Ćwiczenie 2. Analiza pojedynczej zmiennej
Przypomnienie ( a może coś nowego?)
Oznaczmy obserwowane wartości zmiennej X przez x1, x2, …, xn.
Miary położenia
Dla zmiennych wyrażonych w skali interwałowej i ilorazowej klasycznymi miarami tendencji centralnej to najczęściej średnie, które informują o przeciętnym poziomie cechy, nie odzwierciedlając różnic pomiędzy poszczególnymi jednostkami.
W zależności od postaci wartości zmiennej stosujemy:
-średnią arytmetyczną (gdy wartości zmiennej można dodawać),
-średnią geometryczną (gdy wartości zmiennej można mnożyć),
-średnią harmoniczną (gdy wartości zmiennej można dodawać).
Wartość średniej wyznaczamy jeśli wartości zmiennej są jednorodne.
Średnia arytmetyczna
Średnia arytmetyczna równa się sumie wszystkich wartości zmiennej podzielonej przez ich liczbę.
Dla zmiennej, która przyjmuje wartości x1, x2, …, xn średnia arytmetyczna ![]()
wynosi:
![]()
5% średnia ucięta - średnia wyznaczona z wartości zmiennej , z których wyeliminowano 5% największych i 5% najmniejszych wartości.
Wartość 5% średniej uciętej wyznacza się gdy chcemy aby zmienne nietypowe nie zakłócały wartości średniej.
Średni błąd średniej (błąd standardowy) ![]()
.
Błąd standardowy - odchylenie średnie wyników pomiarów tej samej wielkości otrzymanych przy użyciu tego samego narzędzia pomiarowego.
Średnia geometryczna
Średnia geometryczna ![]()
jest pierwiastkiem n - tego stopnia iloczynu n wartości zmiennej. Stosuje się ją głównie przy badaniu zmian tempa zjawisk . Średnia geometryczna w mniejszym stopniu niż średnia arytmetyczna odzwierciedla wpływ wartości ekstremalnych na przeciętny poziom zmiennej. Średnia geometryczną wyznacza się ze wzoru:
![]()
Z definicji wynika, że średnią geometryczną możemy wyznaczać tylko wtedy, gdy wartości obserwacje są liczbami dodatnimi i różnymi od zera.
Średnia harmoniczna
Średnią harmoniczna ![]()
(dla liczb różnych od zera) nazywamy odwrotność średniej arytmetycznej z odwrotności wartości zmiennej. Oblicza się ją, gdy wartości zmiennej są podane w jednostkach względnych. Średnia harmoniczną wyznacza się ze wzoru:
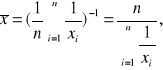
przy czym: ![]()
Dla wszystkich zmiennych, wyrażonych co najmniej na skali porządkowej, można wyznaczać nieklasyczne miary tendencji centralnej. Należą do nich:
-mediana,
-dominanta (moda),
-kwantyle.
Mediana (zwana też wartością środkową) to w wartość w szeregu uporządkowanym, powyżej i poniżej której znajduje się jednakowa liczba wartości zmiennej.
Dominanta (moda) - to najczęściej występująca wartość zmiennej.
Kwantylem rzędu p (Kp), gdzie 1 > p > 0, nazywamy każdą liczbę xp przed, którą znajduje się 100p% wartości zmiennej. Kwantyle dla p = 0,25, p = 0,5, p = 0,75 nazywany kwartylami.
Gdy: p = 0,25 - kwartyl dolny (inaczej kwartyl rzędu 1 oznaczany przez Q1, percentyl 25),
p = 0,5 - mediana (inaczej kwartyl rzędu 2, percentyl 50),
p = 0,75 - kwartyl górny ( inaczej kwartyl rzędu 3 oznaczany przez Q3, percentyl 75).
W programie SPSS wartości kwanty li wyznaczane są kilkoma metodami, są to:
- algorytm standardowy,
- metoda średniej ważonej,
- metoda Empirical,
-metoda Aempirical,
- metoda zawiasów Tukey'a dla wyznaczenia 25, 50 i 75 percentyla (zwanych zawiasami Tukey'a).
W programie SPSS wyznaczane są alternatywne do mediany i średniej wartości tendencji centralnej.
Noszą one nazwę M-estymatorów i wyznaczane są metodami iteracyjnymi. M - estymatory stosowane są gdy rozkład zmiennej jest asymetryczny lub symetryczny lecz z długimi ogonami po lewej i prawej stronie. M - estymatory noszą nazwy pochodzące od nazwisk osób, które je wymyśliły.
Miary zmienności (rozproszenia, dyspersji)
Miary zmienności dzielimy na: Miary klasyczne: |
|
- wariancja (dla zmiennych, które można mnożyć),
Miary pozycyjne: |
|
- rozstęp (dla zmiennych, które można dodawać),
Wariancję |
|
![]()
,
odchylenie standardowe:
![]()
.
Odchylenie standardowe informuje o ile średnio odchylają się wartości zmiennej od wartości średniej ![]()
. Im mniejsza wartość odchylenia tym wartości zmiennej są bardziej skupione wokół średniej.
Rozstęp R to wartość bezwzględna (moduł) różnicy pomiędzy wartością maksymalną
i minimalną badanej zmiennej.
![]()
![]()
Odchylenie ćwiartkowe Q (rozstęp międzykwartylowy) - jest to wielkość określająca odchylenie wartości zmiennej od mediany. Mierzy poziom zróżnicowania tylko części jednostek; po odrzuceniu jednostek o wartościach niewiększych niż Q1 oraz jednostek o wartościach niemniejszych niż Q3. Im większa szerokość rozstępu ćwiartkowego, tym większe zróżnicowanie wartości zmiennej.
![]()
.
Współczynnik zmienności wyznacza się ze wzoru![]()
.
Miary asymetrii
Istnieje wiele miar służących do wyznaczania asymetrii rozkładu do najczęściej stosowanych należy trzeci moment centralny , który wyznacza się ze wzoru:
![]()
,
lub współczynnik skośności ![]()
.
Współczynnik skośności przyjmuje wartość zero dla rozkładu symetrycznego, wartości ujemne dla rozkładów o lewostronnej asymetrii (wydłużone lewe ramię rozkładu) i wartości dodatnie dla rozkładów o prawostronnej asymetrii (wydłużone prawe ramię rozkładu).
*Błąd skośności : 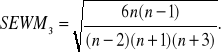
Miary koncentracji
Miary koncentracji mierzą koncentrację wartości zmiennej wokół średniej. Do najczęściej stosowanych współczynników koncentracji należy kurtoza Definiuje się ją następującym wzorem:
![]()
,
gdzie ![]()
nazywane czwartym momentem centralnym wyznacza się ze wzoru:
![]()
.
* Błąd kurtozy: 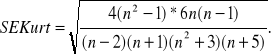
Rozkłady zmiennych można podzielić ze względu na wartość kurtozy na rozkłady:
mezokurtyczne - wartość kurtozy wynosi 0, spłaszczenie rozkładu jest podobne do spłaszczenia rozkładu normalnego (dla którego kurtoza wynosi dokładnie 0)
leptokurtyczne - kurtoza jest dodatnia, wartości cechy bardziej skoncentrowane niż przy rozkładzie normalnym (wykres wysmukły)
platokurtyczne - kurtoza jest ujemna, wartości cechy mniej skoncentrowane niż przy rozkładzie normalnym (wykres spłaszczony).
( *) Wartości błędów skośności i kurtozy mają interpretację, jeśli badane obserwacje traktowane są jako próba z populacji (w statystyce matematycznej).
Jeśli ![]()
to przyjmuje się że w badanej populacji nie występuje asymetria.
Jeśli ![]()
to przyjmuje się że w badanej populacji badana zmienna ma rozkład mezokurtyczny.
Przekształcanie wartości obserwowanej zmiennej.
Rangowanie to przekształcenie polegające na zastąpieniu wartości zmiennej wyrażonej w co najmniej w skali porządkowej rangami ( najczęściej ich miejscami na liście uporządkowanych wartości).
Standaryzacja to przekształcenie polegające na zastąpieniu wartości xi zmiennej X wyrażonej w skali ilorazowej wartością standaryzowaną
![]()
.
Po wykonaniu standaryzacji wiadomo, że około 99% wartości zi należy do przedziału [-3; 3].
Standaryzacja pozbawia wartości zmiennej miana, doprowadzając do porównywalności wartości zmiennych w zasadzie nieporównywalnych. Wartości te można wtedy dodawać (własność addytywności). Standaryzacja nie koryguje własności symetrii rozkładu.
Unitaryzacja to przekształcenie polegające na zastąpieniu wartości xi zmiennej X wyrażonej w skali ilorazowej wartością zunitaryzowaną
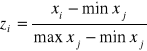
.
Po wykonaniu standaryzacji wiadomo, że wszystkie wartości zi należą do przedziału [0; 1].
Unitaryzacja pozbawia wartości zmiennej miana, doprowadzając do porównywalności wartości zmiennych w zasadzie nieporównywalnych. Wartości te można wtedy dodawać (własność addytywności). Standaryzacja nie koryguje własności symetrii rozkładu.
W celu symetryzacji rozkładu stosuje się transformację logarytmiczną.
Zadanie 1. Analiza statystyczna zmiennej jakościowej wyrażonej w skali nominalnej
Przeprowadzić analizę zmiennej Miejscowość zamieszkiwana.
Rysunek 1. Procentowy podział badanych na mieszkańców miast, gmin i wsi.
Aby program SPSS wyznaczył wszystkie statystyki wybieramy:
Pojawi się okno Częstości.
W oknie tym wybieramy Statystyki
Zaznaczono wszystkie statystyki, które można otrzymać w oknie Częstości.
Wynikiem będą tabele.
Tabela 1. Liczba brakujących i ważnych obserwacji |
||
Miejscowość zamieszkiwana |
||
N |
Ważne |
221 |
|
Braki danych |
0 |
Tabela 2. Procent osób mieszkających w miastach, gminach i wsiach |
|||||
|
Częstość |
Procent |
Procent ważnych |
Procent skumulowany |
|
Ważne |
gmina |
116 |
52,5 |
52,5 |
52,5 |
|
miasto |
38 |
17,2 |
17,2 |
69,7 |
|
wieś |
67 |
30,3 |
30,3 |
100,0 |
|
Ogółem |
221 |
100,0 |
100,0 |
|
Jak widać pomimo zaznaczenia wszystkich statystyk dla zmiennej wyrażonej w skali nominalnej SPSS podaje jedynie podział procentowy.
Zadanie 2. Analiza statystyczna zmiennej jakościowej wyrażonej w skali porządkowej
Przeprowadzić analizę statystyczną zmiennej Wykształcenie. Zmienna Wykształcenie została zakodowana i zapisana jako zmienna kodwyksz. Przeprowadzimy więc analizę zmiennej kodwyksz.
Wyniki analiz ( wykresy i tabele) umieść w dokumencie Word.
Ponieważ na kodach nie można wykonywać działań arytmetycznych w oknie Częstości: Statystyki zaznaczone tylko statystyki, które można wyznaczyć.
Wynikiem będzie histogram oraz Tabele 3 i 4.
Tabela 3.Statystyki |
||
Wykształcenie |
||
N |
Ważne |
221 |
|
Braki danych |
0 |
Mediana |
2,0000 |
|
Dominanta |
3,00 |
|
Percentyle |
25 |
1,0000 |
|
50 |
2,0000 |
|
75 |
3,0000 |
|
90 |
3,0000 |
|
99 |
3,0000 |
Tabela 4. Procent badanych ze względu na poziom wykształcenia |
|||||
|
Częstość |
Procent |
Procent ważnych |
Procent skumulowany |
|
Ważne |
wykształcenie średnie |
45 |
20,4 |
20,4 |
20,4 |
|
wykształcenie średnie z maturą |
60 |
27,1 |
27,1 |
47,5 |
|
wykształcenie wyższe licencjat, inżynierskie |
35 |
15,8 |
15,8 |
63,3 |
|
wykształcenie wyzsze magisterskie |
81 |
36,7 |
36,7 |
100,0 |
|
Ogółem |
221 |
100,0 |
100,0 |
|
Zadanie do wykonania . Opisz na podstawie powyższych tabeli wykształcenie badanych osób.
Zadanie 3. Analiza statystyczna zmiennej jakościowej wyrażonej w skali porządkowej w rozbiciu na grupy obserwacji.
Przeprowadź analizę poziomu wykształcenia ze względu na płeć ankietowanych. Wyniki, wykresy i komentarze zapisz w dokumencie Word.
Tabela 5. Informacja o analizowanych danych |
|||||||
|
Płeć |
Obserwacje |
|||||
|
|
Uwzględnione |
Wykluczone |
Ogółem |
|||
|
|
N |
Procent |
N |
Procent |
N |
Procent |
kodwyksz |
kobieta |
86 |
100,0% |
0 |
,0% |
86 |
100,0% |
|
mężczyzn |
135 |
100,0% |
0 |
,0% |
135 |
100,0% |
Tabela 6. Percentyle |
|||||||||
|
|
Płeć |
Percentyle |
||||||
|
|
|
5 |
10 |
25 |
50 |
75 |
90 |
95 |
Przeciętne ważone (Definicja 1) |
kodwyksz |
kobieta |
,00 |
,00 |
1,00 |
1,50 |
3,00 |
3,00 |
3,00 |
|
|
mężczyzn |
,00 |
,00 |
1,00 |
2,00 |
3,00 |
3,00 |
3,00 |
Zawiasy Tukey'a |
kodwyksz |
kobieta |
|
|
1,00 |
1,50 |
3,00 |
|
|
|
|
mężczyzn |
|
|
1,00 |
2,00 |
3,00 |
|
|
Zadanie 4. Analiza statystyczna zmiennej ilościowej
Przeprowadzić analizę statystyczną zmiennej Waga.
Skorzystamy z Analiza![]()
Opis statystyczny![]()
Częstości
Statystyki |
||
Waga |
||
N |
Ważne |
221 |
|
Braki danych |
0 |
Średnia |
72,86717 |
|
Błąd standardowy średniej |
1,121876 |
|
Mediana |
70,16900 |
|
Dominanta |
44,286a |
|
Odchylenie standardowe |
16,677890 |
|
Wariancja |
278,152 |
|
Skośność |
,230 |
|
Błąd standardowy skośności |
,164 |
|
Kurtoza |
-,743 |
|
Błąd standardowy kurtozy |
,326 |
|
Rozstęp |
80,394 |
|
Minimum |
36,788 |
|
Maksimum |
117,182 |
|
Percentyle |
25 |
60,78950 |
|
50 |
70,16900 |
|
75 |
86,23350 |
|
||
.
Zadania do wykonania.
Przeprowadzić standaryzację zmiennej Waga . Przeprowadzić analizę statystyczną zestandaryzowanej zmiennej. Porównać wyniki analizy dla zmiennej Waga i jej standaryzacji.
Przeprowadzić unitaryzację zmiennej Waga . Przeprowadzić analizę statystyczną zunitaryzowanej zmiennej. Porównać wyniki analizy dla zmiennej Waga i jej unitaryzacji.
Przeprowadzić analizę statystyczną zmiennej Waga w rozbiciu ze względu na płeć.
Analizę statystyczną można także przeprowadzić korzystając z :
Analiza![]()
Raporty i zestawienia ![]()
Podsumowanie obserwacji,
Analiza![]()
Raporty i zestawienia![]()
Raport w wierszach,
Analiza![]()
Raporty i zestawienia![]()
Raport w kolumnach,
Analiza![]()
Opis statystyczne![]()
Statystyki opisowe.
Wartości:
M -estymatorów,
5% średniej ,
percentyli wyznaczonych różnymi metodami,
skrajnych,
można otrzymać wybierając kolejno Analiza![]()
Opis statystyczne![]()
Eksploracja danych![]()
Statystyki.
Wybierając Analiza![]()
Opis statystyczne![]()
Eksploracja danych![]()
Wykresy możemy otrzymać dodatkowy typ wykresu zwany wykresem Łodyga -i - liście.
Wykres ten ma postać:
Waga Stem-and-Leaf Plot
Frequency Stem & Leaf
1,00 3 . 6
4,00 4 . 2444
13,00 4 . 5555567889999
15,00 5 . 011111111223444
20,00 5 . 55555666667778889999
26,00 6 . 00000111112222223333444444
31,00 6 . 5555666667777778888888899999999
20,00 7 . 01111111111222333344
14,00 7 . 55677788889999
16,00 8 . 0011122333333444
23,00 8 . 55566666677778889999999
13,00 9 . 0011122333334
12,00 9 . 556777778889
7,00 10 . 0111223
5,00 10 . 56679
,00 11 .
1,00 11 . 7
Jak widać jest to odwrócony histogram, w którym zaznaczono wartości tworzące słupki. Analizując trzeci słupek widzimy, że znajduje się tam 13 obserwacji z wartościami zmiennej Waga odpowiednio:
45, 45,45,45,45,46,47,48,48,49,49,49,49.
Zadanie do wykonania .Przeprowadzić analizę statystyczna zmiennej Odległość od miejsca zamieszkania, Dodatkowo wyznaczyć Wartości M- estymatorów, 5% średniej, wykres łodyga i liście. Porównać wartości M -estymatorów z wyznaczoną średnią i medianą.
Zadanie 5. Analiza statystyczna zmiennej ilościowej w rozbiciu na grupy obserwacji.
Przeprowadzić analizę statystyczną zmiennej Waga ze względu na płeć ankietowanych. Wyznaczyć wartości różnych średnich oraz M - estymatorów. Porównać otrzymane wartości.
Ćwiczenie 4: Opis zmiennej (statystyka opisowa) Strona | 13
Wyszukiwarka
Podobne podstrony:
HMS egzamin 1, Socjologia I rok
miary asymetrii, Socjologia I rok
HMS egzamin, Socjologia I rok
RELACJE SPOŁECZNE W DOBIE INTERNET1 moje, Socjologia I rok
Scena i kulisy teatru życia codziennego człowieka - Kopia, Socjologia I rok
wts wse wyklad3, Socjologia I rok
socjologia miasta skrot moje, socjologia 3 rok, socjologia miasta
prezentacje pr, socjologia 3 rok, PR
Zagadnienia - Polityka społeczna, Studia WARSZAWA, Notatki socjologia I rok, polityka społ
Hf2, Socjologia I rok
HMS zagadnienia, Socjologia I rok
Badania jakościowe oraz obserwacja(1), Socjologia 2 rok, Metody badań społecznych
notatka, Socjologia I rok
Zydzi to mniejszosc narodowa, socjologia 3 rok, Socjologia mniejszości narodowych
HMS 50=54, Socjologia I rok
Uniwersytet w Bialymstoku nowe, Socjologia I rok
Wyniki, Socjologia I rok
więcej podobnych podstron