
Rozkład normalny
Spotkanie 3
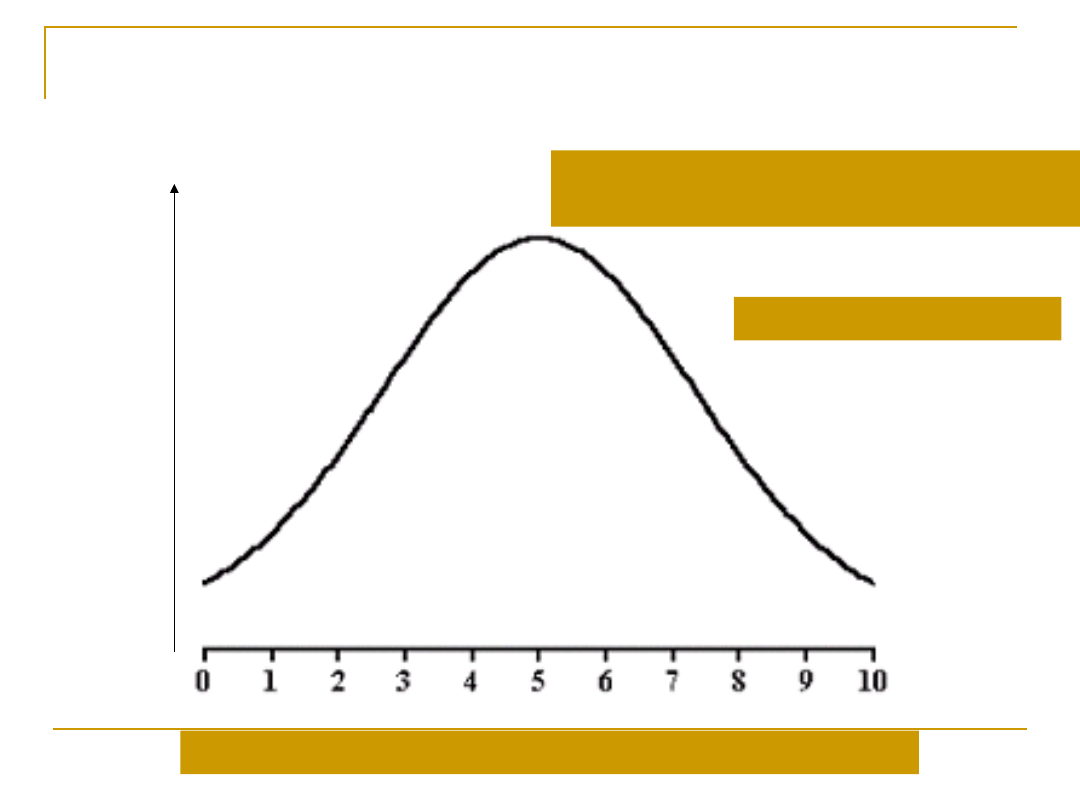
Rozkład normalny
Na osi odciętych mamy możliwe wartości zmiennej X
Na osi rzędnych widzimy gęstość –
częstość występowania danych wartości
Rozkład jednomodalny

Charakterystyki rozkładu
normalnego
Krańce rozkładu normalnego stykają się
z osią x w nieskończoności
Ma kształt dzwonu, jest symetryczny
wokół średniej
Jest funkcją średniej i odchylenia
standardowego
Znając średnią i odchylenie standardowe
możemy wyznaczyć krzywą rozkładu
normalnego
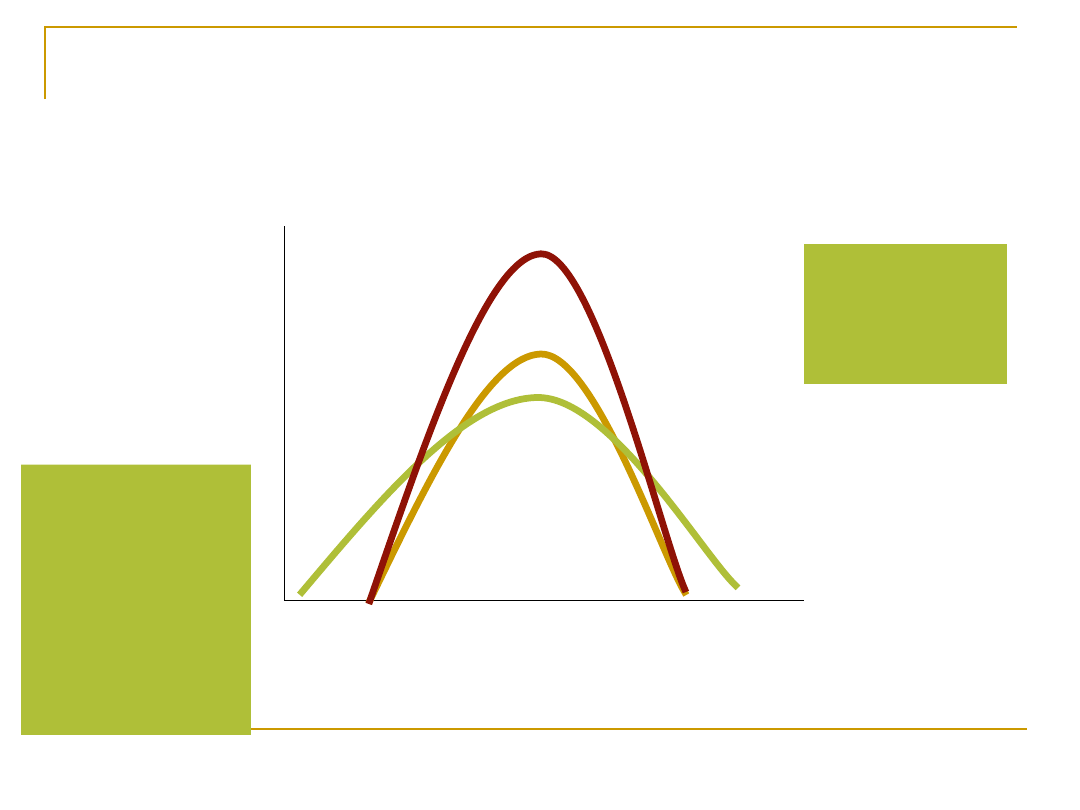
Powinien być symetryczny wokół
średniej
Średnia,
mediana i
modalna są
sobie równe
Wszystkie są
symetryczne,
chociaż, nie są
takie same,
różnią się
rozproszeniem
wyników,
spiczatością
Rozład normalny może nie tylko być przesunięty w lewo
lub prawo ze względu na średnią, ale i rozciągnięty lub
ściśnięty przez odchylenie standardowe
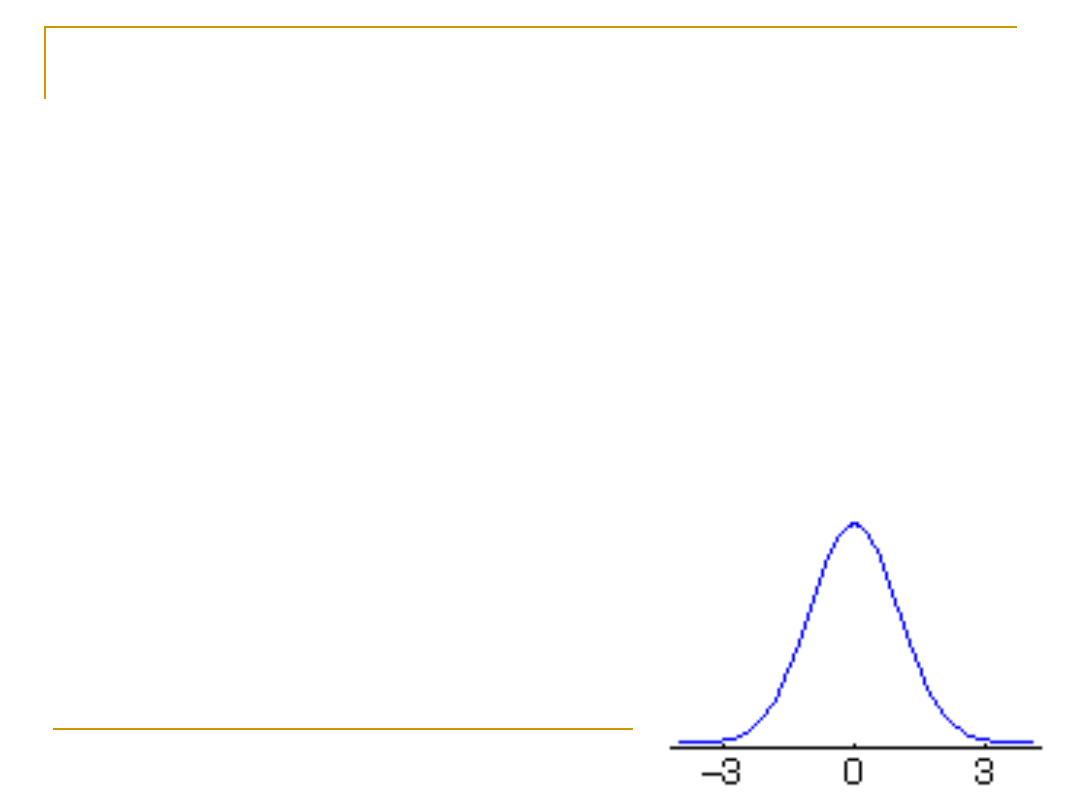
Standaryzowany rozkład
normalny
Rozkłady zależą od wartości średniej i odchylenia
standardowego, wygodnie jest więc wystandaryzować nasz
rozkład,
aby móc, np powiedzieć jaki procent obserwacji leży poniżej lub
powyżej pewnego wyniku, jakie jest prawdopodobieństwo
uzyskania wyniku z danego przedziału
Można to odczytać z tabel dla wystandaryzowanego rozkładu
normalnego
Zamieniamy wszystkie wartości X na wartości standaryzowane
z
tak, aby średnia wynosiła 0, a odchylenie standardowe równało się
1
Powierzchnia pod krzywą jest
równa 1

Sposób na rozkład normalny
Im bardziej zwiększamy naszą próbkę,
dodajemy obserwacje, tym bardziej
zbliża się on do normalnego
http://www.seeingstatistics.com
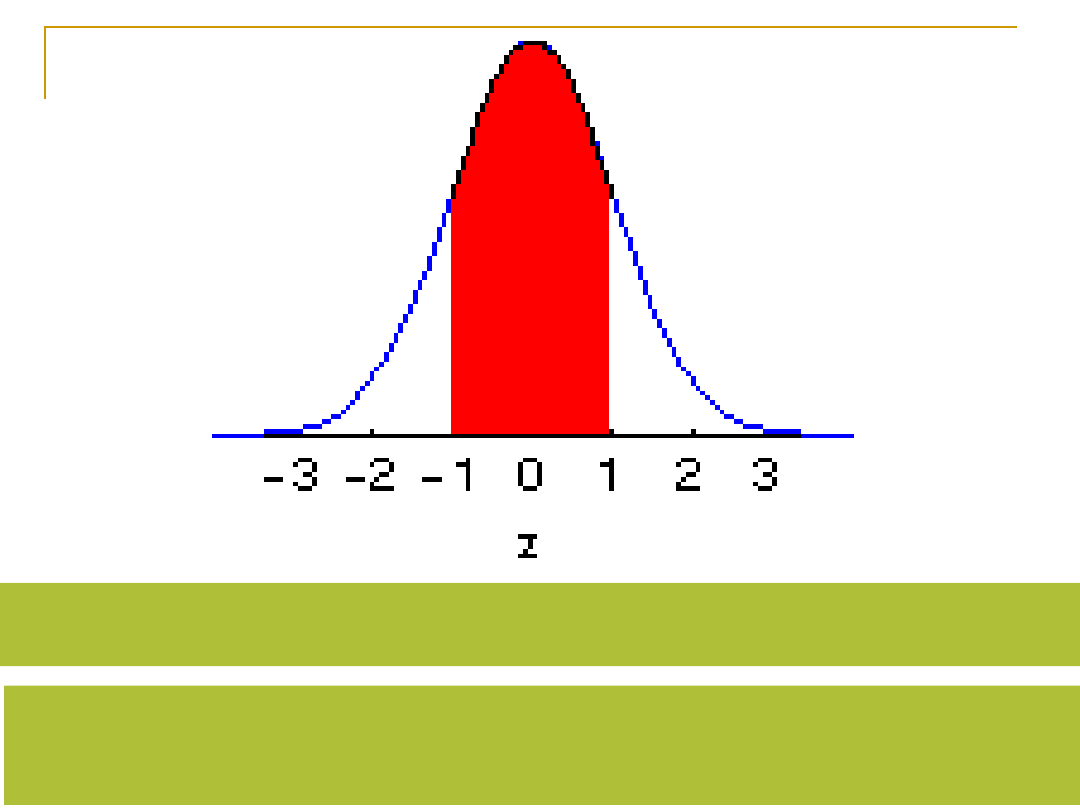
68% przypadków mieści się w ramach 1 odchylenia od średniej (-1; 1)
Między 1 a 2 odchyleniem – 13,5%
Około 95% w 2 odchyleniach od średniej, w 3 odchyleniach – około 99%
Możemy określić prawdopodobieństwo uzyskania wyniku z danego przedziału
Cała powierzchnia pod krzywą to 100%, więc do średniej (mediany) mamy 50%
Wartości „z”
W celu porównania wyników, np który
jest wyższy, czy zaszła zmiana w
stosunku do obiektu postawy,
przekształca się wyniki surowe na wyniki
wyrażone w jednostkach odchylenia
standardowego
są to wyniki standardowe czy
standaryzowane (SPSS),
wartości „z”

Standaryzacja wyników
Proste przekształcenie liniowe X
Wartość standaryzowana “z” danego
wyniku “X” = wynik surowy (X) minus
średnia dzielone przez odchylenie
standardowe
SD
X
X
z

Właściwości wyników
standaryzowanych “z” dla
próby
Średnia danych wystandaryzowanych jest
równa 0
Wariancja (i odchylenie standardowe) dla
danych wystandaryzowanych jest równa 1
wyniki dokładnie równe średniej
są równe zeru
wartości „z” zbliżone do średniej
są bliskie wartości “0”
wartości “z” mniejsze od średniej
są ujemne
wyniki “z” większe od średniej
są dodatnie

Ćwiczenie
Józia w teście praktycznym na kierowcę
skutera dostała 20 punktów
(średnia w grupie zdających wyniosła 25,
odchylenie standardowe 5).
Natomiast w teście teoretycznej wiedzy
o pojazdach mechanicznych dostała 10
punkty (średnia w grupie wyniosła 12,
wariancja 4)
W którym teście wypadła lepiej?

odpowiedź
1
2
12
10
1
5
25
20
z
z
SD
X
X
z

Ćwiczenie
Hrabina Zenobia de’Ouhę w teście
znajomości zasad savoir-vivre’u
otrzymała 20 punktów
(średnia w badanej grupie hrabin wyniosła
25, odchylenie standardowe 5).
Natomiast w teście teoretycznej wiedzy
o tańcach towarzyskich dostała 5
punkty (średnia w grupie wyniosła 3,
odchylenie standardowe 2)
Na czym hrabina zna się lepiej?

odpowiedź
Widać, że
hrabinie lepiej
wychodziło
tańczenie niż
dobre obyczaje
1
2
3
5
...
tan
1
5
25
20
...
z
z
savoir
SD
X
X
z
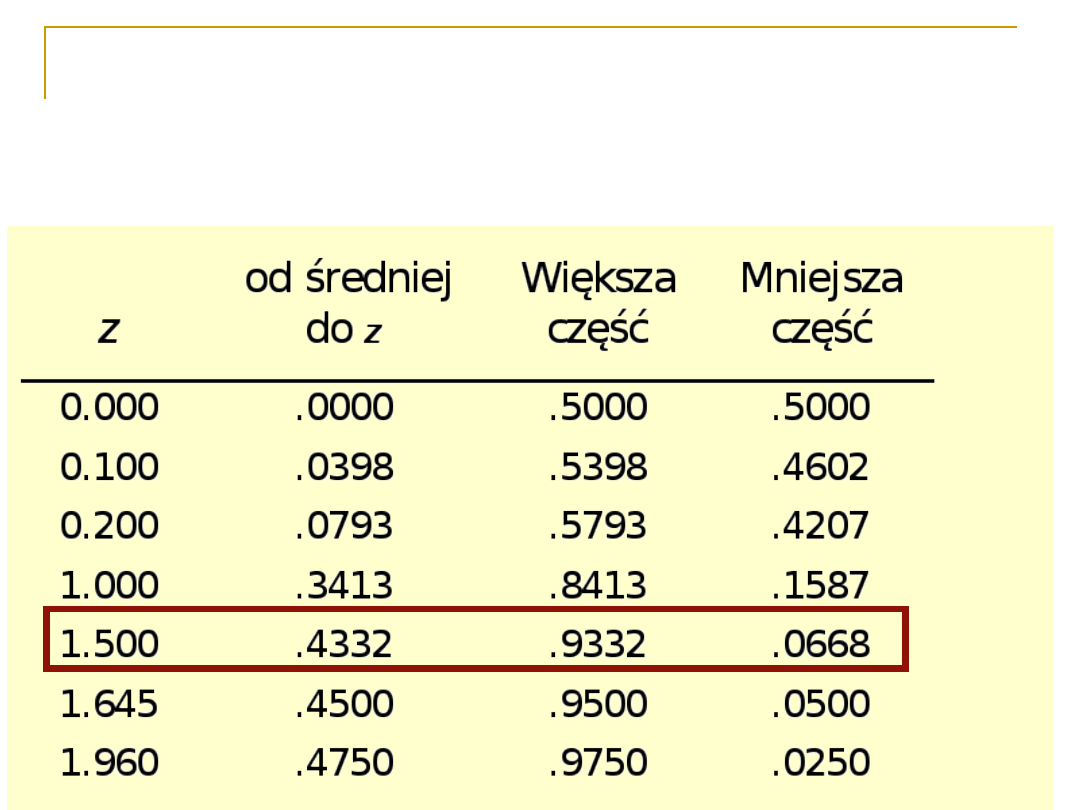
Tabele wartości z
Korzystamy z tabel, aby znaleźć obszar pod krzywą
normalną, w tabeli są tylko pozytywne wartości z
(ale skoro rozkład jest symetryczny to to samo
odnosi się do wartości ujemnych z)
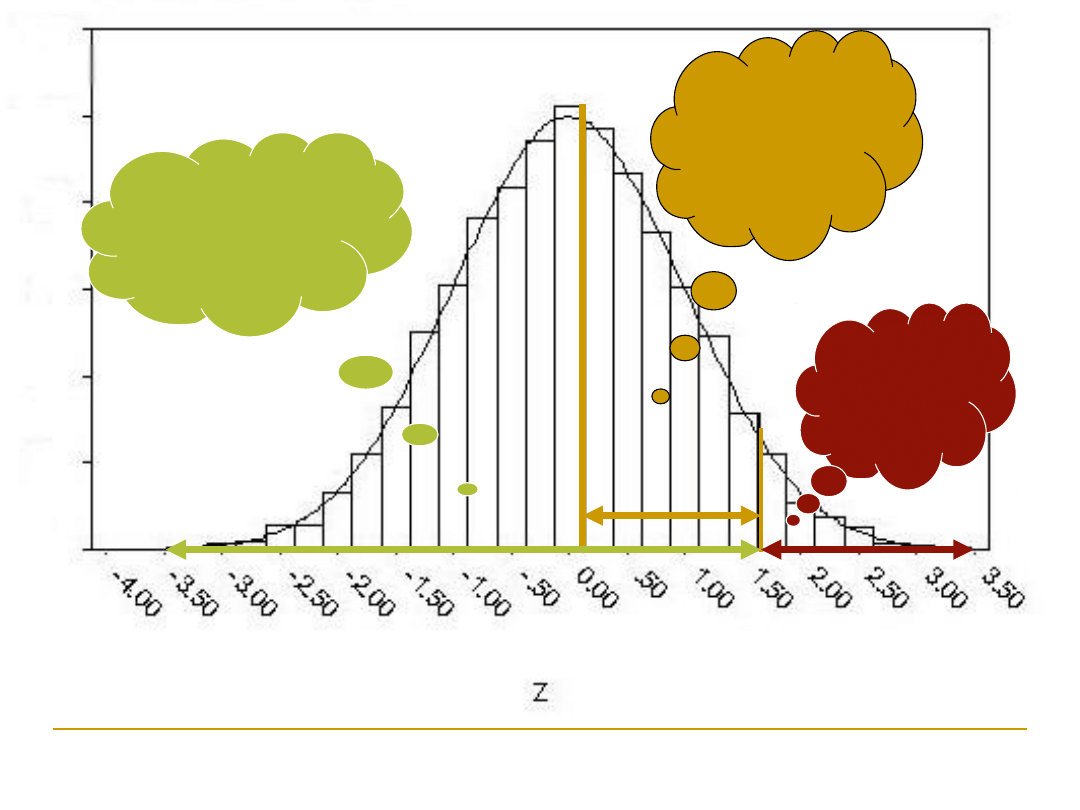
0,0668
Mniejsza
część
0,4332
od średniej
do wartości
z
Większa część
pod krzywą
normalną
0,9332
Patrząc na Tabele wartości z
Możemy obliczyć dokładnie
Jaki procent obserwacji będzie mieścił się w przedziale
między dowolnymi dwoma punktami na krzywej
normalnej wyrażonymi w wartościach z
Np procent między z= -1,5 a z= -1.0
Powierzchnia między średnią a z=-1,5 = 0.4332
Powierzchnia między średnią a z=-1.0 =
0.3413
Odejmujemy obszary 0.0919
Widzimy, że około 9% obserwacji będzie mieściło się
w przedziale między z = -1.0 and z = -1.5
Patrząc na Tabele wartości z
Możemy obliczyć dokładnie
Jaki procent obserwacji będzie mieścił się w przedziale
między dowolnymi dwoma punktami na krzywej
normalnej wyrażonymi w wartościach z
Np procent między z= -1,5 a z= 1.0
Powierzchnia między średnią a z=-1,5 =
0.4332
Powierzchnia między średnią a z=1.0 =
0.3413
Dodajemy obszary 0.7745
Widzimy, że około 77% obserwacji będzie mieściło się
w przedziale między z = 1.0 and z = -1.5

Wracając do surowych
wyników x
Załóżmy że M= 100
and SD = 15,
77% populacji mieści
się w granicach
(85, 122.5)
5
,
122
15
5
,
1
100
85
15
0
,
1
100
x
x
SD
z
M
x
M
SD
x
z

Przykład 2, procent przypadków
Jaki procent obserwacji znajduje się
między z = 0,70 i z = -1.70
Od M do z=0,70 jest 0,2580 czyli 25,80%
Od M do z=-1,70 jest 0,4554 czyli 45,54%,
A ponieważ są po różnych stronach rozkładu
dodajemy procenty i wychodzi 71,34%
Dokładnie 71,34% przypadków znajduje
się między z = 0,70 i z = -1.70

Przedziały
W ostatnim przykładzie M=100, SD=15
Chcemy odciąć skrajne 2,5% obserwacji z
każdego krańca rozkładu (2,5% osób o
najwyższym ilorazie int i 2,5% o najniższym) –
osoby z jakimi wynikami odetniemy
Sprawdzamy w tabeli wartości z
z = + 1.96
6
,
70
15
96
.
1
100
4
,
129
15
96
.
1
100
x
x
SD
z
M
x

Procent wyników w danym
przedziale
Szukamy przedziału w którym będzie
mieściło się 95% wyników.
W naszym przykładzie 95% wyników
będzie się mieścić w przedziale (70,6;
129,4)
Stąd w 95% przypadków wynik losowo
wybranej z populacji osoby będzie się
mieścić w tym przedziale
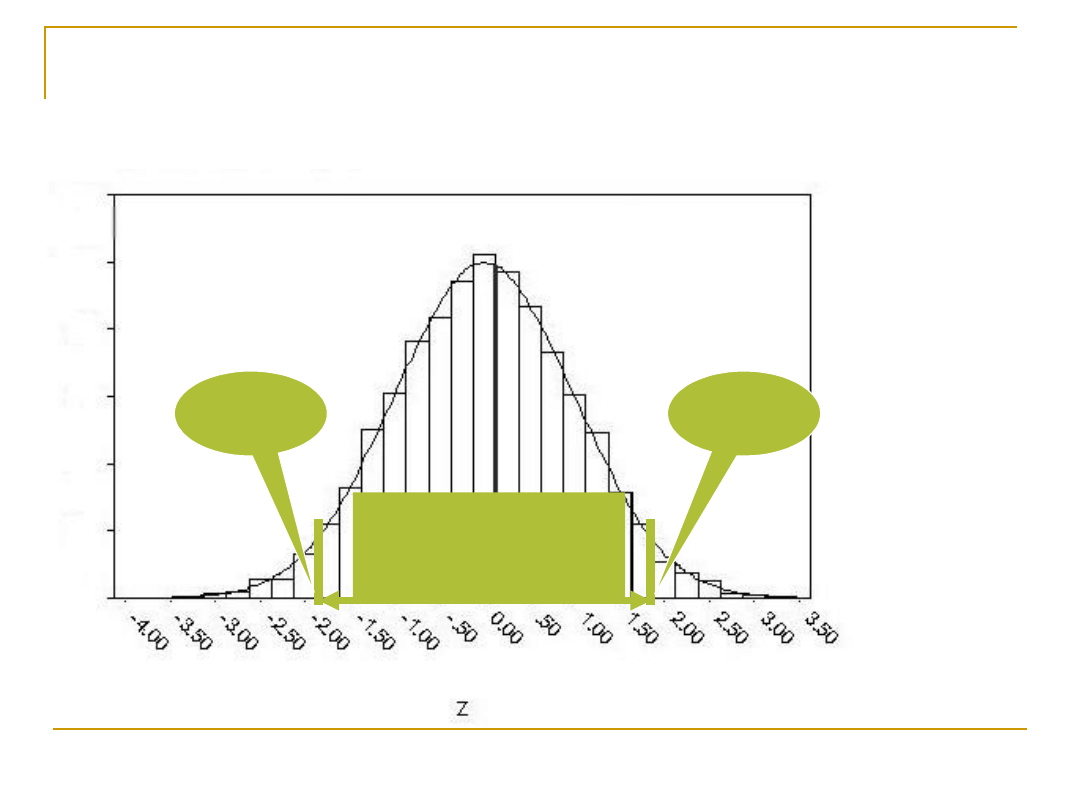
95% wyników
mieści się w tym
przedziale
z=1,9
6
z=-
1,96
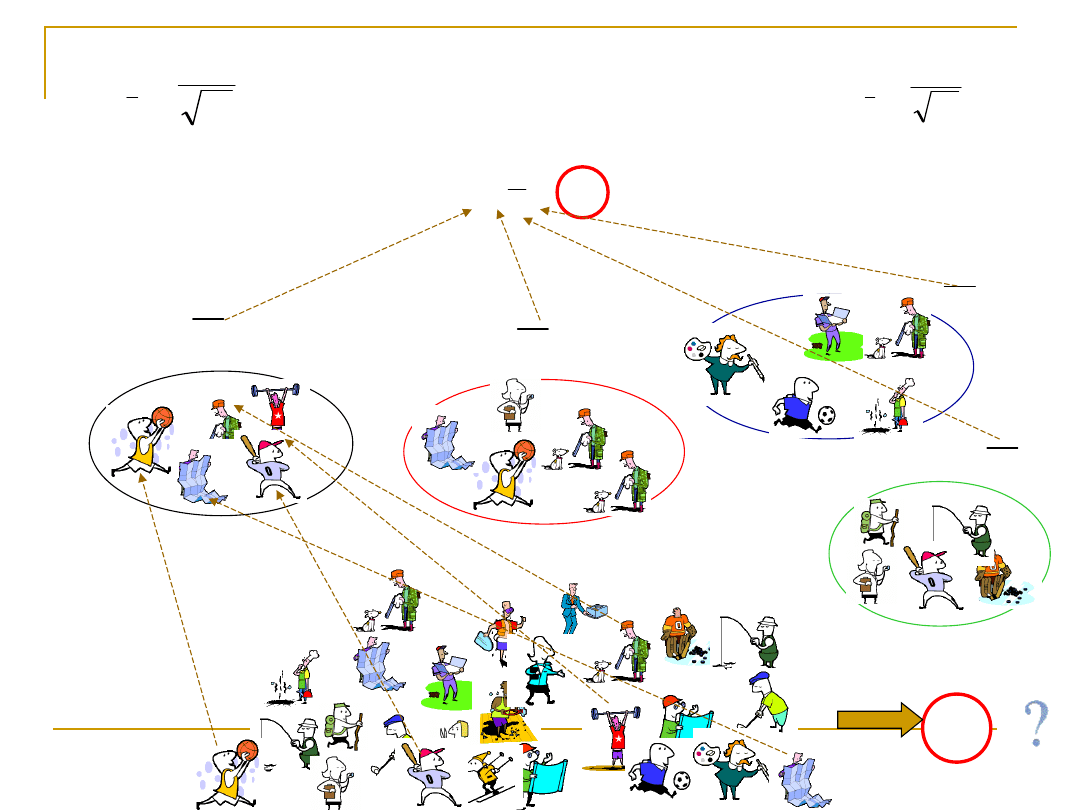
POPULACJA
POPULACJA
PRÓBA
PRÓBA
Losowanie próby
1
X
2
X
4
X
3
X
(statystyka w próbie)
X
Średnia z próby średnich
Średnia z próby średnich
N
X
Błąd standardowy średniej
Błąd standardowy średniej
N
s
s
X
Oszacowanie błędu standardowego średniej
Oszacowanie błędu standardowego średniej
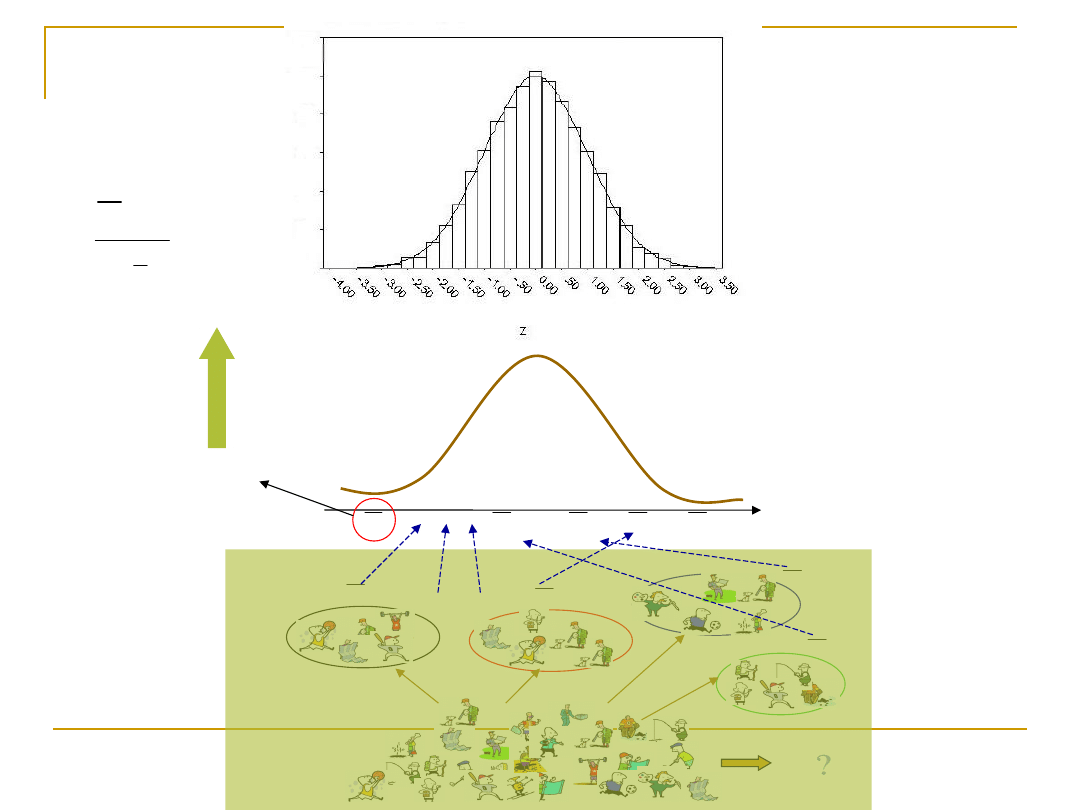
POPULACJA
POPULACJA
PRÓBA
PRÓBA
Losowanie prób
1
X
2
X
4
X
3
X
1
X
2
X
4
X
3
X
n
X
Standaryzujemy naszą średnią i
porównujemy ze standaryzowanym
rozkładem normalnym
STANDARYZOWANY ROZKŁAD NORMALNY
STANDARYZOWANY ROZKŁAD NORMALNY
Teoretyczny ROZKŁAD ŚREDNIEJ Z
Teoretyczny ROZKŁAD ŚREDNIEJ Z
PRÓBY
PRÓBY
(zawsze normalny)
(zawsze normalny)
Jakie jest prawdopodobieństwo, że
średnia w naszej próbie pochodzi z
ogólnej populacji, przy założeniu, że
H
o
jest prawdziwa?
X
X
z
Z tabeli wartości z odczytujemy
prawdopodobieństwo
prawdopodobieństwo
uzyskania naszego wyniku.

Jak znaleźć procent
przypadków znajdujący
się poniżej lub powyżej
danego wyniku
W oparciu o wyniki surowe i tabelę
wartości z

Test Coopera – test 12 minut
Jest to test stosowany przez
amerykańskich kosmonautów dla
sprawdzenia kondycji fizycznej, wydolności
Opracowany przez Kennetha Coopera,
polega na przemierzeniu jak największego
dystansu w ciągu 12 minut
Zakładamy, że zmienna ta ma rozkład
normalny
Kondycja Jasia
W wieku 20-29
średnia= 2400 metrów,
SD=300 metrów
Jaś przebiegł 3000, jaki
procent panów biega
szybciej od Jasia
z=2, w przedziale od
średniej do z mieści się
47,72%,
Czyli 50 – 47,72=2,28%
Od Jasia szybciej biega
jedynie 2,28%
2
300
2400
3000
z
M
SD
x
z
A wolniej biega 97,72%
50+47,72=97,72

Kolejne kroki – procent
powyżej
Aby obliczyć procent przypadków
znajdujących się powyżej danego wyniku
Zamieniamy wyniki surowe na wartości z.
w tabeli dla danej wartości z znajdujemy jej
odległość od średniej
Jeśli nasze z jest dodatnie wtedy,
odejmujemy odczytany procent od 50,
a jeśli jest ujemne, dodajemy ten wynik do
50.
Kondycja Zbyszka
W wieku 20-29 średnia=
2400 metrów, SD=300
metrów
Zbyszek przebiegł 2100,
jaki procent panów biega
szybciej od Zbyszka, jaki
% jest poniżej wyniku
Zbyszka
z=-1, w przedziale od
średniej do z=-1 mieści się
34,13%,
Czyli 50 + 34,13 = 84,13%
84,13% biega szybciej
84,13% osób znajduje się
powyżej wyniku Zbyszka
1
300
2400
2100
z
M
SD
x
z
A wolniej biega 15,87%
50-34,13=15,87%

Kolejne kroki – procent osób
poniżej danego wyniku
Aby obliczyć procent przypadków
znajdujących się poniżej danego wyniku:
Zamieniamy wynik surowy na wartość z
w tabeli dla danej wartości z znajdujemy jej
odległość od średniej
Jeśli nasze z jest dodatnie wtedy dodajemy
odczytany % do 50%
jeśli z jest ujemne, odejmujemy odczytany %
od 50
Zawsze dobrze jest sobie narysować
rozkład i umiejscowić naszą watrość z

Ile metrów trzeba przebiec w
ciągu 12 minut, żeby..
Znaleźć się w grupie 5% najlepszych biegaczy?
średnia=2400, SD=300
Odległość między wynikiem odcinającym górne 5% a
średnią wynosi 45%, odczytujemy z tabeli wartość z
dla odległości najbardziej zbliżonej =44,95%,
wartość z dla tej odległości wynosi 1,64
i podstawiamy dane do wzoru
2892
300
64
,
1
2400
x
SD
z
M
x
Żeby zmieścić się w 5% najlepszych biegaczy
trzeba przebiec co najmniej 2892

Ile metrów trzeba biegać,
żeby..
Znaleźć się w grupie 2% najgorszych biegaczy?
średnia=2400, SD=300
Odległość między wynikiem odcinającym dolne 2% a
średnią wynosi 48%, odczytujemy z tabeli wartość z
dla odległości najbardziej zbliżonej =47,98%,
wartość z dla tej odległości wynosi 2,05, ale wynik jest
poniżej średniej więc z=-2,05
i podstawiamy dane do wzoru
1785
300
05
,
2
2400
x
SD
z
M
x
Żeby zmieścić się w 2% biegaczy z najsłabszą
kondycją nie można przebiec więcej niż 1785
metrów
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
Wyszukiwarka
Podobne podstrony:
Metodologia z elelmentami statystyki dr Izabela Krejtz wyklad 7 Wprowadzenie do analizy war
Metodologia z elelmentami statystyki dr Izabela Krejtz wyklad 17 Analiza kowariancji i anal
Metodologia z elelmentami statystyki dr Izabela Krejtz wyklad 18 Analiza czynnikowa i anali
Metodologia z elelmentami statystyki dr Izabela Krejtz wyklad 12 Analiza danych z eksperyme
Metodologia z elelmentami statystyki dr Izabela Krejtz wyklad 19 Wykład powtórkowy
Metodologia z elelmentami statystyki dr Izabela Krejtz wyklad 4 Pojęcie korelacji
Metodologia z elelmentami statystyki dr Izabela Krejtz wyklad 15 Wprowadzenie do regresji w
Metodologia z elelmentami statystyki dr Izabela Krejtz wyklad 5 Testowanie hipotez Test T
Metodologia z elelmentami statystyki dr Izabela Krejtz wyklad 1 Rodzaje skal pomiarowych
Metodologia z elelmentami statystyki dr Izabela Krejtz wyklad 10 Dwuczynnikowa analiza wari
Metodologia z elelmentami statystyki dr Izabela Krejtz wyklad 11a Dwuczynnikowa analiza war
Metodologia z elelmentami statystyki dr Izabela Krejtz wyklad 11 Dwuczynnikowa analiza wari
Metodologia z elelmentami statystyki dr Izabela Krejtz wyklad 2 Miary tendencji centralnej
Metodologia z elelmentami statystyki dr Izabela Krejtz wyklad 13 Plan mieszany
Metodologia z elelmentami statystyki dr Izabela Krejtz wyklad 9 Zaawansowane plany eksperym
Metodologia z elelmentami statystyki dr Izabela Krejtz wyklad 8 Jednoczynnikowa analiza war
Metodologia z elelmentami statystyki dr Izabela Krejtz wyklad 6 Test T dla prób niezależnyc
więcej podobnych podstron