1.
Odczyt danych (szereg kumulacyjny)
Objaśnienie:
dane_z - wartości zmiennej losowej po
uporządkowaniu i redukcji
dane_c - sumy częstości,
odpowiadające wszystkim wartościom zmiennej losowej nie większym
od danej wartości
2.Prawdopodobieństwo
z próby
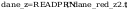
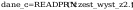


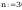
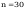
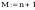
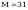




3.
Wybrane parametry zmiennej losowej
Uwaga:
dane nie powtarzają się więc
można skorzystać bezpośrednio z danych pomiarowych z szeregu
kumulacyjnego (dane_z), przy danych powtarzających się trzeba
skorzystać z danych oryginalnych po ich posortowaniu.
4.
Oszacowanie punktowe metodą momentów
5.
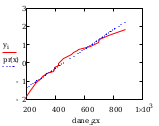
Oszacowanie punktowe metodą graficzną
oś Y
Obliczenie
współczynników prostej regresji y = a + b * x :
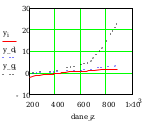
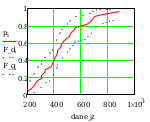
dane_z to na osi x nie przeksztalcone dane, y to dane pi na osi y
przeksztalcone
I-sza metoda
II-ga metoda
Wykres

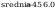
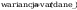
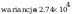
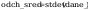
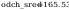
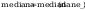
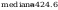
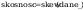
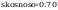
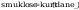
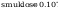


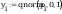
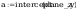
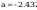


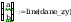
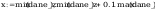
Obliczenie
parametrów rozkładu:
5.
Testy zgodności
test w2
równoważnie można zastosować:
prti:=cnorm(yti)
na poziomie istotności 0.05 wartość
krytyczna W2kryt wynosi:
wniosek:
test
Kołmogorowa - Smirnowa:
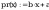



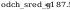
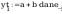


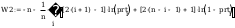

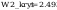


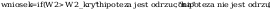
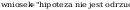
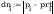
na poziomie istotności 0.05 wartość
krytyczna dnkryt wynosi:
wniosek:
test 2
na poziomie istotności 0.05 wartość
krytyczna 2kryt wynosi:
wniosek:
6.
Oszacowanie przedziałowe
I. obliczenie
jednostronnych granic przedziałów ufności dla parametrów
rozkładu normalnego na poziomie ufności =0.95
- dla
średniej:
t_a - wartosc policzona z rozkladu t-studenta
wniosek:
- dla
odchylenia standardowego:


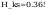
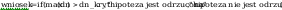
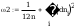
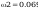
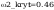
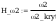

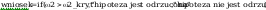


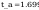

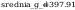
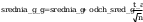
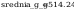

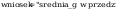
wartosc z rozkladu (hi)czi^2
wniosek:
II. obliczenie
jednostronnych granic przedziałów ufności dla nieznanej
dystrybuanty na poziomie ufności =0.95
kwantyle rozkładu
Snedecora-Fishera
Wzory ponizej dotycza tylko i wylacznie rozkladu normalnego:
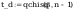

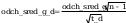
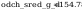
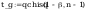
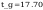
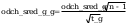

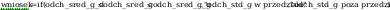
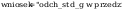


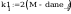
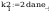

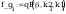
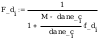
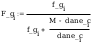

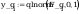

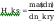
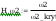
Wyszukiwarka
Podobne podstrony:
04 Wykład 4 Charakterystyka rozkładu normalnegoid 4819
02b Rozkład normalnyid 4039 ppt
Tablica standaryzowanego rozkładu normalnego o wartości oczekiwanej równej zeru i wariancji równej j
T3 Rozkład normalny
sad-materialy-pomocnicze, Rozkład Normalny N, Rozkład Normalny N(0,1)
Prawdopodobieństwo Rozkład dwumianowy Rozkład normalny
Rozkład normalny, sql
rozklad normalny
statystyka wykłady, Wyklad5-6, Rozkład normalny
6 Statystyka w badaniach Rozkład normalny
tablice statystyczne wartosci krytyczne rozkladu normalnego
03 Tablica standardowego rozkladu normalnego
dystrybuanta-rozkladu-normalnego-standaryzowanego
rozklad normalny, centyle
Wykład3 rozkład normalny
3408 rozklad normalny
1 Rozkład normalny