Statystyka matematyczna dr Ryszard Niewczas
Zestaw pytań teoretycznych + zadanie (3,4,5,)
Plan zajęć
Powtórzyć zmienną losową i rozkład normalny
Elementy rachunku prawdopodobieństwa.
Zmienne losowe ciągłe i skokowe oraz ich rozkłady (normalny).
Własności parametrów rozkładów teoretycznych.
Wprowadzenie do statystyki matematycznej (wnioskowania statystycznego).
Estymacja punktowa.
Estymator i jego własności.
Estymacja przedziałowa.
Ogólna zasada budowy przedziałów ufności.
Dokładne i graniczne rozkłady statystyk z próby.
Zastosowanie w estymacji parametrów populacji generalnej.
Wprowadzenie do teorii weryfikacji hipotez statystycznych.
Podstawowe pojęcia i definicje.
Testy istotności dla podstawowych parametrów populacji generalnej jednowymiarowej i dwuwymiarowej.
Nieparametryczne testy istotności.
Test zgodności.
Test losowości.
Test niezależności.
Podsumowanie wykładanej treści.
Literatura podstawowa:
M. Sobczyk, Statystyka
Cz. Domańska, Metody statystyczne teoria i zadania, Uniwersytet Łódzki wyd. 6, 2001
K. Kukuła, Elementy statystyki w zadaniach PWN, wyd 2 , Warszawa 2003
S. Ostasiewicz , Z. Roszak, U. Siedlwecka, Statystyka. Elementy teorii i zadania. Akademia Ekonomiczna, Wrocław 1998
Literatura uzupełniająca:
J. Jóźwiak, J. Podgórski, Statystyka od podstaw. Wyd. 5, PWE, Warszawa 1997
M.H. Aczel , Statystyka w zarządzaniu, PWN, Warszawa 2005
A. Zeljaś, Metody statystyczne, PWE, Warszawa 2002
J. Greń, Statystyka matematyczna modele i zadania. Warszawa, 1982
R. Zieliński, Tablice matematyczne, Wyd. 2, PWN, Warszawa
Wnioskowanie statystyczne związane jest z próbą losową a zatem korzystamy z metod wnioskowania statystycznego.
Próbę losową pozyskujemy w wyniku zastosowania mechanizmu losowego doboru jednostek, musi być ona odpowiednio liczna, aby można było ją uznać za reprezentatywną.
n- liczebność próby
N- liczba jednostek w populacji generalnej
Sposób jednostek do próby:
-losowanie zależne (wylosowana jednostka nie wraca do puli),
-losowanie zależne (wylosowana jednostka wraca do puli),
-losowanie indywidualne (wybieramy do próby pojedyncze jednostki)
-losowanie zespołowe (wybieramy grupy jednostek)
Bazą z której dokonuje się doboru jednostek do próby jest operat losowania. Operat losowania to wykaz wszystkich jednostek wchodzących w skład populacji generalnej. Poszczególne jednostki - elementy losowania - zostają najczęściej ponumerowane. Wyboru poszczególnych elementów do próby dokonujemy najczęściej za pomocą specjalnie skonstruowanych tablic liczb losowych.
Rozkład z próby - podstawowe pojęcia.
Przestrzeń prób losowych jest to zbiór n elementowych prób utworzonych z populacji generalnej liczącej N jednostek( zazwyczaj jest to zbiór nieskończony).
Statystyka z próby jest to wielkość charakteryzująca próbę (np. średnia, mediana dominanta). Statystyka z próby jest zmienną losową. Np.
1 2 3
x1 x2 x3
Zmienna losowa to zmienna, która może przybierać różne wartości z określonym prawdopodobieństwem.
Rozkład statystyki jest to teoretyczny rozkład prawdopodobieństwa zmiennej losowej będącej statystyką. Rozkład ten zależy od rozkłady zmiennej losowej w populacji, z której pochodzi próba, oraz od wielkości próby.
Klasyczny podział próby
Mała próba duża próba
n< 30 n >30
Rozkład graniczny statystyki jest to rozkład, który otrzymuje się przy założeniu nieograniczenie dużej próby n → ∞. Jest to rozkład, do którego przybliża się rozkład danej statystyki, gdy n → ∞. Rozkład graniczny nazywany jest także rozkładem asymptotycznym. ( np. rozkład normalny jest rozkładem granicznym rozkładu
t- studenta).
Rozkłady z dużych prób.
Jeżeli rozkład zmiennej losowej X jest opisany za pomocą rozkładu normalnego to najczęściej mamy doczynienia z rozkładami normalnymi z prób opisywanych statystyk lub z rozkładami asymptotycznie normalnymi
Przykład
Jeżeli interesuje nas parametr średnia arytmetyczna z populacji generalnej to rozkład średniej z prób dużych jest opisany rozkładem normalnym Θ = ![]()
. Naszą statystyką jest ![]()
.
Rozkład średniej z próby ![]()
11 ![]()
21 ![]()
31
Rozkład normalny N[ E(![]()
), D (![]()
)]
E(![]()
)- wartość oczekiwana
D(![]()
) odchylenie standardowe zmiennej losowej
Gdzie
E(![]()
) = E(X)
![]()
n - wielkość próby
Rozkład normalny przyjmuje postać N[E(X), D(![]()
)]
Rozkład z małych prób.
W zależności od parametru Θ rozkład z próby danej statystyki może być opisany za pomocą różnych rozkładów teoretycznych.
Przykład
Jeżeli zmienna losowa x jest opisana z pomocą rozkładu normalnego o znanej wartości oczekiwanej E(X) ale o nie znanych odchyleniach standardowych δ(X) to średnia arytmetyczna z prób losowych ma rozkład :
Normalny w przypadku dużej próby o parametrach
N[E(X),![]()
)]
S - odchylenie standardowe dla próby losowej
Gdzie
E(![]()
) = E(X)
![]()
rozkład t- studenta w przypadku małej próby o parametrach
N[E(X),![]()
)]
S - odchylenie standardowe dla próby losowej
Gdzie
E(![]()
) = E(X)
![]()
Inne rozkłady statystyk z próby:
1. Rozkład wariancji z próby opisywany jest rozkładem chi2 (Χ2).
2. Rozkład ilorazu wariancji opisywany był by rozkładem F-Snedecora
Wnioskowanie statystyczne
Teoria estymacji(szacowania) Teoria weryfikacji hipotez statystycznych
Założenia
Próba powinna być reprezentatywna tzn uzyskana zgodnie z wymogami metody reprezentatywnej.
Próbę uznajemy za reprezentatywną, gdy jest:
Losowa.
Dostatecznie liczna.
Wymogi:
Rozkład badanej próby jest normalny N[E(X),δ(X)].
Próba jest prosta tzn. uzyskana w wyniku korzystania z mechanizmu losowania zwanego losowaniem prostym.
Losowaniem prostym nazywamy losowanie indywidualne nieograniczone i niezależne( ze zwracaniem)
Losowaniem systemtycznym
Podstawy teorii estymacji.
Estymacja jest to podstawowy rodzaj wnioskowania statystycznego polegający na szacowaniu parametrów populacji generalnej bądź postaci funkcyjnej rozkładu populacji na podstawie wyników próby losowej.
Rodzaje estymacji:
parametryczna
nieparametryczna
Techniki estymacji:
a) estymacja punktowa polega na podaniu wielkości szacowanego parametru, która jest równa wartości estymatora Θ = T. Ponieważ z reguły wielkość estymatora różni się od wartości parametru populacji generalnej , podaje się jednocześnie średni błąd szacunku, czyli odchylenie standardowe estymatora Tn
Θ = T + D(Tn)
gdzie:
T- ocena parametru( wartość estymatora dla danej próby)
Tn - estymator
D(Tn) - błąd szacunku estymatora (odchylenie standardowe estymatora)
Dzięki temu uzyskujemy konkretna wartość.
b) estymacja przedziałowa polega na skonstruowaniu pewnego przedziału liczbowego, zwanego przedziałem ufności, który z określonym prawdopodobieństwem pokryje estymowany parametr. Jeśli granice tego przedziału oznaczymy przez kd i kg wówczas możemy zapisać go następująco:
P{kd < Θ <kg} = 1-α
kd - dolna granica przedziału ( kres dolny)
kg - górna granica przedziału ( kres górny)
1-α -współczynnik ufności ( to prawdopodobieństwo z jakim parametr Θ pokryty jest tym przedziałem) może on przybrać wartości 0,90 0,95 0,99
Jeżeli rozkład estymatora opisywany jest za pomocą rozkładu normalnego to przedział ufności zapisujemy następująco:
P{T - uαD(Tn) < Θ < T + uαD(Tn)}= 1 - α
uα - wartość zmiennej standaryzowanej rozkładu normalnego dla danego α (α ≤ 0,10)
Estymator jest to funkcja wyników z próby lub inaczej statystyka służąca do oszacowania nieznanej wartości parametru Θ. Wartość estymatora dla próby losowej jest zmienną losową.
Rozkład estymatora zależy od:
Rozkładu badanej zmiennej losowej.
Schematu losowania.
Wielkości próby.
Własności estymatora:
Nieobciążoność - estymator jest nieobciążony jeżeli wartość oczekiwana jego rozkładu jest równa nieznanemu parametrowi populacji generalnej E (Tn) = Θ
Wyrażenie B(Tn) = E(Tn) - Θ nazywamy obciążeniem estymatora.
Estymator jest asymptotycznie nieobciążony gdy ![]()
jeżeli jego obciążenie maleje wraz ze wzrostem próby.
Zgodność estymatora oznacza że wraz ze wzrostem liczebności próby ,z której go wyznaczamy, jego wartość będzie zbliżała się do wartość będzie zbliżała się do wartości nieznanego parametru zbiorowości całkowitej.
![]()
ε- dowolnie mała stała
Efektywność - estymator jest tym efektywniejszy, im jego zróżnicowanie , które możemy mierzyć wariancją , jest mniejsze. Im mniejsze będzie zróżnicowanie estymatora tym nasze sądy o populacji generalnej na jego podstawie będą bardziej trafne.
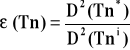
D2 (Tn*) - wariancja najefektywniejszego estymatora ( wtedy gdy dany jest zamknięty zbiór estymatorów)
D2 (Tni) - wariancja i - tego estymatora
0< ε(Tn)
Jeżeli efektywność naszego estymatora zmierza do jedności to możemy powiedzieć że estymator jest najefektywniejszy asymptotyczne
![]()
Dostateczna wystarczalność - estymator parametru Θ jest dostatecznie wystarczalny jeżeli zawiera wszystkie informacje jakie na temat parametru Θ występują w próbie.
(najlepszym estymatorem jest średnia )
Estymacja wybranych parametrów
Przedział ufności dla średniej.
Założenia - rozkład zmiennej losowej jest rozkładem normalnym, próba jest prosta.
Rozkład estymatora
. δ(X)- znane δ(X)- nieznane
próba dowolna, rozkład normalny trzeba skorzystać z odchylenia
standardowego estymatora
dla dużej próby (n>30) dla małej próby (n ≤ 30)
Rozkład normalny (S) Rozkład t- studenta (S Ŝ)
Parametr: Θ = ![]()
= E(X) = m
Estymator Tn = ![]()
= 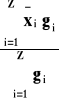
Ocena parametru Tn =![]()
= a - policzalna wartość średniej
Konstrukcja przedziału ufności przy znanym odchyleniu standardowym dla zmiennej losowej.
Wartość funkcji gęstości dla u
P { - u α < u < u α } 1- α
Definicja
![]()
dla zmiennej losowej
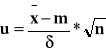
dla rozkładu struktury
![]()
Przedział
Po uwzględnieniu znaku stojącego przy uα otrzymujemy ostatecznie
![]()
Metody znajdowania estymatorów:
metoda momentów,
metoda największej wiarygodności,
metoda najmniejszych kwadratów,
metoda Bayesa
Rodzaje estymatorów:
liniowy
ilorazowy
regresyjny
bayesowski
Wykład 2
(estymacja średniej, wsk struktury, testy istotności)
Test dla dwóch wskaźników struktury.
Przykład
W pewnym roku na egzaminie wstępnym z matematyki na wyższą uczelnię spośród 560 absolwentów techników 240 nie rozwiązało pewnego zadania, natomiast na 1040 zdających absolwentów liceów ogólnokształcących nie rozwiązało tego zadania 380 kandydatów. Na poziomie istotności α = 0,05 zweryfikować hipotezę o jednakowym stopniu opanowania tej partii matematyki której dotyczyło to zadanie przez absolwentów obu typów szkół.
Dane:
Technikum Liceum
n1 = 560 n2 = 1040
m1 = 240 m2 = 380
α = 0,05
1.Układ hipotez
H0 : p1 ≠ p2
H1 : p1 = p2
2. Duża próba n > 30
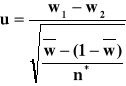
![]()
![]()
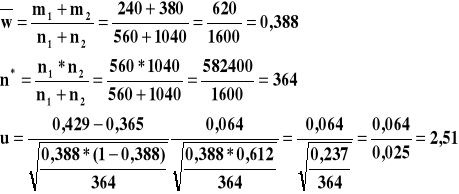
3. Określenie poziomu istotności
Dla pewnego α = 0,05 szukamy wartości krytycznych dla uα w taki sposób by prawdopodobieństwo P {׀u׀ ≥ uα } = α.
Obszar krytyczny jest dwustronny, rozkład statystyki musi być symetryczny
F- dystrybuanta
![]()
uα = 0,05=1,96
Obszar krytyczny ( ![]()
Jeżeli wystąpi ׀u׀ ≥ uα to H0 odrzucamy na korzyść H1
Jeżeli ׀u׀< uα to brak podstaw do odrzucenia hipotezy H0
׀u׀ = 2,51 uα =1,96 ׀u׀ ≥ uα H0 odrzucamy na korzyść H1
Przy poziomie istotności α = 0,05 możemy twierdzić że stopień opanowania pewnej partii matematyki jest różny. Absolwenci liceów opanowali tę partię materiału lepiej bo dla nich wskaźnik struktury jest niższy.
A) Zweryfikować hipotezę że absolwenci liceów lepiej opanowali pewną matematyki niż absolwenci techników
H0 = p1 =P2
H1 = p1 =P2
Nieparametryczne testy istotności
Test losowości służy do badania losowego charakteru próby tzn czy można uznać daną próbę za losową czy nie.
Przykład
Zbadano grupę 15 studentów pod względem wzrostu:
165,180,180,175,177,195,170,182,187,173,178,190,188,175,182
czy jest to próba losowa ? Przyjąć poziom istotności 0,05
Rozwiązanie:
a) układ hipotez
H0 próba losowa
H1 próba nielosowa
b) statystyką sprawdzającą jest liczba serii:
wyznaczam pozycję mediany
![]()
wyznaczamy medianę
Porządkuję szereg rosnąco
165 |
180 |
180 |
175 |
177 |
195 |
170 |
182 |
187 |
173 |
178 |
190 |
188 |
175 |
182 |
165 |
170 |
173 |
175 |
175 |
177 |
178 |
180 |
180 |
182 |
182 |
187 |
188 |
190 |
195 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
A |
|
A |
A |
B |
A |
B |
B |
A |
A |
B |
B |
A |
B |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|||||||
A gdy xi < Me
B gdy xi > Me
Uwaga: xi = Me pomijamy
Seria jest to ciąg jednakowych liter ( sytuacji). Seria może być jednoelementowa
Me = X8 = 180
n = 13 bo 15-2 = gdyż pomijamy wartości równe medianie
k = 8
c) α, kα, P{k ≤ kα }= α odczytujemy z tablic rozkładu serii dla α, oraz n1 i n2
n1 liczba sytuacji oznaczonych literą A
n2 liczba sytuacji oznaczonych literą B
Ostatecznie mamy
n1 = 7 n2 = 6 k0,05 = 3
d) k ≤ kα k=8 > k0,05 =3
Decyzja nie ma podstaw do odrzucenia hipotezy H0
ODP Przy poziomie istotności α = 0,05 nie mamy podstaw do odrzucenia hipotezy głoszącej że próba jest losowa.
Test medianowy z dwustronnym obszarem krytycznym jest lepszy od poprzedniej wersji bowiem reaguje na obserwowalną powtarzalność czyli tendencję
Przykład treść jw
a) układ hipotez
H0 próba losowa
H1 próba nielosowa
b) statystyką sprawdzającą jest liczba serii:
wyznaczamy medianę
tworzymy ciąg złożony z liter A i B gdzie
A gdy xi < Me
B gdy xi > Me
Uwaga: xi = Me pomijamy
Me = X8 = 180
n = 13 bo 15-2 = gdyż pomijamy wartości równe medianie
k = 8
Uwaga: xi = Me pomijamy
Seria jest to ciąg jednakowych liter ( sytuacji). Seria może być jednoelementowa
c) α ,K1 P{K ≤ K1 } = α/2
K2 P{K ≤ K2 } = 1- α/2
Rozkład serii nie jest rozkładem symetrycznym, dlatego należy odczytać dwie wartości krytyczne dla lewostronnego obszaru krytycznego przy n1 i n2
d) jeżeli K ≤ K1 lub K > K2 to odrzucamy hipotezę H0
K1 < K ≤ K2 to nie mamy podstaw do odrzucenia
-α/2 α/2
K1 K2
α/2 = 0,05/2 = 0,025
K1 = K α/2 = 0,025 =3 n1 = 7
K2 =K1 - α/2 = 0,975 =10 n2 = 6
d) K1 = 3 < K =8 < K2 = 10 nie mamy podstaw do odrzucenia hipotezy
Przykład 2 (test z serii z dwustronnym obszarem krytycznym)
W kolejce po świadectwa udziałowe zaobserwowano mężczyzn i kobiety według następującego porządku
M K M K M M M K K M K M K M K M M M M K M K M K M M K K K M
Na poziomie istotności 0,05 sprawdzić hipotezę głoszącą że ciąg ten jest losowy.
Rozwiązanie
a) układ hipotez
H0 ciąg losowy
H1 ciąg nielosowy
b) statystyką sprawdzającą jest liczba serii:
M |
K |
M |
K |
M |
M |
M |
K |
K |
M |
K |
M |
K |
M |
K |
M |
M |
M |
M |
K |
M |
K |
M |
K |
M |
M |
|||||||
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
||||||||||||||
K |
K |
K |
M |
|
||||||||||||||||||||||||||||
20 |
21 |
|
||||||||||||||||||||||||||||||
Ustalamy liczbę serii K = 21
c) α ,K1 P{K ≤ K1 } = α/2
K2 P{K ≤ K2 } = 1- α/2
K1 = K α/2 = 0,025 = 8 n1 = 17
K2 = K1- α/2 = 0,975 = 19 n2 = 13
d) K=21 > K2 = 19
Decyzja odrzucamy hipotezę H0
ODP Na poziomie istotności 0,05 możemy twierdzić że ciąg ten jest nie losowy, układ kolejnych kolejkowiczów był tendencyjny.
Rozkład normalny zmiennej standaryzowanej
N(0,1)
H1 : A ≠ B P { |u| ≥ uα } α obszar dwustronny
F{ (uα) = 1 - α/2 uα dystrybuanta obszar krytyczny
H1 : A > B P { u ≥ uα } α obszar prawostronny
F{ (uα) = 1 - α uα
H1 : A < B P { u ≤ uα } α obszar prawostronny
F{ (-uα) = α uα
Testy zgodności
Jest to obszerna grupa testów do badania rozkładów.
Badanie zgodności dowolnego rozkładu :
empirycznego z zakładanym rozkładem teoretycznym (trzeba patrzeć jakiej zmiennej on dotyczy , zmienna losowa może być dowolna lub tylko ciągła)
Testy służące do badania zgodności dwóch lub więcej rozkładów empirycznych ( czy nasze próby pochodzą z populacji o tym samym rozkładzie, jeśli tak to próby możemy łączyć w większe)
Testy możemy podzielić na klasyczne, podstawowe, i nowoczesne.
Testy możemy także ze względu na wielkość próby czyli związane z małą lub z dużą próbą.
Klasyczne testy zgodności rozkładu empirycznego z rozkładem teoretycznym:
test zgodności χ2 do badania normalności rozkładu ( uniwersalny test dla dowolnej zmiennej losowej
test zgodności λ Kołmogorowa ( służy do badania zgodności dwóch rozkładów empirycznych dla zmiennej losowej ciągłej)
test zgodności Kołmogorowa - Smiernowa
Nieparametryczne testy zgodności
Test klasyczny - test zgodności χ2
Założenia:
Dowolna zmienna losowa
Duża próba n>30 ( grubo powyżej)
Każdej klasie ( wariantowi ) musi być przyporządkowane ni ≥ 8, jeśli tak nie jest to należy łączyć liczebności z sąsiednich klas
układ hipotez
H0 : F(x) = F0 (x)
H1 : F(x) ≠ F0 (x)
Gdzie: F0 (x) dystrybuanta rozkładu teoretycznego w punkcie x
Statystyka sprawdzająca test zgodności χ2
Postać testu 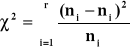
Gdzie ![]()
liczebność teoretyczna
ni ≥ 8
α,χ2 P{ χ2 > χ2 ≥
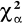
}=α
u = r - l -1
gdzie l- liczba szacowanych parametrów rozkładu teoretycznego
Obszar krytyczny określa nierówność χ2 ≥
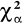
gdzie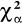
jest wartością krytyczną odczytana z tablic rozkładu χ2 dla z góry ustalonego poziomu istotności. Gdy χ2 ≥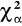
odrzucamy hipotezę H0 gdy χ2 <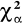
przyjmujemy hipotezę zerową
Przykład
Koszty materiałowe w pewnej gałęzi gospodarki narodowej przy produkcji pewnego wyrobu były w wylosowanych 120 zakładach następujące ( w zł)
Koszt materiałowy |
Liczba zakładów |
150 - 250 |
7 |
250 - 350 |
10 |
350 - 450 |
21 |
450 - 550 |
30 |
550 - 650 |
19 |
650 - 750 |
15 |
750 - 850 |
10 |
850 - 950 |
6 |
950 - 1050 |
2 |
|
Σ 120 |
Na poziomie istotności 0,10 zweryfikować hipotezę głoszącą że rozkład kosztów materiałowych przy produkcji tego wyrobu jest normalny N(540, 200)
Rozwiązanie:
Dane: n = 120 α = 0,10 N(540,120) E(x) = 540 (wartość oczekiwana) δ (x) = 120 ( odchylenie standardowe
układ hipotez
H0 : F(x) = FN (x)
H1 : F(x) ≠ FN (x)
Gdzie: F0 (x) dystrybuanta rozkładu normalnego w punkcie x
Statystyka sprawdzająca test zgodności χ2
Postać testu 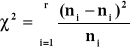
![]()
pi = F(ui) - F(ui-1)
Wyjątek
p1 = F( u1)
![]()
Uwaga przy znanych parametrach rozkładu normalnego możemy łączyć klasy już od początku by ni ≥ 8
|
Klasy które zostały połączone |
1. 2. 3.. p2 = (F(u3) - F(u2) = 0,326 - 0,171 = 0,155
4. Liczymy liczebności teoretyczne 5. Liczymy cząstkowe wartości statystyki
|
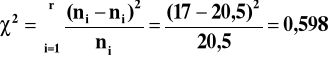
α,χ2 P{ χ2 ≥
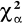
}=α
u = r-l - 1 = 7 - 0 - 1 = 6
7- bo siedem pozycji, l nie występuje gdyż ten typ statystyki ma jeden stopień swobody
Otrzymyjemy:
χ2 = 3,82 α = 0,10 ![]()
= 10,645
χ2 = 3,82 ≥
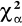
= 10,645
Decyzja niema podstaw do odrzucenia hipotezy H0
ODP Na poziomie istotności 0,10 nie mamy podstaw do odrzucenia hipotezy głoszącej że rozkład kosztów materiałowych przy produkcji tego wyrobu jest normalny.
Przykład
Treść jak wyżej ale nie znamy parametrów rozkładu normalnego
układ hipotez
H0 : F(x) = FN (x)
H1 : F(x) ≠ FN (x)
Gdzie: F0 (x) dystrybuanta rozkładu normalnego w punkcie x
Statystyka sprawdzająca test zgodności χ2
Postać testu 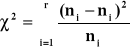
![]()
pi = F(ui) - F(ui-1)
p1 = F(u1)
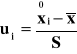
Obliczam wartość średniej
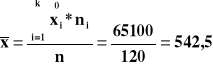
Obliczam odchylenie standardowe
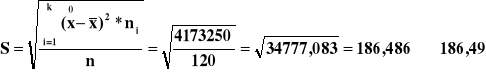
Statystyka χ2 =3,783
α,χ2 P{ χ2 ≥
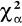
}=α
Obliczam liczbę stopni swobody
u = r - l - 1 = 7 - 2 - 1 = 4
7 bo złączyłem dwie klasy , 2 bo szukam dwóch parametrów
χ2 = 7,779
Otrzymujemy
χ2 = 7,779 α = 0,10 ![]()
= 7,779
Decyzja nie ma podstaw do odrzucenia hipotezy H0
Odp Przy poziomie istotności 0,10 nie mamy podstaw do odrzucenia hipotezy głoszącej, że rozkład kosztów materiałowych przy produkcji tego wyrobu jest rozkładem normalny.
Można przeliczyć to samo zadanie dla N( E(x),200) lub N(540,δ(x))
Wykład dodatkowy zadania
Zad 1
Estymacja wskaźnika struktury
W pewnym mieście wylosowano 500 mieszkań. Stwierdzono że 200 spośród nich było wyposażonych w telefon . Czy na tej podstawie można coś powiedzieć o odsetku mieszkań wyposażonych w telefon w tym mieście? Przyjmij współczynnik ufności na poziomie 0,99.
Rozwiązanie:
n = 500 m = 200 1-α = 0,99
Wersje rozwiązań
bezkrytyczna
- sprawdzamy czy n > 100
krytyczna
sprawdzamy czy n > 100
sprawdzamy czy m jest wystarczające
sprawdzamy czy próba jest losowa
o jaki telefon chodzi
Wniosek : Wobec braku możliwości rozstrzygnięć wątpliwości poza formalnie wymaganą wielkością próby zadanie rozwiązujemy tak jak w wersji bezkrytycznej.
Obliczam wartość wskaźnika struktury:
0,05 < wi < 0,95
![]()
Obliczam wartość u
![]()

wi -Δ = 0,4 - 0,057 = 0,343
wi -Δ = 0,4 + 0,057 = 0,457
0,343 < p < 0,457
34,3 % < p % < 45,7 %
Odp Z ufnością 0,99 przedział o końcach 34,3 % oraz 45,7% pokryje odsetek mieszkań wyposażonych w telefony w tym mieście.
Zad 2
Test dla wskaźnika struktury w populacji
W jednej z politechnik wylosowano niezależnie próbę 150 studentów, z których jedynie 45 zdało wszystkie egzaminy w pierwszym terminie. Na poziomie istotności 0,05 zweryfikuj hipotezę głoszącą że mniej niż jedna trzecia część studentów zdaje egzaminy za pierwszym podejściem.
Rozwiązanie:
n = 150 m = 45 α = 0,05 p0 = 1/3 = 0,333
Uwaga sprawdzam czy n > 100
Obliczam wartość wskaźnika struktury
![]()
Sprawdzam czy wi < p0 0,300 < 0,333
układ hipotez
H0 : p = p0
H1 : p ≠ p
Statystyka sprawdzająca
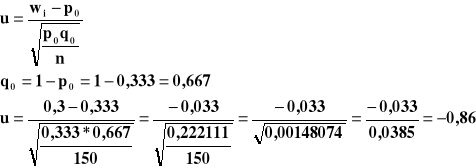
α, uα , p{u ≤ uα}= α
F(-uα) = α = 0,05
uα = 0,05 = -1,64
4. u > uα u = - 0,86 > uα = 0,05 = -1,64
Decyzja nie ma podstaw do odrzucenia hipotezy H0
5. Odp Przy poziomie istotności 0,05 nie mamy podstaw do odrzucenia hipotezy głoszącej że jedna trzecia studentów zdaje egzaminy za pierwszym razem
Zad 3
Test dla dwóch wskaźników struktury
Na 150 wypadków samochodowych w jednym województwie 118 spowodowanych było nadużyciem przez kierowców alkoholu. W drugim województwie liczba wypadków spowodowanych przez tę samą przyczynę wyniosła 130 na 185 zgłoszonych. Na poziomie istotności 0,05 zweryfikuj hipotezę, że odsetek wypadków drogowych spowodowanych nadużyciem alkoholu w obydwu województwach jest identyczny.
Dane
n1 = 150 m1 = 118
n2 = 185 m2 = 130 α = 0,05
Uwaga sprawdzamy czy
n1 >100
n2 > 100
układ hipotez
H0 : p1 = p2
H1 : p1 ≠ p2
Statystyka sprawdzająca
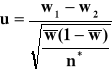

3. α, uα , p{|u | ≥ uα}= α
F(uα) = 1 - α/2 = 1- 0,05/2 = 0,975
uα = 0,05 = 1,96
|u | = 1,74 < uα= 1,96
Decyzja: nie ma podstaw do odrzucenia H0
Odp Przy poziomie istotności 0,05 brak podstaw do odrzucenia hipotezy głoszącej że odsetek wypadków spowodowanych nadużyciem alkoholu jest w obydwu województwach jednakowy
1
Wyszukiwarka
Podobne podstrony:
Matematyka Sem 2 Wykład Całki Powierzchniowe
EGZAMI~2, Egzamin matematyka sem
zakres matarialu z matematyki sem 3, PG Budownictwo, sem. 3, Matematyka
Matematyka sem II
STR1A, ATH, Matematyka, SEM 2
Matematyka sem III wyklad 1
Matematyka Sem 2 Wykład Funkcje Uwikłane
Matematyka Sem 2 Wykład Na Egzamin Obowiązuje
Matematyka 3 sem FiU
EGZAMI~3, Egzamin z matematyki sem
Matematyka sem III wyklad 1
kolokwium matematyka sem 2
Matematyka sem I D
Cwiczenia10-plan, Matematyka sem I, 1 sem
Twierdzenie Cauchy, Matematyka sem I wyższa
Matematyka 3 sem FiU
Matematyka sem III wyklad 2, Studia, ZiIP, SEMESTR III, Matematyka
STR2A, ATH, Matematyka, SEM 2
więcej podobnych podstron