
51
Zajmiemy się obecnie
klasycznym rachunkiem zdań
(w skrócie KRZ), który jest bazowym
rachunkiem logicznym.
Rachunki zdań
to formalne systemy dedukcyjne, w których
analizuje się to, w jaki sposób wynikanie zależy od znaczenia spójników łączących zdania.
Natomiast nie wnika się zupełnie w strukturę wewnętrzną zdań. Dlatego, biorąc pod uwagę ich
zastosowanie, są to systemy dość słabe, ponieważ np. poprawność prostych rozumowań
z tematu 3 w module 1. nie daje się na ich podstawie uzasadnić. Są to jednak systemy istotne,
gdyż zasady poprawności ustalone na ich gruncie, zachowują swoją ważność również
w systemach mocniejszych.
Pośród wielu znanych rachunków zdaniowych, najprostszą logiką jest właśnie KRZ, a jego
znajomość to dziś podstawa wszelkiej edukacji logicznej. Jest to również najstarszy system
logiczny tego rodzaju, gdyż reguły, którymi będziemy się dalej zajmowali, były już znane
logikom stoickim w III w. p.n.e. KRZ we współczesnej postaci jest czysto formalnym systemem
dedukcyjnym – stąd konstrukcje tego rodzaju często określa się jako rachunki.
Dowolna logika, pojmowana w taki sposób, składa się z dwóch komponentów: języka i określonej
na tym języku relacji wynikania. Zarówno język, jak i wynikanie mogą być scharakteryzowane
w różny sposób. Jeżeli można wykazać równoważność tych charakterystyk, to mamy do
czynienia z tą samą logiką, tylko różnie zdefiniowaną.
Język może np. zawierać różne zestawy spójników i różnić się definicją zdania (formuły).
Wynikanie może być charakteryzowane zarówno semantycznie, jak i syntaktycznie. W drugim
przypadku mówi się zazwyczaj o relacji dedukowalności (dowiedlności), a nie wynikania.
Jeżeli chodzi o definicje syntaktyczne (węższe rozumienie słowa rachunek), to najpopularniejsze
są
systemy aksjomatyczne
, w których używa się pewnych formuł (aksjomatów) jako
niepodważalnych punktów wyjścia w dowodzie. Jednak znacznie prostsze
w praktycznym użyciu są różnego rodzaju
systemy dedukcji naturalnej
, zwane też
założeniowymi. Korzysta się w nich z dużej ilości reguł i wykorzystuje techniki dowodzenia,
stosowane w matematyce od starożytności. Podana dalej charakterystyka KRZ również
korzysta z takiego systemu.
Omówimy kolejno język KRZ od strony syntaktycznej, następnie jego semantykę oraz system
dedukcyjny, który umożliwi nam formalną konstrukcję dowodów.

52
Słownik
języka KRZ zawiera następujące symbole:
1. Nieskończony, przeliczalny zbiór
zmiennych zdaniowych
, który będziemy oznaczać krótko
ZZ; jego elementy to litery: p, q, r, s, t, ..., p
1
, q
1
,.... Ich funkcją jest reprezentowanie dowolnych
zdań w sensie logicznym.
2.
Stałe logiczne
, którymi w KRZ są jedynie spójniki, czyli funktory zdaniotwórcze kategorii z/z,
bądź z/z,z . Wyróżnimy tu pięć spójników, oznaczanych następującymi symbolami:
jednoargumentowy funktor negacji
¬
dwuargumentowe funktory:
– koniunkcji
∧
– alternatywy
∨
– implikacji
→
– równoważności
↔
Często stosuje się inne symbole, np. dla negacji ~ , a dla równoważności
≡ . To, jakie symbole
zastosujemy, nie ma znaczenia, ważne jest by się od siebie różniły i były używane
konsekwentnie w tym samym znaczeniu. Intuicyjnie negacja ma odpowiadać zaprzeczeniu
zdania, wyrażanemu w języku polskim np. przez zwrot „nieprawda, że”, koniunkcja odpowiada
polskiemu i, alternatywa – lub, implikacja – jeżeli...to, a równoważność – wtedy i tylko wtedy.
3. Nawiasy, czyli znaki interpunkcyjne.
Podamy teraz definicję formuły języka KRZ (w skrócie For(KRZ)). Ponieważ mówimy o języku
i z tego względu używamy
metajęzyka
, więc dla wygody wprowadzimy pewne symbole
metajęzykowe. Niech
ϕ i ψ oznaczają dowolne skończone ciągi symboli z podanego wyżej
słownika. Zbiór For(KRZ) definiujemy następująco:
a) ZZ
⊆ For(KRZ)

53
b) jeżeli
ϕ i ψ należą do For(KRZ), to ¬ϕ, (ϕ∧ψ), (ϕ∨ψ), (ϕ→ψ), (ϕ↔ψ) też należą do
For(KRZ)
c) nic
więcej nie należy do For(KRZ)
Definicja tego typu to definicja indukcyjna. Określa się w niej pewien zbiór elementów
wyjściowych, które bezwarunkowo należą do definiowanego zbioru (w tym przypadku ZZ) oraz
podaje warunki pozwalające tworzyć nowe elementy tego zbioru. Ostatnia klauzula ma
charakter ograniczający od góry definiowany zbiór. Zbiór posiadający charakterystykę tego
rodzaju pozwala na stosowanie
indukcji matematycznej
do udowadniania, że wszystkie
elementy tego zbioru posiadają pewną własność.
Metazmienne
ϕ, ψ, χ, δ będziemy w dalszym ciągu traktować jako nazwy formuł, a nie
dowolnych ciągów symboli. Ponadto, dla oznaczenia dowolnych zbiorów formuł będziemy
używać symboli
Γ, ∆, Σ. Nazwy negacja, koniunkcja itd. będziemy również używać jako
określenia formuł, których dany spójnik jest główną stałą logiczną. Zdania łączone spójnikiem
będziemy nadal określać – przeważnie – jako argumenty tego spójnika, jednak w przypadku
implikacji będziemy lewy argument nazywali poprzednikiem, a prawy – następnikiem
implikacji, a w przypadku równoważności będziemy mówić o lewej i prawej stronie
równoważności.
Z podanej definicji można wyciągnąć pewne wnioski, odnośnie dopuszczalnych form zdań –
przykładowo: dwie zmienne nie mogą ze sobą bezpośrednio sąsiadować (również pośrednio,
jeżeli oddzielają je tylko nawiasy). Negacja może stać jedynie przed zmienną, przed nawiasem
bądź przed inną negacją; jedyny dopuszczalny symbol, który może ją poprzedzać, to symbol
dowolnej stałej logicznej. Spójnik dwuargumentowy nie może stać w bezpośrednim sąsiedztwie
innego takiego spójnika ani z lewej, ani z prawej (choć może stać przed negacją).
Definicja pozwala ustalić, nawet dla bardzo długich ciągów symboli, czy są one formułami.
Przykładowo, poniższy ciąg jest formułą:
((p
∧¬(q↔r))→¬(s∨¬q))
Można to sprawdzić następująco: q jest formułą, zatem
¬q też nią jest; s jest formułą, zatem
(s
∨¬q) też jest, jak również ¬(s∨¬q). Analogicznie ustalamy, że ¬(q↔r) jest formułą, skoro q i r
są, a ponieważ p też jest, więc (p
∧¬(q↔r)) też jest formułą. Zatem cały ten ciąg jest formułą,
a konkretnie implikacją o poprzedniku (p
∧¬(q↔r)) i następniku ¬(s∨¬q).
Poniższy ciąg nie jest formułą:
(((p
∧¬(q↔r))→¬(s∨¬q))∨((¬p¬q)→(s→t))

54
z dwóch powodów: po pierwsze, brakuje zewnętrznego prawego nawiasu – powinno być ...t))).
Po drugie, nawet po naprawieniu tego błędu analizowany ciąg nie stanie się formułą; głównym
spójnikiem jest w nim druga od lewej alternatywa, jej lewy argument to formuła (ustaliliśmy to
w poprzednim przykładzie), jednak w prawym argumencie mamy niedopuszczalną kombinację
symboli
¬p¬q.
Nawiasy są niezbędne dla uzyskania jednoznaczności (ustalenia hierarchii spójników,
uniknięcia amfibologii), jednak generalnie ich nadmierna ilość może utrudnić odczytanie. Istnieje
radykalny sposób uproszczenia składni, tzw. beznawiasowa notacja Łukasiewicza,
w której spójniki dwuargumentowe stawia się przed argumentami, a nie pomiędzy nimi, jednak
taki zapis jest niezgodny z przyzwyczajeniami większości użytkowników języka naturalnego
i z popularnymi formami zapisu stosowanymi w matematyce. Jednak nadal można postarać się
o uproszczenie zapisu, aby stał się bardziej czytelny. W tym celu wprowadzimy trzy konwencje:
K1) Można pomijać nawiasy zewnętrzne, np. zamiast pisać ((p
∧¬(q↔r))→¬(s∨¬q)) napiszemy
raczej (p
∧¬(q↔r))→¬(s∨¬q). Pamiętajmy jednak, że gdy będziemy chcieli np. zanegować taką
formułę, w której pominęliśmy zewnętrzne nawiasy, to musimy je z powrotem dodać.
K2) Ustalamy hierarchię siły wiązania argumentów dla spójników dwuargumentowych:
najmocniej wiąże swoje argumenty koniunkcja, słabiej alternatywa, jeszcze słabiej implikacja,
a najsłabiej równoważność. Oznacza to, że jeżeli w danym ciągu symboli nawiasy nie
precyzują, jaka jest hierarchia spójników, to za główny spójnik uznamy ten, który najsłabiej
wiąże swoje argumenty, np. ciąg symboli:
p
∨q∧r → ¬q∨s ↔ ¬p∧s∨¬r
należy rozumieć następująco:
((p
∨(q∧r))→(¬q∨s)) ↔ ((¬p∧s)∨¬r)
W dalszym ciągu nie zwalnia nas to z użycia nawiasów w przypadku, gdy zapisywana przez
nas formuła ma inną hierarchię spójników niż ta, która wynika z konwencji K2). Przykładowo,
gdybyśmy chcieli, żeby ten ciąg odczytać inaczej, np., żeby głównym spójnikiem była pierwsza
od lewej koniunkcja, to wtedy oczywiście musimy zastosować nawiasy, zapisując to tak:
(p
∨q)∧(r → ¬q∨s ↔ ¬p∧s∨¬r)

55
Ponadto nawiasy są niezbędne, gdy obok siebie mamy kilka wystąpień takiego samego
spójnika, np. ciąg p
→ q→ r jest syntaktycznie niejasny. Można go sprecyzować tak (p→q)→ r
lub tak p
→(q→ r). Jednak w przypadku niektórych spójników przyjęcie takiej bądź innej
hierarchii nie ma wpływu na sens formuły. Stanie się to jasne po ustaleniu semantyki naszego
języka, jednak już teraz wprowadzimy sobie odpowiednią konwencję.
K3) Dla koniunkcji i alternatywy możemy pomijać nawiasy, jeżeli nie występują między nimi inne
spójniki dwuargumentowe, np. zamiast pisać:
p
∧(q∧r)→(s∨q)∨(p∨r)
możemy napisać:
p
∧q∧r → s∨q∨p∨r
Ta ostatnia konwencja powoduje, że zarówno koniunkcję, jak i alternatywę, można potraktować
także jako spójniki n-argumentowe dla n >2.
56
W poprzednim temacie przypisaliśmy wprawdzie pewien sposób rozumienia wyróżnionych
przez nas spójników, jednak trudno to uznać za semantykę tego języka. Semantyka KRZ jest
ekstensjonalna, tzn., że pod uwagę nie będziemy brali sądów logicznych wyrażanych przez
dane zdanie, a tylko wartość logiczną, jaką ono posiada. Przypomnijmy też, że KRZ jest oparte
na zasadzie dwuwartościowości, co oznacza, iż zakładamy, że przy dowolnej interpretacji
każde zdanie ma ustaloną, jedną (i tylko jedną) z dwóch wartości logicznych. Prawdę będziemy
odtąd oznaczać symbolem 1, a fałsz symbolem 0.
Podstawowym pojęciem naszej semantyki jest pojęcie
wartościowania,
zdefiniowane
następująco:
Wartościowaniem nazywamy dowolne odwzorowanie V ze zbioru ZZ w zbiór {1,0}.
Technicznie jest to zatem funkcja, która każdej zmiennej przypisuje bądź 1, bądź 0. Istnieje
nieskończenie wiele różnych wartościowań, dlatego będziemy w konkretnych przykładach
rozróżniać je, pisząc np. V1, V2,...
Aby móc oceniać wartość logiczną formuł złożonych, musimy ustalić jakiś sposób poszerzania
wartościowań. Ponieważ ograniczyliśmy się do spójników ekstensjonalnych, więc można to
zrobić, definiując znaczenie wszystkich spójników w terminach wartości ich argumentów.
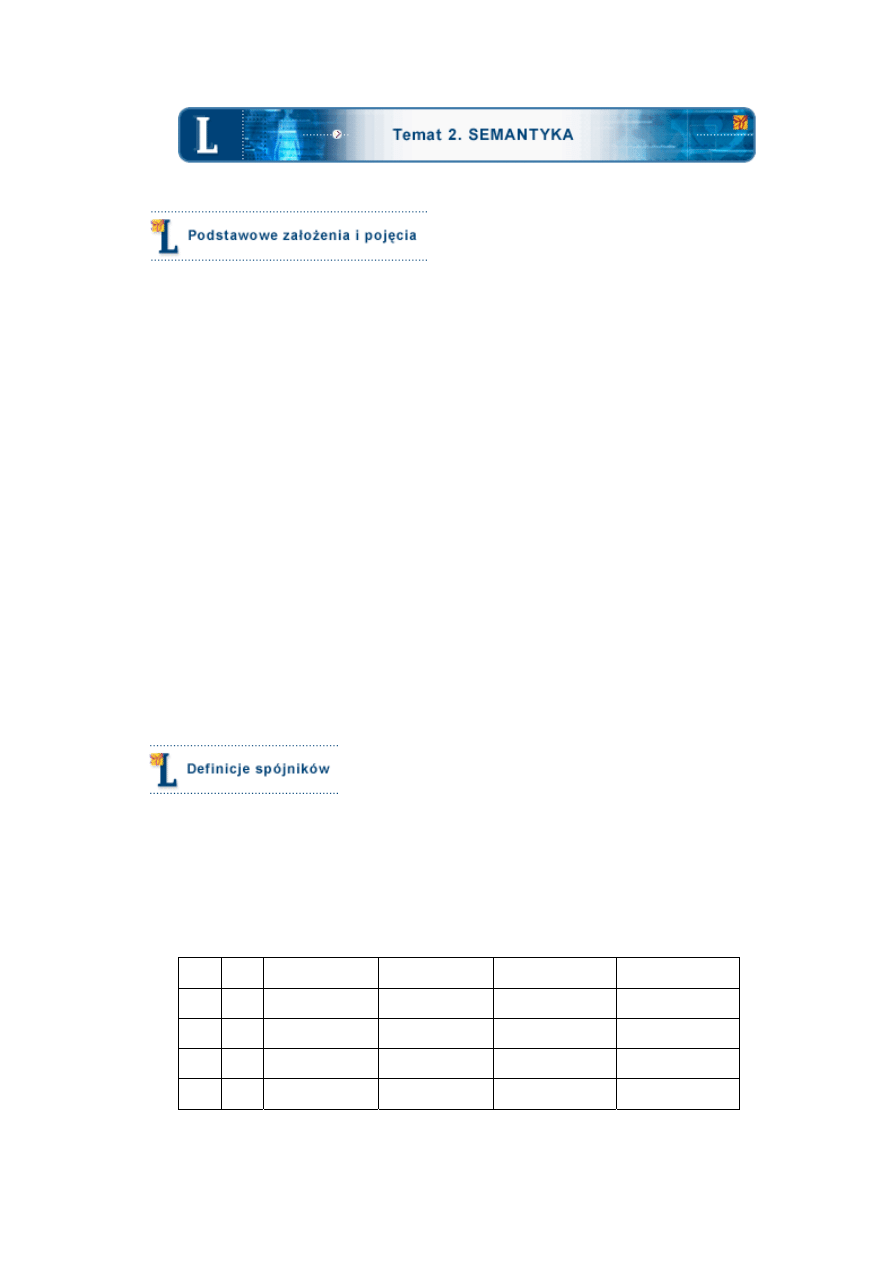
Wygodną formą reprezentacji takich definicji są
tabelki zero-jedynkowe
:
ϕ
ψ
ϕ∧ψ
ϕ∨ψ
ϕ→ψ
ϕ↔ψ
1 1
1
1
1
1
1 0
0
1
0
0
0 1
0
1
1
0
0 0
0
0
1
1
57
Negacja dowolnego zdania po prostu zmienia jego wartość logiczną. Łatwo zauważyć, że
powyższe definicje pozwalają dla dowolnego wartościowania i dowolnej formuły ustalić jej
wartość, np. niech V1(p)=V1(q)=V1(r)=1, to wtedy V1(p
→q∧r )=1.
Jeżeli weźmiemy V2 takie, że V2(p)=V2(q)=1 i V2(r)=0, to wtedy V2(p
→q∧r )=0, gdyż V2(q∧r )=0.
W logice interesuje nas nie tyle to, jaką wartość dana formuła posiada przy określonym
wartościowaniu, ale jak się zachowuje przy wszystkich. Jak to jednak sprawdzać, jeżeli
wartościowań jest nieskończenie wiele? Łatwo jednak zauważyć, że przy sprawdzaniu wartości
formuł bierzemy pod uwagę nie całe wartościowanie, tylko to, co ono przypisuje zmiennym
występującym w analizowanej formule. Jeżeli w formule nie ma zmiennej s, to dla wyniku
sprawdzania nie ma znaczenia, czy s otrzyma 1, czy 0. Tak dokładnie postępowaliśmy
w powyższym przykładzie z wartościowaniami V1 i V2.
Skoro abstrahujemy od zmiennych nie występujących we wzorze, to nasza nieskończona liczba
różnych wartościowań redukuje się do skończonej liczby wartościowań cząstkowych, które
różnią się od siebie tylko dla ustalonych zmiennych. Liczba takich wartościowań jest
wyznaczona wzorem 2n, gdzie n to liczba różnych zmiennych we wzorze, np. dla formuły
z przykładu wyżej mamy 8 różnych podstawień 1 i 0 dla trzech różnych zmiennych p, q, r.
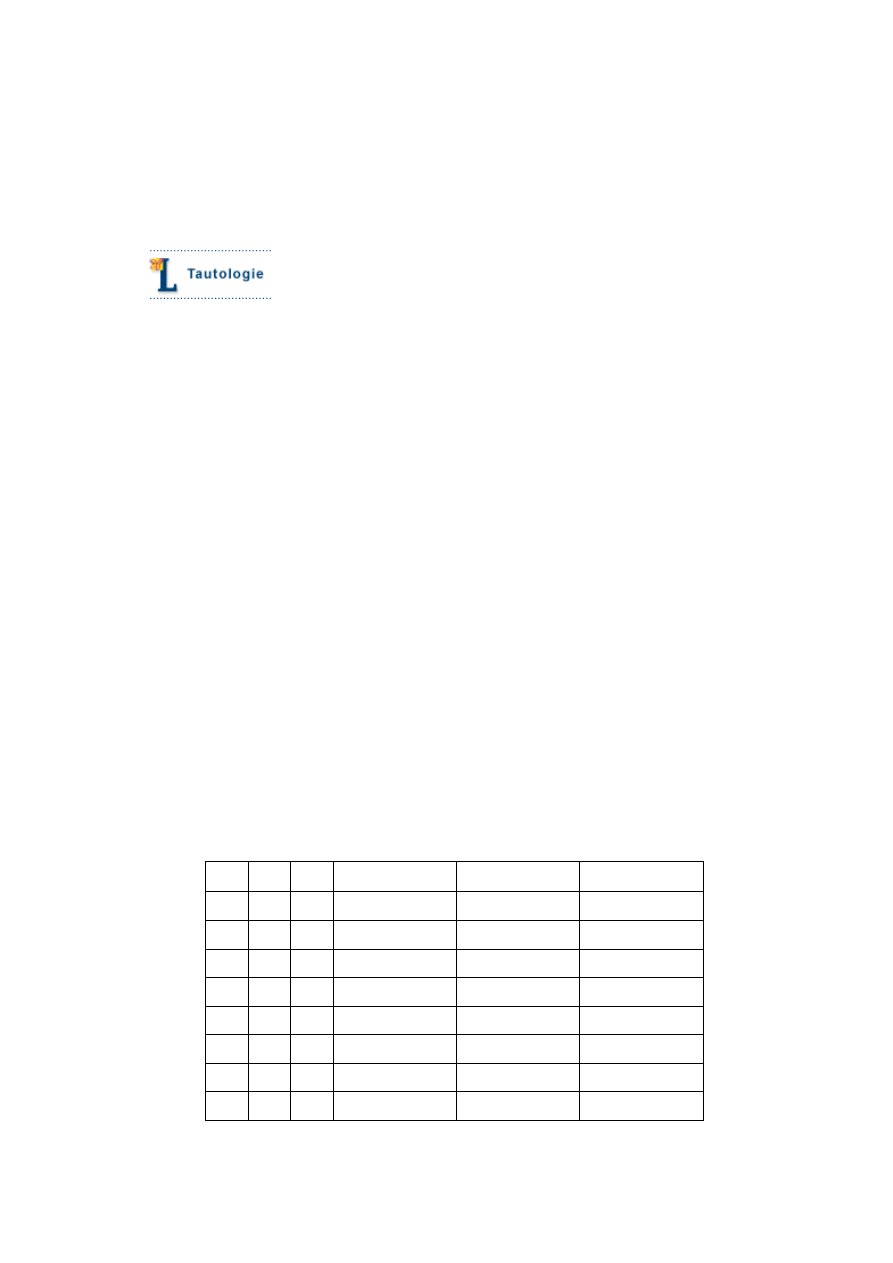
W ten sposób można
metodę tabelkową
stosować do analizy dowolnej formuły. Sprawdźmy to
na przykładzie formuły p
∧q→p∨r, gdzie w tabelce uwzględniamy 8 możliwych rodzajów
wartościowań, a w kolejnych kolumnach podformuły (czyli zdania składowe) sprawdzanej
formuły. Wynik liczymy dla każdego wartościowania po kolei od lewej ku prawej (aż do kolumny
wynikowej).
p q r
p
∧q p∨r p∧q→p∨r
1
1
1
1 1 1
1
1
0
1 1 1
1
0
1
0 1 1
1
0
0
0 1 1
0
1
1
0 1 1
0
1
0
0 0 1
0
0
1
0 1 1
0
0
0
0 0 1

58
Powyższa formuła jest prawdziwa niezależnie od wartościowania. Takie formuły – uniwersalnie
prawdziwe – będziemy określać mianem
tautologii
, czyli prawd logicznych i oznaczać
w następujący sposób:
= ϕ .
Formuła, która przy każdym wartościowaniu jest fałszywa, to
kontrtautologia
albo fałsz
logiczny. Przykładowo – negacja powyższej formuły (i ogólnie każdej tautologii) daje nam
kontrtautologię. Dla oznaczenia dowolnej kontrtautologii będziemy używać symbolu
⊥,
natomiast żeby zaznaczyć, że jakaś konkretna formuła
ϕ jest kontrtautologią (lub zbiór formuł Γ
jest sprzeczny), będziemy pisać
ϕ=⊥ ( Γ=⊥).
Zarówno tautologie, jak i kontrtautologie są zdaniami analitycznymi naszego języka.
Formuły – których wartość logiczna nie jest stała, lecz zmienia się w zależności od
wartościowania (jak w przykładzie z formułą p
→q∧r) – to
formuły kontyngentne
.
W tradycyjnym wykładzie logiki przywiązuje się dużą wagę do tautologii, podając często ich
obszerne listy i obdarzając wybrane formuły nazwami, np.:
prawo wyłączonego środka
prawo (nie)sprzeczności
prawo tożsamości
sylogizm hipotetyczny
modus ponendo ponens
p
∨¬p
¬(p∧¬p)
p
→p (lub w mocniejszej postaci p↔p)
(p
→q)∧(q→r) → (p→r)
(p
→q)∧p → q
Dla nas tautologie mają znaczenie pomocnicze, gdyż metoda weryfikowania
tautologiczności
daje nam możliwość sprawdzania wynikania na gruncie KRZ.
Wynikanie
możemy zdefiniować
następująco:
Ze zbioru
Γ wynika ϕ ( Γ= ϕ) wtw dla dowolnego wartościowania V, przy którym
V(
Γ)=1, to V(ϕ)=1

59
Przez V(
Γ)=1 rozumiemy, że wszystkie formuły z Γ są prawdziwe przy tym wartościowaniu.
Chociaż dopuszczamy, że zbiór
Γ może być nieskończony, to w przypadku KRZ zachodzi tzw.
własność zwartości, która gwarantuje istnienie jakiegoś skończonego podzbioru, z którego
dana formuła wynika. To pozwala nam ograniczyć nasze rozważania do wynikania ze
skończonego zbioru przesłanek, co gwarantuje zachodzenie następującego związku między
wynikaniem a tautologicznością:
ψ
1
,...,
ψ
n
= ϕ wtw = ψ
1
∧...∧ψ
n
→ϕ
Powyższa równoważność daje nam możliwość sprawdzania poprawności rozumowań, przy
wykorzystaniu metody tabelkowej. Jednak metoda ta jest wysoce niepraktyczna – wzór 2n jest
wprawdzie prosty, ale jednak wykładniczy i już przy stosunkowo niewielkich wartościach n (czyli
liczbie różnych zmiennych) zmusza nas do konstruowania olbrzymich tabelek.
W wielu wypadkach znacznie lepsze efekty daje
metoda sprawdzania niewprost
. Zamiast
wypisywać wszystkie możliwe wartościowania i dla każdego liczyć wynik, zakładamy, że
analizowana formuła nie jest tautologią i próbujemy skonstruować wartościowanie
falsyfikujące. Albo nam się to udaje, albo (gdy formuła jest tautologią) popadamy
w sprzeczność, która wyraża się tym, że zmuszeni jesteśmy jakiejś podformule przypisać i 1 i 0.
Załóżmy np., że sylogizm hipotetyczny (p
→q)∧(q→r)→(p→r) nie jest tautologią. Ponieważ jest
to implikacja, więc jest to możliwe tylko przy takim wartościowaniu V, dla którego
V((p
→q)∧(q→r))=1, a V(p→r)=0. Wtedy V(p)=1, a V(r)=0, natomiast oba człony koniunkcji
(p
→q)∧(q→r) są prawdziwe. Skoro V(p→q)=1 i V(p)=1, to V(q)=1, ale skoro V(q→r)=1, a V(r)=0,
to V(q)=0. Mamy zatem sprzeczność na wartości q i nie istnieje wartościowanie falsyfikujące
(p
→q)∧(q→r) → (p→r); zatem jest to tautologia.
Wadą metody zero-jedynkowej, czy to w wydaniu pełnym (tabelkowym), czy zastosowanej
niewprost, jest to, że nie można jej rozszerzyć w prosty sposób na całą logikę klasyczną. Z tego
powodu w dalszym wykładzie skoncentrujemy się na dokładniejszej prezentacji pewnej
syntaktycznej metody dedukcji.

60
Istotą syntaktycznych systemów dedukcyjnych jest to, że buduje się w nich dowody, używając
reguł dedukcji. Istnieje duża różnorodność takich systemów i pojęcie dowodu jest zawsze
zrelatywizowane do rodzaju takiego systemu.
W
systemach aksjomatycznych
korzysta się w dowodzie z pewnych twierdzeń (aksjomatów)
przyjętych bez dowodu; w
systemach tablicowych
dowód buduje się tylko w oparciu o negację
dowodzonej formuły.
W obecnym kursie wykorzystamy system
dedukcji naturalnej
w wersji stworzonej przez
Słupeckiego i Borkowskiego (dalej określany jako S/B). Systemy tego rodzaju mają wiele zalet;
dowody w nich konstruowane są na ogół znacznie prostsze od dowodów w innych systemach
i w elastyczny sposób wykorzystują rozmaite techniki czy strategie dowodowe znane od
starożytności. Wadą tych systemów jest bardziej skomplikowana struktura – dlatego
prezentację systemu przeprowadzimy etapami.
Zacznijmy od udowadniania poprawności rozumowań. Podstawą jest stosowanie
reguł
inferencji
, które pozwalają z pewnych formuł (przesłanek) wydedukować inne formuły
(wnioski). Poniżej przedstawiamy pewien zestaw reguł inferencji, który w systemie S/B jest
przyjęty jako zestaw pierwotny, czyli nie wymagający uzasadnienia:
(DK)
ϕ, ψ− ϕ ∧ψ
(EK)
ϕ∧ψ− ϕ
albo
ϕ∧ψ− ψ
(DA)
ϕ− ϕ∨ψ
albo
ϕ− ψ∨ϕ
(EA)
ϕ∨ψ, ¬ϕ− ψ
(EI)
ϕ → ψ, ϕ− ψ
(DR)
ϕ → ψ, ψ → ϕ− ϕ ↔ψ
(ER)
ϕ ↔ψ− ϕ → ψ albo ϕ ↔ψ− ψ → ϕ
(DS)
ϕ, ¬ϕ−⊥

61
gdzie w nazwach reguł wykorzystaliśmy następujące skróty:
D – dołączanie;
E – eliminacja;
K – koniunkcja;
A – alternatywa;
I – implikacja;
R – równoważność;
S – sprzeczność.
Reguły te przedstawiają schematy stosowalne do dowolnych formuł podpadających pod taką
ogólną formę, np. jeżeli w dowodzie mamy w dwóch różnych miejscach formuły: p
∨r i (q↔r)∨s, to
z pomocą (DK) możemy w tym dowodzie dopisać formułę (p
∨r)∧((q↔r)∨s) lub ((q↔r)∨s)∧(p∨r),
gdyż kolejność przesłanek nie ma wpływu na kolejność członów tworzonej koniunkcji. Zwraca
uwagę fakt, że podane reguły idą parami; dla każdej stałej logicznej (z wyjątkiem
⊥, implikacji
i negacji) mamy reguły dołączania i eliminacji).
Symbolem
− oznaczać będziemy
relację dowiedlności
konstytuowaną przez podane reguły.
ψ
1
,....,
ψ
n
− ϕ oznacza, że ϕ ma dowód z formuł (przesłanek) ψ
1
,....,
ψ
n
w oparciu o podane
reguły. W przypadku gdy n=0 zapis,
− ϕ oznacza, że ϕ jest
tezą systemu
S/B, czyli, że ma
dowód w sensie absolutnym (nie z przesłanek). Zachodzi ścisła odpowiedniość pomiędzy tą
relacją, a relacją wynikania zdefiniowaną w paragrafie poprzednim, co stanowi sens
twierdzenia o adekwatności
(TA):
ψ
1
,....,
ψ
n
− ϕ
wtw
ψ
1
,....,
ψ
n
= ϕ
W szczególnym przypadku gdy n=0, TA mówi nam o identyczności zboru tautologii KRZ i tez
systemu S/B. Dowód TA jest dość złożony i nie będziemy go w tym kursie omawiać.
Dowód, najogólniej rzecz biorąc, jest ciągiem formuł, które z lewej strony są poprzedzane
numerami, a z prawej towarzyszy im kolumna uzasadnień zawierająca informacje, skąd dana
formuła wzięła się w dowodzie (nazwa zastosowanej reguły i numery przesłanek). W S/B mamy
kilka możliwości konstruowania dowodu – na początek omówimy sobie najprostszą z nich –
dowód wprost
z danych przesłanek:

62
Jeżeli chcemy wykazać, że
ψ
1
,....,
ψ
n
− ϕ, to dowód wprost będzie miał strukturę następującą:
będzie to ciąg p-elementowy (p>n), którego pierwsze n wierszy zawiera kolejno wypisane
przesłanki, a pozostałe wiersze zawierają formuły uzyskane za pomocą dopuszczalnych reguł,
przy czym wiersz p (ostatni) zawiera wniosek. Przez dopuszczalne reguły rozumiemy tutaj
reguły inferencji podane wyżej oraz wszystkie inne, które wprowadzimy później. Prosty przykład
pozwoli zrozumieć sens powyższej definicji.
1. p
∧q
2. p
→¬r
3. r
∨s
4. p
(1
EK)
5. q
(1
EK)
6.
¬r (2,4
EI)
7. s
(3,6
EA)
8. q
∧s
(5,7 DK)
Powyższy dowód pokazuje, że p
∧q, p→¬r, r∨s− q∧s.
Niestety dowód wprost nie zawsze pozwala na osiągnięcie sukcesu. Czytelnik, który spróbuje
udowodnić wprost, że p
∨q, q→r, r→s, q→¬s − p szybko (już po wypisaniu przesłanek) stanie
w miejscu; żadna, ze znanych nam do tej pory reguł, nie pozwala na dokonanie jakiejś
sensownej dedukcji. Możemy wprawdzie stosować do naszych przesłanek reguły (DK) i (DA),
ale trudno nazwać taką dedukcję sensowną, gdyż nie wydaje się prowadzić nas do celu. Aby
uzasadnić podany wyżej schemat, musimy zastosować
dowód niewprost
. Definicja jest
następująca:
ψ
1
,....,
ψ
n
− ϕ ma dowód niewprost wtw istnieje ciąg p-elementowy (p>n), którego pierwsze
n wierszy zawiera kolejno wypisane przesłanki, wiersz n+1 zawiera
¬ϕ (założenie niewprost),
a pozostałe zawierają formuły uzyskane za pomocą dopuszczalnych reguł, przy czym wiersz p
(ostatni) zawiera
⊥.
Jak widać, różni się on od dowodu wprost tym, że jako dodatkowe założenie wprowadzamy
negację wniosku, a celem dowodu staje się uzyskanie w nim sprzeczności. Dowód niewprost
dla naszego przykładu wygląda następująco:
1. p
∨q
2. q
→r
3. r
→s

63
4. q
→¬s
5.
¬p
ZN
6. q
(1,5
EA)
7.
¬s (4,6
EI)
8. r
(2,6
EI)
9. s
(3,8
EI)
10.
⊥ (7,9
DS)
gdzie:
ZN – założenie niewprost.
W definicji wymagaliśmy, żeby założenie niewprost pojawiło się bezpośrednio po przesłankach,
jednak w praktyce zalecane jest próbowanie dowodu wprost i dołączanie tego założenia dopiero
wtedy, gdy naprawdę nie mamy pomysłu, co robić dalej. Nie wszystko da się udowodnić wprost,
ale jeżeli jest to możliwe, to taki dowód jest często dużo prostszy niż dowód niewprost.

64
W systemie S/B można również budować dowody założeniowe dla tez zarówno wprost, jak
i niewprost. Przyjmijmy, że każda formuła może być potraktowana jako tzw. implikacja
wstępująca o postaci:
ϕ
1
→(ϕ
2
→(.... (ϕ
n
→ ϕ
n
+1
)...). W szczególności, jeżeli n=0, to formuła po
prostu nie jest implikacją. Dowód wprost dowolnej tezy będziemy odtąd konstruować, wypisując
wszystkie poprzedniki jako założenia dowodu i kończąc go w chwili uzyskania następnika jako
wiersza dowodu. Wpisując ewentualnie negację następnika, konstruujemy założeniowy
dowód niewprost, dążąc w nim do sprzeczności. Przykładowo dowód założeniowy wprost
tezy (p
→(q→r))→((p→q)→(p→r)) wygląda następująco:
1. p
→(q→r) Z
2. p
→q Z
3. p
Z
4. q
(2,3
EI)
5. q
→r (1,3
EI)
6. r
(4,5
EI)
Technikę tę można oczywiście stosować również w przypadku rozumowań: wypisujemy
wszystkie przesłanki rozumowania, a następnie założenia wzięte z wniosku. Uwaga!
w przypadku rozumowań tylko wniosek podlega analizie w terminach implikacji wstępującej,
każda przesłanka jest przepisana w całości, jako wiersz dowodu.
Osobny temat to możliwość wprowadzania do dowodu
dodatkowych założeń
. Jest to
technika niezwykle upraszczająca dowody i jest stosowana w praktyce dowodzenia
powszechnie, tym niemniej musimy ją stosować z dużą ostrożnością, ponieważ łatwo
popełnić tutaj błędy. Najczęstszy błąd polega na nieuprawnionym wykorzystywaniu formuł
zależnych od takich dodatkowych założeń. W systemie S/B w celu uniknięcia problemów
wprowadza się dodatkową numerację w dowodzie, która pokazuje, że w ramach danego

65
dowodu mamy do czynienia z dowodem podporządkowanym (poddowodem) opartym
o założenie dodatkowe.
W praktyce będzie to wyglądało następująco: jeżeli wprowadzamy założenie dodatkowe
i ostatni wiersz dowodu ma numer k, to nowy wiersz (zawierający dodatkowe założenie)
otrzymuje numer k.1 (a nie k+1). Odtąd kolejne wiersze dowodu są numerowane k.2, k.3 itd.,
innymi słowy numeracja dowodu zasadniczego zostaje „zamrożona” w pewnym punkcie,
natomiast poddowód ma numerację własną.
Jeżeli w ramach takiego poddowodu zechcemy wprowadzić kolejne założenie dodatkowe, to
procedurę tę powtarzamy, np. jeżeli ostatni wiersz ma numer k.n, to numer nowego wiersza
(zawierającego nowe założenie) ma postać k.n.1 (a nie k.n+1). Odpowiednie reguły pozwalają
nam w odpowiednim momencie zakończyć taki poddowód i wrócić do dowodu nadrzędnego.
Kiedy wprowadzamy dodatkowe założenia? Wtedy, gdy nie wiemy, co zrobić z formułami, które
już są w dowodzie, ale widzimy, że gdyby w dowodzie wystąpiła pewna formuła, to pozwoliłaby
nam poczynić jakiś postęp. Typowy przypadek zastosowania tej techniki to potrzeba
wprowadzenia do dowodu jakiejś implikacji – w takiej sytuacji wprowadzamy jej poprzednik jako
dodatkowe założenie i dążymy do udowodnienia następnika; jeżeli to się uda, to znaczy, że
udowodniliśmy samą implikację. Jest to w istocie poszerzenie zastosowania techniki dowodu
implikacji wstępujących. Zademonstrujemy na przykładzie, jak w systemie wygląda ta technika,
dowodząc tezy (p
→q∧r)→(p→q)∧(p→r)
1. p
→q∧r
Z
1.1. p
ZD
1.2. q
∧r
(1, 1.1 EI)
1.3. q
(1.2 EK)
2. p
→q
(1.1. – 1.3 DI)
2.1. p
ZD
2.2. q
∧r
(1, 2.1 EI)
2.3. r
(2.2 EK)
3. p
→r
(2.1. – 2.3 DI)
4. (p
→q)∧(p→r) (2,3
DK)
gdzie:
ZD – założenie dodatkowe.

66
Skrót (DI) oznacza, że ta
reguła konstrukcji dowodu
służy dołączaniu implikacji do dowodu,
z powodu braku odpowiedniej reguły inferencji. Zapis w kolumnie uzasadnień, np. (1.1. – 1.3
DI), oznacza, że tym razem uzasadnieniem wprowadzenia tej implikacji do dowodu jest cały
poddowód, od wiersza 1.1. do wiersza 1.3.
(DI) nie jest jedyną regułą umożliwiającą powrót z poddowodu do dowodu nadrzędnego.
Również pojawienie się
⊥ w poddowodzie stanowi świadectwo fałszywości naszego
dodatkowego założenia i podstawę do odrzucenia go, przy równoczesnym przyjęciu
w dowodzie nadrzędnym formuły sprzecznej z dodatkowym założeniem. Jest to
dowód
niewprost w oparciu o dodatkowe założenie
(w skrócie DNW).
Zatem (DNW) możemy zastosować, kiedy potrzebujemy w dowodzie jakiejś formuły, nie
będącej implikacją - wtedy, jako założenie dodatkowe wpisujemy negację tej formuły.
Zastosowanie (DNW) pokazuje następujący dowód niewprost tezy
¬(p→q)→p∧¬q
1.
¬(p→q)
Z
2.
¬(p∧¬q)
ZN
2.1. p
ZD
2.1.1.
¬q
ZDN
2.1.2. p
∧¬q
(2.1, 2.1.1 DK)
2.1.3.
⊥
(2,2.1.2
DS)
2.2. q
(2.1.1. – 2.1.3 DNW)
3. p
→q
(2.1. – 2.2 DI)
4.
⊥
(1,3
DS)
Konstrukcja tego dowodu wymaga komentarza. Teza do udowodnienia jest implikacją o jednym
poprzedniku, więc przyjmujemy go jako założenie wprost Z. Ponieważ nie mamy żadnych
możliwości dowiedzenia koniunkcji z następnika wprost, więc wprowadzamy jej negację jako
założenie niewprost naszego dowodu ZN.
Odtąd celem dowodu staje się uzyskanie sprzeczności; dałoby ją np. udowodnienie implikacji
p
→q. W tym celu wprowadzamy p jako założenie dodatkowe ZD i zaczynamy poddowód,
w którym chcemy dowieść q. Aby to zrobić zaczynamy kolejny poddowód, którego założeniem
dodatkowym niewprost ZDN jest
¬q. W poddowodzie tym uzyskujemy sprzeczność, zatem
możemy go zakończyć przez (DNW), tym sposobem uzyskując q (jako wyrażenie sprzeczne z ZDN

67
w dowodzie nadrzędnym (czyli w pierwszym poddowodzie). To pozwala nam zakończyć
również pierwszy poddowód przez (DI), uzyskując w dowodzie nadrzędnym (czyli w dowodzie
głównym) implikację p
→q. To daje nam ponownie sprzeczność i pozwala zakończyć dowód.
(DI) i (DNW) to jedyne techniki zamykania poddowodu, które tutaj dopuścimy, choć ich
asortyment można zwiększyć. W obu wypadkach implikacja bądź negacja dodatkowego
założenia jest ponownie w dowodzie nadrzędnym. Poddowód zakończony przez (DI) lub (DNW)
jest od tej pory zamknięty i nie wolno dalej używać żadnej formuły, która w nim
występowała!
Przykładowo – w powyższym dowodzie uzyskaliśmy sprzeczność w jednym z poddowodów, ale
to pozwalało nam zakończyć tylko ten poddowód, a nie dowód nadrzędny. Podsumowując:
w poddowodzie możemy używać dowolnych formuł, które występują wyżej w dowodzie
nadrzędnym, ale kiedy poddowód zostaje zamknięty (przez (DI) lub (DNW)), to żaden jego
element nie może być dalej w tym dowodzie użyty!

68
System omówiony do tej pory jest już zasadniczo kompletny, jednak dla ułatwienia praktyki
dedukcyjnej warto go wzbogacić o pewne dodatkowe techniki. Przy niewielkim dodatkowym
wysiłku pozwalają one często znacznie skrócić dowody.
Do dowodu zawsze można dodać w dowolnym miejscu podstawienie tezy, która wcześniej
została dowiedziona. Przykładowo, udowodniliśmy wyżej, że tezą systemu S/B jest
¬(p→q)→p∧¬q, co oznacza, że w innym dowodzie możemy dodać tę formułę, albo każdą inną,
która reprezentuje ten sam schemat, np.
¬(¬s→q∧r)→ ¬s∧¬(q∧r), czyli dowolną formułę
o schemacie
¬(ϕ→ψ)→ϕ∧¬ψ .
Innym sposobem wzbogacania asortymentu środków dowodowych jest dołączanie wtórnych
reguł inferencji. Ich wtórność polega na tym, że poprawność każdej z nich można uzasadnić
budując dowód, w którym przesłanki tej reguły są przesłankami dowodu (i ewentualnie negacja
wniosku założeniem niewprost), a ostatnim wierszem jest wniosek tej reguły (bądź
⊥),
natomiast w dowodzie użyte są tylko reguły pierwotne systemu, bądź wcześniej wprowadzone
reguły wtórne.
Krótko mówiąc, każdy dowód uzasadniający poprawność jakiegoś rozumowania stanowi
podstawę do dołączenia reguły wtórnej, będącej metajęzykowym uogólnieniem tego
rozumowania, np. rozumowanie z przykładu pierwszego w temacie 3 może stanowić podstawę
do używania reguły wtórnej o schemacie:
ϕ∧ψ, ϕ→¬χ, χ∨δ− ψ∧δ
W praktyce podstawę dla reguł wtórnych mogą stanowić jedynie rozumowania proste,
o niedużej liczbie przesłanek i prostej strukturze występujących formuł. Rozumowania złożone
są bowiem trudne do zapamiętania i jest niewielkie prawdopodobieństwo, że w praktyce
napotkamy na inne rozumowania, w których dany schemat można by było zastosować. Poniżej
proponujemy listę reguł wtórnych, których zapamiętanie z pewnością będzie korzystne:

69
(PN)
¬¬ϕ ≅ ϕ
(SH)
ϕ→ψ, ψ→χ− ϕ→χ
(MT)
ϕ→ψ, ¬ψ− ¬ϕ
(TR)
ϕ→ψ ≅ ¬ψ→¬ϕ
(MPR)
ϕ↔ψ, ϕ− ψ lub ϕ↔ψ, ψ− ϕ
(MTR)
ϕ↔ψ, ¬ϕ− ¬ψ lub ϕ↔ψ, ¬ψ− ¬ϕ
(NR)
¬(ϕ↔ψ), ϕ→ψ− ¬(ψ→ϕ) lub ¬(ϕ↔ψ), ψ→ϕ− ¬( ϕ→ψ)
(NK)
¬(ϕ∧ψ) ≅ ¬ϕ∨¬ψ
(NA)
¬(ϕ∨ψ) ≅ ¬ϕ∧¬ψ
(NI)
¬(ϕ→ψ) ≅ ϕ∧¬ψ
Zapisu
ϕ ≅ ψ użyliśmy dla oznaczenia
reguł obustronnie poprawnych
, w tym sensie, że
zarówno
ϕ− ψ, jak i ψ− ϕ (obie formuły są sobie równoważne). (PN) to reguła podwójnej
negacji, która pozwala kasować (lub dodawać) przy dowolnej formule dwie negacje. (SH)
(hipotetyczny sylogizm) pozwala na łańcuchy wnioskowań bazujące na przechodniości
implikacji. (MT) (od Modus Tollens) pozwala na rozbijanie implikacji nie tylko w oparciu
o występowanie poprzednika, ale i o negację następnika. (TR) (reguła transpozycji, czasem
określana jako reguła kontrapozycji) pozwala odwracać człony implikacji.
Reguły (MPR) (Modus Ponens dla równoważności), (MTR) (Modus Tolens dla równoważności)
i (NR) uogólniają na równoważność charakterystyczne reguły dla implikacji. Grupa reguł (NK),
(NA) i (NI) pozwala czynić użytek również z negacji rozmaitych formuł; (NA) i (NK) są często
określane jako reguły DeMorgana.
Uzasadnienie reguły (NI) (w jedną stronę) daje nam ostatni dowód z poprzedniego tematu. Oto
uzasadnienie reguły (NK) (w obie strony):
1.
¬(p∧q)
2.
¬(¬p∨¬q) ZN
2.1.
¬p
ZDN
2.2.
¬p∨¬q
(2.1 DA)
2.3.
⊥ (2,2.2
DS)
3. p
(2.1.-2.3
DNW)
3.1.
¬q
ZDN
3.2.
¬p∨¬q
(3.1 DA)
3.3.
⊥ (2,3.2
DS)

70
4. q
(3.1.-3.3
DNW)
5. p
∧q
(3,4
DK)
6.
⊥ (1,5
DS)
1.
¬p∨¬q
2.
¬¬(p∧q) ZN
3. p
∧q
(2
PN)
4. p
(3
EK)
5.
¬¬p
(4
PN)
6.
¬q
(1,5
EA)
7. q
(3,
EK)
8.
⊥ (6,7
DS)
Szczególnie przydatne mogą się w dowodzie okazać reguły obustronne. O ile reguły
jednostronne są stosowane poprawnie, tylko jeżeli ich przesłanki są samodzielnymi formułami
w dowodzie, to w przypadku reguł obustronnych można je poprawnie stosować także wtedy,
gdy przesłanka jest częścią jakiejś większej formuły (nie stanowi samodzielnego wiersza
dowodu). Przykładowo, mając w dowodzie w dwóch wierszach formuły p
∨(q→r) i q, nie można
zastosować (EI) i uzyskać p
∨r, ale można poprawnie zastosować (TR) i uzyskać p∨(¬r→¬q),
gdyż jest to reguła obustronna. Poprawność takich zabiegów jest zagwarantowana
poprawnością
meta-reguły ekstensjonalności
:
(RE) Jeżeli
ϕ ≅ ψ , to χ ≅ χ[ϕ//ψ]
Zapis
χ[ϕ//ψ] oznacza, że w formule χ zastąpiono jedno lub więcej wystąpień ϕ (jako
podformuły) przez wystąpienia formuły
ψ. W powyższym przykładzie zastąpiono w formule
p
∨(q→r) jedno wystąpienie podformuły q→r – przez równoważną jej (na mocy reguły (TR))
formułę
¬r→¬q.
Standardowe dowody tez o postaci równoważności zazwyczaj są przeprowadzane w dwóch
etapach; udowadnia się, że
ϕ→ψ i ψ→ϕ, aby potem zastosować do tych implikacji regułę (DR)
i otrzymać
ϕ↔ψ.

71
Analogicznie udowadnia się też poprawność reguł obustronnych, czego ilustrację mieliśmy
powyżej w dowodzie uzasadniającym poprawność reguły (NK). Reguły obustronne wraz
z regułą (RE) pozwalają często na uproszczony sposób dowodzenia tez o postaci
równoważności. Przykładowo, zwykły dowód tezy
¬(¬p∧(q→r))↔p∨q∧¬r jest dość
skomplikowany (zwłaszcza, jeżeli nie użyjemy reguł wtórnych), ale z użyciem reguł
obustronnych i (RE) można go otrzymać bardzo prosto:
1.
¬(¬p∧(q→r))
2.
¬¬p∨¬(q→r)
(1
NK)
3. p
∨¬(q→r) (2
PN)
4. p
∨q∧¬r
(3
NI)
W powyższym przykładzie założyliśmy jedną stronę równoważności i przekształcaliśmy ją przy
użyciu wyłącznie reguł obustronnych ((NK), (PN) i (NI)) oraz (RE) (w przejściu od wiersza 2. do
3. i od 3. do 4.), aż otrzymaliśmy drugą stronę równoważności. Taki sposób postępowania
gwarantuje, że nie tylko z
¬(¬p∧(q→r)) można wydedukować p∨q∧¬r, ale i odwrotnie. Należy
jednak pamiętać, że w dowodach tego typu nie wolno nam w ogóle stosować reguł
jednostronnych, czyli takich gdzie zależność między przesłanką a wnioskiem jest wyrażana
tylko przez
− .
Document Outline
- Wstęp do logiki
Wyszukiwarka
Podobne podstrony:
Modul 5 Logika
Modul 2 Logika
Modul 4 Logika
Modul 1 Logika
Modul 6 Logika
moduł 1 logika rozumienie i argumentacja, LOGIKA 2006
moduł 5Elementy metodologii, LOGIKA 2006
logika moduł 3-4, Administracja, logika
moduł 6 błędy logiczne, LOGIKA 2006
moduł 3 Klasyczny rachunek zdań, LOGIKA 2006
moduł 2 analiza jesyka, LOGIKA 2006
modul I historia strategii2002
więcej podobnych podstron