1. Idea systemów kodowania z korekcją błędów
Najprościej mówiąc jest to technika dodawania nadmiarowości do transmitowanych cyfrowo
informacji. Umożliwia całkowitą lub częściową detekcję i korekcję błędów powstałych w wyniku zakłóceń.
Dzięki temu nie ma potrzeby wykorzystywania kanału zwrotnego, do poinformowania nadawcy o błędzie
konieczności ponownego przesłania informacji. Kodowanie korekcyjne jest więc wykorzystywane wtedy, gdy
retransmisja jest kosztowna, kłopotliwa lub niemożliwa, np. ze względu na ograniczenia czasowe.
Główna idea algorytmu polega na zwiększeniu sekwencji symboli.
W ECC możemy wyróżnić:
• Słowo informacyjne – ciąg bitów reprezentujących informację do zakodowania
• Słowo nadmiarowe – ciąg bitów służących do kontroli odczytanej informacji
Przykładowo koder ECC może pobierać sekwencje 4-bitowe i na wyjściu generować sekwencję o zwiększonej
długości, np. 7 bitów. Nadmiarowość bitów pozwala na skorygowanie błędów powstałych w wyniku przesyłania wiadomości.
Przykład: Niech 0 będzie kodowane przez 010 a 1 przez 101. Tylko te dwie sekwencje uznajemy za poprawne.
Mamy także sekwencje: 000,001,011,100,110,111,które są niepoprawne, jednak pozwalają na odczytanie
poprawnego komunikatu mimo zmiany jednego bitu:
Do poprawnej sekwencji 010 podobne są kombinacje 011,110,000 gdyż różnią się od niej tylko jednym
bitem. Podobnie ma się sytuacja dla drugiej sekwencji (do 101 podobne są kombinacje 001,100,111)
Koder ECC może zostać zaimplementowany jako maszyna stanów, która może być reprezentowana na różne
sposoby. Jednym z tych sposobów są kody Trellis, które są diagramem składającym się z 8(L+1) stanów, gdzie L – długość komunikatu.
Algorytm ECC jest stosowany w każdej sytuacji w której musimy przesłać sporą porcję danych, które
są narażone na zakłócenia. Przykładem mogą być chociażby dane zapisane na pytach CD czy DVD narażone na zakłócenia spowodowane zanieczyszczeniami, czy zarysowaniami.
W ECC stosuje się algorytmy oparte między innymi o:
• kod splotowy (tutaj możemy mówić o zastosowaniu kodów Trellis i algorytmu Viterbiego),
• kodowanie korekcyjne Reeda-Solomona,
• sumę kontrolną,
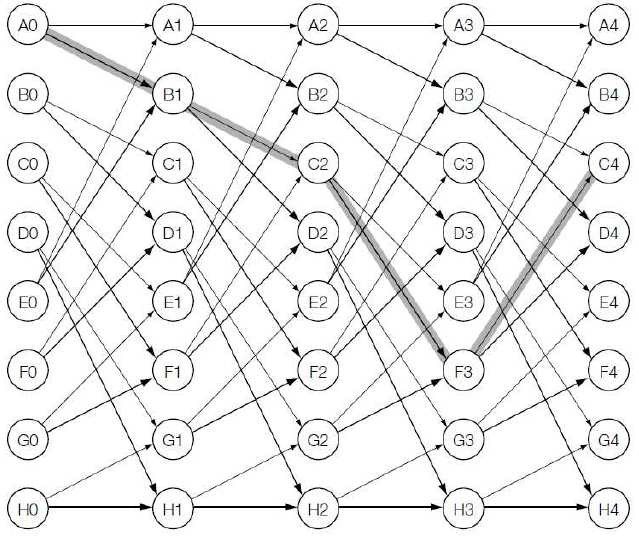
2. Kody trel lis
Kody trellis to algorytm kratowej modulacji kodowej. Wykorzystuje on diagram kratowy, w
którym poruszamy się poziomo zgodnie z upływem czasu. Każda transmisja oznacza, że na
wejście został podany jeden nowy bit.
Rysując taki diagram musimy najpierw nanieść wszystkie możliwe stany 8(L+1) gdzie L jest
ilością podanych bitów na wejściu. Później łączymy każdy stan z dopuszczalnym stanem
następnym. W każdym stanie są tylko dwie możliwości do wybrania. Są one zdeterminowane
przez nadchodzące bity w zależności czy to jest „0” czy „1”. Strzałki są skierowane w
górę bądź w dół, w zależności od tego jaki bit został podany na wejście. Jeżeli podamy „1”
wówczas strzałka jest skierowana w dół, jeżeli natomiast podamy „0” to strzałka skierowana
jest do góry. Zaczynamy z punktu „A0”. Następnie przesuwamy się w prawą stronę – w
zależności od stanów na wejściu: w górę, gdy jest „0” lub w dół, gdy przychodzi „1”.
Niżej przedstawiono tak zbudowaną „ścieżkę” dla przykładowej sekwencji bitów
wejściowych 1010.
3. Algorytm Viterbi’ego
Algorytm Viterbiego - algorytm dekodujący opracowany przez Andrew Viterbiego. Jego pierwszym
zastosowaniem było, i nadal jest, dekodowanie kodów splotowych. Jednak stosowany jest również w innych
zaawansowanych technologiach telekomunikacyjnych, np. jako odbiornik nieliniowy dla kanału z interferencją międzysymbolową.
[W telekomunikacji kod splotowy (ang. convolutional codes) jest typem kodu korekcyjnego. Kody splotowe zwykle są określane przez trzy parametry: (n,k,m). Ideą kodowania splotowego jest przekształcenie wejściowego k-bitowego ciągu informacyjnego na n-bitowy ciąg wyjściowy. Sprawność kodu splotowego wynosi k/n (n ≥ k).
Dodatkowym parametrem jest m, który oznacza liczbę przerzutników "D" w rejestrze układu kodującego albo ilość boksów, z których ten rejestr się składa. Można również wyróżnić wielkość L, która oznacza ograniczoną długość kodu i jest definiowana jako: L=k(m-1). Ograniczona długość L reprezentuje liczbę bitów w pamięci kodera wpływających na generowanie n bitów wyjściowych.]
Działanie tego algorytmu oparte jest o kryterium maksymalnej wiarygodności, a jego ideą jest to, że optymalna ścieżka dojścia przez dekoder do aktualnego stanu składa się ze ścieżki o najmniejszej metryce dojścia do któregoś ze stanów poprzednich oraz przejścia do aktualnego stanu. Jak widać proces ten jest procesem
iteracyjnym.
Im dłuższy czas obserwacji i działania tego algorytmu, tym bardziej wiarygodny wynik otrzymujemy. Można jednak zauważyć, że już po mniej więcej 3L do 5L krokach (gdzie L jest długością wymuszenia kodu)
otrzymujemy na wykresie kratowym, wspólną ścieżkę, tzw. pień, dla kolejnych stanów. Możemy więc
ograniczyć opóźnienie dekodowania właśnie do tego okresu i przyjąć wynik za wystarczająco dokładny.
Algorytm Viterbiego sprawdza się zarówno w przypadku dekodowania twardo-, jak również
miękkodecyzyjnego (przy użyciu algorytmu SOVA - Soft Output Viterbi Algorithm).
Nie jest on oczywiście jedynym algorytmem dekodowania kodów splotowych, aczkolwiek na pewno najbardziej popularnym ze względu na łatwość jego realizacji sprzętowej.
4. Techniki ochrony wartości intelektualnej (w szczególności oprogramowania)
-Ochrona wartości intelektualnej: ochrona prawna; ochrona techniczna (obfuskacja; wykonanie na serwerze[ip protection]; szyfrowanie; bezpieczny kod natywny)
IP protection: udostępnianie usług; udostępnianie usług krytycznych(częściowe wykonanie na serwerze)
Cyfrowe znaki wodne w oprogramowaniu – charakteryzują się: data rate(szybkość transmisji danych);
stealth(podstęp??); resilence(sprężystość, elastyczność).
Dzielimy je na: statyczne(związane z kodem programu lub danymi w programie) mogą mieć proste podejście-zmiany nazw zmiennych funkcji, zmiana kolejności funkcji lub bardziej złożone podejście; i dynamiczne(Easter eggs watermarks, data structure watermarks, execution trace watermarks)
Możliwe ataki na software: substractive, distortive, additive, collusive attack.
Obfuskacja kodu: rodzaje:leksykalna, danych, ścieżki realizacji kodu, prewencyjna
5. Ochrona kodu źródłowego oparta o obfuskację
Obfuskacja danych – składowanie i kodowanie
-dzielenie zmiennych
-zmiana wszystkich zmiennych w jeden wektor
-zmiana kodowania
-zmiana zasięgu zmiennych
-zmiana indeksowania
Agregacje- zmianie ulegają grupowania wyrażeń : łączenie zmiennych; modyfikacja dziedziczenia
Uporządkowanie: zmiana kolejności definicji; zmiana inkrementacji pętli
Obfuskacja ścieżki realizacji kodu: agregacje; włączanie metod; wydzielanie metod; transformacja pętli; klonowanie metod; obfuskacja wyliczeniowa( martwe części kodu; rozszerzenie warunków pętli)
6. Problem potwierdzania autentyczności
Stanowi to obecnie poważny problem – w postaci cyfrowej pliki multimedialne bardzo łatwo jest zmodyfikować.
7. Precyzyjne i selektywne potwierdzanie autentyczności
Uwierzytelnianie dzielimy na precyzyjne i selektywne.
Precyzyjne – weryfikacja obrazu pod kątem stwierdzenia jakiejkolwiek modyfikacji. Dzielimy je na: kruche znaki wodne; osadzone podpisy; usuwalne cyfrowe znaki wodne.
Selektywne – Weryfikacja obrazu pod kątem dozwolonych modyfikacji. Dzielimy na: półkruche cyfr.znaki
wodne; osadzone półkruche podpisy; jasne znaki wodne (tell-take watermarks???)-pozwalają stwierdzić w jaki sposób został obraz zmodyfikowany, a nie tylko czy jest autentyczny
8. Charakterystyka kruchych znaków wodnych
Kruche znaki wodne pozwalają stwierdzić czy obraz był modyfikowany. Należą do metod uwierzytelniania
precyzyjnego – weryfikacja obrazu pod kątem stwierdzenia jakiejkolwiek modyfikacji. Ulegają zniszczeniu w momencie jakiejkolwiek modyfikacji obrazu. Nienaruszony znak wodny jest dowodem autentyczności grafiki.
Zalety: nie potrzebują dodatkowego miejsca w pliku, są osadzone bezpiecznie w obrazie, można używać
stratnych formatów plików, są ukryte-trudniej je usunąć.
obraz oryginalny
i/lub klucz
detektor
znak
klucz
wodny
obraz ze znakiem
odpowiedź
oryginał
koder
obraz ze
znakiem
Rysunek 1 kruche znaki wodne
Rysunek 2 sprawdzanie autentyczności
System kruchych znaków wodnych: wykrywanie zmian – dokładne znalezienie modyfikacji; przezroczystość –
niezauważalny znak w pliku; dekodowanie bez oryginału; zaszyfrowany klucz; odporność na przecięcie – po przycięciu obrazu powinna być możliwość odczytania i zweryfikowania obrazu
Ataki na kruche znaki wodne: ślepa modyfikacja; bez naruszania struktury znaku; zmiana znaku wodnego
9. Algorytm LSB
Jest to historycznie najstarszy algorytm wstawiania znaków wodnych. Informacja o znaku wodnym zapisana jest w najmniej znaczących bitach wartości pikseli, z których składa się obraz cyfrowy. Dla obrazów kolorowych można wykorzystać jasności wszystkich kolorów składowych (RGB). Metoda ta jest bardzo prosta, lecz w ogóle nie odporna na jakiekolwiek zmiany w obrazie, w szczególności na kompresję JPEG.
**************
Jedna z najprostszych technik steganograficznych, przeznaczona do ukrywania informacji niejawnej w obrazach bez kompresji stratnej. Algorytm LSB (ang. Least Significant Bit) najmniej znaczący bit, bazuje na modyfikacji najmłodszych bitów określonych bajtów. Jeżeli obraz zapisany jest z 24 bitową głębią, wówczas każdy piksel reprezentowany jest przez 3 bajty (R – 8 bitów, G – 8 bitów, B – 8 bitów), opisujące poszczególne składowe barwy. Przy modyfikacji jedynie pierwszego najmłodszego bitu, do zapisu 1 bajtu informacji potrzeba 3 pikseli= 9 bajtów. Kolor biały reprezentowany jako funkcjia RGB(255,255,255) po modyfikacji jednego najmłodszego bitu uzyska się kolor biały o jeden stopień ciemniejszy czyli funkcje RGB(254,254,254). Dla niedoskonałego oka ludzkiego taka zmiana koloru jest niezauważalna i całkowicie ignorowana. Dzięki tej zależności można swobodnie modyfikować najmłodsze bity w obrazie zapisując w nich informację niejawną bez narażania obrazu na znaczny spadek jakości lub widoczne gołym okiem zmiany.
10. Algorytm Walton’a
Inaczej algorytm sum kontrolnych. Zgodnie z tajnym kluczem wybierane są pseudolosowe grupy pikseli, a
następnie obliczana jest suma kontrolna dla licz określonych przez 7 najbardziej znaczących bitów
wyznaczonych pikseli – tą sumę osadzamy w najmniej znaczących bitach.
Algorytm:
1. Wybór liczby N – względnie dużej, całkowitej
2. Podział obrazu na bloki 8x8
3. Dla każdego bloku B:
- wygenerować pseudolosową sekwencję 64 liczb całkowitych, podobnych do N
- obliczyć sumę kontrolną = ∑
∙ , gdzie g(pj)-jasność piksela pj obliczona na
podstawie 7 najbardziej znaczących bitów MSB
- obsadzić binarną i zaszyfrowaną postać s w najmniej znaczących bitach bloku
Proces dekodowania: porównanie dla każdego bloku sumy kontrolnej obliczonej z 7 najbardziej znaczących
bitów z sumą kontrolną z najmniej znaczących bitów. Zaleta: nie powoduje widocznych zmian w obrazie,
zapewnia wysokie prawdopodobieństwo wykrycia modyfikacji grafiki. Wada: możliwość zamiany bloków….
11. Algorytm Yeung’a-Mintzer’a
W obrazie umieszczana jest mapa bitowa znaku wodnego. W umieszczaniu bierze udział funkcja WX()
– do niej przekazujemy wartość aktualnie rozpatrywanego piksela i sprawdzamy cza zwrócony wynik jest równy wartości bitu z mapy bitowej znaku wodnego. Jeśli tak jest, to przechodzimy do kolejnego piksela, jeśli nie to zmieniamy wartości aktualnego piksela do momentu aż wynik funkcji będzie równy wynikowi spodziewanemu.
Funkcję WX() dobiera się tak, by konieczne zmiany były niewielkie.
WX() – można oprzeć na tablicy z indeksami o wartościach z zakresu 0-255, a wartościami tablicy –
losowo wygenerowane bity.
12. Algorytm oparty o mapy chaotyczne
Mapa chaotyczna(w skrócie: generator pseudolosowy) np.:
+ 1 = = ⋅ − 1 − ; = ⋅ 1 − ; ∈ [1,4]
Następny parametr można wygenerować na podstawie poprzedniego. Pierwszym elementem jest .
Wykorzystanie mapy chaotycznej i przyjętej permutacji zwiększa bezpieczeństwo algorytmu.
Algorytm: Obraz poddawany jest permutacji, następnie wycinamy (zerujemy) najmłodsze bity np.: 133->132 –
zamieniamy nieparzyste na parzyste. Generujemy mapę chaotyczną. Potem od mapy odejmujemy obraz z zerami i otrzymujemy obraz D. Jeżeli wartość 0-15 a D, to w wynikowej wpisujemy 0, jeśli 15-32 ->1, 32-64-> 0, 65-128->1, 129-256 ->0. Otrzymujemy mapę bitową, do której dodajemy znak wodny (tez mapa bitowa).
Sumujemy znak i otrzymana mapę bitową(xor). Wynik xora dodajemy do wyzerowanej mapy, a potem znowu
robimy permutację. Odczytanie – tak samo jak kodowanie.
Wyszukiwarka
Podobne podstrony:
materiałyTOPAWI kolo2
GN kolo2 pytania, Geodezja, Gospodarka nieruchomosciami, Materialy
pytania-kolo2, Geodezja, Gospodarka nieruchomosciami, Materialy
KOLO2 materialy
kolo2, Handel zagraniczny, Handel zagraniczny, Materiały MSG i HZ
glebo koło2, LEŚNICTWO SGGW, MATERIAŁY LEŚNICTWO SGGW, Gleboznawstwo, Koła
geriatria p pokarmowy wyklad materialy
Materialy pomocnicze prezentacja maturalna
Problemy geriatryczne materiały
Wstęp do psychopatologii zaburzenia osobowosci materiały
material 7
Prez etyka materiały1
Prez etyka materialy7
Med Czyn Rat1 Ostre zatrucia Materialy
Cząsteczkowa budowa materii
Materiały dla studentów ENDOKRYNOLOGIA
więcej podobnych podstron