AKADEMIA GÓRNICZO - HUTNICZA
IM. STANISŁAWA STASZICA W KRAKOWIE
______________________________________________________
WYDZIAŁ ELEKTROTECHNIKI AUTOMATYKI INFORMATYKI I ELEKTRONIKI
KATEDRA INFORMATYKI

Praca dyplomowa
Temat pracy:
System do poglądowego przedstawienia właściwości sieci neuronowych.
Autorzy: |
Piotr Swatowski Tomasz Góźdź |
|
|
Kierunek: |
Informatyka |
|
|
Ocena: |
................................. |
Promotor: |
Prof. dr hab. inż. Ryszard Tadeusiewicz |
Recenzent: |
|
Kraków 1998/99
1 Cel
Cel
Celem naszej pracy jest stworzenie środowiska (dydaktyczno - symulacyjnego programu komputerowego) umożliwiającego użytkownikowi zapoznanie się z możliwościami zastosowań oraz ze sposobem działania sieci neuronowych. Program ten w założeniu jest narzędziem edukacyjnym i służyć ma do wizualizacji wybranych właściwości sieci neuronowych oraz przykładów istotnych aspektów uczenia, testowania i wykorzystania sieci.
Do aplikacji dołączamy również system pomocy dla użytkownika (Help), zawierający wstęp teoretyczny i szczegółowe omówienie prezentowanych przez nas zagadnień.
Sztuczne sieci neuronowe
W rozdziale tym zawrzemy informacje o sieciach neuronowych, ich częściach składowych - neuronach, konstrukcji, typach, sposobach uczenia oraz testowania.
Naszkicujemy również historyczny aspekt ewolucji zainteresowania, budowy teorii jak i jej praktycznego wykorzystania w materii sztucznych sieci neuronowych.
Rys historyczny rozwoju sieci neuronowych
W początkowym okresie, gdy nie było formalnych podstawa nauki sztucznych sieci neuronowych zainteresowanie badaczy osadzonych mocno w dziedzinie neurofizjologii czy bioniki skierowane były na opisie mechanizmów działania mózgu czy pojedynczych komórek układu nerwowego. Dziedzina sieci neuronowych zaistniała samodzielnie wraz z wydaniem historycznej pracy [5], w której po raz pierwszy pokuszono się o matematyczny opis komórki neuronowej. W tejże pracy istotnym elementem było również określenie zasad przetwarzania informacji opartego na kanwie modelu sztucznego neuronu.
Kolejnym kanonem wyznaczającym na długi czas rozwój wiedzy o sieciach neuronowych stanowią dwie pozycje: książka [6] prezentująca tę problematykę od strony rozwiązań technicznych oraz książka [7] stanowiąca podstawowe źródło wiadomości biologicznych, które to od zarania dziedziny sztucznych sieci neuronowych są niedoścignionym wzorem i źródłem inspiracji dla kolejnych pokoleń badaczy.
Pierwszym szeroko znanym przykładem znanej sieci neuronowej był Perceptron [8]. Sieci ta jako układ częściowo elektromechaniczny a częściowo elektroniczny została zbudowana w 1957 w Cornell Aeronautical Laboratory. Sieć ta miała za zadanie rozpoznawać znaki. Programowanie tego rozwiązania oparto na zasadach prostego uczenia co stanowiło o wielkim kroku na przód w dziedzinie sieci neuronowych. Po ogłoszeniu wyników przez twórców nastąpił gwałtowny rozwój tego typu sieci neuronowych na całym świecie. Oczywiście większość naśladowców nie wyszło ponad odtworzenie pierwotnego rozwiązania, ale znaleźli się i tacy którzy twórczo przekształcili pomysły Rosenblatta i Wightmana.
Bardzo istotnym tu przykładem jest rozwiązania zaproponowane przez Bernarda Widrowa z Uniwersytetu Standforda sieć Madaline zbudowana w 1960 roku. Sieć ta składała się z pojedynczych elementów Adaline (ang. Adaptive linear element), który powielony oraz połączony dało układ Madaline (ang. Many Adaline). [9, 10]
W owych pionierskich czasach próbowano nawet tworzyć model całego mózgu. Obecnie gdy o mózgu wiemy już znacznie więcej nikt nie porywa się na takiego rodzaju zaangażowania.
Tempo rozwoju badań nad problematyką sztucznych sieci neuronowych zostało gwałtownie zahamowane na początku lat 70-tych po publikacji książki [11], która to zawierała formalny dowód, że sieci jednowarstwowe (podobne do perceptronu) mają bardzo ograniczony zakres zastosowań. Taki stan - impasu utrzymywał się przez około 15 lat aż do ukazania się serii publikacji, które w sposób bardzo sugestywny pokazywały, że sieci nieliniowe wolne są od ograniczeń pokazanych w pracy [11]. Jednocześnie mniej więcej w tym czasie ogłoszono kilka bardzo efektywnych, formalnych przepisów na uczenie sieci wielowarstwowych.
Okres lat 70-tych nie jest jednak zupełnie bezpłodny jeśli chodzi o tworzone nowe konstrukcje sieci neuronowych. Wymienić tu należy, chociażby zbudowaną przez Stephena Grossberga na uniwersytecie w Bostonie sieć Avalanche. Służyła ona do rozpoznawania mowy oraz sterowaniem ramieniem robota. Z kolei w MIT powstaje Cerebellatron skonstruowany przez badaczy Davida Mara, Jamesa Albusa i Andresa Pollioneze, służący także do sterowania robota. Odmienne zastosowanie miała sieć Brain State in the Box, zbudowana przez Jamesa Andersona z uniwersytetu Browna w 1977 roku. Funkcjonalnie była odpowiednikiem pamięci asocjacyjnej z dwustronnym dostępem (BAM), ale jej działanie nie było związane z iteracyjnym procesem poszukiwania, lecz polegało na szybkich zależnościach typu wejście - wyjście.
W momencie opracowania technologii wytwarzania sztucznych modeli komórek nerwowych w postaci układów scalonych pojawiły się w latach 80-tych pierwsze konstrukcje o dużych rozmiarach oraz znaczących mocach obliczeniowych.
W tym czasie pojawiają się pierwsze sieci ze sprzężeniami zwrotnymi. Istotnym przykładem takiej konstrukcji jest opracowana przez Johna Hopfielda z AT&T Bell Labs sieć wykorzystywana do odtwarzania obrazów z ich fragmentów, a także stosowana do rozwiązywania zadań optymalizacyjnych - słynny problem komiwojażera.
Renesans szerokiego zainteresowania tematyką sieci neuronowych datuję się na drugą połowę lat 80-tych. Wtedy to swoją przełomową książkę publikuje J.A. Anderson [12], , a J.J.Hopfield wprowadza rekurencyjną architekturę pamięci neuronowych i opisuje w swoich pracach obliczeniowe własności sieci ze sprzężeniem zwrotnym. Ożywienie wniosło także opublikowanie monografii opracowanej przez McClellanda i Rumelharta [19] na temat równoległego przetwarzania rozproszonego - publikacja ta spowodowała wzrost zainteresowania możliwościami sieci warstwowych.
Począwszy od lat 1986-87 datuje się wzrost liczby projektów badawczych w dziedzinie sieci neuronowych. Wzrasta również liczba zagadnień, które można rozwiązać przy użyciu sieci neuronowych - dokładna analiza różnego rodzaju zagadnień wskazuje często, że zachowanie się danego złożonego systemu jest zdeterminowane przez lokalne i jednoczesne oddziaływanie wielkiej liczby prostych składowych elementów takiego systemu - co wskazuje, że dla takiego zagadnienia można zastosować sieć neuronową. Wzrost liczby takich właśnie zagadnień i dziedzin powoduje rozszerzanie się zakresu zastosowań sieci neuronowych.
Definicja i podstawowe właściwości sieci neuronowych
Jako obiekt badań sieci neuronowe stanowią bardzo uproszczony (przez co łatwiejszy do ogarnięcia myślą lub do zamodelowania na komputerze), ale bogaty i ciekawy model rzeczywistego biologicznego systemu nerwowego.
Składają się one z połączonych ze sobą obiektów (umownie zwanych neuronami). Istotną cechą sieci takich elementów jest możliwość uczenia się - to jest modyfikowania parametrów charakteryzujących poszczególne neurony w taki sposób, by zwiększyć efektywność sieci przy rozwiązywaniu zadań określonego typu.
Sieci neuronowe mogą być bardzo skuteczne jako narzędzia obliczeniowe - i to w rozwiązywaniu takich zadań, z którymi typowe komputery i typowe programy sobie nie radzą. Jest tak z tego powodu, że sieci neuronowe mają w stosunku do typowych systemów obliczeniowych dwie zasadnicze zalety. Po pierwsze obliczenia są w sieciach neuronowych wykonywane równolegle, w związku z czym szybkość pracy sieci neuronowych może znacznie przewyższać szybkość obliczeń sekwencyjnych. Drugą zaletą sieci jest możliwość uzyskania rozwiązania problemu z pominięciem etapu konstruowania algorytmu rozwiązania problemu.
Sieci nie trzeba programować. Istnieją metody uczenia i samouczenia sieci pozwalają uzyskać ich celowe i skuteczne działanie nawet w sytuacji, kiedy twórca sieci nie zna algorytmu, według którego można rozwiązać postawione zadanie.
Zarówno program działania oraz informacje stanowiące bazę wiedzy, a także dane na których wykonuje się obliczenia, jak i sam proces obliczania - są w sieci całkowicie rozproszone.
Sieć działa zawsze jako całość i wszystkie jej elementy mają swój wkład w realizację wszystkich czynności, które sieć realizuje. Jedną z konsekwencji takiego działania sieci jest jej zdolność do poprawnego działania nawet po uszkodzeniu znacznej części wchodzących w jej skład elementów.
Struktura sieci powstaje w ten sposób, że wyjścia jednych neuronów łączy się z wejściami innych. Oczywiście konkretna topologia sieci powinna wynikać z rodzaju zadania, jakie jest stawiane przed siecią. Jednak decyzje dotyczące struktury sieci nie wpływają na jej zachowanie w stopniu decydującym. Zachowanie sieci w zasadniczy sposób determinowane jest przez proces jej uczenia, a nie przez strukturę czy liczbę użytych do jej budowy neuronów.
Znane są doświadczenia, w których strukturę sieci wybierano w sposób całkowicie przypadkowy (ustalając na drodze losowania, które elementy należy ze sobą połączyć i w jaki sposób), a sieć mimo to zdolna była do rozwiązywania stawianych jej zadań.
Sieci neuronowe mogą całą swoją wiedzę zyskiwać wyłącznie w trakcie nauki i nie muszą mieć z góry zadanej, dopasowanej do stawianych im zadań, jakiejkolwiek precyzyjnie określonej struktury. Sieć musi jednak mieć wystarczający stopień złożoności, żeby w jej strukturze można było w toku uczenia "wykrystalizować" potrzebne połączenia i struktury. Zbyt mała sieć nie jest w stanie nauczyć się niczego, gdyż jej "potencjał intelektualny" na to nie pozwala - rzecz jednak nie w strukturze, a w liczbie elementów.
Opis działania neuronu
Sztuczne neurony charakteryzują się występowaniem wielu wejść i jednego wyjścia. Sygnały wejściowe xi (i = 1, 2, . . . , n) oraz sygnał wyjściowy y mogą przyjmować wartości, odpowiadające pewnym informacjom. W ten sposób zadanie sieci sprowadzone do funkcjonowania jej podstawowego elementu polega na tym, że neuron przetwarza informacje wejściowe xi na pewien wynik y. Neurony traktować można jako elementarne procesory o następujących właściwościach:
każdy neuron otrzymuje wiele sygnałów wejściowych i wyznacza na ich podstawie swoją odpowiedź to znaczy jeden sygnał wyjściowy;
z każdym oddzielnym wejściem neuronu związany jest parametr nazywany wagą ( określa stopień ważności informacji docierających tym właśnie wejściem - na wyjście ma wpływ waga przemnożona przez wejście);
sygnał wchodzący określonym wejściem jest najpierw przemnażany przez wagę danego wejścia, w związku z czym w dalszych obliczeniach uczestniczy już w formie zmodyfikowanej: wzmocnionej (gdy waga jest większa od 1) lub stłumionej (gdy waga ma wartość mniejszą od 1) względnie nawet przeciwstawnej w stosunku do sygnałów z innych wejść gdy waga ma wartość ujemną (tzw. wejścia hamujące);
sygnały wejściowe (przemnożone przez odpowiednie wagi) są w neuronie sumowane, dając pewien pomocniczy sygnał wewnętrzny nazywany czasem łącznym pobudzeniem neuronu (w literaturze angielskiej net value);
do tak utworzonej sumy sygnałów dodaje niekiedy (nie we wszystkich typach sieci) pewien dodatkowy składnik niezależny od sygnałów wejściowych, nazywany progiem (w literaturze angielskiej bias);
suma przemnożonych przez wagi sygnałów wewnętrznych z dodanym (ewentualnie) progiem może być bezpośrednio traktowana jako sygnał wyjściowy neuronu ( w sieciach o bogatszych możliwościach sygnał wyjściowy neuronu obliczany jest za pomocą pewnej nieliniowej zależności między łącznym pobudzeniem a sygnałem wyjściowym);
Każdy neuron dysponuje pewną wewnętrzną pamięcią (reprezentowaną przez aktualne wartości wag i progu) oraz pewnymi możliwościami przetwarzania wejściowych sygnałów w sygnał wyjściowy.
Z powodu bardzo ubogich możliwości obliczeniowych pojedynczego neuronu - sieć neuronowa może działać wyłącznie jako całość. Wszystkie możliwości i właściwości sieci neuronowych są wynikiem kolektywnego działania bardzo wielu połączonych ze sobą elementów (całej sieci, a nie pojedynczych neuronów).
Uczenie sieci neuronowych
Cykl działania sieci neuronowej podzielić można na etap nauki, kiedy sieć gromadzi informacje potrzebne jej do określenia, co i jak ma robić, oraz na etap normalnego działania (nazywany czasem także egzaminem), kiedy w oparciu o zdobytą wiedzę sieć musi rozwiązywać konkretne nowe zadania. Możliwe są dwa warianty procesu uczenia : z nauczycielem i bez nauczyciela.
Uczenie z nauczycielem
Uczenie z nauczycielem polega na tym, że sieci podaje się przykłady poprawnego działania, które powinna ona potem naśladować w swoim bieżącym działaniu (w czasie egzaminu). Przykład należy rozumieć w ten sposób, że nauczyciel podaje konkretne sygnały wejściowe i wyjściowe, pokazując, jaka jest wymagana odpowiedź sieci dla pewnej konfiguracji danych wejściowych. Mamy do czynienia z parą wartości - przykładowym sygnałem wejściowym i pożądanym (oczekiwanym) wyjściem, czyli wymaganą odpowiedzią sieci na ten sygnał wejściowy. Zbiór przykładów zgromadzonych w celu ich wykorzystaniu w procesie uczenia sieci nazywa się zwykle ciągiem uczącym. Zatem w typowym procesie uczenia sieć otrzymuje od nauczyciela ciąg uczący i na jego podstawie uczy się prawidłowego działania, stosując jedną z wielu znanych dziś strategii uczenia.
Uczenie bez nauczyciela
Obok opisanego wyżej schematu uczenia z nauczycielem występuje też szereg metod tak zwanego uczenia bez nauczyciela (albo samouczenia sieci). Metody te polegają na podawaniu na wejście sieci wyłącznie szeregu przykładowych danych wejściowych, bez podawania jakiejkolwiek informacji dotyczącej pożądanych czy chociażby tylko oczekiwanych sygnałów wyjściowych. Odpowiednio zaprojektowana sieć neuronowa potrafi wykorzystać same tylko obserwacje wejściowych sygnałów i zbudować na ich podstawie sensowny algorytm swojego działania - najczęściej polegający na tym, że automatycznie wykrywane są klasy powtarzających się sygnałów wejściowych i sieć uczy się (spontanicznie, bez jawnego nauczania) rozpoznawać te typowe wzorce sygnałów.
Samouczenie jest też bardzo interesujące z punktu widzenia zastosowań, gdyż nie wymaga żadnej jawnie podawanej do sieci neuronowej zewnętrznej wiedzy , a sieć zgromadzi wszystkie potrzebne informacje i wiadomości.
Organizacja uczenia sieci
Kluczowym pojęciem dla uczenia sieci są wagi wejść poszczególnych neuronów. Każdy neuron ma wiele wejść, za pomocą których odbiera sygnały od innych neuronów oraz sygnały wejściowe podawane do sieci jako dane do obliczeń. Z wejściami tymi skojarzone są parametry nazywane wagami; każdy sygnał wejściowy jest najpierw przemnażany przez wagę, a dopiero później sumowany z innymi sygnałami. Jeśli zmienią się wartości wag - neuron zacznie pełnić innego rodzaju funkcję w sieci, a co za tym idzie - cała sieć zacznie inaczej działać. Uczenie sieci polega więc na tym, by tak dobrać wagi, żeby wszystkie neurony wykonywały dokładnie takie czynności, jakich się od nich wymaga.
Ze względu na rozmiar sieci (w wielu wypadkach mamy do czynienia z b. dużą liczbą neuronów) niemożliwe jest zdefiniowanie potrzebnych wag dla wszystkich wejść w sposób jednorazowy i arbitralny ręcznie. Można jednak zaprojektować i zrealizować proces uczenia polegający na rozpoczęciu działania sieci z pewnym przypadkowym zestawem wag i na stopniowym polepszaniu tych wag. W każdym kroku procesu uczenia wartości wag jednego lub kilku neuronów ulegają zmianie, przy czym reguły tych zmian są tak pomyślane, by każdy neuron sam potrafił określić, które ze swoich wag ma zmienić, w którą stronę (zwiększenie lub zmniejszenie) a także o ile. Oczywiście przy określaniu potrzebnych zmian wag neuron może korzystać z informacji pochodzących od nauczyciela (o ile stosujemy uczenie z nauczycielem), nie zmienia to jednak faktu, że sam proces zmiany wag (będących w sieci jedynym śladem pamięciowym) przebiega w każdym neuronie sieci w sposób spontaniczny i niezależny dzięki czemu może być realizowany bez konieczności bezpośredniego stałego dozoru ze strony osoby sterującej tym procesem.
W praktycznych zastosowaniach korzysta się czasem z dodatkowego mechanizmu "rywalizacji" między neuronami, który w niektórych zastosowaniach pozwala uzyskiwać znacznie lepsze wyniki działania sieci. Zaobserwowanie działania sieci z rywalizacją (competition network) możliwe jest po wprowadzeniu do sieci elementu porównującego ze sobą sygnały wyjściowe wszystkich neuronów i typującego wśród nich "zwycięzcę". Zwycięzcą w tej konkurencji zostaje neuron o największej wartości sygnału wyjściowego. Z wytypowaniem "zwycięzcy" mogą wiązać się różne konsekwencje (na przykład tylko temu jednemu neuronowi można nadać prawo uczenia się (sieci Kohonena), najczęściej jednak wytypowanie zwycięzcy służy do tego, by silniej spolaryzować wyjściowe sygnały z sieci - na przykład tylko neuron będący "zwycięzcą" ma prawo wysłać swój sygnał na zewnątrz, wszystkie pozostałe sygnały są natomiast zerowane. Taka zasada działania sieci, nazywana czasem WTA (Winner Takes All - zwycięzca zabiera wszystko) pozwala łatwiej interpretować zachowanie sieci (szczególnie wtedy, gdy ma ona wiele wyjść), ale niesie ze sobą pewne niebezpieczeństwa (wzmiankowane wyżej).
Projektowanie zbioru uczącego dla sieci neuronowej
Rozmiar zbioru
Jeśli sieć neuronowa ma działać efektywnie, zbiór uczący użyty musi spełniać dwa podstawowe warunki:
po pierwsze każda klasa powinna być reprezentowana w zbiorze uczącym (na ogół dane uczące składają się z kilku podgrup, z których każda określona jest przez pewien wzorzec - wszystkie takie wzorce powinny być reprezentowane w ciągu uczącym)
po drugie w ramach każdej klasy powinna być reprezentowana zmienność statystyczna (praca sieci odbywać się będzie na ciągach zawierających dane „zaszumione”, a nie idealnie czyste wzorce - projekt ciągu uczącego musi zapewniać odpowiednią różnorodność efektów szumu).
Z drugiej strony ograniczeniem dla wielkości zbioru jest czasochłonność procesu uczenia - wraz ze zbiorem uczącym wzrasta ona liniowo. Tak więc ze wzglądu na szybkość procesu należy dążyć do minimalizacji rozmiaru zbioru uczącego.
Błędy przypadkowe
Są to pojawiające się w trakcie pracy sieci niechciane „zdarzenia losowe” - zakłócenia w ciągu wejściowym dla sieci. Gdy wszystkie próbki określonej podklasy zakłócone są w ten sam sposób, to sieć nauczy się zakłóconego wzorca. W sytuacji, gdy w rzeczywistej pracy sieci wzorzec pojawi się bez zakłócenia sieć może go nie rozpoznać - bo nie nauczyła się go na podstawie ciągu uczącego.
Problem ten staje się szczególnie uciążliwy w sytuacji, gdy rozpatrywany przypadek znajduje się w pobliżu granicy „obszaru decyzyjnego” danej podklasy.
W takiej sytuacji, aby uniknąć uczenia wzorców przypadkowych zwiększa się liczność zbioru uczącego.
Zależność rozmiaru sieci i rozmiaru zbioru uczącego
Wielkość ciągu uczącego jest zależna od wielkości sieci, dla której jest on projektowany. Im większa jest sieć - tym większy ciąg uczący jest konieczny do nauczenia jej.
Skłonność do nadmiernego dopasowania sieci jest również proporcjonalna do wielkości sieci. Przy założeniu, ze jest n wejść oraz m neuronów ukrytych - sieć ma m x ( n + 1) wag . Przy n - rzędu kilkuset i m - kilkanaście (co jest możliwe w zastosowaniach przemysłowych) otrzymujemy w sieci b. dużą ilość parametrów swobodnych. Jedynym rozwiązaniem, które uchroni sieć przed „nauczeniem się na pamięć” danego ciągu jest zbudowanie ciągu tak dużego, by sieć nie mogła nauczyć się wszystkich szczegółów.
Można zalecić by minimalna liczba próbek była dwukrotnie większa od liczby wag sieci (choć liczba czterokrotnie większa od ilości wag wydaje się odpowiedniejsza). [2]
Rozwarstwienie zbioru uczącego
Jest to sytuacja, która wymusza zastosowanie bardzo dużego zbioru uczącego. Obecność wielu podklas stwarza bowiem konieczność powiększania tego zbioru, ponieważ częściej mogą pojawiać się błędy przypadkowe.
Ukryte błędy systematyczne
Jednym z istotnych niebezpieczeństw przy konstruowaniu zbiorów jest nieświadome uczenie sieci ludzkich błędów systematycznych. Sieć uczy się takich błędów tak samo jak innych wzorców. Jeśli ciąg uczący obciążony jest błędami systematycznymi, może to doprowadzić do sytuacji, gdy nauczona sieć działająca poprawnie na takim ciągu uczącym, zawiedzie przy pracy na danych nieobciążonych błędem systematycznym.
Reguły uczenia
Zostaną omówione dwie podstawowe reguły uczenia: reguła Delta leżącą u podstaw większości algorytmów uczenia z nauczycielem oraz reguła Hebba stanowiąca przykład uczenia bez nauczyciela.
Reguła Delta
Reguła delta jest regułą uczenia z nauczycielem. Polega ona na tym, że każdy neuron po otrzymaniu na swoich wejściach określone sygnały (z wejść sieci albo od innych neuronów, stanowiących wcześniejsze piętra przetwarzania informacji) wyznacza swój sygnał wyjściowy wykorzystując posiadaną wiedzę w postaci wcześniej ustalonych wartości współczynników wzmocnienia (wag) wszystkich wejść oraz (ewentualnie) progu. Sposoby wyznaczania przez neurony wartości sygnałów wyjściowych na podstawie sygnałów wejściowych omówione zostały dokładniej w poprzednim rozdziale. Wartość sygnału wyjściowego, wyznaczonego przez neuron na danym kroku procesu uczenia porównywana jest z odpowiedzią wzorcową podaną przez nauczyciela w ciągu uczącym. Jeśli występuje rozbieżność - neuron wyznacza różnicę pomiędzy swoim sygnałem wyjściowym a tą wartością sygnału, która była by - według nauczyciela prawidłowa. Ta różnica oznaczana jest zwykle symbolem greckiej litery δ (delta) i stąd nazwa opisywanej metody.
Sygnał błędu (delta) wykorzystywany jest przez neuron do korygowania swoich współczynników wagowych (i ewentualnie progu), stosując następujące reguły:
wagi zmieniane są tym silniej, im większy błąd został wykryty;
wagi związane z tymi wejściami, na których występowały duże wartości sygnałów wejściowych, zmieniane są bardziej, niż wagi wejść, na których sygnał wejściowy był niewielki.
Znając błąd popełniony przez neuron oraz jego sygnały wejściowe możemy łatwo przewidzieć, jak będą się zmieniać jego wagi.
Sieć stosując opisane metody w praktyce sama przerywa proces uczenia gdy jest już dobrze wytrenowana, gdyż małe błędy powodują jedynie minimalne korekty wag. Jest to logiczne, podobnie jak zasada uzależniania wielkości korekty od wielkości wejściowego sygnału przekazywanego przez rozważaną wagę, te wejścia, na których występowały większe sygnały miały większy wpływ na wynik działania neuronu, który okazał się błędny, trzeba je więc silniej "temperować". W szczególności opisany algorytm powoduje, że dla wejść, na których w danym momencie nie były podawane sygnały (podczas obliczeń miały one zerowe wartości) odpowiednie wagi nie są zmieniane, nie wiadomo bowiem, czy są dobre czy nie, gdyż nie uczestniczyły w tworzeniu aktualnego (błędnego, skoro trzeba coś poprawiać) sygnału wyjściowego.
W praktycznych realizacjach opisanego wyżej algorytmu dochodzi kilka dalszych godnych uwagi elementów. W pierwszej kolejności twórca sieci musi zdecydować, jak silne powinny być zmiany wag powodowane przez określone wartości sygnałów wejściowych i określoną wielkość błędu. Ten współczynnik proporcjonalności η, zwany learning rate, może być wybierany dowolnie, jednak każda konkretna decyzja ma określone konsekwencje. Wybranie współczynnika za małego prowadzi do bardzo powolnego procesu uczenia (wagi są poprawiane w każdym kroku bardzo słabo, żeby więc osiągnęły pożądane wartości trzeba wykonać bardzo dużo takich kroków). Z kolei wybór za dużego współczynnika uczenia powoduje bardzo gwałtowne zmiany parametrów sieci, które w krańcowym przypadku prowadzić mogą nawet do niestabilności procesu uczenia. Konieczny jest więc kompromisowy wybór współczynnika uczenia, uwzględniający zarówno korzyści związane z szybką pracą, jak i względy bezpieczeństwa, wskazujące na konieczność uzyskania stabilnej pracy procesu uczenia.
Reguła Hebba
Jest to jedna z najpopularniejszych metod samouczenia sieci neuronowych. Polega ona na tym, że sieci pokazuje się kolejne przykłady sygnałów wejściowych, nie podając żadnych informacji o tym, co z tymi sygnałami należy zrobić. Sieć obserwuje otoczenie i odbiera różne sygnały, nikt nie określa jednak, jakie znaczenie mają pokazujące się obiekty i jakie są pomiędzy nimi zależności. Sieć na podstawie obserwacji występujących sygnałów stopniowo sama odkrywa, jakie jest ich znaczenie i również sama ustala zachodzące między sygnałami zależności.
Po podaniu do sieci neuronowej każdego kolejnego zestawu sygnałów wejściowych tworzy się w tej sieci pewien rozkład sygnałów wyjściowych - niektóre neurony sieci są pobudzone bardzo silnie, inne słabiej, a jeszcze inne mają sygnały wyjściowe wręcz ujemne. Interpretacja tych zachowań może być taka, że niektóre neurony „rozpoznają” podawane sygnały jako „własne” (czyli takie, które są skłonne akceptować), inne traktują je „obojętnie”, zaś jeszcze u innych neuronów wzbudzają one wręcz „awersję”. Po ustaleniu się sygnałów wyjściowych wszystkich neuronów w całej sieci - wszystkie wagi wszystkich neuronów są zmieniane, przy czym wielkość odpowiedniej zmiany wyznaczana jest na podstawie iloczynu sygnału wejściowego, wchodzącego na dane wejście (to którego wagę zmieniamy) i sygnału wyjściowego produkowanego przez neuron, w którym modyfikujemy wagi. Łatwo zauważyć, że jest to właśnie realizacja postulatu Hebba - w efekcie opisanego wyżej algorytmu połączenia między źródłami silnych sygnałów i neuronami które na nie silnie reagują są wzmacniane.
Dokładniejsza analiza procesu samouczenia metodą Hebba pozwala stwierdzić, że w wyniku konsekwentnego stosowania opisanego algorytmu początkowe, najczęściej przypadkowe „preferencje” neuronów ulegają systematycznemu wzmacnianiu i dokładnej polaryzacji. Jeśli jakiś neuron miał „wrodzoną skłonność” do akceptowania sygnałów pewnego rodzaju - to w miarę kolejnych pokazów nauczy się te sygnały rozpoznawać coraz dokładniej i coraz bardziej precyzyjnie. Po dłuższym czasie takiego samouczenia w sieci powstaną zatem wzorce poszczególnych typów występujących na wejściu sieci sygnałów. W wyniku tego procesu sygnały podobne do siebie będą w miarę postępu uczenia coraz skuteczniej grupowane i rozpoznawane przez pewne neurony, zaś inne typy sygnałów staną się „obiektem zainteresowania” innych neuronów W wyniku tego procesu samouczenia sieć nauczy się, ile klas podobnych do siebie sygnałów pojawia się na jej wejściach oraz sama przyporządkuje tym klasom sygnałów neurony, które nauczą się je rozróżniać, rozpoznawać i sygnalizować.
Proces samouczenia ma niestety wady. W porównaniu z procesem uczenia z nauczycielem samouczenie jest zwykle znacznie powolniejsze. Co więcej bez nauczyciela nie można z góry określić, który neuron wyspecjalizuje się w rozpoznawania której klasy sygnałów. Stanowi to pewną trudność przy wykorzystywaniu i interpretacji wyników pracy sieci. Co więcej - nie można określić, czy sieć uczona w ten sposób nauczy się wszystkich prezentowanych jej wzorców. Dlatego sieć przeznaczona do samouczenia musi być większa niż sieć wykonująca to samo zadanie, ale trenowana w sposób klasyczny, z udziałem nauczyciela. - Szacunkowo sieć powinna mieć co najmniej trzykrotnie więcej elementów warstwy wyjściowej niż wynosi oczekiwana liczba różnych wzorów, które sieć ma rozpoznawać.
Bardzo istotną kwestią jest wybór początkowych wartości wag neuronów sieci przeznaczonej do samouczenia. Wartości te mają bardzo silny wpływ na ostateczne zachowanie sieci, ponieważ proces uczenia jedynie pogłębia i doskonali pewne tendencje istniejące w sieci od samego początku, przeto od jakości tych początkowych, „wrodzonych” właściwości sieci silnie zależy, do czego sieć dojdzie na końcu procesu uczenia. Nie wiedząc z góry, jakiego zadania sieć powinna się uczyć, trudno wprowadzać jakikolwiek zdeterminowany mechanizm nadawania początkowych wartości wag, jednak pozostawienie wszystkiego wyłącznie mechanizmom losowym może powodować, że sieć (zwłaszcza mała) może nie zdołać wystarczająco zróżnicować swego działania w początkowym okresie procesu uczenia i wszelkie późniejsze wysiłki, by znaleźć w strukturze sieci reprezentację dla wszystkich występujących w wejściowych sygnałach klas, mogą okazać się daremne. Można jednak wprowadzić pewien mechanizm wstępnego „rozprowadzania” wartości wag w początkowej fazie procesu uczenia. Metoda ta, zwana convex combiation modyfikuje początkowe wartości wag w taki sposób, by zwiększyć prawdopodobieństwo równomiernego pokrycia przez poszczególne neurony wszystkich typowych sytuacji pojawiających się w wejściowym zbiorze danych. Jeśli tylko dane pojawiające się w początkowej fazie uczenia nie będą różniły się istotnie od tych, jakie sieć będzie potem analizować i różnicować - metoda convex combination stworzy w sposób automatyczny dogodny punkt wyjścia do dalszego samouczenia i zapewni stosunkowo dobrą jakość nauczonej sieci w większości praktycznych zadań.
Opis implementacji poglądowej prezentacji wybranych przykładów sieci neuronowych
W rozdziale tym skoncentrujemy się na opisie zagadnień przedstawionych w poszczególnych modułach systemu. Określimy sposób dojścia do otrzymanego efektu - edukacyjnego programu komputerowego. Zaprezentujemy najistotniejsze fragmenty kodu źródłowego, formalnie opisanego w języku Pascal, określającego sposób implementacji wybranych cech rozpatrywanych sztucznych sieci neuronowych. Układ tej części został zorganizowany w modułu dokładnie odpowiadające częściom aplikacji tworzonej w Delphi.
Prezentacja neuronu
Sfera sztucznych sieci neuronowych opiera się na formalnych definicjach modeli neuronu (następnie ich układów - sieci) oraz ich późniejszej implementacji w postacie sprzętowej - np. układy VLSI lub oprogramowania - wszelkiego rodzaju symulacje.
Pierwszą formalną definicję neuronu opartą na uproszczonym modelu rzeczywistym podali McCulloch i Pitts (1943). [5]
Sygnały wejściowe xi, i=1,2,...,n maja wartości 1 lub 0 w zależności od tego czy w danej chwili k impuls wejściowy pojawił się, czy też nie. Reguła aktywacji neuronu ma dla tego modelu postać:
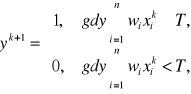
gdzie k=0,1,2,... oznacza kolejne momenty czasu, wi zaś jest multiplikatywną wagą przypisaną połączeniu wejścia i z błoną neuronu.
Mimo swej prostoty, model ten wykazuje duże potencjalne możliwości . Przy odpowiednim doborze wag i progów można z jego pomocą zrealizować funkcje logiczne NOT, OR oraz AND bądź NOR lub NAND. Wprowadzając sprzężenie zwrotne można jednak budować także układy sekwencyjne. W przypadku sygnałów binarnych neuron z jednym wejściem pobudzającym i jednostkowym progiem wytwarza sygnał yk+1 = xk. Otrzymany prosty obwód zachowujący się jak jednobitowy rejestr jest zdolny zapamiętać stan wejścia pomiędzy dwoma momentami czasu. Zamykając pętlę sprzężenia zwrotnego powstaje komórka pamięci.
Ze względu na to, że model McCullocha-Pittsa zawiera szereg istotnych uproszczeń (obsługa jedynie stanów binarnych 0 i 1, założenie dyskretnego czasu pracy, synchronizm działania wszystkich neuronów w sieci, wagi i progi są niezmienne) wprowadza się ogólny opis sztucznego neuronu.
Ogólny model neuronu zakłada, że każdy neuron składa się z elementu przetwarzającego połączonego z wejściami synaptycznymi oraz jednym wyjściem. Przepływ sygnałów jest jednokierunkowy.
Sygnał wyjściowy neuronu dany jest zależnością:
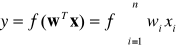
gdzie w jest wektorem wag zdefiniowanym jako
![]()
x jest wektorem wejściowym:
![]()
Funkcja ![]()
określana jest zwykle nazwą funkcji aktywacji. Jej dziedziną jest zbiór łącznych pobudzeń neuronu. W literaturze często łączne pobudzenie określane jest symbolem net. W związku z czym funkcję aktywacji można zapisać jako ![]()
Łączne pobudzenie net jest odpowiednikiem potencjału pobudzającego w neuronie biologicznym.
Typowymi funkcjami aktywacji, najczęściej stosowanymi przy konstruowaniu zarówno programowych jak i sprzętowych realizacji sztucznych sieci neuronowych są
![]()
oraz
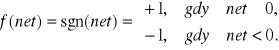
Powyższe funkcje aktywacji zwane są odpowiednio bipolarną funkcją ciągłą i bipolarną funkcją binarną (dyskretną). Odpowiednio skalując powyższe funkcje możemy otrzymać odpowiednio unipolarną funkcję ciągłą oraz unipolarną funkcję binarną dane wzorami:
![]()
oraz
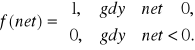
Pierwsze z tych funkcji nazywane są funkcjami sigmoidalnymi.
Istotnymi z punktu widzenia projektowego parametrami opisującymi neuron są moc śladu pamięciowego (wektor wag), moc sygnału wejściowego.
W naszym programie zaprezentujemy model sztucznego neuronu umożliwiające zmianę wartości wektora wag oraz sygnału wejściowego. Oraz automatyczne obliczenie mocy sygnału wejściowego, mocy śladu pamięciowego jak i łącznego pobudzenia neuronu. Pokazane też zostaną wartości dwóch funkcje aktywacji: ciągłej sigmoidalnej oraz bipolarnej dla wyznaczonego łącznego pobudzenia neuronu.
Poniżej przedstawiamy algorytmy obliczające wyjście neuronu (dwie funkcje) przy zadanych wagach oraz sygnale wejściowym oraz parametry: moc śladu pamięciowego i moc sygnału wejściowego oraz łączne pobudzenie.
struktury danych algorytmu:
sygnały [5] - wektor sygnałów wejściowych (5 sygnałów wejściowych),
wagi [5] - wektor wag dla wejść (5 wartości wektora wag),
moc_sladu - moc śladu pamięciowego,
moc_sygnalu - moc sygnału wejściowego,
net - łączne pobudzenie neuronu obliczone z zadanych wektorów wag oraz sygnału wejściowego,
lambda - parametr λ ciągłej sigmoidalnej funkcji aktywacji neuronu,
c_funkcja - wartość ciągłej funkcji aktywacji ![]()
dla obliczonego łącznego pobudzenia neuronu,
d_funkcja - wartość dyskretnej, unipolarnej funkcji aktywacji 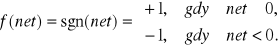
dla obliczonego łącznego pobudzenia neuronu,
moc sygnału wejściowego:
moc_sygnalu := 0;
for i := 1 to 5 do
moc_sygnalu := moc_sygnalu + sygnaly[i] * sygnaly[i];
moc śladu pamięciowego:
moc_sladu := 0;
for i := 1 to 5 do
moc_sladu := moc_sladu + wagi[i] * wagi[i];
łączne pobudzenie neuronu:
net := 0;
for i := 1 to 5 do
net := net + wagi[i] * sygnaly[i];
ciągła funkcja aktywacji:
c_funkcja := -1.0 + 2.0/(1+exp(-lambda*net));
dyskretne, unipolarna funkcja aktywacji:
d_funkcja := -1.0;
if net >= 0 then
d_funkcja := 1.0;
Jak widać z przedstawionego algorytmu neuron w przykładzie jest jedne (jeden zestaw wejść i wag) ale posiada, dla potrzeb prezentacji, trzy rodzaje odpowiedzi: Łączne pobudzenie, Ciągłą funkcję aktywacji oraz Binarną funkcję aktywacji przez co reprezentuje dwa rodzaje neuronów: zarówno liniowe jak i nieliniowe.
Prosta sieć neuronowa (z WAT)
Sieć neuronowa złożona jest z trzech nie powiązanych ze sobą neuronów. Każdy z neuronów posiada pięć wag; do każdego neuronu doprowadzony jest ten sam sygnał wejściowy. Działanie jednowarstwowej , trzyelementowej sieci oparte jest na zasadzie WAT (ang. Winer Take All) - zwycięzca bierze wszystko. Polega ona na tym, że do każdego z neuronów sieci doprowadza się ten sam sygnał wejściowy, następnie zostaje wyliczona wartość wyjściowa dla każdego neuronu. Neuron o największej (powyżej progowej wartości) wartości wyjścia zostaje zwycięzcą co dalej dla takiej sieci i takiego neuronu może rodzić różnorakie konsekwencje. Może to predysponować taki neuron do dalszego uczenia albo może np. stanowić wskazanie przynależności (faza eksploatacji lub testowania) obiektu definiowanego przy pomocy wektora wejściowego do klasy obiektów rozpoznawanych przez dany neuron (np. opis wrony poprzez odpowiednie wejście może być rozpoznane przez poprawnie nauczoną sieć jako obiekt przynależny do ptaków i do niczego więcej).
Praca danej sieci z zaimplementowanym progiem i przepisem działania WAT odbywa się według algorytmu:
struktury danych algorytmu:
NA1, NA2, NA3, NA4, NA5 - wagi neuronu A, wektor wag neuronu A to [NA1, NA2, NA3, NA4, NA5]
NB1, NB2, NB3, NB4, NB5 - wagi neuronu B, wektor wag neuronu B to [NB1, NB2, NB3, NB4, NB5]
NC1, NC2, NC3, NC4, NC5 - wagi neuronu C, wektor wag neuronu C to [NC1, NC2, NC3, NC4, NC5]
Ob1, Ob2, Ob3, Ob4, Ob5 - kolejne wartości wektora sygnału wejściowego wektor wejściowy to [Ob1, Ob2, Ob3, Ob4, Ob5]T
{ ----- wyjście dla neuronu A ----- }
Wyj := NA1 * Ob1 + NA2 * Ob2 + NA3 * Ob3 + NA4 * Ob4 + NA5 * Ob5;
TabPom[1] := Wyj;
{ ----- wyjście dla neuronu B ----- }
Wyj := NB1 * Ob1 + NB2 * Ob2 + NB3 * Ob3 + NB4 * Ob4 + NB5 * Ob5;
TabPom[2] := Wyj;
{ ----- wyjście dla neuronu C ----- }
Wyj := NC1 * Ob1 + NC2 * Ob2 + NC3 * Ob3 + NC4 * Ob4 + NC5 * Ob5;
TabPom[3] := Wyj;
{ zostały wyliczone wartości wyjść dla poszczególnych neuronów}
{teraz przechodzimy do ustalenia zwycięzcy - neuronu który zidentyfikował obiekt}
struktury danych algorytmu klasyfikacji WAT z progiem:
MaxWin - wartość progowa dla rozpoznawanych obiektów - wyjść poszczególnych neuronów zapisanych w trzyelementowej tablicy TabPom.
Winner - numer neuronu który rozpoznał obiekt
MaxWin - wartość określa próg przy którym można mówić o zwycięzcy. Jeśli wszystkie wartości wyjściowe poszczególnych neuronów są mniejsze od wartości progowej algorytm nie wyłania zwycięzcy przez co dany wektor sygnałów wejściowych jest odrzucany przez sieć trzech neuronów.
Winer := 0;
MaxWin := Prog;
for I := 1 to 3 do
if MaxWin <= TabPom[I] then
begin
MaxWin := TabPom[I];
Winer := I;
end;
{jeśli Winner jest równy 0, to znaczy, ze sieć nie potrafi zidentyfikować obiektu}
W przykładzie zostały wagi odpowiednio nazwane a wybór odpowiedniego - zwycięskiego - neuronu jest równoważny w rozpoznaniu wejścia jako nazwanego obiektu o określonych cechach (wartościami wag).
Uczenie pojedynczego neuronu
Sztuczny neuron przetwarza informacje wejściowe xi na pewien sygnał wyjściowy y. Neurony traktować można jako elementarne procesory o następujących właściwościach:
każdy neuron otrzymuje wiele sygnałów wejściowych i wyznacza na ich podstawie jeden sygnał wyjściowy,
z każdym oddzielnym wejściem neuronu związany jest parametr nazywany wagą,
sygnał wchodzący określonym wejściem jest najpierw przemnażany przez wagę danego wejścia, w związku z czym w dalszych obliczeniach uczestniczy już w formie zmodyfikowanej,
sygnały wejściowe (przemnożone przez odpowiednie wagi) są w neuronie sumowane, dając pewien pomocniczy sygnał wewnętrzny nazywany czasem łącznym pobudzeniem neuronu (w literaturze angielskiej net value),
do tak utworzonej sumy sygnałów dodaje niekiedy (nie we wszystkich typach sieci) dodatkowy składnik niezależny od sygnałów wejściowych, nazywany progiem (w literaturze angielskiej bias),
suma przemnożonych przez wagi sygnałów wewnętrznych z dodanym (ewentualnie) progiem może być bezpośrednio traktowana jako sygnał wyjściowy neuronu ( w sieciach o bogatszych możliwościach sygnał wyjściowy neuronu obliczany jest za pomocą zależności nieliniowej między łącznym pobudzeniem a sygnałem wyjściowym).
Każdy neuron dysponuje pewną wewnętrzną pamięcią (reprezentowaną przez aktualne wartości wag i progu) oraz pewnymi możliwościami przetwarzania wejściowych sygnałów w sygnał wyjściowy.
Proces uczenia neuronu sprowadza się do modyfikowania współczynników wagowych neuronu w taki sposób, by neuron działał zgodnie z oczekiwaniami użytkownika. W przykładzie tym wykorzystaliśmy uczenie z nauczycielem.
Uczenie z nauczycielem polega na tym, że neuronowi podaje się przykłady poprawnego działania, które powinien on potem naśladować w swoim bieżącym działaniu. Przykład należy rozumieć w ten sposób, że nauczyciel podaje konkretne sygnały wejściowe i wyjściowe, pokazując, jaka jest wymagana odpowiedź sieci dla pewnej konfiguracji danych wejściowych. W typowym procesie uczenia sieć otrzymuje od nauczyciela ciąg uczący i na jego podstawie uczy się prawidłowego działania, stosując jedną z wielu znanych dziś strategii uczenia
Najbardziej znaną z reguł uczenia z nauczycielem jest reguła delta.
Polega ona na tym, że każdy neuron po otrzymaniu na swoich wejściach określone sygnały (z wejść sieci albo od innych neuronów, stanowiących wcześniejsze warstwy sieci) wyznacza swój sygnał wyjściowy wykorzystując posiadaną wiedzę w postaci wcześniej ustalonych wartości wag, wartości wejść oraz (ewentualnie) progu. Wartość sygnału wyjściowego, wyznaczonego przez neuron na danym kroku procesu uczenia porównywana jest z odpowiedzią wzorcową podaną przez nauczyciela w ciągu uczącym. Jeśli występuje rozbieżność - neuron wyznacza różnicę pomiędzy swoim sygnałem wyjściowym a tą wartością sygnału, która była by - według nauczyciela prawidłowa. Ta różnica oznaczana jest zwykle symbolem greckiej litery δ (delta) i stąd nazwa opisywanej metody.
Sygnał błędu (delta) wykorzystywany jest przez neuron do korygowania swoich współczynników wagowych (i ewentualnie progu), stosując następujące reguły:
wagi zmieniane są tym silniej, im większy błąd został wykryty,
wagi związane z tymi wejściami, na których występowały duże wartości sygnałów wejściowych, zmieniane są bardziej, niż wagi wejść, na których sygnał wejściowy był niewielki.
W naszym przykładzie o zakończeniu procesu uczenia decyduje użytkownik. Proces uczenia może zostać uznany za zakończony gdy wyliczane po każdym kroku uczenia błędy są małe - powodują one minimalne korekty wag.
Program wczytuje dane z pliku zawierającego ciąg uczący (dane wejściowe i wzorcowe odpowiedzi) klasyfikuje obiekty, których dane są w tym pliku kolejno zapisane.
Podczas symulowanego uczenia użytkownik może śledzić w kolejnych krokach postęp uczenia, obserwując, jak zmieniają się współczynniki wag i błąd.
struktury danych algorytmu:
wyjscie - sygnał wyjściowy, odpowiedź neuronu dla zadanego sygnału wejściowego
wagi - wektor wag neuronu, modyfikowany w trakcie uczenia neuronu,
sygnaly - sygnały wejściowe; sygnały wczytywane są z pliku zewnętrznego - ciągu uczącego,
blad - wartość błędu wyliczana po każdej iteracji uczenia,
prawidlowe - wzorcowa prawidłowa wartość wyjścia (wczytywana z ciągu uczącego),
wspolczynnik - wartość współczynnika uczenia, ustalana przez użytkownika
-->Neuron ma 5 wejść, początkowe wartości współczynników wagowych są otrzymywane za pomocą generatora liczb pseudolosowych.[Author ID1: at Fri Sep 24 12:11:00 1999 ]
wyliczanie sygnału wyjściowego:
wyjscie := 0;
for i := 1 to 5 do
wyjscie := wyjscie + wagi[i] * sygnaly[i];
błąd po każdym kroku:
blad := prawidlowe - wyjscie;
modyfikacja wag, na podstawie wyliczonego błędu:
for i := 1 to 5 do
wagi[i] := wagi[i] + wspolczynnik * blad * sygnaly[i];
Testowanie neuronu polega na podawanie na jego wejścia określonych przez użytkownika sygnałów. Neuron wylicza dla tych wartości wejść sygnał wyjściowy.
Uczenie prostej sieci
Możliwe są dwa warianty procesu (strategii) uczenia sieci neuronowej: z nauczycielem i bez nauczyciela.
Uczenie z nauczycielem polega na tym, że sieci podaje się przykłady poprawnego działania które powinna ona potem naśladować w swoim bieżącym działaniu (w czasie egzaminu). Przykład należy rozumieć jako konkretnych sygnałów wejściowych i odpowiadających im sygnałów wyjściowe. W typowym procesie uczenia sieć otrzymuje od nauczyciela ciąg uczący i na jego podstawie uczy się prawidłowego działania.
Obok opisanego wyżej schematu uczenia z nauczycielem występuje też szereg metod tak zwanego uczenia bez nauczyciela (albo samouczenia sieci). Metody te polegają na podawaniu na wejście sieci wyłącznie szeregu przykładowych danych wejściowych, bez podawania informacji dotyczącej oczekiwanych sygnałów wyjściowych. Odpowiednio zaprojektowana sieć potrafi zinterpretować sygnały wejsciowe i zbudować na ich podstawie sensowny algorytm swojego działania - najczęściej polegający na tym, że automatycznie wykrywane są klasy powtarzających się sygnałów wejściowych i sieć uczy się (spontanicznie, bez jawnego nauczania) rozpoznawać te typowe wzorce sygnałów.
Uczenie może odbywać się zgodnie z jedną z wielu reguł uczenia. Do najbardziej znanych należą:
Reguła Hebba
W tej regule przyrost wag łączących węzeł [i] i węzeł [j] jest proporcjonalny do współczynnika uczenia, do wartości aktywacji wyjścia yj z neuronu [j] oraz agregacji wejść do neuronu [i], tj. xi.
![]()
Reguły należy do reguł uczenia bez nadzoru.
Reguła Delta
Jest to reguła uczenia z nauczycielem. Można zapisać ja w postaci:
![]()
Inne znane reguły uczenia to reguła LMS oraz reguła Widrow-Hoffa.
Przygotowany przez nas program wczytuje dane z pliku zawierającego ciąg uczący (dane wejściowe i wzorcowe odpowiedzi) klasyfikuje obiekty, których dane są w tym pliku kolejno zapisane.
Podczas symulowanego uczenia użytkownik może śledzić w kolejnych krokach postęp uczenia, obserwując, jak zmieniają się współczynniki wag i błąd .
Sieć składa się z 3 neuronów, z których każdy ma 5 wejść, początkowe wartości współczynników wagowych są otrzymywane za pomocą generatora liczb pseudolosowych.
struktury danych algorytmu:
wyjscie - wektor sygnałów wyjściowych,
wagi - tablica zawierająca wagi wszystkich neuronów,
sygnaly - wektor sygnałów wejściowych; sygnały wczytywane są z pliku zewnętrznego - ciągu uczącego,
blad - wektor wartość błędu wyjść sieci wyliczany po każdej iteracji uczenia,
prawidlowe - wzorcowa prawidłowa wartość wyjścia j (wczytywana z ciągu uczącego),
wspolczynnik - wartość współczynnika uczenia, ustalana przez użytkownika.
wyliczenie sygnałów wyjściowych:
for j := 1 to 3 do begin
wyjscie[j] := 0;
for i := 1 to 5 do
wyjscie[j] := wyjscie[j] + wagi[j, i] * sygnaly[i];
blad[j] := prawidlowe[j] - wyjscie[j];
end;
błąd po każdym kroku:
blad[j] := prawidlowe[j] - wyjscie[j];
modyfikacja wag, na podstawie wyliczonego błędu:
for i := 1 to 5 do
wagi[j, i] := wagi[j, i] + wspolczynnik * blad[j] * sygnaly[i];
Testowanie odbywa się poprzez podanie na wejścia sieci określonych przez użytkownika sygnałów.
Sieć neuronowa jako filtr sygnału z zakłóceniami
Kiedy sieć neuronowa ma dokładnie tyle samo neuronów wejściowych co wyjściowych oraz jej proces uczenia oraz pracy zasadza się na stanie przyporządkowania (odtworzenia) sygnałowi wejściowemu dokładnie określonego sygnału wyjściowego mamy wtedy do czynienia z siecią autoasocjacyjną (albo skojarzeniową). Sieci takie w swym zamyśle konstrukcyjnym nie mają za zadanie odtwarzać dokładnie sygnału wejściowego na wyjściu. Idea pracy takiej sieci polega na tym, że sieć po otrzymaniu na wejście sygnału podobnego do sygnału uczestniczącego w procesie uczenia odtworzy (skojarzy) na wyjściu wzorzec odpowiadający sygnałowi z fazy uczenia.
Podstawową zasadą uczenia jest to aby sieć trenowała swe „umiejętności” odtwarzanie wzorca (kilku - kilkunastu wzorców - to zależy od pojemności pamięciowej sieci, w przybliżeniu od ilości neuronów w warstwie ukrytej) podawanego na wejście w różnych odmianach (np. w różny sposób zakłóconego). Jeśli dane mają postać szeregu czasowego, to warianty otrzymuje się dla różnych opóźnień w czasie (kątów przesunięcia fazowego).
Jednym z istotnych zastosowań autoasocjacyjnej sieci neuronowej jest wykrywanie sygnału na tle szumu.
W naszym programie zaprezentujemy uczenie sieci filtrowania zadanego sygnału. Sygnał wprowadzany jest do programu przy pomocy pliku zawierającego trzy kolumny:
sygnał synchronizujący (można interpretować jako czas lub oś x na wykresie)
sygnał czysty, wzorcowy taki jaki sieć ma rozpoznawać z zaszumionego
sygnał zakłócony, stanowiący postawę uczenia sieci, jak i stanowiący postawę wstępnego testowania.
W przypadku gdy jesteśmy zadowoleni już z efektów działania naszej wytrenowanej sieci na wejście (zmiana pliku) można podać inaczej zakłócony sygnał wejściowy - dla testowania.
struktury danych dla algorytmu uczenia:
NRob - liczność zbioru uczącego, określana automatycznie na podstawie ilości elementów zapisanych w pliku ciągu uczącego
M - ilość wag w neuronie, w programie ustalona arbitralnie na 5, można to zmodyfikować poprzez ingerencję w dostarczony kod źródłowy programu prezentacyjnego,
WagiSieci - tablica określająca rozmiar sieci, ilość elementów sieci - neuronów o M. wagach wynosi NRob, liczebność tablicy to iloczyn M*NRob
WykArr - tablica z ciągami wzorcowym oraz zaszumionym (liczebność NRob*2)
aynok - stała określająca wektor ciągu uczącego w tablicy WayArr - wzorzec z zakłóceniami
ayok - stała określająca wektor ciągu uczącego w tablicy WayArr - wzorzec bez zakłóceń
Wspolczynnik - parametr określający szybkość uczenia neuronów, przed procesem uczenia użytkownik może
Randomize;
for J := 1 to NRob do
begin
for I := 1 to M do
WagiSieci[J, I] := -0.1 + 0.2 * Random;
if { uczenia ma uwzględniać wagę środkową } then
WagiSieci[J, Krok] := 1.0;
end;
for K := 1 to { ilość prezentacji ciągu uczącego} do
begin
for J := Krok - 1 TO (NRob - Krok) do
begin
Wyjscie := 0.0;
for I := 1 to M do
Wyjscie := Wyjscie+WagiSieci[J,I]*WykArr[J+I-Krok, aynok];
{ obliczenie błędu między wyjściem a wzorcem }
Blad := WykArr[J, ayok] - Wyjscie;
{ korekta wag }
for I := 1 to M do
WagiSieci[J, I] := WagiSieci[J,I]+ Wspolczynnik* Blad*WykArr[J+I-Krok, aynok];
end; {of J := ...}
end; {of K := ...}
Testowanie odbywa się poprzez podanie na wejście sieci sygnału zaszumionego. Uzyskuje się w ten sposób wykresy z nałożonym (opcjonalnie) sygnałem wzorcowym, sygnałem zakłóconym lub/i sygnałem przefiltrowanym.
Rozpoznawanie obrazu
Jak widać było we wcześniejszej części niniejszego opracowania dziedzina sieci neuronowych przeżywa wzloty i upadki. Niewątpliwie wielkim osiągnięciem w tej materii jest opracowanie mechanizmów definicji oraz konstrukcji wielowarstwowych sieci nieliniowych. Sieci takie posiadają wręcz nieograniczone możliwości przynajmniej jak na razie nie zostały one znalezione jak miało to miejsce dla sieci liniowych - publikacja Minsky'ego i Paperta. [11] Na pewno to opracowanie nie stanowiłoby przynajmniej próby ogarnięcia i zaprezentowania najistotniejszych zagadnień sieci neuronowych gdybyśmy nie pokusili się o przedstawienie uczenia i pracy takiej sieci.
W przypadku konstrukcji wielowarstwowych sieci neuronowych korzysta się przeważanie z definicji nieliniowości neuronu określonej rozdziale Prezentacja neuronu tej pracy. Jeśli zaś chodzi o sferę związaną z topologią połączeń to wyróżnia się w takich układach następujące elementy:
warstwa wejściowa - zawiera ona tyle neuronów aby pokryć w pełni dziedzinę cech opracowywanego zjawiska czy obiektu; w większości przypadków warstwa ta nie będzie podlegać uczeniu; pełnić będzie rolę dyskryminacyjne oraz normalizacyjne dla sygnałów podlegających obróbce w dalszej strukturze sieci
warstwa ukryta - raczej powinno się tu mówić o warstwach ukrytych; one to stanowią o jakości sieci, jej potencjale pamięciowym, skomplikowaniu możliwego odwzorowania realizowanego przez sieć, o sposobie uczenia całej sieci; połączenie pomiędzy warstwami odbywają się na zasadzie wyjścia jednej warstwy stanowią wejścia następnej warstwy; uczeniu podlegają wszystkie neurony wchodzące w skład warstw ukrytych
warstwa wyjściowa - ma w zasadzie dwa zadania odebrać „odpowiedź” (przetworzony sygnał) warstw ukrytych oraz odpowiednio go przeskalować dla potrzeb danej realizacji; warstwa wyjściowa zwykle podlega uczeniu ale może być zmienione zgodnie z potrzebami konkretnej implementacji.
Rysunek poniższy w sposób obrazowy przedstawia jak modelowo konstruuje się wielowarstwowe sieci neuronowe:
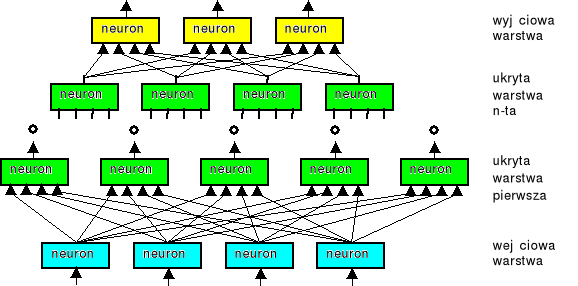
Rys. 1. Model budowy wielowarstwowej sieci neuronowej
W programie przedstawiono aspekt uczenia i testowania po każdym kroku sieci neuronowej, wielowarstwowej z definicją nieliniowości pojedynczego neuronu daną wzorem:
![]()
gdzie net jest wartością dla neuronu (m) w warstwie (0..n+1):
dla warstwy wejściowej (0) - neuron posiada n1 - wag z doprowadzonymi sygnałami wejściowymi
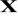
:
![]()
dla warstw ukrytych (1..n); k - jest to ilość wag warstwy (j) a jednocześnie ilość neuronów w warstwie poprzedniej; y(i)(j-1) - odpowiedź i-tego neuronu warstwy (j-1)
![]()
dla warstwy wyjściowej mamy związek odpowiednio taki, jak dla warstw ukrytych
![]()
Sieć posiada dwa neurony warstwy wejściowej dwie warstwy ukryte o ilości elementów definiowanych przez użytkownika oraz jeden neuron wyjściowy. Taka konstrukcja posłuży nam do nauczenia sieci rozpoznawania obrazu dwuwymiarowego przedstawionego w postaci figur geometrycznych (kół) nakładanych na siebie.
struktury danych algorytmu:
LW - ogólna liczba warstw (ukryte plus dwie); jeśli w określeniu ilości neuronów w warstwach ukrytych podamy 0 to możemy otrzymać sieć wielowarstwową z warstwą wejściowa i wyjściową,
n - tablica z informacją ile elementów (neuronów) znajduje się w poszczególnych warstwach - tablica ta pełni funkcje sterująca dla ogólnej tablicy wag,
yy - tablica odpowiedzi poszczególnych neuronów w danym kroku dla wszystkich warstw,
Wagi - wielowymiarowa tablica wag całej sieci (trzy wymiarowa: warstwa, neuron, nr wagi w neuronie),
alfa - momentum - wpływ zmian w poprzednim kroku na zmiany w kroku bieżącym
eta - współczynnik uczenia
sigma - tablica pomocnicza pamiętająca propagację błędu w danym kroku
generacja wartości odpowiedzi sieci w bieżącym kroku:
for i := 1 to LW do
for k := 0 to n[i] - 1 do
begin
yy[i,k] := 0;
yy[i-1,n[i-1]] := -1;
for j := 0 to n[i-1] do
yy[i,k] := yy[i,k] + yy[i-1,j]*Wagi[i,j,k];
yy[i,k] := 1.0 / (1.0+Exp(-yy[i,k]));
end;
uczenie wielowarstwowej sieci neuronowej (backpropagation):
for i := LW downto 1 do
for j := 0 to n[i] - 1 do
begin
if i = LW then
blad := dd[j] - yy[i,j]
else
begin
blad := 0.0;
for k := 0 to n[i+1] - 1 do
blad := blad + sigma[i+1,k]*Wagi[i+1,j,k];
end;
sigma[i,j] := blad*yy[i,j]*(1-yy[i,j])
end;
Wagi2 := Wagi;
for i := 1 to LW do
for j:= 0 to n[i-1] do
for k := 0 to n[i] - 1 do
begin
zmiana := alfa*(Wagi[i,j,k]-Wagi1[i,j,k]);
zmiana := eta*sigma[i,k]*yy[i-1,j] - zmiana;
Wagi[i,j,k] := Wagi[i,j,k] + zmiana;
end;
Wagi1 := Wagi2;
Wielowarstwowe, nieliniowe sieci neuronowe stanowią obecnie jedną z najważniejszych dziedzin sfery określanej mianem Sztuczne sieci neuronowe.
Backpropagation - najpopularniejsza metoda uczenia liniowych sieci neuronowych
Algorytm wstecznej propagacji błędu (backpropagation) jest obecnie podstawowym (i jednym z najskuteczniejszych) algorytmem nadzorowanego uczenia wielowarstwowych jednokierunkowych sieci neuronowych.
Nazwa tego algorytmu wynika z kolejności obliczania sygnałów błędu δ, która przebiega w kierunku odwrotnym niż przechodzenie sygnałów przez sieć, to znaczy od warstwy wyjściowej poprzez warstwy ukryte w kierunku warstwy wejściowej.
Ogólnie algorytm propagacji wstecznej wymaga dla każdego wzorca uczącego wykonania następujących czynności:
Założenia: dana jest sieć o M warstwach, oraz zestaw danych uczących E = {E1, E2...EN}, gdzie każdy z przykładów składa się z wektora danych wejściowych X i z wektora wyjść D.
Przypisz wszystkim wagom wartości losowe bliskie 0. Wybierz wzorzec uczący EK.
Podaj wektor uczący EK na wejście sieci
Wyznacz wartości wyjść każdego elementu dla kolejnych warstw przetwarzania, od pierwszej warstwy ukrytej do warstwy wyjściowej
Oblicz wartość δMi błędów dla warstwy wyjściowej
δMi = f (xil-1 (t)) [di - yiM(t)]
Wyznacz kolejno błędy w warstwach l = M., M.-1, ...2 według postępowania
δl-1i (t) = f (xil-1 (t) ) Σi wlji (t) δli (t)
Wyznacz zmianę wartości wag
Δwlij (t) = γ δli (t) xil-1 (t)
Modyfikuj wszystkie wagi
wlji (t+1) = wlji (t) + Δwlij (t)
Wybierz kolejny wzorzec (o ile istnieje) i przejdź do punktu 2 (wczytanie wzorca)
W trakcie uczenia sieci można zaprezentować dowolną liczbę wzorców uczących. Jeśli sieć ma pracować z danymi zakłóconymi to część wektorów uczących powinna również zawierać zakłócenie. Jest to związane ze zdolnością sieci do uogólniania - niewielkie zaburzenie sygnałów wzorcowych może spowodować przyspieszenie zbieżności procesu uczenia ( choć sygnał zaburzony nigdy może się nie pojawić w rzeczywistej pracy sieci ).
Inne zasady obowiązujące przy konstruowaniu ciągów uczących zostały przedstawione w punkcie Projektowanie zbioru uczącego.
Pierwszą operacją w procesie uczeni jest inicjalizacja początkowego układu wag. Należy unikać symetrii w warstwach wag początkowych (mogłoby to spowodować nie nauczenie się sieci ). Najskuteczniejszym rozwiązaniem wydaje się być losowy wybór wag początkowych.
Istotnym problemem jest wybór współczynnika uczenia η. Parametr ten decyduje o szybkości i stabilności procesu uczenia. Przy zbyt małej wielkości tego współczynnika uczenie postępuje w bardzo wolnym tempie, i sieć potrzebuje b. dużej liczby operacji, by się nauczyć. W przypadku zbyt dużej wartości tego współczynnika algorytm może stać się niestabilny.
Wartość współczynnika η dobiera się zazwyczaj z przedziału [0.05 , 0.25].
obliczenia przejścia sygnału w sieci - struktury danych algorytmu:
iKrok - zmienna kontrolna programu - pokazująca, na którym kroku jest sieć
RN1, RN2, RN3, RN4 - obiekty typu neuron, przy czym RN1 i RN2 stanowią warstwę ukrytą, RN3 i RN4 - warstwę wyjściową.
begin
if (iKrok1 < 1) or (iKrok1 > 5) then
iKrok1 := 1;
case iKrok1 of
1: begin
Tytul1(`OBLICZENIE SUMY ILOCZYNÓW SYGNAŁÓW
WEJŚCIOWYCH ORAZ',0);
Tytul1(`WAG WARSTWY UKRYTEJ',1);
RN1.Krok1(We1.Value,We2.Value,Bias.Value);
RN2.Krok1(We1.Value,We2.Value,Bias.Value);
{przerysowanie ekranu, uwzględnienie zmian}
end;
2: begin
Tytul1(`OBLICZENIE ODPOWIEDZI NEURONÓW WARSTWY
UKRYTEJ',0);
Tytul1(`',1);
RN1.Krok2;
RN2.Krok2;
end;
3: begin
Tytul1(`OBLICZENIE SUMY ILOCZYNÓW WYJŚĆ
WARSTWY UKRYTEJ ORAZ',0);
Tytul1(`WAG WARSTWY WYJŚCIOWEJ',1);
RN3.Krok1(RN1.Odp.Value,RN2.Odp.Value,
Bias.Value);
RN4.Krok1(RN1.Odp.Value,RN2.Odp.Value,
Bias.Value);
{przerysowanie ekranu, uwzględnienie zmian}
end;
4: begin
Tytul1(`OBLICZENIE ODPOWIEDZI NEURONÓW WARSTWY
WYJŚCIOWEJ',0);
Tytul1(`',1);
RN3.Krok2;
RN4.Krok2;
end;
5: begin
Czysc;
Tytul1(`PARAMETRY SIEĆ NEURONOWEJ ZOSTAŁY
OKREŚLONE',0)
end;
end;
{przerysowanie ekranu - uwzględnienie zmian}
Inc(iKrok1);
end;
Procedury wywoływane w algorytmie głównym:
procedure TRN.Krok2;
begin
Odp.Value := 1.0/(1.0+exp(-SumWe.Value));
Odp.Text := FloatToStrF(Odp.Value,ffFixed,18,4);
end;
procedure TRN.Krok1(x1,x2,x3: Extended);
begin
Wej[1] := x1;
Wej[2] := x2;
Wej[3] := x3;
SumWe.Value := W[1].Value*x1 + W[2].Value*x2 + W[3].Value*x3;
SumWe.Text := FloatToStrF(SumWe.Value,ffFixed,18,4);
end;
uczenie sieci - struktury danych algorytmu:
RN21, RN22, RN23, RN24, RN25, RN26 - obiekty typu neuron, przy czym RN21 i RN22 stanowią warstwę wejściową, RN23 i RN24 - warstwę ukrytą, RN25 i RN26 - warstwę wyjściową.
Wyznaczenie błędów dla warstwy wyjściowej
begin
Tytul2('SIEĆ WYZNACZA BŁĘDY NEURONÓW WARSTWY
WYJŚCIOWEJ');
RN21.SetEtaAlfa(eta.Value,alfa.Value);
RN22.SetEtaAlfa(eta.Value,alfa.Value);
RN23.SetEtaAlfa(eta.Value,alfa.Value);
RN24.SetEtaAlfa(eta.Value,alfa.Value);
RN25.SetEtaAlfa(eta.Value,alfa.Value);
RN26.SetEtaAlfa(eta.Value,alfa.Value);
RN25.SetBlad(z1.Value);
RN26.SetBlad(z2.Value);
end;
Wsteczne rzutowanie błędu
begin
Tytul2('SIEĆ RZUTUJE WSTECZNIE BŁĘDY DO WARSTW
UKRYTYCH');
{ wylicznie sigmy dla neuronu }
RN25.ClcSigma;
RN26.ClcSigma;
{ proagacja wsteczna błędu }
RN23.ClcBladBP(RN25,RN26,1);
RN24.ClcBladBP(RN25,RN26,2);
RN23.PokazBlad(True);
RN24.PokazBlad(True);
{ wylicznie sigmy dla neuronu }
RN23.ClcSigma;
RN24.ClcSigma;
end;
Modyfikacja wag :
begin
Tytul2('SIEĆ USTALA NOWE WARTOŚCI
WSPÓŁCZYNNIKÓW WAG NEURONÓW');
RN23.ObliczNoweWagi(alfa.Value,eta.Value);
RN23.PokazNoweWagi(True);
RN24.ObliczNoweWagi(alfa.Value,eta.Value);
RN24.PokazNoweWagi(True);
RN25.ObliczNoweWagi(alfa.Value,eta.Value);
RN25.PokazNoweWagi(True);
RN26.ObliczNoweWagi(alfa.Value,eta.Value);
RN26.PokazNoweWagi(True);
end;
Kluczowe procedury wywoływane w algorytmie głównym:
procedure TRN.ObliczNoweWagi(pAlfa,pEta: Extended);
var
zm,W2: Extended;
i: integer;
begin
for i := 1 to 3 do begin
W2 := W[i].Value;
zm := pAlfa * (W[i].Value-W1[i]);
zm := pEta * Sigma*Wej[i] - zm;
WNew[i].Value := W[i].Value + zm;
W1[i] := W2;
end;
end;
procedure TRN.ClcSigma;
begin
Sigma := Blad.Value * Odp.Value * (1.0 - Odp.Value);
{ funckcja odwrotna dla funkcji aktywacji neurony }
end;
procedure TRN.ClcBladBP(pRN1,pRN2: TRN; nrWagi: integer);
begin
Blad.Value := pRN1.Sigma*pRN1.W[nrWagi].Value +
pRN2.Sigma*pRN2.W[nrWagi].Value;
end;
procedure TRN.SetBlad(pZadana: extended);
begin
Blad.Value := Odp.Value - pZadana;
PokazBlad(True);
end;
Sieć Kohonena
Sieci samoorganizujące w procesie ucznia spontanicznie tworzą odwzorowanie (ang. mapping) zbioru sygnałów wejściowych na zbiór sygnałów wyjściowych. Cechy jakimi musi charakteryzować się sieć samoorganizująca oraz proces uczenia, to koherentność i kolektywność.
Koherentności jest to efekt grupowania danych wejściowych w klasy podobieństwa. Grupowanie w klasy podobieństwa opisywane jest przez zestaw technik matematycznych (w większości przypadków statystycznych) zwanych analizą skupień (ang. cluster analysis). Wśród technik analizy skupień na uwagę szczególnie zasługują mechanizmy kwantyzacji wektorowej.
Kolektywność jest to efekt, który zachodzi w sieciach samoorganizujących. Główne cechy tego mechanizmu to, to że co rozpoznaje jeden neuron, w dużej mierze zależy także od tego co rozpoznają inne neurony. Ten efekt związany jest z pojęciem sąsiedztwa.
Ogólna zasada uczenia sieci Kohonena opiera się na następujących założeniach:
wektor sygnałów wejściowych X jest przed procesem uczenia normalizowany ||X|| = 1, co można zapisać jako
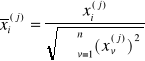
wszystkie neurony sieci dostają ten sam zestaw sygnałów wejściowych
wyliczana jest odpowiedź dla wszystkich neuronów
proces modyfikacji wag następuje w neuronie który zwyciężył w rywalizacji - posiada największą wartość odpowiedzi
wyliczanie nowej wartości wag dla neuronu który zwyciężył następuje według poniższego przepisu:
![]()
gdzie:
h(m,m*) - jest funkcją określającą sąsiedztwo
η(j) - określa współczynnik uczenia dla (j)-tego kroku
Sąsiedztwo jest to metoda, która pozwala na redukcję niepożądanych skutków uczenia sieci samoorganizujących w oparciu o konkurencje. Konkurencja w procesie uczenia może doprowadzić do sytuacji takiej, że tylko niewielki odsetek neuronów uzyska możliwość rozpoznawania obiektów pokazywanych sieci (nauczy się). Reszta neuronów nie będzie w trakcie uczenia zmieniać swoich wag i w ten sposób zatraci na zawsze swe użytkowe cech jako elementy wytrenowanej sieci neuronowej. Sąsiedztwo jest miarą w jakim stopniu sąsiad neuronu zwycięskiego będzie miał zmieniane wagi w danym kroku procesu uczenia. Zwykle wartość tego parametru jest określana na wartość 0 - 1.
Sąsiedztwo rozpatruje się w układach:
jednowymiarowych, neurony sąsiednie leżą na jednej linii,
dwuwymiarowych, neurony są ułożone w warstwie a sąsiadami są neurony położone na lewo i na prawo oraz u góry i u dołu rozpatrywanego neuronu, inny przypadek opisuje dodatkowe kontakty po przekątnych
wielowymiarowe, neurony ułożone są swobodnie w przestrzeniach wielowymiarowych a twórca danej sieci określa zasady sąsiedztwa.
Do najbardziej istotnych i użytecznych układów sąsiedztwa zaliczamy organizacje jedno- i dwuwymiarowe, dla nich właśnie dodatkowym istotnym parametrem jest określenie ile neuronów obok (sąsiadów z lewej, prawej itd.) ma podlegać uczeniu w przypadku zwycięstwa danego neuronu.
Po raz pierwszy opracowania na temat sieci samoorganizujących z konkurencją i sąsiedztwem pojawiły się w latach 70-tych za przyczyną opisów eksperymentów fińskiego badacza Kohonena. Stąd też tego typu sieci wraz z metodami uczenia nazywamy sieciami Kohonena. [13,14,15]
W naszym programie przedstawiamy przykład procesu uczenia sieci Kohonena rozpoznawania zadanej przez użytkownika figury geometrycznej. Po każdorazowym cyklu prezentacji określonej ilości losowych punktów następuje automatyczny test skuteczności sieci w rozpoznawaniu danej figury.
struktury danych algorytmu:
alfa0, alfa1 - parametry określające szybkość procesu uczenia sieci (parametr modyfikacji wag w kolejnych krokach uczenia);
epsAlfa - określa o ile ma się zmieniać wartość alfa0 oraz alfa1 w kolejnych krokach uczenia (po każdej prezentacji);
sąsiedztwo - parametr określający ile neuronów na się uczyć wraz z neuronem zwycięskim;
epsSasiedztwo - określa o ile ma się zmieniać wartość „sąsiedztwo” w kolejnych krokach uczenia (po każdej prezentacji);
m, n - rozmiar sieci (sieć ma konstrukcję obszaru o długości m na n neuronów);
MaxI - ilość prezentacji w epoce uczenia;
uczenie sieci Kohonene:
iInc := 1;
while iInc < MaxI do
begin
x := 5.0 - 10.0*Random;
y := 5.0 - 10.0*Random;
{ PokazPunkt - i dobry i zły }
if not „punkt należy do obszaru figury” then
continue
else
begin { uczenie dla dobrego punktu }
OdlMin := 10000.0;
imin := 1; jmin := 1;
{ obliczanie maksymalnej odpowiedzi sieci }
for i := 1 to m do
for j := 1 to n do
begin
odl := sqrt(sqr(w[i,j,0]-x) + sqr(w[i,j,1]-y));
if odl >= OdlMin then
continue;
OdlMin := odl; imin := i; jmin := j;
end;
{ ustawianie wag zwycięskiego neuronu oraz wag jego sąsiadów - parametr sąsiedztwo}
s := sasiedztwo;
for i := imin-s to imin+s do
for j := jmin-s to jmin+s do
begin
odl := Max(Abs(i-imin),Abs(j-jmin));
{ obliczenie parametru modyfikacji wag )
alfa := (alfa0*(s-odl) + alfa1*odl)/s
w[i,j,0] := w[i,j,0] + alfa*(x-w[i,j,0]);
w[i,j,1] := w[i,j,1] + alfa*(y-w[i,j,1]);
end;
{ zmiana parametrów uczenia }
alfa0 := alfa0*epsAlfa;
alfa1 := alfa1*epsAlfa;
sasiedztwo := (sasiedztwo-1.0)*epsSasiedztwo + 1.0;
Inc(iInc);
end; { koniec pętli uczącej }
Samouczenie sieci neuronowej
W przypadku gdy sieć nie może być uczona pod nadzorem nauczyciela poczytne miejsce zajmują strategie uczenia oparte na idei wprowadzonej do dziedziny neuropsychologii przez amerykańskiego badacza D.O. Hebba w 1949 roku. [16] Jednak ta idea znaczenia dla dziedziny sieci neuronowych zaistniała naprawdę w 1981 roku kiedy to inny badacz Sutton opracował formalne metody wykorzystania jej w uczeniu sieci neuronowych. Opracowana technika uczenia zwykle nazywana jest uczeniem Hebba lub uczeniem bez nauczyciela (ang. unsupervised lerning albo hebbian learning). Zasada tego uczenia polega na tym, że waga ![]()
i-tego wejścia m-tego neuronu wzrasta podczas prezentacji j-tego wektora wejściowego ![]()
proporcjonalnie do iloczynu i-tej składowej sygnału wejściowego ![]()
docierającego do rozważanej synapsy i sygnału wyjściowego ![]()
rozważanego neuronu. Opis formalny tego w postaci wzoru wygląda następująco:
![]()
przy czym oczywiście
![]()
Indeksy górne przy wagach neuronu ![]()
z jednej strony określają numerację neuronów, do którego wagi należą (m) z drugiej zaś numerację kroków określających kolejne pokazy.
Jeśli pokusić się o intuicyjną interpretację samouczenia sieci to można to określić jako stwierdzenie: „wzmocnieniu ulegają w niej te wagi, które są aktywne (duże ![]()
) w sytuacji, gdy „ich” neuron jest pobudzony (duże ![]()
)”. Tego też wynika, że sieci uczona taką strategią należy do klasy sieci autoasocjacyjnych.
Stosując prawa Hebba jako regułę uczenia uzyskuje się takie dopasowanie wag aby korelacja pomiędzy sygnałem wejściowym a zapamiętanym w formie wag wzorcem sygnału, na który dany neuron ma reagować. Stąd nazwa klasy takich strategii uczenia określana mianem uczenie korelacyjne (ang. correlation learning).
Sieć swoje działanie opiera na grupowaniu sygnałów wejściowych w klasy podobieństwa (ang. cluster) w trakcie procesu uczenia, by następnie nadchodzące sygnały klasyfikować pod względem podobieństwa do określonej klasy (dany neuron - reprezentant klasy - posiada największą wartość wyjscia).
Nasz program zawiera przykład, który obrazuje uczenie sieci neuronowej oparte o strategię reguł Hebba. Pozwala on w sposób krokowy bądź ciągły (cykle prezentacji sygnału wejściowego) obserwować zmiany wartości wag dwuwejściowych neuronów rzutowane na płaszczyznę.
struktury danych algorytmu:
LN - liczna neuronów w sieci
eta - współczynnik uczenia
lPokaz - liczba pokazów sygnału uczącego wykonanych w danej ćwiartce układu współrzędnych
lNeuron - liczba neuronów które w bieżącym kroku znajdują się w danej ćwiartce układu współrzędnych
cbxCiasno - przełącznik czy wagi początkowe mają być losowane z przedziału [-2,2] czy [-10,10] wokół losowego punktu startowego
wagi - tablica wag rozmiar tablicy jest ustalany przez wartość zmiennej LN, neurony posiadają po dwa wejścia więc wagi na neuron jest dwie
cbxLosowe - przełącznik czy ćwiartka układu współrzędnych do prezentacji ma być losowana czy zadana arbitralnie
sygnaly - wektor zawierający współrzędne punktu (sygnału) uczącego sieć
pobudzenie - tablica odpowiedzi neuronów w danym kroku przy ustalonej tablicy wag oraz zadanym sygnale uczącym
{ ile neuronów będzie uczestniczyć w pokazie }
LN := Trunc(enLiczbaNeuronow.Value);
{ ustalenie początkowej wartości współczynnika uczenia }
eta := 0.1;
{ wyczyszczenie informacji o położeniu neuronów w odpowiednich ćwiartkach układu współrzędnych }
for i := 1 to 4 do begin
lPokaz[i] := 0; lNeuron[i] := 0;
end;
for i := 1 to LN do
moc[i] := 0.0;
{ początkowe wartości wag ułożone wokół punktu startowego (x,y) }
Randomize;
x := 16.0*Random-8.0;
y := 16.0*Random-8.0;
for i := 1 to LN do
if not cbxCiasno then begin
wagi[i,1] := 20.0*Random-10.0;
wagi[i,2] := 20.0*Random-10.0;
moc[i] := sqr(wagi[i,1]) + sqr(wagi[i,2]);
end
else begin
wagi[i,1] := x-2.0*Random;
wagi[i,2] := y-2.0*Random;
moc[i] := sqr(wagi[i,1]) + sqr(wagi[i,2]);
end;
{ główna pętla losowania punktu uczącego, modyfikacji wag oraz wizualizacji tego procesu na ekranie }s
while True do
begin
{ wyczyszczenie obrazka }
.....
{ rysunek sieci }
for i := 1 to LN do begin
ix := pbrAuto.XRToPoint(wagi[i,1]);
iy := pbrAuto.YRToPoint(wagi[i,2]);
pbrAuto.Canvas.Polygon([Point(ix-2,iy-2),Point(ix+2,iy-2),Point(ix+2,iy+2),Point(ix-2,iy+2)]);
end;
{ losowanie ćwiartki lub wskazanie arbitralne przez użytkownika oraz wylosowanie punktu jako sygnału uczącego }
.....
{ zliczanie liczby pokazow }
.....
{ rysunek sygnału uczącego }
.....
{ wyliczenie pobudzenia neuronów przez wyznaczone sygnały }
.....
{ określenie maksymalnego pobudzenia }
max := 0.0;
for i := 1 to LN do begin
pobudzenie[i] := wagi[i,1]*sygnaly[1] + wagi[i,2]*sygnaly[2];
pobudzenie[i] := 4.0*pobudzenie[i]/moc[i];
if pobudzenie[i] > max then
max := pobudzenie[i];
end;
{ zerowanie liczników neuronów dla odpowiednich ćwiartek układu współrzędnych }
for i := 1 to 4 do lNeuron[i] := 0;
{ samouczenie sieci w oparciu o wyznaczone parametry pobudzenia }
for i := 1 to LN do begin
{ zapamiętanie starych wartości wag }
wagiOld[i,1] := wagi[i,1];
wagiOld[i,2] := wagi[i,2];
if pobudzenie[i] < 0.2 * max then pobudzenie[i] := 0.3 * pobudzenie[i];
if pobudzenie[i] < 0.0 then pobudzenie[i] := 0.1 * pobudzenie[i];
wagi[i,1] := wagi[i,1] + eta * pobudzenie[i] * (sygnaly[1]-wagi[i,1]);
wagi[i,2] := wagi[i,2] + eta * pobudzenie[i] * (sygnaly[2]-wagi[i,2]);
moc[i] := moc[i] + Sqr(wagi[i,1]) + Sqr(wagi[i,2]);
end;
{ zliczanie liczby neuronów w odpowiednich ćwiartkach }
.....
{ opisanie legendy uczenia w danym kroku }
WypiszLiczbyPN;
{ zerowanie liczników neuronów dla odpowiednich ćwiartek układu współrzędnych }
for i := 1 to 4 do lNeuron[i] := 0;
{ rysunek nowych wartości wag oraz obrazowanie zmiany }
.....
{ rysunek zmiany }
.....
{ rysunek starych pozycji w kolorach Czerwonym - pobudzany i Niebieskim - pobudzany przeciwnie }
.....
{ zliczanie liczby neuronów w odpowiednich ćwiartkach }
.....
{ opisanie legendy uczenia w danym kroku }
WypiszLiczbyPN;
{ zmniejszenie współczynnika uczenia }
eta := eta * 0.99;
end;
Sieć Hopfielda
Sieci Hopfielda są najczęściej stosowaną podklasą sieci neuronowych wykorzystywanych w praktyce. Zostały one zdefiniowane w historycznej pracy tego badacza, której publikacja w 1982 roku stała się punktem zwrotnym w badaniach sieci neuronowych i przywróciła zainteresowanie tymi systemami sferze dociekań naukowych. Sieci te charakteryzują się występowaniem sprzężeń zwrotnych. Wszystkie połączenia, które w tej sieci występują są sprzężeniami zwrotnymi, wszystkie sygnały wyjściowe są wykorzystywane jako wejścia i wszystkie wejścia do wszystkich neuronów przenoszą sygnały sprzężenia zwrotnego. W sieciach tych neurony mają nieliniowe charakterystyki:
![]()
gdzie
![]()
a nieliniowość ![]()
dana jest prostą binarną funkcją
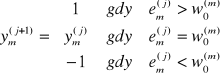
Warto przy tym zwrócić uwagę na dwa szczegóły podanych wyżej wzorów. Otóż po pierwsze, współczynniki wagowe ![]()
łączące wyjście i-tego neuronu z wejściem m-tego neuronu nie zależą od j. Wynika to z faktu, że rozważając sieć Hopfielda na tym etapie nie dyskutujemy jej uczenia. Zakładamy, że wartości ![]()
zostały wcześniej ustalone za pomocą jakiegoś algorytmu ( najczęściej przyjmuje się tu algorytm Hebba) i obecnie nie podlegają zmianom. Numer j oznacza natomiast chwilę czasową, określającą w jakim momencie procesu dynamicznego następującego pop pobudzeniu sieci obecnie się znajdujemy. Zagadnienie to będzie niżej dokładnie dyskutowane. Po drugie sumowanie sygnałów wyjściowych ![]()
z poszczególnych neuronów w wzorze definiującym łączne pobudzenie ![]()
odbywa się po wszystkich elementach ![]()
czyli po wszystkich elementach sieci. Oznacza to, że w sieci przewidziane są także połączenia z warstw dalej położonych (wyjściowych) do warstw wcześniejszych - czyli sprzężenie zwrotne.
Jak było to wcześniej odnotowane, sieć o takim schemacie połączeń nazywana jest siecią autoasocjacyjną. W ramach tego sprzężenia każdy neuron jest także połączony jednym z wejść ze swoim własnym wyjściem, zatem zasada autoasocjacyjności odnosi się także do pojedynczych neuronów. Każdy neuron sieci ma także kontakt z pewnym, odpowiadającym mu sygnałem wejściowym ![]()
, zatem zaciera się tu podział na warstwę wejściową i pozostałe warstwy sieci.
Procesy zachodzące w sieciach Hopfielda są zawsze stabilne. Stabilność procesów w sieci Hopfielda osiągnięto dzięki:
wprowadzeniu bardzo regularnej struktury wewnętrzną sieci - w całej sieci neurony są łączone na zasadzie "każdy z każdym";
zabronione są sprzężenia zwrotne obejmujących pojedynczy neuron.
wprowadzane współczynniki wagowe muszą być symetryczne - to znaczy jeśli połączenie od neuronu o numerze x do neuronu o numerze y charakteryzuje się pewnym współczynnikiem wagi w, to dokładnie taką samą wartość w ma współczynnik wagowy połączenia biegnącego od neuronu o numerze y do neuronu o numerze x.
Z siecią Hopfielda kojarzy się tzw. „funkcje energii” (nazwa ta ma charakter czysto umowny - nie jest związana z rzeczywistą energią), zwaną też funkcją Lapunowa. Funkcja ta opisuje zbiór stanów sieci Hopfielda, zdefiniowanych przez zbiór wartości wyjść elementów przetwarzających tejże sieci. Można udowodnić, ze funkcja taka, dla sieci Hopfielda w skończonej ilości kroków osiągnie swoje minimum lokalne oraz że jest to funkcja nierosnąca w czasie - co jest równoznaczne ze stwierdzeniem, że procesy zachodzące w sieci Hopfielda są procesami stabilnymi.
Łatwość budowy i stosowania sieci Hopfielda powoduje, że są one bardzo popularne. Znajdują one liczne zastosowania - między innymi przy rozwiązywaniu zadań optymalizacji, a także przy generacji określonych sekwencji sygnałów, następujących po sobie w pewnej kolejności. Pozwala to za pomocą takich sieci tworzyć i wysyłać do różnych obiektów sygnały sterujące. Sieci Hopfielda mogą także pracować jako tzw. pamięci autoasocjacyjne.
Koncepcja pamięci autoasocjacyjnej wiąże się z jedną z podstawowych funkcji mózgu - z odtwarzaniem całości informacji na podstawie informacji niepełnej. Jest to zdolność sieci do prawidłowego zinterpretowania danych zniekształconych lub niekompletnych. Sieć pracująca jako pamięć autoasocjacyjna może także usuwać zakłócenia i zniekształcenia różnych sygnałów - także wtedy, gdy stopień „zaszumienia” sygnału wejściowego wyklucza praktyczne użycie jakichkolwiek innych metod filtracji.
struktury danych algorytmu:
Wagi - wektor wag neuronów w sieci
Wzorzec - wektor wzorców rozpoznawanych przez sieć
rozM - rozmiar sieci - poziomo (domyślnie 25)
rozN rozmiar sieci - pionowo (domyślnie 25)
nMax - ilość neuronów w sieci
Użyta w programie procedura TabNaWzorzec przepisuje do wzorca wartość elementy tymczasowego, procedura WzorzecNaTab działa dokładnie odwrotnie.
for k := 1 to 16 do
if tZrB[k] then begin
Inc(nElem);
if nrWzorca = k then nrWz := nElem;
TabNaWzorzec(tZr[k],Wzorzec[nElem]);
end;
if nrWz = 0 then
Exit;
( ustawinie wag sieci }
for k := 1 to nMax do begin
for i := 1 to k-1 do begin
Wagi[k,i] := 0;
for j := 1 to nElem do
Wagi[k,i] := Wagi[k,i] + (Wzorzec[j,k]*Wzorzec[j,i]);
Wagi[i,k] := Wagi[k,i];
end;
end;
Randomize;
{ przpisanie wzorca 1 do wzorca 2 i wprowadzenie zmian dla wzorca 2}
for i := 0 to 25 do
for j := 0 to 25 do
tOdp[2,i,j] := tOdp[1,i,j];
for i := 1 to Trunc(enZmPkt.Value) do begin
j := Trunc(rozM*Random);
k := Trunc(rozN*Random);
tOdp[2,j,k] := 1 - tOdp[2,j,k];
end;
{przerysowanie ekranu}
.....
{ przepisanie zmienionego wzorca do obszaru roboczego }
TabNaWzorzec(tOdp[2],Wzorzec[21]);
TabNaWzorzec(tOdp[2],Wzorzec[22]);
Licz1 := 0; Licz2 := 0;
{ rozpoznawanie }
repeat
for i := 1 to nMax do
Wyj[i] := Wzorzec[21,i];
{ oblicznie odpowiedzi sieci }
for i := 1 to nMax do begin
wy := 0;
for j := 1 to nMax do
if i <> j then
wy := wy + (Wyj[j]*Wagi[j,i]);
if wy > 0 then
Wyj2[i] := 1;
if wy < 0 then
Wyj2[i] := -1;
if wy = 0 then
Wyj2[i] := Wyj[i];
end;
{ oblicznie różnic i ustawienie liczników }
rozn1 := 0; rozn2 := 0;
for i := 1 to nMax do begin
if Wyj2[i] <> Wzorzec[22,i] then
Inc(rozn2);
Wzorzec[22,i] := Wyj[i];
Wzorzec[23,i] := -1;
if Wyj2[i] <> Wyj[i] then begin
Inc(rozn1);
Wzorzec[23,i] := 1;
end;
Wyj[i] := Wyj2[i];
Wzorzec[21,i] := Wyj[i];
end;
if rozn1 = 0 then Inc(Licz1);
if rozn2 = 0 then Inc(Licz2);
{ rysuneki i opisy kroku rozpoznania }
if (Licz1 < 2) and (Licz2 < 3) then begin
Inc(iKrok);
WzorzecNaTab(Wzorzec[21],tOdp[iKrok]);
WzorzecNaTab(Wzorzec[23],tRoz[iKrok-2]);
{wyrysowanie kroku rozpoznawania na ekranie}
end;
until (Licz1 = 2) or (Licz2 = 3) or (iKrok = 49);
Opis środowiska Delphi jako przykład narzędzia typu RAD
Obecnie warsztat projektanta - programisty zdominowały narzędzia programistyczne umownie nazywane RAD. Skrót ów utworzony jest od nazwy ang. Rapid Application Development co w tłumaczeniu na język polski oznacza Szybkie tworzenie aplikacji.
O środowiskach programistycznych tego typu wywodzących się z generatorów programów zwykło się mówić, że odciążyły one projektanta (w zasadzie tak niewiele jest programowania w RAD'ach, większość czynności to właśnie projektowanie) tak, że przestało być trudne konstruowanie całej otoczki (tzw. interfejs użytkownika) głównej logiki programu, a całość prac związanych z powstawaniem aplikacji (prototypu) skoncentrowała się na „konsultowaniu” procesu tworzenia programu.
Praca programisty - projektanta przeniosła się ze sfery żmudnego tworzenia interfejsu użytkownika na poziom dostarczania logiki, która skłania ten interfejs do wykonywania produktywnych działań.
Jednym z ważnych środowisk programistycznych należących do klasy narzędzi typu RAD jest rodzina produktów firmy Inprise znanych pod nazwą handlową Delphi.
Nasz dydaktyczno - symulacyjny program komputerowy napisany został w środowisku programistycznym Delphi 3.0.
Charakterystyka środowiska
Delphi 3 jest produktem firmy Inprise (dawniej Borland). Jest to środowisko do szybkiego i uproszczonego dla programisty tworzenia aplikacji użytkowych działających w systemie Windows.
Środowisko Delphi działa w oparciu o język programowania Pascal.
Język programowania: Pascal (zarys)
Pascal jest dziełem umysłu Niclausa Wirtha - programisty (również prowadził zajęcia dydaktyczne na Uniwersytecie Stanforda, a później w ETH na Politechnice w Zurychu), który potrzebował języka, za pomocą którego mógłby uczyć innych ludzi pisania czegoś innego niż kilometrowych programów. Stworzył coś, co teraz jest znane jako standard Pascal; nieco ograniczony język do tworzenia małych aplikacji zaprojektowany w latach 1970-1971.
Pascal jest pochodną PL1 (Język programowania 1) i ALGOLU (ALGOrytmiczny język). Pascal otrzymał nazwę na cześć Blaise Pascala - francuskiego matematyka, który w roku 1690, mając zaledwie 18 lat, zbudował pierwszą mechaniczną maszynę liczącą.
Jedną z głównych cech pierwszej wersji Pascala było to, że używany kompilator wymagał bardzo małej pamięci. Kiedy w końcu lat siedemdziesiątych na scenie zaczęły pojawiać się pierwsze mikrokomputery, wiele instytucji edukacyjnych wybrało Pascal do nauki programowania na tych maszynach.
Następna wersja Pascala (UCSD Pascal) była nieco silniejsza. Pozwalała ona programistom na tworzenie dojrzałych aplikacji, a nie tylko małych programów użytkowych, do czego Wirth początkowo przeznaczył Pascala.
Kiedy w roku 1984 Borland wprowadził Turbo Pascala, środowisko programistów rzeczywiście go zauważyło. Produkt ten charakteryzował się bardzo wysokimi osiągami jeśli chodzi o czas kompilacji.
Następnym krokiem Borlanda było wprowadzenie wersji Pascala pod Windows. W niedługim czasie notacja zaproponowana przez Wirtha została rozszerzona o specyfikację obiektową. Ten zabieg dokonany pod koniec lat osiemdziesiątych dał nową jakość, bądź co bądź lekko już wiekowemu rozwiązaniu jakim był Pascal Wirtha.
I właśnie ten już obiektowy, rozbudowany o potężne mechanizmy wspomagania projektowania język a właściwie środowisko z rdzeniem jakim pozostały język programowania Pascal.
Środowisko RAD: Delphi
Jak już było nadmienione Delphi, a w szczególności jego wersja 3.0 zasadza się na języku programowania Pascal z mechanizmami obiektowymi (Inprise preferuję nazwę ObjectPascal). Jest to już w tym momencie narzędzie Windows 95/98/NT w pełni 32 bitowe (np. posiada „prawie ciągłą” przestrzeń adresową - o segmencie około 4 miliardy adresów itp.).
Poniższy rysunek przedstawia środowisko Delphi z otwartą do pracy aplikacją „PNeuron 1.0” (tak nazywa się program komputerowy, przedmiot niniejszego opracowania):
Środowisko pracy programisty przedstawione na rysunku zwane IDE (ang. Integrated Development Environment - zintegrowane środowisko tworzenia aplikacji) jest podzielone na trzy obszary funkcjonalne:
Pasek szybkości (ang. Speed Bar) - dzieli się na trzy sekcję: menu w którym zgrupowane są opcje i narzędzia całego środowiska, zbiór przycisków (graficznie dość wyraźnie się odróżniających) z lewej strony - są to standardowe mechanizmy związane z ogólną obsługą realizowanego projektu (otwarcie pliku, otwarcie projektu, nowy formularz, nowy moduł, uruchom, praca korkowa, zatrzymaj itd.), zbiór zakładek i przycisków z prawej strony zawierający komponenty dołączone z pakietem Delphi oraz wytwarzane przez programistę na potrzeby projektów (bardzo istotne jest to, że nie są one związane z konkretnym projektem, ale stanowią bibliotekę gotowych, sprawdzonych mechanizmów i procedur możliwych do wykorzystanie w innych przedsięwzięciach),
Kontroler obiektu (ang. Object Inspector) - każdy element ze zbioru komponentów jest obiektem, który zgodnie z definicją udostępnia jakichś zasób cech stałych (ang. Properies) oraz funkcjonalności, które w momencie użycia (wytworzenia instancji) powinny być zainicjowane i właśnie do tego ma służyć kontroler obiektu,
Formularz z edytorem kodu (ang. Form & Code Edior) - formularz jest to obiekt z rodziny GUI (ang. Graphical User Interface - graficzny interfejs użytkownika), na który zgodnie z projektem nakładane są odpowiednie komponenty, które to stanowią kręgosłup i krwioobieg logiki działania okna, formularza czy całej aplikacji (programu); edytor kodu pozwala na wpisywanie procedur składających się na program a nie koniecznie powiązanych z dostępnymi komponentami, tam też można zobaczyć jak dodawanie komponentów modyfikuję istniejący kod programu w języku ObjectPascal.
Oczywiście to co jest widoczne na rysunku oraz zostało opisane powyższym wypunktowaniem nie stanowi jeszcze pełnego zakresu mechanizmów Delphi. Obok podstawowego IDE istnieje cała gama dodatkowych elementów wspomagających proces tworzenia aplikacji np. BDE (ang. Borland Database Engine - mechanizmy obsługi baz danych), SQL (ang. Structured Query Language) - język strukturalnych zapytań do baza danych, cała sfera funkcjonalności związanych obsługą sieci lokalnych (LAN) itd.
Komponenty - nowa jakość w programowaniu
Jak opisywaliśmy w poprzednim punkcie w Delphi powstała nowa jakość związana z tworzeniem kodu programu: są nią komponenty. Są one magazynowane w bibliotekach komponentów VCL (ang. Visual Component Library - wizualne obiekty Delphi) oczekując tam na użycie w aplikacji.
Coraz częściej można się spotkać z twierdzeniem, że tworzenie aplikacji w Dephi nie polega na kodowaniu ale na pozyskiwaniu, katalogowaniu oraz wykorzystywaniu gotowych elementów programu: komponentów. Takie postawienie sprawy pozwala projektantowi przy wsparciu „bibliotekarza” (osoba lub instytucja zajmująca się doradztwem w zakresie bibliotek komponentów) naprawdę skupić się na konstrukcji logiki prototypu a później aplikacji.
Wśród zakresu różnorodności komponentów można wyróżnić bardzo proste - napisy (obiekt z dość pokaźną ilością właściwości związanych np. z położeniem, rozmiarem, kolorem itp.), pola do wprowadzania danych poprzez całe gotowe okna (np. okno typu About - opis o programie) aż do wysoce skomplikowanych oraz zaawansowanych technologicznie części lub całych serwerów internetowych stron WWW.
Mocne i słabe strony Delphi
Delphi jest potężnym narzędziem dla większości aplikacji, jakie obecnie powstają w zakresie szeroko rozumianej informatyki. Jest to z pewnością właściwe narzędzie dla sekcji interfejsu użytkownika dowolnej aplikacji. Tu właśnie można zaznaczyć, że Delphi doskonale nadaje się do wykonywanie programów symulacyjno - dydaktycznych takich jak w celu tej pracy. Składa się na to:
łatwość oraz wysoki poziom efektowności konstruowanych oknie aplikacji,
doskonały język programowania ObjectPascal (oparty o sztandarowy język algorytmiczny Pascal z rozszerzeniami w kierunku obiektowości) pozwalający w sposób z jednej strony formalny, zaś z drugiej wysoce wydajny oddać sferę logiki części symulacyjnej,
dobrze przemyślane i wykonane przez firmę Inprise środowisko dla tworzenia oraz późniejszego uruchamiania aplikacji.
Jak widać Delphi dostarcza wielu bardzo efektywnych mechanizmów i funkcjonalności dla tworzenia aplikacji dla systemu Windows.
Niestety nie jest i raczej nie powinno to być jedyne narzędzie znajdujące się w zakresie wykorzystanie dla współczesnego, czynnego projektanta - programisty.
Bardzo duża elastyczność, która czyni Delphi tak wielkim narzędziem ogólnego przeznaczenia, nie pozwala dostarczyć tych, których potrzebuje twórca DBMS (ang. Database Management System - systemy zarządzania bazą danych) dla stworzenia dużego oraz kompleksowego sytemu.
Prezentacja programu komputerowego
W tym rozdziale opiszemy sposób posługiwania się edukacyjnym programem komputerowym. Określimy zakres zmian oraz znaczenie poszczególnych parametrów udostępnionych użytkownikowi w kolejnych modułach. Parametry te umożliwiają: określić wartości wagi oraz wejście neuronu czy prostej sieci, ustawiać parametry procesu uczenia sieci, testować wytrenowaną sieć itp.
Opis konstrukcji programu
Dydaktyczno - symulacyjny program komputerowy realizujący stawiany w temacie pracy cel, zbudowany jest na zasadzie podziału na odrębne, aczkolwiek wspólne w sferze konstrukcji oraz obsługi, obszary tematyczne odpowiadające przykładom prezentowanych zagadnień sieci neuronowych. Staraliśmy się ujednolicić obsługę jak i konstrukcję aplikacji. Z jednej strony było to podyktowane wybranym środowiskiem Windows 95 (lub Windows NT) i narzędziem implementacyjnym Delphi 3.0. Z drugiej zaś chodziło nam aby określony parametr, cecha sieci neuronowej bądź aspekt procesu uczenie lub testowania dla wszystkich przypadków był ujednolicony.
Poszczególne moduły programu komputerowego
Moduł pierwszy - Prezentacja neuronu
Przykład zaimplementowany w module pierwszym pozwala zrozumieć procesy które zachodzą w sztucznym neuronie. Taki neuron charakteryzuje się następującymi cechami:
wektorem wag - w programie jest udostępniony do modyfikacji przez użytkownika pięcioelementowy zbiór pól edycyjnych zgrupowanych w sekcję Wagi neuronu widoczną na poniższym rysunku:
wektor sygnałów wejściowych - jest to zestaw sygnałów jakie będą podawane na wejście neuronu w przykładzie zestaw ów zgrupowany jest w sekcję Sygnały wejściowe - udostępnione są tam pola do zadawania wartości - obszar jest widoczny na poniższym rysunku:
parametry pracy neuronu - zestaw danych informujący w jaki sposób neuron przetworzył wektor sygnałów wejściowych przez wektor wag aż do wyliczenia odpowiedzi jako wartości funkcji aktywacji. Neuron posiada możliwość (modelowo) odpowiedzi w wartościach dwóch funkcji aktywacyjnych: ciągłej funkcji sigmoidalnej oraz dyskretnej, unipolarnej funkcji binarnej. Dla funkcji sigmoidalnej użytkownik może określić parametr λ przez wprowadzenie odpowiedniej wartości w pole Lambda. Wyliczane przez program wartości: moc sygnału wejściowego, moc śladu pamięciowego (wagi neuronu), łączne pobudzenie, wartości ciągłej funkcji aktywacji, wartość binarnej funkcji aktywacji są zgrupowane w sekcję Parametry pracy neuronu. Opisane informacje można zobaczyć na załączonych poniżej rysunkach:
Wszystkie powyższe sekcje są umieszczone na oknie stworzonym do prezentacji oraz symulacji działania pojedynczego, sztucznego neuronu który w swej definicji prezentacyjnej posiada odpowiedzi właściwe zarówno dla neuronów liniowych (Łączne pobudzenie) jak i neuronów z nieliniową funkcją aktywacji (Ciągła funkcja aktywacji, Binarna funkcja aktywacji). Czyli użytkownik może zaobserwować działanie jakby trzech różnych neuronów, które mając takie same wejście oraz wagi ale różne elementy odpowiadające za „jakość” pracy, odpowiedzi.
Ekran zawierający główne okno modułu Prezentacja pojedynczego neuronu załączony został na poniższym rysunku:
Na powyższym oknie są umieszczone dwa przyciski operacyjne: Przelicz oraz Zeruj. Po wprowadzeniu wartości w sekcjach Sygnały wejściowe, Wagi neuronu oraz Lambda należy użyć przycisku Przelicz w celu obliczenia odpowiedzi neuronu zgrupowanej w sekcji Parametry pracy neuronu. Zadaniem przycisku Zeruj jest ustawienie prezentacji w jej stanie początkowym.
Moduł drugi - Prosta sieć neuronowa (z WAT)
Przykład składa się z dwóch ekranów znajdujących się pod dwoma zakładkami - „Określenie sieci” i „Testowanie sieci”.
Ekran „Określenie sieci” zawiera opis pięciu cech oraz trzech neuronów, dla których użytkownik ma możliwość edytowania i modyfikacji poszczególnych wag jak i skojarzonych z poszczególnymi wagami cech.
Cechy określamy dla wszystkich obiektów - neuronów. Co jest widoczne na umieszczonym poniżej rysunku pól zgrupowanych w sekcję Informacje o cechach. Określenie cechy polega na nazwaniu wejścia neuronu tzn. określamy, że pierwsze wejście będzie stanowić o ilości nóg rozpoznawanego obiektu, tak ustanowiona uwaga pozwala nam na odpowiednie konstruowanie wag odpowiednich neuronów jak i podawanie w sposób oczywisty parametrów dla badanych obiektów.
Następnie dla każdej klasy obiektów określamy jej cech indywidualne. Np. jako cechę wybieramy ilość nóg, klasy obiekty to ssak - ma 4 nogi, ptak - 2 nogi, płaz - brak (0) nóg, co zapisujemy jako bezpośrednie wartości poszczególnych neuronów A, B, C.
Dla każdego neuronu automatycznie wyliczana jest jego moc zestawu wag - co inaczej jest nazywane moc śladu pamięciowego.
Po określeniu parametrów sieci użytkownik może przejść do jej testowania (zakładka „Testowanie sieci”).
Na ekranie testowania sieci użytkownika określa sygnał testowy (dane dla badanego obiektu skojarzone z jego cechami), po czym testuje sieć. Sieć podaje odpowiedź dla zdefiniowanego przez użytkownika obiektu i wskazuje, który z neuronów rozpoznał testowany obiekt. Wyznaczane przez sieć wartości to moc sygnału wejściowego, odpowiedzi ilościowe każdego z neuronów, klasyfikacja jakościowa odpowiedzi - porównanie z zadanym progiem poprawnej klasyfikacji, wskazanie jednego (WTA) obiektu najlepiej pasującego swoimi wagami do wektora sygnałów wejściowych oraz spełniającego wymogi jakości klasyfikacji (ponad próg).
Moduł trzeci - Uczenie pojedynczego neuronu
Moduł ten ilustruje uczenie neuronu o charakterystyce liniowej, o 5 wejściach.
Użytkownik ma w tym przykładzie do dyspozycji 2 ekrany, znajdujące się pod odpowiednimi zakładkami - ekran wczytywania ciągu uczącego oraz ekran nauki i testowania neuronu. Na pierwszym ekranie użytkownik określa jaki jest ciąg uczący użyty do uczenia sieci.
W tym celu może wykonać jedną z poniższych operacji:
może otworzyć (ikona koperty w górnej części ekranu) jeden z przygotowanych ciągów uczących
może wygenerować własny ciąg uczący (przycisk „Generuj” w górnej części ekranu)
Plik wczytany do edytora może być przez użytkownika dowolnie modyfikowany i zapisywany. Format pliku jest stały, następują w nim po sobie (wielokrotnie powtórzone):
linia komentarza (rozpoczynająca się średnikiem)
5 liczb będących sygnałami wejściowymi
sygnał wyjściowy
Po wczytaniu ciągu uczącego (i ewentualnym naniesieniu na nim poprawek) użytkownik ma możliwość użycia tego ciągu do uczenia i testowania sieci. W tym celu należy wybrać zakładkę „Uczenie i testowanie” w dolnej części ekranu.
Na oknie Uczenia i testowania użytkownik może uczyć neuron (jednorazowe użycie przycisku „Uczenie neuronu” jest równoznaczne z podaniem na wejście sieci jednego elementu wybranego ciągu uczącego „),
a również może w dowolnym momencie przeprowadzić test neuronu (określając poszczególne wejścia i naciskając przycisk „Testowanie neuronu” ).
Wtedy dla określonych przez użytkownika sygnałów wejściowych neuron wyliczy sygnał wyjściowy.
Moduł czwarty - Uczenie prostej sieci
Przykład ten obrazuje proces uczenia prostej liniowej sieci neuronowej.
Zaprojektowaliśmy dla tego przykładu ciąg zawarty w pliku uczący_s.ctg. Struktura sieci jest stała i użytkownik nie może jej zmieniać. Ciąg uczący ma następującą strukturę:
;komentarz
zestaw sygnałów wejściowych
wzorcowy zestaw sygnałów wyjściowych
W zestawie sygnałów wejściowych podawane będą pięcioelementowe wektory (porcje po pięć sygnałów dla pięciu wejść rozważanego neuronu), zaś wzorcowych sygnałów jest 3.
Podobnie jak w poprzednim przykładzie użytkownik programu pracuje na dwóch oknach - na pierwszym wczytuje i modyfikuje ciąg uczący, na drugim uczy i testuje działanie sieci.
Konstrukcja tego przykładu jest bardzo zbliżona do przykładu poprzedniego. Na pierwszym ekranie użytkownik pracuje z ciągiem uczącym (podobnie jak w poprzednim przykładzie może go wczytać z pliku bądź wygenerować i zmodyfikować). Po zakończeniu pracy z ciągiem uczącym użytkownik przechodzi do etapu uczenia i testowania.
Na oknie uczenia i testowania użytkownik może uczyć sieć (jednorazowe użycie przycisku „Uczenie sieci” jest równoznaczne z podaniem na wejście sieci jednego elementu ciągu uczącego), a również może w dowolnym momencie przeprowadzić test sieci (określając poszczególne wejścia i naciskając przycisk „Testowanie sieci” ).
Test sieci polega na tym, że dla określonych przez użytkownika wejść sieci sieć wylicza wszystkie sygnały wyjściowe.
Moduł piąty - Sieć neuronowa jako filtr sygnału z zakłóceniami
Przykład ten prezentuje działanie sieci neuronowej stanowiącej autoasocjacyjny filtr sygnałów z zakłóceniami. Okno prezentacyjne posiada dwie zakładki a co za tym idzie dwa ekrany robocze: Ciąg uczący oraz Uczenie sieci - wykresy. Operacje na ekranie Uczenie sieci - wykresy możliwe jest dopiero po określeniu ciągu uczącego: wygenerowaniu nowego lub wczytani wcześniej przygotowanego w pliku tekstowym (istotne jest aby plik posiadał rozszerzenie .cgn)
Po wskazaniu zakładki Ciąg uczący otrzymujemy obrazek jak na poniższym rysunku:
Okno to zawiera listę na której są umieszczone przyciski oraz kontrolki operacyjne. Przycisk Generuj służy do automatycznego wygenerowania ciągu uczącego (zawiera on sygnał sinusoidy jako sygnał wzorcowy oraz jego losowo zakłócony obraz). Przycisk Wczytaj pozwala powtórnie wczytać zawartość wskazanego pliku z ciągiem uczącym. Przycisk otwarcia pliku powoduje wywołanie okna dla wybierania „Plik z ciągami uczącymi”. Znajduje się tu również pole z nazwą pliku, pasek określający postęp przeprowadzanej czynności (wczytywanie pliki, generacja nowego ciągu uczącego) oraz duży edytor zawierający obraz wczytanego lub wygenerowanego ciągu z danymi do uczenia i testowania sieci neuronowej.
Wybrany ciąg może zostać przegenerowany przez użytkownika (na tym etapie użytkownik ma możliwość dowolnej modyfikacji ciągu testowego - np. w edytorze Notepad.exe), a następnie jest wczytywany do
Okno do wyboru pliku z ciągiem uczącym, jeśli wprowadzimy tu nazwę nieistniejącego pliku a następnie wykonamy operację Generuj nastąpi utworzenie nowego pliku z ciągiem uczącym o podanej nazwie.
Następnym etapem jest przystąpienie do uczenia oraz testowania sieci neuronowej co możemy wykonać przełączając okno na ekran skojarzony z zakładką Uczenie sieci - wykresy. Po wybraniu akcji przerysowania wykresu (przycisk Przerysuj) otrzymujemy obraz jak na rysunku poniżej:
Ekran ten zawiera duże pole do prezentacji wykresów oraz standardowo listę z narzędziami dostępnymi w tej części prezentacji. Możliwe operacje to wskazanie parametrów dla akcji Przerysuj (przełączniki: sygnał wzorcowy, sygnał zaszumiony, sygnał przefiltrowany - kolory tych przełączników odpowiadają odpowiednim krzywym i łamanym na wykresie), wykonanie akcji Przerysuj - co można wykonywać po dowolnej ilości kroków uczących przez co łatwym staje się proces podglądania postępu uczenia oraz jego jakości. Następną bardzo istotną częścią listwy operacji jest klasa parametrów i funkcji związanych z procesem uczenia sieci neuronowej filtrowania sygnału zakłóconego. Do tej grupy należą: parametr ile kroków - poprzez ustawienie tego parametru określamy ile pełnych prezentacji ciągu uczącego ma zostać wykonana w danym cyklu treningu, przełącznik waga środkowa - pozwala wprowadzić do procesu zadawania początkowych (losowych) wag neuronów ustaloną wartość na środku wag (w naszym wypadku na wadze numer 3) wartość stałą dla wszystkich neuronów równą 1, parametr współczynnik - jest to wartość określająca szybkość uczenia (im większy typ proces uczenia jest bardziej forsowny - wagi w każdym kroku są mocno modyfikowane).
Listwa narzędziowa sekcji Uczenie sieci - wykresy jest zobrazowana na poniższym rysunku:
Po ustaleniu tych wartość możemy przystąpić do uczenia poprzez wybór przycisku Ucz sieć. zakończenie procesu uczenia obrazowane zatrzymaniem się zmian wartości pola wykonany krok na liczbie ilości kroków do wykonanie pozwala nam wykonać funkcję przerysowania przez co możemy ocenić jakość przeprowadzonego procesu uczenia.
Złożenie wykresów po wykonanym procesie uczenia (parametry: wykonane kroki uczące w ilości 3, współczynnik postępu uczenia równy 0,15, bez wagi środkowej) obrazuje poniższy rysunek:
Ja łatwo zaobserwować dobre efekty przy filtrowaniu zakłóconych (nie za mocno) sygnałów można otrzymać przy użyciu bardzo prostej sieci liniowej - jedna warstwa oraz bardzo krótkim procesie uczenia - 3 iteracje pokazowe. (Uwaga: wszystkie okienka tej prezentacji są wykonywane na tym samym zestawie ciągu uczącego)
Moduł szósty - Rozpoznawanie obrazu
Moduł zawiera mechanizmy pozwalające skonstruować prostą figurę płaską złożoną z nakładających się kół, następnie określić jak zbudowana jest sieć neuronowa (ile i jak licznych warstw ukrytych posiada), dla tej sieci umożliwia prowadzenie przyrostowego procesu uczenia (użytkownik podaje ile ma być wykonanych prezentacji ciągu uczącego, złożonego z losowo wybieranych punktów z określonego wcześniej obrazka) każdy etap (epoka) procesu uczenie kończy się wizualizacją możliwości sieci w rozpoznawaniu powyższego obrazka. Tempem uczenia użytkownik steruje poprzez ustalenie początkowych wartości parametrów uczenia: η (eta) oraz α (alfa).
Obszar roboczy jaki dostaje użytkownik po wybraniu modułu Rozpoznawanie obrazów wygląda jak na poniższym rysunku.
Dla tego okna wyróżniamy obszar w dolnej części ekranu (około 2/3) zawierający elementy związane z prowadzonym przez użytkownika procesem uczenia i testowania wielowarstwowej, nieliniowej sieci neuronowej zaimplementowanej w typ programie. Górna część wygląda jak poniższy rysunek
oraz zawiera następujące grupy funkcjonalności (są one wymienione w kolejności jak użytkownik powinien jej określać i używać):
Definicja figury płaskiej - określenie musi zawierać (przynajmniej jej fragment) figurę na płaszczyźnie w kwadracie ograniczonym punktami (-5,-5) - (5,5); można zdefiniować maksymalnie (również nakładające się na siebie) trzy koła; w przypadku określenia koła o promieniu R równym zero lub koła nie zawierającego się we wskazanym kwadracie nie będzie ono miało wpływu na uczenia a tym samym nie będzie rozpoznawane przez nauczoną sieć neuronową; po określeniu trzech kół (zaznaczone przełączniki „okrąg 1..3”) można przystąpić do następnego etapu definicji warunków symulacji - określenie sieci neuronowej;
Określenie struktury sieci neuronowej i początkowych parametrów uczenia - w tym module została zaimplementowana, wielowarstwowa sieć neuronowa dla której użytkownik definiuje ilość neuronów w dwóch warstwach ukrytych (warstwa wejściowa arbitralnie zawiera dwa neurony, zaś warstwa wyjściowa - jedne); maksymalna ilość neuronów w warstwach ukrytych wynosi; jeśli określone zostanie zero lub brak neuronów w warstwie ukrytej to użytkownik rezygnuje z jej istnienia w tej instancji sieci neuronowej; w skrajnym wypadku sieć składa się z dwu neuronów wejściowych i jednego wyjściowego; następnie można zmodyfikować wartości parametrów: intensywności eta oraz zależności od wyników poprzednich kroków - alfa; kolejnym etapem jest naprzemienne wykonywanie w dwóch poniższych punktach
Gęstość próbkowania losowego wyznaczania ciągu uczącego - użytkownik może określić krok (siatkę próbkowania) z jakim losowane będą kolejne elementy ciągu uczącego danej epoki; położenie suwaka w skrajnie górnym położeniu jest to ustawienie największego oka siatki próbkowania; po ustawieniu w skrajnie dolnym położeniu próbkowanie zachodzi w sposób ciągły (no może jest zakłócone to dyskretną reprezentacją liczby zmiennopozycyjnej w komputerze);
Ilość pokazów (Kroków ucznia) i uruchomienie (również zatrzymanie- na żądanie) procesu uczenia - w tym kroku użytkownik określa ile ma być wykonanych losowań punktów uczących w jednej epoce; następnie należy uruchomić akcję (przycisk) Ucz sieć; napis na tym samym przycisku (dla dużej ilości kroków i wolnego komputera) zmienia się na Stop - to aby można było przerwać uczenie w dowolnej chwili; po zakończeniu uczenia nastąpi automatyczne testowanie sieci poprzez zapełnienie kolejnego wolnego obszaru testowego ekranu prezentacji (2/3 od dołu).
W czasie procesu uczenia użytkownik ustala kolejne epoki (ich liczebność) i następuje automatyczne testowanie w postaci wyrysowania przez program aktualnych umiejętności sieci. Użytkownik ma możliwość również prowadzenia eksperymentów z generowaniem pokazów o określonej gradacji poprzez użycie do tego udostępnionego suwaka zmiany kroku próbkowania. Na załączonym poniżej rysunku widać prowadzony proces kolejnych iteracji uczenia i testowani:
Jak można zauważyć z tych eksperymentów wielowarstwowe sieci nieliniowe stanowią - nawet w tak prostej konstrukcji, jakim dysponuje użytkownik w tym module do dwóch warstw ukrytych, do dziewięciu neuronów w każdej z niech - potężne, wydajne i stosunkowo proste w konstrukcji i uczeniu środowisko równoległego przetwarzania danych a co za tym idzie i jak w tym przykładzie skutecznego rozpoznawania obrazów.
Moduł siódmy - Backpropagation - najpopularniejsza metoda uczenia liniowych sieci neuronowych
Backpropagation to najpopularniejsza metoda uczenia sieci wielowarstwowych. Umożliwia ona w takich oszacowanie błędów warstw pośrednich, oraz uczenie tych warstw poprzez rzutowanie błędów poszczególnych warstw sieci na warstwy poprzednie.
Program pokazuje szczegółowo działanie sieci złożonej z czterech neuronów tworzących trzy warstwy - wejściową, nie podlegającą uczeniu (w dolnej części ekranu), wyjściową, której sygnały będą podlegały uczeniu (w górnej części ekranu) oraz warstwę ukrytą, w centralnej części ekranu.
Użytkownik ma do dyspozycji 2 ekrany, znajdujące się pod dwiema zakładkami - „Działanie sieci” oraz „Uczenie sieci””
Działanie sieci wielowarstwowych
Wybierając zakładkę „Działanie sieci” użytkownik programu ma możliwość zapoznać się z działaniem sieci warstwowej składającej się z 2 wejść, 2 neuronów w warstwie ukrytej i 2 neuronów w warstwie wyjściowej.
Program ustala współczynniki wagowe dla wszystkich neuronów w całej sieci. Użytkownik ma możliwość modyfikacji parametrów sieci, ale tylko gdy przełącznik „ustaw parametry sieci” na ekranie pokazującym uczenie sieci nie jest zaznaczony.
Po prawidłowym określeniu parametrów (i zaznaczeniu przełącznika) sieci użytkownik może zacząć prezentację. Kolejne kroki prezentacji są uruchamiane poprzez wybranie myszką przycisku „Krok”.
Pierwszym krokiem jest obliczenie iloczynów sygnałów wejściowych oraz wag warstwy ukrytej, drugim obliczenie odpowiedzi warstwy ukrytej, a kolejnym. Wszystkie wyliczane w tych krokach parametry są kolejno umieszczane na oknie programu.
Poniżej prezentujemy zrzut ekranu z tego etapu pracy programu.
Ostatnim etapem prezentacji jest wyliczenie odpowiedzi warstwy wyjściowej. Po zakończeniu prezentacji użytkownik może przystąpić do uczenia sieci metodą backpropagation.
Uczenia sieci wielowarstwowych - Backpropagation
W tym celu należy wybrać zakładkę „Uczenie sieci - BACKPROPAGATION”. Na pierwszym ekranie tego przykładu pokazana jest struktura sieci (analogiczna jak w poprzedniej prezentacji) oraz początkowe (zainicjowane losowo) wartości wag neuronów warstwy ukrytej i wyjściowej.
Użytkownik może modyfikować współczynnik (learning rate) oraz momentum.
Współczynnik uczenia musi być wybierany z dużą rozwagą, gdyż zarówno zbyt duża, jak i zbyt mała jego wartość źle wpływa na przebieg procesu uczenia. Zbyt mała wartość tego współczynnika powoduje, że uzcenie się sieci jest bardzo długotrwałe (wagi są poprawiane w każdym kroku bardzo słabo, żeby więc osiągnęły pożądane wartości trzeba wykonać bardzo dużo takich kroków). Z kolei wybór za dużego współczynnika uczenia powoduje bardzo gwałtowne zmiany parametrów sieci, które w krańcowym przypadku prowadzić mogą nawet do niestabilności procesu uczenia
Drugi współczynnik - momentum - określa stopień "konserwatyzmu" procesu uczenia. Określa on stopień zależności zmian wag od zmian stosowanych w procesie uczenia na poprzednim wzorcu. Im większa wartość współczynnika momentum, tym bardziej stabilny i bezpieczny jest proces uczenia - chociaż zbyt duża wartość może prowadzić do trudności z wykryciem przez sieć najlepszych (optymalnych) wartości współczynników wagowych dla wszystkich wchodzących w grę neuronów.
Po podaniu współczynników oraz wartości obydwu sygnałów wejściowych, jakie sieć ma otrzymać na swoich wejściach program zaczyna demonstrację. Na początku pokazuje on tylko strukturę sieci (miejsca, gdzie znajdują się poszczególne neurony oraz miejsca, gdzie wyświetlone będą poszczególne sygnały). W górnej części okna wyświetlany jest tytuł „Prezentacja struktury sieci z wagami”.
Po naciśnięciu przycisku Krok, sieć pokazuje wartości sygnałów wejściowych (podawane z zewnątrz przez neurony wejściowe), a także wartości współczynników wagowych - dla wszystkich wejść wszystkich neuronów (wyświetlane w kolorze fioletowym).
Następnie jest wczytywany kolejny element ciągu uczącego (o czym informuje zmiana tytułu w oknie - na „Nauczyciel podał sygnały wejściowe i wyjściowe”).
Kolejne naciśniecie klawisza „Krok” rozpoczyna proces symulacji przetwarzania sygnałów w sieci. Początkowo obliczane są odpowiedzi warstwy wejściowej. W każdej kolejnej warstwie obliczane są i wyświetlane (na niebiesko) sumy wartości przemnażanych przez odpowiednie wagi sygnałów wejściowych (wraz ze składnikiem BIAS). Drogi przesyłania tych sygnałów oznaczone są w postaci niebieskich linii.
Po kolejnym naciśnięciu przycisku „Krok” uruchamiany jest proces symulacji procesu przesyłania i przetwarzania sygnałów w modelowanej sieci. Początkowo wyliczane są odpowiedzi warstwy wejściowej (tytuł okna zmienia się na „Obliczanie odpowiedzi warstwy wejściowej”).W każdej kolejnej warstwie obliczane są i wyświetlane (na niebiesko) sumy wartości przemnażanych przez odpowiednie wagi sygnałów wejściowych (wraz ze składnikiem BIAS). Drogi przesyłania tych sygnałów oznaczone są w postaci niebieskich linii.
Następnie pokazywane są obliczone wartości sygnałów wyjściowych poszczególnych neuronów, powstałych po przepuszczeniu zsumowanych sygnałów wejściowych przez funkcję przejścia neurony. Potem odpowiedzi neuronów niższej warstwy stają się wejściami dla neuronów wyższej warstwy.
W momencie, gdy sieć (jako całość) popełni błąd - obliczane są błędy poszczególnych neuronów. Najpierw wyznaczane są wartości błędów dla wyjściowych neuronów sieci. Potem błędy te przeliczane są na odpowiadające im wartości na wejściach neuronów.
Po wyznaczeniu wartości błędów dla wszystkich neuronów w sieci - kolejny krok programu prowadzi do wyznaczenia nowych (poprawionych) wartości współczynników wag w całej sieci. (patrz rysunek poniżej). Potem następuje kolejna iteracja procesu uczenia.
Zaprezentowany moduł przedstawia w szczegółowy i czytelny dla użytkownika sposób przebieg sygnałów w sieciach neuronowych.
Moduł ósmy - Sieć Kohonena
Moduł prezentuje model sieci Kohonena, której zadaniem będzie nauczenie się rozpoznawania wskazanej figury geometrycznej. Dla określonej struktury sieci (podano ile sieć prostokątna zawiera elementów na krawędzi poziomej oraz pionowej) należy ustawić parametry: szybkości uczenia, zakresu sąsiedztwa, zmiany szybkości uczenia oraz zakresu sąsiedztwa wraz z kolejnymi prezentacjami, ilość prezentacji losowych punktów figury, której rozpoznawania na się nauczyć szkolona sieć Kohonena.
Główne okno modułu, na którym wyróżniamy w górnej części sekcje funkcjonalności sterujących eksperymentem, zaś w dolnej są umieszczone obszary, na których będą prezentowane efekty kolejnych etapów prowadzonych symulacji.
Ekran okna głównego modułu jest umieszczony na rysunku poniżej:
Jak już wcześniej wspominaliśmy, w górnej części powyższego ekranu znajduje się sekcja funkcjonalności sterujących procesem definicji rozpoznawanej figury poprzez określenie struktury sieci samoorganizującej Kohonena, aż po ustalenie parametrów procesu uczenia oraz sterowanie kolejnymi etapami uczenia i testowania i otrzymywanych wyników. Mechanizmy ustalania warunków i parametrów przeprowadzania eksperymentu znajdują się na poniższym rysunku:
gdzie możemy wyróżnić następujące sekcje funkcjonalności:
Wybór figury geometrycznej - użytkownik wskazuje tu w polu przełącznika radiowego (ang. radio-set) jedną z dostępnych tam figur: kwadrat, trójkąt, krzyż, koło, gwiazda, elipsa; po wyborze następuje w obszarze obok (biały kwadrat) następuje wizualizacja wskazanej figury, która w dalszej części eksperymentu będzie podlegała najpierw uczeniu przez sieć a później rozpoznawaniu (testowaniu),
Określenie struktury sieci Kohonena oraz „rozrzutu” wag początkowych - strukturę sieci użytkownik może określić jako pewnego rodzaju sieć płaską opartą o konstrukcję prostokąta: podawana jest ilość neuronów na boku i podstawie prostokąta; istotnym dla późniejszego procesu uczenia parametrem jest rozrzut (trzecie pole edycyjne - wartość rzeczywista), który to mające małą „ustaloną wartość” określa, że początkowe wagi są losowane z przedziału [-ustalona wartość, ustalona wartość] przez co użytkownik może sterować „rozrzutem” struktury sieci odwzorowanej na płaszczyźnie w czerwonych kwadracikach połączonych przez szarymi kreseczkami obrazującymi najbliższe sąsiedztwo;
Określenie parametrów uczenia sieci - użytkownik może określić tu wartości początkowe parametrów sterujących procesem uczenia: Alfa0, Alfa1, Eps(Alfa), Sąsiedztwo, Eps(Sąsiedztwo) - znaczenie tych parametrów wyjaśnia wstęp teoretyczny i zamieszczony algorytm uczenia dla tego przykładu,
Sterowanie procesem uczenia i testowania - użytkownik określa ile kroków (losowań) musi zostać wykonana dla danego etapu uczenia, po typ procesie następuje automatyczne odrysowanie struktury sieci (sieć wag na następnym wolnym obszarze prezentacji); każda epoka może mieć inną liczebność co użytkownik definiuje przed naciśnięciem Ucz sieć; na obszarze po prawej stronie (biały kwadrat na wysokości przycisku Ucz sieć) wizualizowany jest proces losowania punktów z epoki uczącej; poniżej przycisku znajduje się pasek postępu procesu oraz pole informacyjne pokazujące ile pozostało losowań do końca procesu uczenia; użytkownik może przerwać w każdej chwili proces uczenia poprzez wciśnięcie przycisku Ucz sieć który kontekstowo przy trwającym procesie uczenia zmienia swój opis i znaczenia na Stop.
Ekran prezentujący etap określenia figury geometrycznej do rozpoznawania oraz definicji struktury sieci (została określona jako prostokąt o boku sześciu neuronów oraz postawie piętnastu neuronów) znajduje się na poniższym rysunku:
Ekran po dziewięciu krokach uczenia i testowania jest pokazany na kolejnym rysunku:
Zaimplementowany przez nas moduł prezentujący zasadza się na idei samoorganizującej mapie podobieństwa cech, generowanych w sieci neuronowej Kohonena w trakcie procesu uczenia. [15]
Moduł dziewiąty - Samouczenie sieci neuronowej
Moduł prezentuje procesy jakie zachodzą w sieciach neuronowych w czasie przeprowadzanie uczenia bez nadzoru według reguł podanych przez Hebba. Model sieci oparty jest na neuronie posiadającym dwa wejścia przez co można taki neuron zobrazować w postaci punktu na płaszczyźnie układu współrzędnych. W momencie wylosowania punktu odpowiadającego sygnałowi uczącemu następuje pokazanie go na ekranie - duży kwadrat. Następnie obrazowany jest proces samouczenia sieci poprzez odrysowanie starych i nowych wag, uczonych na plus przy pomocy koloru czerwono - czarnego oraz neuronów którym wagi modyfikowane są na minus - kolorem niebieskim.
Moduł zawiera okna gdzie w większej części po lewej stronie umiejscowiony ,jest obszar układu współrzędnych (z naniesionymi osiami współrzędnych) prezentacji neuronów (punkty o współrzędnych odpowiadających wagom neuronów), z prawej strony u góry znajdują się przyciski, pola edycyjne oraz suwak sterujący pracą symulacji procesu samouczenia, z prawej stronie u dołu znajduje się legenda zawierająca informacje o ilości pokazów i neuronów znajdujących się w poszczególnych ćwiartkach płaszczyzny symulacyjnej. Poniższy rysunek obrazuje wygląd ekranu przed rozpoczęciem procesu samouczenia:
Sekcja okna widoczna na poniższym rysunku zawiera następujące parametry udostępnione użytkownikowi celem inicjacji oraz sterowania procesem samouczenia:
Pięć grup elementów udostępnionych dla sterowania procesem symulacji zawiera następujące mechanizmy:
Przycisk uruchomienia i zatrzymania symulacji - rozdziela on w sposób operacyjny etap definicji struktury sieci oraz właściwego procesu prezentacji samouczenia
Parametry definiujące początkową strukturę sieci - użytkownik określa tu ile neuronów w sieci będzie poddawane procesowi uczenia; przełącznik czy generacja początkowych wartości wag ma odbywać się w przedziale [-2,2] - skupione czy te [-10,10] wokół losowego punktu startowego
Informacje o przebiegu samouczenia - η (eta) - parametr określający tempo procesu samouczenia (wielkość zmian wag w kolejnych krokach), iteracje - ilość wykonanych pokazów w procesie samouczenia
Określenie sposobu generacji sygnałów uczących - losowe pokazy - generacja sygnału z wybranej arbitralnie ćwiartki układu współrzędnych lub całości udostępnianej do symulacji płaszczyzny (od punktu [-10,-10] do [10,10]), ćwiartka oraz grupa przełączników {1,2,3,4} - pozwala na arbitralne wskazanie ćwiartki w której ma być prezentowany jedynie punkt sygnału uczącego
Sterowanie tempem procesu symulacji - umieszczenie suwaka w lewym skrajnym położeniu wyłącza opóźnienie, przesuwanie się w prawą stronę powoduje wzrost przerw pomiędzy kolejnymi krokami symulacji aż do pojawienia się przycisku Krok - prawe skrajne położenie - który umożliwia pracę krokową symulacji; ten element jest widoczny na rysunku poniżej, który zawiera legendę wraz ze statystyką prowadzonego procesu uczenia:
Rysunek następny zawiera krok procesu samouczenia zdefiniowanej sieci neuronowej:
Powyższy moduł prezentuje najistotniejsze cechy procesu samouczenia opartego na regułach Hebba wykorzystujące możliwości nowoczesnego narzędzia programistycznego.
Moduł dziesiąty - Sieć Hopfielda
Pamięcią asocjacyjną nazywamy zdolność sieci do prawidłowego zinterpretowania danych zniekształconych lub niekompletnych. Sieć taka może także usuwać zakłócenia i zniekształcenia różnych sygnałów - także wtedy, gdy stopień „zaszumienia” sygnału wejściowego wyklucza praktyczne użycie jakichkolwiek innych metod filtracji
Moduł prezentuje model sieci Hopfielda pracującej jako pamięć autasocjacyjna.
Zadaniem będzie zapamiętywanie i odtwarzanie prostych obrazów.
Sieć potrafi odtworzyć pierwotny wzorzec na podstawie sygnału silnie zniekształconego lub zakłóconego, działa więc jako pamięć asocjacyjna. Użytkownik podaje sieci ciąg wzorców, a następnie wygenerowany sygnał zbliżony do jednego z tych wzorców.
Zadaniem sieci jest rozpoznanie wybranego wzorca („podobnego” do sygnału na wejściu).
Poniżej prezentujemy ekran początkowy programu - przed wprowadzeniem wzorców przez użytkownika.
Pierwszym krokiem użytkownika przy pracy z programem jest określenie wzorców, które program ma rozpoznawać.
Ciąg wzorców może być generowany przez użytkownika automatycznie lub manualnie.
Przy generacji automatycznej użytkownik ma możliwość określenia czy chce generować ciąg wzorców (przycisk „Generuj wzorce” w górnej części okna programu).
losowych
ortogonalnych (w stosunku do ostatniego z wprowadzonych wcześniej manualnie wzorców)
ortogonalnych z inwersją (w stosunku do ostatniego z wprowadzonych wcześniej manualnie wzorców)
Przy manualnej generacji (klikając na „Numer wzorca” użytkownik ma możliwość wejść do okna edycji wzorca) wzorca użytkownik określa, które punkty w matrycy wzorca są zapalone, a które „wygaszone”. Istnieje też możliwość przepisania znaku z klawiatury bezpośrednio do matrycy - należy w tym celu wprowadzić znak do pola edycyjnego i nacisnąć przycisk „Przepisz”.
Poniżej prezentujemy zrzut okna edycji wzorca.
Za pomocą przycisku „Inwersja” użytkownik ma możliwość wygenerowania wzorca „odwrotnego” od poprzednio wprowadzonego. Check-box „Użyj definicji symbolu” określa czy dany wzorzec jest wykorzystywany przez sieć, czy tez nie.
Dodatkowo użytkownik programu ma możliwość edycji i wprowadzenia zmian na dowolnym ze wzorców (przycisk „Numer wzorca” pod wzorcem) oraz przepisania ciągu wzorców z łańcuchu znaków (przycisk „Przepisz wzorce” w górnej części okna programu ).
Po zbudowaniu ciągu wzorców użytkownik wybiera jeden z nich (klikając dwukrotnie na tym wzorcu) i zaburza go w określonej przez siebie liczbie punktów.
Proces rozpoznawania uruchamiany jest za pomocą przycisku „Rozpoznaj”. Kolejne kroki procesu rozpoznawania obrazu są przedstawiane w matrycach w dolnej części okna programu.
W edytorze w centralnej części ekranu wyświetlane są parametry rozpoznawania - iloczyn skalarny oraz odległość Hamminga (ilość punktów w których sygnały się różnią) pomiędzy zaburzonym wzorcem, a kolejnym krokiem rozpoznawania wzorca.
Poniżej prezentujemy zrzut ekranu, na którym sieć w sposób prawidłowy rozpoznała zaburzony wzorzec.
Sieć może nie być w stanie rozpoznać wzorca w sposób prawidłowy.
Wiąże się to z tzw. efektem „przesłuchów” występującym gdy podane wzorce są do siebie podobne. Przy podobnych wzorcach ślady pamięciowe bardziej nakładają się na siebie. Jeśli jednak są bardzo podobne, to ich zapisy w postaci składników wag poszczególnych neuronów tak bardzo mieszają się, że w gotowej sieci zaczyna być problematyczne prawidłowe odtworzenie któregokolwiek z zapamiętanych obrazów
Dlatego uzasadnione i sensowne jest korzystanie z ciągu wzorców różniących się od siebie w stopniu jak największym. Taką właśnie rolę spełnia generacja ciągu wzorców ortogonalnych - dla takich wzorców sieć wykazuje mniejszą „wrażliwość na podobieństwo wzorców”.
Poniżej zrzut ekranu z sytuacji, gdy rozpoznanie nie zakończyło się powodzeniem
Zjawisko odtwarzania poprawnych obrazów z bardzo mocno zakłóconych wzorców w sieci Hopfilelda zapamiętującej ortogonalne sygnały też ma swoje granice. Jeśli zostanie zniekształcony zbyt mocno - nastąpi bezpowrotna utrata możliwości jego odtworzenia.
Poniżej - prawidłowe rozpoznanie wzorca zakłóconego w 14 punktach - dla wzorców ortogonalnych.
Powyższy moduł prezentuje najistotniejsze cechy sieci Hopfielda pracującej jako pamięć autoasocjacyjna.
Podsumowanie
Wnioski
Propozycje dalszej ewolucji programu
można wprowadzać do zaimplementowanych modułów nowe parametry w celu bardziej szczegółowego oddania sfery symulacyjnej zagadnienia np. w przypadku konstrukcji sieci Kohonena można dodać bardziej wyrafinowaną funkcję określającą sąsiedztwo;
można dodawać nowe zagadnienia, które chcielibyśmy włączyć do kanonu uczenia przy pomocy tej aplikacji np. można dołączyć bardzo ciekawy aspekt dwuetapowego uczenia sieci typu Counter Propagation;
wykorzystanie nowszego środowiska programistycznego - może to dać np. efekt bardziej intuicyjnego przedstawienia prezentowanych zagadnień związanych z sieciami neuronowymi;
osobnym zagadnieniem jest rozwijanie Pomocy do programu, zarówno poprzez uszczegółowienie istniejących tematów jak i poprzez dodanie nowych.
Literatura
Ryszard Tadeusiewicz, „Sieci Neuronowe”, Państwowa Oficyna Wydawnicza RM 1993
Timothy Masters, „Sieci neuronowe w praktyce”, Wydawnictwa Naukowo - Techniczne 1996
J. Żurada, M. Barski, W. Jędruch, „Sztuczne Sieci Neuronowe”, Wydawnictwo Naukowe PWN 1996
J. Korbicz, A. Obuchowicz, D. Uciński, „Sztuczne Sieci Neuronowe - podstawy i zastosowania”, Akademicka Oficyna Wydawnicza PLJ 1994
W.S. McCulloch, W. Pitts, „A logical calculus of the ideas immanent in nervous activity”, Bulletin of Mathematica Biophysics, No 5, 1943, pp. 115-133
J. von Neumann, „The Computer and the Brain”, Yale Univ. Press, New Haven, 1958
W.K. Taylor, „Computers and the nervous system. Models and analogues in biology”, Cambridge Univ. Press, Cambridge, 1960
F. Rosenblatt, „The perceprton. A theory of statistical separability in cognitive system”, Cornell Aeronautical ab. Inc. Rep. No. VG-1196-G-1, 1968
B. Widrow, M.E. Hoff, „Adaptive switching circuits”, IRE WESCON Convention Record, New York, 1960, pp. 96-104
B. Widrow, „The Original Adaptive Neural Net Broom-Balancer”, Proceedings of 1987 IEEE Int. Symp. on Circuits and Systems, Philadelphia, PA, May 1987 pp. 351-357
M. Minsky, S. Papert, „Perceptrons”, MIT Press, Cambridge 1969
J.A. Anderson, E. Rosenfeld, „Neurocomputing - Foundation of Research“, MIT Press, Cambridge, Mass., 1988
T. Kohonen, „Associative Memory: A System - Theoretical Approch”, Springer - Verlag, Berlin, 1982
T. Kohonen, „Adaptive, associative, and self-organizing functions in neural computing ”, Appl. Opt., 26(23), 4910-4918, 1987
T. Kohonen, „The self-organizing map”, Proc. IEEE, 78, nr 9, 1494-1480, 1990
D.O. Hebb, „The Organization of Behaviour, a Neuropsychological Theory”, Wiley, New York, 1949
D. Rutkowska, M. Piliński, L. Rutkowski, „Sieci Neuronowe, Algorytmy Genetyczne i Systemy Rozmyte“ Wydawnictwo Naukowe PWN 1997
Praca zbiorowa pod redakcją M. Rymarczyka, „Decyzje, Symulacje, Sieci Neuronowe“, Wydawnictwo Wyższej Szkoły Bankowej w Poznaniu 1997
T.L. McClelland, D.E. Rumelhart, and the PDP Research Group, „Paralell Distributed Processing“, MIT Press, Cambrideg, Mass. 1986
Opracowana przez nas dydaktyczno - symulacyjna aplikacja komputerowa może być wykorzystywana przez osoby, które prowadzą zajęcia związane z szeroko rozumianą sferą sztucznych sieci neuronowych, stanowić będzie wtedy bardzo pomocny element pokazujący praktyczne aspekty wykładanych zagadnień teoretycznych. Pozwala „namacalnie” przekonać się o możliwościach, różnorodności oraz elementach mających wpływ na konstrukcję, uczenie, testowanie oraz wykorzystywanie sztucznych sieci neuronowych.
Dla osób samokształcących się w temacie sieci neuronowych nasza aplikacja stanowić może bardzo ciekawą ofertę, która z jednej strony pomoże zrozumieć konstrukcję oraz działanie sieci neuronowych zaś z drugiej strony stanowi szeroki pomost pomiędzy wiedzą teoretyczną (zawartą w Pomocy) a praktycznymi aspektami jej implementacji i wykorzystania. Istotą tego mariażu jest skumulowanie w jednym miejscu - programie komputerowym - tych dwu aspektów dydaktyki: wiedzy teoretycznej bezpośrednio przekładającej się na symulację i propozycję praktycznego wykorzystania.
Przyszłe rozwijanie naszego programu może być ukierunkowane na następujące ścieżki ewolucji:
101
|
Numer porządkowy cech
Nazwa cech - dla wszystkich klas obiektów
Nazwa klasy obiektów rozpoznawanych przez neuron
Wartości określające posiadane przez obiekty klasy - danej cech
Wybór figury geometrycznej
Określenie parametrów uczenia sieci
Określenie struktury sieci Kohonena oraz „rozrzutu” wag początkowych
Sterowanie procesem uczenia i testowania
Wartości wektora wag neuronu
Kolejne numery wag w wektorze
Kolejne numery wag w wektorze
Wartości wektora sygnałów wejściowych
Moc śladu pamięciowego
Moc sygnału wejściowego
Łączne pobudzenie
Wartość odpowiedzi neuronu: dyskretna, unipolarna funkcja aktywacji
Wartość odpowiedzi neuronu: ciągła funkcja aktywacji
λ (lambda) - parametr ciągłej funkcji aktywacji
Przyciski operacyjne
Nazwa pliku, pasek postępu, edytor z ciągiem uczącym
Przyciski: Generuj, Wczytaj, otwórz plik
Lista plików, wybór katalogu, przycisk Otwórz
Nazwa pliku (może być nowy), rozszerzenie, opcja tylko do odczytu
Parametry oraz funkcja Przerysuj (Testowanie)
Akcja „Ucz sieć” oraz jej parametry: ilość kroków, waga środkowa, współczynnik uczenia
Pole rysowania wykresów, pasek postępu akcji: Przerysuj oraz Ucz sieć, pole Kroki wykonane w procesie uczenia
Parametry definiujące początkową strukturę sieci
Określenie sposobu generacji sygnałów uczących
Informacja o przebiegu samouczenia
Przycisk uruchomienia i zatrzymania symulacji
Sterowanie tempem symulacji
Sterowanie tempem symulacji wraz z przyciskiem Krok
Gęstość próbkowania losowego wyznaczania ciągu uczącego
Legenda objaśniająca znaczenie powyższego obszaru informacyjnego
Określenie struktury sieci neuronowej oraz początkowych parametrów uczenia
Informacja o ilości wykonanych prezentacji sygnałów uczących oraz ilość neuronów w poszczególnych ćwiartkach
Definicja prostej figury płaskiej
Ilość pokazów (Kroków ucznia) i uruchomienie (również zatrzymanie- na żądanie) procesu uczenia
Obszar prowadzenia prezentacji efektów pokazów (uczenia) kolejnych epok
Przyciski: Generuj, Zapisz plik, otwórz plik
Przyciski: Generuj, Zapisz plik, otwórz plik
Pasek szybkości
Główny formularz aplikacji „PNeuron 1.0” oraz okno edytora programu w ObjectPascalu
Kontroler obiektu
Przyciski Krok oraz przełącznik zatwierdzający ustalone parametry
Przyciski Krok oraz parametry procesu uczenia sieci metodą Backpropagation
Przyciski uruchamiające edycję symbolu do rozpoznawania
Legenda wzorców, przyciski: Przepisz wzorce oraz Generuj wzorce
Wyszukiwarka
Podobne podstrony:
Praca na lekcjach, Różności, Dla nauczycieli
Praca na lekcjach, Różności, Dla nauczycieli
praca z uczniem zdolnym i słabym 2
Praca psychoterapeutyczna z DDA wykład SWPS
PRACA NA 4 RECE (aga)(1)[1]
praca 4
PRACA HODOWLANA Podstawy
Praca osób niepełnosprawnych
PRACA Z UCZNIEM NIEWIDOMYM I SŁABO WIDZĄCYM
8 Właściwa Praca, moc, energia całość
Praca zespolowa z elementami komunikacji interpersonalnej ed wczesn
Prezentacja praca dyplom
Praca szkoly w zakresie organizacji opieki pomocy
CECHY STRUKTUR ORGANIZACYJNYCH PRACA GRUPOWA 17 KWIETNIA[1]
PRACA Z DZIECKIEM NIESMIALYM
Praca z komputerem
więcej podobnych podstron