
W wielu badaniach medycznych
gromadzimy dane będące liczebnościami. Na
przykład możemy klasyfikować chorych w
badanej próbie do różnych kategorii pod
względem wieku, płci czy natężenia choroby,
czyli kilku badanych cech. Przedstawiane do
tej pory w naszym cyklu metody statystyczne
stają się użyteczne dla danych jednej cechy,
danymi jakościowymi lub ilościowych.
Techniki statystyczne omówione w tym
odcinku należą do najbardziej przydatnych w
analizie danych jakościowych i ilościowych.
Umożliwiają one dokonanie oceny zależności
między zmiennymi tego typu.
Wykład 3.
ANALIZA
WSPÓŁZALEŻNOŚCI
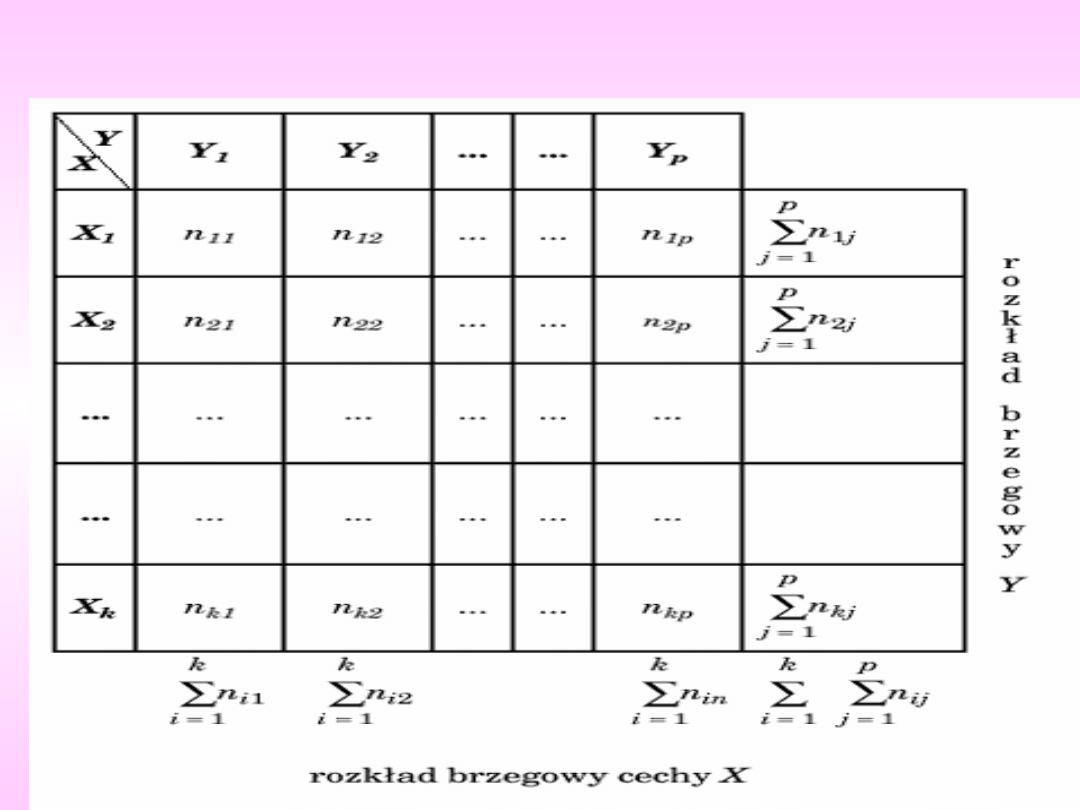
Tabele wielodzielcze (kontyngencji).

Tabele wielodzielcze (kontyngencji).
• Pierwszym krokiem jest przedstawienie zebranych danych
indywidualnych w postaci tabeli wielodzielczej (kontyngencji).
Wymaga to zliczenia jednostek w odpowiednich komórkach
tabeli z danymi. Zliczanie to bez użycia komputera jest
żmudne, zwłaszcza dla dużej liczby przypadków.
• Tabele wielodzielcze stanowią podstawę do obliczania
pozostałych statystyk określających siłę związku. Tabela
wielodzielcza przedstawia rozkład obserwacji ze względu na
kilka cech jednocześnie.
Załóżmy, że dysponujemy n obserwacjami dla jakościowej cechy
X (posiadającej kategorie X1, X2, ... Xk) i jakościowej cechy Y
(o kategoriach Y1, Y2, ...Yp) (tab. 1).
Liczebności nij określają liczbę elementów próby, dla których
cecha X ma wariant Xi i jednocześnie cecha Y - wariant Yj.
Tablica wielodzielcza pokazuje więc określony łączny rozkład
obu cech. Liczebności w ostatnim wierszu i w ostatniej
kolumnie nazywamy empirycznymi brzegowymi rozkładami,
odpowiednio cechy Y i cechy X.
Na przykład, chcąc ocenić wpływ używek (papieros, kawa,
alkohol) na pewną chorobę, zebraliśmy dane na temat ich
używania w grupie 90-osobowej. Zastosowano podział na 4
kategorie: nigdy (tzn. nie używano nigdy), niewiele (używano w
małych ilościach), średnio (używano w średnich ilościach) i
dużo (używano w dużych ilościach).
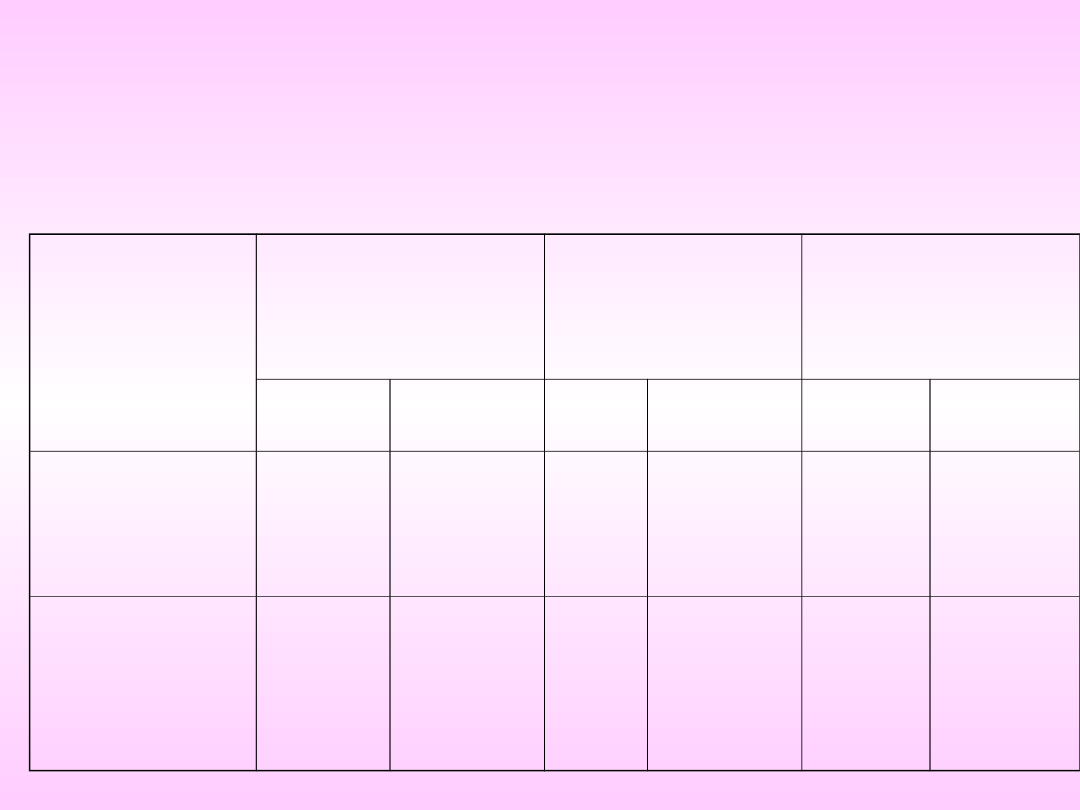
Przykład tabeli wielodzielczej
Grupa
Kobiety
Mężczyźni
Razem
n
%
n
%
n
%
Cukrzyca
25
35,7
20
40,0
45
37,5
Bez
cukrzycy
45
64,3
30
60,0
75
62,5
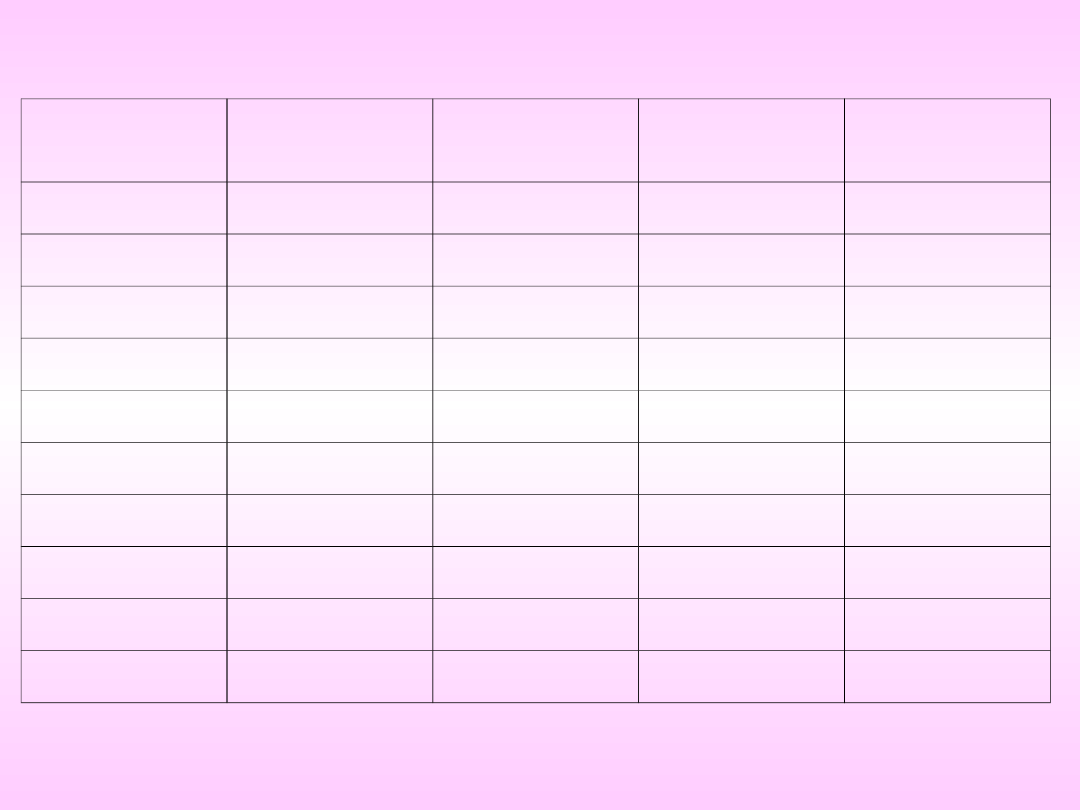
Tabela
Lp.
Kawa
Papierosy
Alkohol
Płeć
1
nigdy
dużo
niewiele
m
2
niewiele
nigdy
nigdy
m
3
dużo
dużo
średnio
k
4
niewiele
niewiele
dużo
m
5
średnio
niewiele
niewiele
k
6
dużo
dużo
dużo
m
7
nigdy
średnio
niewiele
k
8
srednio
dużo
nigdy
m
9
nigdy
nigdy
średnio
k
10
dużo
dużo
dużo
m
Zliczając otrzymane dane dla papierosów i płci, otrzymamy
następującą tabelę wielodzielczą (tab. 3)

Tabela 3
Płeć
Papiero
s
nigdy
Papiero
s
niewiel
e
Papiero
s
średnio
Papiero
s
dużo
Razem
kobieta 11
8
6
5
30
mężczy
zna
4
4
28
24
60
razem
15
12
34
29
90
Widać wyraźną przewagę mężczyzn w grupie
palących dużą lub średnią liczbę papierosów, natomiast
około 3-krotnie więcej kobiet niż mężczyzn nigdy nie
paliło. Informacje byłyby bogatsze po dołączeniu danych
odsetkowych. Odsetki wylicza się względem: ostatniej
rubryki (płci), ostatniego wiersza (liczby wypalanych
papierosów) oraz całkowitej liczby respondentów.
Następny etap analizy statystycznej tak zebranych danych
to próba weryfikacji hipotezy, że dwie jakościowe cechy w
populacji są niezależne
.

Najczęściej stosowanym narzędziem jest test .
.
Został on opracowany przez Karla Pearsona w
1900 roku i jest metodą, dzięki której można się
upewnić, czy dane zawarte w tabeli
wielodzielczej dostarczają wystarczającego
dowodu na związek tych dwóch zmiennych. Test
polega na porównaniu częstości
zaobserwowanych z częstościami oczekiwanymi
przy założeniu hipotezy zerowej (o braku związku
między tymi dwiema zmiennymi). Częstości
oczekiwane obliczamy, wykorzystując częstości
marginalne (z tablicy wielodzielczej) według
następującego wzoru:
Wówczas hipotezę zerową orzekającą, że cechy X
i Y są niezależne, możemy zweryfikować testem
według następującego schematu:
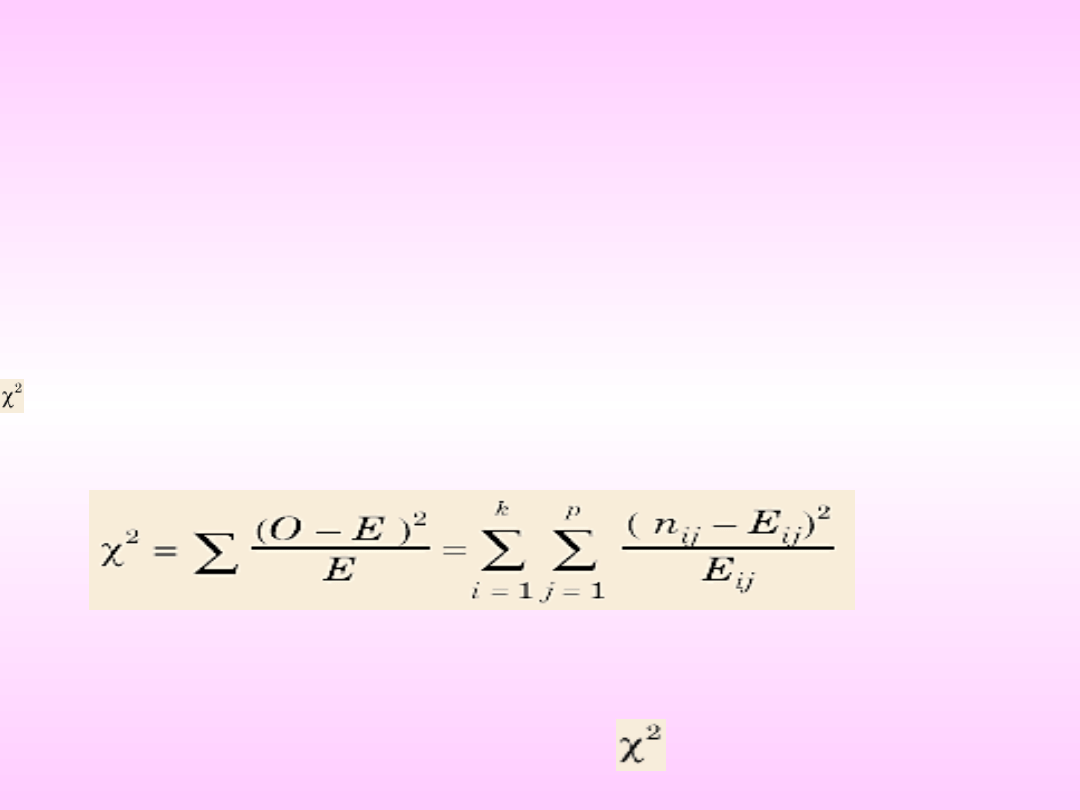
Weryfikacja hipotezy
zerowej:
H0: cechy X i Y są
niezależne
Wobec hipotezy
alternatywnej: H1: cechy X
i Y są zależne
Do weryfikacji hipotezy
stosujemy statystykę:
gdzie E - oczekiwana częstość komórki oraz O -
obserwowana częstość komórki
Przy założeniu hipotezy zerowej opisywana
statystyka ma asymptotyczny rozkład
o s = (k - 1) (p - 1)
stopniach swobody
Rys. 1.
Na przykład badano zależność między liczbą
wypalanych papierosów a wystąpieniem
pewnych zmian patologicznych w płucach w
grupie 1500 osób. Zebrane dane przedstawiono
w wielodzielczej tabeli 4.
Tabela 4
Niepalący
Palący
mało
Palący
dużo
Razem
zmiany
występują
ce
51
250
560
861
zmian nie
ma
370
210
59
639
razem
421
460
619
1500
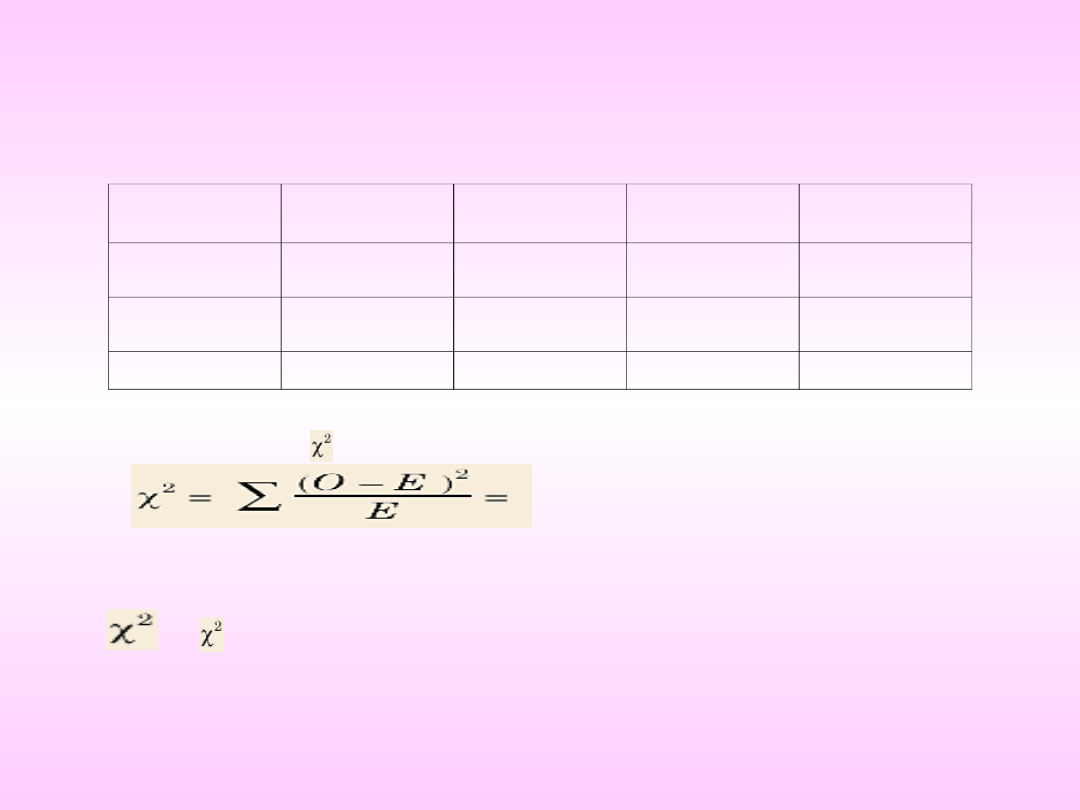
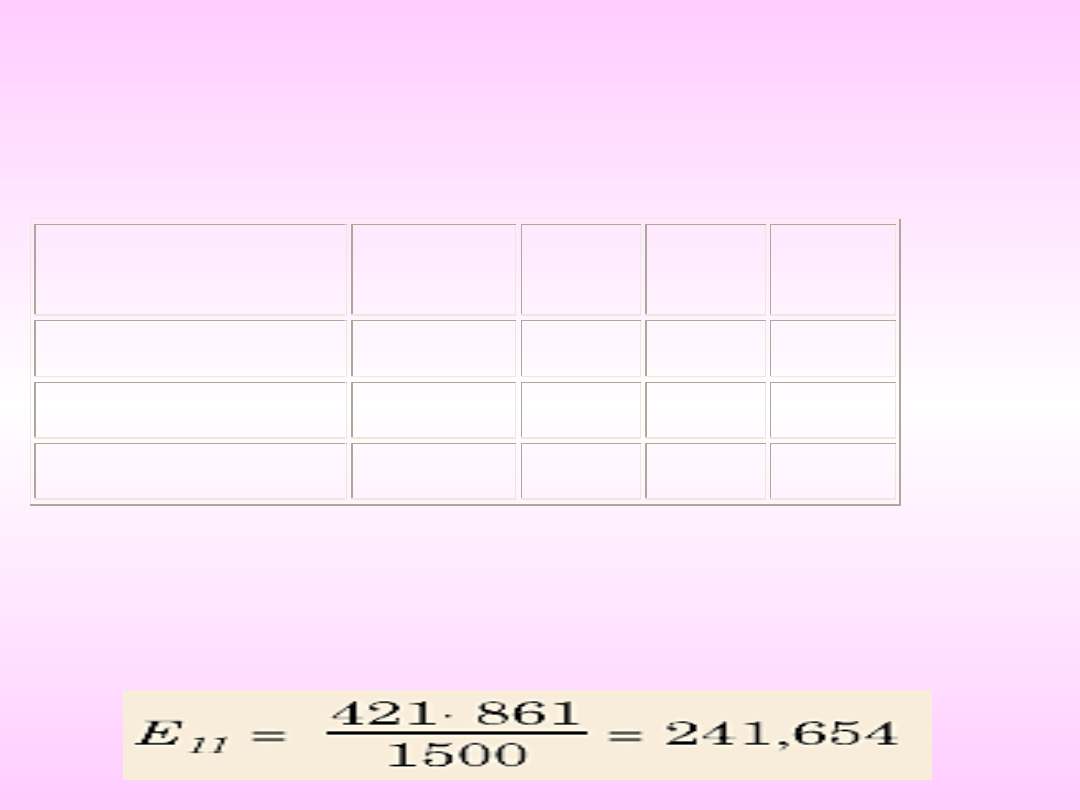
Wyliczymy wartość oczekiwaną E11. Zgodnie z
definicją:
Wyniki obliczeń pozostałych wartości oczekiwanych
przedstawiono w tabeli 5. w nawiasach obok wartości
obserwowanych.
Tabela 5
Niepalący
Palący
mało
Palący
dużo
Razem
zmiany
występują
51
(241,654)
250
(264,04)
560
(353,306)
861
zmian
nie ma
370
(179,346)
210
(195,96)
59
(263,694)
639
razem
421
460
619
1500
Wartość statystyki
wynosi
701,0731
Z kolei wartość krytyczna odczytana z tablic dla poziomu istotności alfa = 0,001 wynosi 13,817
alfa
= 13,817. Pozwala więc nam odrzucić
hipotezę zerową
>
i stwierdzić, że na poziomie istotności alfa = 0,001 istnieje
zależność między liczbą wypalanych papierosów dziennie a
wystąpieniem patologicznych zmian w płucach.
701,0731.

Błąd standardowy SE=
n
S
Rozstęp = wartość największa-wartość
najmniejsza
Mediana Me=wartość środkowa w
posortowanych danych
Modalna – wartość najczęściej
występująca
Są to miary położenia i rozproszenia
(zmienności)
Zadanie: s=4; SE=?
125,134,146,134,130
Me=? Modalna=?

Przedział ufności dla średniej
w populacji
- nieznana średnia w populacji,
• , s średnia i odchylenie standardowe
obliczone z próby dla cechy X, mającej
rozkład normalny, to
• P( -1,96s<
< +1,96s)=0,95
• Przykład =175; s=10, to
• P(155,4<
< 194,6)=0,95

ANALIZA
WSPÓŁZALEŻNOŚCI
Analiza struktury zjawisk dotyczyła jednej
cechy. W praktyce jednak bywa tak, że
badane jednostki statystyczne
charakteryzowane są przez kilka cech.
Cechy te nie są od siebie odizolowane,
mają na siebie wpływ oraz posiadają
wzajemne uwarunkowania. Dlatego często
zachodzi potrzeba badania
współzależności między tymi cechami.

Kowariancja jest średnią arytmetyczną
iloczynu odchyleń zmiennych X i Y
od ich średnich arytmetycznych:
Rozpatrując kowariancję uzyskać
można następujące informacje o
istniejącym związku pomiędzy
zmiennymi X i Y:
1. Jeżeli cov(x,y)>0 – dodatnia korelacja
2. Jeżeli cov(x,y)<0 – ujmena korelacja
3. Jeżeli cov(x,y)=0 – brak korelacji
n
i
i
i
y
y
x
x
n
y
x
1
1
,
cov

Przeprowadzając analizę można spotkać
dwa rodzaje współzależności zmiennych:
1. Współzależność funkcyjną, polegającą
na tym, że zmiana wartości jednej
zmiennej pociąga określoną zmianę
wartości drugiej zmiennej.
2. Współzależność stochastyczną
(probabilistyczną), polegającą na tym,
że wraz ze zmianą jednej zmiennej
zmienia się rozkład prawdopodobieństwa
drugiej zmiennej. Szczególnym
przypadkiem zależności
stochastycznej jest zależność
korelacyjna.

Zależności korelacyjne zachodzą
wówczas, gdy określonym wartościom
jednej zmiennej odpowiadają ściśle
określone średnie wartości
drugiej zmiennej.
Zdarzają się jednak sytuacje, w
których nie istnieje
współzależność (korelacja) ale ma
miejsce zbieżność występowania
zjawisk. Taką zbieżność określa się
mianem korelacji pozornej.

Najczęściej spotykanymi metodami
wykrywania związków korelacyjnych są:
Metoda porównywania
przebiegu szeregów statystycznych.
Metoda graficzna.
y
i
0 x
i
y
i
0 x
i
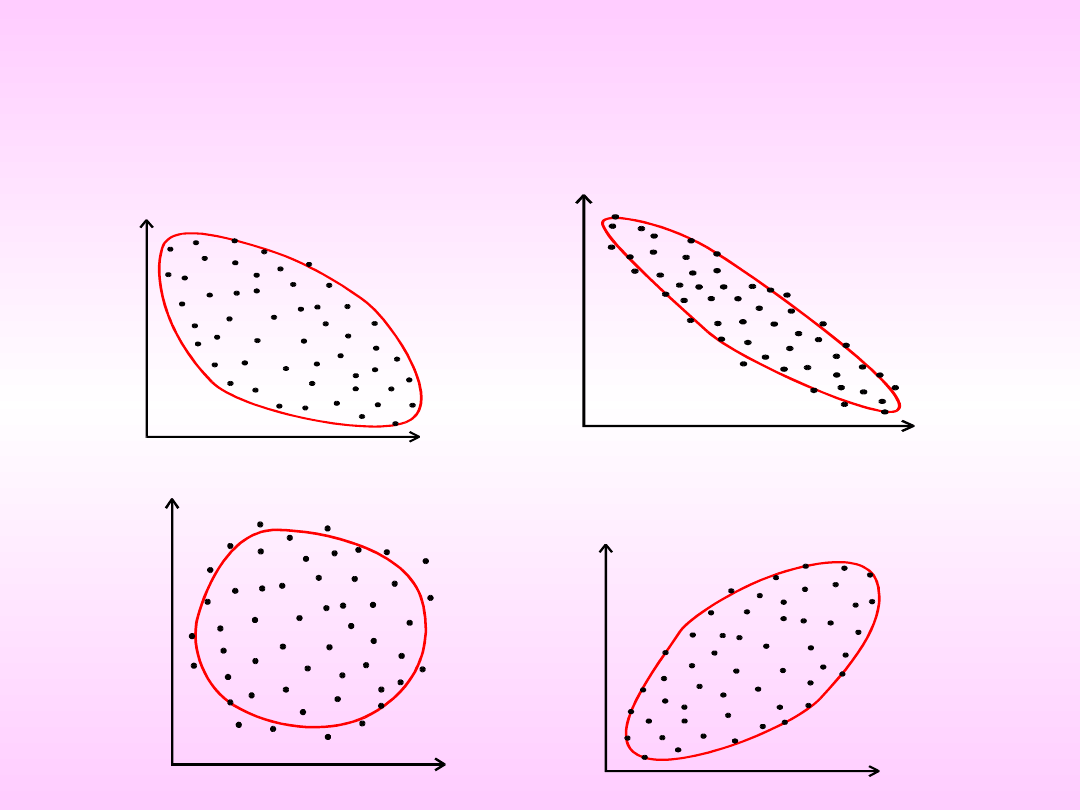
Związek ujemny (wzrost wartościchy X indukuje obniżanie
wartości cechy Y)
X
Y
X
Y
X
Y
X
Y
Związek dodatni
Brak związku

Cechę dwuwymiarową oznacza się jako
uporządkowaną parę (X,Y). Składowymi
mogą być zarówno cechy ilościowe
jak i jakościowe. To od tego, z jakimi cechami
mamy do czynienia zależy wybór sposobu
opisu współzależności.
Podstawą analizy jest zbiorowość
jednostek scharakteryzowanych parą
własności ,
gdzie i=1,2,...,n.
Badając zbiorowość jednostek pod względem
wyróżnionych cech otrzymuje się ciąg par wartości:
.
,
,...,
,
,
,
2
2
1
1
n
n
y
x
y
x
y
x
i
i
y
x ,

MIARY
WSPÓŁZALEŻNOŚCI
Do badania zależności między zmiennymi
X i Y wykorzystuje się najczęściej
współczynnik korelacji liniowej
Pearsona, będący miarą siły związku
prostoliniowego między dwiema
cechami mierzalnymi. Współczynnik ten
wylicza się ze wzoru:
gdzie:
cov(x,y) - kowariancja zmiennych X i Y
s - odchylenie standardowe.
y
s
x
s
y
x
r
xy
,
cov

Kowariancja jest średnią
arytmetyczną iloczynu odchyleń
zmiennych X i Y od ich
średnich arytmetycznych:
n
i
i
i
y
y
x
x
n
y
x
1
1
,
cov
Rozpatrując kowariancję uzyskać
można następujące informacje o
istniejącym związku pomiędzy
zmiennymi X i Y:
Jeżeli cov(x,y)>0 – dodatnia korelacja
Jeżeli cov(x,y)<0 – ujmena korelacja
Jeżeli cov(x,y)=0 – brak korelacji

Kowariancji nie można stosować
do bezpośrednich porównań. Dlatego
jest ona standaryzowana przez odchylenia
standardowe, dzięki czemu otrzymuje
się współczynnik korelacji liniowej
Pearsona.
Właściwości współczynnika korelacji:
1. Przyjmuje wartości z przedziału <-1;1>
2. Dodatni znak świadczy o dodatnim, zaś
ujemny o ujemnym związku korelacyjnym
3. Im , tym związek
korelacyjny jest silniejszy.
0
xy
r
Sposoby komentowania współczynnika
korelacji
:
a) - współzależność nie występuje,
b) - słaby stopień współzależności,
c) - umiarkowany (średni) stopień
współzależności,
d) - znaczny stopień współzależności,
e) - wysoki stopień współzależności,
f) - bardzo wysoki stopień
współzależności,
g) - całkowita (ścisła) współzależność
(zależność funkcyjna pomiędzy
badanymi cechami).
0
XY
r
3
,
0
0
XY
r
5
,
0
3
,
0
XY
r
7
,
0
5
,
0
XY
r
9
,
0
7
,
0
XY
r
1
9
,
0
XY
r
1
XY
r

• Współczynnik korelacji liniowej Pearsona
(dalej nazywany po prostu współczynnikiem
korelacji), wymaga, aby zmienne były
ciągłe. Określa on stopień proporcjonalnych
powiązań wartości dwóch zmiennych.
Wartość korelacji (współczynnik korelacji)
nie zależy od jednostek miary, w jakich
wyrażamy badane zmienne, np. korelacja
pomiędzy wzrostem i ciężarem będzie taka
sama bez względu na to, w jakich
jednostkach (cale i funty czy centymetry i
kilogramy) wyrazimy badane wielkości.
Określenie "proporcjonalne" znaczy zależne
liniowo, to znaczy, że korelacja jest silna,
jeśli może być opisana przy pomocy linii
prostej (nachylonej do góry lub na dół).

Analizę współzależności należy
uzupełnić o współczynnik
determinacji, będący kwadratem
współczynnika korelacji liniowej
Pearsona ( ).
Współczynnik determinacji
informuje, jaka część zmiennej
objaśnianej jest wyjaśniona przez
zmienną objaśniającą. Przy pomocy
tego współczynnika można
wnioskować, czy na zmienną
objaśniającą wpływają również inne
czynniki, nie podlegające badaniu.
2
xy
r

Prosta regresji: y=ax+b,
gdzie
a = cov(x,y)/
S^2; b= - a
• Linia, o której mowa, nazywa się linią regresji
albo linią szacowaną metodą najmniejszych
kwadratów, ponieważ jej parametry określane są
w ten sposób, by suma kwadratów odchyleń
punktów pomiarowych od tej linii była
minimalna. Zwróćmy uwagę, że fakt podnoszenia
odległości do kwadratu powoduje, iż
współczynnik korelacji reaguje na sposób
rozmieszczenia danych (jak to zobaczymy w
dalszej części opisu).
•
x
y
yy

Tabele wielodzielcze
• Tabele wielodzielcze
• W wielu badaniach medycznych
gromadzimy dane będące
liczebnościami. Na przykład możemy
klasyfikować chorych w badanej próbie
do różnych kategorii pod względem
wieku, płci czy natężenia choroby.
Przedstawiane do tej pory w naszym
cyklu metody statystyczne stają się
bezużyteczne dla danych tego typu,
zwanych danymi jakościowymi.

W sytuacji, gdy obserwacje
statystyczne dotyczące badanych
zmiennych są liczne, bazowanie na
wartościach szczegółowych może być
uciążliwe. W celu zapewnienia
przejrzystości zebranych danych
sporządza się wówczas tablicę korelacyjną.
Na skrzyżowaniu kolumn z
wierszami wpisuje się liczebności
jednostek zbiorowości statystycznej, u
których zaobserwowano jednoczesne
występowanie określonych wartości
i .
i
x
i
x
i
y
Schemat tablicy
korelacyjnej:
x
i
y
j
y
1
y
2
...
y
t
i
t
i
ij
n
n
1
x
1
x
2
.
.
.
x
k
n
11
n
21
.
.
.
n
k1
n
12
n
22
.
.
.
n
k2
.
.
.
.
.
.
n
1t
n
2t
.
.
.
n
kt
n
1
n
2
.
.
.
n
k
j
k
i
ij
n
n
1
n
.1
n
.2
…
n
.t
n

Tabele wielodzielcze stanowią podstawę do
obliczania pozostałych statystyk
określających siłę związku.
gdzie E - oczekiwana liczebność komórki oraz O
lub nij - obserwowana liczebność komórki
Na przykład badano zależność między liczbą
wypalanych papierosów a wystąpieniem pewnych
zmian patologicznych w płucach w grupie 1500
osób. Zebrane dane przedstawiono w następującej
tabeli wielodzielczej
Niepalący
Palący
mało
Palący
dużo
Razem
zmiany występujące
51
250
560
861
zmian nie ma
370
210
59
639
razem
421
460
619
1500
Wyliczymy wartość oczekiwaną E
11
. Zgodnie z
definicją:
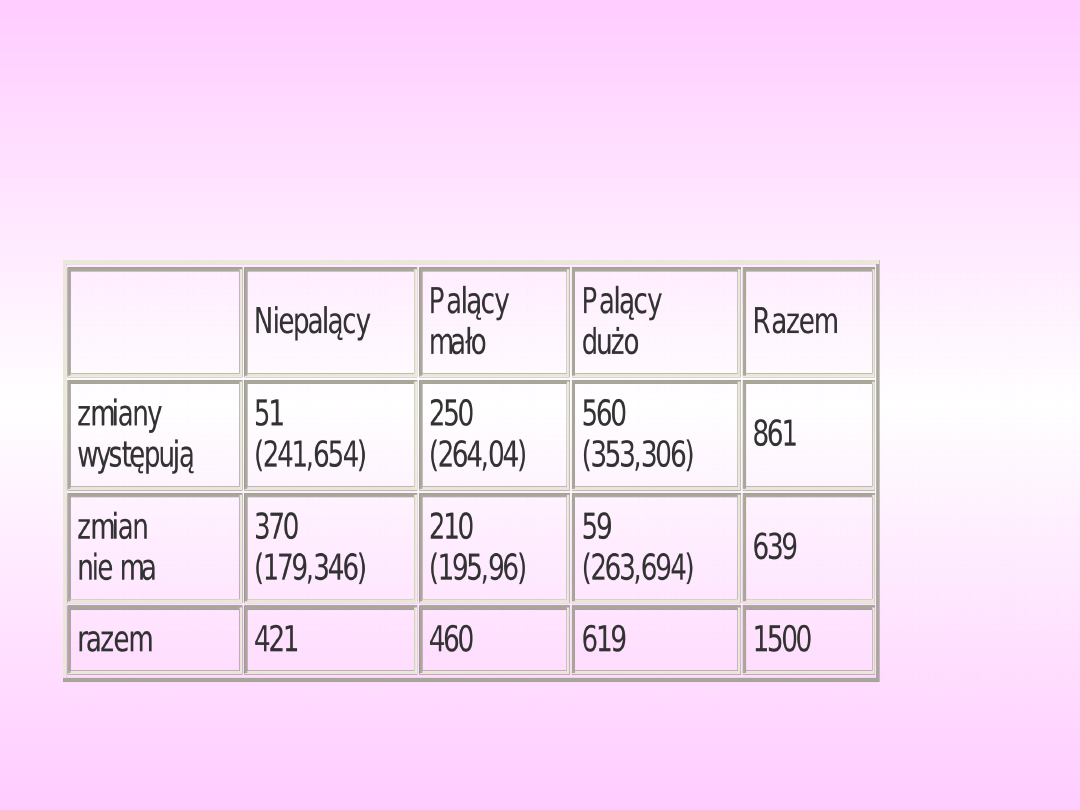
Wyniki obliczeń pozostałych wartości
oczekiwanych przedstawiono w tabeli. w
nawiasach obok wartości obserwowanych.
•

Inny przykład tabeli korelacyjnej.
Wykształcenie badanych osób
przebywających w Domach Pomocy
Społecznej z uwzględnieniem płci
Wykształcenie
Płeć
Żeńska
Męska
Liczba
podstawowe
%
53
86,9%
16
43,2%
Liczba
zawodowe
%
2
3,3 %
14
37,8 %
Liczba
średnie
%
6
9,8 %
5
13,5 %
Liczba
wyższe
%
0
0,0 %
2
5,4 %
Liczba
Razem
%
61
100,0 %
37
100,0 %

W tablicy korelacyjnej zawarte są
rozkłady brzegowe i warunkowe.
Rozkład brzegowy (por. ostatnia
kolumna określa rozkład brzegowy
cechy X, ostatni wiersz – rozkład
brzegowy cechy Y) prezentuje
strukturę wartości jednej zmiennej (X
lub Y) bez względu na kształtowanie
się wartości drugiej zmiennej.
Rozkłady brzegowe i warunkowe
mogą być scharakteryzowane pewnymi
sumarycznymi wielkościami (najczęściej
są to średnie arytmetyczne)

Średnie arytmetyczne z
rozkładów brzegowych wyznacza
się ze wzorów:
Średnie arytmetyczne z
rozkładów warunkowych oblicza
się następująco:
i
k
i
i
n
x
n
x
1
1
j
t
i
j
n
y
n
y
1
1
ij
k
i
i
j
j
n
x
n
x
1
.
1
ij
t
i
j
i
i
n
y
n
y
1
.
1

W sytuacji, gdy wraz ze
wzrostem (spadkiem) wartości jednej
zmiennej następuje wzrost (spadek)
warunkowych średnich drugiej
zmiennej, wówczas można stwierdzić
istnienie korelacji dodatniej
między zmiennymi. W sytuacji,
kiedy występuje przeciwny kierunek
zmian, można mówić o korelacji
ujemnej.

Jeżeli różnice pomiędzy
średnimi są takie same, tzn.:
wówczas związek między
zmiennymi jest liniowy.
1
2
3
1
2
...
t
t
x
x
x
x
x
x
1
2
3
1
2
...
k
k
y
y
y
y
y
y
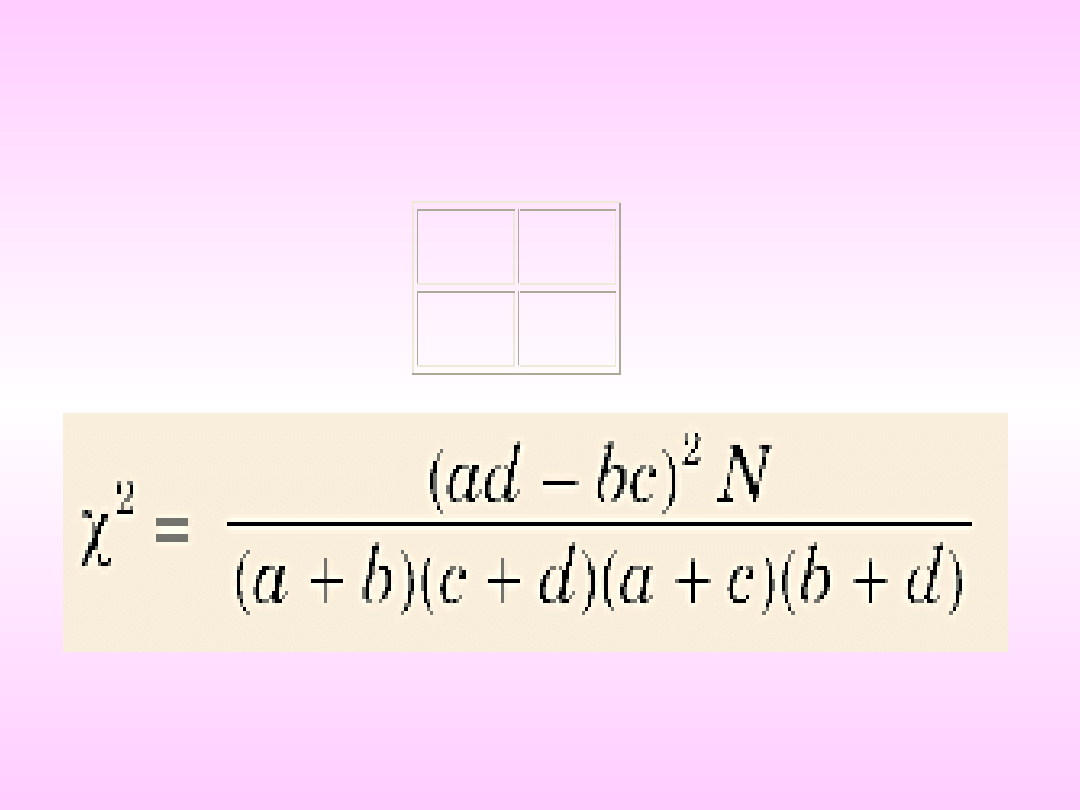
Dla tabel dwudzielczych 2x2 postaci
wartość statystyki wyznaczamy według
prostszego, praktycznego wzoru:
a
b
c
d

Na przykład w próbie liczącej 100 mężczyzn
w wieku 50-60 lat zbadano częstość
występowania choroby wieńcowej i
podwyższonego ciśnienia tętniczego.
Chcemy ocenić, czy choroba wieńcowa
współistnieje z podwyższonym ciśnieniem
tętniczym
Obliczając
według wzoru podanego wyżej,
otrzymujemy
=
26,23

Innym miernikiem korelacyjnego związku cech
jest współczynnik korelacji rang
Spearmana. Współczynnik ten stosowany
jest głównie do badania współzależności
cech niemierzalnych, bądź cechy mierzalnej i
niemierzalnej. Może być on również
stosowany w badaniu związku
korelacyjnego pomiędzy cechami
mierzalnymi (szczególnie w przypadku małej
próby).
Konstrukcja współczynnika korelacji
rang opiera się na zgodności pozycji, którą
zajmuje każda z odpowiadających sobie
wielkości we wzrastającym lub
malejącym szeregu wartości cechy.

Współczynnik korelacji rang Spearmana
(Q) wylicza się w oparciu o wyznaczone
różnice rang ( ) oraz liczby par
obserwacji (n):
przy czym:
gdzie:
- rangi zmiennej X oraz Y (i=1,2,...n)
n
n
d
Q
n
i
i
3
1
2
6
1
i
i
y
x
i
v
v
d
i
i
y
x
v
v ,

gdy
Współczynnik korelacji rang
przyjmuje wartości z przedziału
, a jego interpretacja
jest analogiczna do
współczynnika korelacji Pearsona
1
Q
0
1
2
n
i
i
d
1
1
Q
Przykład. W celu zbadania, czy istnieje związek
między zdyscyplinowaniem pacjentów względem
zaleceń personelu medycznego a wynikami
terapii na pewną dolegliwość poddano
obserwacji 10 pacjentów. Otrzymano
następujące wyniki obserwacji zestawione w
tabeli
:
Pacjent
Ranga
zdyscyply-
-nowanie
Ranga
terapii
Różnica
rang (d)
Kwadrat
różnicy
rang (d
2
)
1
2
3
4
5
6
7
8
9
10
6
2
5
1
10
4
9
3
8
7
4
1
5
3
10
7
6
2
9
8
2
1
0
-2
0
-3
3
1
-1
-1
4
1
0
4
0
9
9
1
1
1
Razem
0
30
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
Wyszukiwarka
Podobne podstrony:
wyklad4b ANALIZA WSPÓŁZALEŻNOŚCI
Wyklad 3b Handel elektroniczny wyniki badan
Wykład II Analiza podstawowych pojęć eksploatacyjnych i użytkowanie obiektów ED
ćw 5 analiza współzależności zmiennych
analiza-wyklady sciaga, Analiza finansowa
wyklady calosc, analiza instrumentalna
statys ANALIZA WSPÓŁZALEŻNOŚCI
Wyklad IIb Analiza
Wykład 11 Analiza opóźnień w sieciach kolejkowych
wyklad2 narzedzia analizy ekonomicznej
Wyklad 3b Obciazenia
analiza leku- 1 wykład, FARMACJA, Analiza leku
Wykład 5 AR Analiza sezonowości
Analiza współzależności i korelacji
Wykład 2 AR ANALIZA RYNKU W WARUNKACH HIPERKONKURENCJI
Wykład 3b Ekonomia, Transport ZUT, rok 1, Ekonomia
Analiza współzależności zmiennych na różnych skalach pomiarowych
więcej podobnych podstron