
R O Z D Z I A Ł 4
ZARZĄDZANIE DANYMI
W rozdziale drugim omówiliśmy p o d s t a w o w e funkcje modyfikacji zmiennych
i przypadków. Obecnie przedstawimy bardziej zaawansowane i równie potrzebne narzędzia
zarządzania danymi. Należą do nich między innymi:
* sortowanie przypadków
* tworzenie podzbiorów pliku danych
* łączenie dwóch plików danych
* weryfikacja wprowadzonych danych
W programie STATISTICA zebrane są one w specjalnym m o d u l e Zarządzanie
danymi/MFM. Po naciśnięciu przycisku
programu poza arkuszem danych otworzy się okno Przełącznika M o d u ł ó w (STATISTICA
Module Switcher). W oknie tym wybieramy m o d u ł Zarządzanie danymi/MFM
i naciskamy przycisk Zakończ i przełącz do. Otworzy się okno m o d u ł u Zarządzanie
danymi/MFM, widoczne na rysunku poniżej:
Rys. 4.1 O k n o m o d u ł u zarządzania danymi
W
oknie tym wyróżniają się dwie grupy:
73
lub d w u k r o t n y m kliknięciu w oknie

Przystępny kurs statystyki
grupa opcji związana z - Megafile Menager - specjalistycznym systemem zarządzania
bazą danych. U ż y w a n y jest najczęściej do importowania nietypowych danych
i wstępnego ich opracowania (np. dużych baz z długimi rekordami). System ten
dysponuje też językiem programowania M M L (Megafile M a n a g e r Language) do
zarządzania bazami danych i ich transformowania do pakietu STATISTICA. D o k ł a d n e
omówienie tych opcji - j a k o bardzo zaawansowanych - wykracza poza ramy niniejszego
opracowania i zostanie o m ó w i o n e w następnych t o m a c h .
grupa opcji związana z zarządzaniem danymi, pokazana na poniższym rysunku:
Rys. 4.2 Opcje zarządzania danymi
O m ó w i m y teraz najważniejsze opcje drugiej grupy.
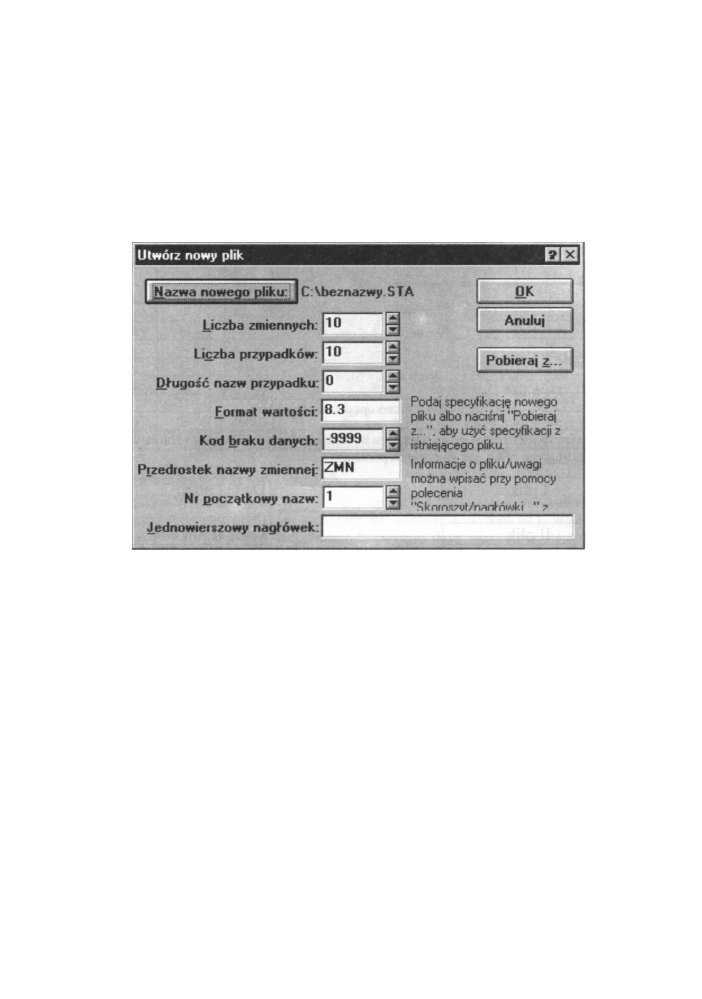
I. Tworzenie nowego pliku danych
Dotychczas tworzyliśmy nowy plik danych przy p o m o c y m e n u Plik (File).
Otrzymywaliśmy pusty domyślny arkusz danych (10 przypadków na 10 zmiennych).
Opcja, którą o m ó w i m y tutaj, ma o wiele większe możliwości. T w o r z y m y nowy arkusz
danych wedle własnych kryteriów i upodobań. M o ż e m y określić b o w i e m (rysunek
poniżej):
1. N a z w ę i położenie n o w e g o pliku - przycisk N a z w a nowego pliku
W oknie, które się otworzy po naciśnięciu tego przycisku, określamy n a z w ę
i ścieżkę dostępu do n o w o tworzonego pliku.
2. Liczbę zmiennych
W p r o w a d z a m y n o w ą liczbę zmiennych. Pliki programu STATISTICA m o g ą
zawierać maksymalnie 4092 zmienne. Pliki o większej ilości z m i e n n y c h (do
32 000) m o ż e m y tworzyć wykorzystując m o d u ł Megafile Menedżer.
3. Liczbę przypadków
Liczba przypadków jest prawie nieograniczona. Jak podają twórcy programu
w dokumentacji - liczba przypadków m o ż e osiągnąć astronomiczną liczbę 2,14
miliardów.
74
Zarządzanie danymi
Długość nazw przypadków
Pliki danych programu STATISTICA m o g ą mieć nazwy przypadków
o maksymalnej długości do 20 znaków.
Format wyświetlania wartości zmiennych
Określamy tutaj format postaci X.Z, gdzie X całkowita szerokość pola liczby,
a Z - ilość miejsc po przecinku. D o m y ś l n e ustawienie to postać 8.3. Ustawienie
to nie ma wpływu na precyzję przechowywania danych.
Rys. 4.3 O k n o opcji - Utwórz n o w y plik
6. Kod braku danych
Wartością domyślną jest liczba -9999, ale użytkownik m o ż e podać własną.
Wartość ta jest używana do reprezentowania brakujących danych dla
wszystkich zmiennych w arkuszu danych.
7. Przedrostek nazwy zmiennej
D o m y ś l n e ustawienie to przedrostek V A R lub Z M N . Służy on do
zdefiniowana nazw kolejnych zmiennych ( V A R 1 , VAR2, VAR3,...).
8. N u m e r początkowy zmiennej
Podajemy numer początkowy zmiennej dla przedrostka zmiennej. Domyślną
wartością jest 1.
9. Jednowierszowy nagłówek pliku
Podajemy tutaj krótki (do 77 znaków) komentarz o pliku. Jest on wyświetlany
w nagłówku arkusza danych i m o ż e być drukowany wraz z arkuszem danych
lub raportem.
Przycisk Pobieraj z... w o m a w i a n y m oknie umożliwia wykorzystanie ustawień z innych
plików danych dla określenia (skopiowania) omawianych powyżej opcji. Wystarczy
jedynie podać nazwę istniejącego pliku dla pobrania specyfikacji.
75
Przystępny kurs statystyki
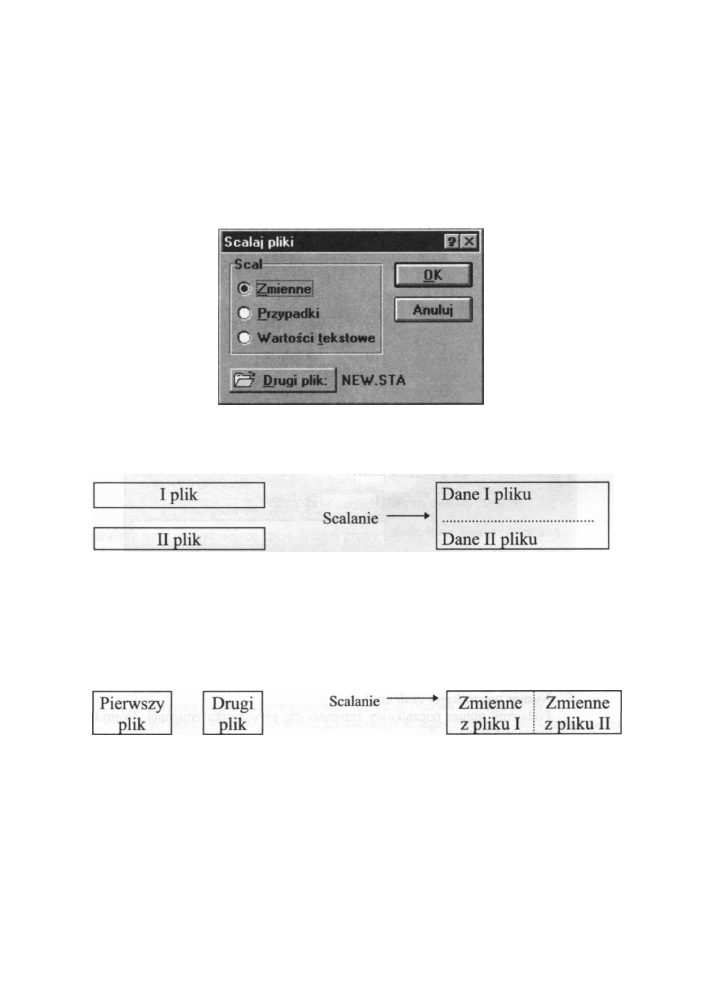
II. Scalanie plików
Czasami tworzymy duże arkusze danych na d w ó c h różnych komputerach (lub równolegle
przez dwie osoby) i chcemy następnie połączyć dane w jeden plik. M o ż e m y też chcieć
dołączyć dane do utworzonego j u ż wcześniej pliku. Wykorzystujemy w celu opcję scalanie
plików (rysunek poniżej).
Rys. 4.4 O k n o opcji scalania plików
Łączenie przypadkami polega na dopisaniu na końcu danych z pierwszego zbioru wartości
danych z drugiego pliku, j a k na rysunku poniżej:
Rys. 4.5 Scalanie przypadkami
Przy takim łączeniu liczba zmiennych w obu plikach musi być taka sama.
Innym razem m o ż e m y chcieć do istniejącego pliku danych dodać nie n o w e przypadki, lecz
nowe zmienne zapisane w innym pliku. Stosujemy wówczas łączenie zmiennych. N o w e
zmienne z dołączanego pliku zostają umieszczone na p r a w o od j u ż istniejących, j a k
pokazano to na następnym rysunku:
Rys 4.6 Scalanie „ z m i e n n y m i "
Istnieją też inne sposoby scalania (relacyjne, hierarchiczne) rzadziej używane i dlatego
dokładne ich omówienie zostanie pominięte. Zainteresowanych odsyłam do doskonałego
„elektronicznego podręcznika" (menu P o m o c ) .
Dla zilustrowania pozostałych opcji załóżmy, że utworzyliśmy następujący arkusz danych -
tabela 1:
76

Zarządzanie danymi
Nazwisko Wiek
Wzrost
W a g a
Płeć
P c u k r u
H e m o g l o
bina
Skala
(natęż,
choroby)
L-ciąż
Nowak
18
175
51,5
M
5,40
14,10
II
0
Tomal
34
169
52
M
6,70
16,80
I
0
Nosal
48
169
61
K
5,80
17,00
I
2
Ząb
56
156
48
K
5,30
14,50
II
3
Abacka
21
164
60,5
K
6,60
14,40
I
1
Nowak
74
165
71
M
6,20
14,50
Ul
1
Banach
23
172
70
M
7,00
16,80
I
0
Moroz
47
170
49,5
M
6,20
16,00
I
0
Kowalska
43
156
48,5
K
5,90
16,20
I
0
Sikora
54
160
73
M
5,80
14,20
II
0
Dobosz
41
168
87
M
6,60
16,60
I
0
Babacka
36
166
49
K
6,00
16,50
II
2
Tomal
31
165
54
K
6,40
14,30
III
1
Kwatera
56
168
51
K
6,90
14,50
V
2
Dawid
27
172
47,5
M
6,80
14,10
11
1
III. Sprawdzanie wartości danych
Jest to doskonałe narzędzie do weryfikacji arkusza danych (sprawdzenie kompletności,
sensowności, spełnienia kryteriów logicznych dla określenia zakresu itd.). Wybranie tej
opcji powoduje otwarcie okna dialogowego Sprawdzaj dane widocznego na poniższym
rysunku:
W oknie tym określamy warunki weryfikacji. M o ż e m y podać dwa rodzaje warunków:
• warunki uznające przypadek za „poprawny", jeśli spełnia on podane kryterium -
opcja „poprawny jeżeli";
• warunki uznające przypadek za „zafałszowany", jeśli nie spełnia on podanego
kryterium - opcja „ błędny jeżeli".
Podane warunki możemy łączyć spójnikiem „i" (opcja „wszystkie warunki"), a także
spójnikiem "lub" (opcja „przynajmniej jeden warunek").
W konstrukcji warunków weryfikacji możemy wykorzystać operatory z trzech
omawianych już grup:
77
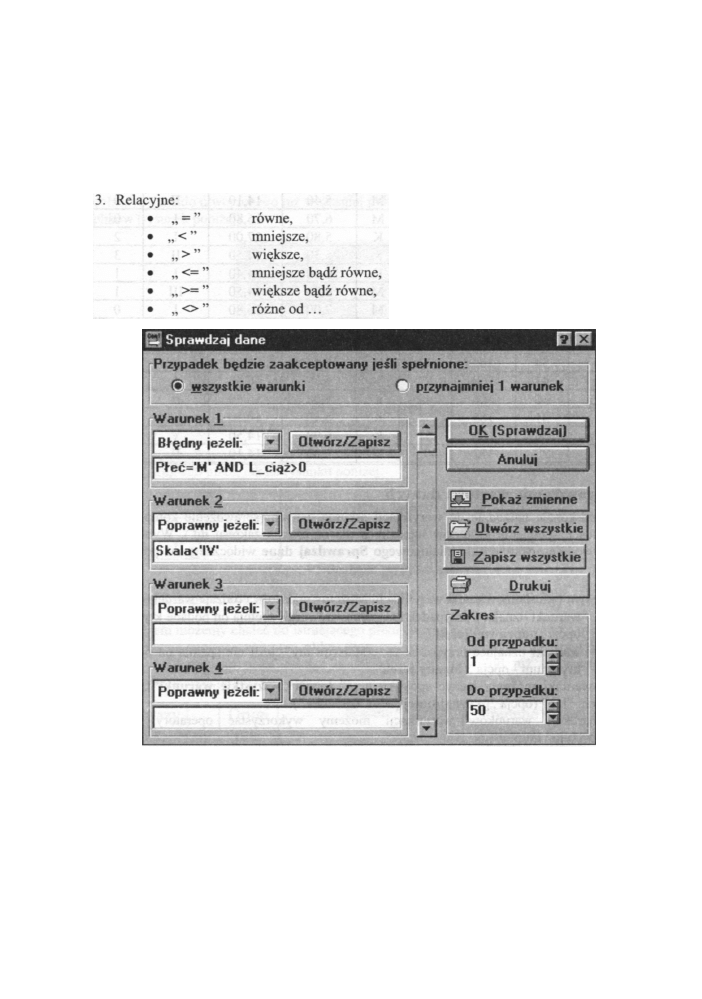
Przystępny kurs statystyki
2. Logiczne:
• A N D (równoważny z &)
• OR (równoważny z |)
• - N O T (równoważny z ~)
• koniunkcja (iloczyn logiczny),
• alternatywa (suma logiczna),
• negacja (zaprzeczenie).
Rys. 4.7 O k n o opcji weryfikacji danych
W warunkach do zmiennych odwołujemy się albo przez ich nazwy (np. = L E K 1 - L E K 2 ) ,
albo przez ich numery (np. = v l - v2). Przez v0 oznaczamy n u m e r przypadku.
Po określeniu warunków weryfikacji w celu jej rozpoczęcia naciskamy przycisk
OK. Jeżeli znaleziony zostanie przypadek „zafałszowany" (nie spełniający w a r u n k ó w )
wyświetlone zostanie okno dialogowe Sprawdzanie danych. Umożliwia ono wybór jednej
z trzech dalszych dróg przebiegu weryfikacji:
78

Zarządzanie danymi
• modyfikowanie danych;
Po modyfikacji naciskamy przycisk Sprawdzaj aby kontynuować weryfikację.
• ignorowanie błędu i kontynuacja sprawdzianu;
• zakończenie procesu weryfikacji.
Przykład 1
Dla danych przedstawionych w powyższej tabeli, m o ż e m y sprawdzić, czy dla mężczyzn
„prawidłowo" wprowadzone zostanie dane dla zmiennej L_ciąż oraz czy skala natężenia
choroby przyjmuje wartości tylko postaci -I, II, III. W tym celu postępujemy następująco:
• Krok 1 -
wybieramy dla warunku 1 opcję „ błędny jeżeli"
• Krok 2 -
w oknie wpisujemy warunek - P ł e ć = ' M ' A N D L_ciąż>0
• Krok 3 -
wybieramy dla warunku 2 opcję„poprawny jeżeli"
• Krok 4 - w
oknie poniżej wpisujemy warunek - S k a l a < ' I V '
• Krok 5 -
wybieramy opcję „wszystkie warunki"
• Krok 6
- naciskamy przycisk OK
Proces weryfikacyjny wykryje n a m błędy dla przypadku 6 i 15 (mężczyzna i dodatnia
liczba ciąż) oraz dla przypadku 14 (skala natężenia choroby - V).
Wiele warunków sprawdzających m o ż e być bardzo skomplikowanych,
a jednocześnie wielokrotnie wykorzystywanych. Program STATISTICA umożliwia
zapisanie określonych warunków. Z a c h o w a ć m o ż e m y poszczególne warunki (przycisk
Zapisz lub wszystkie utworzone warunki (przycisk Zapisz wszystkie). Zapisane warunki
możemy wykorzystać (przycisk Otwórz lub Otwórz wszystkie przy sprawdzeniu
poprawności w innym arkuszu danych. Weryfikacji m o g ą podlegać wszystkie przypadki
lub tylko te przez nas wybrane w oknie Z a k r e s . Podajemy tam przed weryfikacją n u m e r
początkowy (Od p r z y p a d k u ) i końcowego (Do p r z y p a d k u ) ) pliku przypadków, który
chcemy sprawdzić. Chcąc otrzymać k o ń c o w y raport przeprowadzonej weryfikacji
naciskamy przycisk Drukuj.
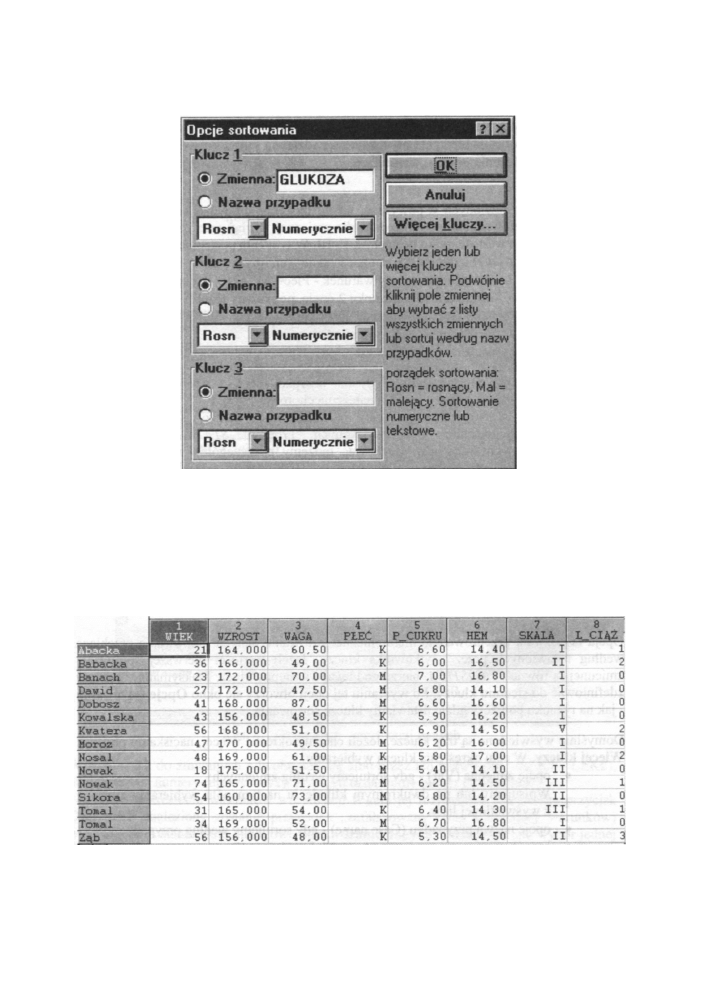
IV. Sortowanie danych.
Opcja ta pozwala przeprowadzić hierarchiczne sortowanie danych. Sortowanie przebiega
według ustawionych przez użytkownika kluczy. Jeżeli wartości pierwszej sortowanej
zmiennej są równe STATISTICA, bierze pod u w a g ę następny klucz. M a k s y m a l n i e m o ż e m y
zdefiniować do siedmiu kluczy. Po wybraniu tej opcji otworzy się okno Opcje sortowania
-jak na rysunku poniżej - gdzie ustawiamy klucze sortowania.
Domyślnie wyświetlone są trzy klucze. Jeżeli chcemy określić więcej, naciskamy przycisk
Więcej kluczy. W celu określenia klucza wybieramy:
• opcję zmienna (Var) - gdy sortujemy według zmiennych;
Wpisujemy lub po dwukrotnym kliknięciu na t y m polu wybieramy zmienną
z wyświetlonej listy.
• opcję nazwa przypadku (Case name) - gdy sortujemy według przypadków;
• sposób sortowania - rosnący (Ascen) lub malejący (Desc);
• tryb sortowania - tekstowy (Text) lub numeryczny (Numeric).
79
Przystępny kurs statystyki
Rys. 4.8 O k n o Opcje sortowania
Przykład 2
Dla danych zebranych w tabeli 1 przeprowadzimy sortowanie według nazw przypadków
(nazwisko) - 1 klucz i według zmiennej wiek - 2 klucz. Ustawiamy klucze tak jak na
powyższym rysunku.
Następnie klikamy przycisk OK w celu wykonania sortowania. O t r z y m a m y następujący
wynik:
Rys. 4.9 Wynik sortowania danych z tabeli 1
80
Zarządzanie danymi
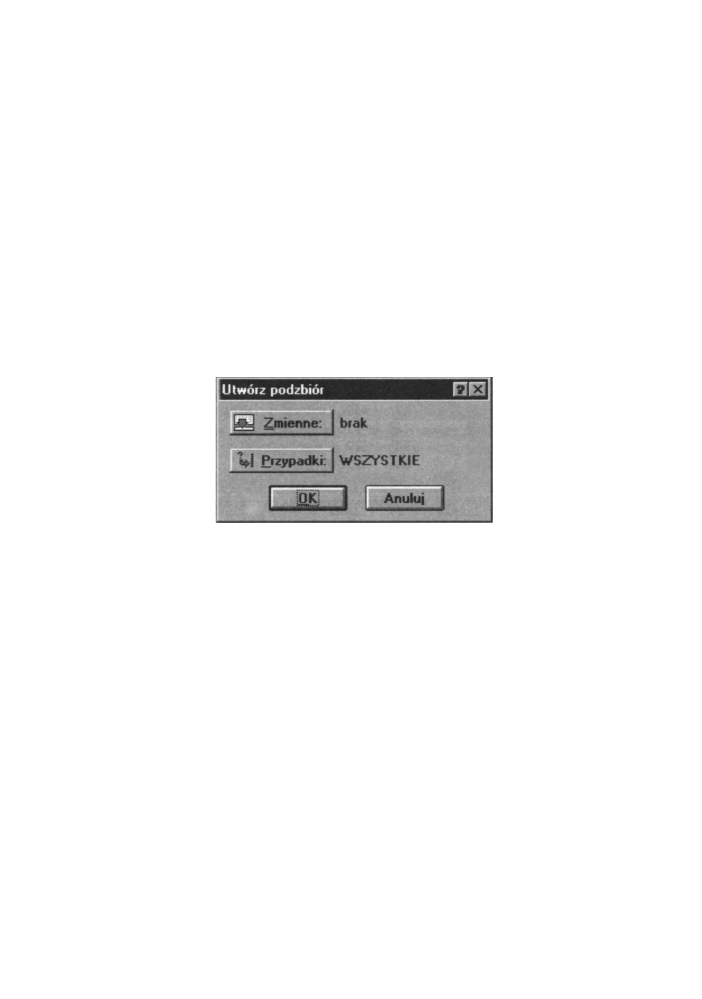
V. Tworzenie podzbiorów
Opcja ta umożliwia tworzenie podzbiorów danych. Poprzednio przy p o m o c y W a r u n k ó w
Selekcji przypadków tworzyliśmy chwilowe podzbiory dla potrzeb aktualnej analizy
statystycznej. Obecna opcja wyświetla otrzymany podzbiór na ekranie i umożliwia
zapisanie go pod inną (niż cały zbiór) nazwą. Po wyborze tej opcji otwiera się okno,
w którym podajemy warunki tworzenia podzbiorów. O k n o to widoczne jest poniżej:
Rys. 4.10 O k n o z opcjami do tworzenia podzbiorów
Przykład 3
Dla danych z tabeli 1 utworzymy następujący podzbiór. Interesują nas wiek, waga, płeć
i poziom cukru osób, dla których skalę natężenia choroby określono na I. Tworzenie
podzbioru opiszemy w kolejnych krokach:
• Krok 1. Wybieramy opcję Podzbiór.
• Krok 2. Klikamy przycisk Zmienne i w otwierającym się oknie wybieramy
zmienne - Wiek, Waga, Płeć i P c u k r u .
• Krok 3. Klikamy przycisk Przypadki, otwierając o k n o Warunki Selekcji
Przypadków. W oknie tym wpisujemy warunek
Skala = „I"
i klikamy O K
dla wcielenia warunku w życie.
• Krok 4. Klikamy przycisk OK dla uruchomienia procedury tworzenia
podzbioru.
Otrzymujemy następujący podzbiór:
Przystępny kurs statystyki
Rys. 4.11 Wynik tworzenia podzbioru dla danych z tabeli 1
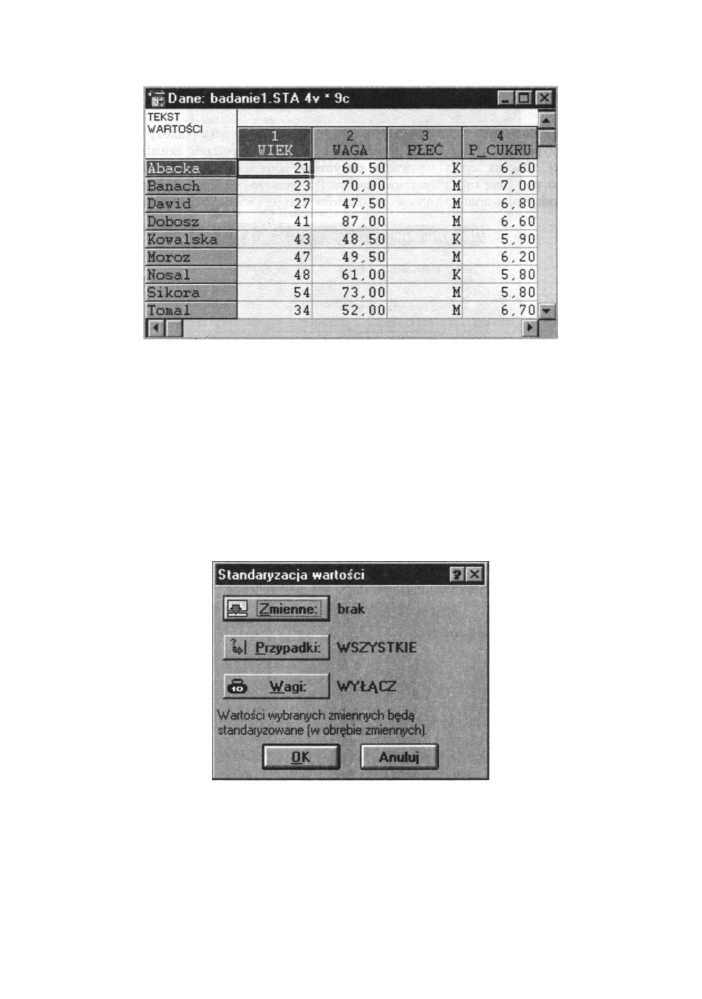
VI. Standaryzowanie danych
Pozwala ono na standaryzowanie dowolnie wybranych wartości. Z m i e n n a standaryzowana
charakteryzuje się tym, że jej średnia jest równa 0, a odchylenie standardowe 1.
Standaryzacja pozwala na transformacje zmiennej mianowanej w zmienną niemianowaną.
Dzięki temu średnie otrzymane z różnych źródeł (w różnych jednostkach) m o g ą być ze
sobą porównywalne. Opcja standaryzowania dostępna jest też po kliknięciu p r a w y m
przyciskiem myszy. M o ż e m y wówczas dokonać standaryzacji k o l u m n (zmiennych) lub
wierszy (przypadków). Po wybraniu tej opcji pojawia się okno pokazane na rysunku
poniżej:
Rys. 4.12 O k n o ustawiania opcji dla standaryzacji
W oknie Standaryzacja wartości m a m y trzy przyciski dla ustawienia opcji standaryzacji
Umożliwiają one określenie:
82

Zarządzanie danymi
* Zmiennych - przycisk
Umożliwia określenie zmiennej ważącej (zawierającej wagi przypadków) dla
określenia wpływu każdego przypadku na obliczanie standaryzacji.
Wartości standaryzacji obliczone są według tradycyjnych reguł:
wartość standaryzowana = (wartość początkowa - średnia grupy)/odchylenie standardowe
Przykład 4
Dla danych z tabeli 1 przeprowadzimy standaryzowanie zmiennej „ w a g a " tylko dla grupy
mężczyzn. W tym celu postępujemy następująco:
• Krok 1. Wybieram opcję Standaryzuj (Standarize).
• Krok 2. Klikamy przycisk Z m i e n n e (Variables) i wybieramy zmienną „ w a g a " do
standaryzacji.
• Krok 3. Klikamy przycisk przypadki (Cases) i w p r o w a d z a m y warunek
„włącz jeżeli" P ł e ć = " M "
Klikamy przycisk OK zamykając omawiane okno.
• Krok 4. Klikamy OK uruchamiając proces standaryzacji.
Fragment arkusza danych przed i po standaryzacji widoczny jest na poniższym rysunku:
83
* Wkładu każdego przypadku - przycisk
Po kliknięciu tego przycisku otwiera się okno W a r u n k i selekcji przypadków.
W oknie tym podajemy warunki na wybranie przypadków do standaryzowania.
M o ż e m y dzięki temu przeprowadzić osobne standaryzowanie tworzonych
podzbiorów. Domyślne wszystkie przypadki są standaryzowane;
* Przypadków - przycisk
Po kliknięciu tego przycisku pojawia się okno, w którym wybieramy zmienne
przeznaczone do standaryzacji;

Przystępny kurs statystyki
Przed standaryzacją Po standaryzacji
Rys. 4.13 Wynik procesu standaryzacji zmiennej „waga" dla grupy mężczyzn
84
Wyszukiwarka
Podobne podstrony:
zarzT dzanie kadrami sciagi, Zarządzanie OK, ZARZĄDZANIE
ZarzT dzanie strategiczne
TEST Zarz dzanie logistyczne1
(2) zarz dzanie wyk?y ci ga
ZARZ DZANIE POLITYKA I STRA, Zarządzanie projektami, Zarządzanie(1)
Zarz dzanie pytania(1)
ZARZ DZANIE JAKO CIA TQM I , Zarządzanie projektami, Zarządzanie(1)
ZARZ DZANIE FINANSAMI, Zarządzanie projektami, Zarządzanie(1)
Zarz dzanie personelem, Zarządzanie zasobami ludzkimi - to uporządkowany i systematyczny zespół oddz
Zarz dzanie ci ga 1 kolos, Szkoła, prywatne, Sesja, Organizacja i Zarządzanie, Organizacja i Zarz d
zarza dzanie na egz
Zarz dzanie ściąga 1 kolos
Zarz dzanie zasobami ludzkimi dzienne W 1
AllData 10 53 – dodawanie dysków z danymi
zarz-dzanie strategiczne 11
W02 Zarz dzanie jako ci
Modu Zarz dzanie Ekonomia 1
więcej podobnych podstron