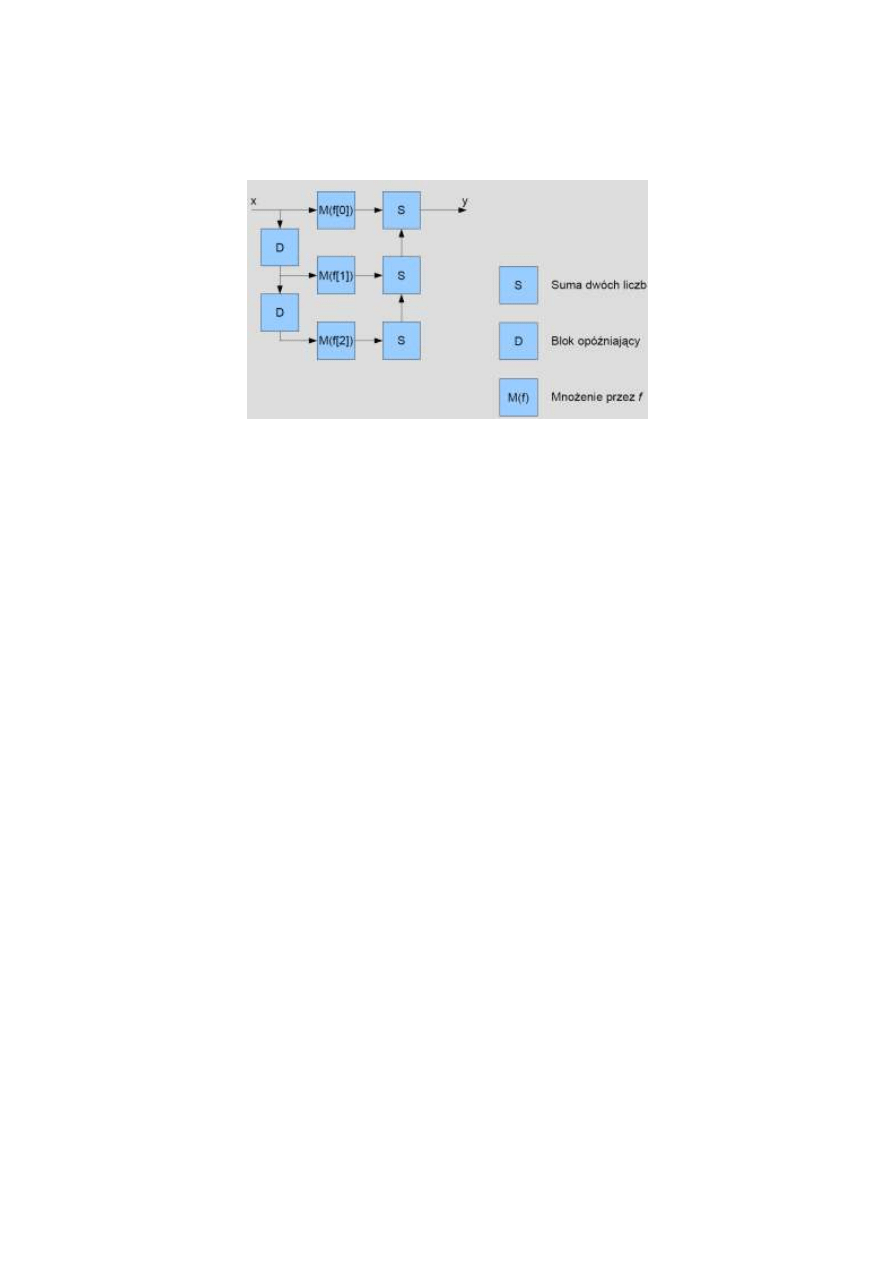
1. Możliwości implementacyjne filtrów SOI i NOI
w procesorze
TMS320C6713
4:
FILTR SOI
w procesorze TMS320C6713
4
/*genearalnie obowiązuje większośd komentarzy z ECHA.*/
//zmienne globalne
int16 BUF[8]; //tymczasowy bufor
int pos*8+; //zmienna określająca pozycje
float H*8+ = ,-; //tablica ze współczynnikami filtru
int ch; //zmienna określająca aktualny kanał, bo na jeden wysyłaliśmy 0, na drugi // //sygnał, zeby
wyciszyc dzwiek w jednej sluchawce
//definicja i deklaracja funkcji przerwania
interrupt void FILTR_SOI(){
int s;
s = MCBSP__read();
f(ch==0) ,s=0; //jeśli kanał pierwszy, to wstaw tam zero, i zmien na drugi
ch=1;
}
else{
int y = 0; //zmienna do sumowania wartosci
BUF[pos] = s;
for(i=0; i <7; ++i){
y+=H * BUF*pos+; //przetwarzanie sygnału – pod jakas /*zmienna y cały czas pakujemy sume
iloczynow wspolczynnikow filtru i elementuBUF[pos] */
pos = (pos-1) & (8-1);
} //koniec petli for
pos = ((pos+2) & 7)); //inkrementacja pos o 2.
s = y;
MCBSP_write(s, … )
}while(.....)

FILTR NOI
w procesorze TMS320C6713
4
//zmienne globalne
int16 BUF[8]; //tymczasowy bufor
int pos; //zmienna określająca pozycje
float H*8+ = ,-; //tablica ze współczynnikami filtru
ch = 0; //zmienna określająca aktualny kanał, bo na jeden wysyłaliśmy 0, na drugi sygnał, zeby
wyciszyc //dzwiek w jednej sluchawce
//definicja i deklaracja funkcji przerwania
interrupt void filtr_noi(){
int s;
s = MCBSP__read();
f(ch==0) ,s=0; //jeśli kanał pierwszy, to wstaw tam zero, i zmien na drugi
ch=1;
}
else{
int y = 0; //zmienna do sumowania wartosci
BUF[pos] = s;
for(i=0; j=pos; i<8; i++){
y+=H * BUF[j];
j = (j+1) & (8 - 1);
}
BUF[(pos+4) & 7] = y;
pos = (pos+1) & 7;
s = y;
ch = 0;
MCBSP_write(s,...);
}while(...)

2. Cechy procka sygnałowego:
●
Szybkie układy mnożące
●
Układy typu mnóż i akumuluj
●
Kilka jednostek obliczeniowych
●
Efektywny dostęp do pamięci
●
Większośd procesorów sygnałowych operuje na liczbach
stałoprzecinkowych ( są wyjątki)
●
Możliwośd implementacji pętli programowych bez opóźnienia dla
obliczenia warunku wyjścia
●
Zintegrowane urządzenia wejścia wyjścia wraz efektywnym układem
kontroli przerwao i układem bezpośredniego dostępu do pamięci
●
Specjalne instrukcje umożliwiające wykonanie kilku operacji w ramach
jednej instrukcji Duża ilośd rejestrów przeznaczonych do
przechowywania tymczasowych wyników obliczeo
●
Specjalnie zaprojektowane generatory adresów do odczytywania tablic z
pamięci
●
Sprzętowe wsparcie obsługi buforów kołowych
3. Klasyfikacja proc sygnałowych:
●
Niska cena, niski pobór mocy, niska wydajnośd (20-50 MHz)
– zawierają jeden mnożnik i jedną jednostkę arytmetyczno-logiczną
– wykonują jedną instrukcję w jednym cyklu
– zawierają specjalne rozkazy wykonujące kilka operacji równolegle
– stosowane w różnego rodzaju napędach dysków i automatycznych sekretarkach (ADADSP
21xx, TI – TMS320C2xx, M- DSP 560xx, LT- DSP16xx)
●
Średnia wydajnośd (100-150 MHz), niski pobór mocy, mimo wszystko niska cena
– dodatkowe układy (przesuwnik, pamięd podręczna instrukcji)
– więcej faz w potokowym przetwarzaniu instrukcji
– stosowane w bezprzewodowej telekomunikacji i szybkich modemach (TITMS320C54x,
M- DSP563xx)
●
Wyższa wydajnośd, cena i pobór mocy porównywalne
– dodatkowe układy mnożnik, sumator
– szersze słowo instrukcji szersze magistrale
– więcej operacji wykonywanych równolegle
(LT- DSP16xxx)
●
Bardzo wysoka wydajnośd, ale kosztem ceny i poboru mocy(1GHz dla p.
stałoprzecinkowych)
– architektura VLIW
– kompilatory produkują efektywny kod
– pamięd podręczna instrukcji i danych lub kilka magistral i pamięci wieloportowe
– zwykle dwie ścieżki danych
– od 4 do 8 operacji wykonywanych w jednym cyklu

4. Przetwarzanie potokowe w procesorze TMS320C6713
4
Ogólnikowo: Dzięki przetwarzaniu potokowemu co jeden cykl zegarowy jedna instrukcja
kooczy działanie, a w jednym cyklu zegarowym wykonywane jest kilka rozkazów ( w
przykładzie pokazanym na rysunku wykonywane są 4 instrukcje) Przetwarzanie potokowe
zakłócają występujące w kodzie instrukcje skoków warunkowych. Prowadzi do równoległego
przetwarzania więcej niż jednego polecenia w danej chwili co zwiększa wydajnośd CPU.
●
Faza wczytywania instrukcji
– etap generacji adresu pakietu instrukcji
(PG)
– etap wysłania adresu pakietu na
magistralę adresową (PS)
– etap oczekiwania na pakiet instrukcji (PW)
– etap pobrania pakietu instrukcji (PR)
●
Faza dekodowania instrukcji
– etap rozsyłania instrukcji (DP)
– etap dekodowania instrukcji (DC)
●
Faza wykonania instrukcj (E1-E10)
Faza wczytywania instrukcji
●
Etap (PG)- obliczenie adresu pakietu
instrukcji
●
Etap (PS)- adres pakietu jest przsyłany do
pamięci
●
Etap (PW)- trwa dostęp do danych w pamięci
●
Etap (PR)- pakiet jest zapamiętywany w
obrębie jednostki centralnej
Faza dekodowania instrukcji
●
Etap (DP)- określany jest kolejny pakiet
wykonywalny i odpowiednie kody operacji
przesyłane są do odpowiednich jednostek
funkcjonalnych
●
Etap (DC)- dekodowanie kodów operacji w
poszczególnych jednostkach funkcjonalnych
Faza wykonywania instrukcji
●
Etap (E1)
– dla wszystkich instrukcji sprawdzane są warunki wykonania i
wczytywane są argumenty
– dla operacji odczytu/zapisu wykonywane są modyfikacje
adresów i zapisywane w rejstrach wynikowych
– dla instrukcji rozgałęzieo modyfikowany jest adres
wczytywanego pakietu na etapie PG
– dla instrukcji wykonywanych w jednym cyklu wyniki są

zapisywane w rejestrach
– dla operacji z podwójną precyzją wczytywane są młodsze 32
bity argumentów
– dla operacji z podwójną precyzją wykonywanych w 2 cyklach
zapisywane są młodsze 32 bity wyników
Faza wykonywania instrukcji
●
Etap (E2)
– dla operacji odczytu do pamięci przesyłany jest adres, dla
operacji zapisu adres i dane
– dla operacji wykonywanych jednym cyklu, które stosują
nasycenie wyników, ustawiany jest bit SAT w rejestrze SCR (o
ile nasycenie wystąpiło)
– dla operacji mnożenia i porównania, wykonywanych w 2
cyklach z podwójną precyzją, zapisywane są wyniki
– dla operacji porównania i rozkazów ADDDP/SUBDP z
podwójną precyzją wczytywane są starsze 32 bity
argumentów
– dla operacji MPYDP odczytywane są młodsze 32 bity src1 i
starsze 32 bity src2
– dla operacji MPYI i MPYID wczytywane są argumenty
Faza wykonywania instrukcji
●
Etap (E3)
– oczekiwanie na dostęp do danych w pamięci
– operacje mnożenia, które nasyciły swoje wyniki ustawiają bit
SAT w rejestrze SCR
– instrukcja MPYDP wczytuje starsze 32 bity src1 i młodsze 32
bity src2
– instrukcje MPYI i MPYID odczytują swoje argumenty
●
Etap (E4)
– dane do instrukcji odczytu odbierane
– instrukcje MPYI i MPYID pobierają argumenty
– instrukcje wykonujące się w 4 cyklach zapisują swoje wyniki
– instrukcja INTDP zapisuje wynik obliczeo w rejestrze
●
Etap (E5)
– instrukcje odczytu zapisują dane w rejestrach
– instrukcja INTDP zapisuje starsze 32 bity wyniku
Faza wykonywania instrukcji
●
Etap (E6)- instrukcje ADDDP i SUBDP
zapisują młodsze 32 bity wyników
●
Etap (E7)- instrukcje ADDDP i SUBDP
zapisują starsze 32 bity wyników
●
Etap (E8)- etap pusty
●
Etap(E9)-
– Instrukcja MPYI zapisuje wyniki do rejestrów
– Instrukcje MPYDP i MPYID zapisują młodsze 32 bity wyników

●
Etap (E10)- instrukcje MPYDP i MPYID
zapisują starsze 32 bity wyników
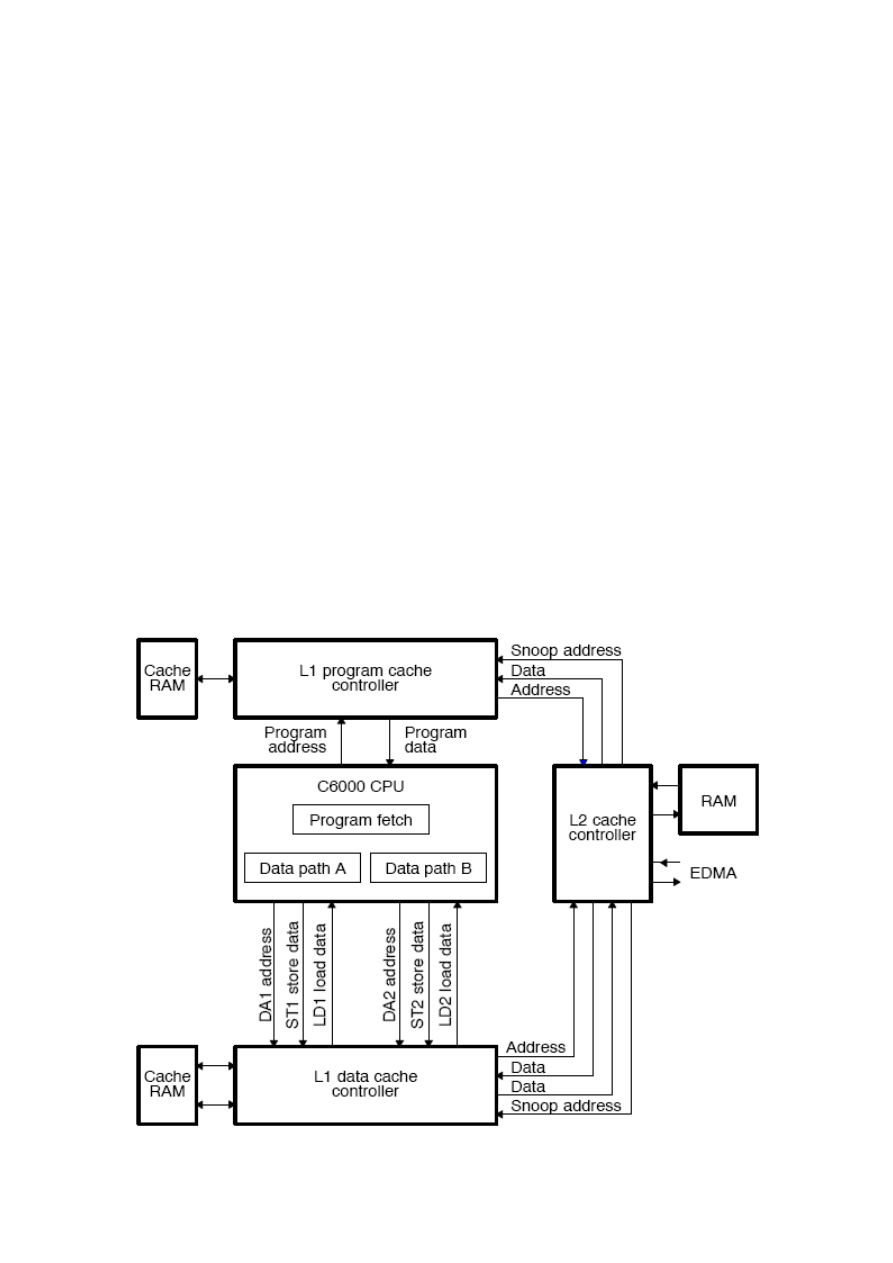
5. Architektura procesora
TMS320C6713:
Procesor pobiera z pamięci podręcznej pakiety 8 instrukcji. Każdy pakiet może składad się z
od 1 do 8 pakietów wykonawczych. W pojedynczym pakiecie wykonawczym znajdują się
rozkazy wykonywane równolegle w jednym cyklu.
Ścieżki danych: 32 x 32bitowe rejestry ogólnego przeznaczenia 8 jednostek funkcjonalnych:
jednostki L i S do obliczeo arytmetycznych i logicznych oraz instrukcji rozgałęzieo, jednostki
M zawierające szybkie równoległe mnożniki, jednostki D odpowiadające za generację
adresów, ścieżki odczytu/zapisu do pamięci LD i ST.
6. Obsługa przerwao
w procesorze TMS320C6713
4:
Uint32 DevId; //identyfikator urządzenia potrzebny do prawidłowej konfiguracji przerwao
extern far void vectors(void); //deklaracja wskaznika do tablicy kodu obslugi przerwan (16
blokow po 8 rozkazow)
IRQ_setVecs(vectors); //ustawienie zadeklarowanej tablicy kodu
obslugi przerwan
hDev = DEV_open( ... ); // wlaczenie obslugi urzadzenia
DevId = DEV_getEventId(hDev); //pobranie identyfikatora dla zdarzeo pochodzących od
urzadzenia
IRQ_map(DevId, 15); //mapowanie zdarzenia od urzadzenia z numerem przerwania
IRQ_reset(DevId); //resetowanie przerwania od URZĄDZENIA
IRQ_enable(DEV); //wlaczenie obslugi przerwania od urzadzenia
IRQ_globalEnable(); //wlacznie obclugi przerwan procesora
IRQ_nmiEnable(); //wlacznie przerwan niemaskowanych
7. Obsługa urządzeo za pomocą przerwao w procesorze TMS320C6713
4
:
●
Sygnalizacja przerwania od urządzenia zewnętrznego
●
Zapamiętanie bieżącej wartości licznika rozkazów
●
Wpisanie do licznika rozkazów adresu początku funkcji obsługi przerwania
●
Wykonywanie rozkazów funkcji obsługi przerwania
●
Rozkaz powrotu z przerwania przywraca zapamiętaną wartośd licznikowi rozkazów
●
W następnym takcie procesor rozpoczyna wykonanie programu od rozkazu następnego po
rozkazie, w którym wystąpiło przerwanie
8. Transmisja wielokanałowa w procesorze TMS320C6713
4:
●
Transmisja wielokanałowa zrealizowana jest za pomocą
multipleksowania kanałów w czasie
●
Układ umożliwia transmisję do 32 dwóch elementów w ramce
spośród maksymalnie 128 kanałów
●
Jeżeli kanał odbiornika jest zablokowany
– RRDY nie jest ustawiany na 1 jeżeli zostanie odczytany
ostatni bit elementu nadawanego
– RBR nie jest kopiowany do DRR
●
Jeżeli kanał nadajnika jest zablokowany
– Linia DX jest w stanie wysokiej impedancji
– XRDY i XEMPTY nie są ustawiane w przypadku nadawania
danych
– Zakooczenie wysyłania danej nie generuje ani przerwania
procesora ani zdarzenia dla układu EDMA
●
Odblokowany kanał nadajnika może byd w dowolnym momencie
zamaskowany (dane są wysyłane do układu nadajnika ale
nadajnik ich nie przesyła linią DX
9. Struktura pamięci
w procesorze TMS320C6713
4:

9. Bufor kołowy - opis, zasada działania i implementacje.
Bufor kołowy można porównad do tablicy danych która nie ma początku ani kooca. Do pracy
na takim buforze niezbędne są dwa wskaźniki. Pierwszy z nich pokazuje gdzie należy zapisad
daną w buforze, drugi skąd odczytad. Po każdej operacji zapisu lub odczytu odpowiedni
wskaźnik jest inkrementowany, aby pokazywad na następny element bufora (wskaźnik do
zapisu pokazuje następny wolny element a wskaźnik do odczytu pierwszy nieodczytany
element). Jeżeli wskaźnik dojdzie do kooca tablicy, to po kolejnym zapisie danej do bufora
powinien on ustawid się na pierwszy element tablicy.
REALIZACJA BUFORA KOŁOWEGO
Do pracy na takim buforze niezbędne są:
● tablica o określonej długości N,
● wskaźnik do zapisu danych,
● wskaźnik do odczytu danych.
Dla wygody korzystania z bufora warto stworzyd gotowe procedury do jego obsługi:
● inicjacja wskaźników,
● zapis danej
● odczyt danej
10. Bufor Ping-Pong
- opis, zasada działania i implementacje.
Metoda ta polega na takim oprogramowaniu układu DMA, aby zapisywał dane
naprzemiennie do dwóch buforów – bufora ping i bufora pong. Wówczas układ DMA
synchronizuje się procesorem po przesłaniu całego jednego bufora. W czasie gdy układ DMA
zapisuje lub odczytuje dane z bufora ping, mikroprocesor przetwarza bufor pong, a potem
odwrotnie. W tej metodzie układ DMA pracuje najefektywniej, dlatego jest ona
wykorzystywana do przetwarzania sygnałów VIDEO.
11. Układ EDMA
Uk
ład EDMA jest to układ tzw. bezpośredniego dostępu do pamięci. Bezpośredniość
ta polega na tym,
że do kopiowania danych z jednego miejsca pamięci do drugiego
nie jest w najmniejszym nawet stopniu wykorzystywany rdze
ń procesora. Dane
przesy
łane są po magistrali danych z jednego miejsca pamięci do drugiego. W
klasycznym kopiowaniu danych natomiast dana jest pobierana do rejestru
mikroprocesora i za pomoc
ą drugiego rozkazu zapisywana z rejestru do
pami
ęci. Przepływ danych zatem odbywa się poprzez mikroprocesor. Przesyłanie
danych za pomoc
ą układu DMA jest efektywne wtedy, gdy mikroprocesor w tym
samym czasie realizuje inne zadania. Typow
ą sytuacją, w której wykorzystywany jest
uk
ład DMA jest akwizycja danych z przetworników analogowo – cyfrowych i
wysy
łanie przetworzonych danych do przetworników cyfrowo – analogowych.
Zaanga
żowanie układu DMA do odbierania i nadawania danych jest w
takiej sytuacji niezwykle efektywne, poniewa
ż procesor, pracujący zwykle z
cz
ęstotliwością wielokrotnie większą niż układy przetworników, nie musi czekać aż
przetwornik b
ędzie gotowy do odebrania nadawanej danej. Zamiast tego umieszcza

on przetworzon
ą próbkę w specjalnym buforze obsługiwanym przez układ DMA i
zaczyna kolejny cykl przetwarzania, pozostawiaj
ąc zadanie wysłania próbki układowi
DMA. Jeszcze bardziej efektywnym sposobem wykorzystania uk
ładu DMA jest
zastosowanie
podwójnego buforowania albo inaczej buforowania typu ping – pong.
Metoda ta polega na takim oprogramowaniu uk
ładu DMA, aby zapisywał dane
naprzemiennie do dwóch buforów – bufora ping i bufora pong. Wówczas układ DMA
synchronizuje si
ę procesorem po przesłaniu całego jednego bufora. W czasie gdy
uk
ład DMA zapisuje lub odczytuje dane z bufora ping, mikroprocesor przetwarza
bufor pong, a potem odwrotnie. W tej metodzie uk
ład DMA pracuje najefektywniej,
dlatego jest ona wykorzystywana do przetwarzania sygna
łów VIDEO.
hEDMA_Handle EDMA_open(int chaNum, Uint32 flags)
Aktywowanie miejsca w pamięci do przechowywania parametrów aktualnie wykonywanego
transferu.
hEDMA_Handle EDMA_allocTable(int tableNum);
Alokuje miejsce dla konfiguracji, która będzie przeładowywana po wykonaniu transferu. Aby
wybrad pierwsze wolne miejsce, należy wywoład funkcję z argumentem „-1”. Układ DMA nie
może modyfikowad zawartości tej tablicy.
gEdmaConfigXmt.dst = MCBSP_getXmtAddr(hMcbsp1);
pobiera adres rejstru nadajnika portu szeregowego i wpisuje go do adresu przeznaczenia dla
DMA.
int EDMA_intAlloc(int tcc);
Alokuje Transfer Completion Code. Jest to kod zgłaszany po zakooczeniu transferu i jest
indywidualny dla każdego kanału DMA. Aby wybrad pierwszy wolny kod należy użyd
argumentu „-1”.
gEdmaConfigXmt.opt |= EDMA_FMK(OPT,TCC,gXmtChan);
Zapisanie kodu TCC dla kanału nadawczego.
EDMA_config(EDMA_Handle hEdma, EDMA_Config *config);
Wpisanie konfiguracji pod wskazany adres.
gEdmaConfigXmt.src= EDMA_SRC_OF(gBufferXmtPong);
Wskazanie źródła(buforu), z którego kopiowane są dane.
EDMA_link(EDMA_Handle parent,EDMA_Handle child);
Linkowanie konfiguracji(transferów). Pierwszy argument funkcji to „rodzic”, a drugi to
„dziecko”. Najpierw należy użyd wskaźnika który był używany z EDMA_open, aby przypisad
go do konkretnego urządzenia(czyli McBSP1). Następnie wpisujemy konfiguracje do tablicy
parameters RAM. Do konfiguracji Pong linkowana jest struktura Ping, a Ping jest łączone z
Pong, czyli wracamy następuje zapętlenie. W późniejszej fazie wzajemne linkowanie
następuje tylko dla transferów zainicjowanych funkcją EDMA_allocTable. Należy również
zwrócid uwagę na zamianę miejsc pomiędzy parent i child w następnych linkowaniach.
EDMA_intEnable(intNum);
Aktywuje przerwanie dla wybranego kodu TCC poprzez modyfikację rejestru CIER.
EDMA_enableChannel(EDMA_Handle hEdma);
Musi nastąpid jawne aktywowanie kanału. Przyjmuje tylko uchwyty od EDMA_open.
Wyszukiwarka
Podobne podstrony:
,algorytmy przetwarzania sygnałów, opracowanie kolokwium I
,algorytmy przetwarzania sygnałów, opracowanie kolokwium II
,algorytmy przetwarzania sygnałów, opracowanie kolokwium I
biernacki,algorytmy przetwarzania sygnałów L,Okna czasowe
biernacki,algorytmy przetwarzania sygnałów L, filtry SOI sprawozdanie
biernacki,algorytmy przetwarzania sygnałów L, autokorelacja i korelacja wzajemna sprawozdanie
biernacki,algorytmy przetwarzania sygnałów L, wpływ rozmieszczebnia zer i biegunów na funkcję transm
biernacki,algorytmy przetwarzania sygnałów L, porównywanie filtrów SOI i NOI sprawozdanie
biernacki,algorytmy przetwarzania sygnałów L, analiza sygnału rzeczywistego sprawozdanie
biernacki,algorytmy przetwarzania sygnałów L, średnia i wariancja sygnału sprawozdanie
biernacki,algorytmy przetwarzania sygnałów L, interpolacja i decymacja sprawozdanie
zarzycki, algorytmy przetwarzania sygnałów ,pytania i opracowanie
Piapsy zagadnienia, Edukacja, studia, Semestr IV, Podstawy i Algorytmy Przetwarzania Sygnałów
zarzycki, algorytmy przetwarzania sygnałów ,algorytm Schura
zarzycki, algorytmy przetwarzania sygnałów ,metoda LPC
,Algorytmy Przetwarzania sygnałów,pytania i odpowiedzi
zarzycki, algorytmy przetwarzania sygnałów ,filtr modelujący
Cw8LPCPS, Edukacja, studia, Semestr IV, Podstawy i Algorytmy Przetwarzania Sygnałów, Ćwiczenia, Cwic
więcej podobnych podstron