strukturą, umożliwiają zaawansowane przeszukiwanie oraz są łatwe w aktualizacji. Jednakże, poza tymi ograniczonymi zastosowaniami, tego typu plik jest nieodpowiedni w większości przypadków.
Alokowane przez programistę w trakcie wykonania programu za pomocą jawnych poleceń, np. new, malloc.
Dealokowane również jawnie (w C i C++ za pomocą free i delete) lub niejawnie poprzez mechanizm odśmiecania (Java, C#).
Nie mają nazwy; dostępne są poprzez wskaźnik lub referencję.
Zalety: Mogą być używane do tworzenia dynamicznych struktur danych, np. list wiązanych i drzew.
Wady: Niska efektywność z powodu pośredniego trybu adresowania i skomplikowanego zarządzania stertą. Także duże ryzyko nadużyć ze strony nieostrożnego programisty.
Uwaga: W poniższej sytuacji wiązanie typu jest statyczne; dynamiczne jest natomiast wiązanie pamięci.
int *p;
p = new int;
...
delete p;
Zmienne dynamiczne na stercie, niejawne [3]:
Alokowane i dealokowane niejawnie w trakcie wykonania programu w chwili wykonania podstawienia.
Przykład: Napisy i tablice w Perlu.
Zalety: Elastyczność posunięta do granic.
Wady: Wysoki koszt, związany z dynamicznym przechowywaniem atrybutów.
Sprawdzanie zgodności typów
Zgodność typów będziemy rozważali w szerokim sensie. Podprogramy będziemy traktowali jako operatory, których operandami są parametry. Instrukcję przypisania będziemy uważali za operację dwuargumentową, której operandami są lewa i prawa strona przypisania.
Sprawdzanie zgodności typów to sprawdzenie, czy typy operandów są odpowiednie. Określenie „odpowiedni (lub zgodny) typ” oznacza typ bezpośrednio dozwolony w danym kontekście lub typ, który jest dozwolony po zastosowaniu niejawnej konwersji narzuconej przez reguły języka programowania.
Błąd typu to użycie operatora z operandem nieodpowiedniego typu. Wspomniane wyżej automatyczne, niejawne konwersje wykonywane są przez kod wygenerowany przez kompilator.
Przykład: W poniższym fragmencie wartość zmiennej j jest automatycznie zamieniana z typu int na float i wykonywane jest dodawanie zmiennopozycyjne.
float x, y; int j; x = y + j;
Zastanówmy się, kiedy sprawdzanie zgodności typów może być statyczne. Jeśli wiązanie typów jest statyczne, to sprawdzanie zgodności typów na ogół także może być statyczne, tzn. robione w czasie kompilacji. Istnieją jednak wyjątki, np. unie, które mogą zawierać wartości różnych typów w tym samym miejscu pamięci. Jeśli zatem odwołania do pól unii mają być sprawdzane pod względem zgodności typów, to musi się to dziać dynamicznie, tzn. w trakcie wykonania programu. Zauważmy, że unie trudno właściwie nazwać wyjątkiem: unie są przykładem „nieprawdziwego” wiązania statycznego typu. Jeśli natomiast wiązanie typów jest dynamiczne, to sprawdzanie zgodności typów musi być dynamiczne.
Języki silnie typowane
Język nazywamy silnie typowanym, jeśli błędy typu są w nim zawsze wykrywane. Obejmuje to również dynamiczne sprawdzanie pól w uniach. Oczywistą zaletą silnego typowania jest możliwość wykrywania wielu pospolitych błędów. Wiele języków jest „prawie” silnie typowanych. Bliskie tego są Ada, C# i Java - odstępstwem jest w nich możliwość wykonania jawnej konwersji typów. Pascal nie jest silnie typowany ze względu na unie, występujące tu pod nazwą wariantów w rekordzie, choć poza tym niewiele brakuje... Natomiast C i C++ zdecydowanie nie są silnie typowane. Można w nich np. uniknąć sprawdzania typów parametrów, nie mówiąc już o polach unii...
Jaki jest związek silnego typowania z niejawnymi konwersjami? Występowanie w języku niejawnych konwersji może istotnie osłabić sens silnego typowania.
Konwersje te powodują, że np. błędne podstawienia mogą formalnie przestać być błędami typu. Silne typowanie chcemy przecież mieć po to, by wykrywać jak najwięcej błędów. Zatem silne typowanie bez konwersji sprzyja niezawodności (kosztem wygody programisty). Przykładowo, zasady niejawnych konwersji (przede wszystkim) sprawiają, że sprawdzanie zgodności typów w Adzie jest bardziej skuteczne niż w Javie; to z kolei jest bardziej skuteczne niż w C++.
Jak konkretnie zdefiniować zgodność typów?
W zarysie już to zrobiliśmy... Rzecz nie jest jednak tak oczywista, jak z pozoru wygląda. Szczegółowe zasady zgodności typów mają wpływ na projektowanie i używanie typów. Zwykle rozróżniamy dwa rodzaje zgodności typów - zgodność nazwy i zgodność struktury, które omawiamy poniżej. Zajmujemy się też pokrótce podtypami i typami pochodnymi, jako że pojęcia te w naturalny sposób wiążą się z kwestią zgodności typów.
Zgodność nazwy [3]:
Dwie zmienne uznajemy za zgodne, co do typu, jeśli zostały zdefiniowane w tej samej deklaracji lub, jeśli do ich zadeklarowania użyto tej samej nazwy typu.
Tak rozumiana zgodność typów jest łatwa w implementacji, ale bardzo restrykcyjna.
Przykład: Podzakresy typu całkowitego nie są z nim zgodne.
Zgodność struktury [3]:
Dwie zmienne uznajemy za zgodne, co do typu, jeśli mają taką samą strukturę.
Tu trzeba odpowiedzieć na szereg szczegółowych pytań...
Czy np. rekordy o takiej samej strukturze, ale innych nazwach pól, są zgodne? Czy tablice o takim samym typie elementów są zgodne, jeśli jedna ma zakres indeksów 0..99, a druga - 1..100?
Nie da się rozróżnić typów o takiej samej strukturze, nawet, jeśli w naszym zamierzeniu służą zupełnie różnym celom.
Przykład: Odległość wyrażona w dwóch różnych jednostkach, w obydwu przypadkach przechowywana w zmiennych typu float. Zauważmy, że stosowanie zgodności nazwy pozwala ten problem rozwiązać przez „rozdzielenie” typu float na dwa nowe typy (zob. przykład poniżej).
Problem ten można rozwiązać za pomocą dwóch osobnych mechanizmów: podtypów i typów pochodnych. Tak jest w Adzie.
Zatem zdefiniowanie zgodności typu przez zgodność struktury jest znacznie bardziej elastyczne, ale trudniejsze w implementacji.
Typy pochodne [3]:
Typ pochodny to nowy typ oparty na już istniejącym.
Dziedziczy wszystkie własności typu bazowego.
Zakłada się, że nie jest zgodny z typem bazowym.
To pozwala konstruować typy, które są identyczne, co do struktury, ale niezgodne.
Przykład:
type metry is new Float;
type stopy is new Float;
Podtypy [3]:
Podtyp to typ już istniejący z pewnym ograniczeniem zakresu.
Zakłada się, że jest zgodny z typem bazowym.
Przykład:
subtype SmallInt is Integer range 0..99;
Kwestie praktyczne [3]:
Języki programowania zwykle stosują mieszany sposób sprawdzania zgodności typów.
Zasady zgodności typów są bardzo istotne, gdy język jest oszczędny w aplikowaniu niejawnych konwersji.
Rozważmy deklarację w Adzie:
A, B: array (1..100) of Integer;
W tym przypadku Ada tworzy dwa „anonimowe” typy i nadaje je tablicom A i B. W rezultacie tablice te mają niezgodne typy.
Możemy jednak użyć deklaracji, która zapewni zgodność typu tych tablic:
type Tab100 is array (1..100) of Integer;
A, B: Tab100;
Zakres widoczności
Zakres widoczności zmiennej to zbiór tych instrukcji programu, w których zmienna ta jest widoczna, tzn. można się do niej odwołać. Mówimy, że zmienna jest lokalna (w jednostce programu lub w bloku), jeśli jest zadeklarowana w tej jednostce. Mówimy, że zmienna jest nielokalna, jeśli jest widoczna, ale zadeklarowana gdzie indziej. Zasady rozstrzygania zakresu w danym języku mówią, w jaki sposób odwołania do nazw są wiązane ze zmiennymi.
Zakres statyczny
Zakres statyczny opiera się na kodzie programu (w sensie tekstowym). Jest powszechnie stosowany w językach wywodzących się z Algolu. Spotykamy dwie kategorie języków z zakresem statycznym: dopuszczające zagnieżdżanie podprogramów (np. Ada, Pascal) i nie dopuszczające takiego zagnieżdżania (np. C). W tym drugim przypadku zagnieżdżanie zakresów może jednak nastąpić poprzez zagnieżdżenie definicji klas.
W dalszych rozważaniach zakładamy, że wszystkie zakresy są związane z jednostkami programu i że rozstrzyganie zakresu jest jedyną metodą odwołania się do zmiennych nielokalnych. Powyższe założenie nie we wszystkich językach jest prawdziwe (np. operator :: w języku C++ pozwala na dostęp do „niewodocznej” zmiennej). Rozważamy teraz parę kwestii związanych ze statycznym zakresem widoczności.
Odwoływanie się do zmiennych w językach z zakresem statycznym
Napotkawszy odwołanie do zmiennej, kompilator musi odnaleźć jej deklarację i określić jej atrybuty.
Deklaracji szuka się najpierw w bieżącej jednostce programu.
Jeśli tu jej nie ma, trzeba szukać w jednostce „okalającej”, zwanej poprzednikiem statycznym.
Jeśli i tu jej nie ma, trzeba szukać w poprzedniku poprzednika itd. (czyli w przodkach statycznych), być może docierając aż do zakresu globalnego.
Zmienne mogą się przesłaniać. Jeśli w bliższym przodku statycznym jest zadeklarowana zmienna o takiej samej nazwie, jak w dalszym przodku, to przesłania ona tę dalszą.
Dostęp do przesłoniętych zmiennych
Język może oferować mechanizmy pozwalające na dostęp do przesłoniętych zmiennych.
W języku C++ jest to operator ::; do przesłoniętej zmiennej można się odwołać, pisząc nazwa_klasy::nazwa_zmiennej.
W Adzie podobną rolę spełnia kropka, np. nazwa_jednostki.nazwa_zmiennej.
Bloki
Niektóre języki pozwalają na deklarowanie zmiennych w blokach wewnątrz jednostek programu.
Przykładowo, w języku C i jego pochodnych można zadeklarować zmienną na początku dowolnego bloku wyznaczonego przez nawiasy klamrowe.
Podobnie można zrobić w Adzie, używając konstrukcji declare przed blokiem wyznaczonym przez begin ... end.
W Javie, C++ i C# można zadeklarować zmienną w instrukcji pętli for.
We wszystkich tych przypadkach zakresem widoczności zmiennej jest rozważany blok („od klamry do klamry”).
Tak zadeklarowane zmienne są dynamiczne na stosie. Pamięć jest alokowana przy wejściu do bloku, a dealokowane przy wyjściu z niego.
Problemy z zakresem statycznym
Zwykle problemy biorą się ze zbyt swobodnego dostępu do zmiennych lub podprogramów.
Wszystkie zmienne w głównym programie (tzn. w zakresie globalnym) są widoczne dla wszystkich procedur (podprogramów).
Nie ma sposobu, by narzucić szczegółowe ograniczenia w dostępie do podprogramów.
To często prowadzi do nadużywania globalnych zmiennych i procedur.
Przykład
Rozważmy program z następującymi zakresami; przyjmijmy, że są to zagnieżdżone definicje procedur.
P0 {
P1 {
P3 {
}
P4 {
}
}
P2 {
P5 {
}
}
}
Zakres P0 to zakres globalny, P1 i P2 są zadeklarowane wewnątrz P0 itp.
W typowym układzie wywołania mogłyby być ułożone tak: P0 wywołuje P1 i P2; P1 wywołuje P3 i P4; P2 wywołuje P1 i P5.
Co zrobić, jeśli się okaże, że P4 potrzebuje odwołać się do danych w zakresie P2?
Można przenieść P4 do wnętrza P2, ale wówczas nie będzie możliwe wywołanie P4 przez P1, a P4 straci dostęp do danych w P1.
Można też „uwspólnić” dane potrzebne dla P4, przenosząc je z P2 do P0.
Tego rodzaju problemy występują i dla danych, i dla procedur.
Stąd bierze się nadużywanie bytów globalnych.
Zakres dynamiczny
Zakres dynamiczny opiera się na kolejności wywołań podprogramów, a nie na ich rozmieszczeniu „przestrzennym”. Jako kryterium rozstrzygania o dostępie przyjmujemy więc bliskość czasową, a nie przestrzenną. Tym razem zastanówmy się więc nad problemami dynamicznego zakresu widoczności.
Odwoływanie się do zmiennych w językach z zakresem dynamicznym
Napotkawszy odwołanie do zmiennej, kompilator musi odnaleźć jej deklarację i określić jej atrybuty.
Deklaracji szuka się najpierw w bieżącym podprogramie (podobnie jak dla zakresu statycznego).
Jeśli tu jej nie ma, trzeba szukać w podprogramie, który wywołał bieżący podprogram, zwanym poprzednikiem dynamicznym.
Jeśli i tu jej nie ma, trzeba szukać w poprzedniku poprzednika itd. (czyli w przodkach dynamicznych), być może docierając aż do zakresu globalnego, czyli do programu głównego.
Zmienne mogą się przesłaniać. Jeśli w bliższym przodku dynamicznym jest zadeklarowana zmienna o takiej samej nazwie, jak w dalszym przodku, to przesłania ona tę dalszą.
Przykład
Rozważmy program z następującymi deklaracjami:
P0() {
int x;
P1() {
int x;
P2();
}
P2() {
Put(x);
}
P1();
}
W języku, który stosuje zakresy dynamiczne, odwołanie do zmiennej x w wywołaniu Put(x) odnosi się do zmiennej zadeklarowanej w P1, gdyż P1 jest poprzednikiem dynamicznym dla P2.
Gdyby język stosował zakresy statyczne, to to samo odwołanie odnosiłoby się do zmiennej zadeklarowanej w P0.
Problemy z zakresem dynamicznym
Zaletą jest w wielu sytuacjach wygoda programisty oraz prosta implementacja.
Wad jest niestety więcej...
Gorsza efektywność, gdyż rozstrzyganie zakresu musi być robione dynamicznie.
Nie da się statycznie sprawdzić zgodności typów dla zmiennych nielokalnych.
Słaba czytelność odwołań.
Podprogramy są wykonywane w środowisku wcześniej wywołanych podprogramów, które jeszcze nie zakończyły działania.
Stąd pomiędzy rozpoczęciem a zakończeniem działania podprogramu jego lokalne zmienne są widoczne dla innych podprogramów, niezależnie od ich bliskości przestrzennej.
A zatem ponownie problemem jest niekiedy zbyt swobodny dostęp.
Zakres widoczności a okres życia
Zakres widoczności i okres życia to dwa różne pojęcia. Zakres widoczności (zwłaszcza statyczny) to pojęcie związane z rozmieszczeniem kodu, czyli przestrzenią. Okres życia to pojęcie związane z czasem. W wielu typowych sytuacjach jest między nimi związek.
Przykładowo, rozważmy zmienną zadeklarowaną w metodzie, która nie wywołuje innych metod. Jej zakres widoczności rozciąga się od deklaracji do końca metody. Jej okres życia zaczyna się przy wejściu do metody i kończy się w chwili, gdy kończy się wykonanie metody. W tym przypadku obydwa pojęcia są bardzo bliskie.
Często jest jednak zupełnie inaczej. Zmienna zadeklarowana w języku C jako static wewnątrz funkcji ma lokalny zakres widoczności (tę funkcję, w której jest zadeklarowana), ale globalny okres życia (tzn. cały czas wykonania programu). Gdy wewnątrz podprogramu następuje wywołanie innego podprogramu, zmienne lokalne tego pierwszego przestają być widoczne na czas wywołania. Ich „życie” trwa jednak nadal i są ponownie widoczne po powrocie z podprogramu.
Inne problemy dotyczące zmiennych
Oto kilka problemów związanych ze zmiennymi, których nie mieliśmy dotychczas sposobności omówić.
Środowisko odwołań
Zbiór wszystkich nazw widocznych w danym punkcie programu nazywamy środowiskiem odwołań tego punktu.
W języku z zakresami statycznymi środowisko tworzą wszystkie zmienne zadeklarowane lokalnie wraz ze zmiennymi z przodków statycznych, z wyjątkiem zmiennych przesłoniętych.
Mówimy, że podprogram jest aktywny, jeśli jego wykonanie się rozpoczęło i jeszcze nie zakończyło.
W języku z zakresami dynamicznymi środowisko tworzą wszystkie zmienne zadeklarowane lokalnie wraz ze zmiennymi z aktywnych podprogramów, z wyjątkiem zmiennych przesłoniętych.
Stałe nazwane
Stała nazwana to zmienna, która jest wiązana z wartością tylko raz — w chwili wiązania z pamięcią.
Przykład: Można by używać stałej o nazwie pi zamiast 3.1415926...
To w oczywisty sposób polepsza czytelność i ułatwia modyfikowanie programu.
Niektóre języki stosują statyczne wiązanie wartości dla stałych nazwanych. W takim przypadku do definiowania stałych można używać jedynie wyrażeń stałych.
Inne języki pozwalają na wiązanie dynamiczne. Wówczas do definiowania stałych można użyć zmiennych (w zakresie widoczności). Tak jest np. Adzie, C++ i Javie.
Inicjacja zmiennych
Wiązanie zmiennej z wartością w chwili, gdy jest ona wiązana z pamięcią, nazywane jest inicjacją.
Rzecz jest podobna, jak w przypadku nazwanej stałej, ale wartość zmiennej może oczywiście się zmieniać.
Jeśli wiązanie z pamięcią (alokacja) jest statyczne, to inicjacja także jest statyczna (w czasie kompilacji lub bezpośrednio przed wykonaniem).
Jeśli wiązanie z pamięcią (alokacja) jest dynamiczne, to inicjacja także jest dynamiczna.
Dla zmiennych statycznych inicjacja następuje zatem tylko raz, natomiast dla dynamicznych — przy każdej alokacji.
W wielu językach inicjacji można dokonać przy deklaracji zmiennej, np. int i = 2;
Reprezentacja algorytmu wymaga użycia pewnej formy języka. Ludzie mogą wykorzystywać język naturalny (etniczny, np. polski, angielski, francuski,…) lub język obrazowy (np. algorytm składania ptaka z kwadratowego kawałka papieru [2]). Często komunikowanie się w języku naturalnym prowadzą do nieporozumień ze względu na wieloznaczność (np. słowo: „lalka”, „zamek”; zdanie: „Odwiedziny wnuków mogą być stresujące” - może oznaczać problemy, gdy nas odwiedzają, albo też, że wizyta u nich jest stresująca). Często pojawiają się także problemy dotyczące wymaganego poziomu (stopnia) szczegółowości (poziom szczegółowości należy dobierać w zależności od tego, do kogo jest adresowany algorytm, zależy od jego wiedzy, doświadczenia…). Oznacza to, że źródłem problemów jest brak precyzyjnej definicji języka (języka algorytmicznego) stosowanego do opisu algorytmu lub niewłaściwy poziom szczegółowości przekazywanej informacji [2].
W informatyce rozwiązywane są te problemy poprzez tworzenie dobrze określonego zestawu cegiełek, z których można konstruować reprezentacje algorytmów. Takie cegiełki nazywane są konstrukcjami pierwotnymi (primitives). Problemy niejednoznaczności usuwa się, przypisując pierwotnym konstrukcjom ścisłe definicje. Natomiast wymaganie, aby algorytmy opisywano za pomocą tych konstrukcji pierwotnych (cegiełek), ustanawia jednolity poziom szczegółowości [2].
Zestaw konstrukcji pierwotnych razem z zestawem reguł definiujących sposób ich łączenia ze sobą (w tym zestaw reguł budowy złożonych konstrukcji z pierwotnych konstrukcji) w celu reprezentacji bardziej złożonych obiektów składają się na język programowania [2].
Każdą konstrukcję pierwotną definiuje się za pomocą dwóch elementów [2]:
Składni (syntax).
Semantyki (semantics).
Składnia opisuje symboliczną reprezentację konstrukcji pierwotnej.
<Składnia>::= <opis symbolicznej reprezentacji konstrukcji pierwotnej>.
Semantyka jest znaczeniem konstrukcji pierwotnej, czyli pojęcie, które konstrukcja reprezentuje [2].
< Semantyka >::= < znaczenie konstrukcji pierwotnej, pojęcie, które konstrukcja reprezentuje>.
Na przykład, napis „powietrze”- składniowo jest ciągiem 9 symboli (liter alfabetu), a semantyką jest znaczenie tego słowa - jest substancja lotna otaczająca kulę ziemską [2]. Zdanie „Ten kamień jest głupi” nie ma znaczenia (nie ma sensu).
Zestaw konstrukcji pierwotnych do reprezentacji algorytmów przeznaczonych do wykonania na komputerze można uzyskać na podstawie rozkazów maszynowych konkretnego komputera (z listy rozkazów mikroprocesora). Algorytm wyrażony na tym poziomie szczegółowości z całą pewnością pozwoliłby na otrzymanie programu, który można by wykonać na komputerze. Reprezentacja algorytmu na tym poziomie szczegółowości jest jednak żmudna (złożona)i podatna na błędy, dlatego też zwykle stosuje się pierwotne konstrukcje językowe „ z wyższego poziomu”. Każda z nich jest narzędziem abstrakcyjnym, które można zbudować, posługując się konstrukcjami pierwotnymi niższego poziomu dostępnymi w języku maszynowym komputera. Dzięki takiemu zabiegowi uzyskuje się formalny język programowania, w którym algorytmy można wyrażać na wyższym poziomie abstrakcji niż w języku maszynowym konkretnego komputera [2].
Składnia to zbiór reguł, opisujących jak wygląda poprawny program w danym języku, czyli np. [3]:
Jak powinno się tworzyć poprawne polecenia i wyrażenia?
Jaką postać powinny mieć struktury sterowania (if, while, for itp.)?
Jak powinno się zapisywać deklaracje?
Jak widać z powyższego wyliczenia, jesteśmy tak bardzo przywiązani do języków imperatywnych i obiektowych, że chyba nie bardzo wyobrażamy sobie język bez poleceń, pętli while, zmiennych...
Semantyka to znaczenie wspomnianych wyżej form, czyli „co one robią”. Weźmy dla przykładu typową instrukcję warunkową [3]:
Składnia może wyglądać tak: if "(" wyrażenie ")" instrukcja
Semantyka jest następująca: sprawdź podane „wyrażenie” i jeśli jest prawdziwe, to wykonaj podaną instrukcję.
Powyższy opis semantyki instrukcji warunkowej jest, co prawda niezbyt formalny, ale zupełnie zrozumiały [3]:
W ogólności byłoby dobrze, gdyby semantykę dało się łatwo odgadnąć, patrząc na składnię języka.
Dla prostych konstrukcji tak zazwyczaj bywa; bardziej skomplikowane twory są niestety mniej oczywiste.
Stąd potrzebne są ścisłe metody opisu i składni, i semantyki.
Na razie warto zrezygnować z wprowadzenia formalnego języka programowania. W miejsce jego można zdefiniować mniej formalny, bardziej intuicyjny system notacyjny, zwany pseudokodem.
<Pseudokod>::= <intuicyjny system notacyjny, w którym nieformalnie wyraża się koncepcje związane z opracowywanym algorytmem>.
Pseudokod można uzyskać, rozluźniając wymagania stawiane językowi formalnemu, w którym ma być wyrażona końcowa wersja algorytmu. Takie podejście stosuje się często, jeśli jest znany z góry docelowy język programowania. Pseudokod stosowany we wczesnych fazach tworzenia oprogramowania składa się ze struktur składniowo - semantycznych, które przypominają struktury występujące w docelowym języku programowania, lecz są mniej formalne.
Czym jest język i jak go opisać?
Pojęcie język jest rozumiane jako skończony zbiór symboli języka (alfabet) wraz ze zbiorem reguł łączenia (składania) poszczególnych symboli (liter /znaków alfabetu) w ciągi (słowa) i zbiorem reguł (semantycznych) nadających ciągom symboli znaczenie (sens) merytoryczne.
Język jest to, więc ogólna nazwa zdefiniowanego zbioru znaków oraz reguł lub konwencji określających sposoby i kolejności, w jakich znaki te mogą być łączone dla nadania im znaczenia w tym języku.
Język można traktować jako uporządkowaną czwórkę elementów [26]:
J = {A, W, D, Z},
gdzie: A jest alfabetem języka, W - zbiorem wyrażeń poprawnych, D - dziedzina języka, Z - znaczenie języka.
Alfabet języka jest to zbiór skończony znaków zwanych literami. Każdy ciąg skończony liter nazywamy napisem.
Zbiór wyrażeń poprawnych języka jest to pewien wyróżniony zbiór napisów w alfabecie tego języka. O tym, czy dany napis jest wyrażeniem poprawnym języka, czy też nim nie jest decydują reguły gramatyczne języka, które określają strukturę wyrażeń poprawnych. Spis tych reguł tworzy gramatykę języka (w szerokim sensie obejmuje również reguły morfologii języka). Wyrażeniem poprawnym jest, więc nie tylko zdanie ( w tym ujęciu), lecz także każdy poprawnie zbudowany wyraz. Od reguł gramatycznych nie wymaga się, aby określały sens wyrażeń, uznanych przez nie za poprawne.
Dziedzina języka jest zbiór wiadomości /informacji, którego elementy stanowią treść (sens) wyrażeń poprawnych języka. Inaczej mówiąc, dziedziną języka jest zbiór wszystkich wyrażalnych w tym języku wiadomości / informacji (może zawierać pojęcia nie wyrażalne w innych językach).
Znaczenie języka jest relacja wiążąca wyrażenia poprawne języka z elementami jego dziedziny.
Element dziedziny pozostający w tej relacji z pewnym wyrażeniem poprawnym języka nazywa się znaczeniem tego wyrażenia. Jedno wyrażenie może mieć wiele znaczeń, np. lalka, skok, zamek itp. Wiele wyrażeń może mieć to samo znaczenie, np. samochód, auto, pojazd dwuśladowy itp.; wyrażenia pozbawione sensu nie maja znaczeń. Reguły określające omawianą relację nazywamy regułami znaczeniowymi lub semantycznymi języka. Język, który jest stosowany do przedstawienia algorytmów, nosi nazwę języka algorytmicznego, a przy stosowaniu go do celów programowania, określany jest jako język programowania.
Algorytm przedstawiony w języku programowania nazywa się programem.
Programem nazywamy opis sposobu przetwarzania danych. Jest to uporządkowany zbiór (ciąg) rozkazów (instrukcji) i innych danych (struktur danych) związanych z rozkazami [36]. Program działa na podstawie algorytmu, który z kolei jest ściśle związany ze strukturami danych (obiekty proste, złożone), na których operuje tzn. [37]:
ALGORYTMY + STRUKTURY DANYCH = PROGRAMY.
Język to zbiór napisów utworzonych ze znaków z ustalonego alfabetu [3]:
Przyjmujemy, że mamy ustalony alfabet; nazwijmy go np. Σ.
Alfabet to skończony i niepusty zbiór liniowo uporządkowany; jego elementy nazywamy symbolami, znakami lub literami.
Zbiór wszystkich napisów, jakie można utworzyć z symboli alfabetu Σ, oznaczamy przez Σ*.
Każdy podzbiór zbioru Σ* to pewien język.
Rzecz jasna, nie każdy język jest interesujący.
Mówiąc o językach programowania, chcemy takie właśnie języki móc precyzyjnie opisywać [3]:
Jeśli za alfabet Σ przyjmiemy np. zbiór znaków ASCII, to języki programowania są pewnymi szczególnymi podzbiorami zbioru Σ*.
Są to oczywiście nieskończone podzbiory, których nie sposób opisać przez wyliczenie elementów; potrzebne są gramatyki.
Nas szczególnie interesują dwa rodzaje gramatyk: regularne i bezkontekstowe.
Te pierwsze doskonale nadają się do opisu prostych elementów języka — jednostek leksykalnych, czyli rzeczy takich, jak liczby i identyfikatory.
Te drugie są przydatne do definiowania „większych” elementów składni: różnych rodzajów instrukcji, deklaracji czy wreszcie całego programu.
Gramatyka pozwala opisać składnię języka, jednak nic (lub prawie nic) nie mówi o jego semantyce.
Do opisu semantyki istnieją takie narzędzia, jak gramatyki atrybutowane oraz semantyki operacyjne, aksjomatyczne i denotacyjne.
Jak zatem my będziemy opisywać języki programowania lub ich elementy?
Składnię języków będziemy opisywali za pomocą powszechnie znanej notacji BNF, odpowiadającej gramatykom bezkontekstowym.
Semantykę rozmaitych konstrukcji będziemy na ogół opisywali w sposób „naiwny”, czyli zwyczajnie, po polsku.
Ironią losu jest to, że stworzone przez informatyków - teoretyków narzędzia opisu semantyki nie są zbyt chętnie stosowane w praktyce inżynierii oprogramowania...
Notacja BNF (Backus Naur Form) jest powszechnie używana właśnie do opisu składni języków programowania. Stworzona została w trakcie prac nad językami Fortran i Algol na przełomie lat pięćdziesiątych i sześćdziesiątych XX wieku
Definicja języka w notacji BNF to zbiór reguł.
Poszczególne reguły mają postać <symbol> ::= <definicja symbolu>
Sens takiej reguły jest następujący: symbol występujący po lewej stronie znaku ::= można zastąpić tym, co pojawia się po prawej stronie.
Innymi słowy, stwierdzamy, że to, co stoi po lewej stronie, może wyglądać jak to, co stoi po prawej.
Symbole pojawiające się po lewej stronie reguł zwane są symbolami nieterminalnymi.
Symbole pojawiające się wyłącznie po prawej stronie to symbole terminalne.
Generalnie symbole terminalne to symbole z alfabetu definiowanego języka, a zatem „docelowe”; symbole nieterminalne spełniają natomiast rolę pomocniczą przy jego definiowaniu.
BNF to, zatem w istocie sposób zapisywania produkcji gramatyk bezkontekstowych.
Często stosuje się dodatkowe symbole i konwencje, upraszczające zapis
Pionowa kreska | oznacza alternatywne warianty reguły, np.
typ ::= char | int | float | double
Nawiasy kwadratowe [...] oznaczają opcjonalną część reguły, np.
instr_warunkowa ::= if wyr_logiczne then instr [ else instr ]
Nawiasy klamrowe {...} oznaczają fragment, który może być powtórzony dowolnie wiele razy (być może zero razy, czyli pominięty), np.
lista_arg ::= arg { "," arg }
Zwykłych nawiasów okrągłych (...) używa się do grupowania alternatywnych fragmentów definicji, np.
liczba_ze_znakiem ::= ("+" | "-") liczba_bez_znaku
Jednoznakowe symbole terminalne umieszcza się w cudzysłowie, dla odróżnienia ich od symboli samej notacji BNF.
Symbole terminalne pisze się czcionką wytłuszczoną; nie jest wówczas konieczne pisanie nawiasów kątowych wokół symboli nieterminalnych.
Chcąc opisać powtarzające się elementy, możemy stworzyć definicję rekurencyjną lub wykorzystać nawiasy klamrowe:
Zdefiniujmy dla przykładu niepustą listę identyfikatorów, rozdzielonych przecinkami:
lista_identyfikatorów ::= identyfikator
| lista_identyfikatorów "," identyfikator
Alternatywnie piszemy:
lista_identyfikatorów ::= identyfikator { "," identyfikator }
Klasyczny przykład użycia notacji BNF to opis składni notacji BNF:
składnia ::= { reguła }
reguła ::= identyfikator "::=" wyrażenie
wyrażenie ::= składnik { "|" składnik }
składnik ::= czynnik { czynnik }
czynnik ::= identyfikator
| symbol_zacytowany
| "(" wyrażenie ")"
| "[" wyrażenie "]"
| "{" wyrażenie "}"
identyfikator ::= litera { litera | cyfra }
symbol_zacytowany ::= """ { dowolny_znak } """
Zauważmy, że niektóre symbole, formalnie terminalne, są właściwie niedodefiniowanymi symbolami nieterminalnymi. Gwoli ścisłości powinniśmy, zatem dopisać:
litera ::= "A" | "B" | "C" | ...
cyfra ::= "0" | "1" | ... | "9"
dowolny_znak ::= ...
Jak widać, użyliśmy kolejnego niedodefiniowanego symbolu, a mianowicie wielokropka. Nie brnijmy jednak dalej w formalizowanie rzeczy jasnych i znanych...
Na pewno wszyscy wiedzą, jak uruchomić program napisany np. w języku C++. Dla naszych rozważań istotne jest to, że program taki musi zostać przetłumaczony na język wewnętrzny maszyny, na której program zamierzamy uruchomić. Owo tłumaczenie może być dokonane na jeden z dwóch sposobów:
Kompilacja to przetłumaczenie całego programu „za jednym zamachem”. Otrzymujemy kod wynikowy, który (po konsolidacji, zwanej wulgarnie linkowaniem) wykonuje się bezpośrednio na maszynie docelowej.
Interpretacja to tłumaczenie i wykonywanie programu instrukcja po instrukcji, cały czas za pomocą programu zwanego interpreterem.
Są także formy pośrednie: kompilacja do kodu pośredniego, który jest następnie interpretowany lub ponownie kompilowany „w ostatniej chwili”. Taka forma jest bardzo często stosowana w przypadku języka Java. Daje nam to dobry kompromis między efektywnością a przenośnością kodu na różne komputery.
Nie zamierzamy zagłębiać się tu w tajniki budowy kompilatorów, czyli programów tłumaczących
To jest temat na oddzielny wykład.
Ponieważ jednak chcemy mówić o implementacji rozważanych mechanizmów językowych, będziemy musieli wspominać o konsekwencjach dla kompilatora (lub ewentualnie interpretera) związanych z tymi mechanizmami.
Nie będziemy stronili od pewnych pomysłów na implementację, np. jak kompilator może przygotować wywołania polimorficzne.
Jak już wspominaliśmy, rola kompilatora bywa trudna: musi on przetłumaczyć program napisany według jakiegoś paradygmatu na program w języku wewnętrznym komputera, czyli na raczej „toporny” program imperatywny.
Dlaczego w takim razie chcemy mówić o implementacji?
To zdecydowanie ułatwia zrozumienie omawianych mechanizmów.
Implementacja języka programowania, czyli, praktycznie rzecz biorąc, stworzenie kompilatora to moment, gdy semantyka języka staje się namacalna i bezwzględnie obowiązująca.
Jeśli twórca kompilatora źle ją zrozumiał, to powstanie kompilator nieco innego języka...
Przykład
Ten przykład pokazuje, jaki wpływ na efektywność programu może mieć (nie)znajomość semantyki języka programowania
Rozważmy pętlę for w Pascalu i w C:
for i := 1 to length(s) do ...
for (i = 1; i <= strlen(s); ++i) ...
Na pierwszy rzut oka pętle te powinny zachowywać się tak samo.
Jest jednak bardzo istotna różnica: w Pascalu długość napisu s zostanie policzona tylko raz, natomiast w języku C będzie ona liczona przy każdym obiegu pętli.
To prowadzi do fatalnego pogorszenia złożoności obliczeniowej: zamiast liniowej, mamy kwadratową zależność od długości napisu s (przy założeniu, że operacje w pętli są niezależne od tej długości).
Nie ma, co liczyć na optymalizację wykonaną przez kompilator, gdyż ten na ogół nie może zbyt wiele zakładać o wywoływanych funkcjach.
A zatem trzeba po prostu wiedzieć, co i gdzie można napisać, by nie trwonić czasu...
Uwagi bibliograficzne
Pisząc wykłady omawiające kwestie implementacyjne (2-4) oraz wykłady przeglądowe (5-7) korzystaliśmy z ciekawie opracowanej, rozległej tematycznie książki Sebesty „Concepts of Programming Languages”.
Wykład o rachunku lambda bazuje na „Wybranych zagadnieniach z teorii rekursji”, zaś wykład o rachunku sigma — na „A Theory of Objects” Abadiego i Cardellego. Wiele informacji do wykładów o Haskellu zaczerpnęliśmy z „Introduction to Functional Programming using Haskell” Birda, zaś do wykładów o Prologu — z „Logic, Programming and Prolog” Nilssona i Małuszyńskiego. Pozostałe pozycje ze spisu literatury również stanowiły cenne źródło informacji.
Wykaz literatury podstawowej:
Bertrand M. Programowanie zorientowane obiektowo, Helion, Gliwice 2005
Brookshear J. G. Informatyka w ogólnym zarysie. WNT, Warszawa 2003
Kluźniak F., Szpakowicz S. Prolog, WNT, Warszawa 1983
Oficjalna strona języka CLIPS: http://www.ghg.net/clips/CLIPS.html
Prata S. Szkoła Programowania. Język C. Wyd. V, Helion, Gliwice 2006
Prata S. Szkoła Programowania. Język C++. Wyd. V, Helion, Gliwice 2006
Sebesta R., Concepts of Programming Languages, Addison Wesley, 2005
Ullman L., Liyanage M. Programowanie w języku C. Szybki startEdytuj. Błyskawiczny kurs programowania w języku C. HELION, Gliwice 2005
Ullman L., Singel A. Szybki start. Programowanie w języku C++. Błyskawiczny kurs tworzenia aplikacji w jednym z najpopularniejszych języków programowania. HELION, Gliwice 2007
Wykaz literatury uzupełniającej:
Daniluk A. C++ Builder Borland Developer Studio 2006. Helion, Gliwice 2006
Garbacz B., Koronkiewicz P., Grażyński A. Programowanie, koncepcje, techniki i modele. Helion, Gliwice 2005
Grębosz J.: Symfonia C++ standard, Edition 2000, 2005
Grębosz J.: Pasja C++, Oficyna Kallimach, Kraków, 2003
Eckel B.: Thinking in Java. Edycja polska. Wydanie IV, Helion 2006
Kochan S. G. Język C. Wprowadzenie do programowania. Helion 2005
Liberty J. C++ księga eksperta. Helion, Gliwice 1999
Liberty J. C++ dla każdego. Helion, Gliwice 2002
Liberty J., MacDonald B.: C# 2005. Wprowadzenie, Helion 2007
Neibauer A. R. Języki C i C++”. HELP Warszawa 1995, Wyd. IV, 2005
Nilsson U., Małuszyński J., Logic, Programming and Prolog, John Wiley & Sons, 1995
Savitch W. W tonacji C++. RM, Warszawa 2005
Solter N. A., Kleper S. J. C++. Zaawansowane programowanie. Helion, Gliwice 2006
Stasiewicz A. Wkrocz w świat programowania w C ++. Ćwiczenia praktyczne C++. Wyd. II, Helion, Gliwice 2006
Thinking in C++ Edycja polska BRUCE ECKEL (tłumaczenie: Imiela P.). HELION, Gliwice 2002
Wykaz literatury dodatkowej:
Borowiec J. i inni pod red. R. Marczyńskiego. Problemy przetwarzania informacji. WNT, Warszawa, 1970
Jankowscy J. i M.: Przegląd metod i algorytmów numerycznych. Część 1, WNT, Warszawa 1988
Majgier D. Kurs XHTML / HTML/CSS http://algorytmy.pl/doc/xhtml/
Maguire S. Niezawodność oprogramowania. Helion, Gliwice 2002
Myers G. J. Projektowanie niezawodnego oprogramowania. WNT, Warszawa 1980
Myers G. J.,Sandler C., Badgett T., Thomas T. M. Sztuka testowania oprogramowania. Helion, Gliwice 2005
Nabajyoti Brkakati. Biblia Turbo C++. Oficyna Wydawnicza LT&P
Oualline S. Jak nie programować w C++, czyli 111 programów z błędami i 3 działające. MIKOM, Warszawa 2003
Sysło M. Algorytmy. Wyd. Szkolne i Pedagogiczne, Warszawa 1997
Tanenbaum A. S. Organizacja maszyn cyfrowych w ujęciu strukturalnym. WNT, Warszawa 1980
Turski W. M. Propedeutyka informatyki. PWN, Warszawa 1989
Wirth N. Algorytmy + struktury danych = programy. WNT, Warszawa 1980
55
Wyszukiwarka
Podobne podstrony:
Paradygmaty Składnia Semantyka, Składnia i semantyka
go czas semant, filologia polska, językoznawstwo, gramatyka opisowa, słowotwórstwo i składnia
Bierwisch Semantyka składnikowa
003 zmienne systemowe
Badanie korelacji zmiennych
Modsim Skladnia
prąd zmienny malej czestotliwosci (2)
Prezentacja Składniki chemiczne kwasu nukleinowego
zapotrzebowanie ustroju na skladniki odzywcze 12 01 2009 kurs dla pielegniarek (2)
W2 Chemiczne skladniki komorki
Składniki mineralne w diecie kobiet ciężarnych prezentacja
Analiza Składniowa
Istota , cele, skladniki podejscia Leader z notatkami d ruk
WEM 1 78 Paradygmat
FiR Zmienne losowe1
SKŁADNIA JM
4 operacje na zmiennych I
Wyklad 2 zmiennosc standaryzacja 5 III 2014 b
17 G11 H09 Składniki krwi wersja IHiT
więcej podobnych podstron